
Abstract
Acute kidney injury (AKI) is commonly present in critically ill patients with sepsis. Early prediction of short-term reversibility of AKI is beneficial to risk stratification and clinical treatment decision. The study sought to use machine learning methods to discriminate between transient and persistent sepsis-associated AKI. Septic patients who developed AKI within the first 48 h after ICU admission were identified from the Medical Information Mart for Intensive Care III database. AKI was classified as transient or persistent according to the Acute Disease Quality Initiative workgroup consensus. Five prediction models using logistic regression, random forest, support vector machine, artificial neural network and extreme gradient boosting were constructed, and their performance was evaluated by out-of-sample testing. A simplified risk prediction model was also derived based on logistic regression and features selected by machine learning algorithms. A total of 5984 septic patients with AKI were included, 3805 (63.6%) of whom developed persistent AKI. The artificial neural network and logistic regression models achieved the highest area under the receiver operating characteristic curve (AUC) among the five machine learning models (0.76, 95% confidence interval [CI] 0.74–0.78). The simplified 14-variable model showed adequate discrimination, with the AUC being 0.76 (95% CI 0.73–0.78). At the optimal cutoff of 0.63, the sensitivity and specificity of the simplified model were 63% and 76% respectively. In conclusion, a machine learning-based simplified prediction model including routine clinical variables could be used to differentiate between transient and persistent AKI in critically ill septic patients. An easy-to-use risk calculator can promote its widespread application in daily clinical practice.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
Acute kidney injury (AKI) is a common and severe complication in critically ill patients, especially in patients with sepsis1,2. The complex condition in which patients meet consensus criteria for sepsis and AKI simultaneously is recognized as sepsis-associated AKI (SA-AKI), which is associated with significantly higher risks of mortality and chronic renal insufficiency3,4,5. Up to now, the prophylactic and therapeutic options for SA-AKI are still limited. Both severity and duration of SA-AKI can affect short- and long-term adverse outcomes.
Most recently, the Acute Disease Quality Initiative (ADQI) 16 Workgroup suggested that AKI be classified as transient (a complete reversal of AKI within 48 h) or persistent (the continuance of AKI beyond 48 h)6. Compared to transient AKI, persistent AKI is related to enhanced and sustained host response dysregulation and adverse consequences in critically ill septic patients7,8. Early recognition of persistent AKI is significant for risk stratification and individualized therapy, such as fluid management and the use of renal replacement therapy (RRT)6,9. However, since complex mechanisms including microcirculatory dysfunction and inflammatory response may co-exist in the pathophysiology of SA-AKI, traditional indicators for renal blood flow have been reported to play a limited role in differentiating between transient and persistent AKI10,11,12,13. Additionally, a few studies assessing the predictive value of function or damage biomarkers for persistent AKI have suggested that most biomarkers showed poor performance while the others need further clinical validation14,15,16,17. At present, there is a lack of clinical information on how to identify patients who are likely to develop persistent AKI.
The development of machine learning algorithms may provide an opportunity for early prediction of persistent AKI by integration of a large quantity of data from electronic health records, such as demographics, diagnoses, routinely collected measurements and interventions. These advanced data-driven approaches can deal with high-dimension data, fit complex relationships and identify important variables associated with the outcome. They outperform conventional modeling methods which require the independence between predictors and include variables selected mainly according to their statistical significance or known clinical relevance. Machine learning has been applied in the biomedical domain, such as disease diagnosis, outcome prediction, medical image analysis and treatment18,19,20,21.
The primary objective of this study was to use machine learning methods to develop a prediction model for the persistence of SA-AKI in an attempt to identify patients at high risk of persistent AKI in daily clinical practice.
Methods
Source of data
Data were extracted from the Medical Information Mart for Intensive Care III (MIMIC-III) database v1.422. MIMIC-III is a large and openly accessible database comprising electronic health records of 61,532 intensive care unit (ICU) stays from the Beth Israel Deaconess Medical Center (BIDMC, Boston, MA) between 2001 and 2012. The database was approved by the Institutional Review Boards of BIDMC and Massachusetts Institute of Technology and informed consent was waived by them because all patient identifiers in the database were removed. One of the authors has completed the required training course and obtained access to the database (certification number: 40010711). The study was performed in accordance with the Declaration of Helsinki.
Study population
This study included adult patients who were admitted to ICU with sepsis and developed AKI within the first 48 h of the ICU stay. Sepsis was defined based on the updated Sepsis-3 criteria as suspected infection (the concomitant administration of antibiotics and sampling of body fluid culture) with the Sequential Organ Failure Assessment (SOFA) score ≥ 2 points23,24. Patients with suspicion of infection more than 24 h before or after ICU admission were excluded. The microbiology information was extracted to verify the locations and pathogens of positive cultures taken during the suspected infection time. SOFA score was calculated using data within the first 24 h after ICU admission. AKI was diagnosed and staged according to the Kidney Disease: Improving Global Outcomes (KDIGO) guideline using both serum creatinine (SCr) and urine output (UO) criteria25. Baseline SCr was defined as the lowest SCr value during 7 days before ICU admission26,27. For patients without available pre-admission SCr, we used the first SCr measurement after ICU admission as the baseline SCr26. UO rate was calculated by dividing the volume of UO into 6-h, 12-h and 24-h time periods. We analyzed only the first ICU stay for patients who were admitted to ICU more than once. We also excluded patients with age < 18 years old, end-stage renal disease, ICU stay < 48 h, non-AKI and missing data for AKI during the first 48 h.
Outcomes
The primary outcome was the persistence of AKI, which was determined in accordance with the ADQI 16 workgroup consensus6. Transient AKI was defined as reversal of AKI within 48 h after AKI diagnosis and for at least 48 h. In contrast, AKI was considered persistent if AKI criteria or RRT use remained present beyond 48 h after AKI diagnosis, or if the condition reversed within 48 h but relapsed within the next 48 h6,7. Patients with follow-up time < 48 h or missing data for the persistence of AKI were excluded from the analysis. Secondary outcomes included 28-day mortality, 90-day mortality and use of RRT within 28 days after ICU admission.
Data extraction
We obtained demographic and clinical data within the first 48 h after ICU admission using PostgreSQL tools (version 9.6.20) and Navicat Premium (version 15.0.12). Comorbidities and diagnoses were identified based on the recorded International Classification of Diseases 9th Edition code. Vital signs including temperature, heart rate, respiratory rate and mean arterial pressure were extracted from the electronic charted data. Laboratory data including hemoglobin, white blood cell count, platelet count, bilirubin, albumin, arterial pH, partial pressure of oxygen, partial pressure of carbon dioxide, anion gap, serum electrolytes (sodium, potassium, chloride and bicarbonate), lactate, international normalized ratio and partial thromboplastin time were also recorded. We used the values related to the greatest disease severity for variables measured more than once during the first 48 h. Accordingly, both the maximum and minimum values of some variables were included. In addition, the use of mechanical ventilation, vasopressors, diuretics and RRT and the volume of mean daily intravenous infusion within the first 48 h were collected. We left out RRT initiation when determining the AKI stage, as we chose to record it as another variable.
Statistical analysis
Baseline characteristics and outcomes were compared between patients with transient and persistent AKI. Continuous variables were presented as medians (with interquartile ranges) and compared using Mann–Whitney U test. Categorical variables were presented as numbers (with percentages) and compared using chi-square tests. To ensure the facticity and reliability of the prediction model, we removed two variables with > 30% missing data from model construction, namely maximum bilirubin and minimum albumin (see Supplementary Table S1 online). Random forest (RF) method was used to impute missing values in variables with ≤ 30% observations missing (R package missForest, version 1.4). Supplementary Table S2 online lists all 44 candidate predictors included for application to machine learning.
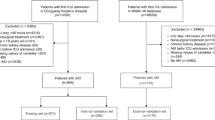
The sample was randomly divided into the training and testing set by the ratio of 7 to 3. Five machine learning algorithms were used to develop prediction models for persistent AKI in the training set, including logistic regression, RF, support vector machine (SVM), artificial neural network (ANN) and extreme gradient boosting (XGB). RF is a tree-based algorithm, which integrates multiple decision trees through majority voting to determine the results of classification28. Gini index was used as the criteria for impurity measurement during the training process. SVM is a supervised classifier, the purpose of which is to establish the optimal maximum-margin hyperplane as decision boundary29. We chose Gaussian kernel function as the kernel when developing the SVM model. ANN is a mathematical model simulating the structure and function of biological neural networks, which contains connected nodes named artificial neurons and multiple layers (typically input layer, hidden layer and output layer)30. XGB is also a tree-based ensemble classifier, which obtains the final output by weight of multiple weak learners (decision trees) and gradient descent algorithm for minimizing the loss function31. Before model construction, categorical variables were preprocessed by one-hot encoding and the prediction variables were standardized. For each machine learning algorithm, we firstly set default hyper-parameters to establish an initial model. After that, parameter tuning was performed by manual grid search. We used five-fold cross-validation to identify optimal hyper-parameters and avoid over-fitting. Briefly, the training set was randomly divided into 5 roughly equal-sized subsets, and then 4 of them were fit into the model while the other was used for model validation. This process was repeated 5 times so that every subset could serve as a validation set. Subsequently, the performance of the final model was assessed on the testing set. We calculated several evaluation indexes of each model, including the area under the receiver operating characteristic curve (AUC), accuracy, precision, recall and F1 score. AUC was selected as the primary performance metric, which was considered an ideal evaluation metric for classifiers independent of threshold setting.
To further extend the clinical applicability of machine learning methods, we also developed a risk prediction model by simplifying the input variables. Firstly, all features were sorted by XGB according to their contribution to each tree in the learning process, and the top 20 important features were selected31. Then we used least absolute shrinkage and selection operator (LASSO) method for further feature selection32. During the process, cross-validation was performed and the value of λ was identified according to the most regularized model, in which the cross-validated error is within one standard error of the minimum. Fourteen variables were selected as predictors of persistent AKI. Finally, logistic regression was used to construct the simplified prediction model. Model performance was evaluated in the testing set, with the optimal cutoff identified by the maximum Youden index in the training set.
Statistical analyses were conducted using R 4.0.4 (https://cran.r-project.org) and Python 3.8 (https://www.python.org). P value < 0.05 was considered statistically significant.
Results
Patient characteristics
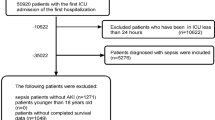
A total of 5984 SA-AKI patients were enrolled in our study from 24,225 septic patients admitted to ICU during the study period. Among them, 2179 (36.4%) patients had an early complete reversal and 3805 (63.6%) developed persistent AKI (Fig. 1).

Flow diagram of patient selection, model establishment and internal validation. MIMIC-III, Medical Information Mart for Intensive Care III; ICU, intensive care unit; AKI, acute kidney injury.
Baseline characteristics and outcomes of patients stratified by the persistence of AKI are shown in Table 1. Compared to patients with transient AKI, patients with persistent AKI had a higher proportion of emergency admission and medical ICU stay. The prevalence of diabetes mellitus, congestive heart failure, liver disease and chronic kidney disease (CKD) were higher in the persistent AKI patients. Most of the vital signs and laboratory data differed significantly between the two groups, and the measurements were mainly associated with higher disease severity in the persistent AKI group. Furthermore, a larger percentage of the persistent AKI patients received mechanical ventilation, vasopressors and RRT during the first 48 h. Renal dysfunction was more severe in the persistent AKI group, as reflected by higher AKI stage according to SCr or UO criteria. The locations and pathogens of microbiology cultures in SA-AKI patients are shown in Supplementary Tables S3, S4 online, and the 20 most common diagnoses in SA-AKI patients are shown in Supplementary Table S5 online.
Prediction models using machine learning algorithms
We randomly allocated 70% of SA-AKI patients to the training set and the remaining 30% to the testing set. Baseline characteristics were not significantly different between the training and testing set (see Supplementary Table S6 online). Among the five machine learning models, the ANN model and the logistic regression model exhibited the highest AUC (0.76, 95% confidence interval [CI] 0.74–0.78) in the testing set (Table 2, Fig. 2). The ANN model achieved the highest accuracy of 0.71. Moreover, the XGB model showed the highest recall of 0.81, while the RF model showed the highest precision and F1 score of 0.89 and 0.80 respectively (Table 2).

Receiver operating characteristic curves of the machine learning models in the testing set. LR, logistic regression; RF, random forest; SVM, support vector machine; ANN, artificial neural network; XGB, extreme gradient boosting; AUC, area under the receiver operating characteristic curve.
Simplified risk prediction model
The simplified risk prediction model was established based on the features selected by XGB and LASSO algorithms. The top 20 important features derived from the XGB model are shown in Fig. 3. Ultimately, fourteen variables were selected and entered into the logistic regression model (Table 3). The simplified model showed adequate discrimination, with an AUC of 0.76 (95% CI 0.74–0.77) in the training set and 0.76 (95% CI 0.73–0.78) in the testing set (Fig. 4). The calibration of the model was overall good, except that it underestimated the risk of persistent AKI when the observed frequency was relatively low (Fig. 5). At the optimal cutoff of 0.63, the simplified model achieved a sensitivity of 63%, specificity of 76%, positive predictive value of 83% and negative predictive value of 53% in the testing set (Table 4).

The top 20 important features derived from the XGB model. UO, urine output; SCr, serum creatinine; PaO2, partial pressure of oxygen; RRT, renal replacement therapy; ICU, intensive care unit; CCU, coronary care unit; CSRU, cardiac surgery recovery unit; INR, international normalized ratio; PaCO2, partial pressure of carbon dioxide; PTT, partial thromboplastin time.

Receiver operating characteristic curve of the simplified risk prediction model in the training and testing set.

Calibration curve of the simplified risk prediction model in the training set. The Brier score of the model was 0.189 (95% confidence interval 0.184–0.194).
We used Matlab software (version 9.2) to establish a risk calculator, which could be applied to automatically compute the risk of persistent AKI for SA-AKI patients in clinical settings (see Supplementary Fig. S1 online).
Discussion
In the present study, we explored the applicability of machine learning methods to differentiate between transient and persistent AKI in a large population of SA-AKI patients. The ANN and logistic regression models exhibited the highest AUC among the five machine learning models. Additionally, a simplified risk prediction model was proposed, based on the combination of machine learning algorithms and logistic regression, and could be easily implemented using the risk calculator in daily routines.
A growing body of evidence suggests that duration of AKI or renal recovery is associated with outcomes in critically ill septic patients2,7,8,33,34. Several clinical tools, including urinary indices10,11,12, imaging techniques13,17, prediction models35,36, and biomarkers14,15,16,17, were investigated in previous studies to predict renal recovery or its surrogate, namely progression to severe AKI. Nevertheless, they were found to be poorly effective or have not been validated in patients with sepsis9. A recent study enrolling 184 septic shock patients with AKI found a poor performance of urine cell cycle arrest biomarkers for predicting persistent AKI, with an AUC of 0.67 (95% CI 0.59–0.73). Of note, they also proposed a prediction model combining SCr, UO, norepinephrine dose and extrarenal SOFA at baseline, which performed well with an AUC of 0.81 (95% CI 0.74–0.86)16. Due to the complexity of SA-AKI, the clinical model integrating routine parameters may be more effective for predicting short-term reversibility of AKI than any parameter considered alone. A possible way to achieve this is to utilize advanced machine learning approaches, which have been applied in the prevention and management of AKI, such as predicting the development of AKI37,38,39,40,41, volume responsiveness in patients with oliguria42 and mortality in critically ill AKI patients43,44,45. Our study corroborated the promise indicated by these previous studies and extended them by demonstrating the applicability of machine learning methods for predicting persistent AKI in a large cohort of SA-AKI patients.
In the current study, ANN and logistic regression achieved the highest AUC among the five machine learning methods. Compared with traditional modeling methods, ANN has the advantages of strong nonlinear mapping ability, great adaptability and high fault tolerance. Several recent studies have shown the effectiveness of neural network-based models in predicting the development of AKI. Le et al. proposed a convolutional neural networks prediction system, which outperformed the XGB model and the SOFA score in predicting AKI 48 h before onset in ICU patients40. Similarly, Kim et al. used recurrent neural network to assess future AKI occurrence and individualized AKI risk factors in real time among hospitalized patients41. Hofer et al. applied the deep neural networks to create models for postoperative AKI, mortality, reintubation, and the combined outcome, which exhibited superior performance to the ASA score46. However, due to its “black box” characteristic, ANN is also hard to calculate and interpret. It is difficult to exhibit the complex association between different layers and nodes intuitively and to explain the exact impact of each input variable on the final result, which may limit its rapid clinical application. In this study, the conventional logistic regression showed higher AUC than several novel machine learning algorithms. The results were mainly determined by the nature of the dataset, as any specific modeling approach could not be the optimal method for all tasks47. In the logistic regression model, each variable’s influence on outcome can be directly reflected by the regression coefficient. Hence, we further utilized it to propose a simplified prediction model with features selected by XGB and LASSO algorithms. The high interpretability and promising performance of the simplified model make it suitable to be applied. Since the present study is an initial attempt, future studies will investigate the extensibility of advanced approaches from other domains48 and improvement of the existing algorithms49,50 in predicting the persistence of AKI.
Our study has important clinical significance. The prediction model for persistent AKI can assist risk stratification and therapeutic strategies of SA-AKI patients at an early stage9. For high-risk patients, large fluid infusion should be cautious to avert detrimental fluid overload. The requirement and optimal timing of RRT can be evaluated for patients without the indication of urgent hemodialysis. Constant monitoring is necessary, especially for high-risk patients, to assess the hemodynamic and fluid status, kidney function, complications of AKI and the risk of long-term adverse sequelae. Additionally, high-risk patients may be the ideal population for AKI clinical trials because they tend to experience no spontaneous and rapid reversal of AKI.
Many factors, including demographics, comorbidities and disease severity, can affect short-term renal recovery51. In this study, fourteen predictors of persistent AKI were identified by XGB and LASSO algorithms. The SCr and UO criteria of AKI stage were both strong predictors of persistent AKI. The results further supported that patients who meet both the SCr and UO criteria for AKI are at higher risk of death or RRT52. Among patient-related variables, age, CKD, diabetes mellitus and congestive heart failure were identified as predictors of persistent AKI, as they may cause reduced glomerular reserve and delayed or incomplete renal recovery51. During sepsis, systemic disease status and distant organ dysfunction may affect the evolution of AKI53. Recent studies have suggested that acute respiratory distress syndrome is associated with a strong trend toward developing AKI54,55. A close relationship between mechanical ventilation and worsening of renal function was observed in a large cohort of ICU patients56. Metabolic acidosis is common in SA-AKI patients and can directly influence cardiac contractility and sensitivity of adrenergic receptors57. Coagulopathy, mainly caused by the activation or injury of endothelial cells, plays an important role in the pathogenesis of SA-AKI through microcirculatory dysfunction58. Our results further demonstrated that sepsis-related factors, including those relevant to respiratory failure, metabolic acidosis and coagulation disorder, could contribute to the prediction of persistent AKI. Further studies are required to investigate the exact pathophysiological mechanisms of reversibility of SA-AKI and determine whether modification of these factors can facilitate renal recovery and improve prognosis.
There are some strengths of our study. Firstly, with the combination of logistic regression and feature selection by machine learning algorithms, we established a simplified risk prediction model with high practicability and interpretability. Secondly, fourteen predictors of persistent AKI were selected by state-of-the-art algorithms. The unbiased machine learning methods can help identify important features, which are clinically significant but may be ignored by clinicians according to their traditional experience. Thirdly, an easy-to-use risk calculator was developed to allow automatic quantified assessment of the risk of persistent AKI, which is a useful tool for clinicians to identify high-risk patients and improve clinical decision-making abilities.
However, this study is also subject to some limitations. Firstly, it was a single-center retrospective study based on a publicly accessible database, which may limit the generalizability of the prediction model in patients with differently distributed features. External validation is still necessary, and clinical impact studies should be conducted to assess the model’s effectiveness before its clinical implementation. Secondly, although we only included variables with ≤ 30% missing values, there were still 2.2% of all observations missing. Some candidate variables were excluded owing to a large percentage of missing values. Finally, similar to other machine learning models, the performance of our model was not perfect38,45,47. Possible reasons include the limited set of predictors, retrospective study design and heterogeneity of SA-AKI patients. Novel biomarkers, which were potential predictors of persistent AKI but not routinely measured in clinical settings, were not included in the prediction model. Based on this study, there is a continuing need for future studies to combine the clinical prediction model and biomarkers to predict persistent AKI.
In conclusion, machine learning algorithms are helpful to distinguish between transient and persistent AKI and identify the predictors of persistent AKI in critically ill septic patients. A simplified 14-variable risk prediction model was developed and validated with high practicability and interpretability. A risk calculator was established to facilitate its widespread application in daily clinical practice, which may help identify high-risk patients, guide treatment decisions and improve prognosis. Future prospective studies are needed to demonstrate the model’s generalizability and effectiveness and determine whether the addition of novel biomarkers could improve the predictive ability.
Data availability
The datasets analyzed during the current study are available in the MIMIC-III database (https://mimic.physionet.org/).
References
Kellum, J. A. & Prowle, J. R. Paradigms of acute kidney injury in the intensive care setting. Nat. Rev. Nephrol. 14, 217–230 (2018).
Peters, E. et al. A worldwide multicentre evaluation of the influence of deterioration or improvement of acute kidney injury on clinical outcome in critically ill patients with and without sepsis at ICU admission: Results from the intensive care over nations audit. Crit. Care 22, 188 (2018).
Bellomo, R. et al. Acute kidney injury in sepsis. Intensive Care Med. 43, 816–828 (2017).
Peerapornratana, S., Manrique-Caballero, C. L., Gomez, H. & Kellum, J. A. Acute kidney injury from sepsis: Current concepts, epidemiology, pathophysiology, prevention and treatment. Kidney Int. 96, 1083–1099 (2019).
Poston, J. T. & Koyner, J. L. Sepsis associated acute kidney injury. BMJ 364, k4891 (2019).
Chawla, L. S. et al. Acute kidney disease and renal recovery: Consensus report of the acute disease quality initiative (ADQI) 16 workgroup. Nat. Rev. Nephrol. 13, 241–257 (2017).
Uhel, F. et al. Mortality and host response aberrations associated with transient and persistent acute kidney injury in critically ill patients with sepsis: A prospective cohort study. Intensive Care Med. 46, 1576–1589 (2020).
Ozrazgat-Baslanti, T. et al. Clinical trajectories of acute kidney injury in surgical sepsis: A prospective observational study. Ann. Surg. (2020).
Darmon, M., Truche, A. S., Abdel-Nabey, M., Schnell, D. & Souweine, B. Early recognition of persistent acute kidney injury. Semin. Nephrol. 39, 431–441 (2019).
Darmon, M. et al. Diagnostic performance of fractional excretion of urea in the evaluation of critically ill patients with acute kidney injury: A multicenter cohort study. Crit. Care 15, R178 (2011).
Pons, B. et al. Diagnostic accuracy of early urinary index changes in differentiating transient from persistent acute kidney injury in critically ill patients: Multicenter cohort study. Crit. Care 17, R56 (2013).
Vanmassenhove, J. et al. Urinary output and fractional excretion of sodium and urea as indicators of transient versus intrinsic acute kidney injury during early sepsis. Crit. Care 17, R234 (2013).
Darmon, M. et al. Performance of doppler-based resistive index and semi-quantitative renal perfusion in predicting persistent aki: Results of a prospective multicenter study. Intensive Care Med. 44, 1904–1913 (2018).
Dewitte, A. et al. Kinetic eGFR and novel AKI biomarkers to predict renal recovery. Clin. J. Am. Soc. Nephrol. 10, 1900–1910 (2015).
Hoste, E. et al. Identification and validation of biomarkers of persistent acute kidney injury: The ruby study. Intensive Care Med. 46, 943–953 (2020).
Titeca-Beauport, D. et al. Urine cell cycle arrest biomarkers distinguish poorly between transient and persistent AKI in early septic shock: A prospective, multicenter study. Critical Care 24 (2020).
Garnier, F. et al. Reversibility of acute kidney injury in medical ICU patients: Predictability performance of urinary tissue inhibitor of metalloproteinase-2 x insulin-like growth factor-binding protein 7 and renal resistive index. Crit. Care Med. 48, e277–e284 (2020).
Wu, P. et al. An effective machine learning approach for identifying non-severe and severe coronavirus disease 2019 patients in a rural chinese population: The wenzhou retrospective study. IEEE Access 9, 45486–45503 (2021).
Ye, H. et al. Diagnosing coronavirus disease 2019 (covid-19): Efficient harris hawks-inspired fuzzy k-nearest neighbor prediction methods. IEEE Access 9, 17787–17802 (2021).
Liu, L. et al. Ant colony optimization with cauchy and greedy levy mutations for multilevel covid 19 x-ray image segmentation. Comput. Biol. Med. 136, 104609 (2021).
Wu, S. et al. Evolving fuzzy k-nearest neighbors using an enhanced sine cosine algorithm: Case study of lupus nephritis. Comput. Biol. Med. 135, 104582 (2021).
Johnson, A. E. et al. MIMIC-III, a freely accessible critical care database. Sci. Data 3, 160035 (2016).
Singer, M. et al. The third international consensus definitions for sepsis and septic shock (sepsis-3). JAMA 315, 801–810 (2016).
Johnson, A. E. W. et al. A comparative analysis of sepsis identification methods in an electronic database. Crit. Care Med. 46, 494–499 (2018).
Kidney disease: Improving global outcomes (KDIGO) acute kidney injury work group. KDIGO clinical practice guideline for acute kidney injury. Kidney Int. Suppl. 2, 1–138 (2012).
Zhao, G. J. et al. Association between furosemide administration and outcomes in critically ill patients with acute kidney injury. Crit. Care 24, 75 (2020).
Chaudhary, K. et al. Utilization of deep learning for subphenotype identification in sepsis-associated acute kidney injury. Clin. J. Am. Soc. Nephrol. 15, 1557–1565 (2020).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Cortes, C. & Vapnik, V. Support-vector networks. Mach. Learn. 20, 273–297 (1995).
Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 65, 386–408 (1958).
Chen, T., Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 785–794 (2016).
Tibshirani, R. Regression shrinkage and selection via the lasso: A retrospective. J. Roy. Stat. Soc. Ser. B. Stat. Method. 73, 273–282 (2011).
Fiorentino, M. et al. Long-term survival in patients with septic acute kidney injury is strongly influenced by renal recovery. PLoS ONE 13, e0198269 (2018).
Truche, A. S. et al. ICU survival and need of renal replacement therapy with respect to AKI duration in critically ill patients. Ann. Intensive Care 8, 127 (2018).
Matsuura, R. et al. A simple scoring method for predicting the low risk of persistent acute kidney injury in critically ill adult patients. Sci. Rep. 10, 5726 (2020).
Bhatraju, P. K. et al. A prediction model for severe AKI in critically ill adults that incorporates clinical and biomarker data. Clin. J. Am. Soc. Nephrol. 14, 506–514 (2019).
Koyner, J. L., Carey, K. A., Edelson, D. P. & Churpek, M. M. The development of a machine learning inpatient acute kidney injury prediction model. Crit. Care Med. 46, 1070–1077 (2018).
Sandokji, I. et al. A time-updated, parsimonious model to predict AKI in hospitalized children. J. Am. Soc. Nephrol. 31, 1348–1357 (2020).
Tomasev, N. et al. A clinically applicable approach to continuous prediction of future acute kidney injury. Nature 572, 116–119 (2019).
Le, S. et al. Convolutional neural network model for intensive care unit acute kidney injury prediction. Kidney Int. Rep. 6, 1289–1298 (2021).
Kim, K. et al. Real-time clinical decision support based on recurrent neural networks for in-hospital acute kidney injury: External validation and model interpretation. J. Med. Internet Res. 23, e24120 (2021).
Zhang, Z., Ho, K. M. & Hong, Y. Machine learning for the prediction of volume responsiveness in patients with oliguric acute kidney injury in critical care. Crit. Care 23, 112 (2019).
Lin, K., Hu, Y. & Kong, G. Predicting in-hospital mortality of patients with acute kidney injury in the ICU using random forest model. Int. J. Med. Inform. 125, 55–61 (2019).
Huang, H., Liu, Y., Wu, M., Gao, Y. & Yu, X. Development and validation of a risk stratification model for predicting the mortality of acute kidney injury in critical care patients. Ann. Transl. Med. 9, 323 (2021).
Kang, M. W. et al. Machine learning algorithm to predict mortality in patients undergoing continuous renal replacement therapy. Crit. Care 24, 42 (2020).
Hofer, I. S., Lee, C., Gabel, E., Baldi, P. & Cannesson, M. Development and validation of a deep neural network model to predict postoperative mortality, acute kidney injury, and reintubation using a single feature set. NPJ Digit. Med. 3, 58 (2020).
Kendale, S., Kulkarni, P., Rosenberg, A. D. & Wang, J. Supervised machine-learning predictive analytics for prediction of postinduction hypotension. Anesthesiology 129, 675–688 (2018).
Wang, S. J., He, Y., Li, J. & Fu, X. Mesnet: A convolutional neural network for spotting multi-scale micro-expression intervals in long videos. IEEE Trans. Image Process. 30, 3956–3969 (2021).
Chen, H. et al. Efficient multi-population outpost fruit fly-driven optimizers: Framework and advances in support vector machines. Expert Systems with Applications 142 (2020).
Pei, H., Yang, B., Liu, J. & Chang, K. Active surveillance via group sparse bayesian learning. IEEE Trans. Pattern. Anal. Mach. Intell. PP (2020).
Forni, L. G. et al. Renal recovery after acute kidney injury. Intensive Care Med. 43, 855–866 (2017).
Kellum, J. A. et al. Classifying AKI by urine output versus serum creatinine level. J. Am. Soc. Nephrol. 26, 2231–2238 (2015).
Doi, K. & Rabb, H. Impact of acute kidney injury on distant organ function: Recent findings and potential therapeutic targets. Kidney Int. 89, 555–564 (2016).
Darmon, M. et al. Acute respiratory distress syndrome and risk of AKI among critically ill patients. Clin. J. Am. Soc. Nephrol. 9, 1347–1353 (2014).
Clemens, M. S. et al. Reciprocal risk of acute kidney injury and acute respiratory distress syndrome in critically ill burn patients. Crit. Care Med. 44, e915-922 (2016).
Geri, G. et al. Cardio-pulmonary-renal interactions in ICU patients. Role of mechanical ventilation, venous congestion and perfusion deficit on worsening of renal function: Insights from the MIMIC-III database. J. Crit. Care 64, 100–107 (2021).
Zhang, Z., Mo, L., Ho, K. M. & Hong, Y. Association between the use of sodium bicarbonate and mortality in acute kidney injury using marginal structural cox model. Crit. Care Med. 47, 1402–1408 (2019).
Katayama, S. et al. Markers of acute kidney injury in patients with sepsis: The role of soluble thrombomodulin. Crit. Care 21, 229 (2017).
Acknowledgements
We thank Yu-Jia Liao (Northwestern Polytechnical University, Xi’an, China) for his help in this manuscript.
Funding
Funding was provided by National Natural Science Foundation of China (Grant Nos. 81873607, 81570618), Development and Reform Commission of Hunan Province (Grant No. 2014-658), Scientific Foundation of Hunan Province, China (Grant No. S2013F1022) and Clinical Medical Technology Innovation Guide Project of Hunan Province (Grant No. 2017SK50117).
Author information
Authors and Affiliations
Contributions
S.B.D. designed and supervised the study. X.Q.L. performed the data extraction, analyzed and interpreted the data and drafted the manuscript. P.Y., N.Y.Z. and B.L. analyzed and interpreted the data and critically revised the manuscript. M.W., Y.H.D., T.W., X.W., Q.L., H.S.W., L.W. and Y.X.K. analyzed the data and revised the manuscript critically for important intellectual content. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Luo, XQ., Yan, P., Zhang, NY. et al. Machine learning for early discrimination between transient and persistent acute kidney injury in critically ill patients with sepsis. Sci Rep 11, 20269 (2021). https://doi.org/10.1038/s41598-021-99840-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-99840-6
- Springer Nature Limited
This article is cited by
-
Development and external validation of a machine learning model for the prediction of persistent acute kidney injury stage 3 in multi-centric, multi-national intensive care cohorts
Critical Care (2024)
-
Künstliche Intelligenz und akute Nierenschädigung
Medizinische Klinik - Intensivmedizin und Notfallmedizin (2024)
-
Effectiveness of Artificial Intelligence (AI) in Clinical Decision Support Systems and Care Delivery
Journal of Medical Systems (2024)
-
Construction and validation of machine learning models for sepsis prediction in patients with acute pancreatitis
BMC Surgery (2023)
-
A retrospective study using machine learning to develop predictive model to identify urinary infection stones in vivo
Urolithiasis (2023)