
Abstract
This research introduces a novel multi-objective adaptation of the Geometric Mean Optimizer (GMO), termed the Multi-Objective Geometric Mean Optimizer (MOGMO). MOGMO melds the traditional GMO with an elite non-dominated sorting approach, allowing it to pinpoint Pareto optimal solutions through offspring creation and selection. A Crowding Distance (CD) coupled with an Information Feedback Mechanism (IFM) selection strategy is employed to maintain and amplify the convergence and diversity of potential solutions. MOGMO efficacy and capabilities are assessed using thirty notable case studies. This encompasses nineteen multi-objective benchmark problems without constraints, six with constraints and five multi-objective engineering design challenges. Based on the optimization results, the proposed MOGMO is better 54.83% in terms of GD, 64.51% in terms of IGD, 67.74% in terms of SP, 70.96% in terms of SD, 64.51% in terms of HV and 77.41% in terms of RT. Therefore, MOGMO has a better convergence and diversity for solving un-constraint, constraint and real-world application. Statistical outcomes from MOGMO are compared with those from Multi-Objective Equilibrium Optimizer (MOEO), Decomposition-Based Multi-Objective Symbiotic Organism Search (MOSOS/D), Non-dominated Sorting Genetic Algorithm (NSGA-II), Multi-Objective Multi-Verse Optimization (MOMVO) and Multi-Objective Plasma Generation Optimizer (MOPGO) algorithms, utilizing identical performance measures. This comparison reveals that MOGMO consistently exhibits robustness and excels in addressing an array of multi-objective challenges. The MOGMO source code is available at https://github.com/kanak02/MOGMO.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Multi-objective optimization (MOO) serves as a multifaceted decision-making tool, focusing on the simultaneous optimization of problems with various objective functions [1,2,3]. As a cornerstone in fields ranging from economics to informatics to engineering. MOO aids in deriving optimal decisions by evaluating trade-offs between different objectives [4,5,6]. The significance of MOO in addressing real-world problems is substantial [7,8,9].
Addressing multi-objective issues generally yields a collection of compromise solutions, known as the Pareto optimal set [10]. Three core classifications utilizing stochastic optimization algorithms for handling these problems are a priori, a posteriori and interactive. In the a priori category, several objectives consolidate into a singular one [11], emphasizing the weight of each objective as perceived by decision-makers. Once combined, conventional single-objective algorithms can identify the optimal solution without alterations. Although computationally efficient, this method has limitations: it may require multiple algorithms runs to achieve the Pareto optimal set and can struggle with uniformly distributed solution sets and sensitivity to non-convex Pareto optimal fronts.
In contrast, the a posteriori approach maintains and simultaneously optimizes multi-objective problem (MOP) formulations [12]. This technique can derive a Pareto optimal solution set in a single run, facilitating post-optimization decision-making. Ensuring a broad diversity of solutions across all objectives is crucial, providing decision-makers with a comprehensive spectrum of choices. Scholarly works abound with algorithms developed from this approach can be found in literature [13,14,15].
The interactive approach evaluates and integrates decision-makers' preferences during the MOO process [16]. While maintaining the multi-objective setup, these methods intermittently halt optimization to seek input from decision-makers, avoiding non-viable search domains. However, the reliance on human input makes the interactive method more intricate and time-consuming than its counterparts.
David Schaffer introduced the concept of using evolutionary algorithms (EAs) for MOO in 1984 [17]. EAs, which mimic natural evolution, are randomized search and optimization methods compatible with MOPs due to their distinctive traits. For instance, they can yield a non-dominated set in one attempt and adeptly navigate vast and intricate search realms with minimal problem-specific demands. This compatibility led to the development of multi-objective evolutionary algorithms (MOEAs), which have seen a surge in research and applications across various domains over the last twenty years. MOEAs can be categorized into three primary types: Pareto-dominance-based, Decomposition-based and Indicator-based, with Pareto-based MOEAs emerging as a preferred strategy for effectively approximating the authentic Pareto front due to their intuitive mechanisms.
The Vector Evaluated Genetic Algorithms (VEGA) is often considered the first Pareto-based MOEA [18]. Evolving from the foundational Genetic Algorithm (GA), VEGA was adapted to tackle MOPs. It divides the population into subsets corresponding to the number of objective functions, with each subset focusing on a singular objective. However, VEGA often produces non-uniformly distributed non-dominated solutions across the Pareto front, particularly in areas of compromise. In contrast, the Non-Dominated Sorting Genetic Algorithm II (NSGA-II) is recognized as a favored MOEA in the literature [19]. Developed to address issues in its predecessor, NSGA, such as the absence of a sharing parameter, neglect of elitism and the substantial computational demands of non-dominated sorting, NSGA-II introduced a fast non-dominated sorting method, a diversity conservation technique and a crowded-comparison operator.
Other notable MOEAs include the Multi-objective Particle Swarm Optimization (MOPSO), introduced by Coello Coello & Lechuga [20], which uses Pareto dominance to steer particle flight direction and a mutation operator to enhance randomness and solution diversity. However, MOPSO's rapid convergence can sometimes lead to premature termination with an inaccurate Pareto front. The Multi-Objective Differential Evolution (MODE) [21] branched from the foundational DE algorithm and typically employs non-dominated sorting and rank selection on a combined group of parent and offspring populations.
Many algorithms rely heavily on the Pareto dominance philosophy, providing a practical toolkit for addressing MOPs. With numerous optimal solutions in the MOO realm, many algorithms use an archive (or repository) to store superior solutions, refining this archive throughout the optimization process. Recent years have seen the development of various novel and efficient Pareto-based MOEAs, each with unique mechanics, such as the multi-objective ant lion optimizer [22], MO equilibrium optimizer (MOEO) [23], MO slime mould algorithm [24], MO arithmetic optimization algorithm [25], non-dominated sorting ions motion algorithm [26], social cognitive optimization algorithm [27], multi-objective multi-verse optimization (MOMVO) [28], non-dominated sorting grey wolf optimizer [29], MO Gradient-Based Optimizer [30], MO plasma generation optimizer (MOPGO) [31], non-dominated sorting Harris hawks optimization [32], MO thermal exchange optimization [33], decomposition based multi-objective heat transfer search [34], Decomposition-Based Multi-Objective Symbiotic Organism Search (MOSOS/D) [35], MOGNDO Algorithm [36], Non-dominated sorting moth flame optimizer [37], Non-dominated sorting whale optimization algorithm [38] and Non-Dominated Sorting Dragonfly Algorithm [39]. However, the No-Free-Lunch theorem (NFL) [40] highlights that no single optimization technique can universally solve all MOPs, underscoring the need for continuous refinement of existing algorithms or the development of new ones.
Recently, Farshad Rezaei et al. introduced a metaheuristic technique: the Geometric Mean Optimizer (GMO) [41]. With strengths in both exploration and exploitation phases, the GMO harnesses potential solutions to create a search group, demonstrating efficacy across various engineering challenges [41] and emerging as a potent tool in the optimization toolkit.
No-Free-Lunch theorem (NFL) [40] posits that algorithms cannot be strictly classified as good or bad; rather, their suitability varies depending on the specific optimization problem at hand. It is challenging for a solitary algorithm to effectively address all facets of Multi-objective Optimization Problems (MOPs), including exploration, exploitation, convergence, coverage and computational efficiency, simultaneously. This reality indicates a continual opportunity for creating new meta-heuristic methods designed to tackle multi-objective optimization challenges effectively. In MOPs characterized by complex constraints tend to have intricate feasible zones, leading to a constrained Pareto Front (PF) rather than a true PF. This situation often traps algorithms in local optima, posing challenges for achieving satisfactory convergence and distribution. To address these issues, numerous MOPs have been developed. While these algorithms boast distinct features and benefits, they also exhibit limitations, particularly in scenarios involving narrow feasible spaces, multiple feasible zones and intricate distributions of these zones. Balancing convergence, diversity and feasibility remains a challenge for these algorithms. In response, this study introduces a Multi-Objective Geometric Mean Optimizer (MOGMO), designed for MOPs. MOGMO adapts the original GMO to serve the broader MOO ecosystem. The contributions of this paper include the development of a new multi-objective technique based on GMO, integrated with the memeplex structure of NSGA-II to address MOPs effectively. This integrated MOGMO with Information Feedback Mechanism (IFM) aims to efficiently and robustly uncover solutions in the multi-objective realm. The paper also verifies MOGMO's proficiency through various case studies, including unconstrained and constrained multi-objective benchmarks and complex engineering design challenges. The results are compared with those of esteemed MOO methods using various performance metrics and statistical tools. Analyses suggest that MOGMO is robust and versatile in addressing varied MOPs, consistently achieving Pareto optimal fronts marked by both convergence and diversity.
The structure of this paper is organized as follows: Sect. 2 offers foundational definitions relevant to GMO algorithm. Section 3 describes the proposed MOGMO algorithm. Section 4 is dedicated to the statistical evaluation of MOGMO against benchmark challenges and its application in multi-objective engineering design. Finally, Sect. 5 describes the conclusion and future research directions.
2 Geometric Mean Optimizer (GMO)
The Geometric Mean Optimizer (GMO) [41] represents an advanced meta-heuristic method that takes inspiration from the collective social behavior of multiple searching agents. Any optimization technique must define the most effective manner in which these agents collaborate. Initially, we delve into the GMO algorithm's inherent mathematical traits tailored for optimization tasks. Following this, an in-depth exploration of its problem-solving formulation is provided. Consider the representations \({X}_{i}=\left({x}_{i1},{x}_{i2},\dots ,{x}_{iD}\right)\) and \({V}_{i}=\left({v}_{i1},{v}_{i2},\dots ,{v}_{iD}\right)\) as the position and velocity of the \(i\)th agent, respectively. GMO can concurrently appraise both the efficiency associated fuzzy membership function (MF) values. This amplification process is synonymous with the product-based Larsen implication function, a prevalent technique in fuzzy logic. Conversely, the geometric mean of n membership degrees (MD) is represented by \(\sqrt[n]{{\mu }_{1}\times {\mu }_{2}\times \dots \times {\mu }_{n}}\). Therefore, multiplying various MDs i.e., \(\left({\mu }_{1}\times {\mu }_{2}\times \dots \times {\mu }_{n}\right)\), can be perceived as their geometric mean without factoring in the \(n\)th root, in which \({\mu }_{i}\) is the \(i\) th \({\text{MD}}\) and \(i=\mathrm{1,2},\dots ,n\). This version, termed the pseudo-geometric average calculated across the MF values of numerous variables, concurrently illustrates their average and likeness. Informed by the mathematical basis shared earlier, the GMO's architecture is further elucidated. Within GMO, a search agent's holistic fitness is determined by contrasting it with the fitness levels of its counterparts. Here, "counterparts" of a specific agent encompass the entire agent population excluding that specific agent. Each cycle identifies the most optimal position an agent has achieved until that point. Subsequently, for every contrasting top-performing agent relative to a specific one, the multiplication of the goal values, transmuted into fuzzy MFs, is ascertained. It is vital to note that in GMO's execution, the fuzzy membership functions should have a direct positive correlation with the fuzzified variables. For a minimization function, an agent is deemed more competent if the pseudo-geometric mean of the MFs, associated with its counterparts, is larger. This insinuates two simultaneous accomplishments for the agent in focus: first, the mean MF values of the counterparts are greater, signifying a lower MF value for the focused agent. Secondly, there is a heightened consistency among the counterparts' MF values, indicating a concentrated cluster and reduced diversity. As a result, the main agent exists in a relatively diverse area within the search space. This illuminates the agent's potential to possess a more beneficial status, merging both efficacy and variety, in comparison to another agent with a lower pseudo-geometric mean concerning its counterparts. The formulation used to determine MFs is elaborated in subsequent sections.
In the given equation Eq. (1), parameters a and c represent characteristics of the sigmoidal MF. The variables \(a\) and \(c\) in Eq. (1) are undetermined during every fuzzification effort, prompting the need for their calibration using a trial-and-error approach. However, this method is recognized to be imprecise and lengthy for parameter adjustments in fuzzy systems. A more proficient alternative would be to rely on other methods, like tying the parameters of the fuzzy membership functions in Eq. (1) to statistical measures. Building on this approach, Rezaei et al. (Rezaei et al. 2017) demonstrated that within a rising sigmoidal MF, \(c=\mu\) and \(a=\frac{-4}{\sigma \sqrt{e}}\); where \(\mu\) and \(\sigma\) denote the average and the spread of x values, respectively. Also, \(e\) represents Napier's constant. Replacing \(x\) with the value from the objective function for a top-performing search agent up to that point allows the determination of this agent's fuzzy MF value, as indicated in Eq. (2).
where \({Z}_{\text{best. }j}^{t}\) signifies the objective value for the \(j\)th top-performing agent during the \(t\) th cycle. \({\mu }^{t}\) and \({\sigma }^{t}\) illustrate the average and spread for the objective values of all leading agents during that cycle, respectively, while \({{\text{MF}}}_{j}^{\mathrm{^{\prime}}}\) indicates the MF value for the \(j\) th top-performing agent. \(N\) remains the total population count. Moving forward, we introduce a unique metric termed the DFI as depicted:
To ensure every top-performing agent collaboratively informs the creation of a single guiding global agent for each participant, we introduce a weighted average of all contrasting top-performing agents. These weights are represented by their associated DFI values. Equation (4) encapsulates this relationship.
where \({Y}_{i}^{t}\) is the position vector for the unique global guiding agent deduced for the \(i\) th agent during the \(t\) th cycle, while \({X}_{j}^{\text{best}}\) refers to the position vector for the best performance of the \(j\) th searching agent up to that point. \(DF{I}_{j}^{t}\) indicates the dual-fitness metric for the \(j\) th search agent during that cycle. Notably, a minuscule positive number, \(\varepsilon\), is integrated into the denominator of Eq. (4) to avert singularities. This inclusion is especially pertinent for more straightforward challenges, mainly those with optimal solutions centralized within their domains. However, for intricate challenges, especially when the optimal solution lies distant from the domain's center, \(\varepsilon\) becomes redundant. Absent any prior insights into the problem at hand, excluding ε from the denominator of Eq. (4) and subsequently from Eq. (5) is advised. To augment the search efficacy of the algorithm and reduce its computational load, focusing solely on the elite top-performing agents when deducing each guiding agent is recommended. To achieve this, all top-performing agents are ranked based on their DFI, from the highest to the lowest, with the top \(Nbest\) agents labeled as elite. An uncomplicated approach to determine \(Nbest\) is to reduce its value linearly across cycles. It should match the population count at the outset and 2 at the culmination. Fixing \(Nbest\) to 2 during the concluding cycle ensures that the elite agents perpetually modify their positions to preserve diversity. Therefore, when elitism is integrated into determining guide agents, Eq. (4) evolves into Eq. (5).
In an attempt to boost the stochastic properties of \({Y}_{i}^{t}\), ensuring better conservation of guide agent diversity, these agents undergo mutation in GMO. This mutation is characterized by a Gaussian mutation approach. The mutation's mathematical representation is as shown:
within this representation, \(rand n\) signifies a random vector derived from a typical normal distribution. The \(w\) parameter attenuates the mutation step magnitude as iterations progress, which is derived from Eq. (9). The end product, \({Y}_{i,\text{ mut }}^{t}\), is the mutated \({Y}_{i}^{t}\) that directs the search agents. A notable observation is that this ensures the conservation of existing rich diversity among leading agents, which in turn fosters an overall diverse population in the search area. Conversely, a diminished standard deviation for a dimension prompts a larger mutation step, broadening the search area and amplifying agent diversity for that specific dimension. The refresh equations for each search agent are described by Eqs. (7) to (9):
within these equations, \(w\) is an influential parameter, \(t\) denotes the present cycle and \({t}_{max}\) stands for the ultimate cycle count. \({V}_{i}^{t}\) signifies the velocity vector for the \(i\) th search agent during the \(t\) th cycle. \({V}_{i}^{t+1}\) represents the \(i\) th agent's velocity vector in the subsequent cycle, while \({X}_{i}^{t}\) shows the position vector for the \(i\) th agent at that cycle. Additionally, \(\varphi\) serves as a scaling vector, illustrating the trajectory of agent \(i\) towards its guide. The rand is a stochastic number from the range [0,1]. Evidently, the magnitude of the \(\varphi\) vector diminishes and changes through ranges like \([\mathrm{0,2}],[0.1\), \(1.9],[\mathrm{0.2,1.8}],\dots ,[\mathrm{0.8,1.2}],[\mathrm{0.9,1.1}]\) and so on, until it reaches \([\mathrm{1,1}]=\{1\}\), as iterations advance. The declining pattern adopted for the \(\varphi\) intervals boost GMO's exploration ability during the early cycles and accentuates exploitation towards the end, ensuring a harmonious exploration–exploitation shift.
3 Proposed Multi-objective Geometric Mean Optimizer (GMO) (MOGMO)
3.1 Basic Definitions of Multi-objective Optimization
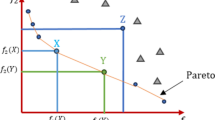
In multi-objective optimization tasks (MOPs), there is a simultaneous effort to minimize or maximize at least two clashing objective functions. While a single-objective optimization effort zeroes in on one optimal solution with the prime objective function value, MOO presents a spectrum of optimal outcomes known as Pareto optimal solutions. The majority of MOO techniques harness the idea of domination in their quest to manage diverse objectives and identify these Pareto solutions. An elaboration on the idea of domination and associated terminologies are illustrated in Fig. 1.

Multi-objective all definitions in search space of MO-Problem
3.2 Multi-objective Geometric Mean Optimizer (GMO) (MOGMO)
MOGMO algorithm starts with a random population of size \(N\). the current generation is \(t, {x}_{i}^{t}\) and \({x}_{i}^{t+1}\) the \(i\) th individual at \(t\) and \((t+1)\) generation. \({u}_{i}^{t+1}\) the \(i\) th individual at the \((t+1)\) generation generated through the GMO algorithm and parent population\({P}_{t}\). the fitness value of \({u}_{i}^{t+1}\) is \({f}_{i}^{t+1}\) and \({U}^{t+1}\) is the set of\({u}_{i}^{t+1}\). Then, we can calculate \({x}_{i}^{t+1}\) according to \({u}_{i}^{t+1}\) generated through the GMO algorithm and Information Feedback Mechanism (IFM) Eq. (10)
where \({x}_{k}^{t}\) is the \(k\) th individual we chose from the \(t\) th generation, the fitness value of \({x}_{k}^{t}\) is \({f}_{k}^{t},{\partial }_{1}\) and \({\partial }_{2}\) are weight coefficients. Generate offspring population \({Q}_{t}\). \({Q}_{t}\) is the set of \({x}_{i}^{t+1}.\) The combined population \({R}_{t}={P}_{t}\cup {Q}_{t}\) is sorted into different w-non-dominant levels \(\left({F}_{1},{F}_{2},\dots ,{F}_{l}\dots ,{F}_{w}\right)\). Beginning from \({F}_{1}\), all individuals in level 1 to \(l\) are added to \({S}_{t}={\bigcup }_{i=1}^{l} {F}_{i}\) and remaining members of \({R}_{t}\) are rejected, illustrated in Fig. 2. If \(\left|{S}_{t}\right|=N,\) no other actions are required and the next generation is begun with \({P}_{t+1}={S}_{t}\) directly. Otherwise, solutions in \({S}_{t}/{F}_{l}\) are included in \({P}_{t+1}\) and the remaining solutions \(N-{\sum }_{i=0}^{l-1} \left|{F}_{i}\right|\) are selected from \({F}_{l}\) according to the Crowding Distance (CD) mechanism, the way to select solutions is according to the CD of solutions in \({F}_{l}\). The larger the crowding distance, the higher the probability of selection and check termination condition is met. If the termination condition is not satisfied, \(t=t+1\) than repeat and if it is satisfied, \({P}_{t+1}\) is generated represent in Algorithm-1, it is then applied to generate a new population \({Q}_{t+1}\) by GMO algorithm. Such a careful selection strategy is found to computational complexity of \(M\)-Objectives \(O\left({N}^{2}M\right)\). MOGMO that incorporates proposed information feedback mechanism to effectively guide the search process, ensuring a balance between exploration and exploitation. This leads to improved convergence, coverage and diversity preservation, which are crucial aspects of multi-objective optimization. MOGMO algorithm does not require to set any new parameter other than the usual GMO parameters such as the population size, termination parameter and their associated parameters. The flowchart of MOGMO algorithm can be shown in Fig. 3.

The procedure of the NDS approach based on MOGMO algorithm

Flowchart of MOGMO algorithm

4 Results and Discussion
4.1 Algorithmic Comparison and Settings
To validate the results, MOGMO is weighed against NSGA-II widely acknowledged MOO methods. In addition, MOGMO is contrasted with the newer MOO algorithms: MOEO, MOSOS/D, MOMVO and MOPGO. Original papers recommended parameter settings were retained for this study.
4.2 Benchmark Settings and Parameters
This section utilizes thirty prominent multi-objective benchmark challenges, sourced from reputable academic works, to assess the efficacy of MOGMO. These challenges encompass objective functions with unique attributes and varying dimensions of design parameters. They are organized ZDT [42] (Appendix A), DTLZ [43] (Appendix B and Appendix C), Appendix D based on Constraint [44, 45] (CONSTR, TNK, SRN, BNH, OSY and KITA) and Appendix E based on real-world engineering design problems: Brushless DC wheel motor [46] (RWMOP1), Safety isolating transformer [47] (RWMOP2), Helical spring [45] (RWMOP3), Two-bar truss [45] (RWMOP4) and Welded beam [48] (RWMOP5). All mathematical models for these challenges can be found in Appendices A, B, C, D and E.
4.3 Evaluative Metrics
MOO fundamentally pursues two objectives: achieving solutions converging to the Pareto optimal front and ensuring diverse solutions within the Pareto set. Hence, a range of performance metrics is essential to accurately evaluate MOO algorithm outcomes. Within this work, 'PFtrue' represents the consistent Pareto optimal front as defined by functions constituting an MOP. On the other hand, 'PFob' denotes the Pareto optimal front derived from a specific MOO algorithm. In multi-objective optimization (MOO), the performance metrics [49] of algorithms in terms of faster convergence Generational Distance (GD), combined uniformity-convergence-coverage spread (SD), Hyper Volume (HV) and Inverted Generational Distance (IGD), Computational complexity (RT) and coverage spacing (SP) metrics shown in Fig. 4 to offer a comprehensive performance assessment. Comparative analysis employs four performance metrics: GD, IGD, SP, SD and HV. It is crucial to note that all performance metrics here are assessed in a normalized objective space. Optimal Pareto fronts are indicated by smaller values for GD, IGD, SP, SD and larger values for HV. Subsequent sections detail the metrics employed here. During benchmark optimization, every technique is independently executed thirty times per case, facilitating a statistical evaluation. “ + / − / ~ ” Wilcoxon signed-rank test (WSRT) was conducted at a significance level of 0.05 between the total amount of test problems on which the corresponding optimizers has a better performance, a worse performance and an equal performance of MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO w. r. t. MOGMO algorithm.

Mathematical and schematic view of the a GD, b IGD, c SP, d SD and e HV metrics
4.4 Analysis and Observation
Simulations were conducted 30 times for each test issue on a system featuring: Windows 10 (64-bit), Intel i5 CPU, 8 GB RAM and MATLAB R2021a. This section delves into the results from distinct metrics and offers insights.
4.4.1 ZDT Benchmark Analysis
Tables 1, 2, 3, 4, 5, 6 provide the comprehensive statistical analysis using GD, IGD, SP, SD, HV and RT measurements for various algorithms like MOGMO, MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO. These are all tested against the ZDT suite. From the results in Table 2, it is evident that MOGMO outperforms the other algorithms, especially when we focus on the average and standard deviation for the IGD metric. A majority of the other algorithms could not achieve a near-optimal Pareto front. Their struggle is evident in their high IGD values. Notably, MOGMO leads in the SP and SD metrics and it also tops in the HV measurement. For visual clarity, Fig. 5 shows how MOGMO's results align with the true Pareto fronts for ZDT suites. The results depict a consistent alignment of MOGMO outputs with the true Pareto optimal fronts.

Best Pareto optimal front obtained by the MOGMO algorithm on a ZDT1, b ZDT2, c ZDT3, d ZDT4, e ZDT5 and f ZDT6 problems
4.4.2 DTLZ 2 and 3-Objective Benchmark Insights
Tables 7, 8, 9, 10, 11 and 12 dive into the performance metrics of each algorithm when tested on DTLZ1-DTLZ7 two and three objectives’ functions. MOGMO continues to shine, surpassing MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO, especially in DTLZ functions. Notably, MOMVO ranks after MOGMO in terms of performance. In general, MOGMO demonstrates better spread and distribution in Pareto optimal solutions compared to its counterparts. Using the HV metric to assess performance, MOGMO consistently ranks higher than its peers for the majority of functions. Figures 6 and 7 provide a visual representation for DTLZ1-DTLZ7 two and three objectives’ functions. The graphs solidify MOGMO ability to closely align with the true Pareto fronts.

Best Pareto optimal front obtained by the MOGMO algorithm on DTLZ1-DTLZ7 problems with 2-objectives

Best Pareto optimal front obtained by the MOGMO algorithm on DTLZ1-DTLZ7 problems with 3-objectives
From Table 1, we observe that for the GD metric, MOGMO and MOSOS/D outperform other algorithms in most cases for ZDT1-ZDT6 problems, showing better convergence. MOGMO shows best results in 4 / 6 cases, whereas MOSOS/D and NSGA-II achieve 2 best results each. In Table 2, for the IGD metric, MOGMO again demonstrates superior performance in 3/6 cases, indicating better convergence and diversity. MOGMO, MOSOS/D and MOMVO each achieve the best results in some cases, with MOGMO leading. Table 3 shows the SP metric, where MOGMO stands out in 3/6 cases, indicating better divergence. MOGMO, MOSOS/D and MOPGO demonstrate competitive performance, but MOGMO leads in achieving the best results. As seen from Table 4 for the SD metric, MOGMO again leads by achieving the best performance in 3/6 cases. This suggests that MOGMO has a better spread of non-dominated solutions. Other algorithms like MOSOS/D and MOMVO also show good performance in some cases. In Table 5, considering the HV metric, MOGMO exhibits superior performance in 4/6 cases, indicating a better balance between convergence and diversity. MOSOS/D and NSGA-II also show competitive results in certain cases. Finally, Table 6 presents the RT metric, where MOGMO shows the best performance in 4/6 cases, indicating a faster running speed and minimal computational burden. Other algorithms like MOEO and MOSOS/D also perform well in certain instances. From Table 7, observing the GD metric, we can see that MOGMO, MOEO and MOSOS/D generally exhibit better convergence compared to other algorithms across most DTLZ problems. MOGMO particularly shows strong performance in DTLZ2 and DTLZ4 for both 2 and 3 objectives. In Table 8, analyzing the IGD metric, MOGMO and MOEO have superior performance in several instances, particularly in DTLZ1 and DTLZ2 for both 2 and 3 objectives. This indicates their better convergence and diversity in these scenarios. Looking at Table 9 for the SP metric, MOGMO, MOEO and MOSOS/D show competitive performances, with MOGMO excelling in DTLZ2 and DTLZ5 for both 2 and 3 objectives, suggesting better divergence capabilities. As seen in Table 10 for the SD metric, MOGMO consistently achieves strong performance across most DTLZ problems, indicating a better spread of non-dominated solutions. MOEO and MOSOS/D also show good results in specific instances like DTLZ2 and DTLZ3. In Table 11, examining the HV metric, MOGMO, MOEO and MOSOS/D again demonstrate superior performance in several instances, particularly in DTLZ2 and DTLZ4 for both 2 and 3 objectives. This suggests their effective balance between convergence and diversity. Finally, Table 12 presents the RT metric, where MOGMO and MOEO frequently exhibit better performance, indicating faster running speeds and lower computational burdens in scenarios like DTLZ1 and DTLZ2 for both 2 and 3 objectives. Overall, MOGMO appears to be the most consistent performer across different metrics for the ZDT 2-objective benchmark, MOGMO and MOEO appear to be the most consistent performers across different metrics for the DTLZ 2 and 3-objective benchmark demonstrating its effectiveness in various aspects such as convergence, diversity and computational efficiency.
4.4.3 Evaluation of Constraint Benchmark
Tables 13, 14, 15, 16, 17 and 18 present the performance data on GD, IGD, SP, SD, HV and RT metrics, as determined by the MOGMA for test operations including CONSTR, TNK, SRN, BNH, OSY and KITA. To manage constraints within MOGMO, a death penalty function is utilized. Other algorithms like MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO were also tested on these functions for a comparative view. Insights from Table 13 suggest that MOGMO consistently outperforms its counterparts, especially in the domain of constrained multi-objective scenarios. Table 14 also underscores the standout average and SD values for the IGD metric associated with MOGMO. Further, MOSGA achieves superior results in producing well-distributed Pareto optimal results. Moreover, the SP and SD indicators from Tables 15 and 16 signify MOGMO dominance over other methodologies. Regarding the HV metric in Table 17, MOGMO outcomes are more promising, pointing towards its enhanced convergence and stability. Amongst the algorithms considered, NSGA-II ranks just behind MOGMO in terms of IGD outcomes for the majority of test functions. However, the solutions derived from this algorithm exhibit subpar distribution characteristics, evident from its SP and SD metric values. Conversely, MOMVO lags in convergence. Figure 8 offers visual representations of the Pareto outcomes achieved by MOGMO across various test functions. Certain tests reveal unique Pareto optimal fronts; for instance, CONSTR possesses a combined concave and linear front. Moreover, while the KITA function showcases a continuous concave front, TNK's front is more erratic. The depicted results in Fig. 8 demonstrate MOGMO proficiency in aligning closely with true Pareto optimal outcomes, ensuring even distribution across all regions. This analysis underlines MOGMO adeptness at managing constraints and delivering high-convergence Pareto results.

Best Pareto optimal front obtained by the MOGMO algorithm on constrained CONSTR, TANK, SRN, OSY, BIN and KITA
4.4.4 Real-World Applications of MOGMO
While standard multi-objective test functions provide valuable insights, grappling with real-world optimization dilemmas often poses unique challenges. To test its real-world applicability, MOGMO is applied to five engineering design challenges, with their mathematical formulations found in Appendix E. Replicating earlier methods, MOGMO is run thirty times for every problem. The results are stacked against MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO, with all algorithms retaining consistent parameters. the six MOO algorithms are assessed using GD, IGD, SP, SD, HV and RT metrics. Tables 19, 20, 21, 22, 23 and 24 provide a comprehensive comparison, highlighting MOGMO knack for delivering a broader array of Pareto optimal solutions. This is further validated by MOGMO superior average and minimal deviation in SP, SD and HV metrics, establishing its edge in convergence and diversity. Further insights can be gleaned from Fig. 9, which exhibits the Pareto optimal front achieved by MOGMO. The outcomes underscore MOGMO efficiency, better in terms of convergence (GD, SP), divergence (IGD, HV), computational burden (RT) and solution distribution (SD) compared MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO algorithms for solving real world problems This underscores MOGMO supremacy in consistency and reliability over other MOO algorithms. Tables 6, 12, 18 and 24 delve into the mean CPU durations of all algorithms, showcasing that MOGMO computation speed trumps most others in 19 out of 25 test problems. In the remainder, MOGMO is a close second in computational speed.

Best Pareto optimal front obtained by the MOGMO algorithm on real-world engineering problems: a RWMOP1 b RWMOP2 c RWMOP3 d RWMOP4 e RWMOP5
The effectiveness of MOGMO has been assessed using 25 benchmark functions and five engineering problems oriented towards multiple objectives. In this assessment, MOGMO performance is juxtaposed with MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO, employing indicators like GD, IGD, SP, SD, HV and RT. Within this context, GD and IGD metrics evaluate the precision and convergence of the algorithm. Simultaneously, SP and SD metrics gauge the spread and distribution of the outcomes. Among the five metrics, HV stands out as a comprehensive measure, assessing an MOO method's convergence and diversity prowess. Analytical approaches like non-parametric statistical tests, robustness scrutiny and visual representations of Pareto optimal fronts showcase MOGMO outcomes. A perusal of the performance statistics highlights MOGMO capacity to deliver superior results relative to its counterparts. For all testing functions, the Pareto fronts generated by MOGMO splendidly align with genuine Pareto fronts, demonstrating considerable diversity. Non-parametric tests, including the Wilcoxon rank-sum tests, indicate MOGMO superior performance over MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO across most metrics. MOGMO balance between exploration and exploitation is commendable, stemming from the perturbation coefficient and strategies in the global and local stages. Its diversity, in terms of distribution and spread, is also noteworthy, originating from novel search group selections and Pareto archive updates. MOGMO utilizes tournament selection, favoring less-populated regions and selectively discards solutions from overcrowded regions when necessary, bolstering solution diversity throughout the optimization. Despite these strengths, MOGMO is not without its constraints. As it leans on Pareto dominance, MOGMO excels in solving MOPs with two or three conflicting objectives. However, with problems encompassing more than three objectives, MOGMO archive fills rapidly with non-dominated solutions, which might hamper its efficiency. As such, MOGMO is optimally geared for MOPs with two to three objectives.
From Tables 13 and 19, we can observe that MOGMO outperforms 7 out of 11 best results, whereas MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO achieves 0, 1, 0, 1 and 2 best results in terms of the GD values, respectively. Therefore, MOGMO has a better convergence for solving Constraint and real-world application. In Tables 14 and 20, IGD value compared to MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO, the proposed MOGMO is better in 9, 10, 10, 11 and 11 out of 11 cases. Therefore, MOGMO has a better convergence and diversity for solving Constraint and real-world application. In Tables 15 and 21, SP value compared to MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO, the proposed MOGMO worse in 0, 2, 0, 1 and 1 out of 11 cases. Therefore, MOGMO has a better divergence for solving Constraint and real-world application. As can be seen from Tables 16 and 22, MOGMO achieves the best performance in terms of SD values, having obtained 7 best results, followed by MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO that have obtained 1, 3, 0, 0 and 0 best results, respectively. Therefore, MOGMO has a better spread of non-dominated solutions on true PF for solving Constraint and real-world application. In Tables 17 and 23 on the HV values, when, respectively compared to MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO, the proposed MOGMO is better in 10, 10, 10, 11 and 11 out of 11. Therefore, MOGMO has a better balance between convergence and diversity for solving Constraint and real-world application. In Tables 18 and 24, RT value compared to MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO, the proposed MOGMO is better in 9, 9, 11, 11 and 11 out of 11 cases. Therefore, MOGMO has a faster running speed and minimum computational burden for solving Constraint and real-world application.
5 Conclusions
This study introduces the inaugural multi-objective adaptation of the GMO, termed MOGMO. The traditional workings of the GMO are evolved through the incorporation of two novel modules to shape MOGMO. To start, an elitist non-dominated sorting strategy is executed to identify non-dominated solutions, focusing on three pivotal processes: offspring creation and selection. The second module leverages the CD with IFM selection mechanism, ensuring the continuous enhancement of convergence and variety in non-dominated solutions throughout the optimization process.
MOGMO's efficiency is showcased through its application to twenty-five benchmark problems, both unconstrained and constrained. Metrics such as GD, IGD, SP, SD, HV and RT facilitate its performance evaluation. Statistical outcomes reveal that MOGMO yields higher quality solutions compared to the five esteemed MOEO, MOSOS/D, NSGA-II, MOMVO and MOPGO algorithms reviewed in this research. When measuring convergence using the GD, IGD metric, MOGMO consistently emerges on top. Moreover, in assessing diversity via the SP and SD metrics, MOGMO once again surpasses competing algorithms in the majority of cases. For the HV metric, MOGMO retains its superior stance. All Pareto optimal outcomes derived from MOGMO are closely aligned with genuine Pareto optimal solutions, demonstrating impressive diversity.
Furthermore, the research extends the application of MOGMO to five practical engineering challenges, confirming its versatility. Across all these scenarios, MOGMO consistently delivers superior solution quality when matched against alternative algorithms. This heightened convergence and variety of the yielded Pareto optimal outcomes can be credited to MOGMO 's robust exploitation and exploration capabilities. A thorough analysis validates that MOGMO efficiently tackles problems featuring two to three objectives with characteristics like convexity, non-convexity and discontinuity in their Pareto optimal fronts. It is recommended that MOGMO be further refined and adapted for real-world engineering challenges in forthcoming research. There is also potential in expanding MOGMO capabilities to address problems with a broader array of objectives. The MOGMO source code is available at: https://github.com/kanak02/MOGMO.
Data Availability
The data presented in this study are available through email upon request to the corresponding author.
Change history
22 April 2024
A Correction to this paper has been published: https://doi.org/10.1007/s44196-024-00505-9
References
Menchaca-Mendez, A., Coello Coello, C.A.: GD-MOEA A new multiobjective evolutionary algorithm based on the generational distance indicator. In: Gaspar-Cunha, J., Henggeler Antunes, C., Coello, C.C. (eds.) Evolutionary Multicriterion Optimization A. Springer International Publishing, Cham. pp 156–170 (2015)
Zhang, L., Sun, C., Cai, G., Koh, L.H.: Charging and discharging optimization strategy for electric vehicles considering elasticity demand response. eTransportation 18, 100262 (2023). https://doi.org/10.1016/j.etran.2023.100262
Cao, B., Gu, Y., Lv, Z., Yang, S., Zhao, J., Li, Y.: RFID reader anticollision based on distributed parallel particle swarm optimization. IEEE Internet Things J. 8(5), 3099–3107 (2021). https://doi.org/10.1109/JIOT.2020.3033473
Cao, B., Zhao, J., Lv, Z., Gu, Y., Yang, P., Halgamuge, S.K.: Multiobjective evolution of fuzzy rough neural network via distributed parallelism for stock prediction. IEEE Trans. Fuzzy Syst. 28(5), 939–952 (2020). https://doi.org/10.1109/TFUZZ.2020.2972207
Xiao, Z., Shu, J., Jiang, H., Lui, J.C.S., Min, G., Liu, J., Dustdar, S.: Multi-objective parallel task offloading and content caching in D2D-aided MEC networks. IEEE Trans. Mobile Comput. (2022). https://doi.org/10.1109/TMC.2022.3199876
Cao, B., Zhao, J., Yang, P., Gu, Y., Muhammad, K., Rodrigues, J.J.P.C., de Albuquerque, V.H.C.: Multiobjective 3-D topology optimization of next-generation wireless data center network. IEEE Trans. Ind. Inform. 16(5), 3597–3605 (2020). https://doi.org/10.1109/TII.2019.2952565
Xia, B., Huang, X., Chang, L., Zhang, R., Liao, Z., Cai, Z.: The arrangement patterns optimization of 3D honeycomb and 3D re-entrant honeycomb structures for energy absorption. Mat. Today Commun. 35, 105996 (2023). https://doi.org/10.1016/j.mtcomm.2023.105996
Li, S., Chen, H., Chen, Y., Xiong, Y., Song, Z.: Hybrid method with parallel-factor theory, a support vector machine and particle filter optimization for intelligent machinery failure identification. Machines 11(8), 837 (2023). https://doi.org/10.3390/machines11080837
Cao, B., Zhao, J., Gu, Y., Ling, Y., Ma, X.: Applying graph-based differential grouping for multiobjective large-scale optimization. Swarm Evol. Comput. 53, 100626 (2020). https://doi.org/10.1016/j.swevo.2019.100626
Marler, R.T., Arora, J.S.: The weighted sum method for multi-objective optimization: New insights. Struct. Multidiscip. Optim. 41(6), 853–862 (2010). https://doi.org/10.1007/s00158-009-0460-7
Zhang, C., Zhou, L., Li, Y.: Pareto optimal reconfiguration planning and distributed parallel motion control of mobile modular robots. IEEE Trans. Ind. Electron. (2023). https://doi.org/10.1109/TIE.2023.3321997
Duan, Y., Zhao, Y., Hu, J.: An initialization-free distributed algorithm for dynamic economic dispatch problems in microgrid: Modeling, optimization and analysis. Sustain Energy, Grids Netw. 34, 101004 (2023). https://doi.org/10.1016/j.segan.2023.101004
Deb, K.: Multi-objective genetic algorithms: Problem difficulties and construction of test problems. Evol. Comput. 7(3), 205–230 (1999). https://doi.org/10.1162/evco.1999.7.3.205
Deb, K.: Multi-objective optimization using evolutionary algorithms, p. 1. Wiley, Hoboken (2001)
Coello, C.C., Van Veldhuizen, D.A., Lamont, G.B.: Evolutionary algorithms for solving multi-objective problems. Kluwer Academic Publishers: New York, NY, USA (2002)
Meignan, D., Knust, S., Frayret, J.-M., Pesant, G., Gaud, N.: A review and taxonomy of interactive optimization methods in operations research. ACM Trans. Interact. Intell. Syst. 5(3), 1–43 (2015). https://doi.org/10.1145/2808234
Coello Coello, C.A.: Evolutionary multi-objective optimization: A historical view of the field. IEEE Comput. Intell. Mag. 1(1), 28–36 (2006). https://doi.org/10.1109/MCI.2006.1597059
Schaffer, J.D.: Multiple objective optimization with vector evaluated genetic algorithms. In Proceedings of the 1st International Conference on Genetic Algorithms, L (pp. 93–100). Erlbaum Associates, Inc. (1985)
Deb, K., Pratap, A., Agarwal, S., Meyarivan, T.: A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 6(2), 182–197 (2002). https://doi.org/10.1109/4235.996017
Coello, C.A.C., Pulido, G.T., Lechuga, M.S.: Handling multiple objectives with particle swarm optimization. IEEE Trans. Evol. Comput. 8(3), 256–279 (2004). https://doi.org/10.1109/TEVC.2004.826067
Varadarajan, M., Swarup, K.S.: Solving multi-objective optimal power flow using differential evolution. IET Gener. Transm. Distrib. 2(5), 720–730 (2008). https://doi.org/10.1049/iet-gtd:20070457
Mirjalili, S., Jangir, P., Saremi, S.: Multi-objective ant lion optimizer: A multi-objective optimization algorithm for solving engineering problems. Appl. Intell. 46(1), 79–95 (2017). https://doi.org/10.1007/s10489-016-0825-8
Premkumar, M., Jangir, P., Sowmya, R., Alhelou, H.H., Mirjalili, S., Kumar, B.S.: Multi-objective equilibrium optimizer: Framework and development for solving multi-objective optimization problems. J. Comput. Design Eng. 9(1), 24–50 (2021). https://doi.org/10.1093/jcde/qwab065
Premkumar, M., Jangir, P., Sowmya, R., Alhelou, H.H., Heidari, A.A., Chen, H.: MOSMA: Multi-objective slime mould algorithm based on elitist non-dominated sorting. IEEE Access 9, 3229–3248 (2020). https://doi.org/10.1109/ACCESS.2020.3047936
Premkumar, M., Jangir, P., Santhosh Kumar, B., Sowmya, R., Haes Alhelou, H., Abualigah, L., Yildiz, A.R., Mirjalili, S.: A new arithmetic optimization algorithm for solving real-world multiobjective CEC-2021 constrained optimiza- tion problems: Diversity analysis and validations. IEEE Ac-Cess 9, 84263–84295 (2021)
Buch, H., Trivedi, I.N.: A new non-dominated sorting ions motion algorithm: Development and applications. Deci- SionSci. Lett. 9(1), 59–76 (2020)
Zhu, B., Sun, Y., Zhao, J., Han, J., Zhang, P., Fan, T.: A critical scenario search method for intelligent vehicle testing based on the social cognitive optimization algorithm. IEEE Trans Intell Trans Syst 24(8), 7974–7986 (2023). https://doi.org/10.1109/TITS.2023.3268324
Jangir, P., Jangir, N.: A new non-dominated sorting grey wolf optimizer (NS-GWO) algorithm: Development and application to solve engineering designs and economic constrained emission dispatch problem with integration of wind power. Eng. Appl. Artif. Intell. 72, 449–467 (2018). https://doi.org/10.1016/j.engappai.2018.04.018
Premkumar, M., Jangir, P., Sowmya, R.: MOGBO: A new Multiobjective Gradient-Based Optimizer for real-world structural optimization problems. Knowl.-Based Syst. 218, 106856 (2021). https://doi.org/10.1016/j.knosys.2021.106856
Kumar, S., Jangir, P., Tejani, G.G., Premkumar, M., Alhelou, H.H.: MOPGO: A new physics-based multi-objective plasma generation optimizer for solving structural optimization problems. IEEE Access 9, 84982–85016 (2021). https://doi.org/10.1109/ACCESS.2021.3087739
Jangir, P., Heidari, A.A., Chen, H.: Elitist non-dominated sorting Harris hawks optimization: Framework and developments for multi-objective problems. Expert Syst. Appl. 186, 115747 (2021). https://doi.org/10.1016/j.eswa.2021.115747
Kumar, S., Jangir, P., Tejani, G.G., Premkumar, M.: MOTEO: A novel physics-based multiobjective thermal exchange optimization algorithm to design truss structures. Knowledge-Based Syst 242, 108422 (2022). https://doi.org/10.1016/j.knosys.2022.108422
Kumar, S., Jangir, P., Tejani, G.G., Premkumar, M.: A decomposition based multi-objective heat transfer search algorithm for structure optimization. Knowledge-Based Syst 253, 109591 (2022). https://doi.org/10.1016/j.knosys.2022.109591
Ganesh, N., Shankar, R., Kalita, K., Jangir, P., Oliva, D., Pérez-Cisneros, M.: A novel decomposition-based multi-objective symbiotic organism search optimization algorithm. Mathematics 11(8), 1898 (2023). https://doi.org/10.3390/math11081898
Pandya, S.B., Visumathi, J., Mahdal, M., Mahanta, T.K., Jangir, P.: A novel MOGNDO algorithm for security-constrained optimal power flow problems. Electronics 11(22), 3825 (2022). https://doi.org/10.3390/electronics11223825
Jangir, P.: Non-dominated sorting moth flame optimizer: A novel multi-objective optimization algorithm for solving engineering design problems. Eng. Technol. open Access J 2(1), 17–31 (2018)
Jangir, P., Jangir, N.: Non-dominated sorting whale optimization algorithm. Global J. Res. Eng. 17(4), 15–42 (2017)
Jangir, P.: ‘MONSDA:-A Novel Multi-objective Non-Dominated Sorting Dragonfly Algorithm. glob. J. Res. Eng.: F Electr Electron Eng 20, 28–52 (2020)
Mirjalili, S., Gandomi, A.H., Mirjalili, S.Z., Saremi, S., Faris, H., Mirjalili, S.M.: Salp Swarm algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 114, 163–191 (2017). https://doi.org/10.1016/j.advengsoft.2017.07.002
Wolpert, D.H., Macready, W.G.: No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1(1), 67–82 (1997). https://doi.org/10.1109/4235.585893
Rezaei, F., Safavi, H.R., Abd Elaziz, M., Mirjalili, S.: GMO: Geometric mean optimizer for solving engineering problems. Soft. Comput. 27(15), 10571–10606 (2023). https://doi.org/10.1007/s00500-023-08202-z
Zitzler, E., Deb, K., Thiele, L.: Comparison of multiobjective evolutionary algorithms: Empirical results. Evol. Comput. 8(2), 173–195 (2000). https://doi.org/10.1162/106365600568202
Deb, K., Thiele, L., Laumanns, M., Zitzler, E.: Scalable test problems for evolutionary multiobjective optimization, p. p105. Springer, Cham (2005)
Binh, T. T., & Korn, U. (1997). MOBES: A multiobjective evolution strategy for constrained optimization problems. In The Third International Conference on Genetic Algorithms (Mendel 97) p. 27.
Osyczka, A., Kundu, S.: A new method to solve generalized multicriteria optimization problems using the simple genetic algorithm. Struct. Optim. 10(2), 94–99 (1995). https://doi.org/10.1007/BF01743536
Branke, J., Kaußler, T., Schmeck, H.: Guidance in evolutionary multi-objective optimization. Adv. Eng. Softw. 32(6), 499–507 (2001). https://doi.org/10.1016/S0965-9978(00)00110-1
Kim, I.Y., De Weck, O.L.: Adaptive weighted-sum method for bi-objective optimization: Pareto front generation. Struct. Multidiscip. Optim. 29(2), 149–158 (2005). https://doi.org/10.1007/s00158-004-0465-1
Ray, T., Liew, K.M.: A swarm metaphor for multiobjective design optimization. Eng. Optim. 34(2), 141–153 (2002). https://doi.org/10.1080/03052150210915
Xu, J., Tang, H., Wang, X., Qin, G., Jin, X., Li, D.: NSGA-II algorithm-based LQG controller design for nuclear reactor power control. Ann Nuclear Energy 169, 108931 (2022). https://doi.org/10.1016/j.anucene.2021.108931
Funding
No funding.
Author information
Authors and Affiliations
Contributions
Conceptualization: Sundaram B. Pandya, Pradeep Jangir, and Kanak Kalita; formal analysis: Sundaram B. Pandya, and Pradeep Jangir; investigation: Sundaram B. Pandya, and Pradeep Jangir; methodology: Sundaram B. Pandya, Pradeep Jangir, Kanak Kalita, Ranjan Kumar Ghadai, and Laith Abualigah; software: Sundaram B. Pandya, Pradeep Jangir, and Kanak Kalita; writing—original draft: Sundaram B. Pandya, Pradeep Jangir, Kanak Kalita, Ranjan Kumar Ghadai, and Laith Abualigah; writing—review and editing: Sundaram B. Pandya, Pradeep Jangir, Kanak Kalita, Ranjan Kumar Ghadai, and Laith Abualigah. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Informed consent
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pandya, S.B., Kalita, K., Jangir, P. et al. Multi-objective Geometric Mean Optimizer (MOGMO): A Novel Metaphor-Free Population-Based Math-Inspired Multi-objective Algorithm. Int J Comput Intell Syst 17, 91 (2024). https://doi.org/10.1007/s44196-024-00420-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-024-00420-z