
Abstract
Many physics problems involve integration in multi-dimensional space whose analytic solution is not available. The integrals can be evaluated using numerical integration methods, but it requires a large computational cost in some cases, so an efficient algorithm plays an important role in solving the physics problems. We propose a novel numerical multi-dimensional integration algorithm using machine learning (ML). After training a ML regression model to mimic a target integrand, the regression model is used to evaluate an approximation of the integral. Then, the difference between the approximation and the true answer is calculated to correct the bias in the approximation of the integral induced by ML prediction errors. Because of the bias correction, the final estimate of the integral is unbiased and has a statistically correct error estimation. Three ML models of multi-layer perceptron, gradient boosting decision tree, and Gaussian process regression algorithms are investigated. The performance of the proposed algorithm is demonstrated on six different families of integrands that typically appear in physics problems at various dimensions and integrand difficulties. The results show that, for the same total number of integrand evaluations, the new algorithm provides integral estimates with more than an order of magnitude smaller uncertainties than those of the VEGAS algorithm in most of the test cases.
Similar content being viewed by others
Introduction
Monte Carlo integration is a numerical method evaluating the integral of an integrand over a finite region using random sampling. As a consequence of the random sampling, in contrast to deterministic methods, the result of the Monte Carlo integration is an estimate of the true value that comes with a statistical uncertainty. For higher-dimensional integral problems, the Monte Carlo integration methods provide smaller uncertainties than deterministic methods, such as the trapezoidal rule1, for a given number of integrand evaluations. As a result, the Monte Carlo integration methods are broadly used in numerous physics calculations that involve numerical integrations2,3,4,5,6.
The most widely used strategies reducing the variance of the Monte Carlo integration estimate are importance sampling and stratified sampling. These strategies are implemented in many algorithms, such as the VEGAS7,8,9 and MISER1. Recently, an idea utilizing generative machine learning (ML) models to perform the importance sampling is also proposed10.
In this paper, we present a novel algorithm numerically evaluating multi-dimensional integrals. The new algorithm involves computations for the training of and prediction with the ML algorithms, in addition to the evaluation of the integrand. Assuming that evaluations of the integrand is computationally much more expensive than the ML calculations, throughout the paper, we focus on reducing the variance of an integral estimate for a given number of integrand evaluations.
Method
Suppose that we have a ML regression model \(\tilde{f}(\mathbf {x})\) that approximates a multi-dimensional function \(f(\mathbf {x}) \approx \tilde{f}(\mathbf {x})\equiv \tilde{y}\). Here \(\mathbf {x}\) is the input vector of the regression model, which is called the independent variable, and \(\tilde{y}\) is the output of the regression model, which is called the dependent variable. The integral of \(f(\mathbf {x})\) over an integration region \(\Omega \in \mathbb {R}^D\) can be split into two integrals.
Here the \(I_\text {(a)}\) is an integration of the ML regression model, which does not require an evaluation of \(f(\mathbf {x})\) to calculate. Depending on the regression model, the integral \(I_\text {(a)}\) may be calculated analytically or numerically. Since \(\tilde{f}(\mathbf {x})\) approximates \(f(\mathbf {x})\), the \(I_\text {(a)}\) provides an approximation of the target integral I. The \(I_\text {(b)}\) in Eq. (2) provides a correction to the bias of the approximation in \(I_\text {(a)}\). The integral can be evaluated using a numerical method, such as the Monte Carlo integration. In the Monte Carlo integration, variance of the \(I_\text {(b)}\) is proportional to
where the second line assumes a good ML regression model that gives \(\text {Var}\big [\tilde{f}(\mathbf {X})\big ] \approx \text {Var}\big [f(\mathbf {X})\big ]\). Therefore, the \(I_\text {(b)}\) can be estimated precisely with a small number of Monte Carlo samples when correlation between \(f(\mathbf {X})\) and \(\tilde{f}(\mathbf {X})\) is high. The total uncertainty of the integral, \(\sigma _I\), can be calculated by combining the errors of the two terms: \(\sigma _I^2 = \sigma _{I_{\text {(a)}}}^2 + \sigma _{I_{\text {(b)}}}^2\). The idea replacing an observable by its approximation with a proper correction term was used in the field of lattice quantum chromodynamics11,12,13. In this paper, we generalize the idea for multi-dimensional integral problems using ML regression algorithms.
Note that the equalities in Eqs. (1) and (2) hold independently of the regression accuracy. When \(\tilde{f}(\mathbf {x})\) poorly approximates \(f(\mathbf {x})\), the \(I_\text {(b)}\) becomes difficult to calculate, and a numerical evaluation of \(I_\text {(b)}\) yields large \(\sigma _{I_{\text {(b)}}}^2\) for a given number of integrand evaluations. Therefore, this approach always provides a correct error estimation with an unbiased expectation value of the integral, provided good integration algorithms for the evaluation of \(I_\text {(a)}\) and \(I_\text {(b)}\). However, a good ML regression model accurately describing the integrand is essential for obtaining the integral estimate with a small statistical uncertainty.
Machine learning models
In this paper, we examine three regression algorithms: Multi-layer Perceptron (MLP), Gradient Boosting Decision Tree (GBDT), and Gaussian Process (GP). MLP is a feedforward artificial neural network that produces outputs from inputs based on multiple layers of perceptrons14. The model is flexibly applicable to various kinds of data and scales well up to a large number of data. GBDT is a sequence of shallow decision trees such that each successive decision tree compensates for the prediction error of its predecessor15,16. The model provides a good regression performance with no complicated tuning of hyperparameters and pre-processing of training data. An integration of the GBDT regression models can be calculated analytically because the model is simply a set of intervals of input variables and their output values10. GP regression is a nonparametric model that finds an optimal covariance kernel function explaining training data17. The model is good at interpolating the observations and works well with a small dataset. Analytic integrability of the regression model depends on kernel choice. For example, in the case of the Radial Basis Function (RBF) kernel, which is one of the most popular kernels in GP, prediction of an input vector is given by the dot product of a Gaussian function of the input vector and a constant vector, as described in Eq. (7), so its analytic integration is given by error functions.
Training data
Building a ML regression model approximating \(f(\mathbf {x})\) requires training samples of \(\{(\mathbf {x}_i, f(\mathbf {x}_i))\}_{i=1}^{N_{\text {train}}}\). To minimize the prediction error for a given number of training data, \(N_{\text {train}}\), it is essential to collect the training samples near the peaks of the function (importance sampling) and where the function changes rapidly (stratified sampling). Such training data can be sampled by utilizing conventional numerical integration algorithms, such as the VEGAS, which includes efficient sampling algorithms based on the importance sampling and stratified sampling. When the peaks of the function are localized, the training samples obtained using VEGAS build a much more accurate ML regression model than those from a uniform sampling method.
Data scaling
Many ML regression algorithms benefit from scaling the dependent variable. Especially when the dependent variable varies by orders of magnitude within the range of interest, which is a typical situation in difficult multi-dimensional integral problems, the data scaling plays a crucial role in obtaining a good regression performance. The most widely used scaling algorithms are min-max scaling and standardization:
where \(y'\) is the scaled variable, \(\text {min}(y)\) and \(\text {max}(y)\) are the minimum and maximum of y, \(\overline{y}\) is the average of y, and \(\sigma _y\) is the standard deviation of y. For the data with large scale variation, however, these scaling methods are dominated by the data of large magnitude and lose sensitivity to the data of small values.
To avoid the scale issue, we use the nth-root scaling defined as
where \(\text {sgn}(y)\) is the sign of y, and n is a positive integer. This is a strictly monotonic transformation whose inverse is \(y = \text {sgn}(y') \cdot |y'|^n\). When n is too small, the transformation will not remove the large scale variation that makes ML algorithms difficult to fit, and when n is too large, the transformation will wash out (or flatten) the information of the data that is essential for training a ML algorithm. Therefore, an optimal choice of n is important in obtaining a good regression model and is different for different ML algorithms. The optimal value of n can be obtained using the training data. Taking a small portion (e.g. 10–50%) of the training data as a validation dataset, one can train a regression model on the remaining training samples with various choices of n and find the optimal value of n that gives the minimum prediction error on the validation dataset. Once the n is determined, a final regression model can be obtained using the full training data.
This nth-root scaling plays a crucial role in building a good regression model for most of the integral problems. In this study, we standardize the y after the nth-root scaling to maximize the regression performance.
Evaluation of \(I_{\text {(a)}}\) and \(I_{\text {(b)}}\)
When \(n=1\), \(I_{\text {(a)}}\) of Eq. (2) can be calculated analytically for certain regression algorithms. When \(n>1\), however, the ML predictions should be processed by the inverse of the nth-root transformation, so the analytic integral becomes complicated. For example, GP regression with a RBF kernel for a nth-root scaled data can be written as
where \(||\mathbf {x}||\) is the Euclidean norm of \(\mathbf {x}\), \(\mathbf {x}_i\) are the training data, and \(\alpha _i\) and l are constants that are determined from the training. To obtain the prediction of the integrand \(\tilde{f}(\mathbf {x})\), the GP regression needs to be transformed as \(\tilde{f}(\mathbf {x}) = \text {sgn}(\tilde{f}'(\mathbf {x})) |\tilde{f}'(\mathbf {x})|^n\). For a positive integrand, the power of n of Eq. (7) can be expanded analytically, but the number of terms is large for large N and n.
For simplicity, we use a numerical method, the VEGAS algorithm, to evaluate \(I_{\text {(a)}}\) and \(I_{\text {(b)}}\). Since the peaks of the \(f(\mathbf {x})\) are flattened by subtracting the \(\tilde{f}(\mathbf {x})\) in the integrand of \(I_{\text {(b)}}\), a simple Monte Carlo integration works well for \(I_{\text {(b)}}\). However, the VEGAS outperforms the simple Monte Carlo integration when the regression is not accurate enough.
Numerical experiments
In this section, we present numerical experiments of the proposed integration algorithm using ML. The precisions of the integral estimates are compared with those of the VEGAS algorithm, which is one of the best performing algorithms on the market18, at a similar number of integrand evaluations.
Test integrands
In order to test the performance of the numerical integration, we use the six families of the integrands proposed in Ref.19 that typically appear in physics problems:
Here, D is the dimension of \(\mathbf {x}\), and \(w_i \in [0, 1)\) is the parameter that is supposed to shift the peaks of the integrand without changing the difficulty of the integral problem. One exception is \(f_6(\mathbf {x})\), as the small value of \(w_1\) or \(w_2\) makes the function to be localized in small region and makes the integral problem difficult. To avoid the unwanted effect, we restrict \(w_i \in [0.1, 0.9)\) for \(f_6(\mathbf {x})\). \(c_i\) is a positive parameter that controls the difficulty of the integral. In general, increasing the value of \(c_i\) increases the difficulty of the integral problem. To fix the difficulty of the integral, we randomly choose \(c_i\) from a uniform distribution in [0, 1) and renormalize the vector by multiplying a constant factor so that \(||\mathbf {c}||_1 = \sum _i |c_i|\) becomes the target constant. In this study, we carry out the integration for 36 different random choices of \(\mathbf {w}\) and \(\mathbf {c}\) and take average performance. To fix the integration difficulty, we normalize \(\mathbf {c}\) to three different values of \(||\mathbf {c}||_1 = 1, 3\), and 8. Integration is performed in a D-dimensional unit hypercube, and the results are compared at three different dimensions of \(D=5, 8\), and 10.
ML regression algorithms and hyperparameters
For the implementation of the MLP, GP, and GBDT regression algorithms, we use the scikit-learn python library20. For MLP, four hidden layers of 128, 128, 128, and 16 neurons with rectified linear unit (ReLU) activation functions are used. Training is performed using Adam optimization algorithm21 with the learning rate of \(10^{-4}\). Training updates are performed until there is no decrease of the validation score with a tolerance of \(10^{-6}\) for 20 epochs with 10% of validation fraction. For GP, RBF with a constant kernel is used, and length scale and constant are determined using L-BFGS-B optimizer22. For GBDT, we use 1000 weak estimators with a learning rate of 0.01 and a subsampling ratio of 0.3. The maximum depth of each decision tree is limited to 4. Note that here we use a relatively large number of estimators with a small subsampling ratio so that the regression output becomes a smooth function in \(\mathbf {x}\). In this proof-of-principal study, we did not explore the extensive phase space of the hyperparameters but took the best solution among the few choices around the default values of the scikit-learn library20 we tried.
The powers of the nth-root scaling \(n \in [1,50]\) for MLP and GP regressions are determined by using 20% of training data as a validation dataset. The performance of the GBDT algorithm is not very sensitive to the scaling but \(n>1\) gives better performance than the \(n=1\) case. So, we use a fixed number \(n=3\) for GBDT regression.
VEGAS setup
For the VEGAS numerical integration, we use Lepage’s VEGAS python library version 3.4.59,23. The library has two damping parameters: \(\alpha \) and \(\beta \). The parameter \(\alpha \) controls the remapping of the integration variables in the VEGAS adaptation. A smaller value gives the slower grid adaption for a conservative estimate. Here, we use \(\alpha =0.5\), which is the default value of the library, for most of the calculations. One exception is the discontinuous integrand family \(f_6(\mathbf {x})\), which is more difficult to evaluate than other integrand families and requires a large number of samples per iteration or slow grid adaptation to converge to the exact integral solution. To make the VEGAS integral stable, we use \(\alpha =0.2\) for \(f_6(\mathbf {x})\). The parameter \(\beta \) controls the redistribution of integrand evaluations in the stratified sampling. \(\beta =1\) is the theoretically optimal value, and \(\beta =0\) means no redistribution. Here, we use \(\beta =0.75\), which is the default value of the library.
Another important parameters are the number of iterations for the VEGAS grid adaptation (\(N_{\text {itn}}\)) and the approximated number of integrand evaluations per iteration (\(N_{\text {eval}}\)). These parameters are set differently for different VEGAS tasks performed in this study: (1) calculation of the target integral I in Eq. (1) for a comparison, (2) sampling the training data, (3) calculation of \(I_{\text {(b)}}\) in Eq. (2), and (4) calculation of \(I_{\text {(a)}}\) in Eq. (2).
-
In task (1), we use \(N_{\text {itn}}=20\) at two different values of \(N_{\text {eval}}=500\), and 1000. When \(\beta =0\), the total number of integrand evaluations will be \(N_{\text {itn}}\times N_{\text {eval}}\). Because of the redistribution that happens when \(\beta >0\), however, the total number of integrand evaluations for this task drops to around \(N \approx N_{\text {itn}}\times N_{\text {eval}}/2\) for the test functions used in this study.
-
In task (2), we use \(N_{\text {itn}}=10\) for the most of the integrand families with the same \(N_{\text {eval}}\) values used in task (1). In this task, all the integrand calls, \(\big (\mathbf {x}, f(\mathbf {x})\big )\), are collected as the ML training data. The total number of integrand evaluations in this task is \(N_{\text {train}} \approx N/2\). Two exceptions are \(f_3(\mathbf {x})\), where we use \(N_{\text {itn}}=14\), and \(f_6(\mathbf {x})\), where we use \(N_{\text {itn}}=6\), which are the choices that stabilize the VEGAS integration of task (3). The choice of \(N_{\text {itn}}\) determines the ratio of the number of integrand evaluations for the training (\(N_{\text {train}})\) and bias correction (\(N_{\text {crxn}}\)). The parameter can be tuned for a given problem so that it minimizes the integral uncertainty. In this proof-of-principal study, however, we take \(N_{\text {itn}}=10\), which makes the ratio \(N_{\text {train}}:N_{\text {crxn}} \approx 1:1\), as our default value and change it only when we find an instability in the VEGAS integration of task (3).
-
In task (3), our target total number of integrand evaluations is \(N - N_{\text {train}}\), so that the total number of integrand evaluations in the ML integrator is the same as that of the VEGAS integration in task (1). To make \(N_{\text {crxn}}\) as close as possible to \(N - N_{\text {train}}\), we set \(N_{\text {eval}} = (N - N_{\text {train}})/5\) with \(\alpha =0.5\) and carry out the VEGAS iterations until the accumulated number of integrand evaluations becomes greater than or equal to \(N - N_{\text {train}}\), saving the results for each iteration, separately. Then, we find the iteration number that gives the accumulated number of integrand evaluations closest to \(N - N_{\text {train}}\) and take the integral estimate at the number of iterations as our final results.
-
In task (4), we use \(N_{\text {itn}}=30\) and set \(N_{\text {eval}}\) to those used in task (1) multiplied by a factor of 1000. We stop the VEGAS iteration when the error of \(I_{\text {(a)}}\) becomes smaller than 20% of the error of \(I_{\text {(b)}}\). In this study, we use a numerical integration method to evaluate \(I_{\text {(a)}}\) so that all results for different integrand families and ML algorithms could be obtained from the same condition. However, a numerical approach requires evaluation of the ML model \(\tilde{f}(\mathbf {x})\), so it provides a cost reduction only when the evaluation of the ML model is cheaper than the evaluation of the target integrand \(f(\mathbf {x})\). We recommend using an analytic approach for the evaluation of \(I_{\text {(a)}}\) whenever it is available. When analytic approach is not available or computationally expensive due to a large scaling power, \(N_{\text {eval}}\) should be tuned considering the evaluation cost of \(\tilde{f}(\mathbf {x})\) and the integral precision required.
VEGAS integral estimates are obtained by taking a weighted average of the estimates from each VEGAS iteration. Whenever the p-value of the weighted average is smaller than 0.05, we discard the results and rerun the VEGAS integration with a different random seed.
Results
Table 1 shows the precision gain of the proposed integration algorithm over VEGAS.
Total number of integrand evaluations of the ML integrator (\(N_{\text {train}}+N_{\text {crxn}}\)) is similar to that of the VEGAS integration (N). The full list of N, \(N_{\text {train}}\), \(N_{\text {crxn}}\), and precision of the integral algorithms are given in Supplementary Tables S1 to S6.
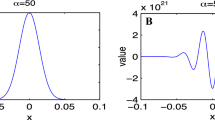
The best performing ML algorithms are GP for the integrand families 1–4, MLP for the integrand family 5, and GBDT for the integrand family 6. Figure 1 clearly explains these results: GP with a RBF kernel shows very good performance in describing smooth functions but fails in \(C^0\) and discontinuous functions. MLP shows mediocre performance for the all functional forms, and GBDT, which is a combination of the discrete decision trees, outperforms the MLP in describing the discontinuous integrands.

Integrands \(f_i(\mathbf {x})\) and their ML predictions \(\tilde{f}_i(\mathbf {x})\) (left), and the prediction errors \({f_i(\mathbf {x}) - \tilde{f}_i(\mathbf {x})}\) (right) for \(N\approx 5000\), D=8, and \(||\mathbf {c}||_1=8.0\). Those are plotted as a function of \(x_1\), while rest of the \(\mathbf {x}\) are fixed to \(x_{i=2,3,\ldots ,8}=0.5\).
For all test cases, the ML integrator performs better than VEGAS. The gain is higher when D is smaller and when \(||\mathbf {c}||_1\) is smaller. Also, the gain tends to be increased when N is larger, which indicates a better scaling behavior than VEGAS. In case of the integrations with the GP regression algorithm, the \(\sigma _I\) of the ML integrator is up to four orders of magnitude smaller than that of VEGAS. When GP is efficiently applied, the difference between the target integrand and its ML prediction is tiny, which makes the value and error of \(I_{\text {(b)}}\) small. As a result, the final error is dominated by the error of \(I_{\text {(a)}}\), which can be improved without increasing the number of \(f(\mathbf {x})\) evaluations. As an example, \(I_{\text {(a)}}\) and \(I_{\text {(b)}}\) of the integrands shown in Fig. 1 are given below:
Since the ML integrator uses VEGAS, it inherits the potential instability of the VEGAS for small \(N_{\text {eval}}\), which introduces a systematic bias in the integration results. In general, the instability can be avoided by increasing N or decreasing the value of \(\alpha \); a detailed description of how to deal with the instability is given in Ref.24. For the ML integrator, the most fragile part is the integration for \(I_{\text {(b)}} = \int (f - \tilde{f})d\mathbf {x}\). When such instability is observed, for a given N, one can increase the ratio of \(N_{\text {train}}\) for a better prediction or increase the ratio of \(N_{\text {crxn}}\) for a more stable integrand evaluation, depending on the integral problem. It is also important to use a ML regression algorithm that yields a smooth \(\tilde{f}(\mathbf {x})\). As shown in the right column of Fig. 1, a non-smooth \(\tilde{f}(\mathbf {x})\), such as the one from GBDT, makes \(f(\mathbf {x})-\tilde{f}(\mathbf {x})\) highly oscillating and the integral difficult to evaluate. Among the three regression algorithms used in this study, we find that the smooth prediction of GP gives the most stable integration for \(I_{\text {(b)}}\). To check the instability, we do not manually tune the integration parameters for each integral problem but use a general setting for most of the calculations. As a result, we could observe a few integral results deviating from the true answer by more than \(4\sigma \), mostly in case the integral families 3 and 6. It shows that the ML integrator is more stable than VEGAS for the integral family 6, but less stable for the integral family 3 mainly due to the non-smooth prediction of the MLP and GBDT. Since the number of more than \(4\sigma \) deviations is small compared to the total number of random samples, inclusion of those occurrences does not change the average results, so we did not exclude those occurrences from our average results. The number of more than \(4\sigma \) deviations for each integral problem is given in Supplementary Tables S1 to S6.
Table 2 gives a comparison of the training and prediction cost of the wallclock time for different ML models. For the prediction cost, we measure the regression wallclock time of trained models on \(10^5\) random samples. It shows that training a ML algorithm is much more expensive than making predictions using a trained ML model. It also shows that GP is more expensive than MLP and GBDT. Note that the ML training and prediction costs can be reduced significantly by changing the model parameters at the cost of slightly worse prediction ability. For example, MLP cost can be reduced by increasing the learning rate and lowering the number of epochs, or by reducing the neural network size. The GBDT cost also can be reduced by lowering the number of weak estimators. The main reason for the expensive cost of GP is its computational complexity of \(\mathcal {O}(N_{\text {train}}^3)\), and it can be improved by using scalable variants of the GP25. Also, note that all timing measurements are done with the ML implementations in the scikit-learn library. The cost comparison could be changed with the faster implementations dedicated for each ML algorithm, such as the PyTorch26, XGBoost27, and GPflow28.
Conclusion
In this paper, we proposed a novel algorithm calculating multi-dimensional integrals using ML regression algorithms. In this algorithm, a ML regression model is trained to mimic the target integrand and is used to estimate an approximated integral. Any bias of the estimate induced by the ML prediction error is corrected by using a bias correction term, as described in Eq. (2), so that the final integral result could have a statistically correct estimation of the uncertainty. Two essential prescriptions for obtaining a good the training efficiency are (1) collecting training samples using the VEGAS algorithm, and (2) scaling the training data using the nth-root scaling defined in Eq. (6).
The performance of the proposed ML integrator is compared with that of the VEGAS algorithm on six different integrand families listed in Eq. (8). Three ML regression algorithms of MLP, GBDT, and GP are examined, and the best performing algorithm is selected for each integrand family. For all test cases, the ML integrator shows better performance than the VEGAS for a given total number of integrand evaluations. In most of the cases, the ML integrator is able to provide integration results with more than an order of magnitude smaller uncertainty than the VEGAS algorithm. The performance gain is presented in Table 1.
In this study, we compared the precision of the algorithms for a fixed number of integrand evaluations, ignoring the computational cost used for the ML training and predictions. Depending on the ML algorithm, when the ML cost is very expensive, the application of this algorithm could be limited to the problems whose integrand is expensive to evaluate, such as the problems reported in Ref.6. To make the algorithm applicable to a wider class of problems, a study of cost effective ML regression models will be needed in the future.
We find that the performance and the stability of the proposed algorithm largely depend on the smoothness of the regression output. Developing a ML algorithm specifically targeting the ML integrator will be able to improve the performance and stability of the algorithm. One possible approach is to augment the training data by adding a small amount of noise to the training data29,30, which could improve the smoothness of the MLP and GBDT models. We also find that the GP regression algorithm with a RBF kernel fails in describing \(C^0\) and discontinuous functions because of the singular points in the integrands. For a given integrand with known such singular points, one would be able to build a combination of multiple GP models defined on each domain divided by the singular points for a better performance. It will be also promising to explorer different types of kernels31 and to develop a hybrid model of decision tree and GP that can be generically applicable for such integrands.
References
Press, W. H., Teukolsky, S. A., Vetterling, W. T. & Flannery, B. P. Numerical Recipes 3rd Edition: The Art of Scientific Computing 3rd edn. (Cambridge University Press, Cambridge, 2007).
Melnikov, K. & Petriello, F. Phys. Rev. D 74, 114017. https://doi.org/10.1103/PhysRevD.74.114017 (2006). arXiv:hep-ph/0609070.
Gavin, R., Li, Y., Petriello, F. & Quackenbush, S. Comput. Phys. Commun. 182, 2388. https://doi.org/10.1016/j.cpc.2011.06.008 (2011). arXiv:1011.3540 [hep-ph].
Denner, A. & Dittmaier, S. Nucl. Phys. B 734, 62. https://doi.org/10.1016/j.nuclphysb.2005.11.007 (2006). arXiv:hep-ph/0509141.
Taruya, A., Nishimichi, T. & Bernardeau, F. Phys. Rev. D 87, 083509. https://doi.org/10.1103/PhysRevD.87.083509 (2013). arXiv:1301.3624 [astro-ph.CO].
Sievert, M. D., Vitev, I. & Yoon, B. Phys. Lett. B 795, 502. https://doi.org/10.1016/j.physletb.2019.06.019 (2019). arXiv:1903.06170 [hep-ph].
Peter Lepage, G. J. Comput. Phys. 27, 192. https://doi.org/10.1016/0021-9991(78)90004-9 (1978).
Lepage, G. P. VEGAS—an adaptive multi-dimensional integration program, Technical Report CLNS-447 (Cornell University Laboratory of Nuclear Studies, Ithaca, NY, 1980). http://cds.cern.ch/record/123074
Lepage, G. P. J. Comput. Phys. 439, 110386. https://doi.org/10.1016/j.jcp.2021.110386 (2021). arXiv:2009.05112 [physics.comp-ph].
Bendavid, J. (2017). arXiv:1707.00028 [hep-ph]
Bali, G. S., Collins, S. & Schafer, A. Comput. Phys. Commun. 181, 1570. https://doi.org/10.1016/j.cpc.2010.05.008 (2010). arXiv:0910.3970 [hep-lat].
Blum, T., Izubuchi, T. & Shintani, E. Phys. Rev. D 88, 094503. https://doi.org/10.1103/PhysRevD.88.094503 (2013). arXiv:1208.4349 [hep-lat].
Yoon, B., Bhattacharya, T. & Gupta, R. Phys. Rev. D 100, 014504. https://doi.org/10.1103/PhysRevD.100.014504 (2019). arXiv:1807.05971 [hep-lat].
Rojas, R. Neural Networks: A Systematic Introduction (Springer, Berlin, 1996).
Breiman, L., Friedman, J., Stone, C., & Olshen, R. Classification and Regression Trees, The Wadsworth and Brooks-Cole statistics-probability series (Taylor & Francis, 1984). https://books.google.com/books?id=JwQx-WOmSyQC
Friedman, J. H. Ann. Stat. 29, 1189. https://doi.org/10.1214/aos/1013203451 (2001).
Rasmussen, C. & Williams, C. Gaussian Processes for Machine Learning, Adaptive Computation and Machine Learning 248 (MIT Press, Cambridge, 2006).
Hahn, T. Comput. Phys. Commun. 168, 78. https://doi.org/10.1016/j.cpc.2005.01.010 (2005). arXiv:hep-ph/0404043.
Genz, A. A package for testing multiple integration subroutines. In Numerical Integration: Recent Developments, Software and Applications (eds Keast, P. & Fairweather, G.) 337–340 (Springer, Netherlands, 1987). https://doi.org/10.1007/978-94-009-3889-2_33.
Pedregosa, F. et al. J. Mach. Learn. Res. 12, 2825 (2011).
Kingma, D. P., & Ba, J. Adam: A method for stochastic optimization (2014). cite arxiv:1412.6980Comment: Published as a conference paper at the 3rd International Conference for Learning Representations, San Diego, 2015 arXiv:1412.6980
Byrd, R., Lu, P., Nocedal, J. & Zhu, C. SIAM J. Sci. Comput. 16, 1190. https://doi.org/10.1137/0916069 (1995).
Lepage, P. gplepage/vegas: vegas version 3.4.5 (2020a). https://doi.org/10.5281/zenodo.3897199
Lepage, P. vegas Documentation (2020b). https://vegas.readthedocs.io/en/latest/index.html
Liu, H., Ong, Y.-S., Shen, X., & Cai, J. When gaussian process meets big data: A review of scalable gps (2019). arXiv:1807.01065 [stat.ML]
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., L. Fang, Bai, J., & Chintala, S. In Advances in Neural Information Processing Systems 32, edited by Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R. 8024–8035 (Curran Associates, Inc., 2019). http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf
Chen, T. & Guestrin, C. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16 ( ACM 785–794 (New York, NY, USA, 2016).
Matthews, A.G. d.G., van der Wilk, M., Nickson, T., Fujii, K., Boukouvalas, A., León-Villagrá, P., Ghahramani, Z., & Hensman, J. GPflow: A Gaussian Process Library using TensorFlow. J. Mach. Learn. Res. 18, 1. http://jmlr.org/papers/v18/16-537.html (2017).
Holmstrom, L. & Koistinen, P. IEEE Trans. Neural Netw. 3, 24 (1992).
An, G. Neural Comput 8, 643 (1996).
Schulz, E., Speekenbrink, M. & Krause, A. J. Math. Psychol. 85, 1. https://doi.org/10.1016/j.jmp.2018.03.001 (2018).
Acknowledgements
Computations were carried out using Institutional Computing at Los Alamos National Laboratory. This work was supported by the U.S. Department of Energy, Office of Science, Office of High Energy Physics under Contract No. 89233218CNA000001, and the LANL LDRD program.
Author information
Authors and Affiliations
Contributions
B.Y. designed the research, conducted numerical experiments, and wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The author declares no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yoon, B. A machine learning approach for efficient multi-dimensional integration. Sci Rep 11, 18965 (2021). https://doi.org/10.1038/s41598-021-98392-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-98392-z
- Springer Nature Limited
This article is cited by
-
High-precision regressors for particle physics
Scientific Reports (2024)