
Abstract
With the ongoing challenge of air pollution posing serious health and environmental threats, particularly in rapidly industrializing regions, accurate forecasting and effective pollutant identification are crucial for enhancing public health and ecological stability. This study aimed to optimize air quality management through the prediction of the Air Quality Index (AQI) and identification of air pollutants. Our study spans nine representative cities (Hohhot, Yinchuan, Lanzhou, Beijing, Taiyuan, Xi’an, Shanghai, Nanjing, Wuhan) in China, with data collected from January 1, 2015, to November 30, 2021. We proposed a new model for daily AQI prediction, termed VMD-CSA-CNN-LSTM, which employed advanced machine learning techniques, including convolutional neural networks (CNN) and long short-term memory (LSTM) networks, and leveraged the chameleon swarm algorithm (CSA) for hyperparameter optimization, integrated through a variational mode decomposition approach. The model was developed using data from Lanzhou, with a split ratio of 8:1:1 into training, validation, and test sets, achieving an RMSE of 2.25, MAPE of 0.02, adjusted R-squared of 98.91%, and training efficiency of 5.31%. The model was further externally validated in the other eight cities, yielding comparable results, with an adjusted R-squared above 96%, MAPE below 0.1, and RMSE below 7.5. Additionally, we employed a random forest algorithm to identify the primary pollutants contributing to AQI levels. Our results indicated that PM2.5 was the most significant pollutant in Beijing, Taiyuan, and Xi’an, while PM10 was dominant in Hohhot, Yinchuan, and Lanzhou. In Shanghai, Nanjing, and Wuhan, both PM2.5 and PM10 were critical, with ozone also identified as a major air pollutant. This study not only advances the predictive accuracy of AQI models but also aids policymakers by providing a reliable tool for air quality management and strategic planning aimed at pollution reduction. The integration of these advanced computational techniques into environmental monitoring practices offers a promising avenue for enhancing air quality and mitigating pollution-related risks.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
Air pollution poses a significant and ongoing threat to human health and ecological stability. Extreme weather events such as dust storms, high ozone concentrations, and haze adversely affect human, animal, and plant life1. According to the World Health Organization (WHO), global populations are frequently exposed to air quality levels that exceed WHO guidelines, particularly in developing countries2. This issue is especially severe in nations like China, India, and Mongolia, where recent years have seen a substantial deterioration in the air quality index (AQI)3. This decline has led to frequent sandstorms, haze, and elevated ozone concentrations. Prolonged exposure to such conditions can result in respiratory ailments, including coughing, chest tightness, lung cancer, and other diseases4. Additionally, air pollution significantly disrupts plant growth and the delicate balance between terrestrial and aquatic ecosystems5,6. Given these impacts, it is crucial for governments to enhance air quality management. However, the primary challenges include accurately forecasting future AQI and identifying regional air pollutants.
Traditional AQI prediction models, which rely on physical and chemical methodologies such as the weather research and forecasting model (WRF), master chemical mechanism, community multiscale air quality modelling system (CMAQ), and meso-scale model, have shown limited fitting capabilities7. Integrated models like WRF-CMAQ8 aimed to address these shortcomings, but uncertainties in meteorological fields and emission inventories remain challenges for these models. Currently, AQI prediction models based on artificial intelligence can be broadly categorized into two types: regression models and time-series models. Liu et al. proposed an improved extreme learning machine based on a genetic algorithm for predicting AQI9. Wu et al. employed a combination of random forest and maximum relevance minimum redundancy to identify key features influencing AQI, and subsequently developed a long short-term memory (LSTM) model optimized by an improved squirrel search algorithm for AQI prediction10. Although these multiple regression models, which leveraged various indicators affecting AQI, demonstrated strong performance, they were costly and lacked timeliness.
Autoregressive integrated moving average (ARIMA)11 and grey modelling12 represent traditional time-series approaches but suffer from issues such as lag and poor fitting. In contrast, deep learning algorithms, with their robust computational capabilities, address the underfitting problems inherent in traditional models13. Zhang et al. proposed a model based on convolutional neural network and long short-term memory (CNN-LSTM) to predict the AQI in Beijing14. In this model, the CNN component primarily extracted time series features, which were then transmitted to the LSTM component. Similarly, Duan et al. combined the ARIMA model to predict the linear components of the AQI with a CNN-LSTM model to address the non-linear components, optimizing parameters using the dung beetle optimizer algorithm15. Combined deep learning models demonstrated improved goodness-of-fit and reduced lag compared to traditional models and single deep learning models.
Time-series decomposition further enhanced model performance, and finding the optimal number of modes was crucial for maximizing the benefits of decomposition approaches. The empirical wavelet transform technique analysed signals by decomposing them into different frequency wavelet basis functions; however, an improper number of modes could result in unexpected errors16. Ensemble empirical mode decomposition (EEMD) improved noise suppression by introducing random perturbations, yet faced challenges such as mode aliasing and end effects, which reduced its effectiveness17. Ji et al. employed complete EEMD with adaptive noise and sample entropy techniques to decompose and reconstruct the AQI18. In their approach, high-frequency components were predicted using LSTM, while low-frequency components were learned using a regularized extreme learning machine. Singular spectrum analysis (SSA), a sequence decomposition method based on power reconstruction of time series, also encountered issues of over-decomposition and end effects19. Zhang et al. used SSA to decompose the hourly AQI and predicted the SSA-decomposed signals using a Bi-Directional Long Short-Term Memory (BiLSTM) network and a Light Gradient-Boosting Machine (LightGBM). Their results showed that the SSA-BiLSTM-LightGBM model performed well in predicting the hourly AQI20. Wang et al. enhanced the adaptive multi-scale SSA (AMSSA) to determine the number of modes in variational mode decomposition (VMD) and optimized LSTM model parameters using the sparrow search algorithm, demonstrating superior fitting and generalization ability compared to other models21.
In recent years, aerosol particulate matter has significantly impacted urban air quality, particularly those pollutants with small particle sizes that pose high health risks. However, relying solely on the AQI is insufficient for accurately identifying the sources of regional pollutants, which is crucial for improving air quality and formulating related policies. Nurshad et al. demonstrated a strong association between air pollution and major public events and confirmed that prolonged exposure to outdoor air increases the risk of COVID-1922. Wenming et al. found that pregnant women exposed to elevated levels of PM2.5, PM10, and NO2 have an increased likelihood of experiencing preterm births, both naturally and in patients undergoing in vitro fertilization23.
This study aimed to establish an AQI prediction model by investigating time-series air quality data and identify the characteristics of air pollutants in representative cities in China to offer recommendations for future improvements in air quality and support governmental decision-making.
Methods
Data source
The AQI and pollutant concentration data used in this study were obtained from the China National Environmental Monitoring Centre (CNEMC), covering the period from January 1, 2015, to November 30, 2021 (a total of 2524 days). CNEMC is an authority agency that provides comprehensive monitoring data on six key pollutants: fine particulate matter (PM2.5), respirable particulate matter (PM10), nitrogen dioxide (NO2), sulphur dioxide (SO2), ozone (O3), and carbon monoxide (CO). The measurements were conducted following the international standards outlined in GB3095-2012. Various analytical methods were employed: β ray absorption for particulate matter, fluorescence for SO2, chemiluminescence for NO2, non-dispersive infrared absorption for CO, and ultraviolet absorption for O3. Data collection adhered to the Technical Guidelines for Environmental Testing Quality Management (HJ630-2013) and the Ambient Air Quality Data Standard (GB3095-2012).
Study design
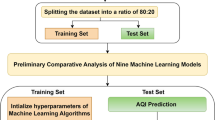
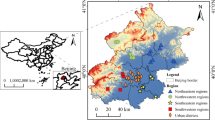
The framework of this study was illustrated in Fig. 1. We selected nine cities as representative samples (Part A). Six cities (Hohhot, Yinchuan, Lanzhou, Beijing, Taiyuan, and Xi’an) were chosen for their even and symmetrical distribution (vertical distance) along the Heihe-Tengchong line, a significant demarcation line in China based on population density. Additionally, we selected three economic centres (Shanghai, Nanjing, Wuhan) in the Yangtze River Basin region due to their high levels of economic development, industrial strength, technological advancement, and presence of numerous high-tech enterprises. For data processing (Part B), we used the Isolation Forest algorithm to detect outliers in the air quality data and applied cubic spline interpolation to impute missing values. We then proposed an ensemble model (VMD-CSA-CNN-LSTM) for time series forecasting of daily AQI (Part C). CNN-LSTM was the model architecture, and the chameleon swarm algorithm (CSA) was utilized to optimize the hyperparameters of our models. To extract time-series features of the daily AQI, we employed EEMD and VMD. An enumeration method was used to determine the optimal number of modes for VMD within the range of 1 to 10, and this optimal value was validated through Pearson correlation coefficient (PCC) test. Detailed information on the algorithms was provided in the supplementary material. The AQI prediction model was developed based on AQI data from Lanzhou. The dataset was divided into training, validation, and test sets in a ratio of 8:1:1. The remaining eight cities served as external validation sets. Evaluation metrics included adjusted R-squared, root mean square error (RMSE), mean absolute percentage error (MAPE), and training efficiency (calculated as the adjusted R-squared divided by the training time). Finally, we developed a comprehensive model based on the random forest algorithm to assess the feature importance of air pollutants in each city (Part D).

Framework of this study.
Results
Study area
We selected nine representative cities in China to encompass a wide range of urban profiles, considering their diverse climatic, economic, and demographic characteristics (Table 1). Lanzhou and Yinchuan, both with temperate continental climates, cover 16,410.54 km2 and 9025.38 km2, respectively. Hohhot, with a medium-temperate continental monsoon climate, spans 17,200 km2. Xi’an and Taiyuan, featuring temperate monsoon climates, cover 10,752 km2 and 6988 km2, respectively. Beijing, characterized by a warm temperate semi-humid and semi-arid monsoon climate, spans 13,100 km2. Wuhan, Nanjing, and Shanghai, with subtropical monsoon climates, cover 8569.15 km2, 6587.02 km2, and 6340.5 km2, respectively, with Shanghai having a subtropical oceanic monsoon climate. The GDP of these cities varies significantly, ranging from 47,200 billion Chinese Yuan of Shanghai and 43,800 billion of Beijing to 3477 billion of Lanzhou and 2685.6 billion of Yinchuan. Population figures also show substantial variation, with Shanghai hosting 24.75 million residents, Beijing 21.84 million, and Wuhan 13.74 million. Xi’an, Nanjing, Taiyuan, Hohhot, Lanzhou, and Yinchuan have populations of 12.996 million, 9.491 million, 5.435 million, 3.551 million, 4.415 million, and 2.897 million, respectively.
Air quality index prediction model
The CSA algorithm was employed to optimize key parameters of the LSTM and CNN-LSTM architectures over 350 iterations, where the Adam optimization algorithm was used for gradient optimization, and RMSE was adopted as the loss function. The optimized hyperparameters are presented in Table 2. To determine the optimal number of components in the modal decomposition by VMD, experiments were conducted within the range of 1–10. Our findings revealed that the CSA-optimized CNN-LSTM model exhibited superior accuracy when the VMD modal parameter (k) was set to 9. The extracted time series and original values are shown in Fig. 2. All PCC between the modal components derived from VMD and the original data surpassed 0.2 (Fig. 3). The VMD(9)-CNN-LSTM and VMD(9)-CSA-CNN-LSTM models demonstrated superior performance compared to other models, with a visually better agreement between predicted and actual values (Fig. 4). Evaluation metrics also indicated that these two models outperformed the others (Fig. 5). Specifically, the VMD(9)-CSA-CNN-LSTM model achieved the lowest RMSE of 2.25, MAPE of 0.02, the highest adjusted R-squared of 98.91%, and the highest training efficiency of 5.31% (Table 3). In contrast, the LSTM model had the highest RMSE (18.40) and MAPE (0.22), with an adjusted R-squared of only 22.76%. Time-series predictions from each model on the test set are shown in Fig. 6. In the external validation set, which included data from eight representative cities, the model performance varied across locations but remained comparable to the test set results (Table 4). Adjusted R-squared values were high across all cities, ranging from 96.04 to 98.31%. Hohhot achieved the lowest RMSE of 3.82 and a MAPE of 0.05, while Xi’an had the highest RMSE of 7.42 and MAPE of 0.10.

Modal components of air quality index (AQI) by VMD. AQI = air quality index; VMD = variational mode decomposition; IMF = intrinsic mode function.

Pearson correlation coefficient (PCC) between the original value of air quality index (AQI) and modal components by variational mode decomposition (VMD). IMF: intrinsic mode function.

Calibration plots of prediction models on the test set.

Model performance of prediction models on the test set in terms of adjusted R-squared, mean absolute percentage error (MAPE), and root mean square error (RMSE).

Predicted values from prediction models and actual values on the test set.
Air pollutants identification
The characteristics of air pollutants varied across different cities (Fig. 7). PM2.5 emerged as the most significant air pollutant in Beijing, Taiyuan, and Xi’an, with a percent increase in mean square error exceeding 0.7. Similarly, PM10 was the dominant air pollutant in Hohhot, Yinchuan, and Lanzhou, showing almost three times the percent increase in mean square error compared to the second most dominant air pollutant. In Shanghai, Nanjing, and Wuhan, PM2.5 and PM10 were critical pollutants; however, O3 was also identified as a major comparable air pollutant.

Percent increase in the mean squared error of air pollutants in nine representative cities in China.
Discussion
Accurate prediction of the AQI is crucial for improving human health and developing effective air quality management policies24. Traditional time series methods for AQI prediction have faced challenges such as lag and underfitting. In contrast, deep learning architectures like CNN and LSTM networks have shown superior performance in time-series predictions. The fusion of CNN and LSTM models effectively captures local patterns and features in temporal data, offering significant advantages over using only LSTM networks. In this study, we developed a VMD-CSA-CNN-LSTM prediction model. This model was trained and tested using data from Lanzhou, demonstrating good performance with low RMSE and MAPE, high adjusted R-squared, and training efficiency. The model was further validated with data from eight additional cities, confirming its effectiveness in AQI prediction.
The regional atmospheric environment is a complex system characterized by multi-scale and multi-factor interactions25. To comprehensively understand the factors influencing the AQI, this study used the random forest algorithm to investigate various influencing factors and dominant sources of regional air pollutants. AQI at a given moment is determined by the air pollutant with the highest individual AQI (IAQI). The overall contribution of air pollutants to AQI over an extended period may be assessed by the frequency with which each pollutant records the highest IAQI. However, this method, while straightforward, only accounts for the frequency of the highest IAQI values and not their magnitudes. Our approach addresses this limitation by capturing the severity and duration of high pollution events. The findings revealed the significant influence of PM10 on the AQI in Lanzhou, Yinchuan, and Hohhot. High levels of PM10 in these regions were primarily attributed to seasonal dust storms, buoyancy effects, and residential coal burning during winter. The weakening of atmospheric circulation due to global warming has resulted in longer retention times for PM10 particles smaller than 10 µm, reducing pollutant dispersion. Conversely, cities such as Xi’an, Taiyuan, and Beijing, located near the Heihe-Tengchong Line, experience a notable impact on the AQI due to elevated levels of PM2.5, primarily from excessive energy consumption. In addition to PM2.5 and PM10, Wuhan, Nanjing, and Shanghai exhibit significant ozone levels affecting AQI. High ozone levels in these regions were attributed to minimal cloud cover, intense solar radiation, and frequent westerly winds. Furthermore, near-surface pollutants showed a strong correlation with atmospheric particulate matter concentration. Therefore, governments in these areas are recommended to continue managing atmospheric particulate matter while prioritizing the reduction of O3 pollution through intensified reductions in NOx and VOCs. In summary, region-specific air quality management policies are essential to improve overall air quality, which should target the primary air pollutants in each region, such as PM10, O3, and PM2.5, by reducing their sources and enhancing pollutant dispersion measures.
Despite its strengths and significant implications, this study has several limitations. First, AQI is influenced by numerous factors that should be incorporated into the modelling analysis to provide a more comprehensive understanding of the AQI. Additionally, migration learning models may be further explored to enhance the predictive capabilities of the developed model. Second, our study is constrained by data availability, restricting the analysis to a limited number of areas for air pollutants and pollution source identification. Future research should expand the scope to include a broader range of areas to achieve more comprehensive pollution source identification. This expansion would facilitate the development of refined management strategies for mitigating pollution and improving air quality. Moreover, is oversimplified. As mentioned, it was determined by the individual air pollutatnt that gives the highest AQI. It may not tell the actual air situation for the general public. The determination of AQI should be carefully examined while refining the policy. Moreover, the current practice of determing AQI is oversimplified, as it relies solely on the individual air pollutant with the highest AQI. This approach may not accurately reflect the overall air quality situation for the general public. Therefore, the method for determining AQI should be carefully examined and refined in future policy development.
Conclusion
Our study successfully developed an advanced AQI prediction model, VMD-CSA-CNN-LSTM, demonstrating high accuracy and robustness across nine representative cities in China. By leveraging advanced machine learning techniques, we improved AQI forecasting and identified air pollutants, providing a valuable tool for policymakers to enhance air quality management and develop targeted strategies for reducing pollution and improving public health.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Yan, M. & Li, T. A review of the interactive effects of climate and air pollution on human health in China. Curr. Environ. Health Rep. https://doi.org/10.1007/s40572-024-00432-z (2024).
Hoffmann, B. et al. WHO air quality guidelines 2021-aiming for healthier air for all: A joint statement by medical, public health, scientific societies and patient representative organisations. Int. J. Public Health 66, 4. https://doi.org/10.3389/ijph.2021.1604465 (2021).
Faiz, A. Automotive emissions in developing countriesrelative implications for global warming, acidification and urban air quality. Transp. Res. A, Policy Pract. 27, 167–186. https://doi.org/10.1016/0965-8564(93)90057-r (1993).
Junlapeeya, P., Lorga, T., Santiprasitkul, S. & Tonkuriman, A. A descriptive qualitative study of older persons and family experiences with extreme weather conditions in Northern Thailand. Int. J. Environ. Res. Public Health 20, 1445. https://doi.org/10.3390/ijerph20126167 (2023).
Middleton, J. T. & Darley, E. F. Plant damage: an indicator of the presence and distribution of air pollution. Bull. World Health Organ. 34, 477–480 (1966).
Samanta, A., Chatterjee, A. & Singh, M. K. Impact of air pollution on groundwater contamination through water reservoir. Geosyst. Eng. https://doi.org/10.1080/12269328.2023.2187888 (2023).
Koo, Y. S., Kim, S. T., Cho, J. S. & Jang, Y. K. Performance evaluation of the updated air quality forecasting system for Seoul predicting PM10. Atmos. Environ. 58, 56–69. https://doi.org/10.1016/j.atmosenv.2012.02.004 (2012).
Guo, Y. R., Zhu, T. T., Li, Z. Y. & Ni, C. Auto-modal: Air-quality index forecasting with modal decomposition attention. Sensors 22, 13. https://doi.org/10.3390/s22186953 (2022).
Liu, C., Pan, G., Song, D. & Wei, H. Air quality index forecasting via genetic algorithm-based improved extreme learning machine. IEEE Access 11, 67086–67097. https://doi.org/10.1109/access.2023.3291146 (2023).
Wu, H., Yang, T., Li, H. & Zhou, Z. Air quality prediction model based on mRMR-RF feature selection and ISSA-LSTM. Sci. Rep. 13, 12825. https://doi.org/10.1038/s41598-023-39838-4 (2023).
Liu, T. & You, S. Analysis and forecast of Beijing’s air quality index based on ARIMA model and neural network model. Atmosphere https://doi.org/10.3390/atmos13040512 (2022).
Xiong, P. P., Yan, W. J., Wang, G. Z. & Pei, L. L. Grey extended prediction model based on IRLS and its application on smog pollution. Appl. Soft. Comput. 80, 797–809. https://doi.org/10.1016/j.asoc.2019.04.035 (2019).
Han, Z. Y., Zhao, J., Leung, H., Ma, A. & Wang, W. A review of deep learning models for time series prediction. IEEE Sens. J. 21, 7833–7848. https://doi.org/10.1109/jsen.2019.2923982 (2021).
Zhang, J. X. & Li, S. Y. Air quality index forecast in Beijing based on CNN-LSTM multi-model. Chemosphere 308, 7. https://doi.org/10.1016/j.chemosphere.2022.136180 (2022).
Duan, J., Gong, Y., Luo, J. & Zhao, Z. Air-quality prediction based on the ARIMA-CNN-LSTM combination model optimized by dung beetle optimizer. Sci. Rep. 13, 12127. https://doi.org/10.1038/s41598-023-36620-4 (2023).
Luo, Z., Liu, T., Yan, S. & Qian, M. Revised empirical wavelet transform based on auto-regressive power spectrum and its application to the mode decomposition of deployable structure. J. Sound Vib. 431, 70–87. https://doi.org/10.1016/j.jsv.2018.06.001 (2018).
Meijun, Z., Hao, C., Chuang, W. & Qing, C. Threshold noise reduction research of improved EEMD method. Appl. Mech. Mater. 226–228, 237–240. https://doi.org/10.4028/www.scientific.net/AMM.226-228.237 (2012).
Ji, C. L. et al. A multi-scale evolutionary deep learning model based on CEEMDAN, improved whale optimization algorithm, regularized extreme learning machine and LSTM for AQI prediction. Environ. Res. 215, 14. https://doi.org/10.1016/j.envres.2022.114228 (2022).
Moskvina, V. & Schmidt, K. M. Approximate projectors in singular spectrum analysis. SIAM J. Matrix Anal. Appl. 24, 932–942. https://doi.org/10.1137/s0895479801398967 (2003).
Zhang, X., Jiang, X. & Li, Y. Prediction of air quality index based on the SSA-BiLSTM-LightGBM model. Sci. Rep. 13, 5550. https://doi.org/10.1038/s41598-023-32775-2 (2023).
Wang, K., Fan, X., Yang, X. & Zhou, Z. An AQI decomposition ensemble model based on SSA-LSTM using improved AMSSA-VMD decomposition reconstruction technique. Environ. Res. 232, 116365. https://doi.org/10.1016/j.envres.2023.116365 (2023).
Ali, N. & Islam, F. The effects of air pollution on COVID-19 infection and mortality-a review on recent evidence. Front. Public Health 8, 7. https://doi.org/10.3389/fpubh.2020.580057 (2020).
Shi, W. et al. Association Between ambient air pollutants exposure and preterm birth in women who underwent in vitro fertilization: A retrospective cohort study from Hangzhou, China. Front. Med. (Lausanne) 8, 7856. https://doi.org/10.3389/fmed.2021.785600 (2021).
Guo, Z. D. & Zhang, X. N. Has the healthy city pilot policy improved urban air quality in China? Evidence from a quasi-natural experiment. Energy Econ. 129, 14. https://doi.org/10.1016/j.eneco.2023.107260 (2024).
Guo, Q., Wang, J. Y., Yin, H. L. & Zhang, G. A comprehensive evaluation model of regional atmospheric environment carrying capacity: Model development and a case study in China. Ecol. Indic. 91, 259–267. https://doi.org/10.1016/j.ecolind.2018.03.059 (2018).
Funding
The research was financially supported by the National Natural Science Foundation of China (21677001, 51978003), the major science and technology project of Anhui Province (201903a06020034, 17030801028), the State Key Laboratory of Cryospheric Science, Chinese Academy of Sciences (SKLCS-ZZ-2024), the Natural Science Foundation of Anhui Provincial Education Department (2023AH053239, 2022AH052481, 2022AH052463), and the Anhui Provincial Natural Science Foundation for youth projects (1908085QE241).
Author information
Authors and Affiliations
Contributions
Data curation: Zhilong Guo, Xiangnan Jing, Yuewei Ling; Writing original draft: Zhilong Guo, Xiangnan Jing; Conceptualization: Zhilong Guo, Xiangnan Jing, Yuewei Ling; Methodology: Xiangnan Jing, Yuewei Ling; Visualization: Xiangnan Jing, Yuewei Ling; Review & Editing: Yuewei Ling, Ying Yang, Nan Jing, Rui Yuan, Yixin Liu. All authors reviewed the manuscript, and accepted responsibility to submit for publication.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Guo, Z., Jing, X., Ling, Y. et al. Optimized air quality management based on air quality index prediction and air pollutants identification in representative cities in China. Sci Rep 14, 17923 (2024). https://doi.org/10.1038/s41598-024-68972-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-68972-w
- Springer Nature Limited