
Abstract
The emergence of convolutional neural network (CNN) and transformer has recently facilitated significant advances in image super-resolution (SR) tasks. However, these networks commonly construct complex structures, having huge model parameters and high computational costs, to boost reconstruction performance. In addition, they do not consider the structural prior well, which is not conducive to high-quality image reconstruction. In this work, we devise a lightweight interactive feature inference network (IFIN), complementing the strengths of CNN and Transformer, for effective image SR reconstruction. Specifically, the interactive feature aggregation module (IFAM), implemented by structure-aware attention block (SAAB), Swin Transformer block (SWTB), and enhanced spatial adaptive block (ESAB), serves as the network backbone, progressively extracts more dedicated features to facilitate the reconstruction of high-frequency details in the image. SAAB adaptively recalibrates local salient structural information, and SWTB effectively captures rich global information. Further, ESAB synergetically complements local and global priors to ensure the consistent fusion of diverse features, achieving high-quality reconstruction of images. Comprehensive experiments reveal that our proposed networks attain state-of-the-art reconstruction accuracy on benchmark datasets while maintaining low computational demands. Our code and results are available at: https://github.com/wwaannggllii/IFIN.
Similar content being viewed by others


Introduction
Image super-resolution (SR) involves the process of restoring a high-resolution (HR) image from a corresponding degraded low-resolution (LR) image. Currently, image SR is favored for its broad applications in medical imaging, surveillance, and face recognition. The ill-posed problem of SR, however, presents a challenge where multiple HR images can be reconstructed from a single LR image. Many SR methods have been introduced to tackle this issue, such as interpolation-based, reconstruction-based, and learning-based methods.
The emergence of convolutional neural networks (CNN) recently instigated a profound revolution in SR tasks. From SRCNN1 (incorporating only three convolutional layers) to RCAN2 (encompassing over 400 layers), there has been a consistent increase in network depth, width, and complexity. This development trend benefits network representation capabilities while achieving reconstruction performance improvements. For example, enhanced deep SR network (EDSR)3 and non-local sparse attention (NLSA)4 with parameters of 43M and 42M, respectively, can produce significant restoration effects by powerful nonlinear learning. Nevertheless, the practical application of the majority of these CNN-based methods in real-world scenarios remains challenging, primarily owing to their demanding memory and computational requirements. Despite various efforts directed toward reducing the number of network parameters and operations, most methods struggle to maintain good reconstruction performance. A deeply recursive convolutional network(DRCN)5 has fewer model parameters by recursive paradigm, but the reconstruction accuracy is lower. Cascading residual network (CARN)6 implemented a cascading residual architecture by introducing a cascading mechanism, where the whole structure is lightweight but poorly performing. To better balance network performance and computational cost, researchers have introduced attention mechanisms into the SR task. LatticeNet7, DRSAN8, and A2F9 exploited different attention mechanisms to focus on informative features, boosting reconstruction performance while maintaining moderate computational demands. Notably, most existing attention mechanisms lack structural priors, which are crucial for image detail recovery. Therefore, it is essential to devise an effective and lightweight network that explores structural information within attention mechanisms for reconstructing high-quality HR images.
Conversely, CNN-based SR approaches struggle to address global dependencies, primarily attributed to the inherent local properties of convolutional operations. As an alternative to CNN, Transformer can capture global interactions between contexts through the self-attention mechanism, making them widely adopted in the field of SR. Swin Transformer10 has exhibited significant promise by harnessing the advantages of both CNN and Transformer. Later, the hybrid structure of CNN and Transformer has gradually become a mainstream trend in research. An efficient long-range attention network (ELAN)11 proposed a share attention technique to speed up the calculation in its group multi-head self-attention. Hybrid network of CNN and Transformer (HNCT)12 combined CNN and Transformer to extract deep features in consideration of both local and non-local priors. Similarly, cross-receptive focused inference network (CFIN)13 elegantly integrated CNN and Transformer and achieved competitive performance. In aggregate enriched features extracted from both CNN and Transformer (ACT)14, it exploited multi-scale local and non-local attributes to improve SR quality. Benefiting from the advantages of this hybrid architecture, we further explore the processing of local and global information to obtain more valuable information for HR reconstruction.
In this study, a lightweight interactive feature inference network (IFIN) is implemented for image SR tasks. Specifically, a series of interactive feature aggregation modules (IFAM) capture more abstract depth features in a coarse-to-fine fashion. IFAM is supported by structure-aware attention block (SAAB), Swin Transformer block (SWTB), and enhanced spatial adaptive block (ESAB), complementing and integrating different features synergistically. SAAB and SWTB extract local structure and global aware priors, respectively. These two different feature properties are merged and fused in ESAB, recovering natural and realistic textures of HR images. As reported in Fig. 1, our proposed networks deliver a favorable trade-off between performance and model size, outperforming most renowned SR models.

PSNR and model size comparison of our methods (red star) with mainstream SR networks on Set14 for scale factor \(\times \)2.
In brief, we make three primary contributions.
-
1.
We introduce a lightweight and efficient model, dubbed IFIN, which utilizes chain-stacked IFAMs to extrapolate image features from coarse to fine granularity. Supported by SAAB, SWTB, and ESAB, the IFAM effectively leverages both local and global a priori knowledge, thereby enhancing the network’s discriminatory capabilities. IFIN achieves favorable performance with modest computing requirements, surpassing most well-known lightweight approaches.
-
2.
We propose SAAB, which incorporates asymmetrical convolution within the attention mechanism. This integration facilitates the learning of intricate structural information and the generation of more generalized weights, effectively emphasizing critical target regions.
-
3.
We propose ESAB, which synergistically aggregates local structural information from SAAB and global aware information from SWTB. In such a way, ESAB can enhance the network’s adaptability to various image contents and scenes, thereby significantly improving image reconstruction performance.
Related work
CNN-based image SR
Dong et al.1 were pioneers in applying CNN to the SR domain, developing the SRCNN model which outperformed traditional methods in achieving superior SR results. Inspired by this idea, Kim et al.15 increased the network depth to 20 layers and further improved the reconstruction performance. Later, a wide variety of CNN-based SR network designs emerged to facilitate reconstruction accuracy, such as increasing network depth, expanding network width, and designing complex network architectures. For instance, enhanced deep SR network (EDSR)3, residual dense network (RDN)16, holistic attention network (HAN)17, and dual interactive implicit neural network (DIINN)18 were very deep networks that had very dominant restoration accuracy, but they suffered from a very large number of parameters and computations. Instead of designing huge networks, efficient SR methods provide a good balance of performance and model capacity. CARN6 leveraged group convolution and a cascade scheme to decrease model capacity and enhance network representation. IDN19 distilled more useful information for SR reconstruction via distillation technology to reduce network parameters. LatticeNet7 designed lattice blocks that favor the lightweight SR framework, reducing the number of parameters by about half while maintaining similar SR performance. Additionally, to promote the efficiency of feature utilization, several works have incorporated the attention mechanism into the SR field. MemNet20 and channel-wise and spatial feature modulation (CSFM)21 aggregated channel attention and spatial attention, exploring the interdependencies between channel and spatial attributes. Plus, PAN22 and DRSAN8 conducted attention mechanisms that adaptively rescaled features using three-dimensional (3D) attention maps, resulting in improved SR outcomes. Although different solutions can generate different lightweight SR results, they ignore the exploration and use of structural priors which are beneficial for image detail reconstruction.
Transformer-based image SR
As an alternative to CNN, Transformer which adopts the self-attention mechanism has escalated the accuracy of various computer vision tasks. One pioneering work is Vision Transformer (ViT )23, which flattened two-dimensional (2D) image patches in a vector and delivered them into the Transformer structure, obtaining remarkable performance gains. Shortly afterward, an increasing number of Transformer-based approaches have sprung up in SR tasks. Image processing Transformer (IPT)24, based on ViT, acquired better restoration results in denoising, deraining, and SR tasks. Instead of the standard self-attention, Swin Transformer10 adopted the Swin Transformer block by incorporating convolutional layers within the block to enforce local connectivity. Currently, the popular direction of research in the SR domain is the hybrid structure of CNN and Transformer. Many research efforts have demonstrated the effectiveness of this hybrid architecture, mainly thanks to the fact that CNN structure can extract local features while the Transformer structure can establish global features. For instance, efficient super-resolution Transformer (ESRT)25, ELAN11, hierarchical patch Transformer (HIPA)26, and ACT27 extracted and enhanced feature representations by hybridizing CNN backbone and Transformer backbone, acquiring better performance than most Transformer-based and CNN-based methods. Indeed, effectively incorporating both local features and global information into lightweight networks is crucial for achieving high-performance results. In this study, we aim to enhance the flexibility and robustness of local structure and global feature priors, thereby achieving HR image restoration.
Proposed method
Overall network architecture
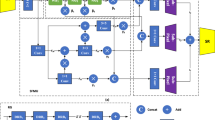
In this work, we construct a lightweight interactive feature inference network (IFIN) for image SR fields. As depicted in Fig. 2, the entire workflow of IFIN consists of a shallow feature extraction module, several interactive feature aggregation modules (IFAM), and an upsample part. Firstly, the LR image passes through a 3 \(\times \) 3 convolution to distill shallow features, which can be defined as:

The architecture of our proposed IFIN, which consists of T IFAMs to gradually infer rich contextual features.
where \({I^{LR}} \in {{\mathbb {R}}^{H \times W \times 3}}\) denotes the LR input images. H and W indicate the height and width of the image. \({H_{SFE}}( \cdot )\) is the 3\(\times \)3 convolution operation and \({F_0} \in {{\mathbb {R}}^{H \times W \times C}}\) is the extracted shallow features, where C is the number of channels. Then, \({F_0}\) will be transmitted to T chained stacking IFAMs for learning more abstract high-level features. IFAM is composed of a structure-aware attention block (SAAB), Swin Transformer block (SWTB), and enhanced spatial adaptive block (ESAB), which will be described in “Interactive feature aggregation module (IFAM)” . The process can be expressed as follows:
where \(\mathrm{{\;}}H_{\mathrm{{IFAM}}}^t( \cdot )\) indicates the operation of the t-th IFAM. \({F_{_{IFAM}}^{t - 1}} \in {{\mathbb {R}}^{H \times W \times C}}\) and \({F_{_{IFAM}}^t} \in {{\mathbb {R}}^{H \times W \times C}}\) are the input and output feature maps of the t-th IFAM. Finally, the extracted deeper features \({F_{_{IFAM}}^T \in {{\mathbb {R}}^{H \times W \times C}}}\) is upsampled to the ideal HR image size, which can be expressed as:
where \({I^{HR}} \in {{\mathbb {R}}^{rH \times rW \times 3}}\) is the HR image, where r is the scale factor. \({H_{HU}}(\cdot )\) and \({H_{LU}}(\cdot )\) denote the upsampling operations for the deeper features and input LR image, respectively. Similar to work28, both operations integrate a 3 \(\times \) 3 convolution for \({H_{HU}}(\cdot )\) and 5\(\times \)5 convolution for \({H_{LU}}(\cdot )\), as well as a sub-pixel convolutional layer. With this technique, the stability of network training is improved.
We utilize \({L_1}\) norm as the objective function of the proposed IFIN. Assuming a training dataset \(\{ I_i^{LR},I_i^{SR}\} _{i = 1}^N\), where \(I_i^{LR} \in {{\mathbb {R}}^{H \times W \times 3}}\) and \(I_i^{SR} \in {{\mathbb {R}}^{rH \times rW \times 3}}\) denote the i-th LR image and the corresponding ground-truth image, respectively. A powerful non-linear mapping function \({H_{IFIN}}(\cdot )\) , capturing the relationship \(I_i^{LR}\) and \(I_i^{SR}\) using the \(L_1^{}\) norm, can be defined as:
where \(\Theta \) is the learnable parameter set of IFIN.
Interactive feature aggregation module (IFAM)
As the backbone of IFIN, IFAM allows collaborative exploration of the local and global prior of the image, helping to reconstruct a more texture-rich HR image. IFAM is made up of SAAB, SWTB, and ESAB, which are described as follows.
Structure-aware attention block (SAAB)
Asymmetric convolution explores structural information by leveraging the vertical and horizontal gradient information parallelly, not only reducing model operations but also helping to recover high-quality images. For instance, Tian et al.29 introduced ACNet, which utilizes asymmetric blocks with higher efficiency and fewer parameters. Analogously, Xu et al.30 proposed asymmetric attention convolution (AAConv) to gradually extract advanced spatial patterns and spectral features. Considering the excellent structural prior of asymmetric convolution, we embed it into the attention mechanism to focus on more important structural features and improve network representation. Therefore, we propose a structure-aware attention block (SAAB), which embeds asymmetric convolution within the attention path and modulates it with the convolutional path to acquire rich structure-aware features. In contrast to AAConv, we advocate for leveraging structural priors to empower the attention path in learning more generalized weights, followed by adaptive reweighting of the convolutional path to emphasize essential target structural information.
As shown in Fig. 3, SAAB starts with 1 \(\times \) 3 and 3 \(\times \) 1 convolutions for structural information exploration, and then passes to three 3 \(\times \) 3 convolutions for feature learning, followed by sigmoid to generate 3D modulation coefficients \({\alpha ^t} \in {{\mathbb {R}}^{H \times W \times C}}\). Additionally, to gather more important generalized features \(F_{gen}^t \in {{\mathbb {R}}^{H \times W \times C}}\), we use two 3 \(\times \) 3 convolutions that are independent of the attention path. Finally, the generalized features are recalibrated by 3D modulation coefficients, acquiring rich discriminative feature representation \(F_{SAAB}^t \in {{\mathbb {R}}^{H \times W \times C}}\) for accurate SR reconstruction. The above process can be formulated as follows:
where \(\sigma \left( \cdot \right) \) denotes the sigmoid function. \(H\left( \cdot \right) \) and \(f\left( \cdot \right) \) are different convolution operations, where the subscripts indicate the sizes of convolution.

The architecture of SAAB that concentrates on rich structural-aware features.
Swin transformer block (SWTB)
SWTB is derived from the literature31 that introduces local attention and shifted window mechanisms to decrease model complexity and achieve efficient learning. We adopt SWTB to learn global context information, acquiring more valuable information to realize detail restoration.
Figure 4 presents the structure of two consecutive SWTB, containing a LayerNorm (LN) layer, a multi-head self-attention block, residual connection, and two multi-layer perceptrons (MLP). The window-based multi-head self-attention (W-MSA) unit and the shifted window-based multi-head self-attention (SW-MSA) unit are employed in the two successive Transformer blocks, respectively. \(F_{IFAM}^{^{t - 1}} \in {^{H \times W \times C}}\) will be linearly projected and reshaped into \({\hat{F}}_{IFAM}^{^{t - 1}} \in {{\mathbb {R}}^{N \times C}}\), where \(N = H \times W\). The input feature will be separated into non-overlapping windows, with each window containing M\(\times \)M patches (set to 8 by default). With the window partitioning mechanism, the continuous SWTB can be represented as:
where \({\hat{F}}_{SWTB}^t\), \({\bar{F}}_{SWTB}^t\), \({\tilde{F}}_{SWTB}^t\), and \(F_{SWTB}^t\) are the outputs of the (S)W-MSA module and the MLP of the t-th block, respectively. The self-attention figured in W-MSA and SW-MSA can be summarized by the following formula:
where Q, K, \(V \in {{\mathbb {R}}^{{M^2} \times d}}\) indicate querie, key, and value matrices, respectively. d indicates size of the query and key. \(B \in {{\mathbb {R}}^{{M^2} \times {M^2}}}\) indicates the relative position bias.

The architecture of SWTB that can model global information effectively.
Enhanced spatial adaptive block (ESAB)
It is recognized that both the local and global priors of an image contribute to the reconstruction of rich texture details. While we have independently considered the local and non-local features of images from SAAB and SWTB, there is room for further exploration to enhance the flexibility of fusion. By exploiting local and global priors, the network becomes more robust to changes in the input image and is better able to handle different image contents and scenes, favouring the recovery of richer high-frequency information.
Figure 5 illustrates the structure of ESAB. Firstly, the output features \(F_{SAAB}^t\) and \(F_{\mathrm{{SWTB}}}^t\) are concatenated and processed by 1\(\times \)1 convolutional layer to harvest diverse types of fused characteristics. Then, 3\(\times \)3 convolutional layer is exploited to generate the modulation parameters \({\alpha _1^t}\) and \({\beta _1^t}\), which will be updated with the mean and standard deviation of fused characteristics. Subsequently, a sigmoid operation is applied to yield modulation coefficients. Finally, the spatial features \(F_{_{SAAB}}^t\) enhanced by a 1\(\times \)1 convolution are multiplied with modulation coefficients and then added with \({\beta _1^t}\), to acquire spatial modulation features \({{\hat{F}}_{SAAB}^t} \in {{\mathbb {R}}^{H \times W \times C}}\).
Analogously, the modulated features \({{\hat{F}}_{SAAB}^t}\) are convolved to produce another modulation parameters \({\alpha _2^t}\) and \({\beta _2^t}\), and whose are multiplied and added to the enhanced global features \({\hat{F}}_{\mathrm{{SWTB}}}^t\), distilling global modulation features \(F_{\mathrm{{SWTB}}}^t\), which is also the output features \(F_{_{IFAM}}^t\) of the t-th IFAM.
where \(\sigma \left( \cdot \right) \) denotes the sigmoid function. \({f_{1 \times 1}}\left( \cdot \right) \) denoete 1\(\times \)1 convolution.

The architecture of ESAB that autonomously aggregates local structure and global feature priors.
Experiments
Datasets and metrics
IFIN-S and IFIN are trained on DIV2K32 dataset, in which 800 high-quality images are available. Then we test on five benchmark datasets: Set533, Set1434, B10035, Urban10036, and Manga10937. Besides, three degradation models, known as bicubic (BI), blur-downscale (BD), and downscale-noise (DN), are leveraged to demonstrate the effectiveness of IFIN. The experimental outcomes are estimated utilizing two metrics, the peak signal-to-noise ratio (PSNR) and structure similarity index (SSIM), on the Y channel of the transformed YCbCr color space.
Implementation details
In order to build a lightweight architecture, we devise two network variants, referred to as IFIN-S and IFIN. The channels of C are configured to 50. We construct IFIN-S by stacking three IFAMs and configuring the group size of the 3 \(\times \) 3 convolutions in SAAB to 2. For IFIN, we stack five IFAMs.
Following the BI degradation model, we downsampled the datasets by scale factors of \(\times \)2, \(\times \)3, and \(\times \)4 to produce the corresponding LR images. For the BD and DN degradation models, however, we specifically process the dataset using a scale factor of \(\times \)3. Each mini-batch comprises 16 image patches, each of size 60 \(\times \) 60. To augment the database, both the LR and HR image patches undergo random horizontal flipping as well as rotations of 90\(^\circ \), 180\(^\circ \), and 270\(^\circ \). Before inputting the mini-batch into the model, we normalize it by subtracting the average RGB value calculated from the entire training dataset. The \({L_1}\) paradigm is minimized by employing the Adam optimizer, whose parameters are given as \(\beta _1 = 0.9\), \(\beta _2 = 0.999\), and \(\varepsilon = 10^{-8}\). The initial learning rate is set to 1e−3 at the beginning and is halved every 500 epochs. The detailed hyperparameters utilized for our network architecture are listed in Table 1. Our IFIN-S and IFIN are implemented by exploiting the PyTorch framework on an NVIDIA TESLA V100 GPU.
Ablation study
In this section, we implement ablation studies to demonstrate the effectiveness of various components of IFIN in enhancing reconstruction accuracy. We respectively get rid of SAAB, ESAB, and SWTB, thus obtaining three additional models. Table 2 reports model capacity, PSNR/SSIM, and time consumption for four models on five benchmark datasets. The time consumption tests are performed on an NVIDIA GeForce RTX 3060 GPU, with results averaged across the datasets. Additionally, we explore the impact of varying the number of IFAMs on network performance, aiming to identify the optimal balance between computational efficiency and enhancement efficacy.
-
(1)
Investigation of SAAB. Our proposed SAAB inherits the property of asymmetric convolution and can learn the structural features of the image for better detail restoration. As reported in Table 2, it is evident that IFIN equipped with SAAB acquires a substantial performance improvement, especially on the structurally complex Urban100 and Manga109 datasets, where SSIM respectively improves by 0.0027 and 0.0035. Despite the fact that the addition of SAAB increases the parameter count by 328K, the performance improvement is significant. Additionally, the increase in time consumption is only 7%. As expected, SAAB facilitates the recovery of high-quality images by embedding structural priors. Figure 6 is the visual heatmap of different stages of IFAM, produced by IFIN w/o SAAB and IFIN, respectively. As for IFIN enabled by SAAB (Fig. 6f–j), obviously, it can effectively outline clear and sharp edge information, validating the ability to explore structural textures. While IFIN w/o SAAB (Fig. 6a–e) not only has low reconstruction accuracy but also displays blurred and distorted structural information.
Figure 6 
Visualized feature maps of IFIN with and without SAAB. (a–e) Heatmaps of IFIN without SAAB, (f–j) show heatmaps of IFIN with SAAB.
-
(2)
Investigation of SWTB. SWTB has a strong representation ability and global information utilization, thus facilitating the recovery of more useful characteristics. As depicted in Table 2, by introducing SWTB, the reconstruction results provide at least 0.10 dB gains, which indicates the importance of global dependence in image restoration. The convergence analysis is presented in Fig. 7. We can find that IFIN w/o SWTB converges faster, while the other models are relatively slower. Inevitably, the inference time of the model becomes longer with the introduction of SWTB architecture. However, the loss of time extrapolation is a necessary concession to the improvement of reconstruction accuracy.
Figure 7 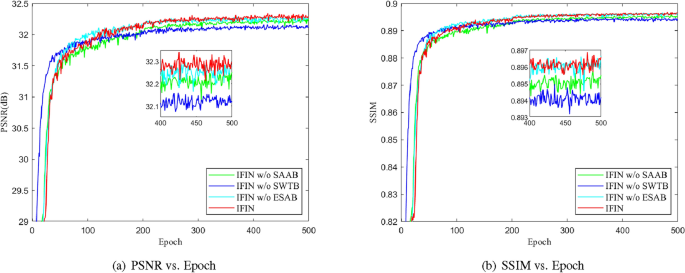
Convergence results of different models on Set5 for scale factor \(\times \)4.
-
(3)
Investigation of ESAB. As one of the key components of IFIN, the proposed ESAB effectively explores local structural and global dependence from SAAB and SWTB for better feature aggregation. It can be seen from Table 2 that IFIN augmented with ESAB attains improvements of 0.06dB in PSNR and 0.0010 in SSIM on Urban100, albeit with an increase in the number of model parameters by 8.2% and Multi-Adds by 20%. Additionally, we give visual heatmaps of IFIN with and without ESAB in Fig. 8, observing how ESAB acts on local and global responses. From Fig. 8a–e, high-frequency texture features present blurry and checkerboard artifacts in the absence of ESAB. On the contrary, detailed features of the image are clearer and more comprehensive after ESAB processing in Fig. 8f–j. Among them, the model not only focuses on the repeated small patterns but also emphasizes the sharp edge details. Combining all the improvements, SAAB, ESAB, and SWTB have exhibited great reasonableness and effectiveness.
Figure 8 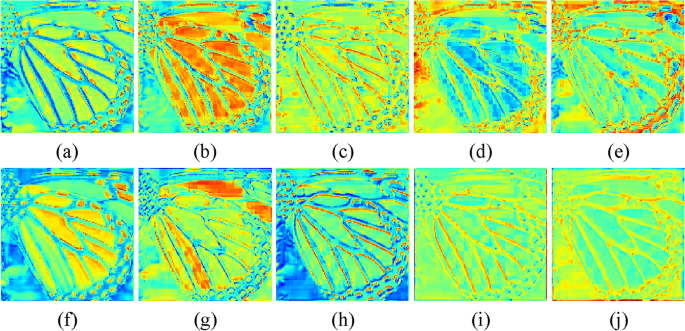
Visualized feature maps of IFIN with and without ESAB. (a–e) Heatmaps of IFIN without ESAB, (f–j) show heatmaps of IFIN with ESAB.
-
(4)
Investigation of IFAM. In Fig. 9, we illustrate visual features to analyze the interaction between the modules within the last IFAM. Based on the visualization, the output features of the three modules demonstrate minimal attention towards the low-frequency regions. Specifically, the output feature of SAAB focuses on texture structure details, such as lines and small patterns. In contrast, the output feature of SWTB shows an even distribution of activation values across the feature map. More importantly, the output characteristics of ESAB fuse global and local properties, resulting in a more pronounced representation of the target area and higher overall activation values. This observation suggests that the complementary fusion of local and global features facilitates the generation of additional high-frequency information, thereby aiding in the reconstruction of high-quality images.
Figure 9 
Average feature visualization inside the last IFAM.
-
(5)
Analysis of different numbers of IFAMs. To investigate the impact of model depth on network performance, we conduct analyses by varying the number of IFAM, setting T to 2, 3, 4, 5, and 6. As reported in Table 3, one can find that increasing the depth of the model by adding more IFAMs generally leads to better performance in terms of both PSNR and SSIM, but performance changes slowly when T exceeds 5. Meanwhile, we opt for T = 5 as the number of IFAMs to balance model performance against computational costs.
Table 3 Average PSNR and SSIM results on Set14 for scale factor \(\times \)4.




Results with BI degradation
We make comparisons of the proposed IFIN-S and IFIN against existing SR approaches on the BI degradation model: SRCNN1, FSRCNN38, VDSR15, DRCN5, LapSRN39, DRRN40, MemNet20, CARN6, CBPN41, AWSRN-M42, OISR-RK2-s43, A2F-S9, LESRCNN44, SPBP-L45, RMUN46, FALSR47, WMRN48, LMAN-s49, MADNet-L150, MSWSR51, Cross-SRN52, ACNet29, CRMBN53, DRSAN-48m8, FMEN54, AFAN55, ESRT56, LBNet57, CFGN58, and Ngswin59.
Quantitative comparison
For a practical comparison that aligns with real-world application needs, we focus on selecting mainstream models that have a total network parameter count of less than 2000K. To enhance the comprehensibility of the comparison, we utilize Multi-Adds calculated by recovering a 1280 \(\times \) 720 (720P) HR image. According to the results presented in Tables 4, 5 and 6, the proposed IFIN-S and IFIN exhibit competitive or superior PSNR and SSIM at different scales compared to popular SR networks. Compared to CNN-based methods, IFIN-S and IFIN exhibit better reconstruction performance at similar computational complexity. Note that our IFIN-S shows comparable results to CFGN, Cross-SRN, and FMFN, which suffer from more parameters and computations than ours. And IFIN-S achieves competitive results with ESRT while requiring less model capacity. Additionally, IFIN stands out by producing promising SR results with modest network parameters and Multi-Adds, even when compared to recently proposed Transformer-based methods. For example, in Table 6, IFIN has 0.19 dB higher PSNR and 0.0016 higher SSIM on Urban100 for \(\times \)4 over Ngswin. Although the Multi-Adds of IFIN are higher than that of Ngswin, the judicious increase in Multi-Adds is a necessary trade-off for improving accuracy. In essence, the superiority of our proposed methods is even more remarkable in reconstructing large-scale factors. This phenomenon can be attributed to the fact that LR images contain fewer pixel values at larger scale factors, necessitating the extraction of richer features to accurately restore HR images. Our proposed models, which implement both local and global strategies, exhibit strong representational capabilities. This strategy enables our network to capture intricate details more effectively, thereby enhancing performance significantly in SR tasks.
Qualitative comparison
We offer visual comparisons on selected portions of benchmark datasets, as depicted in Figs. 10, 11, 12, 13 and 14. Our IFIN exhibits superior restoration of stripes and line patterns, demonstrating finer and more accurate super-resolved images. As Fig. 10 depicts, our IFIN produces sharper details, which are close to HR image. In Figs. 12 and 13, ESRT, LBNet, and CFGN can yield stripe characteristics but with visible blurring. For Figs. 11 and 14, which are rich in stripe information, the comparison methods show severe distortions and deformations. Conversely, our IFIN effectively mitigates these issues, thereby recovering finer and more accurate detail information. This efficacy stems from IFIN’s specialization in capturing minute textures and extracting high-frequency cues, resulting in clearer and more precise image restorations.

Qualitative comparison of popular networks on Set14 for scale factor \(\times \)2.

Qualitative comparison of popular networks on Urban100 for scale factor \(\times \)2.

Qualitative comparison of popular networks on B100 for scale factor \(\times \)3.

Qualitative comparison of popular networks on Set5 for scale factor \(\times \)4.

Qualitative comparison of popular networks on Urban100 for scale factor \(\times \)4.
Results with BD and DN degradations
In this section, we conduct SR experiments on BD and DN degradation models to display the effectiveness and robustness of the proposed IFIN further. In this comparison, IFIN is evaluated against some popular SR methods, containing SRCNN1, FSRCNN38, VDSR15, IRCNN_G60, IRCNN_C60, SRMDNF61, RDN16, and AFAN55. According to the results presented in Table 7, our IFIN achieves optimal and suboptimal reconstruction results. Note that our IFIN outperforms RDN on the DN degradation model, which suffers from more parameters and operations than ours. The number of parameters and operations in IFIN are around 4.5% (0.98M vs. 22M) and 4.7% (107G vs. 2282G) of RDN, respectively. In addition, IFIN is superior to AFAN because it excels in exploring local and global priors, which considerably boosts the network’s discriminative ability. All experiments indicate that our IFIN strikes an advantageous trade-off between model capacity and reconstruction accuracy when compared to the state-of-the-art SR methods.
Results on real remote-sensing images
To further demonstrate the efficacy of our proposed methods, we test them on remote-sensing images of relatively low quality and spatial resolution. Following the methodologies established in works62,63, we use two test sets named RS-T1 and RS-T2 from the UC Merced dataset64. Both RS-1 and RS-2 contain 120 images and cover diverse scenes with complicated image patterns. We exploit existing remote-sensing SR methods for comparison, including SRCNN1, VDSR15, LGCNet65, LapSRN39, IDN19, LESRCNN44, CARN-M6, FENet63, FDENet66, and DRAN67. All the aforementioned methods are directly evaluated on remote sensing data utilizing pre-trained models provided by relevant workers. Meanwhile, these approaches are trained on the DIV2K dataset to ensure the fairness of comparison results.
As presented in Table 8, it is noted that our IFIN obtains the best PSNR and SSIM scores, surpassing advanced remote sensing SR methods such as LGCNet, FeNet, DRAN, and FDENet. For instance, the proposed IFIN obtains 0.04-0.16 dB PSNR and 0.0004-0.0051 SSIM gains compared with lightweight DRAN. It is important to note that IFIN-S, which holds lower parameters than DRAN, attains competitive results on RS-T1 and RS-T2 datasets, exhibiting strong flexibility and stability. Figures 15 and 16 give visual comparisons of some methods. As we can see, our methods exhibit a better reconstruction effect than the comparison networks, particularly in terms of object outlines and texture details. In Fig. 16, LGCNET, LESRCNN, and FENet can not recover the stripe information, resulting in serious blurring, distortion, and artifacts respectively. Contrastively, our IFIN-S and IFIN with SAAB, SWTB, and ESAB can reconstruct details more clearly and accurately, visually consistent with the HR image.

Qualitative comparison of popular networks on RS-T1 for scale factor \(\times \)3.

Qualitative comparison of popular networks on RS-T2 for scale factor \(\times \)4.
Model complexity
As we recognize the importance of model parameters and computational operations in designing lightweight methods, time consumption emerges as a critical metric for assessing the suitability of these methods for real-time applications. To this end, we perform time testing on some representative SR approaches exploiting the same device with an NVIDIA GeForce RTX 3060 GPU. Notably, we assess the time consumption of each method four times and subsequently compute the average score as the final result.
We depict the model parameters, Multi-Adds, PSNR/SSIM, and time consumption on B100 dataset in Table 9. Compared to CNN-based methods, the difference in performance and time cost between IFIN-S and AWSRN-M is not significant, but the computational complexity of IFIN-S is half that of AWSRN-M. Additionally, the time inference of CFGN is 24.7% longer than that of IFIN-S. Crucially, our IFIN obtains the highest PSNR and SSIM scores while utilizing fewer model parameters and calculations. However, the inclusion of a self-attention mechanism in ESAB, which necessitates a greater number of multiplication operations, somewhat diminishes the computational efficiency of our method. Nevertheless, our IFIN-S and IFIN exhibit superior computational efficiency in comparison to Transformer-based SR approaches. For instance, the time cost associated with DRSAN-48m and Ngswin is 8 and 2.5 times greater than that of our IFIN, respectively. Consequently, it is reasonable to conclude that our proposed IFIN-S and IFIN present a beneficial balance among network complexity, reconstruction accuracy, and time consumption.
Limitations
In this study, our proposed method demonstrates slower inference speeds compared to most CNN-based methods, primarily due to the higher computational complexity of the Transformer. Also, although the structure we designed achieves high performance, there is still a limitation that we employ a fixed upsampling strategy. In future work, we intend to focus on improving the inference speed of the network and designing adaptive upsampling strategies while ensuring reconstruction accuracy.
Conclusion
In this study, an efficient and lightweight interactive feature aggregation network (IFIN) is devised for the image SR task. Specifically, we propose an interactive feature aggregation module (IFAM), which consists of three key components: a structure-aware attention block (SAAB), a Swin Transformer block (SWTB), and an enhanced spatial adaptive block (ESAB). The SAAB focuses on capturing local salient structural features using asymmetric convolution, aiding in the restoration of texture details. Additionally, it collaborates with the SWTB to integrate global information efficiently into the ESAB. The ESAB plays a crucial role in seamlessly fusing and complementing local and global characteristics, generating more expressive feature representations and reconstructing natural and realistic image details. Extensive experiments indicate that our IFIN-S and IFIN are superior with respect to model capacity and reconstruction performance, exceeding mainstream lightweight SR methods.
Data availibility
All datasets are publicly available. Correspondence and requests for materials should be addressed to Li Wang.
References
Dong, C., Loy, C. C., He, K. & Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38, 295–307. https://doi.org/10.1109/TPAMI.2015.2439281 (2016).
Zhang, Y. et al. Image super-resolution using very deep residual channel attention networks. In European Conference on Computer Vision (ECCV). 286–301. https://doi.org/10.1007/978-3-030-01234-2_18 (2018).
Lim, B., Son, S., Kim, H., Nah, S. & Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. 136–144. arXiv:org/abs/1707.02921 (2017).
Mei, Y., Fan, Y. & Zhou, Y. Image super-resolution with non-local sparse attention. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 3516–3525. https://doi.org/10.1109/CVPR46437.2021.00352 (2021).
Kim, J., Lee, J. K. & Lee, K. M. Deeply-recursive convolutional network for image super-resolution. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1637–1645. https://doi.org/10.1109/CVPR.2016.181 (2016).
Ahn, N., Kang, B. & Sohn, K.-A. Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network. 256–272. https://doi.org/10.1007/978-3-030-01249-6_16 (2018) (event-place: Munich, Germany).
Luo, X. et al. LatticeNet: Towards lightweight image super-resolution with lattice block. In European Conference on Computer Vision (ECCV). 272–289. https://doi.org/10.1007/978-3-030-58542-6_17 (2020).
Park, K., Soh, J. W. & Cho, N. I. A dynamic residual self-attention network for lightweight single image super-resolution. IEEE Trans. Multimed. 25, 907–918. https://doi.org/10.1109/TMM.2021.3134172 (2023).
Wang, X. et al. Lightweight single-image super-resolution network with attentive auxiliary feature learning. In Asian Conference on Computer Vision(ACCV). 268–285. https://doi.org/10.1007/978-3-030-69532-3_17 (2020).
Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV). 9992–10002. https://doi.org/10.1109/ICCV48922.2021.00986 (2021).
Zhang, X., Zeng, H., Guo, S. & Zhang, L. Efficient long-range attention network for image super-resolution. In European Conference on Computer Vision (ECCV). 649–667. https://doi.org/10.1007/978-3-031-19790-1_39 (2022).
Fang, J., Lin, H., Chen, X. & Zeng, K. A hybrid network of CNN and transformer for lightweight image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. 1103–1112. https://doi.org/10.1109/CVPRW56347.2022.00119 (2022).
Li, W. et al. Cross-receptive focused inference network for lightweight image super-resolution. arXiv:2207.02796 [cs.CV] https://doi.org/10.48550/ARXIV.2207.02796 (2022).
Yoo, J. et al. Enriched CNN-transformer feature aggregation networks for super-resolution. In 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). 4945–4954. https://doi.org/10.1109/WACV56688.2023.00493 (2023).
Kim, J., Lee, J. K. & Lee, K. M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1646–1654. https://doi.org/10.1109/CVPR.2016.182 (2016).
Zhang, Y., Tian, Y., Kong, Y., Zhong, B. & Fu, Y. Residual dense network for image super-resolution. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2472–2481. https://doi.org/10.1109/CVPR.2018.00262 (2018).
Niu, B. Single. et al. 16th European Conference, Glasgow, UK, August 23–28, 2020. Proceedings, Part XII. 191–207. https://doi.org/10.1007/978-3-030-58610-2_12 (Springer, 2020) (event-place: Glasgow, United Kingdom).
Nguyen, Q. H. & Beksi, W. J. Single image super-resolution via a dual interactive implicit neural network. In 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). 4925–4934. https://doi.org/10.1109/WACV56688.2023.00491 (IEEE, 2023).
Hui, Z., Wang, X. & Gao, X. Fast and accurate single image super-resolution via information distillation network. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 723–731. https://doi.org/10.1109/CVPR.2018.00082 (2018).
Tai, Y., Yang, J., Liu, X. & Xu, C. MemNet: A persistent memory network for image restoration. In 2017 IEEE International Conference on Computer Vision (ICCV). 4549–4557. https://doi.org/10.1109/ICCV.2017.486 (2017).
Hu, Y., Li, J., Huang, Y. & Gao, X. Channel-wise and spatial feature modulation network for single image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 30, 3911–3927. https://doi.org/10.1109/TCSVT.2019.2915238 (2020).
Zhao, H., Kong, X., He, J., Qiao, Y. & Dong, C. Efficient Image Super-Resolution Using Pixel Attention. 56–72. https://doi.org/10.1007/978-3-030-67070-2_3 (Springer, 2020).
Dosovitskiy, A. et al. An Image is Worth 16 x 16 Words: Transformers for Image Recognition at Scale. arXiv:2010.11929 (2020).
Chen, H. et al. Pre-trained image processing transformer. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 12294–12305. https://doi.org/10.1109/CVPR46437.2021.01212 (2021).
Lu, Z. et al. Transformer for single image super-resolution. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). 456–465. https://doi.org/10.1109/CVPRW56347.2022.00061 (2022).
Cai, Q. et al. HIPA: Hierarchical patch transformer for single image super resolution. IEEE Trans. Image Process. 32, 3226–3237. https://doi.org/10.1109/TIP.2023.3279977 (2023).
Yoo, J. et al. Rich CNN-Transformer Feature Aggregation Networks for Super-Resolution. arXiv:2203.07682https://doi.org/10.48550/arXiv.2203.07682 (2022).
Yu, J. et al. Wide Activation for Efficient and Accurate Image Super-Resolution. arXiv:1808.08718 [cs.CV] https://doi.org/10.48550/arXiv.1808.08718 (2018).
Tian, C., Xu, Y., Zuo, W., Lin, C.-W. & Zhang, D. Asymmetric CNN for image superresolution. IEEE Trans. Syst. Man Cybern. Syst. 52, 3718–3730. https://doi.org/10.1109/TSMC.2021.3069265 (2022).
Xu, M., Peng, Y., Zhang, Y., Jia, X. & Jia, S. AACNet: Asymmetric attention convolution network for hyperspectral image dehazing. IEEE Trans. Geosci. Remote Sens. 61, 1–14. https://doi.org/10.1109/TGRS.2023.3321294 (2023).
Liang, J. et al. SwinIR: Image restoration using swin transformer. In 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). 1833–1844. https://doi.org/10.1109/ICCVW54120.2021.00210 (2021).
Timofte, R., Agustsson, E., Gool, L. V., Yang, M. H. & Guo, Q. NTIRE 2017 challenge on single image super-resolution: Methods and results. In IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). 114–125 (2017).
Bevilacqua, M., Roumy, A., Guillemot, C. & Morel, M.-l. A. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the 23rd British Machine Vision Conference (BMVC). 1–10. https://doi.org/10.5244/C.26.135 (British Machine Vision Association, 2012).
Zeyde, R., Elad, M. & Protter, M. On single image scale-up using sparse-representations. In International Conference on Curves and Surfaces. 711–730. https://doi.org/10.1007/978-3-642-27413-8_47 (2010).
Martin, D., Fowlkes, C., Tal, D. & Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings Eighth IEEE International Conference on Computer Vision(ICCV). Vol. 2. 416–423. https://doi.org/10.1109/ICCV.2001.937655 (2001).
Huang, J.-B., Singh, A. & Ahuja, N. Single image super-resolution from transformed self-exemplars. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 5197–5206. https://doi.org/10.1109/CVPR.2015.7299156 (2015).
Matsui, Y. et al. Sketch-based Manga retrieval using Manga109 dataset. Multimed. Tools Appl. 76, 21811–21838. https://doi.org/10.1007/s11042-016-4020-z (2017).
Chao, D., Chen, C. L. & Tang, X. Accelerating the super-resolution convolutional neural network. In European Conference on Computer Vision (ECCV). 391–407. https://doi.org/10.1007/978-3-319-46475-6_25 (2016).
Lai, W.-S., Huang, J.-B., Ahuja, N. & Yang, M.-H. Deep Laplacian pyramid networks for fast and accurate super-resolution. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 5835–5843. https://doi.org/10.1109/CVPR.2017.618 (2017).
Tai, Y., Yang, J. & Liu, X. Image super-resolution via deep recursive residual network. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2790–2798. https://doi.org/10.1109/CVPR.2017.298 (2017).
Zhu, F. & Zhao, Q. Efficient single image super-resolution via hybrid residual feature learning with compact back-projection network. In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW). 2453–2460. https://doi.org/10.1109/ICCVW.2019.00300 (2019).
Wang, C., Li, Z. & Shi, J. Lightweight Image Super-Resolution with Adaptive Weighted Learning Network. arXiv:1904.02358https://doi.org/10.48550/arXiv.1904.02358 (2019).
He, X. et al. ODE-inspired network design for single image super-resolution. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 1732–1741. https://doi.org/10.1109/CVPR.2019.00183 (2019).
Tian, C. et al. Lightweight image super-resolution with enhanced CNN. Knowl.-Based Syst. 205, 106235. https://doi.org/10.1016/j.knosys.2020.106235 (2020).
Banerjee, S., Ozcinar, C., Rana, A., Smolic, A. & Manzke, M. Sub-Pixel Back-Projection Network For Lightweight Single Image Super-Resolution. arXiv:2008.01116https://doi.org/10.48550/arXiv.2008.01116 (2020).
Jiang, Z., Zhu, H., Lu, Y., Ju, G. & Men, A. Lightweight super-resolution using deep neural learning. IEEE Trans. Broadcast. 66, 814–823. https://doi.org/10.1109/TBC.2020.2977513 (2020).
Chu, X., Zhang, B., Ma, H., Xu, R. & Li, Q. Fast, accurate and lightweight super-resolution with neural architecture search. In 2020 25th International Conference on Pattern Recognition (ICPR). 59–64. https://doi.org/10.1109/ICPR48806.2021.9413080 (2021).
Sun, L. et al. Lightweight image super-resolution via weighted multi-scale residual network. IEEE/CAA J. Autom. Sin. 8, 1271–1280. https://doi.org/10.1109/JAS.2021.1004009 (2021).
Wan, J., Yin, H., Liu, Z., Chong, A. & Liu, Y. Lightweight image super-resolution by multi-scale aggregation. IEEE Trans. Broadcast. 67, 372–382 (2021).
Lan, R. et al. MADNet: A fast and lightweight network for single-image super resolution. IEEE Trans. Cybern. 51, 1443–1453. https://doi.org/10.1109/TCYB.2020.2970104 (2021).
Zhang, H., Xiao, J. & Jin, Z. Multi-scale image super-resolution via a single extendable deep network. IEEE J. Sel. Top. Signal Process. 15, 253–263. https://doi.org/10.1109/JSTSP.2020.3045282 (2021).
Liu, Y. et al. Cross-SRN: Structure-preserving super-resolution network with cross convolution. IEEE Trans. Circuits Syst. Video Technol. 32, 4927–4939. https://doi.org/10.1109/TCSVT.2021.3138431 (2022).
Wei, D. & Wang, Z. Channel rearrangement multi-branch network for image super-resolution. Digit. Signal Process. 120, 103254. https://doi.org/10.1016/j.dsp.2021.103254 (2022).
Du, Z. et al. Fast and memory-efficient network towards efficient image super-resolution. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). 852–861. https://doi.org/10.1109/CVPRW56347.2022.00101 (2022).
Wang, L., Li, K., Tang, J. & Liang, Y. Image super-resolution via lightweight attention-directed feature aggregation network. ACM Trans. Multimedia Comput. Commun. Appl. 19https://doi.org/10.1145/3546076 (2023) (Association for Computing Machinery).
Lu, Z., Liu, H., Li, J. & Zhang, L. Efficient Transformer for Single Image Super-Resolution. arXiv:2108.11084https://doi.org/10.48550/arXiv.2108.11084 (2021).
Gao, G. et al. Lightweight Bimodal Network for Single-Image Super-Resolution via Symmetric CNN and Recursive Transformer. 896–902. https://doi.org/10.24963/ijcai.2022/126 (2022).
Dai, T. et al. CFGN: A lightweight context feature guided network for image super-resolution. In IEEE Transactions on Emerging Topics in Computational Intelligence. 1–11. https://doi.org/10.1109/TETCI.2023.3289618 (2023).
Choi, H., Lee, J. & Yang, J. N-Gram in Swin transformers for efficient lightweight image super-resolution. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2071–2081. https://doi.org/10.1109/CVPR52729.2023.00206 (2023).
Zhang, K., Zuo, W. & Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3262–3271. https://doi.org/10.1109/CVPR.2018.00344 (2018).
Zhang, K., Zuo, W., Gu, S. & Zhang, L. Learning deep CNN denoiser prior for image restoration. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2808–2817. https://doi.org/10.1109/CVPR.2017.300 (2017).
Dong, X. et al. Remote sensing image super-resolution using novel dense-sampling networks. IEEE Trans. Geosci. Remote Sens. 59, 1618–1633. https://doi.org/10.1109/TGRS.2020.2994253 (2021).
Wang, Z. et al. FeNet: Feature enhancement network for lightweight remote-sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 60, 1–12. https://doi.org/10.1109/TGRS.2022.3168787 (2022).
Yang, Y. & Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, GIS ’10. 270–279. https://doi.org/10.1145/1869790.1869829 (Association for Computing Machinery, 2010) (event-place: San Jose, California).
Lei, S., Shi, Z. & Zou, Z. Super-resolution for remote sensing images via local-global combined network. IEEE Geosci. Remote Sens. Lett. 14, 1243–1247. https://doi.org/10.1109/LGRS.2017.2704122 (2017).
Gao, F. et al. A lightweight feature distillation and enhancement network for super-resolution remote sensing images. Sensorshttps://doi.org/10.3390/s23083906 (2023).
Wang, Q., Wang, S., Chen, M. & Zhu, Y. DARN: Distance attention residual network for lightweight remote-sensing image superresolution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 16, 714–724. https://doi.org/10.1109/JSTARS.2022.3227509 (2023).
Acknowledgements
This work was supported by Jiangsu Higher Education Teaching Reform Research General Project (No.2021JSJG519).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, L., Li, X., Tian, W. et al. Lightweight interactive feature inference network for single-image super-resolution. Sci Rep 14, 11601 (2024). https://doi.org/10.1038/s41598-024-62633-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-62633-8
- Springer Nature Limited