
Abstract
Forensic dental examination has played an important role in personal identification (PI). However, PI has essentially been based on traditional visual comparisons of ante- and postmortem dental records and radiographs, and there is no globally accepted PI method based on digital technology. Although many effective image recognition models have been developed, they have been underutilized in forensic odontology. The aim of this study was to verify the usefulness of PI with paired orthopantomographs obtained in a relatively short period using convolutional neural network (CNN) technologies. Thirty pairs of orthopantomographs obtained on different days were analyzed in terms of the accuracy of dental PI based on six well-known CNN architectures: VGG16, ResNet50, Inception-v3, InceptionResNet-v2, Xception, and MobileNet-v2. Each model was trained and tested using paired orthopantomographs, and pretraining and fine-tuning transfer learning methods were validated. Higher validation accuracy was achieved with fine-tuning than with pretraining, and each architecture showed a detection accuracy of 80.0% or more. The VGG16 model achieved the highest accuracy (100.0%) with pretraining and with fine-tuning. This study demonstrated the usefulness of CNN for PI using small numbers of orthopantomographic images, and it also showed that VGG16 was the most useful of the six tested CNN architectures.
Similar content being viewed by others
Explore related subjects
Find the latest articles, discoveries, and news in related topics.Introduction
Dental examination findings are unique among individuals because they consist of a combination of decayed, filled, prosthetic, and missing teeth1. Additionally, teeth are harder and more resistant to heat than other body tissues, including bones. Therefore, forensic dental examination has played an important role in personal identification (PI), even in large-scale accidents and disasters. Digitalization in medical and dental examinations and treatments has progressed, providing clinicians with great support in diagnoses and surgical procedures2,3,4. However, in forensic dental examination, PI has essentially been based on traditional visual comparisons of the antemortem dental records and radiographs with those obtained by postmortem dental examinations5. Moreover, such traditional forensic dental examinations have the disadvantage of lacking widely accepted reference points between antemortem records and postmortem examinations1. Finally, analyses of traditional written dental records are subjective6. Therefore, traditional forensic dental examinations are vulnerable to oversights and/or mistakes in PI6. The authors believe that one way to improve on these traditional dental examinations for dental PI that are currently used around the world would be to digitize and standardize them. Although forensic odontology with digital technologies has progressed, there is no globally accepted PI method based on digital technology due to various factors, such as special equipment and costs. With the progression of digital technologies, global digitization of forensic odontology should be promoted. In the future, such technologies will make a significant social contribution to PI in the wake of large-scale accidents and disasters.
In a position statement published by the Institute of Electrical and Electronics Engineers, the following definition of artificial intelligence (AI) is suggested: AI is that activity devoted to making machines intelligent, and intelligence is that quality that enables an entity to function appropriately and with foresight in its environment7. The development of AI technologies has made great strides along with the growth and evolution of personal computers. At present, there is a possibility that machines will displace humans in various fields, including medicine8. AI technology includes deep learning, which improves a machine’s ability to represent data by deepening the layered structure of neural networks; a convolutional neural network (CNN) is a type of network for deep learning9,10,11,12,13,14,15. The authors believe that CNNs may be useful for forensic PI because they have high recognition accuracy, mainly in the field of image recognition9. Thus, a convergence between dental imaging examination and CNNs in the forensic field may have great potential to bring social benefits by improving preparedness for large-scale accidents and disasters due to the frequency of imaging examinations in clinical dentistry.
The aim of this preliminary study was to evaluate the usefulness of PI with orthopantomography using the following six CNN architectures: VGG16, ResNet50, Inception-v3, InceptionResNet-v2, Xception, and MobileNet-v210,11,12,13,14,15.
Results
Participants and materials
Thirty participants (14 male and 16 female) were included in this study (Table 1). Thus, 30 pairs of orthopantomographs, for a total of 60 orthopantomographs, were analyzed in this study. The youngest participant was 15 years old, and the oldest was 86 years old. The mean ± standard deviation was 31.00 ± 15.21 years old. Twenty-nine participants underwent orthopantomography before and after tooth extractions, and one participant underwent orthopantomography twice in follow-up examinations (Table 1: No. 11). The mean ± standard deviation of the number of extracted teeth among the thirty participants was 2.03 ± 1.07, and the most common extracted tooth was the mandibular third molar. The mean and standard deviation of the number of teeth “before orthopantomography” was 29.00 ± 6.34, and that “after orthopantomography” was 26.97 ± 6.08. The mean ± standard deviation of the interval between “before orthopantomography” and “after orthopantomography” was 64.03 ± 70.29 days.
Training and testing a CNN model
In the training phase, the CNN used a training dataset composed of input images X and their correct personal identifiers y to adapt the weights (filters) of the network. After training the model, the CNN estimated the correct label \(\widehat{y}\) from unlabeled image X′ in the testing phase. Finally, the estimated label \(\widehat{y}\) and the correct label y were compared to calculate evaluation indexes such as accuracy, precision, and recall. In this study, the authors used accuracy as an evaluation index.
The authors identified a suitable CNN architecture and training parameters for this task through comparison experiments. Each model was trained using the “before orthopantomography” dataset for 300 epochs and tested using the “after orthopantomography” dataset. In this study, the authors validated six types of CNN architecture: VGG16, ResNet50, Inception-v3, InceptionResNet-v2, Xception, and MobileNet-v2. These architectures were implemented in Keras (https://keras.io/), which is a Python deep learning library. The parameters and original papers are found in the official Keras documentation (https://keras.io/applications/#applications). The authors also validated some optimizers: SGD, RMSProp, Adadelta, Adagrad, and Adam, with a learning rate of 10−5 to 10−3. The batch size was 10. Furthermore, the authors validated two types of transfer learning methods: pretraining and fine-tuning. In pretraining, all weights in the model were trained in advance using a large-scale dataset for other tasks, and some of the weights were trained using the target dataset (e.g., the dental PI dataset in this study). The authors trained only the weights of the final layer after pretraining. In fine-tuning, all weights in the model were retrained using the target dataset after pretraining. Both transfer learning methods used the ImageNet dataset, which is a very large-scale image recognition dataset including over 14 million labeled images. In total, the authors validated 180 training patterns (6 models × 5 optimizers × 3 learning rates × 2 transfer methods).
Evaluation results
The values in the table represent the validation accuracies in the final epoch (Table 2). The authors selected the maximum accuracies from all optimizers for each method because the best optimizer and learning rate differ for each CNN architecture. In this evaluation, the VGG16 model achieved the highest accuracy, at 100.0% (Fig. 1). When drawing comparisons in transfer learning, the most accurate method to use is fine-tuning. Under fine-tuning, some CNN architectures also achieved greater than 90.0% accuracy. VGG16, despite having a relatively shallow layer structure, had the highest estimation accuracy because this dataset was very small.

The loss (blue line) and accuracy (red line) in training. The x-axis measures epochs, the left y-axis measures loss, and the right y-axis measures accuracy (%). Focusing on the red line, the training and testing accuracies converge after 30 epochs. Although the training data are perfectly classified, the testing data are sometimes misclassified.
Discussion
In this study, the authors evaluated the usefulness of the application of CNN technology in PI based on orthopantomography by validating the identification accuracy of six different CNN architectures. The results demonstrated that VGG16 was the most useful CNN architecture for PI using orthopantomography. Furthermore, VGG16 pretraining and fine-tuning using the ImageNet dataset achieved 100% identification accuracy. In cases of forensic medicine and forensic dentistry such as fire and murder victims, excluding large-scale disasters, it is important to identify individuals from a small number of people. To resolve this problem, this study indicated the possibility of accurate PI from orthopantomography image by using CNNs.
According to the PubMed database, studies of CNN application have been reported since 2013 in various medical including orthopedics, oncology, ophthalmology, and neurosurgery16,17,18,19. In the dental field, Miki et al. first reported the application of CNNs with cone-beam computed tomography in 201720. In recent years, applications of CNNs in cariology, periodontology, and endodontics have been reported, and applications in real dental clinical experience may be realized in the near future21,22,23. Tuzoff et al. reported a method of tooth detection and numbering with orthopantomography using simple CNNs, which could help save time and improve the process of filling out dental charts24. Kahaki et al. tried to establish an age estimation method based on global fuzzy segmentation and local feature extraction using a projection-based feature transform and a designed deep CNN model; the molars were isolated from 456 young participants' orthopantomography as an analysis target25. Schwendicke et al. performed a scoping review of CNNs for dental image diagnostics and concluded that CNNs may be used in diagnostic-assistance systems in the dental field26. At present, CNN technology is not easy for dentists to implement. In the future, generalization of such technology will further advance through the development of simple software.
As a limitation of this study, the authors must note that the mean ± standard deviation of the periods between the date obtained “before orthopantomography” and the date obtained “after orthopantomography” was 64.03 ± 70.29 days; in other words, the paired orthopantomographs under comparison were obtained at relatively short intervals. This condition was due to the inclusion criteria for the study participants to rule out age-related oral changes and oral diseases such as periodontal disease and caries. Twenty-nine of the 30 participants were examined orthopantomographically before and after wisdom tooth extraction, while one participant did not undergo tooth extraction during the study. The authors considered that the reason why the VGG16 model achieved 100.0% accuracy was because the images taken as “before orthopantomography” and “after orthopantomography” were obtained under almost the same conditions and were very similar. Therefore, the results of this preliminary experiment verified the applicability of PI in an ideal environment with pairs of very similar images indicated that CNNs can classify individual orthopantomographs according to which patients they depict. In addition, because the authors were able to use only two datasets at this time, they established only a training set and a validation set. The authors have been able to perform only limited verification. Normally, it is necessary to prepare the test data. Additionally, it is necessary to train the model with a training set, perform parameter tuning with a validation set, and then verify the final estimation accuracy with a test set. This is one of the limitations of this study. In addition, the authors understand that the application of deep neural networks to small datasets may lead to the problem of overfitting. On the other hand, there are several issues with long-term changes, including periodontal bone loss, dental caries, and prosthetic rehabilitation, in studies of PI based on orthopantomography, as mentioned above. Additionally, experimental orthopantomography examination will lead to radiation exposure and ethical issues. In this study, participants who underwent orthopantomography for clinical treatment in a relatively short period were collected retrospectively and analyzed. Therefore, it was difficult to construct a large-scale image dataset. To use CNN technology for orthopantomography in preparation for large-scale accidents and disasters in the future, further validation of the number of paired orthopantomographs and the interval periods between “before orthopantomography” and “after orthopantomography” is required. Additionally, the main cause of death might be facial trauma with tooth or bone fractures. Therefore, various clinical situations such as changes in maxillofacial and dental status should be considered in PI, and PI should be performed with high accuracy. Based on this preliminary study, it is important to proceed with PI research using CNN technology but also considering the cause of death in order to apply the results of this study to actual forensic cases in the future. Regarding the loss function, the best-known loss function for classification tasks is cross-entropy loss, which is defined by the equation in this study. Mean squared error and mean absolute error can also be used as loss functions in classification, and there are other loss functions as well, such as focal loss, class-balanced loss, and triplet loss. Because this experiment was a preliminary study, the authors adopted the best-known loss function: cross-entropy loss.
Generally, orthopantomography requires standing and/or proper posture. Therefore, obtaining postmortem orthopantomographs may be difficult. Franco et al. suggested that postmortem full-body CT images could become a valuable tool in individual dental identification procedures27. Ohtani et al. reported radiographic imaging examination using portable devices acceptable for prone position28. In the future, the authors suggest that dentists and engineers should consider methods of constructing an orthopantomography-like image that is acceptable for postmortem examination by using data from another modality, such as CT images; CNN technology could then be applied for PI with those images.
In conclusion, this study demonstrated the usefulness of CNN for PI using a small number of orthopantomographic images and that VGG16 was more useful than five other CNN architectures. Further validation in the number of paired images and in the interval between “before orthopantomography” and “after orthopantomography” is required to use this technology for large-scale accidents and disasters in the future.
Materials and methods
Participants and materials
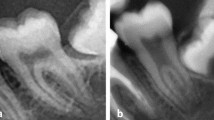
The authors designed a retrospective study. The participants were patients who received orthopantomography for clinical treatment at the University of Fukui Hospital twice from January 2018 to September 2019 and at relatively short intervals to rule out age-related oral changes and oral diseases such as periodontal disease and caries. Paired orthopantomographs of those participants were analyzed for the development of the PI method. In this study, based on the examination date, paired orthopantomographs were defined as “before orthopantomography” and “after orthopantomography” (Fig. 2). The orthopantomography data used in this study are stored in the Image Management System of the University of Fukui Hospital, and the details of the participants are shown in Table 1.

The design of this study was based on paired orthopantomographs analyzed with six convolutional neural network architectures. The paired orthopantomographs of participant No. 1 are shown as (A) “before orthopantomography” and (B) “after orthopantomography”, and tooth extraction sites are indicated by white arrows in this figure.
Simple convolutional neural networks
Machine learning is a method to explore a function f(⋅) that can convert x to y from a dataset consisting of input data x with the correct label y. The goal is to optimize the formula y = f(x) from a given dataset. A CNN is a neural network model composed of many layers, including a convolution layer and a pooling layer. CNNs are aggressively applied in the image recognition field—for example, cancer detection from X-ray images. The basic principle of the convolution process is to calculate the convolution from a raw image with filters. Filters, which are similar to weights in a neural network, are adoptively adjusted in the training process. By this process, a computer aims to acquire the effective filters to detect the target from the dataset. The basic principle of the pooling process is to calculate the representative value from fixed-size windows—for example, a 2 × 2 max pooling layer calculates the max values from each 2 × 2 array of pixels. Through this process, it is said that a computer acquires a robust feature representation of the target position.
Formulation of this problem
The authors formulated a dental PI task to complete via a CNN model. In this task, a dental image is given, and the personal identifier is required as an output. The input for machine learning is a dental image X, and the output is a personal identifier y. Therefore, CNN model f(⋅) takes the role of a converter that converts input image X into personal identifier y. This is a simple classification task represented by the formula y = f(X).
In order to accurately estimate the personal identifier y, CNN filters are adapted based on the loss function. There are many CNN architectures and loss functions in the facial recognition field; however, as a preliminary experiment, this study adopted a simple CNN classifier with a common loss function called categorical cross-entropy loss (Lce). Lce is represented by the following formula:
where N is the number of target people, t is a correct label (one-hot vector), and f(X)i is the i-th CNN’s output. CNN adopts its filters to minimize Lce in the training phase.
Ethics approval and informed consent
This study was approved by the Institutional Research Board (Ethical Committee of the University of Fukui, Faculty of Medical Sciences, No. 20190043). There were no ethical issues in conducting this study because it was a retrospective study targeting examination images obtained for clinical treatment, and the authors declared that all methods were performed in accordance with the relevant guidelines and regulations (Declaration of Helsinki). Additionally, informed consent was obtained from all subjects or, if subjects were under 18, from a parent and/or legal guardian.
Data availability
The data used to support the findings of this study are available from the corresponding author upon request.
References
Flint, D. J., Brent Dove, S., Brumit, P. C., White, M. & Senn, D. R. Computer-aided dental identification: an objective method for assessment of radiographic image similarity. J. Forensic Sci.54, 177–184 (2009).
Matsuda, S. et al. Usefulness of computed tomography image processing by OsiriX software in detecting wooden and bamboo foreign bodies. Biomed. Res. Int.2017, 3104018 (2017).
Matsuda, S. et al. Application of a real-time three-dimensional navigation system to dental implant removal: a five-year single-institution experience. J. Hard Tissue Biol.27, 359–362 (2018).
Matsuda, S., Yoshimura, H. & Sano, K. Application of a real-time 3-dimensional navigation system for treatment of synovial chondromatosis of the temporomandibular joint: a case report. Medicine (Baltimore)98, e15382 (2019).
Sweet, D. Why a dentist for identification?. Dent. Clin. N. Am.45, 237–251 (2001).
Forrest, A. S. Collection and recording of radiological information for forensic purposes. Aust. Dent. J.57, 24–32 (2012).
IEEE Board of directors. Artificial Intelligence: IEEE position statement. IEEE Advancing Technology for Humanity (2019).
Wallis, C. How artificial intelligence will change medicine. Nature576, S48 (2019).
Hasegawa, T. et al. Automatic electron density determination by using a convolutional neural network. IEEE Access7, 163384–163394 (2019).
Shimonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. Proc. Int. Conf. Learn. Represent.2015, 1–14 (2015).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2818–2826 (2016).
Szegedy, C., Ioffe, S., Vanhoucke, V. & Alemi A. Inception-v4, inception-ResNet and the impact of residual connections on learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, 4278–4284 (2017).
François C. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 1800–1807 (2017).
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. & Chen, L. C. MobileNetV2: inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4510–4520 (2018).
Prasoon, A. et al. Deep feature learning for knee cartilage segmentation using a triplanar convolutional neural network. Med. Image Comput. Comput. Assist. Interv.16, 246–253 (2013).
Wang, H. et al. Mitosis detection in breast cancer pathology images by combining handcrafted and convolutional neural network features. J. Med. Imaging (Bellingham)1, 034003 (2014).
Chen, X., Xu, Y., Wong, D. W. K., Wong, T. Y. & Liu, J. Glaucoma detection based on deep convolutional neural network. Conf. Proc. IEEE Eng. Med. Biol. Soc.2015, 715–718 (2015).
Kleesiek, J. et al. Deep MRI brain extraction: a 3D convolutional neural network for skull stripping. Neuroimage129, 460–469 (2016).
Miki, Y. et al. Classification of teeth in cone-beam CT using deep convolutional neural network. Comput. Biol. Med.80, 24–29 (2017).
Lee, J. H., Kim, D. H., Jeong, S. N. & Choi, S. H. Detection and diagnosis of dental caries using a deep learning-based convolutional neural network algorithm. J. Dent.77, 106–111 (2018).
Krois, J. et al. Deep learning for the radiographic detection of periodontal bone loss. Sci. Rep.9, 8495 (2019).
Ekert, T. et al. Deep learning for the radiographic detection of apical lesions. J. Endod.45, 917-922.e5 (2019).
Tuzoff, D. V. et al. Tooth detection and numbering in panoramic radiographs using convolutional neural networks. Dentomaxillofac. Radiol.48, 20180051 (2019).
Kahaki, S. M. M., Nordin, M. J., Ahmad, N. S., Arzoky, M. & Ismail, W. Deep convolutional neural network designed for age assessment based on orthopantomography data. Neural Comput. Appl.32, 9357–9368 (2020).
Schwendicke, F., Golla, T., Dreher, M. & Krois, J. Convolutional neural networks for dental image diagnostics: a scoping review. J. Dent.91, 103226 (2019).
Franco, A. et al. Feasibility and validation of virtual autopsy for dental identification using the Interpol dental codes. J. Forensic Leg. Med.20, 248–254 (2013).
Ohtani, M., Oshima, T. & Mimasaka, S. Extra-oral dental radiography for disaster victims using a flat panel X-ray detector and a hand-held X-ray generator. J. Forensic Odontostomatol.35, 28–34 (2017).
Acknowledgements
This work was supported by The Fukui Bank, Ltd. in an industry-university cooperation.
Author information
Authors and Affiliations
Contributions
S.M., T.M., and T.H. contributed to conception, design, data acquisition, analysis, and interpretation and drafted and critically revised the manuscript. H.Y. contributed to the conception, design, and critically revision of the manuscript. All authors read the final version and gave final approval and agreement to submit the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Matsuda, S., Miyamoto, T., Yoshimura, H. et al. Personal identification with orthopantomography using simple convolutional neural networks: a preliminary study. Sci Rep 10, 13559 (2020). https://doi.org/10.1038/s41598-020-70474-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-70474-4
- Springer Nature Limited
This article is cited by
-
Personal identification with artificial intelligence under COVID-19 crisis: a scoping review
Systematic Reviews (2022)
-
Dental biometric systems: a comparative study of conventional descriptors and deep learning-based features
Multimedia Tools and Applications (2022)
-
An improved multipath residual CNN-based classification approach for periapical disease prediction and diagnosis in dental radiography
Neural Computing and Applications (2022)