
Abstract
Uplift modeling, a predictive modeling technique, empowers marketers or other researchers to identify the ‘true’ treatment responders who would be most positively influenced by the treatment or intervention through uncovering their characteristics separately from the characteristics of baseline or control responders (that is, those who would have responded anyway). This article briefly reviews the concept of uplift modeling and extends the current work to multiple treatment situations (where at least two treatments are available as options). It discusses the mathematical problem of optimizing treatment at the individual level, and proposes a practical heuristic solution. Finally, it presents a framework accounting for the variability in estimates when handling multiple assignments. An example from an online retailer is used to illustrate the methodologies.


Similar content being viewed by others


Notes
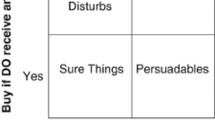
We will later introduce the concept of uplift modeling, where
 would represent the incremental response (or lift) from the baseline control group. The objective function would then be to maximize the number of incremental responders due to treatment (over natural responders).
would represent the incremental response (or lift) from the baseline control group. The objective function would then be to maximize the number of incremental responders due to treatment (over natural responders).There may be a different cost associated with contacting each individual – for example, the highest value customers may be reached with outbound telemarketing but the rest with a lower cost touch such as direct mail or email. Alternatively, higher value customers may have a different service level so the direct mail creative material for them may be different, or customers in different geographic regions may be contacted differently.
Prescriptive analytics is a recently popular industry term for applying analytics to support decision making, similar to operations research and management science; see Lustig et al (2010) and Banerjee et al (2013).
In marketing, this means contacting them would produce a negative effect. This can happen in certain retention efforts where customer contacts could lead to a higher attrition rate (sometimes known as ‘waking up the sleeping dog’ phenomenon). In medicine, this refers to the situation where the medical treatment has an adverse effect on certain individuals.
Separating model training and model assessment in randomly split training sample and holdout sample, respectively, is a standard practice recommended in the machine learning or data mining literature to minimize the bias of model assessment; see, for example, Hastie et al (2011) and James et al (2013).
Alternative clustering algorithms can be attempted and the number of clusters, K, can be pre-specified or determined through data analysis such as a scree plot; see Hastie et al (2011) for example.
In case more than one cluster solution is available (because of different clustering algorithms or different uplift models), one may choose the cluster solution with the cluster level lift scores as far from the overall sample lift scores as possible, that is, the solution such that the following Euclidean distance is the greatest, in order to support optimization: Euclidean distance to the overall sample mean=
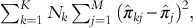 where
where  are the overall sample lift scores for treatments 1, …, M, respectively (averaging over all individuals in the entire holdout sample), and N
k
is the sample size of cluster k.
are the overall sample lift scores for treatments 1, …, M, respectively (averaging over all individuals in the entire holdout sample), and N
k
is the sample size of cluster k.Details of the data can be found at Kevin Hillstrom’s site at: http://blog.minethatdata.com/2008/03/minethatdata-e-mail-analytics-and-data.html. The data set has been analyzed in other papers such as Kane et al (2014).
In this example, two original clusters are merged into cluster 1 due to low quantities.
The efficient frontier can be calculated in multiple ways. It can be obtained by solving the MVO problem (5) in the section ‘A risk/return tradeoff approach’, or by solving one of two equivalent formulations: minimize the variance subject to a constraint on the expected lift, or maximize the expected lift subject to a constraint on the variance. See Chapter 7 in Fabozzi et al (2007) for a discussion of the three equivalent approaches.
 would represent the incremental response (or lift) from the baseline control group. The objective function would then be to maximize the number of incremental responders due to treatment (over natural responders).
would represent the incremental response (or lift) from the baseline control group. The objective function would then be to maximize the number of incremental responders due to treatment (over natural responders).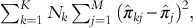 where
where  are the overall sample lift scores for treatments 1, …, M, respectively (averaging over all individuals in the entire holdout sample), and N
k
is the sample size of cluster k.
are the overall sample lift scores for treatments 1, …, M, respectively (averaging over all individuals in the entire holdout sample), and N
k
is the sample size of cluster k.References
Angrist, J.D. and Pischke, J.-S. (2014) Mastering Metrics: The Path from Cause to Effect, Princeton, NJ: Princeton University Press.
Banerjee, A., Bandyopadhyay, T. and Acharya, P. (2013) Data analytics: Hyped up aspirations or true potential? Vikapla 38 (4), http://www.vikalpa.com/pdf/articles/2013/04-Perspectives.pdf, accessed 20 April 2015.
Ben-Tal, A., El Ghaoui, L. and Nemirovski, A. (2009) Robust Optimization, Princeton, NJ: Princeton University Press.
Bertsimas, D. and Tsitsiklis, J.N. (1997) Introduction to Linear Programming, Belmont, MA: Athena Scientific.
Cai, T., Tian, L., Wong, P.H. and Wei, L.J. (2011) Analysis of randomized comparative clinical trial data for personalized treatment selections. Biostatistics 12 (2): 270–282.
Cornuejols, G. and Tutuncu, R. (2007) Optimization Methods in Finance, New York, NY: Cambridge.
Dasgupta, S., Papadimitriou, C.H. and Vazirani, U.V. (2006) Algorithms, New York, NY: McGraw-Hill.
Davison, A.C. and Hinkley, D.V. (1997) Bootstrap Methods and Their Applications, Cambridge, UK: Cambridge University Press.
Efron, B. and Tibshirani, R.J. (1993) An Introduction to the Bootstrap. Chapman & Hall/CRC.
Fabozzi, F.J., Kolm, P.N., Pachamanova, D.A. and Focardi, S.M. (2007) Robust Portfolio Optimization and Management, Hoboken, NJ: Wiley.
Goldberg, D.E. (1989) Genetic Algorithms in Search, Optimization & Machine Learning, Addison-Wesley.
Guelman, L., Guillen, M. and Perez-Marin, A.M. (2014) A survey of personalized treatment models for pricing strategies in insurance. Insurance: Mathematics and Economics 58: 68–76.
Hastie, T., Tibshirani, R. and Friedman, J. (2011) The Elements of Statistical Learning. 2nd edn. New York, NY: Springer.
Haughton, D., Haughton, J. and Lo, V.S.Y. (2016) Cause-and-Effect Business Analytics, CRC/Chapman & Hall.
Holland, C. (2005) Breakthrough Business Results with MVT, Hoboken, NJ: Wiley.
James, G., Witten, D., Hastie, T. and Tibshirani, R. (2013) An Introduction to Statistical Learning: With Applications in R, New York, NY: Springer.
Kane, K., Lo, V.S.Y. and Jane, Z. (2014) Mining for the truly responsive customers and prospects using true-lift modeling: Comparison of new and existing methods. Journal of Marketing Analytics 2 (4): 218–238.
Kubiak, R. (2012) Net Lift Model for Effective Direct Marketing Campaigns at 1800flowers.com. SAS Global Forum, Paper 108-2012.
Ledolter, J. and Swersey, A.J. (2007) Testing 1–2–3: Experimental Design with Applications in Marketing and Service Operations, Stanford, CA: Stanford University Press.
Lo, V.S.Y. (2002) The true-lift model – A novel data mining approach to response modeling in database marketing. ACM SIGKDD Explorations 4 (2): 78–86.
Lo, V.S.Y. (2008) New opportunities in marketing data mining. In: J. Wang (ed.) Encyclopedia of Data Warehousing and Mining. 2nd edn. Idea Group Publishing.
Lund, B. (2012) Direct Marketing Profit Model. In: Proceedings of Midwest SAS Users Group, Paper CI-04.
Lustig, I., Dietrich, B., Johnson, C. and Dziekan, C. (2010) The analytics journey. Analytics Magazine, Nov/Dec: 11–18.
Manzi, J. (2012) Uncontrolled: The Surprising Payoff of Trial-and-Error for Business, Politics, and Society, Philadelphia, PA: Basic Books.
Markowitz, H. (1952) Portfolio selection. Journal of Finance VII (1): 77–91.
Michalewicz, Z. and Fogel, D.B. (2002) How to Solve It: Modern Heuristics, Berlin, Germany: Springer.
Nassif, H., Kuusisto, F., Burnside, E.S. and Shavlik, J. (2013) Uplift modeling with ROC: An SRL case study. Proceedings of the International Conference on Inductive Logic Programming (ILP’13), Rio de Janeiro, Brazil.
Papadimitriou, C.H. and Steiglitz, K. (1998) Combinational Optimization: Algorithms and Complexity, Mineola, NY: Dover.
Pisinger, D. (1995) Algorithms for knapsack problems. PhD dissertation, Department of Computer Science, University of Copenhagen.
Porter, D. (2013) Pinpointing the persuadables: Convincing the right voters to support Barack Obama. Presented at Predictive Analytics World; October, Boston, MA. http://www.predictiveanalyticsworld.com/patimes/pinpointing-the-persuadables-convincing-the-right-voters-to-support-barack-obama/, accessed 1 March 2013 (available with free subscription).
Radcliffe, N.J. (2007a) Using control groups to target on predicted lift. DMA Analytic Annual Journal (Spring): 14–21.
Radcliffe, N.J. (2007b) Generating Incremental Sales: Maximizing the Incremental Impact of Cross-Selling, Up-Selling and Deep-Selling Through Uplift Modelling. Stochastic Solutions Limited.
Radcliffe, N.J. and Surry, P.D. (1999) Differential response analysis: Modeling true response by isolating the effect of a single action. Proceedings of Credit Scoring and Credit Control VI, Credit Research Centre, University of Edinburgh Management School.
Radcliffe, N.J. and Surry, P.D. (2011) Real-world uplift modelling with significance-based uplift trees. Portrait Technical Report TR-2011-1 and Stochastic Solutions White Paper 2011. http://stochasticsolutions.com/pdf/sig-based-up-trees.pdf, accessed 31 December 2011.
Rexer, K. (2012) 5th Annual Data Mining Survey – 2011 Survey Summary Report. Rexer Analytics.
Rexer, K. (2013) 6th Annual Data Mining Survey – 2012 Survey Summary Report. Rexer Analytics.
Samuelson, D.A. (2013) Analytics: Key to Obama’s victory. OR/MS Today February: 20–24.
Scherer, M. (2012) How Obama’s data crunchers helped him win. CNN News.http://www.cnn.com/2012/11/07/tech/web/obama-campaign-tech-team/index.html?hpt=hp_bn5, accessed 7 November 2012.
Siegel, E. (2011) Upilft Modeling: Predictive Analytics Can’t Optimize Marketing Decisions Without It. Prediction Impact white paper sponsored by Pitney Bowes Business Insight.
Siegel, E. (2013a) The real story behind Obama’s election victory. The Fiscal Times 01/21/2013. http://www.thefiscaltimes.com/Articles/2013/01/21/The-Real-Story-Behind-Obamas-Election-Victory.aspx#page1, accessed 31 January 2013.
Siegel, E. (2013b) Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die, New Jersey: Wiley.
Siroker, D. and Koomen, P. (2013) A/B Testing: The Most Powerful Way to Turn Clicks Into Customers, Hoboken, NJ: Wiley.
Storey, A. and Cohen, M. (2002) Exploiting response models: Optimizing cross-sell and up-sell opportunities in banking. In Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 325–331, ACM, New York, NY.
Taha, H.A. (2010) Operations Research. 9th edn. Prentice-Hall.
Williams, H.P. (2003) Model Building in Mathematical Programming. 4th edn. Wiley.
Yong, F.H. (2015) Quantitative methods for stratified medicine. PhD dissertation, Department of Biostatistics, Harvard T.H. Chan School of Public Health, Harvard University.
Zenios, S.A. (2007) Practical Financial Optimization: Decision Making for Financial Engineers, Malden, MA: Blackwell Publishing.
Acknowledgements
The authors would like to thank Florence H. Yong and Kathleen Kane for reviewing an earlier version of this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Lo, V., Pachamanova, D. From predictive uplift modeling to prescriptive uplift analytics: A practical approach to treatment optimization while accounting for estimation risk. J Market Anal 3, 79–95 (2015). https://doi.org/10.1057/jma.2015.5
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1057/jma.2015.5