
Abstract
The transformation of innovation and entrepreneurship practice teaching and education methods has put forward higher requirements for the intelligence and personalization of online education platforms. The aim of this study is to predict learning outcomes based on students' learning outcomes and habits, identify weak areas of knowledge, and provide targeted guidance and recommend the most suitable teaching resources. According to the concept of LightGBM model and the method of Feature selection, the research puts forward an integrated classification model ELO–LightGBM based on Elo Rating System (ELO) scoring system and Light Gradient Boosting Machine (LightGBM), trying to further mine the potential information of the practical teaching management data set. The model obtained a score of 0.7928 when using the dataset training, and a large number of comparative experiments were carried out between the ELO–LightGBM model and other classification models in different public datasets. The experimental results proved that the ELO–LightGBM model is more accurate than other classification models. In the comparative experiment on the practical teaching data set, the accuracy of the ELO–LightGBM model also surpassed the LightGBM model and the linear support vector machine model that performed well in small data sets, and the model was in the accuracy rate. The accuracy rate of winners in the comparison of micro-average is as high as 82.6%. It can be seen that the ELO–LightGBM model is of great significance to the intelligence and personalization of the online education platform.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Innovation and entrepreneurship practice teaching is a key link to improving the quality of college students' talent training [1]. In recent years, major universities in China are making every effort to develop practical teaching construction for innovative and entrepreneurial students [2]. Under this general environment, many colleges and universities have built innovative and entrepreneurial practice teaching systems that conform to their school conditions, officially launched the construction of practical teaching information platforms, and have collected a large amount of real data on students in practical teaching [3]. Online education is a hot research field in recent years, and the data on online education are varied and large, which is an ideal environment for data mining [4]. As for the potential information in this kind of big data in the field of education, a large number of researchers have begun to carry out data mining research work on it. Usually, in the study of educational data, the main methods used include data mining methods, such as classification, clustering, and association rule mining [5]. In the prediction of academic performance, researchers apply the classification and regression-related algorithms in supervised learning, and the same is true in the prediction of practical teaching performance [6]. The classification algorithms used in this process mainly include decision tree algorithm, neural network, naive Bayesian, support vector machine, generalized linear model and K nearest neighbor algorithm, etc., by dividing students' grades into multiple grade intervals to achieve prediction classification. For example, predicting whether students' grades will pass [7]. Regression predicts continuous data by discovering dependencies between variables or attributes, such as predicting students' GPA scores [8]. Although there are many types of classification algorithms, due to the complexity and diversity of practical application problems, the most widely used classification algorithm is an integrated classification model combined with multiple single classifiers [9]. In recent years, the leader in the field of machine-learning classification problems is the Light Gradient Boosting Machine (LightGBM) algorithm developed by Microsoft. Accurately predicting students' current learning effects is the basis for realizing the intelligence and personalization of online practical education platforms, but previous studies have rarely paid attention to the differences between students [10]. The use of the ELO scoring system can quickly assess the learning level of students, which is suitable for practical teaching with short-course duration and relatively simple evaluation methods. The ELO grading system can also quantify the students' learning foundation well, and update the grading grades according to the students' follow-up answer results. The fluctuation range of the grading grades reflects the students' learning efficiency, so students are treated differently according to their own characteristics [11]. Therefore, the study analyzes the learning data of students in the practical teaching of innovation and entrepreneurship from the characteristics of students' practical learning, so as to achieve more efficient practical teaching of innovation and entrepreneurship.
2 Literature Review
With the development of education informatization and the development of network distance education, various types of data in the field of education have emerged in large quantities, which provides a lot of potential value for education managers. How to find potential high-value information from the huge student data, so as to provide guidance and suggestions to educators and students, and improve the teaching effect of teachers and the learning efficiency of students, has become an important field of current data mining technology research [12]. Ashraf et al. used a variety of classifiers and filtering procedures to achieve the classification and performance prediction of students. The method proposed in the study has made significant progress in predicting student performance, and has also shown superior performance compared with many traditional classifiers [13]. Neural networks are often used in student learning prediction. Pandey et al. proposed a self-attention knowledge tracking model based on the attention mechanism, which maps high-dimensional sparse vectors to low-dimensional compact vectors through word embedding, improving network generalization ability and efficiency, At the same time, the attention mechanism can also make the model focus more on the connection between topics and achieve more accurate predictions [14]. Muchuchuti et al. believe that feature selection on the original features can also improve prediction accuracy. They collected students' grades in business, programming, and other courses, and reduced the number of features from 9 to 4 through feature selection, which increased the prediction accuracy of the random forest model by 5% [15]. Rahman et al. proposed an online evaluation system based on the MK-means clustering algorithm. Experimental results show that the proposed framework effectively extracts useful features, patterns, and rules from problem-solving data, and can be used to provide advice for students’ programming learning [16]. Li et al. proposed a fuzzy C-means clustering algorithm, which uses 2D and 3D clustering to evaluate students, and the final results are based on test scores. The results show that the algorithm can accurately evaluate students, and teachers can better understand students' performance and adjust teaching methods [17].
Similar to the research institute selection model, many researchers have paid attention to the application of gradient boosting machines (Gradient Boosting Machine, GBM), LightGBM and ELO scoring algorithms in teaching data mining. Fernandes et al. proposed a GBM-based classification model to predict the academic performance of students at the end of the school year. The data used in the test came from public schools in the capital of Brazil, and the results showed the impact of grades, absenteeism, community, school, and age on students' academic outcomes [18]. Ng et al. focused on the problem of student dropout in massive open online courses, and proposed an algorithm based on LightGBM and Optuna tuning methods to predict the probability of users dropping out of the course in the next 10 days. The results of the study show that compared with the related algorithms, the proposed algorithm has a better performance in terms of performance [19]. Wen et al. paid attention to the application of data mining technology in children's Chinese character learning. They constructed a dichotomous mathematical problem based on the LightGBM model to classify children's cognitive difficulty with different Chinese characters. The model achieves good prediction results on both training and test datasets. When the predictive model was applied to the test dataset, the accuracy rate was 81.1% and the recall rate was 82.5% [20]. Pankiewicz et al. paid attention to the application of the ELO scoring algorithm in the online learning environment. The research evaluated the performance of the algorithm by comparing it with the correct ratio and learner feedback. The results showed that the performance of the ELO scoring algorithm in educational data mining was better than that of the application performance of this comparison scheme [21]. Pankiewicz et al. focused on the application of the ELO scoring algorithm in the evaluation of online programming courses. This study also used the proportional correct method as a comparison. The results show that the correlation between the ELO rating algorithm and the reference value has reached 0.702 when the sample size is n = 5, and the correlation is 0.905 when the sample size is n = 50. It can be seen that the ELO algorithm is better than the proportional correct method in small sample size [22].
To sum up, the existing research mainly studies the correlation between students' learning behavior, curriculum-related content, and academic performance, and explores the important factors that affect academic performance. According to the different research directions, corresponding improvements are made to the model, and phase effects are achieved. However, there are still some deficiencies; for example, the interpretation of the model is insufficient, it is difficult to point out which behaviors have a greater impact on the prediction results for a specific student, and which behaviors have little impact on the prediction results; the previous studies have rarely paid attention to the differences between students, ignoring the different learning foundations and learning efficiency of students; most of them study the overall behavior of some students, such as the number of course discussions and the number of absenteeism. Considering the above deficiencies, the study proposes the ELO–LightGBM model based on feature selection and an ELO scoring system. By accurately predicting students' learning effects, it lays the foundation for the intelligent education platform to evaluate students' abilities and recommend appropriate learning resources.
3 Efficient Innovation and Entrepreneurship Practice Teaching Data Analysis Model Based on Improved LightGBM Classification Algorithm
3.1 LightGBM Model Concept and Feature Selection Method
Study the use of LightGBM for feature selection, which is a framework based on GBDT. With its performance advantages of high training efficiency, low memory usage, and high accuracy, it quickly surpasses the same type of Gradient Boosting Decision Tree (GBDT) algorithm. At the same time, it has the advantages of supporting parallel and GPU computing and supporting large-scale data. Now, LightGBM and Extreme Gradient Boosting (XGBoost) are the two most widely used GBDT implementations.
The GBDT boosting tree is an integrated algorithm based on the idea of boosting. It usually uses the CART decision tree as the base classifier, trains the base classifier by continuously reducing the residual, and finally weights the base classifier to form a strong classifier. Assume that the training sample is \(D = \left\{ {\left( {x_{1} ,y_{1} } \right),\left( {x_{2} ,y_{2} } \right), \ldots ,\left( {x_{m} ,y_{m} } \right)} \right\}\); a \(T,L,f\left( x \right)\) strong learner representing the maximum number of iterations of the model, the loss function of the model, and the final output of the model. Then, the algorithm steps of GBDT are as follows. Initialize the weak classifier first, which \(c\) is the output value of the classifier. For the mean square error loss \(y\), the average value of the sample data set is set \(c\) to \(L\left( {T,f\left( x \right)} \right)\) represent the loss function of the GBDT algorithm, such as formula (1)
Then, for the number of iterations, calculate \(t = 1,2,3, \ldots ,T\), the negative gradient for each sample, as in Eq. (2). \(i = 1,2,3, \ldots ,m\)
Fit the data set with a decision tree, and get the first \(\left\{ {\left( {x_{i} ,r_{ti} } \right)} \right\}\left( {i = 1,2,3, \ldots ,m} \right)\) tree after training \(t\). Assuming that the tree has \(J\) a leaf node, and the \(J\) set of the leaf node is expressed as \(R_{tj} ,j = 1,2,3, \ldots ,J\). Calculate the optimal fitting value of all leaf nodes, such as formula (3)
In formula (3), it is the optimal fitting value of \(c_{tj}\) the \(j\) th leaf node. If the loss function is the mean square error loss, then its \(c_{tj}\) is \(j\) the average value of all samples of the leaf node. Obtain the \(c_{tj}\) updated strong learner, such as formula (4)
The meaning of the \(R_{tj}\) function is that if the sample is in the set, \(I\left( {x \in R_{tj} } \right)\), the value is 1; otherwise, the value is 0. Finally, the entire strong learner model is obtained, such as formula (5)
Therefore, in fact, the first \(t\) learner fits the first \(t - 1\)-order Taylor expansion of the accumulated loss of the previous learner. Such a function estimate has a certain error. GBDT adopts the gradient descent method to obtain the best model, because every time when building a subtree, all sample points must be traversed to find the optimal segmentation point, which is very time-consuming when faced with large-scale data. LightGBM optimizes GBDT by performing gradient-based unilateral sampling on samples and mutually exclusive feature bundling on features, which greatly improves the training speed and generalization ability of the model. In addition, LightGBM further accelerates the calculation speed through the histogram algorithm, uses leave-wise to generate leaf nodes, cooperates with the maximum depth limit of the tree, reduces errors, and supports parallel optimization to reduce memory usage. Compared with the original GBDT, LightGBM is more suitable for processing large-scale data.
The LightGBM model is an ensemble tree model. Although the Gini coefficient can be used to calculate the feature importance, as long as a certain feature is slightly changed, the importance value and ranking of the remaining features will change accordingly. The feature importance obtained by the LightGBM model is unstable, you can use Shapley Additive exPlanations (SHAP) to ensure that the feature importance of the model is independent of other features and improve the credibility of the model interpretation. The Shapley value of a feature is the difference between the contribution of the original set and the contribution of the new feature. If \(D\), the Shapley value of the feature, is calculated, the existing feature set is \(S\), and \(v\left( S \right)\) is the contribution degree of the existing set, then \(D\) the Shapley value of the feature is formula (6)
The simplest interpretation of a model is the model itself. However, for the integrated model and neural network, the original model cannot be used as an explanation model, so the research needs an explanation model with simpler definition, which is used as an approximate explanation of the original model. SHAP proposes an explanation model for unrelated model categories, additive feature attribution methods. The additive feature contribution mode is defined as a linear function of a two-variable variable, such as formula (7)
In Eq. (7), \(g\) is an explanation model, in which \(M\) is a set of features, and 0 is the mean value of the input data in the predicted value of the model, in which \(i\) represents the Shapley value of the first feature. The \(z^{\prime}_{i}\) value is 0 or 1, which represents whether the feature exists. Therefore, the core part of the interpretation model is to find the Shapley value of the corresponding feature. Since Eq. (6) requires a set of features, all feature combinations except for this feature are required, and then, the Shapley value of the corresponding combination is calculated and weighted and summed, as in Eq. (8)
In formula (8), it \(S\) is the subset of features used in the model, which \(x\) is the vector of the eigenvalues of the samples to be explained, which is the \(p\) number of features, and is \(val\left( S \right)\) the model output value in the case of \(p!\) feature combinations, \(S\) representing \(p\) the number of combinations in the case of features, fixed After a feature j, the remaining number of combinations is \(\left( {p - \left| S \right| - 1} \right)!S!\) species, and the combination of formula (7) and formula (8) is the method of SHAP to calculate the importance of features.
3.2 Construction of Data Analysis Model Based on ELO–LightGBM Classification Algorithm
The machine-learning algorithm lacks the distinction of students' differences. Different students have different learning foundations and learning efficiency in practical courses. The study uses the ELO scoring algorithm to quantify the learning foundation of students, and updates the scores according to the test results of the student stage, and the fluctuation range of the scores. Reflecting the learning efficiency of students, it can predict the evaluation results of students more accurately. The ELO scoring system consists of three main parameters, winning percentage \(P\), scoring \(\theta\), and weighting \(K\). In the calculation of the winning rate, the master does not always beat the players whose level is lower than him, and the master only has a high probability of beating the players whose level is lower than him, so when calculating the winning rate, the normal distribution function can be used to calculate the corresponding winning rate, such as Formula (9)
In formula (9), \(D\) is the score difference between the two sides, in which \(\sigma\) is the stability of strength, and \(e\) is a natural constant. However, using a normal distribution to calculate the winning rate is too complicated, the actual player's performance fluctuation is closer to the logistic distribution (logistic regression), and the winning rate is calculated as formula (10)
There is a baseline value in the calculation of the score, and then, it is updated according to the actual competitive performance of the player. According to formula (10), the player's expected winning rate and the player's victory or defeat in the competition are obtained, and the player's ELO score is updated. The update formula is formula (11)
In formula (11), \(R\) is the outcome of the player, \(R \in \left\{ {0,1} \right\}\), which has only two values of 0 and 1. \(K\) is the weight parameter. It represents the speed of score update. If it is too small, the convergence speed will be slow, and if it is too large, it will cause oscillation. Therefore, it is necessary to select an appropriate \(K\) value according to different situations. In the field of education, the students' answering process can be regarded as a competitive competition. The two sides of the competition correspond to the students and the questions respectively, so as to apply the ELO scoring system and make corresponding adjustments to the formula and parameters. The first is the prediction accuracy rate, which corresponds to the winning rate in the standard ELO system, and the calculation formula is shown in formula (12)
In formula (12), \(\theta_{s}\) represents the student \(s\)'s learning effect score, \(\theta_{d}\) represents the difficulty score of the \(P_{sample}\) topic, and \(d\) is the probability of the student's random guess. For multiple-choice questions, students can randomly guess an option, so it needs to be added on the basis of the original formula \(P_{sample}\). If the question type is non-choice, \(P_{sample}\) is 0. The second is scoring. The student learning effect score \(\theta_{s}\) and the difficulty score of the topic \(\theta_{d}\) correspond to the scores of the two opponents in the standard ELO scoring system \(\theta\). The updated formulas for scoring according to the students' actual answering results are shown in formula (13) and formula (14)
In Eqs. (14) and (15), \(\theta_{s}\) and \(\theta_{d}\) are initial values and are set to 0, \(correct_{sd}\) is the actual answer result \(correct_{sd} \in \left\{ {0,1} \right\}\) of the students \(s\) on the question, and \(d\), \(K_{s}\) and are \(K_{d}\) the weight parameters of the student's learning effect score \(\theta_{s}\) and the difficulty score of the question, respectively. The education field mostly uses variable values \(\theta_{d}\) rather than constant \(K\) values. For new students, a larger \(K\) value is needed to quickly evaluate the student's ability level. As the student's learning accumulates, the \(K\) value should gradually decrease, so that the student's score converges to about his actual ability level. However, the complex dynamic weighting algorithm does not bring significant effect improvement, so the \(K\) value calculation formula used in the study is shown in formula (16)
where \(n\) is the number of answers and \(a,b\) is an optional parameter. It can be seen that when the \(n\) value is large, \(K\) is inversely proportional to the \(n\) number of answers. When the \(n\) value is very large, the value tends to 0, and the score tends to be stable at this time. Compared to question weight \(K_{d}\), student weight \(K_{s}\) remains constant \(k\) after students answer a certain number of questions, ensuring that changes in students' learning outcomes can still be tracked after prolonged learning. The weight calculation formula for students needs to have the characteristics of low change amplitude and low initial value compared to the weight calculation formula for questions. A low degree of weight change ensures that students' impact on ELO scores is not significantly different each time they answer questions. A low initial value prevents the weight change from taking too long, making it difficult for ELO scores to converge. Therefore, the value range of parameter a is (0.2,0.8), the value range of parameter b is (0.01, 0.03), and the value range of parameter k is (0.03,0.05). Assuming there are a total of 393,656 students, 38,000 students with a number of answers above 600, accounting for 10% of the total number. However, for students with a number of answers above 600, the total number of answers is 67.5 million, accounting for 68% of the total number. Therefore, during calculation, the student's rating weight is converted to the lowest weight \(k\). The calculation process of student weight derived from Eq. (16) is shown in Eq. (17)
From Eq. (17), it can be seen that when the number of answers reaches 650, the weight remains constant at 0.04.\(K\), question scores, and \(\theta_{d}\) predict the probability of students answering correctly \(P\) during the student learning process. Adding \(\theta_{s}\) to these three ELO score-related features to the LightGBM model can achieve different treatment for different students and quantify the difficulty of the questions at the same time. The specific calculation process of the ELO score is shown in Fig. 1.

ELO score calculation flow diagram
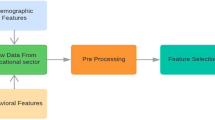
To improve the prediction ability of the model, on the basis of feature extraction and ELO scoring features, the ELO–LightGBM model was subsequently added the time factor to study the influence of learning and forgetting mechanism on the prediction results. The overall structure of the ELO–LightGBM model can be divided into three components, namely feature engineering, feature selection, and hyperparameter optimization, as Fig. 2.

Overall structure of ELO–LightGBM model
As Fig. 2, the feature engineering part sequentially generates ELO scoring features, forgetting curve features, knowledge concept features, and feature extraction to generate new features; the feature selection part calculates the importance of SHAP features based on the pre-training model, and generates a comprehensive ranking with LightGBM feature importance Determine the proportion of feature discarding; the hyperparameter optimization part determines the optimal hyperparameters for the LightGBM model according to the filtered features. The overall structure of ELO–LightGBM model can be divided into three parts, namely, Feature engineering, Feature selection, and super parameter optimization. Among them, Feature engineering refers to generating ELO scoring features, forgetting curve features, knowledge concept features, and feature extraction to generate new features described above. Feature selection refers to the combination of global interpretation and local interpretation feature algorithms to screen out redundant features. Hyperparameter optimization refers to the optimization of leaf node number, maximum tree depth, and learning rate parameters of LightGBM model. Using random search method, N groups of parameters are randomly selected from the parameter range, and a group of super parameters with the best model effect is selected.
4 Analysis of Simulation Experiment Results
The research uses the UCI public data set and EdNet, a large-scale educational data set composed of students' historical behavior records collected by the intelligent education platform Santa, for model training and algorithm comparison experiments. Table 1 is a comparison of Are under Curve (AUC) scores in the three stages of ELO–LightGBM. The final AUC score of ELO–LightGBM is 0.794, which is 0.034 higher than the AUC score of 0.760 of the base model Base-LightGBM model, and the improvement rate reaches 4.4%. Compared to the FE LightGBM model, the AUC score of 0.788 has increased by 0.006, with an increase of 0.76%. In the universal test set, the AUC score of the ELO–LightGBM model was 0.790, which increased by 0.03 and 0.004 compared to the AUC scores of the Base-LightGBM model and the FE LightGBM model of 0.760 and 0.786, respectively, with an increase of 3.9% and 0.5%, respectively. In the hidden test set, the AUC score of the ELO–LightGBM model was 0.791, which increased by 0.031 and 0.014 compared to the AUC scores of the Base-LightGBM model and the FE LightGBM model of 0.760 and 0.777, respectively, with an increase of 4.0% and 1.8%, respectively. Compared with the ordinary LightGBM model prediction, ELO–LightGBM model greatly improves accuracy of online evaluation prediction results.
On the basis of the Base-LightGBM model, add knowledge concept features, feature extraction-related features, forgetting curve features, and ELO scoring features, respectively, train the model with different features, obtain experimental results, and analyze the impact of adding different features on the prediction accuracy of the model. A total of eight groups of experiments were carried out to verify, and the description of the eight groups of realization is shown in Fig. 3. R1: Base-LightGBM model, without adding new features; R2: adding knowledge concept features; R3: adding various new features generated by feature extraction; R4: adding forgetting curve features; R5: adding ELO scoring related features; R6: adding features The new features generated by extraction and ELO score-related features; R7: add new features generated by feature extraction, ELO score-related features, and knowledge concept-related features; R8: use all features, that is, the ELO–LightGBM model. It can be seen that adding any of the four types of features alone can improve the prediction effect of the model. From the AUC scores of R2–R5, it can be seen that adding new features generated by feature extraction has the greatest impact on the model effect, and the AUC score has increased by 0.0225, followed by a feature related to the ELO score, and the AUC score has increased by 0.0084, and the addition of the forgetting curve factor feature and the knowledge concept feature has also brought about different levels of AUC score improvement, which proves the effectiveness of this study. Subsequent experiments in R3, R6, R7, and R8 showed that even if the current model has added a large number of new features after feature extraction, the subsequent addition of knowledge concept features, forgetting curve features, and ELO scoring features can still bring certain improvements, proving that these features the hidden information is not included in the previous features are mined, which proves the effectiveness of the research ideas.

Comparative experimental analysis of ELO–LightGBM model
For data mining, the quality of features significantly affects the quality of learning effects. After a certain screening, a total of 51 features were generated in the feature extraction process. Compared with simply using the original six features, the final improvement effect of the model is very significant. The histogram in Fig. 4 represents the SHAP contribution of features to predicting students’ answers to this question enhancement. After averaging the LightGBM feature importance and SHAP feature importance rankings, the comprehensive ranking of ELO–LightGBM model features is obtained. The experimental results of different screening ratio features are compared in Table 2.

Top 20 SHAP feature importance distribution
Table 2 shows that when the comprehensive screening ratio of feature importance is 15%, the effect of the model is the best. After feature selection, the number of iterations of the model remains roughly the same, the number of features is reduced by 10, the AUC of the model is increased by 0.0009, and the ranking is improved. 21 candidates, proved the effectiveness of the feature selection strategy in this experiment, removed redundant features, and increased the generalization ability of the model. After feature selection, the ELO–LightGBM online evaluation prediction model has improved by 1.49% compared with the historical best record of 0.7811 on this data set, with a score of 0.7951 on the verification set and 0.7918 on the public test set. The score on the test set is 0.7928, ranking 172 among 3395 participants. The ranking is limited by the fact that only one-fourth of the training data is used in the operating environment. If all the training data are used, the ranking will be greatly improved, and the feature importance of the ELO scoring feature elo_pb ranks first, which proves that ELO-the validity and practicability of the LightGBM model in the online assessment link, and the ELO score assessment of students' learning level can better predict the accuracy of students' answering questions.
In addition, the ELO–LightGBM model is cross-tested with SVM, logistic regression, and random forest models to compare the performance of the ELO–LightGBM model with other models. Figure 5 shows the gap values of the four algorithms after the micro-average comparison in the multi-category dataset experiment. In the 12 sets of multi-category data sets, the ELO–LightGBM model has 9 sets of experimental micro-average wins, and the micro-average winning ratio is 75%. In the Glass dataset, the micro-average of ELO LightGBM model achieves the maximum value of 5.1, which is 29.4%, 100%, and 45.1% higher than the micro-average of 3.6, 0, and 2.8 of SVM, Logistic regression, Random forest, and other models, respectively. Overall, it can be seen that the ELO–LightGBM model has better performance compared to other models.

Comparison of the micro-average gap of algorithms for multi-classification datasets
Figure 6 shows the gap values of the four algorithms after the macro-average comparison in the multi-category dataset experiment. In the 12 sets of multi-category data sets, the ELO–LightGBM model has 8 sets of experimental macro-average wins, and the macro-average win rate is 66.7%. The ELO–LightGBM model outperformed the other three groups of models in the comparison of micro-average and macro-average in 8 experiments, and none of the experiments that won was the lowest value. The most obvious comparison is the multi-category dataset balance scale. The balance scale dataset has 625 samples, 3 categories, and 4 features. In the micro-average comparison, the ELO–LightGBM model performed nearly 7% better than the other three models. In the macro-average comparison, it outperformed the other best performers outperformed by nearly 10%.

Comparison of the macro-average gap of algorithms for multi-classification datasets
The research uses the ROC curve to show the performance of the classification model. The light blue curve in Fig. 7 is the ROC curve of the ELO–LightGBM model. From the figure, it can be observed that the ELO–LightGBM curve is closer to the upper left corner, and the value of the AUC area calculated is 0.88 larger compared with other models. To more intuitively observe the performance advantages of the research model in this paper, the ELO LightGBM model in this paper is compared with the performance of classical classification models, such as SVM, Logistic regression, and Random forest. The performance comparison of the four classification models is shown in Table 3. It can be seen from Table 3 that the ELO–LightGBM model studied in this paper has significantly better classification performance than other classification models. The classification accuracy of ELO–LightGBM model is 95.79%, which is 5.33%, 6.38%, and 13.15% higher than SVM, Logistic regression, Random forest, and other models, respectively. The recall rate of ELO LightGBM model is 92.46%, which is 2.82%, 9.12%, and 16.82% higher than that of SVM, Logistic regression, Random forest, and other models, respectively. The F1 value of ELO LightGBM model is 89.64%, which is 3.0%, 6.76%, and 9.92% higher than that of SVM, Logistic regression, Random forest, and other models, respectively. The AUC score of ELO LightGBM model is 79.42%, which is 1.1%, 3.01%, and 3.83% higher than that of SVM, Logistic regression, Random forest, and other models, respectively. Overall, it can be seen that the ELO–LightGBM model in this article has excellent classification performance.

Macro-average ROC curve comparison
5 Conclusion
The intelligence and personalization of the online education platform put forward higher requirements. The intelligent education platform should be able to predict the learning effect according to the learning effect and learning habits of the students, judge the weak points of the students' knowledge, and then provide targeted guidance and recommend the most suitable ones, and education resources. Accurately predicting the current learning effect of students is the basis for realizing the intelligence and personalization of the online education platform. This paper proposes the ELO–LightGBM model, which proves the positive effect of the student learning effect quantification system on prediction and the intelligentization and personalization of the online education platform, played a good role. Compared with the three compared classification models, in the 12 sets of multi-category data sets, the ELO–LightGBM model has 9 sets of micro-average wins, and 8 sets of micro-average and macro-average win simultaneously. In the most obvious set of comparisons, the ELO–LightGBM model performed the best than the other three models, with nearly 7% more micro-average and nearly 10% more macro-average. Combining the comparison of all data sets, the ELO–LightGBM model outperformed in the comparison of accuracy (micro-average) by as high as 82.6%. In the public testing set, the AUC score of the ELO–LightGBM model was 0.790, which increased by 0.03 and 0.004 compared to the AUC scores of the Base-LightGBM model and the FE LightGBM model of 0.760 and 0.786, respectively, with an increase of 3.9% and 0.5%, respectively. In the hidden test set, the AUC score of the ELO–LightGBM model was 0.791, which increased by 0.031 and 0.014 compared to the AUC scores of the Base-LightGBM model and the FE LightGBM model of 0.760 and 0.777, respectively, with an increase of 4.0% and 1.8%, respectively. The classification accuracy of ELO LightGBM model is 95.79%, which is 5.33%, 6.38% and 13.15% higher than that of SVM, Logistic regression, Random Forest, and other models, respectively. However, there is still the possibility of improving the model. For example, setting the corresponding time-scoring formula can quantify the historical learning behavior of students from the perspective of time.
Availability of Data and Materials
The datasets generated during the current study are available from the corresponding author on reasonable request.
Change history
27 March 2024
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s44196-024-00478-9
Abbreviations
- LightGBM:
-
Light gradient boosting machine
- GBDT:
-
Gradient boosting decision tree
- XGBoost:
-
Extreme gradient boosting
- SHAP:
-
Shapley Additive exPlanations
- AUC:
-
Are under curve
References
Zhang, L.: Practical teaching system reform for the cultivation of applied undergraduates in local colleges. Int. J. Emerg. Technol. Learn. (IJET) 16(19), 59–68 (2021). https://doi.org/10.3991/ijet.v16i19.26159
Xiao, J.: Digital transformation in higher education: critiquing the five-year development plans (2016–2020) of 75 Chinese universities. Distance Educ. 40(4), 515–533 (2019). https://doi.org/10.1080/01587919.2019.1680272
Wang, Y., Chen, J., Chen, X., Zeng, X., Kong, Y., Sun, S., Liu, Y.: Short-term load forecasting for industrial customers based on TCN-LightGBM. IEEE Trans. Power Syst. 36(3), 1984–1997 (2020). https://doi.org/10.1109/TPWRS.2020.3028133
Nguyen, G., Dlugolinsky, S., Bobák, M., Tran, V., López García, Á., Heredia, I., Malík, P., Hluchý, L.: Machine learning and deep learning frameworks and libraries for large-scale data mining: a survey. Artif. Intell. Rev. 52(1), 77–124 (2019). https://doi.org/10.1007/s10462-018-09679-z
Shaker, B., Yu, M., Song, J.S., Ahn, S., Ryu, J.Y., Oh, K.S., Na, D.: LightBBB: Computational prediction model of blood–brain-barrier penetration based on LightGBM. Bioinformatics 37(8), 1135–1139 (2021). https://doi.org/10.1093/bioinformatics/btaa918
Huang, A.Y., Lu, O.H., Huang, J.C., Yin, C.J., Yang, S.J.: Predicting students’ academic performance by using educational big data and learning analytics: Evaluation of classification methods and learning logs. Interact. Learn. Environ. 28(2), 206–230 (2020). https://doi.org/10.1080/10494820.2019.1636086
Sutradhar, P., Tarefder, P.K., Prodan, I., Saddi, M.S., Rozario, V.S.: Multi-modal case study on MRI brain tumor detection using support vector machine, random forest, decision tree, K-nearest neighbor, temporal convolution & transfer learning. AIUB J. Sci. Eng. 20(3), 107–117 (2021). https://doi.org/10.53799/ajse.v20i3.175
Saber, M., Boulmaiz, T., Guermoui, M., Abdrabo, K.I., Kantoush, S.A., Sumi, T., Mabrouk, E.: Examining LightGBM and CatBoost models for wadi flash flood susceptibility prediction. Geocarto Int. 37(25), 7462–7487 (2022). https://doi.org/10.1080/10106049.2021.1974959
Zhu, J., Wang, Z., Gong, T., Zeng, S., Li, X., Hu, B., Li, J., Sun, S., Zhang, L.: An improved classification model for depression detection using EEG and eye tracking data. IEEE Trans. Nanobiosci. 19(3), 527–537 (2020). https://doi.org/10.1109/tnb.20017
Vinutha, D.C., Kavyashree, S., Vijay, C.P., Raju, G.T.: Innovative practices in education systems using artificial intelligence for advanced society. New Adv. Soc. 3(16), 351–372 (2022). https://doi.org/10.1002/9781119884392.ch16
Gray, A., Rahat, AA., Crick, T., Lindsay, S., Wallace, D.: Using Elo Rating as a Metric for Comparative Judgement in Educational Assessment. In: 2022 6th International Conference on Education and Multimedia Technology 2022, 7(1):272–278. https://doi.org/10.1145/3551708.3556204
Jones, K.M., Rubel, A., LeClere, E.: A matter of trust: Higher education institutions as information fiduciaries in an age of educational data mining and learning analytics. J. Am. Soc. Inf. Sci. 71(10), 1227–1241 (2020). https://doi.org/10.1002/asi.24327
Ashraf, M., Zaman, M., Ahmed, M.: An intelligent prediction system for educational data mining based on ensemble and filtering approaches. Proc. Comput. Sci. 1(167), 1471–1483 (2020). https://doi.org/10.1016/j.procs.2020.03.358
Pandey, S., Karypis, G.: A self-attentive model for knowledge tracing. In: 12th International Conference on Educational Data Mining, EDM. International Educational Data Mining Society.2019, 1(1):384–389. https://doi.org/10.48550/arXiv.1907.06837
Muchuchuti, S., Narasimhan, L., Sidume, F.: Classification model for student performance amelioration. In: Future of Information and Communication Conference. Springer, Cham. 2020, 1(1):742–755. https://doi.org/10.1007/978-3-030-12388-8_51
Rahman, M.M., Watanobe, Y., Matsumoto, T., Kiran, R.U., Nakamura, K.: Educational data mining to support programming learning using problem-solving data. IEEE Access. 3(10), 26186–26202 (2022). https://doi.org/10.1109/ACCESS.2022.3157288
Li, Y., Gou, J., Fan, Z.: Educational data mining for students’ performance based on fuzzy C-means clustering. J. Eng. 2019(11), 8245–8250 (2019). https://doi.org/10.1049/joe.2019.0938
Fernandes, E., Holanda, M., Victorino, M., Borges, V., Carvalho, R., Van, E.G.: Educational data mining: Predictive analysis of academic performance of public-school students in the capital of Brazil. J. Bus. Res. 1(94), 335–343 (2019). https://doi.org/10.1016/j.jbusres.2018.02.012
Ng, K., Lei, P.: A lightweight method using light GBM model with optuna in MOOCs dropout prediction. In: 2022 6th International Conference on Education and Multimedia Technology 2022 Jul 13 (pp. 53–59). https://doi.org/10.1145/3551708.3551732
Zhang, J., Mucs, D., Norinder, U., Svensson, F.: LightGBM: An effective and scalable algorithm for prediction of chemical toxicity–application to the Tox21 and mutagenicity data sets. J. Chem. Inf. Model. 59(10), 4150–4158 (2019). https://doi.org/10.1021/acs.jcim.9b00633
Pankiewicz, M., Bator, M.: Elo rating algorithm for the purpose of measuring task difficulty in online learning environments. e-mentor. 5(82), 43–51 (2019). https://doi.org/10.15219/em82.1444
Weng, T., Liu, W., Xiao, J.: Supply chain sales forecasting based on lightGBM and LSTM combination model. Ind. Manag. Data Syst. 120(2), 265–279 (2020). https://doi.org/10.1108/IMDS-03-2019-0170
Acknowledgements
None.
Funding
None.
Author information
Authors and Affiliations
Contributions
BBH: writing. CYW: review and editing.
Corresponding author
Ethics declarations
Conflict of Interest
The author declares that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s44196-024-00478-9
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Huang, B., Wang, C. RETRACTED ARTICLE: Research on Data Analysis of Efficient Innovation and Entrepreneurship Practice Teaching Based on LightGBM Classification Algorithm. Int J Comput Intell Syst 16, 145 (2023). https://doi.org/10.1007/s44196-023-00324-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00324-4