
Abstract
Dementia is a progressive neurological disorder that affects the daily lives of older adults, impacting their verbal communication and cognitive function. Early diagnosis is important to enhance the lifespan and quality of life for affected individuals. Despite its importance, diagnosing dementia is a complex process. Automated machine learning solutions involving multiple types of data have the potential to improve the process of automated dementia screening. In this study, we build deep learning models to classify dementia cases from controls using the Pitt Cookie Theft dataset from DementiaBank, a database of short participant responses to the structured task of describing a picture of a cookie theft. We fine-tune Wav2vec and Word2vec baseline models to make binary predictions of dementia from audio recordings and text transcripts, respectively. We conduct experiments with four versions of the dataset: (1) the original data, (2) the data with short sentences removed, (3) text-based augmentation of the original data, and (4) text-based augmentation of the data with short sentences removed. Our results indicate that synonym-based text data augmentation generally enhances the performance of models that incorporate the text modality. Without data augmentation, models using the text modality achieve around 60% accuracy and 70% AUROC scores, and with data augmentation, the models achieve around 80% accuracy and 90% AUROC scores. We do not observe significant improvements in performance with the addition of audio or timestamp information into the model. We include a qualitative error analysis of the sentences that are misclassified under each study condition. This study provides preliminary insights into the effects of both text-based data augmentation and multimodal deep learning for automated dementia classification.
Similar content being viewed by others


Introduction
Dementia is a complex disease associated with declines in cognitive functions such as memory, thinking, and reasoning. There exists an estimated 47.5 million people globally who are affected by dementia, with some portion demonstrating severe emotional and language impairments1.
The diagnostic process for dementia requires an overall review of the patient’s medical history, genetic testing, psychiatric evaluations, and cognitive assessments, often supplemented by neuroimaging techniques2,3. This multi-faceted nature of dementia diagnosis is complex, leading to growing interest in simplifying the process using more accessible and lower-cost methods4,5,6. Among the cognitive problems caused by dementia, verbal and speech impairments can be easily observed. Therefore, verbal fluency features can serve as a promising diagnostic biomarker7.
One widely used assessment for verbal fluency is to elicit participants’ responses to visual stimuli, measuring their ability to retrieve lexical items. DementiaBank8, the largest publicly available dataset related to dementia, provides such data collected from patients who underwent such assessments. DementiaBank includes audio recordings and text transcripts, serving as a useful resource for machine learning (ML) modeling of dementia.
Prior research efforts have built machine learning models for classifying dementia, with the end goal of creating a screening tool or diagnostic aid. Some studies fine-tuned pre-existing language models9, while others developed models from scratch10. Most prior work focused on singular data types—either audio11,12 or text data13—for model training. Only a few prior studies have explored the synergistic effects of integrating these data types into a single multimodal model 14,15.
In this study, we combined multiple data modalities—audio, text, and timestamps - from DementiaBank to classify dementia using short participant responses to the structured task of describing a picture of a cookie theft. We fine-tuned pre-trained Wav2vec and Word2vec models and tested them with a text-based data-augmentation method: synonym replacement.
The remainder of this paper is structured as follows: Section “Related work” is an overview of relevant literature; Section “Methods and models” provides details of our six experimental models, each crossed with different combinations of data modalities and the data augmentation method; Section “Results” includes our experimental results and discussions; Section “Discussion and conclusion” summarizes our observations and provides future directions for this type of research. To our knowledge, this is the first study to incorporate timestamps with text and audio data for a multimodal approach to automated dementia diagnosis.
Related work
Previous studies have focused on detecting a specific type of dementia, such as Alzheimer’s Disease (AD). Within DementiaBank, the Alzheimer’s Dementia Recognition through Spontaneous Speech (ADReSS) Challenge10 contains multiple shared tasks, allowing researchers to base their methodologies on common datasets for comparative analysis. Prior AD classification techniques in these shared tasks have leveraged fine-tuning of existing models, data augmentation, and feature engineering. Studies that utilized feature engineering10,12,14,16 extracted audio and text features—either manually or through existing models—and trained models on a binary classification task.
Other studies have fine-tuned pre-trained language models like BERT17 and obtained high performances13,16. Data augmentation strategies including audio and text augmentation techniques (noise, lexical substitution, and paraphrasing) were also applied to handle the challenges associated with data sparsity15.
In addition to aiming for high performance in classification tasks, an important objective is to identify features that can assist with AD diagnosis in clinical settings. Some studies emphasized various semantic and lexico-syntactic features such as the proportion of personal pronouns and average sentence length16.
Beyond the ADReSS Challenge, researchers have also explored the Pitt Corpus18 within DementiaBank. Some studies constructed models from scratch19 while others leveraged pre-existing models20. Among these, some studies solely used text transcripts21, while others focused exclusively on audio recordings22. Only a few integrated multiple modalities, including both audio and text data14,23,24.
To summarize, it has been suggested in the existing literature that a multimodal approach that integrates different types of data, such as audio, text, and timestamps, can potentially lead to a more effective approach to the classification of dementia. Traditional methods often relied on a single data type, which may not capture the complexity of the condition. Although some studies reviewed above have used multiple modalities and suggested that embedding-based models can be promising23,24, further examination is needed to understand the synergistic performance of multiple embedding models, particularly across audio and text modalities. We hypothesized that the combination of Wav2vec and Word2Vec, two popular embeddings that have not yet been explored for dementia classification to the best of our knowledge, might classify dementia more effectively than using either feature extractor alone.
Methods and models
We evaluated two data modalities, audio and text, as well as text-based synonym data augmentation and the inclusion of timestamps as a model input.
Datasets and data preprocessing
Data source
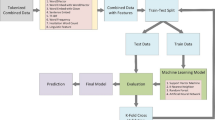
We used the “Pitt Cookie Theft” dataset from DementiaBank18. This dataset contains participants’ responses when they were asked to describe what they saw in a stimulus photograph depicting a cookie theft. We selected this dataset because it contains timestamps for each word, allowing us to study the incorporation of an explicit time representation - analogous to positional embeddings in many large language models. It should be noted that the dataset also included a few non-AD patients, with conditions such as Parkinson’s and depression. We kept these datapoints because their relatively small proportion was not expected to affect the dataset’s overall representation of AD patients.
Data preparation
Because participant descriptions of of the cookie theft image tended to be brief, both audio and text data were divided into individual sentences, with each sentence being considered as a single datapoint. There were a total of 9447 such datapoints, of which 3873 were from dementia patients and 5574 from controls. The control datapoints were sentences spoken by investigators as well as those spoken by patients in the control data. Dementia datapoints, on the other hand, were sentences spoken by dementia patients.
In order to process audio data, the dataset was first processed through a Wav2vec feature extractor, with similar sampling rates used during the model’s pre-training. The text data underwent tokenization using the index token of a custom dictionary, enabling the mapping of words to their corresponding pre-trained word2vec embeddings in Gensim’s ‘word2vec-google-news-300’25. Words without corresponding embeddings were marked as Out-of-Vocabulary (OOV) and were represented by zero vectors.
We retained the starting times and ending times of each word. The timestamp for the first word in each sentence was normalized to start at 0 and processed as decimal digits.
Four dataset conditions were created:
Original condition: the original dataset with 9447 datapoints, including 3873 dementia and 5574 control datapoints.
Shorts-removed condition: excluded sentences shorter than two words, resulting in 4318 control and 3368 dementia datapoints.
Original-augmented condition: augmented from the dataset in the Original Condition, leading to 31,273 control and 22,664 dementia datapoints.
Shorts-augmented condition: augmented from the dataset in the Short-Removed Condition, yielding 28,964 control and 22,039 dementia datapoints.
For all four conditions, the datasets were randomly divided into training and test sets using a 4:1 ratio. Furthermore, the training datasets were also split into training and validation segments using a 4:1 ratio. These splits were used to perform fivefold cross-validation with hyperparameter optimization.
Ethics and inclusion statement
Ethical approval was obtained in writing from the DementiaBank (https://dementia.talkbank.org) owners to obtain access to the database. This database has specific ground rules in place, including fundamental data sharing rules, principles, and a code of Ethics of TalkBank designed to protect confidentiality (https://talkbank.org/share/rules.html). All authors have followed the ground rules in using the database for this research. The speech recordings used were handled in strict confidence.
Since our research did not require the collection of new data from live subjects with dementia during the model’s training or evaluation, the requirement for ethical approval by an ethics review committee was not required. We conducted our experiments solely with data from DementiaBank, which did not involve any recruitment from our end. Our methods were therefore in strict compliance with the appropriate standards and directives, such as the Declaration of Helsinki.
All individuals whose recordings were used from DementiaBank had provided their informed consent before the inclusion of their data into the database. We anticipate no legal, social, or financial implications arising from this study.
Audio model
We created an audio model (Fig. 1), which was fine-tuned using Wav2vec as the baseline representation. The audio data was processed through Wav2vec to obtain audio embeddings and was passed to a dense layer for binary classification. We used binary cross-entropy loss for optimization. We note that the weights from the pretrained Wav2vec feature extractor were frozen during the training and only the other layers of architecture were updated.

Architecture of the audio-only classification model.
Wav2vec
Wav2vec26 is a self-supervised convolutional architecture that transforms audio waveforms into embeddings. Initially trained on unlabeled audio data, these embeddings were passed through a transformer for a masked prediction task. In this task, half of the audio embeddings were masked and predicted using the remaining unmasked portions. Wav2vec is particularly notable in speech recognition tasks due to its adaptability to various audio recordings and its superior performance compared to prior methods.
Text model
The text model (Fig. 2) included the embedding layers from Word2vec and used an LSTM model that was connected to a dense layer for final classification.

Architecture of the text-only classification model.
Word2vec
Word2vec27 is a feed-forward neural network that is designed to produce vector representations of words. It uses surrounding words as input to generate these vectors, and captures semantic relationships between the words. The generated vectors position semantically similar words closer in the vector space. As with the audio model, the weights from the pretrained Word2vec feature extractor were frozen during the training and only the other layers of the architecture were updated.
LSTM
We used an LSTM model with 16 units to process embedded sentences and used a recurrent dropout rate of 0.2. A dense layer with sigmoid activation was appended to the LSTM layer to perform binary classification.
Timestamps
Timestamps for each word were extracted from the corpus. In the text + time model (Fig. 3), timestamps were concatenated with the word embeddings before feeding them as input into subsequent layers. In the audio + time model (Fig. 4), timestamps were passed through an LSTM layer first, and later were concatenated with the audio embeddings, which were passed through an average pooling layer. Finally, the concatenated output was passed through the dropout layer before final classification.

Architecture of the model combining text and timestamps.

Architecture of the model combining audio and timestamps.
Concatenated models
In the concatenated audio-text model (Fig. 5), word embeddings from the text model were processed through an LSTM layer. The audio model was then passed through the same average pooling and dropout layers before concatenation with the text model. A final dense layer was added for classification. We also developed a model combining data from audio, text, and timestamps (Fig. 6). The architecture for these models remained consistent with the previously described models. These segments were concatenated for the final classification task.

Architecture of the model combining audio and text.

Architecture of the model combining all three modalities.
Data augmentation
Due to the relatively small dataset size, we implemented text-based data augmentation. Specifically, we used the Synonym Replacement (SR) method28, where a synonym for a word was used to create a duplicated sentence with the original word replaced by its synonym. Each word was replaced by its synonym once (n=2). For instance, if a sentence contained 5 words, all of which had synonyms available in the NLTK dictionary, five new sentences were generated, each having one original word replaced by a synonym.
Experimental setup
All models were trained for 50 epochs with a batch size of 16. The objective was to minimize binary cross-entropy loss. To prevent overfitting, early stopping was added to stop training if the validation loss failed to decrease for 10 consecutive epochs. All code was developed using the TensorFlow Keras library29.
Results
The experiments were conducted with five separate and independent train-test splits to ensure generalizability and reliability. We report the mean and standard deviation for all results. We include five evaluation metrics: accuracy, precision, recall, F1 score, and AUC ROC scores. The highest test scores for each metric are noted in bold.
Our results highlight the challenges and opportunities associated with multimodal dementia classification using speech data. As evidenced in Table 1 as well as Figs. 7a and 8a, unimodal audio models underperformed compared to the text models. The audio+time model (Fig. 8d) also yielded suboptimal results. This suggests that the audio modality may be challenging to engineer with current state-of-the-art models such as Wav2vec. On the other hand, the text model (Table 1 as well as Figs. 7a and 8b) performed well, and its performance was even better when combined with time, as demonstrated by the superior performance of the text+time model (Table 1 and Figs. 7a, 8e,f).

AUC-ROC curves for the four data augmentation conditions we evaluated: using original data, exclusion short sentences with the original data, augmenting the original data, and augmenting the data with the short sentences removed.

AUC-ROC curves for all six modality combinations we evaluated: audio only, text only, audio and text, audio and timestamps, text and timestamps, and all three.
We observe higher standard deviations in some modalities, mostly in the audio-based models, suggesting that the model was more prone to poor fitting in several data splits. This is likely due to the failure of the audio embedding to yield a good classification signal.
As observed in Table 2 and Fig. 7c (the audio+text+time model we saved had an above-average performance), the exclusion of shorter sentences during preprocessing did not lead to significant improvement in the overall model performance. However, Table 3, Fig. 7b, Table 4 and Fig. 7d show a noticeable improvement after data augmentation was applied. AUROC scores in models using text data surpassed 90% (Fig. 8b–e), and both accuracy and F1 scores were consistently above 80%. This uplift in performance suggests that the text-based augmentations based on synonym replacement may have captured important semantic features related to dementia.
Qualitative error analysis
We conducted a qualitative error analysis to understand which types of prompt responses were frequently misclassified, providing insights into the types of sentences that may be archetypal of dementia. We observe the following patterns:
False positives: Our text model tended to misclassify certain types of sentences from control patients as dementia patients, providing insights into the types of prompt responses that patients with dementia may have commonly spoken. These sentences generally had one or more of the following characteristics:
-
Noun-phrase sentences: Examples include ‘curtain on the window’, ‘down on this side of the picture’.
-
Ungrammatical sentences: Sentence types that were uttered by patients in the control group but were slightly unnatural. Examples include ‘the boy is uh taking cookies out of the cookie jar’, ‘uh mother’s drying dishes’, and ‘that’s real good then’.
-
Repetition: The repetition of patients’ sentences from the investigator, e.g., ‘climbing a stool’.
False negatives: Sentence archetypes from dementia patients that were misclassified as coming from control participants, providing insights into the types of prompt responses that the model learned are not specifically associated with dementia, include:
-
Correct and transcribed correctly: Sentences that were grammatically correct and transcribed correctly. Examples include ‘that’s about all’, and ‘and the girl’.
-
Short and Correct: Examples include sentences like ‘here,’ ‘okay’.
-
Common responses: Sentences that patients often responded to or asked and were transcribed correctly ‘okay’, ‘that’s terrible’, ‘that’s about it, right?’
The original-augmented model often misclassified the following sentence archetypes:
-
Unlikely connotations: Augmented sentences sometimes yielded unlikely or misleading connotations.
-
\(\checkmark\) ‘I’ve got the tape recorder on so’.
(original, control, predicted as control)
-
\(\checkmark\) I’ve got the videotape recorder on so’.
(augmented, control, predicted as dementia)
-
\(\checkmark\) I’ve got the tape registrar on so’.
(augmented, control, predicted as dementia)
-
-
Word usage: Augmented words were common in control data and were sometimes present in sentences from dementia patients.
-
\(\checkmark\) It shows the mother in the kitchen wiping dishes’.
(original, dementia, predicted as dementia)
-
\(\checkmark\) It testify the mother in the kitchen wiping dishes’. (augmented, dementia, predicted as control)
-
-
Augmented and incorrect sentences: Sentences that were originally grammatical but became ungrammatical after augmentation. For example:
-
\(\checkmark\)‘The little girl’s standing there’.
(original, dementia, predicted as dementia)
-
\(\checkmark\) The little miss standing there’.
(augmented, dementia, predicted as control)
-
In the Shorts-removed condition, the incorrectly predicted sentences generally were similar to that of the original dataset, minus the influence of short sentences. This suggests that the presence or absence of short sentences in the data did not dramatically affect the types of errors the model makes, implying that the model’s predictive ability is not significantly affected by sentence length alone. Interestingly, the errors made by the model in the Shorts-augmented condition were similar to those in the original-augmented condition. This might suggest the robustness of data augmentation, regardless of the presence or absence of short sentences. The findings further suggest that while data augmentation significantly enhanced the model’s overall performance, it did not necessarily change the nature of the mistakes made by the model in prediction.
Discussion and conclusion
We have explored dementia classification by leveraging audio, text, and timestamp data from short participant descriptions of a visual stimulus. Using pre-trained models such as Wav2vec and Word2vec, we observed that the presence of text data seemed to bolster the performance of the model significantly, even making up for the more noisy and lower-performing audio data representation. This suggests that text-based data can be a crucial component for improving the diagnostic performance of dementia classification models applied to data collected in response to a prompt.
While the performance of audio and timestamp data was relatively modest, their inclusion within a multimodal framework did sometimes lead to marginal improvements. Further work is required to discover more successful ways to incorporate audio data into classification procedures. In particular, our results suggest that Wav2vec audio representations are insufficient for dementia classification in this context. This result is somewhat surprising in light of previous work that was able to classify autism using audio from naturalistic yet semi-structured home videos with Wav2vec feature representations30. Part of the success of these prior efforts is likely attributable to the relatively structured nature of the input audio, where fine-grained structure was imposed by the mechanics of a mobile game31,32,33,34,35. While the Cookie Theft task was structured in that the same visual stimulus was provided to all participants, we hypothesize that using a series of fixed specific questions about the content of the image rather than a single broad prompt could possibly improve prediction outcomes. Future work is required to properly extract audio features that are relevant to the classification of dementia using the DementiaBank data.
The limitations of our procedures are as follows. First, we only used a single dataset consisting of short responses to a very specific prompt, undermining the generalizability of this approach to other data collection procedures. Second, there might exist other audio representations that can enhance the overall performance, possibly leading to better performance of the audio modality. However, we only tried Wav2vec; further audio representations should be empirically examined. Third, we only integrated different modalities using basic concatenation, but other methods of multimodal fusion and an empirical study of the differences in performance between early and late-stage fusion architectures would lead to greater understanding of multimodality.
Data availability
The Pitt datasets used in this study are sourced from DementiaBank (https://dementia.talkbank.org), which requires approval for access. The datasets generated in the current study are available from the corresponding author upon reasonable request.
Code availability
Code available at https://github.com/limkhaiin/dementia.
References
Organization, W. H. Global Action Plan on the Public Health Response to Dementia 2017–2025 (World Health Organization, Geneva, 2017).
Arvanitakis, Z., Shah, R. C. & Bennett, D. A. Diagnosis and management of dementia: Review. JAMA 322, 1589–1599. https://doi.org/10.1001/jama.2019.4782 (2019).
McConathy, J. & Sheline, Y. I. Imaging biomarkers associated with cognitive decline: A review. Biological Psychiatry 77, 685–692. https://doi.org/10.1016/j.biopsych.2014.08.024 (2015) (Mechanisms of Progression in Alzheimer 's disease).
Irfan, M., Shahrestani, S. & Elkhodr, M. Enhancing early dementia detection: A machine learning approach leveraging cognitive and neuroimaging features for optimal predictive performance. Appl. Sci. 13, 10470. https://doi.org/10.3390/app131810470 (2023).
Li, R. et al. Applications of artificial intelligence to aid early detection of dementia: A scoping review on current capabilities and future directions. J. Biomed. Inform. 127, 104030. https://doi.org/10.1016/j.jbi.2022.104030 (2022).
Whelan, R., Barbey, F., Gillan, C. & Rosická, A. Developments in scalable strategies for detecting early markers of cognitive decline. Transl. Psychiatry 12, 473. https://doi.org/10.1038/s41398-022-02237-w (2022).
Wright, L., De Marco, M. & Venneri, A. Current understanding of verbal fluency in Alzheimer’s disease: evidence to date. Psychol. Res. Behav. Manag. 16, 1691–1705. https://doi.org/10.2147/PRBM.S284645 (2023).
Lanzi, A. M. et al. Dementiabank: Theoretical rationale, protocol, and illustrative analyses. Am. J. Speech-Lang. Pathol. 32, 426–438. https://doi.org/10.1044/2022_AJSLP-22-00281 (2023).
Yuan, J. et al. Disfluencies and fine-tuning pre-trained language models for detection of Alzheimer’s disease. Interspeech (2020).
Luz, S., Haider, F., de la Fuente, S., Fromm, D. & MacWhinney, B. Alzheimer’s dementia recognition through spontaneous speech: The adress challenge (2020). arXiv:2004.06833.
Torre, I. G., Romero, M. & Álvarez, A. Improving aphasic speech recognition by using novel semi-supervised learning methods on aphasiabank for English and Spanish. Appl. Sci. 11, 8872. https://doi.org/10.3390/app11198872 (2021).
Chlasta, K. & Wołk, K. Towards computer-based automated screening of dementia through spontaneous speech. Front. Psychol. 11, 623237. https://doi.org/10.3389/fpsyg.2020.623237 (2021).
Guo, Y., Li, C., Roan, C., Pakhomov, S. & Cohen, T. Crossing the cookie theft corpus chasm: Applying what Bert learns from outside data to the adress challenge dementia detection task. Front. Comput. Sci. 3, 642517. https://doi.org/10.3389/fcomp.2021.642517 (2021).
Sarawgi, U., Zulfikar, W., Soliman, N. & Maes, P. Multimodal inductive transfer learning for detection of Alzheimer’s dementia and its severity (2020). arXiv:2009.00700.
Hlédiková, A., Woszczyk, D., Akman, A., Demetriou, S. & Schuller, B. Data augmentation for dementia detection in spoken language (2022). arXiv:2206.12879.
Balagopalan, A., Eyre, B., Rudzicz, F. & Novikova, J. To Bert or not to Bert: Comparing speech and language-based approaches for Alzheimer’s disease detection. https://doi.org/10.21437/Interspeech.2020-2557 (2020).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding (2019). arXiv:1810.04805.
Becker, J., Boller, F., Lopez, O., Saxton, J. & McGonigle, K. The natural history of Alzheimer’s disease. Description of study cohort and accuracy of diagnosis. Arch. Neurol. 51, 585–594. https://doi.org/10.1001/archneur.1994.00540180063015 (1994).
Karlekar, S., Niu, T. & Bansal, M. detecting linguistic characteristics of Alzheimer’s dementia by interpreting neural models. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) 701–707 https://doi.org/10.18653/v1/N18-2110 (Association for Computational Linguistics, New Orleans, Louisiana, 2018).
Matošević, L. & Jović, A. Accurate detection of dementia from speech transcripts using Roberta model. In 2022 45th Jubilee International Convention on Information, Communication and Electronic Technology (MIPRO) 1478–1484 https://doi.org/10.23919/MIPRO55190.2022.9803462 (2022).
Guo, Z. et al. Text classification by contrastive learning and cross-lingual data augmentation for Alzheimer’s disease detection. 6161–6171 https://doi.org/10.18653/v1/2020.coling-main.542 (2020).
Kumar, M. R. et al. Dementia detection from speech using machine learning and deep learning architectures. Sensors 22, 9311. https://doi.org/10.3390/s22239311 (2022).
Ilias, L., Askounis, D. & Psarras, J. A multimodal approach for dementia detection from spontaneous speech with tensor fusion layer. In 2022 IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI)https://doi.org/10.1109/bhi56158.2022.9926818 (IEEE, 2022).
Zhu, Y., Obyat, A., Liang, X., Batsis, J. A. & Roth, R. M. Wavbert: Exploiting semantic and non-semantic speech using wav2vec and Bert for dementia detection. In Proceeding of the Interspeech 2021 3790–3794 https://doi.org/10.21437/Interspeech.2021-332 (2021).
Rehurek, R. & Sojka, P. Gensim-python framework for vector space modelling. NLP Centre Fac. Inform. Masaryk Univ. Brno Czech Republic 3, 2 (2011).
Baevski, A., Zhou, Y., Mohamed, A. & Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. In Advances in Neural Information Processing Systems Vol. 33 (eds Larochelle, H. et al.) 12449–12460 (Curran Associates Inc, Glasgow, 2020).
Mikolov, T., Chen, K., Corrado, G. & Dean, J. Efficient estimation of word representations in vector space (2013). arXiv:1301.3781.
Wei, J. & Zou, K. EDA: Easy data augmentation techniques for boosting performance on text classification tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) 6382–6388 https://doi.org/10.18653/v1/D19-1670 (Association for Computational Linguistics, Hong Kong, China, 2019).
Chollet, F. et al. Keras (2015).
Chi, N. A. et al. Classifying autism from crowdsourced semistructured speech recordings: machine learning model comparison study. JMIR Pediatr. Parent. 5, e35406 (2022).
Kalantarian, H. et al. Guess what? Towards understanding autism from structured video using facial affect. J. Healthc. Inform. Res. 3, 43–66 (2019).
Kalantarian, H. et al. A gamified mobile system for crowdsourcing video for autism research. In 2018 IEEE International Conference on Healthcare Informatics (ICHI) 350–352 (IEEE, 2018).
Washington, P. et al. Improved digital therapy for developmental pediatrics using domain-specific artificial intelligence: Machine learning study. JMIR Pediatr. Parent. 5, e26760 (2022).
Kalantarian, H., Jedoui, K., Washington, P. & Wall, D. P. A mobile game for automatic emotion-labeling of images. IEEE Trans. Games 12, 213–218 (2018).
Kalantarian, H. et al. Labeling images with facial emotion and the potential for pediatric healthcare. Artif. Intell. Med. 98, 77–86 (2019).
Acknowledgements
We acknowledge the grants NIA AG03705 and AG05133 for supporting the development of DementiaBank, Pitt Corpus. The technical support and advanced computing resources from the University of Hawaii Information Technology Services—Cyberinfrastructure, funded in part by the National Science Foundation CC awards 2201428 and 2232862, are gratefully acknowledged. We acknowledge the use of Grammarly and ChatGPT in the editing of grammar and phrasing.
Author information
Authors and Affiliations
Contributions
P.W. conceived the experiments, K.L. conducted the experiments and analysed the results. K.L. wrote the main manuscript text. P.W. edited the text. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lin, K., Washington, P.Y. Multimodal deep learning for dementia classification using text and audio. Sci Rep 14, 13887 (2024). https://doi.org/10.1038/s41598-024-64438-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-64438-1
- Springer Nature Limited