
Abstract
Recent research on partial least squares structural equation modeling (PLS–SEM) extended the classic importance–performance map analysis (IPMA) by taking the results of a necessary condition analysis (NCA) into consideration. By also highlighting necessary conditions, the combined importance–performance map analysis (cIPMA) offers a tool that enables better prioritization of management actions to improve a key target construct. In this article, we showcase a cIPMA’s main steps when using the SmartPLS 4 software. Our illustration draws on the technology acceptance model (TAM) used in the cIPMA’s original publication, which features prominently in business research.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Partial least squares (PLS) is a composite-based approach to structural equation modeling (SEM) that allows estimating complex interrelationships between constructs and their indicator variables (Hair et al. 2017; Lohmöller 1989; Wold 1982). PLS has gained much prominence in marketing applications of SEM, as evidenced in various reviews across different subfields (e.g., Guenther et al. 2023; Sarstedt et al. 2022, 2024; Wang et al. 2023). In recent years, researchers have introduced various extensions that expand on the original PLS–SEM algorithm and statistics (Hair et al. 2022, 2024). One such extension is the importance–performance map analysis (IPMA) that interprets the composite scores that the PLS–SEM algorithm generates as indicative of construct performances (Ringle and Sarstedt 2016; Streukens et al. 2017). The core of the IPMA is a two-dimensional map that contrasts these performance scores with the constructs’ total effects (i.e., the importance) on a specific target construct. The IPMA has been used in a variety of contexts, including research on customer loyalty (Damberg et al. 2022), sustainable consumption (Saari et al. 2021), and technology adoption (Mkedder and Özata 2024).
A potential limitation in the application of the standard IPMA is that it is restricted to a sufficiency logic. According to this logic, combinations of antecedent constructs are sufficient for impacting the target construct and each construct’s influence can, in principle, be compensated for by the others. This logic differs from the necessity perspective that has recently experienced more coverage in the marketing literature through the introduction of the necessary condition analysis (NCA; Dul 2016; 2020; Dul et al. 2021). The NCA identifies necessary conditions by establishing whether a specific condition must be present so that an outcome can exist. In other words, it establishes whether the absence of a specific condition prevents the outcome from existing. In the case of a necessary condition, the analysis can also quantify the level of an antecedent variable that must be achieved so that a specific outcome level in the target becomes possible. Originally proposed in a standard regression context, Richter and Hauff (2022) and Richter et al. (2023b, 2020) suggested using PLS–SEM-based composite scores as input for the NCA. Several authors have used this approach to introduce a necessity perspective into their PLS–SEM analyses (e.g., Sukhov et al. 2022; Tan et al. 2024; Tiwari et al. 2024).
Hauff et al. (2024) have recently merged these perspectives into a unifying analysis framework called combined IPMA (cIPMA). Their cIPMA introduces the results from the NCA as an additional dimension in an importance–performance map—see Riggs et al. (2024) for an initial application. Figure 1 shows a sample map from a cIPMA analysis. This hypothetical example considers three antecedent constructs with different total effects on the target construct (i.e., importance, shown on the x-axis) and the average construct values (i.e., performance, shown on the y-axis). The map also distinguishes between constructs with high versus low necessity effect sizes. Constructs that are not necessary for achieving the target construct’s desired level are shown as black circles (Y1 in Fig. 1), while the necessary constructs are displayed as white circles (Y2 and Y3 in Fig. 1). The size of the white circles indicates the percentage of observations whose case values are below those required for achieving a specific value in the target construct. Researchers have to specify this target value a priori, based on theoretical considerations or managerial requirements. In this example, the target value is set to 80. The larger the white circle, the larger the percentage of cases that have not achieved the necessary condition’s required level. Consequently, large white circles indicate that, from a necessity perspective, researchers should focus their attention on this aspect.

Combined importance–performance map analysis (cIPMA) example
Running a cIPMA requires some data management effort as researchers need to combine elements from different analysis steps. Addressing this concern, this tutorial article illustrates the main steps of a cIPMA using SmartPLS 4 (Ringle et al. 2024), currently the most prominent software for conducting PLS–SEM analyses (e.g., Cheah et al. 2023b; Sarstedt and Cheah 2019). Our illustrations draw on the same model and dataset as in Hauff et al. (2024) to facilitate the method’s implementation and interpretation of results.
Case study illustration using SmartPLS 4
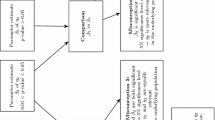
Hauff et al. (2024) outline an eight-step procedure for systematically applying the cIPMA (Fig. 2). Since this tutorial article endeavors to explain how to initiate the analyses and extract the relevant information from the output by using SmartPLS 4 software (Ringle et al. 2024), we focus on Steps 5 and 6, but also comment on the other elements of the analysis.

A systematic procedure for running the cIPMA
The authors illustrate the cIPMA’s application by using an extended version of Davis’s (1989) technology acceptance model (TAM; Fig. 3), which has served as a blueprint for researching consumer behavior in various contexts. The dataset used in the illustration draws on N = 174 responses from French consumers. Richter et al.’s (2023a) article introduces the dataset in detail.

Extended technology acceptance model (TAM)
The model and the dataset are included in SmartPLS 4 as a sample project, which we can install in the software with a mouse click. Do so by going to the Project window, click on Regression/PROCESS under Sample projects and thereafter select NCA (extended TAM) from the drop-down menu (Fig. 4). SmartPLS will include a new sample project in the Workspace menu on the right of the window (Fig. 5). Note that this project already includes the final NCA model and the dataset derived from the IPMA analysis. However, to demonstrate the analysis steps, we start by analyzing the PLS path model; do so by double-clicking on PLS–SEM for extended TAM (Fig. 5).

SmartPLS Project window

Workspace
SmartPLS then opens the Modeling window with the TAM readily specified (Fig. 6). Following the procedure that Hauff et al. (2024) outlined, the next step would be to run the standard PLS–SEM algorithm (i.e., by selecting Standardized for the Type of results option in the PLS–SEM algorithm’s start dialog; Step 3 in Fig. 2). Assess the measurement models’ reliability and validity in respect of these outcomes (Step 4 in Fig. 2). As part of this analysis, we also need to check whether all the indicator weights are positive. Here, we do not present the detailed analysis, which follows the well-known standards in PLS–SEM, but refer the reader to Richter et al. (2020) and to Hauff et al.’s (2024) Table A2 (in their “Appendix”).

Modeling window
We continue our illustration by running the IPMA (Step 5 in Fig. 2). To do so, we click on Calculate in the menu bar and select the option Importance–performance map analysis (IPMA) (Fig. 6). In the menu that opens, we choose Technology Use as the target construct, and All predecessors of the selected target construct under the IPMA results (Fig. 7, left tab). The lower part of the dialog box shows the indicators’ observed minimum and maximum values and the theoretical minimum and maximum values (Scale min and Scale max), which the software derives from the data structure. We see that the theoretical values in this illustration correspond to those considered in the original survey (i.e., the complete theoretical scales were used by respondents). If this were not the case, the estimated average performance values of the constructs would be biased along the empirical range of the indicators. In this case, PLS–SEM researchers advise to manually adjust the theoretical values in the Data window (i.e., by correcting the Scale min and Scale max in SmartPLS where necessary), which we could access by double-clicking on the dataset in the Workspace (Fig. 5). This is followed by clicking on Setup in the menu bar, where we can ultimately implement the desired changes and Update the file. To continue with the IPMA, we click on the PLS setup tab and select the settings shown in Fig. 7 (right tab), before clicking on Start calculation.

IPMA dialog box
Next, the SmartPLS software shows the estimates in the Results window. Figure 8 shows the graphical output of the results report. The numbers in the constructs are the average performance scores (i.e., the average rescaled constructs scores, which range from 0 to 100). For example, while Compatibility has a performance score of 61.557, Ease of use achieves a considerably higher performance score of 75.640. The numbers on the arrows represent the direct effects between the constructs. To extract the total effects that the antecedent constructs have on the final target construct (Technology use), click on Final results → Total effects. Figure 9 shows that Adoption intention has the strongest total effect, followed by Emotional value, Usefulness, and Compatibility.

IPMA results

Total effects
SmartPLS can display the standard importance–performance map (Fig. 10), which we can access by clicking on Quality criteria → Importance–performance map. However, the software currently (version 4.1.0.3) does not include a feature for creating a combined importance–performance map. To create such a combined map, we need to save these importance and performance scores as input for the cIPMA. For example, researchers could copy and paste the results on an Excel spreadsheet similar to the one which we provide as a cIPMA example on the following webpage: https://www.pls-sem.net/downloads/additional-useful-downloads/.

Importance–performance map
Having extracted the importance (i.e., total effects) and performance scores, we need to export the rescaled latent variable scores into a separate dataset for processing in the NCA. Do so by clicking on Create data file in the menu bar (Fig. 8). In the dialog box that opens (Fig. 11), we specify a file name (e.g., Latent variable scores for the NCA), check the box next to Rescaled latent variable scores, and confirm by clicking on Create. SmartPLS will now generate a new dataset under the project. Next, we click on Edit followed by Back to return to the Project window (Fig. 12). The new dataset called Latent variable scores for the NCA is now shown under the PLS–SEM for extended TAM project.

Create data file dialog box

SmartPLS project window with new dataset
We next initiate the NCA by using the previously extracted latent variable scores as input (Step 6 in Fig. 2). We do so by clicking on Regression in the menu bar. In the window that opens (Fig. 13), we have to specify the project to which the model should be assigned (here, Example—NCA (extended TAM), the model type (here, REGRESSION), and the model’s name (e.g., cIPMA). Next, we click on Save (Fig. 13).

Regression dialog box
In the window that opens, we first need to select the newly created Latent variable scores for the NCA dataset by clicking on the  symbol above the variable list (Fig. 14). Then, we drag and drop the dependent variable (LV scores—Technology use) on the modeling window. Next, we need to drag and drop the independent variables (LV scores—Adoption intention, LV scores—Compatibility, LV scores—Ease of Use, LV scores—Emotional value, LV scores—Usefulness) on the box labeled LV scores—Technology use in the modeling window. Figure 15 shows the final modeling window. We can now run the analysis by clicking on Calculate → Necessary condition analysis (NCA). In the dialog box that opens (Fig. 16), we choose 20 as the Number of steps for bottleneck table option as we are interested in identifying the necessary levels of the independent variables for a rescaled score of Technology use of 85 (which would not be shown, if we just selected the default 10 steps). Then, we click on Start calculation.
symbol above the variable list (Fig. 14). Then, we drag and drop the dependent variable (LV scores—Technology use) on the modeling window. Next, we need to drag and drop the independent variables (LV scores—Adoption intention, LV scores—Compatibility, LV scores—Ease of Use, LV scores—Emotional value, LV scores—Usefulness) on the box labeled LV scores—Technology use in the modeling window. Figure 15 shows the final modeling window. We can now run the analysis by clicking on Calculate → Necessary condition analysis (NCA). In the dialog box that opens (Fig. 16), we choose 20 as the Number of steps for bottleneck table option as we are interested in identifying the necessary levels of the independent variables for a rescaled score of Technology use of 85 (which would not be shown, if we just selected the default 10 steps). Then, we click on Start calculation.

Regression modeling window

Regression modeling window with model

NCA setup
SmartPLS now opens the results report that documents the metrics that are relevant for the NCA. Specifically, under Final results → Ceiling line effect size overview (Fig. 17), we can request the effect size d. We focus on the effect size for the CE-FDH ceiling line, which is the relevant line for our data (see Hauff et al. 2024). The results show that Emotional value has the strongest necessary effect size (0.331), followed by Adoption intention (0.294), and Usefulness (0.243). We need to substantiate these effect sizes’ significances by running a permutation analysis. However, we will first complete the illustration of the NCA results’ output that is useful for the interpretation of findings, before running the NCA permutation in SmartPLS (as we know which variables show significant necessity effect sizes from our previous studies). For our analyses, we would first identify the significance of effect sizes and may then need to go back to these outputs to not make interpretations on not significant necessity effects.

NCA output (I)
For the cIPMA, we identify the percentage of cases that do not achieve the antecedent constructs’ required level to generate a specific level of Technology use. To request the corresponding table, go to Final results → Bottleneck tables—CE-FDH → Percentiles (Fig. 18). Hauff et al. (2024) assume a desired Technology use level of 85. Assuming this level, our results show that 39.080% of all cases did not achieve the necessary level of Adoption intention to enable such a Technology use score (see highlighted row in Fig. 18). Compared to Adoption intention, the percentage of cases that did not achieve the necessary level of Compatibility is considerably lower (8.621%).

NCA output (II)
In the next step (Step 7 in Fig. 2), we need to evaluate the structural model in terms of PLS–SEM and NCA results. For the former, we refer the reader to Richter et al. (2023a) and move directly to testing whether the necessity effect size d is significant. We do so by returning to the Modeling window by clicking on Edit in the menu bar. Next, we go to Calculate and NCA permutation. In the dialog box that opens (Fig. 19), we retain the default settings (5000 permutations, parallel processing, a significance level of 0.05, and a fixed seed) and click on Start calculation. In the Results window that opens, we go to Final results → Ceiling line effect size overview → CE-FDH. We find that all necessity effect sizes are significantly larger than zero, since the estimates lie above the 95% percentile. For example, the necessity effect size of Adoption intention is 0.294, which is higher than the 95% percentile of 0.180 (Fig. 20). These results are further supported by the p values, which are all lower than 0.05.

NCA permutation dialog box

NCA permutation results
Table 1 summarizes the results of the IPMA and the NCA. Specifically, the table shows the importance of constructs for Technology use and average performance scores from PLS–SEM. In addition, it shows the percentage of cases that do not meet the necessity condition (i.e., those cases that remain below the necessary level of 85 for Technology use), and the necessity effect size d, including the p value for each antecedent construct. In terms of the necessity conditions, we find that all antecedent constructs are indeed necessary, as their effect sizes are medium (i.e., 0.1 ≤ d < 0.3) and significant (p < 0.05).
We can now use the results from Table 1 to generate the combined importance–performance map with (1) the importance scores on the x-axis, (2) the performance scores on the y-axis, (3) the circle type indicating whether the antecedent construct is necessary (white = yes, black = no), and (4) the size of the white circles indicating the percentage of cases that do not achieve the required levels. To do so, we may use the Excel template, which we can access at https://www.pls-sem.net/downloads/additional-useful-downloads/. In our case, all five conditions are necessary, so we always use the percentage of cases that do not meet the required level as the input for the size of the white circle. If a condition is not necessary, the size of the black circle is standardized to 1.
Entering the values from Table 1 generates the combined importance–performance map shown in Fig. 21.Footnote 1 In line with Hauff et al. (2024), the results suggest that Adoption intention is highly important and already shows a high performance. The NCA adds to this basic IPMA result, since its results identify several necessary conditions for Technology use. Specifically, 39% of the cases did not achieve Adoption intention’s required level to produce the desired performance level of 85 for Technology use. Despite their relatively low importance obtained by PLS–SEM, Usefulness and Ease of use warrant attention, as many cases do not achieve the required levels (47% for Usefulness, 29% for Ease of use). Failure to do so would hinder Technology use’s improvement to the desired level. Finally, while Emotional value and Compatibility are also necessary, only few cases fail to achieve the required levels (namely 6%, and 9%). Consequently, these constructs should receive less priority.

Combined importance–performance map of the TAM
Observations and conclusions
During the last decade, research on PLS–SEM has made considerable progress regarding advancing the method’s capabilities—see, for example, Cheah et al. (2023a), Richter and Tudoran (2024), and Sarstedt and Liu (2024). One such extension is Hauff et al.’s (2024) cIPMA, which combines results from an IPMA and NCA to form a joint map that allows managerial actions seeking to improve a certain target construct. The IPMA may, for example, identify certain antecedent constructs of relatively minor importance and performance, while they are simultaneously necessary to realize a desired value of the target construct. Similarly, in the same context, a construct may be important, but not necessary. The cIPMA allows its users to identify such relationships and dependencies. To facilitate its adoption, this article demonstrates the implementation of the cIPMA by means of the SmartPLS 4 software, which features prominently in marketing research and beyond (e.g., Cheah et al. 2023b; Richter et al. 2022; Sarstedt and Cheah 2019). Our step-by-step illustration of how to run the cIPMA in SmartPLS helps researchers and practitioners to introduce a necessity perspective in their IPMA.
While the cIPMA offers a valuable way of combining sufficiency and necessity perspectives, future research should extend its scope further. For example, researchers may investigate routines that test the associations between the constructs involved in PLS–SEM when a specific bottleneck identified in the NCA is bypassed and their implications for the interpretation of should-have factors. Also, researchers may engage in discussing and evaluating if and how indirect or mediation effects could be integrated into the NCA and therewith cIPMA. Likewise, advancements such as in Streukens et al. (2017) who have extended the standard IPMA to accommodate nonlinear effects whose specification and estimation has become more prominent (Basco et al. 2021) may be integrated in a cIPMA context. Researchers may also engage further in the discussion of relevant aspects related to the philosophies (Dul 2024a) and core research design elements when triangulating routines and methods (e.g., related to sampling and sample size, see for instance, Dul 2024b).
The cIPMA also provides relevant input to further conceptualize on the importance–performance management toolset itself. Sever (2015), for instance, outlined that further conceptualization is needed with regards to the definition of the term importance, the definition of thresholds to demark the cut-off between high and low performance, and the differentiation of attributes positioned in the same quadrant and close to thresholds. The cIPMA offers input to all these areas of concern. The integration of the necessity logic into the IPMA does not only offer relevant new input to the definition of importance but can also aid the definition of relevant threshold levels and guide the interpretation of constructs positioned within quadrants of the map. Researchers engaged in the development of the managerial toolset are invited to combine and test our approach in combination with or contrast to previous developments (such as sensitivity analyses, iso-rating lines and further).
Finally, there is room for researchers to address the interpretation of findings when assumptions that underly our cIPMA approach are not met. This relates, for instance, to research designs in which constructs use indicators with different scales (e.g., a construct using indicators measured on a scale from 1 to 5 and 1 to 7). While all of the above are relevant areas to further advance the cIPMA and its related toolsets, we are confident that the method offers a valuable means to advance both managerial decision making and academic research.
Data availability
The dataset used and the Excel file employed for additional cIPMA analyses are publicly available on the website https://www.pls-sem.netunderDownloads. See also Richter et al. (2023a).
Notes
For clarity, we also included construct labels.
References
Basco, R., J.F. Hair, C.M. Ringle, and M. Sarstedt. 2021. Advancing family business research through modeling nonlinear relationships: Comparing PLS–SEM and multiple regression. Journal of Family Business Strategy 13 (3): 100457.
Cheah, J.-H., W. Kersten, C.M. Ringle, and C. Wallenburg. 2023a. Guest editorial: Predictive modeling in logistics and supply chain management research using partial least squares structural equation modeling. International Journal of Physical Distribution and Logistics Management 53 (7/8): 709–717.
Cheah, J.-H., F. Magno, and F. Cassia. 2023b. Reviewing the SmartPLS 4 software: The latest features and enhancements. Journal of Marketing Analytics 12 (1): 97–107.
Damberg, S., M. Schwaiger, and C.M. Ringle. 2022. What’s important for relationship management? The mediating roles of relational trust and satisfaction for loyalty of cooperative banks’ customers. Journal of Marketing Analytics 10 (1): 3–18.
Davis, F.D. 1989. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Quarterly 13 (3): 319–340.
Dul, J. 2016. Necessary condition analysis (NCA): Logic and methodology of “necessary but not sufficient” causality. Organizational Research Methods 19 (1): 10–52.
Dul, J. 2020. Conducting necessary condition analysis. London: SAGE.
Dul, J. 2024a. A different causal perspective with necessary condition analysis. Journal of Business Research 177: 114618.
Dul, J. 2024b. How to sample in necessary condition analysis (NCA). European Journal of International Management 23 (1): 1–12.
Dul, J., S. Hauff, and Z. Tóth. 2021. Necessary condition analysis in marketing research. In Handbook of research methods for marketing management, ed. R. Nunkoo, V. Teeroovengadum, and C.M. Ringle, 51–72. Cheltenham: Edward Elgar.
Guenther, P., M. Guenther, C.M. Ringle, G. Zaefarian, and S. Cartwright. 2023. Improving PLS–SEM use for business marketing research. Industrial Marketing Management 111: 127–142.
Hair, J.F., G.T.M. Hult, C.M. Ringle, M. Sarstedt, and K.O. Thiele. 2017. Mirror, mirror on the wall: A comparative evaluation of composite-based structural equation modeling methods. Journal of the Academy of Marketing Science 45 (5): 616–632.
Hair, J.F., G.T.M. Hult, C.M. Ringle, and M. Sarstedt. 2022. A primer on partial least squares structural equation modeling (PLS–SEM), 3rd ed. Thousand Oaks: SAGE.
Hair, J.F., M. Sarstedt, C.M. Ringle, and S.P. Gudergan. 2024. Advanced issues in partial least squares structural equation modeling (PLS–SEM), 2nd ed. Thousand Oaks: SAGE.
Hauff, S., N.F. Richter, M. Sarstedt, and C.M. Ringle. 2024. Importance and performance in PLS–SEM and NCA: Introducing the combined importance–performance map analysis (cIPMA). Journal of Retailing and Consumer Services 78: 103723.
Lohmöller, J.-B. 1989. Latent variable path modeling with partial least squares. Heidelberg: Physica.
Mkedder, N., and F.Z. Özata. 2024. I will buy virtual goods if I like them: A hybrid PLS–SEM-artificial neural network (ANN) analytical approach. Journal of Marketing Analytics 12 (1): 42–70.
Richter, N.F., and S. Hauff. 2022. Necessary conditions in international business research: Advancing the field with a new perspective on causality and data analysis. Journal of World Business 57: 101310.
Richter, N.F., and A.A. Tudoran. 2024. Elevating theoretical insight and predictive accuracy in business research: Combining PLS–SEM and selected machine learning algorithms. Journal of Business Research 173: 114453.
Richter, N.F., S. Schubring, S. Hauff, C.M. Ringle, and M. Sarstedt. 2020. When predictors of outcomes are necessary: Guidelines for the combined use of PLS–SEM and NCA. Industrial Management and Data Systems 120 (12): 2243–2267.
Richter, N.F., S. Hauff, C.M. Ringle, and S.P. Gudergan. 2022. The use of partial least squares structural equation modeling and complementary methods in international management research. Management International Review 62: 449–470.
Richter, N.F., S. Hauff, A.E. Kolev, and S. Schubring. 2023a. Dataset on an extended technology acceptance model: A combined application of PLS–SEM and NCA. Data in Brief 48: 109190.
Richter, N.F., S. Hauff, C.M. Ringle, M. Sarstedt, A.E. Kolev, and S. Schubring. 2023b. How to apply necessary condition analysis in PLS–SEM. In Partial least squares path modeling: Basic concepts, methodological issues and applications, ed. H. Latan, J.F. Hair, and R. Noonan, 267–297. Cham: Springer.
Ringle, C.M., and M. Sarstedt. 2016. Gain more insight from your PLS–SEM results: The importance–performance map analysis. Industrial Management and Data Systems 116 (9): 1865–1886.
Ringle, C.M., S. Wende, and J.-M. Becker. 2024. SmartPLS 4. Bönningstedt: SmartPLS. https://www.smartpls.com/.
Riggs, R., C.M. Felipe, J.L. Roldán, and J.C. Real. 2024. Deepening big data sustainable value creation: Insights using IPMA, NCA, and cIPMA. Journal of Marketing Analytics. Advance online publication. https://doi.org/10.1057/s41270-024-00321-2
Saari, U.A., S. Damberg, L. Frömbling, and C.M. Ringle. 2021. Sustainable consumption behavior of Europeans: The influence of environmental knowledge and risk perception on environmental concern and behavioral intention. Ecological Economics 189: 107155.
Sarstedt, M., and J.H. Cheah. 2019. Partial least squares structural equation modeling using SmartPLS: A software review. Journal of Marketing Analytics 7 (3): 196–202.
Sarstedt, M., and Y. Liu. 2024. Advanced marketing analytics using partial least squares structural equation modeling (PLS–SEM). Journal of Marketing Analytics 12 (1): 1–5.
Sarstedt, M., J.F. Hair, M. Pick, B.D. Liengaard, L. Radomir, and C.M. Ringle. 2022. Progress in partial least squares structural equation modeling use in marketing research in the last decade. Psychology and Marketing 39 (5): 1035–1064.
Sarstedt, M., S.J. Adler, C.M. Ringle, G. Cho, A. Diamantopoulos, H. Hwang, and B.D. Liengaard. 2024. Same model, same data, but different outcomes: Evaluating the impact of method choice in structural equation modeling. Journal of Product Innovation Management, Advance online publication.
Sever, I. 2015. Importance–performance analysis: A valid management tool? Tourism Management 48: 43–53.
Streukens, S., S. Leroi-Werelds, and K. Willems. 2017. Dealing with nonlinearity in importance–performance map analysis (IPMA): An integrative framework in a PLS–SEM context. In Partial least squares path modeling, ed. H. Latan and R. Noonan, 367–403. Cham: Springer.
Sukhov, A., L.E. Olsson, and M. Friman. 2022. Necessary and sufficient conditions for attractive public transport: Combined use of PLS–SEM and NCA. Transportation Research Part A: Policy and Practice 158: 239–250.
Tan, K.-L., C.-M. Leong, and N.F. Richter. 2024. Navigating trust in mobile payments: Using necessary condition analysis to identify must-have factors for user acceptance. International Journal of Human-Computer Interaction. https://doi.org/10.1080/10447318.2024.2338319.
Tiwari, P., R.P.S. Kaurav, and K.Y. Koay. 2024. Understanding travel apps usage intention: Findings from PLS and NCA. Journal of Marketing Analytics 12 (1): 25–41.
Wang, S., J.-H. Cheah, C.Y. Wong, and T. Ramayah. 2023. Progress in partial least squares structural equation modeling use in logistics and supply chain management in the last decade: A structured literature review. International Journal of Physical Distribution and Logistics Management. https://doi.org/10.1108/IJPDLM-06-2023-0200.
Wold, H. 1982. Soft modeling: The basic design and some extensions. In Systems under indirect observations: Part II, ed. K.G. Jöreskog and H. Wold, 1–54. Amsterdam: North-Holland.
Acknowledgements
This article uses the statistical software SmartPLS (https://www.smartpls.com). Christian M. Ringle acknowledges a financial interest in SmartPLS.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
This research uses the statistical software SmartPLS 4 (https://www.smartpls.com/). Christian M. Ringle acknowledges a financial interest in SmartPLS.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sarstedt, M., Richter, N.F., Hauff, S. et al. Combined importance–performance map analysis (cIPMA) in partial least squares structural equation modeling (PLS–SEM): a SmartPLS 4 tutorial. J Market Anal (2024). https://doi.org/10.1057/s41270-024-00325-y
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1057/s41270-024-00325-y