
Abstract
Our study presents a 319-gene panel targeting inherited retinal dystrophy (IRD) genes. Through a multi-center retrospective cohort study, we validated the assay’s effectiveness and clinical utility and characterized the mutation spectrum of Taiwanese IRD patients. Between January 2018 and May 2022, 493 patients in 425 unrelated families, all initially suspected of having IRD without prior genetic diagnoses, underwent detailed ophthalmic and physical examinations (with extra-ocular features recorded) and genetic testing with our customized panel. Disease-causing variants were identified by segregation analysis and clinical interpretation, with validation via Sanger sequencing. We achieved a read depth of >200× for 94.2% of the targeted 1.2 Mb region. 68.5% (291/425) of the probands received molecular diagnoses, with 53.9% (229/425) resolved cases. Retinitis pigmentosa (RP) is the most prevalent initial clinical impression (64.2%), and 90.8% of the cohort have the five most prevalent phenotypes (RP, cone-rod syndrome, Usher’s syndrome, Leber’s congenital amaurosis, Bietti crystalline dystrophy). The most commonly mutated genes of probands that received molecular diagnosis are USH2A (13.7% of the cohort), EYS (11.3%), CYP4V2 (4.8%), ABCA4 (4.5%), RPGR (3.4%), and RP1 (3.1%), collectively accounted for 40.8% of diagnoses. We identify 87 unique unreported variants previously not associated with IRD and refine clinical diagnoses for 21 patients (7.22% of positive cases). We developed a customized gene panel and tested it on the largest Taiwanese cohort, showing that it provides excellent coverage for diverse IRD phenotypes.
Similar content being viewed by others
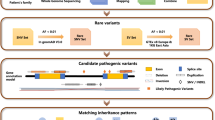


Introduction
Molecular diagnosis of rare diseases is challenging, and few treatments for genetic disorders are currently available1,2. Globally, 2.7 billion individuals (36% of the population) carry gene mutations responsible for autosomal recessive inherited retinal dystrophy (AR-IRD), and 5.5 million are afflicted with these mostly untreatable disorders3. Recent advances in DNA sequencing technologies and gene therapies have improved diagnostic yield and increased treatment options4. However, clinical translation needs to catch up to scientific discovery. For mutations in more than 300 genes associated with IRD identified to date, only mutations in fifteen genes (ABCA4, CEP290, CHM/REP1, CYP4V2, GUCY2D, MERTK, NR2E3, PDE6A, PDE6B, RHO, RPE65, RLBP1, RPGR, RS1, USH2A) are currently investigated for therapy. Clinical trials based on the mutations in these genes have been studied for seven IRDs (Enhanced S-cone syndrome (ESCS), Leber’s Congenital Amaurosis (LCA), Rod-Cone dystrophy (RCD), Retinitis Pigmentosa (RP), Stargardt’s dystrophy (SD), Usher’s syndrome (US) (Supplementary Table 1). In 2017, Luxturna (voretigene neparvovec-rzyl) became the first FDA-approved gene therapy in the USA, targeting biallelic mutations in RPE65 for LCA2, and remains the only approved IRD gene therapy available. As the vast majority of this group of disorders is untreatable, most patients progress to early blindness. Establishing the molecular diagnosis of IRDs is the first step in identifying possible therapeutic targets, and characterizing the mutational spectrum of IRD in the population can help prioritize efforts to develop treatments.
IRDs are genetically heterogeneous diseases that manifest a spectrum of phenotypes. IRDs exist as syndromic and non-syndromic forms where the former is associated with extra-ocular features, and the latter is confined to the eye. It has been estimated that up to 30% of IRD are syndromic, so ocular manifestations and molecular diagnosis obtained before the development of extra-ocular features may aid in timely diagnosis and management5,6,7. This paper presents the highly efficient molecular diagnostic approach for IRDs based on next-generation sequencing of a gene panel of 319 IRD-associated genes. We tested this approach on 425 patients and critical family members, representing the largest Taiwanese IRD cohort to date, and obtained a diagnostic yield of 68.5% of the probands received molecular diagnoses, and 53.9% of those consisted of solved diagnoses. Our results established the Taiwanese IRD genetic landscape and demonstrated that gene panel sequencing could be a cost-effective and highly efficient diagnostic method for IRD in both research and clinical settings.
Results
Cohort characteristics
This study identified 493 individuals, including 425 probands, with clinically suspected IRD (Table 1) (Supplementary Data 1: Phenodata). Age of onset was known in 365/425 probands, and the mean proband onset age was 25.0 (range, 0.08-74.0). Detailed clinical information per phenotype is delineated in Table 2. A tenth of the probands (46/425, 10.8%) had extra-ocular signs and symptoms consistent with syndromic IRDs, including Usher (38/425, 8.9%), Stickler (5/425, 1.2%), Alstrom (1/425, 0.002%), and Bardet-Biedl (2/425, 0.005%) syndromes. The subjects were grouped according to their initial clinical diagnosis. The breakdown of the 425 study probands among high-order diagnostic categories is shown in Table 2. RP is the most prevalent IRD (273/425, 64.2%), with the five most common conditions (RP, CRD, US, LCA, and BCD) accounting for 90.8% of the cohort (387/425).
Diagnostic yield and genetic findings
We developed a high-throughput sequencing panel test and achieved over 200X coverage of 94.2% of the 1.20 Mb target region (Supplementary Data 2). We sequenced 782 subjects in total, including 425 probands, and made molecular diagnoses for 68.5% (291/425) of the probands (Supplementary Data 3: GenoData). The diagnostic yield of cases with a positive family history of IRD (88.9%, 112/129) is notably higher than that for sporadic cases (60.5%, 179/296). In addition, syndromic patients have a higher diagnostic rate (80.4%) compared to that for non-syndromic cases (60.5%) (Table 1). Overall, our approach achieved a high diagnostic yield for all IRD subtypes (Table 2) in patients of all age groups (Supplementary Table 3). Furthermore, among the 291 probands with positive molecular diagnoses, the clinical diagnoses were confirmed in 92.8% of the cases, while the molecular diagnoses in 7.22% of the cases led to alternate clinical diagnoses. (Table 1).
Collectively, 568 variants (457 reported and 111 previously unreported) in 87 unique genes were identified (Table 3) (Supplementary Data 4). Mutations in 5 genes account for 40.8% (119/291) of the molecular diagnoses made: USH2A (40, 13.7%), EYS (33, 11.3%), CYP4V2 (15, 4.8%), ABCA4 (13, 4.5%), RPGR (9, 3.4%), and RP1 (9, 3.1%). Almost half of the positive cases (49.8%) are due to mutations found in the top 10 genes: the five genes listed above plus RDH12 (7, 2.4%), CHM (7, 2.4%), ADGRV1 (7, 2.4%), RP2 (6, 2.1%) (Fig. 1).

Pie chart showing the distribution of mutated genes in the 293 probands who received a molecular diagnosis after HRD panel genetic testing. Others denote accumulation of genes with <1.5% contribution.
Evaluating the mode of inheritance for all probands by pedigree (n = 425), we found that two-thirds of the probands have no family history of IRD (sporadic cases, 61.6%) (Table 4). We next studied the genotype and mode of inheritance for 291 positive cases. About half of the cases are sporadic (46.4%), 34.4% are of autosomal recessive inheritance, 11.3% are autosomal dominant, and 7.9% are X-linked recessive (Fig. 2a). Half of the positive cases (50.3%) have compound heterozygous mutation genotypes (Fig. 2b). Evaluating the ACMG pathogenicity classification of the 568 variants identified in the cohort, we found that 57.9% are pathogenic, 27.8% are likely pathogenic, and 14.3% are variants of unknown significance (Fig. 2c). Among the variants found, 111 variants have not been reported previously in databases associated with IRD (Table 3). Detailed genetic information on previously unreported variants is shown in Supplementary Data 3.

Pie chart showing the distribution of mutated gene characteristics in the 293 probands. Genotype and Inheritance are based on probands (293). Mutation characteristics and ACMG pathogenicity are variant-based such that they represent a total number of variants in the cohort of 293 probands (a total of 512 variants; homozygous variants are duplicated as alleles in the number of occurrences).
Discussion
In this study, we custom-designed a high-quality target capture probe set for NGS of a panel of 319 IRD-associated genes and tested the IRD panel sequencing approach on the largest Taiwanese IRD cohort to date. The IRD gene panel design is optimized for coverage of as many IRD genes as possible, and the sequencing protocol ensures that very high read depth is achieved while we scan the samples in batches of 200 samples in one experiment. The result is a highly efficient process with uniformly high depth coverage (>200×) for the target region, minimal sample failures, and much higher diagnostic yield for a wide range of IRDs than most rare genetic disease sequencing studies8,9,10,11,12,13,14,15,16. In the process, we also identified 111 previously unreported causal variants that could be used for therapeutic target development. In addition, the mutation spectrum and heterogeneity in our IRD cohort are significantly different from those in cohorts of other studies and ancestries. We found that our IRD landscape follows that of East Asia, with top genes consisting of USH2A, EYS, and CYP4V2, and not ABCA4, which is mainly found in European cohorts (Supplementary Fig. 2, Supplementary Table 4)9,13.
Visual impairment in children is challenging to diagnose in the early stages as IRD is complicated by complex, ambiguous phenotypes, hampering timely clinical diagnosis. Although IRD is considered a pediatric genetic disease, the patients’ mean onset age is 25.0. Moreover, 61.6% reported a negative family history, implying a high carrier rate in Taiwan with asymptomatic parents or underdiagnosed family members (Table 2). Genetic testing provides an opportunity to confirm or refine clinical diagnosis, guide disease management, inform prognosis, and assist in family planning17. Increased access to testing may make a difference in how patients interpret, adapt to, and experience their condition and are informed as gene therapies become available. Where genetic mutations still present with no cure, genetic results allow the family to prepare and plan for the future to support their child as required and reduce psychosocial burden. The IRD panel we designed provides a high success rate in diagnosis for patients regardless of their family history, phenotype, disease status, gender, and age. With a high diagnostic yield for diverse IRD subtypes, the IRD sequencing panel we designed is useful for early genetic testing and routine implementation in the clinic for IRD patients.
Methods
Patient enrollment and DNA preparation
This study was approved by the Institutional Review Board (IRB) of Academia Sinica (AS-IRB01-21064(N)), Taipei Veterans General Hospital (TVGH, 2021-04-009A), and Tzu Chi University (TCU, REC107-24) and adheres to the tenets of the Declaration of Helsinki. Written informed consent was obtained from all participants and their guardians if they were under legal age. Four hundred ninety-three patients, including 425 probands aged 0–96 years with suspected IRD and no previous genetic diagnosis, visited the Department of Ophthalmology at the TVGH and TCU between January 2018 and May 2022. DNA from 289 unaffected family members was also analyzed (total participants 782). Age and symptom onset, family history, gender, and best-corrected visual acuity (BCVA, logMAR) were recorded during the first clinic visit. Where visual acuity was recorded as counting fingers, a BCVA of 2.1 logMAR was noted; for hand movements, a BCVA of 2.4 logMAR was noted; for light perception, a BCVA of 2.7 logMAR; and for no light perception, a BCVA of 3.0. Clinical diagnosis of every proband was evaluated with thorough ophthalmology examinations and extra-ocular features recorded. The phenotype was determined with color and autofluorescence fundus (AF), optical coherence tomography (OCT), visual evoked potential (VEP), electroretinogram (ERG), visual field (VF), and, when suspected, audiometry. Their clinical blood samples have been in a collection maintained in a −50 °C freezer prior to the NGS experiment. The frozen blood samples were thawed, and the genomic DNA was extracted using the Gentra Puregene Blood kit (Qiagen, USA) according to the manufacturer’s protocol.
Sequencing data have been deposited at NCBI sequence read archive (SRA) (PRJNA952821) and ClinVar. All other data and materials are available from the corresponding authors upon reasonable request.
IRD gene panel screening
We designed the custom gene panel for the primary screening of IRD, which includes 319 genes associated with IRD (collected from Retnet: https://sph.uth.edu/retnet/ and OMIM: http://www.ncbi.nlm.nih.gov/omim/) (Supplementary Table 2). In addition, the panel also includes 81 noncoding sequences reported for association with IRD. The panel probes were synthesized by IDT (Integrated DNA Technologies, USA), and target capture experiments were conducted in 4 batches of ~200 samples.
For genomic library preps from each sample, the Illumina Nextera Flex for Enrichment kit was applied using 500 ng gDNA and amplified by nine PCR cycles. The individual libraries were quality control (QC) checked by Qubit HS DNA assay (ThermoFisher Scientific, USA) and Fragment Analyzer DNA 6k kit (Agilent, USA) for proper profiles. Then, the libraries were equally pooled and subjected to panel capture according to the Nextera enrichment protocol (Illumina, USA) followed by 12 cycles to amplify the enriched DNA pools. After QC check, the captured DNA pools were sequenced on Illumina HiSeq2500 sequencer (Illumina, USA) to obtain greater than 200-fold coverage per sample.
Bioinformatics analysis pipeline, variant filtering, in-house BioIT protocol
After short-read sequencing, the Illumina data were mapped and aligned based on GRCh38 (hg38) from the Genome Reference Consortium reference sequence by BWA (bwa-mem). Pipeline output was limited to variants in the target region ±20 bp. First, variants and indels are identified by the joint variant calling pipeline of the Genome Analysis Toolkit (GATK) with HaplotypeCaller and GenotypeVCFs. Then, variant annotation and variant effect prediction are performed with ANNOVAR. After filtering out synonymous SNVs, we removed common SNVs (>1%) based on the frequency in the public database, including those with minor allele frequency (MAF)_ > 0.01 in 1000 G all, 1000 G EAS, ExAC all, ExAC EAS, gnomAD exome all, gnomAD exome EAS, and gnomAD genome all. Finally, variants were classified using a 5-class system consistent with American College of Medical Genetics (ACMG) standards and guidelines for interpreting sequence variants (Supplementary Fig. 1).
The determination of disease-causeative variants is accompanied by an evaluation of three possible modes of genetic inheritance (autosomal recessive, autosomal dominant, and X-linked recessive) based on their pedigree information. This includes examining the sequencing data from affected and unaffected family members to confirm the co-segregation of candidate mutations with the disease. After identifying the putative IRD-associated mutations, Sanger sequencing was performed for predicted class III–V variants to confirm their presence in the study subjects.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
Sequencing data have been deposited at NCBI Sequence Read Archive (SRA) (PRJNA952821) and ClinVar. All other data and materials are available from the corresponding authors upon reasonable request.
Code availability
No custom code or scripts were used.
References
Rare diseases, common challenges. Nat Genet. 54, 215 https://doi.org/10.1038/s41588-022-01037-8 (2022).
Rehm, H. L. Time to make rare disease diagnosis accessible to all. Nat. Med. 28, 241–242 (2022).
Hanany, M., Rivolta, C. & Sharon, D. Worldwide carrier frequency and genetic prevalence of autosomal recessive inherited retinal diseases. Proc. Natl Acad. Sci. USA 117, 2710–2716 (2020).
Tambuyzer, E. et al. Therapies for rare diseases: therapeutic modalities, progress and challenges ahead. Nat. Rev. Drug Discov. 19, 93–111 (2020).
Hartong, D. T., Berson, E. L. & Dryja, T. P. Retinitis pigmentosa. Lancet 368, 1795–1809 (2006).
Sadagopan, K. A. Practical approach to syndromic pediatric retinal dystrophies. Curr. Opin. Ophthalmol. 28, 416–429 (2017).
Werdich, X. Q., Place, E. M. & Pierce, E. A. Systemic diseases associated with retinal dystrophies. Semin. Ophthalmol. 29, 319–328 (2014).
Carrigan, M. et al. Panel-based population next-generation sequencing for inherited retinal degenerations. Sci. Rep. 6, 33248 (2016).
Chen, T. C. et al. Genetic characteristics and epidemiology of inherited retinal degeneration in Taiwan. NPJ Genom. Med. 6, 16 (2021).
Ellingford, J. M. et al. Molecular findings from 537 individuals with inherited retinal disease. J. Med. Genet. 53, 761–767 (2016).
Jespersgaard, C. et al. Molecular genetic analysis using targeted NGS analysis of 677 individuals with retinal dystrophy. Sci. Rep. 9, 1219 (2019).
Khan, K. N. et al. Advanced diagnostic genetic testing in inherited retinal disease: experience from a single tertiary referral centre in the UK National Health Service. Clin. Genet 91, 38–45 (2017).
Liu, X., Tao, T., Zhao, L., Li, G. & Yang, L. Molecular diagnosis based on comprehensive genetic testing in 800 Chinese families with non-syndromic inherited retinal dystrophies. Clin. Exp. Ophthalmol. 49, 46–59 (2021).
Sheck, L. H. N. et al. Panel-based genetic testing for inherited retinal disease screening 176 genes. Mol. Genet Genom. Med. 9, e1663 (2021).
Weisschuh, N. et al. Genetic architecture of inherited retinal degeneration in Germany: A large cohort study from a single diagnostic center over a 9-year period. Hum. Mutat. 41, 1514–1527 (2020).
Whelan, L. et al. Findings from a genotyping study of over 1000 people with inherited retinal disorders in Ireland. Genes https://doi.org/10.3390/genes11010105 (2020).
Zhao, P. Y., Branham, K., Schlegel, D., Fahim, A. T. & Jayasundera, K. T. Association of no-cost genetic testing program implementation and patient characteristics with access to genetic testing for inherited retinal degenerations. JAMA Ophthalmol. 139, 449–455 (2021).
Acknowledgements
This research was supported by the Tzu Chi Medical Foundation and Tzu Chi University under grant number TCAS-107-02 to S.-P.H. and supported by the Academia Sinica under grant number AS-TM-110-02-02 to T.-Y.L. and AS-GMM-111-01 to P.-Y.K.
Author information
Authors and Affiliations
Contributions
Conceptualization: S.-P.H., P.-Y.K., S.-H.C., and M.-Y.J.L.; methodology, software, validation, formal analysis, and investigation: H.-J.K., T.-Y.L., F.-J.H. J.-Y.C., E.-C.Y., W.-J.L., Y.-H.C., K.-H.C., K.-H.D., Y.Y., S.-C.C., P.-H.T., C.-C.H., D.-K.H., H.-Y.T., M.-L.P., S.-H.L., S.-F.C., C.-Y.C., W.-M.C., S.-J.C., P.-Y.K., S.-H.C., M.-Y.J.L., and S.-P.H.; resources: P.-Y.K., S.-H.C., M.-Y.J.L., and S.-P.H.; writing—original draft preparation: H.-J.K., T.-Y.L., F.-J.H. J.-Y.C., E.-C.Y., W.-J.L., Y.-H.C., K.-H.C., K.-H.D., Y.Y., S.-C.C., P.-H.T., C.-C.H., D.-K.H., H.-Y.T., M.-L.P., S.-H.L., S.-F.C., C.-Y.C., W.-M.C., and S.-J.C.; writing—review and editing: H.-J.K., T.-Y.L., F.-J.H. J.-Y.C., and E.-C.Y.; supervision and project administration, funding acquisition: P.-Y.K., S.-H.C., M.-Y.J.L., and S.-P.H. All authors have read and agreed to the published version of the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kao, HJ., Lin, TY., Hsieh, FJ. et al. Highly efficient capture approach for the identification of diverse inherited retinal disorders. npj Genom. Med. 9, 4 (2024). https://doi.org/10.1038/s41525-023-00388-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41525-023-00388-3
- Springer Nature Limited