
Abstract
In this paper, six types of air pollutant concentrations are taken as the research object, and the data monitored by the micro air quality detector are calibrated by the national control point measurement data. We use correlation analysis to find out the main factors affecting air quality, and then build a stepwise regression model for six types of pollutants based on 8 months of data. Taking the stepwise regression fitting value and the data monitored by the miniature air quality detector as input variables, combined with the multilayer perceptron neural network, the SRA-MLP model was obtained to correct the pollutant data. We compared the stepwise regression model, the standard multilayer perceptron neural network and the SRA-MLP model by three indicators. Whether it is root mean square error, average absolute error or average relative error, SRA-MLP model is the best model. Using the SRA-MLP model to correct the data can increase the accuracy of the self-built point data by 42.5% to 86.5%. The SRA-MLP model has excellent prediction effects on both the training set and the test set, indicating that it has good generalization ability. This model plays a positive role in scientific arrangement and promotion of miniature air quality detectors. It can be applied not only to air quality monitoring, but also to the monitoring of other environmental indicators.
Similar content being viewed by others


Introduction
Air quality is becoming more and more important. It affects both the natural environment and human health. The relationship between cardiovascular disease, lung cancer, respiratory system disease and air pollution has been confirmed by some documents1,2,3. Real-time monitoring of the concentration of major pollutants (''two dusts and four gases" includes PM2.5, PM10, CO, NO2, SO2, O3) in the atmosphere is becoming more and more necessary for relevant national departments. The national monitoring and control station (national control point) can measure the concentration of pollutants, and the "two dust and four gases" monitoring data of the national control point (ncp) is considered accurate. However, due to cost issues, the number of national control points is small, and it is difficult to meet the requirements for real-time monitoring of air quality. Some miniature air quality detectors (self-built points) are gridded and deployed in some areas. They can realize real-time monitoring of air quality, and can also monitor other meteorological parameters (temperature, humidity, wind speed, pressure and precipitation) in the area. Since the electrochemical sensor used in the self-built point (sbp) will be interfered by external factors, it will cause measurement errors4. We need to use the national control point data to calibrate the self-built point data.
Mechanism models based on atmospheric chemical analysis and statistical models based on machine learning are often used to predict the concentration of pollutants. The former uses meteorological principles and mathematical methods to simulate the chemical and physical processes of pollutants to realize the prediction of pollutant concentration5,6. The latter uses statistical methods to analyze the collected pollutant data and uses mathematical algorithms to model the relationship between variables. For the research based on machine learning models, the main algorithms are artificial neural networks7,8,9, multiple linear regression10,11,12, hidden Markov models13,14, random forest models15,16,17, and support Vector machine18,19,20 and so on.
Artificial neural network (ANN) is an information processing system that simulates human brain thinking and reasoning. It has been a research hotspot in the field of artificial intelligence since the 1980s, and has made certain progress in various research fields. Its advantage is that it has strong nonlinear fitting ability, can map arbitrarily complex nonlinear relationships. Artificial neural networks have strong associative storage capabilities, robustness, non-linear mapping capabilities, and autonomous learning capabilities. However, it turns all the characteristics of the problem into numbers and turns all reasoning into numerical calculations21,22,23, so it has no ability to explain its reasoning process and reasoning process. As a mature method for solving linear problems, multiple linear regression (MLR) has been widely used in various fields. Its advantage is that it is more convenient and simple when analyzing a multi-factor model. If the data used is the same as the model, the calculation result is unique, and each regression coefficient in the model is better explained11,24,25. However, multiple linear regression models have strict requirements on independent variable selection and error terms, and multiple linear regression methods are also greatly restricted in solving nonlinear problems.
Artificial neural networks and multiple linear regression models are widely used in air quality prediction models. The two-step calibration method of multiple linear regression and machine learning was used by Elangasinghe et al. to correct the NO2 concentration measured by the sensor. They compared different machine learning methods through 5 evaluation indicators and gave the best model7. Artificial neural networks are used by Reich, S. L. et al. to identify pollution sources in the air. They chose to use a three-layer feedforward ANN trained by the backpropagation algorithm and successfully repaired some of the data in the model9.Spinelle, L. et al. compared linear/multilinear regression and supervised learning techniques, and carried out on-site calibration of NO, CO and CO2 pollutant sensors10. However, both linear regression and artificial neural network have shortcomings in air quality prediction models26. In this paper, by combining the prediction effects of the two methods in the air quality forecast model data, a calibration model of the main pollutants in the air is given to improve the interpretability and accuracy of the air quality calibration model.
Material and methods
Data source and preprocessing
This article selects 2019 Chinese college students' mathematical modeling D problem data. It provides hourly data of a national control point from November 14, 2018 to June 11, 2019. It also provides a self-built point data corresponding to the national control point (corresponds to the national control point time and the interval is within 5 min). Before conducting exploratory analysis on the data of national control points and self-built points, the data is pre-processed. First, delete the data that the self-built point and the national control point cannot correspond to and the data that is obviously abnormal. Second, the various data within each hour of the self-built point are classified and aggregated and averaged to correspond to the hourly data of the national control point. After data preprocessing, a total of 4135 sets of data were obtained as research objects27. Table 1 shows the range, mean, and standard deviation of each variable.
Data exploratory analysis
The establishment of statistical models usually starts with exploratory analysis of the data11,28,29. Based on the national control point data, the “two dusts and four gases” concentration data measured at the self-built points are corrected in this paper. In order to more intuitively reflect the difference between the national control point and the self-built point data, we calculated the daily average value of the preprocessed 4135 sets of data and compared these pollutant concentration data.
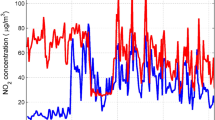
In Fig. 1, the blue curve indicates the national control point measurement value, and the red curve indicates the self-built point measurement value. It can be seen that the measurement data of the “two dusts and four gases” concentration national control point and the self-built point are generally consistent, but there is a certain deviation between the two. The deviation between the two in the previous period is significantly larger, which may be caused by the season or the zero drift of the measuring instrument. As the PM2.5, PM10, and O3 concentrations change significantly over time, we draw a box-line diagram10 of the monthly changes in the concentration of the “two dusts and four gases” national control points as shown in Fig. 2.

Comparison of daily average data of six types of pollutants at national control points and self-built points.

Comparison of monthly average data of six types of pollutants at national control points and self-built points. Figures are generated using Matlab (Version R2016a, https://www.mat-hworks.com/) (software).
It can be seen from Fig. 2: The average PM2.5, PM10, CO, and SO2 concentrations are highest in November, the average NO2 concentration is highest in January, and the average O3 concentration is highest in June. The average PM2.5, CO, and SO2 concentrations are lowest in May, the average PM10 concentration is lowest in June, the average NO2 concentration is lowest in November, and the average O3 concentration is lowest in December. The concentration of "two dusts and four gases" varies significantly in different months, so time is an important factor affecting the concentration of "two dusts and four gases".
Correlation analysis
The quality of air is judged based on the concentration of pollutants in the air1. There are many factors that affect air quality, and they affect each other. In order to determine the correlation between the "two dusts and four gases" concentration and the five climate factors30, we use Eq. (1) to find the Pearson correlation coefficient between them, as shown in Table 2. It can be seen that, except for NO2 concentration and temperature, all other variables have significant correlations with each other, indicating that the factors affecting the concentration of each pollutant are very complex. The correlation coefficient between PM2.5 concentration and PM10 concentration is as high as 0.89, indicating a high positive correlation between the two, and the correlation coefficient between temperature and air pressure is -0.85, which indicates that the higher the temperature, the lower the pressure. Figure 3 is a matrix color block diagram between the concentration of "two dusts and four gases" and five climatic factors, which visually shows the correlation coefficients between the variables. The size of the matrix color block represents the absolute value of the correlation coefficient. As the color becomes lighter, the value of the correlation coefficient gradually increases.

Correlation coefficient matrix color block diagram between six types of air pollutant concentrations and climate.
Establishment of sensor calibration model
Introduction to basic principles
Artificial neural network is one of the most commonly used methods to predict the concentration of atmospheric pollutants. It has the ability to approximate any non-linear mapping through learning. It has a wide application prospect in the prediction of non-linear systems. The working principle of artificial neural network prediction is mainly divided into two steps: first, use the training samples to design and train the network to obtain prediction rules; then predict the test samples according to the obtained rules to verify its reliability with the accuracy of the test results. The main advantage of artificial neural network algorithms is their strong adaptability to training samples. It has a strong ability to process uncertain information. It can still work normally for the presence of noisy or non-linear data. Artificial neural network has strong robustness, memory ability, non-linear mapping ability and strong self-learning ability in training. It can quickly get prediction results for complex prediction problems. After consulting relevant literature, the most commonly used model in the research and application of neural networks are multilayer perceptron neural network31,32,33.
Multilayer Perceptron (MLP) neural network is a unidirectional propagation multilayer feedforward network structure based on error back propagation algorithm. As shown in Fig. 4: its structure can be divided into three layers, namely the input layer, the hidden layer and the output layer. Each layer of it consists of multiple nodes, and each layer can be passed to the next layer until the output layer. Except for the input nodes, each node is a neuron with a non-linear activation function. Equation (2) is its output, \({\upomega }_{nj}\) is the node weight, and \({b}_{jk}\) is the deviation.

Multilayer perceptron neural network structure.
MLP is a typical supervised learning algorithm, and its loss function is defined as Eq. (3). \({o}_{\upomega ,b(x)}\) is the output value of MLP, and y is the actual value. In this paper, the parameters are adjusted by the conjugate gradient method to minimize the loss function. The conjugate gradient method calculation formulas are Eqs. (4) and (5). The hidden layer in the MLP neural network model can be single or several. However, as long as the number of neuron nodes in the hidden layer is appropriately adjusted, a single hidden layer neural network can approximate any nonlinear function34,35. Therefore, a single hidden layer can meet most engineering needs. In the process of using SPSS software for auxiliary calculation, the number of hidden layer neurons can be automatically calculated by SPSS, and the relatively optimal number of neurons that is most suitable for this model is given.
The concentration of "two dusts and four gases" is affected by various factors such as various climatic factors and other pollutant concentrations, as well as the sensor's own range drift. The simple regression model can only describe the linear effect of each variable on the concentration of pollutants. The appropriate weighted average of the model by the neural network, and introducing other non-linear effects into the model, can effectively improve the prediction accuracy of the model and improve the correction effect of the self-built point pollutant concentration.
In this paper, we will build a combination model of stepwise regression analysis (SRA) and artificial neural network, called SRA-MLR model. Firstly, a stepwise regression model is established through the influence of various factors on the concentration of pollutants, and the stepwise regression model is used to give the fitted value of each pollutant at the corresponding moment. Then the SRA-MLP neural network model is established by taking the fitted value and other data and time measured by the self-built point as input values and the national control point data as output values. The process of building the model is shown in Fig. 5.

The flux diagram of the regression process.
Stepwise regression model construction
We want to establish a multiple regression model with the pollutant concentration at the national control point as the dependent variable and the observation data from the self-built point as the independent variable. The key to establishing a multiple regression model is the choice of independent variables. If too few independent variables are selected, it is easy to miss key variables and the regression effect is not ideal. Too many independent variables are introduced into the model, which is prone to multicollinearity problems, which makes the model very unstable, and even problems such as inversion of sign. Commonly used independent variable selection methods are forward, backward, stepwise method. We use stepwise regression to build the model. The variables introduced in the model and their regression coefficients are given in Table 3.
The F-test p-values in the six types of pollutant regression models are all less than 0.01, indicating that at a significant level of 0.01, the variables introduced into the model as a whole have a significant effect on the concentration of pollutants. The t-test p-value of each independent variable introduced into the model is less than 0.05, indicating that at a significant level of 0.05, each independent variable introduced into the model has a significant effect on the concentration of pollutants. The coefficient of determination in the PM2.5 concentration model is 0.908, indicating that the fitting effect is very good; the coefficients of determination in the PM10 and O3 concentration models are all greater than 0.8, indicating that the fitting effect is good; the coefficients of determination in the CO, NO2, and SO2 concentration models are all greater than 0.5, indicating that the fitting effect is acceptable.
SRA-MLP model construction
The miniature air quality detector can not only implement grid-based monitoring of the air quality in the area, but also monitor meteorological parameters such as temperature, humidity, wind speed, air pressure, and precipitation. The fitting values of the air pollutant concentrations of the stepwise regression model and the data from the self-built points were used as covariate factors in the MLP model, and the air pollutant concentrations at the national control point were used as the dependent variables. We use SPSS 20.0 to fit the non-linear relationship between the covariate factors and the dependent variables.
In the MLP neural network, it is particularly important to choose the number of hidden layers and the number of neurons in each layer. In a small data set, too many hidden layers will not only make the model more complicated, but also lead to overfitting of the model and poor model generalization ability. Therefore, in small data sets, one or two hidden layers MLP neural network is generally used for modeling. We establish one hidden layer and two hidden layers MLP models for six types of pollutants, and choose the model with less error as the final prediction model of the pollutants. In the modeling process, 4135 samples are randomly assigned as training samples, test samples, and holdout samples, and the allocation ratio is 7:2:1, and the activation functions of the input layer and output layer adopt hyperbolic tangent function and identity function respectively. The batch is selected as the type of training, and scaled conjugate gradient is selected as the optimization algorithm. The software automatically calculates the number of units in the hidden layer and finally obtains SRA-MLP model36.
This article uses root mean square error(Eq. 6), mean absolute error(Eq. 7), and mean absolute percent error(Eq. 8) to determine the final hidden layer number. The specific results are shown in Table 4. It can be seen that in NO2 and O3 prediction models, the two hidden layers MLP model performs better, so NO2 and O3 finally choose the two hidden layers SRA-MLP model. The numbers of neurons in the first and second layers of the NO2 prediction model are 8 and 6, and the numbers of neurons in the first and second layers of the O3 prediction model are 8 and 6. PM2.5, PM10, CO and SO2 finally choose one hidden layer SRA-MLP model, and the number of their hidden layer neurons are 7, 6, 5, and 8. The effect of our randomly selected PM10 prediction model is shown in Fig. 6. It can be seen that the prediction effect of the SRA-MLP model is very good whether it is the training set, validation set or test set.

The prediction effect of PM10’s SRA-MLP model on the training set, validation set and test set.
Discussion
In the air quality prediction problem, stepwise regression models, MLP and SRA-MLP models can fit the data of self-built points. We can verify each model by the error between the model prediction value and the national control point data. Obviously, which model has a smaller error between the predicted value and the national control point value, which model is better. This article uses root mean square error, mean absolute error, and mean absolute percent error to evaluate the model30. The specific results are shown in Tables 5, 6 and 7.
It can be seen that whether it is a stepwise regression model, or the MLP and SRA-MLP models, the prediction accuracy is better than the measurement accuracy of self-built points. This shows that using the three established mathematical models to calibrate the measurement data of self-built points can achieve better results. Since the error evaluation index of the SRA-MLP model is the smallest among the three models, the SRA-MLP model is selected to calibrate the measurement data of self-built points. Among the six types of pollutant prediction models, the accuracy of the PM10 prediction model's RMSE has the largest increase, with an accuracy increase of 74.4%. The PM10 prediction model's MAE has the largest increase in accuracy, with an accuracy increase of 76.3%. The NO2 prediction model's MAPE has the largest increase in accuracy, with an accuracy increase of 86.5%.
The concentration of pollutants in the atmosphere has an obvious correlation with the periodic activities of human beings. The weekly averages of the six pollutant concentrations are plotted in Fig. 7. It can be seen that there is a significant deviation between the red self-built point data curve and the blue national control point data curve, but the black model fitting value (smp) curve deviates very little from the national control point data curve. The results show that the accuracy of the SRA-MLP model for predicting the concentration of pollutants is better than the accuracy of the self-built point measurement data.

Comparison of weekly average data of six types of pollutants at national control points, self-built points and SRM-MLP model correction points.
Conclusions
The air quality index (AQI) is a dimensionless index that quantitatively describes the condition of air quality. It is often used to measure the quality of air quality. The main pollutants participating in the air quality assessment are PM2.5, PM10, CO, NO2, SO2, O3, etc. Therefore, to realize the monitoring of air quality, it is very important to monitor the concentration of ''two dusts and four gases" in real time.
Many countries have established national monitoring and control stations to monitor air pollutant concentrations. Although the national control point is more accurate in monitoring pollutants, the cost of deployment is high, the number of deployments is small, and the maintenance costs are high. Therefore, it is difficult for the national control point to achieve full control. The miniature air quality detector developed by some companies has successfully improved these shortcomings, but the accuracy of monitoring needs to be improved.
The pollutant correction model based on the stepwise regression model has some corrections to the self-built point data, and the results obtained are easier to interpret, but the correction effect needs to be improved. Compared with regression models, artificial neural networks have a greater advantage in data correction. The artificial neural network does not rely on the typical distribution of the original data. It simulates human thinking to derive a non-linear mapping relationship between the input and output of the system, and then makes intelligent reasoning and prediction.
The SRA-MLP model given in this article combines the advantages of a stepwise regression model and an artificial neural network combined model. It not only provides the quantitative relationship between the monitoring data of self-built points and the concentration of the six pollutants, but also greatly improves the accuracy of the prediction of the concentration of the six pollutants. The data used in the model is 4135 groups, the time span is 206 days, and the data of all four seasons are involved, and it shows good predictive ability in the training set and the test set, so the model is very stable. This model plays a positive role in grid-based monitoring of the concentration of various pollutants and guides the scientific deployment of miniature air quality detectors. It can also be popularized and applied to the prediction of environmental pollution indexes such as water pollution, soil pollution, noise pollution and light pollution. But because this research uses a small data set, it is not suitable for deep learning. In future research, we hope to collect more data and use deep learning to improve the model.
References
Qiu, H. et al. Differential effects of fine and coarse particles on daily emergency cardiovascular hospitalizations in Hong Kong. Atmos. Environ. 64, 296–302 (2013).
Akimoto, H. Global air quality and pollution. Science 302, 1716–1719 (2004).
Johanna, L., Francine, L., Douglas, D. & Joel, S. Chronic exposure to fine particles and mortality: an extended follow-up of the Harvard six cities study from 1974 to 2009. Environ. Health Perspect. 120, 965–970 (2012).
Spinelle, L., Gerboles, M., Villani, M. G., Aleixandre, M. & Bonavitacola, F. Field calibration of a cluster of low-cost available sensors for air quality monitoring. Part A: Ozone and nitrogen dioxide. Sensor Actuator B-Chem. 215, 249–257 (2015)
Lu, C. et al. Chemical composition of fog water in Nanjing area of China and its related fog microphysics. Atmos. Res. 97, 47–69 (2010).
Liu, Q., Liu, Y., Yang, Z., Zhang, T. & Zhong, Z. Daily variations of chemical properties in airborne particulate matter during a high pollution winter episode in Beijing. Acta Sci. Circumst. 34, 12–18 (2014).
Elangasinghe, M. A., Singhal, N. , Dirks, K. N., Salmond, J. A., & Samarasinghe, S. Complex time series analysis of PM10 and PM2.5 for a coastal site using artificial neural network modelling and k-means clustering. Atmos. Environ. 94, 106–116 (2014).
Feng, X. et al. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 107, 118–128 (2015).
Reich, S. L., Gomez, D. R. & Dawidowski, L. E. Artificial neural network for the identification of unknown air pollution sources. Atmos. Environ. 33, 3045–3052 (1999).
Spinelle, L., Gerboles, M., Villani, M. G., Aleixandre, M. & Bonavitacola, F. Field calibration of a cluster of low-cost commercially available sensors for air quality monitoring. Part B: NO, CO and CO2. Sensor Actuator B-Chem. 238, 706–715 (2016).
Vallius, M. et al. Sources and elemental composition of ambient PM2.5 in three European cities. Sci. Total Environ. 337, 147–162 (2005).
Tai, A. P. K., Mickley, L. J. & Jacob, D. J. Correlations between fine particulate matter (PM2.5) and meteorological variables in the United States: Implications for the sensitivity of PM2.5 to climate change. Atmos. Environ. 44, 3976–3984 (2010).
Sun, W. et al. Prediction of 24-hour-average pm2.5 concentrations using a hidden Markov model with different emission distributions in Northern California. Sci. Total Environ. 443, 93–103 (2013).
Dong, M. et al. PM2.5 concentration prediction using hidden semi-Markov model-based times series data mining. Expert. Syst. Appl. 36, 9046–9055 (2009).
Zimmerman, N. et al. A machine learning calibration model using random forests to improve sensor performance for lower-cost air quality monitoring. Atmos. Meas. Tech. 11, 291–313 (2018).
Liu, D. & Li, L. Application study of comprehensive forecasting model based on entropy weighting method on trend of PM2.5 concentration in Guangzhou, China. Int. J. Environ. Res. Pub. HE. 12, 7085–7099 (2015).
Kamińska, J. A. The use of random forests in modelling short-term air pollution effects based on traffic and meteorological conditions: A case study in Wrocaw. J. Environ. Manag. 217, 164–174 (2018).
Dun, M., Xu, Z., Chen, Y. & Wu, L. Short-term air quality prediction based on fractional grey linear regression and support vector machine. Math. Probl. Eng. 2020, 1–13 (2020).
Deo, R. C., Wen, X. & Qi, F. A wavelet-coupled support vector machine model for forecasting global incident solar radiation using limited meteorological dataset. Appl. Energy 168, 568–593 (2016).
Ortiz-Garcia, E. G., Salcedo-Sanz, S., Perez-Bellido, A. M., Portilla-Figueras, J. A. & Prieto, L. Prediction of hourly O3 concentrations using support vector regression algorithms. Atmos. Environ. 44, 4481–4488 (2010).
Rahman, N. H. A., Lee, M. H., Suhartono & Latif, M. T. Artificial neural networks and fuzzy time series forecasting: An application to air quality. Qual. Quant. 49, 1–15 (2015).
Kyriakidis, I., Karatzas, K., Kukkonen, J., Papadourakis, G. & Ware, A. Evaluation and analysis of artificial neural networks and decision trees in forecasting of common air quality index in Thessaloniki, Greece. Eng. Intell. Syst. Electr. 2, 111–124 (2013).
Tu, J. V. Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J. Clin. Epidemiol. 49, 1225–1231 (1996).
Huang, Z. & Zhang, R. Efficient estimation of adaptive varying-coefficient partially linear regression model. Stat. Probab. Lett. 79, 943–952 (2009).
Vesely, S., Kloeckner, C. A. & Dohnal, M. Predicting recycling behaviour: Comparison of a linear regression model and a fuzzy logic model. Waste Manag. 49, 530–536 (2016).
Li, M. & Wang, J. An empirical comparison of multiple linear regression and artificial neural network for concrete dam deformation modelling. Math. Probl. Eng. 2019, 1–13 (2019).
Liu, B., Jin, Y. & Li, C. Analysis and prediction of air quality in Nanjing from autumn 2018 to summer 2019 using PCR-SVR-ARMA combined model. Sci. Rep.-UK. https://doi.org/https://doi.org/10.1038/s41598-020-79462-0.
Song, Z., Deng, Q. & Ren, Z. Correlation and principal component regression analysis for studying air quality and meteorological elements in Wuhan, China. Environ. Prog. Sustain. 39, 1–11 (2020).
Lei, M. T., Monjardino, J., Mendes, L. & Ferreira, F. Macao air quality forecast using statistical methods. Air. Qual. Atmos. Health. 2, 249–258 (2019).
Cordero, J. M., Borge, R. & Narros, A. Using statistical methods to carry out in field calibrations of low cost air quality sensors. Sensor Actuator B-Chem. 267, 245–254 (2018).
Voukantsis, D. et al. Intercomparison of air quality data using principal component analysis, and forecasting of PM10 and PM2.5 concentrations using artificial neural networks, Thessaloniki and Helsinki. Sci. Total Environ. 409, 1266–1276 (2011).
He, H., Lu, W. & Xue, Y. Prediction of particulate matters at urban intersection by using multilayer perceptron model based on principal components. Stoch. Environ. Res. Risk A. 29, 2107–2114 (2015).
Chaudhuri, B. B. & Bhattacharya, U. Efficient training and improved performance of multilayer perceptron in pattern classification. Neurocomputing 34, 11–27 (2000).
Sheela, K. G. & Deepa, S. N. Review on methods to fix number of hidden neurons in neural networks. Math. Probl. Eng. 2013, 1–11 (2013).
Hornik, K. M., Stinchcomb, M. & White, H. Multilayer feedforward networks are universal approximator. Neural Netw. 2, 1–12 (1989).
Tunc, T. A new hybrid method logistic regression and feedforward neural network for lung cancer data. Math. Probl. Eng. 2012, 907–921 (2012).
Acknowledgements
This work was supported by the Youth Program of National Natural Science Foundation of China (no. 71602051) and Key Scientific Research Fund Project of Nanjing Vocational University of Industry Technology (no. 901050617YK002).
Author information
Authors and Affiliations
Contributions
B.L. and Q.Z. wrote the main manuscript text, Y.J. and J.S. prepared figures, and C.L. processed the data.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, B., Zhao, Q., Jin, Y. et al. Application of combined model of stepwise regression analysis and artificial neural network in data calibration of miniature air quality detector. Sci Rep 11, 3247 (2021). https://doi.org/10.1038/s41598-021-82871-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-82871-4
- Springer Nature Limited
This article is cited by
-
A convenient nomogram for predicting early death or liver transplantation after the Kasai procedure in patients with biliary atresia
Langenbeck's Archives of Surgery (2024)
-
Computational deep air quality prediction techniques: a systematic review
Artificial Intelligence Review (2023)
-
Survey on Deep Fuzzy Systems in Regression Applications: A View on Interpretability
International Journal of Fuzzy Systems (2023)
-
Applications of remote sensing vis-à-vis machine learning in air quality monitoring and modelling: a review
Environmental Monitoring and Assessment (2023)
-
Application of RR-XGBoost combined model in data calibration of micro air quality detector
Scientific Reports (2021)