
Abstract
In the context of autism spectrum disorder (ASD) triage, the robustness of machine learning (ML) models is a paramount concern. Ensuring the robustness of ML models faces issues such as model selection, criterion importance, trade-offs, and conflicts in the evaluation and benchmarking of ML models. Furthermore, the development of ML models must contend with two real-time scenarios: normal tests and adversarial attack cases. This study addresses this challenge by integrating three key phases that bridge the domains of machine learning and fuzzy multicriteria decision-making (MCDM). First, the utilized dataset comprises authentic information, encompassing 19 medical and sociodemographic features from 1296 autistic patients who received autism diagnoses via the intelligent triage method. These patients were categorized into one of three triage labels: urgent, moderate, or minor. We employ principal component analysis (PCA) and two algorithms to fuse a large number of dataset features. Second, this fused dataset forms the basis for rigorously testing eight ML models, considering normal and adversarial attack scenarios, and evaluating classifier performance using nine metrics. The third phase developed a robust decision-making framework that encompasses the creation of a decision matrix (DM) and the development of the 2-tuple linguistic Fermatean fuzzy decision by opinion score method (2TLFFDOSM) for benchmarking multiple-ML models from normal and adversarial perspectives, accomplished through individual and external group aggregation of ranks. Our findings highlight the effectiveness of PCA algorithms, yielding 12 principal components with acceptable variance. In the external ranking, logistic regression (LR) emerged as the top-performing ML model in terms of the 2TLFFDOSM score (1.3370). A comparative analysis with five benchmark studies demonstrated the superior performance of our framework across all six checklist comparison points.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The number of autism spectrum disorder (ASD) diagnoses has greatly increased according to World Health Organization (WHO) statistics [1]. Often, ASD is detected during the process of examinations using Magnetic Resonance Imaging (MRI), Electroencephalogram (EEG), and demographic data [2, 3]. Over the last few years, more efforts have been directed toward the application of a new model for the diagnosis and triage of autistic patients, which involves a combination of medical and sociodemographic features [4, 5]. This holistic mode has earned recognition and has also led to the creation of smart methods that have facilitated the labeling and detection of autism patients, thus improving the triage process [6].
Triage is vital for determining the priority level of individuals with ASD, such as urgent, moderate, and minor individuals. This process undeniably assists autistic individuals who receive early diagnosis and fast-tracked medical services [6]. It appears increasingly evident that context-based triage has become necessary in the age of evolving technology and immediate applications. The triage system provides a way of prioritizing and locating problems across any domain, including telehealth systems. In other words, triage ensures the optimal performance and efficiency of real-time health applications [7].
However, there is still an inception of ASD triage applications that are performing as a part of real-time systems, most importantly in terms of patient privacy and unimpeded treatment, especially during crisis periods such as pandemics or disasters [5, 8]. Triage applications are mostly based on artificial intelligence (AI) and machine learning (ML) algorithms. The effectiveness of these models is strongly dependent on factors such as the structuring of the data, the behavior of the data and the processing of the data [9]. Dataset preprocessing covers a range of stages, such as imputations, normalizations, and balances of datasets. On the other hand, there is a need for feature engineering, which is also very important, although it involves the creation of new features from the original numeric attributes [10]. The progression of ML models, which are based on the recent fusion of these features, promises to aid in the development of performance evaluation indices. However, there are also areas of AI applications, especially those working under normal conditions in real time, that are prone to a variety of security threats, such as adversary attacks on machine models. Such attacks could be used to influence the data classification of ASD triage applications by manipulating initial data and consequentially altering the behavior of the ML model. Hence, such interference may decrease the precision of triage processes or even result in the complete failure of the system in certain cases [11]. As a result, ASD triage models should demonstrate robustness and reliability. With regard to the issue of robustness, the concept has recently become more noticeable and considered to be a vital part of AI [8].
An ML model is considered robust when it makes accurate outputs with the same metrics and performance under the circumstance of sudden significant changes in data inputs or perspectives due to unintended circumstances [11]. Another scenario is adversarial attacks, which are specifically engineered to deceive the ML models, making them make incorrect predictions through the injection of false data and the so-called "adversarial example" [12]. The "adversarial example" means inaccurate input is introduced into the model, which leads to a requirement of robustness in the model's ability to address this adversarial example. Attacking methods can be divided into two broad categories: white boxes and black boxes [13]. White-box attacks emerge when attackers gain full access to the model architecture and the model itself. In contrast, black-box attacks are made by attackers who do not have access to the internals of the model. As a result of our study, white-box adversarial attacks are predominantly exploited. With these attacks, adversaries have access to the entire structure and parameters of the model they want to exploit; thus, they can design malicious inputs that generate undesirable outputs [14]. Through white-box attacks, however, we aim to evaluate the robustness of our ASD triage system against threats from hackers who are able to extract the required model.
Furthermore, this area still poses one of the major challenges for scientists, and the development of early ASD triage models is currently among the priorities, with various studies aiming to apply ML models for the sake of creating new diagnostic tools or triage mechanisms. These studies, however, differ in terms of their accentuation; none of them are centered on the dataset, while others are concentrated on the ML models involved in their proposed models. This criticism was based on a study that used a sociodemographic ASD dataset and did not employ the triage method [1]. Instead, the study illustrated a number of ML approaches, such as support vector machine (SVM), decision tree (DT), AdaBoost, random forest (RF), Naïve Bayes (NB), neural network (NN), logistic regression (LR), and neural network multilayer perceptron (MLP), for building a prediction model for ASD diagnosis, paying more attention to sociodemographic features. In contrast, a study [15] suggested a hybrid model for ASD diagnosis that comprises the integration of both medical and sociodemographic ASD datasets, as well as the use of multicriteria decision-making (MCDM) during development. [16] employed a dataset of family characteristics of patients with ASD for training models such as SVM, DT, and AdaBoost; therefore, they developed a diagnostic model for ASD. Notably, some studies, such as [17, 18], incorporated diverse datasets and ML models, often within non-real-time contexts. However, the surge in real-time technology applications and the looming threat of adversarial attacks on online systems necessitate a recalibration of ASD model development strategies. As exemplified by [19, 20], a shift is underway toward the incorporation of these considerations, whether by merging traditional datasets with adversarial samples or by introducing innovative methods that leverage neural network (NN) or graph neural network (GNN) approaches to train ASD datasets.
The adaptability of ML models for real-time applications and the selection of the most resilient model for ASD triage are pressing concerns in the research community [9]. Consequently, multiple-ML models have emerged, each demonstrating distinct performance evaluation metric values. The imperative lies in enhancing and adapting ML models across diverse scenarios using a spectrum of classifiers. These models encompass a wide array of ML algorithms, including k-nearest neighbors (kNN), DT, stochastic gradient descent (SGD), support vector machines (SVMs), RF, NB, NN, and LR. Among these, certain models are particularly desirable as foundational learning tools due to their ease of implementation and computational efficiency [21,22,23]. These models undergo meticulous training and testing, employing various preprocessing approaches and encompassing both normal test and adversarial attack scenarios. Undoubtedly, this challenge aligns with the realm of machine learning theory, offering fertile ground for innovative solutions that promise valuable insights and resolutions.
The adaptability and selection of the most robust ML models for healthcare applications for ASD triage or other health fields are crucial [24]. The construction of ML models involves numerous circumstances and procedures, resulting in several choices [9]. Consequently, choosing the best model becomes an essential need. However, evaluating and benchmarking ML models present a complex decision-making challenge due to the necessary trustworthiness requirements, including (1) model robustness—performance on diverse datasets or under varying conditions [11]; (2) model generalization—performance on unseen data; and (3) model flexibility—adaptability to different types of data and problem domains [4, 25]. To address these challenges, specific problems can be described as follows:
1st Issue: Impact of Preprocessing Approaches: Prioritizing verified datasets through precise preprocessing is crucial during the training and testing of ML models [26]. Preprocessing, which involves pivotal approaches such as standard and feature fusion preprocessing, serves as the foundation for ML model development [9]. Despite the comprehensive perspective different preprocessing approaches provide, a central question emerges from the hypothesis: "Do distinct preprocessing approaches influence the development of the optimal ML model? ".
2nd Issue: Multiperspective Decision Matrix: Enhancing and adapting ML models across diverse scenarios using a spectrum of classifiers is imperative. These models encompass a wide array of ML algorithms, undergo meticulous training and testing, employ various preprocessing approaches, and include two perspectives: normal test (nonadversarial) and adversarial attack scenarios [27]. Therefore, evaluating and benchmarking various ML models considering both perspectives in a unified decision matrix simultaneously raises another critical issue.
3rd Issue: Analysis of Performance Metrics and Decision Criteria: The evaluation process for ML models involves a meticulous examination of various criteria or metrics, including classification accuracy (CA), precision, recall, and computational efficiency [24]. These criteria enable comparisons between models to identify strengths and weaknesses [4]. However, four subissues faced in the evaluation and benchmarking of these performance metrics are as follows:
-
Criteria Importance: Assigning appropriate weights to each metric, reflecting their relative importance, is pivotal. A notable challenge arises from simultaneously considering both benefit and cost criteria. Benefit criteria advocate higher values as desirable, such as CA, while cost criteria favor lower values, such as training and testing time [28].
-
Criteria Trade-off: A trade-off involves sacrificing some of one criterion to gain more of another criterion [29]. Achieving one objective or criterion may necessitate sacrificing another. In the context of ML model evaluation and benchmarking, there might be a trade-off between model complexity and interpretability. A more complex model may provide better CA but could be harder to interpret.
-
Criteria Conflict: Conflicts arise when there is a direct clash or disagreement between different criteria [30]. Optimizing one criterion may negatively impact another, and there is no easy compromise. For example, conflict might occur when trying to balance the need for model CA and the requirement for model simplicity. Improving CA (reducing error) may conflict with the goal of keeping the model simple for easier understanding.
-
Data Variation: The varied data values for the metric criteria make the selection decision a more complex task [31]. For example, training and testing time are measured in seconds, CA is measured in percentages, and log loss is measured between 0 and 1. Additionally, some evaluation criteria tend to be subjective, involving high or low values.
Undoubtedly, these issues align with the realm of machine learning theory, while others fall under complex multicriteria decision problems in the evaluation and benchmarking process, where fuzzy MCDM has emerged as a vital and indispensable tool for selecting the most trustworthy ML model for healthcare applications.
The utilization of fuzzy MCDM in evaluating and benchmarking ML models provides a new research direction to contribute to a reliable and trustworthy selection process. Explaining why this combination was chosen and its advantages in the context of ASD triage would provide valuable context for healthcare sectors. Although model selection based on confusion matrix metrics can provide valuable insights into the performance of ML models, it may not fully address the complexities and uncertainties inherent in real-world scenarios [32]. The need for the development of a decision-making framework can be justified as follows:
-
1.
ML models include numerous specifications and considerations that are not limited to simple CA. The training time, precision, specificity, and ability to support different performance metrics are some of the specifications [24].
-
2.
It is possible that a confusion matrix alone cannot show the dilemmas and conflicts that are inherent in the different evaluation metrics. Such cases include, for instance, high-sensitivity models that have low specificity; thus, they may cause misdiagnoses and false positives/negatives[33].
-
3.
An expert system with a decision-making framework provides the facilities for the integration of user preferences and knowledge into the system. The model will, however, be validated to align with the goals and objectives of ASD triage stakeholders, such as clinicians and patients [9].
-
4.
Fuzzy decision-making can cope with imprecision and uncertainty by incorporating them into the evaluation and selection process, resulting in a better mechanism in real-world ASD triage scenarios where the data provided can be incomplete or noisy [34].
-
5.
A decision-making framework enables consideration of multiple criteria together, such as those from a confusion matrix, to carry out a more holistic approach to assessing ML models. Therefore, we will incorporate a holistic approach to the model to fulfill all criteria for efficient ASD triage [15].
In addition, it is of paramount importance to give preference to credible datasets when training and testing ML models [35], especially in regard to maintaining the smooth operation of ASD triaging in real time [28]. The first step in building the model for real-time triage of ASDs, which is resilient to changes in data, is stressing the need for the use of datasets, which are verified and serve as the basis for the training and testing of ML models [32]. The validation and verification of these datasets, on the other hand, are mandatory steps, which eventually leads to the use of feature fusion preprocessing as a foundation for ML model production [36]. In addition, triage is applied in the process of helping patients prioritize patients based on their cases [9].
The MCDM helps determine the efficiency of ML models and optimally selects the most suitable model to be applied [37, 38]. The FDOSM is a good emphasis, for instance, for identifying difficulties and intricate problems [39]. FDOSM is combined to create a problematic section regarding assessment metrics and to distinguish the most promising ML algorithms [24]. This method of approach is built on the concept of the ideal or the most desirable solution, takes into account preferences and inconsistencies, reduces the number of required comparisons, provides fair and implicit comparisons and involves fewer complex arithmetic operations [26]. Furthermore, FDOSM is able to successfully solve the aspects of normalization and weighting that are typical for MCDM procedures [40]. Another factor that stands out in FDOSM is that it is capable of dealing with vague and fuzzy data. This makes it a very reliable tool in circumstances where such data are present. FDOSM aids in the selection of the most efficient ML model by deploying a general evaluation process taking into account several factors and the overall performance of the ML model. Moreover, the model has access to 2-tuple linguistic Fermatean [41, 42], which makes it more potent in solving numerous difficult decisions. The 2-tuple linguistic Fermatean method is an extension of the advanced application of fuzzy set theory [43] and provides multiple benefits for the fuzzy-based FDOSM method. This approach can improve decision-making by providing a more exact representation of linguistic variables with both membership and nonmembership values, thus reducing uncertainty and increasing precision. The superiority of this technique is that it is capable of handling intricate circumstances with many criteria, managing conflicts, and guaranteeing consistency in decision-making [44, 45]. It is noteworthy that FDOSM addresses imprecise data, increases interpretability, and allows decision-makers to better understand the outcomes. Thus, the 2-tuple linguistic Fermatean empowers FDOSM to exercise critical and systemic decision-making without any deviations.
In addition, our goal is to introduce the 2-tuple linguistic Fermatean fuzzy decision by opinion score method (2TLFFDOSM). This new paradigm incorporates the effectiveness of FDOSM, the 2-tuple linguistic method and the Ferman fuzzy group to solve issues of evaluation and benchmarking, particularly conflicts and trade-offs [41]. The main contributions of this work include the following:
-
1.
Produce of a novel ASD-triaged fused dataset based on algorithm 1.
-
2.
Development of multiple-ML models based on the ASD-triaged fused dataset that addresses both normal and adversarial scenarios, founded on algorithm 2.
-
3.
Development of a new decision matrix for multiple-ML models considered for both normal test and adversarial attack scenarios.
-
4.
The 2TLFFDOSM method was formulated to evaluate, benchmark, and select the most robust ML model.
2 Framework
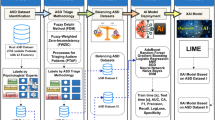
The proposed development framework is structured around three essential phases, as shown in Fig. 1. The initial phase, detailed in Sect. 2.1, focuses on the identification and preprocessing of an authentic ASD triage dataset. The subsequent phase, discussed in Sect. 2.2, delves into the development of multiple machine learning models (referred to as multiple-ML) tailored for normal test and adversarial attack scenarios. The third and final phase involves the development of an evaluation and benchmarking methodology for multiple MLs intended for real-time ASD patient triage. The significance of scrutinizing various ML models in terms of their performance on the ASD triage dataset should be considered for both normal and adversarial test examples. This comparative analysis is fundamental for observing the models being adopted for both the effectiveness and reliability of triage applications in the real world. In addition, it addresses the trends that are important from the points of view of practical, ethical and security issues.

The developed framework for evaluating and benchmarking robust ML models
2.1 Phase 1: ASD Triage Dataset Identification and Preprocessing
This stage incorporates two major steps: first, the description of the ASD triage dataset and, second, the implementation of the PCA feature fusion technique. The method of choice is applied to the ASD triage dataset in its raw form using the recently developed Algorithm 1. This phase of fusion of the ASD dataset results in a merged sample, which is used for comparison of the effectiveness of multi-ML models, which can learn from both normal and adversarial inputs. The detailed procedures of data preprocessing covered in this phase are explained below, including the data description. Figure 2 shows the flow chart of the preprocessing in this phase.

Preprocessing stages for the ASD triage dataset
2.1.1 Dataset Identification
The data for this study were sourced from a prior research project [6]. This dataset comprises authentic information, encompassing 538 patients who received autism diagnoses from specialized psychologist experts. It also includes 19 distinct features comprising medical and sociodemographic data. These patients were categorized into one of three triage labels: urgent (70 patients), moderate (432 patients), or minor (36 patients). The assignment of these labels was conducted through an intelligent triage method known as processes for triaging autism patients (PTAP) (as detailed in [6, 9]). This method involved the collaboration of four psychologist experts, AI specialists, and fuzzy decision-making experts.
To ensure data quality, the ASD triage dataset underwent a rigorous cleaning process, including the imputation of missing values. Additionally, the data were transformed into a numerical format for analysis. Notably, the initial dataset exhibited class imbalance among the three triage labels, prompting efforts to balance the classes. A visualization of the dataset points is presented in Fig. 3 using a 3D scatter plot that incorporates the 19 features, including medical and sociodemographic features.

3D scatter plot of the numerical features of medical and sociodemographic data
Consequently, each triage label was adjusted to contain 432 samples, resulting in a total of 1296 samples in the ASD triage dataset (as discussed in [29]). For more comprehensive details regarding the dataset's description and feature definitions, readers are encouraged to refer to a previous study [6, 49].
2.1.2 Feature Fusion Process
The quality of the raw data is subsequently magnified by feature fusion. Feature fusion involves the consolidation of multiple features or variables to a single feature set, leaving behind the most meaningful information in the original features [46]. This is done by a mathematical function termed principal component analysis, which reduces the number of dimensions of a dataset while maintaining as much variance as available; it achieves this through the transformation of the original features to a new set of a sexually uncorrelated variable described as a principal component; these components capture the features’ largest patterns or variations [47].
The purpose of employing PCA for feature fusion with the 19 autism-related features in this stage is to address several critical issues. These issues include dimensionality reduction, model interpretability, and generalizability improvement. As a group, these advantages tend to improve the ability of multiple-ML models to learn from the fused data source; consequently, the resulting ASD patient triage will be more accurate. As explained in Algorithm 1, the steps of the PCA algorithm involve processing a balanced ASD triage dataset \(X\) with \(n\) samples and \(p\) features.

Algorithm 1
Algorithm 1 standardizes the data, calculates the covariance matrix, identifies the principal components, and projects the data into a reduced-dimensional space. PCA is effectively performed on the balanced ASD triage dataset to achieve feature fusion while retaining essential information.
2.2 Phase 2: Development of Multiple-ML Models
In this phase, we developed multiple-ML models based on the fused ASD triage dataset. The approach began with the development of models for normal test examples, followed by the extension of our efforts to address adversarial test examples. Eight ML algorithms, including logistic regression, DT, NN, SGD, RF, kNN, NB, and SVM, were rigorously tested using nine performance metrics: training time, test time, area under the curve (AUC), CA, F1, precision, recall, log loss, and specificity. Considering both normal and adversarial test example scenarios allowed us to approach model development from multiple angles. This not only deepened our understanding of their strengths and limitations but also provided valuable insights into real-time triage applications. By encompassing a broader spectrum of potential scenarios, multiple MLs are better prepared to perform effectively and robustly in real-world situations, thus enhancing their applicability in ASD patient triage. The process for developing these multiple-ML models is depicted in Fig. 4.

The development process for multiple supervised ML models for normal and adversarial attack examples
Figure 4 shows the development process of eight ML models in the context of normal tests and adversarial attack examples. For the normal test examples, the experiment was applied to the fused ASD dataset to measure the classifiers' performance metrics without an adversarial perspective. Algorithm 2 measures the classifiers' performance with adversarial attack examples. The equations for the performance metrics are shown below, while Table 1 details the parameter settings used for each classifier algorithm.
where \(TP\): true positives, \(TN\): true negatives, \(FP\): false positives, \(FN\): false negatives, \({y}_{i}\): actual class label, \({\widehat{\text{y}}}_{\text{i}}\): predicted probability per label, and \(n\): number of instances.
Optimizing the parameters of a classifier is of paramount importance when aiming to enhance its performance on the fused ASD triage dataset. Additionally, this process can yield valuable insights that can contribute to the optimization of algorithm parameters in future applications [48]. It is well acknowledged that default parameter settings for multiple-ML classifiers often result in suboptimal model performance [49, 50]. Consequently, fine-tuning these parameters enables precise control over the training process, leading to improved performance for multiple-ML models [51]. The parameters incorporated within each model were meticulously adjusted to suit the training of the fused ASD triage dataset. Subsequently, the above parameter settings were obtained through an initial analysis of the dataset size and the types of features present to promote high-level compatibility with numerous ML models; these parameters were also kept flexible to enable continued adjustment of model performance based on the evolving nature and size of the dataset. To better understand the ML models developed from both ends, consider the subsequent subsections.
2.2.1 ML Models Based on Normal Test Examples
The learning of the developed models with normal test examples is conducted by applying them to the fused ASD triage dataset. These models are then used to learn the data via eight previously defined ML algorithms. Finally, the nine performance metrics of the resulting prediction models without adversarial attack learning examples are measured. This effort is focused on understanding the achieved performance quality of the models in a normal scenario architecture.
2.2.2 ML Models Based on Adversarial Attack Examples
Adversarial training is recognized as an effective strategy for fortifying ML models against adversarial samples, thereby enhancing their robustness [52, 53]. Various methodologies have been proposed to construct adversarial examples with the goal of altering predictions while minimizing the dissimilarity between the original instance and the adversarial variant. In the context of this study, ML models were trained using the fused ASD triage dataset. Adversarial attacks were generated employing the fast gradient sign method [54], as delineated in Eq. (8). Subsequently, the Adversarial Robustness Toolbox (ART) classifier, described in Eq. (9), was employed for training purposes. By harnessing the Python-based ML security library ART, scholars and developers are equipped to assess and fortify ML models and applications against adversarial risks such as evasion, poisoning, extraction, and inference [55]. Figure 5 illustrates the workflow of the model development process, which involves the integration of adversarial attack examples into the dataset.
where xadv is the adversarial example and x is the original input example.

ML models developed for adversarial attack examples
ϵ is a small scalar value used to control the magnitude of the perturbation. The purpose of the scalar ϵ is to control the magnitude of the perturbation applied to the original input, determining how much the adversarial example deviates from the original example.
sign: returns the sign of its input.
x(θ, true) is the gradient of the loss function concerning the input x evaluated at θ, y, where θ is the model parameter and y is the true label.
where \(A(x)\) is the ART classifier output for input \(x\), \(k\) is the number of classes, \((f\text{i}(x)\) is the probability of the input \(x\) belonging to class \(i,\text{and} \omega \text{i}\) is the weight for class \(i.\)
In the context of defensive distillation [55], a distinct approach was undertaken. The model depicted in Fig. 5 was trained to exhibit a smoother decision boundary, particularly in the directions that potential attackers are prone to exploit. This strategic choice presents adversaries with a formidable challenge when attempting to identify adjustments in input data that lead to misclassification. Notably, this model's training process differed from that without adversarial attacks, as it leveraged "soft" probability outputs derived from the primary model rather than relying on the "hard" (0/1) true labels from the original training data. This distinctive technique has demonstrated efficacy in fortifying against initial iterations of adversarial attacks. Moreover, the same set of eight ML algorithms underwent training using the fast gradient method for adversarial test examples. The learning procedure followed Algorithm 2, as outlined below:

Algorithm 2
2.3 Phase 3: Evaluation and Benchmarking Methodology
In this phase, we delve into the decision-making methodology for evaluating and benchmarking the multiple-ML models developed based on the fused ASD triage dataset. The first section centers on the creation of the DM, while the second section provides an in-depth exploration of the 2TLFFDOSM. This method aids in selecting a robust ML model within the contexts of normal and adversarial test example learning scenarios.
2.3.1 Development of the DM
The malignant influence of adversarial attacks on the decision-making process may result in incorrect choices. Second, ML models differ in complexity, which complicates the task of objectively comparing their performance. Therefore, the critical element of our evaluation and benchmarking approach is the construction of the DM. The DM includes two components: criteria and alternatives. In total, there are 18 criteria that reflect the evaluation metrics of two perspectives: a test example without adversarial attacks and a test example with adversarial attacks. The alternatives to DM are eight ML models. Table 2 outlines the process of constructing the DM.
The developed DM serves as a pivotal tool in addressing the challenges associated with evaluating and benchmarking multiple-ML models. It offers several key advantages, providing a comprehensive view of the effectiveness of various multiple-ML models across diverse scenarios. However, it is important to note that the DM's full potential is realized when integrated with an appropriate MCDM method. The formulation process of the 2TLFFDOSM enhances the evaluation process, considering the relative importance of criteria, resolving inherent conflicts, and ultimately aiding in the selection of the robust ML model. The combination of the DM and the 2TLFFDOSM methodology provides a powerful and nuanced approach to evaluating multiple-ML models and selecting robust models, ensuring informed decisions in the context of ASD triage applications.
2.3.2 Formulation of 2TLFFDOSM
FDOSM, a robust mathematical model, offers a compelling solution to the intricate challenges associated with selecting the most robust ML model for ASD triage applications [56]. Structured into two principal stages, FDOSM begins with the input unit, where it leverages a DM as a pivotal starting point for evaluating robust models. The DM encapsulates crucial evaluation criteria and alternative ML models for consideration. Transitioning to the data transformation unit, FDOSM performs a sophisticated transformation, converting the DM into an Opinion DM. This transformation process is further enhanced through the application of the Likert scale, resulting in the creation of a fuzzy opinion matrix. The culmination of the FDOSM process involves direct aggregation, a strategic technique used to ascertain the ultimate ranking of the alternatives, representing the eight ML models under scrutiny. Figure 6 visually represents the intricate stages involved in FDOSM.

FDOSM stages
2.4 Data Transformation Unit
To translate the DM into an opinion matrix, the data transformation unit consists of two fundamental phases [57].
Step 1: Based on the following factors, the optimum solution (robust ML model) is chosen as the best option:
The 'max' in the FDOSM formulation for choosing the robust ML model denotes the optimum value for the benefit criteria, denoting the highest possible acceptable value. The 'min' term, on the other hand, denotes the lowest permissible value and provides the best answer for the cost criterion. When the ideal intermediate value is located between the minimum and maximum values, the word "\({{{O}}{{p}}}_{{{i}}{{j}}}\)" refers to the critical value. The decision maker must determine this significant value based on the unique context and demands of the evaluation criteria.
The determination of a crucial value for the assessment criteria is of utmost relevance when choosing a reliable ML model. For instance, in the DM, the remaining criteria are classed as advantages, while criteria such as C1 (training time), C2 (testing time), and C7 (logloss) are labeled as costs. Establishing a critical value empowers the decision maker to conduct a comprehensive evaluation, taking into account both the benefits and costs associated with each subject. This meticulous assessment process ultimately guides the selection of the most adversarially robust ML model.
Step 2: Following the identification of the ideal solution, the next phase involves a comparative analysis where this ideal solution is contrasted with alternative values within the same criterion. This assessment is carried out by experts in the field of machine learning and employs a five-tier language system to categorize the extent of variance between the values. These linguistic terms encompass negligible deviation, minimal difference, moderate discrepancy, substantial variation, and considerable shift. This process can be represented mathematically using the following equation:
Here, the symbol ⊗ denotes the comparison procedure discussed earlier. The linguistic term opinion matrix, which has the following definition, is the output of the data transformation unit:
After the formulation of the opinion matrix, the subsequent phase involves its conversion into fuzzy numbers through the application of appropriate fuzzy membership functions. This transformation serves to quantify the linguistic terms present in the opinion matrix, rendering them fuzzy numbers. This conversion process enhances precision and provides a quantitative representation of the expert's assessments.
Data-Processing Unit The opinion matrix [58], which contains the expert's evaluations and comparisons of the options within each criterion, is the output of the data transformation unit. The third phase involves data processing, which is divided into various parts to identify the reliable ML model. The following is a description of these data processing steps:
Step 1: The opinion decision matrix obtained from the data transformation unit is fuzzified during this initial stage. This step's main goal is to convert the opinion matrix's linguistic terms into 2-tuple linguistic Fermatean fuzzy sets (2TLFFSs). The 2TLFFSs are capable of handling situations where language terms are applied to specific facts. The use of membership and nonmembership grades in the form of 2TL words is required in the development of a 2TLFFS. Because of the inherent uncertainty and slow transition between different linguistic words, 2TLFFSs define the degrees of membership and nonmembership associated with each linguistic term. The definition of 2TLFFSs is given below.
Definition 1
[41]: A FFS on a nonempty set X is given by.
where \({M}_{\widetilde{\mathcal{F}}}\left(x\right):X\to \left[\text{0,1}\right]\) and \({N}_{\widetilde{\mathcal{F}}}\left(x\right):X\to \left[\text{0,1}\right]\) are the membership and nonmembership grades of an element \(x\) in \(\widetilde{\mathcal{F}}\), respectively, under the constraint.
Definition 2
[41]. Each term in a linguistic term set (LTS) \(\mathcal{S}=\left\{{{{S}}}_{0,}{{{S}}}_{1},\dots ,{{{S}}}_{\mathbf{\rm K}}\right\}\), where \(\mathbf{\rm K}\) is an even number, represents the linguistic variable’s potential value, e.g., \(\mathcal{S}=\left\{{{{S}}}_{0}={{e}}{{x}}{{t}}{{r}}{{e}}{{m}}{{e}}{{l}}{{y}},\boldsymbol{ }{{{S}}}_{1}={{m}}{{o}}{{d}}{{e}}{{r}}{{a}}{{t}}{{e}}{{l}}{{y}},{{{S}}}_{2}={{n}}{{o}}{{t}}\boldsymbol{ }{{a}}{{t}}\boldsymbol{ }{{a}}{{l}}{{l}}\right\}\).
Definition 3
[59]. Suppose that the result of aggregating the indices of some linguistic terms in \(\mathcal{S}\) is a noninteger value \(\rho \in \left[0,\mathbf{\rm K}\right]\), \(\rho\) can be represented by the 2-tuple \(\left({S}_{k},\mathcalligra{k}\right), {S}_{k}\in \mathcal{S} \text{and} \mathcalligra{k}\in [-\text{0.5, \, 0.5})\), where \({S}_{k}\) is a linguistic term, and \(\mathcalligra{k}\) is the symbolic translation to the nearest index \(k\) in \(\mathcal{S}\).
Definition 4
[59]. Given an LTS \(\mathcal{S}=\left\{{S}_{0,}{S}_{1},\dots ,{S}_{\text{\rm K}}\right\}\) and \(\rho \in \left[0,\text{\rm K}\right]\), the following mapping is used to obtain the 2-tuple equivalent to \(\rho\):
The inverse mapping \({\Delta }^{-1}\) transforms a 2-tuple to \(\rho\):
Definition 5
[41]. A 2TLFFS is a Fermatean fuzzy set in which the membership and nonmembership grades are represented by the 2-tuple \(\left({S}_{\mathcalligra{m}},\mu \right)\) and \(\left({S}_{\mathcalligra{n}},\nu \right)\), respectively, where \({S}_{\mathcalligra{m}},{S}_{\mathcalligra{n}}\in \mathcal{S}=\left\{{S}_{0,}{S}_{1},\dots ,{S}_{\text{\rm K}}\right\}\) and \(\mu ,\nu \in [-\text{0.5, \, 0.5})\), written as.
For simplicity, a 2TLFFS can be written in the form \(\langle \left({S}_{\mathcalligra{m}},\mu \right)\left({S}_{\mathcalligra{n}},\nu \right)\rangle\).
The 2TLFFSs of all linguistic terms are shown in Table 3 based on the LTS \(\mathcal{S}=\left\{{S}_{0,}{S}_{1},\dots ,{S}_{6}\right\}\).
A rigorous approach is used to choose values for linguistic concepts and their related 2TLFFSs to make it easier to express subjective judgments using fuzzy logic. The inherent ambiguity and imprecision in human perception and interpretation are successfully captured by these 2TLFFSs, which help to produce seamless transitions between linguistic concepts.
Step 2: The fuzzy opinion decision matrix is subjected to direct aggregation, employing an aggregation operator such as the arithmetic mean. For a set of 2TLFFSs \(\left\{{\widetilde{\mathbb{F}}}_{1},{\widetilde{\mathbb{F}}}_{2},\dots ,{\widetilde{\mathbb{F}}}_{\text{n}}\right\},\), this aggregation procedure (the weighting averaging operator) can be executed using the following equation, where \({{\upomega}}=\left[{\omega }_{1},{\omega }_{2},\dots ,{\omega }_{\text{n}}\right]\) is the vector of weights that satisfy \({\omega }_{i}\in \left[\text{0,1}\right]\) and \(\sum_{i=1}^{\text{n}}{\omega }_{i}=1\) [41].
Step 3: The defuzzification process can be implemented through the following equation [60]:
It is worth noting that the best-ranking order corresponds to the highest score.
External Group Aggregation: This method involves aggregating fuzzy opinion matrices from various decision matrices (DMs), each of which has been processed independently using the instructions provided in the processing unit [61]. The final group decision is then created by combining the results of various DMs using the arithmetic mean aggregation approach. With the help of the group's experts, this method makes it easier to produce the final ranking. This thorough assessment aids in the assessment of reliable machine learning models for ASD triage applications, facilitating a thorough knowledge of their efficacy.
3 Results and Discussion
This section provides a comprehensive examination of the outcomes achieved in each of the phases, with the presentation structured as follows:
3.1 Fusion Results for the ASD Triage Dataset
The outcomes of the data fusion process employing PCA, as outlined in Algorithm 1, on the ASD triage dataset yield 12 principal component (PC) attributes. As previously mentioned, these PC attributes are derived from the initial set of 19 autism-related features subjected to PCA. The results of the new ASD-triaged fused dataset with 12 corresponding PCs are shown in the supplementary file. To the best of the author's knowledge, and in accordance with the previous systematic review paper presented in [9], this is the first ASD dataset in the literature constructed based on medical and sociodemographic features. To provide a visual representation of these results, Fig. 7 illustrates the plotted outcomes of each PC. Additionally, comprehensive results of the newly fused ASD triage dataset, comprising 1296 samples, are provided as a supplementary file. It is important to emphasize that this fused ASD dataset offers a multitude of advantages to researchers and scholars. Furthermore, a 3D line plot of PCA features is shown in Fig. 8, while the variance results stemming from the PCA fusion preprocessing are depicted in Fig. 9.


Plotting of the 12 PC attribute results obtained from Algorithm 1

A 3D line plot of PCA features generated by Algorithm 1

Average results of PCA variance analysis
The analysis of variance results obtained from the PCA fusion preprocessing, as depicted in Figs. 7 and 8, provides valuable insights into the distribution of information among the 12 PCs. The proportion of variance explained by each PC is a critical indicator of its contribution to the overall ASD dataset.
In Fig. 9, we observe that the variance proportions vary across the 12 PCs. Specifically, the individual variance proportions range from 0.039 for some PCs, indicating a relatively lower contribution to the dataset's overall variability, to higher values for other PCs. It is noteworthy that while certain PCs may have lower variance proportions, they still capture important patterns or variations present in the original dataset. Therefore, they should not be dismissed as insignificant. Instead, they collectively contribute to the comprehensive understanding of the data. The cumulative variance, represented by the cumulative value of 0.796, demonstrates the combined explanatory power of all 12 PCs. In essence, this cumulative variance signifies the extent to which these PCs collectively account for the dataset's total variability. In our case, a cumulative variance of 0.796 implies that the 12 PCs together capture approximately 79.6% of the overall variance present in the ASD triage dataset.
This level of variance coverage is highly meaningful, as it implies that the majority of the dataset's inherent variability has been retained, even after dimensionality reduction through PCA. In these contexts, the variance results obtained from Algorithm 1 emphasize the effectiveness of PCA in preserving essential dataset characteristics. Researchers can leverage this fused dataset to develop and evaluate robust machine learning models for ASD triage applications, as it strikes a balance between dimensionality reduction and information retention.
3.2 Multiple-ML Model Results
The results of the performance evaluation metrics for the developed multiple-ML models applied to the fused ASD triage dataset are presented in Table 4 and Table 5. These tables provide a comprehensive overview of how these models perform under different scenarios, specifically concerning normal test examples (Table 4) and adversarial attack examples (Table 5).
In the analysis of the performance metrics presented in both Tables 4 and 5, several critical considerations arise, primarily concerning model selection, trade-offs, and conflicts:
-
Selection Considerations: The central objective of this evaluation is to pinpoint the most robust ML model for real-time ASD patient triage applications. To accomplish this, decision-makers must identify models that excel in specific criteria or metrics. For instance, in Table 4, the SVM model has exceptionally high AUC, CA, and precision values, positioning it as a strong contender for selection, especially when prioritizing these metrics. Similarly, in Table 5, the NN model exhibits noteworthy performance in terms of the AUC, CA, and precision, making it a viable choice, particularly in adversarial attack scenarios.
-
Trade-off Analysis: The process of selecting a robust ML model necessitates navigating trade-offs among diverse evaluation criteria. A single model rarely excels in all aspects simultaneously. For instance, the kNN model in Table 4 achieves a high specificity score but lags behind in CA and precision. Here, conducting a trade-off analysis becomes indispensable in identifying models that strike a balance between various performance metrics.
-
Resolving Conflicts: It is necessary to evaluate the behavior of ML models under adversarial attacks, as shown in the table below in Table 5. This is the place where the robustness of models is ultimately tested. The trade-offs that are observed under adversarial conditions can vary from those of normal testing samples. As an example, the RF model stands out with respect to CA, AUC, and precision because it offers a reliable option in a noisy environment. The performance assessment in extreme cases is an important factor for understanding the efficiency of a model that can be used in real-world ASD triage applications.
-
Robustness Assessment: It is necessary to evaluate the behavior of ML models under adversarial attacks, as shown in the table below in Table 5. This is the place where the robustness of models is ultimately tested. The trade-offs that are observed under adversarial conditions can vary from those of normal testing samples. As an example, the RF model stands out with respect to CA, AUC, and precision because it offers a reliable option in a noisy environment. The performance assessment in extreme cases is an important factor for understanding the efficiency of a model that can be used in real-world ASD triage applications.
Decision-making in regard to opting for the robust ML model to deploy for ASD triage services is premised on the metrics in Tables 4 and 5. Consequently, the review and benchmarking process should use the DM and 2TLFFDOSM to assess the trade-offs and conflicts while choosing an ML model that is robust. Finally, the selection process should be oriented toward both normal and adversarial testing, and this operation should be performed in such a way that the positive aspects of both scenarios are maintained and a balanced trade-off is achieved.
3.3 Evaluation and Benchmarking Results
The results of this section are a reflection of the framework developed in the third phase, representing the most critical aspect of showcasing the robust ML model. The evaluation and benchmarking results are constructed based on two crucial components: the developed DM and 2TLFFDOSM. However, these two components cannot fully elucidate patient outcomes without considering the results of the multiple-ML models presented in the previous section. First, it is essential to showcase the outcomes of the decision-makers, represented by the three experts, through the opinion matrix results derived from Eq. 12, as demonstrated in Table 6. Table 6 contains three opinion matrices, each corresponding to an expert, illustrating their comparisons and evaluations.
There is a noticeable variation among the three opinion matrices presented in Table 6, leading to different rankings for each expert. The individual rankings obtained by applying the mathematical model of 2TLFFDOSM to these matrices and incorporating the developed DM are presented in Table 7.
Definition 6
[59]. To compare 2-tuple linguistic information \(\left({S}_{k1},{\mathcalligra{k}}_{1}\right)\) and \(\left({S}_{k2},{\mathcalligra{k}}_{2}\right)\), the following rules are applied:
-
\(\text{if} \, k1<k2, \text{then} \left( {S}_{k1},{\mathcalligra{k}}_{1}\right)<\left( {S}_{k2},{\mathcalligra{k}}_{2}\right)\)
-
\(\text{if} \, k1=k2, \text{then}\)
-
\(\left({S}_{k1 },{\mathcalligra{k}}_{1}\right)=\left( {S}_{k2},{\mathcalligra{k}}_{2}\right), \text{if} \, {\mathcalligra{k}}_{1} = {\mathcalligra{k}}_{2},\)
-
\(\left({S}_{k1} ,{ \mathcalligra{k}}_{1}\right) < \left( {S}_{k2},{ \mathcalligra{k}}_{2}\right), \text{if} \, {\mathcalligra{k}}_{1} < {\mathcalligra{k}}_{2},\)
-
\(\left({S}_{k1 },{ \mathcalligra{k}}_{1}\right) > \left( {S}_{k2},{ \mathcalligra{k}}_{2}\right), \text{if} \, { \mathcalligra{k}}_{1} > {\mathcalligra{k}}_{2}.\)
Table 7 displays the individual ranking results provided by three experts for the ML models (A1 to A8) based on the opinion matrices. While some agreements in rankings exist for certain alternatives, differences are notable for others, underscoring the subjectivity involved in decision-making and evaluation processes. Figure 10 visualizes the ranking orders of the eight ML models, revealing that obtaining a unique rank is challenging for the three experts. Therefore, external group aggregation is essential for obtaining a unique rank and determining a robust ML model, as shown in Table 8.

Variance in individual rankings among three experts
Table 8 presents the results of the 2TLFFDOSM ranking based on external group aggregation for the eight ML models. Each ML model is associated with fuzzy scores and 2-tuple scores, which are then synthesized into a crisp score to facilitate ranking. The rankings are as follows: A8 (LR) ranks first with a 2TLFFDOSM score of 1.3370, followed by A3 (SVM) with a score of 1.3162, A5 (RF) with a score of 1.2930, A6 (NN) with a score of 1.2575, A7 (NB) with a score of 1.1763, A2 (DT) with a score of 1.0519, A1 (kNN) with a score of 1.0267, and A4 (SGD) with a score of 0.9805. These rankings provide valuable insights into the suitability of ML models for real-time ASD patient triage based on the developed evaluation methodology, encompassing both scenarios: normal test examples and adversarial attack examples.
To delve deeper into the discussion of these results, it is essential to revisit the performance metrics of the ML models presented in the previous section (Tables 4 and 5). The top-ranking model based on 2TLFFDOSM is A8 (LR). In terms of the performance of LR under both scenarios, for the normal test examples, 0.9720, 0.0870, 0.9906, 0.9367, 0.9360, 0.9369, 0.9367, 0.1728, and 0.9684 for the criteria C1 = Train time, C2 = Test time, C3 = AUC, C4 = CA, C5 = F1, C6 = Precision, C7 = Recall, C8 = LogLoss, and C9 = Specificity, respectively. Additionally, the results of the LR during adversarial attack examples for the same sequence of criteria were 1.2720, 0.3010, 0.9206, 0.8767, 0.8760, 0.8769, 0.8757, 0.0828, and 0.8284. These detailed metrics shed light on various aspects of LR performance, which contributes to its top-ranking position in the 2TLFFDOSM evaluation.
Given the strong performance of the LR model and its architectural features, the model appears to be a serious option for real-time ASD patient triage applications. LR exhibits high testing example accuracy on the normal test set, which is quite desirable for cases where fast predictions are needed. Furthermore, LR has a high AUC of 0.9906, meaning that the LR model more accurately discriminates between the three triage classes—urgent, moderate, and minor. Furthermore, LR boasts an excellent competitive CA, a balanced F1 score, and a sensational precision and recall score that guarantees minimum false negatives and false positives. The model performs very well in terms of the log loss, which is a likelihood estimate, and provides robust specificity for differentiating the correct classes of triage level 3. LR has a linear classification model that is well suited to the traits of the dataset.
Thus, PCA-based fusion of the ASD triage dataset significantly contributed to improving the performance of the LR model. With 12 PCs generated by algorithm 1, the PCA dimensionality reduction process was implemented to retain vital input information. Therefore, although the number of inputs was reduced, so was the computational complexity and the risk of overfitting. As a result, in the comparison of the ML models for the triage of ASD patients, the LR model outperformed the others the most. Moreover, the quality of the LR model performance and its resistance to adversarial attacks were also boosted by PCA preprocessing. The synergy between LR's classification capabilities and PCA-based data fusion highlights the potential of this utilized approach for real-world ASD triage applications.
Furthermore, based on the above distinct results, the selection process has reached its peak, and the trade-off issue has been effectively addressed. The conflicts and other issues discussed earlier have been meticulously resolved through the developed framework, which amalgamates the power of PCA for data fusion, multiple-ML models, and fuzzy decision-making methodology for robust ML models. The comprehensive evaluation and benchmarking methodology presented in this study has paved the way for the identification of LRs as the optimal model for real-time ASD patient triage.
4 State of the Art: Comparison of Study
In this section, a comprehensive comparison of the proposed framework with the literature is conducted using a checklist benchmarking approach. One of the recent comparison methodologies frequently used in the literature is checklist benchmarking. This approach involves comparing various important checklists presented as factors to emphasize the novelty of the presented work. The definitions of these checklists are provided below, and Table 9 illustrates how the proposed framework contributes to the existing body of literature based on the results obtained.
-
1st Normal/Adversarial Perspectives: This point signifies how the proposed work emphasizes the consideration of both normal test examples and adversarial attack examples during the development of machine learning models for triaging autistic patients.
-
2nd Fusion improvements: This point underscores the significance of feature fusion in enhancing the development of machine learning models. Therefore, this highlights the approach taken to preprocess the ASD dataset, emphasizing that studies meeting this checklist comparison point should address feature fusion during the preprocessing stage.
-
3rd, Development of the MCDM Selection Method: This point highlights the distinction between utilizing existing methods and developing new methods for selecting the best machine learning model for ASD triage. Model selection is a fundamental challenge addressed in the present study, and it advocates for the use of an appropriate MCDM method to effectively address this issue. Consequently, studies that investigate the development of novel MCDM methods are considered to satisfy this comparison point.
-
4th Decision Matrix Development: Building upon the context of "Selection Method Development," this point pertains to the creation of new decision matrices or enhancements to this crucial component of the decision-making process. It emphasizes the significance of innovating or improving decision matrices, which play a pivotal role in the study's methodology.
-
5th Medical and Sociodemographic Features: The incorporation of both medical and sociodemographic features has demonstrated its impact on the detection, diagnosis, and triage of ASD patients. Consequently, this point underscores the integration aspects of both types of features when developing the study framework for assessing autistic patients.
-
6th ML Criteria Issues: This point addresses the resolution of the aforementioned issues encountered during the evaluation and benchmarking of ML models. These issues encompass aspects such as the significance of criteria, trade-offs, and conflicts.
A comparison of the proposed framework with the literature highlights significant differences among benchmark studies. The total score represents how well each study and the proposed framework have addressed the comparison points. The proposed framework scores 100%, while the benchmarks have varying scores, ranging from 20 to 70%. Among the benchmarks, Benchmark#1 stands out as the most relevant, particularly in terms of its focus on the development of ML models in normal scenarios, the evaluation of these models through decision matrix development, and the integration of medical and sociodemographic features. However, these methods are inadequate for addressing adversarial attack examples and feature fusion aspects. Interestingly, all benchmark studies, including Benchmark#1, did not consider adversarial attack examples or feature fusion when developing ML models. Moreover, the development of new MCDM methods was also overlooked in these benchmarks. This analysis underscores the unique contributions and areas of improvement in both the proposed framework and the benchmark studies, emphasizing the need for a more comprehensive approach in future research to address these critical aspects.
5 Conclusion
The development of real-time triage applications for ASD is an early-stage and critical venture given the importance of autism in the health sector. Advancing ASD triage solutions requires a study on which experimental-based theories, well-structured frameworks, and well-known methodologies are developed. For the first time, this study undertook a thorough exploration of ASD triage and included all aspects to overcome the identified limitations of previous studies and to achieve effective solutions. This study successfully established machine learning theories with fuzzy decision-making, which was crucial in the accomplishment of our objectives. The multiphase development process concluded with the creation of the formulated mathematical model FDOSM, where 2TLFFDOSM was indeed quite an achievement. These phases successfully identified a robust model based on the fused ASD dataset, which is rare in the current literature. Notably, our study presents the first fused ASD triage dataset through two PCA algorithms, thus providing researchers with a valuable resource for further investigation and research development.
Moreover, the developed DM in conjunction with 2TLFFDOSM efficiently addressed key challenges such as model selection, criterion importance, trade-offs, and conflicts. Additionally, our multi-ML models exhibited promising performance across various metrics, encompassing both normal test examples and adversarial attack examples. Although the overall performance results favor normal test examples, the determination of the robust ML model requires consideration of both scenarios simultaneously. Our study emphasized this critical aspect, which can serve as a model for researchers in other fields to follow a similar development sequence to validate their experiments and make informed decisions regarding robust ML models. However, the developed ML models are limited under default parameter settings in this study while adaptation of these parameters could provide more explainable results. The explainability of the robust model is not presented which is also the limitation we faced in this study. This can be achieved through the LIME or SHAP method.
Future research could explore ASD triage based on genetic contributions, a burgeoning area of interest. The development of a dynamic DM in tandem with a suitable fuzzy MCDM method could pave the way for the first triage method based on genetic analysis. This would further enhance our understanding and capabilities in ASD diagnosis and treatment. Finally, we plan to include more explicit numerical examples to further demonstrate the effectiveness of our proposed framework in handling complicated cases in ASD triage. The significance of models' parameter settings could be more considered in future works. Each model has different parameter settings and this can be further optimized by optimization techniques such as genetic or SWARM intelligence algorithms.
Data Availability
The dataset generated during and/or analyzed during the current study is available from the corresponding author upon reasonable request. The results of the preprocessed dataset are attached as a supplementary file.
References
Albahri, A.S., Hamid, R.A., Zaidan, A.A., Albahri, O.S.: Early automated prediction model for the diagnosis and detection of children with autism spectrum disorders based on effective sociodemographic and family characteristic features. Neural Comput. Appl. (2022). https://doi.org/10.1007/s00521-022-07822-0
Dichter, G.S.: Functional magnetic resonance imaging of autism spectrum disorders. Dialogues Clin. Neurosci. 14(3), 319–351 (2012). https://doi.org/10.31887/dcns.2012.14.3/gdichter
Zhang, Y., et al.: Predicting the symptom severity in autism spectrum disorder based on EEG metrics. IEEE Trans. Neural Syst. Rehabil. Eng. 30, 1898–1907 (2022). https://doi.org/10.1109/TNSRE.2022.3188564
Alqaysi, M.E., Albahri, A.S., Hamid, R.A.: Diagnosis-based hybridization of multimedical tests and sociodemographic characteristics of autism spectrum disorder using artificial intelligence and machine learning techniques: a systematic review. Int. J. Telemed. Appl. 11, 10 (2022). https://doi.org/10.1155/2022/3551528
Joudar, S.S., Albahri, A.S., Hamid, R.A.: Triage and priority-based healthcare diagnosis using artificial intelligence for autism spectrum disorder and gene contribution: a systematic review. Comput. Biol. Med. 146, 105553 (2022). https://doi.org/10.1016/j.compbiomed.2022.105553
Joudar, S.S., Albahri, A.S., Hamid, R.A.: Intelligent triage method for early diagnosis autism spectrum disorder (ASD) based on integrated fuzzy multi-criteria decision-making methods. Inform. Med. Unlock. 36, 101131 (2023). https://doi.org/10.1016/j.imu.2022.101131
Albahri, O.S., et al.: Systematic review of real-time remote health monitoring system in triage and priority-based sensor technology: taxonomy, open challenges, motivation and recommendations. J. Med. Syst. 42(5), 80 (2018). https://doi.org/10.1007/s10916-018-0943-4
Albahri, A.S., et al.: A systematic review of trustworthy and explainable artificial intelligence in healthcare: assessment of quality, bias risk, and data fusion. Inf. Fusion 96, 156–191 (2023). https://doi.org/10.1016/j.inffus.2023.03.008
Joudar, S.S., et al.: Artificial intelligence-based approaches for improving the diagnosis, triage, and prioritization of autism spectrum disorder: a systematic review of current trends and open issues. Artif. Intell. Rev. (2023). https://doi.org/10.1007/s10462-023-10536-x
Kuhn, M., Johnson, K.: Feature engineering and selection: A practical approach for predictive models. Chapman and Hall/CRC (2019). https://doi.org/10.1201/9781315108230
LHancox-Li, L.: Robustness in machine learning explanations: does it matter? In: FAT* 2020 - Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pp. 640–647, (2020). https://doi.org/10.1145/3351095.3372836.
Stanly, H., Shalinie, M. S., Paul, R.: A review of generative and non-generative adversarial attack on context-rich images. Eng. Appl. Artif. Intell. 124, 106595 (2023). https://doi.org/10.1016/j.engappai.2023.106595
Roshan, K., Zafar, A., Ul Haque, S.B.: Untargeted white-box adversarial attack with heuristic defence methods in real-time deep learning based network intrusion detection system. Comput. Commun. 218, 97–113 (2024). https://doi.org/10.1016/j.comcom.2023.09.030
Albahri, A.S., et al.: Fuzzy decision-making framework for explainable golden multi-machine learning models for real-time adversarial attack detection in vehicular ad-hoc networks. Inf. Fusion 105, 102208 (2023). https://doi.org/10.1016/j.inffus.2023.102208
Alqaysi, M.E., Albahri, A.S., Hamid, R.A.: Hybrid diagnosis models for autism patients based on medical and sociodemographic features using machine learning and multicriteria decision-making (MCDM) techniques: an evaluation and benchmarking framework. Comput. Math. Methods Med. 2022, 9410222 (2022). https://doi.org/10.1155/2022/9410222
Akter, T., et al.: Machine learning-based models for early stage detection of autism spectrum disorders. IEEE Access 7, 166509–166527 (2019). https://doi.org/10.1109/ACCESS.2019.2952609
Alahmari, F.: A comparison of resampling techniques for medical data using machine learning. J. Inf. Knowl. Manag. (2020). https://doi.org/10.1142/S021964922040016X
Altay, O., Ulas, M.:“Prediction of the autism spectrum disorder diagnosis with linear discriminant analysis classifier and K-nearest neighbor in children. In: 6th International Symposium on Digital Forensic and Security, ISDFS 2018 - Proceeding, 2018, vol. 2018-Janua, pp. 1–4. https://doi.org/10.1109/ISDFS.2018.8355354.
Ahmed, U., Lin, J.C.W.: Robust adversarial uncertainty quantification for deep learning fine-tuning. J. Supercomput. 79(10), 11355–11386 (2023). https://doi.org/10.1007/S11227-023-05087-5/FIGURES/12
Chen, Y., et al.: Adversarial learning based node-edge graph attention networks for autism spectrum disorder identification. IEEE Trans. Neural Netw. Learn. Syst. (2022). https://doi.org/10.1109/TNNLS.2022.3154755
Triwiyanto, T., et al.: Embedded machine learning using a multi-thread algorithm on a raspberry Pi platform to improve prosthetic hand performance. Micromachines 13(2), 191 (2022). https://doi.org/10.3390/mi13020191
Zeng, C., Li, S., Chen, Z., Yang, C., Sun F., Zhang, J.: Multifingered Robot Hand Compliant Manipulation Based on Vision-Based Demonstration and Adaptive Force Control. In: IEEE Trans. Neural Netw. Learn. Syst. 34(9), 5452–5463 (2023). https://doi.org/10.1109/TNNLS.2022.3184258.
Nayak, S.R., Nayak, D.R., Sinha, U., Arora, V., Pachori, R.B.: Application of deep learning techniques for detection of COVID-19 cases using chest X-ray images: a comprehensive study. Biomed. Signal Process. Control 64, 102365 (2021). https://doi.org/10.1016/j.bspc.2020.102365
Ahmed, M.A., et al.: Intelligent decision-making framework for evaluating and benchmarking hybridized multi-deep transfer learning models: managing COVID-19 and beyond. Int. J. Inf. Technol. Decis. Mak. (2023). https://doi.org/10.1142/S0219622023500463
Alzubaidi, L., et al.: Towards risk-free trustworthy artificial intelligence: significance and requirements. Int. J. Intell. Syst. 2023, 4459198 (2023). https://doi.org/10.1155/2023/4459198
Al-Qaysi, Z.T., Albahri, A.S., Ahmed, M.A., Mohammed, S.M.: Development of hybrid feature learner model integrating FDOSM for golden subject identification in motor imagery. Phys. Eng. Sci. Med. (2023). https://doi.org/10.1007/s13246-023-01316-6
Mittal, S., Tyagi, S.: Computational techniques for real-time credit card fraud detection. Handb. Comput. Networks Cyber Secur. Princ. Paradig. (2019). https://doi.org/10.1007/978-3-030-22277-2_26
Alamoodi, A.H., et al.: Systematic review of MCDM approach applied to the medical case studies of COVID-19: trends, bibliographic analysis, challenges, motivations, recommendations, and future directions. Complex Intell. Syst. (2023). https://doi.org/10.1007/s40747-023-00972-1
Albahri, O.S., et al.: Systematic review of artificial intelligence techniques in the detection and classification of COVID-19 medical images in terms of evaluation and benchmarking: taxonomy analysis, challenges, future solutions and methodological aspects. J. Infect. Public Health 13(10), 1381–1396 (2020). https://doi.org/10.1016/j.jiph.2020.06.028
Alamoodi, A.H., Albahri, O.S., Zaidan, A.A., Alsattar, H.A., Zaidan, B.B., Albahri, A.S.: Hospital selection framework for remote MCD patients based on fuzzy q-rung orthopair environment. Neural Comput. Appl. 35(8), 6185–6196 (2023). https://doi.org/10.1007/s00521-022-07998-5
Alsalem, M.A., et al.: Rise of multiattribute decision-making in combating COVID-19: A systematic review of the state-of-the-art literature. Int. J. Intell. Syst. 37(6), 3514–3624 (2022)
Alsalem, M.A., et al.: Evaluation of trustworthy artificial intelligent healthcare applications using multi-criteria decision-making approach. Expert Syst. Appl. 246, 123066 (2024). https://doi.org/10.1016/j.eswa.2023.123066
Albahri, A.S., et al.: A trustworthy and explainable framework for benchmarking hybrid deep learning models based on chest X-ray analysis in CAD systems. Int. J. Inf. Technol. Decis. Mak. (2024). https://doi.org/10.1142/S0219622024500019
Albahri, A.S., Joudar, S.S., Hamid, R.A. et al.: Explainable artificial intelligence multimodal of autism triage levels using fuzzy approach-based multi-criteria decision-making and lime. Int. J. Fuzzy Syst. 26, 274–303 (2024). https://doi.org/10.1007/s40815-023-01597-9
Mihna, F.K.H., Habeeb, M.A., Khaleel, Y.L., Ali, Y.H., Al-saeedi, L.A.E.: Using information technology for comprehensive analysis and prediction in forensic evidence. Mesopotamian J. CyberSecurity 2024, 4–16 (2024). https://doi.org/10.58496/mjcs/2024/002
Albahri, A.S.A., Yaseen, M.G., Aljanabi, M., Ali, A.H.A.H., Kaleel, A.: Securing tomorrow: navigating the evolving cybersecurity landscape. Mesopotamian J. CyberSecurity 2024, 1–3 (2024)
Piwowarski, M., Singh, U.S., Nermend, K.: Application of EEG metrics in the decision-making process. In: Springer Proceedings in Business and Economics, pp. 187–199 (2020). https://doi.org/10.1007/978-3-030-30251-1_14.
Marisa, F., Syed Ahmad, S.S., Kausar, N., Kousar, S., Pamucar, D., Al Din Ide, N.: Intelligent gamification mechanics using fuzzy-AHP and K-means to provide matched partner reference. Discret. Dyn. Nat. Soc. 20, 22 (2022). https://doi.org/10.1155/2022/8292991
Alamoodi, A.H., et al.: Based on neutrosophic fuzzy environment: a new development of FWZIC and FDOSM for benchmarking smart e-tourism applications. Complex Intell. Syst. 8(4), 3479–3503 (2022). https://doi.org/10.1007/s40747-022-00689-7
Al-Samarraay, M.S., et al.: Extension of interval-valued Pythagorean FDOSM for evaluating and benchmarking real-time SLRSs based on multidimensional criteria of hand gesture recognition and sensor glove perspectives[Formula presented]. Appl. Soft Comput. 116, 108284 (2022). https://doi.org/10.1016/j.asoc.2021.108284
Akram, M., Bibi, R., Deveci, M.: An outranking approach with 2-tuple linguistic Fermatean fuzzy sets for multi-attribute group decision-making. Eng. Appl. Artif. Intell. 121, 1–25 (2023). https://doi.org/10.1016/j.engappai.2023.105992
Palanikumar, M., Kausar, N., Garg, H., Ahmed, S.F., Samaniego, C.: Robot sensors process based on generalized Fermatean normal different aggregation operators framework. AIMS Math. 8(7), 16252–16277 (2023). https://doi.org/10.3934/math.2023832
Sabahi, K., Zhang, C., Kausar, N., Mohammadzadeh, A., Pamucar, D., Mosavi, A.H.: Input-output scaling factors tuning of type-2 fuzzy PID controller using multi-objective optimization technique. AIMS Math. 8(4), 7917–7932 (2023). https://doi.org/10.3934/math.2023399
Akram, M., Bibi, R., Ali Al-Shamiri, M.M.: A decision-making framework based on 2-tuple linguistic fermatean fuzzy Hamy mean operators. Math. Probl. Eng. 15, 10 (2022). https://doi.org/10.1155/2022/1501880
Alamoodi, A.H., et al.: Selection of electric bus models using 2-tuple linguistic T-spherical fuzzy-based decision-making model. Expert Syst. Appl. 249, 123498 (2024). https://doi.org/10.1016/j.eswa.2024.123498
Xu, W., Li, X., Zhang, J.: Multi-feature fusion imaging via machine learning for laser ultrasonic based defect detection in selective laser melting part. Opt. Laser Technol. 150, 107918 (2022). https://doi.org/10.1016/J.OPTLASTEC.2022.107918
Liu, Y., Liu, Z., Zuo, H., Wang, H., Ding, S.: A prognostics approach based on feature fusion and deep BiLSTM neural network for aero-engine. In: 2022 Glob. Reliab. Progn. Heal. Manag. Conf. PHM-Yantai 2022, (2022) https://doi.org/10.1109/PHM-YANTAI55411.2022.9941781.
Zhu, M., et al.: A review of the application of machine learning in water quality evaluation. Eco-Environment Heal. 1(2), 107–116 (2022). https://doi.org/10.1016/J.EEHL.2022.06.001
Ihme, M., Chung, W.T., Mishra, A.A.: Combustion machine learning: Principles, progress and prospects. Prog. Energy Combust. Sci. 91, 101010 (2022). https://doi.org/10.1016/J.PECS.2022.101010
Al-Ghabawi, H.H.M., Khattab, M.M., Zahid, I.A., Al-Oubaidi, B.: The prediction of the ultimate base shear of BRB frames under push-over using ensemble methods and artificial neural networks. Asian J. Civ. Eng. (2023). https://doi.org/10.1007/S42107-023-00855-3/METRICS
Albahri, A.S., et al.: Role of biological data mining and machine learning techniques in detecting and diagnosing the novel coronavirus (COVID-19): a systematic review. J. Med. Syst. 44(7), 122 (2020). https://doi.org/10.1007/s10916-020-01582-x
Tuna, O.F., Catak, F.O., Eskil, M.T.: Exploiting epistemic uncertainty of the deep learning models to generate adversarial samples. Multimed. Tools Appl. 81(8), 11479–11500 (2022)
Alzubaidi, L., et al.: MEFF—a model ensemble feature fusion approach for tackling adversarial attacks in medical imaging. Intell. Syst. with Appl. 22, 200355 (2024). https://doi.org/10.1016/j.iswa.2024.200355
Zhao, S., Li, J., Wang, J., Zhang, Z., Zhu, L., Zhang, Y.: attackGAN: adversarial attack against black-box IDS using generative adversarial networks. Proc. Comput. Sci. 187, 128–133 (2021). https://doi.org/10.1016/J.PROCS.2021.04.118
Liu, J., et al.: An efficient adversarial example generation algorithm based on an accelerated gradient iterative fast gradient. Comput. Stand. Interfaces 82, 103612 (2022). https://doi.org/10.1016/J.CSI.2021.103612
Salih, M.M., Zaidan, B.B., Zaidan, A.A.: Fuzzy decision by opinion score method. Appl. Soft Comput. J. 96, 106595 (2020). https://doi.org/10.1016/j.asoc.2020.106595
Alsalem, M.A., et al.: Based on T-spherical fuzzy environment: A combination of FWZIC and FDOSM for prioritising COVID-19 vaccine dose recipients. J. Infect. Public Health 14(10), 1513–1559 (2021). https://doi.org/10.1016/j.jiph.2021.08.026
Albahri, O.S., et al.: Multidimensional benchmarking of the active queue management methods of network congestion control based on extension of fuzzy decision by opinion score method. Int. J. Intell. Syst. 36(2), 796–831 (2021). https://doi.org/10.1002/int.22322
Herrera, F., Martínez, L.: A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans. Fuzzy Syst. 8(6), 746–752 (2000). https://doi.org/10.1109/91.890332
Akram, M., Niaz, Z.: 2-Tuple linguistic fermatean fuzzy decision-making method based on COCOSO with CRITIC for drip irrigation system analysis. J. Comput. Cogn. Eng. (2022). https://doi.org/10.47852/bonviewjcce2202356
Al-qaysi, Z.T., Albahri, A.S., Ahmed, M.A., Salih, M.M.: Dynamic decision-making framework for benchmarking brain–computer interface applications: a fuzzy-weighted zero-inconsistency method for consistent weights and VIKOR for stable rank. Neural Comput. Appl. 11, 1–24 (2024). https://doi.org/10.1007/s00521-024-09605-1
Funding
No funding.
Author information
Authors and Affiliations
Contributions
All the authors contributed equally to this work.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflicts of interest.
Ethical Approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed Consent to Participate
Not applicable.
Consent for Publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shayea, G.G., Zabil, M.H.M., Albahri, A.S. et al. Fuzzy Evaluation and Benchmarking Framework for Robust Machine Learning Model in Real-Time Autism Triage Applications. Int J Comput Intell Syst 17, 151 (2024). https://doi.org/10.1007/s44196-024-00543-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-024-00543-3