
Abstract
Recent conservation efforts to protect rare and endangered aquatic species have intensified. Nevertheless, the ornate spiny lobster (Panulirus ornatus), which is prevalent in the Indo-Pacific waters, has been largely ignored. In the absence of a detailed genomic reference, the conservation and population genetics of this crustacean are poorly understood. Here, We assembled a comprehensive chromosome-level genome for P. ornatus. This genome—among the most detailed for lobsters—spans 2.65 Gb with a contig N50 of 51.05 Mb, and 99.11% of the sequences with incorporated to 73 chromosomes. The ornate spiny lobster genome comprises 65.67% repeat sequences and 22,752 protein-coding genes with 99.20% of the genes functionally annotated. The assembly of the P. ornatus genome provides valuable insights into comparative crustacean genomics and endangered species conservation, and lays the groundwork for future research on the speciation, ecology, and evolution of the ornate spiny lobster.
Similar content being viewed by others
Background & Summary
Lobsters, with a prestigious status as valuable marine resources, are highly sought after in global fisheries for their economic and culinary significance. This has placed considerable focus on lobsters within the realms of biology, fisheries, and taxonomy1. The marine lobster family presently encompasses 49 acknowledged species, including 11 genera2. Lobsters, notable for their large size as benthic invertebrates, have exceptionally long lives, with some species estimated to live over 50 years and possibly up to 100 years3. However, the high market demand for lobsters resulted in intensive overfishing. Few countries have implemented effective management strategies to ensure sustainable harvests, and inadequate enforcement of fishing and marketing regulations have, in many regions, put significant strain on lobster populations. Consequently, to safeguard these valuable species and ensure their long-term sustainability, there is an urgent need to explore and implement alternative management approaches, such as co-management4.
The ornate spiny lobster, Panulirus ornatus, is an endangered species found on coral reefs and inshore habitats widely distributed in China, the South Pacific, and the Indian Ocean (Fig. 1a,b). In global aquaculture, it ranks as one of the most valued and highly priced fisheries5, and is consequently overexploited in unregulated fisheries6,7. On February 5, 2021, the ornate spiny lobster (P. ornatus) was classified as a Second Class species on China’s National Key Protected Wild Animals List—a notable conservation milestone, making P. ornatus the first crustacean to be recognized and included in this crucial protection list8. Like many other valued marine species around the globe, the ornate spiny lobster population faces several critical threats, including marine environmental pollution, injuries from fishing activities, loss of vital habitats, and a decline in fish resources9. The combined effects of global climate change and human activities exacerbate these challenges, posing significant risks to the survival and health of lobsters10. In conclusion, the population size of P. ornatus is in decline, and the pursuit of further conservation measures for these species is imperative.

Photograph and location distribution of the long-tailed marine-living ornate spiny lobster, Panulirus ornatus. (a) A photo of the adult P. ornatus. (b) A natural distribution map of P. ornatus (red star).
Previous attempts to sequence the genome of this species resulted in an incomplete and fragmented assembly, with an estimated genome size of 3.23 Gb compared to the actual assembled genome size of 1.93 Gb and a contig N50 of 5,451 bp, limiting the depth of potential research11. Here, we successfully achieved the first chromosome-level genome assembly for an endangered lobster species by integrating a combination of Illumina short reads, PacBio long read DNA sequencing, and Hi-C technology (Fig. 2). The project amassed 182.90 Gb of Illumina short-read data, 115.67 Gb of PacBio continuous long read data, and 456.71 Gb of Hi-C data, culminating in an assembled genome size of 2.65 Gb and a scaffold N50 of 51.05 Mb (Tables 1 and 2). Our high-quality genome assembly enhances the genomic resources available for crustaceans and provides essential data for their further protection.

Genomic landscape of P. ornatus. Circos plot of P. ornatus. From outside to inside, gene density. (a), GC content (b), and the densities of DNA transposons (c), LTRs (d), LINEs (e), and SINEs (f), all represented in 200-kb genomic windows.
Methods
Sample collection and nucleic acid extraction
We collected male adult P. ornatus from Huangliu Co., LTD. in Sanya, Hainan, China. In this study, muscle tissue samples were collected and meticulously washed three times with sterile phosphate-buffered saline (PBS). The samples were then instantly froze with liquid nitrogen and subsequently stored at −80 °C. Total genomic DNA (gDNA) was extracted for genome survey and construction of the genome sequence libraries using the AMPure bead cleanup kit following the manufacturer’s instructions (Beckman Coulter, High Wycombe, UK). Meanwhile, we extracted total RNA from eight tissues (testis, intestines, hepatopancreas, hemocytes, muscle, gills, heart, and eyestalk) of the same individual by utilizing the TRIzol reagent according to the manufacturer’s instructions and subjected to RNA-seq analysis for genome structure annotation. The integrity and quality of the extracted nucleic acids were evaluated using 1.5% agarose gel electrophoresis and nucleic acid concentrations were accurately quantified using a Qubit fluorometer (Thermo Fisher Scientific based in Waltham, MA).
Library construction and sequencing
A short-read library was prepared with an insert size of 350 bp and sequenced utilizing the Illumina Platform to generate 2 × 150 bp reads with NEB Next* UltraTM DNA Library Prep Kit (NEB, USA) for Illumina short-read sequencing following the manufacturer’s recommendations. For PacBio sequencing, we used genomic DNA to construct SMRTbell libraries following the manufacturer’s guidelines. We then sequenced the libraries using a PacBio Sequel platform equipped with single molecule real-time (SMRT). These sequencing efforts led to the generation of 182.90 Gb of Illumina short-read data and 292.02 Gb of raw continuous long reads (CLR), achieving a comprehensive 179-fold coverage of the P. ornatus genome (Table 1).
For Hi-C library construction, we used the MboI restriction enzyme to digest cross-linked high molecular weight (HMW) gDNA. After 5′ overhang biotinylation and blunt-end ligation, we physically sheared DNA into 300–500 bp fragments. Finally, we sequenced the Hi-C library with a strategy of 2 × 150 bp on the Illumina HiSeq using the NovaSeq 6000 platform, resulting in 456.71 Gb of paired-end raw reads. The sequencing libraries were then constructed using the NEBNext® UltraTM RNA Library Prep Kit for Illumina® (NEB, USA), with all procedures strictly adhering to the manufacturer’s recommendations. We then sequenced the RNA-seq library using the Illumina HiSeq 6000 platform to generate 2 × 150 bp reads. From this process, we generated 54.38 Gb of paired-end short clean reads, as we detail in Table 1.
Genome survey and assembly
The adapter sequences and low-quality reads obtained from the Illumina platform were removed before the assembly process, using fastp software (version 0.23.1)12, retaining only clean reads for the subsequent stages of genome survey and assembly. We conducted genome surveys to determine key genomic characteristics such as overall size, heterozygosity, and repeatability, employing SOAPec (version 2.01)13 and GenomeScope (version 2.0)14 software to analyze 17 different K-mer frequencies. From these analyses, with a dominant peak depth of 59, we calculated the estimated genome size of P. ornatus to be 2917.34 Mb. We also approximated the heterozygosity and repetitive sequence content of the genome at 0.92% and 63.86%, respectively. In Table S1 and Fig. S1, we comprehensively detail these findings and estimates.
For genome assembly of P. ornatus, we employed a dual approach using two distinct assemblers—Wtdbg2 (version 2.5)15 and Flye (version 2.9)16—each of which produced an initial assembly using default parameters, which we then refined using the Arrow polishing process (version 8.0)17. Arrow is a consensus algorithm that generates highly accurate consensus sequences from PacBio subreads. After polishing, we merged the assemblies from Wtdbg2 and Flye using Quickmerge (version 0.3)18— a tool specifically designed to combine multiple genome assemblies into a single, unified consensus assembly. The resulting merged assembly was then polished twice using two rounds of Arrow and two rounds of Pilon (version 1.22)19 with default parameters. We performed PacBio subreads for Arrow and Illumina short reads for pilon, generating a total of 8,061 contigs with a total length of 2,651,872,113 bp (Table 2).
Hi-C scaffolding
In the Hi-C scaffolding phase of this study, we first processed the raw Hi-C reads to eliminate adapters and low-quality bases, using fast software (version 0.23.1)20 with the parameters set to -q 20-l 50. Subsequently, we aligned these processed reads to the preliminary assembly using the Juicer pipeline21. Following alignment, we used the 3D-DNA pipeline22 to perform several critical tasks, including grouping the contigs into chromosomes, and orienting and ordering the contigs within each chromosome. To enhance the accuracy of the assembly, we manually corrected errors using Juicebox Assembly Tools (version 2.13.06)21. The scaffolding process allowed for accurate anchoring of 2,628.95 Mb of the assembly to 73 chromosomes (Fig. 3)—accounting for 99.11% of the total assembly (Table S2). The scaffold N50, a measure of assembly continuity, reached a length of 51.05 Mb in the final assembly (Table 2). This assembly is noteworthy for the contiguity of 14 chromosomes, each with no more than 30 gaps (Table 3).

Hi-C heatmap (200-kb resolution) showcasing the interaction frequencies between different chromosomes of the ornate spiny lobster.
Genomic repeat annotation. We identified repeat sequences in the P. ornatus genome using both homology-based and de novo strategies23. Initially, we merged the de novo predicted repetitive sequence database with the Repbase homologous repetitive sequence database24. We used a suite of tools—RepeatScout (version 1.0.5)23, RepeatModeler (version 2.0.1)25, Piler (version 1.0)26, and LTR-FINDER (version 1.0.6)27—to identify transposable element (TE) families, whereafter we employed Repeatmasker (version 4.1.0)25, RepeatProteinMask (version 4.1.0), and TRF (version 4.0.9)28 to classify different repetitive elements. We achieved this classification by aligning the P. ornatus genome sequences with the integrated database. After eliminating redundant results from these three methods, we established that repeat sequences constituted 65.67% of the P. ornatus genome (Table S3). In addition, we calculated the Kimura divergence value of TEs using the script ‘calcDivergenceFromalign.pl29 and created TE landscapes with ‘createRepeatLandscape.pl30. Among the identified repeat elements, we identified DNA elements as comprising 4.58% of the genome, with long interspersed nuclear elements (LINEs) accounting for 40.30%. Short interspersed nuclear elements (SINEs) and long terminal repeats (LTRs) constituted only 0.01% and 30.07% of the genome, respectively (Table 4 and Fig. 4).

Distribution of divergence rates for TEs in the P. ornatus genome.
In the process of annotating noncoding RNA (ncRNA) within the P. ornatus genome, we employed specific tools for different types of ncRNA predictions. For tRNA prediction, we used tRNAScan (version 1.4)31, whereas for rRNA prediction we used Blast (version 2.2.26)32. To identify other types of ncRNAs, such as miRNA and snRNA, we aligned the sequences to the Rfam database33 using the INFERNAL tool (version 1.0)34. Using these methods, we successfully identified four distinct types of noncoding RNAs in the P. ornatus genome. including 12,771 miRNAs, 5,187 tRNAs, 1,716 rRNAs, and 1,296 snRNAs (Table 5).
Protein-coding gene prediction and annotation
For gene structure prediction of the P. ornatus genome, we employed a combination of de novo, homology-based, and transcriptome sequencing-based predictions. For the de novo approach, we used a suite of tools–Augustus (v3.2.3)35, GlimmerHMM (v3.02)36, SNAP (v2013.11.29)37, Geneid (v1.4)38, and Genscan (v1.0)39—to predict gene structures directly from the genome sequence. For homologous-based annotation, the protein sequences of Portunus trituberculatus (swimming crab), Cherax quadricarinatus (Australian red claw crayfish), Penaeus vannamei (Pacific white shrimp), Procambarus virginalis (marbled crayfish), Homo sapiens (human), Drosophila melanogaster (fruit fly), Tribolium castaneum (red flour beetle), Caenorhabditis elegans (nematode), and Crassostrea gigas (Pacific oyster) were downloaded from the NCBI’s Genbank database, and aligned against spiny lobster genome using Blast (v2.2.26)32 and Genewise (v2.4.1)40. With this multifaceted approach, we ensured a thorough and accurate prediction of the protein-coding genes in the P. ornatus genome, thereby enhancing our understanding of its genetic architecture. We identify a total of 5,087–58,220 homolgous genes when comparing against the nine target species (Table 6) (Table 6). We analyzed the lengths of genes, CDS, exons, and introns in P. ornatus and compared them with those of five other species (Fig. 5). We found the average lengths for P. ornatus to be 29,875.91 bp for transcripts, 1,420.49 bp for CDS, 257.65 bp for exons, and 6,300.84 bp for introns (Table S4).

Comparisons of genomic elements of closely related species.
Two assembly methods including transcript assembly with reference to the genome and de novo assembly using Trinity software (version 2.11.0)41 were utilized to process clean RNA-seq data. Open reading frames (ORFs) were identified using PASA (version 2.1.0)42, and gene sets predicted by the different methods were merged into a comprehensive, non-redundant gene set containing 22,752 protein-coding genes with Evidence Modeler (version 1.1.1)43 (Table 7 and Fig. 6a).

Gene prediction and functional annotation of the P. ornatus genome. (a) Venn diagram of the gene set prediction. (b) Venn diagram of functional annotation based on different databases.
We functionally annotated the protein-coding genes using Blastp (version 2.2.26)44 and Diamond (version 0.8.22)45 to align the genes against several protein databases, including SwissProt46, NCBI Nonredundant protein (NR), KEGG47, InterPro48, GO Ontology (GO)49, and Pfam50, setting the E-value cutoff at 1E-5. We further annotated protein domains and motifs using InterProScan (version 5.52–86.0)51. We annotated 22,568 (99.20%) of the 22,752 predicted genes, by at least one of these databases (Table 7). All four databases supported 14,884, or 65.42% of these functionally annotated proteins (Fig. 6b).
Data Records
We deposited the genomic Illumina sequencing data in the SRA at NCBI SRR2680148252 and SRR2680148353.
We deposited the genomic PacBio sequencing data in the SRA at NCBI SRR2680147754 and SRR2680147855.
We deposited the transcriptomic sequencing data in the SRA at NCBI SRR SRR2694589956-SRR2694590657,58,59,60,61,62,63.
We deposited the Hi-C sequencing data in the SRA at NCBI SRR26801479–SRR 2680148164,65,66.
This Whole Genome Shotgun project has been deposited at GenBank under the accession https://identifiers.org/ncbi/insdc.gca:GCA_036320965.167. The version described in this paper is version ASM3632096v1. The final chromosome assembly and genome annotation files are also available in Figshare68.
Technical Validation
Evaluation of genome assembly and annotation
We rigorously evaluated the quality of P. ornatus genome assembly using multiple methods. First, with the Benchmarking Universal Single-Copy Orthologs (BUSCO) (version 3.0.2)69 assessment, using the BUSCO database (arthropoda_odb9) of single-copy orthologous genes along with tools such as tblastn, augustus, and hmmer, we confirmed the presence of 93.6% of gene orthologs in P. ornatus, with 93.6% being complete and 3.2% fragmented, indicating a comprehensive assembly (Table S5). Second, employing the Core Eukaryotic Genes Mapping Approach (CEGMA) (version 2.5)70, we revealed that P. ornatus genes had homologs for 226 highly conserved core genes, accounting for 91.13% (248) of the total, further confirming the completeness of the assembly (Table S6). Finally, we aligned Illumina sequencing reads to the nuclear genome using BWA (version 0.7.8)71, resulting in a high read mapping rate of 97.85% and a coverage rate of 96.80%, demonstrating the better integrity of the assembled genome as well as the homogeneity of the sequencing data (Table S7). These collective findings indicate the high quality of P. ornatus genome assembly.
Collinearity analysis
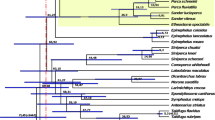
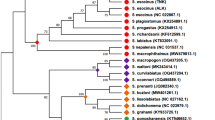
For whole genome synteny comparison, we aligned the chromosome-level genomes of two decapod species, Penaeus chinensis and Procambarus clarkii, with the P. ornatus genome assembly, using LASTZ (version 1.02.00)72 with default parameters. We found that nearly 73 chromosome-level scaffolds of P. ornatus exhibited significant similarity with the corresponding chromosomes of P. chinensis and P. clarkii (Fig. 7). This similarity underscores the high quality of the sequencing and assembly of the P. ornatus genome, while improving the reliability of phylogenetic analyses.

Chromosome sequence synteny comparisons. (a) Syntenic relationship between the P. ornatus genome and the P. chinensis genome. (b) Syntenic relationship between the P. ornatus genome and the P. clarkii genome. Each line connects a pair of homologous sequences between the two species.
In conclusion, we successfully assembled a high-quality chromosome-level genome of P. ornatus. This newly generated reference genome represents a significant contribution to our knowledge of lobster genetic diversity. It will not only advance comparative evolutionary studies but also play a crucial role in conservation efforts for this endangered species.
Code availability
We detail all commands and pipelines employed for data processing in the methods section. For any software where specific parameters were not mentioned, we used the default settings recommended by the software developers. The core code is available at https://github.com/sundongfang/Chromosome-level-genome-of-Panulirus-ornatus.
References
Radhakrishnan, E. V. et al. Lobsters: biology, fisheries and aquaculture. Springer Nature Singapore Pte Limited. (2019).
Chan, T. Y. Updated checklist of the world’s marine lobsters. In Lobsters: biology, fisheries and aquaculture (pp. 35-64). Springer, Singapore. (2019).
Vogt, G. Ageing and longevity in the Decapoda (Crustacea): a review. Zool. Anz. 251, 1–25 (2012).
Vogt, G. How to minimize formation and growth of tumours: potential benefits of decapod crustaceans for cancer research. Int. J. Cancer 123, 2727–2734 (2008).
Priyambodo, B., Jones, C. M. & Sammut, J. Assessment of the lobster puerulus (Panulirus homarus and Panulirus ornatus, Decapoda: Palinuridae) resource of Indonesia and its potential for sustainable harvest for aquaculture. Aquaculture 528, 735563 (2020).
Sachlikidis, N. G., Jones, C. M. & Seymour, J. E. The Effect of Temperature on the Incubation of Eggs of the Tropical Rock Lobster Panulirus Ornatus. Aquaculture 305, 79–83 (2010).
Lewis, C. L., Fitzgibbon, Q. P., Smith, G. G., Elizur, A. & Ventura, T. Transcriptomic analysis and time to hatch visual prediction of embryo development in the ornate spiny lobster (Panulirus ornatus). Front. Mar. Sci. 9, 1009 (2022).
Chen, J. F., Wu, X. J., Lin, H. & Cui, G. F. A comparative analysis of the List of State Key Protected Wild Animals and other wildlife protection lists. Biodiversity Science 31, 22639 (2023).
Bauer, R. T. Fisheries and aquaculture. In Shrimps: Their Diversity, Intriguing Adaptations and Varied Lifestyles (pp. 583-655). Cham: Springer International Publishing (2023).
Leiva, L. et al. European lobster larval development and fitness under a temperature gradient and ocean acidification. Front. Physiol. 13, 809929 (2022).
Veldsman, W. P. et al. Comparative genomics of the coconut crab and other decapod crustaceans: exploring the molecular basis of terrestrial adaptation. BMC Genomics 22, 1–15 (2021).
Chen, S. Ultrafast one‐pass FASTQ data preprocessing, quality control, and deduplication using fastp. Imeta 2, e107 (2023).
Li, R. et al. De novo assembly of human genomes with massively parallel short read sequencing. Genome Res. 20, 265–272 (2010).
Ranallo-Benavidez, T. R., Jaron, K. S. & Schatz, M. C. GenomeScope 2.0 and Smudgeplot for reference-free profiling of polyploid genomes. Nat. Comm. 11, 1432 (2020).
Ruan, J. & Li, H. Fast and accurate long-read assembly with wtdbg2. Nat. Methods. 17, 155–158 (2020).
Kolmogorov, M., Yuan, J., Lin, Y. & Pevzner, P. A. Assembly of long, error-prone reads using repeat graphs. Nat. Biotechnol. 37, 540–546 (2019).
Zhao, H., Lai, Z. & Chen, Y. Global-and-local-structure-based neural network for fault detection. Neural Networks 118, 43–53 (2019).
Chakraborty, M., Baldwin-Brown, J. G., Long, A. D. & Emerson, J. Contiguous and accurate de novo assembly of metazoan genomes with modest long read coverage. Nucleic Acids Res. 44, e147–e147 (2016).
Walker, B. J. et al. Pilon: an integrated tool for comprehensive microbial variant detection and genome assembly improvement. PloS one 9, e112963 (2014).
Chen, S., Zhou, Y., Chen, Y. & Gu, J. fastp: an ultra-fast all-in-one FASTQ preprocessor. Bioinformatics 34, i884–i890 (2018).
Durand, N. C. et al. Juicer Provides a One-Click System for Analyzing Loop-Resolution Hi-C Experiments. Cell Syst. 3, 95–98 (2016).
Dudchenko, O. et al. De novo assembly of the Aedes aegypti genome using Hi-C yields chromosome-length scaffolds. Science 356, 92–95 (2017).
Price, A. L., Jones, N. C. & Pevzner, P. A. De novo identification of repeat families in large genomes. Bioinformatics 21(Suppl_1), i351–358 (2005).
Jurka, J. et al. Repbase Update, a database of eukaryotic repetitive elements. Cytogenet Genome Res. 110, 462–467 (2005).
Tarailo-Graovac, M. & Chen, N. Using RepeatMasker to identify repetitive elements in genomic sequences. Curr Protoc Bioinformatics. Chapter 4, 4.10.11–14.10.14 (2009).
Edgar, R. C. & Myers, E. W. PILER: identification and classification of genomic repeats. Bioinformatics 21(Suppl 1), i152–158 (2005).
Xu, Z. & Wang, H. LTR_FINDER: an efficient tool for the prediction of full-length LTR retrotransposons. Nucleic Acids Res. 35, W265–W268 (2007).
Benson, G. Tandem repeats finder: a program to analyze DNA sequences. Nucleic Acids Res. 27, 573–580 (1999).
Hubley, R. GitHub repository, https://github.com/rmhubley/RepeatMasker/blob/master/util/createRepeatLandscape.pl (2023).
Rosen, J. GitHub repository, https://github.com/rmhubley/RepeatMasker/blob/master/util/calcDivergenceFromAlign.pl (2020).
Lowe, T. M. & Eddy, S. R. tRNAscan-SE: a program for improved detection of transfer RNA genes in genomic sequence. Nucleic Acids Res. 25, 955–964 (1997).
Mount, D. W. Using the Basic Local Alignment Search Tool (BLAST). CSH Protoc. 2007, pdb.top17 (2007).
Griffiths-Jones, S. et al. Rfam: annotating non-coding RNAs in complete genomes. Nucleic Acids Res. 33, D121–124 (2005).
Nawrocki, E. P., Kolbe, D. L. & Eddy, S. R. Infernal 1.0: inference of RNA alignments. Bioinformatics 25, 1335–1337 (2009).
Stanke, M. et al. AUGUSTUS: ab initio prediction of alternative transcripts. Nucleic Acids Res. 34, W435–439 (2006).
Majoros, W. H., Pertea, M. & Salzberg, S. L. TigrScan and GlimmerHMM: two open source ab initio eukaryotic gene-finders. Bioinformatics 20, 2878–2879 (2004).
Korf, I. Gene finding in novel genomes. BMC Bioinformatics 5, 1–9 (2004).
Blanco, E., Parra, G. & Guigó, R. Using geneid to identify genes. Curr. Protoc. Bioinformatics Chapter 4, Unit 4.3 (2007).
Burge, C. & Karlin, S. Prediction of complete gene structures in human genomic DNA. J. Mol. Biol. 268, 78–94 (1997).
Birney, E., Clamp, M. & Durbin, R. GeneWise and Genomewise. Genome Res. 14, 988–995 (2004).
Grabherr, M. G. et al. Full-length transcriptome assembly from RNA-Seq data without a reference genome. Nat. Biotechnol. 29, 644–652 (2011).
Haas, B. J. et al. Improving the Arabidopsis genome annotation using maximal transcript alignment assemblies. Nucleic Acids Res. 31, 5654–5666 (2003).
Haas, B. J. et al. Automated eukaryotic gene structure annotation using EVidenceModeler and the Program to Assemble Spliced Alignments. Genome Biol. 9, R7 (2008).
Altschul, S. F., Gish, W., Miller, W., Myers, E. W. & Lipman, D. J. Basic local alignment search tool. J. Mol. Biol. 215, 403–410 (1990).
Buchfink, B., Xie, C. & Huson, D. H. Fast and sensitive protein alignment using DIAMOND. Nat. Methods 12, 59–60 (2015).
Bairoch, A. & Apweiler, R. The SWISS-PROT protein sequence database and its supplement TrEMBL in 2000. Nucleic Acids Res. 28, 45–48 (2000).
Kanehisa, M., Sato, Y., Kawashima, M., Furumichi, M. & Tanabe, M. KEGG as a reference resource for gene and protein annotation. Nucleic Acids Res. 44, D457–462 (2016).
Finn, R. D. et al. InterPro in 2017-beyond protein family and domain annotations. Nucleic Acids Res. 45, D190–d199 (2017).
Ashburner, M. et al. Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat. Genet. 25, 25–29 (2000).
Finn, R. D. et al. Pfam: the protein families database. Nucleic Acids Res. 42, D222–230 (2014).
Mulder, N. & Apweiler, R. InterPro and InterProScan: tools for protein sequence classification and comparison. Methods Mol. Biol. 396, 59–70 (2007).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26801482 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26801483 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26801477 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26801478 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26945899 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26945900 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26945901 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26945902 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26945903 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26945904 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26945905 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26945906 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26801479 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26801480 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26801481 (2023).
NCBI GenBank https://identifiers.org/ncbi/insdc.gca:GCA_036320965.1 (2024).
Ren, X. Y. The chromosome-level genome of the long-tailed marine-living ornate spiny lobster, Panulirus ornatus. Figshare https://doi.org/10.6084/m9.figshare.24654915.v1 (2023).
Simão, F. A., Waterhouse, R. M., Ioannidis, P., Kriventseva, E. V. & Zdobnov, E. M. BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics 31, 3210–3212 (2015).
Parra, G., Bradnam, K. & Korf, I. CEGMA: a pipeline to accurately annotate core genes in eukaryotic genomes. Bioinformatics 23, 1061–1067 (2007).
Li, H. Fast and Accurate Short Read Alignment with Burrows-Wheeler Transform. Bioinformatics 25, 1754–1760 (2009).
Harris, R. S. Improved Pairwise Alignment of Genomic DNA. Ph.D. dissertation, The Pennsylvania State University, Pennsylvania (2017).
Acknowledgements
This work was supported by the project of the First National Survey of Aquaculture Germplasm Resources in the Yellow and Bohai Seas (17210247), the China Agriculture Research System (CARS-48), the Basic scientific research business expenses of Chinese Academy of Fishery Sciences of “Innovation team project of ecological aquaculture in seawater pond” (2020td46), and Central Public-interest Scientific Institution Basal Research Fund, CAFS (2023TD50).
Author information
Authors and Affiliations
Contributions
P. L. and J. L. conceived the the study and supervised the project. X.Y.R. collected the sample and wrote the manuscript. D.F.S. and J.J.L. performed the data analysis and data uploading. B.Q.G. and J.T.L. supervised this work and assisted in data analysis. S.T.J., X.Q.B. and K.C.Z. collected the samples. All authors contributed to the final manuscript editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ren, X., Sun, D., Lv, J. et al. Chromosome-level genome of the long-tailed marine-living ornate spiny lobster, Panulirus ornatus. Sci Data 11, 662 (2024). https://doi.org/10.1038/s41597-024-03512-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03512-9
- Springer Nature Limited