
Abstract
The gut microbiome is widely analyzed using high-throughput sequencing, such as 16S rRNA gene amplicon sequencing and shotgun metagenomic sequencing (SMS). DNA extraction is known to have a large impact on the metagenomic analyses. The aim of this study was to compare DNA extraction protocols for 16S sequencing. In that context, four commonly used DNA extraction methods were compared for the analysis of the gut microbiota. Commercial versions were evaluated against modified protocols using a stool preprocessing device (SPD, bioMérieux) upstream DNA extraction. Stool samples from nine healthy volunteers and nine patients with a Clostridium difficile infection were extracted with all protocols and 16S sequenced. Protocols were ranked using wet- and dry-lab criteria, including quality controls of the extracted genomic DNA, alpha-diversity, accuracy using a mock community of known composition and repeatability across technical replicates. SPD improved overall efficiency of three of the four tested protocols compared with their commercial version, in terms of DNA extraction yield, sample alpha-diversity, and recovery of Gram-positive bacteria. The best overall performance was obtained for the S-DQ protocol, SPD combined with the DNeasy PowerLyser PowerSoil protocol from QIAGEN. Based on this evaluation, we strongly believe that the use of such stool preprocessing device improves both the standardization and the quality of the DNA extraction in the human gut microbiome studies.
Similar content being viewed by others

Introduction
In recent years, advances in next-generation sequencing (NGS) have revolutionized the analysis of complex microbial ecosystems including the gut microbiota, leading to advanced understanding of its role in health and disease1,2,3,4,5,6. Alterations in the composition and diversity of the gut microbiota communities have been correlated with a large number of diseases, such as inflammatory bowel disease7,8,9,10,11, irritable bowel syndrome12,13, metabolic disorders [e.g. type 2 diabetes (T2D), obesity and nonalcoholic fatty liver disease (NALFD)]14,15,16,17,18,19, and more recently, cancer20,21,22,23,24,25,26,27,28,29,30.
Nevertheless, metagenomics methods are known to be prone to errors at different steps of the workflow, from sample collection31,32,33,34, DNA extraction35,36,37, library preparation and sequencing37,38,39 to data analysis40,41. In order to facilitate the implementation of these methods into clinical routine practice, standardized methods are urgently needed42,43,44,45,46. Although a standard operating procedure for fecal samples DNA extraction has been provided by the International Human Microbiome Standards (IHMS, http://www.microbiome-standards.org/), the area of nucleic acids preparation is rapidly evolving and regular protocol benchmarking is required.
The choice of the DNA extraction method has been demonstrated to strongly affect the detection of bacterial communities35,36,47,48,49. DNA extraction is a sophisticated process, including sample weighing, sample homogenization, bacterial cell lysis, and DNA purification, for which each step still requires improvements and guidelines. For instance, the standard weighing procedure can be tedious and time-consuming to collect the same volume of fecal material for all samples. Sample homogenization could also have an impact on the bacteria that can be detected50,51. Surprisingly, few studies have reported the use of commercial devices to standardize the handling of fecal samples prior to DNA extraction31,52,53. Also, as the cell wall of Gram-positive bacteria is composed of a thick layer of peptidoglycan, bead-beating is now recommended to improve the lysis37,54,55. Nevertheless, beads can vary in size and material (e.g. ceramic, glass, zirconia or silica), which may also play a role in the lysis efficiency. Even if commercial solutions provide standardized methods for bacterial lysis and DNA purification, some laboratories still use in-house protocols, making difficult the selection of one gold-standard protocol.
Recently, twenty-one DNA extraction protocols were compared in a multicentric study across three continents using Shotgun Metagenomic Sequencing (SMS)35. From the analysis of two healthy individuals, the authors proposed a QIAGEN protocol, named Q, as the standardized reference protocol for DNA extraction in human gut microbiome studies. However, it has been shown that different fecal samples may vary in terms of bacterial composition (Gram-positive vs Gram-negative cells)35,56, microbial load (high vs low bacterial cells per fecal material)57,58, disease-related clinical status (healthy vs sick individuals)59,60,61 and stool consistency (separate hard lumps vs watery)62,63,64. A comparison study with a higher number of individuals including both healthy and sick donors would be of both clinical and technological interests to address the variability and heterogeneity of fecal samples.
Although SMS has the potential to deeply investigate microbial communities65,66, amplicon sequencing targeting the 16S rRNA gene is often the preferred and the most cost-effective metagenomic method in the analysis of clinical cohorts67,68. Obviously, these sequencing methods have their own limitations and biases, which are important to consider for the selection of one DNA extraction protocol in human gut microbiome studies.
To address these considerations, our study evaluated four commercially available DNA extraction methods, using 16S rRNA amplicon sequencing. These protocols were tested as recommended by the manufacturers, but also with an upstream stool preprocessing device (SPD), designed to facilitate DNA extraction52. The protocols were evaluated according to wet-lab as well as dry-lab criteria, using nine healthy individuals and nine Clostridium difficile infected (CDI) patients.
Results
Study design
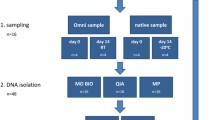
In our study, four commercial DNA extraction protocols were evaluated based on the supplier’s recommendations: the NucleoSpin Soil kit (Macherey–Nagel, named MN), the DNeasy PowerLyzer PowerSoil kit (QIAGEN, named DQ), the QIAamp Fast DNA Stool kit (QIAGEN, named QQ), and the ZymoBIOMICS DNA Mini kit (ZymoResearch, named Z). In order to facilitate the first steps of DNA extraction, they were also tested with an upstream stool preprocessing device, named SPD (see Supplementary Methods for detailed protocols). The resulting protocols were named as follows: S-MN stands for SPD + MN, S-DQ for SPD + DQ, S-QQ for SPD + QQ and S-Z for SPD + Z.
We analyzed fecal samples from nine healthy volunteers (CDI−) and nine patients suffering from CDI (CDI+). A defined mixture of bacterial species (mock community) was also prepared and sequenced to assess the efficiency and accuracy of DNA extraction by comparing the observed bacterial abundances to the theoretical ones. DNA extraction protocols were compared using 16S rRNA gene amplicon sequencing for a total of 456 samples (18 fecal samples and 1 mock community, in triplicates) (Fig. 1).

Workflow of sample processing.
Quality and quantity of extracted DNA
When selecting a DNA extraction protocol, sufficient genomic DNA of high quality is desirable for preparing metagenomic libraries. In the present study, we evaluated the DNA yield, DNA fragment size and DNA quality. A protocol that performs poorly on these criteria would likely skew measured bacterial compositions as only a small portion of bacterial communities present in the original sample would be analyzed. A summary of DNA extraction performance for all human fecal samples is presented in Supplementary Table 1.
Considerable variability was found in the extraction yield for the tested protocols (Fig. 2a), which is in line with previous studies36, and was not dependent on health status (Supplementary Fig. 1a). Except for MN, DNA extraction protocols in combination with SPD seemed to recover as much or more DNA compared to their commercial versions. Notably, increases were observed for S-QQ (p-value < 0.1) and S-Z (p-value < 0.05), compared to QQ and Z respectively. A same DNA yield was obtained for the protocol DQ with and without the use of SPD (p-value > 1). SPD seemed to negatively affect the extraction yield when coupled with the protocol MN (p-value < 0.01). Out of the eight extraction protocols tested, protocols S-MN and Z significantly recovered the lowest DNA concentrations.

Quantity and quality of extracted DNA from human fecal samples and mock samples with eight different extraction protocols. (a) DNA concentration (ng/µl). The orange horizontal line represents the threshold at 5 ng/µl. (b) DNA size (bp). (c) Absorbance ratios at 260/280. DNA of good quality should have a ratio between the two orange horizontal lines (between 1.8 and 2, preferably close to 1.8). All boxplots are topped by a heatmap showing the pairwise Wilcoxon test p-values. Significant differences between protocols are highlighted in green.
In practice, a best performing protocol would be a protocol for which the highest number of samples could be prepared for sequencing. Here, for a given protocol, we measured the percentage of samples whose DNA concentration was superior to 5 ng/µl, threshold corresponding to the minimal DNA concentration recommended to prepare 16S rRNA gene sequencing libraries (Table 1). In our hands, none of the tested protocols was able to retrieve, for all the samples, DNA with a concentration superior to this threshold. Except for S-MN, the best performances were observed when the protocols were combined with SPD. S-Z recovered enough DNA material for 88% of samples, followed by MN (86%), S-QQ (82%) and S-DQ (81%).
Regarding the fragment size of DNA, variations were also observed between the extraction protocols. QQ and MN protocols yielded the shortest DNA fragments with a median size around 12,000 bp, which was shorter than S-QQ (p-value > 0.1) and significantly shorter than the other ones (p-value < 0.01, Fig. 2b). The longest DNA fragment sizes were observed for S-MN, with an average size of 21,000 bp, followed by DQ, S-DQ and Z with DNA fragments around 18,000 bp (p-value > 0.1). DNA fragments were significantly higher in CDI positive patients when extracted with MN (p-value ≤ 0.05), S-QQ or DQ (p-value < 0.01), but other protocols showed similar DNA fragment size regardless of health status (Supplementary Fig. 1b).
We also assessed DNA purity using the A260/280 ratio. A ratio of 1.8, which is generally accepted as “pure” for DNA, was observed for S-DQ (Fig. 2c). A ratio below 1.8 was observed for the protocols MN, S-MN, Z, S-Z and DQ, which may indicate the presence of protein, phenol or other contaminants. A ratio close to 2 was assessed for QQ and S-QQ suggesting the possible presence of RNA in samples (p-value < 0.01 in comparison with the other protocols). Except for MN, the protocols combined with SPD generated DNA of purity equal or superior to their standard versions. Besides QQ and Z, all protocols showed equivalent DNA purity between CDI+ and CDI− samples (Supplementary Fig. 1c).
Observed microbial diversity and performance in extracting Gram-positive bacteria
In addition to the wet-lab criteria, the extraction quality was also evaluated, using 16S rRNA gene amplicon, by investigating the observed microbial diversity of samples (Fig. 3). This alpha-diversity has been recently described as a good indicator of DNA extraction performance, being positively correlated with the Gram-positive bacteria extraction35.

Shannon α-diversity index of human fecal sample composition. Shannon diversity calculated from the abundance table of 16S rRNA gene profiling. Standard protocols are colored in sky blue, whereas protocols associated with SPD are colored in purple. Boxplots are topped by a heatmap showing the pairwise Wilcoxon test p-values. Significant differences between protocols are highlighted in green.
No significant difference in microbial diversity was observed for CDI+ patients compared to healthy volunteers (Supplementary Fig. 2). Previous studies have shown a significant decrease in microbial diversity in patients with recurrent CDI but not with initial CDI69,70. As a considerable variability was found within each group of individuals, we corrected the individual effect in the statistical model to emphasize differences between extraction protocols. The median alpha-diversity values were between 4.0 and 4.2 for all tested protocols (Fig. 3). Interestingly, the alpha-diversity was equal or the highest when samples were extracted with an SPD-associated protocol except for MN which performed better than S-MN according to 16S data (p-value ≤ 0.05) (Fig. 3). Preliminary SMS data also showed improved alpha-diversity with SPD-associated protocols compared to commercial protocols (Supplementary Fig. 3a).
We then evaluated if the observed diversity was associated with an effective Gram-positive bacteria recovery. For this purpose, we assessed the ratio Firmicutes/Bacteroidetes, two main phyla commonly found in the gut microbiota. Firmicutes and Bacteroidetes are phyla of bacteria, which are, for the most part, Gram-positive and Gram-negative respectively. In theory, the ratio Firmicutes/Bacteroidetes should be improved by a protocol performing well for the extraction of Gram-positive bacteria71. Remarkably, this ratio was increased for the four protocols combined with SPD in comparison to their standard versions, in both 16S and SMS data (Table 2 and Supplementary Table 2). To quantify more precisely the SPD effect on microbial community composition, DESeq2 was used to test the differential abundance of taxa between standard vs SPD-combined protocols. For each patient, the relative abundance of the Firmicutes phylum increased significantly, whereas the Bacteroidetes phylum decreased significantly with the use of SPD. This analysis was also performed at the family level (Supplementary Fig. 4), where SPD led to a significant decrease of Gram-negative families and a significant increase of Gram-positive families (Supplementary Table 4). Altogether, our results were consistent with a positive effect of SPD on the observed alpha-diversity by improving the recovery of Gram-positive bacteria.
Extraction protocol accuracy
In order to estimate the accuracy of the extraction protocols, a mock community consisting of nine bacterial species of known respective abundances was prepared and sequenced. The protocol accuracy was estimated by calculating the Aitchison distance (the lower the distance, the better the prediction) between observed and expected abundances at the genus level (Fig. 5). Interestingly, the bacterial abundances were better predicted using 16S rather than SMS (Fig. 4 and Supplementary Fig. 3b). Independently of the metagenomics methods, these predictions were improved when SPD was used upstream for the protocols QQ and MN. Based on 16S rRNA gene data, DQ was the most accurate protocol, followed by S-MN, S-Z, Z and S-QQ. Detailed bacterial abundances at the genus level are plotted in Supplementary Fig. 4. As observed for human samples, SPD improved the recovery of Gram positive bacteria compared to standard protocols. Discrepancies between expected and observed abundances seem mostly related to GC content72. Considering both approaches, bacterial families with high GC content such as Pseudomonas tend to be overestimated whereas families with low GC content such as Listeria tend to be underestimated. However, this pattern is not as visible with SPD-associated protocols.

Accuracy of the observed bacterial abundance in the mock community. Aitchison distances were calculated between observed and expected bacterial abundances (CLR transformed data) in mock samples for each of three replicates of each extraction protocol, for 16S rRNA gene sequencing data.
Protocol repeatability
The eight protocols were next evaluated for repeatability across the variations of bacterial abundances between triplicates of a same stool sample (Fig. 5). We observed an increase of the repeatability when the protocols were coupled with SPD compared to their standard versions except for QQ but this increase was not significant (p-value > 0.1). The median of the Aitchison distance was divided by 1.01 between QQ (14.99) and S-QQ (14.90), 1.08 between Z (13.44) and S-Z (12.40), 1.22 between MN (14.70) and S-MN (12.01) and 1.09 between DQ (15.30) and S-DQ (14.05). S-MN was the most repeatable protocol, closely followed by S-Z.

Protocol repeatability. An Aitchison distance was calculated between replicates for each genus within each human fecal sample. Standard protocols are colored in sky blue, whereas protocols with SPD are colored in purple.
Protocols overall performance
In our study, eight DNA extraction protocols were evaluated using both wet- and dry-lab criteria, with 16S rRNA sequencing read-outs. To help in data interpretation, we ranked the protocols according to a custom designed scoring system which was assigned to each criterion based on the observed 16S rRNA gene profiling results (Fig. 6). For each criterion, a score of 0 (the worst result obtained in our dataset), 1 or 2 (the best result obtained in our dataset) was given. These scores were then plotted using a spider chart: a score of 0 represents the center, whereas a score of 2 is the vertex. Protocols were given the same score if no significant difference was observed. The generated areas were then used to help in selecting the best-overall performing DNA extraction protocol.

Overall performance of the eight extraction protocols based on studied criteria using 16S rRNA gene profiling. (a) Protocols in combination with SPD. (b) Standard protocols (no SPD). A score of 0, 1 or 2 was given to each protocol. Scores of 0 correspond to the weakest values, whereas scores of 2 are the best values of the considered criteria. The area value obtained for each protocol is indicated in the tables below each chart.
The protocols Z and QQ combined with SPD performed better compared to their standard version while performance of the MN protocol was diminished when combined with the SPD (Fig. 6). Protocols S-DQ and DQ showed equivalent overall performances for the represented criteria with S-DQ showing higher microbial diversity and DQ, improved accuracy. Considering SPD associated protocols, in our hands, S-DQ showed the best overall performance (Fig. 6a). Although other protocols showed similarly good results for some criteria, S-DQ was the only protocol being among the best performing protocols for all tested criteria. The S-DQ performance was slightly inferior to S-QQ and S-Z regarding DNA yield but this difference was not significant (p-value > 0.05, Fig. 2a). Even if S-DQ was not the best protocol for this criterion, enough DNA material was produced for more than 80% of samples to prepare and sequence the metagenomics libraries. S-DQ was also found to be less repeatable than S-Z and S-MN but the slight differences were not significant (Fig. 5).
Considering the standard versions of the protocols, DQ had the best overall performance (Fig. 6b). This protocol performed well in terms of accuracy and extracted DNA yield and quality. MN performed significantly better than DQ for microbial diversity (p-value < 0.01, Fig. 3), but performed poorly on other criteria. Finally, MN, QQ and Z were slightly more repeatable than DQ, but not significantly (p-value > 0.1, Fig. 6).
Discussion
DNA extraction is a crucial step of the metagenomics workflow known to be influenced by many parameters, which are difficult to evaluate exhaustively. In addition to in-house protocols, new commercial solutions are now emerging, making difficult the choice of a good protocol for the gut microbiota. Benchmarking protocols is thus crucial to understand the potential biases and to avoid errors during data interpretation. Recent gut microbiome studies compared various DNA extraction protocols but were limited to a low number of fecal samples, mainly from healthy individuals27,28,29,30,37,73,74. As a consequence, the performance of such protocols may not be guaranteed for a clinical cohort.
Our study is the first, to our knowledge, to compare four commercial DNA extraction protocols using 16S rRNA amplicon sequencing method on an adequate number of stool samples for statistical analysis and biological conclusion (n = 18). In an effort to streamline fecal preparation prior to DNA extraction, the commercial protocols were also tested in combination with a stool preprocessing device. As recommended by recent studies, we also included a positive control, the mock community, so that we could reliably assess the accuracy of extraction protocols. The mock was made up of nine bacterial species and processed alongside fecal specimens. The eight protocols tested were ranked based on wet- and dry-lab criteria. The global aim was to identify one method that performs well and generates the most accurate and reproducible data.
In addition to healthy donors, patients suffering from a Clostridium difficile Infection were also recruited, allowing to test the protocols on samples with various microbial composition, consistency and biomass. CDI is a burning issue, as Clostridium difficile, a Gram-positive bacterium, is the leading cause for diseases from mild diarrhea to pseudomembranous colitis in hospitalized patients75. Fecal microbiota transplant (FMT) is emerging as a new option for recurrent CDI76. Identifying which bacteria are already present (recipient) and have been transferred (donor) is essential and requires the use of highly sensitive, robust and fast metagenomics techniques70,77.
In our study, a total of 456 and 56 samples were analyzed using 16S rRNA gene sequencing and SMS respectively, allowing to have an important dataset for comparison results. Even if, as expected, SMS is more sensitive in bacterial detection, our present findings indicate good agreement between the two sequencing methods. However, it is to be noted that only one replicate of the SMS experiment was performed and further validation is needed. Our data also show good agreement between the samples from the two groups of individuals. Interestingly, our results show that no single DNA extraction protocol performed best on all the criteria tested. However, differences were not all significant, and considering the strategy of selection described above, the standard DQ protocol and S-DQ appeared as the best-performing protocols among commercial and SPD-associated solutions for extracting DNA from human fecal samples. The DQ protocol with or without the SPD generated an amount of good quality DNA that was compatible with subsequent library preparations for all samples. Extracted DNA quantity was superior to 5 ng/μl for 81% and 77% of samples using S-DQ and DQ respectively. Regarding the dry-lab criteria, for 16S rRNA profiling, DQ showed improved accuracy whereas S-DQ combined the best results in terms of alpha-diversity, extraction of Gram-positive bacteria, repeatability and accuracy in bacterial detection.
Remarkably, the bioinformatics analysis also shed light on the added value of the stool preprocessing device for some extraction protocols. In our study, the protocols in combination with SPD have in common the first steps of the procedure. This includes the shaking and the mechanical lysis with zirconia and silica beads 0.1 mm. In such combination, we observe an increase of the observed alpha-diversity. Our results are in good agreement with Costea et al. who showed that these parameters of the protocol were positively associated with the observed diversity, which is a good indicator of an efficient lysis35. Biased protocols are also known to cause overrepresentation of Gram-negative bacteria due to the inefficient lysis of Gram-positive bacteria. For the SPD-combined protocols, we observed an increase of the relative abundance of Gram-positive bacteria and a corresponding decrease in the relative abundance of Gram-negative bacteria, which led to an increase of the Firmicutes/Bacteroidetes ratio. The SPD can therefore provide more accurate characterization of the microbiota by reducing the ratio bias. In terms of repeatability, SPD also showed promising results. This device would be of particular interest to limit variations when several experimenters, and even different labs in case of multi-centric studies, perform DNA extraction. Other approaches such as the OMNIgene®•GUT system (DNA Genotek) or RNAlater (Thermo Fisher) preservation tubes also exhibit higher DNA extraction yield compared to snap-frozen samples (Neuberger-Castillo et al., 2020), further highlighting the added value of sample preprocessing. Lastly, the use of our in-house mock community, composed of both Gram-positive and Gram-negative bacteria cells, made possible to benchmark the protocols in terms of bacterial abundance predictions. Our results demonstrate that SPD in combination with most of the tested protocols is more accurate in assessing the bacterial abundances than the protocols in their standard versions. Comparison of the performance of the SPD device used in this study with other sample preprocessing methods is required to establish a new standard method. Such device prior DNA extraction may add additional costs and extra time and labor to the DNA extraction reactions but, from our perspective, getting unbiased and comparable microbiome data across labs and countries is priceless.
In this study, we focused on sample preprocessing and commercial solutions for DNA extraction. However, several other steps such as sample homogenization and library preparation are also crucial for accurate microbial community profiling. We are also aware that all the protocols may not have been tested in optimal parameters. The commercial protocols were tested using the beads provided in the kit on a Retsch system for 5 min. In our hands, protocol Z was one of the worst performer according to wet-lab criteria. Today, Zymo Research recommends other bead-beating protocols than the one tested. As shown by Tourlousse et al., vigorous bead-beating regimes allows effective recovery of Gram-positive bacteria. Optimizing this step may, therefore, improve extraction performance of all methods37,78. In a similar way the DNeasy PowerSoil kit (Catalog No. 12888-100), a previous version of the DNeasy PowerLyzer PowerSoil kit (Catalog No. 12855-100), was compared to other commercial solutions including the NucleoSpin Soil kit by Yang et al. In their hands, the QIAGEN protocol showed a lesser performance than the other protocols unlike the most recent kit which performed best in our study. This highlights the difficulty to establish a gold-standard for gut microbiome analysis with the numerous, ever-evolving protocols. Moreover, great progress is been made in the field of automated nucleic acid extraction. Assessing performance of such systems would also be relevant in the scope of clinical studies.
Conclusion
We recommend the S-DQ protocol to extract microbial DNA from human stool samples. While we have only tested S-DQ on fecal samples, we suppose that it might also work well with other types of microbiota samples, although some modifications may be necessary.
In addition to the DNA extraction protocol, sample preprocessing appears to be a new way to improve the overall performance of most DNA extraction protocols. We propose to now include stool-preprocessing devices in new microbiome studies to streamline and standardize DNA extraction.
Methods
Ethics approval and consent to participate
Fecal samples used in this study corresponds to left-over samples collected for diagnostic purpose. Each patient was informed regarding collection, storage and use for research activities. As this study was out of the regulations related to clinical trials, non-opposition statement was obtained from all subjects and was sufficient to process the fecal samples according to the French legal and medical ethical guidelines. Both collection and use of fecal samples for metagenomic analyses were authorized by the French Ministry of Higher Education, Research and Innovation (Declaration N°DC-2018-3240).
Stool samples
Fecal samples from nine healthy volunteers and nine patients with Clostridium difficile infection (CDI) were provided by a certified testing laboratory in France and tested for Clostridium difficile toxins. Upon reception, each fecal sample was freshly aliquoted into 24 tubes (8 protocols × 3 replicates) and frozen at − 80 °C until extraction, the − 80 °C storage being known to maintain a stable microbial community for long-term period79.
Microbial mock community
The microbial mock community was prepared by mixing nine bacteria (Table 3), including four easy-to-lyse Gram-negative bacteria (Pseudomonas aeruginosa, Escherichia coli, Salmonella enterica and Rhizobium radiobacter) and five more difficult to lyse Gram-positive bacteria (Lactobacillus fermentum, Enterococcus faecalis, Staphylococcus aureus, Listeria inocula and Bacillus subtilis). Bacterial cells were obtained from ATCC and cultivated according to ATCC’s recommendations. The number of viable cells was estimated by plate counting. The mock community was prepared by mixing between 2.7 × 107 and 3.6 × 108 cells of nine bacteria and stored at − 80 °C until extraction.
DNA extraction
Four commercial protocols were compared in this study, according to the manufacturers’ recommendations: the NucleoSpin Soil kit (#740780.50, protocol May 2016/Rev. 06, Macherey–Nagel), the DNeasy PowerLyzer PowerSoil Kit (#12855-100, protocol 07272016, QIAGEN), the QIAamp Fast DNA Stool kit (#51604, QIAGEN, protocol modified from Ref.36) and the ZymoBIOMICS DNA Mini kit (#D4300, protocol 1.1.0, ZymoResearch). These protocols were also tested in combination with a stool preprocessing device (SPD, #421061, bioMérieux52). This device was designed to facilitate and standardize fecal sample preparation before nucleic acid extraction. It includes a spoon for a 200 mg calibrated sample and a vial containing a buffer for sample resuspension, glass beads for homogenization and two filters for retaining fecal debris. After 5 min hands-on-time, the filtrate is ready-to-use for downstream DNA extraction. Protocols of extraction methods as well as SPD are detailed in Supplementary Methods. DNA was extracted in triplicates from fecal samples and from the microbial community. A260/A280 ratio was assessed using the DropSense 96 system (Trinean). Genomic DNA size was assessed using the Genomic DNA ScreenTape (#5067-5364, Agilent) on the 2200 TapeStation system (Agilent). DNA concentrations were estimated using the QuantiFluor One dsDNA kit (#E4870, Promega) with the GloMax system (Promega).
16S rRNA gene library preparation and sequencing
16S rRNA gene libraries were prepared according to Illumina’s protocol (# 15044223 RevB80). In order to minimize the risk of cross-contamination and pipetting errors, the workflow was automated using a high-throughput liquid handler; the Freedom EVO NGS workstation (TECAN)81. Briefly, V3-V4 hypervariable regions were first amplified from 12.5 ng of genomic DNA, using the following primers: (i) Forward Primer: TCGTCGGCAGCGTCAGATGTGTATAAGAGACAGCCTACGGGAGGCAGC-AG and (ii) Reverse Primer: GTCTCGTGGGCTCGGAGATGTGTATAAGAGACAGGACTACHVG-GGTWTCTAAT and 2X KAPA HiFi HotStart ReadyMix (Kapa Biosystems). PCR cycle conditions were 95 °C for 3 min, 25 cycles of (95 °C for 30 s, 55 °C for 30 s 72 °C for 30 s), then a final extension of 72 °C for 5 min. The libraries were purified using AMPure XP beads (Beckman Coulter). Dual indexes and sequencing adapters from the Illumina Nextera XT index kits (Illumina) were added in a second PCR using 2× KAPA HiFi HotStart ReadyMix (Kapa Biosystems). Cycle conditions were 95 °C for 3 min, 8 cycles of (95 °C for 30 s, 55 °C for 30 s, 72 °C for 30 s), then a final extension of 72 °C for 5 min. Ready-to-sequence libraries were purified using AMPure XP beads (Beckman) and quantified by fluorescence using the QuantiFluor One dsDNA kit (# E4870, Promega) with the GloMax system (Promega). Quality control was performed using a 2200 TapeStation system with the DNA 1000 ScreenTape (# 5067-5582, Agilent). The library pool was quantified by qPCR with the KAPA Library Quantification Kit for Illumina platforms (Kapa Biosystems). Sequencing was performed on a MiSeq system (Illumina) with the MiSeq Reagent v3 kit (600 cycles) in a 2 × 300 bp mode.
Shotgun metagenomic library preparation and sequencing
SMS libraries were prepared using the Nextera XT DNA Library Preparation Kit (# FC-131-1096, Illumina), following Illumina’s instructions (protocol # 15031942 v03 February 2018). Briefly, 1 ng of genomic DNA was used for the tagmentation reaction for a total volume of 20 µl. After 5 min at 55 °C, the reaction was stopped by adding 5 µl of the Neutralize Tagment (NT) Buffer. A limited-cycle PCR amplification was then performed to amplify the tagmentated DNA [addition of 15 μl of Nextera PCR Master Mix (NPM)] and to add Illumina sequencing adapters (addition of 5 µl of both Index 1 primer and Index 2 primer from the Nextera XT index kit, Illumina) for a total volume of 50 µl. The following PCR cycle program was used: 72 °C for 3 min, 95 °C for 30 s, 12 cycles of (95 °C for 10 s, 55 °C for 30 s, 72 °C for 30 s), 72 °C for 5 min. SMS libraries were quantified using the QuantiFluor One dsDNA kit (# E4870, Promega) with the GloMax system (Promega). The quality of libraries was assessed using the High Sensitivity DNA kit on the Agilent 2100 Bioanalyzer. Sequencing was performed on a NextSeq500 system (Illumina) with the NextSeq 500/550 High Output v2 kit (300 cycles) in 2 × 150 bp.
16S rRNA gene profiling
The analysis was done using Snaq82, a snakemake pipeline for 16S data analysis with QIIME2. Briefly, quality trimming was done using bbduk (BBTools) with a quality threshold of 20. During the PCR amplification process, artefactual sequences can be generated from multiple parent sequences, and are called chimeric sequences. These sequences were removed using the DADA283 algorithm, which, in addition, joins paired end reads and produce Amplicon Sequence Variant tables (ASVs). The taxonomy assignment of ASVs was done using the “feature-classifier” plugin with SILVA classifier trained on V3 and V4 regions (cls-silvaV3484,85).
Shotgun metagenomic profiling
After quality control with FastQC (v0.11.9), reads were trimmed and filtered based on the sequence quality and length using fastp (v0.20.0) with the default parameters. Contamination with host DNA was discarded by mapping the filtered reads on the human reference genome version GRCh37 using BBMap (v38.90)86. Clean reads were annotated using the kraken2 software (v2.1.1)87 against the Unified Human Gastrointestinal Genome (UHGG) catalog88.
Statistical analysis
All analyses were performed in R (version 3.3.1). The analysis of microbiome compositional data were done on centered log-ratio (CLR) transformed matrices using the clr function from the “compositions” R package. The repeatability was assessed by calculating a Aitchison distance between replicates of a condition for every patient. Alpha-diversity (Shannon indices) was calculated for each sample using the vegan package. The taxonomical analysis of the mock community samples was done by mapping their SMS and 16S data using bowtie2 (v.2.3.5.1)89 on indexes created with the 9 expected species (Table 3). The accuracy of the protocols was evaluated on those samples by calculating the Euclidean distance between expected and predicted abundances after CLR transformation using the “philentropy” R package. Differentially abundant bacteria between protocols with or without the SPD were identified using the DESeq2 package. For each criterion (except for alpha-diversity), the statistical significance of the differences between protocols was computed with a pairwise Wilcoxon rank test. For multiple comparisons, p-values were corrected by Benjamini Yakuteli correction and adjusted p-values below 0.05 were considered statistically significant. The alpha-diversity values varied greatly from one patient to another, so the patient effect was controlled in a linear model using the “limma” package, and statistics were computed with the empirical Bayes method.
Data availability
The datasets generated during the current study are available on the BioProject database (ID PRJNA648321), at the following link: http://www.ncbi.nlm.nih.gov/bioproject/648321.
Abbreviations
- SMS:
-
Shotgun metagenomic sequencing
- SPD:
-
Stool preprocessing device
- T2D:
-
Type 2 diabetes
- NAFLD:
-
Nonalcoholic fatty liver disease
- Q:
-
Protocol QIAGEN from 35
- CDI:
-
Clostridium difficile Infection
- PCR:
-
Polymerase chain reaction
- NPM:
-
Nextera PCR master mix
- OTU:
-
Operational taxonomic units
- NT:
-
Neutralize tagment
- MN:
-
The NucleoSpin Soil kit (Macherey–Nagel)
- DQ:
-
The DNeasy PowerLyzer PowerSoil kit (QIAGEN)
- QQ:
-
The QIAamp Fast DNA Stool kit (QIAGEN)
- Z:
-
The ZymoBIOMICS DNA Mini kit (ZymoResearch)
- S-MN:
-
SPD in combination with MN
- S-DQ:
-
SPD in combination with DQ
- S-QQ:
-
SPD in combination with QQ
- S-Z:
-
SPD in combination with Z
References
Gilbert, J. A. et al. Current understanding of the human microbiome. Nat. Med. 24(4), 392–400 (2018).
Chiu, C. Y. & Miller, S. A. Clinical metagenomics. Nat. Rev. Genet. 20(6), 341–355 (2019).
Salk, J. J., Schmitt, M. W. & Loeb, L. A. Enhancing the accuracy of next-generation sequencing for detecting rare and subclonal mutations. Nat. Rev. Genet. 19(5), 269–285 (2018).
Goodwin, S., McPherson, J. D. & McCombie, W. R. Coming of age: Ten years of next-generation sequencing technologies. Nat. Rev. Genet. 17(6), 333–351 (2016).
Loman, N. J. & Pallen, M. J. Twenty years of bacterial genome sequencing. Nat. Rev. Microbiol. 13(12), 787–794 (2015).
Metzker, M. L. Sequencing technologies—The next generation. Nat. Rev. Genet. 11(1), 31–46 (2010).
Sartor, R. B. Mechanisms of disease: Pathogenesis of Crohn’s disease and ulcerative colitis. Nat. Clin. Pract. Gastroenterol. Hepatol. 3(7), 390–407 (2006).
Halfvarson, J. et al. Dynamics of the human gut microbiome in inflammatory bowel disease. Nat. Microbiol. 2, 17004 (2017).
Vieira-Silva, S. et al. Quantitative microbiome profiling disentangles inflammation- and bile duct obstruction-associated microbiota alterations across PSC/IBD diagnoses. Nat. Microbiol. 4, 1826–1831 (2019).
Manichanh, C. et al. The gut microbiota in IBD. Nat. Rev. Gastroenterol. Hepatol. 9(10), 599–608 (2012).
Lavelle, A. & Sokol, H. Gut microbiota-derived metabolites as key actors in inflammatory bowel disease. Nat. Rev. Gastroenterol. Hepatol. 17(4), 223–237 (2020).
Simren, M. et al. Intestinal microbiota in functional bowel disorders: A Rome foundation report. Gut 62(1), 159–176 (2013).
Mayer, E. A. et al. Towards a systems view of IBS. Nat. Rev. Gastroenterol. Hepatol. 12(10), 592–605 (2015).
Musso, G., Gambino, R. & Cassader, M. Interactions between gut microbiota and host metabolism predisposing to obesity and diabetes. Annu. Rev. Med. 62, 361–380 (2011).
Larsen, N. et al. Gut microbiota in human adults with type 2 diabetes differs from non-diabetic adults. PLoS One 5(2), e9085 (2010).
Qin, J. et al. A metagenome-wide association study of gut microbiota in type 2 diabetes. Nature 490(7418), 55–60 (2012).
Aron-Wisnewsky, J. et al. Gut microbiota and human NAFLD: Disentangling microbial signatures from metabolic disorders. Nat. Rev. Gastroenterol. Hepatol. 17, 279–297 (2020).
Canfora, E. E. et al. Gut microbial metabolites in obesity, NAFLD and T2DM. Nat. Rev. Endocrinol. 15(5), 261–273 (2019).
Caussy, C. et al. A gut microbiome signature for cirrhosis due to nonalcoholic fatty liver disease. Nat. Commun. 10(1), 1406 (2019).
Helmink, B. A. et al. The microbiome, cancer, and cancer therapy. Nat. Med. 25(3), 377–388 (2019).
Yachida, S. et al. Metagenomic and metabolomic analyses reveal distinct stage-specific phenotypes of the gut microbiota in colorectal cancer. Nat. Med. 25(6), 968–976 (2019).
Routy, B. et al. Gut microbiome influences efficacy of PD-1-based immunotherapy against epithelial tumors. Science 359(6371), 91–97 (2018).
Zitvogel, L. et al. Anticancer effects of the microbiome and its products. Nat. Rev. Microbiol. 15(8), 465–478 (2017).
Routy, B. et al. The gut microbiota influences anticancer immunosurveillance and general health. Nat. Rev. Clin. Oncol. 15(6), 382–396 (2018).
Fulbright, L. E., Ellermann, M. & Arthur, J. C. The microbiome and the hallmarks of cancer. PLoS Pathog. 13(9), e1006480 (2017).
Gopalakrishnan, V. et al. Gut microbiome modulates response to anti-PD-1 immunotherapy in melanoma patients. Science 359(6371), 97–103 (2018).
Thomas, R. M. & Jobin, C. Microbiota in pancreatic health and disease: The next frontier in microbiome research. Nat. Rev. Gastroenterol. Hepatol. 17(1), 53–64 (2020).
Hofseth, L. J. et al. Early-onset colorectal cancer: Initial clues and current views. Nat. Rev. Gastroenterol. Hepatol. 17, 517 (2020).
Wirbel, J. et al. Meta-analysis of fecal metagenomes reveals global microbial signatures that are specific for colorectal cancer. Nat. Med. 25(4), 679–689 (2019).
Thomas, A. M. et al. Metagenomic analysis of colorectal cancer datasets identifies cross-cohort microbial diagnostic signatures and a link with choline degradation. Nat. Med. 25(4), 667–678 (2019).
Lim, M. Y. et al. Changes in microbiome and metabolomic profiles of fecal samples stored with stabilizing solution at room temperature: A pilot study. Sci. Rep. 10(1), 1789 (2020).
Tap, J. et al. Effects of the long-term storage of human fecal microbiota samples collected in RNAlater. Sci. Rep. 9(1), 601 (2019).
Moossavi, S. et al. Assessment of the impact of different fecal storage protocols on the microbiota diversity and composition: A pilot study. BMC Microbiol. 19(1), 145 (2019).
Martinez, N. et al. Filling the gap between collection, transport and storage of the human gut microbiota. Sci. Rep. 9(1), 8327 (2019).
Costea, P. I. et al. Towards standards for human fecal sample processing in metagenomic studies. Nat. Biotechnol. 35(11), 1069–1076 (2017).
Knudsen, B. E. et al. Impact of sample type and DNA isolation procedure on genomic inference of microbiome composition. mSystems 1(5), e00095-16 (2016).
Tourlousse, D. M. et al. Validation and standardization of DNA extraction and library construction methods for metagenomics-based human fecal microbiome measurements. Microbiome 9(1), 95 (2021).
Sze, M. A. & Schloss, P. D. The impact of DNA polymerase and number of rounds of amplification in PCR on 16S rRNA gene sequence data. mSphere 4(3), e00163-19 (2019).
Whon, T. W. et al. The effects of sequencing platforms on phylogenetic resolution in 16 S rRNA gene profiling of human feces. Sci. Data 5, 180068 (2018).
Breitwieser, F. P., Lu, J. & Salzberg, S. L. A review of methods and databases for metagenomic classification and assembly. Brief Bioinform. 20(4), 1125–1136 (2019).
Sczyrba, A. et al. Critical assessment of metagenome interpretation-a benchmark of metagenomics software. Nat. Methods 14(11), 1063–1071 (2017).
Kuczynski, J. et al. Experimental and analytical tools for studying the human microbiome. Nat. Rev. Genet. 13(1), 47–58 (2011).
Knight, R. et al. Best practices for analysing microbiomes. Nat. Rev. Microbiol. 16(7), 410–422 (2018).
Sinha, R. et al. Assessment of variation in microbial community amplicon sequencing by the Microbiome Quality Control (MBQC) project consortium. Nat. Biotechnol. 35(11), 1077–1086 (2017).
Gohl, D. M. The ecological landscape of microbiome science. Nat. Biotechnol. 35(11), 1047–1049 (2017).
Vandeputte, D. et al. Practical considerations for large-scale gut microbiome studies. FEMS Microbiol. Rev. 41(Supp_1), S154–S167 (2017).
Fouhy, F. et al. 16S rRNA gene sequencing of mock microbial populations-impact of DNA extraction method, primer choice and sequencing platform. BMC Microbiol. 16(1), 123 (2016).
Albertsen, M. et al. Back to basics-the influence of DNA extraction and primer choice on phylogenetic analysis of activated sludge communities. PLoS ONE 10(7), e0132783 (2015).
Wesolowska-Andersen, A. et al. Choice of bacterial DNA extraction method from fecal material influences community structure as evaluated by metagenomic analysis. Microbiome 2, 19 (2014).
Hsieh, Y. H. et al. Impact of different fecal processing methods on assessments of bacterial diversity in the human intestine. Front. Microbiol. 7, 1643 (2016).
Gorzelak, M. A. et al. Methods for improving human gut microbiome data by reducing variability through sample processing and storage of stool. PLoS ONE 10(8), e0134802 (2015).
Feghoul, L. et al. Evaluation of a new device for simplifying and standardizing stool sample preparation for viral molecular testing with limited hands-on time. J. Clin. Microbiol. 54(4), 928–933 (2016).
Panek, M. et al. Methodology challenges in studying human gut microbiota—Effects of collection, storage, DNA extraction and next generation sequencing technologies. Sci. Rep. 8(1), 5143 (2018).
Kennedy, N. A. et al. The impact of different DNA extraction kits and laboratories upon the assessment of human gut microbiota composition by 16S rRNA gene sequencing. PLoS ONE 9(2), e88982 (2014).
Maukonen, J., Simoes, C. & Saarela, M. The currently used commercial DNA-extraction methods give different results of clostridial and actinobacterial populations derived from human fecal samples. FEMS Microbiol. Ecol. 79(3), 697–708 (2012).
Truong, D. T. et al. Microbial strain-level population structure and genetic diversity from metagenomes. Genome Res. 27(4), 626–638 (2017).
Vandeputte, D. et al. Quantitative microbiome profiling links gut community variation to microbial load. Nature 551(7681), 507–511 (2017).
Stammler, F. et al. Adjusting microbiome profiles for differences in microbial load by spike-in bacteria. Microbiome 4(1), 28 (2016).
Shreiner, A. B., Kao, J. Y. & Young, V. B. The gut microbiome in health and in disease. Curr. Opin. Gastroenterol. 31(1), 69–75 (2015).
Falony, G. et al. The human microbiome in health and disease: Hype or hope. Acta Clin. Belg. 74(2), 53–64 (2019).
Cani, P. D. Human gut microbiome: Hopes, threats and promises. Gut 67(9), 1716–1725 (2018).
Lewis, S. J. & Heaton, K. W. Stool form scale as a useful guide to intestinal transit time. Scand. J. Gastroenterol. 32(9), 920–924 (1997).
Vandeputte, D. et al. Stool consistency is strongly associated with gut microbiota richness and composition, enterotypes and bacterial growth rates. Gut 65(1), 57–62 (2016).
Falony, G. et al. Population-level analysis of gut microbiome variation. Science 352(6285), 560–564 (2016).
Quince, C. et al. Shotgun metagenomics, from sampling to analysis. Nat. Biotechnol. 35(9), 833–844 (2017).
Almeida, A. et al. A new genomic blueprint of the human gut microbiota. Nature 568(7753), 499–504 (2019).
Gohl, D. M. et al. Systematic improvement of amplicon marker gene methods for increased accuracy in microbiome studies. Nat. Biotechnol. 34(9), 942–949 (2016).
Fraher, M. H., O’Toole, P. W. & Quigley, E. M. Techniques used to characterize the gut microbiota: A guide for the clinician. Nat. Rev. Gastroenterol. Hepatol. 9(6), 312–322 (2012).
Chang, J. Y. et al. Decreased diversity of the fecal microbiome in recurrent Clostridium difficile—Associated diarrhea. J. Infect. Dis. 197(3), 435–438 (2008).
Staley, C. et al. Complete microbiota engraftment is not essential for recovery from recurrent Clostridium difficile infection following fecal microbiota transplantation. mBio. 7(6) (2016).
Santiago, A. et al. Processing faecal samples: A step forward for standards in microbial community analysis. BMC Microbiol. 14, 112 (2014).
Benjamini, Y. & Speed, T. P. Summarizing and correcting the GC content bias in high-throughput sequencing. Nucleic Acids Res. 40(10), e72 (2012).
Yang, F. et al. Assessment of fecal DNA extraction protocols for metagenomic studies. Gigascience 9(7), giaa071 (2020).
Lim, M. Y. et al. Comparison of DNA extraction methods for human gut microbial community profiling. Syst. Appl. Microbiol. 41(2), 151–157 (2018).
Abt, M. C., McKenney, P. T. & Pamer, E. G. Clostridium difficile colitis: Pathogenesis and host defence. Nat. Rev. Microbiol. 14(10), 609–620 (2016).
Kociolek, L. K. & Gerding, D. N. Breakthroughs in the treatment and prevention of Clostridium difficile infection. Nat. Rev. Gastroenterol. Hepatol. 13(3), 150–160 (2016).
Weingarden, A. et al. Dynamic changes in short- and long-term bacterial composition following fecal microbiota transplantation for recurrent Clostridium difficile infection. Microbiome 3, 10 (2015).
Research, Z. The Lysis Bias Crisis. https://www.zymoresearch.com/blogs/blog/the-lysis-bias-crisis.
Shaw, A. G. et al. Latitude in sample handling and storage for infant faecal microbiota studies: The elephant in the room?. Microbiome 4(1), 40 (2016).
Illumina, 16S Metagenomic Sequencing Library Preparation. https://support.illumina.com/documents/documentation/chemistry_documentation/16s/16s-metagenomic-library-prep-guide-15044223-b.pdf.
Tecan, Automated library preparation for Illumina® 16S metagenomic sequencing. https://lifesciences.tecan.com/applications_and_solutions/genomics/ngs_sample_preparation?p=Literature.
Mohsen, A. et al. Snaq: A dynamic snakemake pipeline for microbiome data analysis with QIIME2. Front. Bioinform. 2, 63 (2022).
Callahan, B. J. et al. DADA2: High-resolution sample inference from Illumina amplicon data. Nat. Methods 13(7), 581–583 (2016).
Robeson, M. S. et al. RESCRIPt: Reproducible sequence taxonomy reference database management for the masses. bioRxiv. 2020.10.05.326504 (2020).
Bokulich, N. A. et al. Optimizing taxonomic classification of marker-gene amplicon sequences with QIIME 2’s q2-feature-classifier plugin. Microbiome 6(1), 90 (2018).
Bushnell, B. BBMap: A fast, accurate, splice-aware aligner. In Conference: 9th Annual Genomics of Energy & Environment Meeting, Walnut Creek, CA, March 17–20, 2014. United States. p. Medium: ED (2014).
Wood, D. E., Lu, J. & Langmead, B. Improved metagenomic analysis with Kraken 2. Genome Biol. 20(1), 257 (2019).
Almeida, A. et al. A unified catalog of 204,938 reference genomes from the human gut microbiome. Nat. Biotechnol. 39(1), 105–114 (2021).
Langmead, B. & Salzberg, S. L. Fast gapped-read alignment with Bowtie 2. Nat. Methods 9(4), 357–359 (2012).
Acknowledgements
The authors thank Cécile Chauvel (xDATA Unit, BIOASTER) for her advice on statistical analyses and Adrien Villain (OMICS Unit, BIOASTER) for critical reading of the manuscript. We thank Johann Pellet and Pierre Veyre (xDATA Unit, BIOASTER) for their involvement in the data and computing management and the IN2P3 Computing Center (CNRS, Lyon-Villeurbanne, France) for the provisioning and excellent performance of computing infrastructure essential to our analyses.
Funding
This research project has received funding from the French Government through the Investissement d'Avenir program (Grant n°ANR-10-AIRT-03) and from bioMérieux.
Author information
Authors and Affiliations
Contributions
A.S. and G.G. designed the project. M.P. and A.S. performed the experimental work. C.E., M.P., H.H., A.H., E.S., A.F.-L., P.L, C.V., H.R., F.R., G.G. and A.S. analyzed results and wrote the manuscript. K.L. was in charge of the recruitment of clinical samples.
Corresponding author
Ethics declarations
Competing interests
This research project was partly funded by bioMérieux. bioMérieux provided the Stool preprocessing device and recommendations on its use. All experiments were conducted at BIOASTER by BIOASTER affiliates. C.E., M.P., H.H., E.S., A.H., K.L., A.F.-L., P.L., C.V., H.R., F.R., G.G. and A.S. declare no financial compensation.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Elie, C., Perret, M., Hage, H. et al. Comparison of DNA extraction methods for 16S rRNA gene sequencing in the analysis of the human gut microbiome. Sci Rep 13, 10279 (2023). https://doi.org/10.1038/s41598-023-33959-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-33959-6
- Springer Nature Limited