
Abstract
Climate change is currently one of humanity’s greatest threats. To help scholars understand the psychology of climate change, we conducted an online quasi-experimental survey on 59,508 participants from 63 countries (collected between July 2022 and July 2023). In a between-subjects design, we tested 11 interventions designed to promote climate change mitigation across four outcomes: climate change belief, support for climate policies, willingness to share information on social media, and performance on an effortful pro-environmental behavioural task. Participants also reported their demographic information (e.g., age, gender) and several other independent variables (e.g., political orientation, perceptions about the scientific consensus). In the no-intervention control group, we also measured important additional variables, such as environmentalist identity and trust in climate science. We report the collaboration procedure, study design, raw and cleaned data, all survey materials, relevant analysis scripts, and data visualisations. This dataset can be used to further the understanding of psychological, demographic, and national-level factors related to individual-level climate action and how these differ across countries.
Similar content being viewed by others
Background & Summary
Climate change is a global threat to human thriving1. Combating it more effectively requires massive changes at the individual, collective, and system levels1,2,3,4,5. Research has investigated many factors, including the antecedents, associations, and underlying processes related to climate change mitigation (e.g., beliefs, behaviours)6,7,8,9,10. However, much of this research has been conducted on Western, highly Educated samples from Industrialized, Rich, and Democratic countries (i.e., WEIRD), which limits the generalizability of the findings11. Further, research typically uses correlational methods, precluding an understanding of what factors actually cause climate action. Given that climate change presents a global threat, it is critical to better understand these factors, and how they impact climate change mitigation across the globe12.
This manuscript describes the data gathered for the International Collaboration to Understand Climate Action (https://bit.ly/3VszDE9)13. This collaboration included 258 researchers and data collected from 63 countries across the globe between July 2022 and July 2023 (Supplemental Figure S1). A total of 83,927 participants signed up to participate, of which 59,508 eligible participants are presented in this manuscript (see below for the inclusion/exclusion criteria). When designing this project, our primary aim was to develop and test 11 expert crowd-sourced interventions (described in Table 1) designed to promote climate change mitigation, assessed by multiple outcome variables, in as many countries as possible (the preregistration for this main aim can be found at https://aspredicted.org/blind.php?x=W83_WTL). The outcomes included belief in climate change, support for climate mitigation policies, willingness to share climate-relevant information on social media, and a modified version of the Work for Environmental Protection Task (WEPT; explained further below)14.
Each primary outcome was chosen due to its theoretical and practical relevance (see12). Briefly, belief in climate change is a key antecedent of pro-environmental intentions, behaviour, and policy support6. Public support for a given policy is the top predictor of policy adoption, especially within the realm of climate change3,15. Discussing and sharing information about climate change with one’s peers is an essential step in addressing climate change12,16, thus we also added the willingness to share information on social media variable. Finally, real, effortful pro-environmental behaviour is needed in order to fight climate change, thus we added the WEPT, which is a web-based task that allows us to measure the amount of effort participants are willing to exert to help protect the environment14.
In order to easily assess the average impact of the interventions on each of the main outcome variables (beliefs, policy support, social media sharing, and the WEPT), varied across multiple demographics including nationality, political ideology, age, gender, education, income level and perceived level of socioeconomic status, we provide an easy to use and disseminate webtool called the Climate Intervention Webapp: https://climate-interventions.shinyapps.io/climate-interventions/.
Our secondary aim was to maximise the utility of the data collected. To do that and also keep the survey length similar across all conditions, participants in the no-intervention control condition responded to numerous additional variables. This included items such as trust in climate scientists, degree of environmentalist identity17, and second-order climate beliefs (a full list of included items is reported below). A schematic overview of the survey design is shown in Figure 1.

Schematic overview of the survey flow. The pathways for the control participants are shown in blue, and the intervention participants are shown in red.
Due to the richness of this dataset13, there are a multitude of secondary analyses that are possible. For example, the effectiveness of the interventions can be explored across socio-political variables18, individualism-collectivism19, or a number of other factors20.
In addition to the above-mentioned participant data, we also present data from an intervention tournament which was conducted before the study, where collaborators submitted interventions they wished to see tested in this international context (more information can be found in the section “Intervention tournament”, below). We received 36 submissions, which were sorted and cleaned by the organisational team (see below for more). The remaining 11 interventions were then rank-ordered by 188 of our collaborators in terms of their practical and theoretical support (Figure 2). Given the high levels of support from our collaborators for all interventions, we decided to include all 11 interventions in the main project.

Average support of each crowdsourced intervention. Support was ranked by a sample of 188 behavioural scientists (coauthors on the current paper) who were asked to rate the interventions on perceived efficiency (practical support) and theoretical value (theoretical support). Error bars are bootstrapped confidence intervals around the mean. The mean is a mean rank, where the rank ordinals are defined such that 10 means most support and 0 means least support.
Methods
Collaboration Procedure
In early November of 2021, the organising team (i.e., K. C. Doell, M. Vlasceanu, & J. J. Van Bavel) announced a call for collaboration (https://manylabsclimate.wordpress.com/call-for-collaboration/) on social media, via personal networks, and by posting on various mailing lists and forums.
We announced that researchers could join this collaboration by contributing in one of three ways: (1) collect data (i.e., >500 responses), (2) propose and design an intervention included in the final study, and/or (3) financially contribute to the acquisition of data (i.e., >500 responses) in a country not yet covered in the collaboration. We aimed to limit the cost of collaboration in two specific ways. First, we prioritised creating a relatively short survey (i.e., less than 20 minutes total). This meant the intervention designers had to create interventions that took no more than 5 minutes. Second, while we strongly encouraged data-collection collaborators to recruit representative samples from market research agencies, representative data was not required (see the Participant section for more details).
Intervention tournament
We invited all collaborators to submit proposals for interventions to be tested via the survey platform Qualtrics (https://www.qualtrics.com/). They were required to submit a short abstract that outlined their intervention and included any relevant references. They were also required to calculate the effect sizes of each intervention based on previous work. Finally, they were asked to consider time constraints (i.e., no more than 5 minutes).
We received 36 proposed interventions, which two authors from the organisational team screened (who were blinded to the intervention authors). The screening procedure involved removing interventions that were not feasible in an international context (e.g., removing proposals including videos that needed to be translated), relevance for the dependent variables, and theoretical support from prior work (quantified by previously reported effect sizes). We also aggregated similar interventions and duplicates. We identified 11 unique and feasible interventions. We then asked all collaborators to read the short summaries of the interventions and rank-order them based on their practical support (i.e., Please rank the following climate interventions in order of their practical support (will it be successful?) from 1 = “most important”, to 11 = “least important”) and theoretical support (Please rank the following climate interventions (their descriptions are above) in order of their theoretical importance from 1 = “most important”, to 11 = “least important”). We obtained 188 responses from our collaborators in January 2022 (Figure 2). The Qualtrics file, and the data from this survey can be found in the “ClimateManylabs_InterventionTournamentVote” folder in the data repository.
Intervention design
Given high levels of support for all interventions (Figure 2), we tested all 11 interventions in the main study12. We then contacted the collaborators whose interventions had been selected to be included to coordinate the intervention implementation and programming on the Qualtrics survey platform. All interventions went through two rounds of reviews. First, the organisational team gave the intervention designers feedback on their submissions and allowed them time to address the comments. After receiving the revised interventions, we contacted expert researchers who had published relevant theoretical work, asking them to review each intervention’s implementation critically. For example, Professor John Jost reviewed the System Justification intervention21. Professor Sander van der Linden reviewed the Scientific Consensus intervention22. This process was iterated for each of the 11 interventions.
Finally, the organisational team asked all collaborators from around the world for additional feedback on the entire survey, including all interventions, demographics, and independent variables. This was to improve the overall quality and to help reduce any American-centric researcher biases that may have influenced the original survey.
This revision process lasted until the end of May 2022, when we started piloting the final version of the study, on a sample of 723 participants collected in the United States (Mage = 43.6; SDage = 15.7; 52% women, 46% men, <2% non-binary). After the piloting was completed (July 2022), we sent our collaborators the final version of the study in Qualtrics, along with an in-depth instructions manual (available at https://osf.io/ujzcx) on how to translate and adapt the study to each country. We also instructed our collaborators to obtain ethics approval from their institutions’ review boards before launching data collection.
It should also be noted that multiple interventions included additional questionnaire items mainly meant to increase participant engagement. These additional items, as well as the number of participants that did and did not respond to these items per condition are available in Supplemental Table S4. These results can be used to help estimate the level of engagement of the participants in the cleaned dataset.
Survey translations
Consistency of the survey adaptations was ensured in three ways. First, collaborator teams were instructed to use back-translations to ensure that the text was adequate. Should any disputes arise, they were asked to have multiple native speakers work together to help resolve it. Second, teams that were using the same language were strongly encouraged to work together when translating the survey so that they could more evenly distribute the amount of effort that was required. Not only did this help to reduce the likelihood of fatigue by the translators, but it also meant that there were often several native speakers working on the same translations, ensuring that there was a consensus among them. Finally, the organisational team carefully combed through the submitted survey files using different translation software (e.g., DeepL) to ensure that the entire survey had been translated and adapted sufficiently.
Participants
The data were collected between July 2022 and July 2023. To be included in the cleaned dataset, participants had to be between 18–100 years old, pass two attention checks (i.e., Please select the colour “purple” from the list below.” and “To indicate you are reading this paragraph, please type the word sixty in the text box below.”; the dropout rates by collaborator team are shown in Supplemental Table S6), and pass the WEPT demonstration page. By removing participants who did not pass the attention check, we operated under the assumption that the treatment effects are consistent across both attentive and less attentive groups. This decision was made to enhance data quality while maintaining the assumption of minimal heterogeneous treatment effects.
We also screened the survey files that were uploaded by collaborators to ensure that all translations and country-level adaptations were successfully adopted, and if not, those participants were removed (see the Data Cleaning section). As the main aim of the present data paper is to provide the fullest dataset possible, we opted to include only the above-mentioned inclusion/exclusion criteria when cleaning the data. This allows users to set their own judgements for the boundaries/cutoffs inside of their analyses that make sense for what they would like to do. Thus, there is a small portion of participants included who did not finish the entire survey (2.99% of participants have a 0 in the “Finished” column of the dataset), or participants who did not respond to all items in each subscale.
A total of 83,927 people participated, and 59,508 participants (Mage = 39.12, SDage = 15.77; 51% women, 47% men, 0.6% non-binary; Figure 3) from 63 countries passed both attention checks and correctly completed the WEPT demonstration. All collaborator team-level descriptive data for age and gender is shown in Supplemental Table S1. Table 1 shows the breakdown for the number of participants that were originally assigned to each group (i.e., “Raw N”) and the number of participants that were included in each condition in the final cleaned dataset (i.e., “Cleaned N”). These values can be used to calculate and adjust for attrition rates across the dataset.

Data distributions. The number of participants in each of the 63 countries represented in the sample (Ntotal = 59,508).
Overall, 75.05% of the entire sample was matched to the population in some way (e.g., census matched regarding age), and 66% of the sample was matched for both age and gender (see Table 2 for the breakdown of all matched variables). Ethics approval was obtained independently by each data collection team from their corresponding Institutional Review Board (IRB). Only datasets submitted, along with IRB approval or an ethics waiver from IRB, are included in the repository.
Regarding the heterogeneity in the dataset, there are several things to note. First, the sampling procedures differed between countries (e.g., the U.S. samples were all census matched on age, and gender while the Slovakian sample was matched on age, gender, region, and municipality size; Table 2). Thus, there is a large amount of heterogeneity within the dataset. Second, while having a sample that is broadly representative of key demographics is ideal, recent work has found that representative samples are not necessarily required to obtain generalisable estimates of effect sizes within countries23. Various analyses have highlighted that convenience samples are adequate for estimating treatment effects23,24,25. Thus, the data included in this manuscript should also be suitable, especially for researchers interested in analysing the treatment effects within our sample.
Experimental design
A dedicated schematic representation of the design can be found in Figure 1. Briefly, all participants were first required to read and acknowledge the informed consent page. At the end of the consent page, participants were exposed to the first attention check (“Please select the color “purple” from the list below. We would like to make sure that you are reading these questions carefully.”). They were then randomly assigned to one of 12 conditions, including the 11 intervention groups (Table 1) or a no-intervention control condition. Participants in the control condition were then exposed to a short, thematically unrelated text from the novel “Great Expectations” by Charles Dickens in order to balance the amount of time spent on this phase of the experiment. Next, all participants were exposed to a definition of climate change: “Climate change is the phenomenon describing the fact that the world’s average temperature has been increasing over the past 150 years and will likely be increasing more in the future.” Participants in the intervention groups were then exposed to their intervention.
All participants were then directed to the dependent variable phase, where, in random order, they rated their (1) climate beliefs, (2) climate policy support, and (3) were given the option to create a social media post. Finally, they could contribute to the tree-planting effort by completing the WEPT. Note that the WEPT was always the last outcome variable measured, while the other three outcomes were measured randomly. Next, participants in the control condition were asked to complete a series of additional variables (described below). Finally, participants were asked to report their demographic information, which included another attention check (“In the previous section, you viewed some information about climate change. To indicate you are reading this paragraph, please type the word sixty in the text box below.”).
Primary Outcomes
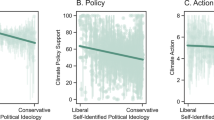
Figure 4 shows graphic illustrations of the four primary outcome variables.

Graphic illustration of the primary outcome variables. (A) climate change belief, (B) climate policy support, (C) willingness to share on social media, (D) the WEPT.
Climate change beliefs
Climate beliefs were measured by participants’ answers to the question “How accurate do you think these statements are?” from 0 = Not at all accurate to 100 = Extremely accurate. The four statements were: “Taking action to fight climate change is necessary to avoid a global catastrophe,” “Human activities are causing climate change,” “Climate change poses a serious threat to humanity,” and “Climate change is a global emergency.”
Climate change policy support
This dependent variable consisted of participants’ level of agreement from 0 = Not at all to 100 = Very much so using a slider (participants could also respond with “not applicable”, which is coded as “NA” in the dataset), with the following nine statements: “I support raising carbon taxes on gas/fossil fuels/coal,” “I support significantly expanding infrastructure for public transportation,” “I support increasing the number of charging stations for electric vehicles,” “I support increasing the use of sustainable energy such as wind and solar energy,” “I support increasing taxes on airline companies to offset carbon emissions,” “I support protecting forested and land areas,” “I support investing more in green jobs and businesses,” “I support introducing laws to keep waterways and oceans clean,” and “I support increasing taxes on carbon-intensive foods (for example, meat and dairy).”
Willingness to share climate information on social media
Participants were first presented with the text, “Did you know that removing meat and dairy for only two out of three meals per day could decrease food-related carbon emissions by 60%? It is an easy way to fight #ClimateChange #ManyLabsClimate${e://Field/cond} source: https://econ.st/3qjvOnn” (where “{e://Field/cond}” was replaced with the condition code for each group; an example can be found here https://bit.ly/3FKcwyq). Participants were then asked, “Are you willing to share this information on your social media?” the answer options were “Yes, I am willing to share this information,” “I am not willing to share this information,” and “I do not use social media.” Participants who indicated they do not use social media (N = 15,252, 25.9% of the sample) were recoded as NA in this variable to avoid confusion and to exclude them from relevant analyses. Moreover, participants were asked to indicate the platform (e.g., Facebook, Twitter, Instagram) on which they posted the information.
WEPT Tree planting efforts
We used a modified version of the Work for Environmental Protection Task (WEPT) to measure an action with a real-world impact performed at an actual cost to participants14. This task is a multi-trial web-based procedure that detects consequential pro-environmental behaviour by allowing participants the opportunity to engage in voluntary cognitive effort (i.e., screening numerical stimuli) in exchange for donations to an environmental organisation. This measure has been validated and has been found to correlate to self-reports and objective observations of other pro-environmental behaviours and conceptually related measures14,26.
Participants were first exposed to a demonstration of the WEPT, in which they were instructed to identify all target numbers for which the first digit is even and the second digit is odd (4 out of 18 numbers were target numbers on the demonstration page). Participants could not advance the page until they correctly completed the WEPT demonstration. They were then told that planting trees is one of the best ways to combat climate change and that they would have the opportunity to plant up to 8 trees if they chose to engage in additional pages of the item identification task (one tree per page of WEPT completed). These pages contained 60 numbers per page, which participants had to screen for target numbers. Alongside these instructions, participants were shown a pictogram of 8 trees, one of which was coloured green to mark their progress in the task (Figure 4D). Participants were allowed to exit the task at any point with no penalty.
Due to the participants’ efforts, 333,333 trees were planted in collaboration with The Eden Reforestation Project. Assuming that the average fully-grown tree absorbs between 10 and 40 kg of carbon dioxide per year, in 5–10 years when all trees are fully grown, the efforts from this project will result in approximately 9,999,990 kg of carbon dioxide sequestered per year, which is the equivalent amount of carbon dioxide used to produce energy for 1,260 US homes per year.
Additional independent variables
As shown in Figure 1, participants from the no-intervention control condition were also required to complete a set of additional independent variables. The items included are listed in Supplemental Table S3.
Demographic block
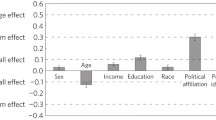
After briefly explaining why we were measuring some background information, we then measured a series of demographic variables (see Supplemental Table S5). The correlation plot between the variables from the demographic block and the primary outcomes is shown in Figure 5.

Correlation matrix showing the Pearson’s correlations between the demographic predictors and the four outcome variables.
Data cleaning
We received individual data files from each collaboration team in either .csv or .xlxs format as well as the Qualtrics files (i.e.,.qsf) from the survey (information about each data submission can be found at: https://osf.io/sd5qb). Each team’s survey file was visually inspected by at least two members of the organisational team (mainly BT & PS) to ensure that they were adapted and translated fully. While some interventions required only translation, others (Work Together Norm, System Justification, Psychological Distance, Pluralistic Ignorance, Dynamic Social Norms, Binding Moral Foundation) required further adaptations on a country-level (the collaborator manual outlining all adaptations can be found at https://osf.io/ujzcx). For example, the Binding Moral Foundation intervention contained an image of a person holding a flag, thus, a different image with the respective flag for the country was required. If the image was not changed, we removed the participants receiving this intervention from that collaborator team’s data. We documented all unsuccessful/partial translations and adaptation of the interventions (see https://osf.io/wu6gf for an overview).
The measure for socioeconomic status contained the respective country name, so we inspected the surveys and documented if the name has not been changed to reflect the correct country (see https://osf.io/ueqgy for an overview). Additionally, we documented which teams had changed the coding of some of the variables (see https://osf.io/qbe84 for gender, https://osf.io/5ypca for education). Before we merged the individual datasets, we changed the data from the participants who did not give consent to NAs. To merge and clean these raw data, minor modifications were introduced, which are briefly described below, and fully documented in the dataset merging script (https://osf.io/uam3y) and cleaning script (https://osf.io/4rm7g).
In the merging script, each dataset was imported into R individually. When encountering ambiguous date formats (such as those found in start date, end date, and record date), we manually specified the correct format and standardized them. Column names which were inconsistent with the original survey were renamed or removed, and the attention checks were recorded to ensure accuracy. The merged raw dataset can be found on OSF (see https://osf.io/snuwd).
In the cleaning script, all variables were checked to ensure they were coded in a consistent and comparable way. For example, there were some mistakes with the way that education was coded for some teams, so the data were individually recoded. Next, the empty rows for the non-consenting participants were removed, as well as survey tests that some teams did not remove when submitting their data. Next, participants who were not assigned a condition due to technical issues were removed (N = 1,753), as well as participants with invalid age values (less than 18 or more than 100, N = 157). Any errors that were identified for the survey translation and adaptation were then corrected individually, and participants were removed accordingly (N = 1,010). Participants who did not pass the two attention checks (first: N = 574, second: N = 20,194), nor the WEPT demonstration (N = 354) were then removed. The cleaned dataset can be found on OSF (see https://osf.io/xum6b).
Data Records
All materials for this project are openly available on the project’s repository hosted on Open Science Framework (https://osf.io/ytf89/)13.
Navigating the repository
The file repository is organised in several folders:
-
ClimateManylabs_Code folder contains R scripts, including the code for merging the raw datasets submitted by each of the collaborators (datapaper_merging_raw.R), the code for cleaning the data (datapaper_cleaning.R) and the code for reproducing the figures (datapaper_figures_code.R).
-
ClimateManylabs_CollaboratorResources contains the document with the information on ethics application (ethics_application_materials.pdf), the manual the collaborators received for adapting the interventions to their country and language (intervention_adaptation_manual.pdf) and a pdf file containing the master survey items (master_survey.pdf).
-
ClimateManylabs_Data contains the single raw data files (i.e. all of the submitted datasets from all of the collaborators in a compressed form - countries_rawdata.7z), the merged raw dataset (data_raw.csv), the cleaned dataset (data_countries.csv), an additional cleaned version without the timers (data_notimers.csv), a codebook for navigating the dataset (codebook.xlsx), the items of the survey we used when asking the collaborators to submit their datasets (data_submission_survey.pdf), and the responses to this survey (manylabsclimate_datasubmission.csv).
-
ClimateManylabs_InterventionTournamentVote contains the Qualtrics survey file (intervention_vote_manylabs.qsf) used for evaluating the interventions, the data of this survey (vote_data.xlsx), and the pdf file where the items of the survey can be seen (tournament_survey_items.pdf).
-
ClimateManylabs_IRBs contains all of the approvals by the ethics boards in the different institutions.
-
ClimateManylabs_QSF contains all the Qualtrics survey files (.qsf) that the collaborators used to collect their data.
-
ClimateManylabs_Supplementary contains a supplementary figure with the data collection dates (data_collection_dates.png), an overview table of how education was coded (education_coding_overview.xlsx), how gender was coded (gender_coding_overview.xlsx), an overview of whether the interventions were translated and adapted correctly (intervention_translation_and_adaptation_overview.xlsx), a table containing the internal consistencies of the measures used in the survey, calculated per country (measures_internal_consistency_per_country.csv), and an overview of the adaptation of the socioeconomic status ladder per country (SES_ladder_countryname_adaptation_overview.xlsx).
An easy to access guide on navigating the repository can be found in the READme.txt file on the OSF platform.
Technical Validation
Similar to a previously published many labs dataset27, we calculated numerous indicators of internal consistency at the country level for any scale (Table 2, Supplemental Tables S4-5) that contained more than two items. This included Cronbach’s Alpha, McDonald’s Omega, Guttman’s split-half reliability, and the proportion of variance explained by a unidimensional factor. The average of these measures is shown in Table 3. The full table of results can be found at https://osf.io/ejtdq, and visualisations of Cronbach’s alpha for climate belief, policy support, and political orientation are shown in Figure 6. Visualisations of Cronbach’s alpha for all other variables from Table 3 are shown in Supplemental Figure S2. Across these reliability measures, the majority of variables had good (Cronbach’s alpha > 0.70) to excellent (Cronbach’s alpha > 0.80) internal consistency.

Internal consistency (Cronbach’s alpha) of the items measuring (A) climate change beliefs, (B) policy support, and (C) political orientation, calculated and plotted separately for each country.
Usage Notes
We recommend using one of the cleaned datasets. One dataset, which includes all participant timers, and number of clicks per page can be found at https://osf.io/xum6b, and a version without any timers/click counts can be found at: https://osf.io/8q6ue. For more information on how to navigate the OSF repository read the uploaded READme.txt file (https://osf.io/8wh9m).
Code availability
All data (raw and cleaned), the materials from the study (e.g., Qualtrics surveys, IRB forms, etc.), codebooks, and the code presented in this manuscript are available at https://osf.io/ytf89.
References
IPCC. Climate Change 2023: Synthesis Report. Contribution of Working Groups I, II and III to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change. https://www.ipcc.ch/report/ar6/syr/, https://doi.org/10.59327/IPCC/AR6-9789291691647 (2023).
Amel, E., Manning, C., Scott, B. & Koger, S. Beyond the roots of human inaction: Fostering collective effort toward ecosystem conservation. Science 356, 275–279 (2017).
Drews, S. & Van Den Bergh, J. C. J. M. What explains public support for climate policies? A review of empirical and experimental studies. Climate Policy 16, 855–876 (2016).
Nielsen, K. S., Nicholas, K. A., Creutzig, F., Dietz, T. & Stern, P. C. The role of high-socioeconomic-status people in locking in or rapidly reducing energy-driven greenhouse gas emissions. Nat Energy 6, 1011–1016 (2021).
Hampton, S. & Whitmarsh, L. Choices for climate action: A review of the multiple roles individuals play. One Earth 6, 1157–1172 (2023).
Hornsey, M. J., Harris, E. A., Bain, P. G. & Fielding, K. S. Meta-analyses of the determinants and outcomes of belief in climate change. Nature Climate Change 6, 622–626 (2016).
Doell, K. C. et al. Leveraging neuroscience for climate change research. Nat. Clim. Chang. 1–10, https://doi.org/10.1038/s41558-023-01857-4 (2023).
Doherty, T. J. & Clayton, S. The Psychological Impacts of Global Climate Change. American Psychologist 66, 265–276 (2011).
Gifford, R. The Dragons of Inaction: Psychological Barriers That Limit Climate Change Mitigation and Adaptation. American Psychologist 66, 290–302 (2011).
Rode, J. B. et al. Influencing climate change attitudes in the United States: A systematic review and meta-analysis. Journal of Environmental Psychology 76, 101623 (2021).
Henrich, J., Heine, S. J. & Norenzayan, A. The weirdest people in the world? Behavioral and Brain Sciences 33, 61–83 (2010).
Vlasceanu, M. et al. Addressing climate change with behavioral science: A global intervention tournament in 63 countries. Science Advances 10, eadj5778 (2024).
Doell, K. C., Todorova, B., Vlasceanu, M. & Van Bavel, J. J. International Collaboration to Understand Climate Action. OSF https://doi.org/10.17605/OSF.IO/YTF89 (2024).
Lange, F. & Dewitte, S. The Work for Environmental Protection Task: A consequential web-based procedure for studying pro-environmental behavior. Behavior Research Methods https://doi.org/10.3758/s13428-021-01617-2 (2021).
Yeganeh, A. J., McCoy, A. P. & Schenk, T. Determinants of climate change policy adoption: A meta-analysis. Urban Climate 31, 100547 (2020).
Anderson, A. A. Effects of Social Media Use on Climate Change Opinion, Knowledge, and Behavior. in Oxford Research Encyclopedia of Climate Science https://doi.org/10.1093/acrefore/9780190228620.013.369 (Oxford University Press, 2017)
Brick, C. & Lai, C. K. Explicit (but not implicit) environmentalist identity predicts pro-environmental behavior and policy preferences. Journal of Environmental Psychology 58, 8–17 (2018).
Berkebile-Weinberg, M., Goldwert, D., Doell, K. C., Van Bavel, J. J. & Vlasceanu, M. The differential impact of climate interventions along the political divide in 60 countries. Nat Commun 15, 3885 (2024).
Goldwert, D., Bao, Y. E., Doell, K. C., Van Bavel, J. J. & Vlasceanu, M. The Effects of Climate Action Interventions along Cultural Individualism-Collectivism. Preprint at https://doi.org/10.31234/osf.io/cv3n4 (2024).
Todorova, B. et al. Machine learning identifies key individual and nation-level factors predicting climate-relevant beliefs and behaviors. Preprint available at: https://doi.org/10.31219/osf.io/um69t (2024).
Jost, J. T. & Banaji, M. R. The role of stereotyping in system-justification and the production of false consciousness. British journal of social psychology 33, 1–27 (1994).
van der Linden, S. L., Leiserowitz, A. A., Feinberg, G. D. & Maibach, E. W. How to communicate the scientific consensus on climate change: plain facts, pie charts or metaphors? Climatic Change 126, 255–262 (2014).
Coppock, A., Leeper, T. J. & Mullinix, K. J. Generalizability of heterogeneous treatment effect estimates across samples. Proceedings of the National Academy of Sciences 115, 12441–12446 (2018).
Weinberg, J., Freese, J. & McElhattan, D. Comparing Data Characteristics and Results of an Online Factorial Survey between a Population-Based and a Crowdsource-Recruited Sample. Sociological Science 1, 292–310 (2014).
Mullinix, K. J., Leeper, T. J., Druckman, J. N. & Freese, J. The Generalizability of Survey Experiments. Journal of Experimental Political Science 2, 109–138 (2015).
Lange, F. & Dewitte, S. Validity and scope sensitivity of the work for Environmental Protection Task. Journal of Environmental Psychology 86, 101967 (2023).
Azevedo, F. et al. Social and moral psychology of COVID-19 across 69 countries. Sci Data 10, 272 (2023).
Sparkman, G. & Walton, G. M. Dynamic Norms Promote Sustainable Behavior, Even if It Is Counternormative. Psychological Science 28, 1663–1674 (2017).
Howe, L. C., Carr, P. B. & Walton, G. M. Normative appeals motivate people to contribute to collective action problems more when they invite people to work together toward a common goal. Journal of Personality and Social Psychology 121, 215–238 (2021).
Goldenberg, A. et al. Testing the impact and durability of a group malleability intervention in the context of the Israeli–Palestinian conflict. Proceedings of the National Academy of Sciences 115, 696–701 (2018).
Lizzio-Wilson, M. et al. How collective-action failure shapes group heterogeneity and engagement in conventional and radical action over time. Psychological Science 32, 519–535 (2021).
Jones, C., Hine, D. W. & Marks, A. D. G. The Future is Now: Reducing Psychological Distance to Increase Public Engagement with Climate Change. Risk Analysis 37, 331–341 (2017).
Feygina, I., Jost, J. T. & Goldsmith, R. E. System Justification, the Denial of Global Warming, and the Possibility of “System-Sanctioned Change”. Pers Soc Psychol Bull 36, 326–338 (2010).
Hershfield, H. E., Cohen, T. R. & Thompson, L. Short horizons and tempting situations: Lack of continuity to our future selves leads to unethical decision making and behavior. Organizational Behavior and Human Decision Processes 117, 298–310 (2012).
Chapman, D. A., Lickel, B. & Markowitz, E. M. Reassessing emotion in climate change communication. Nature Climate Change 7, 850–852 (2017).
Doell, K. C., Conte, B. & Brosch, T. Interindividual differences in environmentally relevant positive trait affect impacts sustainable behavior in everyday life. Scientific Reports 11, 1–11 (2021).
Geiger, N. & Swim, J. K. Climate of silence: Pluralistic ignorance as a barrier to climate change discussion. Journal of Environmental Psychology 47, 79–90 (2016).
Shrum, T. R. The salience of future impacts and the willingness to pay for climate change mitigation: an experiment in intergenerational framing. Climatic Change 165, 1–20 (2021).
Wickersham, R. H., Zaval, L., Pachana, N. A. & Smyer, M. A. The impact of place and legacy framing on climate action: A lifespan approach. PLOS ONE 15, e0228963 (2020).
Wolsko, C., Ariceaga, H. & Seiden, J. Red, white, and blue enough to be green: Effects of moral framing on climate change attitudes and conservation behaviors. Journal of Experimental Social Psychology 65, 7–19 (2016).
Acknowledgements
We would like to acknowledge the following funding contributions: Google Jigsaw grant (Kimberly C. Doell; Madalina Vlasceanu; Jay J. Van Bavel). Swiss National Science Foundation P400PS_190997 (Kimberly C. Doell). Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy – EXC 2117 – 422037984 (Kimberly C. Doell). Dutch Research Council grant 7934 (Karlijn L. van den Broek). European Union Grant No. ID 776608 (Karlijn L. van den Broek). John Templeton Foundation grant 61378 (Mark Alfano). The National Council for Scientific and Technological Development grant (Angélica Andersen). Christ Church College Research Centre grant (Matthew A. J. Apps). David Phillips Fellowship grant BB/R010668/2 (Matthew A. J. Apps). Jacobs Foundation Fellowship (Matthew A. J. Apps). “DFG grant project no. 390683824 (Moritz A. Drupp; Piero Basaglia; Björn Bos)”. NYUAD research funds (Jocelyn J. Bélanger). “The Swiss Federal Office of Energy through the ““Energy, Economy, and Society”“ program grant number: SI/502093-01 (Sebastian Berger)”. The Belgian National Fund for Scientific Research (FRS-FNRS) PDR 0253.19 (Paul Bertin). Fund for scientific development at the Faculty of Psychology at SWPS University in Warsaw (Olga Bialobrzeska). Radboud University Behavioural Science Institute (Daniëlle N. M. Bleize). “Leuphana University Lüneburg research fund (David D. Loschelder; Lea Boecker; Yannik A. Escher; Hannes M. Petrowsky; Meikel Soliman)”. University of Birmingham Start up Seed Grant (Ayoub Bouguettaya). Prime-Pump Fund from University of Birmingham (Ayoub Bouguettaya; Mahmoud Elsherif). University of Geneva Faculty Seed Funding (Tobias Brosch). “Pomona College Hirsch Research Initiation Grant (Adam R. Pearson)”. Center for Social Conflict and Cohesion Studies grant ANID/FONDAP #15130009 (Héctor Carvacho; Silvana D’Ottone). Center for Intercultural and Indigenous Research grant ANID/FONDAP #15110006 (Héctor Carvacho; Silvana D’Ottone). National Research Foundation of Korea NRF-2020S1A3A2A02097375 (Dongil Chung; Sunhae Sul). Darden School of Business (Luca Cian). Kieskompas - Election Compass (Tom W. Etienne; Andre P. M. Krouwel; Vladimir Cristea; Alberto López Ortega). The National Agency of Research and Development, National Doctoral Scholarship 24210087 (Silvana D’Ottone). Dutch Science Foundation (NWO) grant VI.Veni.201S.075 (Marijn H.C. Meijers). The Netherlands Organization for Scientific Research (NWO) Vici grant 453-15-005 (Iris Engelhard). Foundation for Science and Technology – FCT (Portuguese Ministry of Science, Technology and Higher Education) grant UIDB/05380/2020 (Ana Rita Farias). The Slovak Research and Development Agency (APVV) contract no. APVV-21-0114 (Andrej Findor). The James McDonnell Foundation 21st Century Science Initiative in Understanding Human Cognition—Scholar Award grant 220020334 (Lucia Freira; Joaquin Navajas). Sponsored Research Agreement between Meta and Fundación Universidad Torcuato Di Tella grant INB2376941 (Lucia Freira; Joaquin Navajas). Thammasat University Fast Track Research Fund (TUFT) 12/2566 (Neil Philip Gains). HSE University Basic Research Program (Dmitry Grigoryev; Albina Gallyamova). ARU Centre for Societies and Groups Research Centre Development Funds (Sarah Gradidge; Annelie J. Harvey; Magdalena Zawisza). University of Stavanger faculty of Social Science research activities grant (Simone Grassini). Center for the Science of Moral Understanding (Kurt Gray). University of Colorado Boulder Faculty research fund (June Gruber). Swiss National Science Foundation grant 203283 (Ulf J.J. Hahnel). Kochi University of Technology Research Funds (Toshiyuki Himichi). RUB appointment funds (Wilhelm Hofmann). Dean’s Office, College of Arts and Sciences at Seton Hall University (Fanli Jia). Nicolaus Copernicus University (NCU) budget (Dominika Jurgiel; Adrian Dominik Wojcik). Sectorplan Social Sciences and Humanities, The Netherlands (Elena Kantorowicz-Reznichenko). Erasmus Centre of Empirical Legal Studies (ECELS), Erasmus School of Law, Erasmus University Rotterdam, The Netherlands (Elena Kantorowicz-Reznichenko). American University of Sharjah Faculty Research Grant 2020 FRG20-M-B134 (Ozgur Kaya; Ilker Kaya). Centre for Social and Early Emotional Development SEED grant (Anna Klas; Emily J. Kothe). ANU Futures Grant (Colin Klein). Research Council of Norway through Centres of Excellence Scheme, FAIR project No 262675 (Hallgeir Sjåstad and Simen Bø). Aarhus University Research Foundation grant AUFF-E-2021-7-16 (Ruth Krebs; Laila Nockur). Social Perception and Intergroup Inequality Lab at Cornell University (Amy R. Krosch). COVID-19 Rapid Response grant, University of Vienna (Claus Lamm). Austrian Science Fund FWF I3381 (Claus Lamm). Austrian Science Fund FWF: W1262-B29 (Boryana Todorova). FWO Postdoctoral Fellowship 12U1221N (Florian Lange). National Geographic Society (Julia Lee Cunningham). University of Michigan Ross School of Business Faculty Research Funds (Julia Lee Cunningham). The Clemson University Media Forensics Hub (Jeffrey Lees). Norwegian Retailers’ Environment Fund, Poster Competition Grant 2022 (Isabel Richter). John Templeton Foundation grant 62631 (Neil Levy; Robert M. Ross). ARC Discovery Project DP180102384 (Neil Levy). Medical Research Council Fellowship grant MR/P014097/1 (Patricia L. Lockwood). Medical Research Council Fellowship grant MR/P014097/2 (Patricia L. Lockwood). Jacobs Foundation (Patricia L. Lockwood). Wellcome Trust and the Royal Society Sir Henry Dale Fellowship grant 223264/Z/21/Z (Patricia L. Lockwood). JFRAP grant (Jackson G. Lu). Social Sciences and Humanities Research Council (SSHRC) Doctoral Fellowship (Yu Luo). Simon Fraser University Psychology Department Research Grant (Annika E. Lutz; Michael T. Schmitt). GU internal funding (Abigail A. Marsh; Shawn A. Rhoads). FAPESP 2014/50279-4 (Karen Louise Mascarenhas). FAPESP 2020/15230-5 (Karen Louise Mascarenhas). Shell Brasil (Karen Louise Mascarenhas). Brazil’s National Oil, Natural Gas and Biofuels Agency (ANP) through the R&D levy regulation (Karen Louise Mascarenhas). ANR grant SCALUP, ANR-21-CE28-0016-01 (Hugo Mercier). NOMIS Foundation grant for the Centre for the Politics of Feelings (Katerina Michalaki; Manos Tsakiris). “Applied Moral Psychology Lab at Cornell University (Sarah Milliron; Laura Niemi; Magdalena Zawisza)”. Universidad Peruana Cayetano Heredia Project 209465 (Fredy S. Monge-Rodríguez). Belgian National Fund for Scientific Research (FRS-FNRS) grant PDR 0253.19 (Youri L. Mora). Riksbankens Jubileumsfond grant P21-0384 (Gustav Nilsonne). European Research Council funded by the UKRI Grant EP/X02170X/1 (Maria Serena Panasiti; Giovanni Antonio Travaglino). Statutory Funding of Institute of Psychology, University of Silesia in Katowice (Mariola Paruzel-Czachura). Aarhus University Research Foundation AUFF-E-2018-7-13 (Stefan Pfattheicher). São Paulo Research Foundation (FAPESP) grant 2019/26665-5 (Gabriel G. Rêgo). Mistletoe Unfettered Research Grant, National Science Foundation GRFP Award 1937959 (Shawn A. Rhoads). Japan Society for the Promotion of Science grant 21J01224 (Toshiki Saito). Institute of Psychology & the Faculty of Social and Political Sciences, University of Lausanne (Oriane Sarrasin). Universitat Ramon Llull, Esade Business School (Katharina Schmid). University of St Andrews (Philipp Schoenegger). Dutch Science Foundation (NWO) VI.Veni.191 G.034 (Christin Scholz). Universität Hamburg (Stefan Schulreich). Faculty of Health PhD fellowship, Aarhus University (Katia Soud). School of Medicine and Psychology, Australian National University (Samantha K. Stanley). Swedish Research Council grant 2018-01755 (Gustav Tinghög). Russian Federation Government grant project 075-15-2021-611 (Danila Valko). Swedish Research Council (Daniel Västfjäll). Cooperatio Program MCOM (Marek Vranka). Stanford Center on Philanthropy and Civil Society (Robb Willer). Canada Research Chairs program (Jiaying Zhao). For the purpose of open access, the author has applied a CC BY public copyright licence to any Author Accepted Manuscript version arising from this submission.
Author information
Authors and Affiliations
Contributions
Conceptualization: K.C.D., B.T., M.V. Data curation and cleaning: K.C.D., B.T., P.S., M.M.B.-W., Y.P. Project Administration: K.C.D., M.V., J.J.V.B., Data visualization: K.C.D., B.T., P.S. Data acquisition: The entire Climate Collaboration, Writing-original draft: K.C.D., B.T., M.V. Writing- editing and reviewing: The entire Climate Collaboration.
Corresponding authors
Ethics declarations
Competing interests
André Krouwel (Departments of Political Science and Communication Science at Vrije Universiteit Amsterdam) is the founder and stockholder of Kieskompas (data collection service), but has not financially benefited from this data collection or study. All other co-authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Doell, K.C., Todorova, B., Vlasceanu, M. et al. The International Climate Psychology Collaboration: Climate change-related data collected from 63 countries. Sci Data 11, 1066 (2024). https://doi.org/10.1038/s41597-024-03865-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03865-1
- Springer Nature Limited