
Abstract
Recent studies have shown that the microbiome can impact cancer development, progression, and response to therapies suggesting microbiome-based approaches for cancer characterization. As cancer-related signatures are complex and implicate many taxa, their discovery often requires Machine Learning approaches. This review discusses Machine Learning methods for cancer characterization from microbiome data. It focuses on the implications of choices undertaken during sample collection, feature selection and pre-processing. It also discusses ML model selection, guiding how to choose an ML model, and model validation. Finally, it enumerates current limitations and how these may be surpassed. Proposed methods, often based on Random Forests, show promising results, however insufficient for widespread clinical usage. Studies often report conflicting results mainly due to ML models with poor generalizability. We expect that evaluating models with expanded, hold-out datasets, removing technical artifacts, exploring representations of the microbiome other than taxonomical profiles, leveraging advances in deep learning, and developing ML models better adapted to the characteristics of microbiome data will improve the performance and generalizability of models and enable their usage in the clinic.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
Cancer is the second most common cause of death worldwide, with 10M estimated deaths in 20201,2. It is a heterogeneous group of diseases that result from complex gene-environment interactions. There is increasing evidence that in addition to the series of hallmarks featured by cancer, the microbiome can have an important impact on cancer phenotypes3. The human microbiome is the community of all microorganisms that colonize the human body, including bacteria, viruses, and fungi4. The advent of next-generation sequencing (NGS)5 technologies made it possible to study the composition of the human microbiome. The widespread use of omics approaches6,7, together with efforts such as the Human Microbiome Project8, have largely improved our understanding of the impact of the microbiome in health and disease. Knowledge about human-microbial interactions is greater for the microbiome of the gut, since it is easy to non-invasively characterize the microbial communities in fecal samples9. Changes in the gut microbiome have been associated with various diseases, including inflammatory bowel disease (IBD)10, obesity10, colorectal cancer11, and even anxiety and depression12.
Considering the relationship between the microbiome and cancer, a growing amount of clinical and preclinical studies have revealed that the microbiome can impact cancer development, cancer progression, and response to cancer therapies13, suggesting microbiome-based diagnostic, prognostic, and therapeutic approaches. It is now clear that the microbial communities found in the tumor tissues and in the oral and gut microbiomes of patients with various types of cancer are distinct from those found in healthy control individuals14,15,16. Studies that indirectly derived microbial profiles from human genome and transcriptome samples of large databases, such as The Cancer Genome Atlas (TCGA)17, also identified cancer type-specific microbiota signatures18,19. Furthermore, the microbiome found in cancer patients is predictive of their response to chemotherapy and to cancer immune checkpoint therapy20,21,22.
Machine Learning (ML) models are algorithms that make predictions given a dataset of learnable examples. These models can often uncover complex patterns more easily than human experts23. Methods based on ML are now ubiquitous in healthcare, with models used in imaging, to manage electronic health records, and for genetic analysis24. As microbiome-based signatures are complex and involve multiple species, ML approaches are an optimal tool for the investigation of relationships between the microbiome and host phenotypes9. As such, various studies have used ML models for disease prediction based on the gut microbiome25,26. Until recently, most of the applications of ML in the field of microbiome and cancer have focused on colorectal cancer and the gut microbiome27,28,29. However, recent studies using ML approaches have suggested biomarkers for cancer detection, disease prognosis, and response to treatment in different cancer types based on the tumor, gut, and oral microbiomes18,30,31,32,33,34,35. Despite their promising results, these approaches require further improvement in the accuracy of models before widespread use and translation of the findings into the clinic.
This review characterizes the state-of-the-art ML approaches for cancer characterization from microbiome data, analyzing all development steps from sample extraction to inference. It tries to bridge the gap between those familiar with ML and researchers experienced in the microbiome field, and help the development of robust approaches by highlighting the strengths and pitfalls of methods. Zhou and Ghallins36 previously reviewed ML models for host trait prediction, without focusing on cancer, while Cheung and Yu37 focused only on gastrointestinal cancer; however, due to their complexity and recency, cancer-related applications raise challenges that grant a specific discussion. Therefore, this review focuses its analysis on applications linked to the characterization of multiple types of cancer. Furthermore, we aim to analyze ML methods and their performance in greater detail.
We searched PubMed, Scopus, and IEEE Xplore for relevant publications from 1 January 2015 and up to 1 May 2023. Details on the criteria for inclusion are available in Supplementary Methods 1; Supplementary Fig. 1 contains the number of articles included in each stage of selection. Supplementary Table I holds all full-text articles assessed, characterized by the ML method used. In this manuscript, we start by discussing the sample collection and processing strategies for microbiome characterization, and how to address contamination. Then, we assess the possible input microbiome-derived features for an ML model and feature selection and transformation methods used in this domain. We analyze the most popular ML models and promising deep learning approaches, as well as how to evaluate and validate the ML models developed; we address current limitations, discussing why ML-based findings regarding the association between cancer and the microbiome are often contradictory. Finally, we present future research directions and discuss how to circumvent some of the current pitfalls. Figure 1 contains an overview of all these steps needed to develop and validate an ML model using microbiome data for cancer characterization.

The blocks on the left show the factors conditioning each step (represented in the middle blocks). Some of the decisions are also affected by choices made upstream - for instance, the characteristics of the ML model chosen affect how the microbiome data should be pre-processed; these dependencies are represented by the connectors on the left. The blocks on the right represent the contribution of each step to the overall goal of model development and validation. Each step is discussed in detail in this review.
Sample collection, processing, and decontamination
There are various methods for microbiome characterization, but the most widely used are based on nucleic acids. In these methods, the molecular analysis of the microbiome starts with the acquisition of genetic material from a sample. DNA or RNA isolation can be achieved from several sources, such as fecal samples, mucosal swabs, tissue biopsies, and blood. The selection of sample type is important, as different sources can provide different information about the microbiome and its interactions with the human host. For example, tumor biopsies enable the characterization of the local microbiome, which can provide information on how the microbiome directly influences tumor development or progression. On the other hand, sampling the microbiome at a distant location from the tumor can be indicative of dysbiosis in cancer patients but may not provide information on the interaction between the microbiome and the tumor. Some sample types are easier to acquire than others. Fecal, oral, and blood samples are easy to collect, as they can be sampled with non-invasive or minimally invasive methods9, whereas tissues or biopsies require invasive procedures, making sample collection more difficult and demanding.
All types of samples are prone to external contamination with microorganisms, which alter the microbiome composition of the sample leading to biased results. Two main types of contaminations can influence microbiome studies: contamination by external DNA (due to contaminants from the local environment where samples are collected, and during nucleic acid isolation and amplification) and cross-contamination during sample processing. Contaminations can be controlled by acting on two levels: during sample processing and during sequencing data analysis. To account for the potential external contamination, a series of control samples can be prepared by adding all reagents but no genetic material. During sequencing data analysis, the removal of microbial contaminations can be performed by comparing sample microbial content with that observed in the control samples. Extensive decontamination after sequencing has been performed when mining sequencing datasets of the TCGA project for reads of microbial origin. For example, The Cancer Microbiome Atlas (TCMA) provided curated and decontaminated microbiota profiles for oropharyngeal, esophageal, gastrointestinal, and colorectal cancer tissues, after decontamination of species equiprevalent across sample types38. In other cases, contaminants were identified by comparing lists of commonly found microorganisms in laboratory reagents and kits with those identified in samples18. Other contaminants may be identified by assuming that the abundance of a contaminant is inversely correlated with sample concentration: if the sample concentration is small but the abundance of an organism is unusually high, that organism is likely to be a contaminant39.
These in silico approaches do not replace well designed datasets for microbiome analysis, with adequate controls and minimal handling of samples. One study implementing such measures in breast cancer biopsies demonstrated their efficacy, as only low and moderate levels of contamination were found30. Stringent decontamination may also improve the separability of breast tumor and normal tissue samples, decreasing the similarity in the feature space between samples from the same patient30. This sampling procedure, specific for microbiome analysis of cancerous tissue, is the exception rather than the rule. Still, for most cancer types, bespoke datasets are not available, and their usage may provide more reliable results. In conclusion, when choosing the type of sample to use in cancer-related microbiome analysis, one must consider the research question and the information the sample to be collected may provide. Furthermore, care should be taken to avoid contamination during sample collection and processing. Microbiome data generated from clinical samples should clearly describe all steps from sample processing to analysis and the types of controls included to handle possible contaminants to properly develop and validate models for diagnosis and characterization.
Types of data for analyzing the microbiome
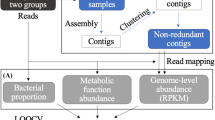
One of the basic aspects when characterizing the microbiome is its taxonomic composition. For that, it is necessary to assign DNA/RNA sequences to taxonomic units. A taxonomic unit is a set of related organisms, whose degree of relatedness depends on the type of unit chosen. It is useful to think of taxonomic units at the species level: in this case, relative abundance features are the proportion of organisms of each species in a sample40. A pipeline for cancer characterization using ML models based on abundance profiles, from sample collection to model validation, is shown in Fig. 2. Although some studies have analyzed microbiome profiles at the species level41, the broader genus level18,42,43, operational taxonomic units (OTUs), or the amplicon sequence variants (ASVs) are more frequently used33,44. OTUs group bacteria based on sequence similarity (usually at 97%), while ASVs identify true biological sequences (100% similarity) allowing the discrimination of closely related taxa. On one hand, it is less computationally demanding to determine OTUs or ASVs than to produce taxonomic classifications for each sequencing read45. On the other hand, the widely used target amplicon-based sequencing makes a species-level characterization of the microbiome difficult, leading to a preference for profiles at the genus level46. Alternatively, some authors have suggested using the abundances of multiple taxonomic levels as input features to an ML model47,48, or incorporating abundance profiles into phylogenetic trees49.

The nucleic acid in the collected samples is sequenced and the resulting reads are assigned taxonomic classifications. Likely contaminants and batch effects are removed. Feature selection methods can be used to select the most relevant features, which are used to train an ML model. Feature selection approaches are discussed in section “Methods for dimensionality reduction”. The model should be evaluated using an independent test set and cross-study validations, as discussed in section “Model validation”.
The microbial abundance data most often used when studying the links between the human microbiome and cancer has a set of characteristics that make the development of ML models challenging. Firstly, it has high dimensionality, as every taxon found in at least one sample constitutes a feature. Machine Learning models using a large number of features tend to overfit the training data, showing poor generalization to unseen samples50. As such, methods for dimensionality reduction are often advantageous when pre-processing microbiome data, prior to training ML models51. As a consequence of including one feature per taxon found, microbiome abundance profiles are sparse, with the abundances of a taxonomical unit typically following zero-inflated negative binomial distributions. This may impact the performance of ML and statistical models, leading to overdispersion52. The microbial abundance profiles of different samples are also usually obtained with variable sequencing depths. Thus, these data are compositional, as samples should not be characterized by the absolute abundance of each taxon, but rather by their relative counts53. However, it is unclear how this compositional framework impacts the performance of ML models51.
Current technologies used to characterize the microbiome allow the quantification of other variables besides the microbial composition profiles. These types of data can improve the performance of ML models over abundance profiles alone. As an example, in ref. 54, ML models trained with functional profiles to distinguish fecal samples from colorectal cancer and adenoma patients achieved greater accuracy than classifiers using taxonomical profiles. Similar results have been reported when predicting cachexia in lung cancer patients55 or the survival time of patients with neuroblastoma31. These functional profiles result from the quantification of the relative abundance of groups of organisms, genes, proteins, and metabolites46,54. Other types of microbiome data used as input for ML models in cancer-related applications include microbial single nucleotide polymorphisms56.
Pre-processing microbial data
The data described in the previous section should be pre-processed to aid ML models in learning robust decision rules. Pre-processing steps may include transformations, which decrease the influence of outliers, normalization57, and feature selection; these will be discussed in this section. These pre-processing steps may greatly improve the performance of ML models. However, many ML models proposed for cancer characterization using microbiome data do not use any pre-processing other than data standardization18,47,58, as it is difficult to predict if such pre-processing steps will improve the performance of ML models before testing them.
Methods for feature transformation
As previously mentioned, taxonomic profiles are heterogeneous, with an abundance of zero-valued features59. Thus, these are usually transformed to decrease the importance of dominant features and outliers, improving the performance of classifiers60. Log transformations (for which the transformed abundances \({x}^{{\prime} }\) are obtained from the original values x according to \({x}^{{\prime} }=log\left(x+c\right)\), with c known as the pseudocount, taking the value of one for most cases) are commonly used61; however, the chosen pseudocount value can impact the downstream analysis of the data, and it is unclear how to best choose this parameter62. Other transformations include a cube-root normalization proposed in Mulenga et al.63 and rescaling feature vectors to a unitary scale48. Mulenga et al.63 further proposed applying two normalization approaches to taxonomic profiles and concatenating the resulting features with the original values. This approach improved classification performance when combined with data augmentation with a variational autoencoder and a deep neural network63.
HARMONIES59 is a more complex transformation method developed for microbiome taxonomic data. This method uses Bayesian models to transform the read counts per taxon, taking different sequencing depths (the number of reads produced in each position in the sample genome) and data sparsity into account. It also considers that one feature may have zero abundance both because that taxon is absent from the sample, or because sequencing failed to capture it. However, HARMONIES59 has not yet been applied in conjunction with ML approaches. Despite the claims that these methods can better reflect the true microbiome or improve the accuracy of models, the most suitable normalization method is dependent on the original dataset: some transformations, such as those based on feature variance, are better at decreasing the influence of outliers, while normalization approaches preserving feature variance, as the cube-root, may be more effective when outliers are absent60,63.
Methods for dimensionality reduction
Microbiome datasets have a large number of features, usually greater than the number of samples. Machine Learning models trained on data with a high number of features relative to the number of samples tend to overfit and show high variance, due to the large number of possible relationships exploited to create decision boundaries, most of them spurious50. Furthermore, training ML models in these settings is computationally expensive64. In these cases, it is recommended to use simpler models that are less likely to overfit the training data, with heavy regularization50; alternatively, methods for dimensionality reduction can be used. These include feature extraction methods, that transform the original data into a dataset with fewer features, and feature selection approaches, that select a subset of the original features for training64,65.
Most approaches to studying the link between cancer and the human microbiome using ML focus on the interpretability of models. Models are used to find biomarkers, such as species linked to a certain cancer type. Because of this, feature extraction methods such as principal component analysis (PCA) or principal coordinates analysis (PCoA), which transform the original feature space, are seldom used. Rather, most of the applied dimensionality reduction methods are filters for feature selection. These are independent of the model and act as a pre-processing step, selecting a subset of features based on the data alone. Typically, filter methods rank features according to a given criterion and select the highest-ranked66. These methods only consider the predictive power of one feature at a time, and not the discriminative capability of a set of features, as is the case for most ML models. As such, the features selected by filter methods may not form the optimal feature subset for the performance of the ML model.
Simple filter feature selectors use statistical tests to rank features according to their relevance. One such test is the Student’s t test for independent samples, which tests if a set of samples from two groups originated from distributions with the same mean. In feature selection for binary classification, samples are divided by class. The sample means for each feature and class are compared using a t test and the features with the highest statistic, reflecting a larger difference in means, are kept50. However, the t test should only be used when the features are approximately normally distributed. When this is not the case, it is possible to use a Mann-Whitney U test, assessing if the values of a feature are larger in one class than another. The Mann-Whitney U test is non-parametric and thus potentially more robust to outliers than the t test. Both tests were used in ref. 44 to find epithelial ovarian cancer from peritoneal fluid microbiota. For multiclass classification, one can resort to a one-way analysis of variance (ANOVA) test. One-way ANOVA tests compare the means of a feature between all classes using the F-distribution. In ref. 54, ANOVA was used to select features for colorectal cancer prediction from stool samples.
One downside of selectors based on statistical tests is their tendency to select many correlated features: if multiple features are correlated and have a large discriminative power, they are likely to all be selected despite being redundant67. Minimum Redundancy - Maximum Relevance (mRMR)68 was developed for microarray gene expression data. It selects uncorrelated and informative features. Reflecting its popularity, mRMR has been widely used in cancer characterization from microbiome data69,70,71. In mRMR, the feature relevance is estimated using information gain (IG) or an F-test between a feature and the target classes, for categorical/discrete and continuous variables, respectively. The first selected feature is that with the highest relevance criterium. For each subsequent iteration, the redundancy of the remaining unselected features is calculated through the sum of Pearson’s correlation coefficients or IG between the tested feature and all those previously selected. The algorithm then selects the features with the maximum ratio or difference of relevance to redundancy68.
Linear Discriminant Analysis Effect Size (LEfSe) is another popular method developed for feature selection on metagenomic data72. Besides statistical significance, LEfSe also takes biological relevance into account. It starts by discarding all features with p values greater than a threshold according to a Kruskall–Wallis test, which extends the Mann-Whitney U test to a multiclass setting. Thus, it selects the most relevant features for further analysis. Then, the dataset is further divided into sub-classes. These should reflect a biological characteristic of a sample (e.g. the sex of a patient, as done in ref. 43, or other clinical covariates in ref. 33). For each previously selected feature, all sub-classes in different classes are pairwise compared using a Wilcoxon signed-rank test. If any comparison results in a p value greater than a threshold, or if there is a difference in sign among the comparisons, the feature is deemed as not biologically robust and excluded. Lastly, Linear Discriminant Analysis is used to estimate the effect size of the resulting features and rank them72. LDA is trained by preserving classes as targets and using the original features along with covariates as input variables. The effect size is quantified by averaging the difference in class means with the difference in class means along the first linear discriminant axis72.
Autoencoders, which are discussed in greater detail in section “Autoencoders”, can also be used as filter feature selectors, despite having rarely been used in cancer-related host trait prediction from microbiome data.
Although used less frequently than filters due to the higher computational cost, feature selection can also be performed using embedded or wrapper methods and surrogate models. Tree-based models, such as Random Forests and Gradient-Boosted Trees can inexpensively give an importance score (such as Gini importance) to the input features73. The best-ranked features can be used as input data for a more powerful downstream model, responsible for the final classification70. However, the features selected by these surrogate models may not be the most adequate for the predictor, as these operate under different constraints and optimization approaches. Wrapper and embedded feature selection methods are dependent on the predictor model74. These include sparsity-aware approaches that set some of the model coefficients to zero, such as Least Absolute Shrinkage and Selection (LASSO) regression75, as used in refs. 41,61,76 and47, or Recursive Feature Elimination Support Vector Machines (SVM-RFE)77, which has been applied in ref. 78. Both approaches will be discussed in greater detail in the next section.
The most effective feature selection approach is dependent on the characteristics of the dataset, namely its sparsity and feature correlation, and the model used. One study compared the efficacy of statistical test-based methods, mRMR, a Fast Correlation Based Filter79, Conditional Mutual Information, and prior selection with Gradient Boosted Trees for dimensionality reduction in colorectal cancer prediction from metagenomic samples70. Statistical test-based methods, along with Gradient Boosted Trees selection achieved the best results when coupled with a Random Forest classifier; however, this may not hold true for other models or data: a feature selection approach should be selected on a case-by-case basis or with cross-validation. The authors also applied an ensemble selection, resulting in an 11% increase of AUC when compared to no feature selection70. Therefore, despite being computationally more expensive, ensemble approaches may provide more robust features selected by multiple different methods, and therefore suitable for a wider range of models.
Table 1 contains an overview of the methods discussed in this section, grouped by type (filter, wrapper, or embedded) along with the major advantages and disadvantages of each. In conclusion, despite being frequently used, it is unclear what feature selection method, if any, is best for each learning task. As such, feature selection approaches should be selected according to cross-validation. Alternatively, ensembles of selectors, or ML models capable of performing feature selection, such as deep learning approaches, may be used.
Machine Learning models
Machine Learning models take a feature vector \({{{\bf{x}}}}\in {{\mathbb{R}}}^{M}\) as input, where M is the number of features, and predict a target value \(\hat{y}\). This is done by applying a decision function ϕ such that \(\hat{y}=\phi \left({{{\bf{x}}}}\right)\). Most ML models try to minimize a loss function that quantifies the difference between the predicted and ground-truth variables80. Learning tasks can be divided into classification or regression, when the target variable is categorical or numerical, respectively75. When studying the cancer-related microbiome, classification is the most common, mainly encompassing cancer diagnosis or tumor type identification. However, regression tasks can also be found in literature, as in survival time prediction31 or predicting the number of tumors formed in murine models81.
In this section, we will discuss the most popular and promising ML methods applied to cancer identification and characterization from the microbiome. Table 2 shows some examples of these applications and lists the ML models used in each.
Support Vector Machines
Support Vector Machines (SVMs)82 are commonly used with microarray data83. Therefore, these are also often employed to identify microbiome-related biomarkers for cancer. In their simplest form, SVMs are binary classification models that define the decision boundary as a hyperplane. When the data is linearly separable, there are infinite hyperplanes that perfectly separate the samples according to their class75. SVMs select the hyperplane with the largest margin to the training data84 and only some of the training samples define the decision boundary; these are called the support vectors80.
Linear SVMs were found to achieve comparable performance to non-linear models in colorectal cancer identification from microbial abundance profiles85. Nevertheless, SVMs can be adapted to non-linear decision boundaries by extending the original feature space with feature transformations50, which results in non-linear decision boundaries in the original feature space and improves separability. Feature extension can be done without increasing the computational load with the so-called kernel trick86. The most used kernel in tumor-associated microbiome analysis is the radial basis function (RBF)85,87, which has achieved good results in colorectal cancer prediction48,71. However, when kernels are used, the prediction for a sample is based on its kernel distance to the support vectors88. Therefore, the decisions of SVMs are more difficult to interpret than with Random Forests or Logistic Regression88.
SVMs have been used to predict colorectal patient survival time89,90, cancer prognosis, and drug responses78 from microbiome and gene expression data, and to identify colorectal cancer patients using taxonomic profiles71,85. Furthermore, SVMs are frequently used as benchmarks when evaluating other methods47,87,91. The popularity of SVMs for cancer-related host trait prediction from the microbiome is due to their widespread availability in ML libraries and the good performance demonstrated by these models in multiple works. In41, SVMs outperformed Logistic Regression when predicting various diseases using taxonomic profiles. In a few cases, SVMs achieved better or comparable results to Random Forrest classifiers41,48. However, in most of the experimental settings, SVMs failed to surpass the performance of Random Forest, namely in survival time prediction90, identification of cancer types69, and colorectal polyp identification92.
Because SVMs are binary classifiers, extending them to multiclass classification comes with multiple problems. Usually, a classifier is trained for each class, in a one-versus-rest approach, with the final prediction taken as the one yielding the highest value for the decision function. Because each classifier is trained with different target labels, there is no assurance that these values are scaled equally80. Furthermore, this approach is computationally expensive, as it requires training a potentially large number of classifiers. These issues make SVMs rarely used for microbiome-based multicancer prediction. In such an application, an SVM achieved a much worse performance than a Random Forest, a k-Nearest Neighbors, and a Decision Tree classifier69, all models that can be directly used in multiclass settings.
Despite all the aforementioned shortcomings, SVMs may prove useful when only a small training set is available. These models are less prone to overfit the training data and can show good generalization performance when the number of features far exceeds that of training samples93. This has motivated its usage in oral carcinoma identification from taxonomic and functional profiles in a study comprising only 38 samples94. However, it is unclear if other models could have achieved comparable performance, as no other approaches were tested. Furthermore, this good generalization performance is dependent on an adequate choice of the regularization parameter controlling the width of the decision boundary margins, which requires costly cross-validation75.
Using a wrapper, SVMs can be adapted to perform feature selection. As previously mentioned, this is known as Recursive Feature Elimination Support Vector Machine (SVM-RFE)77. In SVM-RFE, an SVM is initially trained on all the features. In each iteration, the feature with the smallest contribution according to the model parameters is removed, and the SVM is retrained77.
Decision Tree-based models
Models based on Decision Trees - Random Forests in particular - are the most frequently used ML models when studying the link between cancer and the human microbiome. Decision Trees are sequential models that apply successive rules to yield a final prediction. At each level of the tree, starting from the root, the value of a feature is compared to a threshold learned from the training data. The decision path followed by the model is defined by the result of each comparison and the final prediction is given by the class associated with the leaf reached95. When splitting a node, Decision Trees exhaustively search for the threshold and feature achieving the best purity in the child nodes50. Purity, expressing the homogeneity in target classes of the samples in a leaf, is commonly quantified using the Gini index or entropy96.
Random Forests
Decision Trees are prone to exhibit high variability, as small changes in the training data may result in different splitting thresholds. Alterations in the first nodes propagate into changes in the structure of the subsequent levels, greatly impacting the overall classification rules50. This leads to high variance and helps explain why Decision Trees are rarely used when studying the link between cancer and the microbiome. Bagging decreases the variance shown by Decision Trees: multiple models are trained using samples and features randomly sampled with replacement from the training set50,97. Bagging Decision Trees results in a Random Forest; the different trees have slightly different structures, as they were trained on different data95. The final prediction is the average of the predictions of the individual trees95.
In a work on multicancer identification from microbial abundances, a Random Forest classifier achieved improved generalization performance over a Decision Tree69. A similar result was found in ref. 85 for colorectal cancer identification. Unlike Decision Trees, Random Forest classifiers are highly popular when studying the association between cancer and the microbiome. This is supported by several published benchmarking experiments in which this model outperformed all other tested algorithms in tasks including identifying colorectal cancer85, melanomas in mice87, cancer subtypes69, and other host traits41. Random Forests have been applied to predicting the survival time of colorectal cancer patients from gene expression and microbiome taxonomic profiles90 and identifying several tumor types such as epithelial ovarian cancer44, tonsillar squamous cell carcinoma58, lung adenocarcinoma33, colorectal cancer28, oral squamous cell carcinoma98, and in a multiclass classification setting69.
Boosting
Boosting is another approach to decrease variance and operates on a similar idea to bagging; however, instead of training the standalone estimators independently, it builds models sequentially80 and these are kept shallow99. When boosting Decision Trees, each tree is trained with samples drawn from the dataset, weighted according to the performance of the previous classifier on that data point. This way, the next individual model is trained to improve the performance on data that the previous tree failed to predict80. The final prediction is taken as a weighted average of the prediction of all the trees, or as a majority voting80. The improved generalization performance of boosting methods over Decision Trees was also exemplified in ref. 85. However, it is unclear whether boosting can achieve better performance over Random Forests in cancer-related host trait prediction from the microbiome. In this same publication, a boosting approach and a Random Forest demonstrated comparable performance85, while in ref. 87 a boosting model showed a decreased AUC but improved precision and recall over Random Forests. Boosting methods have also been proposed to predict tissue malignancy in breast cancer using bacterial taxonomic profiles from biopsies30 and to identify several tumor subtypes from microbiome data18.
Interpretability and Explainable Boosting Machines
Besides the excellent performance demonstrated by Random Forests and boosting models in cancer-related microbiome host trait prediction, these models are often used due to their improved interpretability over other black box algorithms such as non-linear SVMs and Neural Networks. For sufficiently shallow Decision Trees, decision rules can be easily analyzed and understood, making finding putative biomarkers easier. Decision tree flowcharts are already widely used in medicine for diagnosis, so they are familiar to doctors and health professionals100. As Random Forests and boosting combine the predictions of several trees, this direct interpretation of feature contribution is lost. However, it is possible to quantify the importance of each feature by analyzing the number of times a feature is used in a node or the average increase in purity achieved with it73. In ref. 42, Random Forests were used to identify acute myeloid leukemia from taxonomic profiles, and the contribution of each taxon for classification was assessed using the average increase in purity. However, these scores do not fully reflect the complex decision rules of the classifier, which depend on the association of multiple features.
With boosting, the link between importance scores and decision rules is even more unclear than for Random Forests, as different trees have a different impact on the final prediction. Explainable Boosting Machines (EBM)101 try to make this association clearer so that the decision of a model is better understood through feature importance scores. EBM is an implementation of Generalized Additive Models102 that also models pairwise feature interactions, and in which the feature transformations are modeled using a boosting algorithm. When training EBMs, each tree can only use one feature. The set of M features is iterated multiple times, with each tree contributing by a small amount to the final classification. Because of this, a large number of trees is needed in EBMs, making training times longer than for other boosting approaches103,104. The importance of each feature can be easily assessed by analyzing the importance scores and using heatmaps for pairwise interactions104. Because each tree can use only one feature and is a weak classifier, these scores provide better insight into the classification rules101. Explainable Boosting Machines have been used to identify colorectal cancer and adenoma from microbial gut functional profiles54, allowing greater interpretability without sacrificing accuracy. Glass-box methods such as EBM may help identify novel biomarkers for cancer, based on the human microbiome.
Logistic Regression
Logistic Regression is a linear model for classification that, due to its simplicity, has been widely used in studies investigating the tumor-specific microbiome, mainly for feature selection and benchmarking47,61. This model assumes that the microbiome data originated from class-conditional Gaussian distributions of equal covariance matrices. The decision function of Logistic Regression, shown in Eq. (1) for binary classification, is the estimated posterior probability of a sample x being of a given class75. The model parameters β and β0 are learned using iterative processes, usually gradient descent with binary cross entropy as a loss function75.
Despite having linear decision boundaries, Logistic Regression classifiers can, in some cases, achieve similar results to non-linear counterparts in microbiome cancer-related host trait prediction: in ref. 85, L2 regularized Logistic Regression achieved a comparable AUC to Random Forest and Boosted Trees for colorectal cancer identification. However, this is seldom observed49,87,91; as examples, Logistic Regression failed to improve colorectal polyp identification over a Multilayer Perceptron and Naïve Bayes classifier92, and colorectal cancer identification over a Multimodal Neural Network47. Because of this decreased performance, Logistic Regression has mainly been used for feature selection.
L1 and L2 regularization are approaches to decrease model variance by constraining its parameters105. L2 regularization penalizes the squared value of the model parameters (β and β0), decreasing their absolute values106. L1 regularization, also known as Least Absolute Shrinkage and Selection Operator (LASSO), constrains the model parameters so that the sum of their absolute values is less than a number105. LASSO regression forces some of the parameters to take null values, effectively disregarding the corresponding features during inference50. Combining L1 and L2 regularization results in a model known as ElasticNet107. Therefore, LASSO and ElasticNet are embedded forms of feature selection and have been used to select microbiome features for a more powerful downstream classifier. As the decision boundary is linear, feature contribution for classification can more intuitively be quantified by the corresponding model parameter. The most relevant features are chosen accordingly44,61. This approach was used for colorectal cancer identification coupled with a Multilayer Perceptron57 and Generalized Neural Networks61. LASSO was also included in the ensemble used for feature selection in ref. 44 for ovarian cancer identification from taxonomic profiles and serum tumor marker levels.
The same properties that make Logistic Regression adequate for feature selection also explain its improved interpretability over methods such as Random Forests and Artificial Neural Networks: the contribution of each feature can be quantified by the parameters of the model85. This allows researchers to more easily identify potential bacterial biomarkers associated with specific types of cancer85. This strategy was used to identify seven genera potentially associated with invasive cervical cancer108 and to access feature contributions when identifying colorectal cancer using taxonomic profiles85.
Artificial Neural Networks
Artificial Neural Networks (NNs) are complex non-linear ML models that usually achieve better performance than their simpler counterparts109. To build an NN, multiple activation units are stacked into layers. Activation units take a vector as input and output a scalar, applying an activation function on the linear combination of inputs and a bias parameter. The outputs of a layer are concatenated and fed into the following layer until the last is reached. This last layer is the output layer, as it outputs the final prediction of the model. The layers between the input and output are called hidden layers110. Architectures with more than one hidden layer are considered Deep Neural Networks110. The model parameters are learned using stochastic gradient descent. Because the gradients for the parameters of each activation unit are computed using the chain rule from the output to the input layer, this computation is referred to as back-propagation110.
Unlike other ML methods, Deep NNs do not require extensive previous feature selection and transformation. These models are complex enough to do the necessary processing of input features111. The output vectors of hidden layers can be perceived as mappings of a sample to a transformed feature space, in which class separability is enhanced110. This transformation can be exploited for dimensionality reduction and data augmentation, as we will discuss briefly. Nevertheless, multiple works on the tumor-specific microbiome have used Deep NNs trained with previously selected features48,87,92. Doing so may hinder performance, as these features may not be ideal given the model.
Because of their complexity and non-linearity, the decision rules of NNs are difficult to understand. Thus, NNs are seen as black box models that make biomarker identification more difficult than Random Forests or linear models. In host trait prediction from microbiome data, works assessing feature importance usually resort to model-agnostic methods: Mulenga et al.63 used L2 regularization, while Arabameri et al.61 employed Derivative-based Feature Selection. These methods do not provide a complete understanding of the model decisions, nor of the interdependencies between features, as provided by Decision Trees, for instance.
Multilayer perceptrons
The Multilayer Perceptron (MLP) is an NN in which consecutive layers are fully connected, as seen in Fig. 3. Multilayer Perceptrons can easily overfit the training data if no regularization is adopted, such as dropout and batch normalization, due to their large number of parameters112. In ref. 48, an MLP failed to improve the performance of an RBF-kernel SVM for colorectal cancer prediction using microbiome taxonomic profiles. However, the MLP used features pre-selected using Linear Regression, which may not be ideal for NN classification. Similar findings have also been reported for melanoma identification in mice while employing feature selection87. On the other hand, the MLP with prior feature selection used in ref. 61 achieved higher accuracy but worse sensitivity when compared to a k-Nearest Neighbors classifier and an SVM. Therefore, it is unclear if MLPs can achieve better predictions than those provided by simpler models such as Random Forests and non-linear SVMs.

The input layer contains the relative abundance of each taxon or OTU. These act as inputs (x) for the activation units in the hidden layers, which apply a function ψ. The output layer returns the probability of the presence and absence of cancer.
One notable approach using MLPs is that of DeepEn-Phy, a model operating on relative abundances incorporated into a phylogenetic tree49. This model uses a set of cascaded MLPs trained end-to-end. The phylogenetic trees are divided into levels, from leaves to roots. Each MLP operates in one level, with a level having multiple MLPs. The first MLPs use relative abundances in the leaf nodes and their outputs are fed into downstream MLPs, until reaching the root MLP. This model achieved better results when predicting smoking status and body mass index using the gut microbiome than Random Forest, Gradient Boosted Trees, and PopPhy-CNN, another deep learning model operating on phylogenetic trees113.
General Regression Neural Networks
General Regression Neural Networks (GRNN)114 are variations of kernel regression networks115. In a GRNN, each of the N activation units applies an RBF centered in each of the training samples during inference. The output of the model is a weighted sum of the activation units114. One advantage of GRNN over MLPs is the smaller number of hyperparameters: only the spread parameter needs to be specified, while in MLPs one must choose the number of layers and activation units, and the optimization parameters61. However, the pattern layer grows with the training set, making learning and inference computationally expensive116.
This model was used to detect colorectal cancer from taxonomic profiles of the gut microbiome, having outperformed an MLP and an RBF kernel SVM61. According to the authors, GRNNs can achieve better accuracy than MLPs, even with a small number of training samples.
Multimodal Neural Networks
Multimodal NNs combine MLPs to integrate features from different modalities. In one cancer and microbiome-related application, a multimodal NN was used to identify several diseases, including colorectal cancer, using taxonomic and functional profiles from the gut microbiome47. MLPs were trained using features from each modality alone. Embeddings were derived by concatenating the outputs from the last hidden layers of each modality. The multimodal NN achieved improved accuracy over MLPs that used just one of the feature types; it also outperformed Random Forest, an SVM, Gradient Boosted Trees, and LASSO regression for colorectal cancer prediction47. This work shows the potential of combining multiple types of data in increasing the accuracy of tumor diagnosis and introduces multimodal NNs as a promising method to integrate various modalities of features that complementarily capture the complex mechanisms that underly cancer development.
Autoencoders
The outputs of hidden layers of NNs can be interpreted as mappings of the input vectors into a latent space. If a layer has less than M activation units, with M the number of input features, these can be used as compressed representations of samples75. Autoencoders are NNs that try to reconstruct the input data. Their goal is not to achieve useful predictions; rather, autoencoders learn representations of the input vectors in a latent space110.
Due to the high dimensionality of microbiome data, autoencoders can be useful in avoiding the curse of dimensionality. However, despite having been proposed for dimensionality reduction in metagenomic studies117, autoencoders are rarely used in cancer-related host trait prediction from the microbiome. In ref. 118, autoencoders coupled with an MLP failed to improve the AUC in identifying colorectal cancer from the gut microbiome over MetAML, which uses Random Forests, SVMs, LASSO regression, or an ElasticNet118. However, it is unclear if this is due to the classifier used or the dimensionality reduction strategy.
Autoencoders can be adapted to generate synthetic samples. Because data augmentation techniques increase the number of training samples, they decrease the variance of a model, assuming that the synthetic samples are derived from a similar distribution to the original data119. This is particularly important for models that are prone to overfit the training data, such as deep NNs. While studying the cancer-related microbiome, this issue is made worse due to the scarcity of data. Therefore, data augmentation can be a powerful aid in the development of more accurate ML models acting on microbiome data. In ref. 63, data augmentation using Variational Autoencoders (VAE) improved the predictions of an NN classifier for colorectal cancer using gut microbial abundances63, with an increase in the AUC of up to 30%.
Choosing the right ML model for the task
The best choice for a microbiome-based ML model for cancer-related applications depends on the diversity, quality, and quantity of the available data and on the learning task. Table 3 lists the main strengths and weaknesses of ML models discussed in this review and is intended to aid researchers in selecting an ML model for their particular use cases. Nevertheless, it is difficult to know a priori which model will achieve the best performance, and testing multiple models is recommended.
As previously mentioned, Random Forests are highly popular, as they achieve a good balance between interpretability and performance for most applications. When inference performance is of the utmost importance (for instance, in cancer screening), more complex methods such as Boosted Trees or NNs may be needed. However, this implies a higher computational cost for training when compared to other, more simple models. The decision rules of Boosted Trees and NNs are also difficult to interpret, making it difficult to validate the decisions of the models and to identify characteristics of the microbiome associated with a given prediction. Furthermore, in the case of deep NNs, any increase in performance and generalizability over Random Forests and other approaches requires large amounts of training data, which are usually not available in cancer-associated microbiome studies. When the datasets available for training are small, SVMs are likely a good choice93,94; however, these models require costly hyperparameter tuning and do not support multiclass classification, hindering their application for multicancer identification80.
When the goal is to identify microbiome-based cancer biomarkers, being able to derive meaning from the decisions of the ML models is more important than achieving the best performance possible. Therefore, in these use cases, simpler and more interpretable models (e.g. Decision Trees and Logistic Regressors) may be the best choice. Both Decision Trees and Logistic Regressors have widely available implementations and their decision rules are easy to analyze. However, Decision Trees tend to show high variance and poor generalizability50, while Logistic Regressors are limited to linear decision boundaries, which may be unsuited for some learning tasks92.
Model validation
After training an ML model, its performance should be properly evaluated to ensure its generalizability and to avoid biases that are not related to the microbiome nor clinically relevant, such as those caused by technical artifacts. Models should be tested with a hold-out dataset, independent of that used for training. Including information about the training data in the test dataset, also known as data leakage, prevents an exact assessment of how the model will behave with previously unseen data. This can lead to an overestimation of model performance and generalizability120. Thus, when studying the links between cancer and the human microbiome, ML model validation should ideally include evaluating the model performance using data generated in a slightly different manner (e.g., from another institution) than that used for training, and excluding patients in the training set. When such data is not available, cross-validation can be used as an alternative. In cross-validation, the training dataset is split into k subsets of the same size. The ML model is trained and evaluated k times, each time using a different subset for validation and the remaining k − 1 for training. The performance metrics are then averaged to yield a final estimate of the performance of the model.
The same care should be taken when selecting hyperparameters. To ensure that the selected values are those that maximize the performance of a model with previously unseen data, these should be selected through cross-validation121.
It is key to also avoid data leakage in the feature transformation and dimensionality reduction steps, as any inference about the structure of the data based on the test set or the entire dataset may compromise generalizability. As an example, if using LEfSe with microbial abundance profiles, only the abundances of samples in the training dataset should be used to evaluate statistical significance and effect sizes. However, promising bacterial biomarkers are often chosen through statistical tests on the whole dataset, before being used as input features to an ML model. This feature selection based on all samples may lead to the overfitting of the dataset and poor generalizability. In other cases, the publications are not clear about the validation strategies employed and the possibility of data leakage, making it difficult to assess the generalization of their conclusions.
Current limitations and future perspectives
In this section, we discuss the current limitations of research on ML methods for microbiome-based cancer characterization, along with how to address them. Future perspectives in this area are also provided here. Figure 4 contains an overview of the limitations discussed in this section.

Improvements in ML models can be achieved through improvements in their accuracy and generalizability. Some of the future perspectives discussed in this review and shown in this figure can aid in improving generalizability (left), model accuracy (right), or both (center).
Many publications on ML for cancer characterization from microbiome data have contradictory results, with questionable generalization. As an example, in refs. 71 and 28, the genus Fusobacterium was found to be more abundant in the gut microbiome of colorectal cancer patients; however, this genus was not identified as a possible biomarker in refs. 18,27 nor 61. Zhou et al.29 aggregated the proposed microbial biomarkers for colorectal cancer from various publications and found inconsistent results. Nevertheless, the overall findings show a difference between colorectal cancer and the healthy microbiome, although the microorganisms responsible may differ across studies. The findings in ref. 18 have also been questioned with models said to be relying on bacteria unlikely to be present in humans to predict cancer types122,123; however the authors have since reproduced their findings with a revised methodology124,125. These conflicting results are caused by three major factors: an inadequate validation of ML models; the usage of small datasets to train and evaluate ML models; and a lack of correction of technical variations.
Besides the lack of agreement in microbial biomarkers, these shortcomings make it difficult to compare the impact of different ML algorithms and pre-processing approaches in model performance - an improvement may not be a result of a different methodology, but due to overfitting. Recently, some studies have focused on improving the generalizability of ML models to detect colorectal cancer, with multiple datasets from different regions and a consistent processing pipeline18,27. However, this should be extended to all works using ML.
Inadequate ML model validation and the need for larger datasets
In section “Model validation”, we have discussed how to properly evaluate the performance of an ML model, with a focus on ensuring its generalizability. However, as previously mentioned, not all research adheres to these recommendations. Most notably, data leakage is frequent during the feature transformation and dimensionality reduction steps, leading to an overestimation of model performance with unseen data and potentially to non-generalizable results.
Furthermore, to achieve sufficient model generalizability, researchers should ensure that the dataset used during development reflects the characteristics of the population the model will be used on. For instance, any model trained with fecal microbiome data of patients of a specific geographic region is likely to perform poorly for patients of a different area, as geography is known to impact the composition of the gut microbiome126. Using large datasets from diverse populations can therefore lead to more generalizable models and in turn to approaches that can be used with a greater number of patients.
However, the creation of these large datasets is costly and time-consuming. Therefore, it is crucial to implement data-sharing protocols between researchers, ensuring that data from patients across the world are integrated into the development and validation of ML models. When possible, collected microbiome data should be made publicly available in online repositories such as NCBI’s SRA127. Alternatively, processed data can also be hosted online, although this limits the ways in which these data can be repurposed. Furthermore, researchers should be transparent about how the microbiome data used in their studies was generated and processed, and how models were developed and validated. All code used should be made publicly available, facilitating future analyses and allowing for a more thorough assessment of model validation. Together, these approaches can improve the generalizability of ML models and accelerate the discovery of further links between the human microbiome and cancer.
Generative ML models can also aid in expanding the available datasets through the generation of synthetic data. These models are often based on NNs and include the Autoencoders discussed in section “Autoencoders” and Generative Adversarial Networks (GANs)128. However, and despite recent breakthroughs in generative ML models for genomics129, these have seldom been used to uncover the association between cancer and the human microbiome.
The effects of technical variations and clinical covariates
The lack of correction for batch effects and data leakage further raises doubts about how the findings of most works can be generalized. Not all differences in the data are linked to biologically relevant processes: rather, some may be due to technical variation or clinical covariates. As an example, the TCGA dataset is known to show strong batch effects linked to sequencing centers18,130,131,132. In these cases, ML models may be relying on these non-biologically relevant patterns for their predictions. This leads to poor generalizability and puts the findings derived from these models into question.
When it is possible to normalize the data to remove technical variations, this should be done. However, in some cases, the biological variable of interest is perfectly correlated with another covariate. Under these conditions, it is almost impossible to determine which changes are biologically relevant. Therefore, this ambiguity should be avoided, or, at least, control samples enabling the normalization of the data should be acquired. Testing models with hold-out datasets, obtained under different conditions than the ones used to train the models can also avoid spurious associations between cancer and traits of the microbiome by flagging ML models with poor generalizability.
Knowing when an ML model is relying on technical artifacts to make accurate predictions is often difficult due to the black box nature of most models. For this reason, more interpretable models, such as Decision Tree-based approaches, should be preferred. Recent advances in post hoc explainability133,134,135 may also enable the assessment of more complex decision rules, such as those from deep NNs. With these advances, researchers can analyze how ML models make decisions, detecting when these are relying on patterns that are unlikely to be related to biological phenomena.
Unclear predictive capability of ML models based on microbiome data
The predictive capability of ML models applied to the tumor-specific microbiome is still unclear. For colorectal cancer identification from gut taxonomic profiles, classifiers can currently achieve a promising performance: the GRNN in ref. 61 had an AUC of up to 85% in an independent test set, while the SVM in ref. 71 achieved 81% accuracy while using microbial abundance features. These metrics are indicative of good performance, however, they are unlikely to be robust enough for widespread use yet. Care should also be taken regarding the evaluation metrics used, to provide representative estimates of model performance. Analyzing the performance of models is difficult due to the small datasets used for development18,43, especially for cancer types other than colorectal, which in some cases have as few as 23 patients30. Furthermore, models are often evaluated using a one-versus-rest approach, which exacerbates class imbalance. Evaluation metrics such as accuracy are not adequate for highly imbalanced datasets. Even the AUC may hide the low precision or recall of a classifier, with a heavily skewed class distribution136. For instance, despite having an AUC of over 82%, in many cases reaching 100%, the classifiers to distinguish between cancer subtypes using the tumor microbiome in ref. 18 have an Area Under the Precision-Recall Curve (AUPR) of as little as 36%. To better understand the potential of ML approaches in identifying tumors based on the microbiome, these should be evaluated using metrics adequate for imbalanced datasets such as AUPR and the F-score136.
Improving the predictive power of ML models applied to cancer microbiome analysis will likely require the implementation of state-of-the-art methods such as NNs, increased regularization, and the aforementioned development of larger bespoke datasets. Despite the increasing popularity of NNs for this purpose, many advances in deep ML architectures are still to be applied. For instance, Autoencoders or attention mechanisms137 are seldom used, despite having achieved improved performance over other methods in biological tasks138,139. We expect these approaches to better model the complex relations between cancer and the human microbiome. However, when using these methods, special care should be taken to avoid overfitting. As such, the current preference for simpler ML models may be explained by a lack of data, which further highlights the need for larger datasets. Furthermore, new ways to constrain the latent representations of the input vectors are needed to avoid overfitting.
Unclear specificity of microbial biomarkers with confounding diseases
It is still unclear if bacterial biomarkers for cancers found using ML models hold specificity in the presence of other diseases. Most of the published research on the tumor-specific microbiome compares the microbiome profiles of cancer patients to those of healthy individuals, excluding those with other diseases71,98. Works developing models capable of identifying other diseases, such as type 2 diabetes or IBD, only include colorectal cancer41,47. Excluding confounding diseases that may affect the microbiome is likely to make it simpler to find alterations linked to cancer. However, these will not be adequate for widespread clinical usage in case they lose their predictive power in the presence of comorbidities. Type 2 diabetes increases the risk of cancer140,141, so employing biomarkers that cannot distinguish between the two diseases may yield incorrect results for a large fraction of the human population. Several publications have also found that type 2 diabetes is linked to disruptions in the gut microbiome142. Therefore, it is unlikely that the patterns differentiating the tumor and healthy microbiomes will be similar to those found between cancer and type 2 diabetes. Further research into the differences between the human microbiota in the presence of tumors and other confounding diseases is required to better understand the limitations of using microbiome-derived biomarkers for cancer diagnosis and analysis.
Microbiome features other than taxonomic profiles are largely unused
The vast majority of ML approaches take on taxonomic abundance profiles as input data. However, these may not be the most informative characteristics of the microbiome: for instance, gut microbiome functional profiles were shown to provide an improvement in performance over the taxonomic counterparts when distinguishing colorectal cancer from adenoma54. Data integration (for instance, using both taxonomic and functional features, as done in47, or coupling the taxonomic profiles with other methods for cancer diagnosis such as fecal occult-blood testing71) may also improve the classification accuracy in cancer diagnosis, but few publications exploit this for tumors other than colorectal.
The emergence of next-generation sequencing (NGS), allowing high-throughput sequencing and shotgun metagenomics, has enabled the cost-effective functional profiling of the microbiome through technologies such as mRNA sequencing (RNA-Seq)143,144. Epigenomics analyses were also made possible by NGS144. Therefore, we expect further work to be undertaken to better understand how these different types of data and biological characteristics relate to one another, and if data integration can yield more powerful methods for cancer diagnosis and characterization.
The need for ML models adapted to the characteristics of microbiome data
The relationships between the host and its microbiome are highly complex, and microbiome data has characteristics that make ML models challenging. For once, abundance taxonomic profiles have many zero values and small variations linked to technical phenomena. This leads to the most common ML approaches overfitting the training data. Thus, the next steps in ML for cancer-related applications using microbiome data likely include the development and application of models that are more robust under zero-inflated data with high variability. Several models have already been proposed for this kind of data145,146,147, some specifically designed for microbial count data148. Such models should find microbial signatures associated with cancer characteristics while filtering out sporadic associations resulting from technical variations. In conjunction with this, we expect further work on feature selection and dimensionality reduction approaches for microbial count data to improve the performance of ML models for cancer characterization from microbiome data. Again, by preserving only the most biologically relevant features, these approaches could reduce the variability of models.
Translation to clinical practice and ethical concerns
Although the performance of ML methods for cancer characterization using microbiome data is currently insufficient for clinical use, it is important to delineate how future models can be incorporated into clinical workflows. So far, most works have focused on discovering microbial biomarkers through the use of ML. These biomarkers, after careful validation, could potentially be the target of diagnostic assays. Blood or stool-derived microbial signatures, in particular, are promising, as these would enable a non-invasive screening of high-risk patients18. Patients exhibiting these biomarkers could then be further examined through imaging, histologic, and cytologic exams to arrive at a diagnosis. Microbiome-based biomarkers could also be used to guide treatment by predicting the efficacy of different approaches32,35,149,150,151. All decisions and diagnoses derived from microbial biomarkers should be discussed and carefully explained to patients, using a patient-centered approach. To this end, it is crucial that patients are aware of the shortcomings of these biomarkers and the uncertainties surrounding the links between cancer and the microbiome.
Although these non-invasive methods could allow for better care and improved survival rates, clinicians are often wary of diagnostic tools derived from ML models due to their black box nature152. This highlights the need for clinicians to be involved in the development of these tools and for ML models with more understandable decision rules. Furthermore, we should avoid increasing the workload of clinicians when integrating these approaches into the clinical workflow152.
Finally, the ethical use of ML in cancer diagnosis and treatment requires stringent measures to safeguard patient privacy and ensure data security. These should include anonymization, encryption, and transparency to guarantee that the identities and health information of patients remain protected153. This is also important for the regulatory approval of tools integrating ML algorithms using microbiome data. Therefore, balancing patient confidentiality and safety with innovation will require adapting existing frameworks to accommodate the dynamic nature of these technologies and their evolving clinical implications.
The need for interdisciplinary approaches
As we have seen, ensuring adequate ML model development and translating these models or their findings to clinical practice is a complex and interdisciplinary endeavor: proper model training and testing requires familiarity with computer science, as expert knowledge is needed to avoid data leakage and to extract understandable insights into the decision rules of ML models. An inadequate understanding of these concepts may lead to overly optimistic estimates of model accuracy and the generalizability of findings. Likewise, biologists should be involved in model validation (especially in the assessment of their decision rules), ensuring that these make reasonable predictions and are not relying on clinically irrelevant artifacts. Furthermore, clinical and microbial field knowledge may also aid in the development of the ML model itself. Finally, clinicians should be a part of model development and validation, ensuring its applicability. This interdisciplinary approach should be fostered and the norm rather than the exception.
Conclusions
The human microbiome holds great potential for cancer diagnosis, prognosis, and therapies, offering a promising avenue for research. However, the biomarkers derived from this complex system present a challenge in their analysis. To address this, ML methods have emerged as crucial tools and have been widely used in recent breakthroughs to unravel cancer-microbiome relationships. In this review, we described and compared current ML approaches from sample collection to the final prediction. Most approaches have focused on gut-derived taxonomic profiles, mainly for colorectal cancer prediction. Tree-based models are the most used and recommended when there is a need to understand the decision rules of models; however, recent works suggest that deep learning architectures such as VAEs and multimodal NNs can achieve better performance and offer a great tool for applications requiring excellent inference performance, such as diagnosis. Many published works do not ensure the generalization of their models, avoiding data leakage and confounding technical variables, leading to conflicting results. Therefore, future research should be careful to implement adequate generalization assessments with expanded hold-out datasets and careful removal of technical variations.
Despite promising, models developed for cancer types other than colorectal do not yet achieve sufficient performance for clinical usage. Improving this performance will likely require integrating microbial taxonomy profiles with other data types, including gene expression and host characteristics, leveraging advances in sequencing technology. This approach will be critical for a better understanding of the complex interplay between the microbiome and the human host in the context of cancer. We also expect the recent advances in deep learning approaches, along with the application of ML methods better suitable to the characteristics of microbiome data to aid in this endeavor. Finally, data-sharing and interdisciplinary efforts are instrumental in ensuring the development of accurate and generalizable models.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The full-text articles assessed in this review are listed in Supplementary Table 1.
References
Ferlay, J. et al. Estimating the global cancer incidence and mortality in 2018: GLOBOCAN sources and methods. Int. J. Cancer 144, 1941–1953 (2019).
WHO. WHO Methods and Data Sources for Country-Level Causes of Death: 2000-2019 (World Health Organization, 2020).
Hanahan, D. Hallmarks of cancer: new dimensions. Cancer Discov. 12, 31–46 (2022).
Gilbert, J. A. et al. Current understanding of the human microbiome. Nat. Med. 24, 392–400 (2018).
Behjati, S. & Tarpey, P. S. What is next generation sequencing? Arch. Dis. Child. Educ. Pract. Ed. 98, 236–238 (2013).
Jiang, D. et al. Microbiome multi-omics network analysis: statistical considerations, limitations, and opportunities. Front. Genet. 10, 995 (2019).
Jovel, J. et al. Characterization of the gut microbiome using 16S or shotgun metagenomics. Front. Microbiol. 7, 459 (2016).
Turnbaugh, P. J. et al. The Human Microbiome Project. Nature 449, 804–810 (2007).
Zeller, G. et al. Potential of fecal microbiota for early-stage detection of colorectal cancer. Mol. Syst. Biol. 10, 766 (2014).
Glassner, K. L., Abraham, B. P. & Quigley, E. M. M. The microbiome and inflammatory bowel disease. J. Allergy Clin. Immunol. 145, 16–27 (2020).
Chen, W., Liu, F., Ling, Z., Tong, X. & Xiang, C. Human intestinal lumen and mucosa-associated microbiota in patients with colorectal cancer. PLoS ONE 7, e39743 (2012).
Carabotti, M., Scirocco, A., Maselli, M. A. & Severi, C. The gut-brain axis: interactions between enteric microbiota, central and enteric nervous systems. Ann. Gastroenterol. Hepatol. 28, 203–209 (2015).
Helmink, B. A., Khan, M. A. W., Hermann, A., Gopalakrishnan, V. & Wargo, J. A. The microbiome, cancer, and cancer therapy. Nat. Med. 25, 377–388 (2019).
Ferreira, R. M. et al. Gastric microbial community profiling reveals a dysbiotic cancer-associated microbiota. Gut 67, 226–236 (2018).
Flemer, B. et al. The oral microbiota in colorectal cancer is distinctive and predictive. Gut 67, 1454–1463 (2018).
Kartal, E. et al. A faecal microbiota signature with high specificity for pancreatic cancer. Gut 71, 1359–1372 (2022).
Cancer Genome Atlas Research Network. The Cancer Genome Atlas Pan-Cancer analysis project. Nat. Genet. 45, 1113–1120 (2013).
Poore, G. D. et al. Microbiome analyses of blood and tissues suggest cancer diagnostic approach. Nature 579, 567–574 (2020).
Rodriguez, R. M., Hernandez, B. Y., Menor, M., Deng, Y. & Khadka, V. S. The landscape of bacterial presence in tumor and adjacent normal tissue across 9 major cancer types using TCGA exome sequencing. Comput. Struct. Biotechnol. J. 18, 631–641 (2020).
Geller, L. T. et al. Potential role of intratumor bacteria in mediating tumor resistance to the chemotherapeutic drug gemcitabine. Science 357, 1156–1160 (2017).
Matson, V. et al. The commensal microbiome is associated with anti–PD-1 efficacy in metastatic melanoma patients. Science 359, 104–108 (2018).
Routy, B. et al. Gut microbiome influences efficacy of PD-1–based immunotherapy against epithelial tumors. Science 359, 91–97 (2018).
Nichols, J. A., Herbert Chan, H. W. & Baker, M. A. B. Machine learning: applications of artificial intelligence to imaging and diagnosis. Biophys. Rev. 11, 111–118 (2019).
Miotto, R., Wang, F., Wang, S., Jiang, X. & Dudley, J. T. Deep learning for healthcare: review, opportunities and challenges. Brief. Bioinf. 19, 1236–1246 (2018).
Liu, W., Fang, X., Zhou, Y., Dou, L. & Dou, T. Machine learning-based investigation of the relationship between gut microbiome and obesity status. Microbes Infect. 24, 104892 (2022).
Radjabzadeh, D. et al. Gut microbiome-wide association study of depressive symptoms. Nat. Commun. 13, 7128 (2022).
Konishi, Y. et al. Development and evaluation of a colorectal cancer screening method using machine learning-based gut microbiota analysis. Cancer Med. 11, 3194–3206 (2022).
Shah, M. S. et al. Leveraging sequence-based faecal microbial community survey data to identify a composite biomarker for colorectal cancer. Gut 67, 882–891 (2018).
Zhou, Z. et al. Human gut microbiome-based knowledgebase as a biomarker screening tool to improve the predicted probability for colorectal cancer. Front. Microbiol. 11, 596027 (2020).
Hogan, G. et al. Biopsy bacterial signature can predict patient tissue malignancy. Sci. Rep. 11, 18535 (2021).
Li, X.et al. The machine-learning-mediated interface of microbiome and genetic risk stratification in neuroblastoma reveals molecular pathways related to patient survival. Cancers 14, 2874 (2022).
Liang, H. et al. Predicting cancer immunotherapy response from gut microbiomes using machine learning models. Oncotarget 13, 876–889 (2022).
Ma, Y. et al. Distinct tumor bacterial microbiome in lung adenocarcinomas manifested as radiological subsolid nodules. Transl. Oncol. 14, 101050 (2021).
Mao, X.-Y. et al. iCEMIGE: integration of CEll-morphometrics, MIcrobiome, and GEne biomarker signatures for risk stratification in breast cancers. World J. Clin. Oncol. 13, 616–629 (2022).
Montassier, E. et al. Pretreatment gut microbiome predicts chemotherapy-related bloodstream infection. Genome Med. 8, 49 (2016).
Zhou, Y.-H. & Gallins, P. A review and tutorial of machine learning methods for microbiome host trait prediction. Front. Genet. 10, 579 (2019).
Cheung, H. & Yu, J. Machine learning on microbiome research in gastrointestinal cancer. J. Gastroenterol. Hepatol. 36, 817–822 (2021).
Dohlman, A. B. et al. The cancer microbiome atlas: a pan-cancer comparative analysis to distinguish tissue-resident microbiota from contaminants. Cell Host Microbe 29, 281–298.e5 (2021).
Davis, N. M., Proctor, D. M., Holmes, S. P., Relman, D. A. & Callahan, B. J. Simple statistical identification and removal of contaminant sequences in marker-gene and metagenomics data. Microbiome 6, 226 (2018).
Noecker, C., McNally, C. P., Eng, A. & Borenstein, E. High-resolution characterization of the human microbiome. Transl. Res. 179, 7–23 (2017).
Pasolli, E., Truong, D. T., Malik, F., Waldron, L. & Segata, N. Machine learning meta-analysis of large metagenomic datasets: tools and biological insights. PLoS Comput. Biol. 12, e1004977 (2016).
Woerner, J. et al. Circulating microbial content in myeloid malignancy patients is associated with disease subtypes and patient outcomes. Nat. Commun. 13, 1038 (2022).
Yang, J. et al. Brain tumor diagnostic model and dietary effect based on extracellular vesicle microbiome data in serum. Exp. Mol. Med. 52, 1602–1613 (2020).
Miao, R. et al. Assessment of peritoneal microbial features and tumor marker levels as potential diagnostic tools for ovarian cancer. PLoS ONE 15, e0227707 (2020).
He, Y. et al. Stability of operational taxonomic units: an important but neglected property for analyzing microbial diversity. Microbiome 3, 20 (2015).
Breitwieser, F. P., Lu, J. & Salzberg, S. L. A review of methods and databases for metagenomic classification and assembly. Brief. Bioinform. 20, 1125–1136 (2019).
Lee, S. J. & Rho, M. Multimodal deep learning applied to classify healthy and disease states of human microbiome. Sci. Rep. 12, 824 (2022).
Zhao, D. et al. A reliable method for colorectal cancer prediction based on feature selection and support vector machine. Med. Biol. Eng. Comput. 57, 901–912 (2019).
Ling, W., Qi, Y., Hua, X. & Wu, M. C. Deep ensemble learning over the microbial phylogenetic tree (DeepEn-Phy). In 2021 IEEE International Conference on Bioinformatics and Biomedicine (IEEE, 2021).
Hastie, T., Tibshirani, R. & Friedman, J. H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction (Springer, 2009).
D’Elia, D.et al. Advancing microbiome research with machine learning: Key findings from the ML4Microbiome COST action. Front. Microbiol. 14, 1257002 (2023).
Corsini, N. & Viroli, C. Dealing with overdispersion in multivariate count data. Comput. Stat. Data Anal. 170, 107447 (2022).
Greenacre, M., Martínez-Álvaro, M. & Blasco, A. Compositional data analysis of microbiome and any-omics datasets: a validation of the additive logratio transformation. Front. Microbiol. 12, 727398 (2021).
Casimiro-Soriguer, C. S., Loucera, C., Peña-Chilet, M. & Dopazo, J. Towards a metagenomics machine learning interpretable model for understanding the transition from adenoma to colorectal cancer. Sci. Rep. 12, 450 (2022).
Ni, Y. et al. Distinct composition and metabolic functions of human gut microbiota are associated with cachexia in lung cancer patients. ISME J. 15, 3207–3220 (2021).
Han, S., Zhuang, J., Pan, Y., Wu, W. & Ding, K. Different characteristics in gut microbiome between advanced adenoma patients and colorectal cancer patients by metagenomic analysis. Microbiol. Spectr. 10, e01593–22 (2022).
Mulenga, M., Kareem, S. A., Sabri, A. Q. M. & Seera, M. Stacking and chaining of normalization methods in deep learning-based classification of colorectal cancer using gut microbiome data. IEEE Access 9, 97296–97319 (2021).
De Martin, A. et al. Distinct microbial communities colonize tonsillar squamous cell carcinoma. Oncoimmunology 10, 1945202 (2021).
Jiang, S. et al. HARMONIES: a hybrid approach for microbiome networks inference via exploiting sparsity. Front. Genet. 11, 445 (2020).
Singh, D. & Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 97, 105524 (2020).
Arabameri, A., Asemani, D. & Teymourpour, P. Detection of colorectal carcinoma based on microbiota analysis using generalized regression neural networks and nonlinear feature selection. IEEE/ACM Trans. Comput. Biol. Bioinform. 17, 547–557 (2020).
Weiss, S. et al. Normalization and microbial differential abundance strategies depend upon data characteristics. Microbiome 5, 27 (2017).
Mulenga, M. et al. Feature extension of gut microbiome data for deep neural network-based colorectal cancer classification. IEEE Access 9, 23565–23578 (2021).
Jović, A., Brkić, K. & Bogunović, N. A review of feature selection methods with applications. In 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), 1200–1205 (IEEE, 2015).
Nogales, R. E. & Benalcázar, M. E. Analysis and evaluation of feature selection and feature extraction methods. Int. J. Comput. Intell. Syst. 16, 153 (2023).
Miao, J. & Niu, L. A survey on feature selection. Proc. Comput. Sci. 91, 919–926 (2016).
Jaeger, J., Sengupta, R. & Ruzzo, W. L. Improved gene selection for classification of microarrays. In Pacific Symposium on Biocomputing 2003 (Lihue, 2003).
Ding, C. & Peng, H. Minimum redundancy feature selection from microarray gene expression data. J. Bioinform. Comput. Biol. 3, 185–205 (2005).
Chen, L. et al. Identifying robust microbiota signatures and interpretable rules to distinguish cancer subtypes. Front. Mol. Biosci. 7, 604794 (2020).
Jabeer, A. et al. Identifying taxonomic biomarkers of colorectal cancer in human intestinal microbiota using multiple feature selection methods. In 2022 Innovations in Intelligent Systems and Applications Conference (IEEE, 2022).
Yuan, B. et al. Fecal bacteria as non-invasive biomarkers for colorectal adenocarcinoma. Front. Oncol. 11, 664321 (2021).
Segata, N. et al. Metagenomic biomarker discovery and explanation. Genome Biol. 12, R60 (2011).
Menze, B. H. et al. A comparison of random forest and its Gini importance with standard chemometric methods for the feature selection and classification of spectral data. BMC Bioinform. 10, 213 (2009).
Venkatesh, B. & Anuradha, J. A review of Feature Selection and its methods. Cybern. Inf. Technol. 19, 3–26 (2019).
Theodoridis, S. Machine Learning: A Bayesian and Optimization Perspective (Academic Press, 2015).
Chen, F. et al. Meta-analysis of fecal viromes demonstrates high diagnostic potential of the gut viral signatures for colorectal cancer and adenoma risk assessment. J. Adv. Res. 49, 103–114 (2022).
Guyon, I., Weston, J., Barnhill, S. & Vapnik, V. Mach. Learn. 46, 389–422 (2002).
Hermida, L. C., Gertz, E. M. & Ruppin, E. Predicting cancer prognosis and drug response from the tumor microbiome. Nat. Commun. 13, 2896 (2022).
Senliol, B., Gulgezen, G., Yu, L. & Cataltepe, Z. Fast Correlation Based Filter (FCBF) with a different search strategy. In 2008 23rd International Symposium on Computer and Information Sciences (IEEE, 2008).
Bishop, C. M. Pattern Recognition and Machine Learning (Springer Verlag, 2006).
Zackular, J. P., Baxter, N. T., Chen, G. Y. & Schloss, P. D. Manipulation of the gut microbiota reveals role in colon tumorigenesis. mSphere 1, e00001–15 (2016).
Cortes, C. & Vapnik, V. Support-vector networks. Mach. Learn. 20, 273–297 (1995).
Noble, W. S. What is a support vector machine? Nat. Biotechnol. 24, 1565–1567 (2006).
Schuldt, C., Laptev, I. & Caputo, B. Recognizing human actions: a local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004 (IEEE, 2004).
Topçuoğlu, B. D., Lesniak, N. A., Ruffin 4th, M. T., Wiens, J. & Schloss, P. D. A framework for effective application of machine learning to microbiome-based classification problems. MBio 11, e00434–20 (2020).
Camps-Valls, G., Gomez-Chova, L., Munoz-Mari, J., Vila-Frances, J. & Calpe-Maravilla, J. Composite kernels for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 3, 93–97 (2006).
Rossi, M. et al. Gut microbial shifts indicate melanoma presence and bacterial interactions in a murine model. Diagnostics 12, 958 (2022).
Karamizadeh, S., Abdullah, S. M., Halimi, M., Shayan, J. & Rajabi, M. J. Advantage and drawback of support vector machine functionality. In 2014 International Conference on Computer, Communications, and Control Technology (IEEE, 2014).
Kishk, A.et al. A Hybrid Machine Learning Approach for the Phenotypic Classification of Metagenomic Colon Cancer Reads Based on Kmer Frequency and Biomarker Profiling. In 2018 9th Cairo International Biomedical Engineering Conference (IEEE, 2018).
Yang, M. et al. A multi-omics machine learning framework in predicting the survival of colorectal cancer patients. Comput. Biol. Med. 146, 105516 (2022).
Ashraf, F. B., Shafi, M. S. R. & Kabir, M. R. Host trait prediction from human microbiome data for Colorectal Cancer. In 2020 23rd International Conference on Computer and Information Technology (IEEE, 2020).
Dadkhah, E. et al. Gut microbiome identifies risk for colorectal polyps. BMJ Open Gastroenterol. 6, e000297 (2019).
Kotsiantis, S. B., Zaharakis, I. D. & Pintelas, P. E. Machine learning: a review of classification and combining techniques. Artif. Intell. Rev. 26, 159–190 (2006).
Warnke-Sommer, J. D. & Ali, H. H. Evaluation of the oral microbiome as a biomarker for early detection of human oral carcinomas. In 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), 2069–2076 (IEEE, 2017).
Kingsford, C. & Salzberg, S. L. What are decision trees? Nat. Biotechnol. 26, 1011–1013 (2008).
Kotsiantis, S. B. Decision trees: a recent overview. Artif. Intell. Rev. 39, 261–283 (2013).
Chen, X. & Ishwaran, H. Random forests for genomic data analysis. Genomics 99, 323–329 (2012).
Zhou, X. et al. The clinical potential of oral microbiota as a screening tool for oral squamous cell carcinomas. Front. Cell. Infect. Microbiol. 11, 728933 (2021).
Ferreira, A. J. & Figueiredo, M. A. T. Boosting algorithms: a review of methods, theory, and applications. In Ensemble Machine Learning, 35–85 (Springer US, 2012).
Podgorelec, V., Kokol, P., Stiglic, B. & Rozman, I. Decision trees: an overview and their use in medicine. J. Med. Syst. 26, 445–463 (2002).
Lou, Y., Caruana, R., Gehrke, J. & Hooker, G. Accurate intelligible models with pairwise interactions. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (ACM, 2013).
Hastie, T. & Tibshirani, R. Generalized Additive Models; Some Applications. J. Am. Stat. Assoc. 82 371–386 (1985).
Lou, Y., Caruana, R. & Gehrke, J. Intelligible models for classification and regression. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (ACM, 2012).
Maxwell, A. E., Sharma, M. & Donaldson, K. A. Explainable boosting machines for slope failure spatial predictive modeling. Remote Sens. 13, 4991 (2021).
Ranstam, J. & Cook, J. A. LASSO regression. Br. J. Surg. 105, 1348 (2018).
Ng, A. Y. Feature selection, L1 vs. L2 regularization, and rotational invariance. In Twenty-First International Conference on Machine Learning - ICML ’04 (ACM Press, 2004).
Friedman, J., Hastie, T. & Tibshirani, R. Regularization paths for generalized linear models via coordinate descent. J. Stat. Softw. 33, 1–22 (2010).
Kang, G.-U. et al. Dynamics of fecal microbiota with and without invasive cervical cancer and its application in early diagnosis. Cancers 12, 3800 (2020).
Goldberg, Y. A primer on neural network models for natural language processing. J. Artif. Intell. Res. 57, 345–420 (2016).
Goodfellow, I., Bengio, Y. & Courville, A.Deep Learning (MIT Press, 2016).
Mahmud, M., Kaiser, M. S., Hussain, A. & Vassanelli, S. Applications of deep learning and reinforcement learning to biological data. IEEE Trans Neural Netw Learn Syst 29, 2063–2079 (2018).
Alzubaidi, L. et al. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J Big Data 8, 53 (2021).
Reiman, D., Metwally, A. A., Sun, J. & Dai, Y. PopPhy-CNN: a phylogenetic tree embedded architecture for convolutional neural networks to predict host phenotype from metagenomic data. IEEE J. Biomed. Health Inf. 24, 2993–3001 (2020).
Specht, D. F. A general regression neural network. IEEE Trans. Neural Netw. 2, 568–576 (1991).
Hannan, S. A., Manza, R. R. & Ramteke, R. J. Generalized regression neural network and radial basis function for heart disease diagnosis. Int. J. Comput. Appl. 7, 7–13 (2010).
Al-Mahasneh, A. J., Anavatti, S. G. & Garratt, M. A. Review of applications of Generalized Regression Neural Networks in identification and control of dynamic systems. arXiv https://doi.org/10.48550/arXiv.1805.11236 (2018).
García-Jiménez, B., Muñoz, J., Cabello, S., Medina, J. & Wilkinson, M. D. Predicting microbiomes through a deep latent space. Bioinformatics 37, 1444–1451 (2021).
Oh, M. & Zhang, L. DeepMicro: deep representation learning for disease prediction based on microbiome data. Sci. Rep. 10, 1–9 (2020).
Shorten, C. & Khoshgoftaar, T. M. A survey on image data augmentation for deep learning. J. Big Data 6, 60 (2019).
Rosenblatt, M., Tejavibulya, L., Jiang, R., Noble, S. & Scheinost, D. Data leakage inflates prediction performance in connectome-based machine learning models. Nat. Commun. 15, 1829 (2024).
Refaeilzadeh, P., Tang, L. & Liu, H. Encyclopedia of Database Systems (eds. Liu, L. & Özsu, M. T.) 532–538 (Springer US, 2009).
Gihawi, A. et al. Major data analysis errors invalidate cancer microbiome findings. mBio 14, e01607–23 (2023).
Gihawi, A., Cooper, C. S. & Brewer, D. S. Caution regarding the specificities of pan-cancer microbial structure. Microb. Genomics 9, 001088 (2023).
Sepich-Poore, G. D.et al. Robustness of cancer microbiome signals over a broad range of methodological variation. Oncogene 43, 1127–1148 (2024).
Sepich-Poore, G. D. et al. Reply to: caution regarding the specificities of pan-cancer microbial structure. Preprint at: https://www.biorxiv.org/content/10.1101/2023.02.10.528049v1 (2023).
Gaulke, C. A. & Sharpton, T. J. The influence of ethnicity and geography on human gut microbiome composition. Nature Medicine 24, 1495–1496 (2018).
Leinonen, R., Sugawara, H., Shumway, M. & on behalf of the International Nucleotide Sequence Database Collaboration. The sequence read archive. Nucleic Acids Res. 39, D19–D21 (2011).
Yelmen, B. & Jay, F. An overview of deep generative models in functional and evolutionary genomics. Annu. Rev. Biomed. Data Sci. 6 173–189 (2023).
Yelmen, B. et al. Creating artificial human genomes using generative neural networks. PLOS Genet. 17, e1009303 (2021).
Cavadas, B. et al. Gastric microbiome diversities in gastric cancer patients from europe and asia mimic the human population structure and are partly driven by microbiome quantitative trait loci. Microorganisms 8, 1196 (2020).
Lauss, M. et al. Monitoring of technical variation in quantitative high-throughput datasets. Cancer Inf. 12, 193–201 (2013).
Rasnic, R., Brandes, N., Zuk, O. & Linial, M. Substantial batch effects in TCGA exome sequences undermine pan-cancer analysis of germline variants. BMC Cancer 19, 783 (2019).
Ribeiro, M. T., Singh, S. & Guestrin, C. "Why Should I Trust You?”: Explaining the predictions of any classifier. arXiv https://doi.org/10.48550/arXiv.1602.04938 (2016).
Lundberg, S. & Lee, S.-I. A unified approach to interpreting model predictions. arXiv https://doi.org/10.48550/arXiv.1705.07874 (2017).
Shrikumar, A., Greenside, P. & Kundaje, A. Learning important features through propagating activation differences. arXiv https://doi.org/10.48550/arXiv.1704.02685 (2019).
Japkowicz, N. Imbalanced Learning, 187–206 (John Wiley & Sons, Inc., 2013).
Vaswani, A. et al. Attention is all you need. arXiv https://doi.org/10.48550/arXiv.1706.03762 (2017).
Feng, C. et al. A deep-learning model with the attention mechanism could rigorously predict survivals in neuroblastoma. Front. Oncol. 11, 653863 (2021).
Lin, M. et al. Application of Deep Learning on predicting prognosis of acute myeloid leukemia with cytogenetics, age, and mutations. arXiv https://doi.org/10.48550/arXiv.1810.13247 (2018).
Larsson, S. C., Orsini, N. & Wolk, A. Diabetes mellitus and risk of colorectal cancer: a meta-analysis. J. Natl. Cancer Inst. 97, 1679–1687 (2005).
Tsilidis, K. K., Kasimis, J. C., Lopez, D. S., Ntzani, E. E. & Ioannidis, J. P. A. Type 2 diabetes and cancer: Umbrella review of meta-analyses of observational studies. BMJ 350, g7607–g7607 (2015).
Li, W.-Z., Stirling, K., Yang, J.-J. & Zhang, L. Gut microbiota and diabetes: from correlation to causality and mechanism. World J. Diabetes 11, 293–308 (2020).
Wensel, C. R., Pluznick, J. L., Salzberg, S. L. & Sears, C. L. Next-generation sequencing: Insights to advance clinical investigations of the microbiome. J. Clin. Investig. 132, e154944 (2022).
Satam, H. et al. Next-generation sequencing technology: current trends and advancements. Biology 12, 997 (2023).
Kong, S. et al. Deep hurdle networks for zero-inflated multi-target regression: application to multiple species abundance estimation. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI’20 (2021).
Lu, Y. & Liao, Y. STS: A novel deep learning method for zero-inflated crime prediction. In Proceedings of the 2022 4th International Conference on Robotics, Intelligent Control and Artificial Intelligence, RICAI ’22, 1097–1103 (Association for Computing Machinery, 2023).
Wei, M., Liu, R., Wang, Y. J. & Huang, C. SoutheastCon 2023, 901–905 (IEEE, 2023).
Osawa, T., Mitsuhashi, H., Uematsu, Y. & Ushimaru, A. Bagging GLM: improved generalized linear model for the analysis of zero-inflated data. Ecol. Inf. 6, 270–275 (2011).
Liu, B., Chau, J., Dai, Q., Zhong, C. & Zhang, J. Exploring gut microbiome in predicting the efficacy of immunotherapy in non-small cell lung cancer. Cancers 14, 5401 (2022).
Heshiki, Y. et al. Predictable modulation of cancer treatment outcomes by the gut microbiota. Microbiome 8, 28 (2020).
Stein-Thoeringer, C. K. et al. A non-antibiotic-disrupted gut microbiome is associated with clinical responses to CD19-CAR-T cell cancer immunotherapy. Nat. Med. 29, 906–916 (2023).
Shamszare, H. & Choudhury, A. Clinicians’ perceptions of artificial intelligence: focus on workload, risk, trust, clinical decision making, and clinical integration. Healthcare 11, 2308 (2023).
Doherty, M., Metcalfe, T., Guardino, E., Peters, E. & Ramage, L. Precision medicine and oncology: an overview of the opportunities presented by next-generation sequencing and big data and the challenges posed to conventional drug development and regulatory approval pathways. Ann. Oncol. 27, 1644–1646 (2016).
Qu, K., Gao, F., Guo, F. & Zou, Q. Taxonomy dimension reduction for colorectal cancer prediction. Comput. Biol. Chem. 83, 107160 (2019).
Zheng, Y. et al. Specific gut microbiome signature predicts the early-stage lung cancer. Gut Microbes 11, 1030–1042 (2020).
Chen, M. et al. Carcinogenesis of male oral submucous fibrosis alters salivary microbiomes. J. Dent. Res. 100, 397–405 (2021).
Chen, J.-W. et al. Taxonomic and functional dysregulation in salivary microbiomes during oral carcinogenesis. Front. Cell. Infect. Microbiol. 11, 663068 (2021).
Shrode, R. L. et al. Breast cancer patients from the Midwest region of the United States have reduced levels of short-chain fatty acid-producing gut bacteria. Sci. Rep. 13, 526 (2023).
Wang, N. et al. Identifying distinctive tissue and fecal microbial signatures and the tumor-promoting effects of deoxycholic acid on breast cancer. Front. Cell. Infect. Microbiol. 12, 1029905 (2022).
An, J. et al. Prediction of breast cancer using blood microbiome and identification of foods for breast cancer prevention. Sci. Rep. 13, 5110 (2023).
Uzelac, M., Li, Y., Chakladar, J., Li, W. T. & Ongkeko, W. M. Archaea microbiome dysregulated genes and pathways as molecular targets for lung adenocarcinoma and squamous cell carcinoma. Int. J. Mol. Sci. 23, 11566 (2022).
Banavar, G. et al. The salivary metatranscriptome as an accurate diagnostic indicator of oral cancer. npj Genom. Med. 6, 105 (2021).
Bukavina, L. et al. Global meta-analysis of urine microbiome: colonization of polycyclic aromatic hydrocarbon–degrading bacteria among bladder cancer patients. Eur. Urol. Oncol. 6, 190–203 (2023).
Bang, S. et al. Establishment and evaluation of prediction model for multiple disease classification based on gut microbial data. Sci. Rep. 9, 10189 (2019).
Su, Q. et al. Faecal microbiome-based machine learning for multi-class disease diagnosis. Nat. Commun. 13, 6818 (2022).
Wickramaratne, D., Wijesinghe, R. & Weerasinghe, R. Human gut microbiome data analysis for disease likelihood prediction using autoencoders. In 2021 21st International Conference on Advances in ICT for Emerging Regions (ICter), 49–54 (IEEE, 2021).
Jiang, P., Lai, S., Wu, S., Zhao, X.-M. & Chen, W.-H. Host DNA contents in fecal metagenomics as a biomarker for intestinal diseases and effective treatment. BMC Genomics 21, 348 (2020).
Jiang, P., Wu, S., Luo, Q., Zhao, X.-m & Chen, W.-H. Metagenomic analysis of common intestinal diseases reveals relationships among microbial signatures and powers multidisease diagnostic models. mSystems 6, e00112–21 (2021).
McDowell, A. et al. Machine-learning algorithms for asthma, COPD, and lung cancer risk assessment using circulating microbial extracellular vesicle data and their application to assess dietary effects. Exp. Mol. Med. 54, 1586–1595 (2022).
Acknowledgements
This work was supported by the Fundação para a Ciência e a Tecnologia (FCT) through national funds: project reference PTDC/BTM-TEC/0367/2021, and grants 2021.05767.BD (F. Silva) and CEECIND/01854/2017 (R.M.F.).
Author information
Authors and Affiliations
Contributions
H.P.O., T.P., R.M.F., and C.F. conceived and designed the study. M.T. performed data curation and analysis. F.S., R.M.F., and C.F. provided technical and biological insights. All authors contributed to the discussion. M.T., R.M.F., and C.F. wrote the manuscript. All authors have read and agreed to the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
R.M.F. and C.F. own patent WO/2018/169423 on microbiome markers for gastric cancer. The remaining authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Teixeira, M., Silva, F., Ferreira, R.M. et al. A review of machine learning methods for cancer characterization from microbiome data. npj Precis. Onc. 8, 123 (2024). https://doi.org/10.1038/s41698-024-00617-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41698-024-00617-7
- Springer Nature Limited