
Abstract
This research examines how the human genome and SES jointly and interactively shape verbal ability among youth in the U.S. The youth are aged 12–18 when the study starts. The research draws on findings from the latest GWAS as well as a rich set of longitudinal SES measures at individual, family and neighborhood levels from Add Health (N = 7194). Both SES and genome measures predict verbal ability well separately and jointly. More interestingly, the inclusion of both sets of predictors in the same model corrects for about 20% upward bias in the effect of the education PGS, and implies that about 20–30% of the effects of parental SES are not environmental, but parentally genomic. The three incremental R2s that measure the relative contributions of the two PGSs, the genomic component in parental SES, and the environmental component in parental SES are estimated to be about 1.5%, 1.5%, and 7.8%, respectively. The total environmental R2 and the total genomic R2 are, thus, 7.8% and 3%, respectively. These findings confirm the importance of SES environment and also pose challenges to traditional social-science research. Not only does an individual’s genome have an important direct influence on verbal ability, parental genomes also influence verbal ability through parental SES. The decades-long blueprint of including SES in a model and interpreting their effects as those of SES needs to be amended accordingly. A straightforward solution is to routinely collect DNA data for large social-science studies granted that the primary purpose is to understand social and environmental influences.
Similar content being viewed by others

Introduction
Cognitive ability has been shown to be one of the most important predictors of life outcomes such as educational attainment, occupational achievement, income, wealth, and health1,2,3,4,5,6. For decades, tests of cognitive ability and related achievement tests were routinely and nearly universally used in elementary and secondary education, college admissions, and admissions of graduate schools and professional schools in the United States7,8.
A critical question about cognitive ability is how much of it is innate and how much is environmental. The answer is related to how much cognitive ability could be improved by schooling and other individual and public efforts. Past few decades have seen two major advances in the understanding of genetic influences on cognitive ability. Behavior geneticists, taking advantage of genetic relatedness among blood relatives, have long established a substantial genetic base for cognitive ability, reporting a heritability estimate of 50% or more from adolescence through older age9,10,11,12. The second major advance came with the genome-wide association study (GWAS) of educational attainment13 and cognitive ability14. These GWAS yield a large number of genetic variables at molecular level that predict cognitive ability.
In this article, we report findings from research that investigates how the human genome and socioeconomic (SES) environment jointly and interactively shape verbal ability among youth in the United States. The research draws on results from two recent GWAS as well as a rich set of longitudinal SES measures at individual, family and neighborhood levels from the National Longitudinal Study of Adolescent to Adult Health (Add Health)15.
Our work promises significant improvements in the assessment of the relative importance of SES and genomic factors for verbal ability. First, recent GWAS provide an opportunity for genomic influence to be measured at individual DNA level. Twin studies decompose the total variance of cognitive ability into proportions due to genetic, shared environmental and unshared environmental factors at population level. Traditional twin data whose genetic information is based on genetic relatedness alone without DNA measures cannot investigate the relative contributions from genetics and environment as do data with correlated genetic and SES measures at the individual level. Second, we build our analysis from a social-science model of verbal ability; such a model often includes a rich set of longitudinal measures of SES. This approach allows us to examine the changes in a traditional social-science model of verbal ability after adding genomic measures. In an era when DNA evidence for human traits was by and large unavailable, twin studies understandably focused on genetic evidence. Typically, environmental information was insufficiently addressed in twin analysis. Understanding the relative importance of genomics and SES requires both sets of measures at individual level. Third, simultaneous inclusion of offspring genomic and family-SES data allows us to evaluate the genomic component within family SES16,17, which in turn allows us to correct for substantial upward bias in the effects of offspring genome and parental SES. Our findings have important implications and challenges for researchers dedicated to establishing genetic impact on cognitive ability and for researchers with a decades-long tradition of examining social and environmental impact on cognitive ability.
The influence of family SES on cognitive measures has been investigated extensively in a variety of academic fields over the past few decades. These previous analyses suggest the kinds of SES measures and analysis models that we can use in this research. SES is an umbrella concept with multiple dimensions at individual, family and community levels that attempts to capture family financial resources, knowledge, social connections, and the larger social context. SES is typically measured by parental income, education and occupation, one vs. two biological parents in the household, sibship size, quality of neighborhood, and quality of school18,19,20,21.
SES is most frequently measured by family income or poverty21,22,23. Other family characteristics such as family instability24 and parenting style25 are also examined. Entwisle and Alexander26 concludes that family SES has a larger impact than the interruption of schooling from summer breaks on cognitive test scores in elementary schools. Using data from the Child Development Supplement in the Panel Study of Income Dynamics, Hill21 shows that after income level is controlled, an increasing 5-year trend in income-to-needs income is positively associated with child achievement. In a meta-analysis of adoption studies of IQ, Locurto27 shows that adoption into high SES families raises the adopted children’s IQ by 10–12 points. These adoptive children tend to come from low SES families.
Mechanism studies explain why SES makes a difference in results of cognitive tests. Employing four waves of Dutch data, Kloosterman et al.28 shows that part of the relationship between parental education and children’s academic performance can be explained by parental reading and school involvement. Guo and Harris29 investigates the mechanisms through which family SES affects children’s cognitive ability. Using data from the National Longitudinal Survey of Youth (NLSY), they show that the effect of family SES is completely mediated by the intervening mechanisms measured by the latent factors of cognitive stimulation in home, home physical environment, parenting style, and child health at birth. Cognitive ability in the study is measured by four Peabody tests including a reading recognition test, a reading comprehension test, a mathematics assessment test, and a Peabody Picture Vocabulary test.
Hart and Risley30 observes children in 42 families for one hour per week for two and a half years and their calculation suggests that large differences exist in the total number of words heard by children from birth to age four across professional families (45 millions words), working class families (25 millions), and families in poverty (13 millions). Using the children of the NLSY, Farkas and Beron31 shows that by the 36th month of age, large gaps in vocabulary already emerge across social classes and racial/ethnic groups, and the gaps are not closed afterwards.
Formal schooling is commonly viewed as the most critical for the development of cognitive ability. Tests of cognitive ability are hardly meaningful out of the context of modern education. Dutch children’s schooling was delayed by the Nazi regime during WWII and these children’s IQ are seven points lower on average than those who went to school at normal ages after the war32,33 p. 41. In a longitudinal study of the effects of family SES, racial mix, and summer breaks on children’s mathematics achievement, Entwisle and Alexander26 concludes that “when school is in session, poor children and better-off children perform at almost the same level. Schools seem to be doing a better job than they have been given credit for (pp.82.)” They demonstrate the effect of schooling by showing the loss in mathematics scores after every summer break on the part of children in poverty relative to children not in poverty. Through a natural experiment, Cahan and Cohen34 reports a schooling effect distinct from the effect of biological age on an IQ test score. The study compares fourth graders and fifth graders (ages 9–11) who were essentially of the same age. Winship and Korenman35 reviews the literature that estimates the effect of education on cognitive ability and carefully reanalyzes the data from the NLSY used by Herrnstein and Murray36. They conclude that each year of education increases 2.7 points of IQ units. In this analysis, we consider respondents’ own schooling a paramount SES determinant of cognitive ability.
The afore-reviewed SES studies almost always assume explicitly or implicitly that all of the SES influences under consideration are environmental. These studies generally do not consider genomic influences. Nor do they address the issue that family SES itself could be partially genetic.
Getting to the root of cognitive ability requires DNA data. When social scientists reflect about genetic influences on cognitive ability, the first thing that often comes to mind is the well-publicized position that considers cognitive ability an “…inborn, all around intellectual ability … inherited, but not due to teaching or training… uninfluenced by industry or zeal37, cited by Nisbett33.” Similarly, Jensen maintains that “… the means for changing intelligence per se lie in the province of biology rather than psychology or education38.” Herrnstein and Murray36 expresses a parallel assessment that the differences in intelligence are mostly at the hand of nature and there is little that government policies could change. This position tends to dismiss the influence of environmental factors and views cognitive ability largely as a genetic trait.
In the meanwhile, mainstream behavior geneticists, relying on twins and other blood relatives, show a heritability estimate of cognitive ability that ranges between 0.2 to 0.89,10 and a shared non-genetic factor that quickly reduces to zero after maturity9. These findings have set a benchmark for ensuing work to be compared and assessed. Nevertheless, twin studies’ estimates at population level and the usual lack of extensive SES measures make them inadequate for understanding how heredity and SES jointly and interactively mold human cognitive ability.
Advances in molecular genetics over the past two decades have brought forth DNA data at individual level. The efforts linking DNA variation to cognitive ability began in earnest in the early 2000s. By then, it is evident that cognitive ability is a complex trait subject to the influence of a large number of genes each with a tiny effect39. The challenge to find specific genes for cognitive ability is enormous. A human genome consists of millions of genetic variants or sections of DNA that may differ across individuals. Testing whether each one of them predicts ability and setting the critical value for significance at the conventional level of 0.05 would by chance generate a large number of false positives. Although the genome is large, it is finite. The solution is to set a stringent critical value of 5 × 10−8 for significance and to request a replication of a discovered genetic variant in an independent data source. Initial successes of the GWAS employing thousands of individuals are performed on human traits such as type 2 diabetes and body mass index (BMI)40,41. The number of GWAS-identified genetic loci are small but tended to be replicated.
It soon became clear that by far the single most important factor in GWAS is sample size. The GWAS of educational attainment in 2018 assembles 1.1 million individuals and reports 1,271 independent SNPs associated with years of education at the genome-wide significance level of 5 × 10−8 13. The polygenic score (PGS) for educational attainment constructed from all common SNPs in the GWAS reports an R2 of about 12% using data from Add Health. Many of the genetic loci are implicated in biological pathways that play a role during prenatal brain development.
The 2018 GWAS of cognitive ability14 employs 269,867 individuals and identifies 205 independent genome-wide significant loci. The analysis data for the GWAS are assembled from more than a dozen cohorts, and different cohorts tend to use different cognitive tests. In spite of the differences in form, cognitive tests are all based on the common underlying fluid intelligence or the Spearman’s g, which is likely to have a large impact on multiple domains of cognitive functioning. The g factors extracted from different cognitive tests are highly correlated42,43, substantiating the approach used in the GWAS.
The GWAS-identified genes are mostly expressed in brain tissues. The genetic correlation between intelligence and education is estimated to be about 0.70 with p = 2.5 × 10−287 44. The genetic correlation computes the correlation between the genetic influence behind cognitive ability and that behind education, suggesting that the education-based GWAS-identified genetic variants ought to be reasonable predictors of cognitive ability. In the present analysis, the latest findings of GWAS for cognitive ability and educational attainment are used to construct the genomic measures to be included in models predicting verbal ability. See additional discussion in Supplementary Materials: I. Genetic terms and concepts.
Gene-environment (G×E) interaction analysis in this context examines how genotype exacerbates or suppresses the effect of SES or vice versa. Our G×E-interaction hypothesis predicts that a favorable SES context enhances the positive effect of genomic measures of verbal ability. The reasoning goes that a favorable SES context would help realize the genetic potential of an individual’s ability. Previous G×E-interaction work on cognitive development using twin data generated mixed results. Several studies report evidence supporting our hypothesis45,46,47; however, an exceptionally large study failed to find any significant G×E-interaction effect48. G×E-interaction analysis is methodologically challenging. To mitigate the threat of multiple testing, our analysis uses a principal component as a summary measure for the multiple dimensions of SES. We have also considered a number of issues raised in recent literature on G×E-interaction studies including the lack of sufficient controls49, coarsened outcome variables and sample selection50, and the collider bias51.
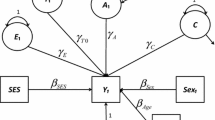
Family SES has a genomic component. Kong et al.16 measures the genomic component in family SES directly by transmitted parental alleles (T) and non-transmitted parental alleles (NT). “T” refers to transmitted from parents to children. Kong et al. estimates the effects of T and NT on children’s educational attainment. Both effects are highly significant. The estimated NT effect confirms the genomic component in parental SES (Fig. 1). The estimated T effect is about three times as large as that of NT; but this is an upward-biased effect of children’s genome. Kong et al. concludes that the unbiased effect of children’s genome is T-NT.

(An arrowed line indicates a causal effect; a double-arrowed line indicates a correlation. Solid lines represent observed relationships while interrupted lines represent unobserved relationships). a While offspring genome receives 50% of genetic alleles from each parent’s genome randomly (path A), parental SES is subject to the influence of all parental alleles (100% from each parent, (path B). b Offspring genome and parental SES are correlated (path C) due to the shared alleles between offspring genome and the subcomponent of the genomic component in parental SES (path D). c The same set of alleles from offspring and parents act on the subcomponent shared between parents and offspring; the subcomponent not shared with offspring is only acted upon by parental alleles not transmitted to offspring. The two subcomponents are hypothesized to be about the same. d In regression of verbal ability, the effects of offspring genome and parental SES are expected to be reduced because of the correlation. e The size of reduction in the offspring-genome effect may reflect the size of an overestimate in a regression in which parental SES is not included. f The effect of parental SES is reduced because the inclusion of offspring genome removes about one half of the entire genomic component in parental SES. The total size of the genetic component in parental SES is reasoned to be about twice as large as the reduction in the effect of parental SES when offspring genome is included.
Without parental genomic data, our analysis is unable to estimate the effect of NT directly. Instead, our analysis capitalizes on offspring genome and parental SES. Figure 1 describes our conceptual model that illustrates what may be learned from a regression of verbal ability on parental SES and offspring genome. In the figure, an arrowed line indicates a causal effect, a double-arrowed line indicates a correlation; solid lines represent observed relationships while interrupted lines represent unobserved relationships. Parental SES is traditionally viewed as environmental. Current literature points to a substantial genomic component in parental SES16,52,53. Parental genomes likely shape family SES such as education, occupation, income, and wealth at the family level as well as the neighborhood the family lives in and the schools the children attend, which is the genomic component in parental SES.
Parental SES could be decomposed into an environmental component and a genomic component. The latter originates from parental genomes. Fifty percent of each parent’s alleles transmit to offspring; but 100% of each parent’s alleles act on parental SES. This observation suggests that (1) a common origin of family SES and offspring genome induces a correlation between the two (path C), (2) the essence of path C is Correlation path D generated by the same set of alleles shared by offspring and parents, (3) the subcomponent not shared with offspring in the genomic component is acted upon by parental alleles that are not transmitted to offspring, (4) the two subcomponents are hypothesized to be about the same since each subcomponent is acted upon by about 50% of total parental alleles, implying that the size of the genomic component is twice as large as the subcomponent shared with offspring; and (5) we most likely have not exhausted the genomic confounding of SES influences.
The recognition of these subtleties when parental SES and offspring genome data are available leads to three payoffs even in the absence of parental genomic data. First, we have the opportunity to correct for the upward bias in the effect of offspring genome. The usually-reported genomic effect includes the effect of offspring genome as well as the impact of the genomic subcomponent in parental SES shared between parents and offspring. This subcomponent could be considered the upward bias in the typically-estimated offspring genome effect. The upward bias could be corrected by including parental SES in the model. Second, including offspring genome and parental SES in the same model provides an estimated size of the genomic component in parental SES, which we hypothesize to be about twice as large as the reduction in the parental SES effect when estimated simultaneously with offspring genome. Third, our analysis yields an estimated size of the environmental component of parental SES, which may be calculated as enviSES = Parental SES-2(ReducedSES), where enviSES is the environmental SES, Parental SES is the estimate from a model including only parental SES, and ReducedSES is the reduced size of parental SES when offspring genome is added.
Ethnic samples complicate genetic analysis. Our analysis is based on European Americans (whites) and Hispanic European Americans (Hispanic whites). We provide results separately for whites, Hispanic whites and the combined sample of the two. African Americans, Asian Americans, Native Americans and Hispanic African Americans are excluded because the published GWAS studies are mostly based on individuals of European descent including the GWAS that identified the genetic loci associated with educational attainment and cognitive ability54. Substantial genomic differences in individuals from different continents have been known since 1990s55. The partial overlap between the European genetic variants, and those of Africans and Asians implies that the related GWAS must have missed a substantial number of genetic loci among the ethnic minorities that are associated with educational attainment and cognitive ability. This, in turn, suggests that the GWAS findings do not apply to racial minorities as well as they do to European Americans56.
Do problem behavior and general health, especially mental health affect cognitive measures? Over the past decades, there has been a sustained effort to examine how educational attainment and educational achievement are impacted by problem behavior57,58,59,60,61 and health62, especially mental health and stress60,61,63,64,65,66. In this project, we test the impact of adding delinquency, self-reported health and depression to the model that already has SES and offspring genome as predictors.
This research has one overall objective and five hypotheses. The present research has an overarching objective of estimating the relative contribution of offspring genome and parental SES to verbal ability and five specific hypotheses. The first two establish in our analysis data what is known previously. The first hypothesizes that collectively, SES significantly predicts verbal ability (path F in Fig. 1) when offspring genome is not included in the model. The second hypothesizes that the two PGSs for education and ability significantly predict verbal ability (path E) without parental SES in the model. The third hypothesizes that the inclusion of SES reduces the effect size of the two PGSs. The fourth hypothesizes that the inclusion of the PGSs reduces the effect size of SES. The fifth is a G×E-interaction hypothesis testing whether favorable SES increases the positive effect of the PGSs.
Results
Main-effect models
Table 1 shows the means and the standard deviations of the continuous variables, and the percentage distribution of categorical variables used in the analysis for whites, Hispanic whites and the combined whites and Hispanic whites. The heritability is estimated to be 0.38; this estimate is based on a small sample of 73 pairs of MZ twins and 92 pairs of DZ twins in our analytic Add-Health sample.
We organize our findings by Table 2 (SES results), Table 3 (genomic results), and Table 4 (SES and genomic results) so that we could observe the impact of SES and genome. Table 2 presents the coefficients and their standard errors of SES context and other covariates from multilevel models of verbal ability for whites, Hispanic whites and the two combined. The model is a 3-level model of verbal ability (Eq. 1). The two random effects at the individual and family levels are highly statistically significant. The OLS R2 is estimated to range from 12.7% to 19.9% across the different samples.
The models presented in Table 2 are traditional social-science models that include a full set of SES predictors without any genomic measure. SES context proves important. All social-contextual characteristics except for mother’s occupation significantly and simultaneously predict verbal ability in direction consistent with expectation. For example, in the combined sample, individuals whose mothers have at least a college degree score 5.65 points higher on verbal ability than those whose mothers have an education less than high school. Those whose fathers have at least a college degree score 1.96 points higher than those whose fathers have an education less than high school. Those whose fathers hold a professional and managerial job are about 2.50 points higher than those whose fathers hold a manual and blue-collar job. Individuals living in a household in the top 20% income group score 3.88 points higher than those in the lowest 20% income group. Individuals living in a household with 3 to 5 siblings score 2.84 points lower than those who are the only child in a family. An increase in one standard deviation in the index of the neighborhood disadvantage is associated with a decrease of 0.60 point of the verbal ability score. Those who are in a school session when taking the test score about 1.47 points higher than those who are not in a school session.
Table 3 presents the coefficients and their standard errors of ability PGSs from multilevel models of verbal ability. Among whites and Hispanic whites, one standard deviation of the education PGS is associated with 2.27 points of verbal ability, and one standard deviation of the ability PGS is associated with 0.44 points of verbal ability. These results establish the importance of the two PGSs.
The models in Table 4 include all SES measures as well as the two ability PGSs. These models could be compared with the models in Table 2 to assess the impact of the two PGSs on the effects of parental SES. Essentially, all SES measures that are statistically significant in the model without the two PGSs have remained significant in the model with the PGSs. As expected, the inclusion of the PGSs attenuates the SES effect sizes. In most cases, the inclusion of the PGSs reduces the SES coefficients in models in Table 2 by about 10–15%. For example, in Table 2, the two categories of mother’s education “high-school graduation/some college” and “at least college degree”, respectively, are associated with 2.63 and 5.65 additional points in the verbal ability score relative to “less than high school” in the model without the PGSs. The two comparable estimates in the model with the two PGSs in Table 4 are 2.21 and 4.98, which represent reductions of 15.9% and 11.8%, respectively. The models in Table 4 could also be compared with the models in Table 3 to assess the impact of parental SES on the two PGS estimates. The effects of both PGSs are reduced, with reductions of 23.6% and 6.8%, respectively, for the education PGS and the ability PGS when parental SES is included in the model.
The incremental or “net” R2s in Table 4 are the R2s due to the two PGSs above and beyond SES. These R2s may be considered a measure of the impact of offspring genome on verbal ability. Such an incremental R2 could be obtained by subtracting the R2 of a model containing SES and the principal components (PCAs) from the R2 in the corresponding model in Table 4. The incremental R2 or “net” R2 in the combined sample is 1.5%. A comparison of another direction can be made between the R2 (21.9%) in Table 4 and that (12.6%) of Table 3. The incremental R2 of 21.9–12.6 = 9.3% due to parental SES is apparently much larger than the incremental R2 of 21.9–20.4 = 1.5% due to the two PGSs, but this R2 of 9.3% needs to be interpreted carefully.
Supplementary table 1 presents findings from three models based on 719 full siblings and DZ twins in Add Health. The analysis tests the robustness of the effects of ability PGSs when controlling for the genomic impact in parental SES17. The first of the three models estimates the effects of the two PGSs alone; the second adds observed parental SES; the third estimates a sibling-fixed-effect model that controls for all shared effects among the siblings. Consistent with the findings from our full-sample analysis (Table 4), adding observed parental SES reduces the effects of the two PGSs. The fixed-effects model reduces further the effects of the PGSs. The PGS effects in the fixed-effects model remain significant and substantial in size.
The models in Table 5 add the Wave-1 verbal ability as a predictor to the model that uses SES measures and the two PGSs to predict the Wave-3 verbal ability (Eq. 2). The Wave-1 verbal ability was measured about seven years before the Wave-3 verbal ability was measured. A total of 2,176 individuals are excluded in the analysis because an individual must contribute two measures of verbal ability to be included in this analysis. Little surprise that the PVT score at Wave 1 is highly predictive of the PVT score at Wave 3. In the combined sample, an increase of one point in the Wave-1 PVT score is associated with an increase of about 0.49 points in the Wave-3 PVT score. The effect of one standard deviation of the education PGS is reduced from 1.73 points in the combined sample in Table 4 to 0.51 points in Table 5. The ability PGS has lost its statistical significance.
Conditional on the Wave-1 PVT, the effects of SES are expected to be largely washed out. This is what we observe. Most of the SES measures no longer significantly predict verbal ability at Wave 3. The two remarkable exceptions are years of education by Wave 3 and neighborhood disadvantage at Wave 1. The former is significantly predictive of Wave-3 PVT with a P value of 0.001, with each additional year of schooling associated with about 0.78 point of verbal ability score. It is neighborhood disadvantage in earlier life at Wave 1 rather than at Wave 3 that has turned out to be negatively associated with verbal ability.
Supplementary Tables 2–5 provide a set of findings parallel to those in Tables 2–5. The difference is that in Supplementary Tables 2–5, the SES measures are represented by a single summary score obtained from the first principal component of a principal component analysis. In the models, the summary score is always highly significant. The results convey a comparable story as that told by using specific SES measures.
G×E interaction and other models
Table 6 shows the main effects and G×E-interaction effects on verbal ability between the PGSs and a PCA summary score of SES. A likelihood ratio test shows that the G×E-interaction model (−2LogL = 67,058; df = 24) has significantly more explanatory power than the main effects model (−2LogL = 67,064; df = 22) at the level of 5% with two degrees of freedom. The interdependence between the education PGS and SES is positive, indicating that a favorable SES environment would enhance the effect of offspring genome.
Supplementary Table 7 tests additional effects of general health, mental health and delinquency behavior on verbal ability when parental SES and the two PGSs are in the model. Out of the three, only mental health significantly predicts verbal ability with an expected negative impact.
We carried out the MICE analysis, an alternative way of addressing missing values and the analysis yielded a very similar set of results as those in the analysis that codes missing values as a separate category.
Discussion
To summarize, our analysis regresses verbal ability on two ability PGSs and parental SES in an Add-Health sample of 7194 individuals. Our first two hypotheses concerning the effects of parental SES alone (Table 2) and the effects of the two PGSs alone (Table 3) are supported. The traditional sociological model of SES context predicts verbal ability well (Table 2). Of the two PGSs, the education PGS has a much more robust prediction of verbal ability than the intelligence PGS; the much larger discovery sample size for the former could be one of the explanations. After demographic variables and immigration status are adjusted, mother’s education, father’s education, father’s occupation, household income, sibship size, neighborhood disadvantage, and in school over the past year are all significantly and simultaneously associated with verbal ability. Only mother’s occupation is an exception. The two PGSs significantly and simultaneously predict verbal ability (Table 3). These SES and PGS estimates are “nominal” effects in the sense that both the PGS and SES estimates are upwardly biased because of the impact of parental genomes (Fig. 1).
Key evidence supporting Hypotheses 3 and 4 is revealed after comparing Table 4 with Tables 2, 3. When SES and PGSs are included in the same model, both continue to significantly predict verbal ability; but the estimates are reduced. The reduction in the education PGS is more than 20% and the reduction in the ability PGS is about 7%. These reductions may be interpreted as the upward biases when parental genomic effects are not controlled. The reduction in the SES effects is about 10–15%. These percentages may be interpreted as one half of the effect in parental SES induced by parental genomes. In other words, about 20–30% of parental SES effects is genomic from parental genomes. Sample variation in a particular study is likely a major source of the variation in these estimates. But the empirical evidence does seem to support an important role of parental genomes in parental SES.
The relative contribution of SES and genomes to verbal ability may be assessed by incremental R2s. GWAS studies routinely report R2 as an indicator of the amount of explanatory power they have secured in explaining an outcome13. Supplementary Table 6 lists the R2s of models with different combinations of parental SES, two ability PGSs and the PCAs. The model in Table 4 yields an R2 of 21.9% reflecting the effects of offspring genome, parental SES and population stratification. Incremental R2s could be derived from comparing the R2s across the models. The incremental R2 of offspring genome measures the explanatory power of offspring genome on verbal ability above and beyond SES. Similarly, the incremental R2 of SES measures the overall explanatory power of SES in addition to offspring genome. To estimate the incremental R2 from the influence of offspring genome, we deduct from 21.9% the R2 of 20.04% in the comparison model that includes parental SES and PCAs; this yields an R2 of 1.5%. This incremental R2 is from offspring genome alone and the impact of the genomic component in parental SES is excluded. Importantly, this R2 is also net of the explanatory power due to population stratification. To estimate the contribution of parental SES, we deduct from 21.9% the R2 of 12.6% in model 3 that includes the two PGSs and the PCAs, obtaining an R2 of 9.3%. However, not all of the 9.3% is explained by environmental SES. Some of it is genomic. The 9.3% excludes the effect of offspring genome, but includes about one half of the effect of the genomic component in parental SES.
To weigh the relative contribution of offspring genome vs. that of SES, we’d like to directly compare the incremental R2 of offspring genome with that of the environmental component in parental SES (Fig. 1). But the latter is unknown even though we know that it must be smaller than 9.3% because the 9.3% results from the impact of environmental parental SES and the impact of one half of the genomic component in parental SES. Drawing from the findings of Kong et al.16 a rough upper bound may be set at 1.5% for the incremental R2 of the genomic component in parental SES. Kong et al.16 estimates the effect of transmitted parental alleles to be three times as large as that of non-transmitted parental alleles. This suggests that the effect of the genomic component in parental SES is about two thirds of the effect of offspring genome; the genomic component is subject to the influence of non-transmitted alleles as well as transmitted alleles. This result suggests that the genomic component in parental SES has an effect smaller than that of offspring genome. Assuming that the genomic component in parental SES has an impact equal or smaller than that of offspring genome (which has an incremental R2 of 1.5%), we set the upper bound of the incremental R2 of the genomic component in parental SES to 1.5%. Thus, our rough estimates of the incremental R2s for offspring genome, the genomic component in parental SES, and the environmental component in parental SES are 1.5%, 1.5% and 9.3 − 1.5 = 7.8%, respectively.
We performed additional analyses and present the results in Supplementary Materials to demonstrate the robustness of the effect of offspring genome. The sibling-fixed-effects model adds evidence that offspring genome indeed predicts verbal ability net of parental genomes in spite of a much smaller sample (Supplementary Table 1). The fixed-effects model may be an over-stringent test in this context. It controls for the genomic component in parental SES and it also unduly controls for some of the effect of offspring genome.
Replacing multiple SES measures by a single summary score of SES produces a set of findings (Supplementary Tables 2–5) that are parallel to those in Tables 2–5. The coefficients of the SES summary score are always highly significant and in the same direction as the SES measures, telling a substantially similar story as those in Tables 2–5. The two approaches each have advantages. The SES summary score is much simpler and the simplicity in the measurement of SES is almost a necessity when carrying out a G×E-interaction analysis. On the other hand, specific SES measures are directly from survey items and can be interpreted much more intuitively.
When general health, mental health and delinquency are entered into the model with SES and the two PGSs, only mental health negatively predicts verbal ability. Importantly, these additions do not change the findings from a model with parental SES and the two PGSs presented earlier.
To further test what SES predictors would remain important to the Wave-3 verbal ability, above and beyond what had already gone into the Wave-1 ability, we condition the prediction of the Wave-3 ability on the Wave-1 ability (Table 5). A coefficient of about 0.5 of Wave-1 ability indicates that the Wave-1 score predicts the Wave-3 score with about 50% accuracy. Conditional on the Wave-1 ability, the effects of the PGS and SES predictors carry a distinct meaning. These effects represent effects additional to measured and unmeasured PGSs, SES and other factors that had already acted upon the Wave-1 ability. In the findings, two SES predictors stand out: number of years of schooling by Wave 3 and neighborhood disadvantage at Wave 1. The large effect of year of schooling by Wave 3 is particularly noteworthy. Years of schooling is not used in analysis presented in Tables 2–4 because the study participants at Wave 1 were aged 12–18 with little variation in schooling after controlling for age. The coefficient of 0.78 implies that an additional year of schooling is associated with about 0.8 point of verbal ability. Four measures are taken to address the difficulty of estimating the causal effect of schooling. First, the ability PGSs are included. Second, the model controls for an earlier version of verbal ability. These controls are equivalent to controlling for the ability for seeking and attaining education. Third, the model controls for age at which the Wave-3 test is taken because of its correlation with schooling. Lastly, we measure schooling by the number of years of schooling before verbal ability is taken at Wave 3. The above comments for schooling could be also said about neighborhood disadvantage at Wave 1, which adds prediction to verbal ability after the conditioning.
Our gene-environment interaction analysis shows a positive interaction between the SES summary score and the education PGS. The interpretation could be interpreted in two ways. A favorable parental SES enhances the effect of the PGS or a higher PGS augments the advantage of a favorable parental SES. G×E-interaction analysis has numerous pitfalls and obtaining credible results is challenging. Before arriving at our current G×E results, we checked against potential issues inherent in G×E-interaction analysis49,50,51. In addition, A G×E-interaction result based on a PGS assumes that the interaction is uniform over the genome. As we discussed earlier, a part of E is genetic.
In conclusion, including both SES and offspring genome in a model of verbal ability results in about a 20% reduction in the effect size of the education PGS and about 10–15% reduction in the effect sizes of SES. The latter implies that about 20–30% of the parental SES effects are not environmental, but genomic. The three incremental R2s corresponding to the two PGSs, the genomic component in parental SES, and the environmental component in parental SES are about 1.5%, 1.5%, and 7.8%, respectively. Thus, the total genomic R2 and the total environmental R2 are estimated to be 3% and 7.8%, respectively.
These findings have implications and challenges for work that is devoted to the study of genetic influence on cognitive ability and for work that focuses on social environmental influences. For the former, our analysis replicates previous finding that offspring genome has a robust and substantial effect on verbal ability even after stringent controls for parental genomic influences. However, the incremental R2 of 1.5% appears surprisingly small, especially in view of the much larger ability heritability of 50% or more from twin studies. The latest GWAS of cognitive ability report R2s of 4.3%67 and 5.2%14, respectively. These estimates do not exclude the effects of parental genomes and PCAs.
The work on genomic influence at DNA level on cognitive ability is ongoing. Substantially larger samples than currently used could be assembled to hunt for more genes in fresh GWAS. Technological breakthroughs in genomics happen all the time. These foreseeable and unforeseeable advances will in all likelihood raise the percentage of variance that can be explained by offspring genomic measures in the future.
The news for social scientists studying social environmental influences is two-fold. Social scientists have long considered SES context fundamentally important in shaping life outcomes including cognitive ability. With the incremental R2 of environmental parental SES estimated to be roughly about 7.8% vs. 1.5% for offspring genome and 1.5% for the genomic component in parental SES, the current evidence confirms the importance of SES context. After all, the development of cognitive ability including verbal ability depends heavily on the context of modern education and society, which in turn are closely related to parental resources and decisions.
The much large incremental R2 of environmental parental SES than that of offspring does not support the dismissal of shared environmental influences. The dismissal is based on the observation that in twin studies the variance due to shared environmental factors tends to go to zero when individuals reach maturity. The discrepancy between twin studies and our analysis may be partially explained by the hypothesis that parental SES is positively correlated with individual-level environmental influences, that is, a higher level of parental SES affords more resources for individual-level interventions. In social-science studies, most SES measures are at shared family level.
Yet, the role of inheritance cannot be ignored. Not only an individual’s genome has an important direct influence on verbal ability; parental genomes also influence verbal ability through parental SES. Our findings suggest that about 20–30% of the conventionally-estimated coefficients of SES are not environmental but parentally genomic. The decades-long blueprint in research of including SES in a model and interpreting their effects as those of SES environment needs to be amended accordingly. A straightforward and ready solution is to include both SES and offspring genome in the same model. This would result in more accurate estimates of the effects of SES and offspring genome. The genetic effects would become more truly a reflection of children’s own genome rather than his or her parents’ genomes. More importantly, about 50% of the upward bias in the effects of parental SES due to parental genomes would be corrected. These findings point to the benefits of collecting DNA data in large social-science studies like Add-Health granted that their primary purpose is to understand social and environmental influences.
Methods
Data source
We use data from Add Health (http://www.cpc.unc.edu/projects/addhealth/), which is an ongoing longitudinal study of a nationally representative sample of more than 20,000 adolescents in grades 7–12 or ages 12–18 in 1994–95 in the United States who have been followed for more than 25 years15. Add Health has conducted one in-school survey in 1994–1995, and five in-home interviews in 1994–1995 (Wave 1), 1996 (Wave 2), 2001–02 (Wave 3), 2008 (Wave 4), and 2016–8 (Wave 5). In accordance with the University of North Carolina School of Public Health Institutional Review Board guidelines which are based upon the Codes of Federal Regulations on the Protection of Human subjects 45CFR46, participants in Add Health provided written informed consent to participate in all aspects of the study. The original purpose of Add Health was to understand the causes of health, health behavior, and educational development with a special emphasis on the role of social context at the levels of family, neighborhoods, and communities.
We start with a sample of 9975 individuals for whom GWAS measures are available. Excluded are those without a measure of verbal ability, those self-identifying as African Americans, Asian Americans, Native Americans or missing on race/ethnicity, and those with covariates missing on neighborhood disadvantage. Our final analysis sample includes 7194 individuals consisting of 5820 whites and 1374 Hispanic whites.
In January 2015, Add Health completed genome-wide genotyping on the Wave IV participants who consented to archive their DNA for future studies. Of the 15,701 respondents interviewed, 12,200 of the eligible respondents agreed to archive their DNA for future analysis “related to long term health.” Add Health utilizes two Illumina platforms for GWAS: the Illumina Human Omni1-Quad BeadChip at first and then the Illumina Human Omni-2.5 Quad BeadChip. The two platforms utilize tag SNP technology to identify and include, respectively, >1.1 million and 2.5 million genetic markers, which are derived from phases 1–3 of the International HapMap Project68 and the 1000 Genomes Project (1KGP)69.
Verbal Ability is measured by an abridged version (PVT) of the Peabody Picture Vocabulary Test-Revised (PPVT-R) implemented twice at Waves 1 and 3 of Add Health. PVT includes 87 or half of the items of PPVT-R. Our analysis uses the standardized score of PVT as the outcome variable. PPVT was first published in 1959 and has been revised three times70. Psychological literature considers PPVT an estimate of verbal intelligence71,72. The correlations between PPVT and full-scale intelligence tests were found to be between 0.40 and 0.6072.
Mother’s and father’s education are, respectively, coded into a four- category categorical variable with less than high school, high school graduation and some college, at least college degree, and missing. Mother’s and father’s occupation in Add Health originally have 16 categories. They are combined into five categories of none and other; manual or blue collar; sales, service, or administrative; professional or managerial; and missing. In the G×E-interaction analysis and the analysis presented in Supplementary Materials, we construct an SES PCA, of which occupation is a component. We test the robustness of three continuous occupation scales: the original 5 categories in Add Health, the 8-level, and the 11-level scales. In the last two, the Add Health 16 categories are mapped onto a well-known occupational prestige ratings73. The three sets of results are almost identical. The findings from the 11-level occupation scale are presented.
Household income is total family income, which is only available from the parental questionnaire at Wave 1 in 1994. Household income is coded into a six-category variable with cutoff points at 20th, 40th, 60th, and 80th percentile plus a category of missing. Family structure is measured by a dichotomous variable taking the value of one if the respondent lives with two biological parents and zero if the respondent is from a household of a single parent, a stepparent, an adopted family, or a foster home at Wave 1. Sibship size is the number of siblings living in the household at Wave 1.
To capture neighborhood disadvantage, we follow the approach used by Wodtke, Harding and Elwert74. Neighborhood disadvantage is measured by the first principal component from a principal component analysis of six neighborhood measures that include the proportion of households living below the poverty line, the proportion of adults who are unemployed, the proportion of female-headed households, the proportion of adult residents without a high school diploma, the proportion of residents with a college degree, and the proportion of workers holding managerial or professional jobs. In school is coded as one if the respondent is in a school session when interviewed or if the respondent is in school in the past school year when the respondent is interviewed in a summer break; and in school is coded as zero otherwise.
In generating covariates, we take advantage of the longitudinal design of Add Health. Whenever it is possible to match the repeated measures of verbal ability at Waves 1 and 3, we use time-varying covariates measured at Waves 1 and 3. For example, we generate two measures of neighborhood disadvantage derived from two rounds of principal component analysis using data at Waves 1 and 3, respectively. These two measures of neighborhood disadvantage are included longitudinally in our analysis. Similarly, parental education and occupation are also measured at Waves 1 and 3 and included as time-varying covariates in analysis.
The genomic measures of educational attainment and cognitive ability are based on the 2018 GWAS of years of schooling13 and the 2018 GWAS of intelligence14, respectively. In the former, the GWAS separately regresses each of a large number of single nucleotide polymorphisms (SNPs) on years of schooling where SNPs are a particular type of genetic variables taking values 0, 1, or 2. The value represents the number of risk alleles at the genetic locus. The GWAS obtained one β from each SNP regression.
The GWAS results are calculated into a summary polygenic score (PGS)75 for each individual using PLINK. To tap all the predictability of a GWAS, a PGS for education for individual i is calculated using all βs from GWAS as weights instead of excluding SNPs above a certain P value for the observed risk alleles Xijs for this individual i: \(PGS_i \,=\, \mathop {\sum}\nolimits_{j \,=\, 1}^n {\beta _{ij}{{{\mathrm{X}}}}_{ij}}\), where j indexes SNP and n stands for the total number of SNPs used in the calculation. The PGS for cognitive ability is similarly constructed.
To facilitate interpretation, a PGS is standardized into a Z score: \(PGS_i^s \,=\, \left[ {PGS_i \,-\, M} \right]/\sigma\), where M is the mean PGS averaged over all individuals in the sample and σ is the standard deviation of the PGS. When \(PGS_i^s\) is included in a regression model predicting verbal ability, its coefficient can be interpreted as the effect of one standard deviation of the PGS. Thus, the standardized PGSs are a way to estimate and interpret the overall genomic influence on a phenotype. The standardization is performed three times separately: within European Americans, within Hispanic whites, and within the combined sample of European and Hispanic white Americans. We have similarly constructed standardized PGS_for cognitive ability. In the rest of this article, we use PGSi to represent \(PGS_i^s\) for simplicity. The original GWAS of education and cognitive ability include data from Add Health and in this project, the Add Health PGSs are calculated using the GWAS results with Add-health data excluded. For more information on the QC procedures, imputation, LD patterns and PGS construction, see Okbay et al.76 at https://addhealth.cpc.unc.edu/wp-content/uploads/docs/user_guides/AH_GWAS_QC.pdf.
Analytical strategies
Appropriate statistical procedures were used to address the correlations in verbal ability measures in Add Health77. One source of the correlation is due to the inclusion of the two measures of verbal ability per individual. The other source of the correlation originates from the study design of Add Health, which includes a genetic-informative sample consisting of full siblings, DZ twins, MZ twins, and other related individuals. In our analysis, we address the data hierarchy using multilevel regression models78,79,80. We implement two forms of multilevel models. The first is a three-level model that addresses the repeated measures of verbal ability in addition to the sibling clusters:
where Vability stands for verbal ability; the subscripts t, i, j, and s index Add-Health Wave, individual, sibship and type of sibship, respectively; SES, G and C are, respectively, vectors of SES, PGSs, and other variables including demographic indicators and principal components for addressing population admixture; B1, B2, and B3 are vectors representing the effects of these observed variables; and etij, νij, and μj(s) are random effects at the levels of Add-Health Wave, individual and sibship, respectively. We estimated models that distinguish different types of sibship and models that do not make that distinction, which is equivalent to ignoring the subscript s. The two sets of estimated coefficients of observed variables are essentially identical. We only present estimates from the models that do not make the distinction.
Our model that conditions on Wave-1 verbal ability is a two-level model that uses verbal ability at Wave 3 as the dependent variable and that estimates the effects of the same set of predictors while controlling for verbal ability at Wave 1:
Adding Wave-1 verbal ability allows a further test of the effects of offspring genome and family-SES in addition to all genomic and environmental influences that had already acted on Wave-1 verbal ability. Both (1) and (2) are random-intercept models.
The regression models are fit by the mixed command in STATA 16 SE. Population admixture or population stratification is a major concern in genetic association studies. Population groups separated over the past 50,000–100,000 years are likely to have developed private genetic variants that differ across population groups and that are unrelated to cognitive ability. If these population groups differ in ability test scores for environmental reasons and if these private variants are not controlled properly, the related genetic variants could be erroneously interpreted as causing differences in cognitive ability. The error can be avoided by the common practice of including the ten or so largest principle components (PCAs) in the regression that links genetic variants to a phenotype81. The PCAs represent ancestral genetic differences among population groups and are highly correlated with self-reported race/ethnicity. G×E-interaction terms can be added to models (1) and (2) readily. Findings are presented based on analysis in which missing values in predictors are coded into a separate category. Alternatively, missing values are addressed by performing the multiple imputation via chained equations (MICE)82. The MICE approach is accomplished by the mim command and the xtmixed command in STATA 16 SE.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The data supporting this work are available from the Add-Health website https://addhealth.cpc.unc.edu/) but restrictions apply to the availability of the data. The restricted-use data can however be available via contractual agreement with the Carolina Population Center (CPC Data Portal: https://data.cpc.unc.edu/projects/2/view).
References
Jencks, C. et al. Who Gets Ahead? The Determinants of Economic Success in America (Basic Books, 1979).
Farkas, G. & Vicknair, K. Appropriate tests of racial wage discrimination require controls for cognitive skill: Comment on Cancio, Evans, and Maume. Am. Sociol. Rev. 61, 557–560 (1996).
Taubman, P. & Wales, T. Mental Ability and Higher Educational Attainment in the 20th Century (NBER Books, National Bureau of Economic Research, Inc, 1972).
Taubman, P. & Wales, T. Higher Education and Earnings (McGraw-Hill, 1974).
Wraw, C., Deary, I. J., Gale, C. R. & Der, G. Intelligence in youth and health at age 50. Intelligence 53, 23–32 (2015).
Farkas, G., England, P., Vicknair, K. & Kilbourne, B. S. Cognitive skill, skill demands of jobs, and earnings among young European American, African American, and Mexican American workers. Soc. Forces 75, 913–938 (1997).
Hauser, R. M. Causes and consequences of cognitive functioning across the life course. Educ. Res. 39, 95–109 (2010).
Lemann, N. The Big Test: The Secret History of the American Meritocracy (Straus and Giroux, 1999).
Bouchard, T. J. Genetic and environmental influences on adult intelligence and special mental abilities. Hum. Biol. 70, 257–279 (1998).
Velden, M. The heritability of intelligence: Neither known nor unknown. Am. Psychol. 52, 72–73 (1997).
Plomin, R. & Deary, I. J. Genetics and intelligence differences: five special findings. Mol. Psychiatry 20, 98–108 (2015).
Haworth, C. M. A. et al. The heritability of general cognitive ability increases linearly from childhood to young adulthood. Mol. Psychiatry 15, 1112–1120 (2010).
Lee, J. J. et al. Gene discovery and polygenic prediction from a genome-wide association study of educational attainment in 1.1 million individuals. Nat. Genet. 50, 1112–1121 (2018).
Savage, J. E. et al. Genome-wide association meta-analysis in 269,867 individuals identifies new genetic and functional links to intelligence. Nat. Genet. 50, 912-+ (2018).
Harris, K. M. et al. The National Longitudinal Study of Adolescent Health: Research design, http://www.cpc.unc.edu/projects/addhealth/design (2009).
Kong, A. et al. The nature of nurture: Effects of parental genotypes. Science 359, 424–428 (2018).
Domingue, B. W., Belsky, D., Conley, D., Harris, K. M. & Boardman, J. D. Polygenic Influence on Educational Attainment: New evidence from The National Longitudinal Study of Adolescent to Adult Health. AERA Open 1, 1–13 (2015).
Braveman, P. A. et al. Socioeconomic status in health research—one size does not fit all. Jama J. Am. Med. Assoc. 294, 2879–2888 (2005).
Link, B. G. & Phelan, J. C. Understanding sociodemographic differences in health—the role of fundamental social causes. Am. J. Public Health 86, 471–473 (1996).
Duncan, O. D., Featherman, D. L. & Duncan, B. Socioeconomic background and achievement (Seminar Press, 1972).
Hill, H. D. Family income level, variability, and trend as predictors of child achievement and behavior. Demography 58, 1499–1524 (2021).
Yeung, W. J., Linver, M. R. & Brooks-Gunn, J. How money matters for young children’s development: Parental investment and family processes. Child Dev. 73, 1861–1879 (2002).
Blau, D. M. The effect of income on child development. Rev. Econ. Stat. 81, 261–276 (1999).
Cavanagh, S. E. & Fomby, P. in Annual Review of Sociology, Vol 45 Vol. 45 Annual Review of Sociology (eds K. S. Cook & D. S. Massey) 493–513 (2019).
Cobb-Clark, D. A., Salamanca, N. & Zhu, A. N. Parenting style as an investment in human development. J. Popul. Econ. 32, 1315–1352 (2019).
Entwisle, D. R. & Alexander, K. L. Summer setback—race, poverty, school composition, and mathematics achievement in the 1st 2 years of school. Am. Sociol. Rev. 57, 72–84 (1992).
Locurto, C. The malleability of iq as judged from adoption studies. Intelligence 14, 275–292 (1990).
Kloosterman, R., Notten, N., Tolsma, J. & Kraaykamp, G. The effects of parental reading socialization and early school involvement on children’s academic performance: a panel study of primary school pupils in the Netherlands. Eur. Sociol. Rev. 27, 291–306 (2011).
Guo, G. & Harris, K. M. The mechanisms mediating the effects of poverty on children’s intellectual development. Demography 37, 431–447 (2000).
Hart, B. & Risley, R. T. Meaningful differences in the everyday experience of young American children (Paul H. Brookes, 1995).
Farkas, G. & Beron, K. The detailed age trajectory of oral vocabulary knowledge: differences by class and race. Soc. Sci. Res. 33, 464–497 (2004).
DeGroot, A. D. The effects of war upon the intelligence of youth. J. Abnorm. Soc. Pcychol. 43, 311–317 (1948).
Nisbett, R. E. Intelligence and how to get it. (W.W. Norton & Company, Inc., 2009).
Cahan, S. & Cohen, N. Age versus schooling effects on intelligence development. Child Dev. 60, 1239–1249 (1989).
Winship, C. & Korenman, S. In Intelligence and Success: Is it all in the Genes? Scientists Respond to The Bell Curve. (eds B. Devlin, S. E., Fienberg, D., Resnick & K., Reder) 215–234 (Springer-Verlag, 1997).
Herrnstein, R. J. & Murray, C. The bell curve: Intelligence and class structure in American life. (Free Press, 1994).
Burt, C., Jones, E., Miller, E. & Moodie, W. How the mind works. (Appleton-Century-Crofts, 1934).
Jensen, A. R. How much can we boost iq and scholastic achievement. Harv. Educ. Rev. 39, 1–123 (1969).
Glazier, A. M., Nadeau, J. H. & Aitman, T. J. Finding genes that underlie complex traits. Science 298, 2345–2349 (2002).
Frayling, T. M. et al. A common variant in the FTO gene is associated with body mass index and predisposes to childhood and adult obesity. Science 316, 889–894 (2007).
Zeggini, E. et al. Replication of genome-wide association signals in UK samples reveals risk loci for type 2 diabetes. Science 316, 1336–1341 (2007).
Deary, I. J. In Annual Review of Psychology, Vol 63 Vol. 63 Annual Review of Psychology (eds S. T. Fiske, D. L. Schacter, & S. E. Taylor) 453–482 (2012).
Deary, I. J., Penke, L. & Johnson, W. The neuroscience of human intelligence differences. Nat. Rev. Neurosci. 11, 201–211 (2010).
Bulik-Sullivan, B. K. et al. LD Score regression distinguishes confounding from polygenicity in genome-wide association studies. Nat. Genet. 47, 291-+ (2015).
Guo, G. & Stearns, E. The social influences on the realization of genetic potential for intellectual development. Soc. Forces 80, 881–910 (2002).
Turkheimer, E., Haley, A., Waldron, M. & D’Onofrio, B. & Gottesman, II. Socioeconomic status modifies heritability of IQ in young children. Psychol. Sci. 14, 623–628 (2003).
Tucker-Drob, E. M., Briley, D. A. & Harden, K. P. Genetic and environmental influences on cognition across development and context. Curr. Directions Psychol. Sci. 22, 349–355 (2013).
Figlio, D. N., Freese, J., Karbownik, K. & Roth, J. Socioeconomic status and genetic influences on cognitive development. Proc. Natl Acad. Sci. USA. 114, 13441–13446 (2017).
Keller, M. C. Gene x environment interaction studies have not properly controlled for potential confounders: the problem and the (simple) solution. Biol. Psychiatry 75, 18–24 (2014).
Domingue, B., Trejo, S., Armstrong-Carter, E. & Tucker-Drob, E. Interactions between Polygenic Scores and Environments: Methodological and Conceptual Challenges. Sociol. Sci. 7, 465–486 (2020).
Akimova, E. T., Breen, R., Brazel, D. M. & Mills, M. C. Gene-environment dependencies lead to collider bias in models with polygenic scores. Sci. Rep. 11, https://doi.org/10.1038/s41598-021-89020-x (2021).
Scarr, S. & McCartney, K. How people make their own environments—a theory of genotype-environment effects. Child Dev. 54, 424–435 (1983).
Belsky, D. W. et al. Genetic analysis of social-class mobility in five longitudinal studies. Proc. Natl Acad. Sci. USA. 115, E7275–E7284 (2018).
MacArthur, J. et al. The New NHGRI-EBI Catalog of Published Genome-Wide Association Studies (Gwas Catalog). Nucleic Acids Res. 45, D896–D901 (2017).
Cavalli-Sforza, L. L., Menozzi, P. & Piazza, A. The History and Geography of Human Genes. (Princeton University Press, 1996).
Duncan, L. et al. Analysis of Polygenic Score Usage and Performance across Diverse Human Populations 2018).
Duncan, G. J. et al. School readiness and later achievement. Dev. Psychol. 43, 1428–1446 (2007).
Kessler, R. C., Foster, C. L., Saunders, W. B. & Stang, P. E. Social-consequences of psychiatric-disorders .1. educational-attainment. Am. J. Psychiatry 152, 1026–1032 (1995).
Breslau, J. et al. The impact of early behavior disturbances on academic achievement in high school. Pediatrics 123, 1472–1476 (2009).
McLeod, J. D. & Kaiser, K. Childhood emotional and behavioral problems and educational attainment. Am. Sociol. Rev. 69, 636–658 (2004).
McLeod, J. D., Uemura, R. & Rohrman, S. Adolescent mental health, behavior problems, and academic achievement. J. Health Soc. Behav. 53, 482–497 (2012).
Ickovics, J. R. et al. Health and academic achievement: cumulative effects of health assets on standardized test scores among urban youth in the United States. J. Sch. Health 84, 40–48 (2014).
Miech, R. A., Caspi, A., Moffitt, T. E., Wright, B. R. E. & Silva, P. A. Low socioeconomic status and mental disorders: A longitudinal study of selection and causation during young adulthood. Am. J. Sociol. 104, 1096–1131 (1999).
Breslau, J., Michael, L., Nancy, S. B. & Kessler, R. C. Mental disorders and subsequent educational attainment in a US national sample. J. Psychiatr. Res. 42, 708–716 (2008).
Veldman, K. et al. Mental Health Problems and Educational Attainment in Adolescence: 9-Year Follow-Up of the TRAILS Study. PLoS ONE 9, https://doi.org/10.1371/journal.pone.0101751 (2014).
Nisbett, R. E. et al. Intelligence new findings and theoretical developments. Am. Psychologist 67, 130–159 (2012).
Davies, G. et al. Study of 300,486 individuals identifies 148 independent genetic loci influencing general cognitive function. Nat. Commun. 9 https://doi.org/10.1038/s41467-018-04362-x (2018).
Altshuler, D. et al. A haplotype map of the human genome. Nature 437, 1299–1320 (2005).
Altshuler, D. et al. A map of human genome variation from population-scale sequencing. Nature 467, 1061–1073 (2010).
Dunn, L. M. & Dunn, D. M. Peabody Picture Vocabulary Test, Fourth Edition (PPVT™-4). (Pearson Education., 2007).
Campbell, J. M. & Dommestrup, A. K. In Corsini Encyclopedia of Psychology (John Wiley & Sons, Inc., 2010).
Beres, K. A., Kaufman, A. S. & Perlman, M. D. in Handbook of Psychological Assessment (eds G., Goldstein & M. Hersen) Ch. Chapter 4—Assessment of Child Intelligence, 65–96 (1999).
Davids, J. A., Smith, T. W., Hodge, R. W., Nakao, K. & Treas, J. Occup. Prestig. Rat. 1989 Genderal Soc. Surv. (ICPSR) https://doi.org/10.3886/ICPSR09593.v1 (2006).
Wodtke, G. T., Harding, D. J. & Elwert, F. Neighborhood effects in temporal perspective: the impact of long-term exposure to concentrated disadvantage on high school graduation. Am. Sociol. Rev. 76, 713–736 (2011).
Dudbridge, F. Power and predictive accuracy of polygenic risk scores. PLoS Genet. 9, e1003348 (2013).
Okbay, A. et al. SSGAC polygenic scores (PGSs) in the National Longitudinal Study of Adolescent to Adult Health (Add Health, 2018).
Diggle, P. J., Heagerty, P., Liang, K.-Y. & Zeger, S. L. Analysis of Longitudinal Data. (Oxford University Press, 2002).
Searle, S. R. Linear Models. (Wiley and Sons, 1971).
Searle, S. R., Casella, G. & McCulloch, C. Variance Components (Wiley & Sons, 1992).
Raudenbush, S. W. & Bryk, A. S. Hierarchical linear models: Applications and data analysis methods. 2nd ed., (Sage, 2002).
Price, A. L. et al. Principal components analysis corrects for stratification in genome-wide association studies. Nat. Genet. 38, 904–909 (2006).
Rubin, D. B. Multiple Imputation for Nonresponse in Surveys., (John Wiley and Sons, 1987).
Acknowledgements
This research uses data from Add Health, a program project directed by Kathleen Mullan Harris and designed by J. Richard Udry, Peter S. Bearman, and Kathleen Mullan Harris at the University of North Carolina at Chapel Hill, and funded by a grant P01-HD31921 from the Eunice Kennedy National Institute of Child Health and Human Development, with cooperative funding from 23 other federal agencies and foundations.
Author information
Authors and Affiliations
Contributions
Guang Guo: overall study design, analysis plan development, writing, revision, finding interpretation, and data access. Meng-Jung Lin: analysis plan development, data analysis, and revision. Kathleen Mullan Harris: Add-Health study Design, data collection and data access, and revision.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Guo, G., Lin, MJ. & Harris, K.M. Socioeconomic and genomic roots of verbal ability from current evidence. npj Sci. Learn. 7, 22 (2022). https://doi.org/10.1038/s41539-022-00137-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41539-022-00137-8
- Springer Nature Limited