
Abstract
Infectious keratitis (IK) is a major cause of corneal opacity. IK can be caused by a variety of microorganisms. Typically, fungal ulcers carry the worst prognosis. Fungal cases can be subdivided into filamentous and yeasts, which shows fundamental differences. Delays in diagnosis or initiation of treatment increase the risk of ocular complications. Currently, the diagnosis of IK is mainly based on slit-lamp examination and corneal scrapings. Notably, these diagnostic methods have their drawbacks, including experience-dependency, tissue damage, and time consumption. Artificial intelligence (AI) is designed to mimic and enhance human decision-making. An increasing number of studies have utilized AI in the diagnosis of IK. In this paper, we propose to use AI to diagnose IK (model 1), differentiate between bacterial keratitis and fungal keratitis (model 2), and discriminate the filamentous type from the yeast type of fungal cases (model 3). Overall, 9329 slit-lamp photographs gathered from 977 patients were enrolled in the study. The models exhibited remarkable accuracy, with model 1 achieving 99.3%, model 2 at 84%, and model 3 reaching 77.5%. In conclusion, our study offers valuable support in the early identification of potential fungal and bacterial keratitis cases and helps enable timely management.
Similar content being viewed by others

Introduction
Infectious keratitis (IK) is a major cause of corneal opacity, the fifth leading cause of blindness worldwide. Annual vision loss due to IK comprises approximately 2 million cases worldwide1. IK exerts a significant burden on the healthcare system, accounting for 1 million visits and $175 million in healthcare expenditures in the USA alone2. Notably, IK contributes to 10% of preventable visual impairments in the world's least-developed regions3,4,5. IK can be caused by a variety of microorganisms, including bacteria, fungi, viruses, and parasites6. Of these, fungal ulcers carry the worst prognosis7. Additionally, fungal cases can be subdivided into filamentous (e.g., Aspergillus spp. and Fusarium spp.) and yeasts (e.g., Candida spp.), which shows fundamental differences regarding mycological and clinical characteristics8.
Delays in diagnosis or initiation of appropriate treatment increase the risk of ocular complications including blindness9. Currently, the diagnosis of IK is mainly made based on slit-lamp examination, corneal scrapings, tissue biopsy, PCR, and confocal microscopy10. However, these diagnostic methods have their drawbacks, including experience-dependency, tissue damage, cost, and time consumption. Moreover, the sensitivity and accuracy of these methods are at times unsatisfying. Diagnosis of IK can be especially challenging in rural areas or in countries with limited resources due to financial constraints, the unreliability of usual laboratory diagnostic tests, and lack of access to standardized laboratory resources11,12. Routinely, ophthalmologists initiate empiric treatment based on clinical features, which demands extensive exposure to diverse clinical scenarios over an extended training period. Furthermore, the broad spectrum of IK presentations makes the interpretation process more complex11,13,14. Collectively, these issues necessitate the development of new, more accurate, and rapid diagnostic methods.
Artificial intelligence (AI), a subfield of computer science designed to mimic and enhance human decision-making, has garnered substantial attention in the medical field in recent years15,16,17. The two main subfields of AI include machine learning (ML) and deep learning (DL). Unlike ML, DL eliminates the necessity for manual feature engineering. DL uses neural networks to learn from data and perform complex tasks18. Previously, ocular AI research was mainly focused on diseases of the posterior segment such as diabetic retinopathy, retinopathy of prematurity, age-related macular degeneration, retinal vein occlusion, and glaucoma optic neuropathy19,20,21,22,23. However, an increasing number of studies have utilized AI in the diagnosis of anterior segment diseases such as IK24,25,26. Using AI to help diagnose and manage IK can provide a much-needed solution to the shortage of ophthalmologists and improve patient care and outcomes. AI algorithms can be trained to recognize patterns in images that are invisible to the naked eye, which allows AI algorithms to diagnose IK with exceptional accuracy. In this paper, we propose to use AI to: (1) diagnose IK (model 1 of our study), (2) differentiate between bacterial keratitis and fungal keratitis (model 2), and 3) discriminate the filamentous type from the yeast type of fungal cases (model 3) based on slit-lamp images.
Methods
Ethics statement
This study was in accordance with the principles of the Declaration of Helsinki. Ethical clearance for this study was granted by the Ethics Committee of Farabi Eye Hospital, with the approval code: IR.TUMS.FARABIH.REC.1400.064. The need for written informed consent was waived by the same Ethic Committee. All methods were performed in accordance with relevant guidelines and regulations.
Subjects and data acquisition
The participants in this study were patients recruited during their visits to the emergency department of Farabi Eye Hospital with a culture-proven diagnosis of bacterial keratitis (BK) or fungal keratitis (FK) between 2014 and 2021. Detailed laboratory investigations are provided here27. A population of healthy individuals was enrolled as well. In total, we analyzed data from a collection of 15619 slit-lamp photographs of 1514 participants. In detail, 2505 slit-lamp photographs were taken from 279 healthy individuals, 6761 slit-lamp photographs from 521 patients diagnosed with BK, and 6353 slit-lamp photographs from 714 patients diagnosed with FK. The slit-lamp photographs were captured using a Canon EOS 1300D camera mounted on slit-lamp microscopes, including the Haag-Streit BX900 and Topcon SL-D8 models. Patients with mixed or other types of infection, culture-negative cases, individuals who had previously undergone corneal graft procedures (e.g., penetrating keratoplasty, corneal patch grafts, and amniotic membrane grafts), patients with other significant ocular surface conditions, and those with confounding factors affecting the clinical assessment such as the presence of cyanoacrylate glue patches and bandage contact lens were excluded from the study. Images with poor quality, including those showing extreme gazes or incompletely opened eyelids, were similarly excluded. Finally, the dataset used in this study included 9329 images (from 977 patients); in detail, 2505 images (from 279 patients), 2008 images (from 280 patients), and 4816 images (from 418 patients) of healthy eyes, FK, and BK, respectively. Additionally, images of the FK class have been divided into two subclasses; Aspergillus/Fusarium spp. (1643 images from 149 patients) and Candida spp. (357 images from 29 patients). Image samples are presented in Fig. 1.

Slit-photo samples of healthy eye and different types of keratitis (e.g., bacterial, Aspergillus, Fusarium, and Candida keratitis) enrolled in the study. Clinical characteristics may vary between different types of keratitis, and different microorganisms may occasionally manifest with a specific infiltrate pattern.
Dataset and hardware details
The original images had a resolution of 4752 × 3168 pixels and were resized into 300 × 300 due to the limited processing power of the computer used. The configuration of used hardware to debug and run the codes was a laptop with AMD RYZEN 9 6000 SERIES, 32 GB DDR5 RAM and Nvidia GEFORCE RTX 3070 Ti with 8 GB VRAM. All codes were developed using Python 3.10 and deep learning-based codes were simulated using TensorFlow package version 2.12 and Windows Subsystem for Linux (WSL) version 2.0.
Notably, a significant imbalance between the main classes and subclasses was present in the data of our study, which posed a challenge for the training of the models. An approach that is commonly employed to address this issue is the assignment of extra weights, i.e., class weights, to the loss value when the samples of the minority class are misclassified by the model. This method resulted in increased sensitivity for the minority samples and more balanced recognition rates for each class. However, a trial-and-error process is usually required for choosing the appropriate value for class weights. Therefore, three different sets of class weights determined by trial and error were trialed in this study. These values, along with the classes of each model, are presented later.
Designed models and simulation details
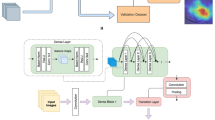
To achieve the goals of our study, two slightly different types of structures were designed to train the models. Both networks were based on Convolutional Neural Networks (CNNs), which are structures that can handle recognition tasks using image-based inputs effectively. These two structures were chosen as the final approaches since they provided results that surpass the other candidates considered for the tasks. Another factor that influenced the selection of the final designs is the minimal size of the chosen networks, which reduces the computational complexity and memory requirements. The details of these two structures are presented in Fig. 2.

Designation of networks. (a) Network 1, Designed to differentiate healthy cases from patients with keratitis, and Aspergillus and Fusarium from Candida in the case of fungal keratitis. (b) Network 2, Designed to differentiate bacterial and fungal types of keratitis.
As shown in Fig. 2, the main difference between these two networks is the presence of a fusion component in Network 1, which joins three different types of feature maps into one array. This approach fulfills two aims of this study, which are the diagnosis of IK (e.g., differentiation between healthy cases and patients with keratitis) and discrimination of Aspergillus/Fusarium spp. from Candida spp. in the case of FK. Network 2 is used for fulfilling the other aim of this study, which is to differentiate between bacterial and fungal types of keratitis. In each network, all layers except the last layer use ReLu function for the activation function, while the last layer uses the Sigmoid function.
The data sources, network architectures, and hyperparameters for each model are summarized in Table 1. Although the models use different sizes of datasets for training, validation, and evaluation, they follow the same procedure: 20% of the data is reserved for evaluation using K-fold cross-validation with K = 5, and the remaining 80% is split into 90% for training and 10% for validation. This means that the training phase uses 72% of the available data, while the validation phase uses 8%. Each model has a unique set of hyperparameters, some of which are shared among all models. As mentioned earlier, although using these values is not mandatory for achieving acceptable results, they are optimized by trial and error based on the limitations of the available hardware.
Results
All results have been validated using the K-fold cross-validation method. The sensitivity and specificity values have been calculated using Eqs. (1) and (2), based on the confusion matrices shown in Fig. 3. Moreover, two heatmap images, extracted from the first layer of the network, designed to differentiate bacterial keratitis from fungal keratitis, are presented in Fig. 4. As it seems, the model is capable of detecting important parts of the input image.

Confusion matrices, regarding each one of three suggested models (e.g., diagnosis of IK (model 1), differentiation between bacterial keratitis and fungal keratitis (model 2), and discrimination between the filamentous type from the yeast type (model 3)).

Heatmaps of two sampled images, regarding the fungal and bacterial keratitis, merged with the original inputs.
It should be noted that the true positive and true negative values are on the diagonal of the confusion matrix, i.e., the values at (0, 0) and (1, 1) positions, while the false negative and false positive values are off the diagonal, i.e., the values at (1, 0) and (0, 1) positions.
In addition to the confusion matrices, Table 2 shows the values of other metrics for each model. The results indicate that the accuracy and other metrics decrease as the recognition task becomes more specific. Figure 5 illustrates the ROC curve and precision-recall (PR) curve of the 3 models. The area under the receiver operating characteristic curve (AUC) is mentioned for each model.

Receiver operating characteristic (ROC) curve and precision-recall curve of the three suggested models.
Discussion
Deep Learning represents a subset of machine learning methods that has garnered substantial worldwide attention in recent years. DL employs techniques for learning representations with multiple layers of abstraction, enabling it to handle input data without the necessity for manual feature engineering. It accomplishes this by automatically identifying complex patterns within high-dimensional data by projecting it onto a lower-dimensional space18,28. DL utilizes intricate architectures of CNNs. Within these CNNs, software-defined “neurons” work in unison to process data and extracting vital information. These neural networks are meticulously designed to mimic the cognitive processes of the human brain, thus enabling the algorithm to independently evaluate the accuracy of predictions produced during the DL process29. Within the field of medicine and healthcare, DL has found multiple applications, particularly in the analysis of medical images. DL systems have demonstrated strong diagnostic capabilities in identifying various medical conditions18. Additionally, DL has been leveraged for ophthalmic imaging, specifically with fundus photographs and optical coherence tomography (OCT). Prominent eye diseases where DL techniques have been employed include diabetic retinopathy (DR), glaucoma, age-related macular degeneration (AMD), retinopathy of prematurity (ROP), and corneal ulcers22,30,31,32.
In this study, we developed three CNN-based DL models to diagnose microbial keratitis. Model 1 differentiated normal individuals from patients with microbial keratitis, and obtained accuracy and AUC of 99.3% and 1.0, respectively. Model 2 differentiated FK from BK, and achieved approximate accuracy and AUC of 84% and 0.96, respectively. Model 3 aimed to distinguish between keratitis resulting from two primary subtypes of fungal species: yeasts (Candida spp.) and filamentous fungi (Aspergillus spp. and Fusarium spp.). This model achieved an accuracy of 77.5% and an AUC of 0.99. These three models were designed based on two distinct CNN architectures, as depicted in Fig. 2. Both models were developed and customized by our research team. One notable characteristic of the CNNs is its initial operation on the input data through three parallel layers (Fig. 2a). Each of these layers utilizes a different kernel size. Specifically, the [5, 5] kernel addresses a smaller area of the analyzed image in contrast to the [20, 20] kernel. Models 1 and 3 were constructed with this CNN architecture. In contrast, model 2 demonstrated superior performance when implemented using CNN as illustrated in Fig. 2b. These models demonstrate exceptional performance for different aspects of keratitis. Moreover, given the size of the images used for training and the limitations of the available hardware, it is reasonable to claim that more accurate models can be designed as more detailed data and more powerful computers become available.
In the present study, model 3 was designed to differentiate between keratitis caused by two primary subtypes of fungal species. This particular model attained an accuracy rate of 77.5% along with an AUC of 0.96. This model represents an effort to distinguish between subtypes of fungal keratitis accurately. Its goal is to steer initial empiric treatment towards the most effective and targeted antifungal therapy. The selection of antifungal medications can be influenced by several factors, including their accessibility and the preferences of the treating clinician or infectious disease specialist. In the United States, topical natamycin 5% is both FDA-approved and readily available, and it has demonstrated better outcomes in cases of Fusarium keratitis. However, it has poor penetration10,33. Topical amphotericin can be the primary choice for treating yeasts and serve as an alternative for filamentous fungi, but it has disadvantages linked to its preparation and stability33. To the best of our knowledge, this is the first successful DL-based model in this regard.
Previously, Kuo et al. developed a model to differentiate FK from non-FK with an average accuracy of 69.4%. The AUC in that model was 0.65. Limited number of training data and a high misclassification rate due to the heterogenicity of the non-FK group may have affected the performance of their model34. Ghosh and colleagues employed an ensemble of three pre-trained CNNs to differentiate FK from BK, which collectively achieved an accuracy measured by the F1 score (the harmonic mean of precision and recall) of 0.83 and a precision-recall AUC of 0.9035. Their findings align closely with the second model in our study and highlights our precision-recall AUC of 0.92. Redd et al., in a multicenter study using ubiquitous hand-held cameras, investigated the diagnostic accuracy of human and AI models. In their study, the AUC of the best CNN architecture, the best human grader, and the ensemble of the best-performing CNN and best-performing human were 0.83, 0.79, and 0.87, respectively. The primary benefit of their MobileNet model lies in its mobility and its potential for use in telemedicine applications32. Hung et al. reported an accuracy of about 70% on distinguishing between FK and BK. However, by cropping slit-lamp images using U2 segmentation, they attained an accuracy of 80% and an AUC of 0.8536. Xu et al. created an advanced deep sequential feature learning model to distinguish between bacterial and fungal keratitis, achieving an accuracy of 84% for fungal keratitis and 65% for bacterial keratitis37.
In the case of IK, clinical diagnosis stands as the pivotal initial step for commencing confirmatory tests and delivering efficient empirical treatment to patients, preceding pathogen confirmation38. The diagnosis of microbial keratitis is established by considering the patient's medical history and conducting microbiology tests. Although microbiological culture continues to serve as the definitive method for diagnosing IK, our DL-based model, alongside other mentioned templates, has demonstrated the promise of AI in diagnosing IK solely through imaging data. These models facilitate early recognition of potential FK cases and can expedite the start of empirical treatment or facilitate appropriate referral management. These models outperform human experts in some cases. Kuo et al. reported the diagnostic accuracy of non-cornea specialty ophthalmologists and cornea specialists were 67.1% and 75.9%, respectively in differentiating FK from BK. Their DL model reached an accuracy of about 70%, which was higher than non-cornea specialty ophthalmologists34. Redd et al. illustrated that even the best human examiners with years of experience (AUC = 0.79) could not outperform their best CNN model (AUC = 0.83)32. Xu et al. also reported the average diagnostic accuracy of expert human examiners to be 49.3%, while their DL-based model attained diagnostic accuracies of 53.3% and 83.3% for BK and FK, respectively37. In this study, we did not include the diagnostic accuracy of human examiners in distinguishing FK from BK in our dataset. However, considering the comparatively high accuracy achieved by our DL-based model, we anticipate it would surpass the performance of human examiners, but further studies would be required to investigate this claim. It should be noted that in our models, each CNN block represents a convolutional layer. Moreover, it is worth mentioning that in the case of this research, early trials showed that using pretrained networks, such as ResNet, Inception and VGG families, leads to weaker results, compared to training networks from scratch, similar to the approach selected in this study.
There are several limitations to the present study which are important to consider when interpreting the results. To begin with, our study did not control for the conditions and context in which the slit-lamp images were captured. Additionally, the inherent lower image quality due to decreased patient cooperation during severe keratitis cases with heightened symptoms may have impacted our models' performance. Corneal images are known to be more susceptible to artifacts compared to retinal images. The quality of these photographs can be influenced by various factors, including reflections from the slit-lamp light beam, camera flashlight glare, ambient lighting conditions, and overall image brightness. These factors were not controlled in our study. A study by Ghosh et al. demonstrated that the incidence of misclassified data was reduced notably when image brightness was carefully controlled within a specific range35. Second, the dataset for this study was collected at a referral medical center, where some patients had already received topical treatments before their examination. Additionally, the ready availability of topical antibacterial medications as over-the-counter options, in contrast to antifungal medications, could have influenced the characteristics of infections. In turn, this disparity may have impacted accuracy of the models as well. Third, the inclusion of multiple images for each eye and the absence of patient matching between the training, validation, and testing groups might have potentially impacted the models’ performance. To mitigate the occurrence of so-called “label leakage”39, we implemented a five-fold cross-validation approach, ensuring that both the validation and test datasets remained entirely separate from the training dataset. Fourth, our study exclusively utilized cases with confirmed bacterial and fungal infections through culture testing. Prior confirmations may have led to an artificially inflated diagnostic accuracy for our models. Furthermore, it reduces the practical applicability of these models in a clinical setting. Further studies should investigate the accuracy of our DL models when applied in an office setting before culture positivity is known.
In conclusion, although clinical diagnosis remains a critical initial step in managing infectious keratitis, our DL-based models offer valuable support in the early identification of potential fungal and bacterial keratitis cases and help enable timely treatment or referral management. We have successfully developed three DL-based models tailored for the diagnosis of infectious keratitis, each with its unique role and purpose. These models exhibit high accuracy and hold great promise in enhancing the diagnostic process: Model 1: Geared towards primary healthcare practitioners, this model effectively discerns individuals presenting with ambiguous symptoms of infectious keratitis from otherwise healthy patients. Model 2: Targeted towards expert caregivers and ophthalmologists, this model serves to differentiate fungal keratitis from bacterial keratitis. Its accuracy and performance provide crucial support in ensuring the correct diagnosis and facilitating treatment decisions. Model 3: Designed for the same expert caregivers, this model further distinguishes between the subtypes of fungal species causing keratitis. This precision enables healthcare professionals to guide empiric treatment towards more effective and tailored options, ultimately improving patient outcomes.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request. Moreover, the codes developed for this study are publicly available in the GitHub repository, addressed: https://github.com/amirrdr/slitlamp-keratitis-1/ (Accessed December 5, 2023).
References
Whitcher, J. P., Srinivasan, M. & Upadhyay, M. P. Corneal blindness: A global perspective. Bull. World Health Organ. 79, 214–221 (2001).
Collier, S. A. et al. Estimated burden of keratitis—United States, 2010. Morb. Mortal. Wkly. Rep. 63, 1027 (2014).
Austin, A., Lietman, T. & Rose-Nussbaumer, J. Update on the management of infectious keratitis. Ophthalmology 124, 1678–1689 (2017).
Mariotti, A. & Pascolini, D. Global estimates of visual impairment. Br. J. Ophthalmol. 96, 614–618 (2012).
Furtado, J. M. et al. Causes of blindness and visual impairment in Latin America. Surv. Ophthalmol. 57, 149–177 (2012).
Lin, A. et al. Bacterial keratitis preferred practice pattern®. Ophthalmology 126, P1–P55 (2019).
Gopinathan, U. et al. The epidemiological features and laboratory results of fungal keratitis: A 10-year review at a referral eye care center in South India. Cornea 21, 555–559 (2002).
Masoumi, A. et al. Clinical features, risk factors, and management of candida keratitis. Ocular Immunology and Inflammation 1–6 (2023).
Izadi, A. et al. Clinical and mycological characteristics of keratitis caused by Colletotrichum gloeosporioides: A case report and review of literature. J. Infect. Dev. Ctries. 15, 301–305 (2021).
Cabrera-Aguas, M., Khoo, P. & Watson, S. L. Infectious keratitis: A review. Clin. Exp. Ophthalmol. 50, 543–562 (2022).
Saini, J. S. et al. Neural network approach to classify infective keratitis. Curr. Eye Res. 27, 111–116 (2003).
Whitcher, J. P. & Srinivasan, M. Corneal ulceration in the developing world—A silent epidemic. Br. J. Ophthalmol. 81, 622–623 (1997).
Rodman, R. C. et al. The utility of culturing corneal ulcers in a tertiary referral center versus a general ophthalmology clinic. Ophthalmology 104, 1897–1901 (1997).
McDonnell, P. J. Empirical or culture-guided therapy for microbial keratitis?: A plea for data. Arch. Ophthalmol. 114, 84–87 (1996).
Esteva, A. et al. Dermatologist-level classification of skin cancer with deep neural networks. Nature 542, 115–118 (2017).
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2818–2826.
Chilamkurthy, S. et al. Deep learning algorithms for detection of critical findings in head CT scans: A retrospective study. Lancet 392, 2388–2396 (2018).
Ting, D. S. W. et al. Artificial intelligence and deep learning in ophthalmology. Br. J. Ophthalmol. 103, 167–175 (2019).
Gu, H. et al. Deep learning for identifying corneal diseases from ocular surface slit-lamp photographs. Sci. Rep. 10, 17851 (2020).
Gulshan, V. et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 316, 2402–2410 (2016).
Gargeya, R. & Leng, T. Automated identification of diabetic retinopathy using deep learning. Ophthalmology 124, 962–969 (2017).
Li, Z. et al. Efficacy of a deep learning system for detecting glaucomatous optic neuropathy based on color fundus photographs. Ophthalmology 125, 1199–1206 (2018).
Burlina, P. M. et al. Automated grading of age-related macular degeneration from color fundus images using deep convolutional neural networks. JAMA Ophthalmol. 135, 1170–1176 (2017).
Ting, D. S. J. et al. Artificial intelligence for anterior segment diseases: Emerging applications in ophthalmology. Br. J. Ophthalmol. 105, 158–168 (2021).
Zhang, Z. et al. Artificial intelligence-assisted diagnosis of ocular surface diseases. Front. Cell Dev. Biol. 11, 1133680 (2023).
Soleimani, M. et al. Artificial intelligence and infectious keratitis: Where are we now?. Life 13, 2117 (2023).
Soleimani, M. et al. Fungal keratitis in Iran: Risk factors, clinical features, and mycological profile. Front. Cell. Infect. Microbiol. 13, 59 (2023).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Moraru, A. D., Costin, D., Moraru, R. L. & Branisteanu, D. C. Artificial intelligence and deep learning in ophthalmology-present and future. Exp. Ther. Med. 20, 3469–3473 (2020).
Ting, D. S. W. et al. Development and validation of a deep learning system for diabetic retinopathy and related eye diseases using retinal images from multiethnic populations with diabetes. JAMA 318, 2211–2223 (2017).
Brown, J. M. et al. Automated diagnosis of plus disease in retinopathy of prematurity using deep convolutional neural networks. JAMA Ophthalmol. 136, 803–810 (2018).
Redd, T. K. et al. Image-based differentiation of bacterial and fungal keratitis using deep convolutional neural networks. Ophthalmol. Sci. 2, 100119 (2022).
Watson, S. L. et al. The clinical and microbiological features and outcomes of fungal keratitis over 9 years in Sydney, Australia. Mycoses 63, 43–51 (2020).
Kuo, M.-T. et al. A deep learning approach in diagnosing fungal keratitis based on corneal photographs. Sci. Rep. 10, 14424 (2020).
Ghosh, A. K., Thammasudjarit, R., Jongkhajornpong, P., Attia, J. & Thakkinstian, A. Deep learning for discrimination between fungal keratitis and bacterial keratitis: DeepKeratitis. Cornea 41, 616 (2022).
Hung, N. et al. Using slit-lamp images for deep learning-based identification of bacterial and fungal keratitis: Model development and validation with different convolutional neural networks. Diagnostics 11, 1246 (2021).
Xu, Y. et al. Deep sequential feature learning in clinical image classification of infectious keratitis. Engineering 7, 1002–1010 (2021).
Dahlgren, M. A., Lingappan, A. & Wilhelmus, K. R. The clinical diagnosis of microbial keratitis. Am. J. Ophthalmol. 143, 940-944.e941 (2007).
Kaufman, S., Rosset, S., Perlich, C. & Stitelman, O. Leakage in data mining: Formulation, detection, and avoidance. ACM Trans. Knowl. Discov. Data (TKDD) 6, 1–21 (2012).
Funding
This work was supported by R01 EY024349 (ARD), UH3 EY031809 (ARD): Core Grant for Vision Re-search EY01792 all from NEI/NIH; Vision Research Program—Congressionally Directed Medical Research Program VR170180 from the Department of Defense, Unrestricted Grant to the department and Physician-Scientist Award both from Research to Prevent Blindness.
Author information
Authors and Affiliations
Contributions
Conceptualization, M.S.; methodology, M.S., S.A.T., and K.S.; formal analysis, A.R., R.M. and S.F.M.; data curation, K.S., M.A., and Z.B.; writing—original draft preparation, M.A. and K.C.; writing—review and editing, K.C. and S.Y.; supervision, A.R.D. and M.S.; project administration, M.S. and S.A.T.; funding acquisition, A.R.D. M.S. and K.S. should be considered the joint first author. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Soleimani, M., Esmaili, K., Rahdar, A. et al. From the diagnosis of infectious keratitis to discriminating fungal subtypes; a deep learning-based study. Sci Rep 13, 22200 (2023). https://doi.org/10.1038/s41598-023-49635-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-49635-8
- Springer Nature Limited