
Abstract
The Climate Hazards Center Coupled Model Intercomparison Project Phase 6 climate projection dataset (CHC-CMIP6) was developed to support the analysis of climate-related hazards, including extreme humid heat and drought conditions, over the recent past and in the near-future. Global daily high resolution (0.05°) grids of the Climate Hazards InfraRed Temperature with Stations temperature product, the Climate Hazards InfraRed Precipitation with Stations precipitation product, and ERA5-derived relative humidity form the basis of the 1983–2016 historical record, from which daily Vapor Pressure Deficits (VPD) and maximum Wet Bulb Globe Temperatures (WBGTmax) were derived. Large CMIP6 ensembles from the Shared Socioeconomic Pathway 2-4.5 and SSP 5-8.5 scenarios were then used to develop high resolution daily 2030 and 2050 ‘delta’ fields. These deltas were used to perturb the historical observations, thereby generating 0.05° 2030 and 2050 projections of daily precipitation, temperature, relative humidity, and derived VPD and WBGTmax. Finally, monthly counts of frequency of extremes for each variable were derived for each time period.
Similar content being viewed by others

Background & Summary
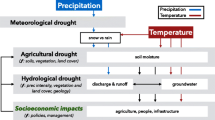
Across the world, people are increasingly exposed to hydrometeorological and temperature extremes—including droughts and heat waves—with significant negative impacts on lives and livelihoods1. Anthropogenic climate change has increased the frequency and intensity of such hazards, exposing more people, places, and seasons to increasingly co-occurring hazards2,3,4. For instance, low precipitation in semi-arid areas combined with hot temperatures are leading to or exacerbating drought conditions5,6 while high temperatures coupled with humidity are exposing new populations to heat stress7,8. The projected increase in anthropogenic forcing for mid-century will likely increase the frequency, intensity, and spatio-temporal extent of such hazards. Given both the current and projected exposure of people and places to climatic hazards, particularly those with the lowest access to resources to support adaptation, the ability to estimate these variables grows increasingly important to support science-based adaptation and early warning efforts. Therefore, there is a growing need for high spatio-temporal resolution data on both current and projected hydroclimatic variables and extremes.
Using raw, coarse spatial resolution climate data is insufficient to resolve the unique and highly variable landscapes across which hazards occur. Furthermore, systematic biases in precipitation or temperature means can translate into large errors when driving impact models or calculating hazard indices. Relatively nearby places may have different baseline climatologies9,10, so an absolute change in a climatic variable (e.g. 2° Celsius of warming) may lead to or exacerbate hazards in one place but not the other. For example, in water-limited growing regions, crop yields will be sensitive to the amount of available soil moisture, which is tightly linked to the amount of growing season precipitation, which can vary across the landscape (e.g.11,12,13). Moreover, many crops are sensitive to very warm air temperatures14,15,16,17. Therefore, a localized two degrees of warming in a hot, dry place or season may have a much greater agro-pastoral impact than two degrees of warming in a cool, moist location13,18. Similarly, the changing magnitude of heat waves that impact human health and well-being can vary drastically over short distances7. In terms of human health and labor productivity, two degrees of warming in a hot, humid place may dramatically increase hazards and resulting impacts19,20, yet not increase hazards in a cooler or drier place. These dependencies can create strong, fine-grained links between geography, climate, and hazards. As coarse resolution data may not be able to distinguish climatic gradients across a landscape relevant to many human-environment systems, they are thus unable to capture more fine-scale variability in local climatic conditions. Therefore, high spatial resolution data that accurately captures extremes are crucial for monitoring such potential hazards.
However, in many areas of the world, there is a lack of high spatial resolution data. There is a very limited number of in situ weather observations for many of the most populated and least resourced countries10, which makes it difficult to monitor hydro-climatic extremes and their impacts on agriculture and human health. For example, there are only about 200 Climatic Research Unit (CRU) temperature observations across all of Africa10, and only about 800 available monthly rainfall stations (Fig. S1). This can be contrasted with the United States, where there are about 5,000 rainfall observations every month (Fig. S1). To some degree, these gaps can be filled with satellite-derived meteorological data, though many satellite-based data suffer from coarse resolution and inaccurately capturing conditions on-the-ground.
Several high-resolution temperature and precipitation products have been developed to address such global gaps. For example, the Climate Hazards InfraRed Precipitation with Stations (CHIRPS) precipitation data product21, and more recently, the Climate Hazards InfraRed Temperature with Stations (CHIRTS-daily) temperature data product10,22, were created to provide high resolution gridded estimates with global coverage. These two products rely on satellite inputs for two key components: high resolution (0.05°) long-term monthly average ‘climatologies’9,10, and high resolution (0.05°) time-varying satellite-only precipitation and temperature estimates. By using satellite data to develop high-resolution climatologies, these products have been shown to perform well with relatively low bias in data sparse regions like Colombia, Afghanistan, Ethiopia, and the Sahel compared to other products which create climatologies based on elevation and location9. Moreover, CHIRPS and CHIRTS-daily also benefit from consistent, long, moderate-resolution geostationary Thermal InfraRed (TIR) satellite observations, which hover over the equator at fixed longitudes and have been providing data since the early 1980s. These TIR values are combined with the CHC climatologies to produce good satellite-only precipitation9 and temperature estimates10. Therefore, these estimates are particularly valuable in data-sparse regions.
However, despite significant advancements in providing high-resolution temperature and precipitation data, there is still a lack of such global, high-resolution observational data for two variables relevant to human heat stress and drought: maximum wet bulb globe temperatures (WBGTmax) and vapor pressure deficits (VPD), which are both related to temperature and RH. Warmer air can hold exponentially more water vapor23,24. Therefore, in places and seasons with ample available moisture, as temperature increases, evaporation will increase, maintaining or increasing RH23. This combination of high temperatures and humidity can lead to increased heat stress for people in hot, humid regions—measured here by WBGT. However, in water-limited environments, evaporation cannot keep pace, so a deficit will grow between the water holding capacity of the air and how much water vapor is actually held, producing greater evaporative demand—measured by VPD—and leading to or exacerbating drought.
WBGT is a widely-used heat stress metric25,26, which provides an estimate of ‘effective temperature’ for applications to human health in hot and humid areas27. WBGT measures what temperatures ‘feel like’ for a person exercising or doing work. As a function of wind speed, radiated heat, temperature, and humidity, it relates to how rapidly humans can cool their bodies through evaporation via sweat27. As a measure of heat stress, WBGT at the hottest time of the day—WBGTmax—is particularly relevant. The advantage of using WBGTmax, as opposed to meteorological indicators like Tmax, is that the former accounts for important nonlinear biophysical responses28. For humans, heat illness (hyperthermia) occurs when core body temperatures exceed 42 °C29. Improved sweating responses can help to lower core body temperatures yet are limited by high relative values29,30. Hot, humid air temperatures can limit the effectiveness of sweating to cool the body—30 °C WBGTmax has been associated with doubling in mortality rates compared to WBGTmax of 20 °C among vulnerable populations working outside31.
Conversely, in water-limited areas, decreasing RH—and therefore increasing VPD—can exacerbate drought conditions. VPD can directly exacerbate hydrologic drought by evaporating surface water bodies and decreasing soil moisture32. Moreover, it can limit plant productivity via two primary pathways: through the indirect effect of reducing soil moisture via increased evaporation, and through the direct effect of affecting stomatal conductance, or the rate of exchange of water vapor and carbon dioxide at the leaf-level13. Plants can sense environmental conditions and adjust their growth rate accordingly13,18. When soil moisture falls below critical thresholds, the plant will close stomata14,33. Moreover, if the plant senses increased VPD at the leaf-level, it will partially close stomata to conserve water. While these mechanisms allow plants to survive during dry times, it is at the expense of photosynthesis34, and can lead to lowered plant productivity, including for pasture and crops13,16,17,18.
The lack of available high-resolution data also exists for climate projections. There have been significant advancements in the accuracy and precision of climate models over the past two decades—climate models have reproduced observed temperatures for the past four decades35; newer versions of climate models are more accurate and precise than their predecessors36; and the scenarios underlying the projections are based on more refined models of human activity37. Yet, even with these advancements, relying on raw climate model output, alone, is insufficient for resolving highly-local hazards. Many climate models, such as those used by the Coupled Model Intercomparison Project (CMIP), have relatively coarse spatial resolution (typically ~100 km, see Table 1) and still contain biases38. Moreover, many models do not sufficiently account for internal climate variability which can lead to the under-identification of climate risk for certain sectors and places39.
In response to the challenges presented by limited available data on climatic hazards in data-sparse regions, the Climate Hazards Center Coupled Model Intercomparison Project Phase 6 climate projection dataset (CHC-CMIP6) was created to provide high-resolution observation and scenario-based projection hydro-climatic data that can be used to support the identification, monitoring, and analysis of current and future potential hazards in data sparse regions. The dataset retains the high spatial resolution and precision of the CHC temperature and precipitation products while projecting changes in hydro-climatic variables using climate model output. The CHC-CMIP6 dataset offers high-resolution (0.05°), global daily hydro-climatic data—minimum temperature (Tmin), maximum temperature (Tmax), precipitation, relative humidity (RH), VPD, and WBGTmax—for the current/observed period (1983–2016) and near-future scenarios (2030 and 2050). It also provides counts of Tmax, Tmin, precipitation, VPD, and WBGTmax ‘extremes’ (Section 2.4) for each of the scenarios.
The CHC-CMIP6 dataset builds on high-resolution temperature and precipitation products developed by the University of California, Santa Barbara Climate Hazards Center; RH data derived from ERA5; and large ensembles of coarse resolution CMIP6 simulations of temperature, precipitation, and RH40. As depicted in Fig. 1, these data were used to create high-resolution projections using the following process: The CMIP6 multi-model ensemble simulations (Fig. 1a) were used to calculate 2030 and 2050 ‘deltas’—or mean changes between the observational and projection periods—for temperature, precipitation, and RH (Fig. 1b). Next, these ‘delta’ files were combined with the high-resolution observations (Fig. 1c) to produce high-resolution 2030 and 2050 projections of temperature, precipitation, and RH for the two CMIP6 scenarios (SSP2–4.5 and SSP5–8.6) (Fig. 1d). WBGTmax and VPD were then derived for the observational (1983–2016) period using the observed temperature and RH fields, and for the projections using the projected temperature and RH fields. Finally, data layers depicting counts of extremes were calculated for the observational period and the four projections.

Process schema for the development of the CHC-CMIP6 0.05° datasets. Large ensembles of CMIP6 precipitation, Tmax, Tmin, and RH simulations (a) were used to calculate monthly “delta” (change) estimates for 2030 and 2050, which are reprojected in space and time to produce global 0.1° daily delta files (b). The daily deltas were then combined with observed precipitation, Tmax, Tmin and RH (c) to produce high resolution (0.05°), time-varying data sets incorporating the CMIP6 changes between 1983–2016 and 2025–2035 and 2045–2055 (d).
Methods
Underlying data products
The CHC precipitation (CHIRPS) and temperature (CHIRTS) products
The CHC-CMIP6 dataset is partially based on the Climate Hazards Center (CHC) precipitation and temperature products: the Climate Hazards InfraRed Precipitation with Stations (CHIRPS) product21 and the Climate Hazards InfraRed Temperature with Stations (CHIRTS) product10,22. The CHC has developed a three-step process that leverages the power of satellite meteorological observations and information from in-situ weather stations to create the high-resolution CHIRPS and CHIRTS products. The use of satellite observations allows for creating high resolution data which captures valuable information about local changes in meteorological variables, especially in data sparse regions of the global south, which is where many of the impacts of climate change are likely to be, and have been, felt most keenly. For example, in Ethiopia, where mean precipitation changes dramatically over short spatial distances, the local variations in climate conditions are well-captured by CHIRPS and its underlying climatology9.
The first step in this process involves the development of high resolution (0.05°) precipitation and temperature climatologies9. The Climate Hazards Center precipitation climatology (CHPclim) was derived by combining satellite-based rainfall estimates with station data and elevation. The CHIRTS climatology product (CHTclim) is similarly based on cloud-screened satellite observations of thermal infrared brightness temperatures, which also provides detailed information related to meteorological conditions on the ground, even in areas with sparse observation networks10,22. As spatial variogram analysis has shown10, the density of monthly air temperature observations in many parts of the world are far from sufficient to support the mapping of monthly air temperature anomalies. Geostationary satellites, however, provide long, rapidly repeated thermal infrared observations of the Earth’s surface at fairly high spatial resolutions. Hence, the next step involves combining gridded 0.05° geostationary thermal infrared data (TIR) with the 0.05° climatologies to produce satellite-only CHIRT and CHIRP. Ultimately, CHIRP relies on the satellites’ ability to see cold cloud tops, while CHIRT relies on direct observations of the non-cloudy land surface. Both types of observations take advantage of the fact that cloud tops tend to be much colder than surface temperatures. The final step involves the addition of station observations, resulting in the CHIRPS and CHIRTS. The development process underlying these products, however, is different. It is relatively easy to obtain reliable and rapidly updated satellite-observations of cloud top temperatures, supporting rapid updates of the CHIRPS. Obtaining reliable estimates of surface temperatures is more difficult and requires inter-satellite calibration. The temperatures of cold cloud tops, used to calculate CHIRPS, are very cold, and a small bias between satellites, or a small change in bias due to sensor or orbit degradation, produces only minor changes in precipitation estimates. Surface temperatures, on the other hand, have variations that can be strongly influenced by relatively small biases. The correction of these biases requires careful satellite-specific inter-calibrations10.
CHIRPS and CHIRTS have different temporal coverages and should be analyzed at different temporal resolutions. While CHIRPS is updated to near-present, the daily CHIRTS product currently ends in 2016, with near-term plans to update both CHIRTS-daily and the CHC-CMIP6 dataset through near-present. Moreover, CHIRTS supports the analysis of daily or monthly temperature. However, CHIRPS should be analyzed at the monthly timescale as this is the accumulation period for which the product is supported by in situ rain gauge observations9,41. These considerations carry over into the CHC-CMIP6 dataset.
ERA5-derived relative humidity
The CHC-CMIP6 dataset also includes RH derived using hourly air temperature (Ta) and dewpoint temperature (Td) from the ERA5 reanalysis42 and daily minimum and maximum CHIRTS (CHIRTS-dailyTmin, CHIRTS-dailyTmax). RH was calculated as the ratio of actual vapor pressure (AVP)—a function of the actual water content of the air—to saturation vapor pressure (SVP)—or the water holding capacity of the air at a certain temperature43, in equations1,2,3. SVP is an exponential function of air temperature, while AVP is an exponential function of dewpoint temperature. This dewpoint temperature-based approach to calculating RH was selected due to its straightforward computational method and to allow direct comparisons in situ station observations for the validation of the dataset, as described in Section 3.2.
Two values of RH were calculated: RH at the hottest hour of the day (RHx) for calculating WBGTmax and daily average RH (RHave) for calculating VPD. To derive both RH values, first, the hourly ERA5 fields were resampled to 0.05 degrees using bilinear interpolation to the same resolution as the CHIRTS products. For RHx, ERA5 Td was selected for each day at the hour of maximum ERA5 Ta (TdTmax). RHx was then calculated using TdTmax and CHIRTSTmax. For RHave, the daily mean ERA5 Td was calculated and used with the average of CHIRTSTmin and CHIRTSTmax. For both calculations, for cases where Td was greater than the corresponding temperature field (CHIRTSTmax or CHIRTSTave) (RH > 100%), Td was set to equal that temperature field (RH = 100%). Notably, we calculate mean daily SVP and AVP from mean daily Ta and Td, respectively, instead of hourly SVP and AVP as a function of hourly Ta and Td, in order to make use of our CHIRTS product. As AVP and SVP are nonlinear equations, using daily means presents a potential source of error, though the error is ~ +/− 1 percentage point.
Note that while minimum RH will often occur at the hour of maximum temperatures, this is not always the case. In the ERA5 data, there are numerous instances in which the hour of maximum Ta is different from the hour of minimum Td, or the difference between Ta and Td varies drastically throughout the day. For these locations, RHave may thus be lower than RHx. Moreover, the computed daily RHx fields have visible artifacts. These arise due to the fact that the hour of RHx may differ significantly from pixel to pixel. For the purposes of calculating WBGTmax, these values of RHx are acceptable. Nonetheless, we detail possible uncertainty in WBGTmax that may arise from errors in our RHx estimation (Supplementary Text S2, Figs. S2, S3).
The coupled model intercomparison project phase 6 (CMIP6) model output
As the magnitude of future increases in radiative forcing is dependent on both the current and future rate of emissions, and is therefore not fixed, we use two scenarios from CMIP6—Shared Socioeconomic Pathway (SSP) 2–4.5 and 5–8.537. The SSP245 scenario is based on ‘middle-of-the-road’ projections of development (SSP2), resulting in 4.5 W m−2 of radiative forcing by 2100. The SSP585 scenario projects rapid fossil fuel development and increased global market integration (SSP5), which is expected to result in 8.5 W m−2 of radiative forcing by 2100. These are generally considered the most-likely scenario (SSP245) and the high-emissions scenario (SSP585)44,45.
CMIP6 multi-model ensemble simulations were accessed from Lawrence Livermore National Laboratory (LLNL) node of the Earth System Grid Federation (ESGF) platform (https://esgf-node.llnl.gov/search/cmip6/). Monthly average near-surface relative humidity (hurs), near-surface minimum and maximum temperature (tasmin, tasmax), and precipitation (pr) were retrieved for 25 models across three experiments—historical (1850–2014), and SSP245 and SSP585 (2015–2100). The average equilibrium climate sensitivity (ECS) of the 25 models used in this study (~3.86) falls within the most likely range of ECS (2.2–4.9 °C, 90% chance)46. Within each model, the same ensemble members were selected for the historical and future scenario experiments. In total, 152 simulations across 25 models were retrieved for the historical and SSP245 experiments, while 167 were retrieved across the same 25 models for the historical and SSP585 (Table 1).
Next, spatio-temporal cubes (1850–2050) were created for each variable (hurs, tasmax, tasmin, pr) and experiment (SSP245 and SSP585) (Fig. 1a). Historical and projection data were stacked using the netCDF Record Concatenator utility (ncrcat). The cubes were then resampled to 100 km resolution using bilinear interpolation with the Climate Data Operator (CDO) software remapbil utility. To avoid over-weighting any individual model, for each variable and scenario, the mean was taken for each model across all simulations to derive the model mean, and then the multi-model mean was taken to derive the ensemble mean47. As such, four projection scenarios were created—2030_SSP245, 2030_SSP585, 2050_SSP245, and 2050_SSP585.
Deriving projections
Projected data were created by perturbing the CHC observational data with ‘delta’ (i.e. change) fields derived from the CMIP6 simulations. This approach therefore retains the precision and variability present in the observational data. It moreover limits the effect of any biases in the CMIP6 temperature fields by focusing on simulation- and model-specific changes rather than raw values: the projected warming trend in CMIP6 models has been found to be correlated with modeled observed warming trends38, meaning any potential bias in CMIP6 would stay relatively constant over time.
Delta fields
Daily ‘deltas’ for Tmin, Tmax, RHave, and precipitation were derived for each grid cell, representing the change in each variable between the observational and projection periods for the four CMIP6 scenarios (2030_SSP245, 2030_SSP585, 2050_SSP245, 2050_SSP585) (Fig. 1b). First, monthly ‘deltas’ were calculated from the CMIP6 spatio-temporal cubes as the difference between the monthly means of the observational period (1983–2016) and the monthly means of the projection periods (2025–2035, 2045–2055). The Tmax, Tmin, and RHave deltas were calculated as monthly arithmetic differences (Eq. 4), while the precipitation deltas were calculated as ratios (Eq. 5). Ratios were used for precipitation because this field is heteroscedastic and bounded at zero (i.e. precipitation cannot be negative).
Precipitation is in units of millimeters per month, and ε is set to 7 millimeters, a value found reasonable based on the production of the CHIRPS dataset.
For each pixel, variable, and climate change scenario (∆2030_SSP245, ∆2030_SSP585, ∆2050_SSP245, ∆2050_SSP585), the monthly deltas produced from Eqs. 4 and 5 were temporally downscaled to daily delta values using the following process. For a 14-month period—including the preceding and following month of the year (Decyear-1 … Janyear+1)—the monthly delta value was first assigned to each of the daily values for that month. This 14-month-long daily time series was iteratively smoothed 10 times with a seven element moving average (boxcar) filter to obtain a smooth seasonal progression. Then, the first and last month were discarded, resulting in 365 daily delta values for each location, variable and scenario. These daily data were then further adjusted so that the daily data mean (temperature and RH) or sum (precipitation) across each month equals the original monthly value, thus resulting in a time series which realistically represents the observed data. These daily deltas were rescaled from 100 km to a global 0.1° resolution. This procedure was selected because it provides a non-parametric means of generating a linear, smoothly varying de-convolution of the original 12 monthly delta values.
Creating the projections
The daily observational Tmin, Tmax, RHx, RHave, and precipitation data were perturbed using the corresponding daily delta fields to create the projected data. A single, stationary delta value was used for each day, location, and variable. For example, the same January 1st Tmax delta was applied to the 1983 January 1st Tmax as the 2016 January 1st Tmax value. Therefore, these datasets correspond to the same period of record as the original observations. For air temperature and RH, the delta fields were added to the observational fields, resulting in 34 years of daily projections for 2030 (2030_SSP245, 2030_SSP585) and 2050 (2050_SSP245, 2050_SSP585). Note that the RHave deltas were used to perturb both the observational RHx and RHave fields. For precipitation, as the deltas were calculated as ratios, the observational fields were multiplied by these deltas. Moreover, for precipitation, only monthly data are provided and analyzed. Because it relies on an indirect proxy for precipitation (TIR), which cannot sense hydrometeors (unlike microwave satellites), CHIRPS is not well-suited to the analysis of sub-monthly precipitation extremes (41; see section 2.1.1).
No attempt was made to detrend the underlying observational datasets. The benefit of the chosen approach is transparency: we can explicitly map and understand the delta fields, and their implications for changes in the distribution of the daily temperature or monthly precipitation values.
Deriving VPD and WBGT observations & projections
Both WBGTmax and VPD were calculated for the observational and projection scenarios using the temperature and relative humidity fields from the respective scenarios. We calculated WBGTmax because we are interested in peak heat stress values that typically occur in the afternoon when air temperatures and relative humidity typically reach their warmest and lowest values, respectively. WBGTmax therefore is constructed with daily Tmax and RHx48. Following previous work7, we first calculated Heat Index (HImax) values with Tmax and RHx according to National Ocean and Atmospheric Administration’s (NOAA) guidelines49. Equations for HImax may be found in the NOAA49 reference and in the accompanying code for this manuscript. The HImax values were used to estimate WBGTmax50. The full WBGT estimation process includes radiant heat and wind speeds25, but indoor or shaded WBGT (°C) with fixed air speeds (0.5 m s−1) can be estimated closely by a quadratic transform of daily HImax (°F) values (50; Eq. 6).
While our objective was to produce WBGTmax, we also provide the HImax observational record and HImax projections in the CHC-CMIP6 dataset. The observed (1983–2016) WBGTmax and HImax fields were calculated using the above equation and the observed Tmin, Tmax, and RHx fields, while the projected WBGTmax and HImax fields were derived from the four scenarios of Tmin, Tmax, and RHx. We note that the WBGTmax observations differ from previous work7 because we updated the parameterization of RHx used here (Section 2.1.2; Supplementary Text S1). Furthermore, as noted above, we overview the range of possible uncertainty in HImax and WBGTmax that may arise from errors in our RHx estimation for extreme hot-dry and hot-humid conditions relevant to heat impacts to human health and well-being (Figs. S2, S3).
We are interested in average daily VPD, however, as it is the prolonged effect of high VPD throughout the day which can lead to depleted soil moisture, stomatal closure, and overall reduced productivity or increased plant stress. VPD therefore was calculated using daily Tave and RHave. VPD is the arithmetic difference between SVP and AVP43,51 (Eq. 7). To derive VPD, first SVPave was calculated by taking the mean of SVPmin and SVPmax (which were derived using Eq. 1), while AVPave was derived from RHave and SVPave (Eq. 8). The observed VPD fields were calculated using observed Tmin, Tmax, and RHave, while the projected VPD fields used the projected Tmin, Tmax, and (RHave).
Deriving extreme counts
Counts of the number of extreme days per month were calculated for Tmin, Tmax, WBGTmax, and VPD for the observations and four scenarios (2030_SSP245, 2030_SSP585, 2050_SSP245, and 2050_SSP585). For these fields, extreme counts are based on daily data, processed on a monthly basis. Validations of daily Tmin and Tmax have documented strong performance22, and as shown later in Sect. 3.2, we identified similar strong performance for VPD and WBGTmax. For these variables, data are available by month, depicting the number of days for each month experiencing an ‘extreme’.
Precipitation extreme counts are calculated on a monthly basis for two reasons: (1) defined extreme thresholds exist on a monthly, not daily, timescale (see below), and (2) confidence in the CHIRPS product is much higher at the monthly scale than the daily scale, as daily CHIRPS has been shown to underestimate precipitation extremes41. For precipitation, the data layers depict whether the total monthly value for that pixel is classified as an extreme. The focus on monthly extremes aligns with the design focus of the CHIRPS product—seasonal crop and rangeland drought stress.
Definitions of extremes for each variable were based on two methods: based on known thresholds (Sect. 2.4.1) and by calculating pixel-specific breakpoints using the 95th and 99th percentile (Sect. 2.4.2).
Calculating threshold-based extremes
A series of fixed thresholds for each variable were identified for temperature, precipitation, WBGTmax. and VPD. Two thresholds were used for Tmin and Tmax: 30 °C and 40.6 °C, respectively, representing moderate and extreme heat exposure. These were chosen based on documented thresholds for agricultural and human heat stress. 30 °C has been used to identify agricultural heat stress as inhibition of photosynthetic activity generally begins at or above 30 °C52. In health research, heat stroke is defined by when human core body temperature reaches or exceeds 40.6 °C53. This threshold has been used in studies identifying extreme heat events due to its relationship to human physiology54. For precipitation, the threshold of 100 mm per month was utilized. This threshold was selected based on typical monthly crop water requirements used in crop models55.
Two thresholds were used for WBGTmax: 28 °C and 30 °C7. A WBGTmax value of 28 °C is defined by the International Standards Organization as the threshold for risk of heat-related illness for acclimated persons at moderate metabolic rates, while 30 °C is the same threshold for a group of persons at low metabolic rates56. Finally, we defined three thresholds for VPD: 2 kPa, 3 kPa, and 4 kPa. Studies have found that stomatal closure begins when VPD increases above 2 kPa16,57,58, and gross primary productivity exhibits a decline for sites and times when VPD exceeds 2 kPa58. When VPD surpasses 3 kPa, evaporative demand can be too high for certain plant types to offset via mitigation strategies59. Furthermore, few sites experience VPD greater than 4 kPa.
For the temperature-related variables (Tmin, Tmax, VPD, and WBGTmax), for each variable, year, and scenario, the number of days surpassing each variables’ thresholds were calculated. For precipitation, the number of months below the fixed threshold were calculated. In other words, the precipitation extremes data will be coded as either ‘1’ (extreme) or ‘0’ (not extreme), which may be analyzed over time by adding these extremes over seasons, years, or other time steps. For the observations and the four CMIP6 scenarios, extreme counts and means are provided for each month, for each year. For the convenience of the users, annual and 1983–2016 count totals are also provided.
Calculating percentile-based extremes
Extremes were also calculated using percentiles. Monthly percentiles were calculated for each pixel based on the observational data, using a 1981–2010 baseline period. For Tmin, Tmax, VPD, and WBGTmax for each pixel, the daily 95th and 99th percentiles were calculated using 1983–2016 daily data, resulting in a 95th and 99th percentile value for each variable. For each of these four variables, each year (1983–2016), and each of the five scenarios, the number of days for each month were calculated at each pixel that surpass these percentile-defined extreme values. Users should be aware that the number of observations used to describe the warmest 1% of the datasets is small (10 or 11 observations), hence the uncertainty associated with precise 99th percentile breakpoints is substantial60. However, as described in the usage notes, despite this uncertainty the data can still provide valuable information about the spatial and temporal evolution of risk. For precipitation, both low and high percentile-based extremes were calculated: the corresponding values for monthly precipitation falling lower than the 20th percentile and higher than the 90th percentile were calculated for each month. Caution should be taken to only utilize counts of low precipitation extremes for wet places and seasons, and to not over-analyze percentile-based precipitation extremes in dry seasons or months: in a dry month or season, an extreme percentile value may be associated with a very small anomaly, in terms of an absolute value in mm.
Data Records
The CHC-CMIP6 dataset is available for free use via ftp at https://doi.org/10.21424/R47H0M61. The dataset is under a Creative Commons Attribution 4.0 International (CC BY 4.0) license.
The data is available as GeoTIFF files. Each file is 25MB, and contains data for a single month, variable, and scenario at 0.05° resolution. The naming convention on files is SCENARIO.VAR.YYYY.MM.DD.tif (e.g. the file “2030_SSP245.RH.1983.01.01.tif” is the RHave data for Jan 1 1983 for the 2030 SSP 245 scenario). The data files are organized first by scenario (observations, the four projection scenarios, and extremes), then by variable, and finally by year. Further description of each of the files is included in the accompanying README file. To facilitate analysis, annual and long-term-average subdirectories in the Tmin, Tmax, VPD, and WBGTmax folders also contain annual and long-term average (34 year) counts for each of the extreme categories and the monthly mean fields.
Technical Validation
To validate the CHC-CMIP6 data layers, we examined accuracy in two stages. First, we tested for accuracy in the observational CHC data layers—this is not only important for the observational data, but also for the projections as the projection data layers are based on perturbations of the observational data. This included an evaluation of bias as well as temporal fidelity (correlation) and Mean Absolute Errors (MAE). Second, we compared the CHC-CMIIP6 biases with the raw CMIP6 data. When and where the CHC-CMIP6 fields reduce bias, they may give more reliable projections than the CMIP6 fields.
This validation focuses on daily Tmin, Tmax, RH, and the derived VPD and WBGTmax. While some evaluation of the daily Tmax values has been previously provided7,22, we examine here for the first time RH and the derived variables at daily time steps. This focus on temperature-related variables was selected because we expect the improved analyses of variables to be the key feature of this CHC-CMIP6 dataset. Evaluation of the monthly observational precipitation data (CHIRPS) can be found in other manuscripts9,21.
Validation data
Validation of the observational data layers was based on using station observations from the Global Summary of the Day (GSOD) provided by NOAA’s Climate Prediction Center. Daily minimum and maximum temperatures (Tmin, Tmax) and dewpoint temperature (Td) were retrieved from GSOD for 1983–2016, for a total of 15,908 stations (Tmin = 15,907, Tmax = 15,908, Td = 9,582). A station screening process was applied to GSOD data, following previous work22.
-
1.
All stations with fewer than 2,920 observations (8 years of data) were discarded, to ensure long enough temporal coverage in the GSOD validation data.
-
2.
All stations that had a high rate of reporting of exactly 0 were discarded. Stations may record 0 if there is no data. To minimize the likelihood of false zero contamination in the validation data, if stations reported exactly 0 more than 15% of the time, or the average across all months or years was exactly 0, the station was discarded.
-
3.
The Tmax GSOD data were compared to Climate Hazards Center Tmax climatology (CHTclim). All GSOD stations were discarded for which the corresponding CHTclim value was NA. Furthermore, as there can be issues within the GSOD dataset–with spatial location being one very common issue, especially in areas with complex topography–GSOD station data were screened for instances where the GSOD and CHTclim Tmax were substantially different, defined by satisfying either of the below conditions (which removed 684 stations):
-
a.
abs(m - CHTclim) > 5 °C (m = station median)
-
b.
abs(m - CHTclim)/s > 3 (m = station median; s = station standard deviation)
-
a.
-
4.
Finally, as Td should not fall above air temperature, all values of Td greater than Tave were set to the value of Tave.
This screening process resulted in a remaining 9,755 Tmin, 8,529 Tmax, and 7,498 Td stations. Of the GSOD stations remaining after the screening process, only the sub-set of stations that were retained across Tmin, Tmax, and Td were used in the validation, a total of 6,649 stations.
For the 6,649 GSOD stations, the GSOD Tmin, Tmax, and Td observations were subset to the local hottest 3-month period, defined using CHTclim. Finally, these resulting observations for the three variables were screened, by removing daily observations which deviated dramatically from the climatological average of the GSOD data. To do so, z-scores were calculated for each observation, and observations were retained only if they satisfied the following conditions:
-
(a)
-4 < z < 4.5
-
(b)
x - m < 20 °C (m = station monthly median; x = station observation)
Technical validation of observational fields in CHC-CMIP6 dataset
To validate the CHC-CMIP6 observational fields, the data were compared with GSOD station data and the raw CMIP6 fields for the local hottest 3-month period for 1983–2016. The CHC-CMIP6 fields for all five variables (Tmin, Tmax, RHave, VPD, and WBGTmax), and raw CMIP6 Tmin, Tmax, and RHave fields, were extracted for the location of each GSOD validation station using bilinear interpolation of the four nearest pixels. Note, the observational CHC-CMIP6 temperature fields are from the CHIRTS products, so the validation statistics for those fields are recalculated here, yet align with earlier validation efforts22.
We first tested the observational data for accuracy by comparing the daily observational CHC-CMIP6 fields and those from GSOD station data. Corresponding variables were derived where necessary. GSOD RHave was derived from GSOD Tmin, Tmax, and Td. VPD and WBGT were calculated for both GSOD and CHC-CMIP6 using the corresponding Tmin, Tmax, and RHave fields. Note, average WBGT, instead of WBGTmax, was derived as only average dewpoint temperature was available from GSOD. The data were then converted to monthly anomalies by subtracting the mean monthly climatological value from each corresponding daily value. For the location of each GSOD station, Spearman’s correlation coefficients and associated p-values, and mean absolute error (MAE) were calculated for the five variables between the two datasets.
Table 2 and Fig. 2 present the validation statistics, broken up by continent and shown as a global average. The CHC-CMIP6 observational data perform well for each of the five variables globally as well as regionally. In particular, Tmax and WBGT have a particularly high correlation with GSOD (0.86 globally). The underlying CHIRTSmin is slightly warmer than GSOD Tmin while the CHC-CMIP6 observational RHave is slightly lower than GSOD RHave (Table 3), which in turn influences VPD, yet there is still high agreement for the three variables, with global average correlations at 0.73–0.76.

Map of correlation between CHC-CMIP6 and GSOD for each variable. Each point depicts the correlation coefficient between CHC-CMIP6 observational fields and GSOD at the location of each GSOD station.
Estimating effect of biases on undercounting of extremes
We then tested for potential biases by comparing GSOD with the raw CMIP6 data and CHC-CMIP6 observational data for the 1983–2016 period. First, the multi-model CMIP6 Tmin, Tmax, and RHave means were calculated from 1983–2016. Then monthly averages were calculated for GSOD and CHC-CMIP6 to compare with the monthly raw CMIP6 data. Next, the differences between GSOD and the two datasets were taken for the three warmest months for each station. The mean biases are reported in Table 3 and shown spatially in Figure 3. To test for statistical significance in difference in biases, a Mann-Whitney test was run comparing the distribution of raw CMIP6 biases and CHC-CMIP6 biases. For cases when the mean bias is smaller for CHC-CMIP6 than for raw-CMIP6, if the Mann-Whitney test p-value is significant, it shows us that the bias in CHC-CMIP6 is statistically significantly lower than the bias in raw CMIP6.

Map of difference between CHC-CMIP6 and GSOD for each variable. Each point depicts the mean difference between CHC-CMIP6 observational fields and GSOD (CHC-CMIP6 minus GSOD) at the location of each GSOD station.
The CHC-CMIP6 biases and raw CMIP6 biases shown in Table 3 are statistically significantly different from each other (Mann-Whitney p-value < 0.05). While GSOD and CHC-CMIP6 Tmax largely agree, the raw CMIP6 multi-model ensemble average Tmax is ~1.5 °C cooler than both GSOD and CHC-CMIP6 Tmax. Importantly, as the CHC-CMIP6 projection fields are based on perturbing observational data with CMIP6-derived deltas, this cool bias should be absent from the CHC-CMIP6 projections. For Tmin, the CHC-CMIP6 estimates are about 2 °C warmer than GSOD. This bias may relate to issues with the ERA5 diurnal cycle, which were used to derive the CHC-CMIP6 Tmin (i.e. CHIRTSmin) values. The CMIP6 Tmin values are a little warmer. Hence the raw CMIP6 multi-model ensemble mean is between the GSOD and CHC-CMIP6 mean. However, as the CHC-CMIP6 dataset has been designed to support analysis of temperature-related extremes, the Tmax values are of greater importance. Finally, the CHC-CMIP6 RHave is slightly lower than GSOD (~4 percentage points). To determine how large the bias is relative to other RH products used for similar analyses, RHave climatological fields were retrieved from the gridded, high-resolution observational global climate product, WorldClim62. On average, the WorldClim RHave climatology is ~8 percentage points higher than GSOD. As such, while a bias is present in the CHC-CMIP6 RHave fields, the fields nonetheless present an improvement compared to other similar products. Note however that the bias will contribute to an undercounting of WBGTmax extremes at high temperatures.
Notably, the CMIP6 Tmax cool bias can lead to a substantial undercounting of VPD and WBGTmax extremes. To determine what type of effect such a cool bias might have on Tmax-related projections (i.e. the magnitude of undercounting of extremes by relying solely on CMIP6 data), we perturbed the projected CHC-CMIP6 Tmax data by subtracting biases of 0 °C, 1.5 °C, and 3 °C. These perturbed estimates, alongside unperturbed estimates, of Tmax were used to calculate the number of pixels globally experiencing extreme WBGTmax and VPD in the 2030_SSP245 and 2050_SSP585 projections, shown in Table 4. The values depicted are for the local hottest day in the first year.
For the 2050_SSP585 projections, ~14% of the pixels in the CHC-CMIP6 data are over 30 °C WBGTmax. However, subtracting 1.5 °C from the Tmax fields used to calculate WBGTmax results in only ~5% of the pixels for that same year reaching over 30 °C WBGTmax. This indicates that a 1.5 °C cool bias in the CMIP6 data leads to a considerable (300%) underestimate of WBGTmax extremes. Similarly, the percent of pixels experiencing VPD over 4 kPa decreases from 20% to 17%. While less substantial an increase, the 1.5 °C cool bias also leads to an undercounting of VPD extremes. These VPD biases will have a distinct spatial pattern, preferentially influencing warmer areas due to the exponential relationship between SVP and temperature (VPD). In sum, these results indicate that the CHC-CMIP6 dataset is able to capture projected extremes that would be otherwise missed by relying solely on raw CMIP6 data. Hence, cool bias matters, and has an especially pronounced impact on very extreme WBGT counts, where a 1.5 °C cool bias can dramatically reduce the estimated impact of climate change.
Usage Notes
When using the CHC-CMIP6 data, please note the following. The CHC-CMIP6 data are available in GeoTiff format, in WGS 1984 projection. Units are degrees Celsius (Tmin, Tmax, WBGTmax), kPa (VPD), percent (RHx, RHave), and mm (precipitation), and all NA values are set to −9999. Finally, please note that, other than the global ocean mask, a water mask was not applied, so users are encouraged to mask out water bodies when using the data.
This is the first iteration of the CHC-CMIP6 dataset. Currently, the observational data are available from 1983–2016. Future versions will include temporally updated data (beyond the current end year in 2016). Furthermore, future versions may include efforts to create a satellite-enhanced RH climatology in an effort to improve the accuracy of the RH fields.
Furthermore, the data descriptor available with the dataset was peer reviewed in 2023 based on the data available on the platform at the time. This data descriptor will be periodically updated for future iterations of the dataset.
Example Application of Data 1 - Projected Changes in Climatologies and Extremes
Here, we present an example application of the CHC-CMIP6 dataset, examining projected changes in Tmax, RH, VPD, and WBGTmax and their associated extremes for some of the highest risk areas for drought and heat stress–the Sahel, southern Africa, and southern Asia.
Figure 4 depicts the deltas, or mean changes, in Tmax, RHave, VPD, and WBGTmax, between the observational and 2050_SSP245 scenario (the ‘most likely’ scenario) for the local hottest month for western Africa (April), southern Africa (October), and southern Asia (May). Each region is projected to experience increases in Tmax. Projected changes in RHave are more varied: much of South Asia and areas of the Sahel are projected to experience increases in RHave while southern Africa is projected to experience decreases. The increases in Tmax, coupled with change in RHave, contribute to increases in both VPD and WBGTmax. However, as expected, the largest projected increases in VPD occur in different locations from the largest projected increases in WBGTmax.

Mean change in Tmax, RH, VPD, and WBGTmax from observational period to 2050 SSP245. Deltas are shown for the Sahel in April, southern Africa in October, and southern Asia in May. Months were chosen as the local hottest month and/or shortly before the arrival of the monsoon.
The largest increases in VPD are seen in the Sahara, inland areas of southern Africa, and in Pakistan and Iran. These areas are projected to experience large increases in Tmax, accompanied by a decrease or no change in RHave (except for Pakistan), indicating that increases in Tmax coupled with reductions in RHave are driving the change for these locations. These areas have some of the lowest current baseline RHave climatologies (Fig. 5), suggesting that areas that are already hot and dry can be expected to experience greater increases in VPD, largely due to the exponential relationship between temperature and saturation vapor pressure.

Climatological average Tmax, RH, VPD, and WBGTmax for the observational period. Climatological average conditions are shown for the Sahel in April, southern Africa in October, and southern Asia in May.
Conversely, the largest increases in WBGTmax are seen along the coastal areas south of the Sahel, southeastern South Africa and Lesotho, and southwestern India. Southeastern South Africa and coastal western Africa are projected to experience an increase in Tmax coupled by a decrease in RHave. Climatological RHave values are already high for these places, so despite a projected decrease in RHave, the increase in Tmax drives an overall increase in WBGTmax. This indicates that due to the non-linear relationship between temperature, relative humidity, and WBGTmax, these already hot-humid areas are projected to experience some of the greatest increases in WBGTmax. For India, both Tmax and RHave are projected to increase, together driving the projected increase in WBGTmax. Note that while much of India experiences a large increase in Tmax and an increase in RHave, the WBGTmax increase is somewhat muted—this may be because our estimation of WBGTmax becomes asymptotic at very high levels of WBGTmax (see Fig. 4 in7 and Fig. 1 in50). Also note that though our parameterization of WBGTmax differs, previous work7 found some locations in southern and southeastern Asia are saturating, whereby the vast majority of days in 2016 exceed WBGTmax of 30 °C and thus these areas cannot face an annual increase going forward.
The projected increase in the number of extreme events for VPD (3 kPa threshold) and WBGTmax (30 °C threshold) from the observational period to 2050_SSP245 for the local hottest month are shown in Fig. 6. Regions that already experience extremes for every day in the observational climatology are grayed out. The patterns largely correspond to the patterns shown in Figs. 4, 5—the hot-humid areas (the Sahel, India) are projected to experience a substantial increase in frequency of WBGTmax extreme days. Conversely, the hot-dry areas of inland southern Africa are projected to experience a large increase in the number of days with high VPD levels.

Change in the number of ‘extreme’ days between the first year (1983) of the observational and 2050 SSP245 scenarios. The extremes are defined as surpassing the 3 kPa threshold for VPD and the 30 °C threshold for WBGTmax. The increase in the number of extreme days is depicted for the local hottest month for the Sahel in April (right column), southern Africa in October (middle column), and southern Asia in May (right column). Note, locations that already experience extremes for all days of the month are grayed out (e.g. across the Sahara for VPD).
Daily extremes for WBGTmax can have direct, acute physiological implications—each day above the corresponding threshold can increase the risk of heat stress for local populations63. However, for VPD, it is the cumulative effect of numerous days over extreme values over weeks to months that results in lowered crop yield or pasture productivity.
Example Application of Data 2 - Extreme July Tmax Counts in India-Pakistan
Here we also include a brief examination of 99th percentile temperature changes over the India-Pakistan region. The 99th percentile values are based on time series 34 × 31 days (1,054). Nevertheless, there will still be substantial uncertainty surrounding the estimated extreme value quantile values60, as one percent of the observations only corresponds to ~10 values. On the other hand, this uncertainty should not preclude the identification of high risk areas, as these fields can still be used to map risk. For example, Fig. 7 displays the estimated, observed 99th percentile Tmax values for a very warm area in July in Pakistan and India. While the individual 99th percentile values will be associated with substantial uncertainty, the spatial distribution of extreme temperatures are clear. The extreme temperatures range from less than 26 °C to more than 46 °C. Many of the warmest areas, such as the low-lying, densely populated Indus River basin in Pakistan, are already associated with extreme warm extreme Tmax values.

Observed 99th percentile July Tmax values. Based on observed CHIRTS daily Tmax data.
The monthly extreme counts data can be used to examine changes in the frequency of very warm (>99th percentile) days. For the region displayed in Fig. 7 (50–85°E, 8–37°N), Fig. 8 displays the mean number of days exceeding the 99th percentiles in the observations and the SSP585 2050 warming scenario. While not part of the pre-computed data set, for illustrative purposes, we also plot on this figure similar counts based on the 98th percentile quantile values: both the 98th and 99th quantile-based counts are very similar. By construction, between 1983 and 2010, the mean number of observed days warmer than the 98th and 99th quantile values will be low. However, when we contrast the observed mean 2011–2016 and 1983–2011 extreme counts, we very similar changes in the 98th and 99th percentile time-series - with a 240% and 230% increase in the frequency of very warm days.

Average number of days in July exceeding the 98th and 99th percentile values for the India-Pakistan region shown in Fig. 7.
Looking at the 2050 SSP585 projections shown in Fig. 8, the 98th and 99th percentile counts both exhibit further dramatic increases. According to these projections, comparing the 1983–2016 July time-series in Fig. 8, the number of days exceeding the 98th and 99th percentile thresholds will increase by five-fold or more over the observed 1983–2016 frequencies. Thus, while caution should be taken when considering counts of very extreme values, this data set can provide a useful foundation for assessing risk, given the strong performance of the CHIRTS data, and the fact that both the observed and projected changes are very large.
Code availability
The equations used to calculate RH, VPD, and WBGTmax are available in R on GitHub (https://github.com/emilylynnwilliams/CHC-CMIP6_SourceCode). The CHC-CMIP6 dataset was processed using code written in the Interactive Data Language and Python.
References
Eckstein, D., Künzel, V., Schäfer, L. & Winges, M. Global climate risk index 2020. Bonn: Germanwatch. (2019).
Lesk, C. et al. Compound heat and moisture extreme impacts on global crop yields under climate change. Nature Reviews Earth & Environment. 3, 872–889 (2022).
Zscheischler, J. & Seneviratne, S. I. Dependence of drivers affects risks associated with compound events. Science Advances. 3, 1–11 (2017).
Aghakouchak, A., Cheng, L., Mazdiyasni, O. & Farahmand, A. Global warming and changes in risk of concurrent climate extremes: Insights from the 2014 California drought. GRL. 41, 8847–8852 (2014).
Diffenbaugh, N. S. et al. Quantifying the influence of global warming on unprecedented extreme climate events. PNAS. 114, 4881–4886, https://doi.org/10.1073/pnas.1618082114 (2017).
Fischer, E. M. & Knutti, R. Anthropogenic contribution to global occurrence of heavy-precipitation and high-temperature extremes. Nature climate change. 5, 560–564 (2015).
Tuholske, C. et al. Global urban population exposure to extreme heat. PNAS. 118, 1–9 (2021).
Knutson, T. R. & Ploshay, J. J. Detection of anthropogenic influence on a summertime heat stress index. Climatic Change. 138, 25–39 (2016).
Funk, C. et al. A global satellite assisted precipitation climatology. Earth Syst. Sci. Data Discuss. 7, 1–13 (2015a).
Funk, C. et al. A High-Resolution 1983–2016 Tmax Climate Data Record Based on Infrared Temperatures and Stations by the Climate Hazard Center. Journal of Climate. 32, 5639–5658 (2019).
Lobell, D. B. & Asseng, S. Comparing estimates of climate change impacts from process-based and statistical crop models. ERL. 12, 1–12 (2017).
Birthal, P. S., Khan, T., Negi, D. S. & Agarwal, S. Impact of Climate Change on Yields of Major Food Crops in India: Implications for Food Security. Agricultural Economics Research Review. 27, 145–155 (2014).
Novick, K. A. et al. The increasing importance of atmospheric demand for ecosystem water and carbon fluxes. Nature Climate Change. 6, 1023–1027 (2016).
Fu, Z. et al. Atmospheric dryness reduces photosynthesis along a large range of soil water deficits. Nature Communications. 13 (2022).
Gourdji, S. M., Mathews, K. L., Reynolds, M., Crossa, J. & Lobell, D. B. An assessment of wheat yield sensitivity and breeding gains in hot environments. Proceedings of the Royal Society B: Biological Sciences. 280, 1–8 (2013).
Lobell, D. B. et al. Greater sensitivity to drought accompanies maize yield increase in the U.S. Midwest. Science. 344, 516–519 (2014).
Kath, J. et al. Vapour pressure deficit determines critical thresholds for global coffee production under climate change. Nature Food. 3, 1–10 (2022).
Grossiord, C. et al. Plant responses to rising vapor pressure deficit. New Phytologist. 226, 1550–1566 (2020).
Parsons, L. A. et al. Global labor loss due to humid heat exposure underestimated for outdoor workers. ERL. 17, 1–11 (2022).
Sherwood, S. C. & Huber, M. An adaptability limit to climate change due to heat stress. PNAS. 107, 9552–9555 (2010).
Funk, C. et al. The climate hazards infrared precipitation with stations—a new environmental record for monitoring extremes. Sci Data. 2, 1–21 (2015b).
Verdin, A. et al. Development and validation of the CHIRTS-daily quasi-global high-resolution daily temperature data set. Scientific Data. 7, 1–14 (2020).
Ahrens, C. D. Meteorology today. An introduction to weather, Climate, and the environment. 5th edn. (Bloomsbury Publishing Plc, 1994).
Held, I. M. & Soden, B. J. Robust responses of the hydrological cycle to global warming. Journal of climate. 19, 5686–5699 (2006).
Kong, Q. & Huber, M. Explicit Calculations of Wet-Bulb Globe Temperature Compared With Approximations and Why It Matters for Labor Productivity. Earth’s Future. 10, 1–21 (2022).
Budd, G. M. Wet-bulb globe temperature (WBGT)—its history and its limitations. Journal of science and medicine in sport. 11, 20–32 (2008).
ISO. 7243: Ergonomics of the Thermal Environment—Assessment of Heat Stress Using the WBGT (Wet Bulb Globe Temperature) Index. International Organization for Standardization Geneva, Switzerland. (2017)
Mora, C. et al. Global risk of deadly heat. Nature climate change. 7, 501–506 (2017).
Bynum, G. D. et al. Induced hyperthermia in sedated humans and the concept of critical thermal maximum. American Journal of Physiology-Regulatory, Integrative and Comparative Physiology. 235, 228–R236 (1978).
Cheung, S. S. & McLellan, T. M. Heat acclimation, aerobic fitness, and hydration effects on tolerance during uncompensable heat stress. Journal of applied physiology. 84, 1731–1739 (1998).
Pradhan, B. et al. Heat stress impacts on cardiac mortality in Nepali migrant workers in Qatar. Cardiology. 143, 37–48 (2019).
Williams, A. P. et al. Large contribution from anthropogenic warming to an emerging North American megadrought. Science. 368, 314–318 (2020).
He, B. et al. Worldwide impacts of atmospheric vapor pressure deficit on the interannual variability of terrestrial carbon sinks. National Science Review. 9, 1–8 (2022).
Sperry, J. S. et al. Predicting stomatal responses to the environment from the optimization of photosynthetic gain and hydraulic cost. Plant Cell and Environment. 40, 816–830 (2017).
Hausfather, Z., Drake, H. F., Abbott, T. & Schmidt, G. A. Evaluating the performance of past climate model projections. GRL. 47, 1–10 (2020).
Flato, G. et al. Evaluation of climate models. In Climate change 2013: the physical science basis. Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change. (Cambridge University Press, 2014).
Meinshausen, M. et al. The shared socio-economic pathway (SSP) greenhouse gas concentrations and their extensions to 2500. Geosci. Model Dev. 13, 3571–3605 (2020).
Tokarska, K. B. et al. Past warming trend constrains future warming in CMIP6 models. Science advances. 6, 1–13 (2020).
Schwarzwald, K. & Lenssen, N. The importance of internal climate variability in climate impact projections. PNAS 119, 1–8 (2022).
Eyring, V. et al. Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization. Geosci. Model Dev. 9, 1937–1958 (2016).
Harrison, L., Funk, C. & Peterson, P. Identifying changing precipitation extremes in Sub-Saharan Africa with gauge and satellite products. ERL. 14, 1–12 (2019).
Hersbach, H. et al. The ERA5 global reanalysis. Quarterly Journal of the Royal Meteorological Society. 146, 1999–2049 (2020).
Daly, C., Smith, J. I. & Olson, K. Mapping atmospheric moisture climatologies across the conterminous United States. PLoS ONE. 10. (2015).
Lee, J.-Y. et al. Future Global Climate: Scenario-Based Projections and NearTerm Information. In Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change. (Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, 2021).
Fricko, O. et al. The marker quantification of the Shared Socioeconomic Pathway 2: A middle-of-the-road scenario for the 21st century. Global Environmental Change. 42, 251–267 (2017).
Sherwood, S. C. et al. An assessment of Earth’s climate sensitivity using multiple lines of evidence. Reviews of Geophysics. 58, 1–92 (2020).
Oldenborgh, G. J., Reyes, F. D., Drijfhout, S. S. & Hawkins, E. Reliability of regional climate model trends. ERL. 8, 1–7 (2013).
Davis, R. E., McGregor, G. R. & Enfield, K. B. Humidity: A review and primer on atmospheric moisture and human health. Environmental research. 144, 106–116 (2016).
NOAA. The heat index equation. https://www.wpc.ncep.noaa.gov/html/heatindex_equation.shtml (2022)
Bernard, T. E. & Iheanacho, I. Heat index and adjusted temperature as surrogates for wet bulb globe temperature to screen for occupational heat stress. JOEH. 12, 323–333 (2015).
Ficklin, D. L. & Novick, K. A. Historic and projected changes in vapor pressure deficit suggest a continental-scale drying of the United States atmosphere. Journal of Geophysical Research. 122, 2061–2079 (2017).
Salvucci, M. E. & Crafts-Brandner, S. J. Inhibition of photosynthesis by heat stress: the activation state of Rubisco as a limiting factor in photosynthesis. Physiologia plantarum. 120, 179–186 (2004).
Luber, G. & McGeehin, M. Climate change and extreme heat events. American journal of preventive medicine. 35, 429–435 (2008).
Mera, R. et al. Climate change, climate justice and the application of probabilistic event attribution to summer heat extremes in the California Central Valley. Climatic Change. 133, 427–438 (2015).
Verdin, J. & Klaver, R. Grid-cell-based crop water accounting for the famine early warning system. Hydrological Processes. 16, 1617–1630 (2002).
Parsons, K. Heat stress standard ISO 7243 and its global application. Industrial health. 44, 368–379 (2006).
Sadok, W. & Sinclair, T. R. Genetic variability of transpiration response to vapor pressure deficit among soybean cultivars. Crop Science. 49, 955–960 (2009).
Zhang, Q. et al. Response of ecosystem intrinsic water use efficiency and gross primary productivity to rising vapor pressure deficit. ERL. 14, 1–9 (2019).
Massmann, A., Gentine, P. & Lin, C. When does vapor pressure deficit drive or reduce evapotranspiration? Journal of Advances in Modeling Earth Systems. JAMES. 11, 3305–3320 (2018).
Coles, S., Bawa, J., Trenner, L. & Dorazio, P. An introduction to statistical modeling of extreme values. (London: Springer, 2001).
Williams, E., Funk, E., Peterson, P. & Tuholske, C. The Climate Hazards Center Coupled Model Intercomparison Project Phase 6 climate projection dataset, CHC-CMIP6, v1., UC Santa Barbara, https://doi.org/10.21424/R47H0M (2023).
Fick, S. E. & Hijmans, R. J. WorldClim 2: new 1‐km spatial resolution climate surfaces for global land areas. International journal of climatology. 37, 4302–4315 (2017).
Koppe, C., Kovats, S., Jendritzky, G. & Menne, B. Heat-waves: risks and responses (No. EUR/03/5036810). World Health Organization. Regional Office for Europe. (2004).
Acknowledgements
The creation and curation of this data set relied upon data and computation resources at the USAID FEWS NET-funded Climate Hazards Center (CHC). We acknowledge the World Climate Research Programme, which, through its Working Group on Coupled Modeling, coordinated and promoted CMIP6. We thank the climate modeling groups for producing and making available their model output, the Earth System Grid Federation (ESGF) for archiving the data and providing access, and the multiple funding agencies who support CMIP6 and ESGF. The research conducted by EW, CF, and PP was supported in part by the Bill & Melinda Gates Foundation. The findings and conclusions contained within are those of the authors and do not necessarily reflect the positions or policies of the Bill & Melinda Gates Foundation. Furthermore, CT received support from the NASA Land-Cover and Land-Use Change Program (Award #80NSSC22K0470 and #80NSSC23K0525) and the Air Force Office of Scientific Research (Grant #FA9550-23-1-0684). Finally, we gratefully acknowledge the support of the United States Agency for International Development (USAID) (Cooperative Agreement #72DFFP19CA00001), and the National Aeronautics and Space Administration (NASA) Global Precipitation Measurement Mission (Award #80NSSC19K0686).
Author information
Authors and Affiliations
Contributions
E.W.: methodology, validation, visualization, and writing. C.F.: conceptualization, data curation (calculating extremes), methodology, and writing. P.P.: data curation (calculating/processing observations, deltas, and projections), managing ftp site. C.T.: data curation (calculating WBGTmax & HImax), methodology, and writing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Williams, E., Funk, C., Peterson, P. et al. High resolution climate change observations and projections for the evaluation of heat-related extremes. Sci Data 11, 261 (2024). https://doi.org/10.1038/s41597-024-03074-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03074-w
- Springer Nature Limited