
Abstract
Background
Although artificial intelligence systems that diagnosis among different conditions from medical images are long term aims, specific goals for automation of human-labor, time-consuming tasks are not only feasible but equally important. Acute conditions that require quantitative metrics, such as acute ischemic strokes, can greatly benefit by the consistency, objectiveness, and accessibility of automated radiological reports.
Methods
We used 1,878 annotated brain MRIs to generate a fully automated system that outputs radiological reports in addition to the infarct volume, 3D digital infarct mask, and the feature vector of anatomical regions affected by the acute infarct. This system is associated to a deep-learning algorithm for segmentation of the ischemic core and to parcellation schemes defining arterial territories and classically-identified anatomical brain structures.
Results
Here we show that the performance of our system to generate radiological reports was comparable to that of an expert evaluator. The weight of the components of the feature vectors that supported the prediction of the reports, as well as the prediction probabilities are outputted, making the pre-trained models behind our system interpretable. The system is publicly available, runs in real time, in local computers, with minimal computational requirements, and it is readily useful for non-expert users. It supports large-scale processing of new and legacy data, enabling clinical and translational research.
Conclusion:
The generation of reports indicates that our fully automated system is able to extract quantitative, objective, structured, and personalized information from stroke MRIs.
Plain language summary
Artificial intelligence (AI) uses computer software to solve problems that normally require human input. It is likely that AI will take over, or help with, certain tasks in medical imaging, particularly where these tasks are time-consuming and laborious for clinicians. Here, we demonstrate the possibility of using AI to generate radiological reports for brain scans from patients who have had a stroke. These reports provide a summary of what is shown in the scans, and are normally written by clinicians. Our system performs similarly to human experts, is fast, publicly available, and runs on normal computers with minimal computational requirements, meaning that it might be a useful tool for researchers and clinicians to use when assessing and treating patients with stroke.
Similar content being viewed by others


Introduction
The advancement in labeling techniques signaled the end of services that require human interpretation of images, such as radiology reading. However, 6 years after the announcement of the “end of the path” for radiologists1, they are still alive and operating. Humans still seem superior than machine to decode high level features and relate them to meaningful concepts. Radiologists might have some time until the massive annotated knowledge representing all the variation in human population and diseases will feed AI models that produce comprehensive results and could rival humans in all aspects.
The development of new unsupervised learning methods2 or the massive labeling of medical images to train supervised methods are daunting projects. It is unlikely that multipurpose reporting systems, that can detect and differentiate among several conditions simultaneously, can be created at short term. However, specific goals for automation are not only feasible but also important3. For instance, the typical work flow for reporting quantitative data, e.g., performing a measure in Picture Archive and Communication System (PACS), is redundant, subjective, time-consuming and hard to record. Automated radiological reports describing consistent lesion features such as location, contrast, volumetric properties, and related effects could be a time-saver, particularly in acute conditions and in those that require quantitative report. In addition, it would produce text-structured information that would, in future, reduce the challenges of natural language processing (NLP) and other artificial intelligence (AI) applications in medical analysis.
The initial attempts to generate automated labels for medical images are based on AI models for automated recognition and classification of abnormalities4,5. The first systems to generate automated reports focused in specific goals and were trained in 2D images as chest X-rays6 (please see7 for a review) and mammography8. These are widely performed medical images, relatively less challenging for human annotation, compared to 3D MRIs. The possibility of aggregating considerable sized datasets of these images has been supporting the nascent development of deep learning models (DL) for report generation9. For 3D MRIs, the scarcity of large datasets and difficulties on expert annotation, as well as the unbalance between abnormal and normal cases to derive the knowledge about populations variation, impose extra challenges for AI. Finally, the current inability of AI models to provide findings as well as underlying justifications reduce their popularity among medical professionals.
We present an automated system, the Acute stroke detection and segmentation, ADS10, to generate radiological reports for MRIs of patients with clinical diagnosis of acute ischemic stroke. This system was developed in a large database of annotated 1878 cases11, associated to a deep-learning algorithm for detection and segmentation of the ischemic core in diffusion weighted images (DWIs)12. It reports the lesion location and volume in terms of arterial brain territories13 and classical brain structures14. It can be combined to other brain segmentation schemes to generate reports in different sets of structures and scores of clinical importance, such as ASPECTS15. Most important, ADS is public, user-friendly, runs in CPU of local, regular personal computers with minimum computational requirements (as described previously12 and in the tool documentation10), outputting the reports with a single command line. It therefore fulfills all the conditions to perform large scale, reliable and reproducible clinical and translational research.
Methods
Cohort and Images
This study included MRIs of patients admitted to the Comprehensive Stroke Center at Johns Hopkins Hospital with the clinical diagnosis of ischemic stroke, between 2009 and 2019. This is a subset of the “Annotated Clinical MRIs and Linked Metadata of Patients with Acute Stroke”, an anonymized dataset organized under waiver of patient consent (IRB00228775), publicly shared11. Briefly, the entire dataset consists of 2888 multimodal clinical MRIs performed at the admission of patients with acute brain strokes, retrospectively archived over 10 years, organized under FAIR principles16. Of note, only patients with MRI diagnosis of acute stroke were included, which represents a subset of all hospital stroke patients. The dataset includes lesion segmentation, expert radiological description, patient demographic information, and basic clinical profile. Details of this publicly available dataset are in the documentation that accompanies the data11 and in the related publication17. We have complied with all relevant ethical regulations from the Johns Hopkins Institutional Review Board that approved this study (IRB00290649).
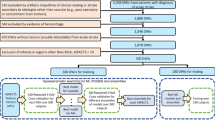
In this study, we included 1,878 mutually exclusive MRIs with evidence of ischemic stroke in the diffusion weighted images (DWI). The flowchart for data inclusion is shown in Fig. 1. The data were random split into training set (n = 1414, 75%) and testing set (n = 464, 25%). The detailed description of the demographic, lesion and scanner profiles of the data used in this study is in Table 1. The distribution of infarcts according to brain location and the demographic characteristics reflect the general population of stroke patients. MRIs were obtained on eleven scanners from four different manufacturers, in different magnetic fields (1.5 T and 3 T), with dozens of different protocols. The DWIs had high in plane (axial) resolution (1.2 × 1.2 mm, or less), and typical clinical high slice thickness (up to 5 mm plus gap). Although a challenge for imaging processing, the technical heterogeneity promotes the potential generalization of the resulting developed tools.

The flowchart describes data inclusion and exclusion, and of the design used for developing and testing of machine learning models.
Our testing set was completely independent and unseen in the machine learning training and validation phases. We reinforce that although we used data from a single National Stroke Center, these data originated from multiple hospitals and a large geographic region, reflecting the profile of the national population with stroke. Still, a second external testing set (STIR (http://stir.dellmed.utexas.edu/), n = 100), was used to test the generalization of our models in a unrelated population. We have complied with all relevant STIR regulations for data usage.
The delineation of the stroke core was defined in the DWI by 2 experienced evaluators and revised by a neuroradiologist until reaching a final decision by consensus, as described in17. The DWIs were mapped to a common template in MNI space18 by 12-parameter linear deformation; the deformation matrix was then applied to the binary stroke masks. The detailed description of these procedures, including used parameters and quality control of the image mapping, is in our publication describing the dataset17.
Visual lesion description and validation
The infarct location was classified by a neuroradiologist according to two schemes:
-
1.
arterial territories, which consists of territories of the following arteries: anterior, medial, and posterior cerebral (ACA, MCA (excluding lenticulostriates)), and PCA (excluding choroidal and thalamoperforating), superior and inferior cerebellar, medial and lateral lenticulostriate, posterior and anterior choroidal and thalamoperforating, and the watershed zone ACA-MCA and MCA-PCA;
-
2.
“classical” anatomy, which defines frontal, temporal, parietal, occipital lobes, insula, internal capsule, deep white matter (corona radiata and centrum semiovale), thalamus, basal ganglia, cerebellum, and brainstem (midbrain, pons, and medulla).
Regions considered injured received a score of 1; the non-injured received 0. The evaluator also recorded the presence (1) or absence (0) of hydrocephalus. The lesion descriptions were validated against the clinical radiological reports in the medical records in a subsample of 110 of cases (6%). The “events” annotated, using BRAT rapid annotation tool (https://brat.nlplab.org/), consisted in words describing stroke type (e.g., “ischemic”, “hemorrhage”, “bleeding”) and location (e.g., words related to arterial territories and brain structures). The annotations were as standardized as possible, to enable the comparison with our standardized description (e.g., “occipital lobe” became “occipital”; “middle cerebral artery” became “MCA”). The comparison between the annotation of the radiological reports and our descriptive metadata was made by the inter-annotator agreement (IAA) with Kohen’s Kappa, using the “irr” R package (https://cran.r-project.org/web/packages/irr/index.html). Values for IAA Kappa range from 0 to 1 (1 is perfect agreement).
There was a total agreement for the description of stroke type (ischemic) between the clinical radiologcal reports and our metadata. For the lesion locations, the mean IAA Kappa was 0.71 ± 0.16, which is a high level of agreement. The indices varied from perfect agreement of 1 (for regions such as thalamus), to the lowest 0.5 (for parietal lobe). We note that the disagreements were, in their vast majority, result of semantic variations or analysis at different levels of granularity, rather than divergence in radiological evaluation. For instance, if the clinical radiological report says “perirolandic area” and our text-standardized description says “parietal” lobe, this was considered a disagreement, although the perirolandic area is part of the parietal lobe. Based on the results of IAA Kappa and these observations, we considered our radiological descriptions aligned with the medical records, and well suited for training the automated models.
Multiple evaluators descriptions
To access the level of variation in visual descriptions, and the agreement of different evaluators with the developed automated reports, two other clinical experts, a neuroradiologist (VY) and a neurologist (RL), with >10 years of experience in stroke care and image reading, classified the infarct location in the whole testing set (n = 464), following the same procedures described above. The comparison among the three evaluators, and among the evaluators and the automated classification was made by the intraclass correlation (ICC) using the function ICC3 of the Python package “pingouin.intraclass-corr”19.
A second question is whether the automated radiological reports would aid the flow of clinical stroke
care, particularly in settings that do not count on highly trained experts or second radiology readers full time in emergency service. Testing clinical impact is beyond the scope of this paper, as it depends on further stages of technical and bureaucratic technology development. Even so, as proof-of-concept, we asked one emergency room physician, not formally trained in neuro-radiology or neurology (VF), to classify the stroke location in a testing subset (n = 155), again using the same procedures described above. The results of the here called non-expert physician and the automated radiological reports were compared to the expert physicians’ readings, and rated as “in agreement”, “in partial agreement”, or “in disagreement” with those. “In disagreement” was used if an infarcted area was not or was wrongly described, and that would have clinical implications, such as change of clinically relevant metrics (e.g. ASPECTS20). “In partial agreement” was used if the error would have no potential clinical implications. We also recorded the time for the non-expert physician reading.
Automatic extraction of feature vectors
The quantitative features used to train the models for automatic classification of the infarct location were defined to be compatible with the visual scoring. Digital atlases, based on arterial territories13 (Arterial atlas—NITRC. https://www.nitrc.org/docman/?group_id=1498) and classical anatomy14 (illustrated in Fig. 2), were overlaid on the brains in standardized space (MNI). These atlases define similar regions of interest (ROI) as those used in the visual analysis, which are the most clinically relevant for the description of the acute infarct location. The quantitative feature vectors (QFV) extracted proportionally reflect the ratio of injury in each ROI (i.e., the proportion of ROI voxels in which the infarct mask = 1). We note that all ROIs are bilateral (except by the brainstem) and homologous ROIs have approximately the same volume. One illustrative example is shown in Fig. 3 and Table 2. The infarct volume (in log ml) was also included in QFVs.

The regions of interest (ROIs) are overlaid in the template18 T1-WI.

The figures show a large acute ischemic infarct in DWI (a). The infarct core, automatically segmented12, is overlaid in ADC (b). Brain atlases representing classical anatomical structures (c) and arterial territories (d) allow to quantify the injury in diverse regions of interest (ROIs). The calculated quantitative feature vectors (QFV) are in Table 2.
We also trained and tested a model to predict hydrocephalus, as this is an important characteristic to be reported in strokes. Two strips of 5-voxel width bandwidth were defined around the five sub-regions of the lateral ventricles (LV, as defined in template brain14): the outside strip of the LV (OLV), and the inside strip of the LV (ILV). After linearly mapping the brain to the template, the number of voxels with ADC intensity >0.0018 mm2/s (CSF voxels) and <0.0018 mm2/s (non-CSF voxels)21 are calculated to generate:
1 γOLVR: the ratio of the number of the deformed non-CSF voxels in OLV over the number of voxels in OLV. γOLVR lower than the dataset average γOLVR indicates ventricular enlargement compared to the expected average ventricle size (although not necessarily hydrocephalus).
2 γILVR: the ratio of the number of the deformed CSF voxels in ILV over the number of voxels in ILV. γILVR lower than the dataset average γILVR indicates possible ventricular compression or midline shift
To access the accuracy of the QFVs extracted, we deliver quality control indices (described in the supplementary material—QCI section) that indicate the agreement between the contour of the brain in question and the atlases in which the brain structures are defined. Lastly, we extracted QFVs from brains non-linearly mapped to the atlases (with Dipy), to evaluate the influence of the brain mapping method (linear vs. non-linear) in the automated prediction of stroke location.
Machine Learning (ML) classification models to predict infarct location
We developed, validated, and tested seven models (described below) to predict the infarct location using the QFV calculated with the human-segmented lesions. All ML models were cross validated over the training set (1414 individuals, 75%) for hyperparameter searching and tested in the completely independent testing set of 464 individuals (flowchart in Fig. 1). We performed 5-fold cross validation on the training set, for a large set of searching parameters. The models’ hyperparameters with the top 3 performances (according to the sum of balanced accuracy (BACC) and F1 score, from this first run of 5-fold cross validation) were further determined and selected via 10 repeat 5-fold cross-validation, on the training set. The details of searching parameters’ sets, final optimal parameters, cross validation results, and the definitions of performance metrics are in the Supplementary Methods and Supplementary Data 1 and 2.
The simplest model, the Binary Threshold (BT), was built to classify the stroke location via thresholding its corresponding ROI component in the QFV for each participant. The threshold can be interpreted as the minimum percentage of the ROI occupied by the infarct mask to lead its classification as injured (and receive a score of 1). The threshold for each ROI was the minimal level to achieve the highest sum of the BACC and F1 score, found by cross-validation of the training set. The optimal thresholds for each ROI are summarized in the Supplementary Data 1. The remaining six models were Linear Discriminant Analysis (LDA), Quadratic Discriminant Analysis (QDA), Random Forest (RF), K-nearest Neighbors (KNN), Support Vector Machine (SVM), and Multi-layer Perceptron (MLP). The measures of models’ performances are described in the Table 3.
Because some ROIs are injured only in a few cases (see Table 1) over our large dataset, deep neural network models would suffer from imbalanced classes issue. In addition, the interpretation of deep learning models is not as straightforward as that of classic ML methods. Furthermore, given that the ML models employed proved sufficiently efficient compared to humans (as we will show in Results), we opted to further investigate the potential of deep learning techniques to improve the classification performance when this dataset is expanded, or when other public sets of clinical data become available.
Feature analysis
The implementation of interpretable models potentially increases their practical usefulness and enable to investigate whether machine uses features of biological relevance, similarly to humans. We explored how the visual classification attributed to different ROIs relate to each other, as well as the relationship between visual analysis and QFV for each ROI, and between different QFV components, using bivariate correlations (Table 4).
We then conducted an analysis of feature importance to inspect how the ML models use the QFVs to describe lesion location. The analyses presented here are based on Random Forest (RF) models, which had the best average performance (BACC, F1) among all ML models. The impurity-based feature importance analysis22,23 was conducted to build 100 RF models on the training set with the optimal parameters selected from cross validation. The Mean Decrease in Impurity (MDI), shown in Fig. 4, indicates the feature importance (high MDIs correspond to the most important features). We also conducted permutation feature importance tests (100 iterations), using the training and testing set separately (Supplementary Tables 1 and 2 and Supplementary Fig. 1 and 2), to illustrate the consistency in feature learning and their potential generalization, respectively.

The MDI is proportional to the importance of the features (the QFVs and lesion volume, in the x-axis) to predict the injury of the region in question (title of each graph). The QFVs represent the proportion of each ROI affected by the infarct. Note that the dominant QFV component agrees with the prediction of injury in the corresponding region and is followed by the QFV of its spatially neighboring regions.
To generate and deliver explanations about the predictions in a new given sample, we adapted the SHapley Additive exPlanations (SHAP)24 module in the ADS. The SHAP computes the Shapley values25 of features via coalitional game theory to indicate how to fairly distribute prediction of an instance among features. Because the Shapley feature value is linearly additive, this value can be directly added or subtracted from the probability of predicts, making the models’ interpretation straightforward. The outputs are intuitively comprehensible graphs of the predicted infarct location (example in Supplementary Fig. 3), explaining how the QFV components were combined to predict injury in each brain area.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Results
Correlations among human expert evaluation and QFVs
Table 4 illustrates how the visual determination of the presence of infarct (yes = 1, no = 0) is related in different ROIs. High correlation between a pair ROIs means that the infarct tends to co-exist on them. As expected, given the spatial coalescence of infarct lesions, neighboring ROIs defined by the classical anatomic atlas (Table 4.II.a) are the highest correlated (e.g., frontal, parietal, and temporal; which are part of the MCA territory). Compared to those, ROIs defined by the arterial territory atlas (Table 4.I.a) are less correlated, since they follow the distribution of the infarcts by definition. Table 4.I.b and II.b demonstrate the correlation between QFV components. They represent the quantitative version of the qualitative scores in Table 4.I.a and II.a, to which they highly agree. This indicates that the quantitative information coded in the QFVs (the proportion of each ROI affected by the infarct) is likely reflecting the qualitative information that humans relay in their visual analysis. Similar to the visual analysis, each QFV component is highly correlated to the QFV components of its neighbor ROIs.
Table 4.I.c and II.c combine the information above, showing the correlation between visual analysis and QFV components. They indicate more directly how humans inconspicuously use the quantitative information about the spatial distribution of the infarct (reflected by the QFV) to determine the infarct injury. The rows indicate that the visual classification attributed to each ROI is mostly correlated to the QFV component that corresponds to the ROI in question, and secondly, to the QFV components corresponding to neighboring ROIs, as expected. Again, as the infarct lesions extend beyond the artificial limits of the semantically defined areas, the human evaluation is not purely based on how individual areas are affected, but also in the regional lesion pattern.
Accuracy of ML models to predict infarct location
The performance of models to predict the stroke location in the testing set is summarized in Table 3. The best models, in BACC and F1, were those created with random forest (RF), achieving an excellent agreement with the visual analysis (vast majority of BACC > 0.8). The lowest agreement, while still satisfactory, occurred in the ACA (considering the arterial territory scheme), and the internal capsule (considering the classical anatomical scheme). The most efficient RF model, retrained with the automated infarct segmentations12, was included in our deployed pipeline to generate reports in ADS10. The hyperparameters and performances on cross-validation in the training set and in the testing set, using ADS infarct segmentation, are reported in Supplementary Data 3, 4 and 5.
As the infarct volume and location are correlated (e.g., small defined areas, such as the thalamoperfurating territory, irrigated by arteries of small caliber, tend to have small strokes), large ROIs had, in general, slightly better accuracy performance for all ML models. There was no significant difference in the prediction accuracy regarding the patient sex (male or female) or race (Black/African America or Caucasian), time from stroke onset (> or <6 h), magnetic field (1.5 T or 3 T), and infarct side (left or right).
The performance of the RF model was slightly higher when using non-linearly normalized brain images (as shown in Supplementary Table 3), compared to linearly normalized. The model was robust in the external unrelated population (from STIR), demonstrating similar performance to that achieved in our independent testing set (results shown in Supplementary Table 4). The automated classification of infarct location was also robust when compared with that of different experts. The mean ICCs of the model against each of the three evaluators were 0.82 ± 0.08, 0.77 ± 0.11, and 0.81 ± 0.08, which rivaled to the ICCs among pairs of inter-evaluators: 0.75 ± 0.12, 0.8 ± 0.09, and 0.81 ± 0.08; with standard deviations consistently lower. The indices of agreement are presented in details and categorized by location in Supplementary Table 5. The regional distribution of ICCs was consistent inter-evaluators and between the model and the evaluators, i.e., regions with the lowest concordance among the model and the evaluators (e.g., ACA and internal capsule) also had the lowest concordance inter-evaluators (Supplementary Table 5 and Fig. 5). Of note, these regions correspond to those with lowest lesion frequency or those with unclear or less consensual boundaries.

Intraclass correlations (ICCs, y-axis) among human evaluators (E1, E2, E3) and among evaluators and our automated model for infarct location classification (auto). ICC = 1 is perfect agreement.
Our system was more accurate than the non-expert physician to classify the infarct location when both were compared to the experts’ evaluation. Both the non-expert physician and the automated reports agreed with the experts’ evaluation in most of cases (71 and 88%, respectively). The non-expert physician was “in partial agreement” with the experts in 39 cases (25%), and the automated generated reports, in 19 (12%). The non-expert physician was “in disagreement” with the experts in 6 cases (4%), while the automated generated reports had no substantial disagreement with the experts’ reports. The mean time of the non-expert physician evaluation was 1 min per scan, with the maximum time of 2.6 min.
Prediction interpretability
Instead of building black-box ML models, we aimed to provide interpretable models to elucidate whether the machine uses features of biological relevance. Figure 4 indicates the importance of features in the RF models. The most important feature was the percentage of injury of the region in question, followed by the injury of neighboring regions. This aligns with the correlations found between regional classification of injury by visual analysis (Table 4.I.a and II.a) and indicated that, in general, RF models and humans are using very similar features for scoring. The permutation feature importance test demonstrated the consistency of the importance of features learned in the training set, and their generalization in the testing set.
While these methods expose general features implied in the classification, it is important to highlight the reasoning of the prediction at individual level. This serves as validation for the ML models, as well to facilitate the calculation of treatment-relevant scores (e.g., ASPECTS) that depend on the reliable identification of injured regions. Therefore, SHAP was implemented in ADS to explain how the features were considered by the pre-trained model to predict infarct location in any given new sample. The Supplementary Fig. 3 illustrates one example of the explanation of our pre-trained model, which is outputted together with the regional predicts of the infarct location and their probabilities (Fig. 3 and Supplementary Note 1).
Discussion
We created a fully automated system to quantify ischemic infarcts and report their location, with accuracy comparable to an expert evaluator, and among the inter-evaluators variation. The system is robust to major technical, lesion, and populational variations, and in an external unrelated population. The random forest (RF) models achieved the best performance in virtually all the regions (Table 3). The RF performance was followed by that of the binary threshold method, BT. However, although the BT accuracy was particularly high in areas with severe class imbalance (e.g., ACA), the general BT performance and its precision, in particular, were significantly lower than that of RF. This indirectly points to the ways AI uses the image features (in this case, the QFVs) to make a prediction. As confirmed by the feature analysis, the main feature determining the injury of a region is, as expected, the proportion of the respective region affected by the infarct. However, joined injury of neighboring regions have a secondary but still important effect in the decision (Fig. 4). Similarly, the human prediction also relays on these joined conditions in which the determination of injury in a given ROI is mostly correlated to its respective and dominant QFV component, followed by the components of the neighboring ROIs (as depicted in Table 4.II.c). Therefore, it is expected that more complex models, that take in account the joined probabilities, will generally have better performance than the simple BT for single ROIs.
From the biological point of view, this phenomenon likely relates to the coalescence of ischemic strokes, that do not respect the semantically-defined boundaries, particularly those defined by the classical structural atlas. From the technical point of view, inaccuracies in brain mapping can lead to mismatches between ROIs and the structures they define. This impacts the quantification, specifically when the injury is located in small ROIs, close to the ROI boundaries, or in mesial and periventricular areas. These areas are particularly challenging for the linear mapping in populations with high frequency of hydrocephalus or midline shifts, as occurs in acute stroke. For example, Fig. 3 shows a visible mismatch between the atlas definition of the ventricles and mesial structures and the brain in question, due to ventricular compression and midline shift, caused by the infarct. Although this inaccuracy did not lead to disagreements between the automated and the human radiological report in this large infarct, it might be the case in more focal lesions. As noted, the complex models employed for the prediction help to diminish this problem.
Another practical strategy we implemented in our automated pipeline (ADS10) is the option to recalculate the QFVs using a non-linear mapping. This theoretically improves the match between the brain in question and the template, which would consequently result in more accurate classification of the stroke location. In fact, we observed slight improvement in the location classification of infarcts when using non-linear brain mapping (as shown in Supplementary Table 3). The mildness on improving might be attributed to the presence of previous strokes or microvascular diseases that often occur in this population. These abnormalities alter the brain anatomy and contrast, reducing the accuracy of the non-linear algorithms. On the other hand, the low degree of deformation elasticity of the non-linear algorithm employed and the low granularity of our ROIs likely prevented mismatches in the classification of the lesion location. Given the cost / benefit (the non-linear deformation takes about 3 extra minutes of processing time) the linear mapping is the default option in ADS10, and the non-linear mapping is offered as an optional.
Regarding the regional accuracy of the prediction, the lowest BACC of all models was in ACA (BACC = 0.712), for the arterial territory scheme, and internal capsule (BACC = 0.752), for the classical structural scheme. Infarcts in these regions were less frequent in our sample (in agreement with the epidemiology of ischemic strokes) which is a limitation for model training and testing. This will be ameliorated by increasing the dataset. In addition, these regions offer extra challenges for both humans and machine, either by having ambiguous / highly variable territories, like the ACA (Arterial atlas—NITRC. https://www.nitrc.org/docman/?group_id=1498), or by their ill-defined limits in low resolution clinical images or small volume, like the internal capsule.
The feature analysis enriched the AI models, increasing their interpretability and their potential usefulness. Therefore, our ADS10 system is suited to output not only the radiological report in semantic format but also the list with the proportion of injury in each area defined (the QFVs), the regional prediction of injury and the prediction probability, as well as explanatory reports showing how the QFVs were combined to predict injury in each area (example of ADS outputs in Supplementary Fig. 3 and Note 1). The QFVs are computable data objects that might serve as lesion loadings for anatomico-functional studies or to train artificial intelligence models. In clinics, these interpretable reports may, theoretically, improve the reliability of the system26,27,28 by increasing transparency, promoting trust, and indirectly serving as quality control. For example, clinicians may identify cases where the model overemphasizes or fails to consider important information. Further quantitative studies (e.g., measuring number of reports generated, turnaround times, and error rates), user surveys, comparison of clinical outcomes, and cost analysis will be needed to test the real impact in practical settings.
A final consideration regards to the producibility of the automated generated reports. Our tool is linked to a public and expandable dataset of clinical images11, and therefore will be supported by a dynamic dataset whose radiological evaluation can be modified / refined over time. The tool is modular, therefore flexible and adaptable to changes, for instance, in brain mapping procedures or parcellation schemes (e.g., different ROIs can be easily adopted, either to test their clinical significance or to train models in order to provide different types of reports). It is easily linkable to other software for image analysis, for example those that work directly in MRI scanner outputs, making them compatible with our image inputs. Therefore, it can be theoretically installed in radiological reading settings. The inclusion of a module that accepts users’ feedback for models’ retraining, maintenance and quality control is in our future plan. It is also in our short-term plan leveraging cloud-based infrastructure which could allow easy and large-scale processing of clinical research data.
In summary, using the original DWI as input, we created a fully automated system that includes automatic detection and segmentation of ischemic injuries and outputs radiological reports, in addition to the previously reported12 3D digital infarct mask, infarct volume, and the feature vector of regions affected by the acute stroke. We speculate that the automated radiological reports might be superior to “non-expert” reports, based on the proof-of-concept comparison with the non-expert physician evaluation. This would be particularly relevant, and potentially time-saver, in centers that lack second readers or neuroradiologists full time in emergency service. However, large scale prospective tests are imperative both to prove the clinical impact as well as to optimize the technology presented here. So far, we limit our contribution on generating a publicly available system that produces computable data objects, runs in real time, in local CPUs of regular personal computers, with minimal computational requirements10,12, and is accessible to non-expert users, fulfilling the conditions to perform large scale, reliable and reproducible clinical and translational research.
Data availability
The data used in this study are available at https://www.icpsr.umich.edu/web/ICPSR/studies/3846411. these data is public and free and can be downloaded directly from this repository after signing the Disclosure of User Agreement. Note that these data include all the images, in native space and post- processed (mapped to common space), the annotation of the stroke core (in the DWI), and the demographic and clinical information. This enables easy validation and replicability test of the results presented here. The STIR data were used under approval from the STIR steering committee for the current study, and so are not publicly available. These data are however available from the STIR / Vista Investigators upon reasonable request to Dr. Marie Luby (lubym@ninds.nih.gov). The source data for this manuscript is in Supplementary Data 6.
Code availability
The tool described in this study is publicly available at https://www.nitrc.org/projects/ads10. The source code is available at https://doi.org/10.5281/zenodo.556523029.
References
Hinton, G. On radiology. In Machine Learning and the Market for Intelligence Conference (Synced, Canada, 2016).
Hinton, G. Deep learning—a technology with the potential to transform health care. JAMA 320, 1101–1102 (2018).
Oren, O., Gersh, B. J. & Bhatt, D. L. Artificial intelligence in medical imaging: switching from radiographic pathological data to clinically meaningful endpoints. The Lancet Digit. Heal 2, e486–e488 (2020).
Esteva, A. et al. Dermatologist-level classification of skin cancer with deep neural networks. Nature 542, 115–118 (2017).
Poplin, R. et al. Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning. Nat. Biomed. Eng. 2, 158–164 (2018).
Shin, H.-C. et al. Learning to read chest x-rays: Recurrent neural cascade model for automated image annotation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2497–2506 (IEEE, 2016).
Monshi, M. M. A., Poon, J. & Chung, V. Deep learning in generating radiology reports: a survey. Artif. Intell. Med. 106, 101878 (2020).
Kisilev, P., Sason, E., Barkan, E. & Hashoul, S. Medical image description using multi-task-loss CNN. In Deep Learning and Data Labeling for Medical Applications 121–129 (Springer, 2016).
Messina, P. et al. A Survey on Deep Learning and Explainability for Automatic Report Generation from Medical Images (ACM, 2022).
Liu, C. F. & Faria, A. V. Acute-stroke Detection Segmentation (ADS). https://www.nitrc.org/projects/ads/ (2022).
Faria, A. V. Annotated clinical MRIs and linked metadata of patients with acute stroke, Baltimore, Maryland, 2009–2019. ICPSR https://doi.org/10.3886/ICPSR38464.v5 (2022).
Liu, C. F. et al. Deep learning-based detection and segmentation of diffusion abnormalities in acute ischemic stroke. Commun. Med. 1, 61 (2021).
Liu, C.-F. et al. Digital 3D brain MRI arterial territories atlas. Sci. Data 10, 74 (2023).
Oishi, K. et al. Human brain white matter atlas: identification and assignment of common anatomical structures in superficial white matter. Neuroimage 43, 447–457 (2008).
Liu, C.-F. et al. Automatic comprehensive aspects reports in clinical acute stroke mris. Sci. Rep. 13, 3784 (2023).
Wilkinson, M. D. et al. The fair guiding principles for scientific data management and stewardship. Sci. Data 3, 1–9 (2016).
Liu, C. F. et al. A Large Dataset of Annotated Clinical MRIs and Linked Metadata of Patients with Acute Stroke. Under consideration in Sci. Data (2022).
Mori, S. et al. Stereotaxic white matter atlas based on diffusion tensor imaging in an icbm template. Neuroimage 40, 570–582 (2008).
Vallat, R. Pingouin: statistics in Python. J. Open Source Softw. 3, 1026 (2018).
Menon, B. K., Puetz, V., Kochar, P. & Demchuk, A. M. Aspects and other neuroimaging scores in the triage and prediction of outcome in acute stroke patients. Neuroimage. Clin 21, 407–423 (2011).
Moraru, L. & Dimitrievici, L. Apparent diffusion coefficient of the normal human brain for various experimental conditions. In AIP Conference Proceedings, 1796, 040005 (AIP Publishing LLC, 2017).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Strobl, C., Boulesteix, A.-L., Zeileis, A. & Hothorn, T. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinform. 8, 1–21 (2007).
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inf. Proc. Syst. 30, 4768–4777 (2017).
Sundararajan, M. & Najmi, A. The many shapley values for model explanation. In International Conference on Machine Learning, 9269–9278 (PMLR, 2020).
Doshi-Velez, F. & Kim, B. Towards a rigorous science of interpretable machine learning. arXiv https://doi.org/10.48550/arXiv.1702.08608 (2017).
Shah, N. D., Steyerberg, E. W. & Kent, D. M. Big data and predictive analytics: recalibrating expectations. JAMA 320, 27–28 (2018).
Lipton, Z. C. The mythos of model interpretability: in machine learning, the concept of interpretability is both important and slippery. Queue 16, 31–57 (2018).
Liu, C. F. & Faria, A. V. Acute-stroke detection segmentation (ADS). Zenodo https://doi.org/10.5281/zenodo.5579390 (2021).
Acknowledgements
This research was supported in part by the National Institute of Deaf and Communication Disorders, NIDCD, through R01 DC05375, R01 DC015466, P50 DC014664 (A.H., A.V.F.), the National Institute of Biomedical Imaging and Bioengineering, NIBIB, through P41 EB031771 (M.I.M., A.V.F.), and the Department of Neurology, University of Texas at Austin, the National Institute of Neurological Disorders and Stroke, NINDS, National Institutes of Health, NIH (STIR / Vista Imaging Investigators).
Author information
Authors and Affiliations
Consortia
Contributions
A.V.F. and C.-F.L. conceived and designed the study, analyzed, and interpreted the data, drafted the work. Y.Z., V.Y., R.L., V.F. analyzed the data. A.E.H. acquired part of the data and significantly revised the manuscript. M.I.M. revised the manuscript. The STIR and VISTA investigators provided part of the data.
Corresponding author
Ethics declarations
Competing interests
The authors declare the following competing interests: Michael I. Miller owns “AnatomyWorks”. This arrangement is managed by Johns Hopkins University in accordance with its conflict-of-interest policies. The remaining authors declare no competing interests.
Peer review
Peer review information
Communications Medicine thanks Namkug Kim, King Chung Ho and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, CF., Zhao, Y., Yedavalli, V. et al. Automatic comprehensive radiological reports for clinical acute stroke MRIs. Commun Med 3, 95 (2023). https://doi.org/10.1038/s43856-023-00327-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s43856-023-00327-4
- Springer Nature Limited
This article is cited by
-
A large public dataset of annotated clinical MRIs and metadata of patients with acute stroke
Scientific Data (2023)