
Abstract
The quality of groundwater resources in artisanal mining districts in Ghana is under threat due to pollution; rendering the resource unsafe for drinking and irrigation purposes. This makes the assessment of the quality of groundwater resources a relevant aspect of groundwater studies as it informs decision making and monitoring. This study adopts 3 Machine Learning (ML) models, Support Vector Regression (SVR), Gradient Boost Regression (GBR), and Artificial Neural Network (ANN), to evaluate a variety of irrigation water quality metrics such as Sodium Percentage (Na%), Soluble Sodium Percentage (SSP), Sodium Adsorption Ratio (SAR), Residual Sodium Carbonate (RSC), Permeability Index (PI), Pollution Index of Groundwater (PIG), Kelly’s Ratio (KR), and Magnesium Hazard (MH). 105 samples were collected from a mining area in Northern Ghana and analysed through traditional methods. The Irrigation Water Quality Indices (IWQIs) demonstrate that all water samples are suitable for use as irrigable water with the exception of MH, Na%, PI, and PIG which revealed that 69.52%, 8.57%, 29.52%, and 3.81% are inappropriate for irrigation. SVR, GBR and ANN were used to establish important factors that may influence IWQIs in the area. The measured data was used as independent variables, and the derived IWQIs, the dependent variables. The results revealed that ANN, GBR, and SVR are all viable options for the prediction of IWQIs, but GBR exhibited variable performance in some indices making it lack consistency and thus falls a bit short compared to ANN and SVR. SVR models overall performed best with SVR-RSC having the highest accuracy.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Water is considered a globally critical resource and is therefore exploited for a variety of uses ranging from industrial to domestic [1]. Entire organisms and ecosystems are completely dependent on water [2]. The earth has an abundance of this very important resource, however, only a small fraction is available for human usage. Globally, less than 1% of the finite freshwater that exists on Earth is accessible for human use. While it only makes up about 2.5 to 3.2% of the Earth’s water, most of it is in glaciers and ice caps (68.7%) or is located underground as groundwater (30%). Only a small fraction of the earth’s freshwater resources (0.3%) is easily accessible as rivers, lakes, and marshes [3, 4]. According to [5], continuous availability of groundwater is associated with the preservation of biodiversity during unconducive weather conditions. Among the various activities the earth’s freshwater resources are used for, irrigation accounts for 70% of it [6]. This has increased the stress on groundwater sources and very little time for replenishment of these sources leading to a steady decline in groundwater availability [7]. Approximately, 70% of Ghana's inhabitants rely on groundwater for household endeavours [8]. Groundwater serves as the water supply for 25% of urban dwellers and 90% of rural inhabitants, as reported by [9]. In Ghana, surface water has predominantly been treated and used as irrigable water in the urban areas. However, the rise in illegal mining also known as “galamsey” has led to a rapid depletion of the resources [10,11,12]. Another cause of strain on surface water is the climate-induced dwindling of the rainfall patterns [13, 14]. According to [15], northern Ghana, where the study area is located; is particularly prone to climatic-induced stress on the water resources. The authors posit that the Savannah zone of northern Ghana has been subjected to sustained patterns of regressions in annual rainfall values coupled with an upsurge in temperature over the last century.
Assessing and evaluating the quality of groundwater sources is integral to its conservation efforts. To determine whether a groundwater source is fit for usage, checks need to be conducted to determine its suitability. There are numerous approaches that can be applied. One of the most often accepted strategies includes water quality indices [16, 17]. The Water Quality Indices (WQIs) can determine the level of appropriateness of the water for usage and emphasize potential dangers it may inhabit. This study evaluates the appropriateness of groundwater as irrigable water and therefore considers WQIs related to irrigation. There are a wide range of irrigation water quality indices employed in assessments globally [18,19,20]. Each has its merits and drawbacks and therefore it is imperative to employ indices that prioritise accuracy over anything else.
Machine Learning Algorithms in recent years have been integral in the development of models employed in the classification and prediction of WQI’s [21, 22]. Palani et al. [23] employed Artificial Neural Networks (ANNs) a machine learning model, programmed to mimic how the human brain processes data, analyses it, and identifies relationships that exist within the data in predicting and forecasting of quantitative properties of water bodies. ANNs are efficient in processing and computing information parallelly and can handle high dimensional data. The algorithm can also discover hidden patterns and complex relationships that exist within the data, but more importantly, they are able to learn from their error, putting them in a unique class when it comes to tools employed in research.
For the above stated reasons and more, machine learning methods are taking over the hitherto used multivariate statistics in the characterization of geo-resources occurrences and as well as their future occurrence through accurate and reliable predictions. Regression techniques are also tools that have been used globally by researchers in both classification and forecasting of geo-resource occurrences [24]. Linear Regression (LR), Random Forest regression (RF), Support Vector regression (SVR), Decision Tree Regression (DT) among others have employed in number of studies worldwide. Balogun and Tella [25] used random forest, decision tree, linear and support vector regression in assessing the correlation between climatic variable and ozone concentrations.
The quality of groundwater and mineralization controls in the study area has been recently conducted by [11]. However, the suitability of the groundwater resources within the catchment’s suitability for irrigation purposes is still an enigma. To maximize the usage of this scarce resource, it is important for a study on its suitability for irrigation to conducted so as to guide reliable and accurate decision-making as well monitoring, within the catchment. To this end, multi-method machine learning techniques were adopted in this study together with a number of groundwater irrigation assessment indices. The aim of the study is to evaluate the suitability of the groundwater for irrigations purposes and also to assess the performance of the various applied machine learning methods in the prediction of the indices. This study is relevant to the attainment of the international goals such as the Strategic Development Goals (SDGs); especially SDG 6 (Clean Water and Sanitation) and SDG 2 (Zero Hunger). The continual assessment of groundwater resources closely aligns with the broader global agenda of ensuring access to clean water and promoting sustainable agriculture practices.
2 Materials and methods
2.1 Study area
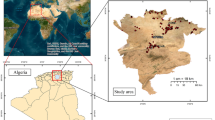
The study area lies within latitudes − 2.52° and − 2.05°, and longitudes 9.72° and 10.02° of Northern Ghana. The area is situated primarily in the Wa East District and Wa West (located in the Upper West region); with the southern part of the area lying within the Sawla-Tuna-Kalba (in the Savannah region) of Ghana. (Fig. 1). According to Salifu et al. [26] and Abu et al. [11], the area is characterised by an arid climate with a singular raining season. Furthermore, the area forms part of northern Ghana’s savannah grassland zone and is characteristically arid for prolonged periods, with a relatively shorter period of precipitation lasting from May to September annually. Aabeyir and Aduah [27] reports an annual rainfall of 1000 mm and average humidity of approximately 90 mm in the area. Similar to other parts of Northern Ghana, the area witnesses temperature fluctuations which change range from 15 °C during the rainy season to upwards of 40 °C during the so-called heat season associated with the peak of the dry season. Generally, the Wa East Area is characterised by undulating hills with a low point of 180 m and a high point of around 1300 m above seas level [28]. The main river which drains the area is the Kulpawn river and its tributaries which traverses the area in a distinct dendritic manner.

Map of the study area
According to the Ghana Statistical Service, the population of the study area is approximately 90,000. Of the employed population, about 88.8% are engaged as skilled agricultural, forestry and fishery workers [29]. The area is very much dominated by small-scale farmers that practice subsistence agriculture such as, farming and livestock farming [30]. The subsistence of the area's population is greatly dependent on irrigation because of the semi-arid climate and low rainfall that make rain-fed farming difficult. The primary aim of irrigation is growing staple crops such as maize, millet, and rice, which are essential for food security in the area [30]. Additionally, irrigation enables the cultivation of cash crops such as the case of vegetables and fruits which then affect the household and local markets. Since agriculture is the main driver of people's livelihoods, access to reliable irrigation water becomes of great significance as it ensures food security and makes crops less susceptible to climatic variations.
The area falls with the western geological province of Ghana which is made up of the Paleoproterozoic Birimian rocks and the closely associated Tarkwaian formation (Fig. 1; [31]). The Birimian in Ghana is constituted by volcanic greenstone belts separated by metasedimentary basins [32]. One of these greenstone belts, the Lawra belt, falls within the area is composed of basalt, andesite as well as some metamorphosed sediments. The Tarkwaian on the hand is made up of sedimentary rocks, including sandstones and conglomerates, as well as metamorphic rocks, particularly phyllite [33]. The geology of the area is similar to the typical greenstone belts of Ghana and contains rocks such as basalts gabbros, metasedimentary units and a variety of granitoids [32, 34].
Typically, groundwater occurrence in the Birimian terrain is controlled by structural discontinuities and the weathered zone, which are in turn determined by the regolith profile [35, 36]. The groundwater in the area are contained within fractured aquifer systems [11, 26]. The degree of weathering in the Birimian varies extensively across Ghana, with eroded profiles recorded at depths between 90 and 120 m in the south where rainfall is substantial [37]. Figure 2 depicts a schematic representation of the hydrostratigraphy in the Birimian, with the respective thicknesses. The hydrogeology of the Wa East area is primarily characterised by secondary permeability which formed within a shallow weathered profile [8]. The structural discontinuities which aid in groundwater localisation and movement were mostly formed by the same geological event responsible for the pathways which localised the gold [34].

(adapted from Carrier et al. [40])
A schematic diagram of the hydrostratigraphy in the Birimian
The Goripie–Bulenga–Choggu–Du watershed of the area is inhabited by a limited number of prominent gold exploration corporations, along with scattered instances of Artisanal and Small-Scale Mining (ASGM) operations. The operation of these mines, particularly the ASGM has been a source of concern due to the level of pollution associated with it [1, 10, 38, 39]. Such activities continue to pose a present danger to both surface and groundwater resources in the area.
2.2 Methodology
2.2.1 Water sample collection and analysis
Water samples were collected during a field study specifically designed to sample from the areas most affected by ASGM activities. During the survey, a total of 105 samples were collected following laid down standards in three separate sampling exercises between November 2021 and January 2022. The collection, storage, and analysis of the water samples adhered to the recommended guidelines set by the American Public Health Association [41]. The altitudes and geographic coordinates of the sampling places were ascertained via the Global Positioning System.
A total of sixteen (16) parameters were analysed for at the Ghana Atomic Energy Commission (GAEC) laboratory. The physical parameters, pH and Electrical Conductivity (EC) were recorded using the WTW 323 model pH meter and EC meter respectively. The calcium (Ca2+), magnesium (Mg2+), and total hardness levels were measured with an Ethylenediaminetetraacetic acid (EDTA) titration. On the other hand, the Potassium (K+) and sodium (Na+), and fluoride (F−) content of the samples were determined with a flame photometric and 2-(parasulfophenylazo)-1,8-dihydroxy-3,6-naphthalene-disulfonate (SPADNS) methods respectively following [42]. The alkalinity and total dissolved Solids (TDS) concentrations of the samples were recorded via by strong acid titration and electronic colorimeter methods. The levels of sulphate (SO42−) was determined with an ultraviolet spectrophotometer. Additionally, the hydrazine reduction, stannous chloride, and azomethine-H methods were employed to assess nitrate (NO3−), and phosphate (PO42−) concentrations [41].
Prior to using the data for subsequent investigation, calculations for Charge Balance Error (CBE) were conducted. According to Hounslow [43], the CBE was calculated using the formula below, resulting in a yield of ± 10% for the parameters which is generally accepted as adequate for groundwater studies [44].
where \(\sum cations\) is the summation of measured cations and \(\sum anions\) is the summation of the measured anions in meq/L and CBE is the charge balance error.
2.2.2 Development of the ML models
The study suggests the use of SVR, RFR, MLR, DTR and ANN models for the assessment and prediction of Irrigation Water Quality (IWQIs). Compared to traditional statistical models, ML models are more flexible, scalable, and more accurate. However, a lot of ML related statistical techniques remain sparse and lack uniformity. There is need to compare and evaluate the performances of several ML models to determine their feasibility for the specific area in which they will be applied [45]. To address this, the study incorporates the use of multiple ML models against multiple IWQIs, rather than one or two of each.
The IWQIs used within the study include SAR, SSP, Na%, MH, KR, RSC. PI and PIG. IWQI combines pH, F, NO3, Cl, SO4, Ca, Mg, TDS, and TH in its determination. PIG uses a combination of NO3, Cl, SO4, HCO3, Na, K, Ca, Mg, TDS, and TH. SSP, SAR and KR combine Na, Mg, and Ca while Na% and PI combine the same 3 elements the addition of K in the case of Na% and HCO3 in PI’s case. MH makes use of only Ca and Mg.
The first step is the data pre-processing phase. The dataset is divided into independent and dependent variables, concentrations of the variables or features are used as input and the indices output. Thus, the values for the IWQIs are shown in Table 1.
2.2.2.1 SAR
According to Sposito and Mattigod [46], Sodium Adsorption Ratio (SAR) is an effective means of determining the sodium levels in water and is regarded as the primary factor to take into account when assessing the viability of an irrigation water source. It is determined using Eq. 2:
where \({\text{Na}}^{ + }\), \({\text{Ca}}^{2 + }\), \({\text{Mg}}^{2 + }\) represent the concentration of sodium, calcium, and magnesium ions respectively in the sample [47].
2.2.2.2 SSP
Soluble Sodium Percentage is a parameter used in the determination of sodium levels in water in the agricultural setting. It was determined using Eq. 3:
where \({\text{Na}}^{ + }\), \({\text{K}}^{ + } ,\) \({\text{Ca}}^{2 + }\), and \({\text{Mg}}^{2 + }\) represent the concentration of sodium, potassium, calcium, and magnesium ions respectively in the sample [48].
2.2.2.3 MH
Magnesium hazard is another parameter employed in the assessment of water quality. Magnesium ions have the ability to disrupt the balance between calcium and magnesium ions, negatively affecting growth of plants making MH an integral tool in determining water viability for agricultural uses [49]. It is calculated using Eq. 4:
where \({\text{Mg}}^{2 + } ,\) \({\text{Ca}}^{2 + }\) represent concentration of magnesium and calcium ions respectively [48].
2.2.2.4 KR
Kelly’s ratio, developed by Kelly [50] and used in the assessment of the negative effects of salt on water quality with respect to irrigation. It calculated by measuring sodium ions against calcium and magnesium ions through Eq. 5:
where \({\text{Na}}^{ + }\), \({\text{Ca}}^{2 + }\), and \({\text{Mg}}^{2 + }\) represent the concentrations of sodium, calcium, and magnesium ions [51].
2.2.2.5 PI
Permeability Index is an integral tool employed in many studies a measure in evaluating how suitable groundwater is for agricultural use [52]. It is calculated using Eq. 6:
where \({\text{Na}}^{ + } ,\) \(\sqrt {{\text{HCO}}_{3}^{ - } }\), \({\text{Ca}}^{2 + }\), and \({\text{Mg}}^{2 + }\) represents the concentrations of sodium, bicarbonate, calcium, and magnesium ions respectively [48].
2.2.2.6 RSC
Residual Sodium Carbonate is as a result of increase in levels of carbonate and bicarbonate beyond the levels of calcium and magnesium [52]. The index is used to determine the alkalinity risk the groundwater presents [53]. It is calculated using Eq. 7:
where \({\text{CO}}_{3}^{2 - } , \;{\text{HCO}}_{3}^{ - }\), \({\text{Ca}}^{2 + }\), and \({\text{Mg}}^{2 + }\) represent the concentration of carbonate, bicarbonate, calcium, and magnesium ions respectively [47].
2.2.2.7 PIG
Pollution index of groundwater is considered an integral tool in the evaluation of the viability of water conveying the overall quality of the water [54]. It is calculated using Eq. 11:
where OW represents the overall water quality, WP represents weight parameter, SC status of concentration, C concentration of the sample, DS drinking water quality standard, and RW relative weight [55].
2.2.2.8 Na%
Sodium percentage is another parameter used in the determination of the level of salinity. It is determined by measuring the concentrations of sodium and potassium against calcium and magnesium [56]. The index is calculated using Eq. 12:
where \({\text{Na}}^{ + } ,\;{\text{Ca}}^{2 + }\), \({\text{Mg}}^{2 + } , \;{\text{and}}\;{\text{K}}^{ + }\) represents sodium, calcium, magnesium, and potassium ions [57].
The variables used in determining the indices are used as input features and the index itself the output or dependent variable. The data was scaled by transforming them to fit within a specific range. This ensures that one or more variables do not dominate the calculations within an algorithm thus improving the accuracy [58]. Two major challenges researchers often face in the development of ML models are overfitting and underfitting. Overfitting occurs when the ML model is unable to generalize thus, unable to accurately predict new data. Several factors could contribute to this some being, limited data, too much noise in the data and the complexity of the dataset [59]. An ML model is classified as underfitted when it is unable to learn the relationships in the data used for its training. To avoid this, the dataset is split into two parts, the training set, and the testing set. 80% of the dataset was used for the training of the models and 20% for testing. A thorough evaluation of the predictive performance of the model cannot be achieved with the same data used for its training, therefore after the training process, the test set (data that the model has not seen before) is used for its evaluation. Regularization a method that penalizes generalization error and cross-validation were employed as well to reduce the possibility of overfitting and improve model accuracy as well [60].
2.2.2.9 ANN architecture
Utilizing nodes, similar to the neurons in the human brain in the analysis and generation of output, artificial neural network (ANN) is a computing system modelled after the human brain. They find utility in many different domains, including research, medicine, engineering, and architecture, where their ability to solve complicated issues is necessary. They can convert data into information that is understandable by humans by extracting noteworthy features from huge databases [61, 62]. The architecture of a neural network plays a crucial role in the network’s ability to decipher the complex relationships that potentially exist with the dataset and extract meaningful information from it. The number of layers, number of nodes, and the general design of the network itself affects its invariance and complexity [63]. To aid in the selection of the right set of hyperparameters for each model, an optimization toolkit was employed. An optimization toolkit is a tool that aids in the selection of the right set of hyperparameters for a neural network. It achieves this by running several iterations of the training of the model changing hyperparameters at each turn until it identifies the model that performed best. After identifying the best model, it takes the hyperparameters used in training it and trains our model with it. Table 1 shows the ANN architecture of the models used in the study.
Table 1 shows the makeup of all ANN models in the study, a total of 8 ANN models were generated for each index used in the study. Each model has 15 input neurons representing the variables from the dataset there is also just one output neuron due to regression being the focus of the study. However, there are differences in the number of neurons in the hidden layers for each model. ANN-KR has 16 neurons in the first hidden layers and 64 in the second. ANN-MH has 64 neurons in the first, and 16 in the second, while ANN-PI has 32 neurons in the first, and 16 in the second. ANN-PIG has 16 neurons in the first hidden layer and 64 in the second just like ANN-KR, ANN-RSC has 64 neurons in the first hidden layer and 32 in the second hidden layer. ANN-SAR also has 16 and 64 neurons in the first and second hidden layers respectively. Finally, ANN-SSP and ANN-Na% 32, 16 and 16, 32 neurons in their first and second hidden layers respectively.
2.2.2.10 Model evaluation
Evaluation metrics are statistical measures employed in the assessment of the performance and effectiveness of a ML model. They give a more holistic understanding of the performance of the model and errors it generated. It also provides a meaningful way to compare different ML models. There are a lot of metrics that could be used in the assessment of ML models; however, it is important to ensure that the appropriate evaluation metric is used [64]. In this study, RMSE, R squared, and MAE were used. Root Mean Square Error (RMSE) measures the average difference that exists between a model’s predicted values and its actual ones. It provides insight about the distribution of prediction errors. Lower RMSE indicate a more suitable model [51]. RMSE is calculated using Eq. 13.
R value or the coefficient of determination measures the ability of the model to replicate observed outcomes. It achieves this by explaining the total variance of outcome the model is able is explain [65]. It is determined using Eq. 14.
Mean Absolute Error measures the average variance that exist between the absolute values in the dataset and the predicted. This calculates the average of the residuals within the dataset. The lower the MAE, the higher the accuracy of the model [65]. The determination of MAE is achieved through Eq. 15.
2.2.2.11 Parameter optimization
In both ML and DL, the output a model produces is dependent on the parameters within the model. Output from models may not be the best they can be due to the fact that these parameters are set to default values. To gain the best results, hyperparameters need to be tuned to optimum values. Proper hyperparameter tuning can result in better accuracy, prevent overfitting and even make the model more robust [66]. In this study, cross validation was employed to ensure the data the model was trained on was balanced, this was achieved through k-fold cross validation [67]. Hyperparameter tuning was achieved through an optimization toolkit. The toolkit runs possible iterations of the models trying out random parameters in each case until it finds a model with the best results. It then obtains the optimum parameters and then trains the model on these parameters [68].
3 Results
3.1 Water quality indices
The results (Table 2) of the analysis show that all water samples are suitable for irrigation in terms of SAR (100% samples classed as “Excellent”), SSP (100% classed as “Good”), RSC (100% classed as “Suitable”) and KR (Fig. 3a; 100% classed as “Suitable”).

Distribution maps of A KR B MH C Na% D PI E PIG
The results of the MH analysis show a range from 17.07 to 95.04 with an average of 56.42. This translates into 30.48% of samples being classed as good while the majority of the samples (69.52%) fall under the unsuitable category. The North (Mengwe) and northeast surrounding Tayiri are characterised as good. The remaining portion of the region contains borehole samples that are categorised as unsuitable for irrigation purposes (Fig. 3b).
Results from the analysis shows a minimum Na% value of 7.93 and a maximum of 99.70, with an average of 37.58. 15% of samples are categorised as excellent, 43.81% as good and 32.38% as permissible. The results further show that 5.71% are poor whiles only 2.86% are classed as unsuitable for irrigational purposes. Both Chasea and Tiza have comparable challenges with their groundwater supplies for irrigation due to high sodium content. These sites have samples which are classified as unsuitable and of poor quality. The centre region of the area has groundwater sources that are classified as having excellent quality for irrigation purposes (Fig. 3c). The overwhelming majority of samples (91.19%) show the groundwater sources were suitable as irrigable water as per the Na% index.
The continual use of irrigable water has an accumulative impact on soil permeability. Therefore, quantifying PI serves as an important metric for evaluating irrigation water quality. This index is controlled by HCO3, Ca2+, Mg2+ and Na+. The results show an average of 68.31, the majority of the samples (69.62%) fall under the “good” category with only 29.52% and 2.86% falling under the “moderate” and “poor” categories respectively. The areas surrounding Chasea are characterised by poor to moderate groundwater resources. Similarly, the northern portion of the region, including Kunfabiala, Siroo, Kparesaga, and Ga, has moderate groundwater quality (Fig. 3d).
The pollution index of groundwater (PIG) for samples similarly paints a favourable picture for the use of groundwater from the area for irrigational purposes. The values for PIG fall between 0.20 and 2.26 with an average of 0.47. The majority of the sample (96.19%) show insignificant pollution while only 4 sample points in general are classed from low pollution to high pollution (1 sample). Only Mengwe in the northern part of the area has groundwater samples identified as having moderate to high pollution (Fig. 3e).
3.2 Correlation matrix analysis
The correlation analysis was undertaken to evaluate the correlations between the dependent variables which are the water quality indices and the independent variables (Total Hardness, Alk, TDS, Mg, Ca, K, Na, HCO3, CO3, SO4, Cl, NO3, F and pH) and also among independent variables, as shown in Fig. 4.

Inter-correlation matrix of the selected water quality variables and the independent variables
pH only shows a positive correlation with CO3 and MH. Cl and SO4 are both positively correlated with each other and with NO3. F does not show a strong positive correlation with any of the other parameters. NO3 shows a positive correlation with TDS, Mg, Ca, SO4 and Cl. SAR on the other hand is only positively correlated with KR. PI is only positively correlated with dependent variables of KR, Na%, RSC and SSP. It however shows a significant negative correlation (− 0.69) with PIG.
A total of 24 models were developed for the study, 8 each for ANN, GBR, and SVR. Table 3 shows the result for each model after testing which include the coefficient of determination (R square), root mean square error (RMSE), and mean absolute error (MAE). The results indicate that all models were able to predict the indices with high level of accuracy. SVR-RSC produced the highest R square with a score of 0.99, an RMSE of 0.09, and MAE of 0.07. GBR-RSC reported the lowest R square with a score of 0.60, RMSE of 0.60, and MAE of 0.32. Overall, models from SVR produced higher R square scores with 6 out of the 8 models reporting R squares above 0.90. SVR models produced low RMSE and MAE when compared to ANN and GBR. This indicates that SVR is a better predictor compared to ANN and GBR. Models from ANN produced better R square scores with 4 out of 8 models with R squares above 0.90. ANN overall had similar RMSE and MAE values as GBR indicating that ANN is a better predictor when compared to GBR.
A comparison between the actual and predicted values of all models is presented in Figs. 5, 6, 7, and 8. Figures 5a–f, 6a, b depict that of ANN models for the indices KR, MH, Na%, PI, PIG, RSC, SAR, and SSP respectively. Figures 6c–f, 7a–d show that of GBR models and Figs. 7e, f, 8a–f SVR models all in the same order. Expectedly the results from Figs. 5, 6, 7, and 8 mirror the results from Table 3. Data points from SVR models are closest to the regression line, indicating a high accuracy in prediction, validating the high R square score from the SVR models. Data points from GBR-RSC are sparsely arranged on the chart with many data points far away from the regression line, indicating a lower accuracy when compared to other models and this supports results from Table 3 as well, GBR-RSC produced the lowest R square score.

A scatterplot comparing the actual or observed values against the predicted in the testing set for ANN models a KR, b MH, c Na%, d PI, e PIG, and f RSC

A scatterplot comparing the actual or observed values against the predicted in the testing set for ANN models a SAR and b SSP and c GBR models KR, d MH, e Na%, and f PI

A scatterplot comparing the actual or observed values against the predicted in the testing set for GBR models a PIG, b RSC, c SAR, and d SSP and SVR models e KR and f MH

A scatterplot comparing the actual or observed values against the predicted in the testing set for SVR models a Na%, b PI, c RSC, d PIG, e SAR, and f SSP
Figures 9, 10, 11, and 12 provide integral information regarding the training and testing process. It depicts the prediction trends of both the training and testing phases and the errors generated during each process. The trends of ANN models are shown in Figs. 9a–f, 10a, b, that of GBR Figs. 10c–f, 11a–d, and SVR Figs. 11e, f, 12a–f. The results indicate no major deviation in the trends between the training and testing sets of all models and this suggests that the likelihood of overfitting occurring is quite low. Results from Figs. 10c–f, 11a–d also indicates that GBR produced the most errors during its testing phase, this can be observed through the differences in errors generated in the training phase when compared to the errors produced in the testing phase. This correlates with the results from Table 3, errors negatively impact the accuracy of the model thereby reducing R square score.

A validation curve comparing the errors generated in the training set against errors generated in the testing set for ANN models a KR, b MH, c Na%, d PI, e PIG, and f RSC

A validation curve comparing the errors generated in the training set against errors generated in the testing set for ANN models a SAR and b SSP and GBR models c KR, d MH, e Na%, and f PI

A validation curve comparing the errors generated in the training set against errors generated in the testing set for GBR models a PIG, b RSC, c SAR, and d SSP and SVR models e KR and f Na%

A validation curve comparing the errors generated in the training set against errors generated in the testing set for SVR models a MH, b PI, c PIG, d RSC, e SAR, and f SSP
Figures 13, 14, and 15 provide a platform for understanding individual predictions made by each model, and which variables contribute most to the model output and whether the impact is positive or negative. Results from Fig. 13a depict sodium as the main contributor to ANN-KR’s output. The intensity suggests sodium affects the model’s output positively. Figure 13b shows calcium as the primary contributor with negative intensity, Fig. 13c shows sodium as the primary contributor as well, similar to Fig. 13a. ANN-PI from Fig. 13d has magnesium as its primary contributor whiles ANN-PIG, Fig. 13e, has nitrate as its own. Examination of the rest of the results outlines sodium as the primary driver in relation to model output for 50% of the models considered in the study.

SHAP summary plot indicating feature importance and intensity for ANN models a KR, b MH, c Na%, d PI, e PIG and f RSC

SHAP summary plot indicating feature importance and intensity for a SVR-MH and b GBR-MH

SHAP summary plot indicating feature importance and intensity for a GBR-PI, b SVR-PI, c GBR-PIG, d SVR-PIG, e GBR-RSC, f SVR-RSC
4 Discussions
The application of diverse indices to evaluate groundwater suitability for irrigation purposes leads to policymakers having more comprehensive information than they would if they only relied upon individual chemical indices. SAR, RSC, and KR indices used in the Water Quality Indices analysis show that the water samples were good enough for irrigation in most cases. On the other side, the MH index shows that more than two-thirds of the samples (69.52%) is considered “Unsuitable” and could involve soil quality outcomes from high Mg2+ concentration as well. The strong correlation between Mg2+ with NO3, SO4, Cl, HCO3 and Ca, suggests a combined influence of geogenic and anthropogenic controls. NO3, SO4 and Cl are known pollution markers [69] which could emanate from the farm inputs used by the farmers in the area, while HCO3 and Ca may come from rock weathering or interaction with the groundwater [1, 11]. Sodium (Na%) analysis mostly indicates that they are suitable for irrigation but sites like Chasea and Tiza may face some challenges due to high sodium content reflecting localized soil permeability issues. These results are similar to findings by [1, 70] who found the majority of the groundwater sources to fall within good to permissible categories in groundwater in the Birimian and Granitoids of southwestern, Ghana. This is considered good since high Na% deflocculates and impairs soil permeability [71]. However, according to Singh et al. [72] the high Na+ found in some water sources may be due to inorganic fertilizer application and the dissolving of minerals from the underlying geology.
The Permeability Index (PI) that is controlled by HCO3, Ca2+, Mg2+, and Na+ values, generally shows that the majority is in a moderate to poor condition, except for a few places including Chasea and northern part of the area. The Pollution Index of Groundwater (PIG) indicates that groundwater quality in the study area is generally good for irrigation. The moderate to high pollution levels identified at Mengwe in the north of the study area, suggests an impact of the high level of illegal mining, which is characteristic of the area. This coupled with agricultural activities may be contributing to the deteriorating quality of irrigable water in the area.
Employing the use of 3 different ML models, ANN, GBR, and SVR, the study sought to ascertain whether IWQIs could be predicted using samples collected from the field. The performance of the model was determined using coefficient of determination (R2), root mean square (RMSE), and mean absolute error (MAE). The results from the study suggest strong predictive abilities by ANN, GBR, and SVR. This conclusion is drawn based on the overall performance of all models which is found acceptable based on the high coefficient of determination [73].
Comparing the performances of ANN models only, results show ANN-SAR as the best performing model due its high R2 of 0.96 and low RMSE and MAE of 0.07 and 0.05. The lowest performing models within ANN were ANN-MH and ANN-PIG with an R2 of 0.72 for both, RMSE of 5.71, and MAE of 4.36 for MH and RMSE of 0.06 and MAE of 0.04 for PIG, making ANN-MH overall the worst performing model in the group.
Results from GBR reveal GBR-SAR and GBR-PIG as the best performing models with high R2 of 0.91 each and RMSE and MAE of 0.10, 0.07 and 0.04, 0.02 respectively, making ANN-PIG overall the best performing model in the group. GBR-PI produced an R2 of 0.90 and RMSE and MAE of 5.40, 3.74 respectively. GBR-SSP had an R2 of 0.87 with RMSE of 2.78 and MAE of 1.83 while GBR-MH produced an R2 of 0.86, RMSE of 4.14, and MAE of 2.91. Both GBR-KR and GBR-Na% produced 0.85 R2 and for RMSE and MAE, 0.07 and 0.05 for KR, and 6.46 and 4.72 for Na%. GBR-RSC exhibited relatively low R2 value compared to the rest of the models with a value of 0.60, RMSE of 0.06 and MAE of 0.32.
SVR-RSC demonstrated excellent performance R2 of 0.99, RMSE of 0.09, and MAE of 0.07. SVR-SSP, R2 of 0.98, RMSE of 1.42, and MAE of 1.13, SVR-PIG, R2 of 0.98, RMSE of 0.04, and MAE of 0.03, SVR-SAR, R2 of 0.97, RMSE of 0.06, and MAE of 0.05, SVR-PI with R2 of 0.97, RMSE of 2.80, and MAE of 2.0, and SVR-MH, R2 of 0.95, RMSE of 2.41, and MAE of 1.94. In the lower end of the SVR models were SVR-KR and SVR-Na%. SVR-Na% had R2 of 0.89, RMSE of 5.60, and MAE of 3.90 while SVR-KR had an R2 of 0.86 with RMSE 0.06 and MAE 0.06 making SVR-KR the worst performing model.
The key observations made from the study with regard to model performance are that SVR models generally outperformed ANN and GBR and had 6 out 8 models performing high with R2 of at least 0.95. This finding closely mirrors the findings from [74, 75] where SVR was also found to have outperformed other models used in their studies indicating a consistency with previous publications. GBR models performed variably with good performances in indices like SAR, PIG, and PI but average in the others, and even bad in the case of RSC therefore lacking consistency as compared to ANN and SVR. Another key observation was ANN, GBR, and SVR all exhibited high predictive performance for the index SAR with R2 of 0.96, 0.91, and 0.97 respectively. This highlights SAR as a consistently high performing index across different predictive techniques, this finding is consistent with results from Mokhtar et al. [76] and Bilali and Taleb [77].
The importance of a predictive variable in terms of model output and its intensity was determined using the SHAP summary plot. Findings indicate sodium as the driving influence with respect to 50% of the models generated in the study. The relationship between sodium and model output was determined to be positive. The means that an increase in sodium would mean an increase in model output and a decrease in sodium would mean a decrease in model output. This highlights the importance of sodium in the evaluation of the quality of water for irrigation purposes. Calcium is outlined as the most important feature in models applied on MH reflecting its importance in the model output of ANN-MH, GBR-MH, and SVR-MH but calcium was found to be negatively correlated with model output per Figs. 13b, 14a, b. This means that a decrease in calcium would cause an increase in model output and an increase in calcium would mean a decrease in model output. The results also show magnesium as the major contributor to all models involving PI, ANN-PI, GBR-PI, and SVR-PI. The relationship observed here is also negative, indicating that an increase in magnesium would spell a decrease in model output and vice versa. 2 models namely ANN-PIG and SVR-PIG had nitrate as the main driver, but GBR-PIG had TDS as its first and nitrate as the second making GBR-PIG a standalone result. The relationship observed in all 3 cases though was positive. A similar finding is observed in the case of models involving RSC where ANN-RSC and SVR-RSC both had magnesium as the main contributor to model output, but GBR-RSC had nitrate as its primary contributor to model output and magnesium placing second. The relationship observed in all 3 cases though was negative.
The study outlines SVR and ANN as a highly effective tool for predicting IWQIs, offering really accurate and reliable predictions across a wide range of IWQIs. This opens its potential as a highly effective method for water quality assessment concerning irrigation. GBR, though effective isolating its results pales in comparison to ANN and SVR and therefore may need some form of optimization to reach the performance levels of ANN and SVR and through the SHAP summary plot sodium, calcium, and magnesium are identified as the primary drivers for the prediction of IWQIs.
5 Conclusion and recommendations
In conclusion, the irrigation water quality indices show that all the water samples are fit for use as irrigable water as per SAR, SSP, RSC and KP. However, MH, Na%, PI and PIG showed that 69.52%, 8.57%, 29.52% and 3.81% are unsuitable as irrigable water. It is noteworthy that samples from Chasea and Tiza have been classed as unsuitable for use as irrigation water as per Na% and PI. This suggests a particularly significant influence of anthropogenic factors on the water in the area. These areas must therefore be monitored closely to ensure that there is no irreparable damage done to the groundwater sources available there.
This study illustrates the application of multi-method machine learning models in estimating groundwater suitability for irrigation purposes. The results lay the groundwork for the selection of suitable models based on the needs of the application and the features of the dataset, which will ultimately help policymakers and managers of water resources make well-informed decisions for efficient management of water quality. This is demonstrated by the designation of water quality indices on areas like Chasea and Tiza which clearly represent poor water quality. The findings show that policies should be formulated in order to reduce anthropogenic impacts especially from illegal mining and agricultural practices in certain parts of the area, to secure the area’s groundwater supply, promote sustainable water usage, and guarantee long-term water safety for the agricultural sector.
Policy makers and workers in the agricultural sector in the area can also gain from the knowledge of the suitability of groundwater for irrigation to make more informed decisions regarding the selection of agricultural crops to grow and soil types to cultivate on. Based on the analysis of several indices most groundwater samples are satisfactory for irrigation purposes but there are parts of the area which can be marked as contaminated and further study and control measures are needed due to human activities. This study demonstrates that machine learning models can provide good predictions of water quality indices and can be further used as a tool for future research or direct application for water quality management. The direct way the human activities affect groundwater quality in some parts of the area necessitates the need to address these particular activities in order to help in conserving this resource.
5.1 Study limitations
It is imperative to recognize the limits of the research, such as the dependence on past data and the presumption of stationarity in the metrics pertaining to water quality. Subsequent investigations may examine the integration of data in real-time and tackle the obstacles posed by dynamic environmental circumstances. Predictive accuracy may also be improved by more research into ensemble approaches and hybrid models that combine the advantages of many algorithms. Elimination of as many outliers as possible and improvement in the quality of data may also provide more insight into how they can affect the accuracy of models.
Data availability
Data supporting this study will be made available upon request from the corresponding author. Contact us via rkazapoe@yahoo.com.
References
Kazapoe RW, Addai MO, Amuah EEY, Dankwa P. Characterization of groundwater in southwest Ghana: implications for sustainable agriculture and safe water supply in a mining-dominated zone. Environ Sustain Indic. 2024;22: 100341.
Dargaville BL, Hutmacher DW. Water as the often neglected medium at the interface between materials and biology. Nat Commun. 2022;13:4222. https://doi.org/10.1038/s41467-022-31889-x.
National Geographic Society. Earth’s fresh water. National Geographic Education. https://education.nationalgeographic.org/resource/earths-fresh-water/. Accessed 18 May 2024.
UNESCO World Water Assessment Programme. United Nations world water development report 2024: water for prosperity and peace. United Nations Educational, Scientific and Cultural Organization. 2024. https://www.unesco.org/reports/wwdr/en/2024/s.
Glanville K, Sheldon F, Butler D, Capon S. Effects and significance of groundwater for vegetation: a systematic review. Sci Total Environ. 2023;875: 162577.
Burke JJ. Groundwater for irrigation: productivity gains and the need to manage hydro-environmental risk. In: Intensive use of groundwater challenges and opportunities. Lisse: A.A. Balkema; 2002. p. 478.
Bera B, Shit PK, Sengupta N, et al. Steady declining trend of groundwater table and severe water crisis in unconfined hard rock aquifers in extended part of Chota Nagpur Plateau, India. Appl Water Sci. 2022;12:31. https://doi.org/10.1007/s13201-021-01550-x.
Akurugu BA, Chegbeleh LP, Yidana SM. Characterisation of groundwater flow and recharge in crystalline basement rocks in the Talensi district, northern Ghana. J Afr Earth Sc. 2020;161: 103665.
Amuah EEY, Boadu JA, Nandomah S. Emerging issues and approaches to protecting and sustaining surface and groundwater resources: emphasis on Ghana. Groundw Sustain Dev. 2022;16: 100705.
Kazapoe RW, Amuah EEY, Abdiwali SA, Dankwa P, Nang DB, Kazapoe JP, Kpiebaya P. Relationship between small-scale gold mining activities and water use in Ghana: a review of policy documents aimed at protecting water bodies in mining communities. Environ Chall. 2023;12: 100727.
Abu M, Zango MS, Kazapoe RW. Controls of groundwater mineralization assessment in a mining catchment in the Upper West Region, Ghana: insights from hydrochemistry, pollution indices of groundwater, and multivariate statistics. Innov Green Dev. 2023;3(1): 100099.
Abanyie SK, Apea OB, Abagale SA, Amuah EEY, Sunkari ED. Sources and factors influencing groundwater quality and associated health implications: a review. Emerg Contam. 2023;9: 100207.
Owusu K, Waylen P, Qiu Y. Changing rainfall inputs in the Volta basin: implications for water sharing in Ghana. GeoJournal. 2008;71:201–10.
Opoku-Ankomah Y, Amisigo BA. Rainfall and runoff variability in the southwestern river system of Ghana. Wallingford: IAHS Publication; 1998. p. 307–14.
Abbam T, Johnson FA, Dash J, Padmadas SS. Spatiotemporal variations in rainfall and temperature in Ghana over the twentieth century, 1900–2014. Earth Space Sci. 2018;5(4):120–32.
Ahirvar BP, Das P, Srivastava V, Kumar M. Perspectives of heavy metal pollution indices for soil, sediment, and water pollution evaluation: an insight. Total Environ Res Themes. 2023;6: 100039.
Uddin MG, Nash S, Olbert AI. A review of water quality index models and their use for assessing surface water quality. Ecol Ind. 2021;122: 107218.
Egbueri JC, Mgbenu CN, Digwo DC, Nnyigide CS. A multi-criteria water quality evaluation for human consumption, irrigation and industrial purposes in Umunya area, southeastern Nigeria. Int J Environ Anal Chem. 2023;103(14):3351–75.
Patel PS, Pandya DM, Shah M. A systematic and comparative study of Water Quality Index (WQI) for groundwater quality analysis and assessment. Environ Sci Pollut Res. 2023;30(19):54303–23.
Poonam T, Tanushree B, Sukalyan C. Water quality indices-important tools for water quality assessment: a review. Int J Adv Chem. 2013;1(1):15–28.
Kouadri S, Elbeltagi A, Islam ARMT, Kateb S. Performance of machine learning methods in predicting water quality index based on irregular data set: application on Illizi region (Algerian southeast). Appl Water Sci. 2021;11(12):190.
Abu M, Musah R, Zango MS. A combination of multivariate statistics and machine learning techniques in groundwater characterization and quality forecasting. Geosyst Geoenviron. 2024. https://doi.org/10.1016/j.geogeo.2024.100261.
Palani S, Liong S-Y, Tkalich P. An ANN application for water quality forecasting. Mar Pollut Bull. 2008;56(9):1586–97. https://doi.org/10.1016/j.marpolbul.2008.05.021.
Abu M, Mvile BN, Kalimenze JD. Provenance studies of Au-bearing stream sediments and performance assessment of machine learning-based models: insight from whole-rock geochemistry central Tanzania, East Africa. Environ Earth Sci. 2024;1:1. https://doi.org/10.1007/s12665-024-11419-2.
Balogun AL, Tella A. Modelling and investigating the impacts of climatic variables on ozone concentration in Malaysia using correlation analysis with random forest, decision tree regression, linear regression, and support vector regression. Chemosphere. 2022;299: 134250.
Salifu M, Aidoo F, Hayford MS, Adomako D, Asare E. Evaluating the suitability of groundwater for irrigational purposes in some selected districts of the Upper West region of Ghana. Appl Water Sci. 2017;7:653–62.
Aabeyir R, Aduah MS. Land cover dynamics in Wa Municipality, Upper West Region of Ghana. 2012.
Dickson B, Benneh G. A new geography of Ghana. revised. Harlow: Longman Group UK Ltd; 1995.
African Centre for Parliamentary Affairs (ACEPA). Wa East constituency profile. 2023. https://acepa-africa.org/wp-content/uploads/2023/06/Wa-East-Constituency-Profile.pdf.
Ministry of Food and Agriculture. Wa East district. https://mofa.gov.gh/site/directorates/district-directorates/upper-west-region/290-wa-east.
Kazapoe RW. A review of the characteristics and geological settings of orogenic gold deposits of the Boule Mossi Domain: implication for gold exploration. Geol Ecol Landsc. 2023. https://doi.org/10.1080/24749508.2023.2256553.
Kesse GO. The mineral and rock resources of Ghana. Rotterdam: AA Balkema; 1985.
Smith AJ, Henry G, Frost-Killian S. A review of the Birimian supergroup-and Tarkwaian group-hosted gold deposits of Ghana. Episodes J Int Geosci. 2016;39(2):177–97.
Amponsah PO, Salvi S, Béziat D, Baratoux L, Siebenaller L, Nude PM, Nyarko RS, Jessell MW. The Bepkong gold deposit, northwestern Ghana. Ore Geol Rev. 2016;78:718–23.
Faye MD, Kafando MB, Sawadogo B, Panga R, Ouédraogo S, Yacouba H. Groundwater characteristics and quality in the cascades region of Burkina Faso. Resources. 2022;11(7):61.
Sako A, Bamba O, Gordio A. Hydrogeochemical processes controlling groundwater quality around Bomboré gold mineralized zone, Central Burkina Faso. J Geochem Explor. 2016;170:58–71 (replace Bombore et al., 2016).
Banoeng-Yakubo B, Yidana SM, Nti E. An evaluation of the genesis and suitability of groundwater for irrigation in the Volta Region, Ghana. Environ Geol. 2009;57:1005–10.
Hilson G, Hilson CJ, Pardie S. Improving awareness of mercury pollution in small-scale gold mining communities: challenges and ways forward in rural Ghana. Environ Res. 2007;103(2):275–87.
Yevugah LL, Darko G, Bak J. Does mercury emission from small-scale gold mining cause widespread soil pollution in Ghana? Environ Pollut. 2021;284: 116945.
Carrier MA, Boyaud C, Lefebvre R, Asare E. Hydrogeological assessment project of the Northern Regions of Ghana (HAP): final technical report: hydrogeological assessment of the Northern Regions of Ghana. 2011.
APHA. Standard methods for the examination of water and wastewater. 2nd ed. Washington: WEF; 1998. p. 1378.
Kumar S, Prasad S, Yadav KK, Shrivastava M, Gupta N, Nagar S, Bach QV, Kamyab H, Khan SA, Yadav S, Malav LC. Hazardous heavy metals contamination of vegetables and food chain: role of sustainable remediation approaches—a review. Environ Res. 2019;179: 108792.
Hounslow A. Water quality data: analysis and interpretation. Boca Raton: CRC Press; 1995.
Niazi A, Bentley LR, Hayashi M. Estimation of spatial distribution of groundwater recharge from stream baseflow and groundwater chloride. J Hydrol. 2017;546:380–92.
Rajula HSR, Verlato G, Manchia M, Antonucci N, Fanos V. Comparison of conventional statistical methods with machine learning in medicine: diagnosis, drug development, and treatment. Medicina. 2020;56(9):455.
Sposito G, Mattigod SV. On the chemical foundation of the sodium adsorption ratio. Soil Sci Soc Am J. 1977;41(2):323–9.
Zaman M, Shahid SA, Heng L, Zaman M, Shahid SA, Heng L. Irrigation water quality. In: Guideline for salinity assessment, mitigation and adaptation using nuclear and related techniques. Cham: Springer; 2018. p. 113–31.
Singh KK, Tewari G, Kumar S. Evaluation of groundwater quality for suitability of irrigation purposes: a case study in the Udham Singh Nagar, Uttarakhand. J Chem. 2020;2020:1–15.
Kelley WP. Permissible composition and concentration of irrigation water. In: Proceedings of the American society of civil engineers, vol. 66. 1940. p. 607–13.
Kelley WP. Use of saline irrigation water. Soil Sci. 1963;95(6):385–91.
Dimple D, Rajput J, Al-Ansari N, Elbeltagi A. Predicting irrigation water quality indices based on data-driven algorithms: case study in semiarid environment. J Chem. 2022. https://doi.org/10.1155/2022/4488446.
Chakraborty M, Tejankar A, Coppola G, Chakraborty S. Assessment of groundwater quality using statistical methods: a case study. Arab J Geosci. 2022;15(12):1136.
Gautam VK, Pande CB, Moharir KN, Varade AM, Rane NL, Egbueri JC, Alshehri F. Prediction of sodium hazard of irrigation purpose using artificial neural network modelling. Sustainability. 2023;15(9):7593.
Sunitha V, Reddy BM. Geochemical characterization, deciphering groundwater quality using pollution index of groundwater (PIG), water quality index (WQI) and geographical information system (GIS) in hard rock aquifer, South India. Appl Water Sci. 2022;12(3):41.
Subba Rao N. PIG: a numerical index for dissemination of groundwater contamination zones. Hydrol Process. 2012;26(22):3344–50.
Amwele HR, Kgabi NA, Kandjibi LI. Sustainability of groundwater for irrigation purposes in semi-arid parts of Namibia. Front Water. 2021;3: 767496.
DeSutter T, Franzen D, He Y, Wick A, Lee J, Deutsch B, Clay D. Relating sodium percentage to sodium adsorption ratio and its utility in the northern Great Plains. Soil Sci Soc Am J. 2015;79(4):1261–4.
Ahsan MM, Mahmud MP, Saha PK, Gupta KD, Siddique Z. Effect of data scaling methods on machine learning algorithms and model performance. Technologies. 2021;9(3):52.
Ying X. An overview of overfitting and its solutions. In: Journal of physics: conference series, vol. 1168. IOP Publishing; 2019. p. 022022.
Tufail S, Riggs H, Tariq M, Sarwat AI. Advancements and challenges in machine learning: a comprehensive review of models, libraries, applications, and algorithms. Electronics. 2023;12(8):1789.
del Campo M, Manninger S. Architecture design in the age of artificial intelligence: the latent ontology of architectural features. In: The Routledge companion to ecological design thinking. London: Routledge; 2022. p. 75–91.
Arbib M, Banasiak M, Villegas-Solís LO. Systems of systems: architectural atmosphere, neuromorphic architecture, and the well-being of humans and ecospheres. In: The Routledge companion to ecological design thinking. London: Routledge; 2022. p. 64–74.
Kim D, Kim Y. Understanding effects of architecture design to invariance and complexity in deep neural networks. IEEE Access. 2021;9:9670–81.
Akshay A, Abedi M, Shekarchizadeh N, Burkhard FC, Katoch M, Bigger-Allen A, Adam RM, Monastyrskaya K, Gheinani AH. MLcps: machine learning cumulative performance score for classification problems. GigaScience. 2023;12: giad108.
An A, Al-Fawa’reh M, Kang JJ. Enhanced heart rate prediction model using damped least-squares algorithm. Sensors. 2022;22(24):9679.
Wu J, Chen XY, Zhang H, Xiong LD, Lei H, Deng SH. Hyperparameter optimization for machine learning models based on Bayesian optimization. J Electron Sci Technol. 2019;17(1):26–40.
Jung Y, Hu J. AK-fold averaging cross-validation procedure. J Nonparametr Stat. 2015;27(2):167–79.
Belete DM, Huchaiah MD. Grid search in hyperparameter optimization of machine learning models for prediction of HIV/AIDS test results. Int J Comput Appl. 2022;44(9):875–86.
Kouacou BA, Anornu G, Adiaffi B, Gibrilla A. Hydrochemical characteristics and sources of groundwater pollution in Soubré and Gagnoa counties, Côte d’Ivoire. Groundw Sustain Dev. 2024;26: 101199.
Gibrilla A, Bam EKP, Adomako D, Ganyaglo S, Osae S, Akiti TT, Kebede S, Achoribo E, Ahialey E, Ayanu G, Agyeman EK. Application of water quality index (WQI) and multivariate 694 analysis for groundwater quality assessment of the Birimian and Cape Coast Granitoid 695 complex: Densu River Basin of Ghana. Water Qual Expo Health. 2011;3(63–78):696.
Karanth KR. Groundwater assessment, development and management. New Delhi: Tata-McGraw Hill; 1987.
Singh AK, Mondal GC, Kumar S, Singh TB, Tewary BK, Sinha A. Major ion chemistry, weathering processes and water quality assessment in upper catchment of Damodar River basin, India. Environ Geol. 2008;54(4):745–58.
Hair JF Jr, Hult GTM, Ringle CM, Sarstedt M, Danks NP, Ray S. Evaluation of formative measurement models. In: Partial least squares structural equation modeling (PLS-SEM) using R: a workbook. Cham: Springer; 2021. p. 91–113.
Mustakim M, Buono A, Hermadi I. Performance comparison between support vector regression and artificial neural network for prediction of oil palm production. Jurnal Ilmu Komputer Dan Informasi. 2016;9(1):1–8.
Huang M, Tian Y. A novel visual modeling system for time series forecast: application to the domain of hydrology. J Hydroinform. 2013;15(1):21–37.
Mokhtar A, Elbeltagi A, Gyasi-Agyei Y, Al-Ansari N, Abdel-Fattah MK. Prediction of irrigation water quality indices based on machine learning and regression models. Appl Water Sci. 2022;12(4):76.
El Bilali A, Taleb A. Prediction of irrigation water quality parameters using machine learning models in a semi-arid environment. J Saudi Soc Agric Sci. 2020;19(7):439–51.
Author information
Authors and Affiliations
Contributions
Raymond Webrah Kazapoe: supervision, conceptualization, analysis and interpretation of data, writing—original draft. Samuel Dzidefo Sagoe: methodology, interpretation of data, writing—original draft. Mahamadu Abu: writing—review and editing. All the authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kazapoe, R.W., Sagoe, S.D. & Abu, M. Predicting irrigation water quality indices in a typical mining dominated area in the Upper West region of Ghana using multiple machine learning techniques. Discov Water 4, 46 (2024). https://doi.org/10.1007/s43832-024-00104-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s43832-024-00104-x