
Abstract
In this study, the influence of different volume fractions (\(\phi\)) of nanoparticles and temperatures on the dynamic viscosity (\(\mu_{nf}\)) of MWCNT–Al2O3 (30–70%)/oil SAE40 hybrid nanofluid was examined by ANN. For this reason, the \(\mu_{nf}\) was derived for 203 various experiments through a series of experimental tests, including a combination of 7 different \(\phi\), 6 various temperatures, and 5 shear rates. These data were then used to train an artificial neural network (ANN) to generalize results in the predefined ranges for two input parameters. For this reason, a feed-forward perceptron ANN with two inputs (T and \(\phi\)) and one output (\(\mu_{nf}\)) was used. The best topology of the ANN was determined by trial and error, and a two-layer with 10 neurons in the hidden layer with the tansig function had the best performance. A well-trained ANN is created using the trainbr algorithm and showed an MSE value of 4.3e−3 along 0.999 as a correlation coefficient for predicting \(\mu_{nf}\). The results show that an increase \(\phi\) has a significant effect on \(\mu_{nf}\) value. As \(\phi\) increases, the viscosity of this nanofluid increases at all temperatures. On the other hand, with increasing temperature, the viscosity of this nanofluid decreases. Based on all of the diagrams presented for the trained ANNs, we can conclude that a well-trained ANN can be used as an approximating function for predicting the \(\mu_{nf}\).
Similar content being viewed by others

Introduction
Today, the issue of heat transfer in power plants and industries has become a major challenge1,2,3,4,5,6,7. Researchers are always looking to increase the efficiency of heating equipment with different methods8,9,10. Nanofluids are one of the newest and best ways to improve the thermal performance of fluid systems. Choi11 first coined the term nanofluid to describe very small particles (nanoparticles less than 100 nm in diameter) suspended in a fluid. In nanofluids, one or more solid particles are added to the fluid, which increases the rate of heat transfer and change in viscosity12, 13. Some nanoparticles are in the form of oxides and play an important role in the dispersion and suspension of fluid, and some are in the form of non-oxide metal particles14,15,16. One of the main properties of fluids is viscosity. Viscosity can be mentioned as the inhibitory force and the magnitude of the frictional properties of the fluid17. In addition, viscosity is a function of temperature and pressure18. Fluid viscosity is commonly used for engineering designs and the definition of dimensionless numbers such as Reynolds and Prandtl19. In addition, fluid viscosity is used to calculate the required power of pumps, mixing processes, piping systems, liquid pulverization, fluid storage, fluid injection, and fluid transport20. Hybrid nanofluids combine two heterogeneous nanoparticles (hybrid nanocomposites) suspended in the base fluid21,22,23,24. The purpose of using hybrid nanocomposites in an intermediate fluid is to improve the heat transfer characteristics of the base fluid through the combined thermophysical characteristics of effective nanomaterials25,26,27,28. In recent years, various fluids such as water, ethylene glycol, and various oils were used as operating fluids in industry and engineering design. Given the growing need for cooling systems with high heat losses due to viscosity changes, scientists and researchers have been encouraged to achieve fluids with higher heat transfer properties (increased heat transfer rate) and effective viscosity over temperature. The amount of viscosity in nanofluid design is very critical for fluid flow29. Due to pressure drops in the pump, fluid concentration is known to be important in industrial applications. In the last decade, researchers have presented various researches on thermophysical parameters (temperature, particle size φ, shape, size, impact of time or agglomeration, μnf, and base fluids) and transverse theoretical and laboratory relations30, 31. The knowledge of predicting the test process is a powerful tool for engineers who want to design and produce their products with excellent quality and the lowest cost. Therefore, ANNs are considered computational methods in artificial intelligence systems and new computational methods to predict the output responses of complex systems32,33,34,35. The main idea of such ANNs is, to some extent (inspired by how the biological neural system works to process data and information to learn and create knowledge. The key element of this idea is to create new structures for the information processing system. Many super-interconnected processing elements called neurons have formed to solve problems and transmit information through synapses (electromagnetic communication). ANNs are among the most advanced and modern methods in simulation36,37,38. Today, they have been widely used in all engineering sciences as a powerful tool in simulating phenomena whose conceptual analysis is difficult. In this method, the observational data is taught to the model, and after training the model, it performs forecasting and simulation work with appropriate accuracy. In recent years, researchers have used ANNs to predict the thermal conductivity of nanofluids and determine the appropriate μnf39,40,41,42,43,44. For example, Miao et al.45 used ANNs to predict the μnf of a mixture of ethanol and methanol over a temperature range. The results show that the ANN model predicts the μnf of the compound with great accuracy. Yousefi et al.46 investigated the viscosities of metal oxides such as SiO2, Al2O3, CuO and TiO2 suspended in ethanol and water by the ANN method. The predicted results were in good agreement with the experimental results obtained. Therefore, this method is suitable for estimating the μnf of nanofluids containing metal oxide. Atashrouz et al.47 predicted the μnf of SiO2, Al2O3, CuO, and TiO2 nanofluids suspended on water, ethylene glycol, and propylene glycol by ANNs. The results show that this method is suitable for predicting the \(\mu_{nf}\). Zhao et al.48 investigated the μnf of Al2O3 and CuO metal oxides water- suspended by ANNs. The predicted results were in good agreement with the experimental values obtained. Esfe et al.49 predicted the \(\mu_{nf}\) of Fe/EG nanofluids by the ANN method. The predicted results are in good agreement with the experimental values obtained. Therefore, this method is very efficient in predicting the \(\mu_{nf}\). Studies show that the prediction of \(\mu_{nf}\) using ANNs is not very old and is being addressed by researchers. Therefore, this manuscript analyzed the influence of different φ alongside variable temperatures on μnf of MWCNT–Al2O3 (30–70%)/oil SAE40 hybrid nanofluid. For this reason, the \(\mu_{nf}\) has been derived for 203 various experiments through a series of experimental tests, including a combination of 7 different \(\phi\), 6 various temperatures, and 5 shear rates. These data were then used to train an ANN to generalize results in the predefined ranges for two input parameters. For this reason, a feed-forward Perceptron ANN with two inputs (T and \(\phi\)) and one output (\(\mu_{nf}\)) was used. The best topology of the ANN was determined by trial and error, and a two-layer with 10 neurons in the hidden layer with the tansig function had the best performance.
As observed in the literature, the use of post-processing methods such as artificial neural networks, response surface and optimization methods in various sciences, including nanofluid science has been very welcomed. The reason for this welcome is the reduction of time and financial costs in laboratory studies. However, the use of artificial neural networks and other post-processing methods to predict the behavior of nanofluids requires access to valid laboratory results. Hemmat Esfe Research Group is one of the active groups in the field of laboratory studies of nanofluids, which has provided more than 200 valuable experimental databases for other researchers to perform post-processing studies on various thermophysical properties of normal and hybrid nanofluids50,51,52,53,54,55,56. Feasibility studies of this research group in the field of application of nanofluids in increasing oil extraction57,58 and also the use of nanofluids in lubricants in order to minimize the damage caused by cold start of the car engine59,60,61 are other activities of this group.
ANN configuration
An ANN is a powerful tool for processing raw data inspired by human brain structure and consists of many neurons that collaborate to model a system62. The configuration of ANNs is made up of several weighted elements. The nodes are the artificial neurons, and the directional arrows and the weights show the relationship between the outputs and the inputs of the neurons. ANNs are categorized into two groups based on their morphology: The first category is called feed-forward ANN, and the latter is called the recurrent ANNs. According to the experimental data in this study that are static and that feed-forward ANNs have high potential in function estimation, a feed-forward perceptron ANN has been used. The relationship between input and output data is nonlinear; therefore, a multilayer Perceptron ANN should simulate this nonlinear relationship. Accordingly, in this study, the network is constructed of two layers with nonlinear functions. This configuration has proven accuracy in function approximation in different studies. The backpropagation algorithms are efficient and effective; hence, several methods in this ANN training scheme are used, and their performance is compared. Different ANNs with various neuron numbers and transfer functions in the hidden layer have been examined. The best topology was determined by trial and error and minimizing the ANN error. The best results were obtained using 10 neurons in the second layer with hyperbolic tangent function and linear function in the output layer. A graph of a typical multilayer ANN is presented in Fig. 1 alongside different inputs and outputs.

A multilayer perceptron ANN graph alongside inputs and outputs data.
For training an ANN, the first step is to create a database of experimental or simulation patterns to feed the network for learning. To this end, 203 different samples in terms of temperature and \(\phi\) were prepared for MWCNT–Al2O3 (30–70%)/oil SAE40 hybrid nanofluid. Usually, the raw data is divided into 70% for training, 15% for validation, and 15% for testing. The validation data prevents the ANN from overtraining using Early stop and generalizes the ANN results. In this study, 203 samples were gained from 7 different \(\phi\), 6 various temperatures, and 5 shear rates. The experimental data used for training the ANN is shown in Table 1.
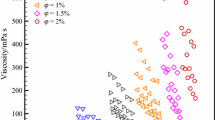
The deviation of \(\mu_{nf}\) and its range is presented in Fig. 2 based on different temperatures, in Fig. 3 versus \(\phi\), and Fig. 4 based on various shear rates.

\(\mu_{nf}\) deviation based on temperature values.

\(\mu_{nf}\) variation versus \(\phi\).

The \(\mu_{nf}\) variation versus shear rate.
The first step in using ANN is to train the ANN with 70% of the training data and assess the ANN training status; then, the 15% of data that is not used for training is fed, and their performance is computed using the comparison between true and true values and real ANN output. The ANN with the highest performance (the lowest error level) is chosen as the best ANN for the simulation of the system. Due to the random nature of training weights of the ANN, each ANN is trained 50 times from random with each training method, and the model with the highest performance is chosen as a model for the system. As indicated previously, determining the number of neurons in the hidden layer has an important influence on the modeling performance; hence various topologies (number of neurons in hidden layer and transfer function) were considered for each ANN, and the best combination is determined trial and error. The best performance is obtained using 10 neurons with tangent-hyperbolic sigmoid function in the second and linear transfer output layer. Detailed information on ANN configuration is shown in Table 2.
Training methods
One novelty of this study is to obtain the more effective method for ANN training which is more robust and has the highest performance in μnf estimation. For this reason, several training methods for feed-forward perceptron ANNs have been used in MATLAB software (Stable release: R2021a/March 17, 2021)63,64,65,66,67,68. The error value for each method alongside other information (including function name in MATLAB and the method e explanation) are gathered in Table 3. Moreover, a detailed comparison of different training methods' error rates is presented in Fig. 5.

A comparison of error value for different training methods in MATLAB.
The presented mean square error (MSE) between the actual output and target values for the various forward-based training methods. Other methods have also been reviewed, which have been omitted due to inconsistencies with the physics of the problem and non-convergence of the answers. Among the applied training methods, the trainbr method showed to be the best training method for this problem due to the highest performance; therefore, this method will be explained and analyzed in the form of Regression and Performance graphs.
Trained ANN performance
One of the most important indexes showing the training state of an ANN is the Performance graph, which presents the variation of MSE versus training stages. The performance chart of \(\mu_{nf}\) is viewed in Fig. 6 for MWCNT–Al2O3 (30–70%)/oil SAE40 nanofluid. The MSE in the vertical axis is presented in this chart versus training iteration on the horizontal axis (Epoch). Three different data, including Training, Validation, and Test, are observed in this figure representing MSE for the trained points, validation, and test points, respectively. At the first training stage, that ANN has random weights, the MSE value is at the highest level, while after several iterations of training, it is reduced. In this figure, the MSE value for training data is much lower than the rest (validation and test) at the stop iteration. This is the effect of the Early stop strategy for preventing overlearning and displays that the untrained new points have higher MSE rates than trained points fed to the system. The best stop time for the highest performance is indicated with a green circle in the figure, with the lowest MSE in the total iterations. As there are 50 different ANNs for each training scheme, the ANN with the least MSE is the best solution to estimate the μnf for any combination of inputs.

Performance diagram of μnf output.
Another indicator to determine the ANN training state is the Regression diagram and the correlation factor between the actual output data and the target values. This diagram is presented in Fig. 7 for \(\mu_{nf}\) and shows the correspondence of real ANN outputs and desired values. The horizontal axis corresponds to target values in this graph, while the vertical axis shows the ANN output. In this figure, three different parameters are important. These indexes include correlation coefficient value (R), slope value (M), and bias (B). An ideal ANN must have the same output as target values, and in this condition, the correlation value and slope are equal to 1, and the bias value should be equal to 0. It can be seen that in all four graphs, the slope of the regression line is almost equal to 1; hence it can be deduced that the results are output values of the ANN that have satisfactory accuracy and are sufficiently close to target values. Moreover, the scattering style of points is at a minimum level, and all of the points are located on the bisector of the plane.

Regression diagram for \(\mu_{nf}\) output.
In Table 4, the error rate of trained ANNs is presented for \(\mu_{nf}\), and it is noticeable that the error value is very low and has an acceptable margin.
The error diagram of different experimental data of \(\mu_{nf}\) is presented in Fig. 8. It indicates that the frequency of zero-range error values is very high, proving that the ANN is well trained and creates a good estimation for \(\mu_{nf}\).

Experimental data error value for \(\mu_{nf}\).
Another important clue for a well-trained ANN is a histogram error value, as shown in Fig. 9. The histogram chart depicts the frequency or count of errors in different error margins in a bar chart. Therefore, the frequency of errors in the vertical axis is presented versus different error margin values in the horizontal axis. The more near-zero frequencies, the more accurate ANN. In this figure, the Zero Error line is indicated by red color. It is seen that most bins with a high frequency of errors are gathered around this line, which is affirmative proof of a suitable choice of training method and its acceptable outcome.

The ANN error histograms for \(\mu_{nf}\).
Another comparison between actual data and ANN outputs is presented in Fig. 10 for \(\mu_{nf}\). As shown in Fig. 10, a very good agreement between these data can be seen, which shows proper ANN training.

Comparison of ANN outputs and target values for \(\mu_{nf}\).
Analyzing untrained data
Another comparison chart is presented in 3D space for \(\mu_{nf}\) versus temperature and \(\phi\) to investigate the trained ANN's appropriateness for predicting \(\mu_{nf}\) for untrained data (see Fig. 11).

3D graph of \(\mu_{nf}\).
This graph shows the ANN output for untrained points in colored mesh, while the trained points are depicted with red stars. Thus, we can see that the stars are located on the 3D surface, and a close correspondence exists between trained ANN results for untrained data and the target values. Based on all of the diagrams presented for the trained ANNs, we can conclude that a well-trained ANN can be used as an approximating function for predicting \(\mu_{nf}\). In addition, the \(\phi\) has a more significant influence on \(\mu_{nf}\) value in contrast to a temperature which has a negligible effect on the output values.
Conclusion
In summary, the dynamic viscosity of MWCNT–Al2O3/oil SAE40 nanofluid is investigated at different nanoparticle percentages and temperatures by ANN. In this study, the best topology of the ANN was determined by trial and error, and a two-layer with 10 neurons in the hidden layer with the tansig function had the best performance. Also, to analyze the effect of various training algorithms on the performance of \(\mu_{nf}\) prediction, 10 different training functions were used. The results show that a well-trained ANN is created using the trainbr algorithm and showed an MSE value of 4.3e−3 along 0.999 as a correlation coefficient for predicting \(\mu_{nf}\). To parameters of nanoparticle percentages and temperatures have a significant effect on the dynamic viscosity. Therefore, an increase \(\phi\) has an impressive growth of \(\mu_{nf}\) value for all temperatures. And by increasing the temperature, the \(\mu_{nf}\) will decrease for all various \(\phi\). At the same time, this decrement is more noticeable in higher \(\phi\). For example, an increase of the temperature from 25 to 50 °C changes the μnf of the pure fluid by only about 200%, while the same changes of temperature in \(\phi\) = 1% will cause a 350% drop in μnf. The academic community and industrial society can use the obtained data in the present manuscript to find the optimal condition in the preparation and production of nanofluids to reduce the energy consumption of industrial instruments. As a suggestion, we recommend using other configuration of neural networks including GMDH network and comparing the obtained results in this paper with the ones obtained through other methods. Moreover, implementation of experiments with other parameters or the same parameters used in this manuscript with other margins is highly recommended for better understanding of this hybrid nano-fluid.
References
Karim, S. H. T., Tofiq, T. A., Shariati, M., Rad, H. N. & Ghasemi, A. 4E analyses and multi-objective optimization of a solar-based combined cooling, heating, and power system for residential applications. Energy Rep. https://doi.org/10.1016/j.egyr.2021.03.020 (2021).
Cao, Y., Rad, H. N., Jamali, D. H., Hashemian, N. & Ghasemi, A. A novel multi-objective spiral optimization algorithm for an innovative solar/biomass-based multi-generation energy system: 3E analyses, and optimization algorithms comparison. Energy Convers. Manag. https://doi.org/10.1016/j.enconman.2020.112961 (2020).
Talebizadehsardari, P. et al. Energy, exergy, economic, exergoeconomic, and exergoenvironmental (5E) analyses of a triple cycle with carbon capture. J CO2 Util. https://doi.org/10.1016/j.jcou.2020.101258 (2020).
Golkar, B. et al. Determination of optimum hybrid cooling wet/dry parameters and control system in off design condition: Case study. Appl. Therm. Eng. https://doi.org/10.1016/j.applthermaleng.2018.12.017 (2019).
Shayesteh, A. A., Koohshekan, O., Ghasemi, A., Nemati, M. & Mokhtari, H. Determination of the ORC-RO system optimum parameters based on 4E analysis; water–energy-environment nexus. Energy Convers. Manag. https://doi.org/10.1016/j.enconman.2018.12.119 (2019).
Ghasemi, A., Heydarnejhad, P. & Noorpoor, A. A novel solar-biomass based multi-generation energy system including water desalination and liquefaction of natural gas system: Thermodynamic and thermoeconomic optimization. Clean. Prod. https://doi.org/10.1016/j.jclepro.2018.05.160 (2018).
Noorpoor, A., Heidarnejad, P., Hashemian, N. & Ghasemi, A. A thermodynamic model for exergetic performance and optimization of a solar and biomass-fuelled multigeneration system. Energy Equip. Syst. https://doi.org/10.22059/ees.2016.23044 (2016).
Salehi, A., Karbassi, A., Ghobadian, B., Ghasemi, A. & Doustgani, A. Simulation process of biodiesel production plant. Environ. Prog. Sustain. Energy https://doi.org/10.1002/ep.13264 (2019).
Heidarnejad, P. Exergy based optimization of a biomass and solar fuelled CCHP hybrid seawater desalination plant. J. Therm. Eng. https://doi.org/10.18186/thermal.290251 (2017).
Cao, Y. et al. The economic evaluation of establishing a plant for producing biodiesel from edible oil wastes in oil-rich countries: Case study Iran. Energy https://doi.org/10.1016/j.energy.2020.118760 (2020).
Choi, S. U. & Eastman, J. A. Enhancing Thermal Conductivity of Fluids with Nanoparticles (Argonne National Lab., 1995).
Mahbubul, I., Saidur, R. & Amalina, M. Latest developments on the viscosity of nanofluids. Int. J. Heat Mass Transf. 55(4), 874–885 (2012).
Mishra, P. C., Mukherjee, S., Nayak, S. K. & Panda, A. A brief review on viscosity of nanofluids. Int. Nano Lett. 4(4), 109–120 (2014).
Patel, H. E., Sundararajan, T. & Das, S. K. An experimental investigation into the thermal conductivity enhancement in oxide and metallic nanofluids. J. Nanoparticle Res. 12(3), 1015–1031 (2010).
Kleinstreuer, C. & Feng, Y. Experimental and theoretical studies of nanofluid thermal conductivity enhancement: A review. Nanoscale Res. Lett. 6(1), 1–13 (2011).
Mahmoud, E. E., Algehyne, E. A., Alqarni, M., Afzal, A. & Ibrahim, M. Investigating the thermal efficiency and pressure drop of a nanofluid within a micro heat sink with a new circular design used to cool electronic equipment. Chem. Eng. Commun. https://doi.org/10.1080/00986445.2021.1935254 (2021).
Karimi, H., Yousefi, F. & Rahimi, M. R. Correlation of viscosity in nanofluids using genetic algorithm-neural network (GA-NN). Heat Mass Transf. 47(11), 1417–1425 (2011).
Thomas, S. & Sobhan, C. A review of experimental investigations on thermal phenomena in nanofluids. Nanoscale Res. Lett. 6, 377 (2011).
Mansouri, S. & Heywood, J. B. Correlations for the viscosity and Prandtl number of hydrocarbon-air combustion products. Combust. Sci. Technol. 23(5–6), 251–256 (1980).
Arasteh, H., Mashayekhi, R., Toghraie, D. et al. Optimal arrangements of a heat sink partially filled with multilayered porous media employing hybrid nanofluid. J. Therm. Anal. Calorim. 137, 1045–1058. https://doi.org/10.1007/s10973-019-08007-z (2019).
Martys, N. S., George, W. L., Chun, B.-W. & Lootens, D. A smoothed particle hydrodynamics-based fluid model with a spatially dependent viscosity: Application to flow of a suspension with a non-Newtonian fluid matrix. Rheol. Acta 49(10), 1059–1069 (2010).
Lv, Y.-P. et al. Numerical approach towards gyrotactic microorganisms hybrid nanoliquid flow with the hall current and magnetic field over a spinning disk. Sci. Rep. 11(1), 1–13 (2021).
Goodarzi, M., Toghraie, D., Reiszadeh, M. & Afrand, M. Experimental evaluation of dynamic viscosity of ZnO–MWCNTs/engine oil hybrid nanolubricant based on changes in temperature and concentration. J. Therm. Anal. Calorim. 136(2), 513–525 (2019).
Yan, S.-R. et al. The rheological behavior of MWCNTs–ZnO/water–ethylene glycol hybrid non-Newtonian nanofluid by using of an experimental investigation. J. Mater. Res. Technol. 9(4), 8401–8406 (2020).
Sajid, M. U. & Ali, H. M. Thermal conductivity of hybrid nanofluids: A critical review. Int. J. Heat Mass Transf. 126, 211–234 (2018).
Sidik, N. A. C., Jamil, M. M., Japar, W. M. A. A. & Adamu, I. M. A review on preparation methods, stability and applications of hybrid nanofluids. Renew. Sustain. Energy Rev. 80, 1112–1122 (2017).
Das, P. K. A review based on the effect and mechanism of thermal conductivity of normal nanofluids and hybrid nanofluids. J. Mol. Liq. 240, 420–446 (2017).
Zheng, Y. et al. Experimental investigation of heat and moisture transfer performance of CaCl2/H2O-SiO2 nanofluid in a gas–liquid microporous hollow fiber membrane contactor. Int. Commun. Heat Mass Transf. 113, 104533 (2020).
Ibrahim, M. et al. Assessment of economic, thermal and hydraulic performances a corrugated helical heat exchanger filled with non-Newtonian nanofluid. Sci. Rep. 11(1), 1–16 (2021).
Namburu, P., Kulkarni, D., Dandekar, A. & Das, D. Experimental investigation of viscosity and specific heat of silicon dioxide nanofluids. Micro Nano Lett. 2(3), 67–71 (2007).
Nguyen, C. et al. Temperature and particle-size dependent viscosity data for water-based nanofluids–hysteresis phenomenon. Int. J. Heat Fluid Flow 28(6), 1492–1506 (2007).
Kumar, K. & Thakur, G. S. M. Advanced applications of neural networks and artificial intelligence: A review. Int. J. Inf. Technol. Comput. Sci. 4(6), 57 (2012).
Khaze, S. R., Masdari, M. & Hojjatkhah, S. Application of artificial neural networks in estimating participation in elections. arXiv preprint https://arxiv.org/abs.1309.2183 (2013).
Ibrahim, M., Algehyne, E. A., Saeed, T., Berrouk, A. S. & Chu, Y.-M. Study of capabilities of the ANN and RSM models to predict the thermal conductivity of nanofluids containing SiO2 nanoparticles. J. Therm. Anal. Calorim. 145, 1–11 (2021).
Ibrahim, M., Saeed, T., Algehyne, E. A., Khan, M. & Chu, Y.-M. The effects of L-shaped heat source in a quarter-tube enclosure filled with MHD nanofluid on heat transfer and irreversibilities, using LBM: Numerical data, optimization using neural network algorithm (ANN). J. Therm. Anal. Calorim. 144, 1–14 (2021).
Azimi, M., Kolahdooz, A. & Eftekhari, S. A. An optimization on the DIN1. 2080 alloy in the electrical discharge machining process using ANN and GA. J. Mod. Process. Manuf. Prod. 6(1), 33–47 (2017).
Naeimi, A., Loh Mousavi, M. & Eftekhari, A. Optimum designing of forging preform die for the H-shaped parts using backward deformation method and neural networks algorithm. J. Mod. Process. Manuf. Prod. 3(3), 79–96 (2014).
Toghraie, D., Sina, N., Jolfaei, N. A., Hajian, M. & Afrand, M. Designing an artificial neural network (ANN) to predict the viscosity of silver/ethylene glycol nanofluid at different temperatures and volume fraction of nanoparticles. Phys. A Stat. Mech. Appl. 534, 122142 (2019).
Broomhead, D. S. & Lowe, D. Radial Basis Functions, Multi-variable Functional Interpolation and Adaptive Networks (Royal Signals and Radar Establishment Malvern (United Kingdom), 1988).
Islamoglu, Y. & Kurt, A. Heat transfer analysis using ANNs with experimental data for air flowing in corrugated channels. Int. J. Heat Mass Transf. 47(6–7), 1361–1365 (2004).
Santra, A. K., Chakraborty, N. & Sen, S. Prediction of heat transfer due to presence of copper–water nanofluid using resilient-propagation neural network. Int. J. Therm. Sci. 48(7), 1311–1318 (2009).
Ziaei-Rad, M., Saeedan, M. & Afshari, E. Simulation and prediction of MHD dissipative nanofluid flow on a permeable stretching surface using artificial neural network. Appl. Therm. Eng. 99, 373–382 (2016).
Papari, M. M., Yousefi, F., Moghadasi, J., Karimi, H. & Campo, A. Modeling thermal conductivity augmentation of nanofluids using diffusion neural networks. Int. J. Therm. Sci. 50(1), 44–52 (2011).
Tian, S., Arshad, N. I., Toghraie, D., Eftekhari, S. A. & Hekmatifar, M. Using perceptron feed-forward artificial neural network (ANN) for predicting the thermal conductivity of graphene oxide-Al2O3/water–ethylene glycol hybrid nanofluid. Case Stud. Therm. Eng. 26, 101055 (2021).
Miao, Y., Gan, Q. & Rooney, D. Artificial neural network model to predict compositional viscosity over a broad range of temperatures. In 2010 IEEE International Conference on Intelligent Systems and Knowledge Engineering. 668–673 (IEEE, 2010).
Yousefi, F., Karimi, H. & Papari, M. M. Modeling viscosity of nanofluids using diffusional neural networks. J. Mol. Liq. 175, 85–90 (2012).
Atashrouz, S., Pazuki, G. & Alimoradi, Y. Estimation of the viscosity of nine nanofluids using a hybrid GMDH-type neural network system. Fluid Phase Equilib. 372, 43–48 (2014).
Zhao, N., Wen, X., Yang, J., Li, S. & Wang, Z. Modeling and prediction of viscosity of water-based nanofluids by radial basis function neural networks. Powder Technol. 281, 173–183 (2015).
Esfe, M. H., Saedodin, S., Sina, N., Afrand, M. & Rostami, S. Designing an artificial neural network to predict thermal conductivity and dynamic viscosity of ferromagnetic nanofluid. Int. Commun. Heat Mass Transf. 68, 50–57 (2015).
Esfe, M. H. et al. Thermal conductivity of Cu/TiO2–water/EG hybrid nanofluid: Experimental data and modeling using artificial neural network and correlation. Int. Commun. Heat Mass Transf. 66, 100–104 (2015).
Esfe, M. H., Arani, A. A. A., Rezaie, M., Yan, W. M. & Karimipour, A. Experimental determination of thermal conductivity and dynamic viscosity of Ag–MgO/water hybrid nanofluid. Int. Commun. Heat Mass Transf. 66, 189–195 (2015).
Esfe, M. H., Yan, W. M., Akbari, M., Karimipour, A. & Hassani, M. Experimental study on thermal conductivity of DWCNT-ZnO/water-EG nanofluids. Int. Commun. Heat Mass Transf. 68, 248–251 (2015).
Alirezaie, A., Hajmohammad, M. H., Ahangar, M. R. H. & Esfe, M. H. Price-performance evaluation of thermal conductivity enhancement of nanofluids with different particle sizes. Appl. Therm. Eng. 128, 373–380 (2018).
Esfe, M. H., Arani, A. A. A. & Firouzi, M. Empirical study and model development of thermal conductivity improvement and assessment of cost and sensitivity of EG-water based SWCNT-ZnO (30%: 70%) hybrid nanofluid. J. Mol. Liq. 244, 252–261 (2017).
Esfe, M. H., Bahiraei, M. & Mahian, O. Experimental study for developing an accurate model to predict viscosity of CuO–ethylene glycol nanofluid using genetic algorithm based neural network. Powder Technol. 338, 383–390 (2018).
Esfe, M. H., Raki, H. R., Emami, M. R. S. & Afrand, M. Viscosity and rheological properties of antifreeze based nanofluid containing hybrid nano-powders of MWCNTs and TiO2 under different temperature conditions. Powder Technol. 342, 808–816 (2019).
Esfe, M. H., Esfandeh, S. & Hosseinizadeh, E. Nanofluid flooding for enhanced oil recovery in a heterogeneous two-dimensional anticline geometry. Int. Commun. Heat Mass Transf. 118, 104810 (2020).
Esfe, M. H., Esfandeh, S. & Hosseinizadeh, E. Nanofluid flooding in a randomized heterogeneous porous media and investigating the effect of capillary pressure and diffusion on oil recovery factor. J. Mol. Liq. 320, 113646 (2020).
Esfe, M. H., Esfandeh, S. & Arani, A. A. A. Proposing a modified engine oil to reduce cold engine start damages and increase safety in high temperature operating conditions. Powder Technol. 355, 251–263 (2019).
Esfe, M. H., Arani, A. A. A., Esfandeh, S. & Afrand, M. Proposing new hybrid nano-engine oil for lubrication of internal combustion engines: Preventing cold start engine damages and saving energy. Energy 170, 228–238 (2019).
Esfe, M. H., Arani, A. A. A. & Esfandeh, S. Improving engine oil lubrication in light-duty vehicles by using of dispersing MWCNT and ZnO nanoparticles in 5W50 as viscosity index improvers (VII). Appl. Therm. Eng. 143, 493–506 (2018).
Braspenning, P. J., Thuijsman, F. & Weijters, A. J. M. M. Artificial Neural Networks: An Introduction to ANN Theory and Practice (Springer, 1995).
MacKay, D. J. Bayesian interpolation. Neural Comput. 4(3), 415–447 (1992).
Foresee, F. D., Hagan, M. T. Gauss–Newton approximation to Bayesian learning. In Proceedings of International Conference on Neural Networks (ICNN'97), vol. 3, 1930–1935 (IEEE, 1997).
Powell, M. J. D. Restart procedures for the conjugate gradient method. Math. Program. 12(1), 241–254 (1977).
Gill, P. E., Murray, W. & Wright, M. H. Practical Optimization (SIAM, 2019).
Møller, M. F. A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw. 6(4), 525–533 (1993).
Riedmiller, M. & Braun, H. A direct adaptive method for faster backpropagation learning: The RPROP algorithm. In IEEE International Conference on Neural Networks. 586–591 (IEEE, 1993).
Author information
Authors and Affiliations
Contributions
All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Esfe, M.H., Eftekhari, S.A., Hekmatifar, M. et al. A well-trained artificial neural network for predicting the rheological behavior of MWCNT–Al2O3 (30–70%)/oil SAE40 hybrid nanofluid. Sci Rep 11, 17696 (2021). https://doi.org/10.1038/s41598-021-96808-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-96808-4
- Springer Nature Limited
This article is cited by
-
Performance Prediction of Aluminum Oxide, Silicon Oxide, and Copper Oxide as Nanoadditives Across Conventional, Semisynthetic, and Synthetic Lubricating Oils Using ANN
Arabian Journal for Science and Engineering (2024)
-
Examining rheological behavior of CeO2-GO-SA/10W40 ternary hybrid nanofluid based on experiments and COMBI/ANN/RSM modeling
Scientific Reports (2022)
-
Comprehensive investigations of mixed convection of Fe–ethylene-glycol nanofluid inside an enclosure with different obstacles using lattice Boltzmann method
Scientific Reports (2021)