
Abstract
Regular drusen, an accumulation of material below the retinal pigment epithelium (RPE), have long been established as a hallmark early feature of nonneovascular age-related macular degeneration (AMD). Advances in imaging have expanded the phenotype of AMD to include another extracellular deposit, reticular pseudodrusen (RPD) (also termed subretinal drusenoid deposits, SDD), which are located above the RPE. We developed an approach to automatically segment retinal layers associated with regular drusen and RPD in spectral domain (SD) optical coherence tomography (OCT) images. More specifically, a shortest-path algorithm enhanced with probability maps generated through a fully convolutional neural network was used to segment drusen and RPD, as well as 11 retinal layers in SD-OCT volumes. This algorithm achieves a mean difference that is within the subpixel accuracy range drusen and RPD, alongside the other 11 retinal layers, highlighting the high robustness of this algorithm for this dataset. To the best of our knowledge, this is the first report of a validated algorithm for the automated segmentation of the retinal layers including early AMD features of RPD and regular drusen separately on SD-OCT images.
Similar content being viewed by others


Introduction
Spectral-domain optical coherence tomography (SD-OCT) is a three-dimensional (3-D), in vivo imaging technique that permits direct visualization of retinal morphology and architecture1.
In the setting of retinal or optic nerve disease, the retinal layer thickness may be affected either locally or globally, depending on the specific disease. In terms of vision and blindness in the United States, the three most important diseases are age-related macular degeneration (AMD), diabetic retinopathy, and glaucoma2,3,4. AMD is the leading cause of blindness in people aged 65 and older in the western world5. Although effective treatments are now available for patients with neovascular AMD (choroidal neovascularization, CNV), many of these patients appear to eventually lose vision due to the development of geographic atrophy (GA). Several agents have been evaluated, including in Phase 3 clinical trials, hoping to slow the progression of GA, but thus far there is no proven, effective treatment. Some researchers have suggested that earlier intervention before the development of irreversible atrophy might be a preferable strategy.
Reticular pseudodrusen and regular drusen are now both accepted as features that are commonly present in early and intermediate AMD, before the development of late features such as CNV or GA. Drusen commonly appear as tiny yellow or white deposits at the level of the Bruch’s membrane on color fundus images, but they are visualized more easily by SD-OCT. The importance of drusen in the diagnosis and progression of AMD has been established in a number of studies6,7,8. Advances in imaging over the past two decades, including in infrared reflectance (IR) and autofluoresence, have revealed another distinct phenotype, known as reticular pseudodrusen (RPD), or subretinal drusenoid deposits (SDD). RPD are strongly associated with the development of late AMD, including Type 3 (intraretinal) NV (also known as retinal angiomatous proliferation or RAP), outer retinal atrophy (ORA) and GA. RPD, which can appear as yellowish interlacing networks in color fundus images, are also better visualized using infrared imaging, blue light fundus autofluorescence (FAF), or SD-OCT. Studies correlating SD-OCT and confocal scanning laser ophthalmoscopy have shown that RPD appear to correspond to subretinal deposits, located internal to the RPE, in contrast to traditional drusen, which are located external to the RPE9. As multiple longitudinal studies have revealed that RPD are strong predictors for progression to GA9,10,11,12,13, interest in understanding the role that RPD play in the pathogenesis of AMD has grown. Quantifying and monitoring the progression of these features of AMD are of interest for understanding the evolution of AMD. Manual segmentation of these AMD features and associated alterations in retinal layers in volumetric SD-OCT images, however, is tedious, time-consuming, and impractical for large studies. While a system for automatically detecting the AMD biomarkers and multiple retinal layers is attractive, automated detection is not trivial due to the complexity of the layer structures relatively low image contrast of OCT, and the disturbance of the retinal layers due to the AMD features/biomarkers, for instance the regular drusen and RPD. RPD are particularly difficult to identify and segment as the borders of these lesions may be poorly demarcated. As such, to the best of our knowledge, there have been no reported validated algorithms for automated segmentation of RPD. We have previously reported semiautomated segmentation of outer retinal layers in eyes with RPD14, but segmentation failures precluded accurate quantification of RPD themselves.
Approaches to the problem of automated segmentation in SD-OCT volumes have included application of shortest path frameworks15,16, active contour modeling17, graph search frameworks18,19,20,21, and deep learning methods22,23,24,25,26. Of these approaches, graph-based approaches have generally performed best. However, graph-search frameworks are slow and shortest-path frameworks do not have interaction constraints. The algorithm discussed in this paper is based on the shortest path framework and makes use of a fully convolutional neural network (i.e. the U-Net22,23,24) to enhance performance. Our major contribution with this algorithm is the automatic segmentation of RPD in SD-OCT images. We are additionally able to automatically segment regular drusen and explore the applicability of this method in the automatic segmentation of 11 retinal surfaces, including the various retinal bands, in SD-OCT images. To the best of our knowledge, this is the first report of a validated algorithm for the automated segmentation of the retinal layers including early AMD features of RPD and regular drusen separately on SD-OCT images.
Methods
Overview
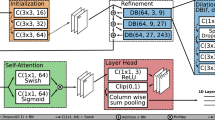
Overall, the Deep Learning – Shortest Path (DL-SP) algorithm as described in this report is a multistage shortest path segmentation approach which is applied to delineate RPD and drusen and can further be applied to segment 11 retinal surfaces in SD-OCT. To be more computationally efficient, instead of performing the retinal layers’ segmentation in OCT volumes using the 3D graph-based approach as in our previous work, the DL-SP algorithm is performed on 2D OCT B-scan images. The pixel to pixel edge weights used in the shortest path algorithm were calculated using the normalized gradient in the z-direction (inverted to measure dark-to-bright or bright-to-dark intensity transition depending on the layer) in combination with probability maps generated from a deep learning fully convolutional neural network based on the U-Net architecture. Figure 1 shows an overview of the method.

Overview of the DL-SP approach for segmentation of retinal layers, where orange boxes represent training steps and gray boxes represent evaluation steps. There was no overlap between training and testing data.
Imaging dataset
45 eyes from 42 subjects were identified from patients at the Doheny-UCLA Eye Centers. Of these eyes, 25 were diagnosed with AMD, and the remaining 20 eyes were healthy. 16 eyes diagnosed with AMD were used to train neural networks to identify RPD and drusen. The healthy eyes were used to train the segmentation of layers largely unaffected by the presence of RPD and drusen. All images were de-identified according to Health and Insurance Portability and Accountability Act Safe Harbor prior to analysis. Ethics review and institutional review board approval from the University of California – Los Angeles were obtained. The research was performed in accordance with relevant guidelines/regulations, and informed consent was obtained from all participants.
Each subject underwent volume OCT imaging using a Heidelberg Spectralis (Heidelberg Engineering, Heidelberg, Germany) SD-OCT. All volume scans consisted of macular cube scan patterns. The image scan dimensions for eyes diagnosed with AMD are 496 (depth) × 1024 (A-scans) × 49 (B-scans) pixels, 496 (depth) × 1536 (A-scans) × 61 (B-scans) pixels, 496 (depth) × 512 (A-scans) × 49 (B-scans) pixels, 496 (depth) × 512 (A-scans) × 97 (B-scans) pixels, or 496 (depth) × 768 (A-scans) × 49 (B-scans) pixels. All images were cropped, stretched, or both in order to resize images to a standard width of 1024 and height of 496. After cropping, the average physical dimensions for these scans are 1.93 mm (depth) × 6.27 mm (A-scans) × 5.82 mm (B-scans). For the healthy eyes, the image scan dimensions are 496 (depth) × 1024 (A-scans) × 37 (B-scans) pixels. The average physical dimensions for these scans are 1.92 mm (depth) × 5.90 mm (A-scans) × 4.57 mm (B-scans). The pixel depth was 8 bits in grayscale. To provide consistency for the quantitative analysis of the retinal layer properties among different volume scans, all the right eye scans were horizontally flipped in the x-direction.
Shortest path
Shortest path segmentation is one of the fully automatic approaches to segmenting retinal layers that DL-SP builds on27. The shortest path algorithm for retinal segmentation is a graph-based approach. For each SD-OCT B-scan image, each pixel acts as a node, with edges reaching out to each of its eight neighboring pixels. With this representation, pathways crossing the image can be thought of as sets of connected edges. By assigning each edge a weight, path preferences can be formed. Once weights are assigned, Dijkstra’s algorithm is used to identify the path between two pixels with the lowest total weight. To ensure that each segmented layer crosses the entire image, two additional columns of pixels are added as buffer nodes with minimal weights assigned to their edges, and the top-left and bottom-right pixels are chosen to be the start and end nodes, respectively, for Dijkstra’s algorithm.
Edge weights are determined by changes in pixel intensity. Each retinal layer to be segmented is associated with a change from high to low or low to high pixel intensity. Therefore, two adjacency matrices are created, one using a normalized intensity gradient and the other using its inverse. The edge weights are calculated using the following equation:
where Wa,b is the weight assigned to the edge connecting pixels a and b, Ga and Gb are the vertical gradients of the image at pixels a and b, and Wmin is the minimal weight used in the two buffer columns.
Layers are segmented in order of prominence of changes of intensity; as such, the inner limiting membrane (ILM) and inner-outer segment junction (IS-OS) are the first layers found. After one layer is successfully segmented, it is used to limit the region of interest that is searched for the next layers. This aids in segmenting layers that exhibit less contrast than the ILM and IS-OS. In the DL-SP approach, probability maps generated by a convolutional neural network for each layer boundary are incorporated into this approach, changing the edge weight calculation and the determination of regions of interest for certain layers (see Section “Deep learning - shortest path”).
Deep learning
The second approach to retinal segmentation DL-SP builds upon uses a deep learning fully convolutional neural network to determine the retinal layers24. This neural network is a U-Net, a state-of-the-art deep learning algorithm for semantic segmentation relying on encoder-decoder type network architecture22. U-Net does not use fully connected layers and does not require sliding windows, resulting in faster performance that maintains precision even with smaller datasets22. The network consists of a contracting path of encoder blocks followed by and expansive (upsampling) path of three decoder blocks. Each encoder block consists of layers of convolution, batch normalization, rectified linear unit (ReLU), and pooling. Each decoder block consists of layers of unpooling, concatenation, convolution, batch normalization, and ReLU. The convolution kernels for all the encoder blocks were maintained at 7 × 3. Finally, a convolutional layer with a 1 × 1 kernel brings the final channel count down to the number of layers being segmented, and a softmax layer calculates the probabilities for the assignment of each pixel into a layer. The U-Net is optimized through the following functions:
where CE is the cross-entropy loss, Dice is the Dice loss, Overall is the overall loss, w(x) is the weight assigned to pixel \(x\in \Omega \), gl(x) is the ground truth probability of a pixel for layer l, pl(x) is the assigned probability of a pixel for layer l, λ is the weight decay, and WF is the Frobenius norm on the weights of the U-net24.
For DL-SP, of the eyes diagnosed with AMD, 16 eyes (831 2D B-scans) were randomly selected to be used for training. The remaining 9 eyes (512 2D B-scans) were used for testing. The loss function is optimized using stochastic mini-batch gradient descent in mini batches of size = 8 slices. Slices were formed by cutting images into nonoverlapping sections of width 64. At the start of training, the learning rate is set to 0.1 and is reduced by an order of magnitude every 20 epochs for a total of 60 epochs. Training was performed at a momentum of 0.95 with a weight decay of 0.0001. Pixel weights were assigned as 1 for outside the targeted layers, 6 for the targeted layers, and 15 for the targeted layer boundaries. Our U-Net was implemented in MATLAB R2017a and run on a desktop PC with an Intel i7-7800X CPU, 16 GB NVIDIA Quadro P5000 GPU, and 16 GB RAM.
Each pixel location was assigned a probability for each class in the label space L = {l} = {1, · · ·, K} for K classes, including RPD and drusen (Fig. 2). Using these layer probabilities, probability maps for the layer boundaries were found following
where \({P}_{i,i+1}\) is the probability of a pixel being part of the boundary between layer classes i and i + 1, and Pj is the probability of a pixel being part of layer class j, as assigned by the neural network. A visualization of these probability maps is shown in Fig. 3. For layers demonstrating low image contrast, comparatively, more focused neural networks were trained and applied to enhance the accuracy of the boundaries found by using prior segmentation to create an upper and lower boundary on which a neural network could train and be utilized on. Specifically, this was done for the choroid-sclera (C-S) boundary and the ganglion cell-inner plexiform (GC-IP) junction.

Results of the deep learning fully convolutional neural network, from which probability maps for the boundaries between layers can be calculated. (a) shows the original B-scan. (b) visualizes the layer assignment generated by the neural network.

Segmentation of drusen, RPD, and eleven retinal layers on SD-OCT B-scans. (a,d,g) are the original B-scans for the segmentations shown in (c,f,h) respectively. The drusen segmentation shown in (c) arises from the deep learning probability map shown in (b) and the RPD segmentation shown in (f) arises from the deep learning probability map shown in (e) The layers in order from top to bottom are the ILM, NF-GC, GC-IP, IP-IN, IN-OP, OP-ON, ELM, IS-OS, RPD, inner RPE, drusen, outer RPE, and C-S.
Deep learning – shortest path
The Deep Learning – Shortest Path algorithm makes use of both the above approaches. The first step in the algorithm is generating the probability maps as described in Section 2.4. These probability maps are incorporated into the calculation of weights of pixel to pixel edges in a variation of equation (1):
where wg is the weight given to the gradient, wp is the weight given to the probability map, and Pa and Pb are the probability map values at pixels a and b. With DL-SP, the importance placed on the vertical gradient and the probability can be varied by changing wg and wp. It is possible for these weightings to be different for each layer segmented. Because weights are calculated uniquely for each layer with this method, an adjacency matrix is required for each layer to be segmented, as opposed to the two required for the aforementioned shortest path method.
The segmentations of the layers were performed in the following sequence: the internal limiting membrane (ILM), inner-outer segment (IS-OS) junction, outer retinal pigment epithelium (RPE), drusen, inner RPE, retinal pseudodrusen (RPD), inner nuclear-outer plexiform (IN-OP) junction, nerve fiber-ganglion cell (NF-GC) junction, inner plexiform-inner nuclear (IP-IN) junction, outer plexiform-outer nuclear (OP-ON) junction, external limiting membrane (ELM), ganglion cell-inner plexiform (GC-IP) junction, and choroid-sclera (C-S) junction.
As in the original shortest-path algorithm, regions of interest for each layer are narrowed down using the layers previously segmented. However, in the cases of drusen and RPD, the region of interest is further limited using the probability maps generated for those layers (Pdrusen and PRPD by the previously established notation). The probability maps were binarized, and the groups of pixels marked as RPD and drusen were isolated. RPD smaller than 5 pixels and drusen smaller than 11 pixels were removed from consideration. Regions of interest for drusen and outer RPE were then established by taking the first and last marked pixels in each column of the drusen probability map, respectively, and the same was done for RPD and inner RPE with the marked pixels of the RPD probability map. Connectivity was then ensured between these probability map-derived regions of interest and the previous, broader region of interest. Through this process, the region of interest for segmentation at the site of the AMD features is much narrowed. This, combined with the calculated boundary layer probability maps, allowed for accurate layer segmentation for layers exhibiting the early AMD pathology.
To summarize, a deep learning fully convolutional neural network was used to calculate probability maps for layer junctions and identify RPD and drusen regions of interests. A shortest path algorithm with weights determined by these probability maps and the gradient of the SD-OCT scan determined the layer segmentation. Finally, a cubic spline fitting was applied to smooth the segmented layers. The fitting was applied mainly to correct the small localized segmentation errors, most notably in regions of vessel shadows cast by overlying large retinal vessels.
Use of human participants
Ethics review and institutional review board approval from the University of California – Los Angeles were obtained. The research was performed in accordance with relevant guidelines/regulations, and informed consent was obtained from all participants.
Results
To evaluate the accuracy of the automated layer segmentation, the layers for each case were manually traced by a certified OCT grader from the Doheny Image Reading Center, who was masked to the automated results. No refinement was performed of the automated segmentations before the comparison with the manual tracing. Because we desired a high-level of precision, even a single pixel discrepancy in the position of the border at any location was deemed to constitute a discrepancy. The reading center medical director re-reviewed and confirmed the gradings and boundaries for each case. The accuracy of the automated surface segmentation was evaluated in terms of the mean and absolute mean differences in the z-position between the segmented layers and the corresponding manually traced layers from the expert grader. For the mean differences, a negative value indicated that a segmented surface was located above the corresponding manually traced surface, and a positive value indicated that a segmented surface was located below the corresponding manually traced surface.
Table 1 shows the mean and absolute average border position differences of 7 layers: ILM, OP-ON, ELM, IS-OS, inner RPE, outer RPE, and the C-S junction from the automated segmentation for a 1:1 probability map to gradient weighting. It also shows the mean and absolute average border position differences for RPD and drusen. The remaining 4 layers, NF-GC, GC-IP, IP-IN, IN-OP, have been segmented to subvoxel accuracy by our group previously21. We believe the DL-SP algorithm will result in similar accuracy. Tables 2–5 show the mean and absolute average border position differences for various other pixel to pixel edge weighting schemes. In Fig. 3, RPD, drusen, and the segmented 11 layers are shown overlaid on SD-OCT images.
Discussion and Conclusions
In this paper, an automated approach was developed to segment RPD and regular drusen separately on SD-OCT images. The approach can be extended to segment a further 11 retinal surfaces on SD-OCT images. The mean difference is within a subpixel accuracy range for all layers, highlighting the robustness of this algorithm. Particularly, the algorithm achieved mean and absolute mean differences in border positions between the automated and manual segmentation for RPD of −0.75 ± 1.99 pixels (−2.92 ± 7.74 μm) and 1.53 ± 1.47 pixels (5.97 ± 5.74 μm), respectively. Additionally, in comparison to segmentation based only on gradient (Table 2), the algorithm produces results with much reduced variance.
Although there have been many studies characterizing the phenotype of non-neovascular AMD12,28,29,30,31; and although we and other groups have also developed algorithms for the segmentation of non-neovascular AMD lesions32,33,34, so far, there has been only one report to our knowledge of an algorithm for separate segmentation of RPD, RPE, and regular drusen on SD-OCT images, our group’s previous work14. However, significant segmentation errors were observed. In this study, we show once again that RPD and regular drusen can be separately segmented on SD-OCT images to allow the distribution and progression of these lesions to be studied separately. To the best of our knowledge, this is the first report of a validated algorithm for the automated segmentation of the retinal layers as well as both RPD and regular drusen separately on SD-OCT. The Deep Learning-Shortest Path strategy used for the segmentation of RPD and drusen is also shown to be generalizable to the segmentation of all layers of the retina.
In conclusion, in this study, an automated shortest path approach was developed utilizing deep learning convolutional neural networks to segment retinal layers associated with non-neovascular AMD. RPD and regular drusen were separately segmented on SD-OCT images to allow the distribution and progression of these lesions to be studied separately, and the approach is generalizable to multiple retina layer segmentation. In the future, this algorithm will be used to help evaluate a prospective dataset of 1000 patients showcasing drusen and RPD. With this inclusion of new data with accurate manual segmentation training data, the limitations of the pilot dataset used to develop the DL-SP algorithm can be addressed, leading to more accurate and generalizable automated segmentation.
Data availability
The image data utilized in this study are not publicly available due to the patients’ privacy and the violation of informed consent.
References
Drexler, W. & Fujimoto, J. G. State-of-the-art retinal optical coherence tomography. Prog. Retinal Eye Res 27, 45–88 (2008).
Leung, C. K. et al. Retinal nerve fiber layer imaging with spectral-domain optical coherence tomography: patterns of retinal nerve fiber layer progression. Ophthalmology. 119, 1858–1866 (2012).
Chung, S. E. et al. Choroidal thickness in polypoidal choroidal vasculopathy and exudative age-related macular degeneration. Ophthalmology. 118, 840–845 (2011).
Sandberg, M. A. et al. Visual acuity is related to parafoveal retinal thickness in patients with retinitis pigmentosa and macular cysts. Invest. Ophthalmol. Vis. Sci. 49, 4568–4572 (2008).
Klein, R. et al. Changes in visual acuity in a population over a 15 year period: the Beaver Dam eye study. Am. J. Ophthalmol. 142, 539–549 (2006).
Farsiu, S. et al. Quantitative classification of eyes with and without intermediate age-related macular degeneration using optical coherence tomography. Ophthalmology. 121, 162–172 (2014).
Kanagasingam, Y. et al. Progress on retinal image analysis for age related macular degeneration. Prog. Retinal Eye Res 38, 20–42 (2014).
Gregori, G. et al. Spectral domain optical coherence tomography imaging of drusen in nonexudative age-related macular degeneration. Ophthalmology. 118, 1373–1379 (2011).
Sohrab, M. A. et al. Image registration and multimodal imaging of reticular pseudodrusen. Invest. Ophthalmol. Visual Sci. 52(8), 5743–5748 (2011).
Finger, R. P. et al. Reticular pseudodrusen: a risk factor for geographic atrophy in fellow eyes of individuals with unilateral choroidal neovascularization. Ophthalmology. 121, 1252–1256 (2014).
Marsiglia, M. et al. Association between geographic atrophy progression and reticular pseudodrusen in eyes with dry age-related macular degeneration. Invest. Ophthalmol. Visual Sci. 54, 7362–7369 (2013).
Querques, G. et al. Analysis of progression of reticular pseudodrusen by spectral domain-optical coherence tomography. Invest Ophthalmol Visual Sci 53(3), 1264–1270 (2012).
Zweifel, S. A. et al. Reticular pseudodrusen are subretinal drusenoid deposits. Ophthalmology. 117(2), 303–312 (2010).
Hu, Z. et al. Semiautomated segmentation and analysis of retinal layers in three-dimensional spectral-domain optical coherence tomography images of patients with atrophic age-related macular degeneration. Neurophotonics. 4(1), 011012 (2017).
Tian, J. et al. Real-time automatic segmentation of optical coherence tomography volume data of the macular region. PloS one, 10(8).
Chiu, S. J. et al. Automatic segmentation of seven retinal layers in SDOCT images congruent with expert manual segmentation. Optics express. 18(18), 19413–19428 (2010).
Yazdanpanah, A. et al. Intra-retinal layer segmentation in optical coherence tomography using an active contour approach. International Conference on Medical Image Computing and Computer-Assisted Intervention (pp. 649–656). Springer, Berlin, Heidelberg (2009).
Li, K. et al. Optimal surface segmentation in volumetric images – a graph-theoretic approach. IEEE Trans. Pattern Anal. Mach. Intell 28, 119–134 (2006).
Garvin, M. K. et al. Automated 3D intraretinal layer segmentation of macular spectral-domain optical coherence tomography images. IEEE Trans. Med. Imaging. 28, 1436–1447 (2009).
Hu, Z. et al. Automated segmentation of the optic disc margin in 3D optical coherence tomography images using a graph-theoretic approach. Proc. SPIE 7262, 72620U (2009).
Hu, Z. et al. Multiple layer segmentation and analysis in three-dimensional spectral-domain optical coherence tomography volume scans. J. Biomed. Opt. 18, 076006 (2013).
Ronneberger, O., Fischer, P., & Brox, T. U-net: Convolutional networks for biomedical image segmentation. International Conference on Medical Image Computing and Computer-Assisted Intervention,, pp. 234–241 (Springer, 2015).
Wang, Z., Sadda, S., Hu, Z. Deep learning for automated screening and semantic segmentation of age-related and juvenile atrophic macular degeneration. Proceedings Volume 10950, Medical Imaging 2019: Computer-Aided Diagnosis; 109501Q https://doi.org/10.1117/12.2511538 (2019).
Roy, A. G. et al. ReLayNet: retinal layer and fluid segmentation of macular optical coherence tomography using fully convolutional networks. Biomedical optics express 8(8), 3627–42 (2017).
Fang, L. et al. Automatic segmentation of nine retinal layer boundaries in OCT images of non-exudative AMD patients using deep learning and graph search. Biomedical optics express 8(5), 2732–2744 (2017).
Kugelman, J. Automatic segmentation of OCT retinal boundaries using recurrent neural networks and graph search. Biomedical optics express, 9(11), 5759–5777 (2018).
Teng, P. Y. Caserel‒An Open Source Software for Computer-aided Segmentation of Retinal Layers in Optical Coherence Tomography Images. Zenodo, DOI 10 (2013).
Ferris, F. L. et al. A simplified severity scale for age-related macular degeneration: AREDS report no. 18. Arch. Ophthalmol. 123(11), 1570–1574 (2005).
Cukras, C. et al. Natural history of drusenoid pigment epithelial detachment in age-related macular degeneration: age-related eye disease study report no. 28. Ophthalmology. 117(3), 489–499 (2010).
Holz, F. G. et al. Progression of geographic atrophy and impact of fundus autofluorescence patterns in age-related macular degeneration. Am. J. Ophthalmol. 143(3), 463–472 (2007).
Alexandre Garcia Filho, C. A. et al. Spectral-domain optical coherence tomography imaging of drusenoid pigment epithelial detachments. Retina. 33(8), 1558–1566 (2013).
Hu, Z. et al. Semi-automated segmentation of the choroid in spectral-domain optical coherence tomography volume scans. Invest. Ophthalmol. Visual Sci. 54, 1722–1729 (2013).
Chiu, S. J. et al. Validated automatic segmentation of AMD pathology including drusen and geographic atrophy in SD-OCT images. Invest. Ophthalmol. Visual Sci. 53, 53–61 (2012).
Chen, Q. et al. Automated drusen segmentation and quantification in SD-OCT images. Med. Image Anal. 17, 1058–1072 (2013).
Acknowledgements
Research reported in this publication was partially supported by the National Eye Institute of the National Institutes of Health under Award Number R21EY030619 and R01EY029595.
Author information
Authors and Affiliations
Contributions
Z. Mishra developed the algorithms, performed experiments, and wrote the main manuscript text. A. Ganegoda1, J. Selicha1, and Z. Wang performed the manual gradings of the retinal layers for ground truth. Ziyuan Wang also helped with the data organization and pre-processing. S. Sadda provided clinical background and wrote part of the manuscript. Z. Hu cultivated the idea of the development, and also wrote part of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mishra, Z., Ganegoda, A., Selicha, J. et al. Automated Retinal Layer Segmentation Using Graph-based Algorithm Incorporating Deep-learning-derived Information. Sci Rep 10, 9541 (2020). https://doi.org/10.1038/s41598-020-66355-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-66355-5
- Springer Nature Limited
This article is cited by
-
AI-based support for optical coherence tomography in age-related macular degeneration
International Journal of Retina and Vitreous (2024)
-
Evaluation of OCT biomarker changes in treatment-naive neovascular AMD using a deep semantic segmentation algorithm
Eye (2024)
-
Enhancing OCT patch-based segmentation with improved GAN data augmentation and semi-supervised learning
Neural Computing and Applications (2024)
-
Hyperparameter-optimized Cross Patch Attention (CPAM) UNET for accurate ischemia and hemorrhage segmentation in CT images
Signal, Image and Video Processing (2024)
-
A comprehensive review of artificial intelligence models for screening major retinal diseases
Artificial Intelligence Review (2024)