
Abstract
The tunneling collapse is the main engineering hazard in the construction of the drilling-and-blasting method. The accurate assessment of the tunneling collapse risk has become a key issue in tunnel construction. As for assessing the tunneling collapse risk and providing basic risk controlling strategies, this research proposes a novel multi-source information fusion approach that combines Bayesian network (BN), cloud model (CM), support vector machine (SVM), Dempster–Shafer (D–S) evidence theory, and Monte Carlo (MC) simulation technique. Those methods (CM, BN, SVM) are used to analyze multi-source information (i.e. statistical data, physical sensors, and expert judgment provided by humans) respectively and construct basic probability assignments (BPAs) of input factors under different risk states. Then, these BPAs will be merged at the decision level to achieve an overall risk evaluation, using an improved D–S evidence theory. The MC technology is proposed to simulate the uncertainty and randomness of data. The novel approach has been successfully applied in the case of the Jinzhupa tunnel of the Pu-Yan Highway (Fujian, China). The results indicate that the developed new multi-source information fusion method is feasible for (a) Fusing multi-source information effectively from different models with a high-risk assessment accuracy of 98.1%; (b) Performing strong robustness to bias, which can achieve acceptable risk assessment accuracy even under a 20% bias; and (c) Exhibiting a more outstanding risk assessment performance (97.9% accuracy) than the single-information model (78.8% accuracy) under a high bias (20%). Since the proposed reliable risk analysis method can efficiently integrate multi-source information with conflicts, uncertainties, and bias, it provides an in-depth analysis of the tunnel collapse and the most critical risk factors, and then appropriate remedial measures can be taken at an early stage.
Similar content being viewed by others

Introduction
The highways are extremely important infrastructures for most countries. It ensures communication and development between different regions, especially in the mountains and hilly areas. Most of the surrounding rocks of highway tunnels are mainly hard rock mass, and the geological conditions of the crossing sections are complex and changeable1. Hard rock tunnels are mostly constructed by drilling and blasting. Due to various risk factors in the complex project environment, safety violations often occur in highway tunnel construction. The collapse is one of the most frequent and harmful geological hazards during the construction of a tunnel. Because the collapse was sudden and instantaneous, it was difficult to predict and the construction workers did not have enough time to escape. Once the tunnel collapse occurs, it may cause serious economic losses, construction delays, and even human casualties. Therefore, it is necessary to research the risk mechanism of tunnel collapse by considering the accident scenario and safety analysis, aiming to provide decision support for assuring the safety of tunnel construction.
In recent years, a lot of research work has been carried out in tunnel collapse risk assessment. Zhou2 proposed a method for tunnel collapse risk analysis based on the fuzzy Analytic Hierarchy Process. He discussed the collapse mechanism of mountain tunnels and proposed a list of risk factors for tunnel collapse. The Bayesian network is used to conduct a quantitative analysis of safety risks in the Wuhan Yangtze River Metro Tunnel3. Wu et al.4 proposed an evaluation method based on a dynamic Bayesian network to provide a real-time dynamic risk assessment for tunnel construction. An optimization method for the preliminary support parameters was proposed based on the genetic algorithm (GA) and combined covariance Gaussian process regression (CCGPR) coupled algorithm presented to provide a complete information-based construction method for tunnel engineering5. There are also many studies using artificial intelligence for risk assessment to realize the automation and intelligence of assessment. Pan6 used artificial intelligence to monitor the entire life cycle of real complex projects. The artificial neural networks are used to assess the risk of shield drilling under severe ground conditions such as squeezing grounds7.
However, since the above evaluation methods only focus on a single information source, the reliability and accuracy of the security risk assessment cannot be guaranteed. Incomplete consideration of information can lead to inaccurate assessment results, which can not provide accurate recommendations to decision makers8. This would defeat the purpose of the risk assessment. In comparison, the fusion model can greatly improve the accuracy of prediction results due to it has a better understanding of risk factors9. For example, a fusion model is proposed to predict the risk of water inrush disasters10. The fusion of sensor data and simulation data improves the accuracy of the structural safety risk assessment9. Nowadays, there has been an increasing interest in the development of modern information technology and Internet technology, which makes the processing and analysis of data from multiple sources particularly important. The data fusion technology may prove to be more helpful to meet the security risk management needs of the tunnel construction than point-based methods11. Over the years, various information fusion studies have been proposed, such as Dempster–Shafer (D–S) evidence theory12,13, maximum entropy method14, rough sets15, etc. Among the above information fusion methods, D–S evidence theory is an effective and commonly used method in the field of information fusion. However, the traditional D–S theory of evidence has two disadvantage that may not be appropriate in practical situations. (1) When multiple sources of information are evaluated differently, D–S theory gives fusion results that are contrary to common sense. (2) The probability distribution is based on a user-defined function or distribution, which is too ideal for practical purposes. To solve the above problems, This research proposes a novel risk assessment approach that integrates Monte–Carlo (MC) simulation technique, normal cloud model (CM), Bayesian networks (BN), probabilistic support vector machine (SVM), and improved D–S evidence theory. The tunneling collapse risk probability distribution is obtained by analyzing different information sources with different models. Finally, the judgment of each model is fused to give the overall collapse risk result. This model aims to achieve the following goals: (1) Constructing models to estimate the collapse risk according to the expert judgment, monitoring data, and tunneling collapse database; (2) The judgment of the models is fused to get the final collapse risk assessment result; (3) Evaluating the performance of the models to quantify the quality of judgment.
Literature review
Dempster–Shafer (D–S) evidence theory
Information sources are usually divided into three categories, namely statistical data, physical sensors, and expert judgment provided by humans14. Among them, statistical data and physical sensors are called hard information. Humans act as soft sensors and execute decision-making processes through a web-based system16. Regarding evidence, each source of information constitutes all the evidence on which the decision is based17. In the complex decision-making process, how to compose multiple sources of evidence that may conflict with each other has become a challenging task. So far, over the years, various information fusion researches have been proposed, such as rough set15,18, Dempster–Shafer (D–S) evidence theory8,17, maximum entropy approach14, and others. Among the above-mentioned information fusion methods, D–S evidence theory is an effective and common method in the field of information fusion. Pan et al.9 proposed a risk analysis method based on SVM and D–S evidence theory to fuse different monitoring data, in order to evaluate the structural health status. Zhang et al.19 developed a novel safety risk assessment method based on D–S evidence theory and the cloud model to perceive the safety risk of buildings adjacent to the tunneling excavation.
However, the traditional D–S evidence theory cannot deal with highly conflicting evidence and will lead to unexpected and counter-intuitive results and make the evidence fusion approach insignificant19. In order to minimize the negative effect of high-conflict evidence, this paper adopted an improved D–S evidence theory by combining the weighted mean rule and the D–S evidence theory to solve the above problem.
Classification method
For classification problems, support vector machines (SVM) and artificial neural networks (ANN) are the two main supervised learning algorithms in the field of machine learning20. Although ANN has provided a powerful tool for the research on tunnel construction21,22. There are still limitations such as long calculation time, spatial disasters, local minima, overfitting, etc.6,23. Due to the small sample of training data for the tunneling collapse case in this paper, classification using neural networks will be prone to overfitting. The support vector machines (SVM), as a method parallel to artificial neural networks (ANN), is a machine learning method established based on the principle of structural risk minimization and the statistical learning theory for a small sample. The SVM has higher accuracy in a small number of training data predictions. Therefore, this article attempts to use SVM to process statistical data for collapse risk assessment.
Methodology
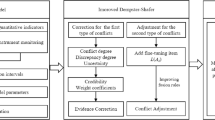
In order to improve the credibility and robustness of the tunnel collapse risk evaluation, a new hybrid multi-source information fusion method is proposed. Figure 1 is a flowchart of the tunnel collapse risk analysis method in this paper. In the developed method, all available data from the construction process is collected for risk analysis to improve the accuracy and robustness of the assessment results. In the process of data fusion, an improved D–S evidence theory is utilized to refine and synthesize different classification results generated from probabilistic models. According to the characteristics of different information sources, choose the corresponding probability model.

Flowchart of the proposed hybrid method for multi-source information fusion decision.
For statistical data, since the statistical data has been classified, SVM with the advantage of small sample classification is used for risk assessment. For physical sensors, quantitative monitoring data needs to be mapped to qualitative collapse risk values. The CM combines fuzzy mathematics and probability theory to map qualitative concepts and quantitative data and is therefore used to process monitoring data during the constructs of BPAs. For expert judgment provided by humans, Bayesian Networks (BN) is used to investigate causal relationships between tunnel collapse and its influential variables based upon the risk/hazard mechanism analysis and expert scores.
In collapse risk assessment, the MC simulation can conduct risk analysis by constructing a calculation model containing a series of inherent uncertain variables24. It can estimate all possible decision results and evaluate the impact of risks in an uncertain environment25. The MC simulation is adopted to simulate measurement and human error, proving the robustness of the hybrid approach. A typical hazard concerning the tunnel collapse in the construction of the Fujian Jinzhupa Tunnel in China is presented as a case study. The results demonstrate the feasibility of the proposed approach and its application potential.
BPA construction
Normal cloud model
The normal cloud model is a new cognition model of uncertainty, proposed by Li et al.26. It can synthetically describe the randomness and fuzziness of elements and implement the uncertain transformation between a qualitative concept and its quantitative value. The normal CM can be determined by numerical characteristics (Ex, En, He). The Expectation “Ex” is the expectation of the cloud droplets in the universe of discourse and the typical sample of a qualitative concept. The Entropy “En” is the entropy of “Ex”, representing the uncertainty measurement of a qualitative concept. Hyper-entropy “He” represents the uncertainty degree of Entropy “En”.
Let X be the universe of discourse and B be a qualitative concept connected with X. If there is a number x, (1)\(x \in X\), (2) x is a random instantiation of concept B, (3) x satisfies Eq. (1), the grade of a certain degree of x belonging to concept B satisfies Eq. (2)26:
The tunneling collapse risk assessment is a multi-source information decision-making problem under uncertain conditions. Various tunnel collapse risk factors Bi are analyzed in the decision-making process. In order to explore useful information from multiple sources, each risk factor should be further divided into different risk states Bij (i = 1, 2, …, M; j = 1,2, …, N). Each risk state can correspond to a specific double limit interval, denoted as [bij(L), bij(R)]. The conversion from the double limit interval [bij(L), bij(R)] to the normal cloud model \(\left( {Ex_{ij} ,En_{ij} ,He_{ij} } \right)\) can be achieved by Eq. (3)26.
where, “Exij” is the expectation; “Enij” is the entropy of “Exij”, “Heij” is the Hyper-entropy. The range of the constant “h” is from 0 to “Enij” which is adapted to reflects the uncertainty degree of those factors.
In the CM framework, the correlation can measure the relative membership between the observed value bij of the factor Bi and the cloud model of a specific risk state Bij. The measurement of BPAs under different risk states of influential factors can be obtained by Eq. (4)19.
where, mi(Bj) is the belief measure; \(En^{\prime}\) represents a random number that satisfies \(En^{\prime} \sim N\left( {En,He^{2} } \right)\), and mi(Φ) represents the BPAs value in uncertain situations, that is, the focus element cannot be determined under the indicator Bi, so all elements are included.
Probabilistic SVM
The traditional linear SVM performs linear division by a hyperplane. This hyperplane is found by maximizing the separation margin, which is the distance between the hyperplane and the closest data point. The kernel function is used to map the original data from a low-dimensional space to a feature space with a high-dimensional space, which can obtain better classification accuracy. Besides, the penalty parameter C of the error term also plays a key role in classification accuracy. A high value of C means a strict classifier that does not admit many misclassified points27. The discrimination function is:
where m is the size of the training data set, αi represents Lagrange multipliers, K(xi, x) is a kernel function, and b is a threshold parameter based on the training set.
The linear SVM only gives one class prediction output that will be either yes or no. To extract the associated probabilities from SVM outputs, several methods have been proposed. This research chooses Platt's approach, which uses the Sigmoid function to map the output of the SVM to the interval [0, 1], as given by Eq. (6)9.
where a and b are the parameters computed from the minimization of the negative log-likelihood function on a set of training examples:
where ti is the new label of the classes: + 1 becomes t+ and − 1 becomes t−, N+ and N− are the number of points that belong to class 1 and class 2 respectively.
Bayesian network
The Bayesian network (BN) is a combination of two different mathematical areas, the probability theory, and graph theory. It consists of several conditional probability tables (CPT) and a directed acyclic graph (DAG)28. A BN model with n nodes can be represented as \(B\left\langle {G,\Theta } \right\rangle\), where G stands for a DAG with n nodes and Θ is defined as the CPT of the BN model. A general BN intuitively represents a complex network with n nodes and direct edges. The nodes \(\left\{ {X_{1} , \cdots ,X_{n} } \right\}\) in the graph are labeled by related random variables. The directed edges between nodes represent the relationship between variables. Each node is attached to a CPT that contains the conditional probability of the parent node.
Assuming \(parents\left( {X_{i} } \right)\) is the parent nodes of \(X_{i}\) in DAG, the conditional probability distribution of \(X_{i}\) is defined as \(P\left( {\left. {X_{i} } \right|parents(X_{i} )} \right)\). The calculation of P(x) can be written as Eq. (8)
Improved D–S evidence theory
In this paper, the D–S theory is used to combine multi-source information to obtain the tunnel collapse risk. Dempster’s combinational rule for multiple evidence is calculated with Eq. (9)19.
where K is defined to be the normalization factor. l is the number of evidence pieces in the process of combination, and i, j, k denotes the ith, jth, and kth hypothesis, respectively.
When the value of K is close to 1, there will be a high conflict, which means that Dempster's evidence aggregation rule will be meaningless. To deal with high-conflict evidence, this paper proposed a hybrid combination rule by combining the weighted mean rule and the Dempster’s rule. This article will use a threshold ξ to indicate high evidence conflicts. When K is greater than ξ, there is high evidence conflict, and the D–S evidence theory will be replaced by the weighted mean rule, as shown in Eq. (10)19. In this research, the value of the threshold ξ is defined to be 0.9519.
where l and L are the numbers of evidence and the number of hypotheses, respectively, and k is the kth hypothesis.
Tunnel collapse risk assessment
The collapse risk assessment can provide support for construction decision-making on site. Once the collapse risk drops to a high-risk level, certain precautions can be taken before the tunnel collapses. After multiple information sources are fused at the decision-making level, the result of tunnel collapse risk assessment depends on the maximum value of BPAs, as shown in Eq. (11). The confidence indicator \(m_{i} \left( \Theta \right)\) is designed to measure the credibility of the fusion result.
where Bi denotes collapse risk levels, Bw indicates the probability of different risk levels \(m\left( B \right) = \left\{ {m\left( {B_{1} } \right),m\left( {B_{2} } \right),...,m\left( {B_{n} } \right),m\left( \Theta \right)} \right\}\).
The sensitivity analysis of the tunneling collapse risk factors is proposed to reveal the sensitivity of system performance to small changes in risk factors. Up to now, some sensitivity analysis methods have been proposed29. To consider the nonlinearity and interaction relationship between risk factors, this paper adopts global sensitivity analysis (GSA). Spearman's rank correlation coefficient (a GSA measure) does not depend on distributions with a similar shape or being linearly related. The GSA measurement of the ith input factor Ci can be calculated by Eq. (12)30.
where P is the number of the repeated interactions; \(R(x_{i}^{p} )\left( {R(t_{{}}^{p} )} \right)\) is the rank of \(x_{i}^{p} \left( {t_{{}}^{p} } \right)\) among the simulated input data; \(\overline{R}(x_{i}^{p} )\left( {\overline{R}(t_{{}}^{p} )} \right)\) is the mean value of \(R(x_{i}^{p} )\left( {R(t_{{}}^{p} )} \right)\).
A case study
The Jinzhupa Tunnel is a twin-tube highway tunnel. The right and left tunnels are 782 m and 771 m long, respectively. This paper takes the left line (ZK242 + 548 ~ ZK243 + 319) as the object of study. The fault structure along the left line of the tunnel is shown in Fig. 2. There are 316 m of V-level surrounding rock section and 455 m of IV-level surrounding rock section. The rock mass is mainly composed of the residual silty clay, granite fully weathered layer, and broken strong weathered layer. Furthermore, there is a fracture fragmentation zone at section ZK243 + 139 ~ 160. Affected by this, the rock mass is relatively broken, showing a huge mosaic structure or broken mosaic structure. The rock mass is broken and has varying degrees of weathering. During the construction process, it is easy to cause tunnel collapse and water burst. Therefore, it is urgent to conduct a collapse risk assessment of the tunnel to reduce the losses caused by the collapse. In the proposed fusion method, the following four steps are adopted:

Fault structures along the Jinzhupa Tunnel (Figure no. 2 was drawn using AutoCAD software with version no. AutoCAD 2017 and link: https://www.autodesk.com.cn/).
Step (1) Collapse risk assessment based on statistical data: The risk mechanism of tunneling collapse is analyzed to reveal the potential risk factors. Then the collected tunneling collapse data set are used to train SVM models.
Step (2) Collapse risk assessment based on expert judgment: According to the construction personnel’s description of the site situation, the Bayesian network is used to assess the collapse risk.
Step (3) Collapse risk assessment based on monitoring data indicator: Using the arch displacement and horizontal convergence displacement monitoring data of the tunnel as the information source, the cloud model is applied for collapse risk assessment.
Step (4) Multi-source information fusion: The results of the above three assessment models are used as information sources and fused using the improved D–S theory to obtain the overall tunneling collapse risk value.
Step (5) Robustness of risk assessment results: Different percentages of deviation (5%, 10%, 15%, and 20%) were added to the collected data. The robustness of the proposed hybrid method is further validated in the presence of unavoidable data biases.
Result and analysis
Collapse risk assessment based statistical data
Risk/hazard identification in the tunnel collapse
In actual engineering, the tunneling collapse may be affected by many factors, which interact with each other. Many scholars31,32,33,34 have studied the risk factors of collapse and established a similar index system. Referring to previous researches, a total of 15 risk factors are selected, as shown in Table 1. The risk factors are analyzed in detail as shown in researches2,35. At the same time, the safety status of each tunnel collapse risk factor is divided into four levels, as shown in Table 1.
Choice of kernel function and parameters
In order to construct the SVM model, a dataset of 70 tunnel collapses was collected from the study2 and classified according to Table 1. The dataset is used as training data, and the optimal hyperparameters (C, γ) of the SVM model are found using the grid search method. Due to the limited input data, the fivefold cross-validation is conducted to determine the best value of the penalty parameter C and the gamma γ. Pairs of (C, γ) with different values are tested in the SVM model, and their corresponding results about the classification accuracy as shown in Fig. 3. The search range for the optimal hyperparameters (C, γ) is [2−8, 28]. When the parameter C = 4, γ = 0.17678, the accuracy of classification is the highest.

Support Vector Machines evaluation accuracy based on pairs of (C, γ). (Figure no. 3 was drawn using Matlab software with version no. Matlab 2020 and link: https://ww2.mathworks.cn/).
Calculation of the collapse risk probability
According to Eq. (6), the probability of different collapse risk levels is calculated. Since the fracture zone is prone to collapse during excavation, this paper assesses the collapse risk of the fracture zone. In tunnel sections (ZK243 + 130 ~ 330), every 10 m of the tunnel section is selected as a testing sample, and 20 samples are taken. The SVM model (C = 4, γ = 0.17678) is utilized to evaluate the collapse risk value of the testing sample(risk factor level probability distribution as input and collapse risk probability as output), the classification results as shown in Table 2. The risk level of tunnel collapse with the highest probability in the bold font in Table 2 represents the classification result. Despite the high accuracy of the probabilistic SVM evaluation results, it is worth noting that the second-highest probability is very close to the highest value in some of the prediction results. For example, a tunnel section No.9, the probability of tunnel collapse for class I (0.45) and class II (0.50) is very close, which means that the results are very uncertain.
Collapse risk assessment based on expert judgment
Establishment of the DAG and CPT
The DAG is mainly constructed by directed edges and node variables that represent the probability causality between node variables. In combination with the risk factors in Table 1, the DAG can be established, as shown in Fig. 4. To reduce the uncertainty of expert judgment, an expert survey based on confidence index is used to construct the conditional probability tables (CPT), the detail as seen in the research34.

DAG of Bayesian network.
Calculation of the tunneling collapse risk
Similarly, taking the above 20 sections as examples, experts were invited to rate the risk factors in Table 1. The each risk score value is entered into CPT, and then the probability distribution of collapse risk values is obtained by Eq. (8), the result as shown in Table 3.
Compared with the prediction results of the probability SVM, the accuracy of the model is lower. The second-highest probability in some prediction results is also very close to the highest value. For example, a tunnel section No.1, the probability of tunnel collapse for class II (0.48) and class III (0.52) is very close, which means that the results are very uncertain.
Collapse risk assessment based on monitoring data indicator
Monitoring data indicator system
The monitoring measurement data includes the displacement of the vault, the surface settlement of the shallow buried section, and the change of the surrounding rock convergence. These data can reflect the stability of the tunnel support after the initial lining, thereby assessing the risk of collapse. Combined with this project, the vault displacement and the convergence displacement are used to analyze the collapse risk. According to the Chinese standards “Technical code for monitoring measurement of highway tunnel (DB 35/T 1067-2010)” and “Technical specification for construction of highway tunnel (JTG/T 3660-2020)”, the daily deformation rate and cumulative deformation of the two-monitoring data are divided into four levels, as shown in Table 4 where, the cumulative deformation (y) should be multiplied by the coefficient (ζ) according to the distance between the measuring point and the excavation surface (D), the detail as shown in Table 5where B is the face span of the excavation section.
Monitoring data collection
The tunnel is excavated by the bench method, and the monitoring points and measuring points are arranged as shown in Fig. 5. Among them, point A, B, and C are the monitoring points for the settlement of the vault, DE and FH are the surrounding rock convergence line. The surrounding rock displacement is monitored once in the morning and once in the evening, and the average value is taken as the monitoring value of the day.

Schematic diagram of monitoring point layout.
Calculation of the tunneling collapse risk
According to Eq. (3), the cloud model parameter values \(\left( {Ex,En,He} \right)\) of the two monitoring indicators are constructed, as shown in Table 6. Finally, the tunnel collapse risk BPAs is constructed by Eq. (4).
The cloud model is used to obtain the BPAs of the cumulative settlement and daily settlement of the monitoring data (A, B, C, DE, and FH), and the improved D–S theory is used to fuse them separately to obtain the risk level. Finally, the maximum value of the two result is selected as the collapse risk value, the flowchart as shown in Fig. 6.

Flowchart of monitoring data processing.
According to the flowchart shown in Fig. 6, The monitoring data from the above 20 sections were used for collapse risk assessment. According to Eq. (4), the monitoring data are converted into risk probability distribution values, the result as shown in Table 7. Obviously, in tunnel sections (No.6 and No.9), the probability of tunnel collapse for class I (0.50) and class II (0.50) is very close, which means that the results are very uncertain. It is difficult to make an accurate judgment on the risk of tunnel collapse.
Multi-source information fusion
In order to settle the problem of unreliable evaluation results of single-information sources, the improve D–S evidence theory (section 2.4) is used to fuse the multi-source data. This method combines the different results of the three above-mentioned single-source assessment methods. According to Eqs. (9) and (10), the fusion results can be calculated, the result as shown in Table 8. To demonstrate the effectiveness of the new fusion method, several sections with conflicting information were selected for comparison with the traditional D–S theory, as shown in Table 9. The following conclusions can be obtained:
-
(1)
The multiple-information fusion method proposed in this paper can improve the accuracy and reduce uncertainty in the tunnel collapse risk evaluation. Only section evaluation error appears at section No. 9, indicating that the evaluation accuracy rate of 20 sections has reached 95%. The confidence indexes m(Θ) of the 20 tunnel sections are all close to 0, which means that the uncertainty of the results is 0.
-
(2)
The proposed method can solve the problem of inconsistent results of the three risk assessment methods effectively. For example, because the results of the three risk categories are different (SVM and CM belong to level I and BN belong to level II), the single-source risk assessment method cannot directly assess the overall tunnel collapse risk level of the monitoring section 4. The multi-source information fusion method is used to evaluate the monitoring section 4 and the results are shown in Table 8. The BPAs value of tunnel collapse risk level II (that is m (II)) is equal to 1, which means that the collapse risk level for the monitoring section 4 is level II with a high confidence level
-
(3)
When the evaluation results of three single information sources are different (e.g. Tunnel section No.1 and No.12), the fusion result of the improve D–S theory is better than the tradional D–S theory. Dempster’s rule accumulates consensus support only and rejects a proposition completely if it is opposed by any evidence, no matter what support it may get from any other evidence. As a result, when three kinds of single information evaluation give different results, the tradional D–S theory will give a fusion result contrary to common sense. The improve D–S theory has high accuracy when merging high conflict information sources because it combines the weighted mean rule.
Verification of evaluation results
When the tunnel was excavated to section ZK243 + 143, the tunnel vault collapsed, as shown in Fig. 7. This is due to the section being in the fracture zone of the surrounding rock and the insufficient strength of the tunnel lining support, resulting in the tunnel collapse. The multi-source information fusion assessment method was applied to this section for collapse risk assessment, the results as shown in Table 8 (No.2 tunnel section). The results indicate that the section is at small-scale collapse risk with a probability of 1. This section is likely to occur a small-scale collapse if the support conditions are not strengthened. The tunneling collapse risk assessment results are consistent with reality, which proves the usefulness of the assessment method in the actual construction process.

Tunnel collapse.
Robustness of risk assessment results
In actual engineering, due to the influence of measurement errors and human factors, data from multi-source observations may have inevitable deviations. This article will use the MC simulation technology to simulate the uncertainty of the data. The factors affecting tunnel collapse are assumed to obey normal distribution. To further verify the robustness of the proposed hybrid method under unavoidable deviations, we added different deviation percentages (i.e. 5%, 10%, 15%, and 20%) to the collected data. In this paper, the number of repeated iterations P is set to 1000. Figure 8 shows the results of tunnel collapse risk assessment after 1000 iterations for 4 tunnel sections (No. 1, 2, 3, and 8) at different offset levels. Figure 9 shows the global sensitivity analysis about tunnel section No. 2. The following conclusions can be obtained:
-
(1)
The proposed multi-source information fusion approach has good robustness to deviation. In order to better understand the bias, Fig. 8 shows the frequency of a certain collapse risk level after 1000 iterations under different biases in 4 tunnel sections (No.1, No.2, No.3, and No.8). When the percentage of bias is increased, the accuracy of the risk assessment will be slightly reduced, but it will remain at a high level. Obviously, all data with a deviation of less than 10% can almost achieve an evaluation accuracy rate close to 100%, proving that the method is accurate and reliable under low bias. When the deviation is 20%, the evaluation accuracy of all tunnel sections is still higher than 90%, which proves that the method has strong robustness under high deviations. Anymore, the accuracy of the assessment of the No. 3 tunnel section under each level of bias has reached 100%. This is because the results of the three single-information evaluation methods of tunnel section No. 3 are consistent [that is, the results of all three different models are risk level II (Deformation)], so no conflicting information will have a negative impact on the result of multi-source information fusion.
-
(2)
Since the No. 2 tunnel section is in a dangerous state (Small-scale collapse), a global sensitivity analysis is performed on this part to find out the key risk factors that affect the tunnel collapse. Therefore, some measures to prevent tunnel collapse can be taken in advance. The Spearman’s rank correlation coefficient [Eq. (12)] is used to measures the degree of influence of risk factors on the risk level of the tunneling collapse. As shown in Fig. 9, X3, X5, X6, and X11 are the top four risk factors that have the greatest impact on tunnel collapse. To reduce the risk level of tunnel section No.2, more attention should be paid to these four risk factors. In addition, when the deviation level increases to 20%, the results of the most sensitive risk factors remain unchanged, again verifying the robustness of the proposed method.

Tunnel collapse risk assessment results after 1000 iterations under different deviation levels at four section: (a) No.1; (b) No.2; (c) No.3; (d) No.8.

Global sensitivity analysis of 15 risk indicators (No. 2 section).
Discussion
There is no doubt that the single-source information assessment method also can estimate the tunnel collapse risk level. However, the single source of information does not fully reflect the environment of the tunnel construction, resulting in a certain bias and low accuracy of the assessment results. To compare the single-source information evaluation method with the multi-source information fusion method, the Monte Carlo simulation is used to simulate the inevitable uncertainty, and the four evaluation methods are calculated 1000 times. The tunneling collapse risk assessment results of four assessment methods iterate 1000 times under different deviation levels at tunnel section No.2, as shown in Fig. 10. The following conclusions can be obtained:

Four risk evaluation methods for tunnel collapse risk assessment after 1000 iterations under different deviation levels: (a) SVM; (b) BN; (c) CM; (d) Multi-source information fusion method.
The single-source information assessment method (Fig. 10a–c) can get an accurate assessment result in case of small deviations, but it performs poorly at high bias. The multi-source information fusion method is more robust than the single-source information assessment method. As seen in Fig. 10d, the multi-source information fusion method has a higher accuracy of assessment under a large bias, proving that the proposed method has good robustness. This is because the proposed method makes full use of available information, including contradictory information. When the data deviation is 20%, the evaluation accuracy of the single-source information evaluation method is less than 80% in 1000 iterations. In order words, the single-source information assessment method has a high sensibility to bias. However, the multi-source information fusion method can still have 97.9% accuracy of assessment in a 20% bias. This method is a good solution to the data bias caused by the large amount of uncertainty and complexity of the underground environment.
Conclusions and future works
This paper proposes a multi-source information fusion method for the tunneling collapse risk assessment, which provides risk warning and decision-making suggestions for tunnel excavation. The analysis process consists of four main steps: (1) Risk assessment systems are established for the three information sources (i.e. statistical data, physical sensors, and expert judgment provided by humans) separately; (2) The three information sources are processed by the BN, CM, and SVM respectively to obtain the BPAs of the collapse risk; (3) All predictions from three different assessment method are fused to obtain the overall tunneling collapse risk; (4) The Monte Carlo simulation method is used for global sensitivity analysis and robustness verification. Finally, the Jinzhupa tunnel in China is used to verify the applicability of the proposed approach. The methods developed in this research have the following innovations and capabilities:
-
(1)
It can synthesize multi-source information to obtain a more accurate result for the tunneling collapse risk assessment. Due to many risk factors, the tunneling collapse risk assessment is a multi-attribute decision-making problem. In this paper, both soft data from domain experts and hard data from electrical sensors and statistical data are used for evaluating the tunnel collapse risk. A hybrid combination rule combining the weighted mean rule and Dempster’s rule is proposed to process multiple conflicting pieces of evidence. Besides, a confidence index, m(Θ) is adopted to measure the reliability of the tunnel collapse risk result. As shown in Table 8, the value of m(Θ) is zero, indicating that the tunneling collapse risk has a high degree of confidence.
-
(2)
As the deviation level of input data increases, the accuracy rate of the single-source information evaluation method is gradually decreasing. However, the proposed multi-source information fusion method is very robust to deviations. Even when the deviation is 20%, the accuracy of the collapse risk assessment still reaches 97.9%. In other words, this method has excellent tolerance to bias, which eliminates the adverse effects of deviation to the maximum extent and ensures the accuracy and reliability of the evaluation results.
-
(3)
When the tunnel section is in a dangerous state, in order to provide advice to decision-makers, global sensitivity analysis is proposed to identify the most influential risk factors. The global sensitivity analysis considers the interaction between risk factors, making the results more in line with actual construction conditions. In the tunnel case of this study, the factors X3 (Rock mass grade), X5 (Unfavorable geology), X6 (Bias angle), and X11 (Timeliness of primary support) are identified to have the greatest impact on the risk of tunnel collapse. Besides, because measurement errors or human errors may cause data deviations, the MC method is used to simulate the data deviations to prove that the proposed method still has good robustness under deviations.
The proposed method in this paper also has some limitations. Experts are still required to participate in the entire evaluation process, which means that a truly automated evaluation has not yet been achieved. In terms of tunnel collapse data collection, the amount of data is still small, and a system needs to be developed to collect data on a global scale. In addition, this method cannot predict the risk status of the next construction process, and further research is needed.
Data availability
The datasets generated during and/or analyzed during the current study are not publicly available but are available from the corresponding author on reasonable request.
References
Sun, J. Study on Collapse Risk and Stability Evaluation in Mining Construction of Mountain Tunnel. Master’s Thesis, Beijing Jiaotong University (2019). (in Chinese)
Zhou, F. Research on Fuzzy Hierarchical Evaluation of Mountain Tunnel Landslide Risk. Master’s Thesis, Central South University, China, Changsha (2008). (in Chinese)
Zhang, L. et al. Bayesian-network-based safety risk analysis in construction projects. Reliab. Eng. Syst. Saf. 131, 29–39 (2014).
Wu, X. et al. A dynamic Bayesian network based approach to safety decision support in tunnel construction. Reliab. Eng. Syst. Saf. 134, 157–168 (2015).
Liu, K. & Liu, B. Intelligent information-based construction in tunnel engineering based on the GA and CCGPR coupled algorithm. Tunn. Undergr. Space Technol. 88, 113–128 (2019).
Pan, Y. & Zhang, L. Roles of artificial intelligence in construction engineering and management: A critical review and future trends. Autom. Constr. 122, 103517 (2021).
Hasanpour, R., Rostami, J., Schmitt, J., Ozcelik, Y. & Sohrabian, B. Prediction of TBM jamming risk in squeezing grounds using Bayesian and artificial neural networks. J. Rock Mech. Geotech. Eng. 12, 21–31 (2020).
Guo, K. & Zhang, L. Multi-source information fusion for safety risk assessment in underground tunnels. Knowl. Based Syst. 227, 107210 (2021).
Pan, Y., Zhang, L., Wu, X. & Skibniewski, M. J. Multi-classifier information fusion in risk analysis. Inf. Fusion 60, 121–136 (2020).
Li, S. et al. Multi-sources information fusion analysis of water inrush disaster in tunnels based on improved theory of evidence. Tunnell. Undergr. Space Technol. 113, 103948 (2021).
Ding, L. Y. & Zhou, C. Development of web-based system for safety risk early warning in urban metro construction. Autom. Constr. 34, 45–55 (2013).
Shang, Q., Li, H., Deng, Y. & Cheong, K. H. Compound credibility for conflicting evidence combination: An autoencoder-K-means approach. IEEE Trans. Syst. Man Cybern. Syst. https://doi.org/10.1109/TSMC.2021.3130187 (2021).
Wahab, O. A., Bentahar, J., Otrok, H. & Mourad, A. Towards trustworthy multi-cloud services communities: A trust-based hedonic coalitional game. IEEE Trans. Serv. Comput. 11, 184–201 (2018).
Yager, R. R. Multi-source information fusion using measure representations. In On Logical, Algebraic, and Probabilistic Aspects of Fuzzy Set Theory Vol. 336 (eds Saminger-Platz, S. & Mesiar, R.) 199–214 (Springer, 2016).
Qian, Y., Liang, J., Yao, Y. & Dang, C. M. G. R. S. A multi-granulation rough set. Inf. Sci. 180, 949–970 (2010).
Balazs, J. A. & Velásquez, J. D. Opinion mining and information fusion: A survey. Inf. Fusion 27, 95–110 (2016).
Leung, Y., Ji, N.-N. & Ma, J.-H. An integrated information fusion approach based on the theory of evidence and group decision-making. Inf. Fusion 14, 410–422 (2013).
Zhang, P. et al. Multi-source information fusion based on rough set theory: A review. Inf. Fusion 68, 85–117 (2021).
Zhang, L., Wu, X., Zhu, H. & AbouRizk, S. M. Perceiving safety risk of buildings adjacent to tunneling excavation: An information fusion approach. Autom. Constr. 73, 88–101 (2017).
Worden, K. & Manson, G. The application of machine learning to structural health monitoring. Philos. Trans. R. Soc. A. 365, 515–537 (2007).
Satpal, S. B., Guha, A. & Banerjee, S. Damage identification in aluminum beams using support vector machine: Numerical and experimental studies: Damage Identification in Al Beams Using SVM: Numerical and Exp Studies. Struct. Control Health Monit. 23, 446–457 (2016).
Zhou, C., Yin, K., Cao, Y. & Ahmed, B. Application of time series analysis and PSO–SVM model in predicting the Bazimen landslide in the Three Gorges Reservoir, China. Eng. Geol. 204, 108–120 (2016).
Huang, Y. Advances in artificial neural networks: Methodological development and application. Algorithms 2, 973–1007 (2009).
Robert, C. P. & Casella, G. Monte Carlo Statistical Methods (Springer, 2004). https://doi.org/10.1007/978-1-4757-4145-2.
Haroonabadi, H. & Haghifam, M.-R. Generation reliability assessment in power markets using Monte Carlo simulation and soft computing. Appl. Soft Comput. 11, 5292–5298 (2011).
Li, D., Liu, C. & Gan, W. A new cognitive model: Cloud model. Int. J. Intell. Syst. 24, 357–375 (2009).
Liu, Y., Lian, J., Bartolacci, M. R. & Zeng, Q.-A. Density-based penalty parameter optimization on C-SVM. Sci. World J. 2014, 1–9 (2014).
Li, N., Feng, X. & Jimenez, R. Predicting rock burst hazard with incomplete data using Bayesian networks. Tunn. Undergr. Space Technol. 61, 61–70 (2017).
Janssen, H. Monte-Carlo based uncertainty analysis: Sampling efficiency and sampling convergence. Reliab. Eng. Syst. Saf. 109, 123–132 (2013).
Kou, G., Lu, Y., Peng, Y. & Shi, Y. Evaluation of classification algorithms using mcdm and rank correlation. Int. J. Info. Tech. Dec. Mak. 11, 197–225 (2012).
Qiao, S., Cai, Z., Tan, J., Xu, P. & Zhang, Y. Analysis of collapse mechanism and treatment evaluation of a deeply buried hard rock tunnel. Appl. Sci. 10, 4294 (2020).
Wang, B. et al. Risk Assessment of a Tunnel Collapse in a Mountain Tunnel Based on the Attribute Synthetic Evaluation System. in Geo-China 2016 198–209 (American Society of Civil Engineers, 2016). https://doi.org/10.1061/9780784480038.025.
Wang, S. et al. Dynamic risk assessment method of collapse in mountain tunnels and application. Geotech. Geol. Eng. 38, 2913–2926 (2020).
Zhang, G.-H., Chen, W., Jiao, Y.-Y., Wang, H. & Wang, C.-T. A failure probability evaluation method for collapse of drill-and-blast tunnels based on multistate fuzzy Bayesian network. Eng. Geol. 276, 105752 (2020).
Ou, G.-Z. et al. Collapse risk assessment of deep-buried tunnel during construction and its application. Tunnel. Undergr. Space Technol. 115, 104019 (2021).
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant Nos.: 51678164; 51478118); Guangxi Natural Science Foundation (Grant Nos.: 2018GXNSFDA138009). The authors would like to express the appreciation and thanks to the managers and San-Ming Pu-Yan Expressway Co. LTD.
Author information
Authors and Affiliations
Contributions
Q.W. wrote the main manuscript text. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wu, B., Qiu, W., Huang, W. et al. A multi-source information fusion approach in tunnel collapse risk analysis based on improved Dempster–Shafer evidence theory. Sci Rep 12, 3626 (2022). https://doi.org/10.1038/s41598-022-07171-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-07171-x
- Springer Nature Limited
This article is cited by
-
A collapse risk assessment method for subway foundation pit based on cloud model and improved Dempster–Shafer evidence theory
Scientific Reports (2024)
-
Evaluation on displacement risks of dismantling temporary lining in tunnel and optimization on temporary lining configuration
Scientific Reports (2023)