
Abstract
Knowledge of the solubilities of hydrocarbon components of natural gas in pure water and aqueous electrolyte solutions is important in terms of engineering designs and environmental aspects. In the current work, six machine-learning algorithms, namely Random Forest, Extra Tree, adaptive boosting support vector regression (AdaBoost-SVR), Decision Tree, group method of data handling (GMDH), and genetic programming (GP) were proposed for estimating the solubility of pure and mixture of methane, ethane, propane, and n-butane gases in pure water and aqueous electrolyte systems. To this end, a huge database of hydrocarbon gases solubility (1836 experimental data points) was prepared over extensive ranges of operating temperature (273–637 K) and pressure (0.051–113.27 MPa). Two different approaches including eight and five inputs were adopted for modeling. Moreover, three famous equations of state (EOSs), namely Peng-Robinson (PR), Valderrama modification of the Patel–Teja (VPT), and Soave–Redlich–Kwong (SRK) were used in comparison with machine-learning models. The AdaBoost-SVR models developed with eight and five inputs outperform the other models proposed in this study, EOSs, and available intelligence models in predicting the solubility of mixtures or/and pure hydrocarbon gases in pure water and aqueous electrolyte systems up to high-pressure and high-temperature conditions having average absolute relative error values of 10.65% and 12.02%, respectively, along with determination coefficient of 0.9999. Among the EOSs, VPT, SRK, and PR were ranked in terms of good predictions, respectively. Also, the two mathematical correlations developed with GP and GMDH had satisfactory results and can provide accurate and quick estimates. According to sensitivity analysis, the temperature and pressure had the greatest effect on hydrocarbon gases’ solubility. Additionally, increasing the ionic strength of the solution and the pseudo-critical temperature of the gas mixture decreases the solubilities of hydrocarbon gases in aqueous electrolyte systems. Eventually, the Leverage approach has revealed the validity of the hydrocarbon solubility databank and the high credit of the AdaBoost-SVR models in estimating the solubilities of hydrocarbon gases in aqueous solutions.
Similar content being viewed by others
Introduction
One of the crucial theoretical and practical challenges in petroleum, chemical, and geochemical engineering is the solubilities of hydrocarbons, such as methane, ethane, propane, n-butane, or their mixtures, in pure water and aqueous electrolyte solutions. Achieving optimal conditions for gas and oil transportation, designing thermal separation processes, coal gasification, and hydrate formation require accurate information about the solubilities of hydrocarbon gases in different aqueous phases1,2,3,4,5. Natural gases coexist with aqueous solutions in petroleum reservoirs under the circumstances of high temperature and high pressure, which makes the solubilities of gases an important challenge for engineers. The water content of gases can undergo a phase alteration from vapor to gas hydrates, water condensate, and ice in the production and transportation of hydrocarbons. The condensed water phase in the compressor can damage impeller blades. Also, corrosion and pipeline blockage, as two serious flow assurance problems, can be caused by the formation of gas hydrates and/or ice throughout the production and transportation of hydrocarbons1,6,7,8. From an environmental point of view, gases solubility in water is a substantial problem because of the legislation and restrictions on the hydrocarbons contents in the water disposal9. In addition, leaking pipelines, underground oil storage tanks, and accidents on oil platforms and ships of the hydrocarbons’ transportation are responsible for oil spillage in water10,11,12.
Because of complex non-idealities from the strong H-bonding of water molecules, an accurate description of the phase behavior of these systems, utilizing theoretical methods is a challenging issue13. Accurate gas solubility data is essential to develop thermodynamic models for giving a qualified evaluation of the water content in the gases phase9. Therefore, the objective of thermodynamic calculations is the estimation of the compositions, content, and other equilibrium properties of the phases. Traditional equations of state (EOSs) are mainly applied to estimate thermodynamic and physical properties such as gas solubility. However, accurate estimates of gases solubility in various solvents by EOSs face serious problems such as iterative calculations, limited flexibility, and adjustable parameters at different temperatures and pressures. This makes the application of current conventional approaches, for example EOSs, unreliable and convinces researchers to seek better predictive techniques14,15,16,17,18,19.
The petroleum industry needs appropriate and precise knowledge of the correlation between operating conditions (i.e., pressure and temperature), vapor and liquid phases compositions, and the salinity of the aqueous phase for the systems containing aqueous electrolyte solutions and natural gas’ components. This knowledge can help design/optimize the operating condition for gas processing units and avoid/diagnose problems accompanying natural gas applications. Literature survey shows that there are many sets of experimental solubility data for various gas − liquid systems. Available experimental sources mainly present the solubility of pure hydrocarbon gases2,4,20,21,22, hydrocarbon gas mixtures1,5,6,9,23,24,25, and non-hydrocarbon gases (e.g., N2 and CO2)26,27,28,29,30 in water/brine systems. On the other hand, due to the difficulties encountered in measuring the low content of water of gases at low-temperature and high-pressure conditions, experimental data of water content of hydrocarbon and non-hydrocarbon gases are limited and scattered. However, Mohammadi et al.1 demonstrated that complexities associated with experimental measurement of the water content in natural gas could be eliminated by gas solubilities data, which provides an accurate estimate of water content1. Attempts to model the vapor–liquid phase equilibria of non-hydrocarbon and hydrocarbon gases and brine solutions have always been considered by researchers due to the limited number of measurements. The activity coefficient, Henry’s constant approach, and EOSs were widely used in thermodynamic models in order to gain information about the equilibrium conditions of non-hydrocarbon and hydrocarbon gases and pure water or aqueous electrolytes solutions5,9,31,32,33,34,35,36,37,38,39,40,41. Although Henry’s law can appropriately be utilized to estimate the solubilities, this approach has several drawbacks. For instance, this approach is correct for unique compounds at low concentrations under equilibria conditions with no chemical reactions for the aqueous phase. Also, it is appropriate for near-ideal or dilute solutions42. Moreover, at low temperatures, there is a limited count of Henry’s constants for the systems containing hydrocarbons-aqueous solutions3. On the other hand, the advantages such as lower count of parameters, the easiness of implementation, and computational efficiency make the use of EOSs widespread2,4,9,43. However, the accuracy of EOSs is highly dependent on the appropriation of empirical adjustments via incorporating the binary interaction parameters. Therefore, reliable sources of experimental data for the vapor–liquid equilibria of binary or even multi-component mixtures are essential to determine these parameters23,44. Hence, developing EOS for extensive applications such as calculations of natural gas’ solubility faces serious problems, and numerous EOSs developed so far are mostly attributed to limited systems. Due to the above discussions, in recent years, researchers have tried to provide accurate and reliable approaches to predict the solubilities of non-hydrocarbon and hydrocarbon gases in pure water and aqueous electrolyte systems. Literature survey shows that many intelligent models have been proposed to estimate the solubilities of non-hydrocarbon gases, especially CO2, in water and brine45,46,47,48,49,50. Regarding hydrocarbons solubility in pure water and brine, Safamirzaei et al.51 utilized a simple artificial neural network (ANN) with overall 101 solubility data points for modeling n-alkanes (nC1–nC6) solubilities in water. They showed that an ANN-based model could be an alternative to other methods such as EOSs with high accuracy51. Samani et al.52 proposed two hybrid models based on least-squares support vector machine and coupled simulated annealing algorithms for estimating the solubility of hydrocarbons (C1–C4) and non-hydrocarbon gases (CO2 and N2) in aqueous electrolyte systems. Regarding hydrocarbon gases, their database had 1175 solubility data points, and the average absolute error of their proposed model was 30.6%52. Nabipour et al.53 used a similar database including 1175 data points and an extreme learning machine algorithm to develop a model for predicting hydrocarbon gases (C1–C4) solubility in electrolyte solutions. The mean relative error of their model was 22.05%53. Although two relatively comprehensive intelligent models have been developed to predict the solubilities of hydrocarbon gases in aqueous electrolyte systems, the error of these models is slightly high. Also, due to the nature of the data-driven soft computing approaches, incorporating a larger number of data, various operating conditions, and adopting different modeling approaches may propel a comprehensive predictive tool for estimating the solubilities of light hydrocarbon gases and their mixture in water and aqueous electrolyte solutions. Furthermore, the development of easy-to-use mathematical correlations by advanced algorithms can simplify and accelerate the prediction of hydrocarbon gas solubilities in brine.
In this research, a huge database (1836 experimental data points) of hydrocarbon gases solubilities in pure water and aqueous electrolyte systems was accumulated from the literature. Next, for developing predictive tools, six robust machine learning algorithms viz., Random Forest, Extra Tree, adaptive boosting support vector regression (AdaBoost-SVR), Decision Tree, genetic programming (GP), and group method of data handling (GMDH) are implemented in this study by considering two different approaches. Additionally, three famous equations of state (EOSs) viz., Peng–Robinson (PR), Valderrama modification of the Patel–Teja (VPT), and Soave–Redlich–Kwong (SRK) are utilized in comparison with machine learning models. Furthermore, the performance of machine learning-based predictive tools and mathematical correlations is studied by employing various statistical and visual error analyses. Besides, a well-known sensitivity analysis, i.e., the relevancy factor, is identified the relative impact of input variables on hydrocarbon gases solubility in brine. Ultimately, the validity of the solubility databank, along with the application domain of the best-developed predictive tools in the present work, is examined by the Leverage mathematical method.
Data acquisition
In this work, a large databank was collected on the basis of experimental solubility data of light hydrocarbon gases and their mixtures in water and aqueous electrolytes. This databank consists of 1836 data points that are 661 data points more than what is used in Samani et al.52 and Nabipour et al.53 works. Table 1 presents the details and references of experimental solubility data for hydrocarbon components of natural gas in pure water and aqueous electrolytes used in this survey. It should be noted that the collected laboratory data for the solubility of gases in pure water and brine is such that most of the solubility values were reported in two-phase conditions (a gaseous phase and an aqueous phase in equilibrium). This means that the temperature and pressure of the system were such that only two phases would exist in equilibrium. This is while there is a possibility of the formation of three phases at conditions of pressure higher than the critical pressure of components or low-temperature conditions. According to the Gibbs phase rule, degrees of freedom are the number of intensive properties that can be altered without varying the number of phases, or the number of components in any phase54. Hence, in some studies such as Amirijafari’s work23, for measuring hydrocarbon gas solubility in water under high-pressure conditions, the temperatures were selected such that only two phases (hydrocarbon gas mixture and the liquid water with hydrocarbons dissolved in it) would be present. Adopting this approach makes measuring gas solubilities easier and the obtained data more reliable. Although in some other studies5,6, in addition to measuring the solubility data in the two-phase state, the solubility values have been measured in the three-phase conditions, i.e. (three-phase equilibrium between the hydrate, the aqueous, and the vapor phase or three-phase equilibrium between water-rich liquid, hydrocarbon-rich liquid, and vapor phase). However, experimental measurements of solubilities in such a condition are challenging and could potentially generate unreliable laboratory data. For example, concentrations of light hydrocarbon gases in water are low, and moreover reaching the equilibrium states near and inside the gas hydrate formation region is a time-consuming process. However, the data collected in this research were all carefully selected from reliable references where considerable time has been spent on conducting experiments and calculated solubility values using specific methods, especially in three-phase conditions. Further explanation of the laboratory process for calculating gas solubility is beyond the scope of this work and interested readers are referred to the literature6,55,56. It should be mentioned that what is mentioned as gas solubility in this study is x = mole fraction of hydrocarbon gas in the aqueous liquid phase, which is collected from reliable references reported in Table 1.
Literature survey reveals that the gaseous phase composition, aqueous phase composition, temperature, and pressure highly affect the solubilities of hydrocarbon gases in the aqueous solutions1,5,6,9,68. The ionic strength (I) as a single characteristic of aqueous electrolyte solutions was utilized in the modeling process instead of multiple salt concentrations of brine solutions in order to reduce the dimensions of the modeling process. Considering mi as the molar concentration of each ion and zi as valance of charged ions in brine solutions, the ionic strength (I) is defined as follows:
In this study, two approaches were considered for modeling. First, hydrocarbon gases solubility (ηh: mole fraction) is assumed to be a function of eight independent parameters: temperature (K), pressure (MPa), ionic strength of the solution (M), the mole percent of each component (C1, C2, C3, and C4) in the gas mixture, and carbon number (IDX: 1, 2, 3, and 4) of the gas component (methane, ethane, propane, and n-butane) whose solubility is to be predicted:
The mentioned approach is similar to that utilized in Samani et al.52 and Nabipour et al.53 works. The second approach is that hydrocarbon gases solubility (ηh: mole fraction) is assumed to be a function of five input parameters: pressure (MPa), temperature (K), ionic strength of the solution (M), the pseudo-critical temperature of the gas mixture (Tpc), and the critical temperature of the gas component (Tcgas) whose solubility is to be predicted:
Here, if Tci is the critical temperature of individual components and yi is the molar fraction of individual components in the gas mixture of n components, Tpc can be calculated as follows69:
In the second approach, although the number of parameters has been reduced, by using the parameters of the pseudo-critical temperature of the gas mixture and the critical temperature of gaseous components instead of the mole percent of each component in the gas mixture and the carbon number, the development of the model becomes more general. Table 2 presents the statistical details of the databank (including all inputs utilized in both modeling approaches along with hydrocarbon gases solubility as the models’ target) utilized to model the solubility of light hydrocarbon gases and their mixtures in water and aqueous electrolyte solutions.
Table 2 reports that the ionic strength of brine solutions based on molarity is in the range of 0–37.351 M. The mole percent of light hydrocarbon gases (C1-C4) in the gaseous mixture was in the range of 0–100%. The experimental solubility data of light hydrocarbons and their mixtures in water and aqueous electrolyte systems have also been gathered over broad ranges of operating temperatures, 273.15–637.15 (K), and pressures, 0.05–113.27 (MPa). Hence, the variety of input variables is broad enough to provide a general machine learning-based predictive tool for estimating light hydrocarbon gases and their mixtures in water and aqueous electrolyte systems.
Model development
Adaptive boosting (AdaBoost)
The Adaptive boosting (AdaBoost) technique established by Freund and Schapire70 seeks to develop a powerful classifier by integrating weak classifiers and benefiting from their failures. In other words, it repeatedly chooses the training inputs in order to complement several classifiers and apply the proper weight for every classifier depending on its performance, with larger weights allocated to miscategorized data sets. The following are the common parts of the AdaBoost procedure71:
Step 1: Weights determination: \({w}_{j}=\frac{1}{n}. j=1.2.\dots .n\)
Step 2: Providing the training data to a weak learner \({Wl}_{i}(x)\), assigning weights, and calculating the weighted error for each i.
Step 3: The weights should be calculated for each i for estimators: \({\beta }_{i}=log\left(\frac{(1-{Err}_{i})}{{Err}_{i}}\right)\)
Step 4: Changing the weights of the data for each i to N (N refers to the count of the learner).
Step 5: Setting a weak learner to the data test (x) as a response.
Support vector regressors are utilized as weak learners in the AdaBoost algorithm in this research.
Support vector machine for regression (SVR)
Although support vector machine is a collection of controlled machine learning techniques that may be applied for regression and classification72, support vector regression (SVR) is routinely used for soft calculation since it has a well-defined mathematical model. Because of its consistency in simulating numerous complicated structures, SVR has recently piqued researchers’ curiosity. Since the main theory of SVR has been published73, it is just shortly presented in this work for the sake of brevity. The SVR objective is to catch a regressor f(x) for such a sample data \([\left({x}_{1}. {y}_{1}\right).\dots ..\left({x}_{n}.{y}_{n}\right)]\), having \(x\in {R}_{d}\) as the d-dimensional input dataset and \(y\in R\) as the output variable (which relies on the inputs), in order to calculate the output:
Here w denotes weight, b indicates bias vectors, and \(\phi \left(x\right)\) represents the kernel function. To get the proper aforementioned parameters, Vapnik et al.74 developed the following minimizing method:
where transposed matrix of w is represented by \({w}^{T}\), error connivance by \(\varepsilon \), positive factors expressing the lower and higher extra variances by \({\upzeta }_{\mathrm{j}}^{+}\) and \({\upzeta }_{\mathrm{j}}^{-}\), and positive regularization parameter indicating the variation from \(\varepsilon \) by C.
The abovementioned constraints optimization issue is transformed into a dual function utilizing Lagrange multipliers, yielding the subsequent solution:
where \({a}_{k}^{*}\) and \({a}_{k}\) indicate the Lagrange multipliers, while \(K\left({x}_{k}.{x}_{l}\right)\) is the kernel function. Figure 1 presents a schematic image of the proposed AdaBoost-SVR in this study.

Schematic illustration of the proposed AdaBoost-SVR.
Decision tree (DT)
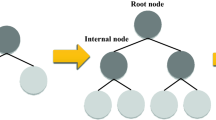
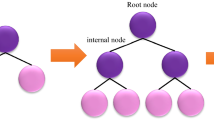
This method75 is derived from natural sources and may be used to tackle both regression and classification problems. Root nodes, leaf nodes, internal nodes, and branches make up this system. The inputs are carried by the root node, which is the initial portion of the proposed technique. The last section of the diagram, known as the leaf nodes or final nodes, represents the model's output. Between the root and leaf nodes are internal nodes. The nodes are linked together by branches. Pruning, dividing, and halting are the three major activities used to build a decision tree76. The data dividing stage begins from the root node just before data is presented to the system. This process of separating proceeds until a stopping condition is met77. Figure 2 depicts the basic DT.

Schematic illustration of a typical decision tree.
Random forest (RF)
The decision tree is an effective machine learning technique; however, it has two flaws. First, while the estimation error of the decision tree is typically low in training data, the forecasting deviation is sometimes high because it is susceptible to small disturbances in the training samples; second, while the separating law in each node is desirable, according to the previous section, this greedy strategy cannot assure that the overall decision tree is the best. By simultaneously training many trees and transforming several weak learners into powerful learners, ensemble techniques can address these two problems. A random forest is made up of a set of different decision trees that are all being learned at the same time. The system determines the superiority and significance of each decision tree78. Furthermore, a constructed attribute of the Classification model that is used to choose different attributes allows the RF to govern various inputs characteristics without the requirement to remove a set of variables for dimension decrement 79. The RF approach uses a process called Bagging throughout the simulation to increase the variety of trees in the forest. Usually, the system provides the number of trees as an input, and the algorithm divides datasets into distinct groupings as a result. Bagging is a sort of sample selection approach that uses only a third of the datasets in the learning phase of the subtree creation procedure, with the other inputs being known as the out-of-bag data (OOB). Moreover, verification of outputs is not necessary for the RF during model building since the correctness of the model may be assessed utilizing OOB's errors80. The RF technique is shown in Fig. 3. If the system is provided with a training dataset as a prerequisite, the training procedure will be completed. If you have a training sample in the form of \(D=[\left({x}_{1}.{y}_{1}\right).\left({x}_{2}.{y}_{2}\right).\ldots \left({x}_{n}.{y}_{n}\right)]\), \({D}_{t}\) is the described training data for tree \({h}_{t}\), and the final estimation of the out-of-bag dataset of sample x is \({H}^{oob}\), as shown:

A schematic of the random forest model.
The error of the OOB data is extended as following for modeling purposes:
The functioning of the RF must be randomized, and this characteristic is regulated by the variable \(k={log}_{2}d\)80. The following equation may be used to determine the importance of a feature of a parameter Xi:
Correspondingly, the ith component is characterized by Xi in the X vector, B represents the number of trees in the existing RF, the original OOB datasets are offered as the \(OOBer{r}_{t}\), which involves the replaced parameters, and the estimated error of the OOB samples is described by \(\widetilde{OOB}er{r}_{{t}^{i}}\), which refers to the attribute Xi of tree t.
Extra tree (ET)
The Extra trees 81 are a novel machine learning approach that was created as an improvement of the random forest model and is less prone to over-fit a database81. Extra tree (ET) randomly selects a set of attributes to train a basic predictor82, using the same idea as random forest. For dividing the node, it chooses the best characteristic and the matching value at random82. For every regression tree, ET utilizes all training data. In contrast, RF's model is trained using a bootstrap replica.
Genetic programming (GP)
GP is an organized method for getting machines to automatically solve a problem beginning with a high-level statement of what ought to be accomplished. GP is a systematic approach that is independent of a problem domain, that genetically reproduces a population of programs to solve a problem83,84. Programs are ‘bred’ through the continuous progress of an initially random population of programs. Actually, in this iterative improvement approach, at each new step of the algorithm, it selects only the fittest of the descendant to pass and regenerate in the subsequent production, which is occasionally referred to as a fitness function85. More explanations related to the application of this algorithm in the implementation of symbolic regression can be found elsewhere in the literature86,87,88.
Group method of data handling (GMDH)
GMDH89 features fully automatic structural and parametric optimization of models and is a kind of inductive algorithm for computer-based mathematical modeling of multi-parametric datasets. In the inner levels of the GMDH method90, there are multiple independent neurons. All neurons per layer are attached in couples via a quadratic polynomial and form individual neurons in the structure of polynomials in the subsequent layer91. Each GMDH neuron's generated value is determined by employing a quadratic polynomial representative that comprises the preceding neuron92,93. The quadratic polynomial procedures merging the neurons in the earlier levels will create the neurons in the subsequent layers94. To amend the limitations of the primary GMDH method89, the hybrid GMDH is usually utilized which has more than two independent variables that can be combined concurrently and it permits the intersection of nodal within diverse layers. The succeeding formula shows the final form of the hybrid GMDH95:
Here, M is the count of inputs, l stands for the count of layers, xi, xj, …, xk are the inputs, a, bij…k denote the polynomial coefficients, and Y indicates the model output.
Equations of state (EOSs)
An EOS is utilized to relate pressure, volume, and temperature (PVT) for both systems of a pure substance and for multi-component mixtures. There are many EOSs in the thermodynamic literature that is used to describe vapor–liquid-equilibria, solubility estimation, thermal features, and volumetric properties of a substance or multi-component mixtures71. In this work, three famous EOSs, namely SRK, VPT, and PR, have been utilized to estimate the solubility of light hydrocarbon gases in water with the purpose of comparing them with machine learning algorithms. Tables S1 in the Supplementary file presents the PVT relationships of these EOSs. Also, the parameters of considered EOSs are presented in Table S2. Besides, acentric factors and critical properties of the light hydrocarbon gases and water are represented in Table S3 used in EOSs.
Assessment of models
The following statistical factors viz., determination coefficient (R2), average absolute percent relative error (AAPRE), root mean square error (RMSE), and standard deviation (SD) were employed to assess the accuracy of the machine learning models. The mathematical formula of these statistical criteria is defined below96,97:
where N refers to the count of data, ηi,exp shows the experimental hydrocarbon gases solubility, and ηi,pred is predicted hydrocarbon gases solubility in the liquid phase by presented models.
In the present research, the subsequent graphical analyses are utilized simultaneously to assess the performance of machine learning-based models and correlations:
Histogram plot: in this graph, the discrepancy between the experiments data and prediction of the model can be seen statistically, which helps to evaluate the model's performance.
Cross-plot: the cross-plot graph illustrates the correlation between experimental solubilities and predicted values by models with the fact that the higher the concentration of data nearby the unit-slope line, the better the model's prediction.
Error distribution plot: the scatter of error (exp-pred) around the zero-error line is evaluated to check for possible error trends.
Trend plot: the experiments data and prediction of the model are plotted versus a special property to assess the model's validation by checking the coverage of these data. High data coverage shows the high validity of the model.
Cumulative frequency graph: it is a statistical plot for quantifying the precision of the models, which is shown by drawing the cumulative frequency of data against absolute error (exp-pred).
Results and discussion
Correlations’ development
As mentioned earlier, this work employed white-box modeling approaches to create precise predictive correlations for the solubility of light hydrocarbon gases and their mixture in brine. The correlations utilize the second modeling approach having five inputs (P, T, I, Tpc of gas mixture, Tcgas) to calculate hydrocarbon gases solubility. The reason for choosing five parameters for the development of mathematical correlations was that, firstly, a simpler mathematical expression was obtained and solubility calculations become easier, and secondly, the correlation become more general by using the pseudo-critical of the gas mixture instead of using the percentage of gas (C1–C4) composition. The proposed correlations by GMDH and GP methods are presented below:
GMDH correlation:
GP correlation:
Evaluation of the models
In the current study, R2, AAPRE, SD, and RMSE were utilized to appraise the models' estimates. The results of these statistical criteria for all predictive tools are presented in Table 3. As can be observed in this table, for both modeling approaches, AdaBoost-SVR, Extra Tree, Random Forest, and DT models can be classified in terms of high exactness for predicting the whole dataset, respectively. However, for the test subset, AdaBoost-SVR, Random Forest, DT, and Extra Tree models, respectively, had the best estimates, which is the most important part of the assessment of models. AAPRE values of 10.64% for the total collection, 11.49% for the test collection, and 10.43% for the train collection, as well as a total R2 value of 0.9999, indicating that the AdaBoost-SVR model developed with 8 inputs had the most precise predictions of hydrocarbon gases solubilities in aqueous electrolyte solutions. After that, in terms of accuracy, the AdaBoost-SVR model developed with 5 inputs with an AAPRE of 12.02% for the total collection and a total R2 value of 0.9999 ranks second among all models. AdaBoost-SVR models have the least overall values of RMSE, SD, and AAPRE along with the highest overall R2 value among the other machine learning models leading us to conclude that this model is the most accurate model for predicting light hydrocarbon gases and their mixtures in water and aqueous electrolyte solutions. Moreover, despite the expected poorer performance than machine learning models, the mathematical correlations yielded by GP and GMDH methods show satisfying results with AAPRE values of 16.44% and 20.95%, respectively.
In the next step, the performance of the machine learning algorithms was compared with SRK, PR, and VPT EOSs. To this end, the solubilities data of light hydrocarbon gases in pure water at different operating conditions, acquired from the literature2,9,22,61, was predicted by the developed machine-learning models, mathematical correlations, and three EOSs. Table 4 reports the predictions of these predictive tools and EOSs as well as calculated AAPRE. Aa represented in Table 4, AdaBoost-SVR models are superior to all machine learning-based predictive tools and EOSs showing AAPRE values of 5.13% (AdaBoost-SVR model with 5 inputs) and 5.45% (AdaBoost-SVR model with 8 inputs), which is the least among these predictive tools. Among the EOSs, VPT, SRK, and PR are ranked in terms of good predictions, respectively. Moreover, the mathematical correlations generated by the GMDH and GP techniques demonstrate satisfactory results with an AAPRE of approximately 10%.
To gain a better vision of the validity of the machine learning models in the training and testing stages, graphical error analyses were conducted along with statistical analyses. First, cross plots of all models are compared in Fig. 4. As pointed out earlier, the nearer the data to the X = Y line, the greater precision of the model in prognosticating hydrocarbon gases and their mixtures in water and aqueous electrolyte systems. As can be observed in Fig. 4, the AdaBoost-SVR models (developed with 8 and 5 inputs) have the high closest data around the X = Y line compared to the other suggested models and correlations, which exhibits the great robustness and validness of these models for the prediction of hydrocarbon gases solubility in aqueous electrolyte systems. However, other models have also performed well. Next, the error distribution graphs of all developed predictive tools based on temperature and pressure are illustrated in Fig. S1 in the supplementary file. These plots help to distinguish the performance of the models at different pressures and temperatures. Fig. S1(a) shows the low scatter of errors around the zero-error line for all models at different pressures, especially AdaBoost-SVR and DT models. Fig. S1(b) demonstrates that the AdaBoost-SVR models have the least scattering of errors around the zero-error line compared to other models and correlations at different temperatures. In relation to Random Forest, Extra Tree, and GMDH models, it seems that although the predictions of these models show a low error at low temperatures, at high temperatures, the scattering of error is high. Overall, the AdaBoost-SVR models are superior to other machine learning models in different temperature and pressure ranges.


Cross-plots of the developed machine learning models and mathematical correlations.
In the next step, the histograms of errors between experimental solubilities and prognosticated values associated with all models are illustrated in Fig. 5. The computed error values for all models are located in a narrow scope from −0.001 to 0.001. This figure shows that the histograms of all machine learning models benefit from normal distributions. However, despite the excellent performance in the training phase, the histogram of the Extra Tree model seems to be a bit skewed in the testing phase. As can be observed in Fig. 5, all histogram plots benefit from the bursts of growing at zero-error value, which indicates the excellent match between the estimated solubility data and experimental values. However, again AdaBoost-SVR and DT models display less error for more data during both testing and training stages in both modeling approaches.


Histograms of residuals for the machine learning models and correlations.
The next step of graphical error analysis is a helpful statistical plot for quantifying the precision of the models and correlations, named cumulative frequency plot. As shown in Fig. 6, the cumulative frequency curves of the AdaBoost-SVR models are very close to the vertical axis, which indicates the high accuracy of these models. Besides, more than 70% of predicted gas solubility data by the AdaBoost-SVR models have an absolute error of less than 0.00004, and more than 90% of the predicted data have an error of less than 0.00013. Meanwhile, other models and correlations including Extra Tree, DT, Random Forest, GP, and GMDH represent absolute errors of 0.00015–0.0003 for 90% of the data, respectively. Therefore, this conclusion can be drawn that the AdaBoost-SVR models are superior to other models and correlations in estimating the solubility of hydrocarbon gases and their mixtures in water and aqueous electrolytes.

Cumulative frequency plot of the proposed predictive tools for estimating the solubility of hydrocarbon gases.
According to the results of statistical and graphical analyses of machine learning models, it can be concluded that the AdaBoost-SVR models (developed with 8 and 5 inputs) are more precise in estimating the solubility of hydrocarbons in water and brine solutions than other models suggested in this work. To assess the accuracy of the proposed AdaBoost-SVR models against the available predictive models in the literature for estimating the solubility of hydrocarbon gases, the AdaBoost-SVR results were compared with two machine learning models, including Samani et al.52 and Nabipour et al.53, which are shown in Table 5. As depicted in Table 5, the AdaBoost-SVR models proposed in this study have the lowest AAPRE values plus the highest R2 value, indicating that the AdaBoost-SVR models are more precise than other artificial intelligence models presented in the literature for estimating the solubility of hydrocarbon gases.
Trend analysis
As mentioned earlier, the AdaBoost-SVR models are more accurate in predicting the solubility of light hydrocarbon gases in aqueous solutions than other models. Hence, the solubilities of hydrocarbon gases in several solubility systems have been investigated to evaluate the ability of the AdaBoost-SVR models in estimating the true physical trend of gases solubility in the liquid phase. In the beginning, the solubilities of methane, ethane, and n-butane in a gas mixture + pure water system at a temperature of 283 K9 were estimated utilizing the AdaBoost-SVR models and three EOSs, and the outcomes are depicted in Fig. 7. As demonstrated in Fig. 7, EOSs overestimated or underestimated the solubilities of hydrocarbon gases in water at low-temperature conditions. However, VPT EOS again is superior to SRK and PR EOSs and provides better estimations. Nevertheless, both AdaBoost-SVR models (developed with 8 and 5 inputs) offer an exceptional ability to track solubility data of hydrocarbon gases with increasing pressure at low-temperature conditions compared to EOSs. Although the accuracy of EOSs has been lower than machine learning models, this does not mean questioning the capabilities of these thermodynamic equations. EOSs predict solubility data based on the thermodynamic variables within an analytical framework and they are valuable tools in the modeling of a wide range of industrial processes. Here, only a comparison between predictions of developed models and EOSs was made to clarify the high predictability of these models. Hence, machine learning models can be considered as an alternative to achieve accurate and fast predictions of the solubility of gases in brine in order to cover the disadvantages of EOSs mentioned earlier.

Experimental values and estimations of the solubilities of (a) methane, (b) ethane, and (c) n-butane in the aqueous phase of the gas mixture + water system by EOSs and AdaBoost-SVR models.
Next, the solubilities of methane and propane mixtures in pure water, which has been experimentally investigated by Amirijafari23 at a temperature of 377.59 K under high-pressure conditions, was predicted by the AdaBoost-SVR models, as demonstrated in Fig. 8. As depicted in the figure, both AdaBoost-SVR models correctly predicted the solubilities of methane and propane in pure water by increasing the pressure as an important parameter affecting solubility.

Experimental solubility data of methane and propane mixture in water at different operating pressures along with AdaBoost-SVR models predictions.
In the next step, the solubility of methane in water versus pressure at different temperatures was predicted by the AdaBoost-SVR models, which has been examined in the literature9. The solubilities of methane, as the basic constituent of natural gas, in pure water and aqueous electrolyte systems at different pressure and temperature is crucial for the petroleum industry. As shown in Fig. 9, the solubility of methane in water at various pressure and temperature conditions is accurately predicted by the AdaBoost-SVR models. As can be seen, the temperature has a decreasing impact on the methane’ solubility in water at the studied pressures, which is correctly estimated by the AdaBoost-SVR models.

Experimental methane solubility data and AdaBoost-SVR models predictions for the methane + pure water system at different temperatures.
Eventually, the solubilities of methane in pure water and in aqueous NaCl solutions with different salt concentrations at a temperature of 324.65 K, which has been studied experimentally in the literature67, was predicted by the AdaBoost-SVR models. As can be observed in Fig. 10, the solubility of methane has an appreciable decrease with an increase in salt concentration or ionic strength of the solution. Again, both AdaBoost-SVR models provide accurate predictions for the systems of methane + water and methane + aqueous salt solution with different concentrations at different pressures with very little deviation from the experimental data.

Experimental methane solubilities in water and aqueous NaCl solutions at a temperature of 324.65 K along with AdaBoost-SVR models predictions.
Sensitivity analysis
In parametric studies, identifying the impacts of all inputs on the output can be valuable. As stated earlier, two modeling approaches with 8 and 5 inputs were adopted in this work. The first approach was that there were 8 inputs including the temperature, pressure, ionic strength of the solution, the mole percent of each component (C1, C2, C3, and C4) in the gas mixture, and carbon number (IDX) of the gas component whose solubility is to be predicted. On the other hand, the second approach considered 5 inputs containing the temperature, pressure, ionic strength of the solution, the pseudo-critical temperature of the gas mixture, and the critical temperature of the gas component whose solubility is to be predicted. To check the relative effects of these input variables on the solubilities of hydrocarbon gases in water and aqueous electrolyte systems, the relevancy factor (r)98 was employed in this research. It should be mentioned that the outcomes of all developed models and correlations developed in this work along with experimental data have been utilized for sensitivity analysis to make a comparison between the results of all models in both modeling approaches. Positive or negative values of r for an input parameter indicate a direct or inverse relationship between that parameter and the output, respectively. The higher value of r between an input variable and output, the greater the impact of that input on the solubilities of hydrocarbon gases in water and aqueous electrolyte systems. The subsequent equation is utilized for calculating the r-values for the input parameters99:
where i could be any of the input parameters considered for modeling; inpm,i and inpi,j respectively indicate the mean and jth value of the ith input parameter. ηm stands for the mean of predicted solubility of hydrocarbon gases in water and aqueous electrolyte systems and ηj is the jth value of predicted solubilities of hydrocarbon gases. Figure 11 illustrates the relative impacts of considered input variables on the solubilities of hydrocarbon gases in water and brine solutions. As seen in Fig. 11a, in the first modeling approach, the temperature, pressure, and methane (mole %) in the gas mixture had the greatest effects on hydrocarbon gases solubility. Also, the mole percent of the n-butane in the gas mixture was the least effective parameter for estimating the solubilities of hydrocarbon gases. Based on results, the temperature, pressure, and mole percent of methane and n-butane in the gas mixture have direct effects, and mole percent of ethane and propane in the gas mixture, IDX, and ionic strength of the solutions have reverse effects on the solubility of investigated hydrocarbon gas. An increase in the ionic strength of the solution decreases the solubilities of hydrocarbon gases in aqueous electrolyte systems. In the second modeling approach, as shown in Fig. 11b, the results of sensitivity analysis for temperature, pressure, and ionic strength variables have been obtained quite similarly to the previous case. Moreover, the pseudo-critical temperature of the gas mixture and the critical temperature of the gas components have negative effects on the solubility of light hydrocarbon gases and their mixture in brine, which exhibits that the solubility decreases with the rise of these parameters. As inferred from the results of the sensitivity analysis of both modeling approaches, the feature-solubility correlations are completely independent of machine learning frameworks and the impact of each specific input variable applied for modeling in each model or correlation developed in this work are the same and similar to the laboratory results.

The impact of input variables on hydrocarbon gases solubility in water and aqueous electrolyte systems in the (a) first and (b) second modeling approaches.
Implementation of Leverage method
Finally, the degree of precision of utilized data along with the application scope of the AdaBoost-SVR models was examined using the Leverage approach100,101,102, which can assess the validity of these model and solubility databank. The subsequent equation was utilized to calculate the variations of the prognosticated solubility values by the model from the real data, which is named standardized residuals (R)103:
in which, the mean square error of the predictive tool is shown by MSE; Hzz shows Leverage of the zth data; and ez denotes the variation of the estimations from the experiments of the zth data. Afterward, the following formula is utilized to calculate the values of Hat matrix Leverage104:
where KT shows the transpose of the matrix K, which is (g × c) matrix; g and c indicate the number of databank points and the number of input variables, respectively. Besides, the critical Leverage limit (H*) is achieved using 3(c + 1)/g.
The reliable zone is considered to be the cut-off area of R-values (−3 and 3) and Hzz ≤ H*, as shown in William's plot in Fig. 12. This figure exhibits that the bulk of data, called valid data, rested in the reliable zone that proves the high reliability of the hydrocarbon solubility databank and high validation of the AdaBoost-SVR models. For the AdaBoost-SVR model developed with 8 inputs, as depicted in Fig. 12a, quantitative identification of the outliers of the used databank shows that only 54 data points (2.94% of the whole data) have an R-value outside the range of −3 to 3, which is considered suspected data. In addition, only 35 data points (1.91% of the whole data) have Hzz > 0.0147, which is regarded as out of Leverage data, while other data have acceptable Leverage (Hzz ≤ 0.0147). For the AdaBoost-SVR model developed with five inputs, due to the reduction of the number of input variables, the critical Leverage limit value is reduced to H* = 0.0098, and the application scope of the model becomes more limited. However, there is no specific change in the number of suspected data points (54 data points means 2.94% of the whole data), and only the out of Leverage data has increased to 70 (3.81% of the whole data). As shown in Fig. 12b, these points are also predicted by the model with a very low error, and they are just statistically beyond the critical Leverage limit. Hence, it cannot be considered a negative point for the model. The results of the Leverage mathematical method reveal the validity of the hydrocarbon solubility databank and the high credit of both AdaBoost-SVR models in estimating the solubility of hydrocarbon gases in water and brine solution systems.

Detection of applicability area, suspected data, and outliers of AdaBoost-SVR models developed with (a) 8 inputs and (b) 5 inputs.
Conclusions
In the present study, the solubilities of the principal hydrocarbon components of natural gas in water and aqueous electrolyte solutions were modeled utilizing six machine learning algorithms. A large databank (1836 experimental data points) of hydrocarbon gases solubility was gathered from numerous sources of literature to cover a wide range of temperature and pressure conditions. Two different approaches including eight and five inputs were adopted for modeling. Also, three famous EOSs, including PR, VPT, and SRK were used in comparison with machine learning models. Based on graphical and statistical analyses, the best-developed models in this work, namely AdaBoost-SVR developed with eight and five inputs, are able to predict the solubility of hydrocarbon gases and their mixture with an overall AAPRE of 10.65% and 12.02%, respectively, and R2 of 0.9999. The AdaBoost-SVR models outperform other models developed in this work, EOSs, and intelligence models proposed in the literature. Also, the Random Forest, DT, and Extra Tree models are positioned subsequent to the AdaBoost-SVR model in terms of high precision in predicting test collection in both modeling approaches. Despite higher errors than machine learning models, two mathematical correlations generated by the GMDH and GP techniques had satisfactory outcomes. Among the EOSs, VPT, SRK, and PR are ranked in terms of good predictions, respectively. Based on sensitivity analysis, the temperature and pressure had the greatest effect on hydrocarbon gases solubility in both modeling approaches. Regarding the gas mixture composition (C1–C4), the percentage of methane and n-butane in the gas mixture was the most and least effective parameter for predicting the solubility of hydrocarbon gases in brine, respectively. Additionally, an increase in the ionic strength of the solution and the pseudo-critical temperature of the gas mixture decreases the solubilities of hydrocarbon gases in aqueous electrolyte systems. Moreover, the influence of input variables on light hydrocarbon gases solubility is completely independent of machine learning frameworks. Eventually, the investigation of the Leverage technique proved the high validity of the hydrocarbon solubility databank and the high credit of the AdaBoost-SVR models in predicting hydrocarbon gases solubility in water and aqueous electrolyte systems.
Data availability
All the data have been collected from literature. We cited all the references of the data in the manuscript. However, the data will be available from the corresponding author on reasonable request.
Abbreviations
- AAPRE:
-
Average absolute percent relative error
- AdaBoost:
-
Adaptive boosting
- AdaBoost-SVR:
-
Adaptive boosting support vector regression
- DT:
-
Decision tree
- EOS:
-
Equation of state
- ET:
-
Extra tree
- exp:
-
Experimental
- PR:
-
Peng–Robinson
- pred:
-
Predicted
- RMSE:
-
Root mean square error
- r:
-
Relevancy factor
- SD:
-
Standard deviation
- SVR:
-
Support vector regression
- SRK:
-
Soave–Redlich–Kwong
- RF:
-
Random forest
- R2 :
-
Coefficient of determination
- VPT:
-
Valderrama modification of the Patel–Teja
References
Mohammadi, A. H., Chapoy, A., Tohidi, B. & Richon, D. Gas solubility: A key to estimating the water content of natural gases. Ind. Eng. Chem. Res. 45, 4825–4829 (2006).
Chapoy, A. et al. Solubility measurement and modeling for the system propane–water from 277.62 to 368.16 K. Fluid Phase Equilib. 226, 213–220 (2004).
Chapoy, A., Haghighi, H. & Tohidi, B. Development of a Henry’s constant correlation and solubility measurements of n-pentane, i-pentane, cyclopentane, n-hexane, and toluene in water. J. Chem. Thermodyn. 40, 1030–1037 (2008).
Kiepe, J., Horstmann, S., Fischer, K. & Gmehling, J. Experimental determination and prediction of gas solubility data for methane+ water solutions containing different monovalent electrolytes. Ind. Eng. Chem. Res. 42, 5392–5398 (2003).
Dhima, A., de Hemptinne, J.-C. & Moracchini, G. Solubility of light hydrocarbons and their mixtures in pure water under high pressure. Fluid Phase Equilib. 145, 129–150 (1998).
Marinakis, D. & Varotsis, N. Solubility measurements of (methane+ ethane+ propane) mixtures in the aqueous phase with gas hydrates under vapour unsaturated conditions. J. Chem. Thermodyn. 65, 100–105 (2013).
Kondori, J., Zendehboudi, S. & Hossain, M. E. A review on simulation of methane production from gas hydrate reservoirs: Molecular dynamics prospective. J. Petrol. Sci. Eng. 159, 754–772 (2017).
Kondori, J., Zendehboudi, S. & James, L. Evaluation of gas hydrate formation temperature for gas/water/salt/alcohol systems: Utilization of extended UNIQUAC model and PC-SAFT equation of state. Ind. Eng. Chem. Res. 57, 13833–13855 (2018).
Chapoy, A., Mohammadi, A. H., Richon, D. & Tohidi, B. Gas solubility measurement and modeling for methane–water and methane–ethane–n-butane–water systems at low temperature conditions. Fluid Phase Equilib. 220, 113–121 (2004).
Abha, S. & Singh, C. S. Hydrocarbon pollution: Effects on living organisms, remediation of contaminated environments, and effects of heavy metals co-contamination on bioremediation. in Introduction to Enhanced Oil Recovery (EOR) Processes and Bioremediation of Oil-Contaminated Sites. 185–206 (2012).
Latimer, J. S., Hoffman, E. J., Hoffman, G., Fasching, J. L. & Quinn, J. G. Sources of petroleum hydrocarbons in urban runoff. Water Air Soil Pollut. 52, 1–21 (1990).
Husaini, A., Roslan, H., Hii, K. & Ang, C. Biodegradation of aliphatic hydrocarbon by indigenous fungi isolated from used motor oil contaminated sites. World J. Microbiol. Biotechnol. 24, 2789–2797 (2008).
Li, Z. & Firoozabadi, A. Cubic-plus-association equation of state for water-containing mixtures: Is “cross association” necessary?. AIChE J. 55, 1803–1813 (2009).
Alvarez, E., Riverol, C., Correa, J. & Navaza, J. Design of a combined mixing rule for the prediction of vapor−liquid equilibria using neural networks. Ind. Eng. Chem. Res. 38, 1706–1711 (1999).
Urata, S., Takada, A., Murata, J., Hiaki, T. & Sekiya, A. Prediction of vapor–liquid equilibrium for binary systems containing HFEs by using artificial neural network. Fluid Phase Equilib. 199, 63–78 (2002).
Mohanty, S. Estimation of vapour liquid equilibria of binary systems, carbon dioxide–ethyl caproate, ethyl caprylate and ethyl caprate using artificial neural networks. Fluid Phase Equilib. 235, 92–98 (2005).
Torrecilla, J. S., Palomar, J., García, J., Rojo, E. & Rodríguez, F. Modelling of carbon dioxide solubility in ionic liquids at sub and supercritical conditions by neural networks and mathematical regressions. Chemom. Intell. Lab. Syst. 93, 149–159 (2008).
Safamirzaei, M. & Modarress, H. Hydrogen solubility in heavy n-alkanes; Modeling and prediction by artificial neural network. Fluid Phase Equilib. 310, 150–155 (2011).
Moosanezhad-Kermani, H., Rezaei, F., Hemmati-Sarapardeh, A., Band, S. S. & Mosavi, A. Modeling of carbon dioxide solubility in ionic liquids based on group method of data handling. Eng. Appl. Comput. Fluid Mech. 15, 23–42 (2021).
Crovetto, R., Fernández-Prini, R. & Japas, M. L. Solubilities of inert gases and methane in H2O and in D2O in the temperature range of 300 to 600 K. J. Chem. Phys. 76, 1077–1086 (1982).
Culberson, O. & McKetta, J. Phase equilibria in hydrocarbon-water systems II—The solubility of ethane in water at pressures to 10,000 psi. J. Petrol. Technol. 2, 319–322 (1950).
Le Breton, J. & McKetta, J. Jr. Low-pressure solubility of n-butane in water. Hydrocarb. Proc. Petr. Ref. 43, 136–138 (1964).
Amirijafari, B. Solubility of Light Hydrocarbons in Water Under High Pressures (The University of Oklahoma, 1969).
Wang, L.-K., Chen, G.-J., Han, G.-H., Guo, X.-Q. & Guo, T.-M. Experimental study on the solubility of natural gas components in water with or without hydrate inhibitor. Fluid Phase Equilib. 207, 143–154 (2003).
Vul’fson, A. & Borodin, O. A thermodynamic analysis of the solubility of gases in water at high pressures and supercritical temperatures. Russ. J. Phys. Chem. A 81, 510–514 (2007).
Tong, D., Trusler, J. M. & Vega-Maza, D. Solubility of CO2 in aqueous solutions of CaCl2 or MgCl2 and in a synthetic formation brine at temperatures up to 423 K and pressures up to 40 MPa. J. Chem. Eng. Data 58, 2116–2124 (2013).
Teng, H. & Yamasaki, A. Solubility of liquid CO2 in synthetic sea water at temperatures from 278 K to 293 K and pressures from 6.44 MPa to 29.49 MPa, and densities of the corresponding aqueous solutions. J. Chem. Eng. Data 43, 2–5 (1998).
Chapoy, A., Mohammadi, A. H., Tohidi, B. & Richon, D. Gas solubility measurement and modeling for the nitrogen+ water system from 274.18 K to 363.02 K. J. Chem. Eng. Data 49, 1110–1115 (2004).
Smith, N. O., Kelemen, S. & Nagy, B. Solubility of natural gases in aqueous salt solutions—II: Nitrogen in aqueous NaCl, CaCl2, Na2SO4 and MgSO4 at room temperatures and at pressures below 1000 psia. Geochim. Cosmochim. Acta 26, 921–926 (1962).
Bando, S., Takemura, F., Nishio, M., Hihara, E. & Akai, M. Solubility of CO2 in aqueous solutions of NaCl at (30 to 60) C and (10 to 20) MPa. J. Chem. Eng. Data 48, 576–579 (2003).
Dhima, A., de Hemptinne, J.-C. & Jose, J. Solubility of hydrocarbons and CO2 mixtures in water under high pressure. Ind. Eng. Chem. Res. 38, 3144–3161 (1999).
Zheng, K. et al. A comparative study of the perturbed-chain statistical associating fluid theory equation of state and activity coefficient models in phase equilibria calculations for mixtures containing associating and polar components. Ind. Eng. Chem. Res. 57, 3014–3030 (2018).
Ahmed, S. et al. A new PC-SAFT model for pure water, water–hydrocarbons, and water–oxygenates systems and subsequent modeling of VLE, VLLE, and LLE. J. Chem. Eng. Data 61, 4178–4190 (2016).
Lee, M.-T. & Lin, S.-T. Prediction of mixture vapor–liquid equilibrium from the combined use of Peng–Robinson equation of state and COSMO-SAC activity coefficient model through the Wong-Sandler mixing rule. Fluid Phase Equilib. 254, 28–34 (2007).
Yan, Y. & Chen, C.-C. Thermodynamic modeling of CO2 solubility in aqueous solutions of NaCl and Na2SO4. J. Supercrit. Fluids 55, 623–634 (2010).
Tabasinejad, F. et al. Water solubility in supercritical methane, nitrogen, and carbon dioxide: measurement and modeling from 422 to 483 K and pressures from 3.6 to 134 MPa. Ind. Eng. Chem. Res. 50, 4029–4041 (2011).
Shabani, B. & Vilcáez, J. Prediction of CO2–CH4–H2S–N2 gas mixtures solubility in brine using a non-iterative fugacity-activity model relevant to CO2-MEOR. J. Petrol. Sci. Eng. 150, 162–179 (2017).
Liu, G. et al. Investigation of gas solubility and its effects on natural gas reserve and production in tight formations. Fuel 295, 120507 (2021).
Avaji, S., Amani, M. J. & Ghaedi, M. Modeling the equilibrium of two and three-phase systems including water, alcohol, and hydrocarbons with CPA EOS and its improvement for electrolytic systems by Debye-Huckel equation. J. Nat. Gas Sci. Eng. 90, 103905 (2021).
Sun, L. & Liang, J. Solubility calculations of methane and ethane in aqueous electrolyte solutions. J. Solut. Chem. 50, 1–21 (2021).
He, H., Sun, B., Wang, Z., Liu, Y. & Sun, X. A constitutive model for predicting the solubility of gases in water at high temperature and pressure. J. Petrol. Sci. Eng. 192, 107337 (2020).
Battino, R. & Clever, H. L. The solubility of gases in liquids. Chem. Rev. 66, 395–463 (1966).
Oliveira, M., Coutinho, J. & Queimada, A. Mutual solubilities of hydrocarbons and water with the CPA EoS. Fluid Phase Equilib. 258, 58–66 (2007).
Bamberger, A., Sieder, G. & Maurer, G. High-pressure (vapor+ liquid) equilibrium in binary mixtures of (carbon dioxide+ water or acetic acid) at temperatures from 313 to 353 K. J. Supercrit. Fluids 17, 97–110 (2000).
Nabipour, N., Qasem, S. N., Salwana, E. & Baghban, A. Evolving LSSVM and ELM models to predict solubility of non-hydrocarbon gases in aqueous electrolyte systems. Measurement 164, 107999 (2020).
Sayahi, T., Tatar, A., Rostami, A., Anbaz, M. A. & Shahbazi, K. Determining solubility of CO2 in aqueous brine systems via hybrid smart strategies. Int. J. Comput. Appl. Technol. 65, 1–13 (2021).
Jeon, P. R. & Lee, C.-H. Artificial neural network modelling for solubility of carbon dioxide in various aqueous solutions from pure water to brine. J. CO2 Util. 47, 101500 (2021).
Hemmati-Sarapardeh, A., Amar, M. N., Soltanian, M. R., Dai, Z. & Zhang, X. Modeling CO2 solubility in water at high pressure and temperature conditions. Energy Fuels 34, 4761–4776 (2020).
Menad, N. A., Hemmati-Sarapardeh, A., Varamesh, A. & Shamshirband, S. Predicting solubility of CO2 in brine by advanced machine learning systems: Application to carbon capture and sequestration. J. CO2 Util. 33, 83–95 (2019).
Ali Ahmadi, M. & Ahmadi, A. Applying a sophisticated approach to predict CO2 solubility in brines: Application to CO2 sequestration. Int. J. Low-Carbon Technol. 11, 325–332 (2016).
Safamirzaei, M. & Modarress, H. Modeling and predicting solubility of n-alkanes in water. Fluid Phase Equilib. 309, 53–61 (2011).
Samani, N. N. et al. Solubility of hydrocarbon and non-hydrocarbon gases in aqueous electrolyte solutions: A reliable computational strategy. Fuel 241, 1026–1035 (2019).
Nabipour, N., Mosavi, A., Baghban, A., Shamshirband, S. & Felde, I. Extreme learning machine-based model for solubility estimation of hydrocarbon gases in electrolyte solutions. Processes 8, 92 (2020).
Ott, J. B. & Boerio-Goates, J. Chemical Thermodynamics: Advanced Applications: Advanced Applications (Elsevier, 2000).
McKetta, J. J. & Katz, D. L. Methane–n-butane–water system in two-and three-phase regions. Ind. Eng. Chem. 40, 853–863 (1948).
Eslamimanesh, A., Mohammadi, A. H. & Richon, D. Thermodynamic consistency test for experimental solubility data in carbon dioxide/methane+ water system inside and outside gas hydrate formation region. J. Chem. Eng. Data 56, 1573–1586 (2011).
Sultanov, R., Skripka, V. & Namiot, A. Y. Solubility of methane in water at high temperatures and pressures. Gazova Promyshlennost 17, 6–7 (1972).
Namiot, A. Y. Solubility of nonpolar gases in water. J. Struct. Chem. 2, 381–389 (1961).
Winkler, L. Solubility of gas in water. Ber. Deut. Chem. Ges 34, 1408–1422 (1901).
Rettich, T. R., Handa, Y. P., Battino, R. & Wilhelm, E. Solubility of gases in liquids. 13. High-precision determination of Henry’s constants for methane and ethane in liquid water at 275 to 328 K. J. Phys. Chem. 85, 3230–3237 (1981).
Mohammadi, A. H., Chapoy, A., Tohidi, B. & Richon, D. Measurements and thermodynamic modeling of vapor−liquid equilibria in ethane−water systems from 274.26 to 343.08 K. Ind. Eng. Chem. Res. 43, 5418–5424 (2004).
Danneil, A., Tödheide, K. & Franck, E. Verdampfungsgleichgewichte und kritische Kurven in den Systemen Äthan/Wasser und n-Butan/Wasser bei hohen Drücken. Chem. Ing. Tec. 39, 816–822 (1967).
Morrison, T. & Billett, F. The salting-out of non-electrolytes. Part II. The effect of variation in non-electrolyte. J. Chem. Soc. (Resumed) 730, 3819–3822 (1952).
Azarnoosh, A. & McKetta, J. The solubility of propane in water. Petrol. Refiner 37, 275–278 (1958).
Kobayashi, R. & Katz, D. Vapor-liquid equilibria for binary hydrocarbon-water systems. Ind. Eng. Chem. 45, 440–446 (1953).
Kresheck, G. C., Schneider, H. & Scheraga, H. A. The effect of D2O on the thermal stability of proteins. Thermodynamic parameters for the transfer of model compounds from H2O to D2O1, 2. J. Phys. Chem. 69, 3132–3144 (1965).
O’Sullivan, T. D. & Smith, N. O. Solubility and partial molar volume of nitrogen and methane in water and in aqueous sodium chloride from 50 to 125 deg. and 100 to 600 atm. J. Phys. Chem. 74, 1460–1466 (1970).
Michels, A., Gerver, J. & Bijl, A. The influence of pressure on the solubility of gases. Physica 3, 797–808 (1936).
Danesh, A. PVT and Phase Behaviour of Petroleum Reservoir Fluids (Elsevier, 1998).
Freund, Y. & Schapire, R. E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 55, 119–139 (1997).
Mohammadi, M.-R. et al. Modeling hydrogen solubility in hydrocarbons using extreme gradient boosting and equations of state. Sci. Rep. 11, 1–20 (2021).
Smola, A. J. & Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 14, 199–222 (2004).
Schölkopf, B., Smola, A. J., Williamson, R. C. & Bartlett, P. L. New support vector algorithms. Neural Comput. 12, 1207–1245 (2000).
Vapnik, V., Golowich, S. E. & Smola, A. Support vector method for function approximation, regression estimation, and signal processing. in Advances in Neural Information Processing Systems. 281–287 (1997).
Amar, M. N., Shateri, M., Hemmati-Sarapardeh, A. & Alamatsaz, A. Modeling oil-brine interfacial tension at high pressure and high salinity conditions. J. Petrol. Sci. Eng. 183, 106413 (2019).
Song, Y.-Y. & Ying, L. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 27, 130 (2015).
Patel, N. & Upadhyay, S. Study of various decision tree pruning methods with their empirical comparison in WEKA. Int. J. Comput. Appl. 60, 12 (2012).
Wu, Y. & Misra, S. Intelligent image segmentation for organic-rich shales using random forest, wavelet transform, and hessian matrix. IEEE Geosci. Remote Sens. Lett. 17, 1144–1147 (2019).
Shaikhina, T. et al. Decision tree and random forest models for outcome prediction in antibody incompatible kidney transplantation. Biomed. Signal Process. Control 52, 456–462 (2019).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Geurts, P., Ernst, D. & Wehenkel, L. Extremely randomized trees. Mach. Learn. 63, 3–42 (2006).
John, V., Liu, Z., Guo, C., Mita, S. & Kidono, K. Image and Video Technology. 721–733 (Springer, 2021).
Koza, J. R. & Poli, R. Search Methodologies. 127–164 (Springer, 2005).
Whigham, P. A. Proceedings of the Workshop on Genetic Programming: From Theory to Real-World Applications. 33–41 (Citeseer, 2021).
Angeline, P. J. & Spector, L. Advances in Genetic Programming Vol. 1 (MIT Press, 1994).
Augusto, D. A. & Barbosa, H. J. Proceedings. Vol. 1. Sixth Brazilian Symposium on Neural Networks. 173–178 (IEEE, 2021).
Haeri, M. A., Ebadzadeh, M. M. & Folino, G. Statistical genetic programming for symbolic regression. Appl. Soft Comput. 60, 447–469 (2017).
Mohammadi, M.-R. et al. Toward predicting SO2 solubility in ionic liquids utilizing soft computing approaches and equations of state. J. Taiwan Inst. Chem. Eng. 133, 104220 (2022).
Ivakhnenko, A. G. Polynomial theory of complex systems. IEEE Trans. Syst. Man Cybern. 4, 364–378 (1971).
Rostami, A., Hemmati-Sarapardeh, A. & Mohammadi, A. H. Estimating n-tetradecane/bitumen mixture viscosity in solvent-assisted oil recovery process using GEP and GMDH modeling approaches. Pet. Sci. Technol. 37, 1640–1647 (2019).
Huang, W. et al. Application of modified GMDH network for CO2-oil minimum miscibility pressure prediction. Energy Sour. Part A Recov. Util. Environ. Effects 42, 2049–2062 (2020).
Menad, N. A. et al. Modeling temperature dependency of oil-water relative permeability in thermal enhanced oil recovery processes using group method of data handling and gene expression programming. Eng. Appl. Comput. Fluid Mech. 13, 724–743 (2019).
Rostami, A. et al. Modeling heat capacity of ionic liquids using group method of data handling: A hybrid and structure-based approach. Int. J. Heat Mass Transf. 129, 7–17 (2019).
Mahdaviara, M., Menad, N. A., Ghazanfari, M. H. & Hemmati-Sarapardeh, A. Modeling relative permeability of gas condensate reservoirs: Advanced computational frameworks. J. Petrol. Sci. Eng. 189, 106929 (2020).
Mohammadi, M.-R., Hemmati-Sarapardeh, A., Schaffie, M., Husein, M. M. & Ranjbar, M. Application of cascade forward neural network and group method of data handling to modeling crude oil pyrolysis during thermal enhanced oil recovery. J. Petrol. Sci. Eng. 205, 108836 (2021).
Nakhaei-Kohani, R., Taslimi-Renani, E., Hadavimoghaddam, F., Mohammadi, M.-R. & Hemmati-Sarapardeh, A. Modeling solubility of CO2–N2 gas mixtures in aqueous electrolyte systems using artificial intelligence techniques and equations of state. Sci. Rep. 12, 1–23 (2022).
Mohammadi, M.-R. et al. Application of robust machine learning methods to modeling hydrogen solubility in hydrocarbon fuels. Int. J. Hydrogen Energy 47, 320–338 (2022).
Chen, G. et al. The genetic algorithm based back propagation neural network for MMP prediction in CO2-EOR process. Fuel 126, 202–212 (2014).
Mohammadi, M.-R. et al. On the evaluation of crude oil oxidation during thermogravimetry by generalised regression neural network and gene expression programming: Application to thermal enhanced oil recovery. Combust. Theor. Model. 25, 1268–1295 (2021).
Leroy, A. M. & Rousseeuw, P. J. Robust regression and outlier detection. rrod (1987).
Goodall, C. R. 13 Computation Using the QR Decomposition. (1993).
Gramatica, P. Principles of QSAR models validation: Internal and external. QSAR Comb. Sci. 26, 694–701 (2007).
Mohammadi, M.-R. et al. Modeling hydrogen solubility in alcohols using machine learning models and equations of state. J. Mol. Liq. 346, 117807 (2021).
Mohammadi, M.-R. et al. Modeling of nitrogen solubility in unsaturated, cyclic, and aromatic hydrocarbons: Deep learning methods and SAFT equation of state. J. Taiwan Inst. Chem. Eng. 131, 104123 (2021).
Author information
Authors and Affiliations
Contributions
Mohammad-Reza Mohammadi: Investigation, Data curation, Visualization, Writing-Original Draft, Fahime Hadavimoghaddam: Conceptualization, Validation, Modeling, Saeid Atashrouz: Writing-Review & Editing, Validation, Ali Abedi: Writing-Review & Editing, Validation, Abdolhossein Hemmati-Sarapardeh: Methodology, Validation, Supervision, Writing-Review & Editing, Ahmad Mohaddespour: Writing-Review & Editing, Validation.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mohammadi, MR., Hadavimoghaddam, F., Atashrouz, S. et al. Modeling the solubility of light hydrocarbon gases and their mixture in brine with machine learning and equations of state. Sci Rep 12, 14943 (2022). https://doi.org/10.1038/s41598-022-18983-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-18983-2
- Springer Nature Limited
This article is cited by
-
Modeling liquid rate through wellhead chokes using machine learning techniques
Scientific Reports (2024)
-
Modeling of ionic liquids viscosity via advanced white-box machine learning
Scientific Reports (2024)
-
Machine learning prediction of methane, ethane, and propane solubility in pure water and electrolyte solutions: Implications for stray gas migration modeling
Acta Geochimica (2024)
-
Applying feature selection and machine learning techniques to estimate the biomass higher heating value
Scientific Reports (2023)