
Abstract
In healthcare, integration of artificial intelligence (AI) holds strong promise for facilitating clinicians’ work, especially in clinical imaging. We aimed to assess the impact of AI implementation for medical imaging on efficiency in real-world clinical workflows and conducted a systematic review searching six medical databases. Two reviewers double-screened all records. Eligible records were evaluated for methodological quality. The outcomes of interest were workflow adaptation due to AI implementation, changes in time for tasks, and clinician workload. After screening 13,756 records, we identified 48 original studies to be incuded in the review. Thirty-three studies measured time for tasks, with 67% reporting reductions. Yet, three separate meta-analyses of 12 studies did not show significant effects after AI implementation. We identified five different workflows adapting to AI use. Most commonly, AI served as a secondary reader for detection tasks. Alternatively, AI was used as the primary reader for identifying positive cases, resulting in reorganizing worklists or issuing alerts. Only three studies scrutinized workload calculations based on the time saved through AI use. This systematic review and meta-analysis represents an assessment of the efficiency improvements offered by AI applications in real-world clinical imaging, predominantly revealing enhancements across the studies. However, considerable heterogeneity in available studies renders robust inferences regarding overall effectiveness in imaging tasks. Further work is needed on standardized reporting, evaluation of system integration, and real-world data collection to better understand the technological advances of AI in real-world healthcare workflows. Systematic review registration: Prospero ID CRD42022303439, International Registered Report Identifier (IRRID): RR2-10.2196/40485.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
With a rising number of patients and limited staff available, the need for changes in healthcare is a pressing issue1. Artificial intelligence (AI) technologies promise to alleviate the current burden by taking over routine tasks, such as monitoring patients, documenting care tasks, providing decision support, and prioritizing patients by analyzing clinical data2,3. AI-facilitated innovations are claimed to significantly reduce the workload of healthcare professionals4,5.
Several medical specialties have already introduced AI into their routine work, particularly in data-intensive domains, such as genomics, pathology, and radiology4. In particular, image-based disciplines have seen substantial benefits from the pattern recognition abilities of AI, positioning them at the forefront of AI integration in clinical care3,6. AI technologies expedite the processing of an increasing number of medical images, being used for detecting artifacts, malignant cells or other suspicious structures, and optionally for the succeeding prioritization of patients7,8,9.
To successfully adopt AI in everyday clinical practice, different ways for effective workflow integration can be conceived, largely depending on the specific aim, that is, enhancing the quality of diagnosis, providing reinsurance, or reducing human workload10,11. Efficiency outcomes related to AI implementation include shorter reading times or a reduced workload of clinicians to meet the growing demand for interpreting an increasing number of images12,13,14. Thus, whether AI fulfills these aims and enables higher efficiency in everyday clinical work remains largely unknown.
Healthcare systems are complex, combining various components and stakeholders that interact with each other15. While the success of AI technology implementation highly depends on the setting, processes, and users, current studies largely focus on the technical features and capabilities of AI, not on its actual implementation and consequences in the clinical landscape2,3,6,16,17. Therefore, this systematic review aimed to examine the influence of AI technologies on workflow efficiency in medical imaging tasks within real-world clinical care settings to account for effects that stem from the complex and everyday demands in real-world clinical care, all not being existent in experimental and laboratory settings18.
Results
Study selection
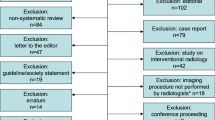
We identified 22,684 records in databases and an additional 295 articles through backward search. After the removal of duplicates, the 13,756 remaining records were included in the title/abstract screening. Then, 207 full texts were screened, of which 159 were excluded primarily because of inadequate study designs or not focusing on AI for interpreting imaging data (Supplementary Table 1). Finally, 48 studies were included in the review and data extraction. Twelve studies underwent additional meta-analyses. A PRISMA flow chart is presented in Fig. 1.

Visual representation of the search strategy, data screening and selection process of this systematic review.
Study characteristics
Of the 48 extracted studies, 30 (62.5%) were performed in a single institution, whereas the 18 (37.5%) remaining studies were multicenter studies. One study was published in 2010, another in 2012, and all other included studies were published from 2018 onward. Research was mainly conducted in North America (n = 21), Europe (n = 12), Asia (n = 11), and Australia (n = 3). Furthermore, one study was conducted across continents. The included studies were stemming from the medical departments of radiology (n = 26), gastroenterology (n = 6), oncology (n = 4), emergency medicine (n = 4), ophthalmology (n = 4), human genetics (n = 1), nephrology (n = 1), neurology (n = 1), and pathology (n = 1). Most studies used computed tomography (CT) for imaging, followed by X-ray and colonoscopes. The most prominent indications were intracranial hemorrhage, followed by pulmonary embolism, and cancer screening. Table 1 presents the key characteristics of all included studies.
Concerning the purpose of using AI tools in clinical work, we classified the studies into three main categories. First, five studies (10.4%) described an AI tool used for segmentation tasks (e.g., determining the boundaries or volume of an organ). Second, 25 studies (52.1%) used AI tools to examine detection tasks to identify suspicious cancer nodules or fractures. Third, 18 studies (37.5%) investigated the prioritization of patients according to AI-detected critical features (e.g., reprioritizing the worklist or notifying the treating clinician via an alert).
Regarding the AI tools described in the studies, 34 studies (70.8%) focused on commercially available solutions (Table 2). Only Pierce et al. did not specify which commercially available algorithm was used19. Thirteen studies (27.1%) used non-commercially available algorithms, detailed information on these algorithms is provided in Table 3. Different measures were used to evaluate the accuracy of these AI tools, including sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and area under the curve (AUC). Sensitivity and specificity were the most commonly reported measures (see Tables 2 and 3).
In total only four studies followed a reporting guideline, three studies20,21,22 used Standards for Reporting of Diagnostic Accuracy (STARD) reporting guideline23 and Repici et al.24 followed the CONSORT guidelines for randomized controlled trials25. Only two studies24,26 pre-registered their protocol and none of the included studies provided or used an open-source available algorithm.
Appraisal of methodological quality
When assessing the methodological quality of the 45 non-randomized studies only one (2.2%) was rated with an overall “low” risk of bias. Four studies (8.9%) were rated “moderate”, 28 studies (62.2%) were rated “serious”, and 12 studies (26.7%) were rated “critical”. All three randomized studies were appraised with an overall high risk of bias. Summary plots of the risk of bias assessments are shown in Fig. 2, full assessments can be found in Supplementary Figs. 1 and 2. The assessment of the quality of reporting using the Methodological Index for Non-randomized Studies (MINORS) is included in Supplementary Figs. 3 and 4. Higher scores indicate higher quality of reporting, with the maximum score being 24 for comparative studies and 16 for non-comparative studies27. Comparative studies reported a Median of 9 of 12 criteria with a median overall score of 15 (range: 9–23) and noncomparative studies reported a Median of 7 of 8 checklist items, with a median overall score of 7 (range: 6–14).

Summary plots of the risk of bias assessments via Risk of Bias in Non-randomized Studies of Interventions tool (ROBINS-I) for non-randomized studies and the Cochrane Risk of Bias tool (Rob 2) for randomized studies.
Outcomes
Of all included studies, 33 (68.8%) surveyed the effects of AI implementation on clinicians’ time for task execution. The most frequently reported outcomes included (1) reading time (i.e., time the clinicians required to interpret an image); (2) report turnaround time (i.e., the time from completing the scan until the report is finalized); and (3) total procedure time (i.e., the time needed for colonoscopy)28,29,30. Times were assessed via surveys, recorded by researchers or staff, retrieved via time stamps, or self-recorded. Seventeen studies did not describe how they obtained the reported times.
Regarding our research question, whether AI use improves efficiency, 22 studies (66.6%) reported a reduction in time for task completion due to AI use, with 13 of these studies proving the difference to be statistically significant (see Table 4). Eight studies (24.2%) reported that AI did not reduce the time required for tasks. The remaining three studies (9.1%) chose a design or implementation protocol in which the AI was used after the normal reading, increasing the task time measured by study design31,32,33.
For our meta-analyses, we established clusters with studies deploying similar methods, outcomes, and specific purposes. Concerning studies on detection tasks, we identified two main subgroups: studies using AI for interpreting CT scans (n = 7) and those using AI for colonoscopy (n = 6). Among studies using AI for interpreting CT images, a meta-analysis was performed for four studies reporting clinicians’ reading times. As shown in Fig. 3a, the reading times for interpreting CT images did not differ between the groups: standardized mean error (SMD): −0.60 (95% confidence interval, −2.02 to 0.82; p = 0.30). Furthermore, the studies showed significantly high heterogeneity: Q = 109.72, p < 0.01, I2 = 96.35%. This heterogeneity may be associated with the different study designs included or the risk of bias ratings, with only one study being rated having a low risk of bias. Furthermore, Mueller et al.8 reported no overall reading time but separated it for resident and attending physician, which we included separately in our meta-analysis. Concerning the use of AI for colonoscopy, five studies reported comparable measures. Our random effects meta-analysis showed no significant difference between the groups: SMD: −0.04 (95% CI, −0.76 to 0.67; p = 0.87), with significant heterogeneity: Q = 733.51, p < 0.01, I2 = 99.45% (Fig. 3b). Four of the included studies had a serious risk of bias, whereas one randomized study included was rated with a high risk of bias. Among 11 studies that reported AI use for the prioritization of patients’ scans, four measured the turnaround time. The study by Batra et al.34 did not report variance measures and was therefore excluded from the meta-analysis. The remaining three studies used the AI tool Aidoc (Tables 2 and 4) to detect intracranial hemorrhage and reported the turnaround time for cases flagged positive. The meta-analysis showed no significant difference in turnaround time between cases with and without AI use: SMD: 0.03 (95% CI, −0.50 to 0.56; p = 0.84), with a significant heterogeneity across studies: Q = 12.31, p < 0.01, I2 = 83.75% (Fig. 3c). All included studies were non-randomized studies, with two studies being rated with a serious risk of bias and one with a moderate risk of bias.

Graphical display and statistical results of the three meta-analyses: a Studies using AI for detection tasks in CT images and reported clinicians’ reading time. b Studies using AI to detect polyps during colonoscopy and measured the total procedure time. c Studies that used AI for reprioritization and measured the turnaround times for cases flagged positive. All included studies used AIDOC for intracranial hemorrhage detection.
In total, 37 studies reported details on the actual workflow adaptations due to AI implementation, which we classified into four main variants (depicted exemplarily in Fig. 4). 16 studies (43.2%) used an AI tool as a triage system, i.e., the AI tool reprioritized the worklist or the AI tool sent an alert to the clinician or referred the patient to a specialist for further examination (Fig. 4a: AI triage). In two studies (5.4%), the AI tool acted as a gatekeeper, only referring cases labeled as suspicious to the clinician for further review, while excluding the remaining cases (Fig. 4a: AI gatekeeper). In 13 studies (35.1%), AI tools were used as a second reader for detection tasks in two variants (Fig. 4b: AI second reader). Eight studies reported that the AI tool functioned as a second reader in a concurrent mode, presenting additional information during the task to clinicians (e.g., in colonoscopy studies, where the workflow remained the same as before displaying additional information during the procedure). Five studies described a workflow in which the AI tool was used additionally after the normal detection task, resulting in a sequential second reader workflow. In five segmentation studies (13.5%), the AI tool served as a first reader with the clinician reviewing and then correcting the AI-provided contours (Fig. 4c: AI first reader).

Visual representation of the different workflows when using AI as reported in the included studies: a Workflows when using AI for prioritization tasks. b Workflow when using AI for detection. c Workflow when using AI for segmentation tasks. Figure created with Canva (Canva Pty Ltd, Sydney, Australia).
In a single study (2.7%), the type of actual workflow implementation was at the radiologist’s choice. Three studies used a study design with the AI tool as a second reader in a pre-specified reading sequence; therefore, we did not classify them as workflow adaptations. The remaining studies did not provide sufficient information on workflow implementation.
In our initial review protocol, we also aimed to include investigations on clinician workload14. Apart from three studies, Liu et al.35, Raya-Povedano et al.36, and Yacoub et al.37, which calculated the saved workload in scans or patients because of AI use, no other study reported AI implementation effects on clinicians’ workload (besides the time for tasks effects, see above). Other reported outcomes included evaluations of the AI performing the task (i.e., satisfaction)8,38; frequency of AI use29,30; patient outcomes, such as length of stay or in-hospital complications39,40; and sensitivity or specificity changes8,21,24,28,41.
Risk of bias across studies
Funnel plots for the studies included in the meta-analyses were created (Supplementary Figs. 5–7). 19 studies declared a relevant conflict of interest and six other studies had potential conflicts of interest, which sum up to more than 50% of the included studies.
Additionally, we ran several sensitivity analyses to evaluate for potential selection bias. We first searched the dblp computer science bibliography, yielding 1159 studies for title and abstract screening. Therein, we achieved perfect interrater reliability (100%). Subsequently, only thirteen studies proceeded to full-text screening, with just one meeting our review criteria. This study by Wismueller & Stockmaster42 was also part of our original search. Notably, this study was the only conference publication providing a full paper (refer to Supplementary Table 2).
Moreover, to ensure comprehensive coverage and to detect potentially missed publications due to excluding conference proceedings, we screened 2614 records from IEEE Xplore, MICCAI, and HICSS. Once again, our title and abstract screening demonstrated perfect interrater reliability (100%). However, despite including 31 publications in full-text screening, none met our inclusion criteria upon thorough assessment. Altogether, this additionally searches showed no significant indication for a potential selection bias and potentially missing out key work in other major scientific publication outlets.
Using AMSTAR-2 (A MeaSurement Tool to Assess Systematic Reviews)43, we rated the overall confidence in the results as low, mainly due to our decision to combine non-randomized and randomized studies within our meta-analysis (Supplementary Fig. 8).
Discussion
Given the widespread adoption of AI technologies in clinical work, our systematic review and meta-analysis assesses efficiency effects on routine clinical work in medical imaging. Although most studies reported positive effects, our three meta-analyses with subsets of comparable studies showed no evidence of AI tools reducing the time on imaging tasks. Studies varied substantially in design and measures. This high heterogeneity renders robust inferences. Although nearly 67% of time-related outcome studies have shown a decrease in time with AI use, a noteworthy portion of these studies revealed conflicts of interest, potentially influencing study design or outcome estimation44. Our findings emphasize the need for comparable and independent high-quality studies on AI implementation to determine its actual effect on clinical workflows.
Focusing on how AI tools were integrated into the clinical workflow, we discovered diverse adoptions of AI applications in clinical imaging. Some studies have provided brief descriptions that lack adequate details to comprehend the process. Despite predictions of AI potentially supplanting human readers or serving as gatekeepers, with humans primarily reviewing flagged cases to enhance efficiency10,11, we noted a limited adoption of AI in this manner across studies. In contrast, most studies reported AI tools as supplementary readers, potentially extending the time taken for interpretation when radiologists must additionally incorporate AI-generated results18,45. Another practice involved concurrent reading, which seems beneficial because it guides clinicians’ attention to crucial areas, which potentially improves reading quality and safety without lengthening reading times45,46. Regardless of how AI was used, a crucial factor is its alignment with the intended purpose and task15.
Although efficiency stands out in the current literature, we were also interested in whether AI affects clinicians’ workload, besides the time measurements, such as number of tasks or cognitive load. We only found three studies on AI’s impact on clinicians’ workload, but no study assessed workload separately (e.g., in terms of cognitive workload changes)18,35,36,37. This gap in research is remarkable since human–technology interaction and human factors assessment will be a success factor for the adoption of AI in healthcare47,48.
Our study included a vast variety of AI solutions reported in the publications. The majority was a large number of commercially available AI solutions which mostly had acquired FDA or CE clearance, ensuring safety of use in a medical context49. Nevertheless, it is desirable that future studies provide more detailed information about the accuracy of the AI solutions in their use case or processing times, which both can be crucial to AI adoption50. Regarding included studies which used non-commercially available algorithms, some of the studies did not specify the origin or source of the algorithm (i.e., developer). Especially with the specific characteristics and potential bias being introduced through the specific algorithm (e.g., for example stemming from a training bias or gaps in the underlying data), it is essential to provide information about the origins and prior validation steps of the algorithm in clinical use51,52. Interestingly, only four included studies discussed the possibility of bias in the AI algorithm53,54,55,56. Open science principles, such as data or code sharing, aid to mitigate the impact of bias. Yet, none of the studies in our review used open-source solutions or provided their algorithm52. Additionally, guidelines such as CONSORT-AI or SPIRIT-AI provide recommendations for the reporting of clinical studies using AI solutions57, as previous systematic reviews have also identified serious gaps in the reporting on clinical AI solutions58,59. Our results corroborate this shortcoming, as none of the studies reporting non-commercial algorithms and only four studies overall followed a reporting guideline. Notwithstanding, for some included studies, AI-specific reporting guidelines were published after their initial publication. Nevertheless, comprehensive and transparent reporting remains insufficient.
With our review, we were able to replicate some of the findings by Yin et al., who provided a first overview on AI solutions in clinical practice, e.g., insufficient reporting in included studies60. By providing time for tasks and meta-analyses as well as workflow descriptions our review substantially extends the scope of their review, providing a robust and detailed overview on the efficiency effects of AI solutions. In 2020, Nagendran et al. provided a review comparing AI algorithms for medical imaging and clinicians, concluding that only few prospective studies in clinical settings exist59. Our systematic review demonstrated an increase in real-world studies in previous years and provides an up-to-date and comprehensive overview on AI solutions currently used in medical imaging practice. Our study thereby addresses one of the previously mentioned shortcomings, that benefits of the AI algorithm in silico or in retrospective studies might not transfer into clinical benefit59. This is also recognized by Han et al.61 who evaluated randomized controlled trials evaluating AI in clinical practice and who argued that efficiency outcomes will strongly depend on implementation processes in actual clinical practice.
The complexities of transferring AI solutions from research into practice were explored in a review by Hua et al.62 who evaluated the acceptability AI for medical imaging by healthcare professionals. We believe that for AI to unfold its full potential, it is essential to pay thorough attention to the adoption challenges and work system integration in clinical workplaces. Notwithstanding the increasing number of studies on AI use in real-world settings during the last years, many questions on AI implementation and workflow integration remain unanswered. On the one hand, limited consideration prevails on acceptance of AI solutions by professionals62. Although studies even discuss the possibility of AI as a teammate in the future63,64, most available studies rarely include perceptions of affected clinicians60. On the other hand, operational and technical challenges as well as system integration into clinical IT infrastructures are major challenges, as many of the described algorithms are cloud-based. Smooth interoperability between new AI technologies and local clinical information systems as well as existing IT infrastructure is key to efficient clinical workflows50. For example, the combination of multimodal data, such as imaging and EHR data, could be beneficial for future decision processes in healthcare65.
Our review has several limitations. First, publication bias may have contributed to the high number of positive findings in our study. Second, despite searching multiple databases, selection bias may have occurred, particularly as some clinics implementing AI do not systematically assess or publish their processes in scientific formats60. Moreover, we excluded conference publications which could be the source for potential biases. Nevertheless, we ran different sensitivity analyses for publication and selection bias, and did not find evidence for major bias introduced due to our search and identification strategy. Yet, aside from one conference paper, all other conference publications merely provided abstracts or posters, lacking a comprehensive base for the extraction of required details. Third, we focused exclusively on medical imaging tasks to enhance the internal validity of clinical tasks across diverse designs, AI solutions, and workflows. Fourth, the low quality rating of our review on the AMSTAR-2 checklist, which is due to the diverse study designs we included, calling for more comparable high quality studies in this field. Nevertheless, we believe that our review provides a thorough summary of the available studies matching our research question. Finally, our review concentrated solely on efficiency outcomes stemming from the integration of AI into clinical workflows. Yet, the actual impact of AI algorithms on efficiency gains in routine clinical work can be influenced by further, not here specified local factors, e.g., existent IT infrastructure, computational resources, processing times. Next to the testing of the AI solutions under standardized conditions or in randomized controlled trials, which can indicate whether AI solution are suitable for the transfer into routine medical care, careful evaluations of how AI solutions fit into everyday clinical workflow should be expanded, i.e., ideally before implementation. Exploring adoption procedures along with identifying key implementation facilitators and barriers provides valuable insights into successful AI technology use in clinical routines. However, it is important to note that AI implementation can address a spectrum of outcomes, including but not limited to enhancing patient quality and safety, augmenting diagnostic confidence, and improving healthcare staff satisfaction8.
In conclusion, our review showed a positive trend toward research on actual AI implementation in medical imaging, with most studies describing efficiency improvements in course of AI technology implementation. We derive important recommendations for future studies on the implementation of AI in clinical settings. The rigorous use of reporting guidelines should be encouraged, as many studies reporting time outcomes did not provide sufficient details on their methods. Providing a protocol or clear depiction of how AI tools modify clinical workflows allows comprehension and comparison between pre- and post-adoption processes while facilitating learning and future implementation practice. Considering the complexity of healthcare systems, understanding the factors contributing to successful AI implementation is invaluable. Our review corroborates the need for comparable evaluations to monitor and quantify efficiency effects of AI in clinical real-world settings. Finally, future research should therefore explore success and potential differences between different AI algorithms in controlled trials as well as in real-world clinical practice settings to inform and guide future implementation processes.
Methods
Registration and protocol
Before its initiation, our systematic literature review was registered in a database (PROSPERO, ID: CRD42022303439), and the review protocol was peer-reviewed (International Registered Report Identifier RR2-10.2196/40485)14. Our reporting adheres to the Preferred Reporting Items for Systematic Review and Meta-Analysis (PRISMA) statement reporting guidelines (Supplementary Table 3). During the preparation of this work, we used ChatGPT (version GPT-3.5, OpenAI) to optimize the readability and wording of the manuscript. After using this tool, the authors reviewed and edited the content as required and take full responsibility for the content of the publication.
Search strategy and eligibility criteria
Articles were retrieved through a structured literature search in the following electronic databases: MEDLINE (PubMed), Embase, PsycINFO, Web of Science, IEEE Xplore, and Cochrane Central Register of Controlled Trials. We included original studies on clinical imaging, written in German or English, retrieved in full-text, and published in peer-reviewed journals from the 1st of January 2000 onward, which marked a new area of AI in healthcare with the development of deep learning14,66. The first search was performed on July 21st, 2022, and was updated on May 19th, 2023. Furthermore, a snowball search screening of the references of the identified studies was performed to retrieve relevant studies. Dissertations, conference proceedings, and gray literature were excluded. This review encompassed observational and interventional studies, such as randomized controlled trials and nonrandomized studies on interventions (e.g., before–after studies). Only studies that introduced AI to actual real-life clinical workflows were eligible, that is, those not conducted in an experimental setting or in a laboratory. The search strategy followed the PICO framework:
-
Population: This review included studies conducted in real-world healthcare facilities, such as hospitals and clinics, using medical imaging and surveying healthcare professionals of varying expertise and qualifications.
-
Exposure/interventions: This review encompassed studies that focused on various AI tools for diagnostics and their impact on healthcare professionals’ interaction with the technology across various clinical imaging tasks67. We exclusively focused on AI tools that interpret image data for disease diagnosis and screening5. For data extraction, we used the following working definition of AI used for clinical diagnostics: “any computer system used to interpret imaging data to make a diagnosis or screen for a disease, a task previously reserved for specialists”14.
-
Comparators: This review emphasized studies comparing the workflow before AI use with that after AI use or the workflow with AI use with that without AI use, although this was not a mandatory criterion to be included in the review.
-
Outcomes: The primary aim of this study was to evaluate how AI solutions impact workflow efficiency in clinical care contexts. Thus, we focused on three outcomes of interest: (1) changes in time required for task completion, (2) workflow adaptation, and (3) workload.
-
(1)
Changes in time for completion of imaging tasks were considered, focusing on reported quantitative changes attributed to AI usage (e.g., throughput times and review duration).
-
(2)
Workflow adaptation encompasses changes in the workflow that result from the introduction of new technologies, particularly in the context of AI implementation (i.e., specifying the time and purpose of AI use).
-
(3)
Workload refers to the demands of tasks on human operators and changes associated with AI implementation (e.g., cognitive demands or task load).
The detailed search strategy following the PICO framework can be found in Supplementary Table 4 and Supplementary Note 1.
Screening and selection procedure
All retrieved articles were imported into the Rayyan tool68,69 for title and abstract screening. In the first step, after undergoing a training, two study team members (KW and JK/MW/NG) independently screened the titles and abstracts to establish interrater agreement. In the second step, the full texts of all eligible publications were screened by KW and JK. Any potential conflicts regarding the inclusion of articles were resolved through discussions with a third team member (MW). Reasons for exclusion were documented, as depicted in the flow diagram in Fig. 170.
Data extraction procedure
Two authors (JK and KW/FZ) extracted the study data and imported them into MS Excel which then went through random checks by a study team member (MW). To establish agreement all reviewers extracted data from the first five studies based on internal data extraction guidelines.
Study quality appraisal and risk of bias assessment
To evaluate the methodological quality of the included studies, two reviewers (KW and JK) used three established tools. The Risk of Bias in Non-randomized Studies of Interventions tool (ROBINS-I) for non-randomized studies and the Cochrane Risk of Bias tool (Rob 2) for randomized studies were used71,72. To assess the reporting quality of the included studies, the MINORS was used27. The MINORS was used instead of the Quality of Reporting of Observational Longitudinal Research checklist73, as pre-specified in the review protocol, because this tool was more adaptable to all included studies. Appraisals were finally established through discussion until consensus was achieved.
Strategy for data synthesis
First, we describe the overall sample and the key information from each included study. Risk of bias assessment evaluations are presented in narrative and tabular formats. Next, where comparable studies were sufficient, a meta-analysis was performed to examine the effects of AI introduction. We used the method of Wan et al.74 to estimate the sample mean and standard deviation from the sample size, median, and interquartile range because the reported measures varied across the included studies. Furthermore, we followed the Cochrane Handbook for calculating the standard deviation from the confidence interval (CI)75. The metafor package in R76 was used to quantitatively synthesize data from the retrieved studies. Considering the anticipated heterogeneity of effects, a random-effects model was used to estimate the average effect across studies. Moreover, we used the DerSimonian and Laird method to determine cross-study variance and the Hartung–Knapp method to estimate the variance of the random effect77,78. Heterogeneity was assessed using Cochran’s Q test79 and the I2 statistic75. In cases where a meta-analysis was not feasible, the results were summarized in narrative form and presented in tabular format.
Meta-biases
Potential sources of meta-bias, such as publication bias and selective reporting across studies, were considered. Funnel plots were created for the studies included in the meta-analyses.
To assess whether our review is subject to selection bias due to the choice of databases and publication types, we conducted an additional search in the dblp computer science bibliography (with our original search timeframe). As this database did not allow our original search string, the adapted version is found in Supplementary Note 2. Additionally, we performed searches on conference proceedings of the last three years, spanning publications from the January 1st 2020 until May 15th 2023. We surveyed IEEE Xplore and two major conferences not included in the database: International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) and Hawaii International Conference on System Sciences (HICSS). We conducted an initial screening of titles and abstracts, with one reviewer (KW) screening all records and JK screening 10% to assess interrater reliability. Full-text assessments for eligibility were then performed by one of the reviewers, respectively (KW or JK). Furthermore, the AMSTAR-2 critical appraisal tool for systematic reviews of randomized and/or non-randomized healthcare intervention studies was used43.
Data availability
All data generated or analyzed during this study is available from the corresponding author upon reasonable request.
Code availability
Code for meta-analyses available via https://github.com/katwend/metaanalyses.
References
Yeganeh, H. An analysis of emerging trends and transformations in global healthcare. IJHG 24, 169–180 (2019).
Asan, O., Bayrak, A. E. & Choudhury, A. Artificial intelligence and human trust in healthcare: focus on clinicians. J. Med. Internet Res. 22, e15154 (2020).
Park, C.-W. et al. Artificial intelligence in health care: current applications and issues. J. Korean Med. Sci. 35, e379 (2020).
Ahmad, Z., Rahim, S., Zubair, M. & Abdul-Ghafar, J. Artificial Intelligence (ai) in medicine, current applications and future role with special emphasis on its potential and promise in pathology: present and future impact, obstacles including costs and acceptance among pathologists, practical and philosophical considerations. a comprehensive review. Diagn. Pathol. 16, 24 (2021).
He, J. et al. The practical implementation of artificial intelligence technologies in medicine. Nat. Med. 25, 30–36 (2019).
Wong, S. H., Al-Hasani, H., Alam, Z. & Alam, A. Artificial intelligence in radiology: how will we be affected? Eur. Radiol. 29, 141–143 (2019).
Arbabshirani, M. R. et al. Advanced machine learning in action: identification of intracranial hemorrhage on computed tomography scans of the head with clinical workflow integration. npj Digit. Med. 1, 9 (2018).
Mueller, F. C. et al. Impact of concurrent use of artificial intelligence tools on radiologists reading time: a prospective feasibility study. Acad. Radiol. 29, 1085–1090 (2022).
Pumplun, L., Fecho, M., Wahl, N., Peters, F. & Buxmann, P. Adoption of machine learning systems for medical diagnostics in clinics: qualitative interview study. J. Med. Internet Res. 23, e29301 (2021).
Dahlblom, V., Dustler, M., Tingberg, A. & Zackrisson, S. Breast cancer screening with digital breast tomosynthesis: comparison of different reading strategies implementing artificial intelligence. Eur. Radiol. 33, 3754–3765 (2023).
Miyake, M. et al. Comparative performance of a primary-reader and second-reader paradigm of computer-aided detection for CT colonography in a low-prevalence screening population. Jpn J. Radio. 31, 310–319 (2013).
Hosny, A., Parmar, C., Quackenbush, J., Schwartz, L. H. & Aerts, H. J. W. L. Artificial intelligence in radiology. Nat. Rev. Cancer 18, 500–510 (2018).
van Leeuwen, K. G., de Rooij, M., Schalekamp, S., van Ginneken, B. & Rutten, M. J. C. M. How does artificial intelligence in radiology improve efficiency and health outcomes? Pediatric Radiol. 52, 2087–2093 (2021).
Wenderott, K., Gambashidze, N. & Weigl, M. Integration of artificial intelligence into sociotechnical work systems—effects of artificial intelligence solutions in medical imaging on clinical efficiency: protocol for a systematic literature review. JMIR Res. Protoc. 11, e40485 (2022).
Salwei, M. E. & Carayon, P. A Sociotechnical systems framework for the application of artificial intelligence in health care delivery. J. Cogn. Eng. Decis. Making 16, 194–206 (2022).
Wolff, J., Pauling, J., Keck, A. & Baumbach, J. Success factors of artificial intelligence Implementation in Healthcare. Front. Digit. Health 3, 594971 (2021).
Felmingham, C. M. et al. The importance of incorporating human factors in the design and implementation of artificial intelligence for skin cancer diagnosis in the real world. Am. J. Clin. Dermatol. 22, 233–242 (2021).
Wenderott, K., Krups, J., Luetkens, J. A., Gambashidze, N. & Weigl, M. Prospective effects of an artificial intelligence-based computer-aided detection system for prostate imaging on routine workflow and radiologists’ outcomes. Eur. J. Radiol. 170, 111252 (2024).
Pierce, J. et al. Seamless integration of artificial intelligence into the clinical environment: our experience with a novel pneumothorax detection artificial intelligence algorithm. J. Am. Coll. Radiol. 18, 1497–1505 (2021).
Diao, K. et al. Diagnostic study on clinical feasibility of an AI-based diagnostic system as a second reader on mobile CT images: a preliminary result. Ann. Transl. Med. 10, 668 (2022).
Duron, L. et al. Assessment of an AI aid in detection of adult appendicular skeletal fractures by emergency physicians and radiologists: a multicenter cross-sectional diagnostic study. Radiology 300, 120–129 (2021).
Kanagasingam, Y. et al. Evaluation of artificial intelligence–based grading of diabetic retinopathy in primary care. JAMA Netw. Open 1, e182665 (2018).
Bossuyt, P. M. et al. STARD 2015: an updated list of essential items for reporting diagnostic accuracy studies. Radiology 277, 826–832 (2015).
Repici, A. et al. Efficacy of real-time computer-aided detection of colorectal neoplasia in a randomized trial. Gastroenterology 159, 512–520.e7 (2020).
Schulz, K. F., Altman, D. G. & Moher, D. CONSORT Group CONSORT 2010 Statement: updated guidelines for reporting parallel group randomised trials. BMJ 340, c332–c332 (2010).
Wang, P. et al. Real-time automatic detection system increases colonoscopic polyp and adenoma detection rates: a prospective randomised controlled study. Gut 68, 1813–1819 (2019).
Slim, K. et al. Methodological index for non-randomized studies (MINORS): development and validation of a new instrument: methodological index for non-randomized studies. ANZ J. Surg. 73, 712–716 (2003).
Conant, E. F. et al. Improving accuracy and efficiency with concurrent use of artificial intelligence for digital breast tomosynthesis. Radiol. Artif. Intell. 1, e180096 (2019).
Nehme, F. et al. Performance and attitudes toward real-time computer-aided polyp detection during colonoscopy in a large tertiary referral center in the United States. Gastrointest. Endosc. 98, 100–109.e6 (2023).
Zia, A. et al. Retrospective analysis and prospective validation of an Ai-based software for intracranial haemorrhage detection at a high-volume trauma centre. Sci. Rep. 12, 19885 (2022).
Tchou, P. M. et al. Interpretation time of computer-aided detection at screening mammography. Radiology 257, 40–46 (2010).
Vassallo, L. et al. A cloud-based computer-aided detection system improves identification of lung nodules on computed tomography scans of patients with extra-thoracic malignancies. Eur. Radiol. 29, 144–152 (2019).
Wittenberg, R. et al. Acute pulmonary embolism: effect of a computer-assisted detection prototype on diagnosis—an observer study. Radiology 262, 305–313 (2012).
Batra, K., Xi, Y., Bhagwat, S., Espino, A. & Peshock, R. Radiologist worklist reprioritization using artificial intelligence: impact on report turnaround times for CTPA examinations positive for acute pulmonary embolism. Am. J. Roentgenol 221, 324–333 (2023).
Liu, X. et al. Evaluation of an OCT-AI-based telemedicine platform for retinal disease screening and referral in a primary care setting. Transl. Vis. Sci. Technol. 11, 4 (2022).
Raya-Povedano, J. L. et al. AI-based strategies to reduce workload in breast cancer screening with mammography and tomosynthesis: a retrospective evaluation. Radiology 300, 57–65 (2021).
Yacoub, B. et al. Impact of artificial intelligence assistance on chest CT interpretation times: a prospective randomized study. Am. J. Roentgenol. 219, 743–751 (2022).
Cha, E. et al. Clinical implementation of deep learning contour auto segmentation for prostate radiotherapy. Radiother. Oncol. 159, 1–7 (2021).
Davis, M. A., Rao, B., Cedeno, P. A., Saha, A. & Zohrabian, V. M. Machine learning and improved quality metrics in acute intracranial hemorrhage by noncontrast computed tomography. Curr. Probl. Diagn. Radiol. 51, 556–561 (2022).
Hassan, A., Ringheanu, V. & Tekle, W. The implementation of artificial intelligence significantly reduces door-in-door-out times in a primary care center prior to transfer. Interv. Neuroradiol. 29, 631–636 (2022).
Ladabaum, U. et al. Computer-aided detection of polyps does not improve colonoscopist performance in a pragmatic implementation trial. Gastroenterol. 164, 481–483 (2023).
Wismüller, A. & Stockmaster, L. A Prospective randomized clinical trial for measuring radiology study reporting time on artificial intelligence-based detection of intracranial hemorrhage in emergent Care Head CT (2020).
Shea, B. J. et al. Amstar 2: a critical appraisal tool for systematic reviews that include randomised or non-randomised studies of healthcare interventions, or both. BMJ 358, j4008 (2017).
Boutron, I. et al. Considering bias and conflicts of interest among the included studies. In Cochrane Handbook for Systematic Reviews of Interventions (eds Higgins, J. P. T. et al.) 177–204 (Wiley, 2019).
Beyer, F. et al. Comparison of sensitivity and reading time for the use of computer-aided detection (CAD) of pulmonary nodules at MDCT as concurrent or second reader. Eur. Radio. 17, 2941–2947 (2007).
Fujita, H. AI-based computer-aided diagnosis (AI-CAD): the latest review to read first. Radio. Phys. Technol. 13, 6–19 (2020).
Asan, O. & Choudhury, A. Research trends in artificial intelligence applications in human factors health care: mapping review. JMIR Hum. Factors 8, e28236 (2021).
Herrmann, T. & Pfeiffer, S. Keeping the organization in the loop: a socio-technical extension of human-centered artificial intelligence. AI Soc. 38, 1523–1542 (2023).
Allen, B. The role of the FDA in ensuring the safety and efficacy of artificial intelligence software and devices. J. Am. Coll. Radiol. 16, 208–210 (2019).
Wenderott, K., Krups, J., Luetkens, J. A. & Weigl, M. Radiologists’ perspectives on the workflow integration of an artificial intelligence-based computer-aided detection system: a qualitative study. Appl. Ergon. 117, 104243 (2024).
Nazer, L. H. et al. Bias in artificial intelligence algorithms and recommendations for mitigation. PLOS Digit Health 2, e0000278 (2023).
Norori, N., Hu, Q., Aellen, F. M., Faraci, F. D. & Tzovara, A. Addressing bias in big data and AI for health care: a call for open science. Patterns 2, 100347 (2021).
Chen, W. et al. Improving the diagnosis of acute ischemic stroke on non-contrast Ct using deep learning: a multicenter study. Insights Imaging 13, 184 (2022).
Potretzke, T. et al. Clinical implementation of an artificial intelligence algorithm for magnetic resonance-derived measurement of total kidney volume. Mayo Clin. Proc. 98, 689–700 (2023).
Sun, J. et al. Performance of a chest radiograph AI diagnostic tool for COVID-19: a prospective observational study. Radiol. Artif. Intell. 4, e210217 (2022).
Tricarico, D. et al. Convolutional neural network-based automatic analysis of chest radiographs for the detection of COVID-19 pneumonia: a prioritizing tool in the emergency department, phase i study and preliminary ‘real life’ results. Diagnostics 12, 570 (2022).
Ibrahim, H. et al. Reporting guidelines for clinical trials of artificial intelligence interventions: the SPIRIT-AI and CONSORT-AI guidelines. Trials 22, 11 (2021).
Liu, X. et al. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: a systematic review and meta-analysis. Lancet Digit. Health 1, e271–e297 (2019).
Nagendran, M. et al. Artificial intelligence versus clinicians: systematic review of design, reporting standards, and claims of deep learning studies. BMJ m689 (2020).
Yin, J., Ngiam, K. Y. & Teo, H. H. Role of artificial intelligence applications in real-life clinical practice: systematic review. J. Med. Internet Res. 23, e25759 (2021).
Han, R. et al. Randomised controlled trials evaluating artificial intelligence in clinical practice: a scoping review. Lancet Digit. Health 6, e367–e373 (2024).
Hua, D., Petrina, N., Young, N., Cho, J.-G. & Poon, S. K. Understanding the factors influencing acceptability of AI in medical imaging domains among healthcare professionals: a scoping review. Artif. Intell. Med. 147, 102698 (2024).
Bruni, S., Freiman, M. & Riddle, K. Beyond the tool vs. teammate debate: exploring the sidekick metaphor in human-AI Dyads. In: Julia Wright and Daniel Barber (eds) Human Factors and Simulation. AHFE (2023) International Conference. AHFE Open Access, 83 (2023).
Flathmann, C. et al. Examining the impact of varying levels of AI teammate influence on human-AI teams. Int. J. Hum.-Comput. Stud. 177, 103061 (2023).
Huang, S.-C., Pareek, A., Seyyedi, S., Banerjee, I. & Lungren, M. P. Fusion of medical imaging and electronic health records using deep learning: a systematic review and implementation guidelines. npj Digit. Med. 3, 136 (2020).
Kaul, V., Enslin, S. & Gross, S. A. History of artificial intelligence in medicine. Gastrointest. Endosc. 92, 807–812 (2020).
Dias, R. & Torkamani, A. Artificial intelligence in clinical and genomic diagnostics. Genome Med. 11, 70 (2019).
Ouzzani, M., Hammady, H., Fedorowicz, Z. & Elmagarmid, A. Rayyan-a web and mobile app for systematic reviews. Syst. Rev. 5, 210 (2016).
Ouzzani, M., Hammady, H., Fedorowicz, Z. & Elmagarmid, A. Rayyan-a web and mobile app for systematic reviews. Syst Rev. 5, 210 (2016).
Page, M. J. et al. The Prisma 2020 statement: an updated guideline for reporting systematic reviews. BMJ 372, n71 (2021).
Sterne, J. A. et al. ROBINS-I: a tool for assessing risk of bias in non-randomised studies of interventions. BMJ 355, i4919 (2016).
Sterne, J. A. C. et al. RoB 2: a revised tool for assessing risk of bias in randomised trials. BMJ 366, l4898 (2019).
Tooth, L., Ware, R., Bain, C., Purdie, D. M. & Dobson, A. Quality of reporting of observational longitudinal research. Am. J. Epidemiol. 161, 280–288 (2005).
Wan, X., Wang, W., Liu, J. & Tong, T. Estimating the sample mean and standard deviation from the sample size, median, range and/or interquartile range. BMC Med Res Methodol. 14, 135 (2014).
Higgins, J. P. T., Thompson, S. G., Deeks, J. J. & Altman, D. G. Measuring inconsistency in meta-analyses. BMJ 327, 557–560 (2003).
Viechtbauer, W. Conducting meta-analyses in R with the metafor Package. J Stat Softw. 36, 1–48 (2010).
DerSimonian, R. & Laird, N. Meta-analysis in clinical trials. Control. Clin. Trials 7, 177–188 (1986).
Hartung, J. An alternative method for meta-analysis. Biom. J. J. Math. Methods Biosci. 41, 901–916 (1999).
Cochran, W. G. The combination of estimates from different experiments. Biometrics 10, 101 (1954).
Carlile, M. et al. Deployment of artificial intelligence for radiographic diagnosis of COVID-19 pneumonia in the emergency department. J. Am. Coll. Emerg. Phys. Open 1, 1459–1464 (2020).
Cheikh, A. B. et al. How artificial intelligence improves radiological interpretation in suspected pulmonary embolism. Eur. Radiol. 32, 5831–5842 (2022).
Elijovich, L. et al. Automated emergent large vessel occlusion detection by artificial intelligence improves stroke workflow in a hub and spoke stroke system of care. J. NeuroIntervent Surg. 14, 704–708 (2022).
Ginat, D. Implementation of machine learning software on the radiology worklist decreases scan view delay for the detection of intracranial hemorrhage on CT. Brain Sci. 11, 832 (2021).
Hong, W. et al. Deep learning for detecting pneumothorax on chest radiographs after needle biopsy: clinical implementation. Radiology 303, 433–441 (2022).
Jones, C. M. et al. Assessment of the effect of a comprehensive chest radiograph deep learning model on radiologist reports and patient outcomes: a real-world observational study. BMJ Open 11, e052902 (2021).
Kiljunen, T. et al. A deep learning-based automated CT segmentation of prostate cancer anatomy for radiation therapy planning-A retrospective multicenter study. Diagnostics 10, 959 (2020).
Levy, I., Bruckmayer, L., Klang, E., Ben-Horin, S. & Kopylov, U. Artificial intelligence-aided colonoscopy does not increase adenoma detection rate in routine clinical practice. Am. J. Gastroenterol. 117, 1871–1873 (2022).
Marwaha, A., Chitayat, D., Meyn, M., Mendoza-Londono, R. & Chad, L. The point-of-care use of a facial phenotyping tool in the genetics clinic: enhancing diagnosis and education with machine learning. Am. J. Med. Genet. A 185, 1151–1158 (2021).
O’Neill, T. J. et al. Active reprioritization of the reading worklist using artificial intelligence has a beneficial effect on the turnaround time for interpretation of head CT with intracranial hemorrhage. Radiol. Artif. Intell. 3, e200024 (2021).
Oppenheimer, J., Lüken, S., Hamm, B. & Niehues, S. A prospective approach to integration of AI fracture detection software in radiographs into clinical workflow. Life (Basel, Switzerland) 13, 223 (2023).
Quan, S. Y. et al. Clinical evaluation of a real-time artificial intelligence-based polyp detection system: a US multi-center pilot study. Sci. Rep. 12, 6598 (2022).
Ruamviboonsuk, P. et al. Real-time diabetic retinopathy screening by deep learning in a multisite national screening programme: a prospective interventional cohort study. Lancet Digit. Health 4, e235–44 (2022).
Sandbank, J. et al. Validation and real-world clinical application of an artificial intelligence algorithm for breast cancer detection in biopsies. npj Breast Cancer 8, 129 (2022).
Schmuelling, L. et al. Deep learning-based automated detection of pulmonary embolism on CT pulmonary angiograms: no significant effects on report communication times and patient turnaround in the emergency department nine months after technical implementation. Eur. J. Radiol. 141, 109816 (2021).
Seyam, M. et al. Utilization of artificial intelligence-based intracranial hemorrhage detection on emergent noncontrast CT images in clinical workflow. Radiol. Artif. Intell. 4, e210168 (2022).
Sim, J. Z. T. et al. Diagnostic performance of a deep learning model deployed at a National COVID-19 screening facility for detection of pneumonia on frontal chest radiographs. Healthcare 10, 175 (2022).
Strolin, S. et al. How smart is artificial intelligence in organs delineation? Testing a CE and FDA-approved deep-learning tool using multiple expert contours delineated on planning CT images. Front. Oncol. 13, 1089807 (2023).
Wang, M. et al. Deep learning-based triage and analysis of lesion burden for COVID-19: a retrospective study with external validation. Lancet Digit. Health 2, e506–e515 (2020).
Wong, J. et al. Implementation of deep learning-based auto-segmentation for radiotherapy planning structures: a workflow study at two cancer centers. Radiat. Oncol. 16, 101 (2021).
Wong, K. et al. Integration and evaluation of chest X-ray artificial intelligence in clinical practice. J. Med. Imaging 10, 051805 (2023).
Yang, Y. et al. Performance of the AIDRScreening system in detecting diabetic retinopathy in the fundus photographs of Chinese patients: a prospective, multicenter, clinical study. Ann. Transl. Med. 10, 1088 (2022).
Elguindi, S. et al. Deep learning-based auto-segmentation of targets and organs-at-risk for magnetic resonance imaging only planning of prostate radiotherapy. Phys. Imaging Radiat. Oncol. 12, 80–86 (2019).
Wang, L. et al. An intelligent optical coherence tomography-based system for pathological retinal cases identification and urgent referrals. Trans. Vis. Sci. Tech. 9, 46 (2020).
Gulshan, V. et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 316, 2402 (2016).
Krause, J. et al. Grader variability and the importance of reference standards for evaluating machine learning models for diabetic retinopathy. Ophthalmology 125, 1264–1272 (2018).
Ruamviboonsuk, P. et al. Deep learning versus human graders for classifying diabetic retinopathy severity in a nationwide screening program. npj Digit. Med. 2, 25 (2019).
Retico, A., Delogu, P., Fantacci, M. E., Gori, I. & Preite Martinez, A. Lung nodule detection in low-dose and thin-slice computed tomography. Comput. Biol. Med. 38, 525–534 (2008).
Lopez Torres, E. et al. Large scale validation of the M5L lung CAD on heterogeneous CT datasets. Med. Phys. 42, 1477–1489 (2015).
Brown, M. S. et al. Automated endotracheal tube placement check using semantically embedded deep neural networks. Acad. Radiol. 30, 412–420 (2023).
Acknowledgements
We sincerely thank Dr. Nikoloz Gambashidze (Institute for Patient Safety, University Hospital Bonn) for helping with the title and abstract screening. We thank Annika Strömer (Institute for Medical Biometry, Informatics and Epidemiology, University of Bonn) for her statistical support. This research was financed through institutional budget, i.e., no external funding.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
K.W.: conceptualization, data curation, formal analysis, investigation, methodology, project administration, software, visualization, writing – original draft, writing – preparation, review, and editing; J.K.: data curation, investigation, visualization, writing – review and editing; F.Z.: investigation, writing – review and editing; M.W.: conceptualization, funding acquisition, supervision, validation. All authors have read and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wenderott, K., Krups, J., Zaruchas, F. et al. Effects of artificial intelligence implementation on efficiency in medical imaging—a systematic literature review and meta-analysis. npj Digit. Med. 7, 265 (2024). https://doi.org/10.1038/s41746-024-01248-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41746-024-01248-9
- Springer Nature Limited