
Abstract
Recognition of species richness spatial patterns is important for nature conservation and theoretical studies. Inventorying species richness, especially at a larger spatial extent is challenging, thus different data sources are joined and harmonized to obtain a comprehensive data set. Here we present a new data set showing vascular plant species richness in Poland based on a grid of 10 × 10 km squares. The data set was created using data from two sources: the Atlas of Distribution of Vascular Plants in Poland and the Polish Vegetation Database. Using this data set, we analysed 2,160 species with taxonomical nomenclature according to the Euro + Med PlantBase checklist in 3,283 squares covering the entire territory of Poland (ca. 312,000 km2). The species were divided into groups according to their status and frequency of distribution, and the statistics for each square were obtained. For purposes of analysis, sampling bias was assessed. The data set promotes theoretical analysis on species richness and reinforces the planning of nature conservations.
Similar content being viewed by others


Background & Summary
Knowledge on the spatial patterns of species richness is essential for ecology, biology and nature conservation1,2,3,4, and it is especially important because of currently accelerating biodiversity loss related to global changes5. In the era of big data, merging data from different sources is desirable to obtain comprehensive data sets3,4,6. Such a data set needs harmonisation7 and bias assessment8, and it should be accessible to the public9.
Poland is a large country in Central Europe with a land surface area of approximately 312,000 km2. The climate is classified as temperate warm transitional10, but the territory is crossed by air masses from both the Atlantic Ocean and the heart of the Eurasian landmass, and the continental impact increases gradually from west to east10. In the north, the vegetation consists of Baltic Sea coastal habitats, while the south is dominated by the alpine vegetation of the Sudety and Carpathian Mountains. In terms of the biogeographical regions of Europe, Poland is within continental and alpine regions and borders a boreal region11. Owing to its geographical location, Poland has various climate types within its borders, leading to the country having boundary ranges of numerous plant species and species representing different floristic elements12. Plant studies in Poland have a long tradition. In particular, the phenomenon of range limits of several tree species within Polish territory intrigued early 19th century naturalists13,14, and it was continuously studied in a scientific way15,16, resulting in the first maps of tree species distribution17,18. The classical phytosociological studies started in the 1920s including, among others, steppe vegetation19, mountain vegetation20, and forests21. The knowledge regarding the vegetation of Poland was synthesized in book ‘The Vegetation of Poland’ in 195922, with English edition23. However, mapping of vascular plant species richness has never been done in Poland. The primary data source that can be used for such mapping is the ATPOL project – Atlas of Distribution of Vascular Plants in Poland24,25,26. Another recently available data set important for mapping purposes is the Polish Vegetation Database (PVD)27. Neither of those projects focused directly on species richness and has not been used for this purpose so far. Here, we present the results of merging and harmonizing the two databases to obtain a comprehensive data set showing the spatial patterns of vascular plant species richness in Poland. The new data set was reinforced by the classification of plants regarding their status in Polish flora. This data set can be used for both biogeographical studies on species richness patterns and for nature conservation purposes.
Methods
Original species distribution data and spatial grid
The original data sources recorded the distribution of plants with different taxonomic levels. Mostly, the taxonomic level was species, but subspecies, varietas, species sensu lato, aggregations, and hybrids were also included. For simplification, we refer to all of them as ‘species’ if a detailed distinction is not necessary.
The ATPOL data were derived from mapping the occurrence of vascular plants, using the cartogram method in 10 × 10 km squares (henceforth, squares). The ATPOL project was launched in the late 1970s by24 and is still running. Floristic data of ATPOL contain the code of a square (or the geographical coordinates) and the geographical name of the locality. All available and reliable floristic data in the territory of Poland are being used for ATPOL: results of original field studies and data from literature and herbarium records. The field data can be both a single species occurrence record in a given locality or a list of many species assigned to a locality. To fill a square, it is only necessary to find a single locality of the species inside its area. The taxonomical nomenclature is mostly based on the floristic list published by28, but it has been extended as the project has progressed24. So far, the project has published two atlases of plant distribution in Poland: the main part was published in 200225 and an appendix followed in 201926. The data contributed by A. Zając, for the purposes of this project, consist of the last version of the ATPOL project (data transferred on 10 November 2020) with information on the distribution of 3,053 plant taxa in 3,283 squares (Fig. 1). The ATPOL project spanned the digital revolution, and the software used for data input, storage and handling has changed over time. Consequently, the number and date of particular records in a square are no longer accessible. The original spatial grid of 10 × 10 km squares has been modified to the recent GIS standards of29 and30, and for our project, we used the grid system from an online source (https://worldbig.org/atpol/).

Scheme of harmonisation. (a) Standardization of nomenclature following Euro + Med. (b) Dataset joining and simplification towards reduction of critical taxa. Among 3,369 species 2,228 were recorded in both data sets, while 750 were contributed exclusively by ATPOL and 391 by PVD. (c) Exclusion of extinct species, cultivars and ephemerophytes. (d) Removal of taxa with unclear typology.
The PVD, which was derived from published and unpublished data for the territory of Poland, was launched in 200727. The PVD stores vegetation plots, including information of species co-occurrences (so-called phytosociological relevés), that are typically collected according to the Central European phytosociological method31. Based on the number of plots it contains, the PVD is among the largest vegetation databases in Europe and worldwide32,33. The database is registered in the Global Index of Vegetation-Plot Databases (GIVD)32 under code EU-PL-001, and it is one of the largest contributors of vegetation data to the European Vegetation Archive33 and sPlot34. The PVD data consist of 117,328 georeferenced vegetation plots. Data on species occurrences were derived from each vegetation plot based on its georeferenced location and assigned to particular squares. The spatial location of plots is estimated based on plot description (e.g., a particular mountain, forest complex or nearest village) or the coordinates measured using the Global Navigation Satellite System. The data contributed by PVD were obtained on 15 February 2022 and consisted of 117,328 georeferenced vegetation plots, covering the time frame from 1925 to 2020 (Fig. 2). In this project, the species occurrence was extracted from the list of in a plot and the location of the point was assigned to a particular square. From the PVD, we obtained information on the distribution of 2,625 plant taxa in 2,593 squares (Figs. 1, 2).

Polish Vegetation Database plot number per square (a) and its distribution (b) as well as plot recording in years (c).
Taxonomical harmonisation
-
a)
For the purpose of unification, Euro + Med PlantBase (http://www.europlusmed.org) was used as a common taxonomical nomenclature source. Species considered in Euro + Med as ‘preliminarily accepted’ were also included in the list. Nonetheless, some aggregations and other taxonomical units (e.g., species sensu lato) were created as needed. This list of operational taxonomic units (OTUs) was used for further analysis. The application of OTUs allowed retaining some taxa inconsistent with the Euro + Med species list (see points c–e, below), which were further included into an aggregation or other taxonomical unit.
-
b)
Cultivars and ephemerophyte species (e.g., Zea mays L., Yucca flaccida Haw.) were excluded from analysis since the distribution of those species was directly related to human decision-making and was not relevant to ecological problems. Further, species extinct in Poland (e.g., Cuscuta epilinum Weihe.) were excluded from the list.
-
c)
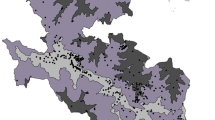
Six genera (Alchemilla, Hieracium, Pilosella, Rosa, Rubus and Taraxacum) were considered at genus level (e.g., Taraxacum sp.) because they consist of species difficult to identify at the species level (so-called microspecies35,36) or their taxonomical status changed over time. Consequently, the knowledge regarding the distribution of species within these genera is fragmentary and usually limited to areas surveyed by a taxonomist specialising in particular genera. An example is the distribution of species within Taraxacum (Fig. 3) for which 286 taxa (mostly species) were identified in both databases. However, in some squares the number of species recorded was above 30, while only one species was recorded in neighbouring squares with similar environment conditions (Fig. 3), which seems unlikely.
Fig. 3 
Taraxacum species richness distribution.
-
d)
Vascular plant species with taxonomical nomenclature that changed over time or those that were difficult to distinguish from one another due to morphological similarity underwent simplification using taxa aggregation (e.g., Festuca ovina agg., Eleocharis palustris agg.) and sensu lato (e.g., Erigeron acris s.l.).
-
e)
Taxa not recognised at a species level (e.g., hybrids between species, and taxa described as Crataegus monogyna et laevigata) were excluded. However, if a hybrid already existed as an aggregation (agg.) of species sensu lato (s.l.) and both parental taxa of the hybrid could be included in the already existing aggregation, it was included in the group.

The procedures of taxonomic harmonisation caused loss of some information. Some taxa reported in ATPOL were included in others after application Euro + Med nomenclature instead of the project’s original checklist (Fig. 1). Thus, the number of taxa originally recorded in ATPOL was reduced from 3,053 to 2,983. In addition, the simplification after merging ATPOL and PVD caused the number of species under consideration to decrease by 420; however, the ‘lost’ species were mostly within five genera: Alchemilla, Hieracium, Pilosella, Rubus, and Taraxacum, with Taraxacum alone initially being represented by 286 species.
Taxa classification
The species were classified according to their affinity to taxonomic units (family, genera), status in Polish flora (native, archeophytes, neophytes), conservation status (Red List species), and frequency of their distribution (rare, moderate and common). The status of species (native, archeophytes and neophytes) was checked according to37. The archeophytes, as species with specific ecology and biology, among which some are considered to have high conservation value, were considered as native taxa in the analysis, thus only the neophytes were considered as alien. The species with high conservation value were distinguished based on the Polish Red List38. Additionally, we classified native species which occupy human made habitats as apophytes. The apophytes were checked based on an unpublished list provided by A. Zając. The frequency distribution classes are represented by three categories: common, moderate and rare. Common species are those species present in more than 75% of the total number of squares (3,283 squares), moderate species are those present in between 25% and 75%, and rare species are found in less than 25% of the total squares.
In the case of species aggregation or species sensu lato, the taxa within the group could represent different affinities towards their status (i.e., native or neophytes) and conservation value (i.e., Red List). In such a case, the rules of classification were the following:
-
a)
If a species is present on the Red List, all subspecies belonging the species are also considered as Red List taxa.
-
b)
If aggregation or species sensu lato consist of two or more taxa, and if all the taxa are considered as Red List, the entire aggregation is considered as Red List.
-
c)
If no more than 5% of species in a group represented different status/conservation value or if the taxa occurred rarely (less than 5% of all squares where taxa belonging to the aggregation were found), their presence was ignored and the entire group was classified according to the dominant category. For example, Diantus superbus aggregation consisting of D. speciosus and D. superbus subsp. alpestris was considered as a Red List aggregation because the non-Red List D. speciosus is very rare (ca. 1% of squares in the entire aggregation) compared with D. superbus subsp. alpestris. However, if the situation was opposite (i.e., the Red List taxon was very rare) the entire aggregation was not considered as a Red List aggregation. For example, very rare D. carhosianorum subsp. Saxigenus was a Red List species, but D. carthusianorum was more frequent and not a Red List species, thus the taxon D. carthosianorum s.l. was not considered as a Red List species.
Additionally, we also excluded some aggregations and genera from the joint data set before analysis because of a status problem: Species present in OTUs as both alien and native exceeding 5% of the squares in number hindered categorization of the group as either native or neophyte. In such a case, the simplification considerably influenced the calculated fraction of neophytes in the square. This case included two genera: Hieracium and Rosa. The same decision was made for the following taxa: Amaranthus hybridus agg., Chenopodium album agg., Gentianella campestris s. l., Gentianella germanica s. l., Laserpitium krapfii subsp. krapfii, Oenothera biennis agg., Onobrychis viciifolia agg. and Polygala chamaebuxus.
Methods of the data set overview
The final list used for analysis and mapping was based on OTUs, and thus, it included taxa at different taxonomical levels (Fig. 1). For simplification, we considered all the OTUs as species, and for the results, we refer to ‘species richness’. Since the observed species richness is correlated with sampling area, we decided to exclude squares placed partially outside the territory of Poland for dataset analysis and visualisation. We decided to consider only squares with more than 80% of area within the terrestrial territory of Poland; nonetheless, data for all squares are stored in the dataset39. A total of 268 cross-boundary squares were excluded because of their location, which consisted of 8% of all analysed squares.
In some areas, the sampling effort was very probably low, which in turn, would have affected the species richness estimation. To detect potentially undersampled squares, we employed a simple procedure: The 20 most frequent species in the dataset were determined, and then the species were checked for their geographical ranges and ecological niche. Since the top 20 frequent species were found over the entire territory of Poland and are common species, we considered them as a ‘wish’ list of species which should be recorded in each square. Next, we searched for squares where three or more species from the wish list were missing, and those squares were considered as undersampled and removed from the analysis. The procedure relied on the assumption that if no data were collected from a square for several species from this group, other species were most probably also omitted from the inventory. An analogous basic assumption applied by Kühn et al.40, relied under the benchmark species approach41,42 and for producing biogeographical ignorance maps43. The applied procedure resulted in the identification of 149 potentially undersampled (low sampling effort) squares, which consisted of 5% of all analysed squares (Fig. 4).

Location of squares considered as undersampled.
The applied exclusion criteria changed the species richness in squares, as shown in the statistic result of different exclusion criteria under Table 1.
Data Records
The data set is available at Zenodo repository39 under a Creative Commons Attribution 4.0 International licence. This dataset consists of 5 files (Files_description, Taxa_list, Taxa_status, Species_richness and Map_data):
Files_description - file with a description of the data stored.
Taxa_list. List of taxa. The nomenclature according to Euro + Med PlantBase (Euro + Med.) and operational taxonomical units (OTUs) used for analysis and mapping in the project. For simplification, the taxonomical operational units are called ‘species’.
Taxa_status. The species affinity to taxonomic units (family, genera), status in Polish flora (native, archeophytes, neophytes), conservation status (Red List species), and frequency of their distribution (rare, moderate and common). The status (native, archeophytes and neophytes) was checked according to37, the high conservation value according to Polish Red List38, and the apophytes according to an unpublished list provided by A. Zając. Common species are those species present in more than 75% of the total number of squares (3,283 squares), moderate species are those present in between 25% and 75%, and rare species are found in less than 25% of the total squares.
Species_richness. Statistics on species richness and frequency in species groups for 10 × 10 km ATPOL squares. The names of squares according to original names in the ATPOL project24. The sampling bias (SB) shows adequately sampled squares labelled with 1, while squares with 0 are those with low sampling effort. Cross-boundary squares (CBS) denoted by 1 are squares with more than 80% of the area within the terrestrial territory of Poland, while squares with CBS of 0 are those with 80% or less of the area within the terrestrial territory of Poland. The detail information about the particular columns is shown in ‘Files_description’ and ‘Taxa_status’ files.
Map_data. A shapefile with squares geospatial locations, codes of their names, and data on species richness and frequency in species groups. The map is registered in WGS 84 coordinate reference system (EPSG code 4326). The abbreviations and square names used in ‘dbf’ file are the same as those used in ‘Species_richness’ file.
Abbreviations used in the dataset are explained in Table 2.
Technical Validation
The dataset is stored in simple formats (xlsx and shp). The data were already used for preparing scientific articles (submitted) and for calculating statistics presented at scientific conferences, which confirms that the data set is functional using typical software for data analysis/visualisation (e.g., Fig. 5).

Native and archeophyte species richness.
Usage Note
-
1.
For visualisation, we suggest using only data for squares with more than 80% of area within the terrestrial territory of Poland. The recommended squares are denoted by value 1 in column CBS in ‘Species_richness’ file (for details see ‘Methods of the data set overview’). The map for native and archeophyte species richness is shown on Fig. 5).
-
2.
For statistical analysis, we suggest excluding squares that are potentially undersampled (for details see ‘Methods of the data set overview’). The squares are denoted by value 1 in column SB in ‘Species_richness’ file. We also suggest excluding squares mentioned in point 1 from analysis.
-
3.
This dataset can be temporally biased: It predominantly reflects the species richness pattern from 1960 to 2000s since most of field data comes from this period. Unfortunately, we did not have field data or models for assessing changes of species richness caused by extinction of species within a square. Regarding the alien species, the ATPOL data were upgraded in 201926.
-
4.
The species richness patterns will change as new data are added, species become extinct, and taxonomical approach and species classification change (e.g., changes in Red List, naturalisation of ephemerophytes). Therefore, we consider the presented data set as version 1.1, designed for further development and actualisation.
Code availability
No specific code was used to produce and analyse the presented data.
References
Kreft, H. & Jetz, W. Global patterns and determinants of vascular plant diversity. Proceedings of the National Academy of Sciences 104, 5925–5930 (2007).
Divíšek, J. & Chytrý, M. High-resolution and large-extent mapping of plant species richness using vegetation-plot databases. Ecological Indicators 89, 840–851 (2018).
Wild, J. et al. Plant distribution data for the Czech Republic integrated in the Pladias database. Preslia 91, 1–24 (2019).
Brummitt, N., Araújo, A. C. & Harris, T. Areas of plant diversity—What do we know? Plants People Planet 3, 33–44 (2020).
Díaz, S. et al. Pervasive human-driven decline of life on Earth points to the need for transformative change. Science 366, eaax3100 (2019).
Wüest, R. et al. Macroecology in the age of Big Data–Where to go from here? Journal of Biogeography 47, 1–12 (2020).
Grenié, M. et al. Harmonizing taxon names in biodiversity data: A review of tools, databases and best practices. Methods in Ecology and Evolution 14, 12–25 (2021).
Petřík, P., Pergl, J. & Wild, J. Recording effort biases the species richness cited in plant distribution atlases. Perspectives in Plant Ecology, Evolution and Systematics 12, 57–65 (2010).
Govaerts, R., Nic Lughadha, E., Black, N., Turner, R. & Paton, A. The World Checklist of Vascular Plants, a continuously updated resource for exploring global plant diversity. Scientific Data 8, 1–10 (2021).
Błażejczyk, K. Climate and bioclimate of Poland. Geographia polonica 77, 31–48 (2006).
Cervellini, M. et al. A grid-based map for the Biogeographical Regions of Europe. Biodiversity Data Journal 8 (2020).
Finnie, T. J., Preston, C. D., Hill, M. O., Uotila, P. & Crawley, M. J. Floristic elements in European vascular plants: an analysis based on Atlas Florae Europaeae. Journal of Biogeography 34, 1848–1872 (2007).
Szubert, M. Opisanie Drzew i Krzewów Leśnych Królestwa Polskiego. (W Drukarni N. Glücksberga, 1827).
Pol, W. Dzieła Wincentego Pola: Wydanie 1 zupełne. Muzeum Natury we Lwowie (Biblioteka Narodowego Zakładu imienia Ossolińskich, 1847).
Połujański, A. Opisanie lasów Królestwa Polskiego i Guberni Zachodnich Cesarstwa Rosyjskiego pod Względem Historycznym, Statystycznym i Gospodarczym: Tomy 1. (W Drukarni Gazety Codziennej, 1854).
Herbich F. Pflanzengeograpische Bemerkungen über die Wälder Galiziens. Verh. Der k.k. zool-bot. Ges. In Wien. (1860).
Strzelecki, H. O Przyrodzonym Rozsiedleniu Drzew Leśnych w Galicji. (Sylwan 12. Lwów, 1894).
Raciborski, M. Rozmieszczenie oraz granice drzew oraz ważniejszych krzewów i roślin na ziemiach polskich. Geografia fizyczna ziem polskich i charakterystyka fizyczna ludności. (Akademia Umiejętności, 1912).
Dziubałtowski, S. Les associations steppiques sur le plateau de la Petite Pologne et leurs successions. Acta Societatis Botanicorum Poloniae 3(2), 164–195 (1925).
Szafer, W., Pawłowski, B. & Kulczyński, S. Zespoły Roślin w Tatrach. Część 1. Zespoły Roślin w Dolinie Chochołowskiej (Polska Akademia Umiejętności, Kraków, 1927).
Nowiński, M. Zespoły roślinne Puszczy Sandomierskiej. Cz. I. Zespoły roślinne torfowisk niskich pomiędzy Chodaczowem a Grodziskiem. Kosmos, ser. A 52(3-4), 457–546 (1928).
Szafer, W. Szata Roślinna Polski (Państwowe Wydawnictw Naukowe, 1955).
Szafer, W. The Vegetation of Poland: International Series of Monographs in Pure and Applied Biology: Botany 9 (Pergamon, 1966).
Zając, A. Atlas of distribution of vascular plants in Poland (ATPOL). Taxon 27, 481–484 (1978).
Zając, A. & Zając, M. Atlas Rozmieszczenia Roślin Naczyniowych w Polsce. Nakładem Pracowni Chorologii Komputerowej Instytutu Botaniki: (Uniwersytetu Jagiellońskiego, 2001).
Zając, A. & Zając, M. Distribution Atlas of Vascular Plants in Poland: appendix. (Institute of Botany, Jagiellonian University, 2019).
Kącki, Z. & Sliwinski, M. The Polish Vegetation Database: structure, resources and development. Acta Societatis Botanicorum Poloniae 81, 75–79 (2012).
Szafer W., Kulczyński S. & Pawłowski, B. Rosliny polskie. (PWN, 1953).
Komsta, Ł. ATPOL geobotanical grid revisited-a proposal of coordinate conversion algorithms. Annales Universitatis Mariae Curie-Skłodowska. Sectio E, Agricultura 71, 31–37 (2016).
Verey, M. Teoretyczna analiza i praktyczne konsekwencje przyjęcia modelowej siatki ATPOL jako odwzorowania stożkowego definiującego konwersję współrzędnych płaskich na elipsoidę WGS 84. Fragmenta Floristica et Geobotanica Polonica 24, 469–488 (2017).
Braun-Blanquet, J. Pflanzensoziologie. Grundzüge der Vegetationskunde. Wien: (Springer-Verlag, 1964).
Dengler, J. et al. The Global Index of Vegetation-Plot Databases (GIVD): a new resource for vegetation science. Journal of Vegetation Science 22, 582–597 (2011).
Chytrý, M. et al. European Vegetation Archive (EVA): an integrated database of European vegetation plots. Applied Vegetation Science 19, 173–180 (2016).
Bruelheide, H. et al. sPlot–A new tool for global vegetation analyses. Journal of Vegetation Science 30, 161–186 (2019).
Dengler, J. et al. The need for and the requirements of EuroSL, an electronic taxonomic reference list of all european plants. In Vegetation databases for the 21st century (ed. Dengler, J. et al). Biodiversity & Ecology 4: (Biodiversity, Evolution and Ecology of Plants (BEE), Biocenter Klein Flottbek and Botanical Garden, University of Hamburg, 2012).
Pescott, O. L., Humphrey, T. A. & Walker, K. J. A short guide to using British and Irish plant occurrence data for research. Report No. N520609CR.v.1.4 (Wallingford, NERC/Centre for Ecology & Hydrology, 2018).
Tokarska-Guzik, B. et al. Rośliny obcego pochodzenia w Polsce. Warszawa: (Generalna Dyrekcja Ochrony Środowiska 2012).
Kaźmierczakowa, R. et al. Polska Czerwona Lista Paprotników i Roślin Kwiatowych. Krakow: (Institute of Nature Conservation, Polish Academy of Sciences 2016).
Szymura, T. et al. Vascular plant species richness in Poland version 1.1, Zenodo, https://doi.org/10.5281/zenodo.8150757 (2023).
Kühn, I., Brandl, R., May, R. & Klotz, S. Plant distribution patterns in Germany–Will aliens match natives? Feddes Repertorium, 114, 393-645 (2003).
Hill, M. O. Local frequency as a key to interpreting species occurrence data when recording effort is not known. Methods in Ecology and Evolution 3, 195–205 (2012).
Maes, D. & van Swaay, C. A. A new methodology for compiling national Red Lists applied to butterflies (Lepidoptera, Rhopalocera) in Flanders (N-Belgium) and the Netherlands. Journal of Insect Conservation 1, 113–124 (1997).
Tessarolo, G., Ladle, R. J., Lobo, J. M., Rangel, T. F. & Hortal, J. Using maps of biogeographical ignorance to reveal the uncertainty in distributional data hidden in species distribution models. Ecography 44, 1743–1755 (2021).
Acknowledgements
We are grateful to botanists participating in the ATPOL project, whose fieldwork made it possible to prepare atlases of plant distribution. We would also like to thank all researchers who submitted their vegetation records for use in the PVD. This work was supported by the National Science Centre, Poland, project number 2019/35/B/NZ8/00273.
Author information
Authors and Affiliations
Contributions
T.S.: conceptualization, methodology, funding acquisition, project administration, writing – original draft. H.K.: formal analysis, data curation, writing – original draft. G.S.: data curation, harmonisation, writing – original draft, M.S.: harmonisation, writing – original draft. A.Z.: resources, data curation, writing – original draft, Z.K.: resources, writing – original draft.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Szymura, T.H., Kassa, H., Swacha, G. et al. Spatial patterns of vascular plant species richness in Poland - a data set. Sci Data 10, 542 (2023). https://doi.org/10.1038/s41597-023-02446-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02446-y
- Springer Nature Limited