
Abstract
Individual impurity atoms in silicon can make superb individual qubits, but it remains an immense challenge to build a multi-qubit processor: there is a basic conflict between nanometre separation desired for qubit–qubit interactions and the much larger scales that would enable control and addressing in a manufacturable and fault-tolerant architecture. Here we resolve this conflict by establishing the feasibility of surface code quantum computing using solid-state spins, or ‘data qubits’, that are widely separated from one another. We use a second set of ‘probe’ spins that are mechanically separate from the data qubits and move in and out of their proximity. The spin dipole–dipole interactions give rise to phase shifts; measuring a probe’s total phase reveals the collective parity of the data qubits along the probe’s path. Using a protocol that balances the systematic errors due to imperfect device fabrication, our detailed simulations show that substantial misalignments can be handled within fault-tolerant operations. We conclude that this simple ‘orbital probe’ architecture overcomes many of the difficulties facing solid-state quantum computing, while minimising the complexity and offering qubit densities that are several orders of magnitude greater than other systems.
Similar content being viewed by others

Introduction
The problem of scalability remains one of the great challenges facing the development of quantum computers. For classical information processing, the semiconductor revolution enabled a spectacularly successful scaling that has led to today’s highly complex consumer devices. It is reasonable to hope that some of this vast expertise could be fruitfully brought to bear on quantum systems. An influential early paper exploring this possibility was written by Kane.1 According to this proposal, impurity atoms implanted in a pure silicon matrix constitute the means of storing qubits. Operations between qubits would occur through direct contact interactions between such spins, which necessitated an inter-qubit spacing of at most nanometres (and therefore a precision considerably greater than this) together with exquisitely small and precisely aligned electrode gates to modulate the interaction. This proposal proved highly influential, and progress towards realising it has been made both through theoretical work advancing the architecture2 and at the experimental level, including impurity positioning via STM techniques that have achieved nanometre precision.3,4 However, it remains extremely challenging as a path to practical quantum computing.
Since 1998 there has been marked progress in understanding the representation and processing of quantum information. Surface codes have emerged as an elegant and practical method for representing information in a quantum computer. The units of information, or logical qubits, can be encoded into a simple two-dimensional array of physical qubits.5 By measuring stabilisers, which essentially means finding the parity of nearby groups of physical qubits, errors can be detected as they arise. Moreover, with a suitable choice of stabiliser measurements the encoded qubits can even be manipulated to perform logical operations. The act of measuring stabilisers over the array thus constitutes a fundamental repeating cycle for the computer, and all higher functions can be built upon it. Importantly, all the required parity measurement operations can be made locally within a simple two-dimensional array, and various studies have established a high level of fault tolerance—of order 1% in terms of the probability for a low-level error in preparation, control or measurement of the physical qubits.6,7
In view of the power and elegance of the surface code picture, one can now revisit the ideas of the Kane proposal and reimagine it as an engine designed ‘from the bottom up’ to efficiently perform stabiliser measurements. This is the task we undertake in the present paper. We find that one can abandon the need for direct gating between physical qubits, and with it the need for extreme precision in the location of impurities and the equally challenging demand for electrical gating of qubit–qubit interactions. This is replaced by a requirement for parity measurement of groups of four spins, which we argue can be performed by a simple repeating cyclical motion. Crucially, we exploit long-range dipole fields rather than contact interactions, and we are thus able to select the scale of the device according to our technological abilities. Presently, we show that the tolerances in our scheme—i.e., the amounts by which dimensions can be allowed to vary—can be orders of magnitude greater than those demanded in the Kane proposal. A further advantage of our approach is that it requires active control of only the electron spins, rather than the nuclear spins. These various advantages come with a new and unique challenge: the device consists of two mechanically separate parts, which are continually shifted slightly with respect to one another in a cyclic motion. Deferring a full discussion of practicality to later in the paper, here we simply note that the requirements in terms of the surface flatness and the precision of mechanical control are considerably less demanding than the tolerances achieved in modern hard-disk drives.
The code written for our numerical simulations is openly available online (please see ‘/naominickerson/fault_tolerance_simulations/ releases’ on GitHub for the code we used).
Results
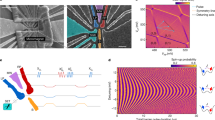
We now specify our main results: the physics we exploit for the parity measurement process: the architecture that can harness this physics; and our detailed numerical simulations establishing the robustness of the device against various kinds of imperfection. The essential elements of the scheme are shown in Figure 1a. Spin- particles suffice for the protocol we describe, and thus we will restrict our analysis to this case; however, we do not foresee any basic obstacle to generalising to higher spin systems. In the figure, four spin- particles referred to as ‘data qubits’ are embedded in a static lattice. In practice, these are likely to be electrons bound to isolated donor impurities in silicon, which we describe in more detail later. Meanwhile, another spin- particle is associated with a mechanically separate element that can move with respect to the static lattice. We assume this ‘probe spin’8,9 is also electronic—for example, either a different species of donor in silicon or a nitrogen-vacancy (NV) defect centre in diamond. It will be necessary to prepare and measure the state of the probe; as we presently discuss, this might be achieved via spin-to-charge conversion for donors in silicon or, alternatively, by optical means for the NV centre. There are two key dimensions: the vertical distance between a probe qubit and a data qubit at closest approach, d, and the separation between qubits in the horizontal plane, D. It is important that d≪D, in order that any interactions between the in-plane spins are relatively weak. As we will discuss, the optimal choice of dimensions varies with several factors, including the nature of the mechanical movement, and moreover the entire structure can be scaled in proportion; however, as an example, for one realisation of the system d=40 nm and D=400 nm will prove to be appropriate. For comparison, note that commercial disk drives can achieve a 3-nm ‘flying height’ between read/write head and platter. Given this set-up, our goal is to measure the parity of the four data qubits—i.e., to make a measurement that reports ‘even’ and leaves the data qubits in the subspace {|0000〉, |1100〉, |0011〉, |0110〉, |1001〉, |0101〉, |1010〉, |1111〉}, or which reports ‘odd’ and leaves the four data qubits in the complementary subspace.

(a) The principle of the orbital probe parity measurement: a probe spin comes into proximity with four data qubits in turn during one cycle. (b) Simplified schematic of a scalable device showing that the probe layer and the data qubit layer both contain extended spin arrays (details of the their relative positions are shown in Figure 3). We depict the probe stage as mobile, whereas the data qubit stage is static, but in fact either may move; it is their relative motion that is key.
In the abstract language of quantum gates, building a parity measurement is straightforward. The following process is typically, although not always,10 used in the quantum-computing literature: we prepare an ancilla (the probe, in our case) in state and then perform two-qubit controlled-phase gate G=diag{1, 1, 1, −1} between the probe and one of the four data qubits. We then repeat this operation between the probe and each of the three remaining data qubits in turn. Finally we measure the probe in the basis {|+〉, |−〉}. The quantum circuit for this parity measurement is shown in Figure 2c (ii). If we see outcome |+〉 then the data qubits are in the ‘even’ space, whereas |−〉 indicates ‘odd’. (This is easy to see by reflecting that the ancilla state toggles |+〉↔|−〉 when it is phase-gated with data qubit in state |1〉, but it is unchanged if that qubit is |0〉; thus the final state is |−〉 if and only if there has been an odd number of such toggles.) Now in the present physical system, we can perform an operation that is essentially identical to the desired phase gate by exploiting the dipole–dipole interaction between the probe and the nearby data qubit. In our scheme the separation between data qubits is at least 10 times greater than the probe–data separation; thus, the interaction of the probe and the three data qubits to which it is not immediately proximal is three orders of magnitude weaker and can be treated as negligible, to an excellent approximation. Therefore, the Hamiltonian of interest describes two S = 1/2 spins, each in a static B field in the Z direction and experiencing a dipole–dipole interaction with one another, is
Here r is the vector between the two spins, is the unit vector in this direction and . In the present analysis we assume that the Zeeman energy of the probe spin differs from the Zeeman energy of the data qubit by an amount Δ=μBB(g1−g2), which is orders of magnitude greater than the dipolar interaction strength J/r3, a condition that prevents the spins from ‘flip-flopping’, as shown in ref. 11. Then in a reference frame that subsumes the continuous Zeeman evolution of the spins their interaction is simply of the form
where the expressions discard irrelevant global phases, 𝟙 is the identity and Z1, Z2 are Pauli matrices acting on the two spins, respectively.

The physical process of parity measurement. (a) The probe and a data qubit move past one another and in doing so a state-dependent phase shift occurs. (b) We consider two ways in which the probe may move: abruptly, site to site, or in a continuous circular motion. (c) The net phase acquired by a probe as it transits the cycle of four data qubits reveals their parity, but nothing else. (i) Two equivalent circuits for measuring the Z-parity of four data qubits. Using U=S(π/2), as we propose, and fixing the unconditional phases V on the data qubits is equivalent to (ii) the canonical circuit composed of controlled-phase gates. Note that only global (boxed) operations are required on the data qubits, and the X- and Z-parity measurements differ only by global Hadamard operations. A full description of the noisy circuit is deferred to Appendix II.
The condition that will certainly be met if, as we suggest, the probe and data qubits are of different species. Suppose that the data qubits are phosphorus donors in silicon, whereas the probes are NV centres in diamond. The zero-field splitting of an NV centre is of order 3 GHz, whereas there is no equivalent splitting for the phosphorus donor qubit; this discrepancy implies that Δ is more than six orders of magnitude greater than J/r3 (the latter being of order 0.8 kHz at r=40 nm). A similar conclusion can be reached even if the probe and data qubits are both silicon-based—for example, if each probe is a bismuth donor and each data qubit is a phosphorus donor. Given the hyperfine interaction strengths for phosphorus and bismuth donors of 118 MHz and 1,475 GHz, respectively, the typical minimum detuning between the two species is nearly six orders of magnitude greater than J/r3. We performed exact numerical simulation of the spin–spin dynamics using these values, finding as expected that deviations from the form of S(θ) given above are extremely small, of order 10−4 or lower.
For our purposes U=S(π/2) is an ideal interaction: it is equivalent to the canonical two-qubit phase gate G (up to an irrelevant global phase) if one additionally applies local single-qubit gates V†=diag{1, −i} to each qubit. Thus the desired four-qubit parity measurement is achieved when the probe experiences an S(π/2) with each qubit in turn, followed by measurement of the probe and application of V† to all four data qubits (Figure 2d).
Our goal is therefore to acquire this maximum entangling value of θ=π/2 during the time that the two spins interact. For the present paper we consider two basic possibilities for the way in which the mobile probe spin moves past each static data qubit; these two cases are shown in Figure 2b. The first possibility is that the probe moves abruptly from site to site, remaining stationary in close proximity to each data qubit in turn. In this case, we simply have θ=αt where —i.e., the phase acquired increases linearly until the probe jumps away. The motion of the probe between sites is assumed to be on a timescale that is very short compared with the dwell time at each site; in practice this motion might be in-plane or it might involve lifting and dropping the probe.
An alternative that might be easier to realise is that the probe moves continuously with a circular motion (as this corresponds to phase-locked simple harmonic motion of the probe stage in the x and y directions). Because the data qubits are widely spaced, from the point of view of a data qubit the probe will come in from a great distance, pass close by and then retreat to a great distance. The interaction strength then varies with time; but by choosing the speed of the probe we can select the desired total phase shift—i.e., we again achieve S(π/2). The nature of the circular orbit has positive consequences in terms of tolerating implantation errors, as we presently discuss (Figure 5, upper panels versus lower panels). However, our simulations indicate that the continuous circular motion does slow the operation of the device by approximately a factor of 10 as compared with abrupt motion; therefore, there is more time for unwanted in-plane spin–spin interactions to occur (Appendix IV). To compensate we may adjust the dimensions of the device, for example choosing d=33 nm with D=700 nm will negate the increase.
The analysis in this paper will establish that it suffices for our device to have local control only of the probe qubits, in order to prepare and to measure in the X, Y or Z basis. (To achieve a probe state initialisation in the X or Y basis, we rely on initialisation in the Z eigenstate basis and subsequent spin rotations using the local probe control.) Global control pulses suffice to manipulate the probe qubits during their cycles, and moreover the data qubits can be controlled entirely through global pulses. The surface code approach to fault tolerance requires one to measure parity in both the Z and the X basis. Crucially, both types of measurements can be achieved with the same probe cycle. The X-basis measurements differ from the Z-basis simply through the application of global Hadamard rotations to the data qubits before, and after, the probe cycle (Figure 2, rightmost). Note that the additional phases V† required in our protocol are easily accounted for in the scheme—e.g., by adjusting the next series of Hadamard rotations to absorb the phase.
However, the surface code protocol does require that the data qubits involved in X- and Z-basis stabilisers are grouped differently. This can be achieved in a number of ways; generally there is a trade-off between the number of probe qubits required, the time taken to complete one full round of stabiliser measurements, and the complexity of the motion of the moving stage. Three possible approaches are detailed in Figure 3. The fastest protocol involves manufacturing identical probe and data grids, and corresponds to the simplest mechanical motion of the moving stage: it can be performed with continuous circular movement. In this approach there must be a method of ‘deactivating’ probes that are not presently involved in the parity measurements. One can achieve this by preparing probes in the |0〉 states so that they do not entangle with the data qubits, instead only imparting an unconditional phase shift (the correction of which can be subsumed into the next global Hadamard cycle). Our simulations assume solution (b) from Figure 3; this solution divides a full cycle into four stages, but has the considerable merit that it requires the fewest probes and therefore the lowest density for the measurement/initialisation systems.

Three approaches to implementing the full surface code. (a) The probe stage is manufactured with an identical lattice to the data qubits. In this approach all the X-stabiliser operations are performed in parallel, with the probes for the Z stabilisers made ‘inactive’ by preparation in the |0〉 state. A global Hadamard is then performed on the data qubits. Finally, the Z stabilisers are all measured with the X probes made inactive. The correction of the extra phase acquired by interaction with inactive probes can be subsumed into the global Hadamard operations. If the time for a probe to complete one orbit is τ then this approach takes to complete a full round of stabiliser measurements. (b) The probe stage has 1/4 the qubit density of the data lattice. All probes are ‘active’ (prepared in |+〉) throughout. A more complex probe orbit is required to achieve this approach: here a ‘four leaf clover’ motion. This protocol has time cost per round. This is the approach simulated to produce our threshold results. (c) The probe stage is manufactured with 1/2 the qubit density of the data stage. An abrupt shift of the probe stage is required between the rounds of X and Z stabilisers. All probes are ‘active’ throughout and this method requires time per round.
The same ‘deactivation’ of probes also allows us the flexibility to perform either three- or two-qubit stabilisers should we wish to, or indeed one-qubit stabilisers—i.e., measurement of a specific data qubit. This can be achieved without altering the regular mechanical motion by appropriately timing the preparation and measurement of a given probe during its cycle: it should be in the deactivated state while passing any qubits that are not to be part of the stabiliser, but prepared in the |+〉 state before interacting with the first data qubit of interest. Probe measurement to determine the required stabiliser value should be performed in the Y basis after interacting with one or with three data qubits, or in the X basis after interacting with two data qubits. Note that the simple phase shifts induced by the ‘deactivated’ probe can either be tracked in the classical control software, or negated at the hardware level by repeating a cycle twice: once using |0〉 for the deactived probe and once using state |1〉.
Numerical simulations
The description above is in terms of ideal behaviour. In our simulations we combined this procedure with a comprehensive set of error sources as specified in Figure 4. Our error model is the standard one in which, with some probability p, an ideal operation is followed by an error event: a randomly selected Pauli error, or simple inversion of the recorded outcome in the case of measurement. Further details of this ‘discretisation’ process and how the numbers enter the simulations are given in Appendix I. Figure 4 shows that the numbers used in our simulation are compatible with the values found in the literature for phosphorus in 28Si, as discussed presently. The relative importance of the different errors is explored in additional simulations presented in Appendix III.

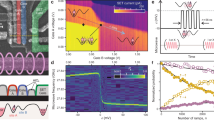
Our error model. (a) The imprecision in donor implantation within the silicon substrate is a systematic error; it is the same on each pass of the probe. We model this as each data qubit being randomly misplaced according to some distribution, which will depend on the method used to manufacture the qubit arrays. Pictured here, a data qubit at a random fixed position with uniform probability inside the blue pillbox. (b) We also include a random fluctuation in the field strength of the dipole–dipole coupling, which we call ‘jitter’. This would correspond to random spatial vibration of the probe qubit, or a random error in the timing of the orbit. This error occurs at each probe–data interaction independently. (c) Full table of the additional sources of error that are considered in our simulations and the experimental state of the art for each in doped 28Si. In each case note that we select fidelities for our simulations, which are comparable to those that have been experimentally demonstrated. See Appendix I for more details of the error model. Note that the experimental numbers for data qubit error are computed from reported rates applied over 1.2 ms, the cycle time given an abruptly moving probe and a 40-nm separation; achieving the same rates for the circular orbit would require improved materials and/or a smaller separation.
In addition to these sources of error, we investigate three particular models of the systematic misalignment of the data qubits versus the two different forms of probe orbit (circular versus abrupt, as discussed earlier). The resulting six variants are shown in Figure 5. Our threshold-finding simulation generates a virtual device complete with a specific set of misalignments in the spin locations (according to one of the distributions), a specific probe orbit and the additional sources of error details in Figure 4c. In order to balance the systematic errors that result from these fixed donor misalignments, we developed a novel protocol for smoothing (see Materials and Methods). Using this protocol, the simulation tests the virtual device to see whether it successfully protects a logical qubit for a given period, and then repeats this process over a large number of virtual devices generated with the same average severity of misalignments. Thus, the simulation determines the probability that the logical qubit is indeed protected in these circumstances. By performing such an analysis for devices of different sizes (i.e., different numbers of data qubits) we determine whether this particular set of noise parameters is within the threshold for fault tolerance—if so, then larger devices will provide superior protection to logical qubits. Repeating this entire analysis for different noise parameters allows us to determine the threshold precisely. The results are shown in Figure 5, and are derived from over six million individual numerical experiments.

Results of threshold-finding numerical simulations. A system has surpassed the threshold for fault-tolerant representation of a logical qubit if, when the system size is increased, we increase the probability of storing that logical qubit without corruption. Thus, the crossing point of the lines reveals the threshold point. Lines from blue to red correspond to increasing array sizes of 221, 313, 421 and 545 physical qubits. Figure 4c specifies the assumed error levels in preparation, control and measurement of the probe qubits. The data in a and d are for the disk-shaped distribution shown in the inset—data qubits are located with a circle of radius R in the x–y plane, and with a z displacement ±R/10. The data in b and e are for a pillbox distribution, with a ratio of 2:1 between lateral and vertical displacement. In c and f the same 2:1 ratio is used, but with a normal distribution where R is now the s.d. Each data point in the figures corresponds to at least 50,000 numerical experiments. Decoding is performed using the Blossom V implementation of Edmond’s minimum weight perfect matching algorithm.53,54
The threshold results are shown in terms of qubit misplacement error as a percentage of the ideal probe–data separation d. The use of the long-range dipole–dipole interaction means one can choose the scale of the device. On each plot we indicate the error tolerated for the specific case of d=40 nm. These show an extremely generous threshold in the deviation in the positioning of the implanted qubits, with displacements of up to 11.7 nm being tolerable in the best case scenario Figure 5d. Thus, if donor qubits can be implanted with better accuracy than these values over a whole device, which otherwise operates with the errors detailed in Figure 4c, we can arbitrarily suppress the logical qubit error by increasing the size of the qubit grid. We note that the continuous motion mode leads to a higher tolerance than the abrupt motion mode, as the smooth trajectory means a lower sensitivity to positional deviations in the x–y plane.
Concerning the three models of distributing the donors we note that the uniform disk-shaped distribution, where error in the z-position of the donor is five times smaller than the lateral positional error (Figure 5, leftmost panels), may be the distribution expected of a more sophisticated fabrication technique involving precise placement of donor in a surface via an STM tip with layers of silicon then grown over. Meanwhile, the pillbox and normal distributions (centre and right panels) might be more representative of the results of using an ion implantation technique with very low or very high levels of straggle, respectively. These possibilities are discussed in more detail below.
Generalisation to quantum computation
Our simulations have found the threshold for a quantum memory using the surface code. It is conventional to take this as an accurate estimate of the threshold for full quantum computing using the surface code.12 The justification for this is non-obvious and we summarise it here. Universal quantum computation requires a universal gate set. One such set is the Clifford group, augmented by a single non-Clifford operation - often the ‘T gate’ (the π/8 rotation) is chosen. Computation then involves, at the logical level, only the Clifford operations and this T gate. A subset of the Clifford group can be performed fault tolerantly within the surface code, while logical X and Z operations can actually be implemented in software by updating the Pauli frame. Logical measurement of {|0〉, |1〉} can be achieved in a transversal way by simply measuring all the data qubits individually in the block, and the CNOT is also transversal in the surface code. The Hadamard gate is almost transversal - when performed transversally the logical qubit is rotated, but this rotation can be ‘fixed’ by a procedure of enforcing a slightly different set of stabilisers at the boundaries,13 which we would achieve through ‘deactivating’ probes as required. To complete the Clifford group the so-called ‘S gate’ (π/4 rotation) is required. Neither this nor the non-Clifford T gate is directly supported in a surface code-based device; they can be achieved by consuming an additional encoded qubit in a magic state.14
The fundamentally new element required for computing is therefore the creation of magic states. For our purposes there are two issues to confirm: can we make such states within our architecture, and does the need to do so revise our threshold? Magic state generation involves injection (mapping a single physical qubit to an encoded qubit) and distillation (improving the fidelity of such encoded states by sacrificially measuring some out). The latter involves only Clifford operations (which may include a previously distilled S gate), and therefore falls under the discussion in our previous paragraph. Injection requires operations on individual data qubits rather than the groups of four, but this is possible within our constraint of sending only global pulses to our data qubits: control of individual probe spins implies the ability to control individual data qubits and indeed to inject a magic state. (For example, suppose we set probes to |1〉 where we wish to have a net effect on the adjacent data qubits, and |0〉 elsewhere. Consider the sequence Y(−π/2)Z(−π/8)S(π/8)Y(π/2), where Y and Z are Pauli rotations both performed on all data qubits and S is the probe–data qubit interaction, Equation (1). The net effect on a data qubit is the identity when the probe is in |0〉, but when the probe is |1〉 it constitutes a rotation of X(π/4) on the data qubit, where X is the Pauli rotation. This operation would take a data qubit from |0〉 to a magic state cos(π/8)|0〉−i sin(π/8)|1〉 if and only if the proximal probe is in state |1〉.) Crucially, the purification threshold for a noisy magic state is known to be much larger than that for a surface code memory; indeed this threshold has just been further relaxed in a recent study.15 Ultimately, therefore, the overall threshold for quantum computation is indeed set by the memory threshold, as discussed by the relatively early literature.12
More generally, one can ask about how multiple qubits should be encoded into a large array of data qubits, and what the impact of flaws such as missing data qubits would be on a computation. Although a detailed analysis lies beyond the scope of the present paper, approaches such as lattice surgery13 can offer one simple solution that is manifestly tolerant of a finite density of flaws. The approach is illustrated in Figure 6. Square patches of the overall array are assigned to hold specific logical qubits; stabilisers are not enforced (i.e., parity measurements are not made) along the boundaries except when we wish to perform an operation between adjacent logical qubits. Importantly, if a given patch is seriously flawed (because of multiple missing data qubits during device synthesis, or for other reasons) then we can simply opt not to use it—it becomes analogous to a ‘dead pixel’ in a screen or charge-coupled device. As long as such dead pixels are sufficiently sparse, we will always be able to route information flow around them.

Example of how one could encode and process multiple logical qubits into a flawed array. Each white circle is a data qubit; each green patch is a subarray representing a single logical qubit. When we wish to perform a gate operation between two logical qubits, we begin making parity measurements at their mutual boundary, according to the lattice surgery approach.13 If a region of the overall array contains multiple damaged or missing data qubits, we simply opt not to use it (red patches). Note that in a real device the patch structure would probably be several times larger in order to achieve high levels of error suppression.
We now discuss the practicality of the proposed device in the light of the simulation results.
Timescales and decoherence
First, we examine the operational timescale of the device: for the aforementioned probe–data qubit separation of d=40 nm, the total interaction time for the four S(π/2) phase gates with the four data qubits is tint=2πd3/J≈1.2 ms. This stabiliser cycle time was chosen because it is short enough to comply with the coherence times of donors in silicon or the NV centre and long enough to avoid a significant operational lag due to the finite operation speed of the stage (see below). In the abrupt motion scenario Figure 2b(i) with negligible transfer times, this would allow an operation of the device at about 1 kHZ. In the continuous circular motion picture, a significant time is required for the probe’s transfer between data qubits, which slows down the device by roughly a factor of D/d=10. As noted earlier and discussed in more detail in Appendix IV, the consequent increased accumulation of unwanted in-plane spin–spin interactions can be negated by varying the dimensions, for example, to d=33 nm and D=700 nm. It is also worthwhile to consider a hybrid mode of operation with slow continuous motion in the vicinity of the data qubits and fast accelerated transfers as an approach that could provide both fast operation and high positional error tolerance. We further note that—because of the 1/d3 dependence of the dipolar interaction—every reduction of d by a factor of two allows eight times faster operation frequencies. Thus, if manufacturing precision continues to improve as seen in the past, this device should be readily scalable to faster operations. In practice, selecting dimensions d and D will be a trade-off between the smallest possible fabrication feature sizes, the achievable translation velocities and the decoherence time of the qubits.
Mechanics and device design
The prototypical mechanical system that enables mechanical motions with sub-nanometre positional accuracy is the tip of an atomic force microscope cantilever. In principle, an array of tips on a single cantilever could incorporate the probe qubits and a cyclic motion of the cantilever would allow the four-qubit phase gates. Practical constraints such as height uniformity of the probe tips, however, impose severe challenges on the scalability of this approach up to larger qubit grid sizes.
A more viable mechanical system could be represented by x–y translation stages realised by micro-electromechanical systems (MEMS). These devices are often manufactured from silicon-on-insulator wafers and could exploit the uniformity of the oxide layer to achieve a high homogeneity of the probe–data qubit separation d across the grid. Various designs for MEMS x–y translation stages have been put forward with travel ranges in the 10-μm range or higher16–18 and positional accuracies in the nm regime,19,20 both meeting essential requirements of our proposal. The motion speed of these stages is limited by their eigenfrequency and designs with frequencies >10 kHz21 permit stabiliser cycle translation times on the order of ~100 μs.
As the probe qubits need to be individually controlled and measured, local electric gates are required. There are two basic strategies depending on whether it is the probe array or the data qubit array that is in motion (recall that either can selected as the moving part; only the relative motion is significant). If the probe stage is mobile, it is necessary to deliver the electrical contacts over the suspension beams at the side of the probe stage, by selecting beam characteristics appropriately. (To circumvent wide beams to incorporate all control leads, which would result in a large in-plane spring constant for the stage motion, we suggest using a multitude of thin beams. The spring constant of the beams for the in-plane motion of the stage scales with the width cubed. N thin beams of width w thus only increase the spring constant by a factor of Nw3 compared with (Nw)3 in the single wide beam case.) If, however, the data qubit grid forms the movable stage, then there is no need for such bridging as the data qubits are controlled purely through global pulses. The control for the probe qubits in the static silicon stage below could then be written in the same process as the probe spins themselves, relying on atomic-precise fabrication of phosphorous impurity SETs and gates (see below refs 4,22).
Material systems
Finally we direct our discussion to the properties of the proposed solid-state qubit systems for this orbital probe architecture—namely, donor impurities in silicon; the NV centres in diamond; and divacancy centres in silicon carbide.
To achieve the aforementioned individual addressability of the probe qubits, either probe spins could be individually Stark shifted into resonance with a globally applied microwave source,23,24 or, alternatively, magnetic field gradients could be applied to detune the individual resonance frequencies within the probe qubit grid. Most of these systems also exhibit a hyperfine structure, meaning that the transition energy between the |0〉 and |1〉 states of the electron spin depends on the nuclear spin state. This effectively results in two or more possible ‘species’ of qubits, each of which must be manipulated by a microwave pulse of a different frequency. To perform the required qubit operations regardless of the nuclear spin state, we propose the use of multi-tone microwave pulses composed of all resonance frequencies of the different species. With this we can ensure that nuclear spin flips—so long as they occur less frequently than the time for a stabiliser cycle—do not affect our ability to implement the proposed protocol.
The following paragraphs discuss both the qubit performance of these systems and the suitability of the host material in MEMS applications.
Donors in silicon
Owing to advanced fabrication processes and its excellent material properties, silicon is the predominant material for the realisation of high-quality MEMS devices. Furthermore, silicon can be isotopically purified to a high degree, which reduces the concentration of 29Si nuclear spins and creates an almost ideal, spin-free host system. Consequently, electron spins of donor impurities, such as phosphorus, show extraordinarily long coherence times of up to 2 s,25 thus enabling a very low data qubit memory error probability (sub 0.1%) over the timescale of a single parity measurement of 1.2 ms. If donors in silicon are used as the probe qubits, then initialisation and read-out of the electron spin of single dopants could be performed using spin-dependent tunnelling to a nearby reservoir and subsequent charge detection using (SETs).26–28 The average measurement fidelity is reported as 97% with read-out timescales on the order of milliseconds. (Although the device tolerates measurement errors quite well, it should be noted that the read-out fidelity can be further increased if, by the end of a stabiliser cycle, the electron spin state is transferred to the nuclear spin29 from which it can then be measured with higher fidelity up to values of 99.99%.28 This advantage has to be traded against the cost of a longer measurement time: reported times of order 100 ms are two orders of magnitude slower than other timescales described here, although faster read-out of the electron spin with the help of optical-assisted ionisation of the donor may improve the timescale markedly.30) The single qubit control fidelity for an electron spin of a single P donor in 28Si in these devices has been reported as 99.95%,31 which could be improved even further by the use of composite microwave pulses (as in ref. 32). Furthermore, it was shown in (ref. 28) that the decoherence time of the qubit is not significantly affected by its proximity to the interface and can reach values up to 0.56 s with dynamical decoupling sequences.
The footprint of the required electronic components to measure a single donor spin in silicon is typically on the order of 200×200 nm2 and is thus small enough to achieve qubit grid separations of D=400 nm. We note that if the required measurement temperatures on the order of 100 mK become difficult to maintain, due to actuation motion and friction, for example, then there are alternative optically assisted spin-to-charge conversion methods that may allow for single spin detection at liquid helium temperaturesp.30
As shown by our threshold calculations, a key figure for this scheme is the implantation accuracy required for the probe and data qubit arrays. Ion implantation methods with resolutions approaching 10 nm can be achieved using either e-beam lithography directly on the substrate33,34 or nanostencil masks drilled into AFM cantilevers.35 For donors in silicon these approaches can be combined with ion impact detection to ensure deterministic single-qubit implantation.36 Another technique for silicon is the STM tip patterning of a hydrogen mask and the subsequent exposure to phosphene gas, which enables atomically precise (±3.8 Å) phosphorus donor incorporation in all three dimensions.3,4 This accuracy is more than an order of magnitude below our calculated thresholds of Figure 5, and the challenge remaining is to maintain this precision over larger qubit arrays.
Diamond NV centres
The electron spin qubit associated with the NV defect centre of diamond features optically addressable spin states, which could be manipulated even at room temperature. By using resonant laser excitation and detection of luminescence photons, fast (40 μs;37) and reliable (measurement fidelity of 96.3%;38) read-out of single NV centre spins could be used for the probe spin measurement and initialisation. (The nuclear spin of 14N or of adjacent 13C may again be exploited to enhance the measurement fidelity (99.6%;39).) The coherence times in isotopically purified diamond samples (T2=600 ms at 77 K using strong dynamical decoupling40) are long enough to allow millisecond-long stabiliser cycles, and individual probe control using a global microwave field similar to donors in silicon is possible using electric gates and the Stark effect.41
Although the qubit operations possible in NV centres are advanced, so far very few micro-electromechanical devices have been realised using diamond. Among them are resonator structures from single crystalline diamond-on-insulator wafers42 and from nano-crystalline diamond.43 In principle, though, diamond possesses promising material properties for MEMS applications44 and, given further research, could become an established material to build translatory stages.
The implantation accuracy for the NV centre is determined by the ion beam techniques discussed above. The most accurate method uses a hole in an AFM cantilever and achieves lateral accuracies of ~25 nm at implantation depths of 8±3 nm45. This precision is only slightly below the threshold of our scheme and it is reasonable to hope that new implantation methods could meet the requirements in the near future. Furthermore, we note that the proposed grid spacing of D=400 nm is well beyond the diffraction limit for optical read-out (250 nm;46).
Another critical factor for all NV centre fabrication methods is the low yield of active NV centres per implanted nitrogen atom, which is typically well below 30%.47 Such a low yield would result in too great a number of ‘dead pixels’ within the layout specified in Figure 6 to allow for the construction of a useful device.
Although there are still significant challenges remaining to an integrated diamond MEMS probe array, it is encouraging that the basic requirement of our proposed scheme—i.e., the control of the dipolar interaction of two electron spins by means of changing their separation mechanically, has already been achieved. Grinolds et al.48 were able to sense the position and the dipolar field of a single NV centre by scanning a second NV centre in a diamond pillar attached to an AFM cantilever across it—at a NV centre separation of 50 nm.
Silicon carbide vacancy defects
In addition to NV centres, divacancy defects of certain silicon carbide polytypes exhibit optically addressable spin states suitable for qubit operations.49 Furthermore, silicon carbide micro-electromechanical devices50 and the required fabrication techniques have evolved in recent years, which could open up the possibility of a material with both optical qubit read-out and scalable fabrication techniques. Some important aspects of qubit operation, however, such as longer decoherence times (1.2 ms reported in ref. 51), single-shot qubit read-out and deterministic defect creation with high positional accuracy, have yet to be demonstrated.
Discussion
We have described a new scheme for implementing surface code quantum computing, based on an array of donor spins in silicon, which can be seen as a reworking of the Kane proposal to incorporate an inbuilt method for error correction. The required parity measurements can be achieved using continuous phase acquisition onto another ‘probe’ qubit, removing the challenging requirement for direct gating between physical qubits. Through simulations using error rates for state preparation, control and measurement that are consistent with reported results in the literature, we find that this approach is extremely robust against deviations in the location of the qubits, with tolerances orders of magnitude greater than those seen in the origin Kane proposal. An additional benefit is that such a system is essentially scale independent, as the scheme is based on long-range dipole interactions, thus the dimensions of the device can be selected to match the available fabrication capabilities.
Although this approach does come with its own challenges, we believe that it provides a new and fruitful avenue of research that can lead to the ultimate goal of a silicon-based universal fault-tolerant quantum computer.
Methods
In obtaining these results, we had to tackle a number of unusual features of this novel mechanical device. The most important point is that we must suppress the systematic errors that arise from fixed imperfections in the locations of the spins. Each data qubit is permanently displaced from its ideal location by a certain distance in some specific direction, and these details may be unknown to us. Our analytic treatment (Appendix II) reveals that the general result is to weight certain elements of the parity projection irregularly. Specifically, whereas the ideal even parity projector is
when the spins involved are misaligned then one finds that different terms in the projector acquire different weights, so that the projector has the form
where is a set of lower weighted projectors on odd states. Meanwhile, the odd parity projector becomes , which is similarly formed of a sum of pairs; each pair such as (|0001〉〈0001|+|1110〉〈1110|) has its own weighting, differing from that of the other permutations. Using these projectors to measure the stabilisers of the surface code presents the problem that the error is systematic: for a particular set of four spins, the constants A, B, C and D will be the same each time we measure an ‘even’ outcome. Each successive parity projection would enhance the asymmetry. In order to combat this effect, and effectively ‘smooth out’ the irregularities in the superoperator, we introduce a simple protocol that is analogous to the ‘twirling’ technique used in the literature on entanglement purification. Essentially we deliberately introduce some classical uncertainty into the process, as we now explain.
Suppose that one were to apply the imperfect projector to four data qubits, but immediately before the projection and immediately after it we flip two of the qubits. For example, we apply XX before and after, where X is the Pauli x operator and 1 is the identity. The net effect would still be to introduce (unwanted) weightings corresponding to A, B, C and D; however these weights would be associated with different terms than for alone; for example the A weight will be associated with |1100〉 and |0011〉. Therefore, consider the following generalisation: we randomly select a set of unitary single qubit flips to apply both before and after the projector, from a list of four choices such as U1=, U2=XX, U3=X X, U4=XX. That is, we choose to perform our parity projection as where i is chosen at random. We then note the parity outcome, ‘odd’ or ‘even’, and forget the i. The operators representing the net effect of this protocol, and are specified in Appendix II. Essentially we replace the weightings A, B, C and D with a common weight that is their average, but at the cost of introducing Pauli errors as well as retaining the problem that has a finite probability of projecting onto the odd subspace. Analogously involves smoothed-out odd projectors, newly introduced Pauli error terms, and a retained risk of projection onto the even subspace. However, these imperfections are tolerable—indeed they will occur in any case once we allow for the possibility of imperfect preparation, rotation, and measurement. Crucially, the ‘twirling’ protocol allows us to describe the process in terms of a superoperator that we can classically simulate. It is formed from a probabilistically weighted sum of simple operators, each of which is either or , together with some set of single qubit Pauli operations—i.e., S1S2S3S4 where Si belongs to the set {, X, Y, Z}. In our simulation we can keep track of the state of the many-qubit system by describing it as the initial state together with the accumulated Pauli errors.
An equivalent effect to the Ui twirling operators can be achieved without actually applying operations to the data qubits. This is possible as flipping the probe spin before and after it passes over a given data qubit is equivalent to flipping that data qubit—i.e., it is only the question of whether there is a net flip between the probe and the data qubit that affects the acquired phase. Therefore, we can replace the protocol above with one in which the probe is subjected to a series of flips as it circumnavigates its four data qubits, while those data qubits themselves are not subjected to any flips. As we are free to choose the same i=1 … 4 for all parity measurements occurring at a given time, these probe-flipping operations can be global over the device. In this approach the only operations that target the data qubits are the Hadamard rotations at the end of each complete parity measurement. This is an appealing picture given that we wish to minimise noise on data qubits, and it is this variant of the protocol that we use in our numerical threshold-finding simulations, the results of which are shown in Figure 5.
An extension relevant to many real systems would be to use a spin echo technique to prevent the probe and data qubits from interacting with environmental spins. In this case we would apply at least one flip to the spins (both the data and probe families simultaneously) during a parity measurement cycle; fortunately it is very natural to combine such echo flips with the flips required for twirling. The time for the parity measurement is thus not limited by the dephasing time , but by the more generous coherence time T2. (Using similar techniques, it is also possible to decouple certain parts of the dipole–dipole interaction between the probe and the data qubits, which would reduce phase gate errors from probe qubits that are too strongly coupled to their data qubits. We note that the results of this paper do not make use of this performance improving technique.)
Before concluding our description of this method, we note that the idea of perturbing our system and then deliberately forgetting which perturbation we have applied, whilst perfectly possible, will not be the best of all possible strategies. We speculate that superior performance would result from cycling systematically though the Ui choosing i=1, 2, 3, 4, 1, 2… over successive rounds; but for the present paper is suffices to show that even our simple random twirl leads to fault tolerance with a good threshold.
References
Kane, B. E. A silicon-based nuclear spin quantum computer. Nature 393, 133 (1998).
Hollenberg, L. C. L., Greentree, A. D., Fowler, A. G. & Wellard, C. J. Two-dimensional architectures for donor-based quantum computing. Phys. Rev. B 74, 045311 (2006).
Schofield, S. R. et al. Atomically precise placement of single dopants in Si. Phys. Rev. Lett. 91, 136104 (2003).
Fuechsle, M. et al. A single-atom transistor. Nat. Nano 7, 242–246 (2012).
Dennis, E., A. L., Kitaev, A. & Preskill, J. Topological quantum memory. J. Math. Phys. 43, 4452 (2002).
Fowler, A. G., Stephens, A. M. & Groszkowski, P. High-threshold universal quantum computation on the surface code. Phys. Rev. A 80, 052312 (2009).
Wang, D. S., Fowler, A. G. & Hollenberg, L. C. L. Quantum computing with nearest neighbor interactions and error rates over 1%. Phys. Rev. 83, 020302 (2011).
Berman, G., Brown, G., Hawley, M. & Tsifrinovich, V. Solid-state quantum computer based on scanning tunneling microscopy. Phys. Rev. Lett. 87, 097902 (2001).
Schaffry, M., Benjamin, S. C. & Matsuzaki, Y. Quantum entanglement distribution using a magnetic field sensor. N. J. Phys. 14, 023046 (2012).
DiVincenzo, D. P. & Solgun, F. Multi-qubit parity measurement in circuit quantum electrodynamics. N. J. Phys. 15, 075001 (2013).
Benjamin, S. C. & Bose, S. Quantum computing in arrays coupled by “always-on” interactions. Phys. Rev. A 70, 032314 (2004).
Raussendorf, R. & Harrington, J. Fault-tolerant quantum computation with high threshold in two dimensions. Phys. Rev. Lett. 98, 190504 (2007).
Horsman, C., Fowler, A. G., Devitt, S. & Meter, R. V. Surface code quantum computing by lattice surgery. N. J. Phys. 14, 123011 (2012).
Bravyi, S. & Kitaev, A. Universal quantum computation with ideal Clifford gates and noisy ancillas. Phys. Rev. A 71, 22316 (2005).
Li, Y. A magic state’s fidelity can be superior to the operations that created it. N. J. Phys. 17, 5 (2015).
Harness, T. & Syms, R. R. A. Characteristic modes of electrostatic comb-drive x - y microactuators. J.Micromech. Microeng. 10, 7 (2000).
Mukhopadhyay, D., Dong, J., Pengwang, E. & Ferreira, P. A soi-mems-based 3-dof planar parallel-kinematics nanoposi-tioning stage. Sens. Actuators A Phys. 147, 340–351 (2008).
Dong, J., Mukhopadhyay, D. & Ferreira, P. M. Design, fabrication and testing of a silicon-on-insulator (SOI) MEMS parallel kinematics XY stage. J. Micromech. Microeng. 17, 1154 (2007).
Koo, B., Zhang, X., Dong, J., Salapaka, S. & Ferreira, P. A 2 degree-of-freedom SOI-MEMS translation stage with closed-loop positioning. J. Microelectromech. Syst. 21, 13–22 (2012).
Chu, L. L. & Gianchandani, Y. B. A micromachined 2d positioner with electrothermal actuation and sub-nanometer capacitive sensing. J. Micromech. Microeng. 13, 279 (2003).
Liao, H.-H. et al. A mems electrostatic resonator for a fast-scan stm system. in 5th IEEE International Conference on Nano/Micro Engineered and Molecular Systems (NEMS) 549–552 (2010).
Hile, S. J. et al. Radio frequency reflectometry and charge sensing of a precision placed donor in silicon. Appl. Phys. Lett. 107, 093504-1–093504-5 (2015).
Pica, G. et al. Hyperfine stark effect of shallow donors in silicon. Phys. Rev. B 90, 093504 (2014).
Laucht, A. et al. Electrically controlling single-spin qubits in a continuous microwave field. Sci. Adv. 1, e1500022 (2015).
Tyryshkin, A. M. et al. Electron spin coherence exceeding seconds in high-purity silicon. Nat. Mater. 11, 143–147 (2012).
Morello, A. et al. Single-shot readout of an electron spin in silicon. Nature 467, 687–691 (2010).
Pla, J. J. et al. A single-atom electron spin qubit in silicon. Nature 489, 541–545 (2012).
Muhonen, J. T. et al. Storing quantum information for 30 seconds in a nanoelectronic device. Nat. Nano 9, 986–991 (2014).
Morton, J. J. L. et al. Solid-state quantum memory using the 31P nuclear spin. Nature 455, 1085–1088 (2008).
Lo, C. et al. Hybrid optical-electrical detection of donor electron spins with bound excitons in silicon. Nat. Mater. 14, 490–494 (2015).
Muhonen, J. T. et al. Quantifying the quantum gate fidelity of single-atom spin qubits in silicon by randomized benchmarking. J. Phys. Condens. Matter 27, 154205 (2015).
Morton, J. J. L. et al. High fidelity single qubit operations using pulsed electron paramagnetic resonance. Phys. Rev. Lett. 95, 200501 (2005).
Vieu, C. et al. Electron beam lithography: resolution limits and applications. Appl. Surf. Sci. 164, 111–117 (2000).
Toyli, D. M., Weis, C. D., Fuchs, G. D., Schenkel, T. & Awschalom, D. D. Chip-scale nanofabrication of single spins and spin arrays in diamond. Nano Lett. 10, 3168–3172 (2010).
Weis, C. D. et al. Single atom doping for quantum device development in diamond and silicon. J. Vacuum Sci. Technol. B 26, 2596–2600 (2008).
Jamieson, D. N. et al. Controlled shallow single-ion implantation in silicon using an active substrate for sub-20keV ions. Appl. Phys. Lett. 86, 154204 (2005).
Robledo, L. et al. High-fidelity projective read-out of a solid-state spin quantum register. Nature 477, 574–578 (2011).
Pfaff, W. et al. Unconditional quantum teleportation between distant solid-state quantum bits. Science 345, 532–535 (2014).
Waldherr, G. et al. Quantum error correction in a solid-state hybrid spin register. Nature 506, 204–207 (2014).
Bar-Gill, N., Pham, L. M., Jarmola, A., Budker, D. & Walsworth, R. L. Solid-state electronic spin coherence time approaching one second. Nat. Commun. 4, 1743 (2013).
Dolde, F. et al. Electric-field sensing using single diamond spins. Nat. Phys. 7, 459–463 (2011).
Ovartchaiyapong, P., Pascal, L. M. A., Myers, B. A., Lauria, P. & Bleszynski Jayich, A. C. High quality factor single-crystal diamond mechanical resonators. Appl. Phys. Lett. 101, 163505 (2012).
Imboden, M., Williams, O. A. & Mohanty, P. Observation of nonlinear dissipation in piezoresistive diamond nanomechanical resonators by heterodyne down-mixing. Nano Lett. 13, 4014–4019 (2013).
Williams, O. A. Nanocrystalline diamond. Diamond Relat. Mater. 20, 621–640 (2011).
Pezzagna, S. et al. Nanoscale engineering and optical addressing of single spins in diamond. Small 6, 2117–2121 (2010).
Lesik, M. et al. Maskless and targeted creation of arrays of colour centres in diamond using focused ion beam technology. Phys. Status Solidi (A) 210, 2055–2059 (2013).
Naydenov, B. et al. Enhanced generation of single optically active spins in diamond by ion implantation. Appl. Phys. Lett. 96, 163108 (2010).
Grinolds, M. S. et al. Nanoscale magnetic imaging of a single electron spin under ambient conditions. Nat. Phys. 9, 215–219 (2013).
Koehl, W. F., Buckley, B. B., Heremans, F. J., Calusine, G. & Awschalom, D. D. Room temperature coherent control of defect spin qubits in silicon carbide. Nature 479, 84–87 (2011).
Adachi, K. et al. Single-crystalline 4h-sic micro cantilevers with a high quality factor. Sens. Actuators A Phys. 197, 122–125 (2013).
Christle, D. J. et al. Isolated electron spins in silicon carbide with millisecond coherence times. Nat. Mater. 14, 160–163 (2015).
Fowler, A. G. & Martinis, J. M. Quantifying the effects of local many-qubit errors and nonlocal two-qubit errors on the surface code. Phys. Rev. A 89, 32316 (2014).
Kolmogorov, V. Blossom V: a new implementation of a minimum cost perfect matching algorithm. Math. Prog. Comp. 1, 43–67 (2009).
Edmonds, J. Paths, trees, and flowers. J. Math. 17, 449–467 (1965).
Acknowledgements
Computing facilities were provided by the Oxford’s ARC service, the Imperial College High Performance Computing Service and the Dieter Jaksch group. We acknowledge helpful conversations with Richard Syms. This work is supported by the EPSRC through a platform grant (EP/J015067/1) and the UNDEDD project (EP/K025945/1), and by the European Research Council under the European Community’s Seventh Framework Programme (FP7/2007–2013)/ERC grant agreement no. 279781. JJLM is supported by the Royal Society. SCB is supported by the EPSRC National Quantum Technology Hub in Networked Quantum Information Processing.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Competing interests
The authors declare no conflict of interest.
Appendices
I. ERROR MODEL
Aside from the permanent misalignment in the physical location of the probe and data qubits, which we discuss in detail in the main paper, we must also account for random errors in the preparation, control and measurement of our spin states. Each has an associated noise model.
1. Preparation of the probe state: this is modelled by assuming the probe is prepared in the ideal state, and then with probability pprep this state is subjected to a randomly selected Pauli X, Y or Z rotation. However, as our ideal state |+〉 is an eigenstate of X, only the latter two operations will be significant.
2. Controlled rotation of a spin (e.g., either a flip of the probe spin as part of the ‘twirl’ process or a Hadamard operation on a data qubit): with probability psingle the ideal operation is followed by a randomly selected Pauli X, Y or Z rotation.
3.‘Jitter’:—i.e., random variations in the interaction between the probe and a data qubit, as opposed to the systematic errors due to permanent misalignment: we assume that the actual phase acquired in the two-qubit operation S varies randomly and uniformly between limits , and in our simulations we found we could set —i.e., 4.4% of the ideal phase—before there was any appreciable impact on the threshold. We therefore selected this level of jitter, as reported in the table within Figure 4. The reason for this remarkable level of tolerance is a quadratic relation between the unwanted phase shift (which is proportional to physical imperfections such as, e.g., a timing error) and the actual probability of a discretised error occurring. The following text summarises the argument.
Consider first the simple bimodal case where phase occurs with probability one half, and occurs with probability one half. The evolution of the quantum state can therefore be written as the ideal phase gate followed by an error mapping ρ of the form
where Z1 and Z2 are Pauli operators on the probe and data qubit as in Equation (1). This is therefore equivalent to discrete error event Z1Z2 occurring with probability or approximately for small ϕb.
If we now consider any symmetric distribution of possible phase errors—i.e., a probability density p(ϕ)=p(−ϕ) of an unwanted phase shift between ϕ and ϕ+dϕ, then we can simply match positive and negative shifts as above and integrate, so that our mapping is with
Taking our uniform distribution of phase error from +ϕe to −ϕe one finds that for small ϕe. With our choice of a 4.4% jitter—i.e., —this corresponds to —i.e., a very small 0.04% probability of the Z1Z2 error event.
4. Measurement: we select a measurement error rate pm, and then a particular outcome of the measurement q∈{0, 1} corresponds to the intended projection Pq applied to the state with probability (1−pm) and the opposite projection applied with probability pm. This noisy projector can be written:
In a refinement of this model, we can enter two different values of pm, one for the cause that j=0 and one for j=1. This reflects the reality of many experimental realisations of measurement where, e.g., |1〉 is associated with an active detection event and |0〉 is associated with that event not occurring (in optical measurement, the event is seeing a photon that is characteristic of |1〉). Because of the asymmetry of the process, once imperfections such as photon loss are allowed for then the fidelity of measurement becomes dependent on the state that is measured, |0〉 or |1〉.
5. Data qubit error: we model decoherence of the data qubits that occurs during the timescale of a stabiliser cycle. At the end of each round of stabiliser measurements each data qubit is subjected to a random Pauli X, Y or Z error with probability pdata.
A. Discretisation of errors
Our numerical simulations use the standard approach: we discretise errors into Pauli events that either do or do not occur, with some given probability. Thresholds found in this way should accurately reflect the performance of a machine in which errors have a more general form, including small coherent imperfections.
If two errors E1 and E2 are correctable with a certain code then every linear combination of these αE1+βE2 with is also correctable. The act of making a syndrome measurement will project into the state where either E1 or E2 occurred, and these errors are by definition correctable. As the Pauli operators form the basis of operators for an n-qubit Hilbert space, the ability to correct Pauli errors of a certain weight allows us to correct all errors up to that weight.
Errors associated with our active manipulations (initialisation, periods of interaction, control pulses and measurements) are modelled as occurring at the time of that manipulation. Meanwhile, it is convenient to model ‘environmental decoherence’ on our data qubits—i.e., errors that are not associated with our active manipulations—by applying Pauli errors at the end of each round of stabiliser measurements. In reality, such effects can occur at any time; however, the consequences of any change to the state of a data qubit arise only once that qubit interacts with a probe. Introducing errors discretely at a fixed time effectively accounts for the accumulation of error probability over the time the data qubit is isolated (and this is the majority of the time: ~98% for the circular orbit model). There will be some small decoherence effect during the probe–data qubit interaction, but even this is approximately captured by our model. To see this we need only consider X-type errors as Z errors have no immediate effect—they commute with the interaction S; see Equation (1). Then note that such an error gives rise to a superposition of two states equivalent to ‘flip suffered immediately before the interaction’ and ‘flip suffered immediately after the interaction’; subsequent measurement of the probe collapses this superposition as the terms lead to different parity measurements.
II. STABILISERS AS SUPEROPERATOR
To characterise the entire process of the stabiliser measurement we carry out a full analysis of the measurement procedure including all sources of noise noted in the section above, and generate a superoperator from the result to completely describe the action of the stabilising measurement procedure.
This probabilistic decomposition describes the operation as a series of Kraus operators Ki applied to the initial state with probabilities pi, which depend on the chosen protocol, noise model and error rates. The leading term i=0 will have corresponding K0 representing the reported parity projection, and large p0. For the protocols considered here, the other Kraus operations can be decomposed and expressed as a parity projection with additional erroneous operations applied.
Consider a known deterministic set of phase errors over a four-qubit stabiliser by probe. The probe and data qubits mutually acquire phase through their dipole–dipole interaction. This interaction between probe and single data qubit leads to the following gate:
where θ=π/2+δ(x, y, z) is a function of the position of the data qubit.
This means that after the probe has passed over one of the four qubits the state of the system is
where V=diag{1, i}, , , Z=diag{1, −1} and the superscripts {a, b, c, d} label the data qubit on which the operator acts.
After the probe has passed four data qubits, each of which injects some erroneous phase δi onto the probe qubit, the state of the system is proportional to
We want to measure the probe in the basis, the result of which will determine our estimate of the parity of the data qubits. Rewriting Equation (7),
If measurement of the probe finds it in the |+〉 then we interpret this as an attempted even parity projection. We neglect for now the unconditional phases VdVcVbVa. The actual projection we have performed on the data qubits is
This is clearly not a true parity projection, as different even parity subspaces have different weightings ci, e.g., for and there is some weight on projection onto odd parity subspaces , e.g., for .
Consider the following protocol to smooth out this systematic error in our parity measurement: we randomly select one of four patterns of X operators on the data qubits and apply it before and after the projector. We choose from the set U1=, U2=XX, U3=X X and U4=XX to smooth the weightings ci and si of Equation (9).
The action of this protocol on the state ρ of the data qubits is thus,
The operations Ui have the effect of permuting the weightings of projecting into the different subspaces in . For example, has the same form as with the weightings redistributed according to the relabelling: 1↔2, 3↔4. Expanding out Equation (10) we find 16 ‘even’ terms , 16 ‘odd’ terms and 32 ‘cross’ terms . We add another level to our protocol, applying () or (ZZZZ) with probability 1/2 to kill off the cross terms.
We then find that it is possible to re-express as the probabilistic sum of perfect odd and even parity projections, followed by Z errors on either one or two data qubits,
where the Kraus operators
are each applied with a certain probability. Writing Equation (11) in terms of and and equating with Equation 10, we see that the probabilities can be expressed as in terms of the weightings ci, si as follows:
where , , , , , , and .
Defining and , the explicit forms of the resulting probabilities expressed as functions of the phase errors δi are
We have thus shown that random application of one of a set of four unitaries before and after an ‘imperfect’ parity projection can be expressed as a superoperator on the data qubits. This has the form of the probabilistic application of ‘perfect’ parity projectors followed by Pauli Z errors on subsets of the data qubits. When the phase errors δi are small, the most probable operation is the desired perfect even parity projection Peven with no errors. This information on stabiliser performance then enables classical simulation of a full planar code array, and its fault tolerance threshold can be assessed.
The above considers the superoperator for a noisy parity projection in our probabilistic protocol predicated on obtaining the ‘even’ result when measuring the probe. A similar result can be derived in the case that the probe is measured and found in the |−〉 state.
The erroneous odd parity projection in this case is thus
Again randomly applying our four Ui allows us to derive a superoperator in terms of perfect parity projections and one- and two-qubit Z errors. This takes the form
where the probabilities are given by
A similar analysis can be applied to the three-qubit stabilisers that define the boundaries of the planar code. The superoperators for these edge stabilisers are also expressed as perfect Peven and Podd projections followed with some probability by one- and two-qubit Z errors.
III. EFFECT OF OTHER PARAMETERS ON THE THRESHOLD
In main paper we determine the threshold value of the required donor implantation accuracy, as this is the crucial parameter for fabricating a large-scale device. In doing so we fixed the errors associated with manipulations and measurement of the qubits to values currently achievable in the experimental state of the art. The threshold is in fact a ‘team effort’: if we are able to reduce, for example, the measurement error then greater error in the other parameters can be tolerated. The ‘thresholds’ we determined are thus single points in a vast parameter space. In this appendix we investigate further the effect that changing some of these parameters will have on the ‘donor implantation error’ threshold values determined in Figure 5. Having made our code openly available we hope that the interested reader will find it easy to make further investigations based on their own favoured parameter regimes.
Figure 7 shows how the threshold value for qubit misplacement depends on other key error parameters. In each graph one error parameter is varied while the others remain fixed to the values stated in Figure 4c. The simulations and the resulting fits show that data qubit decoherence is a key source of error to minimise in comparison with measurement and ‘jitter’ errors, at least in this region of the parameter space. Doubling the data qubit decoherence in this regime will have a more deleterious effect on the tolerance of implantation errors than a similar doubling of jitter or measurement error. However, the low rate of decoherence in donor qubits in silicon is one of the great strengths of the system. Interestingly, jitter errors (which correspond to random fluctuations in the strength of the dipole interaction, which one might envisage being due to random timing error) seem to be even more well tolerated than measurement errors, which are generally seen as one of the less crucial sources of error for surface code thresholds. One might imagine that - in a future where donor placement is very far below threshold - characterisation of the device and individual control of probe orbits might mean that the fixed misplacement errors can become random errors in how well we calibrate our device to the misalignments. This would make ‘jitter’ the main source of error; as such it is encouraging to see it is well tolerated.

Variation in the qubit displacement threshold depending on (a) data qubit decoherence, (b) measurement fidelity and (c) jitter error. Each data point corresponds to a full threshold simulation as shown in the insert to a. All data in this figure are for the case of a ‘circular probe’ orbit with ‘pillbox’-distributed qubit positional errors. As such the red data points correspond to the threshold result shown in Figure 5e.
IV. CONSIDERING THE ‘DIPOLAR BACKGROUND’
The simple of model of decoherence that we use in our simulations can be improved to take into account correlated errors arising from the magnetic dipole–dipole interactions of the data qubits with each other. These will lead to correlated pairs of errors occurring between the qubits, the probability of which decreases with the distance between them.
In this appendix we investigate the more nuanced model of decoherence that incorporates errors of this kind. It has already been shown in (ref. 52) that, despite the provable lack of threshold for these kind of errors in the surface code, practically speaking they are tolerable in that they can be suppressed to a desired degree. In fact, that paper demonstrates that correlated pairs of errors whose probability decays with the square of the distance separating the two qubits are well-handled; this is an even longer range interaction than the one considered here.
In Figure 9. we show threshold plots similar to those presented in the main text and Appendix III that demonstrate that the position of the threshold in terms of the qubit displacement varies slowly as we turn on correlated errors on nearest and next-nearest neighbours in the data qubit array. Here we set data qubit decoherence as modelled previously, that is as IID single-qubit Pauli errors, to occur with a small but non-zero level p=0.001, so that the new correlated errors are the dominant effect for the data qubits. We leave other sources of error at the same level as in the other reported simulations. We then apply correlated errors according to the following procedure.

Variation in the qubit displacement threshold as the dipolar coupling of the data qubits is turned on. All data in this figure are for the case of ‘pillbox’-distributed qubit positional errors, as in Figure 5b, e. The upper three panels are for an abrupt probe orbit, the lower three for a smooth circular orbit. The other sources of error are fixed to the same values as in the main text of the paper as per Figure 4, with the exception of data qubit decoherence, which we now set to 0.1% to reflect than in earlier simulations we had modelled this being due in part to these dipolar couplings.
The Hamiltonians of the dipole–dipole interactions between the data qubits is:
We take an approximation that considers only one- and two-nearest neighbours, which comprise a data qubit and its nearest eight counterparts. Depending on the orientation of the pairs and the distance separating them, their evolution is governed by slightly different Hamiltonians. For example, the Hamiltonians describing a qubit 1 and its eight pairwise interactions with its nearest and next-nearest neighbour neighbours are:
and
where D is the distance between two nearest-neighbour data qubits, and the axes and qubit numberings are defined in Figure 8.

A portion of a larger surface code, with nearest and next-nearest interactions labelled as used in our simulated model of the ‘dipolar background’. To a good approximation the evolution of the data qubits due to their mutual dipolar interactions is modelled by the interaction of nearest and next-nearest-neighbour pairs. The distance between nearest neighbours is D, and the axes are chosen such that nearest neighbours lie either on the x or y axis.
The period of time for which this coupling runs can be estimated as the time to complete a round of stabilisers
where κ∈[2, ~80] is a parameter that reflects that in a slow orbit—such as the smooth circular motion, or a protocol that requires a larger number of orbits per round of stabilisers—there is a longer time between the completion of full stabiliser rounds. For example, an abrupt motion with two orbits required for a full round (i.e., one for X-parity measurements and one for Z-parity measurements) corresponds to κ=2 and slow circular motion with the same number of rounds corresponds to κ=20.
The evolution of the data qubits and its neighbours in a short period of time according to such a Hamiltonian will have the form
Taylor expanding and retaining the leading order terms, i.e., the errors on two qubits, one obtains
where a, b, c… are determined by the relative positions of the data qubits with relation to one another.
At each stabiliser measurement the state of the qubit pairs will be projected into one of the states corresponding to either ‘no error’ or one of the possible two-qubit errors with probability given by the square of its amplitude. We thus model the dipolar background in a similar way to our other sources of error: we now inject correlated two-qubit errors at the end of each round with the relative probabilities determined by the forms of Hij above. The new parameter in our model is therefore .
We find that our threshold plots show the familiar behaviour, i.e., a well-defined crossing point, for the range of pdip considered. To relate the values of pdip investigated in Figure 9 to our proposed device dimensions, consider an abrupt orbit at the dimensions d=40 nm and D=400 nm discussed in the paper. Then pdip~0.016%, which is comparable to the rates investigated in the central plots for which we see only small variation in the qubit displacement threshold. In the main text we suggest that for the slower circular orbits (i.e., increasing κ by a factor of 10) the dimensions d=33 nm and D=700 nm be used, which will achieve the same pdip at the cost of a clock cycle ~10 times slower. We note that in both the circular and abrupt cases our simulations show that when setting pdip=0.04%, larger than the values relevant to our proposed dimensions, the threshold in terms of qubit misplacement reduces by approximately one-tenth, still allowing generous tolerance of the scheme to fabrication error.
The probability of a two-qubit error decreases with in this approximation; the results of (ref. 52) would suggest that practical surface code quantum computation is certainly possible with such a class of error. Although the dipole background can lead to correlated pairs of errors occurring in distant parts of a logical qubit, as far as the code is concerned these just appear as two single-qubit errors, which it tries to correct. The free-running dipolar coupling of the data qubits does not cause the very damaging classes of error, such as long chains or large areas suffering error, which could corrupt the logical qubit more easily.52
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
O’Gorman, J., Nickerson, N., Ross, P. et al. A silicon-based surface code quantum computer. npj Quantum Inf 2, 15019 (2016). https://doi.org/10.1038/npjqi.2015.19
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/npjqi.2015.19
- Springer Nature Limited
This article is cited by
-
EUV-induced hydrogen desorption as a step towards large-scale silicon quantum device patterning
Nature Communications (2024)
-
Noise-robust classification of single-shot electron spin readouts using a deep neural network
npj Quantum Information (2021)
-
Semiconductor qubits in practice
Nature Reviews Physics (2021)
-
Constructing Smaller Pauli Twirling Sets for Arbitrary Error Channels
Scientific Reports (2019)
-
Electron spin relaxations of phosphorus donors in bulk silicon under large electric field
Scientific Reports (2019)