
Abstract
Individual-based models of infectious disease dynamics commonly use network structures to represent human interactions. Network structures can vary in complexity, from single-layered with homogeneous mixing to multi-layered with clustering and layer-specific contact weights. Here we assessed policy-relevant consequences of network choice by simulating different network structures within an established individual-based model of SARS-CoV-2 dynamics. We determined the clustering coefficient of each network structure and compared this to several epidemiological outcomes, such as cumulative and peak infections. High-clustered networks estimate fewer cumulative infections and peak infections than less-clustered networks when transmission probabilities are equal. However, by altering transmission probabilities, we find that high-clustered networks can essentially recover the dynamics of low-clustered networks. We further assessed the effect of workplace closures as a layer-targeted intervention on epidemiological outcomes and found in this scenario a single-layered network provides a sufficient approximation of intervention effect relative to a multi-layered network when layer-specific contact weightings are equal. Overall, network structure choice within models should consider the knowledge of contact weights in different environments and pathogen mode of transmission to avoid over- or under-estimating disease burden and impact of interventions.
Similar content being viewed by others


Introduction
Individual-based models (IBMs) have become increasingly popular in modelling the dynamics of infectious diseases. Such models are preferred over compartmental models such as the Susceptible-Infectious-Recovered (SIR) model proposed by Kermack and McKendrick1 when heterogeneity is necessary to capture individual interactions, or pathogen, host, or epidemiological processes. Transmission of several pathogens and the interventions against them have been modelled using IBMs2, including during the COVID-19 pandemic3,4,5. Combining IBMs with a network structure relaxes the assumption of random or homogeneous mixing, in other words that individuals are equally likely to contact each other. Implicitly, networks therefore allow for specifying an individual’s exposure within a population and resembles social interactions more closely6. Mixing patterns of individuals can be informed through survey-based empirical data7,8 or are imposed by assumptions.
Networks are rooted in graph theory, a sub-discipline of mathematics, and summarise the set of contacts (edges) between individuals (nodes). The number of contacts of an individual is said to be their degree9. Theory provides plenty of stylized structures such as random networks and lattice networks or spatial grids, whereby each structure captures particular features of human behaviour6. In contrast to models with homogeneous mixing, random graph networks allow for restricting individual’s contacts to a subset of the population10. The degree of a node can be fixed or sampled from a distribution to increase flexibility11,12. Small-world networks bridge the gap between regular graphs like lattices and random graphs by introducing long-range connections13, and were found be more representative of human behaviour based on transportation system data14. Clustering within a network describes the fact that some individuals in a contact network are more interconnected than others. This corresponds to, for instance, the small-world property introduced above13. Social networks often also follow a community structure with sparsely linked groups of highly interconnected individuals15. Moreover, several real-world networks fulfil a scale-free property, which implies that the degree distribution of nodes follows a power-law. In other words, nodes that are added to a network preferably bind to nodes that are already highly connected16. Such highly-connected nodes or hubs may turn into super-spreaders once exposed to an infectious disease, as disease propagation may be facilitated by the large number of direct contacts17. In fact, modelling studies have shown the absence of epidemic thresholds in scale-free networks indicating that disease outbreaks may grow to an epidemic even if the probability of transmission is low18. Furthermore, edges between two nodes may be directed, implying that one individual can infect another individual, but not become infected by the same individual. Combining directed and undirected edges in a single network increases flexibility in modelling complex transmission patterns and assessing targeted interventions19,20.
Individual contacts may differ structurally, for instance, in location (e.g. household, school, workplace4) or context (e.g. sexual network and injection network21). Many models account for this observation by introducing contact layers in the form of subnetworks, which follow a specific network structure, often determined by the age or risk-related behaviour of the individual21. In addition, assigning weights to contacts allows for capturing the heterogeneity in intensity or duration of contacts22,23. Summary statistics from network topology include the clustering coefficient which measures the extent of clustering in a network6. Initially developed for unweighted graphs, the metric has later been generalised to take into account the weighting of contacts24. Moreover, several descriptive network statistics were found be suitable predictors for infectious disease dynamics25,26.
While many infectious disease models provide various network structures to their users (e.g.4,23), direct comparisons of epidemic outcome metrics between network structures are often not analysed. Rahmandad et al. compared a variety of network structures in modelling dynamics of the poliovirus and found critical dependence of model outcomes on network structures27. Smieszek et al. found that including contact structures even with only small degrees of clustering already leads to substantial deviations from models with random interactions between individuals28. Accounting for clustering and increasing heterogeneity in individual contact distributions resulted in complex interactions with the final epidemic size29. Moreover, step-wise increase of clustering in a scale-free network was shown to be associated with slowing down an epidemic, thereby delaying the peak time of new infections30. Under certain assumptions, clustering decreases the build-up of an epidemic as measured by the basic reproductive ratio22. Overall, Miller et al. concluded that the decision whether or not to include clustering into a contact network should depend on the epidemic outcome measure of interest22.
Prior research has focused on various outcome metrics such as the basic reproductive ratio, probability of epidemic outbreak, and the proportion of the population infected with a disease22. Similar to Rahmandad et al.27, we analyse the cumulative number of infections, number of peak daily infections, and time to peak daily infections, with the latter two supporting decision-making for public health interventions. Using a real-world application of a COVID-19 IBM, we assess the impact of network structure and network properties on key epidemic outcome metrics with varying degrees of clustering. We analyse different network structures and layer-dependent contact weights by including different contact weightings, with and without a layer-targeted intervention.
Our study has shown that contact clustering reduces the number of cumulative infections by the end of the simulation horizon, decreases the peak number of new infections, and delays the time of peak daily new infections. Moreover, epidemiological dynamics of multi-layer networks may be recovered with single-layer networks, if the transmission probability is changed accordingly. Under the assumption of uniform contact weights, we showed that single-layered networks may be able to approximate the intervention effect estimated in a multi-layer network for a layer-targeted intervention.
Methods
To assess the impact of multi-layer network structures, we used OpenCOVID (version 2.2), a stochastic, discrete-time individual-based model of SARS-CoV-2 transmission and COVID-19 disease (http://github.com/SwissTPH/OpenCOVID/tree/manuscript_network). This open-source, peer-reviewed model was used in evaluating public health interventions in Switzerland3, the impact of new SARS-CoV-2 viral variants31, booster vaccination strategies32, and the cost-benefit of antiviral treatment33. Upon transmission of SARS-CoV-2 to a susceptible individual, newly infected individuals pass through a latent and pre-symptomatic stage. Based on the risk factors age and the presence of comorbidities, infected individuals receive a prognosis for an asymptomatic, mild, or severe course of disease. Patients with severe disease may be admitted to hospital, intensive care units (ICUs), or die from COVID-19. Individuals who recovered from infection become partially susceptible with waning immunity against reinfection and severe disease as specified in Section S1, Supplementary Materials (also refer to Fig. 1 in3 for a schematic of disease state flows).

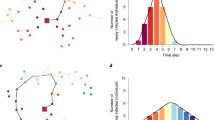
Individual layer allocation: Illustrative diagram displays layer allocation schema by individual age group and data source. The average number of contacts was calibrated using parameters provided in Supplementary Information, Section S1. The number of contacts in the Household layer and the Other layer depend on assumptions. The Community layer (also referred to as Residual) reflects the difference between the calibrated contacts and the sum of contacts from the Household and the Other layer.
We amended OpenCOVID by adding a multi-layer network functionality, which allows for constructing heterogeneous contact structures between individuals. Two different network specifications were compared against each other: (1) a single-layered network with a simple age-structured small-world network (SL), and (2) a multi-layer network structure with up to three contact layers (ML). Contact networks were constructed based on the age-mixing pattern obtained from survey results for Germany, based on the POLYMOD study, which was run in 2005/200634. These were extracted using the function contact_matrix() from the R package socialmixr35. Subsequently, the transmission probability was chosen so that the average number of contacts fell within the range obtained in the POLYMOD study. Individual layer allocation depended on the individual’s age (see Fig. 1). Every individual was allocated to a household, whose size was sampled from a Poisson distribution with mean household size \({\lambda }_{H}\). Individuals between the age of 0 years and 65 years were also allocated to a secondary layer with fixed cluster size and a layer-specific fixed number of contacts. Further details on the layer allocation of individuals are provided in the Supplementary Information, Section S1.
Simulations were run for a synthetic population of 100,000 individuals and demographics were sampled from an age distribution representative of Western Europe. The amended model allowed for scaling the transmission probability using layer-specific contact weights (\({w}_{H}\) for household, \({w}_{S}\) for school, \({w}_{W}\) for workplace, and \({w}_{C}\) for community contacts). Community contacts were used as a reference point with uniform contact weight, \({w}_{C}=1\). In a single-layer simulation, all contacts are assigned the same infectiousness parameter, \(\beta\). To obtain on average the same infectiousness per contact in a multi-layer network with non-uniform contact weights, our model required the specification of an infectiousness of community contacts, \({\beta }_{C}\), as these were treated as reference (see Supplementary Materials, Section S1 for the relationship). Contact weights were set constant over time, with the exception of \({w}_{W}\), which was later altered to implement an intervention. In all non-uniform contact weight scenarios, we assigned the highest weight to household contacts, as their relationship is likely to be the closest compared to all other settings. Contacts between individuals on the school layer and individuals on the workplace layer were weighted equally. Table 1 outlines the detailed parameterization for the simulations. While the sampling of schools and workplaces were based on the number of contacts per cluster, households were parameterized using the average household size, sampled from a Poisson distribution with mean \({\lambda }_{H}\). We provide further details on the construction of networks in the Supplementary Materials, Section S1.
Introducing layers into the contact network structure altered the degree of clustering, measured by the generalised clustering coefficient (GCC) which was used as explanatory variable for the relationship. The GCC considers the number of triangular relationships between individuals including contact weighting24. For mathematical expressions to compute GCCs for weighted networks, we refer the reader to24. GCC values in our study were calculated using the function clustering_w() from the R package tnet with the arithmetic mean method36. New infections and hospital admissions were used as outcomes for the epidemic trajectory. To assess the overall impact of clustering on epidemic outcomes, we used three global descriptive measures: time to peak infections/admissions, peak infections/admissions, and cumulative infections/admissions at the end of the simulation horizon.
To assess whether a multi-layer network can reproduce the dynamics obtained with a single-layer network, we recovered the adjusted infectiousness per contact, \(\widetilde{\beta }\), which minimised the root mean squared error (RMSE) between the average new infections obtained under both network structures in an epidemic scenario without interventions (see Section S1, Supplementary Materials, for details on the process). We simulated an intervention scenario, which corresponds to a temporary shut-down of workplaces, by setting the weight of workplace contacts, \({w}_{W}\), to 0. This intervention was assumed to last for 150 days (day 150 to day 300) and reflected a perfect 150 day home office requirement. The implementation of the intervention in a single-layer network is described in the Supplementary Materials, Section S1. In these simulations, the GCC reflected clustering prior to the implementation of interventions. Under the assumption of an equal transmission probability for single-layer and multi-layer networks, the estimated intervention effect would be driven by two factors: changes in the epidemic outcomes due to clustering, and the actual intervention effect. In order to account for the contribution from clustering and thereby to isolate the true intervention effect, we imposed the adjusted infectiousness per contact derived as described above for the entire simulation period.
All simulations were run with R version 4.1.0 at sciCORE (http://scicore.unibas.ch/), the scientific computing facility at the University of Basel, Switzerland.
Results
Temporal dynamics
Figure 2 presents the temporal dynamics of new infections per 100,000 individuals in a single-layer network (grey line) and five multi-layer networks which differ in contact weights from uniform (red line) to CW4 (orange line). Simulations are initialised with an effective reproductive number, \({R}_{e}=1.0\) at the end of the cooler season. Until approximately day 100, the number of new infections decreases mainly driven by the dampening effect of warmer weather on disease transmission and acquired immunity. Thereafter, new infections increase under all network structures, leading to an epidemic wave with peak infections between day 250 and day 350 depending on contact weights, followed by a decline due to a beneficial seasonality effect and acquired immunity. The GCC value computed for the single-layer networks stand at relatively low levels (< 0.000) due to the large population size assumed in the simulation and the relatively low number of contacts per individual. Higher GCCs are associated with fewer peak infections and a longer time to peak infections. Higher GCCs can be obtained by (1) creating more clustered subnetworks (e.g., more household members, smaller workplaces) keeping the number of total contacts equal, (2) increasing the contact weights of some contacts over others, or (3) a combination of the aforementioned. In addition, more clustered networks are also associated with fewer cumulative infections, again highlighting the dampening effect of clustering and non-uniform contact weights on the overall epidemic (see Supplementary Information, Fig. S1).

Temporal dynamics of new infections: Single-layer (grey line) refers to a layer-free small-world network, whereas all multi-layer networks consist of a household, school, workplace, and community layer. The multi-layer networks (red, blue, green, purple and orange line) assume an average household size of three. Under uniform contact weights (CWs) all contacts are weighted equally (1/1/1/1). Other sets of contact weights are CW1 (2/1.5/1.5/1), CW2 (4/2/2/1), CW3 (5/2.5/2.5/1), and CW4 (8/4/4/1). The mean generalised clustering coefficient for each network structure is provided in the labels. An increase in the generalised clustering coefficient is associated with fewer peak infections and later occurrence of the peak infections. Solid lines indicate the mean over 20 single simulations with shaded areas being the prediction intervals based on minimum and maximum value of the time series. Corresponding trace plots are provided in the Supplementary Information, Fig. S2.
Impact analysis on epidemic outcome metrics
Figure 3 explores the relationship between GCCs and three epidemic outcome metrics: peak infections, time to peak infections, and cumulative infections at day 400. All metrics are provided as differences to the single-layer network structure (black dashed reference line fixed at zero, black diamond marks the GCC of the single-layer network). Linear relationships are fitted through the difference in the means of epidemic outcome metrics obtained under multi-layer and single-layer networks for each set of contact weights. The shaded regions indicate the 95% uncertainty interval around the fitted linear models. Under all sets of contact weights, cumulative infections and peak infections are negatively associated with the GCCs. In the cases analysed, the more pronounced the difference in contact weights, the larger the GCC. Moreover, for every given household size, higher contact weights lead to larger GCCs. If household sizes and differences in contact weights are sufficiently large, the 95% uncertainty intervals around the linear models fitted to multi-layer estimates do not overlap with the x-axis anymore. In contrast, difference in time to peak infections between multi-layer and single-layer network structures is positively associated with GCCs, leading to peak infections occurring later in the simulation horizon, if household sizes and differences in contact weights are sufficiently large.

Relationship between epidemic outcome metrics and GCC: Comparison of cumulative infections (per 100,000 individuals) after 400 days, peak infections (per 100,000 individuals) and time to peak infections (in days) of multi-layer networks against single-layer network (black diamond, black dashed line) as reference. Simulated multi-layer networks differ in household size (indicated by shapes) and contact weights (indicated by colours). Points (shapes) show difference between means obtained under multi-layer and single-layer networks from 20 simulations. A linear relationship is fitted through the difference between means obtained under multi-layer and single-layer networks by set of contact weights. Grey-shaded regions show 95% confidence intervals around fitted linear model.
Layer-targeted intervention
By minimising the RMSE between model projections under single-layer and multi-layer networks, we can recover the adjusted infectiousness per contact (see Supplementary Material, Section S2). In general, this adjusted parameter is higher than the transmission probability of the single-layer network. Since a higher degree of clustering leads to a decrease in cumulative infections with lower and later-occurring peaks, a higher transmission probability is needed to reproduce the same dynamics under clustered networks.
In the intervention scenario, all contacts marked as workplace contacts are cut from the network’s edge list between day 150 and day 300. Figure 4 shows the reduction in cumulative infections/hospital admissions and peak infections/hospital admissions under the intervention to a counterfactual scenario without intervention assuming uniform contact weights under different household sizes (see Fig. S5, Supplementary Material, Section S3 for temporal dynamics of new infections and cumulative infections exemplary for a multi-layer network with uniform contact weights and household size of 3 against a single-layer network). The black diamond indicates the intervention effect in the single-layer network, if a random selection of contacts is removed temporarily during the same period. The vertical lines show the minimum and maximum of intervention effects. Simulations with multi-layer network structures assume an adjusted infectiousness per contact for better comparison of summary metrics.

Intervention effect by network structure with adjusted infectiousness: Reduction in epidemic outcome metrics (cumulative infections and hospital admissions as well as peak infections and peak hospital admissions) by network structure with adjusted infectiousness and uniform contact weights. Points (shapes) show the mean of differences in the respective epidemiological outcome metric with and without the intervention over 20 simulated seeds. The black diamond indicates the intervention effect size of the single-layer network. Vertical lines show the minimum and maximum of the differences in the epidemiological outcome metric with and without the intervention. Solid lines show a linear relationship fitted to the mean of the intervention effect by household size. Grey-shaded regions show the 95% confidence interval around the fitted linear model.
Overall, there is a tendency for the intervention effect to increase with the GCC, as indicated by the linear relationship fitted to the mean difference in the intervention effect obtained under multi-layer network structures. Depending on the household size, the single-layer network over- or underestimates the intervention effect, when compared to the multi-layer networks. However, the prediction intervals around the point estimates are relatively wide for all simulations. Moreover, the prediction intervals around intervention effects for hospital admissions are wider than for new infections due to further parameter uncertainty from prognosis probabilities.
Discussion
The outbreak of the COVID-19 pandemic saw an unprecedented demand for the rapid development of transmission models suitable for answering key policy questions on an international, national and sub-national level. Many of the most powerful models used an individual-based structure, for which developers had to make decisions regarding the complexity of model structure and model features. These decisions were often made whilst under pressure to provide results to decision makers in a timely manner. In this study, we retrospectively analyse the suitability of varying complexities of human contact networks inherent in individual-based models, with the aim of providing generalizable advice to modelling groups as to the usability of relatively simple network structures, and the limitations of such networks in the context of providing public health policy advice.
Our results show that single-layer networks may yield a suitable approximation for the effect size of a layer-targeted intervention obtained under a multi-layer network structure. In our case, using a less complex contact network does not result in a systematic over- or underestimation of the intervention effect under uniform contact weights. In addition, multi-layer networks can recover epidemic trajectories through altering the force of infection under both uniform and non-uniform contact weights. Lastly, clustering within multi-layer networks has a dampening impact on cumulative infections as well as peak infections, and delays time to peak infections compared to a single-layer network. These effects are more pronounced in settings with larger households and when differences in contact weights are widening.
We show that not only the presence of clustering, but also the degree of clustering is instrumental in assessing its effect on epidemic outcomes. It is therefore important to bear in mind the drivers behind elevated levels of clustering. In our case, the household layer and thereby the household size is a strong determinant of clustering. As a result, consistency and knowledge of demographics is important to ensure like-for-like comparison of outcomes. When comparing the intervention effect of single-layered networks against multi-layered networks, we assume uniform contact weights. Therefore, if there is credible evidence for non-uniform contact weights, our conclusions may no longer be valid. Such contact weights can amongst other things be informed by epidemiologically-observed secondary attack rates, particularly from household transmission23, or hypothesised based on the pathogen’s mode of transmission28. This suggests that when little is known about the pathogen, models should be agnostic of contact weights to produce more conservative estimates. The contact weights used in our analyses are not based on empirical observations, but support the intuition behind clustering contacts.
To derive our conclusions we use the software OpenCOVID, which was specifically designed to model transmission and disease of SARS-CoV-2 and COVID-19, respectively. Therefore, OpenCOVID allows for, for instance, modelling disease states and estimating epidemiological outcome metrics targeted for giving policy advice such as hospital admissions and number of admissions to intensive care units. Nevertheless, we deem OpenCOVID to be representative and flexible enough to be applied to other airborne infectious diseases, for instance, influenza and infections with respiratory syncytial virus (RSV). Suitability to specific infectious diseases, however, remains to be discussed in related future studies on case-by-case basis.
Several modelling frameworks for COVID-19 disease control use structures similar to ours, when it comes to, for instance, contact layers and contact weighting4,37,38. Likewise, the assessed public health intervention, the temporary closure of workplaces, has also been evaluated in other intervention modelling studies37,38. Nevertheless, we would like to highlight that assessing the effectiveness of the intervention both stand-alone or in conjunction with others against a counterfactual scenario for policy recommendation falls outside the scope of our study. While workplace closures would belong to the response catalogue to a pandemic, governments would adopt a closing-and-opening workplaces strategy repeatedly, likely based on thresholds imposed on observed infection dynamics. This is in contrast to our one-off workplace scenario for an extended period. However, for our study, we wanted to avoid introducing additional assumptions for decision rules or thresholds as well as starting point and duration of the intervention.
In the set-up of workplaces, we do not consider heterogeneities in the type of labour and assume perfect compliance and the complete ability to work from home for an extended period of time. The latter, however, does not apply to essential workers which were facing elevated risk of infection such as staff in stores38. In addition, patient-facing healthcare staff, who were exposed to disproportionately many infectious individuals, had an elevated risk of admission to hospital due to a SARS-CoV-2 infection. This also applied to their household members39. Our analysis, however, assumes that the weighting of household contacts is homogeneous throughout the population and independent from the occupation of individuals and their household members.
In the scenarios with non-uniform contact weights, we impose the general relationship that the contact weight of individuals in the same household is the highest, which is in line with some previous modelling studies4,38. This is based on the assumption that contacts at home may be closer than encounters in all other locations. Other studies consider a more refined calculation of the transmission probability based on proximity and duration of the contact40 or assume a more continuous spectrum also allowing for contacts outside the household having a higher weight due to potentially longer exposure23,37. Moreover, our simulations use the simplifying assumption of time-invariant contact weights. In contrast, Nande et al. apply time-variant contact weights during a workplace closure scenario. Since more time is then spent with household contacts, their relative infectivity increases, which is reflected by temporarily increased contact weights23.
A crucial input into model calibration and simulation of OpenCOVID are the contact age-mixing patterns, which were obtained as part of the POLYMOD study. By construction, the contact diaries of study participants only contained details about contacts that occurred knowingly34. SARS-CoV-2 spreads via the inhalation of aerosols rather than droplets as in the case of the influenza virus. Therefore, less close contact between infectious and susceptible individuals is sufficient for disease transmission. This is indicative of the self-reported number of contacts underestimating the effective exposure to infectious individuals. In addition, the split of contacts into layers was driven by assumptions, so that the effective number of contacts obtained by model calibration fits into the range of reported contacts in the POLYMOD study. The COVID-19 pandemic has highlighted the relevance of infectious disease modelling for informing decision-makers. As real-world advice is best based on real-world data, we would highly appreciate publicly available contact network data on a granular level such as contact layers for future studies.
Lastly, when constructing contact networks, we mainly consider the household as the driver of clustering and the clustering coefficient. Since households, by construction, form a fully connected subnetwork, they have a more pronounced impact on the GCC when compared to schools and workplaces which are of small-world type. For simplicity, we neither vary school sizes nor workplace sizes and keep the number of contacts per person within these subnetworks constant. Other individual-based models allow for a random number of contacts on each layer, thus accounting for further heterogeneity in contact networks4. Similarly, Simoy and Aparicio find sensitivity of model outcome estimates towards the parameterization of workplace sizes38.
In line with previous research, we showed that including clustering into a contact network model alters the dynamics of new infections22,25,26,30,41. Moreover, we did not find a systematic bias in the impact assessment of a simple layer-targeted intervention. When quick outbreak response is needed, single-layer networks can yield more conservative, in other words, more cautious estimates. Yet, as soon as knowledge about demography and pathogen evolves, models should be revised to reflect particular contact patterns in the population. This becomes especially important when an affected population displays distinct properties or more nuanced interventions are to be evaluated.
Data availability
All model code is open-access and publicly available at http://github.com/SwissTPH/OpenCOVID/tree/manuscript_network. The model code for this study is an adapted version of OpenCOVID version 2.2.
References
Kermack, W. O. & McKendrick, A. G. Contribution to the mathematical theory of epidemics. Proc. R. Soc. Lond. Ser. A 115(772), 700–721 (1927).
Willem, L. et al. Lessons from a decade of individual-based models for infectious disease transmission: A systematic review (2006–2015). BMC Infect. Dis. 17, 612 (2017).
Shattock, A. J. et al. Impact of vaccination and non-pharmaceutical interventions on SARS-CoV-2 dynamics in Switzerland. Epidemics 38, 100535 (2022).
Kerr, C. C. et al. Covasim: An agent-based model of COVID-19 dynamics and interventions. PLoS Comput. Biol. 17(7), e1009149 (2021).
Hinch, R. et al. OpenABM-Covid19–An agent-based model for non-pharmaceutical interventions against COVID-19 including contact tracing. PLoS Comput. Biol. 17(7), e1009146 (2021).
Keeling, M. J. & Eames, K. T. D. Networks and epidemic models. J. R. Soc. Interface 2(4), 295–307 (2005).
Mousa, A. et al. Social contact patterns and implications for infectious disease transmission – a systematic review and meta-analysis of contact surveys. Elife 10, e70294 (2021).
Hoang, T. et al. A systematic review of social contact surveys to inform transmission models of close-contact infections. Epidemiology 30(5), 723–736 (2019).
Erdős, P. & Rényi, A. On the evolution of random graphs. Bull. Int. Stat. Inst. 38(4), 343–347 (1960).
Andersson, H. Limit theorems for a random graph epidemic model. Ann. Appl. Probab. 8(4), 1331–1349 (1998).
Newman, M. E. J. Spread of epidemic disease on networks. Phys. Rev. E 66(1), 16128 (2002).
Miller, J. C. Epidemic size and probability in populations with heterogeneous infectivity and susceptibility. Phys. Rev. E 76(1), 101 (2007).
Watts, D. J. & Strogatz, S. H. Collective dynamics of “small-world” networks. Nature 393(6684), 440–442 (1998).
Eubank, S. et al. Modelling disease outbreaks in realistic urban social networks. Nature 429(6988), 180–184 (2004).
Girvan, M. & Newman, M. E. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 99(12), 7821–7826 (2002).
Barabási, A. L. & Albert, R. Emergence of scaling in random networks. Science 286(5439), 509–512 (1999).
Barabási, A.-L. Network Science. http://networksciencebook.com/.
Pastor-Satorras, R. & Vespignani, A. Epidemic spreading in scale-free networks. Phys. Rev. Lett. 86(14), 3200–3203 (2001).
Meyers, L. A., Newman, M. E. J. & Pourbohloul, B. Predicting epidemics on directed contact networks. J. Theor. Biol. 240(3), 400–418 (2006).
Newman, M. E. J., Strogatz, S. H. & Watts, D. J. Random graphs with arbitrary degree distributions and their applications. Phys. Rev. E 64(2), 118 (2001).
Goedel, W. C. et al. Implementation of syringe services programs to prevent rapid human immunodeficiency virus transmission in rural counties in the United States: A modeling study. Clin. Infect. Dis. 70(6), 1096–1102 (2020).
Miller, J. C. Spread of infectious disease through clustered populations. J. R. Soc. Interface 6(41), 1121–1134 (2009).
Nande, A. et al. Dynamics of COVID-19 under social distancing measures are driven by transmission network structure. PLoS Comput. Biol. 17(2), e1008684 (2021).
Opsahl, T. & Panzarasa, P. Clustering in weighted networks. Soc. Netw. 31(2), 155–163 (2009).
Ames, G. M. et al. Using network properties to predict disease dynamics on human contact networks. Proc. R. Soc. B 278(1724), 3544–3550 (2011).
Shirley, M. D. F. & Rushton, S. P. The impacts of network topology on disease spread. Ecol. Complex. 2(3), 287–299 (2005).
Rahmandad, H. et al. Development of an individual-based model for polioviruses: Implications of the selection of network type and outcome metrics. Epidemiol. Infect. 139(6), 836–848 (2011).
Smieszek, T., Fiebig, L. & Scholz, R. W. Models of epidemics: When contact repetition and clustering should be included. Theor. Biol. Med. Model. 6, 11 (2009).
Volz, E. M. et al. Effects of heterogeneous and clustered contact patterns on infectious disease dynamics. PLoS Comput. Biol. 7(6), e1002402 (2011).
Grabowski, A. & Kosiński, R. A. Epidemic spreading in a hierarchical social network. Phys. Rev. E 70(3), 1908 (2004).
Le Rutte, E. A. et al. Modelling the impact of Omicron and emerging variants on SARS-CoV-2 transmission and public health burden. Commun. Med. 2, 93 (2022).
Kelly, S. L. et al. COVID-19 vaccine booster strategies in light of emerging viral variants: Frequency, timing, and target groups. Infect. Dis. Ther. 11(5), 2045–2061 (2022).
Le Rutte, E. A., Shattock, A. J., Marcelino, I., Goldenberg, S. & Penny, M. A. Efficacy thresholds and target populations for antiviral COVID-19 treatments to save lives and costs: A modelling study. EClinicalMedicine 73, 102683. https://doi.org/10.1016/j.eclinm.2024.102683 (2024).
Mossong, J. et al. Social contacts and mixing patterns relevant to the spread of infectious diseases. PLoS Med. 5(3), 381–391 (2008).
Funk, S. socialmixr: Social Mixing Matrices for Infectious Disease Modelling. R Package Version 0.1.8. https://CRAN.R-project.org/package=socialmixr (2020).
Opsahl, T. (2009) Structure and Evolution of Weighted Networks. University of London (Queen Mary College), London.
Aleta, A. et al. Modelling the impact of testing, contact tracing and household quarantine on second waves of COVID-19. Nat. Hum. Behav. 4(9), 964 (2020).
Simoy, M. I. & Aparicio, J. P. Socially structured model for COVID-19 pandemic: Design and evaluation of control measures. Comput. Appl. Math. 41(1), 705 (2022).
Shah, A. S. V. et al. Risk of hospital admission with coronavirus disease 2019 in healthcare workers and their households: Nationwide linkage cohort study. Bmj 371, m3582 (2020).
Hoertel, N. et al. A stochastic agent-based model of the SARS-CoV-2 epidemic in France. Nat. Med. 26(9), 1417–1421 (2020).
Eames, K. T. D. Modelling disease spread through random and regular contacts in clustered populations. Theor. Popul. Biol. 73(1), 104–111 (2008).
Acknowledgements
The authors acknowledge and thank the members of the Disease Modelling Unit, Swiss Tropical and Public Health Institute, specifically Dr Sherrie L. Kelly, Dr Epke A. Le Rutte and Cassandra Alvarado for their input. Simulations were performed at sciCORE (http://scicore.unibas.ch/) the scientific computing facility at the University of Basel, Switzerland. Furthermore, the authors would like to thank the two anonymous reviewers for their helpful and constructive comments.
Funding
Funding for the study was provided by the Basel Research Centre for Child Health (DZX2165 to MAP), the Swiss National Science Foundation Professorship of MAP (PP00P3_203450) and Swiss National Science Foundation NFP 78 Covid-19 2020 (4078P0_198428).
Author information
Authors and Affiliations
Contributions
MR, AJS, and MAP conceived the study. MR further developed the model with input from AJS. MR performed the analyses and prepared the figures with input from AJS and MAP. MR drafted the manuscript. All authors contributed to interpreting results and editing the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Richter, M., Penny, M.A. & Shattock, A.J. Intervention effect of targeted workplace closures may be approximated by single-layered networks in an individual-based model of COVID-19 control. Sci Rep 14, 17202 (2024). https://doi.org/10.1038/s41598-024-66741-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-66741-3
- Springer Nature Limited