
Abstract
Although hypoxia is a critical factor that can drive the progression of various diseases, the mechanism underlying hypoxia itself remains unclear. Recently, m6A has been proposed as an important factor driving hypoxia. Despite successful analyses, potential genes were not selected with statistical significance but were selected based solely on fold changes. Because the number of genes is large while the number of samples is small, it was impossible to select genes using conventional feature selection methods with statistical significance. In this study, we applied the recently proposed principal component analysis (PCA), tensor decomposition (TD), and kernel tensor decomposition (KTD)-based unsupervised feature extraction (FE) to a hypoxia data set. We found that PCA, TD, and KTD-based unsupervised FE could successfully identify a limited number of genes associated with altered gene expression and m6A profiles, as well as the enrichment of hypoxia-related biological terms, with improved statistical significance.
Similar content being viewed by others


Introduction
Hypoxia1, also known as tissue hypoxia, is a serious symptom with various causes. For example, hypoxia could result in death, such as in the case of COVID-19, a serious pandemic2. Hypoxia also plays a critical role in cancer3. Both brain hypoxia4 and lung cell hypoxia5 can be fatal. Despite the significance of hypoxia, the critical factors of hypoxia are not yet fully understood6. Recently, m6A was reported to be a newly discovered regulator of hypoxia7. Wang et al.8 found that many genes are simultaneously associated with altered m6A and gene expression profiles in hypoxia. Although the investigations were successful, there was one methodological issue with their study; they selected genes associated with altered m6A and gene expression in hypoxia without determining statistical significance. They selected genes based on fold change (FC). Usually, only using FC to select altered expression or any other measurements might be erroneous because a sufficiently large FC might be observed simply by chance when a large number of candidates are considered. In their analysis, all human genes (as many as a few tens of thousands) and whole genome m6A were considered. In this case, if the FC was not validated statistically, a sufficiently large FC might have been observed simply by chance. The genes associated with altered m6A and gene expression based on statistical significance could not be identified because of the small number of samples; there were only four time points (including the control) measured without any replicates. If we consider the large number of genes as well as m6A peaks in the genome, it is unlikely that four samples are enough to achieve statistical significance; small samples result in larger P-values, whereas a large number of genes and m6A peaks result in relatively larger P-values. In this study, we applied principal component analysis (PCA) and tensor decomposition (TD)-based unsupervised feature extraction (FE) to select genes associated with altered m6A as well as gene expression in hypoxia to determine statistical significance. Enrichment analyses of selected genes are reasonable and consistent with previous findings8 and can now be supported with statistical significance. Thus, not only were the critical roles of m6A in hypoxia validated but also the usefulness of PCA-and TD-based unsupervised FE in the case where there are very few samples with a large number of variables.
There are a limited number of genomic studies using TD9,10. Fang proposed tightly integrated genomic and epigenomic data mining using TD11 (445 samples for TCGA-OV and 480 samples for TCGA-HNSC), Hore et al applied TD to multi-tissue gene expression experiments12 (845 related individuals), Ramdhani et al applied TD to stimulated monocyte and macrophage gene expression profiles13 (432 samples), Wang et al. applied TD to multi-tissue multi-individual gene expression14 (544 individuals), Li et al. applied TD to clinical gene-sample-time microarray expression15 (53 genes and 27 samples), Hu et al. applied TD to gene expression of tumor samples16 (more than 11,000 tumor samples), Diaz et al. applied TD to genomic data17 (503 patients), and Bradley et al. applied TD to DNA copy-number alterations18 (a few hundred samples). All methods other than that used by Li et al. included as few as 53 genes and required as many as several hundred samples, whereas our methods generally require only a few samples (in this study as few as eight samples). To our knowledge, ours is the only method applicable to a data set that includes a few samples with as many as \(10^4\) genes.
Results

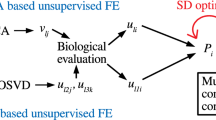
Flow chart of analyses performed in this study.
Figure 1 shows the flow chart of analyses performed in this study.
PCA based unsupervised FE applied to gene expression profiles

PC loading, \(v_{\ell t}\), computed by PCA applied to time points by applying PCA to gene expression profiles. Open black circles: 1st, (0.61) open red triangles: 2nd (− 0.76), green crosses: 3rd (− 0.24), blue crosses: 4th PC loading (− 0.60). The numbers in parentheses are the Pearson’s correlation coefficients. Hours (horizontal axis) represent the duration after the treatments. The horizontal magenta broken line indicates baseline (zero).
Because gene expression profiles are measured solely over four time points, it is formatted as a matrix \({x_{it}} \in {{\mathbb {R}}^{N \times 4}}\), and PCA-based unsupervised FE was applied to \(x_{it}\). Figure 2 shows the PC loading attributed to time points. Because the second PC loading is mostly correlated with time, we decided to employ the second PC score, \(u_{2i}\), in order to attribute P-values to genes i. Using Eq. (7) with \(\ell =2\), \(P_i\)s are attributed to gene i. Then 52 is (genes) with associated corrected P-values less than 0.01, were selected. Table 1 shows the enrichment terms in “KEGG 2019 Human” categories in Enrichr for 52 selected gene symbols. Not all terms are related to hypoxia, whereas a term such as “Oxidative phosphorylation” is known to be related to hypoxia19. “Cardiac muscle contraction” is also known to be related to hypoxia20. Retrograde endocannabinoid signaling is known to be related to hypoxia21. Although three representative neurodegenerative diseases, “Parkinson’s disease,” “Alzheimer’s disease,” and “Huntington’s disease”, are listed, hypoxia is known to be related to neurodegenerative diseases22. Glycolysis is also related to hypoxia23. Most importantly, HIF-1, a hypoxia-inducible factor, is listed. There are additional identified enrichments that can support the success of PCA-based unsupervised FE. Although they are not always top-ranked, the 52 identified genes are also known to be up/downregulated in independent hypoxia experiments (Table 2). In the “GO Biological Process 2018” category in Enrichr, various glucose/glucogenesis related terms are enriched (Table 3). These results suggested that the analyses performed by PCA-based unsupervised FE were successful.
TD-based unsupervised FE applied to m6A profiles

Left: Singular value vector, \(u_{\ell _2 t}\), computed by HOSVD applied to time points with applying HOSVD to m6A profiles. Open black circles: 1st (0.78). Open red triangles: 2nd (− 0.80), green crosses: 3rd (− 0.47), blue crosses: 4th PC loading (0.36). The numbers in parentheses are the Pearson’s correlation coefficients. Hours (horizontal axis) represent the duration after the treatments. Horizontal magenta broken line indicates baseline (zero). Right: scatter plot between \(v_{2t}\), which is the 2nd PC loading attributed to time points when PCA was applied to \(x_{it}\), (horizontal axis) and \(u_{2t}\) (vertical axis). The red broken line indicates \(v_{2t} = u_{2t}\).
Although we successfully applied PCA-based unsupervised FE to some gene expression profiles of hypoxia, the identification of the relationship between altered gene expression and hypoxia was not the primary purpose of this study. Instead, its purpose was to identify the relationship between m6A profiles and hypoxia. To identify the relationship between hypoxia and m6A profiles, HOSVD was applied to \(x_{ktj}\), as described in “Materials and methods”. The left panel in Fig. 3 shows the singular value vectors attributed to time points; the second singular value vector is most significantly correlated with time. Remarkably, \(u_{2t}\) is almost identical to \(v_{2t}\), which is the 2nd PC loading attributed to the time points when PCA was applied to \(x_{it}\) (right panel in Fig. 3). Considering that gene expression and m6A profiles are distinct from each other, this coincidence between \(u_{2t}\), which is attributed to m6A profiles, and \(v_{2t}\), which is attributed to gene expression profiles, suggests that our analysis correctly detects the regulatory relationship between m6A and the gene expression profile. In addition to the fact that \(u_{2t}\) is most significantly correlated with time points, \(u_{2j}\)s have opposite signs between \(j=1\) and \(j=2\) (not shown here), which means that \(\ell _3=2\) is associated with the distinction between the input and m6A. We then determined which \(G(\ell _1,2,2)\) has the largest absolute value to determine which \(u_{\ell _1 k}\) is used to select genomic regions, k (Table 4). Because it is obvious that G(2, 2, 2) has the largest absolute value, we decided to employ \(u_{2k}\) to select genomic regions. \(P_k\)s are attributed to k using Eq. (9) with \(\ell _1=2\). Then 106 ks (genomic regions 25,000 nucleotides in length, see “Materials and methods”) associated with corrected P-values less than 0.01, were selected. These 106 genomic regions included 196 unique gene symbols that were uploaded to Enrichr to evaluate enrichment.
In contrast to the 52 genes identified by PCA-based unsupervised FE applied to gene expression, no KEGG pathway terms or GO BP terms were enriched in these 196 gene symbols. Nevertheless, there are some hypoxia experiments in which genes with altered expression are enriched in 196 gene symbols (Table 5). Therefore, even though 196 genes are less biologically significant than the 52 genes identified in the gene expression analysis, they still have some potential to be related to hypoxia.
Integrated analysis of gene expression and m6A profiles using KTD-based unsupervised FE

Left: Singular value vector, \(u_{\ell _1 t}\), computed by HOSVD applied to \(x_{tjt'j'}\). Open black circles: 1st, (0.61) open red triangles: 2nd (− 0.77), green crosses: 3rd (− 0.41), blue crosses: 4th PC loading (0.48). The numbers in parentheses are the Pearson’s correlation coefficients. Hours (horizontal axis) represent the duration after the treatments. Horizontal magenta broken line indicates baseline (zero). Middle: singular value vector, \(u_{ \ell _3 t'}\), computed by HOSVD applied to \(x_{tjt'j'}\). Open black circles: 1st (0.78). open red triangles: 2nd (− 0.70), green crosses: 3rd (− 0.47), blue crosses: 4th PC loading (0.52). The numbers in parentheses are the Pearson’s correlation coefficients. Hours (horizontal axis) represent the duration after the treatments. Horizontal magenta broken line indicates baseline (zero). Right: scatter plot between \(u_{2t}\) (horizontal axis) and \(u_{2t'}\) (vertical axis). The red broken line indicates \(u_{2t} = u_{2t'}\).
Since TD-based unsupervised FE applied to m6A profiles was not fully successful, we needed to employ more advanced methodology: Kernel TD-based (KTD) unsupervised FE. HOSVD was applied to \(x_{tjt'j'}\), as described in “Materials and methods”. Figure 4 shows the results that are consistent with the results obtained by non-integrated analysis (Figs. 2, 3). The second singular value vectors, \(u_{2t}\) and \(u_{2t'}\), are most consistent with time points; it is coincident with the second PC loading attributed to gene expression, and the second singular value vectors attributed to m6A are coincident with time points. \(u_{2t}\) and \(u_{2t'}\) are also identical; it is coincident with the second PC loading attributed to gene expression, and the second singular value vectors attributed to m6A are identical. In addition, \(u_{2j}\) has the opposite sign between \(j=1\) (control) and \(j=2\) (m6A). Then \(u_{\ell _1 i}\) was computed using Eq. (16), with \(\ell _1=2\), and \(u_{\ell _2 \ell _3 k}\) was computed using Eq. (17), with \(\ell _2=\ell _3=2\). \(P_i\) and \(P_k\) are attributed to i and k, respectively, with Eqs. (18) and (19), respectively. The 53 is (genes) and 128 ks (genome regions) associated with adjusted P-values less than 0.01 were selected. Two hundred gene symbols were retrieved from 128 genomic regions, as previously described.
The 53 and 200 gene symbols were uploaded to Enrichr. Table 6 shows the results of the “KEGG 2019 Human” category in Enrichr. When compared with Table 1, the enrichment for gene expression profiles is similar. Four enrichment terms were identified, whereas no terms were identified when TD-based unsupervised FE was applied to the m6A profile.
Table 7 shows the results of the “Disease Perturbations from GEO down/up” category in Enrichr. Compared with Tables 2 and 5, although enrichment in the “Disease Perturbations from GEO down” for m6A is missing, it still has enrichment for both gene expression and m6A profiles. Table 8 shows the enrichment in the “GO Biological Process 2018” category of Enrichr. Compared with Table 3, enrichment for gene expression does not change, and enrichment for m6A is identified, whereas it was not identified when TD-based unsupervised FE was applied to the m6A profile. Thus, KTD-based unsupervised FE improved the enrichment of m6A profiles without affecting the enrichment for gene expression.
Additional improvement from PCA- and TD-based unsupervised FE to integrated analysis using KTD-based unsupervised FE identified significant associations between gene expression and m6A (Table 9). When PCA-and TD-based unsupervised FE were separately applied to gene expression and m6A profiles, 52 and 196 genes were identified, respectively. The number of common genes between them was seven. However, integrated analysis of gene expression and m6A profiles with TKD-based unsupervised FE identified 53 genes for gene expression and 200 genes for m6A profiles. The number of common genes increased to 12. Although we cannot estimate their significance very accurately, if we can tentatively assume that there are 20,000 human genes in total, both coincidences are significant, and coincidence in KTD-based unsupervised FE is more significant.
In conclusion, integrated analysis of gene expression and m6A profiles using KTD-based unsupervised FE substantially increased the results compared with applying PCA- and TD-based unsupervised FE separately to gene expression and m6A profiles, respectively. KTD-based unsupervised FE could identify the relationship of gene expression and m6A with hypoxia simultaneously for the first time in a statistically significant manner.
Comparisons with other conventional methods
Although we have shown that integrated analysis of gene expression and m6A profiles simultaneously identified the relationship between hypoxia and gene expression as well as hypoxia and m6A profiles, if other simpler conventional methods can achieve similar performances, it is useless to employ complicated methods such as KTD-based unsupervised FE. To confirm that other conventional methods cannot identify similar relationships, we applied a few conventional feature selection methods. As can be seen in the following text, no conventional feature selections were found to be useful.
Linear regression analysis
Linear regressions were applied to the gene expression profiles, \(x_{it}\), and m6A profiles, \(x_{ktj}\). No genes or genomic regions was associated with adjusted P-values less than 0.05, respectively; thus, no genes or genomic regions were associated with adjusted P-values less than 0.01 either.
SAM
Although we tried to apply SAM to gene expression profiles, \(x_{it}\), and m6A profiles, \(x_{ktj}\), we found that SAM requires at least two replicates for each class. In this study, there are no replicated classes in four classes in \(x_{it}\) or eight classes in \(x_{ktj}\); therefore, we could not apply SAM to these data sets.
Limma
Limma was applied to the gene expression profiles, \(x_{it}\), and m6A profiles, \(x_{ktj}\). No genes but 72252 genomic regions were associated with adjusted P-values of less than 0.01, respectively. Therefore, limma was not useful.
Random forest
Random forest was applied to gene expression profiles, \(x_{it}\), and m6A profiles, \(x_{ktj}\). Four hundred and eighty genes and 722 genomic regions had non-zero importance, respectively. Thus, random forest successfully selected a reasonable number of genes and genomic regions. Nevertheless, no hypoxia-related biological terms were enriched in the 480 genes or gene symbols included in the 722 genomic regions. Thus, random forest was not a useful method.
Discussion
One might wonder why linear regression, SAM, limma, and random forest failed to select genes associated with altered gene expression, genomic regions associated with m6A profiles in hypoxia, or genes biologically related to hypoxia. This is because it is a very difficult problem. There are more than 17140 genes as well as 123817 genomic regions, whereas the number of samples measured was four and eight, respectively, which were too small to obtain sufficiently significant P-values. These numbers of genes and genomic regions were too large to obtain significant P-values; although random forest is free from P-values, too small sample numbers often prevent random forest from obtaining results that are not obtainable by chance.
To demonstrate how the KTD-based unsupervised FE outperforms the other four methods, we applied them to two synthetic data sets with \(N=1000\) and \(N_1=10\). When linear regression was applied to the 1st synthetic data set, there were no is associated with adjusted P-values less than 0.01. When limma and random forest were applied to the 1st synthetic data set, there were as many as 500 is associated with adjusted P-values less than 0.01. Thus, neither linear regression nor limma was useful.
The problem is when time points are regarded as a quantitative property (i.e., in linear regression); in this case, eight samples were too small to give significant P-values because there are 1000 features on which P-values must be corrected by considering multiple comparison criteria. However, if they are classified into eight classes with one replicate, too many is were regarded as distinct between eight classes because those values that are constant between any pairs of eight classes are unlikely to be fulfilled when using a null hypothesis.

Left: Singular value vector, \(u_{2 j}\), computed by HOSVD applied to the 1st synthetic data, \(x_{ijk}\). Middle: Singular value vector, \(u_{1 k}\), computed by HOSVD applied to 1st synthetic data, \(x_{ijk}\). Right: \(|G(\ell _1,2,1)|\). In all three sub-panels, the horizontal red broken lines indicate the baseline (zero).

Left: Singular value vector, \(u_{2 j}\), computed by HOSVD applied to the 1st synthetic data, \(x_{ijk}\). Middle: singular value vector, \(u_{2 k}\), computed by HOSVD applied to 1st synthetic data, \(x_{ijk}\). Right: \(|G(\ell _1,2,2)|\). In all three sub-panels, the horizontal red broken lines indicate the baseline (zero).

Schematic figure that explains the correspondence between \(x_{ijk}, i \le N_1\) (red solid arrows) and \(u_{2j}\), \(u_{1k}\) and that between \(x_{ijk}, N_1< i \le 2 N_1\) (red broken arrows) and \(u_{2j}\) and \(u_{2k}\), respectively.
However, when TD-based unsupervised FE was applied to the first synthetic data set, the situation was very different. Figures 5 and 6 show the two combinations of the \(u_{\ell _2,j}\), \(u_{\ell _3 k}\), and \(G(\ell _1 \ell _2 \ell _3)\). Figure 5 (\(\ell _2 =2, \ell _3=1\)) corresponds to \(x_{ijk}, i \le N_1\) since \(x_{ij1} =x_{ij2}\) is coincident with \(u_{\ell _3 1} = u_{\ell _3 2}\) (see Fig. 7). However, Fig. 6 (\(\ell _2 = \ell _3=2\)) corresponds to \(x_{ijk}, N_1 < i \le 2 N_1\) because \(x_{ij1} = - x_{ij2}\), which coincides with \(u_{\ell _3 1} = - u_{\ell _3 2}\) (see Fig. 7). Thus, in contrast to other supervised methods, TD-based unsupervised FE can detect the distinction between \(x_{ij1}= x_{ij2}\) and \(x_{ij1} = - x_{ij2}\). To determine whether TD-based unsupervised FE can correctly identify \(x_{ijk}\)s, we need to attribute P-values to is. Because \(|G(\ell _1,2,1)|\) and \(|G(\ell _1,2,2)|\) have the largest values when \(\ell _1=3\) and \(\ell _1=2\), respectively, we decided to attribute P-values to is using Eq. (13) by assigning \(\ell _1=3\) and \(\ell _1=2\), respectively. Computed P-values were corrected, and is associated with adjusted P- values less than 0.01 were selected. Table 10 shows the performance of TD-based unsupervised FE applied to the first synthetic data set. It perfectly selects i coincident with Eq. (1). As a result, the reason why only PCA and TD-based unsupervised FE could select a reasonable number of genes, while other methods failed, is because PCA and TD-based unsupervised FE are suitable for situations where there are a very small number of samples with a large number of features (observations).
Next, we attempted to demonstrate how KTD-based unsupervised FE integrates two data sets in order to identify common features between the two. Figures 8 and 9 show singular value vectors obtained when KTD-based unsupervised FE was applied to \(x_{jk_1k_2j'k'_1k'_2}\).

Singular value vectors obtained when KTD-based unsupervised FE was applied to the 2nd synthetic data set. Upper left: \(u_{1 j}\), upper right: \(u_{1 k_1}\), lower left: \(u_{1 j'}\), lower right: \(u_{1 k'_1}\). The horizontal red broken line indicates baseline (zero).

Singular value vectors obtained when KTD-based unsupervised FE was applied to the 2nd synthetic data set. Upper left: \(u_{1 j}\), upper right: \(u_{2 k_1}\), lower left: \(u_{1 j'}\), lower right: \(u_{2 k'_1}\). The horizontal red broken line indicates baseline (zero).

Schematic figure that explains the correspondence between \(x_{ijk}, i \le N_1, 2N_1< i \le 3N_1\), \(x'_{ijk}, i \le N_1, \; {\text {and}} \; 4N_1< i \le 5N_1\) (red solid arrows) and \(u_{1j}\) and \(u_{1k}\) and that between \(x_{ijk}, N_1< i \le 2 N_1, 3N_1 < i \le 4N_1\), \(x'_{ijk}, N_1< i \le 2 N_1, \; {\text {and}} \; 5N_1 < i \le 6N_1\) (red broken arrows) and \(u_{1j}\) and \(u_{2k}\), respectively.
Figure 8 shows \(u_{1 j}, u_{1 k_1}, u_{1 j'}\), and \(u_{1 k'_1}\), which is coincident with \(x_{ijk}, i \le N_1\), and \(2N_1 <i \le 3N_1\) and \(x'_{ijk}, i \le N_1\), and \(4N_1 < i \le 5N_1\), since both singular value vectors and \(x_{ijk}\) and \(x'_{ijk}\) for these is increase as j increases and do not depend on k (see Fig. 10). To determine whether we can select these \(x_{ijk}\) and \(x'_{ijk}\) in these is, we reproduced singular value vectors attributed to is using Eq. (22) with \(\ell _1=\ell _2=1\) or Eq. (23) with \(\ell _4=\ell _5=1\). Then P-values were attributed to is using Eq. (24) or Eq. (25). Computed P-values were corrected, and is associated with adjusted P-values less than 0.01 were selected. Table 11 shows a perfect performance.
Figure 9 shows \(u_{1 j}, u_{2 k_1}, u_{1 j'}\), and \(u_{2 k'_1}\), which is coincident with \(x_{ijk}, N_1 < i \le 2N_1\), and \(3N_1 <i \le 4N_1\), and \(x'_{ijk}, N_1 < i \le 2N_1\), and \(5N_1 < i \le 6N_1\), since \(u_{1 j}\) and \(u_{1 j'}\) increase as j increases, and \(u_{2 k_1}\) and \(u_{2 k'_1}\) have opposite signs between \(k_1=k'_1=1\) and \(k_2=k'_2=2\), while \(x_{ij1}\) and \(x'_{ijk1}\) for these is increase as j increases, and \(x_{ij2}\) and \(x'_{ij2}\) for these is decrease as j increases (see Fig. 10). To determine whether we can select these \(x_{ijk}\) and \(x'_{ijk}\) in these is, we reproduced singular value vectors attributed to is using Eq. (22) with \(\ell _1=1, \ell _2=2\) or Eq. (23) with \(\ell _4=1, \ell _5=2\). Then, P-values were attributed to is using Eq. (24) or Eq. (25). Computed P-values were corrected, and is associated with adjusted P-values less than 0.01 were selected. Table 11 shows a perfect performance.
Table 12 shows the confusion matrix between is selected for \(x_{ijk}\) and those selected for \(x'_{ijk}\). This corresponds to Table 9, where genes were selected based on gene expression and m6A profiles. This might be the reason why KTD-based unsupervised FE could identify a significantly overlapping set of genes between gene expression and m6A profiles.
Although TD- and KTD-based unsupervised FE can outperform conventional supervised methods when applied to a small number of samples with a large number of features, TD- and KTD-based unsupervised FE have yet another advantage: j dependence is not monotonic (see the open red triangles in Figs. 2, 3, and 4). Such a non-linear dependence on j cannot be assumed by supervised methods in advance. Wrongly assumed j dependence results in decreased feature selection performance. This is another reason why PCA-, TD-, and KTD-based unsupervised FE can outperform other conventional supervised feature selection methods.
In order to see if our findings are robust, we tried to find alternative data sets in which gene expression and m6A were simultaneously measured for hypoxia, but we could not find any such data sets. Thus, we employed GSE120860, in which only m6A was measured. TD-based unsupervised FE applied to these data sets gave us 54 genes associated with adjusted P-values less than 0.01 (\(\ell _2=\ell _3=1\) and \(\ell _4=2\) were selected, and \(u_{4 i}\) was used to attribute P-values to gene i with Eq. (11) because G(4, 1, 1, 2) has the largest absolute value given \(\ell _2=\ell _3=1\) and \(\ell _4=2\)). Uploading these genes to Enrichr did not identify any terms associated with both hypoxia and significant P-values. As shown in Table 5, when genes were selected by m6A only, there were fewer significant terms. Therefore, we may need to have alternative data sets associated with both gene expression and m6A simultaneously in order to validate the robustness of our results.
One might wonder why we did not compare the proposed methods with conventional unsupervised methods using PCA and TD but only with supervised methods. The reasons for this are as follows. Although there are many papers whose titles include “Feature selection using principal component analysis”, feature selections in these papers mean selecting limited numbers of latent vectors generated by PCA or TD. Thus, they are not applicable to the present study, which needed to select not generated features but original ones (i.e., genomic regions). Although there are a few studies that aim to select original features, and not generated latent vectors, they did not attribute P-values to the features, which would have allowed us to evaluate the significance of the feature selections. For example, Song et al.24 selected a limited number of original features associated with relatively larger absolute values of eigenvectors, and no P-values were attributed to the individual original features. The purpose of the present study is not simply to select features but to evaluate the significance of selected features; as denoted above, Song et al’s study could not help us to evaluate the significance of the feature selections. This is why we did not compare our method with other unsupervised methods using PCA or TD but compared ours with the supervised methods that could give us P-values, by which we could evaluate the significance of the feature selections.
In this study, we applied PCA-, TD-, and KTD-based unsupervised FE to gene expression and m6A profiles in hypoxia. Although these methods identified a limited number of genes significantly related to hypoxia, other conventional methods failed. To understand why PCA-, TD-, and KTD-based unsupervised FE could outperform other conventional methods, we applied these methods to synthetic data sets with small numbers of samples and large numbers of features. As a result, we successfully reproduced the superior performance of TD-and KTD-based unsupervised FE over other conventional methods. Thus, the superiority of PCA-, TD-, and KTD-based unsupervised FE is possibly due to having a small number of samples with a large number of features. In conclusion, despite the limitations of previous studies, we validated a set of genes associated with altered gene expression and m6A profiles in hypoxia in a statistically significant manner.
Materials and methods
m6A and gene expression profiles
m6A and gene expression profiles were downloaded from Gene Expression Omnibus (GEO) using GEO ID GSE141941. For m6A, eight files included in GSE141941_RAW.tar available as part of the Supplementary Information were employed. m6A profiles were summed up within 25,000-nucleotide intervals sequentially divided over the whole genome. As a result, 123,817 genomic regions of 25,000 nucleotides in length were obtained. For gene expression, four profiles included in GSE141941_normoxiaVShypoxia6h.12h.24h_RNA-seq.PROCESSED.DATA.xlsx, which is also available as a part of the Supplementary Information, were employed. Eight files for m6A were composed of four time points (including the control), time input, or treated files. Four profiles for gene expression were composed of four times points as well.
As an alternative data set, we employed GSE120860, in which only the m6A profile was measured. We downloaded 16 bed files provided in the Supplementary Information section in GEO, which correspond to four healthy controls and four patients, of which the tumor and paratumor were measured.
Synthetic data set
In order to demonstrate how well KTD-based unsupervised FE can work when there are a small number of samples associated with a large number of features (observations) and where other conventional supervised methods fail, we prepared a synthetic data set. It has N variables attributed to eight samples whose number is the same as that of the m6A profiles. In the first data set, we aimed to demonstrate the performance when KTD-based unsupervised FE is applied to a single data set. It is composed of \({x_{ijk}} \in {{\mathbb {R}}^{N \times 4 \times 2}}\),
where j corresponds to the first to fourth time points, and \(k=1\) and \(k=2\) correspond to two distinct experimental conditions. \(\epsilon _{ijk}\) obeys \({{\mathcal {N}}}(0,\frac{1}{2})\), where \({{\mathcal {N}}} (\mu , \sigma )\) is a Gaussian distribution with a mean of \(\mu\) and a standard deviation of \(\sigma\). For \(i \le N_1\), the two conditions have the same dependence on time points, whereas for \(N_1 < j \le 2 N_2\), the two conditions have opposite time point dependence.
In the second dataset, we aimed to demonstrate how KTD-based unsupervised FE can identify features that share the same time point dependence on two measurements represented as two tensors, \({x_{ijk}} \; \mbox{and} \; {x'_{ijk}} \in {{\mathbb {R}}^{N \times 4 \times 2}}\), which obey Eq. (1) for \(i \le 2 N_1\), and for \(i > 2 N_1\),
Thus, for \(i \le 2 N_1\), \(x_{ijk}\), \(x_{(i+2N_1) jk}\), \(x'_{ijk}\), and \(x'_{(i+4N_1)jk}\) share the same time-point dependence.
PCA-based unsupervised FE applied to gene expression
Although the details of PCA-based unsupervised FE have been described in a recently published book25, we briefly outline this method. Suppose we have gene expression profiles as a matrix, \({x_{it}} \in {{\mathbb {R}}^{N \times 4}}\), which represents the gene expression of the ith gene at the tth time point. The \(\ell\)th PC score attributed to gene i, \({u_{\ell i}} \in {{\mathbb {R}}^N}\), can be obtained as the ith component of the \(\ell\)th eigenvector, \(\varvec{u}_\ell\), of the gram matrix \(X X^T \in {{\mathbb {R}}^{N \times N}}\), where X is an \(N \times 4\) matrix composed of \(x_{it}\), and \(X^T\) is a transposed matrix of X as
In contrast, the PC loading attributed to the tth time point can be computed as the tth component of the \(\ell\)th PC loading vector, \(\varvec{v}_\ell \in {{\mathbb {R}}^4}\), which can be computed as
This is also the \(\ell\)th eigenvector of \(X^T X \in {{\mathbb {R}}^{4 \times 4}}\) because
In order to select genes, we first need to determine which \(\varvec{v}_\ell\) is associated with time dependence. After identifying the time-dependent \(\varvec{v}_\ell\), we attribute P-values to the ith gene using \(u_{\ell i}\) by assuming that \(u_{\ell i}\) follows a Gaussian distribution (null hypothesis)
where \(P_{\chi }[>x]\) is the cumulative \(\chi ^2\) distribution in which the argument is larger than x, and \(\sigma _\ell\) is the standard deviation. The computed P-values were corrected by the BH criterion25, and genes associated with adjusted P-values less than 0.01 were selected.
TD-based unsupervised FE applied to the m6A profile
Although the details of TD-based unsupervised FE are described in a recently published book25, we briefly outline this method. For GSE141941, suppose that a tensor \(x_{ktj} \in {{\mathbb {R}}^{K \times 4 \times 2}}\) represents the m6A of the kth genomic region at the tth time point of input (control, \(j=1\)) or m6A (\(j=2\)) sample. Individual genomic regions are 25,000-nucleotide sequence length regions sequentially defined over the whole genome without overlaps and adjusted with each other. Higher-order singular value decomposition25 (HOSVD) was applied to \(x_{ktj}\), and TD was obtained as
where \(G \in {{\mathbb {R}}^{K \times 4 \times 2}}\) is the core tensor, \(u_{\ell _1 k} \in {\mathbb {R}}^{K \times K}\), \(u_{\ell _2 t} \in {\mathbb {R}}^{4 \times 4}\), and \(u_{\ell _3 j} \in {\mathbb {R}}^{2 \times 2}\) are singular value matrices and orthogonal matrices.
To select genomic regions that are associated with time dependence and to distinguish between input and m6A treatment, we need to specify which \(u_{\ell _2 t}\) and \(u_{\ell _3 j}\) are associated with time dependence and the distinction between control (input) and m6a, respectively. Once \(u_{\ell _2 t}\) and \(u_{\ell _3 j}\) are fixed, we attempt to find \(G(\ell _1 \ell _2 \ell _3)\) with the largest absolute value, given \(\ell _2\) and \(\ell _3\). Finally, we attribute the P-value to the kth genomic region by assuming that \(u_{\ell _1 k}\) obeys a Gaussian distribution (null hypothesis) as
where \(\sigma _{\ell _1}\) is the standard deviation. The computed P-values were corrected by the BH criterion, and genes associated with adjusted P-values less than 0.01 were selected.
For GSE126860, m6A profiles were formatted as \(x_{ijkm} \in {\mathbb {R}}^{N \times 4 \times 2 \times 2}\), which represents the m6A profiles of the ith gene at the jth subject of the kth group (\(k=1\): annotated as 0204 in GEO, \(k=2\): annotated as patient in GEO) of the mth tissue (\(m=1\):tumor, \(m=2\):paratumor). HOSVD was applied, and we obtained
where \(G \in {\mathbb {R}}^{N \times 4 \times 2 \times 2}\) is the core tensor, and \(u_{\ell _1 i} \in {\mathbb {R}}^{N \times N}\), \(u_{\ell _2 j} \in {\mathbb {R}}^{4 \times 4}\), and \(u_{\ell _3 k}, u_{\ell _4 m},\in {\mathbb {R}}^{2 \times 2}\) are singular value matrices and orthogonal matrices.
In order to select genes that are associated with the distinction between tumor and paratumor, but independent of subjects as well as groups, we need to specify which \(u_{\ell _4 m}\) are associated with the distinction between the tumor and paratumor, but \(u_{\ell _2 j}\) and \(u_{\ell _3 k}\) take constant values. Once \(u_{\ell _2 j}, u_{\ell _3 k}, \; \mbox{and} \; u_{\ell _4 m}\) are fixed, we then attempt to find that \(G(\ell _1 \ell _2 \ell _3 \ell _4)\) with the largest absolute value, given \(\ell _2, \ell _3, \; \mbox{and} \; \ell _4\). Finally, we attribute the P-value to the ith gene by assuming that \(u_{\ell _1 i}\) obeys a Gaussian distribution (null hypothesis) as
where \(\sigma _{\ell _1}\) is the standard deviation. The computed P-values were corrected by the BH criterion, and genes associated with adjusted P-values less than 0.01 were selected.
When HOSVD was applied to the 1st synthetic data set, we obtained
where \(G \in {\mathbb {R}}^{N \times 4 \times 2}\) is the core tensor and \(u_{\ell _1 i} \in {\mathbb {R}}^{N \times N}, u_{\ell _2 j} \in {\mathbb {R}}^{4 \times 4}, \; \mbox{and} \; u_{\ell _3 k} \in {\mathbb {R}}^{2 \times 2}\) are singular value matrices and orthogonal matrices.
After identifying \(u_{\ell _2 j}\) and \(u_{\ell _3 k}\) associated with properties of interest, we attempt to find \(G(\ell _1 \ell _2 \ell _3)\) with the largest absolute value, given \(\ell _2, \ell _3\). Using the selected \(\ell _1\), P-values are attributed to the ith by assuming that \(u_{\ell _1 i}\) obeys a Gaussian distribution,
The computed P-values were corrected by the BH criterion, and genes associated with adjusted P-values less than 0.01 were selected.
Integrated analysis of gene expression and m6A profiles
To integrate gene expression and m6A profiles, we employed a recently proposed KTD-based unsupervised FE26. We define a tensor \(x_{tjt'j'} \in \mathbb{R}^{4 \times 2 \times 4 \times 2}\) as
HOSVD was applied to \(x_{tjt'j'}\), and we obtained
where \(G \in {\mathbb {R}}^{4 \times 2 \times 4 \times 2}\) is the core tensor, and \(u_{\ell _1 t} \in {\mathbb {R}}^{4 \times 4}\), \(u_{\ell _2 t'} \in {\mathbb {R}}^{2 \times 2}\), \(u_{\ell _3 j} \in {\mathbb {R}}^{4 \times 4}\), and \(u_{\ell _4 j'} \in {\mathbb {R}}^{2 \times 2}\) are singular value matrices and orthogonal matrices. Here, it should be noted that \(u_{\ell _2 j}, u_{\ell _3 t'}, \; \mbox{and} \; u_{\ell _4 j'}\) are attributed to m6A profiles, and only \(u_{\ell _1 t}\) is attributed to the gene expression profiles.
In order to identify genes whose expression profiles depend on time and genomic regions where m6A profiles depend on time associated with the distinction between m6A and control, we need to find which \(u_{\ell _1 t}\) and \(u_{\ell _3 t'}\) depend on time and which \(u_{\ell _2 j}\) and \(u_{\ell _4 j'}\) are distinct between control and m6A (since \(x_{tjt'j'}\) does not change even if j is replaced with \(j'\), \(u_{\ell _2 j} = u_{\ell _4 j'}\)). Once \(\ell _1, \ell _2, \ell _3, \; \mbox{and} \; \ell _4\) are identified, we can compute the singular value vectors attributed to gene expression samples, \(u_{\ell _1 i}\), and m6A profiles, \(u_{\ell _2 \ell _3 k}\), can be computed as
The P-values are attributed to is and ks as
where \(\sigma _{\ell _1}\) and \(\sigma _{\ell _2 \ell _3}\) are standard deviations. The computed P-values were corrected by the BH criterion, and genes, i, and genomic regions, k, associated with adjusted P-values less than 0.01 were selected.
Integrated analysis of the 2nd synthetic data set
To integrate \(x_{ijk}\) and \(x'_{ijk}\) in the second synthetic data set, we define a tensor, \(x_{jk_1 k_2 j'k'_1k'_2} \in {\mathbb {R}}^{4 \times 2\times 2 \times 4 \times 2 \times 2}\), as
After applying HOSVD to \(x_{jk_1 k_2 j'k'_1k'_2}\), we obtained
Singular value vectors attributed to is can be reproduced as
After identifying \(u_{\ell _1 j}, u_{\ell _2 k_1}, u_{\ell _4 j}, \; \mbox{and} \; u_{\ell _5 k_1}\) is considered, P-values are attributed to i, as
The computed P-values were corrected by the BH criterion, and is associated with adjusted P-values less than 0.01 were selected.
Retrieval of gene symbols included in selected genomic regions
After selecting genomic regions, we needed to retrieve the gene symbols included in the selected genomic regions. This could be done using the biomaRt package implemented in R by specifying the hg19 human genome to which short reads were mapped.
Ensembl gene ID to gene symbol
Since gene expression profiles are defined using Ensembl gene IDs, we needed to convert these IDs to gene symbols. This was done by uploading gene symbols selected by TD-based unsupervised FE to DAVID27. Uploaded Ensembl gene IDs were converted to gene symbols using the gene ID conversion tool implemented in DAVID by specifying the official gene symbol as the target of conversion.
Enrichment analysis
Identified gene symbols were uploaded to Enrichr28, which is an enrichment server, to evaluate various enrichments within sets of identified gene symbols.
Various conventional feature selections
Linear regression-based feature selection
To select genes or genomic regions using linear regression analysis, the ls function in the base package in R was used. P-values computed by ls were corrected by the BH criterion, and genes or genomic regions associated with adjusted P-values less than 0.01 or 0.05 were selected.
When linear regression was applied to gene expression, \(x_{it}\),
was assumed, where \(T(1)=0, T(2)=6, T(3)=12, \; \mbox{and} \; T(4)=24\).
When linear regression was applied to m6A, \(x_{ktj}\),
was assumed.
When linear regression was applied to the 1st synthetic data,
was assumed.
SAM
When SAM29 was applied to gene expression, \(x_{it}\), or m6A, \(x_{ktj}\), are assumed to be classified into four classes based on t (for gene expression) or eight classes based on the combination of t and j (for m6A), respectively. The sam function was implemented in the siggenes package in R.
Limma
When limma30 was applied to gene expression, \(x_{it}\), or m6A, \(x_{ktj}\), respectively, they were assumed to be classified in the same way as in SAM. Limma was applied to logarithmically converted \(x_{it}\) or \(x_{ktj}\). The limma function was implemented in the limma package in R.
When limma was applied to the first synthetic data set, \(x_{ijk}\) was classified into eight classes based on the pairs of j and k. Because \(x_{ijk}\) takes both positive and negative values, \(x_{ijk}\)s themselves were regarded as logarithmically converted valRes.
Random forest
When random forest31 was applied to gene expression, \(x_{it}\), or m6A, \(x_{ktj}\), respectively, they are assumed to be classified in the same way as in SAM. When it was applied to the first synthetic data set, \(x_{ijk}\) was classified into eight classes, as in the case of limma. The randomForest function was implemented in the randomForest package. Features included in OOB were selected by selecting features with non-zero importance given by the importance function implemented in the randomForest package in R.
References
Roach, R. C. et al. (eds) Hypoxia (Springer, 1999).
Dhont, S., Derom, E., Braeckel, E. V., Depuydt, P. & Lambrecht, B. N. The pathophysiology of ‘happy’ hypoxemia in COVID-19. Respir. Res. 21, 198. https://doi.org/10.1186/s12931-020-01462-5 (2020).
Muz, B., de la Puente, P., Azab, F. & Azab, A. K. The role of hypoxia in cancer progression, angiogenesis, metastasis, and resistance to therapy. Hypoxia 2015(3), 83–92. https://doi.org/10.2147/hp.s93413 (2015).
Hossmann, K.-A. The hypoxic brain. In Advances in Experimental Medicine and Biology 155–169. https://doi.org/10.1007/978-1-4615-4711-2_14 (Springer, New York, 1999).
Schumacker, P. T. Lung cell hypoxia: Role of mitochondrial reactive oxygen species signaling in triggering responses. Proc. Am. Thorac. Soc. 8, 477–484. https://doi.org/10.1513/pats.201103-032mw (2011).
Sarkar, M., Niranjan, N. & Banyal, P. Mechanisms of hypoxemia. Lung India 34, 47. https://doi.org/10.4103/0970-2113.197116 (2017).
Fry, N. J., Law, B. A., Ilkayeva, O. R., Holley, C. L. & Mansfield, K. D. N6-methyladenosine is required for the hypoxic stabilization of specific mRNAs. RNA 23, 1444–1455. https://doi.org/10.1261/rna.061044.117 (2017).
Wang,Y.J. et al. Reprogramming of m6a epitranscriptome is crucial for shaping of transcriptome and proteome in response to hypoxia. RNA Biol. 18(1), 131–143.https://doi.org/10.1080/15476286.2020.1804697 (2020).
Luo, Y., Wang, F. & Szolovits, P. Tensor factorization toward precision medicine. Brief. Bioinform. 18, 511–514. https://doi.org/10.1093/bib/bbw026 (2016).
Yahyanejad, F., Albert, R. & DasGupta, B. A survey of some tensor analysis techniques for biological systems. Quant. Biol. 7, 266–277. https://doi.org/10.1007/s40484-019-0186-5 (2019).
Fang, J. Tightly integrated genomic and epigenomic data mining using tensor decomposition. Bioinformatics 35, 112–118. https://doi.org/10.1093/bioinformatics/bty513 (2018).
Hore, V. et al. Tensor decomposition for multiple-tissue gene expression experiments. Nat. Genet. 48, 1094–1100. https://doi.org/10.1038/ng.3624 (2016).
Ramdhani, S. et al. Tensor decomposition of stimulated monocyte and macrophage gene expression profiles identifies neurodegenerative disease-specific trans-eqtls. PLoS Genet. 16, 1–23. https://doi.org/10.1371/journal.pgen.1008549 (2020).
Wang, M., Fischer, J. & Song, Y. S. Three-way clustering of multi-tissue multi-individual gene expression data using semi-nonnegative tensor decomposition. Ann. Appl. Stat. 13, 1103–1127. https://doi.org/10.1214/18-AOAS1228 (2019).
Li, Y. & Ngom, A. Classification of clinical gene-sample-time microarray expression data via tensor decomposition methods. In Computational Intelligence Methods for Bioinformatics and Biostatistics (eds Rizzo, R. & Lisboa, P. J. G.) 275–286 (Springer, 2011).
Hu, Y., Liu, J.-X., Gao, Y.-L., Li, S.-J. & Wang, J. Differentially expressed genes extracted by the tensor robust principal component analysis (TRPCA) method. Complexity 1–13, 2019. https://doi.org/10.1155/2019/6136245 (2019).
Diaz, D., Bollig-Fischer, A. & Kotov, A. Tensor decomposition for sub-typing of complex diseases based on clinical and genomic data. In 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), 647–651. https://doi.org/10.1109/BIBM47256.2019.8983014 (2019).
Bradley, M. W., Aiello, K. A., Ponnapalli, S. P., Hanson, H. A. & Alter, O. GSVD- and tensor GSVD-uncovered patterns of DNA copy-number alterations predict adenocarcinomas survival in general and in response to platinum. APL Bioeng. 3, 036104. https://doi.org/10.1063/1.5099268 (2019).
Solaini, G., Baracca, A., Lenaz, G. & Sgarbi, G. Hypoxia and mitochondrial oxidative metabolism. Biochim. Biophys. Acta (BBA) Bioenergy 1797, 1171–1177. https://doi.org/10.1016/j.bbabio.2010.02.011 (2010) (16th European Bioenergetics Conference 2010).
Chan, C. K. & Vanhoutte, P. M. Hypoxia, vascular smooth muscles and endothelium. Acta Pharm. Sin. B 3, 1–7. https://doi.org/10.1016/j.apsb.2012.12.007 (2013).
Sugimoto, N., Ishibashi, H., Nakamura, H., Yachie, A. & Ohno-Shosaku, T. Hypoxia-induced inhibition of the endocannabinoid system in glioblastoma cells. Oncol. Rep. 38(6), 3702–3708.Rep.https://doi.org/10.3892/or.2017.6048 (2017).
Jha, N. K. et al. Hypoxia-induced signaling activation in neurodegenerative diseases: Targets for new therapeutic strategies. J. Alzheimer’s Dis. 62, 15–38. https://doi.org/10.3233/JAD-170589 (2018).
Semenza, G. L., Roth, P. H., Fang, H. M. & Wang, G. L. Transcriptional regulation of genes encoding glycolytic enzymes by hypoxia-inducible factor 1. J. Biol. Chem. 269, 23757–23763 (1994).
Song, F., Guo, Z. & Mei, D. Feature selection using principal component analysis. In 2010 International Conference on System Science, Engineering Design and Manufacturing Informatization. https://doi.org/10.1109/icsem.2010.14 (IEEE, 2010).
Taguchi, Y.-H. Unsupervised Feature Extraction Applied to Bioinformatics (Springer International Publishing, 2020).
Taguchi, Y. H. & Turki, T. Application of tensor decomposition to gene expression of infection of mouse hepatitis virus can identify critical human genes and efffective drugs for SARS-CoV-2 infection. IEEE J. Sel. Top. Signal Process. 15(3), 746–758.https://doi.org/10.1109/JSTSP.2021.3061251 (2021).
Huang, D. W., Sherman, B. T. & Lempicki, R. A. Systematic and integrative analysis of large gene lists using DAVID bioinformatics resources. Nat. Protoc. 4, 44–57. https://doi.org/10.1038/nprot.2008.211 (2008).
Kuleshov, M. V. et al. Enrichr: A comprehensive gene set enrichment analysis web server 2016 update. Nucleic Acids Res. 44, W90–W97. https://doi.org/10.1093/nar/gkw377 (2016).
Tusher, V. G., Tibshirani, R. & Chu, G. Significance analysis of microarrays applied to the ionizing radiation response. Proc. Natl. Acad. Sci. 98, 5116–5121. https://doi.org/10.1073/pnas.091062498 (2001).
Ritchie, M. E. et al. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 43, e47. https://doi.org/10.1093/nar/gkv007 (2015).
Liaw, A. & Wiener, M. Classification and regression by randomforest. R News 2, 18–22 (2002).
Acknowledgements
This study was supported by KAKENHI 20K12067, 20H04848, and 19H05270.
Author information
Authors and Affiliations
Contributions
All authors planned the study. Y.H.T. performed the analyses. All authors validated and discussed the results. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Roy, S.S., Taguchi, YH. Identification of genes associated with altered gene expression and m6A profiles during hypoxia using tensor decomposition based unsupervised feature extraction. Sci Rep 11, 8909 (2021). https://doi.org/10.1038/s41598-021-87779-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-87779-7
- Springer Nature Limited
This article is cited by
-
Novel feature selection method via kernel tensor decomposition for improved multi-omics data analysis
BMC Medical Genomics (2022)