
Abstract
This research endeavors to prognosticate gender by harnessing the potential of skull computed tomography (CT) images, given the seminal role of gender identification in the realm of identification. The study encompasses a corpus of CT images of cranial structures derived from 218 male and 203 female subjects, constituting a total cohort of 421 individuals within the age bracket of 25 to 65 years. Employing deep learning, a prominent subset of machine learning algorithms, the study deploys convolutional neural network (CNN) models to excavate profound attributes inherent in the skull CT images. In pursuit of the research objective, the focal methodology involves the exclusive application of deep learning algorithms to image datasets, culminating in an accuracy rate of 96.4%. The gender estimation process exhibits a precision of 96.1% for male individuals and 96.8% for female individuals. The precision performance varies across different selections of feature numbers, namely 100, 300, and 500, alongside 1000 features without feature selection. The respective precision rates for these selections are recorded as 95.0%, 95.5%, 96.2%, and 96.4%. It is notable that gender estimation via visual radiography mitigates the discrepancy in measurements between experts, concurrently yielding an expedited estimation rate. Predicated on the empirical findings of this investigation, it is inferred that the efficacy of the CNN model, the configurational intricacies of the classifier, and the judicious selection of features collectively constitute pivotal determinants in shaping the performance attributes of the proposed methodology.
Similar content being viewed by others

Introduction
Gender estimation of the human skeleton has an important place in forensic science, anatomy, physical anthropology, and archeology1. Morphological differences between male and female skeletons begin to develop before birth and continue to increase during childhood and adolescence, increasing the skeleton's sensitivity to sex determination2. Gender determination draws attention as the first and most important point in identification3. There are bones that have been studied many times and proven to be reliable for sex determination. Of these bones, the skull, pelvis, and long bones are the most studied4,5,6. In cases where the pelvis, skull, and long bones are damaged and examination is difficult, gender estimation is attempted with less dimorphic parts of the human skeleton7,8. The skull bone is among the preferred bones for sex prediction because it is dimorphic and cannot be generalized with other papules9.
Although DNA technologies are seen as the most reliable method in determining gender, they also have disadvantages such as accessibility, time consumption, need for qualified personnel, and cost. For this reason, easy-to-access, low-cost, high-accuracy, easily accessible, fast, and non-expertise methods such as osteometry have started to be preferred in gender estimation10,11. Generating a gender prediction model relies on solving a classification task, and this classification is one of the most frequently performed exploratory tasks in ML algorithms. ML assists forensic teams, anatomists, and anthropologists in many ways in areas such as crime prevention, individual identity analysis, forensic cybersecurity, forensic computing, and forensic criminology12,13. Machine learning (ML) is a specialized method of data analysis that automates model building with machines that learn to use certain algorithms14.
Deep learning is one of the artificial learning approaches based on convolutional neural network models, also known as multilayer neural networks. In this learning model, deep features are mentioned instead of traditional object features. Today, it has been revealed that many systems are developed using deep learning approaches and they give more successful results in modeling complex systems15,16. A convolutional neural network (CNN) is one of the deep learning methods for image analysis. It is a feedforward neural network that is widely used in fields such as image analysis, natural language processing, and other complex image classification problems. It has a unique structure in that it can select and perceive patterns from images and texts and make sense of them. Each developed architecture usually has a different number of layers, and each data processed in these layers generates input data for the next layer(s). While data is convoluted between successive layers of some architectural models, in some layers, input data can be generated to a non-consecutive layer at another level17,18.
The determination of gender is crucial in forensic anthropology for positive identification. There are remarkable number of studies which analysis human bone structures to identify gender. Artificial Intelligence methods such as Backpropagation Neural Network (BPNN) offer potentially more accurate results than Discriminant Function Analysis (DFA). Afrianty et al.19 proposes a BPNN model and compares its accuracy with DFA using pelvic bones and patella data. It is said that compared to DFA, BPNN provides superior accuracy, making it a promising tool for gender determination in forensic anthropology. The identification of gender from incomplete skeletal or decomposing human remains holds significant importance in personal identification. Studies have demonstrated that the lengths of hand bones exhibit sexual dimorphism across various populations. However, as the accuracy of discriminant function equations in gender determination varies based on the population20. Gentil and Mello21 investigate the significance of anatomy in human identification, particularly emphasizing the value of anatomical understanding regarding head, neck bones, and teeth in sex estimation within routine forensic anthropology practices. Metric analyses rooted in anatomy offer dependable precision in determining sex. Comprehensive training and anatomical comprehension can mitigate biases and discrepancies among observers, while employing three-dimensional models and computed tomography images can further augment the precision of these techniques for sex estimation. In forensic investigations, challenges arise when estimating the height and gender of bodies dismembered in mass disasters. To address these challenges, novel methods are being devised. Zeybek et al.22 aim to create formulas for estimating height and gender based on foot measurements when required. Christina-Schulte et al.23 examined flat-panel volumetric computed tomography for estimating the age at death in forensic or anthropological contexts using human skull analysis. They explored the variations dependent on sex. The Table 1. below compares this study with prominent studies in the literature.
Our approach is based on the application of deep learning techniques for the analysis of head CT images, namely deep convolutional neural networks (CNN), which have proven to be very successful in various image analysis tasks. The main advantage of deep convolutional neural networks is the ability to learn features and patterns in data without any prior knowledge or context through parameter optimization. On the other hand, the training of the network needs to be supported by a sample image database containing all possible image variations. This makes the quality and volume of the image database an important factor when designing such systems. Therefore, the hypothesis of this research was determined as "gender estimation can be made using skull computed tomography (CT) images".
In the remainder of the study, information about the relevant dataset and the developed method is presented under the heading of materials and methods. In the next section, experiments and observations are carried out. In the discussion section, the study is examined with reference to the literature. In the last section, the results of the study are discussed.
Materials and methods
Participants and study design
We performed a power analysis using a significance level (α) of 0.05, power (1 − β) of 0.80, an effect size of 0.02, and actual power = 80.0 the analysis indicated that a minimum of 395 subjects would be needed in our study. The study consists of CT images of the skull of 218 male and 203 female individuals (421 total persons) aged between 25 and 65 who applied to Bandırma 17 Eylül University Training and Research Hospital between 01.01.2020 and 20.07.2022. Participants who had a skull trauma, had a lesion on the skull, had a syndrome affecting the skull, had a developmental disorder affecting the cranium, and had an operation on the skull that would affect the images were not included in the study. In addition, cross-sectional cranium and unclear CT images were excluded from the study. Within the scope of this research, necessary permissions were obtained from Bandırma Onyedi Eylul University Health Sciences Institute Non-Interventional Ethics Committee with the decision number 2022/113. All participants were given necessary information about the purpose and importance of the research. It was informed that CT images will only be used in this study. Written permission was obtained from all participants. The research was conducted in accordance with the principles set out in the Declaration of Helsinki.
Imaging (visualization) methods
In the study, cranial (CT) images taken from the GE (Optima 660-128 Section, Germany) Tomography device were taken from the hospital's imaging archive (PACS). CT was performed in the supine position, with scan time of 1.5 s, 120 kV and 150 mA, 5 mm interval and 5 mm thickness in the posterior fossa, 10 mm interval and 10 mm thickness in the supratentorial region, upwards starting from the posterior fossa. DICOM format retrospectively and transferred to medical image imaging software (Horos medical image viewer Version 3.0, USA). Sagittal, transversal and coronal images were obtained from the transferred images using 3D Curved Multiplanar Reconstruction (MPR). Sagittally acquired images were labeled for gender. Cranial CT images of the patients were recorded in jpeg format in the sagittal plane. Since satisfactory success was achieved without data augmentation in the empirical experiments conducted on the existing data set, augmentation is not applied. The dataset specifications have been demonstrated in the following Table 2.
Deep features and learning models
In the classical feature extraction approach, before the features are obtained, the data is denoised, smoothed, etc. may be pre-processed. These features are obtained by using external feature extractor methods on data such as image, text, or sound. For example, extracting vertex information as a feature on an image data can be an example of this situation. The obtained features are then used to train and test a classifier method. As can be seen, many operations are performed in traditional approaches from feature extraction and use. Deep features are extracted from next-generation layered neural network models such as the convolutional neural network model (CNN). These features are obtained from the final fully connected layers of the CNN model and are processed in layers such as convolution, pooling, normalization, and fully connected layers until they reach this layer. The features of the CT images within the scope of the study were also obtained from the pre-trained CNN models.
The basis of CNN models was first developed by Lecun et al.24 as a work called LeNet. The developed model consists of a structure consisting of multi-layered neural network structures and is trained with a gradient-based learning algorithm. It is stated that with the study, various parameter inferences made with the skull can be automated. In this study, features of CT images were extracted using AlexNet, ResNet-101, and EfficientNetb0 models, which are known as pre-trained CNN models. These pre-trained networks refer to the networks trained and tested against 1000 classes in the ImageNet competition. Therefore, the number of extracted features for each data (CT image) is also 1000.
The CNN models with three different structures were selected within the scope of the study: AlexNet, ResNet and EfficientNet. In these models, especially the smaller number of parameters makes the models less costly in the feature extraction process. On the other hand, each of these models was chosen to observe the effect of different layer structures. While AlexNet architecture is a purer model, ResNet-101 stands out with its Residual layer. The EfficientNet architecture was chosen because the depth of the network increased but the complexity was maintained. Empirical pre-tests were also effective in the selection of each model.
The AlexNet model25 is one of the pioneers of modern CNN models that are widely used today. The model has a total of 25 layers, including 5 convolutional and 3 fully connected layers. The ResNet model26 is a model known as the residual network, which includes jump and short-path connections between some layers. The development of ResNet was inspired by pyramidal cells in the cerebral cortex. There are different variants of the ResNet model, the ResNet-101 model was used in this study. The EfficientNet model27 is an architectural model that systematically adjusts the depth, width, and resolution of the network. The AutoML MNAS (Automated Machine Learning Mobile Neural Architecture Search) structure included in the architecture performs a genetic architecture search to optimize performance. The following Fig. 1 summarizes the structure of a general CNN architecture.

A conventional CNN architecture.
Classification
Classifier methods use the features obtained from the data to separate the data into classes with different labels according to supervised or unsupervised learning approaches. Each classifier has different kernel functions, mathematical models, etc. It tries to categorize data using The last layer of pre-trained CNN models uses the SoftMax classifier28. Within the scope of the study, the SoftMax classifier was removed and different classifiers were added instead. For this purpose; the Support Vector Machine (SVM) classifier and neural network classifiers are used.
The SVM classifier29 is a widely used classifier to separate the two classes. It is generally used for classification problems, but it is also used in regression analysis. The SVM classifier can also work if the number of classes is more than two. The SVM classifier searches for a hyperplane that can best separate the classes in multidimensional space. It tries to optimize this hyperplane iteratively to minimize the error. SVM classifier using linear, quadratic, and cubic kernel functions was used in the study. The equation for the dual version of the general SVM method is given in Eq. (1) below.
The neural network classifier30 was developed in a layered structure inspired by the way the brain works. Each layer in the structure contains weighted neurons that take vector sizes as input. Neurons produce an output using the activation function and the produced outputs are sent to the next layer. Neural networks are often described as feed-forward. Output produced in one unit feeds all units in the next layer. There is no feedback to the previous layer in this structure. However, the neuron weights are updated in each iteration where the input data is processed. In the study, a neural network classifier that uses ReLU, Sigmoid, Tanh as activation functions and does not use activation function was used.
Feature selection and fusion
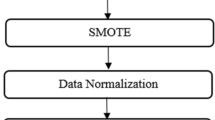
Feature selection is used to choose among those that best represent the data. The main purpose of feature selection is to satisfactorily train the classifier with fewer features. On the other hand, the training and testing process of the classifier will be shorter with fewer features. However, it should be noted that the performance may decrease with the decrease of the feature. The whole process of the proposed method is summarized in the figure below. In the figure, the term FCL is 'Fully Connected Layer', the term FSM is 'Feature Selection Method' and the term M/F is 'Male/Female' (Fig. 2).

Overall proposed method.
The ReliefF method, on the other hand, is a feature selector that works according to the relief31 algorithm. ReliefF is based on a "neighbor number" \(k\), which indicates the \(k\) closest hits and \(k\) closest miss usage in the scoring update for each target sample. This parameter is determined by the user. Close misses and close hits are found using the Manhattan (L1) norm. This increases the weight estimation reliability, especially in noisy problems. It is calculated according to Eq. (2) below, with \(W[{f}_{j}]\) being the weight \({f}_{j}\)26.
For the \({i}^{th}\) sample in the dataset, with the value of the \(f\) property \({Z}_{i}[f]\), \(Hi{t}_{j}\) and \(Mis{s}_{j}\) are \({j}^{th}\) closest hit and \({j}^{th}\) closest loss, respectively. The distance between the \({f}_{j}\) values in \(A\) and \(B\) is \(diff(A[{f}_{j}],B[{f}_{j}])\). The distance value is zero when the values for the nominal characteristics are equal, and one otherwise. Equal to \((A[{f}_{j}]-B[{f}_{j}])/\Gamma \) for numeric properties; The \(\Gamma \) parameter is the range of possible values.
Ethics approval and consent to participate
Institutional Review Board Statement: This study was conducted at Bandırma Onyedi Eylul University Health Sciences Institute Non-Interventional Ethics Committee, according to the principles outlined Declaration of Helsinki. Ethics committee approval was obtained from Bandırma Onyedi Eylul University Health Sciences Institute Non-Interventional Ethics Committee Ethics Committee (Date: 2022, number: 2022/113). All experimental protocols were approved by the Institute’s Clinical Research Ethics Committee.
Results
Experiment configuration
The study was performed using MATLAB 2021A version development environment on a computer with i7 10700 processor, 16 GB memory, 4 GB GPU, and 240 GB SSD hardware capacity and configured with Windows 10 Pro operating system. The MATLAB environment has been used to model overall proposed system except pre-trained CNN models which are employed as feature extractors.
Two different classifiers, SVM and Neural Network, were used in the experiments. Linear, quadratic and cubic kernel functions were used for SVM. Tanh, Sigmoid, and ReLU activation functions are used for the Neural Network classifier. The case where the activation function is not used in neural networks is also analyzed. Thus, a total of 7 different configurations were run for the 2 classifiers. Testing and validation were carried out with tenfold cross-validation. Features were obtained from the fully connected layers of the AlexNet, ResNet-101 and EfficientNetb0 CNN network models named 'fc8', 'fc1000' and 'efficientnet-b0|model|head|dense|MatMul', respectively. Since these networks are pre-trained networks, 1000 features are extracted for each input data, and all features are used in the classifier training and testing process. The Hyperparameter space for training options basic CNN model have been demonstrated in the following Table 3.
Performance metrics
For performance analysis in the experiments, accuracy, precision, sensitivity, quality index (QI), and F-score performance metrics were calculated by using the complexity matrix given in Fig. 1 below (Fig. 3).

Confusion matrix.
TP (True Positive) in the figure—positive class predicted by the classifier (grade 1), FP (False Positive)—incorrectly predicted by the classifier (class 1), FN (False Negative)—negative class predicted incorrectly by the classifier (class 2) and TN (True Negative)—are negative class (class 2) values that the classifier predicts correctly. The Eqs. (3, 4, 5, 6, and 7) given below are used to calculate performance metrics. TT parameter corresponds to training time for a classifier model. The tenfold cross-validation is used to evaluate overall performance.
Experimental results
In experimental studies, features obtained from three different CNN architectures were used to train and test SVM and Neural Network classifiers. Classifier configurations were created with three kernel functions in the SVM classifier. SVM configurations are mentioned in Table 4 below.
In the equations given above, \(x, {x}_{j}\) represents the data that is tried to be classified. \(c\ge 0\) is a free parameter, free from the influence of higher-order lower-order terms in the polynomial. When \(c=0\), the nucleus is said to be homogeneous.
In the neural network, there are four different activation function configurations according to the use case. The following Table 5 shows the neural network parameter settings and the activation functions used in the configurations.
The \(x\) parameter in the activation functions given above represents the input value of the neuron. While the activation function is used in the three cases above, in the last case, the input values are given directly without using the activation function in the neural network. The configuration of Neural Network classifier is made according to common usage approach in the literature. This provides balance between the performance and time complexity. In the experiments it is seen that the ReLU activation function increases the classification accuracy.
In the table below, the performance metric values of the classifiers obtained when the features extracted from the AlexNet CNN model are used are given (Table 6). While the best accuracy (Acc.) value was 93.3% with the QSVM classifier, precision, sensitivity, quality index (QI) and F-Score values were 93.1%, 93.6%, 93.3%, and 93.6% respectively (Table 7).
ROC (Receiver Operating Characteristic) curves with the best performance values for the AlexNet network are given in Fig. 4 below. The ROC curve shows that the QSVM classifier, which has the most successful classification result in the AlexNet CNN model, has a better ability to classify the data of male subjects than females.

ROC curves of QSVM with AlexNet features.
In the Tables 8 and 9, the confusion matrix for ResNet-101 and performance metric values of the classifiers obtained when the features extracted from the ResNet-101. CNN model are used are given. While the best accuracy value (Acc.) was 94.3% with the QSVM classifier, precision, sensitivity, quality index (QI) and F-Score values were 93.2%, 95.3%, 94.3%, and 94.4% respectively (Table 9).
ROC curves with the best performance values for the ResNet-101 network are given in Fig. 5 below. The ROC curve shows that the QSVM classifier, which has the most successful classification result in the ResNet-101 CNN model, has a better ability to classify data of female subjects than males.

ROC curves of QSVM with ResNet-101 features.
The following Table 10 shows the Confusion Matrix for EfficientNet-b0 features and Table 11 shows the performance metrics of the classifiers obtained when the features extracted from the EfficientNet-b0 CNN model are used. While the best accuracy (Acc.) value was 96.4% with the CSVM classifier, precision, sensitivity, quality index (QI) and F-Score values were 96.1%, 96.8%, 96.4%, and 96.6% respectively (Table 11).
ROC curves with the best performance values for the EfficientNet-b0 network are given in Fig. 6 below. The ROC curve shows that the QSVM classifier, which has the most successful classification result in the EfficientNet-b0 CNN model, has a better ability to classify the data of female subjects than males.

ROC curves of CSVM with EfficientNet-b0 features.
In the table below, the features extracted from the CNN models were selected using the Relief F method. In this context, the best hundred features were determined. With the determined features, the classifier configurations that showed the best performance in SVM and neural network were analyzed. In Tables 12 and 13 below, the confusion matrix and performance metric values that emerged in the tests performed on 100 features selected from among the features extracted from the CNN models are given. While the best accuracy (Acc.) for 100 feature selection was 95.0% with the CSVM classifier in the EfficientNetb0 CNN model, precision, sensitivity, quality index (QI) and F-Score values were 95.1%, 95.0%, 95.0%, and 95.2%, respectively.
In order to see the effect of different feature selections in the EfficientNetb0 CNN model, which provides the most successful classification performance in feature selection, 300 and 500 feature selections were made in addition to 100 feature selection. In the table below, the confusion matrix and performance metric values that emerge when choosing different features and using all features are given. The NoF value in the table is an abbreviation of 'Number of Features'.
Accuracy performances in 100, 300, 500 selections of feature numbers and 1000 features without feature selection were 95.0%, 95.5%, 96.2% and 96.4%, respectively. There is a 1.4% difference between the lowest feature selection and the no feature selection. This shows that remarkable success has been achieved even with only 100 features. It is seen that 95.7% success is achieved with the ReLU activation function of the neural network classifier in the selection of 300 features. On the other hand, in the selection of 500 features, the performance was very close to the situation where the feature selection was not made (0.2% difference). It is observed that the accuracy and other performance metric values generally increase as the number of features increases in feature selection (Tables 14 and 15).
Discussion
Anatomical structures in the human body provide important clues in gender analysis. Experts evaluate the output result based on the measurement data they take over the anatomical components of the human body in estimating gender. However, the evaluation and interpretation of the measurements turn out to be a time-consuming task. It is possible to accelerate expert evaluation with computer-aided decision support systems. In this context, three widely known CNN models were used as feature extractors in the study. Extracted features are used as inputs in the training and testing processes of SVM and neural network classifiers instead of the SoftMax classifier. It has been observed that the performance of SVM and neural network classifiers reaches over 96% in different configurations. It is possible to speed up the training and testing processes by catching remarkable rates in performance by reducing the number of features by choosing from among the features. In the experiments conducted for this purpose, it has been determined that the performance reaches 95% even when only 100 features are used. In the observations made in terms of the features that directly affect the classifier performances in the experiments, it has been determined that the best feature extractor model is EfficientNetb0. In order to make a more detailed observation of the feature selections extracted from this model, the 300 and 500 states were added to the feature selection. It was observed that the performance was realized at high rates in these feature selections. While the classifier performance is at a remarkable level with feature selection, it can be stated that resources are used more efficiently because less data is used for classifier training. In this study, it was aimed to predict gender using a deep learning method from machine learning algorithms using cranium CT images. An accuracy value of 96.4% was found according to the deep learning algorithm from the machine learning approaches tested. In the study, 96.1% of 216 men and 96.8% of 202 women were estimated correctly. When we examine the low rate of misclassified data, it should be said that the images also contain CT information that may lead to misclassification. There is also the potential to increase performance even further if such noise is eliminated. In Fig. 7 below, the major performance metrics against the number of features in the EfficientNetb0 model, which is the most successful feature extractor model, are shown graphically.

Change in performance metrics versus change in the number of features.
Gender determination draws attention as the first and most important point in identification3. There are bones that have been studied many times and proven to be reliable for sex determination4,5,32. The pelvis and skull are known as the most dimorphic skeletal parts and form the basis of sex determination research33. Different methods have been reported in the literature for the evaluation of skull bones in terms of dimorphism. Sex determination from these methods has traditionally been done either by visual assessment based on the morphological features presented by the various bones of the craniofacial structures, or by morphometric methods using linear and/or angular dimensions34,35. In our study, we estimated gender from skull images. Gender estimation from visual radiography eliminated the measurement difference between experts and provided us with a shorter estimation rate.
Cranial CT imaging gives more accurate measurement values in a shorter time than other morphological measurement methods (caliper, odontometer, digital distance meter)36,37. Imaizumi et al.38 made a gender estimation by measuring from various points on the CT image and determined the accuracy as 90% (bias-2.3) and 88.3% (bias-5.5), respectively. Other authors have found similar results. With their most precise model after cross-validation, Franklin et al.39 achieved 90% accuracy and − 2.1 deviation, and Zaafrane et al.40 achieved an accuracy of 90.04% and a bias of − 2.9% without cross-validation. These differences in results can be explained by the fact that the assessment of sexually dimorphic traits depends on group-specific standards and skeletal traits differ between different populations, as well as differences in methodological methods and statistical analyzes used. In our study, we only used a deep learning algorithm over images and found the accuracy rate to be 96.4%. This rate was found to be higher than the prediction accuracy in the literature. This situation proves the reliability of our study. The sample of our research consists only of individuals of Turkish ethnic origin. It is thought that studies involving participants from different ethnic origins will contribute to the literature.
Conclusions
In this study, a computer-aided decision support system is proposed to determine gender from the skull. In this system, machine learning-based deep learning models took data as input and features were obtained from fully connected layers. In the tests made with SVM and Neural network classifiers, the final performance was 96.4% without feature selection and 95.0% in the lowest number of feature selections when feature selection was made. Based on these results, it can be said that the CNN model, Classifier configuration, and feature selection are critical factors in the formation of performance values.
In the future, it is aimed to develop a parameter setting optimization module for automating the CNN model and model parameters, classifier configuration, and feature selection. In future studies, it is also aimed to determine gender by making use of other anatomical components as well as skull images used in the study.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Pásztor, E. Anatomy of the skull. Orvostort. Kozl. 56, 97–119 (2010).
Iscan, M. Y., Kennedy, K. A. R. Reconstruction of Life from the Skeleton (Wiley, 1989).
Eshak, G. A., Ahmed, H. M. & Abdel Gawad, E. A. M. Gender determination from hand bones length and volume using multidetector computed tomography: A study in Egyptian people. J. Forensic Leg. Med. 18, 246–252. https://doi.org/10.1016/j.jflm.2011.04.005 (2011).
Best, K. C., Garvin, H. M. & Cabo, L. L. An investigation into the relationship between human cranial and pelvic sexual dimorphism. J. Forensic Sci. 63, 990–1000. https://doi.org/10.1111/1556-4029.13669 (2018).
Gómez Pellico, L. & Fernández Camacho, F. J. Biometry of the anterior border of the human hip bone: Normal values and their use in sex determination. J. Anat. 181, 417–422 (1992).
Rogers, T. L. Determining the sex of human remains through cranial morphology. J. Forensic Sci. 50, 493–500 (2005).
MacLaughlin, S. M. & Oldale, K. N. M. Vertebral body diameters and sex prediction. Ann. Hum. Biol. 19, 285–292. https://doi.org/10.1080/03014469200002152 (1992).
Spradley, M. K. & Jantz, R. L. Sex estimation in forensic anthropology: Skull versus postcranial elements. J. Forensic Sci. 56, 289–296. https://doi.org/10.1111/j.1556-4029.2010.01635.x (2011).
Toy, S. et al. A study on sex estimation by using machine learning algorithms with parameters obtained from computerized tomography images of the cranium. Sci. Rep. 12, 4278. https://doi.org/10.1038/s41598-022-07415-w (2022).
Giurazza, F., Schena, E., Del Vescovo, R., Cazzato, R. L., Mortato, L., Saccomandi, P., Paternostro, F., Onofri, L., Zobel, B. B. Sex determination from scapular length measurements by CT scans images in a caucasian population. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) 1632–1635 (2013).
Öner, S., Turan, M. & Öner, Z. Estimation of gender by using decision tree, a machine learning algorithm, with patellar measurements obtained from MDCT images. Med. Rec. 3, 1–9. https://doi.org/10.37990/medr.843451 (2021).
Ariu, D., Giacinto, G., Roli, F. Machine learning in computer forensics (and the lessons learned from machine learning in computer security). In Proceedings of the Proceedings of the 4th ACM Workshop on Security and artificial intelligence 99–104 (Association for Computing Machinery, 2011).
Awais, M., Naeem, F., Rasool, N. & Mahmood, S. Identification of sex from footprint dimensions using machine learning: A study on population of Punjab in Pakistan. Egypt. J. Forensic Sci. 8, 72. https://doi.org/10.1186/s41935-018-0106-2 (2018).
Bhardwaj, R., Nambiar, A. R., Dutta, D. A study of machine learning in healthcare. In Proceedings of the 2017 IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), vol. 2, 236–241 (2017).
Akhlaghi, M., Bakhtavar, K., Bakhshandeh, H., Mokhtari, T., Farahani, M., Vida, A., Mehdizadeh, F., Sadeghian, M. H. Research paper: Sex determination based on radiographic examination of metatarsal bones in Iranian population ABSTRACT. 7, 203–208 (2017).
Darmawan, M. F., Yusuf, S. M., Abdul Kadir, M. R. & Haron, H. Comparison on three classification techniques for sex estimation from the bone length of Asian children below 19 years old: An analysis using different group of ages. Forensic Sci. Int. 247(130), e1-130.e11. https://doi.org/10.1016/j.forsciint.2014.11.007 (2015).
Dayal, M. R. & Bidmos, M. A. Discriminating sex in South African blacks using patella dimensions. J. Forensic Sci. 50, 1294–1297 (2005).
du Jardin, Ph., Ponsaillé, J., Alunni-Perret, V. & Quatrehomme, G. A comparison between neural network and other metric methods to determine sex from the upper femur in a modern French population. Forensic Sci. Int. 192(127), e1-127.e6. https://doi.org/10.1016/j.forsciint.2009.07.014 (2009).
Afrianty, I., Nasien, D., Kadir, M. R., Haron, H. Determination of gender from pelvic bones and patella in forensic anthropology: A comparison of classification techniques. In 2013 1st International Conference on Artificial Intelligence, Modelling and Simulation, 3–7 (IEEE, 2013). https://doi.org/10.1109/AIMS.2013.9.
Eshak, G. A., Ahmed, H. M. & Gawad, E. A. A. Gender determination from hand bones length and volume using multidetector computed tomography: A study in Egyptian people. J. Forensic Leg. Med. 18(6), 246–252. https://doi.org/10.1016/j.jflm.2011.04.005 (2011).
Mello-Gentil, T. & Souza-Mello, V. Contributions of anatomy to forensic sex estimation: Focus on head and neck bones. Forensic Sci. Res. 7(1), 11–23. https://doi.org/10.1080/20961790.2021.1889136 (2022).
Zeybek, G., Ergur, I. & Demiroglu, Z. Stature and gender estimation using foot measurements. Forensic Sci. Int. 181(1–3), 54-e1 (2008).
Schulte-Geers, C. et al. Age and gender-dependent bone density changes of the human skull disclosed by high-resolution flat-panel computed tomography. Int. J. Leg. Med. 125, 417–425 (2011).
Lecun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324. https://doi.org/10.1109/5.726791 (1998).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet classification with deep convolutional neural networks. Commun. ACM 60, 84–90. https://doi.org/10.1145/3065386 (2017).
He, K., Zhang, X., Ren, S., Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 770–778 (2016).
Tan, M., Le, Q. V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (2020).
Bridle, J. S. Training stochastic model recognition algorithms as networks can lead to maximum mutual information estimation of parameters. In Proceedings of the Proceedings of the 2nd International Conference on Neural Information Processing Systems 211–217 (MIT Press, 1989).
Cortes, C. & Vapnik, V. Support-vector networks. Mach. Learn. 20, 273–297. https://doi.org/10.1007/BF00994018 (1995).
Richard, M. D. & Lippmann, R. P. Neural network classifiers estimate bayesian a posteriori probabilities. Neural Comput. 3, 461–483. https://doi.org/10.1162/neco.1991.3.4.461 (1991).
Urbanowicz, R. J., Meeker, M., La Cava, W., Olson, R. S. & Moore, J. H. Relief-based feature selection: Introduction and review. J. Biomed. Inform. 85, 189–203. https://doi.org/10.1016/j.jbi.2018.07.014 (2018).
Xue, Y., Liang, H., Norbury, J., Gillis, R. & Killingworth, B. Predicting the risk of acute care readmissions among rehabilitation inpatients: A machine learning approach. J. Biomed. Inform. 86, 143–148. https://doi.org/10.1016/j.jbi.2018.09.009 (2018).
Soler, A. The human skeleton in forensic medicine (Third Edition). By Mehmet Yaşar Işcan and Maryna Steyn. Springfield, IL: Charles C. Thomas. 2013. 493 Pp. ISBN 978-0-398-08878-1. $70 (Hardcover). Am. J. Phys. Anthropol. 157, 706–707. https://doi.org/10.1002/ajpa.22754 (2015).
Bertsatos, A., Chovalopoulou, M.-E., Brůžek, J. & Bejdová, Š. Advanced procedures for skull sex estimation using sexually dimorphic morphometric features. Int. J. Leg. Med. 134, 1927–1937. https://doi.org/10.1007/s00414-020-02334-9 (2020).
Kalmey, J. K. & Rathbun, T. A. Sex determination by discriminant function analysis of the petrous portion of the temporal bone. J. Forensic Sci. 41, 865–867 (1996).
Loth, S. R. & Henneberg, M. Mandibular ramus flexure: A new morphologic indicator of sexual dimorphism in the human skeleton. Am. J. Phys. Anthropol. 99, 473–485. https://doi.org/10.1002/(SICI)1096-8644(199603)99:3%3c473::AID-AJPA8%3e3.0.CO;2-X (1996).
Secgin, Y., Oner, Z., Turan, M. K. & Oner, S. Gender prediction with parameters obtained from pelvis computed tomography images and decision tree algorithm. Med. Sci. Int. Med. J. 10, 356–356. https://doi.org/10.5455/medscience.2020.11.235 (1970).
Imaizumi, K. et al. Development of a sex estimation method for skulls using machine learning on three-dimensional shapes of skulls and skull parts. Forensic Imaging 22, 200393. https://doi.org/10.1016/j.fri.2020.200393 (2020).
Franklin, D., Cardini, A., Flavel, A. & Kuliukas, A. Estimation of sex from cranial measurements in a western Australian population. Forensic Sci. Int. 229(158), e1-158.e8. https://doi.org/10.1016/j.forsciint.2013.03.005 (2013).
Zaafrane, M. et al. Sex determination of a tunisian population by CT scan analysis of the skull. Int. J. Leg. Med. 132, 853–862. https://doi.org/10.1007/s00414-017-1688-1 (2018).
Acknowledgements
The authors would like to express their grateful to Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R323), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia
Funding
This research was funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R323), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
Conceptualization, R.Ç., A.K., Ö.E., E.D., N.A.S., R.A.; methodology, R.Ç., A.K., Ö.E., E.D.; formal analysis, A.K., Ö.E.; investigation, R.Ç., A.K., Ö.E., E.D., N.A.S., R.A.; writing-original draft preparation, R.Ç., A.K., Ö.E., E.D., N.A.S., R.A.; writing—review and editing, R.Ç., A.K., Ö.E., E.D., N.A.S., R.A.; All authors have read and agreed to the published version of the manuscript. No individual or indemnifiable data is being published as part of this manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Çiftçi, R., Dönmez, E., Kurtoğlu, A. et al. Human gender estimation from CT images of skull using deep feature selection and feature fusion. Sci Rep 14, 16879 (2024). https://doi.org/10.1038/s41598-024-65521-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-65521-3
- Springer Nature Limited