
Abstract
Fuel moisture content (FMC) is important for the ignitability, behaviour and severity of wildfires. Understanding the drivers of FMC and its spatial and temporal variability can help us develop fuel moisture models and inform assessments of wildfire behaviour and danger. Here we present the first United Kingdom (UK) national-scale temperate FMC dataset of 8,057 samples of eighteen different fuel constituents collected across 58 sampling sites between 2021–2023. We sampled fuels across emerging fire-prone ecosystems in the UK across three studies: (1) UK-wide longer-term sampling characterising the spatio-temporal drivers of FMC; (2) landscape-scale measurement through the North Yorkshire Moors to investigate landscape-driven variability in FMC; (3) plot-scale intensive sampling in the West Midlands to quantify diurnal patterns and among-sampler variability in fuel measurements. This database addresses a global fuel moisture measurement gap within traditionally non-fire prone regions. The database will advance our understanding of temperate fuel moisture dynamics and forms a fundamental contribution towards the development of a fire danger rating system for traditionally non-fire prone regions such as the UK.
Similar content being viewed by others
Background & Summary
Temperate regions which are not typically prone to wildfires are experiencing a greater number of wildfires due to climate and land use change1,2. The UK currently experiences around 30,000 wildfires per year, here defined as any uncontrolled vegetation fire which requires a decision or action regarding suppression3, resulting in a burned area of 6,600 hectares on average3. Fires can result in large economic costs (loss of crops, evacuation of houses, infrastructure closure) and ecological damage (e.g. loss of ground-nesting bird habitat)4, and fire-prone environments such as heathlands and peatlands often contain sequestered carbon stores in organic soils that can be released during severe wildfires4.
Wildfire behaviour is intrinsically linked to fuel moisture content (FMC). Specifically, fuel moisture largely influences ignitability, flammability, fire behaviour and associated severity of wildfire impacts5,6. Understanding the drivers of FMC is therefore critical to predict when wildfires might occur and to develop wildfire management strategies4.
FMC can be measured directly, or estimated using numerical models or remotely sensed data. For example, a number of models have been developed to predict FMC from weather observations such as temperature, humidity, precipitation and wind speed7,8,9,10. Such models were developed for dead fuels in traditionally fire prone regions such as in the pine forests of North America7,8,9,10 and Australia11 and have been applied globally with varying success12,13. Remote sensing can also be used to estimate FMC, particularly for live fuels (e.g. in the Mediterranean14, the United States15,16), although studies report some remaining challenges in the ability of remote sensing to accurately capture FMC14,15,16. The only direct measure of FMC is by destructive field sampling of fuel. This method is extremely labour-intensive and must be repeated over time and across a variety of locations to capture spatial and temporal variability17. Fuel moisture data are currently lacking in traditionally non-fire prone temperate regions, but are urgently needed to develop our understanding of spatio-temporal patterns in fuel moisture which will enable tailored moisture models to be created. Indeed, Globe-LFMC, the largest published database of sampled FMC, contains over 280,000 records of live FMC from eleven countries but only contains 24 samples from England and 250 samples from Scotland taken across six sites. In addition, the majority of these samples (~258,000), are taken from the predominantly western and southern US and Mediterranean France, leaving a large knowledge gap in temperate regions. The most commonly sampled species in this dataset are arid or semi-arid shrubs (Adenostoma fasciculatum, Artemisia tridentata) and pine species17. However, fire-prone ecosystems within the UK are mostly dominated by heather (Calluna vulgaris), gorse (Ulex europeaus), bracken (Pteridium aquilinum) and moor grass (Molinia caerulea). Within the UK, a number of studies have characterised different aspects of FMC; for example, to investigate the ignition thresholds and to characterise the spatial and temporal patterns of FMC for live heather18,19, and to look at the FMC of heather, litter and moss in relation to fire spread20. However, we lack information about FMC over a large spatial scale (e.g. national) and over a longer time period (e.g. of multiple years), and for many of the fuels found within the UK’s fire-prone environments (gorse, bracken, moor grass) there are currently no FMC data available.
Here, we present three datasets, associated with three separate studies, that aim to address these knowledge gaps. First we describe the UK-wide dataset, where sampling was conducted fortnightly to monthly across the UK over two years to examine wide-scale spatial and temporal patterns in FMC. Secondly we describe the North Yorkshire Moors (NYM) dataset, where intensive sampling was conducted over five days between April and July 2021 at 18 sites within the NYM area to examine cross-landscape variation in FMC. This dataset has been used to examine the landscape controls on fuel moisture21. Thirdly we describe the West Midlands (WM) dataset, where intensive sampling at two heathland locations was conducted during one day in a Country Park near Birmingham to characterise both plot-scale diurnal variability in FMC and among-sampler variability in fuel measurements22.
Methods
UK-wide dataset
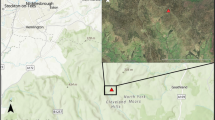
We established fuel moisture monitoring sites at 43 heathland, bog, acid grassland and coniferous forest locations across the United Kingdom (marked in black in Fig. 1; Table 1). The monitoring sites were selected to encompass different land cover types according to the Land Cover Map23, climate regions of the UK24 and the range of soils25,26 within them. We endeavoured to represent the combinations of these factors of interest across our sites as much as possible to allow investigation of their influence on fuel moisture content.

Location of sample sites (a). UK-wide sites were sampled regularly during 2021–2023. Additional sample sites underwent more concentrated sampling: in the North Yorkshire Moors (b), eighteen sites (five of which were also included in UK-wide dataset) were sampled extensively during spring and summer 2021; in Lickey Hills Country Park (c), two sites were sampled at different times on just one day. Sources: Esri, Airbus DS, USGS, NGA, NASA, CGIAR, N Robinson, NCEAS, NLS, OS, NMA, Geodatastyrelsen, Rijkswaterstaat, GSA, Geoland, FEMA, Intermap and the GIS user community. Grey dashed lines and associated grey labels show climate regions24, one of the key factors considered when choosing sampling locations.
Eighteen different fuel constituents (Table 2) were collected at each site on a fortnightly basis from April to October in 2021 and 2022 and monthly from November to March. In 2023 samples were collected across seven days from February to June (Table S1; see supplementary file). These fuels are all found in abundance within fire-prone ecosystems within the UK. In all datasets (UK-wide, NYM and WM) we sampled fuel moisture content following a modified protocol from Norum and Miller27 that has been used for other fuel moisture campaigns in UK peatlands and heathlands21,22. For a full description of sampling protocol for the fuel types collected throughout all three studies see Little & Quiñones28. We established 20 m transects at sample sites and collected vegetation samples (heather, gorse, bracken, moor grass) between 11:00 and 17:00 local time. For heather, gorse and bracken we sampled stems and either canopy (heather, gorse) or leaves (bracken) separately, and for all vegetation both live and dead samples were taken. We also collected live moss samples (by pinching top two cm of moss from the soil surface) and litter samples (by pinching top two cm of dead leaf litter from soil surface) at ca. 10 points along this transect. These two fuel types were sampled separately, and if both occurred together the constituents were separated. For the organic layer, defined as the organic material beneath the surface litter and above the mineral soil, we sampled the top 5 cm of soil at four points along the transect. In forested sites, we collected twigs (<5 mm diameter) from fallen branches at ca. 10 points along the transect, only sampling those which were not in contact with the floor. We combined the same fuel constituents sampled along the transects within aluminium screw-fit tins that were sealed with masking tape. We calculated gravimetric fuel moisture content (Eq. 1) by weighing the collected samples, drying them for 48 h at 80 °C27 and then reweighing the dried samples. The FMC is calculated as:
where W = wet weight (g), D = dry weight (g) and T = the weight of the sample tin (g). A total of 5,845 samples were collected.
Kestrel 3000 weather meters (Kestrel Instruments, Boothwyn, PA) were used to measure temperature, relative humidity and wind speed during sampling at each site. Daily mean temperature and daily precipitation were downloaded at 0.25 degree resolution (roughly 27 km at the equator) from the E-OBS ensemble gridded dataset version 26.029 and these values were assigned to samples at the location and date of sampling. The number of days since precipitation occurred was calculated using these data. The R package ‘elevatr’30 was used to download elevation data, and the R package ‘raster’31 was used to download slope and aspect data for each site.
NYM dataset
We chose eighteen heathland and peatland sample sites within the North Yorkshire Moors National Park in the northeast of England (Fig. 1b) that represented different soils (coarse, fine, peat25), aspect (north or south facing; these were chosen to account for the full range in solar radiation from maximum to minimum; OS Terrain® 50 DTM OS data © Crown copyright and database right 2022), and hillslope position (low (plateau below slope), medium (slope of hill) or high (top of plateau); OS Terrain® 50 DTM OS data © Crown copyright and database right 2022) (see Little et al.21). Each site contained a pair of plots, one with a mature heather canopy (last burned 15–20 years ago with an average height of 60 cm and accumulated moss/litter layer depth of 5 cm32) and a second with a building heather canopy (burned in the last 5–10 years with an average height of 30 cm and accumulated moss/litter layer depth of 2.5 cm32); canopy age was categorised based on land managers’ records21. Five of these sites were also used in the UK-wide dataset (Table 2), but samples were taken from these sites separately for each dataset. Sampling was carried out at all eighteen sites on each of the following dates between 11:00 and 17:00 local time: 15th, 18th and 23rd April, 13th June and 22nd July 2021. These dates were chosen as dry, hot days within the field season so that spatial patterns of FMC during high fire-risk periods could be discerned. In both this dataset and the WM dataset outlined below, seven fuel constituents were sampled: live heather canopy, live heather stems, dead heather canopy, dead heather stems, moss, litter and organic layer (Table 2). A total of 1,124 samples were collected.
WM dataset
This study took place at two heathland sites within Lickey Hills Country Park, Birmingham (Fig. 1c) on 28th March 2022. Sampling was carried out by seventeen different samplers every hour from 10:00 to 18:00 local time. A total of 1,088 samples were collected.
Finally, so that our datasets can be merged more easily with the existing Globe-LFMC dataset17, we provided the same meteorological and land cover data provided by Globe-LFMC. Meteorological data comprised AgERA5 (Agrometeorological indicators from 1979 to present derived from reanalysis)33 variables; 24 h mean and maximum air temperature, 24 h mean dewpoint temperature, 24 h summed precipitation, 24 h mean relative humidity, 24 h mean vapour pressure and 24 h mean wind speed. Land cover data was assigned using the IGBP classification from LP DAAC MCD12Q1.061 (MODIS/Terra + Aqua Land Cover Type Yearly L3 Global 500 m SIN Grid)34.
Data Records
The dataset repository35 contains three .csv files, one for each dataset; please see descriptions below for information about each. Due to differences in the content, scope and purpose of the three datasets we have presented them separately. Figures 2–5 and Tables 3–5 summarise the data collected.

Range in fuel moisture content (FMC, %) of eighteen different fuel types sampled from UK-wide, NYM and WM datasets from 2021–2023. Brown violin plots = dead fuels, green = live fuels and grey = surface fuels. Median values and interquartile ranges are shown with overlaid boxplots. Note different y-axes.

Fuel moisture content (FMC) of eighteen different fuel constituents averaged weekly during sampling period of 2021–2023. Weekly averages were calculated across all sample sites (UK-wide dataset, NYM dataset and WM dataset) and each week is represented by a coloured band. FMC across all fuel constituents was re-scaled using quantile normalization, a technique to standardise the statistical properties (e.g. quantiles) of multiple datasets to allow comparison between data originally on different scales. We can therefore see in which time periods FMC was lower (red) or higher (blue) across all fuels. Although FMC is measured as a percent, quantile normalization means that the legend scale is not representative of the true FMC values. Fuels have been grouped into live, dead and surface fuels to allow easier comparison between fuel types.

Variation in fuel moisture content (FMC) of seven fuel constituents in the North Yorkshire Moors, intensively sampled over 3 days in April and one day each in June and July. No samples were taken for the organic layer on April 15th. Note different y-axes.

Fuel moisture content (FMC) of seven fuel constituents in the WM dataset, sampled from Lickey Hills Country Park, Birmingham, on 28th March 2022 over eight hours. Red lines represent mean FMC at each time, pink ribbons represent standard deviation of means. Note different y-axes due to large variation in FMC ranges between fuels.
The UK-wide dataset contains the following information: Date, Site name, Longitude (WGS84 decimal degrees), Latitude (WGS84 decimal degrees), Region of the UK (defined as separate regions using the Met Office Climate Districts Map24 but with some names changed, e.g. ‘Midlands’ (Fig. 1a) is named ‘Peak District’ in dataset, ‘England E & NE’ (Fig. 1a) is named ‘North York Moors’ in dataset), Land Cover Map23 land cover type, Elevation (m), Slope (degrees), Aspect (degrees), Soil type25, Air temperature at the time of sampling (degrees Celsius), Relative humidity at the time of sampling (%), Wind speed at the time of sampling (m/s), Mean 24 h air temperature (downloaded from E-OBS; degrees Celsius), 24 h precipitation sum (downloaded from E-OBS; mm/day), Number of days since rain, Fuel type (e.g. heather live canopy), Species name (taxonomic Latin names for heather, gorse, bracken and moor grass; NA for moss, litter, twigs and the organic layer; moss and twig species were not identified), Time collected (in hours), FMC (fuel moisture content in %) and Outliers removed (Y if discarded from analyses as an outlier, N if retained for analyses; meteorological data (E-OBS and AgERA5) were not assigned to outliers).
The NYM dataset contains the following information: Date, Site name, Longitude (WGS84 decimal degrees), Latitude (WGS84 decimal degrees), Fuel type (e.g. heather live canopy), Species name (taxonomic Latin name for heather samples, NA for moss, litter and the organic layer; moss species were not identified), landscape characteristics of the sample sites comprising Heather canopy age (mature or building (i.e. growing)), Soil texture (coarse, fine or peat), Hillslope position (low, medium or high) and Aspect (north or south) and FMC (fuel moisture content in %).
The WM dataset contains the following information: Date, Sampler (containing IDs of 17 samplers from A to Q), Site name (either north or south sites within the park), Longitude (WGS84 decimal degrees), Latitude (WGS84 decimal degrees), Fuel type (e.g. heather live canopy), Species name (listed in the same way as for NYM dataset), Time collected (in hours from 1000 to 1800) and FMC (fuel moisture content in %).
All three datasets also contain the following weather variables from AgERA533: 2 m air temperature (24 h mean, Kelvin (K)), 2 m air temperature (24 h maximum, K), 2 m dewpoint temperature (24 h mean, K), 10 m wind speed (24 h mean, m/s), vapour pressure (24 h mean, hPa), 2 m relative humidity at 6 h (%), 2 m relative humidity at 9 h (%), 2 m relative humidity at 12 h (%), 2 m relative humidity at 15 h (%), precipitation 24 h sum (mm/day), precipitation sum for 3 days before (mm/day), precipitation sum for 1 week before (mm/day), precipitation sum for 4 weeks before (mm/day) and precipitation sum for 12 weeks before (mm/day). Finally, the three datasets contain IGBP land cover ID and IGBP land cover type34.
Technical Validation
All sample tins were given a unique identifier, which were recorded carefully to ensure that their weights were assigned to the correct location and date. To ensure that FMC was as accurate as possible, each empty sample tin was weighed individually before sampling to include in the FMC calculation (i.e. we did not use a mean tin weight in calculations). All FMC values were reviewed to ensure that the formatting was consistent. Data were plotted to check for outliers, and two outlying FMC values were identified and removed which fell widely outside the range of FMC for all other samples in a given fuel (>600% FMC in a live heather sample, >400% in a dead gorse sample). The moisture content of eleven samples was below 0. The FMC of seven of these was between −2% and 0% and the FMC of four was lower than −20%. We therefore selected −2% FMC as the threshold below which data were discarded, as negative values above this threshold were likely due to scale error. These six values are marked as outliers in the UK-wide dataset. No outliers were removed from the NYM or WM dataset as these data appeared normally distributed. Samples were collected by several individuals, so data were compiled and sample site names were standardised.
Code availability
No custom computer code or algorithms were used to process or generate the data presented in this manuscript.
References
Fernandez-Anez, N. et al. Current Wildland Fire Patterns and Challenges in Europe: A Synthesis of National Perspectives. Air, Soil and Water Research 14, 11786221211028185 (2021).
Jones, M. W. et al. Global and Regional Trends and Drivers of Fire Under Climate Change. Reviews of Geophysics 60, e2020RG000726 (2022).
Forestry Commission. Wildfire Statistics for England: Report to 2020-21. (2023).
Belcher, C. M. et al. UK Wildfires and their Climate Challenges. Expert Led Report Prepared for the third Climate Change Risk Assessment (2021).
Davies, G. M. & Legg, C. J. Developing a live fuel moisture model for moorland fire danger rating. in 225–236. https://doi.org/10.2495/FIVA080231 (Toledo, Spain, 2008).
Grau-Andrés, R., Davies, G. M., Gray, A., Scott, E. M. & Waldron, S. Fire severity is more sensitive to low fuel moisture content on Calluna heathlands than on peat bogs. Science of The Total Environment 616–617, 1261–1269 (2018).
Anderson, H., Schuette, R. & Mutch, R. Timelag and Equililbrium Moisture Content of Ponderosa Pine Needles. United States Department of Agriculture, Forest Service (1978).
Nelson, R. M. A method for describing equilibrium moisture content of forest fuels. Can. J. For. Res. 14, 597–600 (1984).
Viney, N. R. A Review of Fine Fuel Moisture Modelling. Int. J. Wildland Fire 1, 215–234 (1991).
Van Wagner, C. E. & Pickett, T. L. Equations and FORTRAN Program for the Canadian Forest Fire Weather Index System. (Minister of Supply and Services Canada, Ottawa, 1985).
Matthews, S. et al. Implementation of Models and the Forecast System for the Australian Fire Danger Rating System. (2019).
Davies, G. M. & Legg, C. J. Regional variation in fire weather controls the reported occurrence of Scottish wildfires. PeerJ 4, e2649 (2016).
Anderson, S. A. J. & Anderson, W. R. Ignition and fire spread thresholds in gorse (Ulex europaeus). Int. J. Wildland Fire 19, 589 (2010).
Yebra, M., Chuvieco, E. & Riaño, D. Estimation of live fuel moisture content from MODIS images for fire risk assessment. Agricultural and Forest Meteorology 148, 523–536 (2008).
Dasgupta, S., Qu, J. J., Hao, X. & Bhoi, S. Evaluating remotely sensed live fuel moisture estimations for fire behavior predictions in Georgia, USA. Remote Sensing of Environment 108, 138–150 (2007).
Qi, Y., Dennison, P. E., Spencer, J. & Riaño, D. Monitoring Live Fuel Moisture Using Soil Moisture and Remote Sensing Proxies. fire ecol 8, 71–87 (2012).
Yebra, M. et al. Globe-LFMC 2.0, an enhanced and updated dataset for live fuel moisture content research. Sci Data 11, 332 (2024).
Davies, G. M. & Legg, C. J. Fuel Moisture Thresholds in the Flammability of Calluna vulgaris. Fire Technol 47, 421–436 (2011).
Davies, G. M., Legg, C. J., O’Hara, R., MacDonald, A. J. & Smith, A. A. Winter desiccation and rapid changes in the live fuel moisture content of Calluna vulgaris. Plant Ecology & Diversity 3, 289–299 (2010).
Davies, G. M., Legg, C. J., Smith, A. A. & MacDonald, A. J. Rate of spread of fires in Calluna vulgaris-dominated moorlands. Journal of Applied Ecology 46, 1054–1063 (2009).
Little, K., Graham, L. J., Flannigan, M., Belcher, C. M. & Kettridge, N. Landscape controls on fuel moisture variability in fire-prone heathland and peatland landscapes. fire ecol 20, 14 (2024).
Little, K., Graham, L. J. & Kettridge, N. Accounting for among-sampler variability improves confidence in fuel moisture content field measurements. Int. J. Wildland Fire 33 (2023).
Marston, C., Rowland, C. S., O’Neill, A. W. & Morton, R. D. Land Cover Map 2021 (10m classified pixels, GB). NERC EDS Environmental Information Data Centre. (2022).
Met Office. Climate Districts Map: https://www.metoffice.gov.uk/research/climate/maps-and-data/about/districts-map. (2024).
Farewell, T. S., Truckell, I. G., Keay, C. A. & Hallett, S. H. The use and applications of the Soilscapes datasets. Cranfield University (2011).
Soil Survey of Scotland Staff. Soil maps of Scotland at a scale of 1:250 000. Macaulay Institute for Soil Research, Aberdeen. https://doi.org/10.5281/zenodo.4646891 (1981).
Norum, R. A. & Miller, M. Measuring Fuel Moisture Content in Alaska: Standard Methods and Procedures. PNW-GTR-171, https://doi.org/10.2737/PNW-GTR-171 (1984).
Little, K. & Quiñones, T. Simple Guidelines for Northwest European Stakeholders to Collect Fire Behavior and Fuel Moisture Data. (2022).
Cornes, R. C., van der Schrier, G., van den Besselaar, E. J. M. & Jones, P. D. An Ensemble Version of the E-OBS Temperature and Precipitation Data Sets. Journal of Geophysical Research: Atmospheres 123, 9391–9409 (2018).
Hollister, J., Shah, T., Robitaille, A., Beck, M. & Johnson, M. elevatr: Access Elevation Data from Various APIs. R package version 0.4.2. Zenodo https://doi.org/10.5281/zenodo.5809645 (2022).
Hijmans, R. & van Etten, J. raster: Geographic analysis and modeling with raster data. R package version 2.0-12, http://CRAN.R-project.org/package=raster (2012).
Gimingham, C. H. A reappraisal of cyclical processes in Calluna heath. Vegetatio 77, 61–64 (1988).
Boogaard, H. et al. Agrometeorological indicators from 1979 to present derived from reanalysis. Copernicus Climate Change Service (C3S) Climate Data Store (CDS). https://doi.org/10.24381/cds.6c68c9bb (2020).
Friedl, M. & Sulla-Menashe, D. MCD12Q1.061 MODIS/Terra + Aqua Land Cover Type Yearly L3 Global 500m SIN Grid V061 [Data set]. NASA EOSDIS Land Processes Distributed Active Archive Center. (2022).
Ivison, K. et al. A UK national-scale sampled temperate fuel moisture database. figshare. https://doi.org/10.6084/m9.figshare.c.7130536.v3 (2024).
Acknowledgements
We thank the 2022 University of Birmingham Geography sub-cohort from module 36261: LC Fieldwork Project Design and GIS for their involvement in this field campaign. Finally, thank you to the land holders and managers for permitting sampling to take place on their land. This project has received funding from NERC Highlight project NE/T003553/1.
Author information
Authors and Affiliations
Contributions
N.K., K.L., A.O. and L.G. developed the experimental design and methodology; K.L., A.O. and N.K. collected data; K.I. led the writing of the paper; all authors revised the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ivison, K., Little, K., Orpin, A. et al. A national-scale sampled temperate fuel moisture database. Sci Data 11, 973 (2024). https://doi.org/10.1038/s41597-024-03832-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03832-w
- Springer Nature Limited