
Abstract
Rapid discovery and synthesis of future materials requires intelligent data acquisition strategies to navigate large design spaces. A popular strategy is Bayesian optimization, which aims to find candidates that maximize material properties; however, materials design often requires finding specific subsets of the design space which meet more complex or specialized goals. We present a framework that captures experimental goals through straightforward user-defined filtering algorithms. These algorithms are automatically translated into one of three intelligent, parameter-free, sequential data collection strategies (SwitchBAX, InfoBAX, and MeanBAX), bypassing the time-consuming and difficult process of task-specific acquisition function design. Our framework is tailored for typical discrete search spaces involving multiple measured physical properties and short time-horizon decision making. We demonstrate this approach on datasets for TiO2 nanoparticle synthesis and magnetic materials characterization, and show that our methods are significantly more efficient than state-of-the-art approaches. Overall, our framework provides a practical solution for navigating the complexities of materials design, and helps lay groundwork for the accelerated development of advanced materials.
Similar content being viewed by others


Introduction
Modern materials discovery involves searching large regions of multi-dimensional processing or synthesis conditions to find candidate materials that achieve specific desired properties. For example, the lithium-ion batteries that have enabled both the personal electronics and clean mobility revolutions started out using simple LiCoO2 as the cathode active material, but this has given way to numerous formulations of the form Li(Ni1/3+xCo1/3−2xMn1/3+x)O2 where each metal contributes to various aspects of stability and electrochemistry1. Another example is in the development of high temperature superconducting materials, where the trade-off between different quantum phenomena (e.g., charge density waves and the superconducting state) needs to be addressed via iterative synthesis and characterization of tailored materials2. Often, the rate of discovery is naturally limited by the speed at which experiments can be performed; this is particularly true for materials applications involving low levels of automation, complex multi-step synthesis protocols, and slow/expensive characterization modalities. For these important situations, developing algorithms which can quickly identify desirable conditions under limited experimental budgets is critical to furthering materials discovery3,4.
Intelligent sequential experimental design has emerged as a promising approach to rapidly search large design spaces. Compared to classical techniques such as factorial design of experiments, sequential methods use data collected at each step to reduce the total number of experiments needed to find optimal designs5,6. Current methods typically involve two components: 1) a probabilistic statistical model trained to predict both the value and the uncertainty of a measurable property at any point in the design space (here, defined as a discrete set of all possible measurement or synthesis conditions) and 2) an ‘acquisition function’ which assigns a relative numerical score to each point in the design space. Under this paradigm, measurements are made at the design point with the highest acquisition value.
No matter the accuracy of the model, intelligent data acquisition strategies will be limited by the relevance of the acquisition function, i.e. how closely the acquisition function aligns with the user’s experimental goal. In this work, we focus on the problem of automatically creating custom acquisition functions to target specific experimental goals. This is an important problem, as materials applications often involve precise requirements that are not well addressed by existing sequential design of experiment techniques. Specifically, we will consider the task of finding the ‘target subset’ of the design space that satisfies user-defined criteria on measured properties. An example of a custom experimental goal, the corresponding target subset of the design space and data acquisition scheme is shown in Fig. 1.

a Visualization of the design space and corresponding measured property space for an example materials system. Samples from the design space (a discrete set of design points) map directly to a set of measured properties (measured property space). The set of all possible design points and measurable properties are shown in blue. The ground-truth target subset of the design space corresponding to the user-goal is shown in orange. Importantly, the ground-truth subset which achieves the experimental goal is unknown prior to experimentation. b The next data point is acquired intelligently based on both previously collected measurements and the specific experimental goal. The method for achieving this recommendation strategy is the focus of the manuscript.
Most prior work in adaptive decision making has focused on the goal of single objective optimization: finding the design point corresponding to the global optimum for a property of interest7. An example of this type of goal is finding the electrolyte formulation with the largest electrochemical window of stability8. For single objective optimization, the framework of Bayesian optimization (BO) applies, and there exists a variety of relevant acquisition functions including Upper Confidence Bound (UCB), Probability of Improvement (PI), and Expected Improvement (EI)7,9. For multi-property optimization, typically there does not exist a single design condition that is optimal with respect to all properties. Instead, the goal is to obtain the set of design points which optimally trade-off between competing objectives (Pareto optimal designs)9. Common multi-objective Bayesian optimization acquisition functions include Expected Hypervolume Improvement (EHVI)10,11, Noisy Hypervolume Improvement (NEHVI)12, and ParEGO13. Single and multi-objective Bayesian optimization have been applied in a number of materials settings8,14,15,16,17,18,19,20,21,22,23,24,25,26,26,27,28,29. For further details on materials-focused Bayesian optimization, see ref. 30.
Another well-studied experimental goal is mapping (full-function estimation). Instead of finding global optima, the task is instead to learn the relationship between the design space and the property space. Uncertainty Sampling (US) is a typical acquisition function for this purpose. Such strategies have been used to achieve higher image resolutions in shorter collection times and have found application in fields such as X-ray scattering31,32,33 and microscopy34,35. Generally, mapping tasks are useful in helping elucidate insights about the entire system but come with the downside of needing to perform a large number of (potentially slow) experiments across the entire design space.
The primary subject of this manuscript addresses the larger goal of finding specific target regions of the design space which conform to specific conditions on the properties, which subsumes the aforementioned goals of optimization and full-function estimation, as well as other more complex tasks including level-set estimation36,37. In this more general setting, the goal is to isolate the set of specific design points which achieve precise user-specified property criteria. For subsets that do not involve optimization or mapping, either custom acquisition functions need to be developed or users are forced to use existing acquisition functions which are not necessarily aligned (and thus inefficient) for their specific experimental task. Developing tailored acquisition functions is possible6,38,39, but this often requires significant time and mathematical insight. These limitations restrict accessibility to the broader materials community and hinders the pace of materials innovation.
Various important scientific problems fall into the category of subset estimation, including: determining synthesis conditions targeting varying ranges of monodisperse colloidal nanoparticle sizes for heterogeneous catalysis40 or plasmonics41, enumerating processing conditions corresponding to wide stability windows42, accurately mapping specific portions of phase boundaries6,38,39, charting transition state pathways between distant structural minima in a potential energy landscape43,44, and finding chemically diverse sets of ligands that are strong, non-toxic binders45. The ability to obtain sets of design points which meet user-specifications is particularly important from a practical adoption standpoint. Many developed materials do not achieve widespread industrial application due to long-term failure modes. Common failure modes include degradation mechanisms in batteries46, catalysts47, and solar cells48, and toxicity of various bio-compatible materials and medical therapeutics49. Obtaining a large pool of plausible designs can mitigate against the risk of long term failure, improving the odds of discovering transformative materials. It is worth mentioning that these problems involve identifying a larger set of design points than optimization (which is typically only a few design points) and a substantially smaller set of design points than full-function estimation (the entire domain). Note, while multi-objective optimization does aim to locate a set of design points, this procedure only returns a specific set called the Pareto front, corresponding to the optimal trade-off between measured properties.
In this manuscript, we present a framework for building acquisition functions that can precisely target a subset of the design space corresponding to an experimental goal. The user defines their goal via an algorithmic procedure that would return the correct subset of the design space if the underlying mapping were known. This algorithm undergoes an automatic conversion into an acquisition function that can guide future experimentation, bypassing the need to devise complex acquisition functions for specific applications.
Our work presents both methodological development and showcases application to the domain of materials research. Specifically, we adapt information-based Bayesian algorithm execution (InfoBAX)50 and Multipoint-BAX51 to handle materials science scenarios, characterized by discrete design spaces and multi-property measurements. Second, we develop a multi-property generalization of an exploration strategy that uses model posteriors39,52,53,54, which we call MeanBAX. We observe that MeanBAX and InfoBAX exhibit complementary performance in the small-data and medium-data regimes, respectively. For this reason, we additionally design a parameter-free strategy, named SwitchBAX, which is able to dynamically switch between InfoBAX and MeanBAX, that performs well across the full dataset size range.
For all three approaches, we provide scientists with a simple open-source interface to cleanly and simply express complex experimental goals, implement a variety of custom user-defined algorithms tailored to materials estimation problems, and significantly, evaluate the suitability of the BAX framework to guide practical materials experiments. We highlight the applicability of the multi-property BAX strategies by targeting a series of user-defined regions in two datasets from the domains of nanomaterials synthesis and high-throughput magnetic materials characterization. We anticipate that this method will enable the ability to target important non-trivial experimental goals, paving the way for the accelerated design of advanced materials.
Results
Expressing an experimental goal via algorithm execution
We first consider a design space: a discrete set of N possible synthesis or measurement conditions, each with dimensionality d corresponding to different changeable parameters. Here, \(X\in {{\mathbb{R}}}^{N\times d}\) is the discrete design space, \({{{\bf{x}}}}\in {{\mathbb{R}}}^{d}\) is a single point in the design space with d features. For each design point, it is possible to perform a costly or time-consuming experiment to obtain a set of m measured properties (\({{{\bf{y}}}}\in {{\mathbb{R}}}^{m}\)). The total set of measured properties (measured property space) across the entire design space is denoted \(Y\in {{\mathbb{R}}}^{N\times m}\). The design space (X) and corresponding measurement space (Y) are linked through some true noiseless underlying function, \({f}_{*}\) which is assumed to be unknown (or black-box) prior to any experimentation (Eq. (1)). Real measurements have an additional term, ϵ, corresponding to ‘measurement noise’, which we assume can be modeled by m independent and identically distributed normal random variables with mean vector \({{{\bf{0}}}}\in {{\mathbb{R}}}^{m}\) and covariance matrix \({\sigma }^{2}{{{\bf{I}}}}\in {{\mathbb{R}}}^{m\times m}\):
Within the full design space, there are often specific portions which are particularly desirable to measure. For the purposes of this manuscript, achieving a custom experimental goal is equivalent to finding a specific ground-truth target subset of the design space. We define the ground-truth target subset as \({{{{\mathcal{T}}}}}_{* }=\{{{{{\mathcal{T}}}}}_{* }^{x},{f}_{* }({{{{\mathcal{T}}}}}_{* }^{x})\}\). Here, \({{{{\mathcal{T}}}}}_{* }^{x}\) corresponds to the design points which achieve the experimental goal (\({{{{\mathcal{T}}}}}_{* }^{x}\subseteq X\)) and \({f}_{* }({{{{\mathcal{T}}}}}_{* }^{x})\) corresponds to the corresponding underlying property values. Note, in this framework, the experimental goal dictates the underlying target subset. As an example, one specific goal is that of single-property maximization. Here, \({{{{\mathcal{T}}}}}_{* }^{x}\) would refer to the point (or degenerate sets of points) in the design space with the largest property value; this is the setting of classical Bayesian optimization. However, the subset can also be more complex. In Fig. 2a, we consider a simple experiment of a single property and single design feature (one-dimensional Y and X). In this scenario, the experimental goal is to find the set of points in the design space for which the material property falls within a band between two specified property value thresholds.

a Example of a user specified algorithm (Level Band) executed on a true and unknown measured property. Here, the target subset of the design space are the specific set of design points which have measured property values which fall within the specified level band. b An illustration of using a Gaussian Process model (\({{{\mathcal{GP}}}}\)) which predicts a mean value (red curve) and an uncertainty (blue band) for every point in the design space, and can fit measured data sampled from the true function. Posterior function samples (\({\{{f}_{i}\}}_{i = 1}^{n}\)) are obtained from this probabilistic model via sampling and represent statistically consistent guesses of the true function based on measured training data. c The user algorithm can be executed on either the posterior samples or the posterior mean to build the d BAX acquisition functions (InfoBAX and MeanBAX). The next suggested point to measure corresponds to the design point with the highest acquisition value.
Having defined the ground-truth target subset, we now turn to the concept of defining this subset via an algorithm. First, let us assume that \({f}_{*}\) is known throughout the design space. If this were the case, we could execute an algorithmic procedure (\({{{\mathcal{A}}}}\)) to obtain the region, \({{{{\mathcal{T}}}}}_{* }\) of interest (Eq. (2)).
Figure 2a shows the correspondence between the experimental goal and target subset using the Level Band Algorithm. Here the algorithm \({{{\mathcal{A}}}}\) simply scans through every point in the design space and returns the subset for which the property value falls within the level band.
Of course, the catch is that clearly the underlying mapping, \({f}_{*}\), is unknown. However, it turns out that framing an experimental goal as an algorithm that would correctly yield the ground-truth target subset if the true mapping were known is a powerful concept. It allows the user to precisely state their desired outcome and in the next section, we will see how to sequentially acquire data to estimate the result of the algorithm running on \({f}_{*}\).
Obtaining a target subset using BAX
Bayesian algorithm execution (BAX) is the idea that one may instead execute an algorithm on approximate fitting models (surrogate models) that are designed to mimic the true function but are trained on measurements at only a small number design points. Unlike \({f}_{*}\), these models are fast and inexpensive to evaluate. Data is then acquired in a sequential manner to help estimate the true algorithm output (i.e. the result if the algorithm were to be executed on the true, unknown function). We denote \({{{{\mathcal{D}}}}}_{t}={\{{{{{\bf{x}}}}}_{k},{{{{\bf{y}}}}}_{k}\}}_{k = 1}^{t}\) as the measured dataset at iteration t; \({{{{\mathcal{D}}}}}_{t}^{x}\in {{\mathbb{R}}}^{t\times d}\) and \({{{{\mathcal{D}}}}}_{t}^{y}\in {{\mathbb{R}}}^{t\times m}\) refer to the x and y components of the dataset.
The surrogate models are ‘probabilistic models’ which predict both an average response and an uncertainty estimate for every point in the design space. Specifically, in this work, we use a machine learning model known as a Gaussian process (\({{{\mathcal{GP}}}}\)) as the probabilistic model. In the case that multiple properties are measured for a given point in the design space, multiple independent single-property \({{{\mathcal{GP}}}}\) models are used. A \({{{\mathcal{GP}}}}\) is best conceptualized as a probability distribution over plausible functions. In the absence of data, we can define a prior distribution over functions (Eq. (3)). The mean of the prior distribution is assigned the value 0 everywhere in the domain and the prior covariance function is denoted K and is derived from the squared exponential kernel (See Methods):
As data are collected, the prior distribution is updated to the posterior distribution, \(p(f| {{{{\mathcal{D}}}}}_{t})\). The mean and marginal standard deviation of the updated distribution are termed the posterior mean function (\(\bar{f}\)) and posterior standard deviation function (fσ), respectively. An example of the posterior mean function (shown in red) and posterior standard deviation function (depicted as blue band) is shown in Fig. 2b based on a training dataset of five design points and corresponding measured properties. Note, that the \({{{\mathcal{GP}}}}\) model estimates low uncertainties near measured points.
It is possible to sample from a \({{{\mathcal{GP}}}}\) to yield a series of statistically consistent plausible fitting functions (termed posterior function samples), \({\{{f}_{i}\}}_{i = 1}^{n}\) (Eq. (4)), and displayed as blue curves in Fig. 2b. We denote these as
Given a trained \({{{\mathcal{GP}}}}\) model, an algorithm (such as the Level Band Algorithm) can be executed on the posterior mean function or on a posterior function sample (Eq. (5) and Fig. 2c):
Note that the algorithm execution step is both fast and inexpensive, as it does not require any additional measurements to be performed. The subsets returned by the algorithm are two different types of predictions of the identity of the ground-truth (and unknown) target subset \({{{{\mathcal{T}}}}_{* }}\).
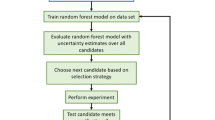
The information obtained from the execution of the algorithms can be used to build a guiding function, termed the acquisition function. Each point in the design space is assigned an acquisition value quantifying the relative importance for subsequent measurement. The next design point to measure is the one with the highest acquisition value (Fig. 2d). Specific BAX acquisition functions are described in the next section. Overall, the data acquisition pipeline follows these steps:
-
1.
Construct an algorithm, \({{{\mathcal{A}}}}(f,X)\), corresponding to a stated experimental goal.
-
2.
Approximate \({f}_{*}\) using a set of independent \({{{\mathcal{GP}}}}\) models trained on limited measurements.
-
3.
Execute the algorithm on either the \({{{\mathcal{GP}}}}\) posterior mean, \(\bar{f}\), or its posterior samples, \({\{{f}_{i}\}}_{i = 1}^{n}\), over the full design space (Eq. (5)). This yields a set of design points that are predicted to conform to the experimental goal.
-
4.
Use the algorithm outputs to build a goal-aware acquisition function.
-
5.
Perform an experiment on the design point with the highest acquisition function and repeat from step 2.
Multi-property BAX acquisition functions
We present three BAX acquisition functions: MeanBAX (based on the posterior mean function), InfoBAX (based on the posterior function samples) and SwitchBAX, which dynamically combines the two. In MeanBAX, the user-algorithm, \({{{\mathcal{A}}}}\), is executed on the posterior mean of the \({{{\mathcal{GP}}}}\) model. Here, the output of the algorithm corresponds to the set of points in the design space that are predicted to satisfy the experimental goal. For MeanBAX, the acquisition function is equal to the average (across the different measured properties) output marginal standard deviation of the \({{{\mathcal{GP}}}}\) models for points in the design space that are predicted to be part of the target subset (Eq. (6)). The acquisition function is zero for all other points in the design space (Fig. 2c, bottom panel). Similar single-property variants of this acquisition function have been proposed in other works for specialized applications39,52,53,54. For the MeanBAX strategy as presented above, two situations often occur that lead to pathological sampling behavior. The first is when no design points are predicted to be in the target subset (i.e. when \({\bar{{{{\mathcal{T}}}}}}^{x}={{\emptyset}}\)); under this condition, the acquisition function is zero across the entire domain. In the second case, the predicted target set may have already been collected (i.e. when \({\bar{{{{\mathcal{T}}}}}}^{x}\subseteq {{{{\mathcal{D}}}}}_{t}^{x}\)); under this condition, the acquisition strategy is forced to repeat queries. Therefore, if either condition is met, we use a default strategy of \(\frac{1}{m}\sum\nolimits_{j = 1}^{m}{f}^{\sigma }{(x)}_{j}\) across the entire domain (i.e., Uncertainty Sampling). We therefore define
For the InfoBAX strategy, the user-algorithm is executed on a series of \({{{\mathcal{GP}}}}\) posterior function samples, each yielding a different set of predicted target points (Fig. 2d, top panel). Since the algorithm output for each posterior function sample may yield a different number of design points, this is not a trivial extension of MeanBAX and requires combining the outputs in a statistically reasonable manner. The InfoBAX acquisition function is defined as
The first term in the InfoBAX acquisition function (Eq. (7)) is the entropy H (spread) of the posterior predictive distribution. The posterior predictive distribution, \(p({{{{\bf{y}}}}}_{j}| {{{{\mathcal{D}}}}}_{t})\), is closely related to the posterior distribution, \(p(f| {{{{\mathcal{D}}}}}_{t})\), and includes the effect of measurement noise: \(p({{{{\bf{y}}}}}_{j}| {{{{\mathcal{D}}}}}_{t})={\int}p(f| {{{{\mathcal{D}}}}}_{t})p({{{{\bf{y}}}}}_{j}| f){{{\rm{d}}}}{{{{\bf{y}}}}}_{j}\). This term essentially performs Uncertainty Sampling and aims to suggest the design point with highest predicted average uncertainty.
The second term captures the experimental goal through the output of a user-algorithm. For each of the n posterior function samples, a corresponding \({{{\mathcal{GP}}}}\) model is trained with the measured dataset plus a predicted dataset corresponding to algorithm execution (i.e. \({{{{\mathcal{D}}}}}_{t}\cup {{{{\mathcal{T}}}}}_{i}\)). Importantly, the predicted datasets and corresponding updated \({{{\mathcal{GP}}}}\) models are only used to calculate the acquisition function and are discarded after selecting the next real design point to measure. The entropy of each model is calculated across the design space and then averaged over the number of posterior samples. Finally, to account for the multi-property case, an average is taken over the m properties. Conceptually, InfoBAX relates variance in the \({{{\mathcal{GP}}}}\) posterior samples to variance in the algorithm outputs; the acquisition function selects points in the design space where both the models are uncertain AND where that uncertainty influences the algorithm output. For further details, refer to Neiswanger et al.50.
Finally, the SwitchBAX strategy is a modification to the MeanBAX strategy which changes the default behavior to InfoBAX rather than US under the condition that either 1) no points are predicted to be in the target subset or 2) all predicted points have already been measured. Based on these conditions, the method dynamically switches between InfoBAX and MeanBAX to guide decision making.
We refer to the BAX strategies (InfoBAX, MeanBAX, and SwitchBAX) as ‘goal-aware’ because the acquisition function incorporates the user goal directly via algorithm specification. We can compare these approaches to typical acquisition functions for searching a multi-property design space: Random Sampling (RS), Uncertainty Sampling (US), and Expected Hypervolume Improvement (EHVI). RS selects a design point uniformly at random (here, without replacement) from the discrete design space at each iteration. For US, the acquisition function is simply the predicted average standard deviation of the \({{{\mathcal{GP}}}}\) models, \(\frac{1}{m}\mathop{\sum }\nolimits_{j = 1}^{m}{f}^{\sigma }{({{{\bf{x}}}})}_{j}\). Intuitively, this corresponds to making measurements where the model is most uncertain about the average value of the measured properties. These two acquisition functions are often used for mapping, in which the goal is to estimate the value of the measured properties over the full design space. EHVI is a specialized multi-objective Bayesian optimization acquisition function that is designed for the specific goal of Pareto front estimation.
The utility of our multi-property BAX framework is that acquisition functions can be aligned to arbitrarily complex questions about an experimental system. As long as an algorithm that could be executed on the true function can be written, the BAX strategies circumvent the lack of knowledge of the true function by running the algorithm on function samples or the mean of a surrogate model (Fig. 2).
Metrics for sequential experimental design
To assess the performance of the various adaptive sampling strategies (RS, US, EHVI, MeanBAX, InfoBAX and SwitchBAX), we introduce two metrics: \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\) and \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\). \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\) quantifies the number of measured data points that achieve the experimental goal (Eq. (8) and Fig. 3a), defined as

The true target subset (gold triangles) of the design space is defined with respect to a specific user goal. a Definition of \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\) as the number of measured points (shown in red) that are ground-truth target points. b Definition of \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\) as the intersection over the union of the design points that are predicted to be targets (shown in purple) and the ground truth target points.
The \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\) quantifies how accurately the \({{{\mathcal{GP}}}}\) model knows the ground-truth target subset. To compute this metric, we execute the user-specified algorithm on \(\bar{f}\) to obtain the set of points that are predicted to be in the target subset. This set of points can be compared with the set of points that are actually in the target subset (using the true function). Here, we use the \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\) (intersection over union), a metric between 0 and 1 which quantifies the degree of set overlap, to compare sets (Eq. (9) and Fig. 3b). We define this as
Note that computing the \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\) assumes that the true target subset of the design space is already known. This information is unknown during a real experiment, and therefore the \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\) is most useful in a benchmarking context to judge the performance of different acquisition schemes on previously collected data.
To aid in metric evaluation, we also present upper bounds for the two metrics as a function of the amount of data collected. Under optimal sampling, at each iteration. \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\) increases by one until all the target subset points have been measured. The \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\) upper bound, in contrast, is 1.0 for each iteration. This would correspond to the exceeding unlikely scenario in which a model initialized with no data perfectly predicts which design points are in the target subset.
Having described the sequential design of experiments approach, the next section presents results from two datasets from the fields of nanoparticle synthesis and magnetic materials to benchmark the performance of various acquisition functions (RS, US, EHVI, InfoBAX, MeanBAX, and SwitchBAX) for the task of targeted subset estimation. To showcase the method, we describe three user-defined algorithms (denoted Library, Multiband and Wishlist Algorithms) relevant to materials application. In Supplementary Discussion A and Supplementary Figs. 4 and 5 we present two additional flavors of algorithms: conditional algorithms which safe-guard against unachievable goals, and percentile-based algorithms which avoid needing explicit property thresholds.
Nanoparticle synthesis
The nanoparticle synthesis dataset consists of discrete samples (pairs of design points and measured properties) from an empirically fit model of the mapping from synthesis conditions (pH, Temperature, Ti(Teoa)2 concentration, TeoaH3 concentration; here Teoa = triethanolamine) to TiO2 nanoparticle size (in nm) and polydispersity (%)55. We added 1% noise to each measurement to simulate noisy acquisition (See Methods).
Algorithm 1
LIBRARY: Monodisperse library of nanoparticles

We consider the experimental goal of preparing a library of monodisperse nanoparticles with a series of precisely specified radii; specifically, our aim is to estimate the subset of synthesis conditions that yield nanoparticles with polydispersity < 5% and with radii that fall into an arbitrarily chosen set of disjoint buckets [6.5, 10, 15, 17.5, 20, 30] ± 0.5 nm. Such tasks are important as monodisperse nanoparticles of different sizes can be optimal for different catalytic reactions40,56. It is important to note that this problem is distinct from constrained multi-objective optimization as the goal is to map out all possible syntheses which meet the user specifications. For this example, the user-defined algorithm corresponds to straightforward filtering logic to select the set of disjoint regions which match the stated goal (see Algorithm 1).
We benchmarked the performance of RS, US, EHVI, MeanBAX, InfoBAX, and SwitchBAX on the library estimation task, using \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\) and \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\) as metrics (Fig. 4a, b). Error bars in these plots correspond to 20 repeats of data acquisition starting with different sets of ten initial points. The BAX strategies outperform RS, US and EHVI in terms of the realistic-setting metric (\({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\)) and perform similarly to US in terms of the \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\) here.

The desired property specifications are: radius ∈ [6.5, 10, 15, 17.5, 20, 30] ± 0.5 nm and polydispersity < 5%; results are presented for a 1% and b 5% noise on the normalized measured properties. BAX strategies, which take into account the user goal, outperform US, RS and EHVI for the \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\) metric. SwitchBAX samples more densely in the target region relative to US, highlighting the effectiveness of goal-aware sampling.
On average, InfoBAX gives superior long term performance relative to MeanBAX for both metrics. However, MeanBAX performs well initially in terms of the \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\) metric. The SwitchBAX algorithm appears to perform well across both dataset size regimes. The measured properties corresponding to the design points collected under US and SwitchBAX are shown in Fig. 4. Here, US samples widely in property space and not necessarily in the subset of interest. In contrast, SwitchBAX typically samples in regions close to the target subset of points (gold diamonds), showing the effectiveness of user-directed acquisition. Sampling in measured property space for RS, EHVI and MeanBAX are shown in Supplementary Fig. 1. A t-distributed stochastic neighbor embedding (TSNE) visualization of the sampling in design space is shown in Supplementary Fig. 2 for US and SwitchBAX.
We also characterized the performance of the acquisition strategies under conditions of higher noise (5%) on the measured properties. Under these conditions, it takes longer to obtain all the target design points for all acquisition strategies. In addition, the \({{{\mathcal{GP}}}}\) model is less confident about the location of the target subset of the design space (lower \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\) relative to 1%). MeanBAX exhibits higher variance in \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\), while InfoBAX and SwitchBAX appear to be relatively robust to different initializations. Results for additional noise levels (0% and 10%) are shown in Supplementary Fig. 3.
Magnetic property estimation
The magnetic materials characterization dataset consists of a design space of 921 ternary compositions approximately evenly spaced across the ferromagnetic Fe-Co-Ni ternary alloy system57. The output measured properties for each composition are the Kerr rotation and the coercivity. The Kerr rotation is a surface-sensitive measure of a material’s magnetic properties. Searching for materials with high Kerr rotation is a route to discovering materials for erasable optical recordings58. Coercivity is the field required in a hysteresis loop to completely demagnetize a ferromagnet. The higher the coercivity the less susceptible a particular magnetization state is to flipping due to defects or other mechanisms.
For this dataset, we highlight two algorithms: the Multiband Algorithm (an intersection of two level bands) and the Wishlist Algorithm (a composition of several multibands).
Multiband Algorithm
The Multiband Algorithm aims to estimate the region of the design space where the measurable properties falls within a specific band of multiple materials properties. This goal can be simply expressed by a filtering algorithm which checks for the intersection of the target subsets for each measured property (see Algorithm 2). Here, the stated experimental goal is to determine the set of design points for which the coercivity falls in the [2.0, 3.0] mT range and the Kerr Rotation falls in the [0.3, 0.4] mrad range; we employ a shorthand [[a, b], [c, d]] = [[2.0, 3.0], [0.3, 0.4]] to describe this region.
Similarly to the nanoparticle synthesis example, goal-driven acquisition functions (InfoBAX, MeanBAX and, SwitchBAX) perform well relative to RS, US, and EHVI (Fig. 5a). EHVI exhibits notably poor performance as it targets a disjoint partition of the design space. Again in this example, we see that MeanBAX performs well in the short term, while InfoBAX has superior long term performance. Here, it is worth noting that although the desired region is tightly clustered in measured property space, it is more disperse in the design space (Fig. 5a).

The notation [[a, b], [c, d]] denotes a < Kerr Rotation (mrad) < b and c < coercivity (mT) < d. a Results for the following multiband: [[2.0, 3.0], [0.3, 0.4]]. b Results for the following wishlist: [[2.0,3.0], [0.2, 0.3]] or [[4.0,6.0], [0.2, 0.4]] or [[9.0, 10.0], [0.0, 0.1]] or [[3.0,4.0], [0.7, 0.8]]. The error bars characterize the robustness to different randomly chosen sets of initial data (one standard deviation computed over 20 repetitions with 10 initial datapoints). Design and property space sampling patterns are shown after 200 iterations for the SwitchBAX acquisition function. The BAX strategies show superior sampling profiles relative to RS, US and EHVI, underscoring the utility of user-directed algorithmic sampling.
Algorithm 2
MULTIBAND: Intersection of two level bands

Wishlist Algorithm
The Wishlist Algorithm is a composition (or union) of a series of multibands. It addresses the case that a user may have a variety of experimental goals to realize in an experimental system (but not necessarily mapping). In this specific example, we target the following sets of multiband regions: [[2.0,3.0], [0.2, 0.3]] or [[4.0,6.0], [0.2, 0.4]] or [[9.0, 10.0], [0.0, 0.1]] or [[3.0,4.0], [0.7, 0.8]]. Here, it is notable that the ground-truth target subset is disjoint in design space, making this problem significantly more challenging than the multiband scenario. MeanBAX, InfoBAX, and SwitchBAX again perform well relative to RS, US, and EHVI. Note, in particular, the BAX strategies have a much higher \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\) relative to US (Fig. 5b).
Algorithm 3
WISHLIST: Composition of a series of multibands

For the given wishlist example, there exists at least one design point which falls into each of the separate multibands. However, in practical experiments, there are scenarios where satisfying the experimental goal is actually unachievable (i.e. there do not exist any design points which satisfy the goal for one or many multibands). We consider this case in more detail in Supplementary Discussion A and Supplementary Fig. 4 where we showcase a more robust type of algorithm (which uses conditional logic) that is capable of dynamically switching strategies based on whether the \({{{\mathcal{GP}}}}\) models predict whether the goal is achievable. Notably, this non-trivial change in sampling behavior is enabled by only a minimal change to the algorithm.
Discussion
Efficiently exploring a design space to find materials candidates with precisely specified measured properties is of fundamental importance to future materials innovation and discovery. While there are existing approaches for finding certain target subsets of the design space, such as Bayesian optimization for identifying global minima or Uncertainty Sampling for full-function estimation, the general task of subset estimation has not been studied within a materials context. In this study, we present a multi-property version of Bayesian algorithm execution (BAX) to develop sequential decision-making strategies aimed at estimating user-specified target subsets of the design space.
Users can encode their target subset using a simple algorithm that requires only a few lines of code. This algorithm is then automatically converted to goal-aware acquisition functions (InfoBAX, MeanBAX, and SwitchBAX) capable of goal-aware exploration. We evaluated BAX strategies on datasets from the fields of nanoparticle synthesis and magnetic materials. For each case, we retrospectively analyzed the performance of different acquisition strategies using metrics that characterize the number of successful experiments (\({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\)) and that characterize the quality of the predictive models in the ground-truth target subset (\({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\)).
For the nanoparticle synthesis example, we target a non-trivial experimental goal: determining synthesis conditions to develop a library of monodisperse nanoparticles. We observed that the BAX strategies significantly outperformed goal-agnostic RS and US (Fig. 4a, b) in terms of \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\). This result highlights that incorporating the experimental goal into the data acquisition process allows for a more targeted and efficient sequence of experimental measurements. Here, EHVI, an algorithm designed for an alternate goal (Pareto front estimation), seems to achieve reasonable performance for nanoparticle library estimation for both the \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\) and the \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\) metrics. However, EHVI does perform worse on \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\) relative to the BAX strategies, mainly because it misses target points with low polydispersity but high nanoparticle size, due to goal misalignment (Supplementary Fig. 1). In this case, both US and EHVI perform well with respect to the \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\), indicating that in this example, a trained \({{{\mathcal{GP}}}}\) model is able to learn a good overall model of the search space in a small number of queries. For this specific case, the mapping is relatively smooth as it is derived from a polynomial model fit on experimental data and therefore a generic \({{{\mathcal{GP}}}}\) model has substantial predictive power across the full design space. This is not generally true for more complex datasets.
For the magnetic materials dataset (real experimental measurements), we introduce two tasks: multiband and wishlist estimation. Once again, the BAX acquisition functions perform favorably when compared to RS, US, and EHVI in terms of \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\). Additionally, the BAX strategies demonstrate superior performance on the \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\) metric. This suggests that while techniques such as US and RS can effectively reduce uncertainty across the entire design space, they may not target the reduction of uncertainty in specific regions of interest. In contrast, \({{{\mathcal{GP}}}}\) models trained on data acquired from BAX sampling strategies are, by construction, more accurate and confident in the specific target subset, forgoing accurate modeling in the rest of the design space. This key result highlights that efficient data collection requires targeted design space sampling. In addition to the Multiband and Wishlist Algorithms, we also compare BAX strategies against a state-of-the-art acquisition function designed for a specific goal. In Supplementary Discussion B and Supplementary Fig. 7, we compare BAX methods against EHVI for the task of Pareto front optimization. We find that all approaches return similar results for this dataset, highlighting that, even in cases where acquisition functions have been designed for a given task (i.e. EHVI for Pareto front optimization), BAX approaches can still perform comparably.
Although MeanBAX, InfoBAX, and SwitchBAX are all BAX acquisition functions, they exhibit qualitatively different behaviors. We generally see that MeanBAX tends to perform better in the short term, but takes longer to fully estimate the target subset of interest (Figs. 4 and 5). This finding can be rationalized under the exploitation/exploration trade off. MeanBAX is more exploitative by design due to its use of the posterior mean function. In cases where the posterior mean prediction closely models the true function, MeanBAX will acquire a target point at each iteration. However, the long term performance of MeanBAX may not be optimal due to the earlier exploitative queries hindering a detailed understanding of the entire target subset. For experiments which involve low automation and short experimental budgets, such as human-intensive nanomaterials synthesis, a strategy like MeanBAX may be preferable to InfoBAX to quickly obtain solutions that match user specifications.
Conversely, InfoBAX, derived from posterior function samples, captures the uncertainty in model predictions and is therefore more successful at exploring the entire target subset. In the presence of noisier data or under-fit models, explorative acquisition functions are also expected to be more robust. We observe this phenomenon in the noise analysis of the nanoparticle synthesis dataset in Fig. 4b and Supplementary Fig. 3. By construction, InfoBAX performs experiments to gain information about the location of the target subset. For this reason, InfoBAX sometimes queries points outside the target subset in order to better understand the overall shape of the target region; practically, this could mean that the \({\mathsf{Number}}\,\)\({\mathsf{Obtained}}\) metric suffers at the expense of potentially improving the \({\mathsf{Posterior}}\,\)\({\mathsf{Jaccard}}\,\)\({\mathsf{Index}}\). Applications involving high-throughput synthesis and characterization or facilities with self-driving laboratories59,60,61,62 may favor the exploratory InfoBAX approach. For such situations, an important direction for future work will be to extend the BAX framework to incorporate batch acquisition, in which experiments can be performed in parallel at a given iteration; this could, for example, involve initiating several chemical reactions in parallel reactors or performing a series of theoretical simulations on-the-fly to assist in real-time data analysis.
We combine the favorable short and long-term performances of MeanBAX and InfoBAX through the dynamic and parameter-free SwitchBAX strategy. Here, the SwitchBAX strategy performs MeanBAX unless there are either (1) no predicted target points or (2) the predicted target points have already been measured. Under either of these scenarios, the strategy switches to InfoBAX. We find that this approach yields the best overall performance for both the small and medium data regimes considered in this work. Interestingly, we also observe a case in Supplementary Fig. 6 where initially InfoBAX outperforms MeanBAX. In this scenario, SwitchBAX still performs well; this finding indicates that initial sampling based on InfoBAX can assist later MeanBAX performance. In general, we expect SwitchBAX to outperform MeanBAX since defaulting to InfoBAX is better than defaulting to US; in other words, it is better to explore with a purpose rather than to perform general exploration. However, it is possible that InfoBAX could outperform SwitchBAX for other datasets or user-algorithms, which is an important point to study in future work.
While BAX strategies generally outperform RS, US, and EHVI for specific target subsets, it may be possible to develop task-specific acquisition functions (like EHVI for Pareto front estimation) that yield equivalent or superior performance. However, creating such acquisition functions requires time and often substantial mathematical insight. Furthermore, these acquisition functions may only be applicable in specific, one-off settings. The power of the BAX framework lies in abstracting custom acquisition function development from the user, making it more accessible for experimentalists to employ specifically targeted search strategies.
While designed for materials, our method is directly applicable to other fields. We anticipate that our approach will find broad application across the natural and physical sciences in problems involving multidimensional design and property spaces.
Methods
Modeling
Independent \({{{\mathcal{GP}}}}\) models with zero prior-mean functions and squared-exponential covariance functions (kernel functions) were used to model the mapping from the design space to each normalized measured property. These \({{{\mathcal{GP}}}}\) models were developed using GPflow63. The relevant hyperparameters for the \({{{\mathcal{GP}}}}\) models were lengthscales ℓ1:d for each design dimension as well as kernel variances α1:m and likelihood variances σ1:m for each of the m predicted properties; the different lengthscales are represented in the diagonal matrix \({{{\bf{L}}}}={{\mathrm{diag}}}\,\left(\left[{\ell }_{1}^{2},{\ell }_{2}^{2},\ldots ,{\ell }_{d}^{2}\right]\right)\).
Overall, the exponential kernel encourages the model to predict similar values for the measured property in local regions of the design space. The lengthscale hyperparameter controls the scale of this smooth behavior; a small lengthscale allows the \({{{\mathcal{GP}}}}\) to capture large changes for small design space displacements. The kernel variance hyperparameter controls the allowable deviation of each of the m predicted properties from the \({{{\mathcal{GP}}}}\) mean. The likelihood variance provides an estimate of the output noise level for the m measured properties. The specific kernel k used for this work is shown in Eq. (10).
The α1:m and ℓ1:d hyperparameters were estimated using five-fold cross validation using the log likelihood as the optimization metric. These hyperparameters were adaptively re-fit every ten data points collected. The σ1:m parameters were set constant in our experiments and not adaptively updated. Generally, a fixed likelihood variance of σ1:m = 0.01 was used for both datasets as the measured properties were assumed to have low noise. Here, 0.01 was chosen instead of 0.0 to avoid numerical issues often encountered with exactly zero noise terms, which can result in non-positive definite matrices. For experiments on the nanoparticle synthesis dataset where the output noise level was systematically varied (0%, 1%, 5%, 10%), the likelihood variance was set to the equivalent corresponding noise levels (0.0, 0.01, 0.05 and 0.1). Note, this procedure assumes that the measurement noise levels are known (at least approximately). In situations where the noise level is unknown, the likelihood variance could alternatively be fitted adaptively using the same procedure used for the kernel variance and lengthscales.
Each design variable was normalized to the range (0, 1) using min-max scalarization. This normalization is possible as the design space is assumed to be discrete and fully specified. Measured properties were normalized to the range (−1, 1) as the initial \({{{\mathcal{GP}}}}\) prior-mean was set to zero. Here, maximum and minimum ranges were estimated based on domain knowledge. For the nanoparticle synthesis dataset, the nanoparticle sizes and polydispersities were assumed to fall in the range of [0, 30] nm and [0, 30] %, respectively. For the magnetic optimization dataset, the measured properties fall between [0,1] mT and [0,10] mrad for the Kerr rotation and coercivity, respectively.
Datasets
Nanoparticle synthesis
The nanoparticle synthesis dataset consists of 1997 random settings for the variables x = [x1, x2, x3, x4] (normalized Ti(Teoa)2 concentration, TeoaH3 concentration, pH and T) from an empirically fit model55 for the nanoparticle radius (y1, Eq. (11)) and the polydispersity (y2, Eq. (12)) as a function of synthesis parameters:
Gaussian noise with σ = 0.01 or 0.05 was added to the normalized values for y1 and y2 at the point of measurement. Supplementary Fig. 3 also shows cases with noise levels of 0.0 and 0.1.
Magnetic property estimation
The magnetic materials dataset corresponds to 921 compositions from the Fe-Co-Ni ternary alloy system14,57. The composition values for each element range from [0, 100]. For each ternary composition, two materials properties are measured: Kerr rotation (mrad) and the coercivity (mT).
Sequential design of experiments
Data acquisition strategies were compared for the Library, Multiband, and Wishlist Algorithms. We used the Trieste EHVI implementation for multi-objective Bayesian optimization64. In general, the following settings were used: 10 random initial datapoints, 20 experimental repeats, adaptive hyperfitting every 10 iterations, and prevention of requerying design points. In Supplementary Discussion C and Supplementary Fig. 6 we also show sampling results for \({{{\mathcal{GP}}}}\) for fixed hyperparameters. The InfoBAX and SwitchBAX strategies used 15 posterior samples from the \({{{\mathcal{GP}}}}\) model for algorithm execution. 300 and 500 datapoints were acquired for the nanoparticle synthesis and magnetic materials datasets, respectively. Visualization of design space sampling use the python-ternary package65.
Data availability
We provide a user-friendly implementation66 of the three Bayesian algorithm execution strategies at https://github.com/src47/multibax-sklearn. This repository contains tutorial notebooks to aid in guiding real experiments. The GPflow code and generated data67 for this study are also available at https://github.com/src47/materials-bax-gpflow. All code and data that support the findings of this study have been deposited in a Zenodo repository (https://zenodo.org/records/10222982) with the accession number https://doi.org/10.5281/zenodo.1022298167.
References
Goodenough, J. B. & Park, K.-S. The li-ion rechargeable battery: a perspective. J. Am. Chem. Soc. 135, 1167–1176 (2013).
Lee, P. A., Nagaosa, N. & Wen, X.-G. Doping a mott insulator: Physics of high-temperature superconductivity. Rev. Mod. Phys. 78, 17 (2006).
Suh, C., Fare, C., Warren, J. A. & Pyzer-Knapp, E. O. Evolving the materials genome: How machine learning is fueling the next generation of materials discovery. Annu. Rev. Mater. Res. 50, 1–25 (2020).
Montoya, J. H. et al. Toward autonomous materials research: Recent progress and future challenges. Appl. Phys. Rev. 9, 011405 (2022).
Shahriari, B., Swersky, K., Wang, Z., Adams, R. P. & De Freitas, N. Taking the human out of the loop: A review of bayesian optimization. Proc. IEEE 104, 148–175 (2015).
Kusne, A. G. et al. On-the-fly closed-loop materials discovery via bayesian active learning. Nat. Commun. 11, 5966 (2020).
Kochenderfer, M. J. & Wheeler, T. A. Algorithms for optimization (Mit Press, 2019).
Dave, A. et al. Autonomous discovery of battery electrolytes with robotic experimentation and machine learning. Cell Rep. Phys. Sci. 1, 100264 (2020).
Greenhill, S., Rana, S., Gupta, S., Vellanki, P. & Venkatesh, S. Bayesian optimization for adaptive experimental design: A review. IEEE access 8, 13937–13948 (2020).
Emmerich, M. T. M., Deutz, A. H. & Klinkenberg, J. W. Hypervolume-based expected improvement: Monotonicity properties and exact computation. In 2011 IEEE Congress of Evolutionary Computation (CEC), 2147–2154 (IEEE, 2011).
Daulton, S., Balandat, M. & Bakshy, E. Differentiable expected hypervolume improvement for parallel multi-objective bayesian optimization. NeurIPS 33, 9851–9864 (2020).
Daulton, S., Balandat, M. & Bakshy, E. Parallel bayesian optimization of multiple noisy objectives with expected hypervolume improvement. NeurIPS 34, 2187–2200 (2021).
Knowles, J. Parego: A hybrid algorithm with on-line landscape approximation for expensive multiobjective optimization problems. IEEE Trans. Evol. Comput. 10, 50–66 (2006).
Wang, A., Liang, H., McDannald, A., Takeuchi, I. & Kusne, A. G. Benchmarking active learning strategies for materials optimization and discovery. Oxf. Open Mater. Sci. 2, itac006 (2022).
Hase, F., Roch, L. M., Kreisbeck, C. & Aspuru-Guzik, A. Phoenics: a bayesian optimizer for chemistry. ACS Cent. Sci. 4, 1134–1145 (2018).
Rohr, B. et al. Benchmarking the acceleration of materials discovery by sequential learning. Chem. Sci. 11, 2696–2706 (2020).
Yamashita, T. et al. Crystal structure prediction accelerated by bayesian optimization. Phys. Rev. Mater. 2, 013803 (2018).
Hickman, R. J., Aldeghi, M., Häse, F. & Aspuru-Guzik, A. Bayesian optimization with known experimental and design constraints for chemistry applications. Digital Discovery 1, 732–744 (2022).
Herbol, H. C., Hu, W., Frazier, P., Clancy, P. & Poloczek, M. Efficient search of compositional space for hybrid organic–inorganic perovskites via bayesian optimization. npj Comput. Mater. 4, 51 (2018).
Zhang, Y., Apley, D. W. & Chen, W. Bayesian optimization for materials design with mixed quantitative and qualitative variables. Sci. Rep. 10, 4924 (2020).
Liang, Q. et al. Benchmarking the performance of bayesian optimization across multiple experimental materials science domains. npj Comput. Mater. 7, 188 (2021).
Shields, B. J. et al. Bayesian reaction optimization as a tool for chemical synthesis. Nature 590, 89–96 (2021).
Häse, F., Aldeghi, M., Hickman, R. J., Roch, L. M. & Aspuru-Guzik, A. Gryffin: An algorithm for bayesian optimization of categorical variables informed by expert knowledge. Appl. Phys. Rev. 8, 031406 (2021).
Hanaoka, K. Bayesian optimization for goal-oriented multi-objective inverse material design. iscience 24, 102781 (2021).
Karasuyama, M., Kasugai, H., Tamura, T. & Shitara, K. Computational design of stable and highly ion-conductive materials using multi-objective bayesian optimization: Case studies on diffusion of oxygen and lithium. Comput. Mater. Sci. 184, 109927 (2020).
Hu, B. et al. Multi-objective bayesian optimization accelerated design of tpms structures. Int. J. Mech. Sci. 244, 108085 (2023).
Khatamsaz, D. et al. Bayesian optimization with active learning of design constraints using an entropy-based approach. npj Comput. Mater. 9, 49 (2023).
Xu, W., Liu, Z., Piper, R. T. & Hsu, J. W. Bayesian optimization of photonic curing process for flexible perovskite photovoltaic devices. Sol. Energy Mater. Sol. Cells. 249, 112055 (2023).
Wang, X. et al. Bayesian-optimization-assisted discovery of stereoselective aluminum complexes for ring-opening polymerization of racemic lactide. Nat. Commun. 14, 3647 (2023).
Packwood, D. Bayesian optimization for materials science (Springer, 2017).
Yager, K. G., Majewski, P. W., Noack, M. M. & Fukuto, M. Autonomous x-ray scattering. Nanotechnology 34, 322001 (2023).
Noack, M. M. et al. A kriging-based approach to autonomous experimentation with applications to x-ray scattering. Sci. Rep. 9, 11809 (2019).
Szymanski, N. J. et al. Adaptively driven x-ray diffraction guided by machine learning for autonomous phase identification. npj Comput. Mater. 9, 31 (2023).
Kalinin, S. V. et al. Automated and autonomous experiments in electron and scanning probe microscopy. ACS Nano 15, 12604–12627 (2021).
Ament, S. et al. Autonomous materials synthesis via hierarchical active learning of nonequilibrium phase diagrams. Sci. Adv. 7, eabg4930 (2021).
Bogunovic, I., Scarlett, J., Krause, A. & Cevher, V. Truncated variance reduction: A unified approach to bayesian optimization and level-set estimation. NeurIPS 29, 1507–1515 (2016).
Ha, H., Gupta, S., Rana, S. & Venkatesh, S. High dimensional level set estimation with bayesian neural network. AAAI 35, 12095–12103 (2021).
Terayama, K. et al. Efficient construction method for phase diagrams using uncertainty sampling. Phys. Rev. Mater. 3, 033802 (2019).
Dai, C. & Glotzer, S. C. Efficient phase diagram sampling by active learning. J. Phys. Chem. B 124, 1275–1284 (2020).
Fong, A. Y. et al. Utilization of machine learning to accelerate colloidal synthesis and discovery. J. Chem. Phys. 154, 224201 (2021).
Feng, E. Y., Zelaya, R., Holm, A., Yang, A.-C. & Cargnello, M. Investigation of the optical properties of uniform platinum, palladium, and nickel nanocrystals enables direct measurements of their concentrations in solution. Colloids Surfaces A Physicochem. Eng. Aspects 601, 125007 (2020).
Rivnay, J. et al. Structural control of mixed ionic and electronic transport in conducting polymers. Nat. Commun. 7, 11287 (2016).
Prentiss, M. C., Wales, D. J. & Wolynes, P. G. The energy landscape, folding pathways and the kinetics of a knotted protein. PLOS Comput. Biol. 6, e1000835 (2010).
Singh, A. R. et al. Computational design of active site structures with improved transition-state scaling for ammonia synthesis. ACS Catal. 8, 4017–4024 (2018).
Foloppe, N. et al. Identification of chemically diverse chk1 inhibitors by receptor-based virtual screening. Bioorg. Med. Chem. 14, 4792–4802 (2006).
Palacín, M. R. & de Guibert, A. Why do batteries fail? Science 351, 1253292 (2016).
Scott, S. L. A matter of life (time) and death. ACS Catal. 8, 8597–8599 (2018).
Jørgensen, M., Norrman, K. & Krebs, F. C. Stability/degradation of polymer solar cells. Sol. Energy Mater. Sol. Cells 92, 686–714 (2008).
Di, L. & Kerns, E. H. Drug-like properties: concepts, structure design and methods from ADME to toxicity optimization (Academic press, 2015).
Neiswanger, W., Wang, K. A. & Ermon, S. Bayesian algorithm execution: Estimating computable properties of black-box functions using mutual information. In International Conference on Machine Learning, 8005–8015 (PMLR, 2021).
Miskovich, S. A. et al. Multipoint-bax: a new approach for efficiently tuning particle accelerator emittance via virtual objectives. Mach. Learn. Sci. Technol. 5, 015004 (2024).
Katsube, R., Terayama, K., Tamura, R. & Nose, Y. Experimental establishment of phase diagrams guided by uncertainty sampling: an application to the deposition of zn–sn–p films by molecular beam epitaxy. ACS Mater. Lett. 2, 571–575 (2020).
Torres, J. A. G., Jennings, P. C., Hansen, M. H., Boes, J. R. & Bligaard, T. Low-scaling algorithm for nudged elastic band calculations using a surrogate machine learning model. Phys. Rev. Lett. 122, 156001 (2019).
Tian, Y. et al. Determining multi-component phase diagrams with desired characteristics using active learning. Adv. Sci. 8, 2003165 (2021).
Pellegrino, F. et al. Machine learning approach for elucidating and predicting the role of synthesis parameters on the shape and size of tio2 nanoparticles. Sci. Rep. 10, 18910 (2020).
Tassone, C. & Mehta, A. Aggregation and structuring of materials and chemicals data from diverse sources. Tech. Rep. (SLAC National Accelerator Lab., 2019).
Yoo, Y. K. et al. Identification of amorphous phases in the fe–ni–co ternary alloy system using continuous phase diagram material chips. Intermetallics 14, 241–247 (2006).
Antonov, V., Oppeneer, P., Yaresko, A., Perlov, A. Y. & Kraft, T. Computationally based explanation of the peculiar magneto-optical properties of ptmnsb and related ternary compounds. Phys. Rev. B 56, 13012 (1997).
Abolhasani, M. & Kumacheva, E. The rise of self-driving labs in chemical and materials sciences. Nat. Synth. 2, 483–492 (2023).
MacLeod, B. P. et al. Self-driving laboratory for accelerated discovery of thin-film materials. Sci. Adv. 6, eaaz8867 (2020).
MacLeod, B. P. et al. A self-driving laboratory advances the pareto front for material properties. Nat. Commun. 13, 995 (2022).
Szymanski, N. J. et al. An autonomous laboratory for the accelerated synthesis of novel materials. Nature 624, 86–91 (2023).
Matthews, A. Gd. G. et al. GPflow: A Gaussian process library using TensorFlow. J. Mach. Learn. Res. 18, 1–6 (2017).
Picheny, V. et al. Trieste: Efficiently exploring the depths of black-box functions with tensorflow. Preprint at https://arxiv.org/abs/2302.08436 (2023).
Harper, M. et al. python-ternary: Ternary plots in python. Zenodo, https://github.com/marcharper/python-ternary.
Chitturi, S., Ramdas, A. & Neiswanger, W. src47/multibax-sklearn. Zenodo, https://doi.org/10.5281/zenodo.10246330 (2023).
Chitturi, S., Ramdas, A. & Neiswanger, W. src47/materials-bax-gpflow: Paper submission. Zenodo, https://doi.org/10.5281/zenodo.10222982 (2023).
Acknowledgements
This work is supported in part by the U.S. Department of Energy, Office of Science, Office of Basic Energy Sciences under Contract No. DE-AC02-76SF00515. A.R. and F.H.J. acknowledge funding from the National Science Foundation (NSF) program Designing Materials to Revolutionize and Engineer our Future (DMREF) via a project DMR-1922312. C.J.T. was supported by the U.S. Department of Energy, Office of Science, Basic Energy Sciences, Chemical Sciences, Geosciences, and Biosciences Division under SLAC Contract No. DE-AC02-76SF00515. The authors thank D. Boe, C. Cheng, S. Gasiorowski, J. Gregoire, T. Lane, W. Michaels, Y. Nashed, M. Robinson, R. Walroth, and C. Wells for manuscript feedback. The authors acknowledge the use of ChatGPT to streamline software development.
Author information
Authors and Affiliations
Contributions
S.R.C. and A.R., and W.N. were responsible for the conception, experiments, analysis, interpretation, and writing of the manuscript. Y.W., B.R., S.E., J.D., F.H.J., and M.D. contributed to the data analysis and writing. C.T., W.N., and D.R. were involved in the conception, analysis, interpretation, and writing and co-supervised the work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chitturi, S.R., Ramdas, A., Wu, Y. et al. Targeted materials discovery using Bayesian algorithm execution. npj Comput Mater 10, 156 (2024). https://doi.org/10.1038/s41524-024-01326-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41524-024-01326-2
- Springer Nature Limited