
Abstract
Empirically investigating the workings of institutional complementarity in organisations has been a challenge in the social sciences domain for a long time. This paper examines data from the World Management Survey (WMS) using a new machine learning method termed as iterative random forest (iRF), which is used in the field of biostatistics. An empirical study of complementarity was conducted in small and medium-sized enterprises using WMS data. The effects of 18 management quality indicators on profitability, growth and viability were examined using machine learning methods (i.e. random forest [RF] and iRF). The analysis revealed the relative importance of whether high performers are properly rewarded, poor performers are reassigned and retrained and the criteria for high and low performance are well established. Furthermore, the study results revealed that the ability to set short-term goals based on a long-term perspective is complementary to many other indicators. These findings are consistent with the findings of a survey study that examined many empirical studies on the workings of institutional complementarity. This indicates that iRF is a credible and promising method for empirical research on institutional complementarity.
Similar content being viewed by others


Introduction
Complementarity has been recognised for its academic and practical importance in management science fields. The history of theoretical development of institutional complementarity and a survey of empirical analysis were detailed from an economics perspective in the work of Brynjolfsson and Milgrom (2013) and summarised in a human-resource management review by Boon et al. (2019). Although theories surrounding institutional complementarity have evolved, the empirical analysis of institutional complementarity is far from being exhaustive. The limited number of studies may be owing to the difficulty of their execution (Athey and Stern, 1998). Theoretically, we have witnessed that complementarity exists not only between two factors but also among several different factors (Roberts, 2007). Thus, it is extremely difficult for traditional econometrics’ regression analysis tools to capture such higher-order relationships. Prior to performing a regression analysis that incorporates higher-order cross terms as explanatory variables, researchers should determine the feasible combinations of such terms. However, because many combination possibilities exist, it is difficult to analyse them all. It is also difficult to use the same variable more than once in an analysis owing to the problem of multi-collinearity. Therefore, a possible alternative is to use a decision tree-based machine learning analysis method.
Machine learning has advantages over regular parametric and regression analysis as it accounts for interactions among many variables, especially higher-order ones. However, the actual structure of those interactions is extremely complex, thereby making it difficult to present analytical results in a human-understandable form. An algorithm to address such problems was proposed by Basu et al. (2018), in which a type of random forest (RF) algorithm termed as iterative RF (iRF) was used. From the process of repeating RF analysis multiple times, the iRF algorithm can be employed to determine commonly and stably observed interactions (i.e. complementarities) among variables (including higher-order variables).
Basu et al. (2018) grew more relevant trees by weighting each feature according to its importance, revealing complex interactions. First, the weighted RF was computed according to the method of Breiman (2001). Second, iteratively, the weighted RF was trained and the importance of the features obtained in one iteration was used as weights in the following iteration. Third, the final weights were used to generate multiple weighted random forests, each trained by a randomly selected sample. Therefore, Basu et al. (2018) used a random intersection tree algorithm to detect clusters of stably co-occurring features.
A great example of the successful application of iRFs to achieve the analysis of high-order complex complementarities is derived from the study of the role of transcription regulators (i.e. activators and repressors) in the initiation of transcription in eukaryotes. It is known that transcription regulators do not exert their effects on their own. Thus, transcription is not initiated via simple binary relationships. However, transcription can be initiated if other factors are intermediate, such as gap proteins. Basu et al. (2018) argued successfully that iRFs could identify these types of factors.
Considering the power of the iRF algorithm, one can intuitively sense its increased potential for application in the field of social sciences. Thus, iRFs can be applied to learn how higher-order policy combinations can be more effective than those implemented individually. The algorithm can also be used effectively for empirical analysis of complementarity in organisations. However, such a study has not yet been performed to the best of our knowledge. This study employs the iRF method to provide an empirical analysis of institutional complementarity. The data used in the analysis were sourced from the World Management Survey by Bloom et al. (2012).
It has been deduced that for-profit companies have better outcome indicators, such as profitability, productivity and growth rate, when management quality indicators are high rather than low. Moreover, higher management quality indicator values are associated with higher values of various outcome indicators in non-profit firms. However, it appears that limited research has been conducted on how each of the 18 categories of management quality indicators relates to one another and functions in a complementary manner. This might indicate that all 18 items are considered important, and the subject of which questions are relatively important or how complementary actions among the variables are important has not been discussed. In terms of both time and money, it is also meaningful to determine which of the 18 items should be improved first, and which would be more effective if worked on improving another item simultaneously.
This exercise is expected to help illuminate the nature of institutional complementarity within corporate organisations. For example, one would expect some complementarity in terms of productivity and profitability outcomes between having a solid measurement of outcome measures and a large portion of the compensation paid in conjunction with the outcome measures. We, therefore, must be empirically certain of the existence of such complementarities.
In other words, the purpose of this study is to obtain a simplified visualisation of how institutions in an organisation exhibit high performance owing to their extremely complex relationships with each other, which cannot be found in the framework of conventional regression analysis by using the iRF method. Thus, this perspective should be the cornerstone of further theoretical and robust empirical research.
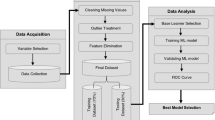
Data
A description of the variables used in this study is represented in Table 1, which mirrors Table 1 from Bloom et al. (2012). In this section, we describe three target variables. First, return on capital employed (ROCE) was used as a measure of profitability. In this study, the target variable was a binary variable that was set to 1 if it was one standard deviation greater than the mean value, and 0 if it was less than that, expressed as ROCE_1. Binary variabilisation is a procedure for iRF analysis preparation. In this case, we examined the 5-year sales growth rate. The dummy variable, D5SALES_1, was set to 1 if it was one standard deviation larger than the mean and 0 if it was smaller. If the firm was liquidated or went bankrupt, this value was set to 1. Otherwise, it became 0 and was expressed as DEAD. Samples containing missing values were excluded from the analysis, bringing the total number of samples to 6339. The descriptive statistics are presented in Table 2a. Table 2b–d provide information on other variables that were not used in analysis but may be useful in understanding the content of the data used in this study. Table 2b presents information on the distribution of countries. Table 2c indicates the distribution of industries. Table 2d provides descriptive statistics for the two variables related to firm size (sales and number of employees).
Analysis and results
First, we created an RF analysis for each case using ROCE_1, D5SALES_1 and DEAD as target variables. The features included 18 types of management quality indicators. We used the R package of randomForest v.4.6–14 (Liaw and Wiener, 2002). For the analysis, the number of features used to create each decision tree (mtry) was determined by tuneRF as the optimal state when the out-of-bag estimate of error rate was the smallest. The number of decision trees to be created was found to be stable when there were more than 100 in all cases. Thus, default values were used for estimates.
Table 3 depicts the results of the analysis in order of feature importance. The top indicators were deduced to be almost identical: talent3 (removing poor performers), perf10 (performance clarity), talent6 (retaining human capital), perf8 (target time horizon) and talent2 (rewarding high performance). Table 3 highlights the importance of revealing the criteria for determining whether results were achieved in an understandable manner, improving the treatment of those who exceed these criteria and retraining and reassigning those who do not.
Second, iRF analyses were performed. The calculation was performed using the R package of iRF v.2.0.0 (Basu and Kumbier, 2017). The ‘cutoff.unimp.feature’ was set to 0.3. The ‘cutoff.unimp.feature’ is a non-negative fraction r. If provided, features with Gini importance score in the top 100*(1−r) percentile were used to determine feature interactions. The ‘n.bootstrap’ is the number of bootstrap replicates used to calculate the stability scores of interactions. It was set to 20. Other parameters in the iRF analysis remained in their default state as the result of tuning in the RF analysis was nearly the same as that of the iRF analysis in its default state. The results are presented in Table 4a–c, where 63 most stable interactions for each estimation are shown. The remaining results were removed for cleaner visualisation. The number under each interaction indicates the stability level. Notably, the stability and importance of perf8 (target time horizon) stand out. The perf8 is represented boldly in Table 4a–c.
The question of whether the firm could set short-term goals based on a long-term perspective played a key role because it is complementary to many other indicators. When relating to employees based on a certain outcome measure, the measure must be evaluated from this perspective. This importance of perf8 is shown to be particularly important in ROCE_1 and DEAD, where the combination of perf8 and talent2 is highlighted in red. We also coloured other important combinations to make them more prominent. However, with respect to sales growth, talent2 was important. There was a strong complementarity between the good treatment of high performers and enrichment of various aspects of performance measurement.
Conclusions
According to the findings of the study, it is relatively important to ask, ‘Are we rewarding high performers properly’? ‘Are we reassigning and retraining poor performers’? and ‘Are the criteria for high and low performance firmly established’? Furthermore, it was deduced that a firm’s ability or inability to set short-term goals based on long-term perspectives plays a vital role because it is complementary to many other indicators. This seems to suggest that it is important to design outcomes and reward incentives appropriately, as suggested by Roberts and Milgrom (1992) and Lazear (2000).
Burdin and Kato (2021) surveyed many studies on complementarity in organisations. As a result, the authors argue that high-performance companies in Japan, the US and Europe tend to adopt high involvement work systems (HIWS) as a common feature.
In other words, authors argue that organisations in which multiple systems cluster together and function in a complementary manner achieve high performance. They argue that such HIWS are characterised by three major factors: opportunities, incentives and ability/skill.
This finding is consistent with the machine learning findings of this study, which reveal the following important results: set short-term goals that lead to long-term goals; clarify the criterion by which you can determine whether individual employees can achieve results that are consistent with those goals (incentives); simultaneously, high performers who exceed the criterion must be offered preferential treatment, whereas poor performers should be reassigned and retrained (opportunities and ability/skill).
As a consequence of learning extensive data encompassing many organisations globally utilising iRF, our study has corroborated what Burdin and Kato (2021) observed after evaluating several studies on a more microscopic and specific level. It is usually assumed that schemes remunerated based on outcomes are often designed on a short-term perspective. However, this study confirms that the design of such schemes can be accomplished with due consideration for long-term perspectives, which is complementary to many factors, especially those related to talent management. From a practical experience, it is notably difficult to set short-term goals consistent with long-term goals, and it is even more difficult to create a criterion for judging outcomes that most employees will agree with. The study results highlight the significance of tenaciously tackling such difficult challenges.
Nevertheless, the following challenges remain. The first is the issue of endogeneity. Bloom et al. (2013) confirm the causality of 18 management quality indicators in field experiments; these indicators have a positive impact on performance improvement. However, it must be stated that there is still a need to consider this issue. Second, and related to the first issue, it is worth noting that management quality indicators cover a variety of areas. We would not have a visible, comprehensive image of the complicated interrelationships across institutions in an organisation if this were not the case. Whether the 18 indicators used in this study do so must be examined in future studies; moreover, solving these problems will continue to be a challenge for the future.
Data availability
The data used in this paper are widely available to the public and do not require research ethics review. The detailed information of the data on how to obtain them is described in Bloom et al. (2012) in detail. All data and variables are accessible under: https://worldmanagementsurvey.org/survey-data/download-data/download-survey-data/.
References
Athey S, Stern S (1998) An empirical framework for testing theories about complementarity in organizational design, No. w6600. National Bureau of Economic Research.
Basu S, Kumbier K, Brown JB et al. (2018) Iterative random forests to discover predictive and stable high-order interactions. Proc Natl Acad Sci USA 115, 1943–1948.
Bloom N, Genakos C, Sadun R et al. (2012) Management practices across firms and countries. Acad Manag Perspect 26(1):12–33
Bloom N, Eifert B, Mahajan A et al. (2013) Does management matter? Evidence from India. Q J Econ 128(1):1–51
Boon C, Den Hartog DN, Lepak DP (2019) A systematic review of human resource management systems and their measurement. J Manag 45(6):2498–2537
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Brynjolfsson E, Milgrom P (2013) Complementarity in organizations. In: Robert G, John R (eds) The handbook for organization economics. Princeton University Press, Princeton, NJ, pp. 11–55
Burdin G, Kato T (2021) Complementarity in employee participation systems: international evidence. IZA Discussion Paper No. 14694.
Basu S, Kumbier K (2017) iRF: iterative random forests. R version 2.0.0. https://CRAN.R-project.org/package=iRF.
Lazear EP (2000) Performance pay and productivity. Am Econ Rev 90(5):1346–1361
Liaw A, Wiener M (2002) Classification and regression by random forest. R News 2(3):18–22
Roberts J (2007) The modern firm: organizational design for performance and growth. Oxford University Press, Oxford
Roberts J, Milgrom P (1992) Economics, organization, and management. Prentice-Hall, Englewood Cliffs
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The author declares no competing interests.
Ethical approval
This paper is a study using only existing data with unlinkable anonymization and does not require ethical review.
Informed consent
Not applicable as the study did not involve human participants.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sannabe, A. How to improve SME performance using iterative random forest in the empirical analysis of institutional complementaritty. Humanit Soc Sci Commun 9, 114 (2022). https://doi.org/10.1057/s41599-022-01123-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1057/s41599-022-01123-6
- Springer Nature Limited