
Abstract
Accurate trajectory prediction of autonomous vehicles is crucial for ensuring road safety. Predicting precise and accurate trajectories is still considered a challenging problem because of the intricate spatio-temporal dependencies among the vehicles. Our study primarily focuses on resolving this issue by introducing a comprehensive system called “TrajectoFormer”, which can effectively represent the spatio-temporal dependency between vehicles. In this system, we have conducted preprocessing on the NGSIM dataset by constructing an 8-neighborhood for each vehicle that represents the spatio-temporal dependency between vehicles effectively. Second, we have deployed a transformer network that captures dependencies between the target vehicle and its neighbor from the constructed neighborhood and predicts future trajectories for the target vehicle with notably reduced training times and significant accuracy compared to existing methods. Experiments on both NGSIM US-101 and US-I80 show that our proposed approach outperforms the other benchmarks in terms of showing low RMSE value for the 5-s prediction horizon of trajectory prediction. Our conducted ablation study also underscores the effectiveness of each component of our proposed TrajectoFormer model relative to traditional time-series prediction models.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Artificial intelligence has enabled autonomous vehicles (AVs) to navigate between destinations without the assistance of a human driver. Though numerous studies on various fields of autonomous driving have been conducted over the past few years, without high situational awareness and a comprehensive understanding of the environment, it will be difficult to adopt autonomous driving completely. Observing the trajectory of the nearby vehicles can help to offer an anticipatory evaluation of the driving conditions around the ego vehicle (the car that is under the autonomous driving system’s control is the ego vehicle), which can help in the precise trajectory prediction of autonomous vehicles and prevent potential hazards to safe driving.
In broad terms, trajectory prediction refers to forecasting a target vehicle’s future motion based on the target vehicle’s and its nearby vehicles’previous motions. In general, anticipating the target vehicle’s future coordinate values involves looking at its and its nearby vehicles’ historical coordinate values. The goal of trajectory prediction is to create a future route by considering the past route of the ego vehicle and its surrounding vehicles. To be precise, the challenge of forecasting the short-term (1–3 s) and long-term (3–5 s) spatial coordinates of different road agents, such as vehicles, buses, pedestrians, rickshaws, and other vehicles, is known as trajectory prediction. Our study mainly concentrated on trajectory prediction for autonomous vehicles.
One crucial characteristic of AVs is the capacity to predict the vehicles’ future paths effectively in terms of trajectory prediction. Since traffic agents may influence one another’s behavior, particularly in highly interactive driving scenarios, it is necessary for the prediction model to capture the social interaction among agents in the scene to produce socially acceptable and accurate trajectory predictions. The difficulty of trajectory prediction arises from the fact that driving is a complex interaction activity in which a vehicle’s trajectory is influenced by its driving style and surroundings. Also, the number of vehicles present in the surroundings might vary depending on the traffic conditions. Autonomous vehicles’ ability to accurately anticipate other traffic participants’ behavior is crucial for their safe and efficient navigation through complicated traffic conditions. Although advanced research has focused on interaction-aware trajectory prediction considering the effect of many nearby vehicles, most autonomous vehicles can not detect the motion status of other vehicles at a distance without communication technologies in a mixed traffic scenario. Thus, our work concentrates on reflecting the traffic interaction between the ego vehicle and its surrounding vehicles to predict computationally efficient and accurate trajectories.
Vehicle trajectory prediction has received a lot of attention from researchers so far. Various approaches have been used in literature for the task of predicting trajectories. LSTM [1]-based model [2], social LSTM [3] were, respectively, introduced for predicting the trajectory of autonomous vehicles and pedestrians using past locations of the target and its neighbors. Deep neural network [4]-based learnable end-to-end models, [5, 6] were also proposed to reason about both high-level behavior and long-term trajectories. These end-to-end trajectory prediction models employ a sequence-to-sequence CNN [7] architecture where a fully connected layer is used for embedding trajectory histories, and to consistently learn about temporal dependencies, stacked convolutional layers are employed. By combining existing techniques with the Markov [8] model and generative adversarial learning [9], trajectory prediction models have recently advanced. The inter-vehicular dependencies, however, have not been seriously considered in these models, and there is much scope for improvement in terms of prediction accuracy.
Intelligent vehicles’ decision-making and path-planning depend heavily on precisely modeling interactions and forecasting the trajectories of nearby vehicles. Realizing the importance of vehicle interaction dependency, [10] developed a unique ensemble learning-based framework to enhance the accuracy of trajectory predictions in interactive settings. [11] also suggested an LSTM encoder–decoder model for learning interdependencies in vehicle motion that leverages convolutional social pooling for trajectory prediction tasks. Though these studies consider interaction dependencies, questions remain, such as what the distance range is for considering interaction dependencies, which neighboring vehicles are affecting the ego vehicle’s movement, etc. Therefore, more insights are needed to capture spatio-temporal dependencies and increase autonomous vehicles’ long- and short-term prediction accuracy.
Capturing inter-vehicular dependency is a crucial task to improve the prediction accuracy of autonomous vehicles. The task is also harder because the ego vehicle is spatially and temporally dependent on its neighbors, indicating that its movements are intricately linked to its neighbors’ movements in terms of its relative positions (spatial) and its interactions with them over time.
Inspired by the above research gaps, a comprehensive transformer-based model incorporate with custom designed preprocessing strategy, at a whole referred as“TrajectoFormer” system, is proposed for long-term trajectory prediction of autonomous vehicles. Our model forecasts a vehicle’s trajectory over a fixed horizon utilizing the target vehicle’s interaction with its neighboring vehicles. Our study aims at predicting a vehicle’s trajectory over a time period of 5 s using only 3 s of its past historical trajectory data. Regardless of whether other factors influence the predicted vehicle’s behavior, its historical motion trajectory always exists objectively, and hence, in this study, we have considered the historical data of both the target vehicle and its surrounding vehicles. Also, to consider interaction dependency, a neighborhood of 8 neighbors has been considered for each ego vehicle. The main contributions of this study are briefly summarized as follows:
1. As vehicles do not operate in isolation, the behavior of neighboring entities deeply influences their movements. Consequently, a distinguishing feature of the traffic situation is the intricate spatio-temporal relationships between entities depicted in Fig. 1. Our prediction model accounts for the precise consideration of these spatio-temporal dependencies by constructing a neighborhood for each target vehicle to produce reliable predictions.

The illustration of inter-dependency between vehicle’s motion. The yellow ego vehicle is an AV, and the rest are the surrounding vehicles whose position impacts the ego vehicle’s movement
2. Our trajectory prediction system TrajectoFormer’s cornerstone lies in its ability to forecast a vehicle’s trajectory over a fixed horizon. More formally, given the past trajectory \(T_\textrm{past}\) that spans a duration of 3.2 s, the model is trained for predicting the future trajectory \(T_\textrm{future}\) for the following 4.8 s.
The remainder of this paper is organized as follows: Sect. 3 presents an overview of the system architecture, Sect. 4 depicts the problem formulation for our trajectory prediction task, Sect. 5 demonstrates the detailed preprocessing stage, and Sect. 6 describes the steps of the method development for TrajectoFormer. In Sect. 7, an ablation research is conducted to evaluate the model’s engineering independently in comparison to others that undergo the same preprocessing. Experimental analysis and comprehensive studies with benchmarks are discussed in Sect. 8, and concluding remarks are drawn in Sect. 9.
2 Related Works
Different kinds of classification strategies for autonomous vehicle’s trajectory prediction have been followed throughout the literature of AV [12]. The present methodologies, primarily used in this study field, may be divided into model-based and data-driven approaches [13, 14]. Most model-based approaches detect typical driving actions, such as switching lanes, making a left or right turn, estimating the vehicle’s maximum turning speed, etc [15]. On the other hand, data-driven approaches often include using a significant amount of training data to educate a black box model (typically a neural network-based model) [16]. Once the model has been trained, it may be used to predict future behavior based on historical data. The models developed using these approaches can be sectioned into physics-based, maneuver-based, and interaction-aware motion models.
Using inputs like steering angle, acceleration rate, vehicle mass, and even the coefficient of friction between the tires and the road surface, physical-based motion models use physical principles to assess a vehicle’s trajectory and anticipate its final location and direction. Kalman filters [17] and Monte Carlo sampling [18] are two examples of physics-based techniques. Manuever-based motion models attempt to predict the sequence of actions that vehicles perform while moving. But, they make the assumption that each vehicle makes decisions independent of the others on the road. These models attempt to identify such motions as soon as they occur, project their continuance into the near future, and then forecast the associated trajectories. The most comprehensive group of models is interaction-aware motion models, which imply that a vehicle’s movements are influenced by adjacent road users. Dynamic Bayesian networks [19] or prototype trajectories are used in these models. Rule-based systems [20], dynamically connected hidden Markov models [21], and coupled hidden Markov models are examples of interaction-based models. Inter-agent dependencies are considered in these models, increasing comprehension of the scenario. Interaction-aware models provide longer-term forecasts than physics-based models and are more reliable than maneuver-based models as they frequently have to calculate all possible pathways [22].
Furthermore, in terms of methodologies primarily applied in these models, the current methodologies can be classified into three categories: methods relying on neural networks, methods relying on stochastic processes, and mixed methods. Many trajectory prediction frameworks are built on deep neural networks, including convolutional neural networks (CNNs), recurrent neural networks (RNNs) [23], long short-term memory (LSTM), networks, or a mix of them, for neural network-based prediction. One of the earliest efficient neural network models DESIRE [24], is a generative system with the purpose of predicting the future positions of many interacting actors in dynamic (driving) settings. Using multi-modal prediction, it can predict many outcomes from the same inputs. It also contains scene atmosphere and traffic participant interactions employing a computationally efficient end-to-end neural network model. [25] proposed an effective data-driven trajectory prediction framework based on an LSTM that uses a tremendous amount of trajectory data to train the vehicles’ complex behavior. Based on the coordinates and speeds of the adjacent automobiles as inputs, the LSTM creates probabilistic information about the future placements of the traffic participants on an occupancy grid map.
Many methods have been introduced relying on stochastic processes. [26] describes a stochastic process for trajectory prediction of autonomous vehicles in a congested city. New York and San Francisco automobile movements were studied for 1000 h. Comparing a vehicle’s current location to a massive database of surrounding movements, its future location was predicted. Additional samples improved this non-parametric technique, removing the need for complex models. Another stochastic framework proposed by [27] includes three interconnected modules: a hidden Markov model (HMM) maneuver recognition module, a trajectory prediction module using motion-based interaction models and maneuver-specific variational Gaussian mixture models, and a vehicle interaction module that manages scene context and minimizes energy for final predictions.
Also, there are a few methods combining different methods for trajectory prediction. Some literature [28, 29] demonstrated how deep learning and mixture models may be used to predict trajectories. These models used a mixture density network (MDN) in the neural model and univariate Gaussian distributions in the mixture model for multi-task learning. Also, literature [30] employed a methodology that relied on vehicle kinematics and minimizing a cost function. The Monte Carlo-based sampling technique and Langevin sampling were utilized to produce better forecasts with more stability, and neural networks were used to expand the cost functions in order to combine the benefits of model-based and model-free learning.
In contrast to these methods, we propose a spatio-temporal neighborhood-aware model that considers the target vehicle’s interaction with its neighborhood to learn about the ego vehicle’s motion dynamics. Instead of simply combining motion encoding and implicitly allowing the decoder to learn their relationship, we employ a transformer-based network to capture complex temporal interactions and spatial relationships between vehicles. After that, positional encoding is added to the embedding to make sequence order more significant for sequential processing. Attention-based encoder–decoder Blocks with multi-head attention mechanisms and feed-forward networks captured complicated vehicle dynamics relationships and patterns. By constructing a neighborhood in the preprocessing stage for spatio-temporal data extraction and using a transformer for capturing interactive motion dynamics, we have built our TrajectoFormer system efficiently for trajectory prediction.
3 System Overview
Existing approaches for predicting vehicle trajectories are diverse, but they fail to account for all of the key aspects that impact the ultimate accuracy of the prediction. This research was inspired to make AVs more aware of their surroundings in a busy traffic environment, which is a key aspect of trajectory prediction. For example, observing the past trajectories of the target vehicle and neighboring vehicles helps to determine the next trajectory position of the ego vehicle and executes trajectory planning. In this study, we conclude that in a non-virtually connected environment, the significant factors responsible for trajectory prediction tasks can be split into the trajectory history of the target vehicle and the trajectory history of its nearby vehicles.
Our research proposes an architecture that incorporates these aspects, allowing AVs to forecast the long-term 5-s trajectory by examining the target vehicle’s and surrounding vehicles’ 3-s history trajectory. As a result, in the early stages of our study, an effective neighborhood was constructed for each ego vehicle that would influence the ego vehicle’s future dynamics.

Overview of TrajectoFormer: our proposed trajectory prediction system
The architectural overview in Fig. 2 comprises of four sections: problem formulation, dataset preprocessing, transformer-based model, and results evaluation. The initial stage of problem formulation was performed to provide clarity of the task and to ensure that the trajectory prediction model aligns with the real-world requirements and constraints typical of dense traffic scenarios. This section delineates the mathematical framework and underlying objectives that steer our prediction model. More formally, given the past trajectory \(\mathbf {T_{past}}\) seconds, the model is tasked with predicting the future trajectory \(\mathbf {T_{future}}\).
The primary objective of the data preprocessing stage was to build a neighborhood that detects the vehicles in close proximity to a certain vehicle in a given data frame. The information appears to be in relation to moving automobiles in various lane locations. In the next stage, Transformer model was trained upon a preprocessed dataset for long-term trajectory prediction of the target or ego vehicle. After training the model with two datasets, it was tested with an independent test set. Later, a comparison with existing benchmarks was performed to evaluate TrajectoFormer system for the trajectory prediction task. This study introduces the TrajectoFormer, which combines an specifically developed preprocessing method with a standard transformer-based model together for accurate long-term vehicle trajectory prediction.
4 Problem Formulation
When regarded from the perspective of an autonomous vehicle traversing a busy metropolitan area, the capacity of an autonomous vehicle to precisely anticipate the probable motions of surrounding entities is a question of safety. The paths of autonomous vehicles are influenced by a variety of factors, ranging from vehicle traits and limitations to the behaviors and intents of neighboring entities. The complex spatio-temporal interactions between vehicles are one of the traffic datasets’ defining qualities, as multiple vehicles are constantly moving on the road, and nearby entities’ actions significantly impact their motions. Consequently, to provide credible predictions, our prediction model must account for these spatio-temporal correlations.
The key feature of our trajectory prediction model is the ability to anticipate a vehicle’s trajectory across a specified horizon. Given the past trajectory \(\mathbf {T_{past}}\), the model is tasked with predicting the future trajectory \(\mathbf {T_{future}}\). Let us represent our past and future trajectories as sequences of positions in a 2D space, such that:
where each \(p_i\) is a vector containing the spatial coordinates at the ith time step. Our prediction function \(f\) can be defined as:
Our historical trajectory \(\mathbf {T_{past}}\) will have 9 positional data points for 9 timestamps during 3.2-s trajectory observation, and our future trajectory \(\mathbf {T_{future}}\) will contain 12 forecasted data points for 12 timestamps during 4.8-s trajectory prediction, assuming that our data updates position every 0.4 s. This level of specificity guarantees that our model’s forecasts are accurate and timely, capturing subtle changes in the vehicle’s trajectory.
5 Data Preprocessing
We have utilized the NGSIM dataset for our study. In the early 2000s, the Next Generation Simulation (NGSIM) project was launched to gather empirical microscopic traffic data [31], and the most extraordinary collection of empirical microscopic traffic data currently made accessible to the scholarly community is the NGSIM data. ITS DataHub and the Federal Highway Administration (FHWA)—NGSIM program offers raw and processed video footage, exact vehicle trajectory data, and data files. Researchers for the NGSIM program collected these data on southbound US 101 and Lankershim Boulevard in Los Angeles, eastbound I-80 in Emeryville, and southbound Peachtree Street in Atlanta [32].
Data were collected via synchronized digital video cameras. NGVIDEO, an NGSIM-specific tool, transcribed vehicle trajectories. These vehicle trajectories located every vehicle in the research region every tenth of a second, providing their lane positions and relative positions [33]. Each NGSIM dataset’s zip file contains location-specific data and vehicle trajectories. Following are the time bounds for NGSIM data sets, two from freeways (I-80 and US-101). Both US-101 and US-I-80 datasets have been preprocessed to train our TrajectoFormer system (Table 1).
In the NGSIM dataset, vehicles are classified into several types. Following shows the vehicle distribution for US-101 dataset in Table 2 [31]:
The NGSIM data collection efforts have resulted in an extensive dataset containing trajectory data for four locations. This dataset comprises of over 11.8 million rows and 25 columns of valuable information [33]. The dataset includes a wide variety of variables that accurately depict the motion and actions of automobiles, trucks, and buses. Some of the more prominent features of the NGSIM dataset are described here that have been considered in most of the literature.
-
Vehicle ID: A vehicle ID is a special number assigned to each vehicle in the collection.
-
Frame ID: A number that is used to track certain time intervals. Typically, the dataset is sampled once every tenth of a second, making each frame a frozen moment in time.
-
Total Frames: A vehicle’s total frames is the sum of all the frames in which it appears.
-
Time (Global Time): Each frame of an audio or video recording will include a timestamp that specifies how much time has elapsed since the recording began, expressed in global time.
-
Local X, Local Y: The vehicle’s local X and Y coordinates in meters. Position “Local X” (across lanes) and “Local Y” (along a direction) are denoted respectively (along the length of the road).
-
Global X, Global Y: The vehicle’s geographical position is indicated by its global X and Y coordinates.
-
Vehicle Length and Width: The length and width of the vehicle are its dimensions.
-
Vehicle Type: Classifies the vehicle as either a car, motorbike, bus, or truck, among other categories.
-
Vehicle Velocity: The vehicle’s speed, expressed in meters per second; abbreviated v.
-
Vehicle’s Acceleration: Acceleration is the rate at which a vehicle’s speed increases or decreases, expressed in meters per second squared.
-
Lane ID: The vehicle’s lane ID shows the lane it is in.
-
Preceding Vehicle, Following Vehicle:Identity of the vehicle immediately before and following the relevant vehicle.
-
Space Headway: The distance between the focus vehicle and the car in front of it, also known as the “space headway”.
-
Time Headway: Time Headway is the amount of time it would take for the target vehicle to advance one place relative to the stationary vehicle in front of it.
-
Vehicle Class: Classification of vehicles according to the number of their wheels.
-
Gap: If both cars keep going at their present speeds, the gap is the time until they collide with the one in front of them.
The abundance of these data enables a wide range of analytics, such as modeling traffic flow, comprehending lane-changing behavior, forecasting traffic congestion, and much more. However, for our study, we have taken into consideration the following features: ‘Local X’, ‘Local Y’, ‘vehicle Length’, ‘vehicle Width’, ‘vehicle Class’, ‘vehicle Velocity’, ‘Space Headway’, ‘Time Headway’, ‘vehicle Acceleration’, and ‘Lane ID’.
5.1 Neighborhood Selection and 8-Neighbor Construction
Complex and dynamic driving makes predicting trajectories challenging owing to changing interactions. Ego vehicles’ and neighboring vehicles’ observed trajectories assist in estimating an autonomous vehicle’s future trajectory. Thus, the ego vehicle’s history and interactions with surrounding vehicles must be examined. Many studies show that a target vehicle’s past movement and neighbor interaction affect forecast accuracy [34]. Our study was initiated by developing an effective neighborhood for each vehicle that affects its dynamics. Therefore, during the data preprocessing stage, a neighborhood was constructed for each existing vehicle ID in the NGSIM dataset.
According to studies [34], eight neighboring vehicles had a higher impact on a target vehicle’s behavior than the other traffic agents presented in a complex traffic condition. Our study used the eight-neighbor notion of an image pixel, and each ego vehicle’s eight nearest neighbors were located at the left, right, front, behind, left front, left behind, right front, and right behind positions. The neighborhood was created to detect automobiles near a vehicle in a data frame. The neighborhood was built in the following way:
-
(i)
In the provided frame, choose the target vehicle The whole row from the dataset was retrieved for a certain vehicle and provided frame.
-
(ii)
Obtaining the vehicle IDs of the cars in front of and behind the target vehicle Vehicle Ids were retrieved from the preceding and following attributes of the dataset to find the front and behind neighbors.
-
(iii)
Determine the target vehicle’s upper and lower boundaries (y-axis) The following equations were used to determine the vehicle’s boundaries along the Y-axis.
$$\begin{aligned}&\textrm{Upper bound} = \textrm{Local} Y + \textrm{vehicle length}/2, \end{aligned}$$(4)$$\begin{aligned}&\textrm{Lower bound} = \textrm{Local} Y - \textrm{vehicle length}/2. \end{aligned}$$(5) -
(iv)
Determining the vehicles in the left lane The vehicles positioned at left, left front, and left behind of the ego vehicle are determined. As vehicles are positioned between Lane ID (0–8) in the NGSIM dataset, no vehicles are set for the left lane if the ego vehicle’s lane is zero. Otherwise, the three left neighbors are constructed in the following manner: Left: The vehicle positioned at lane ID one less than the ego vehicle’s lane Id. Left Front: The vehicle in the left lane that is in front of the ego vehicle. Left Bottom: The vehicle in the left lane that is behind the ego vehicle.
-
(v)
Determine the vehicles in the right lane The approach is similar to the one taken for the left lane, but it checks for the lane to the right. At first, it is checked if the right lane is a valid lane (less than 8 or equal to 8). If not valid, all right-lane vehicles are set to 0. Otherwise, the three right neighbors are constructed in the following manner: Right: The vehicle positioned at lane ID one more than the ego vehicle’s lane Id. Right Front: The vehicle in the right lane that is in front of the ego vehicle. Right Bottom: The vehicle in the right lane that is behind the ego vehicle.
An algorithm for extracting the eight neighbors of each target vehicle has been demonstrated below. This algorithm can be divided into five sections according to the data preprocessing steps. These steps show how each neighbor is extracted gradually, and each step has been commented on in the described algorithm.

Detecting Neighborhood of a Target Vehicle
5.2 Window Creation
Time-series predictions need the creation of temporal windows in sequential data, particularly in the context of autonomous driving. Recording significant vehicle contacts with neighbors over a lengthy period of time became crucial for our study. In light of this, an 8-s window is determined. WindowSize refers to this 8-s window in algorithm 2. An intentional distinction inside this 8-s window is created to ensure that training and prediction were appropriately taken care of. During the first 3.2 s of the window, referred to as TrainingWindow in algorithm 2, the model is trained on historical data to identify the patterns and behaviors of the target and neighboring vehicles. Then, using previously discovered patterns, the following 4.8 s, referred to as PredictionWindow in algorithm 2, were used to forecast vehicle trajectories. Furthermore, adding eight separate features (‘\(\textrm{Local}_X\)’, ‘\(\textrm{Local}_Y\)’, ‘\(v_\textrm{Length}\)’, ‘\(v_\textrm{Width}\)’, ‘\(v_\textrm{Class}\)’, ‘\(v_\textrm{Vel}\)’, ‘\(v_\textrm{Acc}\)’, ‘\(Lane_\textrm{ID}\)’) with each frame, referred to as FeatureSetSize, improved each temporal frame in our TrainingWindow. Thus, the TrainingWindow is structured as a \(9\times 8\) matrix; where 9 refers to the 9 sequential time-frames (3.2 s with 0.4 s frame interval, including the last frame) and 8 refers to the eight predefined features. This feature set provided the vehicle with a full view of its surroundings and increased the model’s ability to forecast accurately. A formal visual notation for this process has been depicted in Fig. 3. Also, an algorithm describing the window creation process in detail has been depicted below with two loops.

Window creation

Creating Temporal Windows for Sequential Data in Autonomous Driving
This windowing strategy also helped to draw a comparison between how well it worked for training and testing scenarios. This ensured that our model TrajectoFormer remains balanced under varying conditions.
5.3 Dealing with Missing Values
One issue that arose during the preprocessing phase of the NGSIM dataset was border vehicles with missing contextual information. Some vehicles, in particular, had to proceed or follow neighbors who were not present in the dataset. This absence could create irregularity in the dataset, reducing the overall dependability and accuracy of any model trained on this data. An elimination technique was devised to address this issue. Vehicles with no preceding or following counterparts were identified. These vehicles were then designated unfit for training but not removed from the dataset. This method ensured that all vehicles in the dataset, including preceding and following vehicles, had comprehensive contextual data. Also, the preprocessing process incorporated with handling missing values, improved the dataset’s consistency and integrity, making it suitable for accurate model training and testing.
6 Methodology
The core of our trajectory prediction model TrajectoFormer system is a transformer-based network that is tuned specifically to capture complex temporal interactions and spatial relationships between vehicles. The model architecture can be broadly divided into some main component blocks, as illustrated in Fig. 4. The model architecture started with the input–output embedding layers, which encoded the observed trajectories over 9 sequential time-frames and 8 vehicle attributes into high-dimensional representations. A combination of slicing, flattening, and repeat vectors was also used to capture the last frame of the target vehicle and to perfectly attach it to the output embedding layer as its input. After that, the embedding is enriched with positional encoding to encapsulate the sequence order, making them more meaningful for sequential processing. Following this, attention-based encoder–decoder blocks served as the computational backbone, wherein multi-head attention mechanisms and feed-forward networks operated to capture complex dependencies and patterns in the vehicle dynamics. Finally, a dense layer acted as a mapper to map the output into our prediction space as a 12 \(\times\) 3 feature vector, representing three prediction features across 12 sequential time-frames, yielding the estimated future trajectories. Together, these component blocks formed a fine-tuned network to predict the target vehicle trajectory. In the following subsections, details of each component block have been described.

Transformer-based trajectory prediction model architecture
6.1 Input–Output Embedding
The input–output embedding layer is the initial stage of the Transformer-based model. These layers were significant for two reasons: first, the obtained data from the neighborhood construction were transformed into a more useful form that helped the model to recognize patterns more effectively. Second, the data for the next stages of the model (the attention mechanisms) were prepared by embedding. This transformation was important because the model was able to understand the complex ways that vehicles move and interact because of embedding, which could not be easily done from the raw data alone.
6.1.1 Input Embedding
The raw vehicular data from neighborhood construction were transformed into continuous vector representations by the input embedding layer in the transformer-based network. This representation is also known as latent space, where each dimension captures some aspect of the data’s original meaning. In our architecture, this embedding is performed via two connected dense layers, the outputs of which are denoted as \(E_1\) and \(E_2\).
Let \(X \in \mathbb {R}^{9 \times 72}\) represent the input feature matrix. The dense layers perform the transformation:
where \(W_1, W_2\) are the weight matrices, \(b_1, b_2\) are the bias vectors, and \(\sigma\) is the activation function.
The reason behind employing two dense layers for input embedding is that in complex interactions like vehicular traffic, one layer might be insufficient to capture the nuances. Both spatial (‘\(\textrm{Local}_X\)’, ‘\(\textrm{Local}_Y\)’) and temporal (‘\(v_\textrm{Vel}\)’, ‘\(v_\textrm{Acc}\)’) features were contained in the 9 \(\times\) 8 input vector for each vehicle of the scenario. Individual relationships between these features were captured by the first dense layer by producing distinct linear combinations. Subsequently, the second dense layer was involved in refining the track by combining the output of the first layer in a manner that allows for more complex relationships between spatial and temporal variables. From a mathematical perspective, a two-tier hierarchical parsing of the input features was efficiently executed by this structure, enriching the model’s understanding of both space and time aspects.
6.1.2 Output Embedding
The output embedding layer is held responsible for producing a feature space for the prediction problem. The core of this embedding layer consists of 2 connected dense layers, but the input of this layer is customized to mitigate the computational complexities associated with error growth. In a typical transformer network, the output embedding block takes the concatenated result of the full sequence and the actual output sequence. However, in our regression-type trajectory prediction problem, tokenization or normalization is avoided to achieve better results while requiring less training time. As a result, the input system of this output embedding block is customized to accept only the last frame data. With this modification,accurate trajectory is predicted without having to worry about the error growing exponentially over time-frame. Mathematically, it can be said that we operated on (\({\text {Traj\_target\_vechicle}}\)) to produce \(V_{\text {repeat}}\) which served as the output embedding. The operations can be described as follows:
As previously mentioned, considering the full sequence for embedding, the model attempted to learn a complex mapping \(f: E_{\text {full}} \rightarrow Y\), where Y is the output sequence. In this setting, small errors in estimating \(E_{full}\) got amplified through over all time-frames, leading to an exponential growth in the error term, denoted as \(\epsilon\):
To counter this, the last frame \(V_{\text {last}}\) was focused on by our architecture, reducing the function’s complexity to \(f': V_{\text {last}} \rightarrow Y\), thereby mitigating error growth:
This adjustment in output embedding also aligns with the Markov property [35] by utilizing \(V_{\text {last}}\) as the pivotal state for future predictions. According to the Markov property, the future state is dependent only on the current state, mathematically expressed as
The sliced vector \(V_{\text {last}} \in \mathbb {R}^{8}\) is replicated \(T=12\) times through the RepeatVector operation. This resulted in \(V_{\text {repeat}}\), which served as a constant initial condition that adhered to the Markov property and minimized error propagation.
Two justifications were provided by the adoption of utilizing \(V_{repeat}\) as the constant initial input:minimizing error while satisfying the Markov property and providing a mathematically concrete foundation for trajectory prediction.
6.1.3 Positional Encoding
Positional encoding in transformer-based architectures is used to provide information about the relative or absolute positions of tokens in a sequence [36]. Since trajectory prediction problems do not have a tokenized form of input but still demand positional information to distinguish the order of vehicle location over time, both sine and cosine functions were employed based on positional encoding to learn time-dependent patterns. Mathematically, for a sequence of length \(T\) and feature dimension \(D\), the positional encoding \(\text {PE}\) is defined as:
The model effectively learned the temporal patterns of complex vehicular traffic by this chosen formula [37]. A damping factor of \(10000^{2j/D}\) ensures that the function has varying wavelengths, enabling the model to capture long-range dependencies in vehicular data.
6.2 Attention-Based Encoder–Decoder Mechanism
Attention-based encoder–decoder [38] pair works at the core of the transformer network inside our proposed TrajectoFormer system. The attention mechanism works by assigning different “attention scores” to different parts of the input. This allows the model to focus on specific parts of the input sequence rather than using fixed-size data, making the architecture more flexible and able to handle longer sequences with complex dependencies. In our study, multi-branch architecture is employed for encoder–decoder models, consisting of 2-way parallel encoder and decoder chains. Here, each chain focused on various aspects of vehicular traffic by forming more latent features, providing a more accurate prediction. The block diagram of the attention-based encoder–decoder mechanism is depicted in Fig. 5.

Attention-based encoder–decoder block [38]
6.2.1 Encoder Block
To encode a sequence of observations into a latent feature space, a two-layer encoder block is employed in the Transformer network. Both short and long-term spatial dependencies are captured by this feature space. A multi-head attention mechanism and a point-wise feed-forward network are entrenched in the configurations of each encoder layer in our model. These parts are arranged hierarchically to capture the complicated spatio-temporal patterns found in the data efficiently.
Let \(\textbf{X} \in \mathbb {R}^{n \times d}\) denote the concatenated input feature tensor for post-positional encoding, where \(n\) is the sequence length and \(d\) is the feature dimension. The model could focus on a variety of input features since this tensor is initially treated to multi-headed attention with 10 attention heads and a 16-dimensional key. Specifically, for each head \(h\), the attention is computed as:
where \({{\text {Attention\_Score}}}_h\) is computed as \(\frac{\textbf{Q}\textbf{K}^\top }{\sqrt{d_k}}\) in line with our custom-defined approach, contrasting the typical softmax-based methods.
The result of concatenating and linearly transforming the output from all the heads is represented by:
where \(W^O\) is the weight matrix for the output projection. The output \(\textbf{O}_i\) for each encoder layer \(i\) is then computed as:
Each encoder layer incorporated a feed-forward neural network with two dense layers post-attention. The first layer increased the feature dimension to 128 and used a ReLU activation, which is formally denoted as \(\text {Dense}_{128}(\text {ReLU}(\textbf{O}_i))\). The dimension is reduced to 64 by the second dense layer, which acts as a bottleneck. It is represented by the \(\text {Dense}_{64}(\textbf{H})\), where \(\textbf{H}\) is the result of the first dense layer.
The encoder in our system consisted of two linked layers, each with a distinct mathematical formalism and function. Considering each encoder layer to be a function,\(\mathcal {T}\), that transfers an input feature space \(\textbf{X}\) to an output feature space \(\textbf{O}\).
Encoding the data’s local spatio-temporal relationships was focused on by the first encoder layer. The mathematical definition of the transformation in the first layer is as follows:
where \(\textbf{W}_{1}\) and \(\textbf{b}_{1}\) are the weight matrix and bias vector, respectively. The keys, queries, and values’\(\textbf{K}_{1}, \textbf{Q}_{1},\) and \(\textbf{V}_{1}\)’are calculated from input trajectory’s local segments.
The second encoder layer can be mathematically demonstrated as follows for capturing long-term relationships:
Here, \(\textbf{Q}_{2}, \textbf{K}_{2}\), and \(\textbf{V}_{2}\) are calculated from more extensive trajectories and even from the complete data set, allowing the model to comprehend global broad patterns.
Finally, the output feature space \(\textbf{O}\) of the entire encoder block is a non-linear composition of these transformations:
With this arrangement, it is guaranteed that both the local and global spatio-temporal properties of the trajectory are accurately captured by \(\textbf{O}\). By organizing the encoder this way, it was ensured that the decoded output trajectories display contextual precision, reflecting spatial dependencies spanning short- and long-term horizons.
6.2.2 Decoder Block
The decoder block is a pivotal component in the architecture, responsible for synthesizing the future trajectory based on the high-level representations derived from the encoder. Specifically, it ingested an aggregated feature set \(\textbf{O} \in \mathbb {R}^{T \times D}\) and forecasted trajectory \(\textbf{Y} \in \mathbb {R}^{T' \times D'}\).
The decoder’s operations were initiated with a causal multi-head attention layer, ensuring the temporal integrity of the sequence by applying a causal mask. This procedure allowed the model to condition each time step’s prediction solely on prior time steps. Mathematically, this is represented as:
The output is then stabilized through an addition and a layer normalization operation:
Following this, another multi-head attention layer is employed to cross-reference the decoder’s inputs with the encoder’s outputs. The operation for this attention mechanism can be formulated as follows:
Likewise before, addition and layer normalization was applied on output:
Subsequently, a feed-forward neural network (FFN) is incorporated into each decoder block. Comprising of two dense layers, this FFN refined the feature set by adding another layer of abstraction. The mathematical representation of this FFN is:
An addition and a layer normalization were applied again for final time:
To adequately capture the spatio-temporal dynamics in the data, the architecture employed two-chained decoder blocks. Short-term pattern extraction was focused on by the first one while understanding the more extended temporal relationships was aimed at by the second one. This hierarchical approach ensured the model’s proficiency in generating future trajectories that are both locally precise and globally coherent.
6.3 Final Mapper
The architecture is completed with a dense layer that efficiently maps the rich feature vectors generated by the decoder into accurate trajectory predictions. A dense neural network generated a \(12 \times 3\) matrix in this layer which represented the three prediction features \(\text {Local}_x\), \(\text {Local}_y\), and \(\text {Lane\_ID}\) over 12 sequential time steps.
Mathematically, the input to the mapping layer can be denoted as \(\textbf{Z} \in \mathbb {R}^{12 \times 72}\), which is the concatenation of two matrices: the decoder output \(\textbf{D} \in \mathbb {R}^{12 \times 64}\) and a repeated vector \(\textbf{R} \in \mathbb {R}^{12 \times 8}\) of the target vehicle’s last frame data. The dense mapping layer then applied a linear transformation to \(\textbf{Z}\) to yield the predicted output \(\textbf{Y} \in \mathbb {R}^{12 \times 3}\); with a weight matrix \(\textbf{W} \in \mathbb {R}^{3 \times 72}\) and a bias vector \(\textbf{b} \in \mathbb {R}^{3}\). This linear mapping is designed to convert the abstract feature space into concrete, meaningful outputs that directly correspond to target prediction features.
This trajectory blueprint in \(\textbf{O}\) captured our model’s ability to discern and predict the future path. Specifically, each row in this matrix provided a precise snapshot of the predicted location and lane status. In illustration, \(\bar{{\text {Local}} X}\), \(\bar{{\text {Local}} Y}\), and \(\bar{{\text {Local}}}\) are represented by matrix’s columns, respectively.
In summation, the final mapper completed our model by seamlessly transitioning the intricacies of historical data to potential future paths, ensuring an informed and accurate prediction.
7 Ablation Study
This study involves conducting an ablation analysis to assess the efficacy of each component in our proposed TrajectoFormer system, including the custom preprocessing and the adopted Transformer neural network model, for predicting trajectories in autonomous vehicles. First, we attempt to evaluate the effectiveness of the adopted Transformer model by contrast a long short-term memory (LSTM)-based model—a traditional choice for time-series analysis. This comparison, utilizing the same dataset, preprocessing strategy and evaluation metrics, aims to highlight the Transformer model’s superior ability to capture spatio-temporal dependencies crucial for predicting vehicle trajectories.

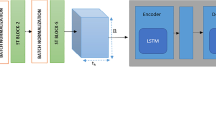
LSTM-based model architecture designed to incorporate with proposed preprocessing strategy
The selection of the LSTM model for the first ablation experiment is motivated by its specific strengths and established track record in the domain of time-series data, including the temporal dependencies. As depicted in Fig. 6, the model architecture incorporates multiple input layers for individual vehicle(target and its eight-neighbor) trajectories, feeding into corresponding LSTM layers designed to capture dynamic temporal behavior. Each LSTM layer is configured with 64 units, ensuring sufficient capacity to learn complex temporal patterns. The outputs of these layers are concatenated and processed through dense layers with LeakyReLU activation, promoting non-linear learning. The model culminates in a final LSTM layer, outputting the predicted future trajectory.
Second, we intend to analyze and compare the efficacy of our customized preprocessing strategy in terms of pattern recognition and overall trajectory prediction. This experiment demands replacing the preprocessing method of TrajectoFormer with a preexisting one from previous scholarly works. However, this task is not straightforward because every aspect of the neural network layers architecture relies on how we input the data, particularly up to the output of the preprocessing stage. Since the existing preprocessing methods(from previous literature) are not specifically tailored for the Transformer model, it is not feasible to incorporate them with Transformer model. So, we employ a straightforward preprocessing technique with an LSTM-based model, which appears to be effective when compared to the previous ablation experiment (Transformer vs LSTM with same preprocessing). The LSTM architecture must be modified based on the preprocessing requirements. Therefore, we have designed a combined preprocessing \(+\) LSTM model setup inspired directly from the CS-LSTM model proposed by Deo et al. [11], as illustrated in Fig. 7.

CS-LSTM model well-suited with traditional preprocessing
In the experimental setup, both the LSTM and Transformer models were trained and evaluated on the preprocessed NGSIM data, and CS-LSTM with traditional preprocessing technique as proposed by Deo et al. [11]. For consistency in evaluation, all of these three setups were configured to process the same past 3 s of trajectory data to predict the next 5 s, mirroring real-world autonomous driving scenarios. The LSTM, CS-LSTM model, as previously described, and the Transformer model were both trained under identical conditions: utilizing the Adam optimizer with a learning rate of 0.001, and the models’ performance was measured using mean squared error (MSE) as the loss function.
To provide a comprehensive comparison, the evaluation focused on key metrics: Root Mean Squared Error (RMSE), the total number of weights in each network, and the required training time. Table 3 presents a direct comparison of the RMSE values for both models, indicating their accuracy in predicting vehicle trajectories. In terms of model complexity, the LSTM model comprises a total of 2,51,847 weights, while the Transformer model consists of 3,21,755 weights, highlighting the differences in their architectural designs. Although, proposed TrajectoFormer system being far heavier than the LSTM-based model in terms of overall weights in the network, it achieves a stable MSE loss value (where we can consider to stop training) in only 15–20 epochs on average. In contrast, the LSTM model requires 30–35 epochs and CS-LSTM require 100 epochs (with higher training time for each epochs) during our experiment. So, in terms of training time, the TrajectoFormer model outperforms the LSTM and CS-LSTM model both and simultaneously achieves a high level of accuracy based on RMSE analysis. These comparative analyses underscore the relative strengths of Transformer models in capturing the complex spatio-temporal patterns within the NGSIM dataset, thereby offering critical insights into their suitability for real-world autonomous vehicle trajectory prediction.
The error analysis results derived from the ablation study, as presented in Table 3, reveal two noteworthy observations. First of all, considering all three of these methods, it becomes apparent that there is a significant variance in performance between typical preprocessing (using CS-LSTM) and our proposed preprocessing (utilizing both LSTM and Transformer). This result unambiguously demonstrates the superiority of our proposed preprocessing model in terms of facilitating input for pattern recognition. Second, in between the two model using our proposed preprocessing (LSTM and Transformer), RMSE values across both US-101 and I-80 datasets consistently show that the Transformer model outperforms the LSTM model, particularly in predicting longer-term future trajectories. Which indicates a more accurate and reliable prediction capability, that is crucial for the safety and efficiency of autonomous vehicle navigation. In terms of model complexity, although the Transformer model has a higher number of weights, its enhanced performance justifies the increased complexity, showcasing its ability to capture more nuanced spatio-temporal patterns in the data. Furthermore, the training time comparison reveals that despite there potential increased in total number of weights in the Transformer model, it require significantly low training time and epoch number compare to LSTM model. These findings underscore the effectiveness of the Transformer architecture in handling the intricacies of real-world driving scenarios, also demonstrate the superiority of our proposed preprocessing strategy in terms of making pattern identification easier. Altogether, the TrajectoFormer system, which consist of proposed preprocessing\(+\)Transformer model, is more feasible choice for complex autonomous vehicle trajectory prediction tasks.
8 Result Analysis and Evaluation
In this section, the data preprocessing outcome and the results and evaluation of our implemented model are described. Additionally, a comparison is drawn with the existing benchmarks.
8.1 Data Preprocessing Outcome
According to studies, a target vehicle’s behavior is more affected by eight nearby vehicles than by a large number of vehicles surrounding the ego vehicle. Table 4 displays the results of the neighborhood construction that we performed. For the sake of our study, each ego vehicle and its eight nearest neighbors were taken into consideration. A number of records of neighbors changing or remaining the same over the frame can be seen here for a particular vehicle (with a specific vehicle ID). This representation helped us to create a window frame and precisely capture patterns by the model.
8.2 Implementation Details
For our study, we have used NGSIM US-101 and US-I-80 datasets. The prediction model is trained independently on the preprocessed training set of each dataset. Initially, data were divided into 80–20 for train and test split. The preliminary step in our training process was the division of our dataset. Ensuring a robust evaluation is paramount, so we opted for an 80–20 split. This 80% training data were again split into an 80–20 ratio for the training and validation set. Allocating 80% of the training data allowed the model to learn from a substantial dataset, ensuring it grasps intricate patterns. Meanwhile, the reserved 20% served as a validation benchmark, helping detect and mitigate overfitting while gauging the model’s generalization capability. Afterward, the model was tested on initially divided independent test sets. Like [39, 40], three seconds of observation were used to predict the next 5 s. Twenty frames per second (FPS) were used for both observation and prediction windows.
The mean squared error (MSE) was selected as the major loss function for both the training and validation phases, as using MSE as a loss function provides insight into the model’s prediction accuracy and convergence during training. Mean squared error (MSE) is a popular regression statistic that estimates the average squared discrepancies between predicted and actual (ground truth) values. It is computed by adding the squared differences between each anticipated and actual value and then dividing by the total number of data points [41]. MSE can be calculated mathematically using the following formula:
where
-
N is the total number of data points.
-
\(y_{\textrm{actual},i}\) is the actual value of the ith data point.
-
\(y_{\textrm{predicted},i}\) is the predicted value of the ith data point.
MSE measures the average squared difference between expected and actual values. Squaring the differences emphasizes larger errors, and outliers impact the metric more. As a result, a lower MSE suggests that the model’s predictions are more accurate, signifying more accuracy. A greater MSE value, on the other hand, indicates that the model’s predictions differ more from the actual values.
Our model’s parameters are iteratively changed during training to minimize the MSE. This statistic indicates the model’s generalization capabilities, offering insight into how well it works on unknown input. MSE, as a loss function, has several advantages, including a focus on greater errors and differentiability, which is essential for gradient-based optimization techniques.
The optimization landscape of deep learning models is intricate. To navigate this, we employed the Adam optimizer with an initial learning rate of 0.001. With its adaptive learning rates, Adam caters to both rapid convergence and stability’a crucial balance in ensuring consistent training dynamics. Furthermore, by adopting the mean squared error (MSE) as our loss function, we ensured that the model is aptly penalized for significant deviations from true trajectory values, pushing it toward greater accuracy. The model was trained for 25 epochs with a batch size of 25 to cap off our training procedure. This batch size was chosen to strike a balance between memory consumption and the granularity of weight updates. Evaluating model performance on the validation set at the end of each epoch served as a crucial feedback loop, guiding subsequent training phases.
8.3 Experimental Result
The root mean square error is the key evaluation metric used in this study (RMSE). The root mean square error (RMSE) is a widely used metric in statistics and machine learning to estimate the accuracy of predictions in regression assignments. It computes the average magnitude of the discrepancies between anticipated and actual (observed) values in a dataset [42]. A lower RMSE number shows that the forecasts are closer to the actual values on average, indicating superior predictive accuracy. A greater RMSE value, on the other hand, indicates that the forecasts differ more from the actual values. The RMSE equation can be stated as follows:
Here, n is the size of the test set, \((x^{*i}_{t_{p}},y^{*i}_{t_{p}})\) and \((x^{i}_{t_{p}},y^{i}_{t_{p}})\) are the predicted position of the target vehicle in data i at time \(t_{p}\) and the corresponding ground truth, respectively. RMSE is calculated for each predictive time step \(t_{p}\) for future twelve timesteps.
The results of our model’s predictions are provided in this section using both visual representation and a prediction horizon. Most of the literature observes a 3-s history trajectory for predicting a 5-s future trajectory. For more accurate prediction, we divided the total 8-s timestamp into the history trajectory interval (0–3.2 s) and the predicted trajectory interval (3.2–8 s). We took into account timestamps at a 0.4-s gap within each interval. In the history interval, we tracked the target vehicle’s trajectory over 9 timestamps, and in the prediction interval, we anticipated its trajectory over 12 timestamps. The historical data served as the input for our prediction model, providing context for predicting its future trajectory, and we used our trained model to forecast the target vehicle’s trajectory for future timestamps. A dynamic picture of the vehicle’s movement over time was produced as a result of the predictions, which were made at intervals of 0.4 s. However, to make a fair comparison with comparing with other existing models, we have predicted trajectory for a 5-s horizon by observing 3-s history data that have been illustrated in Table 5.
Besides RMSE as a base analysis, we further assess the average displacement error (ADE) [43] of our TrajectoFormer model. The measure of ADE is defined as follows:
where \(N\) is the number of data points, \(x_{i}^\textrm{pred}\) and \(y_{i}^\textrm{pred}\) are the predicted longitudinal and lateral positions, respectively, and \(x_{i}^\textrm{true}\) and \(y_{i}^\textrm{true}\) are the actual longitudinal and lateral positions of the vehicle.
We analyze the errors in two scenarios: lane-keeping and lane-changing maneuvers. The prediction errors are categorized into longitudinal and lateral position errors. The error level are depicted in Fig. 8a, b, which are bar charts with the ADE represented by bars and the range of error limits from first quartile (25%) to third quartile (75%) values, indicating the variation in prediction accuracy.

Error analysis of trajectory prediction in autonomous vehicle movement
We showed a visual representation of the target vehicle’s trajectory in the presence of surrounding neighbors to give a simple and intuitive comprehension of the predictions made by our study. The visual representations further demonstrated the alignment between the ground truth and real trajectories, showing our method’s effectiveness. Figure 9 compares the predicted trajectory to the actual trajectory for the NGSIM US-101 dataset, while Fig. 10 does the same for the NGSIM I-80 dataset. This comparison illustrates that our method successfully captured the movement patterns of the vehicle. The projections from our model are very close to the actual trajectory, though some deviations are unavoidable due to the inherent uncertainty of forecasting real-world vehicle trajectories.

Predicted vs actual trajectory comparison over US-101 dataset

Predicted vs actual trajectory comparison over I-80 dataset
8.4 Comparison with Benchmark
Table 6 reports the performance of our implemented trajectory prediction system TrajectoFormer on both NGSIM datasets (US-101 and I-80) against the state-of-the-art trajectory prediction approaches. The analysis focuses on the root mean squared error (RMSE) measure, which offers a quantitative evaluation of the precision of our trajectory forecasts in contrast to various existing methods. These prediction models are those from the literature that report RMSE on any highway trajectory dataset over a 5-s prediction horizon. These models include the Gaussian mixture-based approaches like C-VGMM+VIM [27], the generative adversarial imitation learning model like GAIL-GRU [9], and IETP-CS [10], DSCAN [44] and SIT-ID [36]. Our model reports the least RMSE for a 5-s prediction horizon. The results show that our model outperforms baseline models in the 5-s prediction horizon and that our proposed model has a competitive RMSE value when compared to the established benchmarks. It can be said that our eight-neighbor construction strategy to extract spatio-temporal dependency played a significant role in achieving low RMSE value as even when used different models than our TrajectoFormer system in ablation study the obtained result shown in table 3 surpass most other existing benchmarks. And, finally, our Transformer-based TrajectoFormer system attains lowest RMSE value and predicts future trajectories that are closely aligned to ground truth.
As an alternative approach to RMSE analysis, we also conduct final displacement error(FDE) [43] to evaluate and compare our model with existing benchmarks. While FDE may not be as widely recognized or as impactful as RMSE, it is nevertheless sufficiently significant to be considered as a secondary option for model evaluation, as well as useful for visualize the error level compare to others. The Fig. 11 displays the outcome of FDE analysis for a 5-s prediction of a 3-s observed trajectory in terms of both longitudinal and lateral positional error analysis, using the identical experimental conditions as previous; For this circumstance we conduct the FDE analysis only over NGSIM I-80 dataset.

Final displacement error of trajectory prediction
This line graph clearly demonstrates the enhanced performance of our proposed TrajectoFormer system compared to other existing benchmarks.
9 Conclusion
In this paper, we proposed a novel transformer-based trajectory prediction framework by constructing a neighborhood for each target vehicle that considers spatio-temporal dependency between the vehicles. The precise integration of eight-neighbor concepts for each target vehicle is a noteworthy contribution to our research. This neighborhood captures the deep interdependencies that exist between the ego vehicle and its near surroundings and results in a trajectory prediction model that better mimics the dynamics of real-world traffic events. Employing a transformer-based model with positional encoding also enables our model to learn the latent features of the spatio-temporal data, providing better prediction accuracy. The performance evaluation with known state-of-the-art models indicates that neighborhood construction in the preprocessing stage enhanced the prediction accuracy for our proposed model. Our suggested model surpasses most of the benchmarks in terms of RMSE value over a 5-s prediction horizon. It demonstrates our model’s candidacy in the long-term trajectory prediction of autonomous vehicles; with considering neighborhood interactions. Though our model is capable of navigating a collision-less future path for autonomous vehicles, in the future, we want to incorporate a couple of additions to our model. Our future undertakings will focus on creating an advanced collision detection system. Our goal will be to create a reliable system for spotting probable collisions in real time rather than just forecasting collision-less future paths.Different driving circumstances result in a wide range of driving behaviors. Recognizing and adjusting to these actions is an important component of self-driving. Our future work will also focus on expanding the model to account for the multimodality of driving behaviors, providing a more complete picture of on-road events.
Availability of Data and Materials
Data and materials can be available on request by mailing the corresponding author.
References
Staudemeyer, R.C., Morris, E.R.: Understanding lstm—a tutorial into long short-term memory recurrent neural networks (2019). arXiv preprint arXiv:1909.09586
Deo, N., Trivedi, M.M.: Multi-modal trajectory prediction of surrounding vehicles with maneuver based lstms. In: 2018 IEEE Intelligent Vehicles Symposium (IV), pp. 1179–1184. IEEE (2018)
Alahi, A., Goel, K., Ramanathan, V., Robicquet, A., Fei-Fei, L., Savarese, S.: Social lstm: Human trajectory prediction in crowded spaces. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 961–971 (2016)
Canziani, A., Paszke, A., Culurciello, E.: An analysis of deep neural network models for practical applications (2016). arXiv preprint arXiv:1605.07678
Casas, S., Luo, W., Urtasun, R.: Intentnet: learning to predict intention from raw sensor data. In: Conference on Robot Learning, pp. 947–956. PMLR (2018)
Nikhil, N., Tran Morris, B.: Convolutional neural network for trajectory prediction. In: Proceedings of the European Conference on Computer Vision (ECCV) Workshops (2018)
O’Shea, K., Nash, R.: An introduction to convolutional neural networks (2015). arXiv preprint arXiv:1511.08458
Kaplan, D.: An overview of markov chain methods for the study of stage-sequential developmental processes. Dev. Psychol. 44(2), 457 (2008)
Kuefler, A., Morton, J., Wheeler, T., Kochenderfer, M.: Imitating driver behavior with generative adversarial networks. In: 2017 IEEE Intelligent Vehicles Symposium (IV), pp. 204–211. IEEE (2017)
Li, Z., Lin, Y., Gong, C., Wang, X., Liu, Q., Gong, J., Lu, C.: An ensemble learning framework for vehicle trajectory prediction in interactive scenarios. In: 2022 IEEE Intelligent Vehicles Symposium (IV), pp. 51–57. IEEE (2022)
Deo, N., Trivedi, M.M.: Convolutional social pooling for vehicle trajectory prediction. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 1468–1476 (2018)
De Iaco, R., Smith, S.L., Czarnecki, K.: Universally safe swerve maneuvers for autonomous driving. IEEE Open J. Intell. Transp. Syst. 2, 482–494 (2021)
Fortunato, S.: Community detection in graphs. Phys. Rep.-Rev. Sec. Phys. Lett. 486, 75–174 (2010)
Lefèvre, S., Vasquez, D., Laugier, C.: A survey on motion prediction and risk assessment for intelligent vehicles. ROBOMECH J. 1(1), 1–14 (2014)
Cao, H., Song, X., Zhao, S., Bao, S., Huang, Z.: An optimal model-based trajectory following architecture synthesising the lateral adaptive preview strategy and longitudinal velocity planning for highly automated vehicle. Veh. Syst. Dyn. 55(8), 1143–1188 (2017)
Hu, Y., Fu, J., Wen, G.: Safe reinforcement learning for model-reference trajectory tracking of uncertain autonomous vehicles with model-based acceleration. IEEE Trans. Intell. Veh. (2023)
Welch, G., Bishop, G., et al.: An introduction to the Kalman filter (1995)
Hastings, W.K.: Monte carlo sampling methods using markov chains and their applications (1970)
Mihajlovic, V., Petkovic, M.: Dynamic Bayesian networks: a state of the art. University of Twente Document Repository (2001)
Hayes-Roth, F.: Rule-based systems. Commun. ACM 28(9), 921–932 (1985)
Eddy, S.R.: Hidden Markov models. Curr. Opin. Struct. Biol. 6(3), 361–365 (1996)
Leon, F., Gavrilescu, M.: A review of tracking and trajectory prediction methods for autonomous driving. Mathematics 9(6), 660 (2021)
Medsker, L.R., Jain, L.: Recurrent neural networks. Des. Appl. 5(64–67), 2 (2001)
Lee, N., Choi, W., Vernaza, P., Choy, C.B., Torr, P.H., Chandraker, M.: Desire: Distant future prediction in dynamic scenes with interacting agents. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 336–345 (2017)
Kim, B., Kang, C.M., Kim, J., Lee, S.H., Chung, C.C., Choi, J.W.: Probabilistic vehicle trajectory prediction over occupancy grid map via recurrent neural network. In: 2017 IEEE 20Th International Conference on Intelligent Transportation Systems (ITSC), pp. 399–404. IEEE (2017)
Suraj, M., Grimmett, H., Platinskỳ, L., Ondruska, P.: Predicting trajectories of vehicles using large-scale motion priors. In: 2018 IEEE Intelligent Vehicles Symposium (IV), pp. 1639–1644. IEEE (2018)
Deo, N., Rangesh, A., Trivedi, M.M.: How would surround vehicles move? a unified framework for maneuver classification and motion prediction. IEEE Trans. Intell. Veh. 3(2), 129–140 (2018)
Andersson, J.: Predicting vehicle motion and driver intent using deep learning (2018)
Baheri, A.: Safe reinforcement learning with mixture density network, with application to autonomous driving. Res. Control Optim. 6, 100095 (2022)
Xu, Y., Zhao, T., Baker, C., Zhao, Y., Wu, Y.N.: Learning trajectory prediction with continuous inverse optimal control via Langevin sampling of energy-based models (2019). arXiv preprint arXiv:1904.05453
Federal Highway Administration’s (FHWA), U.: Traffic Analysis Tools: Next Generation Simulation—FHWA Operations. https://ops.fhwa.dot.gov/trafficanalysistools/ngsim.htm. Accessed 9 Oct 2023
Kovvali, V.G., Alexiadis, V., Zhang PE, L.: Video-based vehicle trajectory data collection. Technical report (2007)
ITS DataHub: Next Generation Simulation (NGSIM) Open Data. https://datahub.transportation.gov/stories/s/Next-Generation-Simulation-NGSIM-Open-Data/i5zb-xe34/. Accessed 16 Sep 2023
Mo, X., Xing, Y., Lv, C.: Graph and recurrent neural network-based vehicle trajectory prediction for highway driving. In: 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), pp. 1934–1939. IEEE (2021)
Norris, J.R.: Markov Chains. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, Cambridge (1998)
Li, X., Xia, J., Chen, X., Tan, Y., Chen, J.: Sit: a spatial interaction-aware transformer-based model for freeway trajectory prediction. ISPRS Int. J. Geo Inf. 11(2), 79 (2022)
Kazemnejad, A.: Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad’s Blog. https://kazemnejad.com/blog/transformer_architecture_positional_encoding/. Accessed 17 Sep 2023
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Adv. Neural Inf. Process. Syst. 30 (2017)
Tang, C., Salakhutdinov, R.R.: Multiple futures prediction. Adv. Neural Inf. Process. Syst. 32 (2019)
Mozaffari, S., Sormoli, M.A., Koufos, K., Dianati, M.: Multimodal manoeuvre and trajectory prediction for automated driving on highways using transformer networks. IEEE Robot. Automat. Lett. (2023)
Liu, J., Luo, Y., Zhong, Z., Li, K., Huang, H., Xiong, H.: A probabilistic architecture of long-term vehicle trajectory prediction for autonomous driving. Engineering 19, 228–239 (2022)
c3.ai: Root Mean Square Error (RMSE). https://c3.ai/glossary/data-science/root-mean-square-error-rmse/. Accessed 17 Sep 2023
Hou, L., Xin, L., Li, S.E., Cheng, B., Wang, W.: Interactive trajectory prediction of surrounding road users for autonomous driving using structural-lstm network. IEEE Trans. Intell. Transp. Syst. 21(11), 4615–4625 (2019)
Yu, J., Zhou, M., Wang, X., Pu, G., Cheng, C., Chen, B.: A dynamic and static context-aware attention network for trajectory prediction. ISPRS Int. J. Geo Inf. 10(5), 336 (2021)
Funding
No financial support/funding was provided to complete this research work.
Author information
Authors and Affiliations
Contributions
Both FA and KG contributed equally to this work. FA analyzed and interpreted existing benchmarks in this field, did the literature review, defined the problem statement and conducted the data preprocessing stage. KG developed and implemented the TrajectoFormer framework of this study and also performed the result evaluation portions. Both KG and FA took responsibility for writing the manuscript. BS suggested model architecture, supervised this research work, and helped with his valuable guidance and review. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
No conflict of interest.
Ethics approval
The submitted work is original and has not been published elsewhere in any form or language.
Consent to participate
All authors have approved this manuscript and agreed with its submission.
Consent for publication
All authors have agreed with the publication process.
Code availability
Code will be available on request by mailing the corresponding author.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Amin, F., Gharami, K. & Sen, B. TrajectoFormer: Transformer-Based Trajectory Prediction of Autonomous Vehicles with Spatio-temporal Neighborhood Considerations. Int J Comput Intell Syst 17, 87 (2024). https://doi.org/10.1007/s44196-024-00410-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-024-00410-1