
Abstract
Numerical simulation of continuous variable quantum state preparation is a necessary tool for optimization of existing quantum information processing protocols. A powerful instrument for such simulation is the numerical computation in the Fock state representation. It unavoidably uses an approximation of the infinite-dimensional Fock space by finite complex vector spaces implementable with classical digital computers. In this approximation we analyze the accuracy of several currently available methods for computation of the truncated coherent displacement operator. To overcome their limitations we propose an alternative with improved accuracy based on the standard matrix exponential. We then employ the method in analysis of non-Gaussian state preparation scheme based on coherent displacement of a two mode squeezed vacuum with subsequent photon counting measurement. We compare different detection mechanisms, including avalanche photodiodes, their cascades, and photon number resolving detectors in the context of engineering non-linearly squeezed cubic states and construction of qubit-like superpositions between vacuum and single photon states.
Similar content being viewed by others


Introduction
Quantum information theory exploits fundamental features of quantum physics to design protocols and algorithms that offer significant improvements over their classical counterparts1,2,3,4. There are several candidate physical systems suitable for these applications, each with distinct advantages. Continuous variable quantum information processing with light offers feasible and fast generation and manipulation of entangled Gaussian quantum states that are at the core of the information protocols5,6,7,8,9,10,11,12. However, truly universal quantum information processing also requires elements of quantum non-Gaussianity13,14,15,16,17. Protocols based on Gaussian states and Gaussian operations are not universal13 and can be efficiently simulated on a classical device18.
For continuous variables of light, the non-Gaussianity is commonly introduced by photon number counting detectors, either the most basic on-off detectors capable of discerning presence of light19, or the more advanced detectors truly distinguishing the photon numbers20,21,22,23,24,25,26,27,28,29. Such detectors can be employed for direct conditional implementation of non-Gaussian operations30,31,32,33,34,35,36,37, or for conditional preparation of non-Gaussian quantum states38,39,40,41,42,43,44,45,46,47,48,49,50. The latter can be then used as a resource in deterministic implementation of non-Gaussian gates14,37,51. One thing these approaches have in common is the inherent probabilistic nature of measurement that results in several trade-offs between quality of the implemented operation or the prepared quantum state, the rate with which the desired operation succeeds, and the experimental challenges of the photon number resolving detector26,27,28,29,52. For any given set of realistic detectors and any desired task we then need the ability to faithfully simulate the optical circuit to find out the required parameters leading to the optimal performance, or to find out whether the task is even feasible.
However, numerical simulation of simple quantum optical circuits, even though it is often employed in continuous variable quantum information processing53,54,55,56,57, is not a straightforward task. It is burdened by various difficulties, including discretization errors in numerical models relying on continuous representation, truncation errors in discrete models53, the omnipresent rounding errors due to finite precision of arithmetics58,59,60,61,62 and numerical truncation errors occurring in finite approximations of infinite processes60,62. If not prevented by rigorous analysis, these numerical artifacts can dominate the computed values and lead to rapid divergence from correct results.
In this paper we evaluate the numerical errors arising when an optical circuit for probabilistic preparation of non-Gaussian quantum states of light14,38 is simulated on a classical digital computer. We then propose an alternative method for construction of truncated unitary operators aiming to curtail these errors. Finally we take advantage of these tools to fully simulate the circuit for preparation of resource states for the cubic phase gate51, and single mode qubit-like superpositions of zero and one photon. The goal is to find the optimal trade-offs between the quality of the states and the probability of success for a range of available photon counting detectors20,26,27,28,29,52.
This paper is structured as follows. In the State preparation circuit section we review the state preparation circuit. In the Perils of numerical simulation of CV systems section we describe the errors naturally occurring in numerical simulations. In the The curious case of coherent displacement section we focus on coherent displacement and identify the numerical errors appearing in different methods of its calculation. In the Truncated approximate matrix exponential (TAME) section we propose an alternative method for its calculation, followed by an overview of verification process in the Verification of approximated matrices section. We then proceed with the Numerical simulation of the preparation circuit section, where we describe the methodology of the actual simulation and present the results of its applications in sections eight and nine.
State preparation circuit
The most common method of conditional state preparation is based on suitable manipulation of ENPR state with coherent displacement and subsequent photon counting measurement14,39,63,64. In Fig. 1 we present a variant of the circuit which can be used for preparation of simple non-Gaussian quantum states, including the qubit-like \(\left| 0\right\rangle\) and \(\left| 1\right\rangle\) superpositions. Our circuit accounts for basic imperfections limited to detection inefficiencies and propagation losses. A physical EPR resource, generating the two mode squeezed vacuum (TMSV), lies at its very heart and serves as a source of perfectly correlated photons. One of the entangled modes is then displaced with controllable amplitude and phase and consequently measured. The detection can use either an avalanche photodiode (APD), a photon number resolving detector (PNRD) or its approximation employing an APD cascade52. The resulting marginal state
conditioned on the detection outcome \(\pi\), characterized by the POVM element \({\hat{\Pi }}_{2}(\pi )\), is obtained with the probability of success
In both the expressions (1) and (2) we use the lower right indices to emphasize which modes the operators and channels act on. Starting from the inner-most component, the initial TMSV state is denoted with \({ \left| \gamma \right\rangle _{1,2} = \sum _{i = 0}^{\infty } \mu _{i} (\gamma ) \left| i\right\rangle _{1} \left| i\right\rangle _{2} }\) with coefficients \({\mu _{i} (\gamma ) = \cosh ^{-1} \gamma \tanh ^{i} \gamma }\), where the parameter \({\gamma \in \mathbb {R}}\) sets the experimentally controllable squeezing strength. We model the overall losses and inefficiencies in the preparation scheme as attenuation of the measured mode prior to its displacement. This can represented by a Gaussian quantum channel \({\mathscr {G}}_{2}^{\eta } (\hat{\rho })\) with its action on the mode given in terms of Kraus operators65 as \({ {\mathscr {G}}_{2}^{\eta } (\hat{\rho }) = \sum _{i = 0}^{\infty } {\hat{M}}_{2}(i) \hat{\rho }{\hat{M}}_{2}^{\dagger } (i) }\) with \({ {\hat{M}}_{2} (i) = \frac{1}{\sqrt{i!}} (\sqrt{1 - \eta })^{i} \sqrt{\eta }^{{\hat{N}}_{2}} {\hat{A}}_{2}^{i} }\), where \({{\hat{N}}_{2} :={\hat{A}}_{2}^{\dagger } {\hat{A}}_{2}}\) defines the photon number operator and \({\hat{A}}_{2}\) denotes the annihilation operator respective to the measured mode. The parameter \({\eta \in [0, 1]}\) describes the efficiency of the preparation circuit. Subsequently the converse \({1 - \eta }\) characterizes the overall losses and inefficiencies in the preparation scheme. The displacement of the second mode is given by the unitary operator \({ {\hat{D}}_{2} (\xi ) = \exp ( \xi {\hat{A}}_{2}^{\dagger } - {\xi }^{*} {\hat{A}}_{2}) }\), where \({\xi \in \mathbb {C}}\) is the displacement amplitude66. In a more realistic analysis of the preparation circuit it would be straightforward to include the propagation losses affecting the mode carrying the resulting state. This form of decoherence can be accounted for by modifying the squeezing strength of the non-linearly squeezed state67. Consequently we do not consider this additional attenuation since it does not influence the fundamental properties of these non-Gaussian states.
From the experimental perspective the parameters \(\gamma\) and \(\xi\) can be fine tuned to engineer a desired state \(\hat{\rho }\) with optimal performance given particular experimental configuration characterized by the efficiency \(\eta\) and conditioning on the detection outcome \(\pi\) with respective POVM element \({\hat{\Pi }}(\pi )\).

Variation of the conditional preparation scheme. We start with a two mode squeezed vacuum state \(\left| \gamma \right\rangle\). One of its modes is then displaced with \({\hat{D}}(\xi )\) and measured, using either APD, PNRD or an APD cascade approximating PNRD. The detection outcome is characterized by the POVM element \({\hat{\Pi }}\). We model overall losses and inefficiencies within the scheme using a beam splitter with intensity transmittance \(\eta\) to represent attenuation of the signal state in the setup.
We can utilize this scheme to prepare a variety of quantum states. Consider now a lossless configuration employing an ideal PNRD. Its POVM elements correspond to projectors \(\vert f\rangle \langle f\vert\) onto individual Fock states \(\left| f\right\rangle\). The output state, conditioned on the detection of a particular Fock state \(\left| f\right\rangle\), is then proportional to \({ \sum _{i = 0}^{\infty } \mu _{i} (\gamma ) [D(\xi )]_{fi} \left| i\right\rangle }\) where the coefficients \(\mu _{i} (\gamma )\) follow from the definition of the TMSV state and \({[D(\xi )]_{fi} = \langle f|{\hat{D}}(\xi )|i\rangle }\) are matrix elements of the displacement operator. By tuning the parameters \(\gamma\) and \(\xi\) we can construct a set of states parametrized by the possible combinations of the \(\mu _{i}\) and \([D(\xi )]_{fi}\) coefficients.
Possible applications of this scheme include construction of generally non-classical superpositions of Fock states38,39 and, in particular, non-linearly squeezed non-Gaussian states14,63. Every application can be translated into constrained optimization of the tunable parameters with the constraint and objective functions embodying the nature of the particular application.
For example, if one were to construct a specific state \(\left| \psi \right\rangle\), the optimization objective could be to maximize some metric of similarity with the target state, e.g., fidelity. It would also be practical to construct the state with non-negligible probability of success. This requirement could be expressed either as a constraint \(P \ge \tau\) allowing only solutions with the probability greater than some threshold, or as an additional optimization objective in multi-objective optimization.
The constraint and objective functions generally involve the success probability (2) and the resulting density operator (1). Both of which can be obtained by simulating the preparation procedure numerically on a classical digital computer. But alas, numerical simulations come with their own hurdles which will be identified and subsequently addressed in the following sections.
Perils of numerical simulation of CV systems
Classical digital computers68 encode information into finite sequences of bits and it is therefore impossible to represent arbitrary real numbers. The standard approach59,60,61,62,69 is to approximate real numbers with floating point (FP) numbers. Real numbers are then rounded to their closest representable FP neighbors. This generally introduces rounding errors. To make matters worse, FP arithmetic with FP numbers does not necessarily produce exactly representable floating point numbers. Results of FP arithmetic must be rounded, possibly introducing additional rounding errors59,60,61,62,69. Consequently complex sequences of arithmetic operations possess the potential to accumulate and even amplify rounding errors. Even the most straightforward tasks such as adding up a sequence of FP numbers can produce widely different results with varying degrees of accuracy based on the algorithm of choice59,60,61. Rounding error analysis is therefore a crucial part of algorithm design58,59,60,61 and commonly used numerical algorithms are frequently accompanied by rigorous rounding error analysis. Nevertheless numerical simulation cannot be considered completely accurate as the error analysis only establishes upper bounds on the numerical errors58,60,61,62.
The practical concerns, when dealing with numerical simulation, are therefore always related to size of the errors, rather than to their presence. This is a familiar concept in physics, a discipline which is well acquainted with limited precision of measured quantities70,71. Numerical simulation of CV systems suffers from further issues related to the fundamental representation of quantum states and quantum operations. CV states reside in infinite-dimensional Hilbert spaces and can be, in principle, described in two distinct ways. The first description employs continuous functions, either wave functions given in position or momentum representation, or quasi-probability distributions5,6,7 which combine the two quadratures. The practical issue with this approach is the continuous nature and generally infinite support of these functions as their support must be limited to finite intervals and both their domains and ranges discretized during numerical integration61,62, introducing additional numerical errors.
Alternatively we can take the advantage of the discrete Fock basis spanned by eigenstates of the number operator. This basis is still infinite but, unlike in the case of basis spanned by eigenstates of continuous operators, the number of its elements is countable. While exact representation of CV states in Fock basis remains impossible, we can truncate the basis to a finite number of elements and approximate the original Hilbert space with this truncated, finite-dimensional, restriction. We can thusly avoid discretization errors and deal with truncation errors instead. Consequently numerical simulations utilizing truncated Hilbert spaces spanned by truncated Fock basis are often employed in detailed analysis of CV quantum circuits.
Formal definition of truncated Fock spaces
Let \(\mathscr {H}_{\infty }\) denote the original Hilbert space and let \({S :=\{ \left| j\right\rangle \in \mathscr {H}_{\infty }\Vert \; j = 0, 1, \dotsc \}}\) be the original Fock basis (FB). In this basis the vector components of individual Fock states \(\left| j\right\rangle \in S\) satisfy \({[ \left| j\right\rangle ]_{i}^{S} :=\langle i|j\rangle \equiv \delta _{ij}}\), that is, Fock states form an orthonormal basis. We take the first \(F\) elements of FB, \(\{ \left| 0\right\rangle , \dotsc , \left| F- 1\right\rangle \} \subset S\) and truncate their vector forms to the first \(F\) components, forming the truncated Fock basis (TFB) \({ S_{F} = \{ \left| 0\right\rangle ^{(F)}, \dotsc , \left| F- 1\right\rangle ^{(F- 1)} \} }\) where we use the upper right indices in \(\left| j\right\rangle ^{(F)}\) to denote dimensions of said vectors. Vector components of TFB elements satisfy \({ [ \left| j\right\rangle ^{(F)} ]_{i}^{S_{F}} :={}^{(F)}\negmedspace \langle j | i\rangle ^{(F)} \equiv [ \left| j\right\rangle ]_{i}^{S} \equiv \delta _{ij} \; \forall i = 0, \dotsc , F- 1 }\). The basis therefore remains orthonormal. The linear hull of \(S_{F}\) forms the \(F\) dimensional truncated Fock space (TFS) \(\mathscr {H}_{F}\).
So far we have only defined TFS itself and the transition from FB to TFB. In the following we define the transition of vectors from \(\mathscr {H}_{\infty }\) into \(\mathscr {H}_{F}\) and linear operators from \(\mathscr {L}(\mathscr {H}_{\infty })\) to \(\mathscr {L}(\mathscr {H}_{F})\). Let \(\left| \psi \right\rangle \in \mathscr {H}_{\infty }\) be an arbitrary state expressed as \({ \left| \psi \right\rangle = \sum _{i = 0}^{\infty } c_{\psi }(i) \left| i\right\rangle }\) (where \(\left| i\right\rangle \in S\)) with coefficients \(c_{\psi }(i) = [\left| \psi \right\rangle ]^{S}_{i} :=\langle i|\psi \rangle \in \mathbb {C}\). The expression \(\mathop {\mathrm {trunc}}\nolimits _{F} \{ \left| \psi \right\rangle \} :=\sum _{i = 0}^{F- 1} c_{\psi }(i) \left| i\right\rangle ^{(F)}\) (where \({\left| i\right\rangle ^{(F)} \in S_{F}}\)) then defines its truncated variant from \(\mathscr {H}_{F}\). Let \({{\hat{G}} \in \mathscr {L}(\mathscr {H}_{\infty })}\) be a linear operator on \(\mathscr {H}_{\infty }\) expressed as \({ {\hat{G}} = \sum _{i = 0}^{\infty } \sum _{j = 0}^{\infty } g(i, j) \vert i\rangle \langle j\vert }\) (where \({\left| i\right\rangle , \left| j\right\rangle \in S}\)) with matrix elements \({ g(i, j) = [{\hat{G}}]^{S}_{ij} :=\langle i | {\hat{G}} | j\rangle \in \mathbb {C}}\). Then \(\mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{G}} \} :=\sum _{i = 0}^{F- 1} \sum _{j = 0}^{F- 1} g(i, j) \left| i\right\rangle ^{(F)}\negmedspace \left\langle j\right|\) (where \({\left| i\right\rangle ^{(F)}\!, \left| j\right\rangle ^{(F)} \in S_{F}}\)) defines its truncated analogue on \(\mathscr {L}(\mathscr {H}_{F})\). A natural extension of this approach allows for transitions from higher-dimensional spaces to lower-dimensional spaces.
Navigating truncated Fock spaces
In this description, pure quantum states become complex \(F\) dimensional vectors of numbers, linear operators turn into complex \(F\times F\) matrices and the operations we would otherwise perform, reduce to linear algebraic expressions such as matrix multiplication, Kronecker products and matrix traces. There is, however, a hefty price to be paid for this simplification, manifesting in the form of truncation errors with several distinct effects on the simulation.
Firstly, it is impossible to represent general quantum states exactly. Take an arbitrary quantum state \(\left| \zeta \right\rangle \in \mathscr {H}_{\infty }\) and its truncated variant \(\mathop {\mathrm {trunc}}\nolimits _{F} \{ \left| \zeta \right\rangle \} \in \mathscr {H}_{F}\). The quality of the truncated state can be determined from its normalization, or rather the lack of it, using the cutoff error
where \(c_{\zeta }(i) = [ \left| \zeta \right\rangle ]_{i}^{S} \equiv \langle i | \zeta \rangle\) are the vector components of the state \(\left| \zeta \right\rangle\) in Fock representation. In essence the quality of the representation is loosely given by the support of the state relative to the dimension of the TFS. This is not the only conceivable metric, but it is a convenient one as it is straightforward to calculate.
Secondly, the algebraic structure of the space changes with the transition to finite dimension. As a result the usual commutation rules no longer apply since for any pair of operators \({\hat{G}}\) and \({\hat{H}}\) the relation \({ \mathop {\mathrm {trunc}}\nolimits _{F} \{ [{\hat{G}}, {\hat{H}} ] \} = [ \mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{G}} \}, \mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{H}} \} ] }\) does not necessarily hold anymore. We can illustrate the change in algebraic structure on bosonic creation and annihilation operators. In the regular infinite-dimensional case we have \({[ {\hat{A}}, {\hat{A}}^{\dagger } ] = {\hat{\mathbbm {1}}}}\), that is, the two operators commute to identity. With the truncated commutator the result remains the same \({ \mathop {\mathrm {trunc}}\nolimits _{F} \{ [ {\hat{A}}, {\hat{A}}^{\dagger } ] \} = \mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{\mathbbm {1}}} \} \equiv \mathbbm {1}^{(F)} }\), which is an identity matrix of the corresponding dimension \(F\). Conversely the commutator of the truncated annihilation and creation operators differs from identity in the final element on the diagonal
which can be understood as a truncation error due to the product of two truncated matrices.
Thirdly and finally, replacing infinite-dimensional operators in arguments of operator functions with their truncated versions may not be without consequences. Consider an operator function \(f ({\hat{Q}})\). In principle \(\mathop {\mathrm {trunc}}\nolimits _{F} \{ f({\hat{Q}}) \} \ne f(\mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{Q}} \} )\) for general operator arguments. This has grave consequences for numerical simulation of unitary evolution. It is customary to approximate the exponential operator, \(\mathop {\mathrm {trunc}}\nolimits _{F} \{ \exp ({\hat{Q}}) \}\), with the matrix exponential \({{\,\mathrm{expm}\,}}( \mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{Q}} \} )\) of the truncated operator argument53. However, this method can not be relied upon as \({\mathop {\mathrm {trunc}}\nolimits _{F} \{ \exp ({\hat{Q}}) \} \ne {{\,\mathrm{expm}\,}}( \mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{Q}} \} )}\). We must therefore seek alternative approaches: there are three primary techniques available for numerical simulation. The first one relies on the knowledge of a closed form formula for elements of the unitary operator. It has to be derived analytically and is not always attainable. The second method, proposed in the recent paper53, is numerical and derives individual elements of unitaries by recurrent formulae. In the third approach the matrix exponential is simply computed with the truncated matrix argument as \({{\,\mathrm{expm}\,}}(\mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{Q}} \} )\) and the dimension of the computation space is chosen large enough so that the errors are irrelevant in the particular simulation.
Neither approach is perfect. Each suffers from specific numerical errors. This is a valid concern even for the first method which uses analytical forms: it is because mathematical expressions, especially those involving factorials, large powers of non-negligible numbers or relying on special functions, which are often defined using similar expressions or recurrent formulae, still need to be evaluated numerically with finite precision in floating point arithmetic, leading to introduction and eventual accumulation of rounding errors. The numerical errors cannot be straightforwardly calculated without a priori knowledge of the ideal operator or without thorough numerical analysis of rounding errors, an area of expertise that is mostly out of the scope of theoretical physics and therefore scarcely present in research reports.
In the following section we apply these methods of construction to the simplest experimentally testable example, coherent displacement, and use this particular case study to demonstrate the fundamental shortcomings of each approach.
The curious case of coherent displacement
Coherent displacement is a fundamental Gaussian operation in quantum optics used in a broad range of quantum protocols for quantum state preparation, manipulation, and measurement5,6,7,13,14,66. Coherent displacement is represented by the unitary operator
where \(\xi \in \mathbb {C}\) gives the displacement amplitude and \({\hat{A}}, {\hat{A}}^{\dagger }\) represent the annihilation and creation operators. It is one of the operations for which a closed form formula exists66, given as
where \(L_{\beta }^{\alpha } (x)\) denotes the associated Laguerre polynomial function72. This relation only covers the lower triangular matrix; the rest of the matrix can be easily recovered from (6) using
The formula (6) can be computed in multiple different ways with varying numerical accuracy impacted by the simplifications made in the expression and the order of their evaluation. When implemented exactly as it stands in (6), it is plagued by the limitations of FP arithmetic. Its first term underflows for comparatively large m, while the second term overflows for \(\left| \xi \right| > 1\) and large enough difference \(m - n\). When both the numerical underflow and the overflow coincide, the ill-defined expression \(0 \times \infty\) is evaluated, resulting in error. We discuss the circumstances in detail in Sect. S1 of the Supplementary material and establish a set of acceptable combinations of the m, n and \(\left| \xi \right|\) parameters such that formula (6) is always well defined.
We can utilize the recurrent formulae53 or the plain matrix exponential73,74 with a truncated argument instead of the closed form formula (6). While we can not ascertain their accuracy without a priori knowledge of the ideal operator, we can easily determine whether the generated matrices G are outright incorrect by checking the normalisation
of displaced truncated Fock states \(\{ \left| 0\right\rangle ^{(F)}, \dotsc , \left| F- 1\right\rangle ^{(F)} \}\). It corresponds to the sum of squared absolute values of elements in the jth column of the truncated displacement matrix \(G :=\mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{D}} (\xi ) \}\) or its approximation employing the matrix exponential \({{\,\mathrm{expm}\,}}( \mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{Q}} \} )\) with truncated argument where we set \({\mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{Q}} \} :=\xi \mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{A}}^{\dagger } \} - {\xi }^{*} \mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{A}} \} }\).

Normalisation (8) of individual displaced truncated Fock states \(\left| j\right\rangle ^{(101)}\) with \({0 \le j \le 100}\). The displacement operator \(\mathop {\mathrm {trunc}}\nolimits _{101} \{ {\hat{D}} (3 - 2\imath ) \}\) is constructed on 101 dimensional TFS using the closed form formula (blue solid), the recurrent formula (red dash-dotted), and approximated with the matrix exponential (black dashed line).
In Fig. 2 we show the normalisation (8) for \({\mathop {\mathrm {trunc}}\nolimits _{101}\{{\hat{D}}(3 - 2\imath )\}}\) constructed using the closed form formula (6), represented with a blue solid line, the recurrent formula53 shown with a red dash-dotted line, and approximated with the matrix exponential (black dashed line). We utilize double precision60,69 in the computation and try to avoid numerical issues plaguing the direct method (6) by keeping the working dimension sufficiently low. There are two regions of qualitatively distinct behaviour in the plot. The first region, spanning the first 40 Fock states, shows correct normalization for all three methods of construction. In the following region the normalisation dwindles for both the closed form and the recurrent formulae whilst the matrix exponential remains incorrectly normalized. It remains normalized only because the matrix exponential function, by definition, produces unitary matrices from anti-Hermitian arguments. Unitarity is not necessarily the desired outcome here since the goal is to obtain the correct \(\mathop {\mathrm {trunc}}\nolimits _{101}\{ {{\,\mathrm{expm}\,}}({\hat{Q}}) \}\) matrix rather than the computed approximation \({{\,\mathrm{expm}\,}}( \mathop {\mathrm {trunc}}\nolimits _{101}\{ {\hat{Q}} \} )\).
Let us explicitly discuss the issue at hand. The displacement operator (5) is unitary by definition. Columns of its matrix representation can be understood as coefficient vectors of displaced Fock states. In the infinite-dimensional case these states should be normalized, that is the vector 2–norm75 of each column should satisfy \({ \Vert {\hat{D}} (\xi )\left| j\right\rangle \Vert _{2} \equiv 1 \,\forall \left| j\right\rangle \in S }\). However, this will not generally hold in finite dimension where we can find a threshold state \({\left| \tau \right\rangle ^{(F)} \in S_{F}}\) that, when displaced, will not be properly represented on the TFS. The states \(j \ge \tau\) will suffer from non-negligible errors (3), making their normalization \(\Vert \mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{D}} (\xi ) \} \left| j\right\rangle ^{(F)} \Vert _{2} < 1\).
The plot in Fig. 2 reveals that when the matrix is constructed via (6), the higher states are correctly denormalized. Conversely the matrix exponential produces incorrectly normalized states. In this context such behavior can be considered a manifestation of truncation errors.
The normalisation of the recurrently computed matrix starts to rise exponentially somewhere around \(j \approx 50\) due to accumulation of rounding errors. This behavior depends on the chosen \(\xi\) and the breakdown is more prominent when \(\xi\) is large. Here the displacement \({\xi = 3 - 2\imath }\) was chosen to emphasize this effect. For instance, when \(\xi = 1\), a similar exponential breakdown appears for \({j \approx 400}\) instead.
Truncated approximate matrix exponential (TAME)
So far we have seen that, when it comes to numerically generating truncated representations of unitary operators, both direct calculation and the recurrent formulae have fundamental issues leading to significant rounding errors or numerically invalid expressions. The matrix exponential function avoids these issues mostly at the cost of truncation errors and their subsequent amplification. However, the observations in Fig. 2 also suggest that these errors tend to be significant only in higher regions of said matrices.
This opens up a new possibility of approximating the exponential operators. We can use the matrix exponential on a sufficiently higher dimension \(d_1\) and only then truncate the result to the required \(d_0\), thus avoiding the erroneous areas, while, at the same time, keeping the computational dimension \(d_{1}\) low enough to avoid needlessly increasing the time of computation. We call this approach truncated approximate matrix exponential (TAME). Consider the approximation of the truncated displacement operator, \(\mathop {\mathrm {trunc}}\nolimits _{d_{0}} \{ D(\xi ) \} \in \mathscr {L}(\mathscr {H}_{d_{0}})\), constructed in such a way,
Here \(d_{1}\) represents the initial working dimension and \(d_{0}\) the final dimension of the target TFS. Following (5) we set \({ \mathop {\mathrm {trunc}}\nolimits _{d_{1}} \{ {\hat{Q}} \} :=\xi \mathop {\mathrm {trunc}}\nolimits _{d_{1}} \{ {\hat{A}}^{\dagger } \} - {\xi }^{*} \mathop {\mathrm {trunc}}\nolimits _{d_{1}} \{ {\hat{A}} \} }\).

Normalisation \(\Vert \mathop {\mathrm {trunc}}\nolimits _{101} \{ {\hat{D}}(3 - 2\imath ) \} \left| j\right\rangle ^{(101)} \Vert _{2}\) of displaced Fock states \(0 \le j \le 100\). The matrix was constructed using the closed form formula (black bullets) and approximated with TAME (red, solid) where we set \(d_{0} = 101\) and \(d_{1} = 161\). In both plots the dimension \(d_{1}\) for TAME was determined via Algorithm 1.
In Fig. 3 we compare \(\mathop {\mathrm {trunc}}\nolimits _{101} \{ {\hat{D}}(3 - 2\imath ) \}\) constructed using the closed form formula (6) and approximated with TAME. We chose the dimension \(d_{0}\) and the displacement magnitude \(\left| \xi \right|\) to accommodate the limits established in Sect. S1 of the Supplementary material. The secondary dimension \(d_{1} = 161\) was chosen high enough to suppress the effects of truncation errors. The plot suggests that our method produces results equal to the closed form formula in terms of the normalisation (8). Further comparison of individual matrix elements reveals that, on average, the approximate matrix matches (6) up to 14 decimal places with the worst difference matching only up to 11 decimal places.
What remains to be determined is the proper choice, or rather the methodology of choosing a sufficiently large working dimension \(d_1\) given the target dimension \(d_0\). In the subsequent paragraphs we are going to show that it is practical to set the dimension \(d_{1}\) as small as possible. The de facto standard scaling and squaring matrix exponentiation algorithm73,74 relies on matrix multiplication with the actual number of matrix products depending on the binary logarithm of the 1–norm75 of the exponentiated matrix.
The 1–norm75 of the \(\mathop {\mathrm {trunc}}\nolimits _{d_{1}} \{ {\hat{Q}} \}\) argument inside the matrix exponential within (9) reads
where the final approximation holds asymptotically. Therefore the asymptotic computational complexity of the matrix exponential in (9) scales as \(\mathscr {O}(\log _{2} d_{1})\) in terms of matrix products. The complexity of each matrix multiplication, specified in terms of FP operations, depends on the algorithm it utilizes. A naive textbook implementation scales as poorly as \(\mathscr {O}(d_{1}^{3})\), whereas the more sophisticated Strassen algorithm76 scales approximately as \(\mathscr {O}(d_{1}^{2.807})\). Consequently the computational complexity of (9) scales as \(\mathscr {O}(d_{1}^{2.807} \log _{2} d_{1})\) under optimal conditions. It is therefore imperative to keep the dimension \(d_{1}\) as low as possible.

We propose a simple iterative algorithm for finding optimal \(d_{1}\). Suppose a sufficiently sized \({{\,\mathrm{expm}\,}}(\mathop {\mathrm {trunc}}\nolimits _{q} \{ {\hat{Q}} \})\) matrix is correct on some region spanning \(\{ \left| 0\right\rangle ^{(u)}, \dotsc , \left| u - 1\right\rangle ^{(u)} \}\) where \(u \le q\). Suppose the matrix exponential (\({{\,\mathrm{expm}\,}}\)) algorithm is also consistent: for a differently sized \(\mathop {\mathrm {trunc}}\nolimits _{p} \{ {\hat{Q}} \}\) matrix with dimension \(p > q\) the computed matrix exponential is correct on a region of at least the same size. Given these assumptions, which are upheld by the standard \({{\,\mathrm{expm}\,}}\) implementation73,74, we introduce the Algorithm 1 as follows. First we take the desired dimension \(d_{0}\) of the correct region and set an equality tolerance \(\varepsilon _{1}\) for small numbers: our condition with \(\varepsilon _{1} = 10^{-13}\) proclaims two numbers identical if they match up to their twelfth decimal place. Then we search for a pair of larger matrices such that their \(d_{0}\) regions match. The search process is significantly simplified by taking the dimension of the second larger matrix to be constantly shifted from the first larger matrix. To improve its speed we always recycle one of the matrices in the next iteration instead of recalculating it every time. The depth of the search is specified by the factor h. In our experience the dimension is found somewhere well below \(q = 3 \cdot d_{0}\) in the case of displacement, hence we set the depth h above that. Once the search algorithm finishes successfully, we obtain \(d_{1}\).
Verification of approximated matrices
In general, we can not verify the matrix (9) constructed via TAME simply by comparing its elements against some exact solution for the obvious reason: if we knew the exact solution we would not be in this situation in the first place.
We have used normalisation (8), or more precisely the implied necessary condition of unitarity \(\max _{ij} \left| [ G ]_{ij} \right| \le 1\), to detect outright incorrect matrices in Fig. 2, but alas, necessary conditions alone can not be used to prove the matrix correct. In Fig. 2 we determined that employing the recurrent formula53 in construction of \(\mathop {\mathrm {trunc}}\nolimits _{F} \{ {\hat{D}}(\xi ) \}\) was ill-advised due to accumulation and consequent amplification of rounding errors over the course of the computation. While we can not safely use the recurrent formula to construct an arbitrary truncated displacement matrix, we can use it to determine whether a candidate matrix, for example one constructed via TAME (9), possesses appropriate structure as the formulae define relations between neighboring matrix elements.
We can repurpose the relations Eq. (56–58) from53 to construct an error matrix
for a given candidate matrix G. The rounding errors are not amplified in computation of the error matrix as there is no recursion. Its elements \([E]_{ij}\) give the difference between the actual elements \([G]_{ij}\) of the candidate matrix and the values they should have been based on their neighbors, \([G]_{i - 1, j - 1}\) and \([G]_{i, j - 1}\), and the structural constraints given in53.
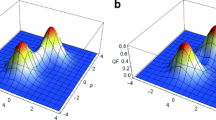
In Fig. 4 we compare the decadic logarithm of the difference \({[L]_{ij} = \log _{10} \left| [E]_{ij} \right| }\) for \({\mathop {\mathrm {trunc}}\nolimits _{201} \{ {\hat{D}}(3 - 2\imath ) \}}\) approximated using (a) TAME (\({d_{0} = 201}\), \({d_{1} = 277}\)) and (b) the plain matrix exponential (\({d_{0} = 201}\)). In each plot we display the row-wise \({{\,\mathrm{mean}\,}}_{i}([L]_{ij})\) value with blue line. The surrounding light-blue area stretches one standard deviation \({{\,\mathrm{std}\,}}_{i}([L]_{ij})\) from the mean. The maximal difference \(\max _{i}([L]_{ij})\) within each column is represented by the red line. Finally the dashed black horizontal line (at \(-16\)) roughly corresponds to the double precision unit round-off60.
In Fig. 4 (a) the matrix is structurally correct, with the maximal difference still matching up to 11 decimal places. On average the differences fall below the unit round-off, essentially making the errors negligible. In Fig. 4 (b) the matrix constructed using the plain matrix exponential maintains the correct structure in the first third of its columns, however, the truncation errors begin to manifest at that point. This can be observed as an exponential explosion in the maximal difference (around the 75th column) and a steady rise in the mean value. We saw a similar manifestation of truncation errors in Fig. 2 where the columns incorrectly retained their normalization as if the truncated matrix remained unitary.

Verification of the \(\mathop {\mathrm {trunc}}\nolimits _{201} \{{\hat{D}}(3 - 2\imath )\}\) matrix approximated using (a) TAME (\(d_{0} = 201\) and \(d_{1} = 277\)) and (b) plain matrix exponential (\(d_{0} = 201\)). Blue lines mark the row-wise \({{\,\mathrm{mean}\,}}_{i}(L_{ij})\) values, light-blue region stretches a standard deviation \({{\,\mathrm{std}\,}}_{i}(L_{ij})\) away from the mean. The maximal difference \(\max _{i}(L_{ij})\) within each column is represented by the red line. The dashed horizontal line corresponds to the unit round-off in double precision floating point number representation. (a) The matrix is structurally correct. The average differences are negligible, their values falling below the unit round-off. The maximal differences match up to 11 decimal places. (b) The matrix maintains correct structure in its first third. The truncation errors manifest in the rest of the matrix as an exponential explosion in the maximal difference (around the 100th column) and a steady rise in the mean value.
Numerical simulation of the preparation circuit
The CV nature of the preparation scheme in Fig. 1, described with relations (1) and (2), makes its exact numerical simulation not only impractical, but outright impossible. We can, however, perform an approximate numerical simulation of the formulae on a TFS. We have already proposed TAME as the method for approximating the truncated displacement operator. We have yet to ascertain a key ingredient of the simulation. We must determine the optimal dimension \(d_{0}\) of the TFS, which should be large enough to support all the quantum states occurring in the simulation.
Following the Fig. 1, we begin with the TMSV state. One of its modes is attenuated by the \({\mathscr {G}}_{2}^{\eta }\) channel. This only reduces its energy and, as a consequence, the required support shrinks in size. We can therefore safely disregard the attenuating channel and simplify the expression for the marginal state (1) into \({ {\hat{\varrho }} \propto {{\,\mathrm{tr}\,}}_{2} \left\{ {\hat{D}}_{2}(\xi ) \vert \gamma \rangle _{1, 2}\langle \gamma \vert {\hat{D}}_{2}(\xi )^{\dagger } {\hat{\Pi }}_{2} \right\} }\). We then require that both the initial and the displaced TMSV states are faithfully approximated on the \(d_{0}\) dimensional TFS for all the possible values of \(\gamma\) and \(\xi\). By taking the largest displacement \(\xi ^{\star }\) and squeezing rate \(\gamma ^{\star }\) considered in the simulation, we can iteratively determine \(d_{0}\) as the least dimension such that the cutoff error (3) falls below some threshold \(\varepsilon _{0}\). This condition reads
for the displaced TMSV state. While the coefficients \({ [ \left| \gamma ^{\star }\right\rangle ]^{S}_{ii} = \cosh ^{-1} \gamma ^{\star } \tanh ^{i} \gamma ^{\star } }\) of the TMSV state are determined trivially, the matrix elements \([ {\hat{D}} (\xi ^{\star }) ]^{S}_{ij}\) of the displacement operator can not be, in general, obtained analytically with (6) and we must employ alternate means such as TAME.
In the simulation we consider \(0 \le \gamma \le 1\), corresponding to roughly \(8.7 \,\mathrm {dB}\) squeezing, and \(0 \le \xi \le 1\), hence we set \(\gamma ^{\star } \equiv \xi ^{\star } \equiv 1\) while searching for \(d_{0}\). Once the dimension \(d_{0}\) is found, we determine its respective \(d_{1}\) using the Algorithm 1. With the thresholds \(\varepsilon _{0} \equiv \varepsilon _{1} \equiv 10^{-13}\) we get \(d_{0} = 70\) and \(d_{1} = 90\) for \(\gamma ^{\star } \equiv \xi ^{\star } \equiv 1\). Note that for this particular \(d_{1}\), the TAME matrices constructed on \(d_{1}\) and \(d_{1} + 1\) dimensional TFS are identical in double precision FP arithmetic.
In the following sections we use the numerical methodology we developed to determine the benefits of using PNRD, APD, and APD cascades in a pair of applications of the preparation circuit. First we discuss preparation of non-linearly squeezed states (Section “Engineering non-linearly squeezed states”) and then follow with construction of well defined non-classical superpositions of Fock states (Section “Preparation of high fidelity qubit in Fock basis”). In both applications the figures of merit are functions depending on the resulting density matrix (1) and the associated probability of success (2). We approach the analysis with a rudimentary grid based exploratory strategy for optimization. We divide the \([ 0 \le \gamma \le 1 ] \otimes [ 0 \le \xi \le 1]\) region into equidistant \(1001 \times 1001\) grid of points \({ p_{j} :=(\gamma _{j}, \xi _{j}) }\) and evaluate the numerically approximated relations (1) and (2) for each point \(p_{j}\) and each experimental scenario \({ q_{i} :=(\eta _{i}, \pi _{i}) }\) defined by the overall efficiency \({ \eta _{i} \in \{ 0.80, 1.00 \} }\) of the setup and expected measurement outcome \(\pi _{i}\) respective to the POVM elements. These entail
representing the click of the ideal APD and the first six PNRD outcomes relevant in our preparation scheme, as well as PNRD approximations employing APD cascades
where \({\hat{\Pi }}_{n}^{M} :=\sum _{k = 0}^{d_{0} - 1} p_{M} (n|k) \vert k\rangle _{2}\langle k\vert\). The POVM elements \({\hat{\Pi }}_{n}^{M}\) represent outcomes where exactly n detectors click within APD cascade comprising M detectors52. The individual probabilities \(p_{M}(n|k)\) read
This way we procure an assortment of probabilities P(i, j) and density matrices \(\varrho (i, j)\) corresponding to the \(p_{i}\) and \(q_{j}\) sequences. We then utilize these values in objective and constraint functions, that will be discussed in detail in the following sections, to analyze the performance of the preparation scheme in particular applications and its response to different experimental configurations.
The numerical simulation and the analysis of its results was implemented using a number of open source software libraries77,78,79,80,81,82,83 in Python.
Engineering non-linearly squeezed states
Nonlinear squeezing was originally introduced51 as a measure quantifying the quality of approximate cubic states suitable for optical measurement-induced quantum gates37,51. It has been shown to apply to higher ordered phase squeezing gates as well37 and was recently discussed in detail67. The ideal cubic operation facilitates unitary evolution with interaction Hamiltonian proportional to \({\hat{X}}^3\). When approximatively implemented in the measurement induced fashion51 its action in the Heisenberg picture can be represented by the operator transformation
where the \({\hat{X}}_{S}, {\hat{P}}_{S}\) operators correspond to the signal state and \({\hat{X}}_{A}, {\hat{P}}_{A}\) to some ancillary mode. The first terms of both relations correspond to the ideal cubic interaction \(\exp (\imath \frac{\nu }{3} {\hat{X}}^{3})\). The additional term (\({{\hat{P}}_{A} - \nu {\hat{X}}_{A}^{2}}\)) represents the nonlinear quadrature of the ancillary mode and embodies the undesirable noisy contribution. It can be suppressed by choosing an appropriate ancillary state with the right structure. Effects of this contribution, or more precisely its variance and mean, vanish for the ideal cubic state. In general, neither the variance nor the mean vanish for physical approximations of the ideal cubic state. Good approximations, however, minimize their values and consequently the variance of this contribution may be used to quantify the quality of these approximate cubic states.
The preparation scheme presented in Fig. 1 can be utilized for production of quantum states approximating the ideal cubic state. We have discussed the methodology of the simulation in detail in Section Numerical simulation of the preparation circuit. In essence we search for optimal values of squeezing \(\gamma\) and displacement \(\xi\) that lead to high quality cubic state approximations while maximizing the probability of successful preparation. The optimization is performed for various experimental scenarios involving different detectors and taking a range of overall losses into account.
To measure the approximation quality we adapted the nonlinear quadrature and the concept of nonlinear squeezing discussed in51 to fit our simulation. We employ the nonlinear quadrature \({\hat{Y}} = \mu {\hat{P}} - \sqrt{2^{-1}} \mu ^{-2} {\hat{X}}^{2}\) and use its variance \({ V(\hat{\rho }) = \langle ({\hat{Y}} - \langle {\hat{Y}} \rangle _{\hat{\rho }})^{2} \rangle _{\hat{\rho }} }\) to measure the nonlinear squeezing of arbitrary states \(\hat{\rho }\). Potential effects of Gaussian squeezing51,67 on \(V(\hat{\rho })\) are eliminated by minimizing over the parameter \(\mu\). Consequently we base our analysis on the minimized quantity \({M (\hat{\rho }) :=\lambda _{G}^{-1} \min _{\mu } V(\hat{\rho })}\) normalized with respect to the minimal variance \(\lambda _{G} :=\min _{\hat{\rho }_{G}} \min _{\mu } V(\hat{\rho }_{G}) \equiv 0.75\) achievable by Gaussian states \(\hat{\rho }_{G}\)67.
The numerical simulation yields density matrices \(\varrho (i, j)\) along with the P(i, j) probabilities of success corresponding to different experimental parameters. We then compute the individual moments required in the calculation of \(V(\hat{\rho })\) from the elements of density matrices \(\varrho (i, j)\). We avoid the matrix representation of the operators in the computation to avert truncation errors and employ closed form formulae instead. The minimization with respect to \(\mu\) within \(M(\hat{\rho })\) is solved analytically.
We thus obtain M(i, j) values for their respective \(\varrho (i, j)\) matrices and P(i, j) probabilities. We then divide the dataset corresponding to each experimental scenario \(q_{i}\) into bins based on values of the variance M(i, j) and find the maximal attainable probability P(i, j) within each bin.

A comparison of attainable variance \(M(\hat{\rho })\) as a function of success probability. The variance is normalized with respect to the minimal variance achievable by Gaussian states. We use the same vertical and horizontal axes in the plots to show the contrast between the almost ideal (a) and lossy (b, c) scenarios with \(99\%\), \(90\%\) and \(80\%\) transmission efficiencies. Horizontal dashed lines are used to mark the optimal cubic state approximations \(\left| v^{\bigstar }\right\rangle \in \mathscr {H}_{v}\) constructed on low-dimensional TFS. We encode the information about the POVM elements as follows: APD click with solid black line, PNRD projection onto \(\left| 3\right\rangle\) with solid red, APD cascades comprising four (\({\hat{\Pi }}_{3}^{4}\), dashed magenta), five (\({\hat{\Pi }}_{3}^{5}\), magenta) and ten (\({\hat{\Pi }}_{3}^{10}\), blue) detectors where three detectors click. Overall, utilizing the PNRD \(\left| 3\right\rangle\) (solid red) produces states with lowest non-linear variance, therefore producing comparatively better approximations of the cubic state. In both (b) and (c) a single APD outperforms the APD cascades comprising five and four detectors for probabilities greater than \(1\%\). In this regime the cascade comprising ten detectors still offers advantage over single APD. In (c) a single APD outperforms APD cascades comprising either four, five or ten detectors for success probabilities larger than roughly \(5\%\).
In Fig. 5 we present a comparison of the attainable variance \(M(\hat{\rho })\) as a function of success probability P. We examine different detection outcomes, in particular the PNRD projection onto \(\left| 3\right\rangle\) (red line) and its three approximations realized through an APD cascade52 where three APD detectors out of four (dashed magenta), five (magenta) and ten (blue) click. Their respective POVM elements \({\hat{\Pi }}_{3}^{4}\), \({\hat{\Pi }}_{3}^{5}\) and \({\hat{\Pi }}_{3}^{10}\) are given by the relation (14). We consider a single APD detector (black line) as well. The plots show (a) \(99\%\), (b) \(90\%\), and (c) \(80\%\) transmission efficiency \(\eta\). The results are normalized with respect to the minimal variance achievable by Gaussian states. The optimal cubic state approximations51 \(\left| v^{\bigstar }\right\rangle \in \mathscr {H}_{v}\) constructed on v dimensional TFS are marked with dashed horizontal lines. These states were found by searching for pure states spanning the first v Fock states that would minimize the variance \(M(\hat{\rho })\) of the non-linear quadrature51. Their inclusion makes it possible for qualitative comparison with the states produced by our scheme.
In general using PNRD yields the best results. In the idealized scenario with \(99\%\) efficiency the PNRD projecting onto \(\left| 3\right\rangle\) approaches the variance of the optimal \(\mathscr {H}_{4}\) non-linearly squeezed state \(\left| 4^{\bigstar }\right\rangle\). It also attains the best values consistently across the considered transmission efficiencies, therefore producing comparatively better approximations of the cubic state than either the APD cascades or a single APD. In the \(90\%\) and \(99\%\) regimes, the APD cascade comprising ten detectors promises better performance than a single APD or any other cascade configuration for that matter. In the low-efficiency mode (\(80\%\)) we can see that a single APD outperforms APD cascades for probabilities of success greater than \(5\%\). This can be attributed to the imperfections inherent to APD cascades52. Their flaws become emphasized with increased loss, rendering a single APD to be the better choice.
In conclusion, unless a PNRD capable of distinguishing at least three photons is available, it is advantageous to use a single APD in any practical scenario with non-ideal transmission efficiency as long as success probabilities larger than approximately \(5\%\) are desired. The advantage of a single APD can be offset by using an exorbitant number of detectors within APD cascade.
Preparation of high fidelity qubit in Fock basis
The qubit-like superposition \(\left| \vartheta \right\rangle :=\cos \vartheta \left| 0\right\rangle + \sin \vartheta \left| 1\right\rangle\) represents one of the simplest non-Gaussian quantum states of light. It serves an important role in quantum information processing84 and is one of the resources available in contemporary experimental quantum optics85,86,87. As such it is has been employed in experimental demonstrations of various theoretical concepts including witnessing of non-Gaussianity88,89,90,91 and hybrid entanglement44,92 in quantum communication.
This family of quantum states can be produced with the preparation scheme we have previously introduced in Fig. 1. We can search for the optimal squeezing \(\gamma\) and displacement \(\xi\) parameters to obtain a given target state \(\left| \vartheta \right\rangle\) with sufficient fidelity \(F = \langle \vartheta | \hat{\rho }| \vartheta \rangle\) and maximal performance in terms of success probability.
We compute the corresponding \(F_{\vartheta } (i, j)\) values for the P(i, j) probabilities and \(\varrho (i, j)\) density matrices obtained in the simulation described in detail in Section Numerical simulation of the preparation circuit. We then divide the dataset for each experimental scenario \(q_{i}\) into bins comprising subsets of data satisfying \(F_{\vartheta } (i, j) \ge \tau\) where \(\tau\) specifies a moving fidelity threshold. The maximal attainable probability P(i, j) is then found for each subset.

Benchmarking the performance of PNRD and its approximations using APD cascades relative to a single APD detector in preparation of particular superpositions \({\left| \vartheta \right\rangle :=\cos \vartheta \left| 0\right\rangle + \sin \vartheta \left| 1\right\rangle }\) parametrized with \(\vartheta \in \mathbb {R}\). The PNRD projection onto \(\left| 1\right\rangle\) is represented by red line, whereas the magenta line corresponds to APD cascade comprising ten detectors where a single detector clicks (\(\Pi _{1}^{10}\)), blue line to cascade of five detectors (\(\Pi _{1}^{5}\)) and black line depicts the case with two detectors (\(\Pi _{1}^{2}\)). The plots demonstrate preparation of two distinct states while considering different transmission efficiencies. In (a) and (c) we aim to prepare \(\left| \frac{\pi }{3}\right\rangle\). In (b) and (d) we target \(\left| \frac{\pi }{6}\right\rangle\). In plots (a) and (b) we consider \(99\%\) transmission efficiency, while in (c) and (d) we consider mere \(80\%\). The horizontal dashed line marks a twofold improvement in each plot. (a) In the high-efficiency regime we obtain roughly tenfold improvement in the high-fidelity preparation of the \(\left| \frac{\pi }{3}\right\rangle\) state. The PNRD approximations using more than two detectors offer a significant improvement as well. (b) While the advantage of PNRD is reduced when targeting the state biased towards \(\left| 0\right\rangle\), it still offers roughly four times better performance. (c) The PNRD detector and its approximations offer 2-3x higher success probability even in the lower-efficiency scenario. (d) The PNRD detector and its approximations offer roughly twofold improvement.
In Fig. 6 we demonstrate the relative improvement in probability of successfully engineering \(\left| \vartheta \right\rangle\) states by employing different detectors instead of a single APD. We consider a pair of target states, \(\left| \frac{\pi }{3}\right\rangle\) and \(\left| \frac{\pi }{6}\right\rangle\), both evaluated for \(99\%\) and \(80\%\) transmission efficiencies. These target states were chosen to probe the improvement for unbalanced superpositions biased either towards \(\left| 0\right\rangle\) or \(\left| 1\right\rangle\) states. In the plot we show the result obtained for projection onto \(\left| 1\right\rangle\) (red line) realized by PNRD and the results obtained with its approximations realized through APD cascades where a single detector out of ten (\({\hat{\Pi }}_{1}^{10}\), magenta), five (\({\hat{\Pi }}_{1}^{5}\), blue) and two (\({\hat{\Pi }}_{1}^{2}\), black) clicks. The POVM elements \({\hat{\Pi }}_{n}^{M}\) of the cascades were defined in (14). The figure of merit is defined as \(L :=(\log _{10} P_{\bullet } - \log _{10} P_{\text {APD}})\) with \(P_{\bullet }\) respective to individual detection outcomes.
In general, conditioning on the PNRD \(\left| 1\right\rangle\) detection outcome yields the best results. In the high-fidelity regime with \(99\%\) efficiency the relative improvement is roughly tenfold for \(\left| \frac{\pi }{3}\right\rangle\) and roughly four times better for \(\left| \frac{\pi }{6}\right\rangle\). The APD cascades comprising ten and five detectors follow. The relative lead of the PNRD diminishes in the \(80\%\) efficiency regime. Its advantage also dwindles when we consider target states closer to \(\left| 0\right\rangle\), such as the \(\left| \frac{\pi }{6}\right\rangle\) state. While the cascade comprising two detectors falls short in every case, it still outperforms a single APD, albeit not by a lot.
Conclusions
We have analyzed the numerical accuracy of several currently available methods53,66 used in construction of the truncated coherent displacement operator, an essential ingredient of state preparation in quantum optics14,30,32,36 and many protocols used in quantum information processing5,6,7,13,14,66. We have proposed an alternative approach promising a better accuracy. Our method is based on the standard matrix exponential73,74 with truncated argument. We compute the matrix exponential on a higher-dimensional space and truncate the resulting matrix to the target dimension, thus stripping erroneous matrix elements away from the truncated displacement operator. To avoid negatively impacting computational performance, the higher dimension should be ideally kept as low as possible. To this end we provide an off-line search algorithm that can be used to determine its optimal value. To ascertain the accuracy of the resulting matrix we complement the construction method with a verification strategy based on the recurrent formulae discussed in53.
We have used our construction method for analysis of non-Gaussian state preparation scheme based on suitable manipulation of a two mode squeezed vacuum with subsequent photon counting measurement14,39,63,64 in the context of engineering non-linearly squeezed cubic states14,38,51 for measurement induced cubic gates14,37,51 and construction of qubit-like superpositions between vacuum and single photon states. The latter application can be verified experimentally with currently available technology. We have compared the effects of different detection mechanisms, including APD, PNRD and its approximations using APD cascades52 with varying number of APD detectors, to determine practical approach towards state preparation. In our analysis we have optimized the free parameters of the prepraration scheme, the initial squeezing and the displacement, to attain optimal results in both applications. This analysis also provides additional metric which can be used to quantify the quality of APD cascades. We have found that in practical applications when PNRD is not available, using a single APD to engineer non-linearly squeezed states offers better performance compared to employing APD cascades comprising small number of detectors. We attribute this counter-intuitive result to the imperfections inherent to APD cascades52 which are exaggerated with increased loss; these flaws became significant for \(20\%\) overall loss. The primary cause of this behaviour lies within the employed avalanche detectors as a single click may be triggered by multiple photons. While this is a critical issue for multi-photon state engineering, it is not as significant for single-photon states. We have determined that using APD cascade, even if one comprising only a pair of APD detectors, improves upon using a single APD in preparation of high-fidelity non-Gaussian qubit-like superpositions.
Our circuit variant can be extended to utilize multiple displacements and detectors. Similarly the proposed method for numerical construction of truncated unitary operators is not limited to displacement only can be applied to, for example, squeezing or cubic phase-shift operators. Furthermore, the method could be employed in preparation of a wider variety of quantum states with practical applications, such as GKP states14.
Data availability
The datasets generated and analyzed in the current study are available from the corresponding author on reasonable request.
Code availability
The source code used to generate and analyze the datasets is available from the corresponding author on reasonable request.
References
Montanaro, A. Quantum algorithms: An overview. NPJ Quant. Inf. https://doi.org/10.1038/npjqi.2015.23 (2016).
Nielsen, M. Quantum computation and quantum information (Cambridge University Press, Cambridge New York, 2000).
Zhong, H.-S. et al. Quantum computational advantage using photons. Science 370, 1460–1463. https://doi.org/10.1126/science.abe8770 (2020).
O’Brien, J. L. Optical quantum computing. Science 318, 1567–1570. https://doi.org/10.1126/science.1142892 (2007).
Braunstein, S. L. & van Loock, P. Quantum information with continuous variables. Rev. Mod. Phys. 77, 513–577. https://doi.org/10.1103/revmodphys.77.513 (2005).
Weedbrook, C. et al. Gaussian quantum information. Rev. Mod. Phys. 84, 621–669. https://doi.org/10.1103/revmodphys.84.621 (2012).
Adesso, G., Ragy, S. & Lee, A. R. Continuous variable quantum information: Gaussian states and beyond. Open Syst. & Inf. Dyn. 21, 1440001. https://doi.org/10.1142/s1230161214400010 (2014).
Asavanant, W. et al. Generation of time-domain-multiplexed two-dimensional cluster state. Science 366, 373–376. https://doi.org/10.1126/science.aay2645 (2019).
Larsen, M. V., Guo, X., Breum, C. R., Neergaard-Nielsen, J. S. & Andersen, U. L. Deterministic generation of a two-dimensional cluster state. Science 366, 369–372. https://doi.org/10.1126/science.aay4354 (2019).
Chen, M., Menicucci, N. C. & Pfister, O. Experimental realization of multipartite entanglement of 60 modes of a quantum optical frequency comb. Phys. Rev. Lett. https://doi.org/10.1103/physrevlett.112.120505 (2014).
Asavanant, W. et al. Time-domain-multiplexed measurement-based quantum operations with 25-MHz clock frequency. Phys. Rev. Appl. https://doi.org/10.1103/physrevapplied.16.034005 (2021).
Larsen, M. V., Guo, X., Breum, C. R., Neergaard-Nielsen, J. S. & Andersen, U. L. Deterministic multi-mode gates on a scalable photonic quantum computing platform. Nat. Phys. 17, 1018–1023. https://doi.org/10.1038/s41567-021-01296-y (2021).
Lloyd, S. & Braunstein, S. L. Quantum computation over continuous variables. Phys. Rev. Lett. 82, 1784–1787. https://doi.org/10.1103/physrevlett.82.1784 (1999).
Gottesman, D., Kitaev, A. & Preskill, J. Encoding a qubit in an oscillator. Phys. Rev. A. https://doi.org/10.1103/physreva.64.012310 (2001).
Lachman, L., Straka, I., Hloušek, J., Ježek, M. & Filip, R. Faithful hierarchy of genuine n-photon quantum non-gaussian light. Phys. Rev. Lett. https://doi.org/10.1103/physrevlett.123.043601 (2019).
Chabaud, U., Markham, D. & Grosshans, F. Stellar representation of non-gaussian quantum states. Phys. Rev. Lett. https://doi.org/10.1103/physrevlett.124.063605 (2020).
Chabaud, U. et al. Certification of non-gaussian states with operational measurements. PRX Quant. https://doi.org/10.1103/prxquantum.2.020333 (2021).
Mari, A. & Eisert, J. Positive wigner functions render classical simulation of quantum computation efficient. Phys. Rev. Lett. https://doi.org/10.1103/physrevlett.109.230503 (2012).
Pan, J.-W. et al. Multiphoton entanglement and interferometry. Rev. Mod. Phys. 84, 777–838. https://doi.org/10.1103/revmodphys.84.777 (2012).
Lita, A. E., Miller, A. J. & Nam, S. W. Counting near-infrared single-photons with 95% efficiency. Opt. Express 16, 3032. https://doi.org/10.1364/oe.16.003032 (2008).
Calkins, B. et al. High quantum efficiency photon-number-resolving detector for photonic on-chip information processing. In CLEO: 2013. https://doi.org/10.1364/cleo_qels.2013.qm4l.1 (OSA, 2013).
Marsili, F. et al. Detecting single infrared photons with 93% system efficiency. Nat. Photon 7, 210–214. https://doi.org/10.1038/nphoton.2013.13 (2013).
Harder, G. et al. Single-mode parametric-down-conversion states with 50 photons as a source for mesoscopic quantum optics. Phys. Rev. Lett. https://doi.org/10.1103/physrevlett.116.143601 (2016).
Burenkov, I. A. et al. Full statistical mode reconstruction of a light field via a photon-number-resolved measurement. Phys. Rev. A. https://doi.org/10.1103/physreva.95.053806 (2017).
Sperling, J. et al. Detector-independent verification of quantum light. Phys. Rev. Lett. https://doi.org/10.1103/physrevlett.118.163602 (2017).
Endo, M. et al. Quantum detector tomography of a superconducting nanostrip photon-number-resolving detector. Opt. Express 29, 11728. https://doi.org/10.1364/oe.423142 (2021).
Korzh, B. et al. Demonstration of sub-3 ps temporal resolution with a superconducting nanowire single-photon detector. Nat. Photonics 14, 250–255. https://doi.org/10.1038/s41566-020-0589-x (2020).
Höpker, J. P. et al. Integrated transition edge sensors on titanium in-diffused lithium niobate waveguides. APL Photonics 4, 056103. https://doi.org/10.1063/1.5086276 (2019).
Hloušek, J., Dudka, M., Straka, I. & Ježek, M. Accurate detection of arbitrary photon statistics. Phys. Rev. Lett. https://doi.org/10.1103/physrevlett.123.153604 (2019).
Dakna, M., Clausen, J., Knöll, L. & Welsch, D.-G. Generation of arbitrary quantum states of traveling fields. Phys. Rev. A 59, 1658–1661. https://doi.org/10.1103/physreva.59.1658 (1999).
Zavatta, A. Quantum-to-classical transition with single-photon-added coherent states of light. Science 306, 660–662. https://doi.org/10.1126/science.1103190 (2004).
Marek, P., Filip, R. & Furusawa, A. Deterministic implementation of weak quantum cubic nonlinearity. Phys. Rev. A. https://doi.org/10.1103/physreva.84.053802 (2011).
Ourjoumtsev, A., Tualle-Brouri, R., Laurat, J. & Grangier, P. Generating optical schrodinger kittens for quantum information processing. Science 312, 83–86. https://doi.org/10.1126/science.1122858 (2006).
Tipsmark, A. et al. Experimental demonstration of a hadamard gate for coherent state qubits. Phys. Rev. A. https://doi.org/10.1103/physreva.84.050301 (2011).
Usuga, M. A. et al. Noise-powered probabilistic concentration of phase information. Nat. Phys. 6, 767–771. https://doi.org/10.1038/nphys1743 (2010).
Fiurášek, J., García-Patrón, R. & Cerf, N. J. Conditional generation of arbitrary single-mode quantum states of light by repeated photon subtractions. Phys. Rev. A. https://doi.org/10.1103/physreva.72.033822 (2005).
Marek, P. et al. General implementation of arbitrary nonlinear quadrature phase gates. Phys. Rev. A. https://doi.org/10.1103/physreva.97.022329 (2018).
Ghose, S. & Sanders, B. C. Non-gaussian ancilla states for continuous variable quantum computation via gaussian maps. J. Mod. Opt. 54, 855–869. https://doi.org/10.1080/09500340601101575 (2007).
Yukawa, M. et al. Generating superposition of up-to three photons for continuous variable quantum information processing. Opt. Express 21, 5529. https://doi.org/10.1364/oe.21.005529 (2013).
Konno, S. et al. Nonlinear squeezing for measurement-based non-gaussian operations in time domain. Phys. Rev. Appl. https://doi.org/10.1103/physrevapplied.15.024024 (2021).
Tiedau, J. et al. Scalability of parametric down-conversion for generating higher-order fock states. Phys. Rev. A. https://doi.org/10.1103/physreva.100.041802 (2019).
Yoshikawa, J. et al. Heralded creation of photonic qudits from parametric down-conversion using linear optics. Phys. Rev. A. https://doi.org/10.1103/physreva.97.053814 (2018).
Sangouard, N. et al. Quantum repeaters with entangled coherent states. J. Opt. Soc. Am. B 27, A137. https://doi.org/10.1364/josab.27.00a137 (2010).
Huang, K. et al. Experimental quantum state engineering with time-separated heraldings from a continuous-wave light source: A temporal-mode analysis. Phys. Rev. A. https://doi.org/10.1103/physreva.93.013838 (2016).
Takase, K., ichi Yoshikawa, J., Asavanant, W., Endo, M. & Furusawa, A. Generation of optical schrödinger cat states by generalized photon subtraction. Phys. Rev. A. https://doi.org/10.1103/physreva.103.013710 (2021).
Ra, Y.-S. et al. Non-gaussian quantum states of a multimode light field. Nat. Phys. 16, 144–147. https://doi.org/10.1038/s41567-019-0726-y (2019).
Su, D., Myers, C. R. & Sabapathy, K. K. Conversion of gaussian states to non-gaussian states using photon-number-resolving detectors. Phys. Rev. A. https://doi.org/10.1103/physreva.100.052301 (2019).
Pizzimenti, A. J. et al. Non-gaussian photonic state engineering with the quantum frequency processor. Phys. Rev. A. https://doi.org/10.1103/physreva.104.062437 (2021).
Gagatsos, C. N. & Guha, S. Efficient representation of gaussian states for multimode non-gaussian quantum state engineering via subtraction of arbitrary number of photons. Phys. Rev. A. https://doi.org/10.1103/physreva.99.053816 (2019).
Gagatsos, C. N. & Guha, S. Impossibility to produce arbitrary non-gaussian states using zero-mean gaussian states and partial photon number resolving detection. Phys. Rev. Res. https://doi.org/10.1103/physrevresearch.3.043182 (2021).
Miyata, K. et al. Implementation of a quantum cubic gate by an adaptive non-gaussian measurement. Phys. Rev. A. https://doi.org/10.1103/physreva.93.022301 (2016).
Provazník, J., Lachman, L., Filip, R. & Marek, P. Benchmarking photon number resolving detectors. Opt. Express 28, 14839. https://doi.org/10.1364/oe.389619 (2020).
Miatto, F. M. & Quesada, N. Fast optimization of parametrized quantum optical circuits. Quantum 4, 366. https://doi.org/10.22331/q-2020-11-30-366 (2020)
Killoran, N. et al. Strawberry fields: A software platform for photonic quantum computing. Quantum 3, 129. https://doi.org/10.22331/q-2019-03-11-129 (2019).
Quesada, N. et al. Simulating realistic non-gaussian state preparation. Phys. Rev. A. https://doi.org/10.1103/physreva.100.022341 (2019).
Gupt, B., Izaac, J. & Quesada, N. The walrus: A library for the calculation of hafnians, hermite polynomials and gaussian boson sampling. J. Open Sour. Softw. 4, 1705. https://doi.org/10.21105/joss.01705 (2019).
Bromley, T. R. et al. Applications of near-term photonic quantum computers: Software and algorithms. Quant. Sci. Technol. 5, 034010. https://doi.org/10.1088/2058-9565/ab8504 (2020).
Fox, L. How to get meaningless answers in scientific computation (and what to do about it). Inst. Math. its Appl. Bull. 7, 296–302 (1971).
Goldberg, D. What every computer scientist should know about floating-point arithmetic. ACM Comput. Surv. 23, 5–48. https://doi.org/10.1145/103162.103163 (1991).
Higham, N. Accuracy and stability of numerical algorithms (Society for Industrial and Applied Mathematics, Philadelphia, 2002).
Dahlquist, G. Numerical methods (Dover Publications, Mineola, N.Y., 2003).
Heath, M. Scientific computing : An introductory survey (Society for Industrial and Applied Mathematics (SIAM), Philadelphia, Pennsylvania, 2018).
Yukawa, M. et al. Emulating quantum cubic nonlinearity. Phys. Rev. A. https://doi.org/10.1103/physreva.88.053816 (2013).
Bohmann, M. et al. Incomplete detection of nonclassical phase-space distributions. Phys. Rev. Lett. https://doi.org/10.1103/physrevlett.120.063607 (2018).
Ivan, J. S., Sabapathy, K. K. & Simon, R. Operator-sum representation for bosonic gaussian channels. Phys. Rev. A. https://doi.org/10.1103/physreva.84.042311 (2011).
Cahill, K. E. & Glauber, R. J. Density operators and quasiprobability distributions. Phys. Rev. 177, 1882–1902. https://doi.org/10.1103/physrev.177.1882 (1969).
Kala, V., Marek, P. & Filip, R. Cubic nonlinear squeezing and its decoherence. Optics Express 30, 31456–31471. https://doi.org/10.1364/OE.464759 (2022).
Turing, A. M. On computable numbers, with an application to the entscheidungsproblem. Proc. London Math. Soc. s2-42, 230–265. https://doi.org/10.1112/plms/s2-42.1.230 (1937).
Standard for floating-point arithmetic. IEEE. Institute of electrical and electronics engineers. IEEE Std. 754–2008, 1–70. https://doi.org/10.1109/IEEESTD.2008.4610935 (2008).
Barlow, R. Statistics: A guide to the use of statistical methods in the physical sciences (Wiley, Chichester, England New York, 1989).
Bevington, P. Data reduction and error analysis for the physical sciences (McGraw-Hill, Boston, 2003).
Bateman, H. Higher transcendental functions (R.E. Krieger Pub. Co, Malabar, Florida, 1981).
Higham, N. J. The scaling and squaring method for the matrix exponential revisited. SIAM J. Matrix Anal. Appl. 26, 1179–1193. https://doi.org/10.1137/04061101x (2005).
Al-Mohy, A. H. & Higham, N. J. A new scaling and squaring algorithm for the matrix exponential. SIAM J. Matrix Anal. Appl. 31, 970–989. https://doi.org/10.1137/09074721x (2010).
Golub, G. Matrix computations (The Johns Hopkins University Press, Baltimore, 2013).
Strassen, V. Gaussian elimination is not optimal. Numer. Math. 13, 354–356. https://doi.org/10.1007/bf02165411 (1969).
Harris, C. R. et al. Array programming with NumPy. Nature 585, 357–362. https://doi.org/10.1038/s41586-020-2649-2 (2020).
fundamental algorithms for scientific computing in python. Virtanen, P. et al. SciPy 1.0. Nat. Methods 17, 261–272. https://doi.org/10.1038/s41592-019-0686-2 (2020).
Johansson, J., Nation, P. & Nori, F. QuTiP 2: A python framework for the dynamics of open quantum systems. Comput. Phys. Commun. 184, 1234–1240. https://doi.org/10.1016/j.cpc.2012.11.019 (2013).
Dalcin, L. & Fang, Y.-L.L. mpi4py: Status update after 12 years of development. Comput. Sci. & Eng 23, 47–54. https://doi.org/10.1109/mcse.2021.3083216 (2021).
Hunter, J. D. Matplotlib: A 2d graphics environment. Comput. Sci. & Eng 9, 90–95. https://doi.org/10.1109/MCSE.2007.55 (2007).
Kluyver, T. et al. Jupyter notebooks - a publishing format for reproducible computational workflows. In Loizides, F. & Scmidt, B. (eds.) Positioning and Power in Academic Publishing: Players, Agents and Agendas, 87–90 (IOS Press, Netherlands, 2016).
Meurer, A. et al. Sympy: symbolic computing in python. PeerJ Comput. Sci. 3, e103. https://doi.org/10.7717/peerj-cs.103 (2017).
Kok, P. & Lovett, B. W. Introduction to Optical Quantum Information Processing (Cambridge University Press, 2010).
Davidson, O., Finkelstein, R., Poem, E. & Firstenberg, O. Bright multiplexed source of indistinguishable single photons with tunable ghz-bandwidth at room temperature. New J. Phys. 23, 073050. https://doi.org/10.1088/1367-2630/ac14ab (2021).
Higginbottom, D. B. et al. Pure single photons from a trapped atom source. New J. Phys. 18, 093038. https://doi.org/10.1088/1367-2630/18/9/093038 (2016).
Podhora, L., Obšil, P., Straka, I., Ježek, M. & Slodička, L. Nonclassical photon pairs from warm atomic vapor using a single driving laser. Opt. Express 25, 31230. https://doi.org/10.1364/oe.25.031230 (2017).
Filip, R. & Mišta, L. Detecting quantum states with a positive wigner function beyond mixtures of gaussian states. Phys. Rev. Lett. https://doi.org/10.1103/physrevlett.106.200401 (2011).
Ježek, M. et al. Experimental test of the quantum non-gaussian character of a heralded single-photon state. Phys. Rev. Lett. https://doi.org/10.1103/physrevlett.107.213602 (2011).
Straka, I. et al. Quantum non-gaussian depth of single-photon states. Phys. Rev. Lett. https://doi.org/10.1103/physrevlett.113.223603 (2014).
Mika, J., Lachman, L., Lamich, T., Filip, R. & Slodička, L. Single-mode quantum non-gaussian light from warm atoms. https://doi.org/10.48550/ARXIV.2201.05366 (2022).
Le Jeannic, H., Cavaillès, A., Raskop, J., Huang, K. & Laurat, J. Remote preparation of continuous-variable qubits using loss-tolerant hybrid entanglement of light. Optica 5, 1012. https://doi.org/10.1364/optica.5.001012 (2018).
Acknowledgements
J. P. acknowledges using the computational cluster at the Department of Optics for parallel execution of the numerical simulation.
Funding
We acknowledge Grant No. GA22-08772S of the Czech Science Foundation and also support by national funding from MEYS and the European Union’s Horizon 2020 (20142020) research and innovation framework programme under grant agreement program under Grant No. 731473 (project 8C20002 ShoQC). Project ShoQC has received funding from the QuantERA ERA-NET Cofund in Quantum Technologies implemented within the European Union’s Horizon 2020 program. We have further been supported by the European Union’s 2020 research and innovation programme (CSA - Coordination and support action, H2020-WIDESPREAD-2020-5) under grant agreement No. 951737 (NONGAUSS). J. P. acknowledges project IGA-PrF-2022-005 of Palacky University Olomouc. R.F. also acknowledges LTAUSA19099 of the Czech Ministry of Education, Youth and Sports (MEYS).
Author information
Authors and Affiliations
Contributions
J. P. conceived and developed the numerical techniques, performed the calculations, implemented and consequently conducted the numerical simulation. P. M. and R. F. conceived and discussed the applications and evaluations that were simulated. All authors analyzed and discussed the results, and contributed to the writing of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Provazník, J., Filip, R. & Marek, P. Taming numerical errors in simulations of continuous variable non-Gaussian state preparation. Sci Rep 12, 16574 (2022). https://doi.org/10.1038/s41598-022-19506-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-19506-9
- Springer Nature Limited