
Abstract
The microbial communities of the oral cavity are important elements of oral and systemic health. With emerging evidence highlighting the heritability of oral bacterial microbiota, this study aimed to identify host genome variants that influence oral microbial traits. Using data from 16S rRNA gene amplicon sequencing, we performed genome-wide association studies with univariate and multivariate traits of the salivary microbiota from 610 unrelated adults from the Danish ADDITION-PRO cohort. We identified six single nucleotide polymorphisms (SNPs) in human genomes that showed associations with abundance of bacterial taxa at different taxonomical tiers (P < 5 × 10–8). Notably, SNP rs17793860 surpassed our study-wide significance threshold (P < 1.19 × 10–9). Additionally, rs4530093 was linked to bacterial beta diversity (P < 5 × 10–8). Out of these seven SNPs identified, six exerted effects on metabolic traits, including glycated hemoglobin A1c, triglyceride and high-density lipoprotein cholesterol levels, the risk of type 2 diabetes and stroke. Our findings highlight the impact of specific host SNPs on the composition and diversity of the oral bacterial community. Importantly, our results indicate an intricate interplay between host genetics, the oral microbiota, and metabolic health. We emphasize the need for integrative approaches considering genetic, microbial, and metabolic factors.
Similar content being viewed by others


Introduction
The oral cavity harbours several hundred different bacterial species making the oral microbiota one of the most complex microbial communities of the human body1. Attached to various surfaces of the mouth, the resident microbes prevent colonization by pathogens and orchestrate the maintenance of oral health together with the immune system of the host2,3. Thus, a healthy oral microbiota contributes to symbiotic relationships and resilience whereas a disruption of the homeostasis may increase risk of various local or systemic diseases of the host3,4,5,6. Most prevalent oral diseases, like gingivitis, periodontitis, and dental caries, have a clear bacterial etiological component4,5. In addition, epidemiological studies have indicated that an aberrant oral microbiota may play a role in the pathogenesis of systemic diseases6, including cardiovascular disease7,8, obesity, type-2-diabetes (T2D), and other components of metabolic syndrome9,10.
The mechanisms behind the compositional changes leading to dysbiosis of the oral microbiota are still not fully understood. The basis of the complex structure of the oral microbiota is assembled in the early years of life, and it is modulated by several exogenous and endogenous factors including delivery mode, feeding method, sex, and host genetics11,12. Alterations in the individual immune response as well as lifestyle factors, such as diet, oral hygiene and smoking have also been shown to induce dynamic compositional and functional changes of the oral microbiota13,14,15,16. Moreover, prolonged cohabitation increases the similarity in oral microbiota composition among individuals sharing household17.
The first pieces of evidence for associations between the oral microbiota and human host genetics were revealed using targeted approaches of candidate genes. For example, variations within MHC genes were reported to increase the susceptibility for caries-associated bacteria18,19. However, the extent of the influence of genetics on human oral microbiota is debated, with some authors emphasizing the strong influence of non-genetic factors20,21,22. Recent twin studies have demonstrated that a fraction of the oral microbiota is heritable22,23,24; with a study encompassing 752 twin pairs revealing that the oral microbiota of monozygotic twins is compositionally more alike than that of dizygotic twins24. Results from another twin study showed that combined effects of individual host genetic variants explain variation in presence and abundance of certain bacterial species, with the strongest genetic effects identified for Corynebacterium singular, Campylobacter concisus, Veillonella rogosae, and Saccharibacteria (TM7) [G-1] bacterium HMT 34922.
Despite the emerging interest in the field, genome-wide association studies (GWAS) of oral bacterial traits are sparse and only few associations have been identified reaching genome-wide significance24,25,26. Notably, a metagenome-GWAS (mgGWAS) in a Chinese population, that included 1915 individuals in discovery cohort and 1439 in validation cohort, identified two study-wide significant genetic loci rs4911713 and rs36186689, that associated with an unknown species (F0422 uSGB392) from the Veillonellaceae family and with the genus Eggerthia, respectively26. A subsequent study of the same cohort also discovered 11 sex-specific genetic variations influencing the composition of salivary microbiota and found indications supportive of a causal link between several bacterial species and the risk of T2D12.
Here, we provide novel insights into the interaction between oral bacterial microbiota and host genome variation using GWAS of the oral microbiota from an unrelated sample of the Danish ADDITION-PRO cohort27, consisting of older middle-aged individuals at various levels of risk of developing T2D.
Results
In total, 610 participants with information about the oral microbiota and genotype data were included in the analysis. Descriptive characteristics of the participants are summarised in Table 1 (Table 1). We have tested the association between 43 univariate and one multivariate oral bacterial features and 5,195,096 and 5,374,467 human autosomal variants, respectively.
Host genetic variants associated with bacterial beta diversity
Using a distance-based F-test28 based on the Bray–Curtis dissimilarity matrix, we investigated associations between individual genome variants and overall oral bacterial community composition (beta diversity). Two variants on chromosome 15 were significantly associated to beta diversity (P < 5 × 10–8) (Fig. 1a). The effect allele of rs4530093 and the effect allele of rs11073493 were in high linkage disequilibrium (LD) (r2 > 0.8) indicating one independent signal close to RN7SKP181.

Results from the GWAS. (a) Manhattan plot representing results from the GWAS on oral microbial features. The red line represents the genome-wide significance level (P = 5 × 10–8) and the blue line represents study-wide significance level (P = 5 × 10–8 / 44). The rsID and nearest gene annotation is identified and included using topR R package. The color-coding represents 6/44 bacterial features that had variants reaching genome-wide significance level (P < 5 × 10–8). (b) Box plots representing the genetic effect of SNPs identified to significantly associate with abundance of bacterial taxa. The box plot displays the lower quartile, median, and upper quartile values within a box.
Host genetic variants associated with individual bacterial taxa
In total, six loci showed genome-wide significant associations (P < 5 × 10–8) with univariate bacterial features, out of which one locus, rs17793860, reached study-wide significant association (P < 1.19 × 10–9) (Fig. 1a, Table 2). The effect of genotype on the abundance of bacterial taxa is visualised in Fig. 1B. Most of the associations were found at the taxonomical level order (N = 3); while one association each was found at phylum, class and species level, respectively. Two genetic loci were associated with Actinomycetales order (rs1538993; RCAN2 and rs197620; DAB1) (Fig. 2a–c) and one with genus Rothia from Actinomycetales order (rs17793860; CWC22) (Fig. 2b). The KCNQ1 locus (rs4930141) was associated with Clostridiales order (Fig. 2d, Table 2), the NR2F2 locus (rs12593910) was associated with phylum Firmicutes (Fig. 2e), and the SLCO3A1 locus was associated with abundance of an unknown Streptococcus species (Fig. 2f).

Locus Zoom plots showing regional association with univariate bacterial features. (a) DAB1, chromosome 1: 57687078 (rs197620); P = 4.41 × 10−8, (b) CWC22, chromosome 2:180979913 (rs17793860); P = 1.16 × 10−9, (c) RCAN2, chromosome 6:46441428 (rs1538993); P = 3.86 × 10−8, (d) KCNQ1, chromosome 11:2639985 (rs4930141); P = 2.37 × 10−9, (e) NR2F2 chromosome 15:96970958 (rs12593910); P = 2.53 × 10−8, (f) SLCO3A1 chromosome 15:92564182 (rs8043469); P = 3.10 × 10−8.
Single-genetic variant associations with metabolic traits
We queried publicly available GWAS datasets for associations involving the six microbiome-associated variants (Figs. 3, 4). The rs17793860-C allele of the CWC22 locus that associates with decreased abundance of genus Rothia, was also associated with decreased risk of stroke. The rs8043469-C allele of SLCO3A1 locus that associates with increased abundance of unknown species from genus Streptococcus, was associated with lower triglyceride levels, lower risk of T2D, and higher HDL-cholesterol levels. The rs1538993-G allele of the RCAN2 locus that associates decreased abundance of order Actinomycetales, was associated with higher HbA1c levels and risk of T2D. The rs4930141-C allele of the KCNQ1 locus that associates with decreased abundance of order Clostridiales, was strongly associated with higher HbA1c levels and risk of T2D. The rs12593910-T allele of the NR2F2 locus that associates with decreased abundance of phylum Firmicutes, was positively associated with triglyceride levels. The rs197620-A allele of DAB1 locus that associated with decreased abundance of order Actinomycetales, associated with higher risk of periodontitis. No significant associations with publicly available GWAS datasets were identified for rs4530093 of RN7SKP181 (Figs. 1b, 3).

Single variant associations with metabolic, anthropometric and lifestyle traits. For each lead variant from GWAS analysis of univariate and multivariate microbial features (y axis), Z scores (aligned to effect (alternative) allele) were obtained from publicly available GWAS (Table S3) for metabolic, anthropometric and lifestyle traits (x axis). Heatmap reflects the direction and magnitude of the Z score for the association between SNP and common traits, with red indicating positive and blue indicating negative associations. Grey squares indicate that variant was not available in the summary statistics for the given trait. *Indicates P value < 0.05, # indicates FDR adjusted P value < 0.05. Abbreviations: T2D, type-2 diabetes; CAD, coronary artery disease; HbA1c, glycated hemoglobin A1c; DMFS, decayed, missing, filled surfaces; HDL, high-density lipoprotein; LDL, low-density lipoprotein.

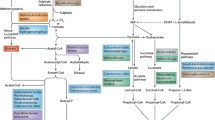
Overview of study results. Graphical table represents summary of the study findings and integration with already published data. The first row represents the results of microbiome-genome wide association study, with identified associations between variants and the abundance of bacterial taxa in saliva. The second row summarizes how the identified variants associate with metabolic traits. The third row integrates observational findings from previously published study on associations between oral microbiome composition and lifestyle factors (1Poulsen et al. Association of general health and lifestyle factors with the salivary microbiota—Lessons learned from the ADDITION-PRO cohort. Front Cell Infect Microbiol. 2022 Nov 16;12:1055117. PMID: 36467723). One arrow in bold represents the association and direction of the effect from GWAS, reaching genome-wide significance level at P < 5 × 10–8, two arrows in bold represent study-wide significant association at P < 1.19 × 10–9. One arrow represents the direction and association at P value < 0.05, two arrows represent association at P value < 0.05 after correction for multiple testing (FDR). Asterisk * represents association of genus Streptococcus. Figure created with Biorender. Abbreviations: p., phylum; g., genus; sp., unknown single species; o., order; SNP, single nucleotide polymorphism; T2D, type-2 diabetes; HDL, high-density lipoprotein; HbA1c, glycated hemoglobin A1c.
Discussion
This study aimed to identify host genome variants that influence oral microbial traits. We report six genome-wide significant associations of genome variants with abundance and prevalence of oral bacterial taxa, and one with overall bacterial community composition as assessed by Bray–Curtis dissimilarity in a high risk pre-diabetes cohort. The identified host genome variants also exhibit effects on metabolic traits, indicating potential implications for metabolic disease (Fig. 4).
The overall impact of genetic factors on the interpersonal variability of the human gut and oral microbiota composition in relation to non-genetic factors is debated20,23,24. While genome-wide analysis approaches targeting the oral microbiota are scarce, there is a growing interest in understanding how host genetics influence the composition of oral microbes. In a recent mgGWAS, Liu et al. identified 455 independent associations for the salivary microbiota in 1,915 Chinese individuals with two study-wide significant associations and one genetic variant (rs73243848) influencing the beta diversity of the saliva microbiota26. Our study was unable to replicate prior findings, possibly due to considerable differences in sequencing methods used, subsequent data processing, including taxonomical classification of bacteria, and the statistical methods. These differences make direct comparison between studies challenging.
Demmitt et al. performed a GWAS analysis of six bacterial traits showing the highest heritability as assessed by ACE-twin modelling and by Genome Complex Trait Analysis (GCTA)29 for 818 unrelated individuals. An unnamed species of Granulicatella (55.8% heritable, CI 0.28–0.63) and principal coordinate 2 (PCo2) of Bray–Curtis dissimilarity (46.3% heritable, CI 0.23–0.55) have been reported with the highest heritability of oral bacterial traits based on analyses of twins. Further, Demmitt et al. have identified an association of a variant located in the gene LIN7A with PCo3 of unweighted UniFrac of oral microbiota24. Likewise, our findings suggest an effect of host genome variants on bacterial beta diversity. But instead of performing an ordination of the dissimilarity matrix in order to condense the variation to lower-dimensional representation, we have used a distance-based F-test (DBF-test)28 directly on the pairwise dissimilarity matrix. Thus, we were able to capture variation that extends beyond what is typically displayed by the first major ordination axes28. Using this approach, we identified one independent signal in the locus of the gene RN7SKP181.
The abundance of the order Clostridiales was associated with genetic variant rs4930141 in the KCNQ1 locus that encodes a potassium channel that is important for cardiac repolarization30. Notably, variations in the KCNQ1 have been found to associate with T2D risk31. Variation in rs4930141, which associated with decreased abundance of order Clostridiales in saliva, also associated with increased risk of T2D. Interestingly, Clostridiales sp. have also been found to be differentially decreased in the gut microbiota of adults with type-1 diabetes32. The abundance of Firmicutes was inversely associated with the effect allele of rs12593910, a variant located near the NR2F2. In a seminal study by Zaura et al., the phylum Firmicutes was identified as one of the core microbes of the healthy oral cavity33. Notably, in our study the same effect allele of rs12593910 also associates with elevated triglyceride levels, suggesting that a decrease in Firmicutes abundance and an increase in triglyceride levels may contribute to dysmetabolism, possibly through overlapping genetic factors. While these associations suggest a relationship between oral microbiota and human metabolic health, it is essential to validate the findings and establish causation.
Several associations were identified with variations in the host genome and members of the commensal Actinobacteria family; including two independent signals, rs1538993 and rs197620, that were linked with a lower abundance of order Actinomycetales, and rs17793860, linked with with lower abundance of genus Rothia. In addition, the genetic variant rs197620 was associated with higher risk of periodontitis and the genetic variant rs17793860 was associated with lower risk of stroke. In a recent study from our group, Poulsen et al. showed a positive association between abundance of Rothia and glycosylated hemoglobin levels34. Other investigators showed that abundance of Rothia associate to childhood dental caries23, and history of colorectal cancer35. While some of the species within the Rothia genus are typically characterized as benign, others are recognized as opportunistic pathogens, playing a putative role in oral diseases36,37 and in lung diseases38.
16S rRNA gene amplicon-based sequencing allows a resolution that is reliable only down to the genus level. This hampers the possibility of identifying or replicating already identified associations on species or strain level. One such example is the variation in rs8043469, associated with increased abundance of a species within the Streptococcus genus, and a better metabolic profile, including lower triglyceride levels, lower risk of T2D and higher HDL cholesterol levels. Given that Streptococcus represents a dominant genus in both healthy and diseased oral microbiota39, achieving species or strain-level resolution becomes imperative for the accurate interpretation of such discoveries.
Bacterial taxa, identified to associate with host genetic variants in our study, are involved in specific metabolic pathways that relate to oral and systemic health. For example, phylum Firmicutes that includes genus Streptococcus, are the main drivers of carbohydrate metabolism in the oral cavity, and certain Streptococcus species are involved in biofilm pathogenicity40,41. On the other hand, genus Rothia is mainly known for its capacity to perform nitrate reduction, which is a crucial biochemical process that contributes to production of nitric oxide (NO). NO is a key signalling molecule that has a central role in blood pressure regulation42. In our study, the findings are conflicting—we find that the variant, that associates with decreased abundance of Rothia genus, also associates with decreased risk of stroke. This highlights the limitation of the inability to resolve taxonomical rank beyond the genus level. The ability to draw precise functional conclusions is hampered, making it challenging to determine the specific metabolic pathways or microbial activities that might be influenced in different conditions.
Our study has limitations. The statistical power to observe true positive associations is dependent on different factors: first, the number of study participants, and second, the number of tests, which is determined by the number of independent genetic variants and the number of bacterial microbiota traits43. To mitigate this, we used clustering approaches reducing the number of associations performed, considering the relatively low sample size (N = 610). Despite the untargeted approach, we have also incorporated multiple testing corrections to mitigate the risk of false positives.
The ADDITION-PRO population consists of older middle aged Danish individuals at various levels of risk of developing T2D. Considering the age of the participants and the different glycemic states, it can be assumed that the health-related non-genetic phenotypes may have affected the oral bacterial composition. Consequently, due to the cohort specific phenotypes, our findings may not be generalizable to other populations. To overcome these limitations, large-scale studies across diverse ethnicities and phenotypes are warranted. Another limiting factor is the large impact of non-genetic factors on oral microbiota. In a previous study conducted within the same population, we identified that among others, glycemic status, sex, smoking, and weekly alcohol intake significantly influenced the composition of salivary microbiota. Therefore, in our current statistical analyses, we adjusted for the potential effects of glycemic status, sex, alcohol consumption, smoking, age, BMI and sequencing run. However, other factors such as diet, lifestyle, medication and technical factors e.g. DNA extraction, were previously shown to affect the oral microbiota44,45,46. Regardless of the adjustment for non-genetic covariates in our analysis, there is a considerable risk that other unassessed factors have confounded the effects of genetics. Additionally, established genetic effects on the oral microbiota in this study may not be direct, but mediated by other mechanisms. To advance towards causal interpretation of our findings, appropriate causal frameworks would have to be developed with carefully chosen adjustment sets for each of the associations.
Conclusion
In the present study, we uncovered multiple novel variants in the host genome that associate with diversity and abundance of oral bacteria in a Danish prediabetic population with varying risk for T2D. Notably, more of the identified genome variants are also linked to cardiometabolic traits, indicating potentially overlapping genetic factors. Findings of this study and the provided data may facilitate future larger studies and meta-analyses comprising various population profiles to achieve a fuller picture of the host-oral bacterial microbiota interactions.
Methods
Study population
The ADDITION-PRO study (2009–2011)27 is a risk-stratified -cohort designed to explore T2D and cardiovascular disease risks and their underlying mechanisms among Danish adults. ADDITION-PRO is a subsidiary study of the Danish arm of the ADDITION trial (baseline: 2001–2006) which assessed the effect of intensive multifactorial cardiometabolic treatment on incident cardiovascular events in people with screen-detected diabetes47. The general-practice based screening programme used to identify the participants of the trial48 also identified a large group of people in various pre-diabetic and high-diabetes risk states; these participants constitute the sampling frame for ADDITION-PRO (2009–2011). The study was approved by the Scientific Ethics Committee in the Central Denmark Region (20000183). All recruited participants gave their written consent for participation in the study. The study was conducted in accordance with the principles of the Declaration of Helsinki.
In total, 786 participants with varied glycemic status were recruited from the Copenhagen study site and provided saliva samples. Participants have undergone an extensive clinical examination including anthropometrics and detailed characterization of glycemic status, as described in detail elsewhere27.
Sample collection
A detailed description of saliva sample collection has been provided in a recent publication34. In brief, saliva was collected from 786 participants at Steno Diabetes Center Copenhagen, Copenhagen, Denmark. Participants were asked to refrain from brushing teeth on the day of the health assessment. Saliva production was stimulated with paraffin wax, and collected samples of whole saliva were stored immediately at − 80 °C.
Saliva sample processing
DNA extraction of saliva samples and 16S rRNA gene amplicon sequencing was done as reported34. Microbial DNA was isolated using the NucleoSpinSoil kit (Macherey–Nagel, Germany). Bacterial cells were lysed using SL1 + Enhancer buffer SX. DNA yield and purity were assessed using a Qubit 2.0 flourometer, and a NanoDrop 2000 spectrometer (Thermo Fisher Scientific Inc., MA, USA), respectively. Genomic DNA in each sample was normalized to 30 ng prior to PCR amplification of the 16S rDNA V4 hypervariable region. The PCR products were purified with the AmpureXP kit. The quality and quantification of the final library was determined using the 2100 bioanalyzer instrument (Agilent, DNA 1000 Reagents), and by real-time quantitative PCR (EvaGreenTM).
All samples were consecutively processed at the same location and with the same equipment. Owing to the sample number, sequencing was carried out in two runs (hereafter referred to as R1 and R2) using paired-end 500 cycles sequencing chemistry on an Illumina HiSeq 2500 platform, generating a total of 29,225,397 reads in the first run (R1, n = 666) and 4,193,449 reads in the second run (R2, n = 120).
16S rRNA gene amplicon sequence processing
Processing of raw sequencing data was done as reported in a recent publication34. In short, raw sequence data were processed using the dada2 algorithm v1.19.149, implemented in metabaRpipe50. Following truncation and filtering of raw sequence reads, error rate learning was performed, and amplicon sequence variants (ASVs) were inferred using a pseudo-pooling strategy. Forward and reverse reads were then merged with a minimum overlap of 40 nucleotides. The previous steps were carried out separately for R1 and R2. ASV tables were then merged, and chimeric sequences were identified and removed. A final clustering step was performed to detect potential batch-specific artefacts and no ASVs were clustered confirming the high sensitivity of the approach.
Taxonomical classification of sequences was performed using the dada2 algorithm and the eHOMD database (version V15.22, https://www.homd.org). A phylogenetic tree of ASV sequences was constructed using the phyloseq package v1.22.351.
Genotyping
Genotyping of 1657 participants from the ADDITION-PRO study27 was performed using the Illumina Infinium HumanCoreExome Beadchip (Illumina, San Diego, CA, USA) as described previously52. Genotypes were called using the Genotyping module (version 1.9.4) of GenomeStudio software (version 2011.1, Illumina). After filtering out first and second-degree relatives, duplicates, individuals identified as ethnically non-European outliers, individuals with extreme inbreeding coefficients, or mislabelled sex, 1548 individuals passed quality control criteria, 610 of whom had provided saliva samples. Hardy–Weinberg Equilibrium filter with a significance threshold of 0.005 was applied to ensure the accuracy and reliability of the genotyping data. Imputation was done using the Michigan Imputation Server53, resulting in a total of 39,117,105 SNPs which were either genotyped or imputed. Genetic principal components (PCs) were computed using plink v1.9054.
Association of oral bacterial features with host genetics
Associations of individual bacterial taxa were tested adapting a previously described workflow55,56. In short, univariate bacterial features including ASVs and taxonomic groups from genus to phylum were tested. Taxonomic groups were derived using tax_glom() function from the phyloseq R package51. Only taxa that were present in more than 100 participants, with median sequence count above 50 were kept for the analysis. To minimize redundancy, taxa that remained after filtering were clustered together based on similarity, evaluated by a Spearmann correlation cut-off of 0.985. This resulted in 43 clusters (Fig. S1). From each cluster, bacterial features from the lowest taxonomic group were selected for univariate tests: two phyla, one class, four order, five families, 12 genera and 19 species (Fig. S2, Table S1).
Statistical association testing between identified bacterial taxa and host genotypes was performed, using R version 4.1.2, following previously described workflow56. In short, zero-truncated non-rarefied count abundances were fit in generalized linear models with negative binomial distributions as predictors, with the function manyglm() from the Mvabund R package57. The following covariates were included to the model: sex, age, BMI, smoking, alcohol, glycemic state, sequencing run, and the first 10 genetic principal components. The logarithm of the total sequence counts of each sample was included to the model as offset. The residual variation from each univariate feature of this model, extracted using the residuals() function, was regressed on the host genotype variants (coded into numeric features, 0 = homozygous for reference allele; 1 = heterozygous; 2 = homozygous for alternative allele) in a linear model. Only common SNPs that had a minor allele frequency (MAF) > 5%, and a call rate > 95% were used. P-values were obtained from the summary() function.
To assess the impact of genetic variants on the overall bacterial community differences (beta diversity), we performed a distance-based F test (DBF-test), as previously described by Rühlemann et al.28. Bray–Curtis dissimilarities were computed from normalized microbiome counts (using rarefy_even_depth() function, 5000 sequences per sample), using the distance() function from the phyloseq R package51. Prior to analysis, Bray–Curtis dissimilarity matrix was corrected for covariates sex, age, BMI, smoking, alcohol, glycemic state, sequencing run, and the first 10 genetic principal components. The correction was done by fitting a distance-based redundancy model (capscale() function of the vegan R package) and selecting the aforementioned covariates to be partialled out. The residual variation of this model was subsequently used for the DBF-test. Only SNPs that had a MAF > 5%, imputation QC > 0.6 and call rate > 95% were used.
P-values that passed the genome-wide significance threshold of P ≤ 5 × 10−8 are reported as statistically significant. P-values meeting the study-wide significance threshold of P ≤ 1.19 × 10−9, derived by dividing the standard genome-wide significance level of P = 5 × 10−8 by the number of GWAS tests performed in this study (n = 44), reported as study-wide significant. For each GWAS, we grouped genetic variants that reached significance in 1 Mb genomic regions, assigned the strongest genetic association as lead variant, and named the locus based on the nearest gene.
The local linkage disequilibrium (LD) between the SNPs in the significantly associated loci was estimated in plink v1.954 and visualized in R using a publicly available script (https://github.com/Geeketics/LocusZooms).
Manhattan- and QQ-plots were generated and variants were annotated using the topR package58.
Summary statistics of suggestive and significant findings from univariate tests (Table S2), and full summary statistics for each of the performed test are available in the supplementary material and GWAS catalog.
Associations between identified SNPs and common oral and metabolic traits
Variants, identified by GWAS as being significantly associated to univariate and multivariate bacterial features, were queried in publicly available European ancestry GWAS datasets of blood pressure, cardiometabolic disease, glycemic traits, oral health traits and traditional lipids59,60,61,62,63,64(Table S3). The phenotype sets were selected based on the findings from previously published observational associations between oral microbiota composition and lifestyle traits in the same cohort34. Z scores (beta/standard error) were extracted from all summary statistics and aligned to the effect allele. The P-value was considered suggestive at 0.05 and significant at 0.05 after FDR correction65.
Ethical approval
The ADDITION-PRO study was approved by the Scientifics Ethics Committee in the Central Denmark Region (20000183). All studies were conducted in accordance with the principles of the Declaration of Helsinki.
Data availability
16S rRNA sequencing data for the full Addition-PRO study (n = 745) has been deposited in the European Nucleotide Archive (ENA) at EMBL-EBI under accession number PRJEB57196 (https://www.ebi.ac.uk/ena/browser/view/PRJEB57196). GWAS summary statistics (N = 44) have been uploaded to EMBL-EBI GWAS catalog66 under study accession numbers GCST90429799-GCST90429842. The raw data are not publicly available due to privacy or ethical restrictions.
References
Deo, P. N. & Deshmukh, R. Oral microbiome: Unveiling the fundamentals. J. Oral Maxillofac. Pathol. JOMFP 23, 122–128 (2019).
Dewhirst, F. E. et al. The human oral microbiome. J. Bacteriol. 192, 5002–5017 (2010).
Wade, W. G. The oral microbiome in health and disease. vol. 69 137–143 Preprint at https://doi.org/10.1016/j.phrs.2012.11.006 (2013).
Petersen, P. E. & Ogawa, H. The global burden of periodontal disease: Towards integration with chronic disease prevention and control. Periodontology 2000(60), 15–39 (2012).
How, K. Y., Song, K. P. & Chan, K. G. Porphyromonas gingivalis: An overview of periodontopathic pathogen below the gum line. Front. Microbiol. 7, 53 (2016).
Seymour, G. J., Ford, P. J., Cullinan, M. P., Leishman, S. & Yamazaki, K. Relationship between periodontal infections and systemic disease. Clin. Microbiol. Infect. Off. Publ. Eur. Soc. Clin. Microbiol. Infect. Dis. 13(Suppl 4), 3–10 (2007).
Beck, J. D. & Offenbacher, S. Systemic effects of periodontitis: Epidemiology of periodontal disease and cardiovascular disease. J. Periodontol. 76, 2089–2100 (2005).
Koren, O. et al. Human oral, gut, and plaque microbiota in patients with atherosclerosis. Proc. Natl. Acad. Sci. U. S. A. 108(Suppl), 4592–4598 (2011).
Genco, R. J., Grossi, S. G., Ho, A., Nishimura, F. & Murayama, Y. A proposed model linking inflammation to obesity, diabetes, and periodontal infections. J. Periodontol. 76, 2075–2084 (2005).
Janem, W. F. et al. Salivary inflammatory markers and microbiome in normoglycemic lean and obese children compared to obese children with type 2 diabetes. PLOS ONE 12, e0172647 (2017).
Xiao, J., Fiscella, K. A. & Gill, S. R. Oral microbiome: Possible harbinger for children’s health. Int. J. Oral Sci. 12, 12 (2020).
Liu, X. et al. Sex differences in the oral microbiome, host traits, and their causal relationships. iScience 26, 105839 (2023).
Stahringer, S. S. et al. Nurture trumps nature in a longitudinal survey of salivary bacterial communities in twins from early adolescence to early adulthood. Genome Res. 22, 2146–2152 (2012).
Belstrøm, D. et al. Salivary microbiota in individuals with different levels of caries experience. J. Oral Microbiol. 9, 1270614 (2017).
Benítez-Páez, A., Belda-Ferre, P., Simón-Soro, A. & Mira, A. Microbiota diversity and gene expression dynamics in human oral biofilms. BMC Genom. 15, 311 (2014).
Wu, J. et al. Cigarette smoking and the oral microbiome in a large study of American adults. ISME J. 10, 2435–2446 (2016).
Valles-Colomer, M. et al. The person-to-person transmission landscape of the gut and oral microbiomes. Nature 614, 125–135 (2023).
Acton, R. T. et al. Associations of MHC genes with levels of caries-inducing organisms and caries severity in African-American women. Hum. Immunol. 60, 984–989 (1999).
Parks, B. W. et al. Genetic control of obesity and gut microbiota composition in response to high-fat, high-sucrose diet in mice. Cell Metab. 17, 141–152 (2013).
Shaw, L. et al. The human salivary microbiome is shaped by shared environment rather than genetics: Evidence from a large family of closely related individuals. mBio 8, e01237-e1317 (2017).
Mukherjee, C. et al. Acquisition of oral microbiota is driven by environment, not host genetics. Microbiome 9, 54 (2021).
Esberg, A., Haworth, S., Kuja-Halkola, R., Magnusson, P. K. E. & Johansson, I. Heritability of oral microbiota and immune responses to oral bacteria. Microorganisms 8, E1126 (2020).
Gomez, A. et al. Host genetic control of the oral microbiome in health and disease. Cell Host Microbe 22, 269-278.e3 (2017).
Demmitt, B. A. et al. Genetic influences on the human oral microbiome. BMC Genom. 18, 659 (2017).
Kolde, R. et al. Host genetic variation and its microbiome interactions within the Human Microbiome Project. Genome Med. 10, 6 (2018).
Liu, X. et al. Metagenome-genome-wide association studies reveal human genetic impact on the oral microbiome. Cell Discov. 7, 1–16 (2021).
Johansen, N. B. et al. Protocol for ADDITION-PRO: A longitudinal cohort study of the cardiovascular experience of individuals at high risk for diabetes recruited from Danish primary care. BMC Public Health 12, 1078 (2012).
Rühlemann, M. C. et al. Application of the distance-based F test in an mGWAS investigating β diversity of intestinal microbiota identifies variants in SLC9A8 (NHE8) and 3 other loci. Gut Microbes 9, 68–75 (2018).
Yang, J., Lee, S. H., Goddard, M. E. & Visscher, P. M. GCTA: A tool for genome-wide complex trait analysis. Am. J. Hum. Genet. 88, 76–82 (2011).
Neyroud, N. et al. A novel mutation in the potassium channel gene KVLQT1 causes the Jervell and Lange-Nielsen cardioauditory syndrome. Nat. Genet. 15, 186–189 (1997).
Unoki, H. et al. SNPs in KCNQ1 are associated with susceptibility to type 2 diabetes in East Asian and European populations. Nat. Genet. 40, 1098–1102 (2008).
Clos-Garcia, M. et al. Multiomics signatures of type 1 diabetes with and without albuminuria. Front. Endocrinol. 13, 1015557 (2022).
Zaura, E., Keijser, B. J., Huse, S. M. & Crielaard, W. Defining the healthy ‘core microbiome’ of oral microbial communities. BMC Microbiol. 9, 259 (2009).
Poulsen, C. S. et al. Association of general health and lifestyle factors with the salivary microbiota—Lessons learned from the ADDITION-PRO cohort. Front. Cell. Infect. Microbiol. 12 (2022).
Kato, I. et al. Oral microbiome and history of smoking and colorectal cancer. J. Epidemiol. Res. 2, 92–101 (2016).
Ruoff, K. L. Miscellaneous catalase-negative, gram-positive cocci: Emerging opportunists. J. Clin. Microbiol. 40, 1129–1133 (2002).
Baker, J. L. et al. Deep metagenomics examines the oral microbiome during dental caries, revealing novel taxa and co-occurrences with host molecules. 804443 Preprint at https://doi.org/10.1101/804443 (2019).
Maraki, S. & Papadakis, I. S. Rothia mucilaginosa pneumonia: A literature review. Infect. Dis. 47, 125–129 (2015).
Chattopadhyay, I., Verma, M. & Panda, M. Role of oral microbiome signatures in diagnosis and prognosis of oral cancer. Technol. Cancer Res. Treat. 18, 1533033819867354 (2019).
Oral Microbiome Metabolism: From “Who Are They?” to “What Are They Doing?” - N. Takahashi (2015). https://journals.sagepub.com/doi/https://doi.org/10.1177/0022034515606045.
Belstrøm, D. et al. Transcriptional Activity of predominant streptococcus species at multiple oral sites associate with periodontal status. Front. Cell. Infect. Microbiol. 11, 752664 (2021).
Lundberg, J. O., Gladwin, M. T. & Weitzberg, E. Strategies to increase nitric oxide signalling in cardiovascular disease. Nat. Rev. Drug Discov. 14, 623–641 (2015).
Goodrich, J. K., Davenport, E. R., Clark, A. G. & Ley, R. E. The relationship between the human genome and microbiome comes into view. Annu. Rev. Genet. 51, annurev-genet-110711–155532 (2017).
Belstrøm, D. et al. Bacterial profiles of saliva in relation to diet, lifestyle factors, and socioeconomic status. J. Oral Microbiol. 6 (2014).
Xu, X. et al. Oral cavity contains distinct niches with dynamic microbial communities. Environ. Microbiol. 17, 699–710 (2015).
Hansen, T. H. et al. Impact of a vegan diet on the human salivary microbiota. Sci. Rep. 8, 5847 (2018).
Griffin, S. J. et al. Effect of early intensive multifactorial therapy on 5-year cardiovascular outcomes in individuals with type 2 diabetes detected by screening (ADDITION-Europe): A cluster-randomised trial. Lancet Lond. Engl. 378, 156–167 (2011).
Lauritzen, T. et al. The ADDITION study: Proposed trial of the cost-effectiveness of an intensive multifactorial intervention on morbidity and mortality among people with Type 2 diabetes detected by screening. Int. J. Obes. Relat. Metab. Disord. J. Int. Assoc. Study Obes. 24(Suppl 3), S6-11 (2000).
Callahan, B. J. et al. DADA2: High-resolution sample inference from Illumina amplicon data. Nat. Methods 13, 581–583 (2016).
Constancias, F. & Mahé, F. fconstancias/metabaRpipe: v0.9. Zenodo https://doi.org/10.5281/zenodo.6423397 (2022).
McMurdie, P. J., Holmes, S., Kindt, R., Legendre, P. & O’Hara, R. phyloseq: An R package for reproducible interactive analysis and graphics of microbiome census data. PLoS ONE 8, e61217 (2013).
Schnurr, T. M. et al. Genetic Correlation between body fat percentage and cardiorespiratory fitness suggests common genetic etiology. PLOS ONE 11, e0166738 (2016).
Das, S. et al. Next-generation genotype imputation service and methods. Nat. Genet. 48, 1284–1287 (2016).
Purcell, S. et al. PLINK: A tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 81, 559–575 (2007).
Rühlemann, M. C. et al. Genome-wide association study in 8,956 German individuals identifies influence of ABO histo-blood groups on gut microbiome. Nat. Genet. 53, 147–155 (2021).
Moitinho-Silva, L. et al. Host genetic factors related to innate immunity, environmental sensing and cellular functions are associated with human skin microbiota. Nat. Commun. 13, 6204 (2022).
Wang, Y., Naumann, U., Wright, S. T. & Warton, D. I. mvabund—An R package for model-based analysis of multivariate abundance data. Methods Ecol. Evol. 3, 471–474 (2012).
Juliusdottir, T. topr: an R package for viewing and annotating genetic association results. BMC Bioinform. 24, 268 (2023).
Shungin, D. et al. Genome-wide analysis of dental caries and periodontitis combining clinical and self-reported data. Nat. Commun. 10 (2019).
Chen, J. et al. The trans-ancestral genomic architecture of glycemic traits. Nat. Genet. 53, 840–860 (2021).
Malik, R. et al. Multiancestry genome-wide association study of 520,000 subjects identifies 32 loci associated with stroke and stroke subtypes. Nat. Genet. 50, 524–537 (2018).
Aragam, K. G. et al. Discovery and systematic characterization of risk variants and genes for coronary artery disease in over a million participants. Nat. Genet. 54, 1803–1815 (2022).
Mahajan, A. et al. Multi-ancestry genetic study of type 2 diabetes highlights the power of diverse populations for discovery and translation. Nat. Genet. 54, 560–572 (2022).
Jurgens, S. J. et al. Adjusting for common variant polygenic scores improves yield in rare variant association analyses. Nat. Genet. 55, 544–548 (2023).
Bland, J. M. & Altman, D. G. Multiple significance tests: The Bonferroni method. BMJ 310, 170 (1995).
Sollis, E. et al. The NHGRI-EBI GWAS catalog: Knowledgebase and deposition resource. Nucleic Acids Res. 51, D977–D985 (2023).
Acknowledgements
We thank the technical staff in our lab, in particular Annemette Forman and Tina Hvidtfeldt Lorentzen. Furthermore, we thank Niels Erik Fiehn for providing paraffin wax and the saliva collection protocol. We are grateful to all GWAS consortia for making data available on metabolic traits and cardiovascular outcomes, including UK Biobank, DIAGRAM, CARDIoGRAMplusC4D, METASTROKE, MAGIC and Glide consortia. Data were downloaded via weblinks listed in Supplementary Table 3.
Funding
The ADDITION-PRO study was funded by an unrestricted grant from the European Foundation for the Study of Diabetes/Pfizer for Research into Cardiovascular Disease Risk Reduction in Patients with Diabetes (74550801), by the Danish Council for Strategic Research and by internal research and equipment funds from Steno Diabetes Center Copenhagen and The Novo Nordisk Foundation (grant number NNF18CC0034900).
Author information
Authors and Affiliations
Contributions
Conceptualization and planning of the study: TK, NG, MA, OP, TH. Data collection and curation: DW, OP, TH. Formal analysis and visualization: ES. Methodology: TK, ES, DiB, ALM, CSP, NN, DaB, MS. Writing—original draft: ES. Writing—review and editing: All authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Stankevic, E., Kern, T., Borisevich, D. et al. Genome-wide association study identifies host genetic variants influencing oral microbiota diversity and metabolic health. Sci Rep 14, 14738 (2024). https://doi.org/10.1038/s41598-024-65538-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-65538-8
- Springer Nature Limited