
Abstract
Accurately characterizing the anomalous diffusion of a tracer particle has become a central issue in biophysics. However, measurement errors raise difficulty in the characterization of single trajectories, which is usually performed through the time-averaged mean square displacement (TAMSD). In this paper, we study a fractionally integrated moving average (FIMA) process as an appropriate model for anomalous diffusion data with measurement errors. We compare FIMA and traditional TAMSD estimators for the anomalous diffusion exponent. The ability of the FIMA framework to characterize dynamics in a wide range of anomalous exponents and noise levels through the simulation of a toy model (fractional Brownian motion disturbed by Gaussian white noise) is discussed. Comparison to the TAMSD technique, shows that FIMA estimation is superior in many scenarios. This is expected to enable new measurement regimes for single particle tracking (SPT) experiments even in the presence of high measurement errors.
Similar content being viewed by others


Introduction
The field of biophysics and biomedicine has seen an immense increase in single particle tracking techniques and experimental results1,2. In the past decade, trajectories have been obtained for almost all biological entities, including in vivo3,4 and in vitro5 measurements that cover dynamics from the cell membrane6,7 to the nucleoplasm8,9. Biological trajectories are usually stochastic and affected by a great deal of randomness arising from thermal motion of surrounding molecules, spatial constraints, complex molecular interactions, water molecules on cell membranes and more10,11,12,13,14,15. While all these sources of stochasticity give rise to diffusive motion, each source has different characteristics, which can give important information regarding the biophysical system16.
The most popular theoretical models for the anomalous diffusion17 present in biophysical experiments are: continuous-time random walk (CTRW)18,19, obstructed diffusion (OD), fractional Brownian motion (FBM), autoregressive fractionally integrated moving average (ARFIMA) and fractional Langevin equation (FLE)2,20. These models can be divided into two categories: with short memory (CTRW, OD) and fractional with long (power-law) memory (FBM and ARFIMA). In this paper we concentrate on the latter class.
A common tool by which the anomalous diffusion of a single particle can be classified is the time-averaged mean square displacement (TAMSD):

defined here for a trajectory x(t) of length T and the averaging window is  . One of the fundamental properties is the scaling of TAMSD, i.e.,
. One of the fundamental properties is the scaling of TAMSD, i.e.,  . For normal diffusion the scaling is linear, α = 1 and anomalous diffusion shows a power law behaviour, with α > 1 termed superdiffusion and α < 1 called subdiffusion. The anomalous exponent α is connected to target finding times21, cellular organization16, reaction rates22 and more. In addition, the anomalous exponent can be connected to many other stochastic characteristics of the random walk, such as self similarity and long range correlations of displacements. Specifically, if we take an H-self-similar process with stationary and Gaussian increments, then α = 2H and the memory parameter d = H − 1/223.
. For normal diffusion the scaling is linear, α = 1 and anomalous diffusion shows a power law behaviour, with α > 1 termed superdiffusion and α < 1 called subdiffusion. The anomalous exponent α is connected to target finding times21, cellular organization16, reaction rates22 and more. In addition, the anomalous exponent can be connected to many other stochastic characteristics of the random walk, such as self similarity and long range correlations of displacements. Specifically, if we take an H-self-similar process with stationary and Gaussian increments, then α = 2H and the memory parameter d = H − 1/223.
Unfortunately, the estimation of α for single trajectories is not a simple task. Usually the TAMSD is fitted to a power law – a method that is prone to estimation errors due to two main effects. The first arises from the fact that displacements in TAMSDs are not independent and the central limit theorem does not work for a single trajectory24,25.
The second error arises from the inherent measurement error in any experimental procedure26. This has been shown to insert a bias towards lower α values at short times27. Thus fitting single particle TAMSDs results in anomalous exponents lower than the true physical process. It has been shown that this bias continues even to times where the TAMSD is larger than the measurement noise standard deviation. This effect cannot be corrected through ensemble averaging or measurement of longer trajectories and can be mitigated only under special conditions28.
Measurement errors, in the common stationary case, are a series of i.i.d. values added to the true location of the tracked particle. Thus the incremental process of the paricle is highly dependent between consecutive time points. If δϵ(t) and δϵ(s) are the increments of the error at time t and s, then they are strongly dependent for  and independent otherwise. This leads to the possibility of separating the measurement error from the actual diffusion process, by distinguishing the transient short time correlation of the error from the long time correlation of the physical process.
and independent otherwise. This leads to the possibility of separating the measurement error from the actual diffusion process, by distinguishing the transient short time correlation of the error from the long time correlation of the physical process.
We introduce the following toy model for experimental data with significant measurement noise. Let {BH(t), = 1,2,…,T} be a fractional Brownian motion (FBM) with the self-similarity index 0 < H < 1. This process will serve us as a basic model for a SPT. The choice of the FBM is well justified in the literature2,12,13,29,30,31,32. Now, we assume that a measurement error is given in the form of white Gaussian noise, namely i.i.d. random variables ϵ(t) with the normal distribution N(0, σ). As a consequence, the observed process is

In all cases we take the variance of the increments of BH(t) to be equal to one. We also assume that BH(t) and ϵ(t) are independent. Thus for this process  which deviates from the pure power law behaviour
which deviates from the pure power law behaviour  of the FBM. The difference can be clearly observed for small
of the FBM. The difference can be clearly observed for small  ’s or large σ’s and it influences the estimation of the anomalous exponent. It can also mimic the transient anomalous diffusion pattern. Moreover, the variance of the increments of A(t) is 1 + 2σ2. The autocorrelation function of the increments of A(t) equals
’s or large σ’s and it influences the estimation of the anomalous exponent. It can also mimic the transient anomalous diffusion pattern. Moreover, the variance of the increments of A(t) is 1 + 2σ2. The autocorrelation function of the increments of A(t) equals

where ρ(h) is the autocorrelation function of the increments of FBM for a time lag h.
In this paper we investigate a new approach for the estimation of α under the presence of measurement errors. We approximate the toy model by the FIMA process which can be treated as a first order approximation of ρA(h). This approximation takes into account the power law decay of the function controlled by the memory parameter d = H − 1/2 and the negative first lag correlation induced by the noise sequence, for h = 1 see equation (3). We also present a comprehensive comparison of the new estimator αFIMA which is obtained by equation (11), with the classical estimator αTAMSD, given by equation (6), based on the time-averaged mean square displacement. To this end we analyze four representative cases of anomalous diffusion: strong subdiffusion α ∈ {0.4, 0.5, 0.6}, weak subdiffusion α ∈ {0.7, 0.8, 0.9}, weak superdiffusion α ∈ {1.1, 1.2, 1.3} and strong superdiffusion α ∈ {1.4, 1.5, 1.6}; and the case of the classical (normal) diffusion.
We compare the performance of the FIMA estimator to that of the common TAMSD for varying trajectory lengths, noise levels and all α regimes. The quality of the estimation of the anomalous exponent α is dependent on the the magnitude of the measurement error, σ, the length of the trajectory, T and the value of the anomalous exponent itself. First, we study an influence of the noise parameter, σ, on the estimation error in Figs 1, 2, 3, 4, 5. To this end, we simulate a thousand of trajectories for σ’s from 0.25 to 2 with step 0.25 and α’s from 0.4 to 1.6 with step 0.1 and estimate α for each trajectory. The trajectories consist of T = 512 time points. Second, in Figs 6, 7, 8, 9, 10, we study an influence of the length of the trajectory, T, on the estimation error. To this end, we simulate a thousand of trajectories for T ∈ {256, 512, 1024, 2048} and α's from 0.4 to 1.6 with step 0.1 and estimate α for each trajectory. The noise parameter σ is fixed and equal to 1. We find that the FIMA estimator is superior to the TAMSD in most cases.

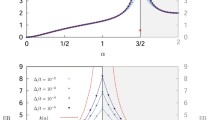
Strong subdiffusion case.
Estimation of the anomalous exponent for different σ’s and α’s for 1000 trajectories of 29 time points using the FIMA (marked with circles) and TAMSD frameworks. Average estimated α (left panel) and average bias (right panel).

Weak subdiffusion case.
Estimation of the anomalous exponent for different σ’s and α’s for 1000 trajectories of 29 time points using the FIMA (marked with circles) and TAMSD frameworks. Average estimated α (left panel) and average bias (right panel).

Classical diffusion case.
Estimation of the anomalous exponent for different σ’s and α = 1 for 1000 trajectories of 29 time points using the FIMA (marked with circles) and TAMSD frameworks. Average estimated α (left panel) and average bias (right panel).

Weak superdiffusion case.
Estimation of the anomalous exponent for different σ’s and α’s for 1000 trajectories of 29 time points using the FIMA (marked with circles) and TAMSD frameworks. Average estimated α (left panel) and average bias (right panel).

Strong superdiffusion case.
Estimation of the anomalous exponent for different σ’s and α’s for 1000 trajectories of 29 time points using the FIMA (marked with circles) and TAMSD frameworks. Average estimated α (left panel) and average bias (right panel).

Strong subdiffusion case.
Estimation of the anomalous exponent for σ = 1 and different α’s and trajectory lengths for 1000 trajectories using the FIMA (marked with circles) and TAMSD frameworks. Average estimated α (left panel). Average bias (right panel).

Weak subdiffusion case.
Estimation of the anomalous exponent for σ = 1 and different α’s and trajectory lengths for 1000 trajectories using the FIMA (marked with circles) and TAMSD frameworks. Average estimated α (left panel). Average bias (right panel).

Classical diffusion case.
Estimation of the anomalous exponent for σ = 1, α = 1 and different trajectory lengths for 1000 trajectories using the FIMA (marked with circles) and TAMSD frameworks. Average estimated α (left panel). Average bias (right panel).

Weak superdiffusion case.
Estimation of the anomalous exponent for σ = 1 and different α’s and trajectory lengths for 1000 trajectories using the FIMA (marked with circles) and TAMSD frameworks. Average estimated α (left panel). Average bias (right panel).

Strong superdiffusion case.
Estimation of the anomalous exponent for σ = 1 and different α’s and trajectory lengths for 1000 trajectories using the FIMA (marked with circles) and TAMSD frameworks. Average estimated α (left panel). Average bias (right panel).
We would also like to draw the attention of the reader to popular methods to determine α of single trajectories of FBM, namely the detrended fluctuation analysis (DFA)33 and detrending moving average (DMA) (34,35, where an interpretation of the possible intrinsic origin of the error in the moving average estimators is given in terms of an excess term in the Shannon entropy). For the extensive comparison of the DFA and DMA methods see36. In contrast, we concentrate here on the toy model A(t), which takes into account the measurement noise and propose the FIMA process as the appropriate approximation of the model.
Results
This paper’s new topic is the extraction of anomalous diffusion exponent from raw single-particle trajectories for different anomalous diffusion regimes. The study’s benchmark is a comparison between the recovered parameters using the FIMA model and the classical TAMSD fit approach.
For both estimation techniques we calculate here the average estimated values:  and
and  and the biases:
and the biases:

In Figs 1, 2, 3, 4, 5 we depict the average estimated values and biases for σ’s from 0.25 to 2 with step 0.25 and α’s from 0.4 to 1.6 with step 0.1. To this end, we simulated a thousand of trajectories of T = 512 time points. First, let us notice that both methods often underestimate true values of the anomalous exponent. We can also observe that the FIMA estimator is superior to the TAMSD in the weak subdiffusion, diffusion and superdiffusion regimes. For the classical diffusion and superdiffusion cases the difference is striking for all σ’s and growing rapidly with the measurement error. In the strong subdiffusion case for α = 0.4 TAMSD yields slightly better results. For α = 0.5 and α = 0.6 TAMSD gives more accurate estimates only for small sigmas, namely σ ≤ 0.6.
Next, in Figs 6, 7, 8, 9, 10 we present the effect of trajectory length on the results. We simulate a thousand of trajectories for T ∈ {256, 512, 1024, 2048} and α’s from 0.4 to 1.6 with step 0.1, estimating α for each trajectory. The noise parameter σ is fixed and equal to 1. For the strong subdiffusion case, for α = 0.4 TAMSD produces better results than the FIMA for all considered lengths of trajectories, but the difference between them is getting smaller as T grows. For α = 0.5 and α = 0.6 TAMSD yields better estimates only for T = 256. For the weak subdiffusion, classical diffusion and superdiffusion cases the FIMA estimator is always superior to the TAMSD and the differences become dramatic in the classical diffusion and superdiffusion regimes. Let us notice that the FIMA estimator, contrary to the TAMSD, clearly converges to the true values with increasing T.
We have also analyzed the relation between the magnitude of the measurement error and the moving average parameter  in both the subdiffusive (α = 0.8) and superdiffusive (α = 1.2) domains. The results are presented in Supplementary Fig. S1. For both anomalous cases with increasing variance of ϵ(t) the coefficient
in both the subdiffusive (α = 0.8) and superdiffusive (α = 1.2) domains. The results are presented in Supplementary Fig. S1. For both anomalous cases with increasing variance of ϵ(t) the coefficient  grows monotonously. Therefore, we may claim that the moving average part contains the information about the measurement error. In the future, it may be possible to conclude the magnitude of the measurement error from
grows monotonously. Therefore, we may claim that the moving average part contains the information about the measurement error. In the future, it may be possible to conclude the magnitude of the measurement error from  without experimental calibration.
without experimental calibration.
Finally, in the supplementary material we provide an extensive statistical analysis of the estimators in the form of box plots, see Supplementary Figs S2–S11. This statistical analysis confirms the previous findings from Figs 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. In particular, the range between whiskers in box plots provides information about variability in a distribution of the estimator. We can see that the variance of the TAMSD estimator is lower than that of FIMA in many cases, which is especially visible in the strong subdiffusion regime. Moreover, in this regime the variance of the FIMA estimator grows as σ increases. The situation changes as we proceed to the weak subdiffusion and further to superdiffusion regimes. In the weak subdiffusion case, the variance of the introduced estimator becomes comparable to the TAMSD for small σ’s. For the superdiffusion regimes, the variance of the FIMA estimator is comparable to the TAMSD’s for almost all possible σ’s.
While the variance of the TAMSD estimator is lower than that of FIMA in many cases, the large bias deems it inaccurate. In many cases, the quartile intervals for TAMSD and FIMA are even disjoint, which statistically disqualifies the TAMSD method.
Discussion
In this paper we showed how to apply an anomalous diffusion exponent estimation algorithm based on the FIMA model. For a toy model representing a typical measurement, we compared the FIMA estimation results with those obtained by the popular TAMSD estimation.
The FIMA model is a special case of the ARFIMA process37,38,39,40,41 (the acronyms “ARFIMA” and “FARIMA” are often used interchangeably in the literature) which, from the physical point of view, is a discrete time analogue of the fractional Langevin equation that takes into account the memory parameter d42. ARFIMA have been already studied in the physical literature43,44,45,46,47,48,49,50. However, interpretation of the various parameters in an experimental context, to the best of our knowledge, is still missing.
The main finding of this paper is that the FIMA approach leads to more accurate values of the anomalous exponent in SPT experiments than by using standard TAMSD data fitting. This was confirmed for trajectories with α ≥ 0.5, σ ≥ 0.5 and T ≥ 512, see Figs 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. The idea put forward in the paper is that the FI part of the process gives rise to long memory effects, while the MA part mimics the short memory effects that appear due to measurement errors. As a consequence the FIMA(d,1) model can identify measurement errors in such experiments. The estimated parameters α and  provide information about the magnitude of the error, see Supplementary Fig. S1. Identification of the measurement error magnitude can be realized by a calibration surface which will be discussed elsewhere.
provide information about the magnitude of the error, see Supplementary Fig. S1. Identification of the measurement error magnitude can be realized by a calibration surface which will be discussed elsewhere.
We showed that the FIMA framework can extract accurate α values even under high measurement error with smaller bias than the common TAMSD technique. It allows a richer modelling scheme than other common models such as FBM29, once the physical interpretation of the parameters is understood. The analysis of stochastic trajectories below the error threshold, reduces the experimental limitations on particle localization, enabling the measurement of biophysical trajectories in faster frame rates and longer trajectories. Moreover, our methodology can be extended to physical and biological systems described by Lévy stable distribution23,51.
Finally, we find that the ARFIMA framework is a promising tool in the analysis of anomalous diffusion processes, especially when physical intuition is coupled to its mathematical components. From an experimental point of view, the FIMA model enables more accurate analysis of trajectories with higher measurement error levels without the need for calibration. This in turn is expected to enable longer and faster measurements and hopefully the study of new phenomena and biophysical entities.
Methods
TAMSD estimation algorithm
If the trajectory comes from a FBM, then

and consequently αMSD = 2H. For the Brownian motion (H = 1/2) we arrive at the diffusion case, namely  . If H < 1/2, so in the negative dependence case, the process follows the subdiffusive dynamics, if H > 1/2, the character of the process changes to superdiffusive.
. If H < 1/2, so in the negative dependence case, the process follows the subdiffusive dynamics, if H > 1/2, the character of the process changes to superdiffusive.
Hence, in order to estimate the anomalous diffusion exponent α, we calculate the following equation:

where  and
and  . For other possibilities see52.
. For other possibilities see52.
FIMA framework
The field of econometrics has a long history of analyzing random motion in order to extract controlling parameters and predicting future behaviour37,38,39. While many of the mathematical models and their basic approach are different than what is common in physical or biological sciences, it is worthwhile to look upon them as a source for novel techniques. In this paper, we study a fractionally integrated moving average FIMA(d,q) process X(t), which is a special case of the general ARFIMA(p,d,q) process38,40,41. FIMA is represented by the fractional difference equation:

where t = 0,±1,… and B is the shift operator: BX(t) = X(t − 1). In addition −1/2 < d < 1/2, taking fractional values, either positive or negative and {Z(t)} is a white noise sequence53.
The fractional difference operator (1 − B)d is defined by means of the binomial expansion, namely  , where
, where  and Γ is the Gamma function. The polynomial
and Γ is the Gamma function. The polynomial  has no roots in the closed unit disk. It corresponds to the moving average (MA) part.
has no roots in the closed unit disk. It corresponds to the moving average (MA) part.
Hence, the model combines two broad classes of time series, namely the fractionally integrated (FI) models and the moving average (MA) models40,41,54. The latter reconstructs a short-term memory structure given by the autocorrelation function for short lags, whereas the former a power-law behaviour for large lags, which leads to the notion of long-term dependence. The MA part provides also a mechanism of transformation of uncorrelated inputs to correlated outputs in many physical systems, see55,56.
In many applications FIMA(d,1) model is sufficient to describe the data well, see, e.g.44. FIMA(d,1) can be considered a first-order approximation of the arbitrary short memory structure (q lags) taking into account only the first lag. In this case the model reduces to:

The basic building block of FIMA(d,1) model is the MA(1) process:  , which is a special case of the MA(q) model40,41. It appears that if X(t) is a stationary 1-correlated time series, i.e., X(s) and X(t) are independent whenever
, which is a special case of the MA(q) model40,41. It appears that if X(t) is a stationary 1-correlated time series, i.e., X(s) and X(t) are independent whenever  (in contrast to an i.i.d. sequence, which is zero-dependent), then it can be represented as the MA(1) process40,41. The dependence is only one lag long and it’s intensity is fully controlled by the parameter
(in contrast to an i.i.d. sequence, which is zero-dependent), then it can be represented as the MA(1) process40,41. The dependence is only one lag long and it’s intensity is fully controlled by the parameter  . Hence, the MA model introduces a short memory of the process. In general, the MA(q) process may reconstruct any arbitrary short time (finite lag) correlation structure from the experimental data. The fractional integration introduces the long (power-law) memory, which is defined by the memory parameter d. The FIMA(d,1) process is well-defined for −1/2 < d < 1/2. Such processes are asymptotically H-self-similar with the parameter H = d + 1/2. The rate of decay of the autocovariance function of the FIMA(d,1) model is
. Hence, the MA model introduces a short memory of the process. In general, the MA(q) process may reconstruct any arbitrary short time (finite lag) correlation structure from the experimental data. The fractional integration introduces the long (power-law) memory, which is defined by the memory parameter d. The FIMA(d,1) process is well-defined for −1/2 < d < 1/2. Such processes are asymptotically H-self-similar with the parameter H = d + 1/2. The rate of decay of the autocovariance function of the FIMA(d,1) model is

Therefore, for d > 0 we have  . This serves as a classical definition of long memory and is equivalent to the case of FBM with H > 1/2. Similarly, for d < 0 we arrive at the negative power law decay, which corresponds to FBM with H < 1/2. The case d = 0 leads to the moving average (MA) model, which has exponentially decaying autocorrelation function40,41,43.
. This serves as a classical definition of long memory and is equivalent to the case of FBM with H > 1/2. Similarly, for d < 0 we arrive at the negative power law decay, which corresponds to FBM with H < 1/2. The case d = 0 leads to the moving average (MA) model, which has exponentially decaying autocorrelation function40,41,43.
Furthermore, Brownian motion (BM) corresponds, in the limit sense57, to FIMA(0,0). Similarly, FBM corresponds to FIMA(d,0) with d = H − 1/2, where H is the self-similarity parameter. The FIMA processes offer flexibility in modelling long power-law and one-lag dependencies by choosing the memory parameter d and the appropriate moving average coefficient  in equation (8). Hence, it is possible to model and characterize more complex processes than using FBM alone.
in equation (8). Hence, it is possible to model and characterize more complex processes than using FBM alone.
FIMA estimation algorithm
To make the FIMA(d,1) model feasible in applications, we need an efficient estimator of its parameters. Modifying58,59, we estimate the vector  . For a sample {x1,x2,…,xN} we denote the normalized periodogram by
. For a sample {x1,x2,…,xN} we denote the normalized periodogram by

The estimator of the parameter vector β is defined as the vector argument  , for which the following function attains its minimum value:
, for which the following function attains its minimum value:

where

is the spectral density of the FIMA process. The idea of the estimator is to find a parameter vector  for which the spectral density
for which the spectral density  is the closest to its empirical counterpart, namely the periodogram
is the closest to its empirical counterpart, namely the periodogram  . Such vector minimizes the value of the integral. The idea is similar to the standard maximum likelihood technique. In order to calculate
. Such vector minimizes the value of the integral. The idea is similar to the standard maximum likelihood technique. In order to calculate  , we have used fminsearch function implemented in Matlab, which applies the simplex search method of60.
, we have used fminsearch function implemented in Matlab, which applies the simplex search method of60.
Additional Information
How to cite this article: Burnecki, K. et al. Estimating the anomalous diffusion exponent for single particle tracking data with measurement errors - An alternative approach. Sci. Rep. 5, 11306; doi: 10.1038/srep11306 (2015).
References
Metzler, R., Jeon, J.-H., Cherstvy A. G. & Barkai, E. Anomalous diffusion models and their properties: non-stationarity, non-ergodicity and ageing at the centenary of single particle tracking. Phys. Chem. Chem. Phys. 16, 24128–24164 (2014).
Höfling, F. & Franosch, T. Anomalous transport in the crowded world of biological cells. Rep. Prog. Phys. 76, 046602 (2013).
Golding, I. & Cox, E. C. RNA dynamics in live E. coli cells. Proc. Natl. Acad. Sci. USA 101, 11310–11315 (2004).
Golding, I. & Cox, E. C. Physical nature of bacterial cytoplasm. Phys. Rev. Lett. 96, 098102 (2006).
Wong, I. Y. et al. Anomalous diffusion probes microstructure dynamics of entangled F-actin networks. Phys. Rev. Lett. 92, 178101 (2004).
Weigel, A. V., Simon, B., Tamkun, M. M. & Krapf, D. Ergodic and nonergodic processes coexist in the plasma membrane as observed by single molecule tracking. Proc. Natl. Acad. Sci. USA 108, 6438 (2011).
Calebiro, D. et al. Single-molecule analysis of fluorescently labeled G-protein-coupled receptors reveals complexes with distinct dynamics and organization. Proc. Natl. Acad. Sci. USA 110, 743–748 (2013).
Kues, T., Peters, R. & Kubitscheck, U. Visualization and tracking of single protein molecules in the cell nucleus. Biophys. J. 80, 2954–2967 (2001).
Bronstein, I. et al. Transient anomalous diffusion of telomeres in the nucleus of mammalian cells. Phys. Rev. Lett. 103, 018102 (2009).
He, Y., Burov, S., Metzler, R. & Barkai, E. Random time-scale invariant diffusion and transport coefficients. Phys. Rev. Lett. 101, 058101 (2008).
Szymanski, J. & Weiss, M. Elucidating the origin of anomalous diffusion in crowded fluids. Phys. Rev. Lett. 103, 038102 (2009).
Meroz, Y., Sokolov, I. M. & Klafter, J. Unequal Twins: Probability distributions do not determine everything. Phys. Rev. Lett. 107, 260601 (2011).
Sokolov, I. M. Models of anomalous diffusion in crowded environments. Soft Matter 8, 9043–9052 (2012).
Palombo, M., Gabrielli, A., Servedio, V. D. P., Ruocco, G. & Capuani, S. Structural disorder and anomalous diffusion in random packing of spheres. Sci. Rep. 3, 2631 (2013).
Yamamoto, E., Akimoto, T., Yasui, M. & Yasuoka, K. Origin of subdiffusion of water molecules on cell membrane surfaces. Sci. Rep. 4, 4720 (2014).
Barkai, E., Garini, Y. & Metzler, R. Strange kinetics of single molecules in living cells. Phys. Today 65, 29–35 (2012).
Bouchaud, J.-P. & Georges, A. Anomalous diffusion in disordered media: Statistical mechanisms, models and physical applications. Phys. Rep. 195, 127–293 (1990).
Weiss, G. H. Aspects and Applications of Random Walks (North-Holland, Cambridge, 1994).
Ben-Avraham, D. & Havlin, S. Diffusion and Reactions in Fractals and Disordered Systems (Cambridge University Press, Cambridge, 2000).
Burnecki, K. & Weron, A. Algorithms for testing of fractional dynamics: a practical guide to ARFIMA modelling. J. Stat. Mech. P10036 (2014).
Metzler, R., Koren, T., Van den Broek, B., Wuite, G. J. & Lomholt, M. A. And did he search for you and could not find you? J. of Phys. A 42, 434005 (2009).
Saxton, M. J. Wanted: a positive control for anomalous subdiffusion. Biophys. J. 103, 2411 (2012).
Burnecki, K. & Weron, A. Fractional Lévy stable motion can model subdiffusive dynamics. Phys. Rev. E 82, 021130 (2010).
Qian, H., Sheetz, M. P. & Elson, E. L. Single particle tracking. Analysis of diffusion and flow in two-dimensional systems. Biophys. J. 60, 910–921 (1991).
Vestergaard, C. L., Blainey, P. C. & Flyvbjerg, H. Optimal estimation of diffusion coefficients from single-particle trajectories. Phys. Rev. E. 89, 022726 (2014).
Michalet, X. Mean square displacement analysis of single-particle trajectories with localization error: Brownian motion in an isotropic medium. Phys. Rev. E 82, 041914 (2010).
Martin, D., Forstner, M. & Käs, J. Apparent subdiffusion inherent to single particle tracking. Biophys. J. 83, 2109–2117 (2002).
Kepten, E., Bronshtein, I. & Garini, Y. Improved estimation of anomalous diffusion exponents in single-particle tracking experiments. Phys. Rev. E 87, 052713 (2013).
Burnecki, K. et al. Universal algorithm for identification of fractional Brownian motion. A case of telomere subdiffusion. Biophys. J. 103, 1839–1847 (2012).
Hellmann, M., Klafter, J., Heermann, D. W. & Weiss, M. Challenges in determining anomalous diffusion in crowded fluids. J. Phys. Condens. Matter 23, 234113 (2011).
Magdziarz, M., Weron, A., Burnecki, K. & Klafter, J. Fractional Brownian motion versus the continuous-time random walk: A simple test for subdiffusive dynamics. Phys. Rev. Lett. 103, 180602 (2009).
Jeon, J.-H., Barkai, E. & Metzler, R. Noisy continuous time random walks. J. Chem. Phys. 139, 121916 (2013).
Peng, C.-K., Buldyrev, S. V., Havlin, S., Simons, M., Stanley, H. E. & Goldberger, A. L. Mosaic organization of DNA nucleotides. Phys. Rev. E 49, 1685 (1994).
Arianos, S., Carbone, A. & Türk, C. Self-similarity of higher-order moving averages. Phys. Rev. E 84, 046113 (2011).
Carbone, A. Information Measure for Long-Range Correlated Sequences: the Case of the 24 Human Chromosomes. Sci. Rep. 3, 2721 (2013).
Shao, Y. et al. Comparing the performance of FA, DFA and DMA using different synthetic long-range correlated time series. Sci. Rep. 2, 835 (2012).
Franke, J., Härdle, W. & Hafner, C. Statistics of Financial Markets: An Introduction (Springer, Berlin, 2010).
Granger, C. W. J. & Joyeux, R. An introduction to long-memory time series models and fractional differencing. J. Time Series Anal. 1, 15–30 (1980).
Granger, C. W. J. who introduced the ARFIMA model, received the Nobel Prize in Economy in 2003.
Brockwell, P. J. & Davis, R. A. Introduction to Time Series and Forecasting (Springer-Verlag, New York, 2002).
Brockwell, P. J. & Davis, R. A. ITSM for Windows: A User’s Guide to Time Series Modelling and Forecasting (Springer-Verlag, New York, 1994).
Magdziarz, M. & Weron, A. Fractional Langevin equation with alpha-stable noise. A link to fractional ARIMA time series. Studia Math. 181, 47–60 (2007).
Slezak, J., Drobczynski, S., Weron, K. & Masajada, J. Moving average process underlying the holographic-optical-tweezers experiments. Appl. Opt. 53, B254–B258 (2014).
Burnecki, K., Muszkieta, M., Sikora, G. & Weron, A. Statistical modelling of subdiffusive dynamics in the cytoplasm of living cells: a FARIMA approach. EPL 98, 1004 (2012).
Weron, A., Burnecki, K., Mercik, Sz. & Weron, K. Complete description of all self-similar models driven by Levy stable noise. Phys. Rev. E 71, 016113 (2005).
Podobnik, B. et al. Fractionally integrated process with power-law correlations in variables and magnitudes. Phys. Rev. E 72, 026121 (2005).
Burnecki, K., Klafter, J., Magdziarz, M. & Weron, A. From solar flare time series to fractional dynamics. Phys. A 387, 1077–1087 (2008).
Podobnik, B. et al. Quantifying cross-correlations using local and global detrending approaches. Eur. Phys. J. 71, 243–250 (2009).
Stanislavsky, A., Burnecki, K., Magdziarz, M., Weron, A. & Weron, K. FARIMA modeling of solar flare activity from empirical time series of soft X-ray solar emission. Astrophys. J. 693, 1877–1882 (2009).
Burnecki, K. FARIMA processes with application to biophysical data. J. Stat. Mech. P05015 (2012).
MacIntosh, A. J. J., Pelletier, L., Chiaradia, A., Kato, A. & Ropert-Coudert, Y. Temporal fractals in seabird foraging behaviour: diving through the scales of time. Sci. Rep. 3, 1884 (2013).
Kepten, E., Weron, A., Sikora, G., Burnecki, K. & Garini, Y. Guidelines for the fitting of anomalous diffusion mean square displacement graphs from single particle tracking experiments. PLoS ONE 10, e0117722 (2015).
Parada, L. M. & Liang, X. A stochastic modeling approach for characterizing the spatial structure of L band radiobrightness temperature imagery. J. Geophys. Res. 108, 8862, (2003).
Beran, J. Statistics for Long-Memory Processes (Chapman & Hall, New York, 1994).
Preatorius, S. K. & Mix, A. C. Synchronization of North Pacific and Greenland climates preceded abrupt deglacial warming. Science 345, 444–448 (2014).
Yuan, J., Raizen, D. M. & Bau, H. H. Gait synchronization in Caenorhabditis elegans. Proc. Natl. Acad. Sci. USA 111, 6865–6870 (2014).
Stoev, S. & Taqqu, M. S. Simulation methods for linear fractional stable motion and FARIMA using the Fast Fourier Transform. Fractals 12, 95–121 (2004).
Kokoszka, P. & Taqqu, M. S. Parameter estimation for infinite variance fractional ARIMA. Ann. Statist. 24, 1880–1913 (1996).
Burnecki, K. & Sikora, G. Estimation of FARIMA parameters in the case of negative memory and stable noise. IEEE Trans. Signal Process. 61, 2825–2835 (2013).
Lagarias, J. C., Reeds, J. A., Wright, M. H. & Wright, P. E. Convergence behavior of the Nelder-Mead simplex algorithm in low dimensions. SIAM J. Optim. 9, 112–147 (1998).
Acknowledgements
K. Burnecki, G. Sikora and A. Weron would like to acknowledge a support of NCN Maestro Grant No. 2012/06/A/ST1/00258. E. Kepten and Y. Garini where supported, in part, by the Israel Centers of Research Excellence (ICORE) No. 1902/12 and Israel Science Foundation No. 51/12. E. Kepten also thanks A.W. and K.B. for the warm hospitality.
Author information
Authors and Affiliations
Contributions
K.B., A.W. and E.K. developed the idea. Y.G. and E.K. analyzed the results from the experimental point of view. K.B. and G.S. prepared the figures. All authors corrected and polished the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Electronic supplementary material
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Burnecki, K., Kepten, E., Garini, Y. et al. Estimating the anomalous diffusion exponent for single particle tracking data with measurement errors - An alternative approach. Sci Rep 5, 11306 (2015). https://doi.org/10.1038/srep11306
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep11306
- Springer Nature Limited
This article is cited by
-
Objective comparison of methods to decode anomalous diffusion
Nature Communications (2021)
-
Diffusion in hierarchical silica monoliths: impact of pore size and probe molecule
Heat and Mass Transfer (2020)
-
Investigation of the Time-Dependent Transitions Between the Time-Fractional and Standard Diffusion in a Hierarchical Porous Material
Transport in Porous Media (2020)