
Abstract
Specific cognitive abilities (SCA) correlate genetically about 0.50, which underpins general cognitive ability (g), but it also means that there is considerable genetic specificity. If g is not controlled, then genomic prediction of specific cognitive abilities is not truly specific because they are all perfused with g. Here, we investigated the heritability of mathematics, reading, and language ability independent of g (SCA.g) using twins and DNA, and the extent to which multiple genome-wide polygenic scores (multi-PGS) can jointly predict these SCA.g as compared to SCA uncorrected for g. We created SCA and SCA.g composites from a battery of 14 cognitive tests administered at age 12 to 5,000 twin pairs in the Twins Early Development Study (TEDS). Univariate twin analyses yielded an average heritability estimate of 40% for SCA.g, compared to 53% for uncorrected SCA. Using genome-wide SNP genotypes, average SNP-based heritabilities were 26% for SCA.g and 35% for SCA. We then created multi-PGS from at least 50 PGS to predict each SCA and SCA.g using elastic net penalised regression models. Multi-PGS predicted 4.4% of the variance of SCA.g on average, compared to 11.1% for SCA uncorrected for g. The twin, SNP and PGS heritability estimates for SCA.g provide further evidence that the heritabilities of SCA are not merely a reflection of g. Although the relative reduction in heritability from SCA to SCA.g was greater for PGS heritability than for twin or SNP heritability, this decrease is likely due to the paucity of PGS for SCA. We hope that these results encourage researchers to conduct genome-wide association studies of SCA, and especially SCA.g, that can be used to predict PGS profiles of SCA strengths and weaknesses independent of g.
Similar content being viewed by others

Introduction
For over a century, psychologists have developed hundreds of cognitive performance measures and several taxonomies of cognitive abilities. One of psychology’s most replicated and accepted findings is that all cognitive abilities substantially correlate with one another [1]. The shared variance between cognitive abilities is known as general cognitive ability (g). A widely accepted taxonomy of cognitive abilities is the Cattell-Horn-Carroll (CHC) hierarchical model of intelligence [2]. The CHC model positions g at the top of the three-stratum model, representing what is in common among 16 factors at the middle level of the model, such as quantitative knowledge, reading and writing and processing speed. These broad factors encompass clusters of scores of correlated cognitive measures that comprise the lowest level. By tradition, we refer to the middle level of the CHC model as specific cognitive abilities (SCA), even though these factors are not independent of g.
Family, twin, and adoption studies have consistently found that individual differences in both g and SCA are substantially heritable [3]. A recent meta-analytic review of 747,567 monozygotic-dizygotic twin comparisons reported that SCA are, on average, 56% heritable, which is similar to the 50% estimate typically found for g [4]. Moreover, it is well established that the genetic influences that contribute to individual differences in SCA substantially covary among SCA with genetic correlations consistently about 0.50 among diverse SCA [1]. Nonetheless, no genetic correlations near 1.0 have been reported, indicating that SCA have a unique genetic component and do not solely reflect the heritability of g.
The few studies that have attempted to investigate the unique genetic component of SCA suggest a surprising finding: the heritabilities of SCA phenotypically corrected for g (SCA.g) via regression are substantially heritable, 53% on average, very similar to the average heritability estimate of 56% for the same measures of SCA uncorrected for g [4].
The high heritability estimates of SCA and SCA.g make them good targets for genome-wide association (GWA) analysis, which identifies associations between DNA variants (single nucleotide polymorphisms, SNPs) and a target complex trait. The effect sizes of single SNP associations with complex traits are extremely small, the largest accounting for less than 0.05% of the variance, but these effects can be aggregated into polygenic scores (PGS) that can be used as genetic predictors of SCA [5]. The development of powerful polygenic scores of SCA would enable the creation of genetic profiles of strengths and weaknesses of cognitive abilities from birth. For instance, a polygenic score for reading could be used to detect risk for reading problems and enable interventions to forestall problems rather than waiting for them to emerge in school. However, due to the high genetic correlation between SCA and g, much of the prediction of reading would be due to g rather than reading per se, the unique aspect of the SCA. In order to develop genetic profiles of SCA independent of g, GWA studies of SCA.g are required.
To date, only one GWA study of SCA.g has been published. Donati et al [6] conducted a GWA study of English, maths and science independent of g, and reported significant SNP heritabilities for maths (24%) and science (15%). However, the sample sizes used were too small to detect significant genome-wide significant SNPs (maximum N = 3260). Moreover, the sample sizes of early GWA studies of SCA were too small—fewer than 10,000 individuals and often fewer than 1000 – to identify replicable associations for the very small effect sizes that we now know are responsible for the heritability of complex traits [7,8,9,10,11,12,13,14,15,16]. As a result, few genome-wide significant associations were found. Sample sizes in the hundreds of thousands are required to identify SNP associations of the expected effect size. Indeed, a recent GWA study of five reading and language traits with sample sizes of up to 34,000, but with a wide age range from 6 to 26 years, found only one genome-wide significant association with one trait [17].
These GWA studies of SCA did not calculate PGS from their GWA summary statistics to ascertain the power of their PGS to predict their target traits in independent samples. However, because the predictive power of PGS is correlated with the number of genome-wide significant associations, their PGS are not likely to predict much variance in the target traits. This trend can be seen in other GWA studies of SCA that reported the predictive power of PGS derived from their GWA summary statistics [18,19,20,21]. In contrast, a GWA study of self-reported mathematics performance in secondary school with sample sizes of about 500,000 from 23andMe yielded PGS that predicted an average of 6% of the variance in an independent sample [20]. Similarly, a PGS derived from the latest GWA study of the extremely broad trait of educational attainment with a sample size of three million predicted 12.4% of the variance for verbal grade point average (GPA), 10.0% for science GPA and 8.4% for mathematics GPA [22].
In summary, in order to develop genetic profiles of strengths and weakness of SCA.g, large GWA studies of SCA.g are needed. Until then, we can use extant PGS jointly in a multi-PGS strategy to increase the proportion of variance predicted by SCA and SCA.g. Analogous to the empirical approach used to create PGS by aggregating SNPs as long as they add to the prediction of the GWA target trait, a multi-PGS approach aggregates diverse PGS as long as they add to the prediction of the target trait [23]. We can widen this multi-PGS net beyond cognitive-related PGS to include PGS for personality and mental health traits that tap into noncognitive aspects of these abilities [24]. Finally, we can push this multi-PGS approach to its agnostic limit by including PGS for traits whose genetic relevance to cognitive traits is at best speculative, such as sub-cortical brain volumes and physical health.
In this study, we used an inclusive multi-PGS approach to maximise the prediction of mathematics, reading and language SCA and SCA.g assessed at age 12 in the Twins Early Development Study (TEDS) [25, 26]. We frame these genomic analyses in the context of heritability estimates of these same measures of SCA and SCA.g from twin analyses and SNP-based methods. This study was preregistered with the Open Science Framework (OSF; https://osf.io/jxbz8/).
Methods
Sample
Our sample was obtained from the Twins Early Development Study (TEDS) [25, 26]. The TEDS is a longitudinal twin study, which recruited over 16,000 twin pairs born in England or Wales between 1994 and 1996. Currently, over 8000 families still participate in the study, and they remain representative of the English and Welsh population in terms of ethnicity and socio-economic status for their birth cohort. The TEDS has collected a wealth of data over multiple time points, including data on the participants’ environment, physical wellbeing, personality, cognitive ability, and educational achievements. In addition, genomic data is available for over 10,000 twins.
In all our analyses, we excluded participants if they had a serious medical condition that could impact their ability to take part in TEDS assessments, severe problems surrounding birth which may have affected their development, or if important background information was missing. The sample sizes of each SCA and SCA.g by zygosity for the twin and genomic analyses is shown in Supplementary Table S1. We combined same and opposite-sex dizygotic twins in all our analyses because previous analyses indicated that sex differences accounted for little variance [27].
Cognitive measures
At age 12, the twins completed a broad battery of 14 internet and telephone-based cognitive assessments, described below. Details of the assessment procedure and measures can be found in the TEDS data dictionary (https://www.teds.ac.uk/datadictionary/home.htm).
We constructed composite measures from the SCA described by Davis et al. [27]. Composite measures were created from standardised scores for reading ability (mean of four measures), mathematical ability (mean of three measures), language ability (mean of three measures) and g (mean of four measures). The composite measures were corrected for age and sex using standardised residuals.
Reading ability
To assess reading ability, the twins completed two online reading comprehension tests and two reading fluency tests, one online and the other via telephone. The two reading comprehension tests included an adaptation of the Peabody Individual Achievement Test [28] and the GOAL Formative Assessment in Literacy for Key Stage 3 [29]. The two reading fluency tests included an online adaptation of Woodcock- Johnson III Reading Fluency Test [30] and the Test of Word Reading Efficiency (TOWRE) [31], which was administered via telephone.
Mathematical ability
To assess mathematical ability, the twins completed three tests from the National Foundation for Education Research (NFER) booklets 6 to 14 [32]: Understanding Numbers, Non-numerical Processes and Computation, and Knowledge.
Language ability
Language ability was assessed using three online language tests of syntax, semantics and pragmatics. The test of syntax was the Listening Grammar subtest of the Test of Adolescent and Adult Language (TOAL-3) [33]. The semantics test was Level 2 of the Figurative Language subtest of the Test of Language Competence [34]. Pragmatics was assessed by the Level 2 of the Making Inferences subtest, Language Competence [34].
General cognitive ability (g)
Rather than extracting a latent variable from the 10 cognitive tests described above, g was assessed independently using four online tests, two verbal reasoning tests and two non-verbal reasoning tests [27]. The two verbal reasoning tests consisted of the WISC-III-PI Multiple Choice Information (General Knowledge) and the Vocabulary Multiple Choice [35]. The non-verbal tests included the WISC-III-UK Picture Completion [35] and the Raven’s Standard and Advanced Progressive Matrices [36, 37]. By deriving g from these four independent tests, we were able to create a balanced g factor and avoided overcorrecting the SCA for education-related tests of reading, mathematics and language. However, as a comparison, we also created a g factor from all 14 tests.
g-corrected SCA (SCA.g)
To construct the SCA.g measures, we regressed the g factor from reading, mathematical and language ability and used the standardised residuals as indices of SCA independent of g. A correlation matrix between the SCA, SCA.g, and g can be found in Supplementary Fig. S1. Each of the newly constructed SCA.g correlated strongly with their respective SCA (0.76 – 0.81), but weakly with the other two uncorrected SCA (0.22–0.29).
We also regressed the g factor derived from all 14 cognitive measures. Supplementary Table S2 shows a correlation matrix between uncorrected SCA, the 4-test g factor, the 14-test g factor, SCA corrected for the 4-test g factor, and SCA corrected for the 14-test g factor. The two g factors correlate highly (0.82). We focus our presentation of results on the 4-test g factor to avoid overcorrection, but results for twin and elastic net regression analyses for reading, mathematics and language ability corrected for the 14-test g factor are included in Supplementary Table S2.
Twin analyses
Twin analyses
The twin method was used to explore the genetic and environmental aetiology of the SCA and SCA.g. Genetic and environmental components of a complex trait can be estimated by taking advantage of the quasi-experimental design provided by twins. Assuming additive genetic effects, monozygotic (MZ) twins share 100% of their inherited DNA variants, while dizygotic (DZ) twins share on average 50% of their DNA variants that vary between people. Both MZ and DZ twins are assumed to share 100% of their shared environment and 0% of their non-shared environment. By comparing MZ and DZ correlations, this standard twin model enables estimates of additive genetic (A), shared environmental (C) and non-shared environmental (E) effects. These ACE components of variance can be estimated by Falconer’s formula, which assumes an additive model. A is calculated as 2(rMZ-rDZ), C is estimated as residual MZ resemblance not explained by A (i.e., rMZ – A), and E is the remaining variance (1 – rMZ). These estimates can be more accurately and elegantly estimated by structural equation modelling [38]. We used maximum-likelihood model-fitting in OpenMx for R to test the fit of the univariate model and to estimate A, C and E parameters and their confidence intervals [39].
Genomic analyses
SNP-based heritability
In addition to using a twin design to estimate heritability of each SCA and SCA.g, we also used genomic data to calculate SNP-based heritabilities. Details of the TEDS genotyping procedures can be found in the supplementary material of a previous TEDS paper by Selzam et al. [40] as well as in the TEDS data dictionary (https://www.teds.ac.uk/datadictionary/studies/dna.htm).
SNP heritability estimates the variance explained by all the SNPs included in genome-wide genotyping [41]. It represents the upper limit for variance explained by a PGS. In order to maximise the sample size of our genomic sample, we estimated SNP heritability using the method proposed by Zaitlen et al. [42] as it allows for the inclusion of family data, fraternal twins in our case.
We used the software, Genome-Wide Complex Trait Analysis (GCTA) to conduct our analyses [43]. For each SCA and SCA.g, two matrices were created. The first was a genomic relationship matrix (GRMg), which estimated the identity by state (IBS) of all pairs of individuals in the dataset. The second matrix was the kinship relationship matrix (GRMk). It was derived from the initial GRMg in which the off-diagonals below 0.05 were set to 0. Restriction maximum likelihood (REML) implemented using GCTA was then applied to estimate the SNP-based and pedigree-based heritability from the two GRMs. We used the first 10 principal components and sex as covariates.
Polygenic scores (PGS)
PGS were constructed for each of the genotyped participants in the TEDS sample. The construction and quality control procedures are documented in previous papers published by the TEDS team [23, 40] and in the TEDS data dictionary: https://www.teds.ac.uk/datadictionary/studies/measures/polygenic_scores.htm. The genome-wide polygenic scores were previously derived using LDpred, and, as of 2022, are now derived using LDpred2-auto [44, 45]. All PGS used all SNPs (i.e., p-value threshold of 1 for SNP selection) and were corrected for the first 10 principal components, batch, and type of SNP chip.
We applied an empirical approach in the selection of PGS for our analyses. We began with 327 PGS available in the TEDS data dictionary as of 1st October 2023 that met our inclusion criteria (https://www.teds.ac.uk/datadictionary/studies/measures/polygenic_scores.htm). We excluded PGS derived from GWA discovery samples with fewer than 10,000 individuals and PGS from GWA that included TEDS participants. In addition, due to 23andMe’s proprietary restrictions, we were not able to use GWA summary statistics that included 23andMe participants. These exclusions left us with 230 PGS.
A sample size of 10,000 individuals was used as a further criterion for selecting studies as this provides 80% power (alpha =0.05) to detect a correlation of 0.03, which is the largest effect size expected (i.e., r2 < .001). We correlated each of the 230 PGS with the three uncorrected composite SCA scores (mathematics, reading and language). For each composite, we excluded PGS that correlated less than 0.03 with them (Supplementary Table S3). We then used a multi-PGS approach to predict each of the three scores, as described in the next section. Supplementary Table S3 lists the PGS included in each approach, and Supplementary Table S4 provides general information on the PGS we included in this study.
Multi-PGS models
In order to maximise the prediction of SCA and SCA.g, we constructed multi-PGS scores to investigate the joint ability of PGS to predict the SCA and SCA.g measures [23]. Due to the large number of correlated predictors, we used elastic net penalised regression models with out-of-sample comparisons to reduce the number of PGS predictors and to provide unbiased estimates of predictive power [46]. Elastic net combines two types of regularisation: L1 regularisation (Lasso) and L2 regularisation (Ridge). Lasso encourages sparsity by reducing the number of predictors, and Ridge discourages extreme coefficient values by reducing the value of large regression coefficients.
We ran the elastic net regression models using the R package glmnet and caret [46, 47]. In all the models, the samples were split into an independent training set (80%) and a hold-out set (20%). In the training set, we performed 10-fold cross-validation repeated 100 times to select the model that minimised the Root Mean Square Error. We estimated variance explained (R2) in the hold-out set.
For comparison, we also conducted parallel standard multiple regression analyses for each of the SCA and SCA.g.
Results
Descriptive statistics
Means and standard deviations of the SCA and SCA.g are presented in Supplementary Table S5. Sex differences were calculated for both samples, and zygosity group differences (MZ and DZ) were also compared in the twin sample. To test for group differences, we conducted analysis of variance (ANOVA) of zygosity and sex and, although we found some significant differences (Supplementary Table S6), the differences accounted for less than 1% of the variance. All the measures in the subsequent analyses were corrected for age and sex, as twins correlate perfectly for age and same-sex twins also correlate perfectly for sex, which will inflate twin correlations for same-sex pairs [48].
Twin analyses
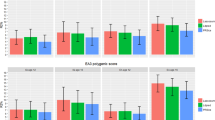
Figure 1 presents the ACE results from our twin model-fitting analyses. Point estimates and confidence intervals are in Supplementary Table S7. All the measures were found to be substantially heritable. The average heritability estimate is 53% for the uncorrected SCA and 40% for SCA.g, although none of these SCA and SCA.g heritabilities differed significantly. The order of heritability is the same for the SCA and SCA.g: heritability is highest for reading and lowest for language, with mathematics in the middle. C estimates were consistently lower for SCA.g than for SCA. The ACE estimates calculated by Falconer’s formula applied to twin intraclass correlations are nearly identical to the model-fitting ACE estimates in Fig. 1 (see Supplementary Table S8).

The additive genetic, shared environmental and non-shared environmental components of reading, mathematics and language ability uncorrected for g (SCA) and corrected for g (SCA.g) at age 12. A= additive genetic influences; C= shared environmental influences; E= non-shared environmental influences. 95% confidence intervals for the additive genetic component are shown in the figure.
SNP heritability
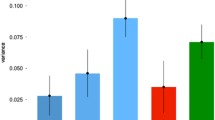
The SNP heritabilities for each SCA and SCA.g are presented in Fig. 2. All SCA and SCA.g are significantly heritable. We observed a similar trend as in our twin analyses: the average SNP heritability of the SCA is higher (35%) than the average SNP heritability of the g-corrected SCA.g (26%). In other words, for both twin and SNP heritability, SCA.g are about 75% as heritable as SCA. The overlapping standard errors for these SNP heritability estimates indicate that differences between each pair of SCA and SCA.g are not significant, including the slightly higher SNP heritability for g-corrected mathematics (37.1%) as compared to uncorrected mathematics (33.2%).

SNP heritability of reading, mathematics and language ability corrected and uncorrected for g with standard errors as error bars.
PGS predictions
Based on the criterion that a PGS correlate at least 0.03 with an SCA, 57 PGS were selected for the multi-PGS analysis of reading ability, 52 for mathematical ability and 50 for language ability. These correlations are reported in Supplementary Table S3. The highest correlations involved the 2022 PGS for educational attainment (EA4) [22], which correlated 0.31, 0.28, and 0.28, respectively, with reading, mathematical and language ability. All PGS generally correlated similarly with the three SCA.
The key finding is that multi-PGS significantly predicted all three SCA.g, although multi-PGS predicted significantly more variance for SCA uncorrected for g (Supplementary Table S9). Figure 3 shows the variance predicted from multi-PGS elastic net penalised regression models. The average variance explained was 11.1% for SCA and 4.4% for SCA.g. We reran the analyses with only one genotyped individual per DZ twin pair and found similar estimates (average SCA = 9.6%; average SCA.g = 4.3%) (Supplementary Table S10). In addition, simple multiple regression analyses yielded a similar pattern of results (average SCA = 10.1%; average SCA.g = 4.0%) (Supplementary Table S11).

Variance explained (R2) from the multi-PGS elastic net penalised regression models of reading, mathematics and language ability uncorrected (SCA) and corrected (SCA.g) for g.
As expected from the simple correlations (Supplementary Table S4), the EA4 PGS provided the strongest independent prediction of all three SCAs. EA4 PGS was also the strongest independent predictor of SCA.g for language ability, but a PGS for intelligence [49] was the strongest independent predictor of SCA.g for reading.g and a PGS for cognitive performance [20] was the strongest independent predictor for mathematics.g.
The multi-PGS approach predicted only slightly more variance than the single most predictive PGS (Supplementary Table S12).
The standardised coefficients for each of the PGS from the multi-PGS elastic net penalized regression are shown in Fig. 4 for SCA and for SCA.g. The number of PGS retained in these regression analyses was 32, 33 and 22 for the three SCA, respectively, and 23, 17 and 19 for the three SCA.g. Squaring these coefficients, the largest independent contributions only explain 4% of the variance. Nonetheless, although the independent predictions from the other PGS are small, they add to the predictive power of the multi-PGS.

Standardised coefficients from elastic net penalised regression model predicting: (a) uncorrected reading ability (Reading) and g-corrected reading ability (Reading.g). b Uncorrected mathematical ability (Maths) and g-corrected mathematical ability (Maths.g). c Uncorrected language ability (Language) and g-corrected language ability (Language.g). Only PGS that contributed to the prediction of the outcome are displayed here. Supplementary Table S3 shows results for all the predictors included in the model.
Discussion
Our twin analyses revealed that the twin heritabilities of reading, mathematics and language ability independent of g (SCA.g) are significant and substantial (average 40%), although lower than SCA uncorrected for g (average 53%). In our previous meta-analytic review of SCA and SCA.g, the average heritability estimates were more similar: 53% for SCA.g and 56% for SCA [4]. We hypothesise that our current estimates of the heritability of SCA.g are more accurate, because they are based on an extensive battery of four tests of g, four reading tests, three mathematics tests and three language tests. The meta-analytic average heritability of SCA.g was instead based on the previous literature on SCA.g which consists of only three studies. One study examined academic performance, rather than cognitive ability, at age 16 [50], and the other two each investigated a single domain of ability—mathematics [51] and spatial ability [52]. Regardless, the average twin heritability of the SCA.g investigated here is substantial and the differences in heritability between the respective g-corrected and uncorrected SCA is non-significant. In addition, we investigated the twin heritability of reading, mathematics and language ability corrected for a g factor derived from all 14 cognitive assessments and found that the confidence intervals between all the corresponding SCA.g overlap when corrected for the 4-test g or the 14-test g (Supplementary Table S2).
We also observed significant and substantial SNP heritabilities for the three SCA.g. As with the twin heritability estimates, we found that SNP heritability estimates for SCA.g were about 75% of the SNP heritabilities for SCA (26% vs 35%).
The drop in heritability from SCA to SCA.g is more pronounced in our multi-PGS prediction analyses (Fig. 3). The average variance explained by multi-PGS was 11.1% for SCA and 4.4% for SCA.g. The likely reason is that the most powerful and predictive PGS in all the multi-PGS analyses are from GWA studies of the highly general traits of educational attainment (EA4) [22], cognitive performance [20], and intelligence (IQ3) [49]. These PGS are highly g-loaded, so their predictive power would be expected to diminish for g-corrected SCA. Our multi-PGS analyses also included PGS from GWA studies of more specific measures of SCA, which added some significant independent prediction of SCA corrected and uncorrected for g in our elastic net analyses. For instance, the PGS for executive function [53] was the second most predictive PGS for mathematics corrected and uncorrected for g. Therefore, although the predictive power is modest for most of the SCA-related PGS included in our analyses, they add to the overall variance explained in our multi-PGS analyses. Importantly, these SCA-related PGS were derived from GWA studies with substantially smaller sample sizes than the most predictive PGS.
We hope these findings encourage more GWA studies of SCA and, in particular, SCA.g. Our twin and SNP heritability estimates indicate that SCA, both corrected and uncorrected for g, are good targets for genomic prediction. In addition, the multi-PGS approache indicate that existing PGS of SCA add to the prediction of both SCA and SCA.g – even in models that include powerful predictors from general traits.
The average results for SCA mask some interesting findings for the individual SCA. For example, reading is significantly less g-loaded compared to mathematical and language ability. Despite the limitations of the extant PGS used in our multi-PGS analyses, they predicted a substantial proportion of the variance for SCA.g for reading (6.9%), but less so for mathematics (3.6%) and language ability (2.5%). The twin heritability results support these PGS findings. Mathematics and language ability have a greater drop in twin heritability (from 50.6% to 34.9%, and from 42.5% to 23.6%, respectively) as compared to a drop from 67.0% to 62.1% for reading. Although these results suggest that reading is less g-dependent than mathematics and language, caution is warranted because a common pathways twin model-fitting analysis of these data reported that the genetic correlation between latent factors representing reading and g is 0.88, similar to the genetic correlations of 0.86 for mathematics and 0.91 for language [27].
In summary, these results provide further evidence for the substantial heritability of SCA.g and provide the first multi-PGS prediction of cognitive abilities independent of g. The results hopefully mark the beginning towards creating PGS for SCA.g that can be used to create genomic profiles of strengths and weaknesses of abilities without the influence of g. This would allow for a more targeted educational system. For example, if genomic strengths of a child were identified for a cognitive skill, interventions can be developed to nurture the skill from an early age because polygenic scores do not change across development. Similarly, if genomic weaknesses were identified, interventions can be implemented before problems emerge in school. However, in order to create SCA.g PGS with sufficient power to be practically useful, GWA studies of SCA.g with samples in the hundreds of thousands are required.
It is daunting to think about creating GWA studies with these sample sizes that include test data for multiple SCA as well as g, which would be needed to investigate SCA.g. Cognitive assessments are time consuming and costly to administer, especially with the sample sizes required to create powerful predictors of SCA.g. However, a cost-effective solution is to create brief but psychometrically valid measures of SCA that can be administered to the millions of people participating in ongoing biobanks for whom genomic data are available. For example, a gamified 15-minute test has been created to assess verbal ability, non-verbal ability, and g [54]. This approach could be extended to assess other SCA and SCA.g. In the meantime, it is possible to use summary statistics from separate GWA studies of SCA and of g using GWAS-by-subtraction to isolate genetic effects on each SCA independent of g [55]. We are currently conducting GWAS-by-subtraction analyses using extant GWA summary statistics from large GWA samples [17, 19] to create PGS for SCA and SCA.g.
Another option is to create PGS from GWA studies of self-reported measures of SCA and g. Because cognitive tests are usually time consuming and costly, self-report measures could be a viable alternative [56]. For example, a large GWA analysis of self-reported math ability (n = 564,698) and the highest math class taken (n = 430,445) was conducted with participants from 23andMe [20]. The derived PGS predicted an average of 6.2% of the variance of math GPA in an independent sample. Unfortunately, due to the proprietary restrictions of 23andMe, we could only include the top 10,000 SNPs in our PGS derived from the GWA analysis of self-reported highest math class taken [20]. This could be why the PGS for the highest math class taken was not a strong independent predictor in our multi-PGS models for mathematics uncorrected and corrected for g.
Limitations
The usual limitations of the twin method apply here [3], as well as the typical limitations of PGS and GCTA analyses such as issues related to conducting genomic analyses limited to additive effects of the common SNPs genotyped on SNP arrays.
Although our sample is representative of the UK population for family socio-economic status and ethnicity, the generalizability of our results may be limited to similar populations [26]. In addition, because the TEDS sample is predominantly white, only participants of white ethnic origin were genotyped and therefore included in our analyses. This means that our findings are largely only generalisable to other white populations. GWA analyses using participants from other ancestral populations are needed.
Conclusion
The average twin heritability estimate of 40% and SNP heritability estimate of 26% for g-corrected mathematical, reading and language ability at age 12 provides further evidence that the heritability of SCA is not merely a reflection of the genetic influence of g. Although we found a substantial decrease in variance explained by multi-PGS approaches for g-corrected SCA compared to uncorrected SCA, this decrease is likely due to the fact that the most powerful predictors in the multi-PGS approach were consistently from GWA studies of the extremely general traits of intelligence and educational attainment. Nonetheless, we were able to predict up to 6.9% of g-corrected cognitive abilities from DNA alone. We hope these results encourage researchers to conduct more GWA studies of SCA, especially SCA.g, that can be used to predict PGS profiles of SCA strengths and weaknesses independent of g.
Data availability
Data for this study was sourced from the Twins Early Development Study (TEDS). For detailed information on accessing TEDS data, please visit: https://www.teds.ac.uk/researchers/teds-data-access-policy
References
Plomin R, Kovas Y. Generalist genes and learning disabilities. Psychol Bull. 2005;131:592–617.
McGrew KS. CHC theory and the human cognitive abilities project: Standing on the shoulders of the giants of psychometric intelligence research. Intelligence. 2009;37:1–10.
Knopik VS, Neiderhiser JM, DeFries JC, Plomin R Behavioral Genetics. Macmillan Learning; 2016. 550.
Procopio F, Zhou Q, Wang Z, Gidziela A, Rimfeld K, Malanchini M, et al. The genetics of specific cognitive abilities. Intelligence. 2022;95:101689.
Visscher PM, Wray NR, Zhang Q, Sklar P, McCarthy MI, Brown MA, et al. 10 years of GWAS discovery: biology, function, and translation. Am J Hum Genet. 2017;101:5–22.
Donati G, Dumontheil I, Pain O, Asbury K, Meaburn EL. Evidence for specificity of polygenic contributions to attainment in English, maths and science during adolescence. Sci Rep. 2021;11:3851.
Baron-Cohen S, Murphy L, Chakrabarti B, Craig I, Mallya U, Lakatošová S, et al. A genome wide association study of mathematical ability reveals an association at chromosome 3q29, a locus associated with autism and learning difficulties: a preliminary study. PLOS ONE. 2014;9:e96374.
Carrion-Castillo A, van Bergen E, Vino A, van Zuijen T, de Jong PF, Francks C, et al. Evaluation of results from genome-wide studies of language and reading in a novel independent dataset. Genes Brain Behav. 2016;15:531–41.
Chen H, Gu Xhong, Zhou Y, Ge Z, Wang B, Siok WT, et al. A genome-wide association study identifies genetic variants associated with mathematics ability. Sci Rep. 2017;7:40365.
Davis OSP, Band G, Pirinen M, Haworth CMA, Meaburn EL, Kovas Y, et al. The correlation between reading and mathematics ability at age twelve has a substantial genetic component. Nat Commun. 2014;5:4204.
Docherty SJ, Davis OSP, Kovas Y, Meaburn EL, Dale PS, Petrill SA, et al. A genome-wide association study identifies multiple loci associated with mathematics ability and disability. Genes Brain Behav. 2010;9:234–47.
Donati G, Meaburn EL, Dumontheil I. The specificity of associations between cognition and attainment in English, maths and science during adolescence. Learn Individ Differ. 2019;69:84–93.
Gialluisi A, Newbury DF, Wilcutt EG, Olson RK, DeFries JC, Brandler WM, et al. Genome-wide screening for DNA variants associated with reading and language traits. Genes Brain Behav. 2014;13:686–701.
Harlaar N, Meaburn EL, Hayiou-Thomas ME, Wellcome Trust Case Control Consortium, Davis OSP, Docherty S, et al. Genome-wide association study of receptive language ability of 12-year-olds. J Speech Lang Hear Res JSLHR. 2014;57:96–105.
Luciano M, Evans DM, Hansell NK, Medland SE, Montgomery GW, Martin NG, et al. A genome-wide association study for reading and language abilities in two population cohorts. Genes Brain Behav. 2013;12:645–52.
Meaburn EL, Harlaar N, Craig IW, Schalkwyk LC, Plomin R. Quantitative trait locus association scan of early reading disability and ability using pooled DNA and 100K SNP microarrays in a sample of 5760 children. Mol Psychiatry. 2008;13:729–40.
Eising E, Mirza-Schreiber N, de Zeeuw EL, Wang CA, Truong DT, Allegrini AG, et al. Genome-wide association analyses of individual differences in quantitatively assessed reading- and language-related skills in up to 34,000 people [Internet]. Genomics; 2021 Nov [cited 2021 Nov 5]. Available from: https://doi.org/10.1101/2021.11.04.466897
Davies G, Marioni RE, Liewald DC, Hill WD, Hagenaars SP, Harris SE, et al. Genome-wide association study of cognitive functions and educational attainment in UK Biobank (N=112 151). Mol Psychiatry. 2016;21:758–67.
de la Fuente J, Davies G, Grotzinger AD, Tucker-Drob EM, Deary IJ. A general dimension of genetic sharing across diverse cognitive traits inferred from molecular data. Nat Hum Behav. 2021;5:49–58.
Lee JJ, Wedow R, Okbay A, Kong E, Maghzian O, Zacher M, et al. Gene discovery and polygenic prediction from a genome-wide association study of educational attainment in 1.1 million individuals. Nat Genet. 2018;50:1112–21.
Rajagopal VM, Ganna A, Coleman JRI, Allegrini AG, Voloudakis G, Grove J, et al. Genome-wide association study of school grades identifies a genetic overlap between language ability, psychopathology and creativity [Internet]. bioRxiv; 2020 [cited 2022 Feb 5]. p. 2020.05.09.075226. Available from: https://doi.org/10.1101/2020.05.09.075226v2
Okbay A, Wu Y, Wang N, Jayashankar H, Bennett M, Nehzati SM, et al. Polygenic prediction of educational attainment within and between families from genome-wide association analyses in 3 million individuals. Nat Genet. 2022;54:437–49.
Krapohl E, Patel H, Newhouse S, Curtis CJ, von Stumm S, Dale PS, et al. Multi-polygenic score approach to trait prediction. Mol Psychiatry. 2018;23:1368–74.
Malanchini M, Rimfeld K, Allegrini AG, Ritchie SJ, Plomin R. Cognitive ability and education: how behavioural genetic research has advanced our knowledge and understanding of their association. Neurosci Biobehav Rev. 2020;111:229–45.
Lockhart C, Bright J, Ahmadzadeh Y, Breen G, Bristow S, Boyd A, et al. Twins early development study (TEDS): a genetically sensitive investigation of mental health outcomes in the mid-twenties. JCPP Adv. 2023;3:e12154.
Rimfeld K, Malanchini M, Spargo T, Spickernell G, Selzam S, McMillan A, et al. Twins early development study: a genetically sensitive investigation into behavioral and cognitive development from infancy to emerging adulthood. Twin Res Hum Genet. 2019;22:508–13.
Davis OSP, Haworth CMA, Plomin R. Learning abilities and disabilities: Generalist genes in early adolescence. Cognit Neuropsychiatry. 2009;14:312–31.
Markwardt, FC Jr Peabody Individual Achievement Test-Revised (Normative Update) Manual. Circle Pines: American Guidance Service; 1997.
GOAL plc. GOAL formative assessment in literacy (Key Stage 3). London, England: Hodder & Stoughton; 2002.
Woodcock RW, McGrew KS, Mather N Woodcock-Johnson III Tests of Achievement. Itasca, IL: Riverside Publishing; 2001.
Torgesen JK, Wagner RK, Rashotte CA Test of Word Reading Efficiency. Austin, TX: Pro-Ed; 1999.
NferNelson Publishing Co. Ltd. Mathematics 5-14 series. UK, Windsor; 1999.
Hammill DD, Brown VL, Larsen SC, Wiederholt JL Test of Adolescent and Adult Language (TOAL-3). Austin, TX: Pro-Ed; 1994.
Wiig EH, Secord W, Sabers D Test of Language Competence. Expanded Edition. San Antonio, TX: The Psychological Corporation; 1989.
Wechsler D Wechsler intelligence scale for children - Third Edition UK (WISC-IIIUK) Manual. London: The Psychological Corporation; 1992.
Raven JC, Court JH, Raven J Manual for Raven’s Progressive Matrices and Vocabulary Scales. Oxford: Oxford University Press; 1996.
Raven JC, Court JH, Raven J Manual for Raven’s Advanced Progressive Matrices. Oxford: Oxford Psychologists Press Ltd.; 1998.
Rijsdijk FV, Sham PC. Analytic approaches to twin data using structural equation models. Brief Bioinform. 2002;3:119–33.
Neale MC, Hunter MD, Pritkin J, Zahery M, Brick TR, Kirkpatrick RM, et al. OpenMx 2.0: extended structural equation and statistical modeling. Psychometrika. 2016;81:535–49.
Selzam S, Coleman JRI, Caspi A, Moffitt TE, Plomin R. A polygenic p factor for major psychiatric disorders. Transl Psychiatry. 2018;8:1–9.
Yang J, Benyamin B, McEvoy BP, Gordon S, Henders AK, Nyholt DR, et al. Common SNPs explain a large proportion of heritability for human height. Nat Genet. 2010;42:565–9.
Zaitlen N, Kraft P, Patterson N, Pasaniuc B, Bhatia G, Pollack S, et al. Using extended genealogy to estimate components of heritability for 23 quantitative and dichotomous traits. PLOS Genet. 2013;9:e1003520.
Yang J, Lee SH, Goddard ME, Visscher PM. GCTA: a tool for genome-wide complex trait analysis. Am J Hum Genet. 2011;88:76–82.
Privé F, Arbel J, Vilhjálmsson BJ. LDpred2: better, faster, stronger. Bioinformatics. 2020;36:5424–31.
Vilhjálmsson BJ, Yang J, Finucane HK, Gusev A, Lindström S, Ripke S, et al. Modeling linkage disequilibrium increases accuracy of polygenic risk scores. Am J Hum Genet. 2015;97:576–92.
Zou H, Hastie T. Regularization and variable selection via the elastic net. J R Stat Soc Ser B Stat Methodol. 2005;67:301–20.
Kuhn M. Building predictive models in R Using the caret package. J Stat Softw. 2008;28:1–26.
McGue M, Bouchard TJ. Adjustment of twin data for the effects of age and sex. Behav Genet. 1984;14:325–43.
Savage JE, Jansen PR, Stringer S, Watanabe K, Bryois J, de Leeuw CA, et al. Genome-wide association meta-analysis in 269,867 individuals identifies new genetic and functional links to intelligence. Nat Genet. 2018;50:912–9.
Rimfeld K, Kovas Y, Dale PS, Plomin R. Pleiotropy across academic subjects at the end of compulsory education. Sci Rep. 2015;5:11713.
Tosto MG, Malykh S, Voronin I, Plomin R, Kovas Y. The etiology of individual differences in maths beyond IQ: insights from 12-year old twins. Procedia - Soc Behav Sci. 2013;86:429–34.
Rimfeld K, Shakeshaft NG, Malanchini M, Rodic M, Selzam S, Schofield K, et al. Phenotypic and genetic evidence for a unifactorial structure of spatial abilities. Proc Natl Acad Sci. 2017;114:2777–82.
Hatoum AS, Morrison CL, Mitchell EC, Lam M, Benca-Bachman CE, Reineberg AE, et al. Genome-wide association study of over 427,000 individuals establishes executive functioning as a neurocognitive basis of psychiatric disorders influenced by GABAergic Processes [Internet]. Genetics; 2019 Jun [cited 2023 Nov 3]. Available from: http://biorxiv.org/lookup/doi/10.1101/674515
Malanchini M, Rimfeld K, Gidziela A, Cheesman R, Allegrini AG, Shakeshaft N, et al. Pathfinder: a gamified measure to integrate general cognitive ability into the biological, medical, and behavioural sciences. Mol Psychiatry. 2021;26:7823–37.
Demange PA, Malanchini M, Mallard TT, Biroli P, Cox SR, Grotzinger AD, et al. Investigating the genetic architecture of noncognitive skills using GWAS-by-subtraction. Nat Genet. 2021;53:35–44.
Jacobs KE, Roodenburg J. The development and validation of the self-report measure of cognitive abilities: a multitrait–multimethod study. Intelligence. 2014;42:5–21.
Acknowledgements
We gratefully acknowledge the ongoing contribution of the participants in the Twins Early Development Study (TEDS) and their families. TEDS is supported by the UK Medical Research Council (MR/V012878/1 and previously MR/M021475/1). WL is supported by a China Scholarship Council PhD scholarship. KR is supported by a Sir Henry Wellcome Postdoctoral Fellowship from the Wellcome Trust (213514/Z/18/Z). MM is supported by a starting grant from the School of Biological and Behavioural Sciences, Queen Mary University of London. SvS is supported by a Nuffield Foundation award (EDO/441110), a British Academy Mid-Career Fellowship (2022-23), and a Jacobs Foundation CRISP Fellowship (2022-27). FP is supported by a National Institutes of Health [NIH] Subaward to King’s College London via The Regents of the University of California, Riverside [AG046938].
Author information
Authors and Affiliations
Contributions
FP, RP, KR and MM conceived and designed the research; FP and WW analyzed the data; FP, WW, KR, MM, SvS, AA and RP wrote the paper; All authors approved the submitted draft of the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval and consent to participate
All procedures conducted in this study adhere to the ethical standards set forth in the Helsinki Declaration of 1975, as revised in 2008. The Twins Early Development Study (TEDS) received ethical approval from the King’s College London Research Ethics Committee (References: PNM/09/10-104 and HR/DP-20/21-22060). Informed consent was obtained from all participants prior to data collection.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Procopio, F., Liao, W., Rimfeld, K. et al. Multi-polygenic score prediction of mathematics, reading, and language abilities independent of general cognitive ability. Mol Psychiatry (2024). https://doi.org/10.1038/s41380-024-02671-w
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41380-024-02671-w
- Springer Nature Limited