
Abstract
Metabarcoding potentially offers a rapid and cheap method of monitoring biodiversity, but real-world applications are few. We investigated its utility in studying patterns of litter arthropod diversity and composition in the tropics. We collected litter arthropods from 35 matched forest-plantation sites across Xishuangbanna, southwestern China. A new primer combination and the MiSeq platform were used to amplify and sequence a wide variety of litter arthropods using simulated and real-world communities. Quality filtered reads were clustered into 3,624 MOTUs at ≥97% similarity and the taxonomy of each MOTU was predicted. We compared diversity and compositional differences between forests and plantations (rubber and tea) for all MOTUs and for eight arthropod groups. We obtained ~100% detection rate after in silico sequencing six mock communities with known arthropod composition. Ordination showed that rubber, tea and forest communities formed distinct clusters. α-diversity declined significantly between forests and adjacent plantations for more arthropod groups in rubber than tea, and diversity of order Orthoptera increased significantly in tea. Turnover was higher in forests than plantations, but patterns differed among groups. Metabarcoding is useful for quantifying diversity patterns of arthropods under different land-uses and the MiSeq platform is effective for arthropod metabarcoding in the tropics.
Similar content being viewed by others

Introduction
Following anthropogenic pressure, global ecosystems have undergone more severe and rapid changes during the past few decades than in any other period in Earth history1,2. These changes constitute the greatest environmental challenges we face today, especially anthropogenic climate change, biodiversity loss and biological invasions2. The massive and ongoing environmental degradation in the Anthropocene emphasizes the need for efficient and fast methods of quantifying and monitoring the spatial and temporal dynamics of biodiversity3,4. This is especially true for megadiverse, highly cryptic and relatively small-sized organisms, where traditional methods of biodiversity assessment are relatively slow, expensive and time consuming5,6. Metabarcoding, the combination of DNA taxonomy and high-throughput sequencing, is a promising tool for the rapid assessment and monitoring of biodiversity in mixed, bulk samples7. Metabarcoding has been successfully applied to taxa that are difficult to assess with traditional methods, including protists8,9, fungi10,11, bacteria12,13, nematodes14,15, and annelids16,17. These studies not only reveal the hidden diversity within these taxa by allowing a more complete discovery of taxonomic diversity when compared to traditional methods, but also reliably quantify patterns of diversity and assemblage composition along environmental gradients. This information is critical for timely biodiversity monitoring, conservation management, land-use planning, and environmental impact assessment.
Although arthropods constitute the most abundant and diverse non-microbial organisms on Earth18,19,20, comprehensive information on large-scale patterns of richness, endemism and biogeography are lacking, especially in the tropics21. Arthropods are hyperdiverse, highly cryptic and relatively small-sized organisms and their low representation in biodiversity databases is due to the high cost (in terms of money, time and labor) associated with sorting and identifying samples from large-scale inventories5,6. Cheap, quick and efficient monitoring methods are therefore urgently needed to address this impediment. Metabarcoding has been successfully used to assess patterns of arthropod diversity and assemblage composition, and this technique has proven to be faster, cheaper, and more comprehensive than traditional morphological taxonomy5,22. However, previous metabarcoding studies on non-microbial organisms have mostly used Roche 454 platforms5,22,23, and to our knowledge only one study has used the MiSeq platform for Malaise trapped arthropod samples24. Since the Miseq platform is more cost-efficient than Roche 454 for metabarcoding6,22,23, and can produce up to ca. 15 times the number of reads produced by a Roche 454 FLX Titanium run22,25,26, it may represent a promising alternative for efficient biodiversity assessment and monitoring.
One limitation of metabarcoding is the efficiency of assigning taxonomy to molecular operational taxonomic units (MOTUs). Though the percentage of MOTUs assigned to order level is usually high, this is not the case for assignments at a lower taxonomic level (e.g. for insects; Order [96–99%], Family [17–37%], Genus [16–36%] and Species [16–35%]6). This problem is not due to the metabarcoding pipeline used, but rather to the lack of comprehensive and taxonomically reliable barcode databases for most taxa6,27. To enhance the utility of metabarcoding for large-scale and long-term biodiversity monitoring, it is important to increase the identification and standard barcoding of species, especially in the highly diverse tropics. Using a new primer combination targeting a 400 bp fragment of the COI gene and Illumina high-throughput sequencing, we seek to show the effectiveness of the Miseq platform for metabarcoding a wide variety of tropical arthropods. While most previous studies focused on general diversity patterns without inferring group-specific (e.g. order) differences5,6, we tried to detect finer patterns by assigning MOTUs to different classes and orders and analyzing diversity patterns for each order/class separately. To investigate the utility of DNA metabarcoding in a study of patterns of litter arthropod diversity across land-use types in Xishuangbanna, we address the following questions:
-
1
Can the MiSeq platform be used effectively for arthropod metabarcoding in the tropics?
-
2
Do clustered MOTUs indicate significant community differentiation across land-use types and measured environmental gradients?
-
3
Which arthropod groups show significant changes across land-uses and deserve further attention?
Results
In silico amplification, sequencing, OTU clustering and mock community validation
To test the efficiency of the MiSeq platform for arthropod metabarcoding, we verified whether the method worked successfully with mock communities. Firstly, we tested whether combining the primers MHemF28 and dgHCO219829 could successfully amplify (in silico PCR) the COI gene for arthropod sequences using 37 reference arthropod sequences combined in 6 different libraries with different numbers of reads. In PCR simulations, the primer set amplified the COI gene of all 37 arthropod species in accordance with each library’s input specifications (Table 1). The quality filtered reads of all mock communities except one (library 2) were faithfully clustered into the correct number of OTUs (Table 1). All OTUs had perfect matching with the reference sequences from which they were generated (Table S2).
Primer efficiency, Illumina sequencing and MOTU recovery on field samples
The primer set MHemF and dgHCO2198 showed high amplification success for a wide range of arthropod species and bulk arthropod samples (Fig. S1, Supporting Information). The total number of reads that passed the default Illumina filtering step was 2,628,704 96 (37,553 [mean] ± 10,373 [s.d.] per site) and the mean length of each read was 439 bp (range: 368–454 bp). After custom quality filtering (primers and barcodes stripped, and read length truncated), 2,573,479 reads (36,764 [mean] ± 10,361 [s.d.] per site) were retained (Table S3, Supporting Information). The dereplication step yielded 1,832,637 sequences (unique sequence with abundance >2) and 1,728,491 unique singletons. The 1,728,491 unique singletons were discarded while the 1,832,637 sequences were clustered into 3,624 MOTUs at 97% similarity. During MOTU clustering, 865 chimeras were detected and discarded.
Taxonomic identification of MOTUs from field samples
Out of the 3,624 MOTUs, UTAX predicted taxonomy for 3,588 MOTUs (99.0% prediction) while USEARCH gave top hits (≥75% identity to reference database) for 3,249 MOTUs (94.6% prediction). UTAX and USEARCH taxonomic assignments showed high similarity across arthropod groups. Out of the 261 MOTUs assigned to Hymenoptera by UTAX, 253 were also assigned by USEARCH (97% correspondence). Details of the comparison between the two taxonomic assignment algorithms (UTAX and USEARCH) for MOTUs assigned to Hymenoptera can be found in Table S4 (Supporting Information).
Differences in species diversity and composition across land-use types
Ordination plots showed that the habitat types have clearly distinct MOTU assemblages, with each habitat type forming a separate group (Fig. 1). Interestingly, forests associated with rubber were also distinct from forests associated with tea. The first axis of the ordination plot (NMDS1) was highly correlated with the horizontal distance between land-use pairs [positive], and elevation [negative], whereas NMDS2 was highly correlated with slope [negative], litter thickness [negative], canopy openness [negative], and litter chemistry (total carbon [negative], total nitrogen [positive], total phosphorus [positive], coarse fiber content [negative] and lignin content [negative]) (Table 2; Fig. S2, Supporting Information). Similar patterns of community composition were also observed across individual arthropod groups, with the exception of Chilopoda which had almost zero stress due to insufficient data (Figs S3–S9, Supporting Information).

R = rubber, T = tea, while rF and tF = forest matched with rubber and tea, respectively.
Local MOTU richness slightly increased with sampling size (total number of reads per site) but this increase did not affect overall α-diversity patterns (Fig. S10). The number of observed MOTUs correlated linearly with the number of rarefied MOTUs (Fig. S10). Pairwise differences in MOTU (α- and β-) diversity varied considerably between land use pairs and across arthropod groups. Overall, MOTU α-diversity was significantly higher in the forest sites adjacent to rubber (hereafter rubber-forest) than in rubber, but not significantly higher in forests adjacent to tea (hereafter tea-forest) than tea (Fig. 2). Pairwise alpha diversity patterns of the main arthropod groups also differed across land use types. Coleoptera richness was lower in tea and rubber plantations than adjacent forests, and richness of All MOTUs and Arachnida, was lower in rubber than in rubber-forests, Diptera richness was lower in tea than in tea-forests whereas Orthoptera richness was higher in tea than tea-forests. Blattodea, Hemiptera, Hymenoptera and Chilopoda richness did not differ across land-uses. Three-way (forest and rubber, forest and tea, and rubber and tea) alpha diversity patterns showed that All MOTUs, Coleoptera, and Hemiptera richness was significantly higher in forests than in rubber (Table 3). Arachnida, Coleoptera, and Diptera richness was significantly higher in forests than in tea. Orthoptera richness was significantly higher in tea than in forests. Coleoptera, Hemiptera and Orthoptera richness was significantly higher in tea than in rubber. We did not detect any substantial differences in diversity between terraced and non-terraced tea, and between monoculture and polyculture tea (Table S5, Supporting Information).

All tests are based on Kruskal–Wallis followed by Mann–Whitney post-hoc comparisons with Bonferroni correction. Significant differences between pairs [R vs. rF and T vs tF] are indicated with different lowercase characters (a, b). R = rubber, T = tea, while rF and tF = forest matched with rubber and tea, respectively.
We detected higher levels of turnover between sites (species replacement by new species not found elsewhere) in rubber-forests than in rubber for All MOTUs, Coleoptera, Diptera, Hymenoptera, Orthoptera and Arachnida (Fig. 3), with rubber characterized by higher nestedness (gain and loss of species also found elsewhere). Similarly, higher levels of turnover were detected in tea-forests than in tea for All MOTUs, Blattodea, Diptera, Orthoptera, Arachnida and Chilopoda (Fig. 4).

These were computed using 1000 bootstrap samples of 15 sites from each land use type. Significant differences between pairs are detected when the peaks of the density plots do not overlap with each other.

These were computed using 1000 bootstrap samples of 15 sites from each land use type. Significant differences between pairs are detected when the peaks of the density plots do not overlap with each other.
When considering species turnover against geographic distance between sampling locations, patterns of turnover with distance were highly significant for tea-forests and tea than for rubber-forests and rubber across arthropod groups (Table 4). There were no significant effects of distance on arthropod turnover in rubber, but distance did significantly influence Coleoptera turnover in rubber-forests. Arthropod species turnover with distance was significant for both tea-forests and tea for All MOTUs, Diptera, Hemiptera, Hymenoptera, and Arachnida, significant for only tea-forests for Coleoptera, and significant only for tea for Orthoptera (Table 4).
Discussion
Previous metabarcoding studies on non-microbial organisms have mostly used Roche 454 platforms5,6,23, and to our knowledge only one study has used the MiSeq platform for Malaise trapped arthropod samples24. The Miseq platform is more cost-efficient than Roche 454 for metabarcoding6,22,23 and can produce up to ca. 15 times the number of reads produced by a Roche 454 FLX Titanium run22,25,26. We used a new primer combination targeting a 400 bp fragment of the COI gene and Illumina high-throughput sequencing to demonstrate the effectiveness of the Miseq platform for metabarcoding a wide variety of tropical arthropods. While this fragment is shorter than the regular barcode fragment (ca. 650 bp), it still allowed a perfect identification of the samples in the mock communities we simulated.
Arthropods constitute the most abundant and diverse non-microbial organisms on Earth, but comprehensive information on large-scale patterns of richness, endemism and biogeography are lacking, especially in the tropics18,19,20,21. The low representation of arthropods in biodiversity databases is due to the high cost (in terms of money, time and labor) associated with sorting and identifying samples from large-scale inventories5,6. A cheap and efficient monitoring method such as presented in this study will greatly help to address this impediment.
A major limitation of this approach is the efficiency of the MOTU taxonomic assignment. While most previous studies focused on general diversity patterns without assigning taxonomy to MOTUs5,6,23, we detected finer patterns by assigning MOTUs to different classes and orders and analyzed diversity patterns for each order/class separately. Though the taxonomy assignment at this high level is very efficient (97 to 99% depending on the method used), it is not the case for assignments at a lower taxonomic level (from 64% in Orthopteras to only 21% for Chilopoda, Table S6). This is not a problem due to the metabarcoding pipeline we used, but rather to the lack of good reference barcode sequences for tropical arthropods. Before being able to use metabarcoding for detailed biodiversity monitoring, we stress the importance of increasing the identification and standard barcoding of arthropod species in the highly diverse tropics.
The four land-use types considered had distinct arthropod communities, showing that each land-use class supports a unique arthropod assemblage. The strong differences in community structure found between tea and adjacent forests and between rubber and adjacent forests suggest that arthropods are rather sensitive to land-use change30,31,32.
Furthermore, species turnover between sites in plantations mainly represented species losses and gains with few new species added (nestedness), while species turnover between sites in forests was dominated by addition of new species not found anywhere else (turnover after accounting for nestedness). Although overall compositional diversity remained high in plantations, our results do point to a homogenizing compositional trend in plantation landscapes33.
Arthropod compositional patterns varied considerably across land-use pairs and arthropod groups. We found strong correlations between environmental gradients and species compositional changes across land-use types, suggesting that the interactions among land-use change, environmental heterogeneity and species life-history might be driving differences in β-diversity34,35. Our study confirms the importance of monitoring and understanding changes in species composition (rather than just species numbers), supporting similar pleas from related studies36,37.
Diversity (α-) was generally high in native tropical forests and lower in adjacent agricultural plantations, with greater changes detected between rubber and forest than between forest and tea. Our findings are consistent with reports that landscape modification has negative effects on biodiversity, and these effects vary across functional guilds31,38,39. The lower numbers of species in monoculture plantations (especially rubber) corroborate previous findings that clearance of natural forests and subsequent conversion to agriculture leads to loss of specialist forest-dwelling species and colonization by generalist landscape species that can tolerate relatively harsh conditions (e.g. high temperature, high solar radiation, pesticide application) within agricultural landscapes36,37.
The effects of land-use change on arthropod diversity were mostly negative, but were also positive or non-existent for some arthropod groups. This is consistent with previous reports that taxa differ in their responses to land-use change31,38,39. One positive effect of forest conversion was the increase in Orthoptera richness in tea relative to tea-forest. A possible explanation may be the increase in open environment species like grasshoppers, which largely colonize and proliferate in tea. The most negatively affected arthropod order was Coleoptera, which showed significantly higher α-diversity in forests than in neighboring plantations (rubber and tea), higher turnover in rubber-forest than in rubber and significant correlations between turnover and geographic distances in forests but not in neighboring plantations (rubber and tea). This confirms the interest in using this group of arthropods to monitor changes in biodiversity and forest degradation40,41,42. For arthropod order Hymenotera, species turnover between sites was higher in rubber-forests than in rubber but lower in tea-forests than in tea, and significant correlations between turnover and geographic distances were detected in tea-forests and in tea plantations but not in rubber-forests and rubber plantations. These findings can be attributed to the higher occurrence of ants (an important component of litter Hymenopterans) in disturbed than in undisturbed habitats31, the positive correlation between ant species richness and temperature43, and the negative correlation between ant species richness and disturbance43. A similar study comparing ant species richness and composition in forest, agroforestry rubber, monoculture rubber and oil palm plantations in Indonesia found that agricultural land-use alters species composition but not species richness of ants44.
Materials and Methods
Study site
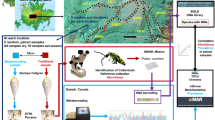
The study was conducted within the Xishuangbanna (XSBN) Dai Autonomous Prefecture (21°08′N-22°36′N, 99°56′E-101°50′E) of Yunnan Province, SW China (Fig. 5). XSBN lies on the northern edge of tropical Southeast Asia45 within the Indo-Burma biodiversity hotspot46. The topography is mountainous, with altitudes ranging from 542–2415 m above sea level. XSBN experiences a tropical monsoon climate with a distinct hot, rainy (May-October) and cool, dry season (November-April). Although XSBN’s climate is generally warm and moist, both temperature and rainfall vary considerably over the prefecture47. Using high resolution geospatial monthly climate data (1960–2000), four bioclimatic zones were identified within XSBN47, ranging from hot/moist climates at low elevations (<600 m a.s.l.) to warm temperate/mesic climates at high elevations (>2,000 m a.s.l.). Mean annual temperature varies from 14.9 °C (>2000 m a.s.l.) to 23.4 °C (<600 m a.s.l.) while mean annual rainfall varies from 1,624 mm (>2,000 m a.s.l.) to 1,222 mm (<600 m a.s.l.).

The green triangles represent forest-tea paired sites and the red circles represent forest-rubber paired sites. The regional map (China, Cambodia, Lao PDR, Myanmar, Thailand and Vietnam) was generated using the TM_world_borders_3 dataset freely available from the thematic mapping website (http://thematicmapping.org/downloads/world_borders.php). The prefecture (XSBN) map was generated using the freely available level three (provincial) maps from Divagis spatial data (http://www.diva-gis.org/; Hijmans, R. J., L. Guarino, C. Bussink, P. Mathur, M. Cruz, I. Barrentes, and E. Rojas. 2004. DIVA-GIS. Version. 5.0. A geographic information system for the analysis of species distribution data). Background data shows the slope aspect, generated from the Shuttle Radar Topography Mission (SRTM) 1 Arc-Second Global using the “aspect” tool in ArcMap 10.1 (ESRI 2015. ArcGIS Desktop: Release 10.1. Redlands, CA: Environmental Systems Research Institute; http://desktop.arcgis.com/en/arcmap/). Points were downloaded from a hand-held GPS (GPSMAP® 62s | Garmin) before being digitized and uploaded as a shapefile.
Although XSBN represents only 0.2% (1.9 million ha) of China’s total area, the region supports an estimated 16% of China’s total higher plants48 and substantial arthropod diversity5,6,22,23. The region’s land cover is substantially fragmented with the most prominent changes caused by forest conversion to agriculture, especially plantations of rubber (Hevea brasiliensis), an exotic crop, in the lowlands, and tea (Camellia sinensis), an indigenous crop, at higher elevations. The area covered by rubber plantations has increased rapidly from 87,000 ha (4.6% of XSBN’s total area) in 1992 to 424,000 ha (22.3% of XSBN’s total area) in 2010, at the expense of tropical forests49. Tea plantations have been part of the landscape for a longer time, but the total land area under tea cultivation in XSBN is unknown. Details of the different land-use types and their characteristics and the variables measured at each site can be found as Supplementary Text.
Sample collection
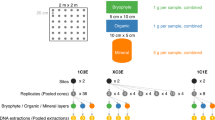
Bulk litter arthropod samples were collected from 35 matched forest-plantation sites across XSBN. Pairs were selected to be as similar as possible and spatially close to minimize confounding differences in environmental conditions. Land-use types studied included native vegetation (forest), rubber plantations (rubber) and tea plantations (tea). In each site, nine leaf-litter samples (placed 10 m apart; one in the middle and two each in north, east, west and south directions) were collected by placing 1 × 1 m PVC frames on the ground (Fig. S11, Supporting Information). All leaf litter and loose humus from within the frame area were collected into a large polythene bag and sieved through a wire mesh (0.8 cm × 0.8 cm) to remove larger leaf-litter materials. The resulting ‘siftate’ was transported to the laboratory in polythene bags, where it was immediately transferred into mesh bags. The mesh bags and their contents were subsequently suspended inside Winkler bags containing bottles with 96% alcohol at the bottom. The Winkler bags were left to dry for three days in a room with air conditioning to make arthropods leave the litter in search of moisture. The suspended ‘siftate’ was gently mixed during incubation to increase the activity of arthropods and their chances of dropping into the collection bottle50,51,52.
Sample preparation and DNA extraction
Arthropod samples from each site were prepared separately by pouring the contents of the collection bottle into a clean sterile petri dish. Each petri dish was placed under a stereomicroscope and sterile forceps were used to pick out all visible arthropods. The arthropods were stored in clean sterile bottles containing 96% ethanol at room temperature until DNA extraction. In order to keep the final DNA quantity similar across individual arthropods, we used two legs from all individuals with body length equal to or greater than 5 mm and whole bodies of everything smaller. These samples were subsequently freeze-dried using liquid Nitrogen, ground and homogenized using a mortar and pestle. Genomic DNA was extracted using the DNeasy Tissue Kit (QIAGEN; Hilden, Germany; protocol for animal tissues) according to the manufacturer’s instructions.
Primer test and pipeline validation with mock arthropod communities
Since the COI barcode fragment is too long for sequencing on the MiSeq platform, we used a new primer combination (MhemF28 and dgHCO219829) to amplify a fragment of ca. 400 bp. We first tested in-vitro PCR efficiency on a wide range of arthropods (Chilopoda, Araneae, Hymenoptera, Blattodea, Mantodea, Coleoptera, Orthoptera, Lepidoptera, and Hemiptera). PCR was carried out in a total volume of 50 μL using 10 ng DNA, 5.0 μL 10 × PCR buffer, 0.5 mM dNTPs, 2.5 U Platinum Taq (TaKaRa Biosystems, Ohtsu, Shiga, Japan) 0.5 μL of each of forward and reverse primers. PCR cycling conditions were 94 °C for 3 min, 5 cycles of 94 °C for 30 s; 45 °C for 20 s; 72 °C for 30 s; then 20 cycles of 94 °C for 20 s; 55 °C for 20 s; 72 °C for 30 s and finally 72 °C for 5 min. PCR products were size-verified by gel electrophoresis. Then, since the UPARSE bioinformatics pipeline has only been validated for microbes (bacteria and fungi)53, we validated the pipeline by simulating reads from mock arthropod communities using Grinder v.0.5.354 and processing the simulated data with USEARCH v.8.153. We downloaded a COI reference database of 3,306,508 arthropod sequences from the Barcode of Life database (BOLD55). We then used a subset of the reference (high quality sequences covering a wide range of arthropod groups from across the entire arthropod phylogeny (Table S1, Supporting Information)) to generate six mock communities. Three mock communities were constructed using 37 reference sequences, with each community assigned a unique multiplex identifier (MID). In silico PCR was simulated from the reference sequences using Illumina sequencing, requesting 200,000 (library 1), 400,000 (library 2) and 600,000 (library 3) reads with 300 bp length, Phred quality scores (10–40) and Illumina errors using the 4th degree polynome 3e-3 + 3.3e-8 × i^456 model. To evaluate the effects of local richness and read abundance on pipeline performance, the remaining three mock communities were generated using 25 of the 37 unique reference sequences, with similar simulations (300 bp length, Phred scores and Illumina error model). The resulting fastq output files were passed to USEARCH v8.1.1861 bioinformatics pipeline for downstream analysis53.
Data preparation
Primer plus barcode sequences were stripped using python scripts (fastq_strip_barcode_relabel2.py) in USEARCH v8.1.1861. Forward and reverse fastq files were merged (-fastq_mergepairs), quality filtered (-fastq_filter), and reads less than 250 bp in length (-fastq_minlen) were discarded53.
Mock community Operational Taxonomic Unit (OTU) recovery
OTU picking for each library was performed using the USEARCH v8.1.1861 Illumina paired reads pipeline53 as follows; Reads were dereplicated, sorted by abundance and singletons were removed. The remaining reads were clustered into OTUs at a minimum similarity of 97%57. This clustering step also discards reads that have chimeric models built from more abundant sequences. Finally, the UPARSE-REF algorithm was used to validate the mock community sequencing experiment53. This algorithm is useful for understanding what picked OTUs actually represent (e.g. whether the OTUs represent expected species, contaminants, read errors, or chimeras).
Library construction and sequencing
Amplification was carried out as described above, and PCR products were quantified using Qubit 2.0 Fluorometer (dsDNA HS Assay, Life Technologies). The amplified DNA was ligated with two standard adaptors that allow the final product to bind or hybridize to short oligos on the surface of the Illumina flow cell. These adaptors included 7 bp unique index sequences to enable multiplexing of more than one sample in the same run. A total of 36 barcode-primer combinations were synthesized and used in two runs (since we had a total of 70 samples). Purified PCR products (with adaptor and barcode sequences) from each run were pooled accordingly to form two separate sequencing libraries. Each library was quantified using Qubit 2.0. Fluorometer to determine an appropriate volume of library for sequencing. For each library, amplification was carried out in a total volume of 50 μL using 20 ng DNA, 5.0 μL 10 × PCR buffer, 0.5 mM dNTPs, 2.5 U Platinum Taq, and 0.5 μL of each of forward and reverse primers. PCR cycling conditions were 95 °C for 30 s, 5 cycles of 95 °C for 15 s; 55 °C for 15 s; 72 °C for 30 s and finally 72 °C for 5 min. Sequencing was performed with 2 × 300 cycles using the MiSeq Reagent Kit v3 (Illumina, Inc., 2015) as per manufacturer’s instructions. PCR amplifications, barcode design, library preparation and sequencing were done at Sangon Biotech (Shanghai) Co., Ltd.
OTU taxonomic prediction for field samples
The taxonomies of clustered OTUs from field samples were predicted using two taxonomy prediction algorithms (UTAX and USEARCH) and the resulting taxonomic identities of each OTU were compared. UTAX is a k-mer based method which looks for words in common between the query sequence and reference sequences with known taxonomy. A score calculated from word counts is used to estimate a confidence value for each taxonomic level53. USEARCH searches a reference database for high-identity hits to one or more reference sequences (“targets”) using word counts to prioritize the database search. Target sequences are compared to the query in order of decreasing unique word count53. For UTAX, we downloaded and used a database of 840,074 Animalia COI sequences and an associated taxconfs file from the previous version of USEARCH v8.1.183153. For USEARCH, we downloaded and used a database of 3,306,508 Arthropoda COI sequences from the Barcode of Life Database (BOLD55). We used a recommended nucleotide top hit identity cutoff of 75% for which USEARCH is effective57.
Diversity and assemblage composition analysis
Since the total number of reads used to pick Molecular Operational Taxonomic Units (MOTUs) varies considerably across sampled sites, a risk of local richness estimation bias exists. Prior to diversity analyses, we tested for an effect of this difference in sampling size using rarefaction in the vegan package58. We sampled an equal number of reads from all sites (rarefied richness) and compared the results with observed patterns (observed richness). To account for PCR amplification bias and reaction stochasticity which affects the linear relationship between sequence abundance and sample abundance in highly diverse organisms, we used site presence-absence data for diversity (alpha and beta), and community composition analyses59. MOTU compositional differences among land-use types were examined using non-metric multidimensional scaling (nMDS) and the Jaccard index coefficient in the vegan package58. Alpha (α)-diversity was estimated as the number of observed MOTUs per site. Beta (β)-diversity was computed as multi-site Sorensen and Simpson indices using the betapart 1.3.package60. Beta-diversity calculations between land-use pairs were computed using 15 random sites from the total number of sites for each land-use type, and resample them 1000 times. We then decomposed the among-sites β-diversity into its turnover (species replacement from site to site) and nestedness (species gain/loss from sites) components. We evaluated differences in rate of species turnover between sites for plantations and for forests by regressing turnover against pairwise geographic distance (Mantel test58) and testing for a difference in slopes. Pairwise and three-way differences in MOTU diversity among land-use types were evaluated using the nonparametric multiple comparison function (dunn.test) implemented in the R package dunn.test 1.2.461. The dunn.test is equivalent to the Kruskall–Wallis and pair-wise Mann–Whitney post hoc tests with Bonferroni correction. These analyses were performed in R62.
Additional Information
How to cite this article: Beng, K. C. et al. The utility of DNA metabarcoding for studying the response of arthropod diversity and composition to land-use change in the tropics. Sci. Rep. 6, 24965; doi: 10.1038/srep24965 (2016).
References
Laurance, W. F., Sayer, J. & Cassman, K. G. Agricultural expansion and its impacts on tropical nature. Trends Ecol Evol 29, 107–116, 10.1016/j.tree.2013.12.001 (2014).
Corlett, R. T. The Anthropocene concept in ecology and conservation. Trends Ecol Evol 30, 36–41, 10.1016/j.tree.2014.10.007 (2015).
Wang, J. Z. et al. A framework for the assessment of the spatial and temporal patterns of threatened coastal delphinids. Sci Rep-Uk 6, Artn 1988310.1038/Srep19883 (2016).
Souza, J. L. P. et al. Taxonomic sufficiency and indicator taxa reduce sampling costs and increase monitoring effectiveness for ants. Divers Distrib 22, 111–122, 10.1111/ddi.12371 (2016).
Ji, Y. Q. et al. Reliable, verifiable and efficient monitoring of biodiversity via metabarcoding. Ecol Lett 16, 1245–1257, 10.1111/ele.12162 (2013).
Yu, D. W. et al. Biodiversity soup: metabarcoding of arthropods for rapid biodiversity assessment and biomonitoring. Methods Ecol Evol 3, 613–623, 10.1111/j.2041-210X.2012.00198.x (2012).
Valentini, A. et al. Next-generation monitoring of aquatic biodiversity using environmental DNA metabarcoding. Mol Ecol 25, 929–942, 10.1111/mec.13428 (2016).
Geisen, S., Laros, I., Vizcaino, A., Bonkowski, M. & De Groot, G. A. Not all are free-living: high-throughput DNA metabarcoding reveals a diverse community of protists parasitizing soil metazoa. Mol Ecol 24, 4556–4569, 10.1111/mec.13238 (2015).
Pawlowski, J., Esling, P., Lejzerowicz, F., Cedhagen, T. & Wilding, T. A. Environmental monitoring through protist next-generation sequencing metabarcoding: assessing the impact of fish farming on benthic foraminifera communities. Mol Ecol Resour 14, 1129–1140, 10.1111/1755-0998.12261 (2014).
Korpelainen, H., Pietilainen, M. & Huotari, T. Effective detection of indoor fungi by metabarcoding. Ann Microbiol 66, 495–498, 10.1007/s13213-015-1118-x (2016).
Geml, J. et al. The Contribution of DNA Metabarcoding to Fungal Conservation: Diversity Assessment, Habitat Partitioning and Mapping Red-Listed Fungi in Protected Coastal Salix repens Communities in the Netherlands. Plos One 9, ARTN e9985210.1371/journal.pone.0099852 (2014).
Ledger, L., Shokralla, S., Gibson, J. F., Dobosz, R. & Hajibabaei, M. A metabarcoding approach to measuring beta diversity: Costa Rican dry forest arthropods and their associated bacteria. Genome 58, 243–243 (2015).
De Tender, C. A. et al. Bacterial Community Profiling of Plastic Litter in the Belgian Part of the North Sea. Environ Sci Technol 49, 9629–9638, 10.1021/acs.est.5b01093 (2015).
Dell’Anno, A., Carugati, L., Corinaldesi, C., Riccioni, G. & Danovaro, R. Unveiling the Biodiversity of Deep-Sea Nematodes through Metabarcoding: Are We Ready to Bypass the Classical Taxonomy? Plos One 10, ARTN e014492810.1371/journal.pone.0144928 (2015).
Fonseca, V. G. et al. Metagenetic analysis of patterns of distribution and diversity of marine meiobenthic eukaryotes. Global Ecol Biogeogr 23, 1293–1302, 10.1111/geb.12223 (2014).
Pansu, J. et al. Landscape-scale distribution patterns of earthworms inferred from soil DNA. Soil Biol Biochem 83, 100–105, 10.1016/j.soilbio.2015.01.004 (2015).
Bienert, F. et al. Tracking earthworm communities from soil DNA. Mol Ecol 21, 2017–2030, 10.1111/j.1365-294X.2011.05407.x (2012).
Basset, Y. et al. Arthropod Diversity in a Tropical Forest. Science 338, 1481–1484, 10.1126/science.1226727 (2012).
Hamilton, A. J. et al. Quantifying Uncertainty in Estimation of Tropical Arthropod Species Richness. Am Nat 176, 90–95, 10.1086/652998 (2010).
Scheffers, B. R., Joppa, L. N., Pimm, S. L. & Laurance, W. F. What we know and don’t know about Earth’s missing biodiversity. Trends Ecol Evol 27, 501–510, 10.1016/j.tree.2012.05.008 (2012).
Gillison, A. N. et al. Plant functional types and traits as biodiversity indicators for tropical forests: two biogeographically separated case studies including birds, mammals and termites. Biodivers Conserv 22, 1909–1930, 10.1007/s10531-013-0517-1 (2013).
Liu, S. L. et al. SOAPBarcode: revealing arthropod biodiversity through assembly of Illumina shotgun sequences of PCR amplicons. Methods Ecol Evol 4, 1142–1150, 10.1111/2041-210X.12120 (2013).
Yang, C. X. et al. Using metabarcoding to ask if easily collected soil and leaf-litter samples can be used as a general biodiversity indicator. Ecol Indic 46, 379–389, 10.1016/j.ecolind.2014.06.028 (2014).
Brandon-Mong, G. J. et al. DNA metabarcoding of insects and allies: an evaluation of primers and pipelines. B Entomol Res 105, 717–727, 10.1017/S0007485315000681 (2015).
Shokralla, S. et al. Next-generation DNA barcoding: using next-generation sequencing to enhance and accelerate DNA barcode capture from single specimens. Mol Ecol Resour 14, 892–901, 10.1111/1755-0998.12236 (2014).
Glenn, T. C. The Molecular Ecologist 2014 NGS Field Guide: Overview. (2014). Available at http://www.molecularecologist.com/next-gen-fieldguide-2014/. (Accessed: 15th February 2016). (2014).
Pompanon, F. & Samadi, S. Next generation sequencing for characterizing biodiversity: promises and challenges. Genetica 143, 133–138, 10.1007/s10709-015-9816-7 (2015).
Park, D. S., Foottit, R., Maw, E. & Hebert, P. D. N. Barcoding Bugs: DNA-Based Identification of the True Bugs (Insecta: Hemiptera: Heteroptera). Plos One 6, ARTN e1874910.1371/journal.pone.0018749 (2011).
Meyer, C. P. Molecular systematics of cowries (Gastropoda : Cypraeidae) and diversification patterns in the tropics. Biol J Linn Soc 79, 401–459, 10.1046/j.1095-8312.2003.00197.x (2003).
Obrist, M. K. & Duelli, P. Rapid biodiversity assessment of arthropods for monitoring average local species richness and related ecosystem services. Biodivers Conserv 19, 2201–2220, 10.1007/s10531-010-9832-y (2010).
Luke, S. H., Fayle, T. M., Eggleton, P., Turner, E. C. & Davies, R. G. Functional structure of ant and termite assemblages in old growth forest, logged forest and oil palm plantation in Malaysian Borneo. Biodivers Conserv 23, 2817–2832, 10.1007/s10531-014-0750-2 (2014).
Ewers, R. M. et al. Logging cuts the functional importance of invertebrates in tropical rainforest. Nat Commun 6, Artn 683610.1038/Ncomms7836 (2015).
Vallejos, M. A. V., Padial, A. A. & Vitule, J. R. S. Human-Induced Landscape Changes Homogenize Atlantic Forest Bird Assemblages through Nested Species Loss. Plos One 11, ARTN e014705810.1371/journal.pone.0147058 (2016).
Tscharntke, T. et al. Landscape moderation of biodiversity patterns and processes - eight hypotheses. Biol Rev 87, 661–685, 10.1111/j.1469-185X.2011.00216.x (2012).
Myers, J. A. et al. Beta-diversity in temperate and tropical forests reflects dissimilar mechanisms of community assembly. Ecol Lett 16, 151–157, 10.1111/ele.12021 (2013).
Dornelas, M. et al. Assemblage Time Series Reveal Biodiversity Change but Not Systematic Loss. Science 344, 296–299, 10.1126/science.1248484 (2014).
De Coster, G., Banks-Leite, C. & Metzger, J. P. Atlantic forest bird communities provide different but not fewer functions after habitat loss. Proceedings of the Royal Society of London B: Biological Sciences 282, 10.1098/rspb.2014.2844 (2015).
Phalan, B., Onial, M., Balmford, A. & Green, R. E. Reconciling Food Production and Biodiversity Conservation: Land Sharing and Land Sparing Compared. Science 333, 1289–1291, 10.1126/science.1208742 (2011).
Newbold, T. et al. A global model of the response of tropical and sub-tropical forest biodiversity to anthropogenic pressures. P Roy Soc B-Biol Sci 281, Artn 2014137110.1098/Rspb.2014.1371 (2014).
Fountain-Jones, N. et al. Living near the edge: being close to mature forest increases the rate of succession in beetle communities. Ecol. Appl. 25, 800–811 (2014).
Filgueiras, B. K. C., Tabarelli, M., Leal, I. R., Vaz-De-Mello, F. Z. & Iannuzzi, L. Dung beetle persistence in human-modified landscapes: Combining indicator species with anthropogenic land use and fragmentation-related effects. Ecol Indic 55, 65–73, 10.1016/j.ecolind.2015.02.032 (2015).
Korasaki, V., Lopes, J., Brown, G. G. & Louzada, J. Using dung beetles to evaluate the effects of urbanization on Atlantic Forest biodiversity. Insect Sci 20, 393–406, 10.1111/j.1744-7917.2012.01509.x (2013).
Gibb, H. et al. Climate mediates the effects of disturbance on ant assemblage structure. Proceedings of the Royal Society of London B: Biological Sciences 282, 10.1098/rspb.2015.0418 (2015).
Rubiana, R. et al. Agricultural land use alters species composition but not species richness of ant communities. ASIAN MYRMECOLOGY 7, 73–85 (2015).
Cao, M. & Zhang, J. H. Tree species diversity of tropical forest vegetation in Xishuangbanna, SW China. Biodivers Conserv 6, 995–1006, 10.1023/A:1018367630923 (1997).
Myers, N., Mittermeier, R. A., Mittermeier, C. G., da Fonseca, G. A. B. & Kent, J. Biodiversity hotspots for conservation priorities. Nature 403, 853–858, 10.1038/35002501 (2000).
Zomer, R. J. et al. Environmental stratification to model climate change impacts on biodiversity and rubber production in Xishuangbanna, Yunnan, China. Biol Conserv 170, 264–273, 10.1016/j.biocon.2013.11.028 (2014).
Zhang, J. H. & Cao, M. Tropical Forest Vegetation of Xishuangbanna, Sw China and Its Secondary Changes, with Special Reference to Some Problems in Local Nature Conservation. Biol Conserv 73, 229–238, 10.1016/0006-3207(94)00118-A (1995).
Xu, J. C., Grumbine, R. E. & Beckschafer, P. Landscape transformation through the use of ecological and socioeconomic indicators in Xishuangbanna, Southwest China, Mekong Region. Ecol Indic 36, 749–756, 10.1016/j.ecolind.2012.08.023 (2014).
Parr, C. L. & Chown, S. L. Inventory and bioindicator sampling: Testing pitfall and Winkler methods with ants in a South African savanna. J Insect Conserv 5, 27–36, 10.1023/A:1011311418962 (2001).
Sabu, T. K. & Shiju, R. T. Efficacy of pitfall trapping, Winkler and Berlese Extraction Methods for Measuring Ground-Dwelling Arthropods in Moist-Deciduous Forests in the Western Ghats. J. Insect Sci. 10, 1–17 (2010).
Krell, F. T. et al. Quantitative extraction of macro-invertebrates from temperate and tropical leaf litter and soil: efficiency and time-dependent taxonomic biases of the Winkler extraction. Pedobiologia 49, 175–186, 10.1016/j.pedobi.2004.10.005 (2005).
Edgar, R. C. UPARSE: highly accurate OTU sequences from microbial amplicon reads. Nat Methods 10, 996–998, 10.1038/Nmeth.2604 (2013).
Angly, F. E., Willner, D., Rohwer, F., Hugenholtz, P. & Tyson, G. W. Grinder: a versatile amplicon and shotgun sequence simulator. Nucleic Acids Res 40, ARTN e9410.1093/nar/gks251 (2012).
Ratnasingham, S. & Hebert, P. D. N. BOLD: The Barcode of Life Data System (www.barcodinglife.org). Molecular Ecology Notes 7, 355–364 (2007).
Korbel, J. O. et al. PEMer: a computational framework with simulation-based error models for inferring genomic structural variants from massive paired-end sequencing data. Genome Biol 10, Artn R2310.1186/Gb-2009-10-2-R23 (2009).
Edgar, R. C. Search and clustering orders of magnitude faster than BLAST. Bioinformatics 26, 2460–2461, 10.1093/bioinformatics/btq461 (2010).
Oksanen, J. et al. vegan: Community Ecology Package. R package version 2.3-2. Available at http://CRAN.R-project.org/package=vegan. (Accessed: 10th January 2016).
Chariton, A. A. et al. Metabarcoding of benthic eukaryote communities predicts the ecological condition of estuaries. Environ Pollut 203, 165–174, 10.1016/j.envpol.2015.03.047 (2015).
Baselga, A. & Orme, C. D. L. betapart: an R package for the study of beta diversity. Methods Ecol Evol 3, 808–812, 10.1111/j.2041-210X.2012.00224.x (2012).
Dinno, A. dunn.test: Dunn’s Test of Multiple Comparisons Using Rank Sums. R package version 1.3.2. (2016). Available at http://CRAN.R-project.org/package=dunn.test. (Accessed: 10th January 2016).
R Core Team (2015). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. URL http://www.R-project.org/.
Acknowledgements
We are grateful to two anonymous reviewers for valuable comments on the earlier version of this manuscript. We would like to thank Lu Yun, Arthur Miller and Loke Thian Yew for field assistance, Dr. Sophie Williams for facilitating the process of getting Arthur to China. Many thanks to the Yunnan Provincial Bureau of Forestry for granting us permission to conduct this research (Research permit: [2014] No. 13). This study was supported by the National Science Foundation of China (NSFC Grant No. 31370538). DNA sequencing was supported by the 1000 Talents Program (WQ20110491035).
Author information
Authors and Affiliations
Contributions
K.C.B. designed the project, did the fieldwork, extracted DNA, tested primers, validated primer performance, analyzed the data and wrote the first draft; K.W.T. designed the project and revised the manuscript; X.H.S tested primers, validated primer performance and revised the manuscript; Y.S.G. designed the project, tested primers and revised the manuscript; A.C.H. designed the project, selected sampling sites, made the map and revised the manuscript; R.T.C. designed the project and revised the manuscript; J.W.F.S. designed the project and revised the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Beng, K., Tomlinson, K., Shen, X. et al. The utility of DNA metabarcoding for studying the response of arthropod diversity and composition to land-use change in the tropics. Sci Rep 6, 24965 (2016). https://doi.org/10.1038/srep24965
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep24965
- Springer Nature Limited
This article is cited by
-
Comparison of traditional and DNA metabarcoding samples for monitoring tropical soil arthropods (Formicidae, Collembola and Isoptera)
Scientific Reports (2022)
-
Identifying prey of the Javan mongoose (Urva javanica) in Java from fecal samples using next-generation sequencing
Mammalian Biology (2021)
-
Next-Generation Sequencing and Its Impacts on Entomological Research in Ecology and Evolution
Neotropical Entomology (2021)
-
Urban areas as hotspots for bees and pollination but not a panacea for all insects
Nature Communications (2020)
-
Drivers of tropical soil invertebrate community composition and richness across tropical secondary forests using DNA metasystematics
Scientific Reports (2020)