
Abstract
Complex field imaging, which captures both the amplitude and phase information of input optical fields or objects, can offer rich structural insights into samples, such as their absorption and refractive index distributions. However, conventional image sensors are intensity-based and inherently lack the capability to directly measure the phase distribution of a field. This limitation can be overcome using interferometric or holographic methods, often supplemented by iterative phase retrieval algorithms, leading to a considerable increase in hardware complexity and computational demand. Here, we present a complex field imager design that enables snapshot imaging of both the amplitude and quantitative phase information of input fields using an intensity-based sensor array without any digital processing. Our design utilizes successive deep learning-optimized diffractive surfaces that are structured to collectively modulate the input complex field, forming two independent imaging channels that perform amplitude-to-amplitude and phase-to-intensity transformations between the input and output planes within a compact optical design, axially spanning ~100 wavelengths. The intensity distributions of the output fields at these two channels on the sensor plane directly correspond to the amplitude and quantitative phase profiles of the input complex field, eliminating the need for any digital image reconstruction algorithms. We experimentally validated the efficacy of our complex field diffractive imager designs through 3D-printed prototypes operating at the terahertz spectrum, with the output amplitude and phase channel images closely aligning with our numerical simulations. We envision that this complex field imager will have various applications in security, biomedical imaging, sensing and material science, among others.
Similar content being viewed by others

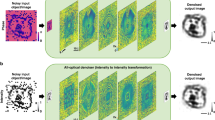
Introduction
Optical imaging can characterize diverse properties of light, including amplitude, phase, wavelength, and polarization, which provides abundant information about samples, such as their morphology and composition. However, conventional image sensors and focal plane arrays, based on e.g., Complementary Metal-Oxide-Semiconductor (CMOS) or Charge-Coupled Device (CCD) technologies, are inherently constrained to detecting only the intensity of the optical field impinging on their active area. Measuring the phase information of a complex field presents challenges, which require indirect encoding through interferometric or holographic detection systems1,2,3. Some of the traditional examples of phase imaging techniques include Zernike phase contrast microscopy and interferometric microscopy. Remarkedly, interferometry-based techniques4,5,6 exhibit very high accuracy in phase measurements (exceeding 1/100 of a wavelength) and allow one to directly obtain wavefront aberrations at very large apertures; however, the relative complexity of decoding interferograms and the sensitivity of the measurement equipment to vibrations hinder their wide applications. Subsequent developments in quantitative phase imaging (QPI) have enabled high-precision characterization of phase information; advances such as the Fourier phase microscopy7, Hilbert phase microscopy8 and digital holographic microscopy9,10,11,12,13,14,15 have also emerged, making QPI a potent label-free optical measurement technique. Nevertheless, these QPI methods often necessitate relatively bulky experimental setups and rely on iterative algorithms based on multiple measurements to digitally reconstruct the desired phase information, leading to slow imaging speeds. In parallel, Shack-Hartmann sensors16,17 can provide phase information by analyzing wavefront distortions inferred from the displacement of light spots created by a perforated mask. This approach, while eliminating the need for a reference wavefront or field, faces challenges in detection resolution due to its discrete measurement nature and still demands data processing for precise phase or wavefront reconstructions. In addition to these, there are other methods that decompose the wavefront into discrete elements, such as Zernike polynomials, offering a direct path to understanding aberrations in wavefronts exhibiting small phase variations18,19,20,21. However, these approaches are less suitable for investigating phase objects with complex structures and high spatial frequencies, underscoring a limitation in their broad applicability.
Recently, fueled by the advances made in deep learning, the application of deep neural networks has been adopted for accurate and rapid reconstruction of phase information in complex fields through a single feed-forward operation22,23,24,25,26,27,28,29. While these deep learning-based approaches offer considerable benefits, they typically demand intensive computational resources for network inference, requiring the use of graphics processing units (GPUs). Simultaneously, the progress in micro- and nano-fabrication technologies has facilitated the development of metasurfaces30,31,32,33,34,35,36,37,38 and thin-film optical components39,40 for QPI applications. However, the functionality of these devices still relies on indirect encoding processes that generate intensity variations on the sensor plane, such as diffused speckles30 or polarized interference patterns38. These existing solutions, therefore, necessitate digital computation for image reconstruction and, in certain cases, also require the incorporation of additional hardware along the optical path, such as polarizers and polarization cameras.
In this work, we demonstrate the design of a complex field imager that can directly capture the amplitude and phase distributions of an incoming field using an intensity-only image sensor array. As shown in Fig. 1a, this complex field imager is composed of a series of spatially engineered diffractive surfaces (layers), which are jointly optimized using supervised deep learning algorithms to successively perform the modulation of incoming complex fields. This diffractive architecture, known as a diffractive optical neural network, has previously been explored for all-optical information processing covering various applications, including all-optical image classification41,42, space-to-spectrum encoding42,43, logic operations44,45,46, optical phase conjugation47, among others48,49,50,51,52,53,54,55,56,57,58,59,60. Within the architecture of our diffractive complex field imager, the diffractive surfaces are trained to simultaneously perform two tasks: (1) an amplitude-to-amplitude (A → A) transformation and (2) a phase-to-intensity (P → I) transformation. Here, the first task involves mapping the amplitude of the incoming complex field to a specific output field of view (FOV) that is solely dedicated to amplitude imaging, independent of the input wave’s phase profile. The second task, on the other hand, aims to approximate a nonlinear transformation by converting the phase of the incoming wave into an intensity pattern at another output FOV, exclusively used for quantitative phase imaging, QPI. Therefore, by placing complex objects or feeding complex fields into the input FOV of the diffractive complex field imager and measuring the intensity distributions at its output FOVs, the amplitude and phase information of the input complex objects/fields can be directly obtained within a single intensity-only image recording step, eliminating the necessity for any form of image reconstruction algorithms. In addition to this spatially multiplexed design of the diffractive complex field imager, termed design I (Fig. 1a), we also explored additional complex field imager designs by incorporating wavelength multiplexing. As illustrated in Fig. 1b, c, these wavelength multiplexed designs, termed designs II and III, operate by detecting the output amplitude and phase signals at two distinct wavelengths (\({\lambda }_{1}\) and \({\lambda }_{2}\), respectively). The difference between designs II and III is that design II utilizes a shared FOV for both the amplitude and phase channel outputs, while design III maintains two spatially separated FOVs, each dedicated to either the output amplitude or phase images.

Schematics for different designs of our diffractive complex field imager. a Illustration showing a spatially multiplexed design for the diffractive complex field imager (design I), which performs imaging of the amplitude and phase distributions of the input complex object simultaneously by channeling the output amplitude and phase images onto two spatially separate FOVs at the output plane, i.e., the amplitude and phase FOVs (or FOVAmp and FOVPhase). b Illustration for an alternative design of the diffractive complex field imager using wavelength multiplexing (design II), wherein the output amplitude and phase profiles are directly measured using a common output FOV but at different wavelengths, i.e., \({\lambda }_{1}\) and \({\lambda }_{2}\), respectively. c, Illustration for design III of the diffractive complex field imager, wherein the output amplitude and phase images are measured using two spatially separate FOVs (FOVAmp and FOVPhase) and also at different wavelengths (\({\lambda }_{1}\) and \({\lambda }_{2}\), respectively)
After completing the training of these different designs, we blindly tested the performance and generalization capabilities of our trained diffractive complex field imager models. We quantified their imaging errors using thousands of examples of input complex fields, each composed of independent information channels encoded in the amplitude and phase of the input field. The results demonstrated that our diffractive models could successfully generalize to new, unseen complex test fields, including those with structural features distinctly different from the training objects. Through numerical simulations, we further analyzed the spatial resolution and sensitivity of both the amplitude and phase channels of our diffractive complex field imagers. These analyses revealed that our designs could resolve amplitude features with a linewidth of ≥1.5\({\lambda }_{{\rm{m}}}\) and phase features with a linewidth of ≥3\({\lambda }_{{\rm{m}}}\), where \({\lambda }_{{\rm{m}}}\) represents the mean wavelength. Furthermore, our studies showed that by integrating an additional diffraction efficiency-related loss term into the training function, one could achieve diffractive imager models with enhanced output power efficiencies with minimal compromise in imaging performance.
Apart from these numerical analyses, we also conducted an experimental proof-of-concept demonstration of our diffractive complex field imagers using the terahertz part of the spectrum by fabricating the resulting diffractive layers using 3D printing. For our experiments, we constructed test objects (never seen during the training) with spatially structured amplitude or phase distributions through 3D printing and surface coating techniques. Our experimental results successfully reconstructed the amplitude and phase images of the test objects, closely matching our numerical simulations and the ground truth, validating the effectiveness of our diffractive complex field imager designs. While our experimental demonstrations were conducted in the terahertz spectrum, our designs are scalable and can be adapted to other spectral bands by scaling their dimensions proportional to the wavelength of operation. The compact size of our diffractive designs, with an axial span of ~100 × \({\lambda }_{{\rm{m}}}\), facilitates easy integration into existing optical imaging systems and focal plane arrays that operate at different parts of the electromagnetic spectrum, including the visible spectrum. For operation within the visible band, our design can be physically implemented through various nano- and microfabrication techniques, such as two-photon polymerization-based nanolithography50,61. Furthermore, this complex field imager design also does not include any components that are sensitive to the polarization of light, maintaining its amplitude and phase imaging function regardless of the input polarization distribution of the input field. Given all these advantages, including the small footprint, speed of all-optical computation and low-power operation, we believe that this all-optical complex field imaging approach will find broad applications in e.g., defense/security, biomedical imaging, sensing and material science.
Results
Designs of diffractive complex field imagers
Figure 1a illustrates a spatially multiplexed design of our diffractive complex field imager, termed the design I. This diffractive imager is composed of 5 diffractive layers (i.e., L1, L2, …, L5), where each of these layers is spatially coded with 200 × 200 diffractive features, with a lateral dimension of approximately half of the illumination wavelength, i.e., ~\(\lambda\)/2. These diffractive layers are positioned in a cascaded manner along the optical axis, resulting in a total axial length of 150\(\lambda\) for the entire design. A complex input object, \(i(x,y)=A(x,y){e}^{j\phi (x,y)}\), illuminated at \(\lambda\) is placed at the input plane in front of the diffractive layers. This complex object field exhibits an amplitude distribution \(A(x,y)\) that has a value range of [ADC, 1], along with a phase distribution \(\phi (x,y)\) ranging within [0, απ]. Here, ADC denotes the minimum amplitude value of the input complex field, and α is the phase contrast parameter of the input complex field. Without loss of generality, we selected default values of ADC and α as 0.2 and 1, respectively, for our numerical demonstrations. Note that it’s essential to work with ADC ≠ 0 since otherwise the phase would become undefined. After the input complex fields are collectively modulated by these diffractive layers L1-L5, the resulting optical fields \(o\left(\lambda \right)\) at the output plane are measured by the detectors within two spatially separated output FOVs, i.e., FOVPhase and FOVAmp, which produce intensity distributions \({\left|{o}_{{\rm{Phase}}}\left(\lambda \right)\right|}^{2}\) and \({\left|{o}_{{\rm{Amp}}}\left(\lambda \right)\right|}^{2}\) that correspond to the phase and amplitude patterns of each input complex field, respectively. In addition, we also defined a reference signal region \({\mathcal{R}}\) at the periphery of the FOVPhase, wherein the average measured intensity across \({\mathcal{R}}\) is used as the reference signal \(R(\lambda )\) for normalizing the quantitative phase signal \({\left|{o}_{{\rm{Phase}}}\left(\lambda \right)\right|}^{2}\). This normalization process is essential to ensure that the detected phase information is independent of the input light intensity fluctuations, yielding a quantitative phase image \({O}_{{\rm{Phase}}}\left(\lambda \right)=\frac{{\left|{o}_{{\rm{Phase}}}\left(\lambda \right)\right|}^{2}}{R\left(\lambda \right)}\), regardless of the diffracted output power. Overall, the objective of our training process is to have the phase image channel output approximate the ground truth phase distribution of the input complex field, i.e., \({O}_{{\rm{Phase}}}\left(\lambda \right){\rm{\approx }}\,\phi (\lambda )\), demonstrating an effective phase-to-intensity (P → I) transformation. Concurrently, the training of the diffractive layers also aims to have the diffractive output image in the amplitude channel, i.e., \(\left|{o}_{{\rm{Amp}}}\left(\lambda \right)\right|\), proportionally match the ground truth amplitude distribution of the input complex field after subtracting the amplitude DC component ADC, i.e., \(\left|{o}_{{\rm{Amp}}}\left(\lambda \right)\right|\propto (A\left(\lambda \right)-{A}_{{DC}})\), thereby achieving a successful amplitude-to-amplitude (A → A) transformation performed by the diffractive processor. Note that phase-to-intensity transformation is inherently a nonlinear function58. In the phase imaging channel of our diffractive complex-field imager, the amplitude-squared operation as part of the intensity measurement at the sensor plane represents the only occurrence of nonlinearity within the processing pipeline.
In addition to the spatially multiplexed design I described above, we also created an alternative complex field imager design named design II by incorporating wavelength multiplexing to construct the amplitude and phase imaging channels. As illustrated in Fig. 1b, this approach utilizes a dual-color scheme, where the amplitude and phase of the input images are captured separately at two distinct wavelengths, with \({\lambda }_{1}\) dedicated to the phase imaging channel and \({\lambda }_{2}\) dedicated to the amplitude imaging channel. As an empirical parameter, without loss of generality, we selected \({\lambda }_{2}\) = \({\lambda }_{1}\) × 1.28 and \({\lambda }_{1}\) + \({\lambda }_{2}\) = 2\(\lambda\) for our numerical diffractive designs. With this wavelength multiplexing strategy in design II, the amplitude and phase imaging FOVs can be combined into a single FOV – as opposed to 2 spatially separated FOVs as employed by design I shown in Fig. 1a. Consequently, the output amplitude and phase images, i.e., \(\left|{o}_{{\rm{Amp}}}\left({\lambda }_{2}\right)\right|\) and \({O}_{{\rm{Phase}}}\left({\lambda }_{1}\right)\), can be recorded by the same group of sensor pixels.
As illustrated in Fig. 1c, we also developed an additional complex field imager design, referred to as design III, which integrates both space and wavelength multiplexing strategies in constructing the amplitude and phase imaging channels. Specifically, design III incorporates two FOVs that are spatially separated at the output plane (similar to design I) for amplitude and phase imaging, also utilizing two different wavelength channels (akin to design II) to encode the output amplitude/phase images separately.
Following these design configurations (I, II and III) depicted above, we performed their numerical modeling and conducted the training of our diffractive imager models. For this training, we constructed an image dataset comprising 55,000 images of EMNIST handwritten English capital letters, and within each training epoch, we randomly grouped these images in pairs – one representing the amplitude image and another representing the phase image – thereby forming 27,500 training input complex fields. The phase contrast parameter αtr used for constructing these training input complex fields was set as 1. We utilized deep learning-based optimization with stochastic gradient descent to optimize the thickness values of the diffractive features on the diffractive layers. This training was targeted at minimizing a custom-designed loss function defined by the mean squared error (MSE) between the diffractive imager output amplitude and phase images with respect to their corresponding ground truth. More information about the structural parameters of the diffractive complex field imagers, the specific loss functions employed, and additional aspects of the training methodology can be found in the Methods section.
Numerical results and quantitative performance analysis of diffractive complex field imagers
After the training phase, the resulting diffractive layers of our complex field imager models following designs I, II and III are visualized in Supplementary Figs. S1a, S2a and Fig. 2a, respectively, showing their thickness value distributions. To evaluate and quantitatively compare the complex field imaging performances of these diffractive processors, we first conducted blind testing by selecting 10,000 test images from the EMNIST handwritten letter dataset that were never used in the training set and randomly grouped them in pairs to synthesize 5000 complex test objects. To compare the structural fidelity of the resulting output amplitude and phase images (i.e., \(\left|{o}_{{\rm{Amp}}}\left(\lambda \right)\right|\) and \({O}_{{\rm{Phase}}}\)) produced by our diffractive complex field imager models, we quantified the peak signal-to-noise ratio (PSNR) metrics between these diffractive output images and their corresponding ground truth (i.e., \(A\) and \(\phi\)). Our results revealed that, for the diffractive imager model using design I that performs space-multiplexed complex field imaging, the amplitude and phase imaging channels provided PSNR values of 16.47 ± 0.96 and 14.90 ± 1.60, respectively, demonstrating a decent imaging performance. Additionally, for the diffractive imager models using designs II (and III), these performance metrics became 16.46 ± 1.02 and 14.98 ± 1.51 (17.04 ± 1.06 and 15.06 ± 1.63), respectively. Therefore, design III demonstrated a notable performance advantage over the other two models in both phase and amplitude imaging channels when both the space and wavelength multiplexing strategies were used. Apart from these quantitative results, we also presented exemplary diffractive output images for the three models of designs I, II and III in Supplementary Figs. S1b, S2b and Fig. 2b, respectively. These visualization results clearly show that our diffractive output images in both amplitude and phase channels present structural similarity to their input ground truth, even though these input complex fields were never seen by our diffractive models before. These analyses demonstrate the internal generalization of our diffractive complex field imagers, indicating their capability to process new complex fields that have similar statistical distributions to the training dataset.

Blind testing results of the diffractive complex field imager using design III. a Thickness profile of the trained layers of the diffractive complex field imager following the design III in Fig. 1c. The layout of the amplitude and phase FOVs in comparison to the size of a diffractive layer is also provided. b Exemplary blind testing input complex objects never seen by the diffractive imager model during its training, along with their corresponding output amplitude and phase images. c, d Same as b, except that the testing images are taken from the MNIST and QuickDraw datasets, respectively, demonstrating external generalization to image datasets with different structural distributions
We also conducted blind testing of these diffractive complex field imager designs by synthesizing input fields from other datasets where the complex images exhibit distinctly different morphological features compared to the training complex field images. For this purpose, we selected the MNIST handwritten digits62 and the QuickDraw image63 datasets, and for each dataset, we synthesized 5000 input complex fields to test our diffractive models blindly. When using the MNIST-based complex field images, the amplitude and phase PSNR values of our diffractive complex field imager models using designs I, II and III were quantified as (16.59 ± 0.71, 15.42 ± 1.28), (16.40 ± 0.68, 15.53 ± 1.25) and (17.05 ± 0.78, 15.59 ± 1.32), respectively. The corresponding diffractive output images for these results are also exemplified in Supplementary Figs. S1c, S2c and Fig. 2c. When testing using input complex fields synthesized from the QuickDraw images, these PSNR values revealed (14.42 ± 0.94, 13.34 ± 1.10), (14.17 ± 1.01, 13.54 ± 1.61) and (14.72 ± 0.97, 13.46 ± 1.13), with exemplary diffractive output images visualized in Supplementary Figs. S1d, S2d and Fig. 2d, respectively. Once again, these PSNR values, along with the visualization results of the output patterns, demonstrate that all our diffractive models (following designs I, II and III) achieved successful reconstructions of the amplitude and phase channel information of the input complex fields, wherein the design III model presented slightly improved performance over the other two designs. Importantly, these analyses demonstrate the external generalization capabilities of our diffractive imagers, positioning them as general-purpose complex field imagers that can handle input complex field distributions markedly distinct from those encountered during their training stage.
Next, we quantified the complex field imaging performance of our diffractive models as a function of the phase contrast and spatial resolution of the incoming complex fields. For this analysis, we selected various grating patterns to form our test images, which have different linewidths and are oriented in either horizontal or vertical directions. We first considered using these grating patterns encoded within either the phase or the amplitude channels of the input complex fields, forming phase-only or amplitude-only grating test objects. To be more specific, the phase-only input fields were set to have a uniform distribution within their amplitude channel, while the amplitude-only input fields were set to have their phase channel values set as zero/constant. For both kinds of gratings, we selected their linewidths as 1.5\({\lambda }_{{\rm{m}}}\) or 3\({\lambda }_{{\rm{m}}}\) to generate the grating patterns, and tested the spatial resolution for the amplitude and phase imaging channels using our diffractive models; here \({\lambda }_{{\rm{m}}}\) = \(\lambda\) for the design I model and \({\lambda }_{{\rm{m}}}\) = (\({\lambda }_{1}\) + \({\lambda }_{2}\))/2 for the designs II and III. For phase-only gratings with linewidths of 3\({\lambda }_{{\rm{m}}}\), we also used different phase contrast parameters \({\alpha }_{{\rm{test}}}\in\) {0.25, 0.5, 1} to form grating patterns with different phase contrast so that we can evaluate the sensitivity of phase imaging by our diffractive complex field processors. To better quantify the performance of our diffractive complex field imagers for these test grating patterns, we used a grating image contrast (Q) as our evaluation metric, defined as:
The results of using these amplitude- or phase-only grating patterns as input fields to our diffractive models using designs I, II and III are provided in Supplementary Figs. S3a, b, S4a, b and Fig. 3a, b, respectively. Through visual inspection and quantification of grating image contrast Q values, our diffractive imager models were found to resolve most of the amplitude-only grating objects of different linewidths and orientations, with quantified Q values consistently above 0.17. The only exception is that the diffractive model using design II fell short in resolving the horizontal grating patterns with 1.5\({\lambda }_{{\rm{m}}}\) linewidth, achieving Q < 0.1. For the phase-only grating inputs, all three diffractive models succeeded in resolving the gratings with \({\alpha }_{{\rm{test}}}\in\) {0.5, 1} and linewidths of 3\({\lambda }_{{\rm{m}}}\), presenting Q values consistently over 0.19. However, when using the phase-only grating inputs with \({\alpha }_{{\rm{test}}}=\) 0.25 and linewidths of 3\({\lambda }_{{\rm{m}}}\) or those with \({\alpha }_{{\rm{test}}}=\) 1 and linewidths of 1.5\({\lambda }_{{\rm{m}}}\), all of our diffractive models struggle to provide consistently clear grating images, exhibiting relatively poor Q values of ≤0.1. These findings reveal that our diffractive imager models exhibit similar performance in imaging resolution and phase sensitivity, providing an amplitude imaging resolution of >1.5\({\lambda }_{{\rm{m}}}\) for amplitude-only objects and a phase imaging resolution of ≥3\({\lambda }_{{\rm{m}}}\) for phase-only objects with \({\alpha }_{{\rm{test}}}\) ≥ 0.5. We also calculated the average Q values for different diffractive models using these amplitude- or phase-only grating inputs; the design III model emerges as the most competitive one, presenting average Q values of 0.418 and 0.181 for the amplitude and phase channels, respectively. The suboptimal performance of the design II model, we believe, can primarily be attributed to its utilization of the same output FOV for both the phase and amplitude image formation. This strategy results in the overlap of the diffractive features to serve the two imaging channels, thereby not fully utilizing the degrees of freedom provided by the diffractive layers. This is also corroborated by the visualization of the diffractive layer designs shown in Supplementary Fig. S2a: compared to designs I and III, the areas with significant modulation patterns in the design II layers are significantly smaller and more concentrated in the central region, indicating a less efficient utilization of the diffractive degrees of freedom available for optimization, consequently limiting its imaging performance.

Performance analysis of the diffractive complex field imager model shown in Fig. 2. a Imaging results using phase-only gratings as input fields. The binary phase grating patterns encoded within the phase channel of the input objects are shown and compared with the resulting output amplitude and phase images produced by our diffractive imager (i.e., \(\left|{o}_{{\rm{Amp}}}\left(\lambda \right)\right|\) and \({O}_{{\rm{Phase}}}\)). For each diffractive output image, the grating image contrast Q and SCR values were quantified and shown in red and blue numbers, respectively. b Same as in a, except that the amplitude-only gratings are used as input fields. c Imaging results using complex grating objects as input fields. These grating test objects include ones with the same grating patterns encoded in both the amplitude and phase channels (top), as well as ones where horizontal and vertical gratings are orthogonally placed, with one encoded in the phase channel of the input field and the other encoded in the amplitude channel (bottom)
In addition to the analyses of spatial resolution and phase sensitivity, we also utilized amplitude- and phase-only grating images to investigate the crosstalk between the amplitude and phase imaging channels of our diffractive complex field imagers. Since the amplitude-only grating inputs have constant/zero phase distributions, the ground truth of their corresponding diffractive output images in the phase channel should have zero intensities, where the residual represents the crosstalk coming from the amplitude channel. Similarly, for the phase-only grating inputs that have a uniform amplitude distribution (ADC), their diffractive output images in the amplitude channel should reveal no intensity distributions, with the residual representing the crosstalk coming from the phase channel. As shown by the diffractive output images in Supplementary Figs. S3a, b, S4a, b and Fig. 3a, b, we observe some crosstalk components in the amplitude and phase channel imaging results. To provide a quantitative evaluation of this crosstalk, we used the signal-to-crosstalk ratio (SCR) metric, defined as:
where \({O}_{{\rm{Phase}}\to {\rm{Phase}}}\) and \({O}_{{\rm{Amp}}\to {\rm{Phase}}}\) denote the resulting output phase image when encoding the same grating pattern within the phase and amplitude channels of the input complex field, respectively; the first term represents the true signal, and the latter represents the crosstalk term in Eq. (2). Similarly, \(\left|{o}_{{\rm{Amp}}\to {\rm{Amp}}}\right|\) and \(\left|{o}_{{\rm{Phase}}\to {\rm{Amp}}}\right|\) denote the resulting output amplitude image when encoding the same grating pattern within the amplitude and phase channels of the input complex field, respectively. \(\Sigma\) denotes the intensity summation operation across all the pixels. Following these definitions, we quantified the \({{SCR}}_{{\rm{Phase}}}\) and \({{SCR}}_{{\rm{Amp}}}\) values for all the grating imaging outputs in Supplementary Figs. S3a, b, S4a, b and Fig. 3a, b. These SCR analyses reveal that, for all the diffractive imager models, the grating inputs with 1.5\({\lambda }_{{\rm{m}}}\) linewidth and \({\alpha }_{{\rm{test}}}=\) 1 present a ~30% lower \({{SCR}}_{{\rm{Amp}}}\) and a ~53% lower \({{SCR}}_{{\rm{Phase}}}\) when compared to their counterparts with 3\({\lambda }_{{\rm{m}}}\) linewidth, revealing that imaging of finer, higher-resolution patterns is more susceptible to crosstalk. Furthermore, we found that an increase in the input phase contrast (\({\alpha }_{{\rm{test}}})\) leads to more crosstalk in the output amplitude channel, which results in a lower \({{SCR}}_{{\rm{Amp}}}\) value; for example, from >3.5 for \({\alpha }_{{\rm{test}}}=\) 0.25 down to 2.5-3 for \({\alpha }_{{\rm{test}}}=\) 1. Additionally, we calculated the average \({{SCR}}_{{\rm{Phase}}}\) and \({{SCR}}_{{\rm{Amp}}}\) values across these grating images for different diffractive imager models; for the diffractive models using designs I, II and III, the average \({{SCR}}_{{\rm{Amp}}}\) values are 2.805, 3.178 and 3.155, respectively, and the average \({{SCR}}_{{\rm{Phase}}}\) values are 2.331, 2.262 and 2.252, respectively.
These analyses were performed based on amplitude and phase-only grating objects. Beyond that, we also used complex-valued gratings to further inspect the imaging performance of our diffractive models. Specifically, we created complex test fields that have the same grating patterns encoded in both the amplitude and phase channels. The results reported in the top row of the Supplementary Figs. S3c, S4c and Fig. 3c revealed that all our diffractive imager models are capable of distinctly resolving complex gratings with 3\({\lambda }_{{\rm{m}}}\) linewidth, while being largely able to resolve those with 1.5\({\lambda }_{{\rm{m}}}\) linewidth, albeit with occasional failure. We further created complex fields by orthogonally placing horizontal and vertical gratings, with one of these gratings encoded in the phase channel of the input field and the other encoded in the amplitude channel. As evidenced by the bottom row of Supplementary Figs. S3c, S4c and Fig. 3c, our diffractive models could successfully reconstruct the amplitude and phase patterns of the input complex fields with a grating linewidth of 3\({\lambda }_{{\rm{m}}}\).
Impact of input phase contrast on the performance of diffractive complex field imagers
In the analyses conducted so far, all the input fields fed into our diffractive model maintained a consistent phase contrast with an \(\alpha\) value of 1, i.e., \(\phi \in [0,{\rm{\pi }}]\), regardless of the training and testing phases. Next, we investigated the impact of greater input phase contrast on the performance of diffractive complex field imagers. For this analysis, we utilized the same diffractive design III model shown in Fig. 2 and tested its imaging performance using the same set of complex test objects used in Fig. 2b, but with an increased object phase contrast, \({\alpha }_{{\rm{test}}}\), chosen within a range between 1 and 1.999 (i.e., \(\phi\) ∈ [0, 2π)). The corresponding results are shown as the blue curve in Fig. 4a, illustrating a degradation in the imaging performance of the diffractive model as \({\alpha }_{{\rm{test}}}\) increases. This degradation is relatively minor in the PSNR results for the amplitude channel but more pronounced for the phase channel. Specifically, as \({\alpha }_{{\rm{test}}}\) increases from 1 to 1.5, the average amplitude PSNR value slightly drops from 17.04 to 15.82, while the phase PSNR falls from 15.06 to 11.96. When \({\alpha }_{{\rm{test}}}\) approaches 2, the average amplitude and phase PSNR values further decrease to 15.34 and 9.87, respectively. The visual examples in Fig. 4b and Supplementary Fig. S5a, which correspond to the cases of \({\alpha }_{{\rm{test}}}\) = 1.5 and 1.25, respectively, reveal that the amplitude channel of the diffractive model can consistently resolve the amplitude patterns of the objects, which were never encountered during the training phase. However, in the phase channel, despite the patterns being distinguishable and very well matching the ground truth, their intensities were lower than the correct level, leading to incorrect quantitative phase values and, thus, a drop in the phase PSNR values.

Analysis of the impact of input phase contrast on the imaging performance of diffractive complex field imagers. a Blind testing amplitude and phase PSNR values of diffractive complex imager models trained using complex objects constructed with different values of training phase contrast parameter \({\alpha }_{{\rm{tr}}}\), reported as a function of the phase contrast parameter used in testing (\({\alpha }_{{\rm{test}}})\). b Exemplary output amplitude and phase images created by the diffractive complex field imager model shown in Fig. 2, which was trained using \({\alpha }_{{\rm{tr}}}\) = 1, but tested here using \({\alpha }_{{\rm{test}}}\) = 1.5. c Same as b, except that the diffractive complex field imager model was trained using \({\alpha }_{{\rm{tr}}}\) = 1.5
To address this limitation, we explored training two additional diffractive models using higher phase contrast values \({\alpha }_{{\rm{tr}}}\) of 1.25 and 1.5, respectively. The quantitative evaluation results for these models are presented in Fig. 4a as orange and green curves, respectively. The findings indicate that, compared to the original model trained with \({\alpha }_{{\rm{tr}}}\) = 1, the diffractive model employing \({\alpha }_{{\rm{tr}}}\) = 1.5 exhibits a significantly enhanced imaging performance in the phase channel for \({\alpha }_{{\rm{test}}}\) > 1.25. For instance, at \({\alpha }_{{\rm{test}}}\) = 1.5, the phase PSNR improved from 11.96 to 14.42, while the amplitude PSNR remained almost identical across various \({\alpha }_{{\rm{test}}}\) values. A similar improvement was also observed with the other diffractive model trained using \({\alpha }_{{\rm{tr}}}\) = 1.25. These findings are further confirmed by the exemplary visualization results shown in Fig. 4c and Supplementary Fig. S5b; the quantitative phase signals in the phase channel of these new diffractive models markedly ameliorate the issues encountered by the original model. Nonetheless, it is also noted that these new models exhibited some minor disadvantages; for example, the diffractive model trained using \({\alpha }_{{\rm{tr}}}\) = 1.5 demonstrated slightly inferior phase PSNR results at \({\alpha }_{{\rm{test}}}\) < 1.25 compared to the original model. This suggests a propensity of our diffractive imager models to achieve better imaging performance on complex test objects with phase dynamic ranges akin to those encountered during the training.
It is also important to note that the current design of our diffractive complex field imager is specifically tailored for imaging thin complex objects. For such thin objects, their phase variations are relatively slower. In contrast, substantially thicker objects can exhibit rapidly varying phase distributions, leading to phase wrapping issues. These complexities would pose a challenge for the diffractive network-based complex field imager to perform effective processing and image formation. To potentially address this challenge, incorporating a wavelength-multiplexing strategy (similar to that used in certain QPI methods) into the diffractive imager framework could be a potential path forward. Such an approach, which is left as future work, may involve leveraging the diffractive network for all-optical processing across multiple wavelength channels, followed by minimal digital post-processing to accurately reconstruct quantitative phase signals from wrapped phase information acquired at different wavelengths.
Output power efficiency of diffractive complex field imagers
To quantify the output diffraction efficiencies of our complex field imagers, we utilized 5000 test complex fields created from the EMNIST image dataset, and calculated the average diffraction efficiencies of our diffractive complex field imager models. By integrating an additional loss term into our training loss function to balance the complex field imaging performance along with the output diffraction efficiency, we demonstrated the feasibility of increased power efficiency for all three designs (I, II and III), with minimal compromise in the output image quality. The added loss term, denoted as \({{\mathcal{L}}}_{{\rm{Eff}}}\), is specifically designed to control and improve the output diffraction power efficiency, with its definition given by:
where \({\eta }_{{\rm{Phase}}}\) and \({\eta }_{{\rm{Amp}}}\) denote the output diffraction power efficiency within FOVPhase and FOVAmp, respectively, with their detailed definition provided in the Methods section. \({\eta }_{{\rm{th}}}\) refers to the target diffraction efficiency threshold for \(\eta\). By minimizing the loss function that incorporates the \({{\mathcal{L}}}_{{\rm{Eff}}}\) term, we trained 6 diffractive imager models for each design (I, II and III). For each of these models, we set \({\eta }_{{\rm{th}}}\) at distinct levels: 0.1%, 0.2%, 0.4%, 0.8%, 1.6% and 3.2%, and trained the respective model to satisfy the specified \({\eta }_{{\rm{th}}}\). Note that all these new diffractive complex field imager models maintain the same physical architecture as the designs illustrated in Fig. 1, and they were trained using the same EMNIST-based complex image dataset. A performance comparison for these models is provided in Fig. 5, where their amplitude and phase average PSNR values were calculated across the test set and shown as a function of their average diffraction efficiency values. Taking the architecture of design III as an example, one of our complex field imager designs achieved an output power efficiency of ~0.2% in both amplitude and phase channels, resulting in average PSNR values of 14.72 ± 1.47 and 16.64 ± 1.03 for the two corresponding channels, respectively. An additional model, optimized with a heightened emphasis on the output power efficiency, demonstrated the capability of performing complex field imaging with >0.8% diffraction efficiency in both the phase and amplitude channels, while achieving average amplitude and phase PSNR values of 13.51 ± 1.32 and 16.74 ± 1.05, respectively. A similar trend was also observed for the other models using designs I and II, where a significant increase in the output diffraction efficiency could be achieved with a modest trade-off in the output image quality. Moreover, a comparative assessment of the three different designs under various output diffraction efficiencies reaffirms the overall performance advantage of design III: it presents remarkable advantages over design I in phase imaging while outperforming design II in amplitude imaging. Overall, Fig. 4 serves as a “designer rule plot”, which offers guidance in selecting suitable diffractive complex field imager models by balancing the phase/amplitude imaging fidelity with output power efficiency according to specific application requirements.

The trade-off between the complex field imaging performance and the output diffraction efficiency of diffractive complex field imagers. The PSNR on the y-axis reflects the mean value computed over the entire 5000 complex test objects derived from the EMNIST dataset. The data points with black borders correspond to the diffractive imager models trained exclusively using the structural fidelity loss function while disregarding diffraction efficiency, i.e., the ones shown in Supplementary Figs. S1a, S2a and Fig. 2a. The other data points originate from models trained with a diffraction efficiency-related penalty term, as defined in Eq. (12). These models were trained using varying target diffraction efficiency thresholds (\({\eta }_{{\rm{th}}}\)), specifically set at 0.1%, 0.2%, 0.4%, 0.8%, 1.6% and 3.2% corresponding to the data points from left to right on the plot, demonstrating the trade-off between the imaging performance and the output diffraction efficiency
Experimental validation of diffractive complex field imagers
We performed experimental validation of our diffractive complex field imagers using the terahertz part of the spectrum, specifically employing the design II configuration as illustrated in Fig. 1b; we used \({\lambda }_{1}\) = 0.75 mm and \({\lambda }_{2}\) = 0.8 mm for the phase and amplitude imaging channels, respectively. We used three diffractive layers for our experimental design, each layer containing 120 × 120 learnable diffractive features with a lateral size of ~0.516\({\lambda }_{{\rm{m}}}\) (dictated by the resolution of our 3D printer). The axial spacing between any two adjacent layers (including the diffractive layers and the input/output planes) was chosen as ~25.8\({\lambda }_{{\rm{m}}}\) (20 mm), resulting in a total axial length of ~103.2\({\lambda }_{{\rm{m}}}\) for the entire design. As a proof of concept, we designed two experimental models that use different input phase contrast parameters, \({\alpha }_{\exp }=1\) and 0.5. These experimental models were trained using a dataset composed of phase-only and amplitude-only objects, which feature randomly generated spatial patterns with binary phase values of {0, \({\alpha }_{\exp }\pi\)} or amplitude values of {0, 1}. In these proof of concept experiments, we did not employ input objects with spatial distributions in both the amplitude and phase channels due to the fabrication challenges of such objects; however, the amplitude-only or phase-only objects used here still share a single common input FOV and are processed by the same diffractive imager. Therefore, this experimental demonstration serves as an effective proof of our all-optical complex field imaging framework, which has never been demonstrated before in prior works.
After the training, the resulting layer thickness profiles of the diffractive models with \({\alpha }_{\exp }\) = 1 and 0.5 are visualized in Fig. 6a, d, respectively. These diffractive layers were fabricated using 3D printing, with their corresponding photographs showcased in Fig. 6b, e. Additionally, we constructed phase-only or amplitude-only test objects, which were never seen by the trained diffractive models. The phase-only test objects were fabricated by 3D printing layers with spatially varying height profiles representing the phase distributions, and the amplitude-only objects were created by padding aluminum foils onto 3D-printed flat layers to delineate the amplitude patterns. In our proof-of-concept experiments, these objects were designed to have 5 × 5 pixels, each featuring a size of 4.8 mm (~6.19\({\lambda }_{{\rm{m}}}\)). As shown in Fig. 7b, the printed diffractive layers and input complex objects were assembled using a custom 3D-printed holder to ensure that their relative positions follow our numerical design. In our experiments, we employed a THz source operating at \({\lambda }_{1}\) = 0.75 mm and \({\lambda }_{2}\) = 0.8 mm, and used a detector to measure the intensity distribution at the output plane, yielding the output amplitude and phase images. The photograph and schematic of our experimental setup are provided in Fig. 7a and c, respectively. Further details related to the experiment are provided in the Methods section.

Experimental results for 3D-printed diffractive complex field imagers. a The learned thickness profiles of the layers (L1, L2 and L3) of the diffractive imager model trained with \({\alpha }_{\exp }=\) 1. b Photographs of the 3D-printed diffractive layers in a. c Experimental results of the diffractive imager shown in a, compared with their corresponding numerical simulation results and ground truth images. d The learned thickness profiles of the layers (L1, L2 and L3) of the diffractive imager model trained with \({\alpha }_{\exp }=\) 0.5. e Photographs of the 3D-printed diffractive layers in d. f Experimental results of the diffractive imager shown in d, compared with their corresponding numerical simulation results and ground truth images

Experimental set-up for diffractive complex field imagers. a Photograph of the experimental set-up, including a 3D-fabricated diffractive complex field imager. b Photographs of the 3D printed diffractive complex field imager. c Schematic diagram of the continuous-wave terahertz imaging set-up
The experimental results for these two models are shown in Fig. 6c, f, where the output amplitude and phase images present a good agreement with their numerically simulated counterparts, also aligning well with the input ground truth images. These experimental results demonstrate the feasibility of our 3D fabricated diffractive complex field imager to accurately image the amplitude and phase distributions of the input objects; these results also represent the first demonstration of all-optical complex field imaging achieved through a single diffractive processor.
Discussion
The numerical analyses and experimental validation presented in our work showcased a compact complex field imager design through deep learning-based optimization of diffractive surfaces. We explored three variants of this design strategy, with comparative analyses indicating that the design employing spatial and wavelength multiplexing (design III) achieves the best balance between the complex field imaging performance and diffraction efficiency, albeit with a minor increase in hardware complexity. Leveraging the all-optical information processing capabilities of multiple spatially engineered diffractive layers, diffractive complex field imagers reconstruct the amplitude and phase distributions of the input complex field in a complete end-to-end manner, without any digital image recovery algorithm, setting it apart from other designs in the existing literature for similar applications. This capability enables direct recording of the amplitude and phase information in a single snapshot using an intensity-only sensor array, which obviates the need for additional computational processing in the back-end, thereby significantly enhancing the frame rate and reducing the latency of the imaging process. Furthermore, our diffractive imager designs feature a remarkably compact form factor, with dimensions of ~100λ in both the axial and lateral directions, offering a substantial volumetric advantage. In contrast, conventional methods based on interferometry and holography often involve relatively bulky optical components and necessitate multiple measurements, leading to optical and mechanical configurations that require a large physical footprint. While some of the recent single-shot complex amplitude imaging efforts using metasurfaces have aimed for greater compactness, they typically require metalenses with large lateral sizes of >1000λ32,37,38. Moreover, achieving a similar FOV (covering several tens of wavelengths) as in our work would require imaging path lengths of thousands of wavelengths.
In our previous research, we developed diffractive processor designs tailored for imaging either amplitude distributions of amplitude-only objects51 or phase distributions of phase-only objects53,59,60. However, these designs would become ineffective for imaging complex objects with independent and non-uniform distributions in the amplitude and phase channels. In this work, we have overcome this limitation by training our diffractive imager designs using complex objects with random combinations of amplitude and phase patterns, thus allowing a single imager device to effectively generalize to complex optical fields with various distributions in the amplitude and phase channels.
The diffractive complex field imager designs that we presented also exhibit certain limitations. Our results revealed residual errors in their targeted operations, particularly manifesting as crosstalk coming from the amplitude channel into the phase channel. This suggests that the actual phase-to-intensity transformation represented by our diffractive imager, while effective, is an approximation with errors that are dependent on the object amplitude distribution. The mitigation approach for this limitation might involve further enhancement of the information processing capacity of our diffractive imagers, which can be achieved through employing a larger number of diffractive layers (forming a deeper diffractive architecture), thus increasing the overall number of diffractive features/neurons that are efficiently utilized64. Additionally, we believe another performance improvement strategy could be to increase the lateral distance between the two output FOVs dedicated to the phase and amplitude channels, thereby allowing the trainable diffractive features to better specialize for the individual tasks of phase/amplitude imaging; this approach, however, would increase the size of the output FOV of the focal plane array and also demand larger diffractive layers.
Moreover, in our experimental results, we observed the emergence of noise patterns within certain regions, which did not exist in our numerical simulations. This discrepancy can be attributed to potential misalignments and fabrication imperfections in the diffractive layers that are assembled. A mitigation strategy could be to perform “vaccination” of these diffractive imager models, which involves modeling these errors as random variables and incorporating them into the physical forward model during the training process42,50,65. This has been proven effective in providing substantial resilience against misalignment errors for diffractive processors, exhibiting a noticeably better match between the numerical and experimental results42,50,65.
Leveraging its unique attributes, our presented complex field imaging system can open up various practical applications across diverse fields. For biomedical applications, it can be seamlessly integrated into endoscopic devices66 and miniature microscopes67,68,69 to enable real-time, non-invasive quantitative imaging of tissues and cells, which might also be useful for, e.g., point-of-care diagnostics with its compactness and efficiency. This might potentially pave the way for their use in intraoperative imaging, providing surgeons with critical, high-resolution insights during a medical procedure70,71. For environmental monitoring, as another example, the presented system may facilitate the development of portable lab-on-a-chip sensors capable of quickly identifying microorganisms and pollutants, streamlining on-site quantitative analysis without delicate and tedious sample preparation steps72,73,74,75. Furthermore, the portability and compactness of these diffractive designs can make them a valuable tool for rapid inspection of materials in industrial settings76,77. Overall, this compact and efficient complex field imager design could be used in various settings, opening new avenues in scientific research and expanding the measurement capabilities for practical, real-world applications.
Materials and methods
Numerical forward model of a diffractive complex field imager
In our numerical implementation, the transmissive layers within the diffractive complex field imager were modeled as thin dielectric optical modulation elements with spatially varying thickness profiles. For the \(l\) th diffractive layer, the complex-valued transmission coefficient of its \(i\) th feature at a spatial location \(\left({x}_{i},{y}_{i},{z}_{l}\right)\) was defined depending on the illumination wavelength (\(\lambda\)):
where \(a\left({x}_{i},{y}_{i},{z}_{l},\lambda \right)\) and \(\phi \left({x}_{i},{y}_{i},{z}_{l},\lambda \right)\) denote the amplitude and phase coefficients, respectively. The free-space propagation of complex fields between diffractive layers was modeled through the Rayleigh–Sommerfeld diffraction equation41:
where \({w}_{i}^{l}\left(x,y,z,\lambda \right)\) represents the complex field at the ith diffractive feature of the lth layer at location \(\left(x,y,z\right)\). \(r=\sqrt{{(x-{x}_{i})}^{2}+{(y-{y}_{i})}^{2}+{(z-{z}_{l})}^{2}}\) and \(j=\sqrt{-1}\). Based on Eq. (8), \({w}_{{i}}^{l}\left(x,y,z,\lambda \right)\) can be viewed as a secondary wave generated from the source at \(({x}_{i},{y}_{i},{z}_{l})\). As a result, the optical field modulated by the ith diffractive feature of the lth layer (\(l\) ≥ 1, treating the input object plane as the 0th layer), \({u}^{l}({x}_{i},{y}_{i},{z}_{l},\lambda )\), can be written as:
where \(N\) denotes the number of diffractive features on the (l − 1)th diffractive layer and \({z}_{* }\) represents the location of the \({* }^{{\rm{th}}}\) layer in the z direction parallel to the optical axis. The amplitude and phase components of the complex transmittance of the \(i\) th feature of diffractive layer \(l\), i.e., \({a}^{l}\left({x}_{i},{y}_{i},{z}_{l},\lambda \right)\) and \({\phi }^{l}\left({x}_{i},{y}_{i},{z}_{l},\lambda \right)\) in Eq. (7), were defined as a function of the material thickness over the region of that diffractive feature, \({h}_{i}^{l}\), as follows:
Here the parameters \({n}_{d}\left(\lambda \right)\) and \({\kappa }_{d}\left(\lambda \right)\) represent the refractive index and the extinction coefficient of the diffractive layer material, respectively. These parameters correspond to the real and imaginary parts of the complex-valued refractive index, denoted as \({\widetilde{n}}_{d}\left(\lambda \right)\), such that \({\widetilde{n}}_{d}\left(\lambda \right)={n}_{d}\left(\lambda \right)+j{\kappa }_{d}\left(\lambda \right)\). We determined the values of \({\widetilde{n}}_{d}\left(\lambda \right)\) and \({\kappa }_{d}\left(\lambda \right)\) through experimental characterization of the dispersion properties of the diffractive layer materials, and their values are visualized in Supplementary Fig. S6. The trainable thickness values of the diffractive features \({h}_{i}^{l}\) were limited within the range of [\({h}_{\min }\), \({h}_{\max }\)], representing the learnable parameters of our diffractive complex field imagers. For training the diffractive imager models used for numerical analyses, the values of \({h}_{\min }\), \({h}_{\max }\) were selected as 0.2 and 1.2 mm, respectively. For training the diffractive imager models used for experimental validation, the values of \({h}_{\min }\), \({h}_{\max }\) were selected as 0.4 and 1.4 mm, respectively.
Training loss functions and quantification metrics
The total loss function \({{\mathcal{L}}}_{{\rm{Total}}}\) for the training of our diffractive complex field imagers was defined as:
Here, \({{\mathcal{L}}}_{{\rm{Phase}}}\) stands for the loss term for the quantitative phase imaging function, and is defined as:
where \(R(\lambda )\) is the reference signal measured within the reference signal region \({\mathcal{R}}\), which is a frame region surrounding the FOVPhase with a width of one image pixel.
\({{\mathcal{L}}}_{{\rm{Amp}}}\) represents the loss term for the amplitude imaging function, which is defined as:
where \(E\left[\cdot \right]\) represents the intensity averaging operation across all the spatial pixels of the image.
The definition of \({{\mathcal{L}}}_{{\rm{Eff}}}\) is provided in Eqs. (4)–(6). In Eqs. (5) and (6), both \({\eta }_{{\rm{Phase}}}\) and \({\eta }_{{\rm{Amp}}}\) were defined using the following Equation:
where \({E}_{{\rm{output}}}\) represents the total power of the optical field calculated within the output FOV that is either FOVPhase or FOVAmp, i.e., \({E}_{{\rm{output}}}=\sum _{(x,y)\in {{\rm{FOV}}}_{{\rm{output}}}\,}{\left|{u}^{K+1}(x,y,{z}_{K+1},\lambda )\right|}^{2}\), and \({E}_{{\rm{input}}}\) represents the total power of the complex field within the input FOV, i.e., \({E}_{{\rm{input}}}=\sum _{(x,y)\in {\rm{FO}}{{\rm{V}}}_{{\rm{input}}}\,}{\left|{u}^{0}(x,y,{z}_{0},\lambda )\right|}^{2}\).
The hyperparameters, \({\beta }_{{\rm{Amp}}}\) and \({\beta }_{{\rm{Eff}}}\), in Eq. (12) refer to the weight coefficients associated with the amplitude imaging and output diffraction efficiency penalty-related loss terms, respectively. When training our diffractive imager models shown in Fig. 2a, Supplementary Figs. S1a and S2a, the values of \({\beta }_{{\rm{Amp}}}\) and \({\beta }_{{\rm{Eff}}}\) were set as 3 and 0, respectively, i.e., no diffraction efficiency-related penalty was applied for these models. During the training of the diffractive imager designs exhibiting different output diffraction efficiencies for the analysis in Fig. 4, the values of \({\beta }_{{\rm{Amp}}}\) and \({\beta }_{{\rm{Eff}}}\) were set as 3 and 100, respectively. When training the experimental designs shown in Fig. 6a, d, the values of \({\beta }_{{\rm{Amp}}}\) and \({\beta }_{{\rm{Eff}}}\) were set as 1 and 100, respectively, and \({\eta }_{{\rm{th}}}\) were selected as 4%.
For analyzing the imaging performance of our diffractive complex field imagers, we used PSNR as our evaluation metric. The definition of the PSNR value between an image A and an image B is given by:
where N is the total number of pixels within the image. Another metric employed to quantify the performance of our diffractive complex field imaging is the grating image contrast (Q), and its definition has been provided in Eq. (1). In Eq. (1), \({I}_{\max }\) is determined by taking the average intensity of the grating images along the grating orientation and, finding the maximum intensity values within the bar regions, and \({I}_{\min }\) is computed in a way similar to \({I}_{\max }\) but by locating the minimum values.
Implementation details of diffractive complex field imagers
For the diffractive imager models used for numerical analyses in this manuscript, we used a minimum sampling period of 0.3 mm for simulating the complex optical fields (i.e., 0.375\({\lambda }_{{\rm{m}}}\) for \({\lambda }_{{\rm{m}}}\) = 0.8 mm). The lateral size of each feature on the diffractive layers is also selected as 0.3 mm. Both the input and output FOVs, including FOVPhase and FOVAmp, were set to 18 mm × 18 mm. These fields were discretized into arrays of 15 × 15 pixels, with each pixel measuring 1.2 mm (i.e., ~1.5\({\lambda }_{{\rm{m}}}\)).
For simulating the diffractive imager models used for experimental validation, both the sampling period for the optical fields and the lateral dimensions of the diffractive features were set at 0.4 mm (i.e., ~0.516\({\lambda }_{{\rm{m}}}\) for \({\lambda }_{{\rm{m}}}\) = 0.775 mm). The input and output FOVs in these models were 24 mm × 24 mm (i.e., ~30.97\({\lambda }_{{\rm{m}}}\) × 30.97\({\lambda }_{{\rm{m}}}\)). These fields were discretized into arrays of 5 × 5 pixels, with each pixel measuring 4.8 mm (i.e., ~6.19\({\lambda }_{{\rm{m}}}\)).
For training our diffractive imager models, we randomly extracted 55,000 handwritten English capital letter images from the EMNIST Letters dataset to form our training set. During the training stage, we also implemented an image augmentation technique to enhance the generalization capabilities of the diffractive models. This involves randomly flipping the input images vertically and horizontally. These flipping operations were set to be performed with a probability of 50%. For testing our diffractive models, we used a testing image dataset of 10,000 handwritten English capital letter images, which were also randomly extracted from the EMNIST Letters dataset while ensuring no overlap with the training set. In addition, for preparing the blind test images used for evaluating the external generalization capabilities of our models, we used 10,000 handwritten digit images from the MNIST testing dataset and 10,000 QuickDraw images from the QuickDraw dataset63. Before being fed into our diffractive models, all these training and testing images further underwent a bilinear downsampling and normalization process to match the corresponding dimensions and value ranges of the input amplitude or phase images.
Our diffractive models presented in this paper were implemented using Python and PyTorch. In the training phase, each mini-batch was set to consist of 64 randomly selected EMNIST handwritten letter images from the EMNIST dataset78. Subsequently, these images were randomly grouped in pairs to synthesize complex fields. Within each training iteration, the loss value was calculated, and the resulting gradients were back-propagated accordingly to update the thickness profiles of each diffractive layer using the Adam optimizer79 with a learning rate of 10−3. The entire training process lasted for 100 epochs, which took ~6 h to complete using a workstation equipped with a GeForce RTX 3090 GPU.
Experimental terahertz set-up
For our proof-of-concept experiments, we fabricated both the diffractive layers and the test objects using a 3D printer (PR110, CADworks3D). The phase objects were fabricated with spatially varying thickness profiles to define their phase distributions. The amplitude objects were printed to have a uniform thickness and then manually coated with aluminum foil to define the light-blocking areas, while the uncoated sections formed the transmission areas, resulting in the creation of the desired amplitude profiles for test objects. Additionally, we 3D-printed a holder using the same 3D printer, which facilitated the assembly of the printed diffractive layers and input objects to align with their relative positions as specified in our numerical design. To more precisely control the beam profile for the illumination of the complex input objects, we 3D printed a square-shaped aperture of 5 × 5 mm and padded the area around it with aluminum foil. The pinhole was positioned 120 mm away from the object plane in our experiments. This pinhole serves as an input spatial filter to clean the beam originating from the source.
To test our fabricated diffractive complex field design, we employed a THz continuous-wave scanning system, with its schematic presented in Fig. 7c. To generate the incident terahertz wave, we used a WR2.2 modular amplifier/multiplier chain (AMC) followed by a compatible diagonal horn antenna (Virginia Diode Inc.) as the source. Each time, we transmitted a 10 dBm sinusoidal signal at frequencies of 11.111 or 10.417 GHz (fRF1) to the source, which was then multiplied 36 times to generate output radiation at continuous-wave (CW) radiation at frequencies of 0.4 or 0.375 THz, respectively, corresponding to the illumination wavelengths of 0.75 and 0.8 mm used for the phase and amplitude imaging tasks, respectively. The AMC output was also modulated with a 1 kHz square wave for lock-in detection. We positioned the source antenna to be very close to the 3D-printed spatial pinhole filter, such that the illumination power input to the system could be maximized. Next, using a single-pixel detector with an aperture size of ~0.1 mm, we scanned the resulting diffraction patterns at the output plane of the diffractive complex field imager at a step size of 0.8 mm. This detector was mounted on an XY positioning stage constructed from linear motorized stages (Thorlabs NRT100) and aligned perpendicularly for precise control of the detector’s position. For illumination at \({\lambda }_{1}\) = 0.75 mm or \({\lambda }_{2}\) = 0.8 mm, a 10-dBm sinusoidal signal was also generated at 11.083 or 10.389 GHz (fRF2), respectively, as a local oscillator and sent to the detector to down-convert the output signal to 1 GHz. The resulting signal was then channeled into a low-noise amplifier (Mini-Circuits ZRL-1150-LN+) with an 80 dBm gain, followed by a bandpass filter at 1 GHz (±10 MHz) (KL Electronics 3C40-1000/T10-O/O), effectively mitigating noise from undesired frequency bands. Subsequently, the signal passed through a tunable attenuator (HP 8495B) for linear calibration before being directed to a low-noise power detector (Mini-Circuits ZX47-60). The voltage output from the detector was measured using a lock-in amplifier (Stanford Research SR830), which utilized a 1 kHz square wave as the reference signal. The readings from the lock-in amplifier were then calibrated into a linear scale. In our post-processing, we further applied linear interpolation to each intensity field measurement to align with the pixel size of the output FOV used in the design phase. This process finally resulted in the output measurement images presented in Fig. 6c, f.
Data availability
The deep learning models reported in this work used standard libraries and scripts that are publicly available in PyTorch. All the data and methods needed to evaluate the conclusions of this work are presented in the main text and Supplementary Materials. Additional data can be requested from the corresponding author.
References
Popescu, G. Quantitative Phase Imaging of Cells and Tissues (McGraw-Hill, 2011).
Park, Y., Depeursinge, C. & Popescu, G. Quantitative phase imaging in biomedicine. Nat. Photonics 12, 578–589 (2018).
Mir, M. et al. Quantitative phase imaging. Prog. Opt. 57, 133–217 (2012).
Belashov, A. V., Petrov, N. V. & Semenova, I. V. Processing classical holographic interferograms by algorithms of digital hologram reconstruction. Tech. Phys. Lett. 41, 713–716 (2015).
Malacara, Z. & Servín, M. Interferogram Analysis for Optical Testing, 2nd edn. (CRC Press, 2018), https://doi.org/10.1201/9781315221021.
Khonina, S. N. et al. Analysis of the wavefront aberrations based on neural networks processing of the interferograms with a conical reference beam. Appl. Phys. B 128, 60 (2022).
Popescu, G. et al. Fourier phase microscopy for investigation of biological structures and dynamics. Opt. Lett. 29, 2503–2505 (2004).
Ikeda, T. et al. Hilbert phase microscopy for investigating fast dynamics in transparent systems. Opt. Lett. 30, 1165–1167 (2005).
Cuche, E., Bevilacqua, F. & Depeursinge, C. Digital holography for quantitative phase-contrast imaging. Opt. Lett. 24, 291–293 (1999).
Marquet, P. et al. Digital holographic microscopy: a noninvasive contrast imaging technique allowing quantitative visualization of living cells with subwavelength axial accuracy. Opt. Lett. 30, 468–470 (2005).
Mudanyali, O. et al. Compact, light-weight and cost-effective microscope based on lensless incoherent holography for telemedicine applications. Lab. Chip 10, 1417–1428 (2010).
Greenbaum, A. et al. Imaging without lenses: achievements and remaining challenges of wide-field on-chip microscopy. Nat. Methods 9, 889–895 (2012).
Doblas, A. et al. Shift-variant digital holographic microscopy: inaccuracies in quantitative phase imaging. Opt. Lett. 38, 1352–1354 (2013).
Greenbaum, A. et al. Wide-field computational imaging of pathology slides using lens-free on-chip microscopy. Sci. Transl. Med. 6, 267ra175 (2014).
Matlock, A. & Tian, L. High-throughput, volumetric quantitative phase imaging with multiplexed intensity diffraction tomography. Biomed. Opt. Express 10, 6432–6448 (2019).
Platt, B. C. & Shack, R. History and principles of Shack-Hartmann wavefront sensing. J. Refractive Surg. 17, S573–S577 (2001).
Yu, H. B. et al. A tunable Shack-Hartmann wavefront sensor based on a liquid-filled microlens array. J. Micromech. Microeng. 18, 105017 (2008).
Neil, M. A. A., Booth, M. J. & Wilson, T. New modal wave-front sensor: a theoretical analysis. J. Optical Soc. Am. A 17, 1098–1107 (2000).
Booth, M. J. Direct measurement of Zernike aberration modes with a modal wavefront sensor. In Proceedings of SPIE 5162, Advanced Wavefront Control: Methods, Devices, and Applications. 79–90 (SPIE, 2003).
Khonina, S. N., Karpeev, S. V. & Porfirev, A. P. Wavefront aberration sensor based on a multichannel diffractive optical element. Sensors 20, 3850 (2020).
Khorin, P. A., Porfirev, A. P. & Khonina, S. N. Adaptive detection of wave aberrations based on the multichannel filter. Photonics 9, 204 (2022).
Sinha, A. et al. Lensless computational imaging through deep learning. Optica 4, 1117–1125 (2017).
Rivenson, Y. et al. Phase recovery and holographic image reconstruction using deep learning in neural networks. Light Sci. Appl. 7, 17141 (2018).
Nguyen, T. et al. Deep learning approach for Fourier ptychography microscopy. Opt. Express 26, 26470–26484 (2018).
Rivenson, Y., Wu, Y. C. & Ozcan, A. Deep learning in holography and coherent imaging. Light Sci. Appl. 8, 85 (2019).
Chen, H. L. et al. Fourier Imager Network (FIN): a deep neural network for hologram reconstruction with superior external generalization. Light Sci. Appl. 11, 254 (2022).
Wang, F. et al. Phase imaging with an untrained neural network. Light Sci. Appl. 9, 77 (2020).
Huang, L. Z. et al. Self-supervised learning of hologram reconstruction using physics consistency. Nat. Mach. Intell. 5, 895–907 (2023).
Wang, K. Q. et al. On the use of deep learning for phase recovery. Light Sci. Appl. 13, 4 (2024).
Kwon, H. et al. Computational complex optical field imaging using a designed metasurface diffuser. Optica 5, 924–931 (2018).
Kwon, H. et al. Single-shot quantitative phase gradient microscopy using a system of multifunctional metasurfaces. Nat. Photonics 14, 109–114 (2020).
Engay, E. et al. Polarization-dependent all-dielectric metasurface for single-shot quantitative phase imaging. Nano Lett. 21, 3820–3826 (2021).
Ji, A. Q. et al. Quantitative phase contrast imaging with a nonlocal angle-selective metasurface. Nat. Commun. 13, 7848 (2022).
Zhou, J. X. et al. Fourier optical spin splitting microscopy. Phys. Rev. Lett. 129, 020801 (2022).
Zhang, Y. Z. et al. Dielectric metasurface for synchronously spiral phase contrast and bright-field imaging. Nano Lett. 23, 2991–2997 (2023).
Liu, J. N. et al. Asymmetric metasurface photodetectors for single-shot quantitative phase imaging. Nanophotonics 12, 3519–3528 (2023).
Wu, Q. Y. et al. Single-shot quantitative amplitude and phase imaging based on a pair of all-dielectric metasurfaces. Optica 10, 619–625 (2023).
Li, L. et al. Single-shot deterministic complex amplitude imaging with a single-layer metalens. Sci. Adv. 10, eadl0501 (2024).
Wesemann, L. et al. Nanophotonics enhanced coverslip for phase imaging in biology. Light Sci. Appl. 10, 98 (2021).
Li, L. et al. Single-shot wavefront sensing with nonlocal thin film optical filters. Laser Photonics Rev. 17, 2300426 (2023).
Lin, X. et al. All-optical machine learning using diffractive deep neural networks. Science 361, 1004–1008 (2018).
Li, J. X. et al. Spectrally encoded single-pixel machine vision using diffractive networks. Sci. Adv. 7, eabd7690 (2021).
Li, J. X. et al. Rapid sensing of hidden objects and defects using a single-pixel diffractive terahertz sensor. Nat. Commun. 14, 6791 (2023).
Qian, C. et al. Performing optical logic operations by a diffractive neural network. Light Sci. Appl. 9, 59 (2020).
Wang, P. P. et al. Orbital angular momentum mode logical operation using optical diffractive neural network. Photonics Res. 9, 2116–2124 (2021).
Luo, Y., Mengu, D. & Ozcan, A. Cascadable all-optical NAND gates using diffractive networks. Sci. Rep. 12, 7121 (2022).
Shen, C. Y. et al. All-optical phase conjugation using diffractive wavefront processing. Preprint at https://doi.org/10.48550/arXiv.2311.04473 (2023).
Veli, M. et al. Terahertz pulse shaping using diffractive surfaces. Nat. Commun. 12, 37 (2021).
Işıl, Ç. et al. Super-resolution image display using diffractive decoders. Sci. Adv. 8, eadd3433 (2022).
Bai, B. J. et al. To image, or not to image: class-specific diffractive cameras with all-optical erasure of undesired objects. eLight 2, 14 (2022).
Li, J. X. et al. Unidirectional imaging using deep learning–designed materials. Sci. Adv. 9, eadg1505 (2023).
Li, Y. H. et al. Universal polarization transformations: spatial programming of polarization scattering matrices using a deep learning-designed diffractive polarization transformer. Adv. Mater. 35, 2303395 (2023).
Shen, C. Y. et al. Multispectral quantitative phase imaging using a diffractive optical network. Adv. Intell. Syst. 5, 2300300 (2023).
Rahman, S. S. et al. Universal linear intensity transformations using spatially incoherent diffractive processors. Light Sci. Appl. 12, 195 (2023).
Li, Y. H. et al. Optical information transfer through random unknown diffusers using electronic encoding and diffractive decoding. Adv. Photonics 5, 046009 (2023).
Rahman, S. S. et al. Learning diffractive optical communication around arbitrary opaque occlusions. Nat. Commun. 14, 6830 (2023).
Bai, B. J. et al. Pyramid diffractive optical networks for unidirectional magnification and demagnification. Preprint at https://doi.org/10.48550/arXiv.2308.15019 (2023).
Bai, B. J. et al. Data-class-specific all-optical transformations and encryption. Adv. Mater. 35, 2212091 (2023).
Mengu, D. & Ozcan, A. All-optical phase recovery: diffractive computing for quantitative phase imaging. Adv. Optical Mater. 10, 2200281 (2022).
Li, Y. H. et al. Quantitative phase imaging (QPI) through random diffusers using a diffractive optical network. Light Adv. Manuf. 4, 206–221 (2023).
Goi, E., Schoenhardt, S. & Gu, M. Direct retrieval of Zernike-based pupil functions using integrated diffractive deep neural networks. Nature. Communications 13, 7531 (2022).
Deng, L. The MNIST database of handwritten digit images for machine learning research [Best of the Web]. IEEE Signal Process. Mag. 29, 141–142 (2012).
Jongejan, J. et al. The quick, draw!-AI experiment. Mount View, CA, accessed Feb 17, 4 (2016).
Kulce, O. et al. All-optical synthesis of an arbitrary linear transformation using diffractive surfaces. Light Sci. Appl. 10, 196 (2021).
Mengu, D. et al. Misalignment resilient diffractive optical networks. Nanophotonics 9, 4207–4219 (2020).
Sun, J. W. et al. Quantitative phase imaging through an ultra-thin lensless fiber endoscope. Light Sci. Appl. 11, 204 (2022).
Ghosh, K. K. et al. Miniaturized integration of a fluorescence microscope. Nat. Methods 8, 871–878 (2011).
Zong, W. J. et al. Fast high-resolution miniature two-photon microscopy for brain imaging in freely behaving mice. Nat. Methods 14, 713–719 (2017).
Liberti, W. A. III et al. An open source, wireless capable miniature microscope system. J. Neural Eng. 14, 045001 (2017).
Claus, D. et al. Variable wavefront curvature phase retrieval compared to off-axis holography and its useful application to support intraoperative tissue discrimination. Appl. Sci. 8, 2147 (2018).
Costa, P. C. et al. Towards in-vivo label-free detection of brain tumor margins with epi-illumination tomographic quantitative phase imaging. Biomed. Opt. Express 12, 1621–1634 (2021).
Koydemir, H. C. et al. Rapid imaging, detection and quantification of Giardia lamblia cysts using mobile-phone based fluorescent microscopy and machine learning. Lab. Chip 15, 1284–1293 (2015).
Gӧrӧcs, Z. et al. A deep learning-enabled portable imaging flow cytometer for cost-effective, high-throughput, and label-free analysis of natural water samples. Light Sci. Appl. 7, 66 (2018).
Wang, H. D. et al. Early detection and classification of live bacteria using time-lapse coherent imaging and deep learning. Light Sci. Appl. 9, 118 (2020).
Li, Y. Z. et al. Deep learning-enabled detection and classification of bacterial colonies using a thin-film transistor (TFT) image sensor. ACS Photonics 9, 2455–2466 (2022).
Douti, D. B. L. et al. Quantitative phase imaging applied to laser damage detection and analysis. Appl. Opt. 54, 8375–8382 (2015).
Agour, M. et al. Quantitative phase contrast imaging of microinjection molded parts using computational shear interferometry. IEEE Trans. Ind. Inform. 12, 1623–1630 (2016).
Cohen, G. et al. EMNIST: Extending MNIST to handwritten letters. in 2017 International Joint Conference on Neural Networks (IJCNN) 2921–2926 (2017). https://doi.org/10.1109/IJCNN.2017.7966217 (2017).
Kingma, D. P. & Ba, J. Adam: a method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR, 2015).
Acknowledgements
The Ozcan Research Group at UCLA acknowledges the support of ONR (Grant # N00014-22-1-2016). Jarrahi’s group at UCLA acknowledges the support of the Burroughs Wellcome Fund.
Author information
Authors and Affiliations
Contributions
A.O. conceived and initiated the research, J.L., and T.G. conducted experiments. J.L., Y.L. and T.G. processed the resulting data. All the authors contributed to the preparation of the manuscript. A.O. supervised the research.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, J., Li, Y., Gan, T. et al. All-optical complex field imaging using diffractive processors. Light Sci Appl 13, 120 (2024). https://doi.org/10.1038/s41377-024-01482-6
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41377-024-01482-6
- Springer Nature Limited