
Abstract
The objective of this study is to predict road flooding risks based on topographic, hydrologic, and temporal precipitation features using machine learning models. Existing road inundation studies either lack empirical data for model validations or focus mainly on road inundation exposure assessment based on flood maps. This study addresses this limitation by using crowdsourced and fine-grained traffic data as an indicator of road inundation, and topographic, hydrologic, and temporal precipitation features as predictor variables. Two tree-based machine learning models (random forest and AdaBoost) were then tested and trained for predicting road inundations in the contexts of 2017 Hurricane Harvey and 2019 Tropical Storm Imelda in Harris County, Texas. The findings from Hurricane Harvey indicate that precipitation is the most important feature for predicting road inundation susceptibility, and that topographic features are more critical than hydrologic features for predicting road inundations in both storm cases. The random forest and AdaBoost models had relatively high AUC scores (0.860 and 0.810 for Harvey respectively and 0.790 and 0.720 for Imelda respectively) with the random forest model performing better in both cases. The random forest model showed stable performance for Harvey, while varying significantly for Imelda. This study advances the emerging field of smart flood resilience in terms of predictive flood risk mapping at the road level. In particular, such models could help impacted communities and emergency management agencies develop better preparedness and response strategies with improved situational awareness of road inundation likelihood as an extreme weather event unfolds.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Road networks play a critical role in the transportation of goods, access to food and healthcare, and economic activities (Pregnolato et al. 2017). Road inundations during major flood and storm events reduce the access of impacted communities to essential facilities such as hospitals (Dong et al., 2020a) and grocery stores (Podesta et al., 2021), and present challenges for emergency management agencies to prepare, design and implement response strategies (Yuan et al., 2021a). In addition, drivers may attempt to navigate flooded urban roads, resulting in a loss of life when rescue efforts fail (Drobot et al., 2007). Therefore, the ability to predict road inundations is significant in enhancing emergency managers’ situational awareness regarding the likelihood of flood-disrupted access to critical facilities (e.g., hospitals). The objective of this study is to create and test machine learning models for road inundation probabilities prediction based on topographic, hydrologic, and temporal precipitation features by using crowdsourced Waze reports and fine-grained traffic data as indications of road inundations. The rest of this section will review the relevant literature and discuss their limitations in predicting road inundation probabilities to establish the impetus for this study.
1.1 Hydraulic and hydrologic models for urban flood inundations
Various studies have focused on urban flood inundation with hydraulic and hydrologic (H&H) models (Chen et al., 2018; Jamali et al., 2018), such as 1-D modeling with HEC-RAS (Chaudhry et al., 2018), and 2-D modeling with an urban inundation model (Chen et al., 2007) and LISFLOOD‐FP (Bates & de Roo, 2000). However, H&H models, such as an urban inundation model and LISFLOOD‐FP need to solve the full shallow water equations (SWEs) and further require a considerable amount of computation resources (Jamali et al., 2019). Given the complexity and high computational demands of these models, recent studies have attempted to build models that do not resolve SWEs. Jamali et al., (2019) categorized these latter H&H models into two categories based on their complexity: models based on cellular automata (CA) and models based on topographic depressions. CA-based models divide flood domains into a set of regular grid cells and require small time steps for flood inundation simulations but are also computationally intensive (Liu et al., 2015). Models based on topographic depressions are referred to as rapid flood models in Jamali et al., (2019), and depend mainly on topographic features and the continuity equation for urban flood inundation simulation but lack temporal features such as precipitation (Nguyen & Bae, 2020). Studies integrating H&H models with machine learning approaches (Hou et al., 2021) use the flood depth outputs from hydrodynamic models as training datasets and rainfall data as the primary predictor (Hou et al., 2021), however limited observed urban flood inundation data makes validation difficult (Smith et al., 2012). For instance, Lyu et al., (2019) used limited public reports of flood incidents from websites such as Google and Baidu and from literature (Huang et al., 2017; Yin et al., 2016b) to validate their simulated urban flood inundations in Shanghai. Another limitation for H&H models is that outputs refer mainly to the general pattern of flood inundations over large metropolitan areas (Lyu et al., 2019; Yu et al., 2016), while struggling to accurately predict small-scale flooding such as road inundations.
Despite these limitations, H&H models have been extensively used to estimate road inundations (e.g., Versini, 2012). For example, Coles et al., (2017) employed the hydrodynamic flood inundation model (FloodMap) to simulate two pluvial flood events in York, UK and then, identified the regions with restricted accessibility of emergency responders. Using a road network analysis, their study evaluated emergency service accessibility. Yin et al., (2016a) extended this approach by integrating a hydrodynamic model (FloodMap HydroInundation 2D) and flood depth-dependent measures to assess the road inundations in a pluvial flash flood event in Shanghai, China. Their hydrodynamic model was based on rainfall scenarios from the intensity–duration–frequency relationships of a Shanghai rainstorm and the Chicago Design Storm. But again, their simulated flood inundations cannot be validated with observed flood inundation data. A prior study by Versini (2012) attempted to overcome this limitation by using historical road inundation data to define four road inundation risk levels (high, medium, low, and safe). These risk levels were then evaluated against simulated discharges from a hydrological model and used to establish a real-time flood warning system. However, the models in these studies provide insight only into road inundation exposure based on historical road inundations; they do not determine a continuous road-level inundation probability. This limitation is due partly to the dearth of road-level inundation data to verify the road exposure insights obtained from H&H models (e.g., Hou et al., 2021; Lyu et al., 2019; Smith 2012). Ground-based observations of road-level inundations are essential to validate H&H models and further evaluate their performances. On the other hand, there is a lack of integration between topographic features of roads (e.g., elevation), water depth, and velocity estimates from H&H models (Versini, 2012). Topographic features such as elevation can influence the flow directions of flood water and water depth, which determines whether vehicles and people can be stuck in the flood. Velocity factors such as the roughness of the road surface can impact the accumulation of flood water on the road segments. Accordingly, models integrating these variables are particularly needed for predicting road-level inundation probabilities. This limitation could be potentially addressed with the use of crowdsourced and fine-grained traffic data that provide reliable indications regarding the inundation status of road sections during storm events and with the development of topographic characterization of roads.
1.2 Point of departure
The motivations of this study are due to the necessity of road inundation prediction and the limitation of existing H&H methods. In particular, the limitations of the existing H&H methods include: (i) requiring high computational capacity due to their calculation complexity, (ii) insufficient road-level flood inundations reports and records to validate the developed models, and (iii) lack of integration features other than topographic features. To address these limitations, similar to the methods used by Mobley et al., (2021) and Lee et al., (2017), we employ three categories of input features for random forest and AdaBoost models: (i) topographic features (e.g., proximity to streams and coastlines); (ii) hydrologic features (e.g., land surface roughness); and (iii) temporal precipitation features. Referring to Lyu et al., (2019) and Yu et al., (2016), we use crowdsourced and traffic sensor data to detect road inundation status as a dependent variable for these machine learning models. That is, this study aims to predict road inundation probabilities based on topographic, hydrologic, and temporal precipitation features by using crowdsourced Waze reports and fine-grained traffic data as indications of road inundations. Using 2017 Hurricane Harvey and 2019 Tropical Storm Imelda in Harris County, Texas, as case studies, we train and test these two models for predicting road inundations.
2 Methods and materials
Ten input variables within three feature categories—topographic, hydrologic, and precipitation features—were created using secondary data sources, and the output variable, road inundation status, was developed using Waze reports and INRIX traffic data. Waze software works similarly to Google Maps and provides satellite navigations. Users can report incidents and traffic conditions on the roads through Waze. Compared with the literature (Lyu et al., 2019; Yu et al., 2016) that utilized limited public reports of flood incidents to identify inundation status, the crowdsourced data obtained from Waze in this study has significantly more records, which can be helpful for model training. In addition, Waze data provides inundation information reported by road users that are directly related to the objective of this study. INRIX is a private company that collects location-based traffic speed data from both sensors and vehicles. INRIX traffic data includes road names, segment ID, directions, geographic locations defined by its head and end coordinates, intersection or not, length and average traffic speed at a five-minute interval. Due to limited data availability including the high costs of INRIX traffic data and no Waze data for Hurricane Harvey in 2017 (Waze data become available since 2018), we used INRIX traffic data for the Harvey and Waze reports for Imelda. In particular, we compared the model prediction stability for each case. Two commonly used tree-based methods, random forest and AdaBoost models, were employed for the prediction of road inundation. The framework is illustrated in Fig. 1.

Road flood risk prediction framework of machine learning models
2.1 Case study region
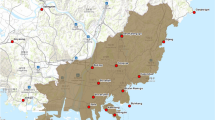
Harris County, home to Houston, is among the most flood-prone counties in the United States due to its coastal location, burgeoning urban development, and the lack of flood control infrastructure development in parallel with the development and population growth (Dong et al., 2020b; Qian, 2010). Hurricane Harvey in 2017 was one of the most devastating floods experienced by Harris County and led to extensive economic and social consequences (NOAA, 2017). Figure 2 illustrates the flooded areas in Harris County during Hurricane Harvey. The flood inundation data comes from the Federal Emergency Management Agency (FEMA 2018). Similarly, Tropical Storm Imelda caused one of the most devastating floods in decades experienced in Southeast Texas. After its landfall on September 19, 2019, widespread flooding occurred in Harris County, with over 40 inches of rainfall recorded, and many of the local rivers and bayous overflowed and inundated a vast area in the county. Therefore, Harris County is an ideal testbed for this study.

Context of Harris County, Texas and flooded areas during Hurricane Harvey
2.2 Data and feature descriptions
2.2.1 Input features
Figure 1 shows the three categories of features used for predicting road flood risk: (1) topographic, i.e., elevation, coastal and stream proximity, and height above nearest drainage, (2) hydrologic, i.e., roughness, imperviousness of surface, and the saturated hydraulic conductivity, and (3) precipitation features, i.e., total rainfall in 1 h, 2 h, and 24 h. The length of the road segments in our study areas ranges from 800 to 1,600 m; therefore, the features of each road segments are computed based on their average values. Table 1 introduces how these features were collected and computed, their scales, and main references.
2.2.2 Road flood status
2.2.2.1 Waze reports data on tropical storm imelda
Tropical Storm Imelda, the fifth-wettest tropical cyclone on record in the United States, made landfall in Harris County on September 19, 2019. Waze, a mobile navigation application, collected time-stamped and location-specific flood incident reports (i.e., road closures due to flooding) during Tropical Storm Imelda. We used Waze flood report data for the assessment of proposed predictive road flooding during Imelda. A total of 41,501 weather hazard or road closure related reports were registered in Harris County during Imelda (5-day), encapsulating flooding alerts in 4,980 road segments (red points in Fig. 3a). For the training dataset, we used the random sample method for the random selection of equivalent-size non-flooded roads from county road data.

Geographic distributions of flooded and non-flooded roads from Waze reports for Tropical Storm Imelda (3a) and from INRIX for Hurricane Harvey (3b). Each point represents the location of a road segment
2.2.2.2 INRIX traffic data on hurricane harvey
We acquired traffic data from August 20 to September 11, 2017 for 19,712 road segments in Harris County from INRIX. The INRIX traffic data includes the average traffic speed on individual road segments at 5-min intervals and the segments’ corresponding historical average traffic speed. Road segments with null value as average traffic speed were assumed to be flooded in Hurricane Harvey (Fan et al., 2020; Yuan et al., 2021b, 2021c). Accordingly, we recorded a road as flooded when it had a null value for average traffic speed. We collected data on 1,063 flooded roads during Hurricane Harvey. The remaining 18,649, roads were presumed to be non-flooded roads. Identifying flooded and non-flooded roads is based on the average traffic speed; therefore, a non-flooded road that is elevated and not affected by flooding may appear in the flooding areas shown in Fig. 2. The distribution of flooded and non-flooded roads is illustrated in Fig. 3b. To create a balanced dataset for implementing the random forest model, we utilized the random sample function to select the equivalent-size dataset of non-flooded roads.
2.3 Machine learning models
Based on the concept of ensemble learning, two common techniques—bagging and boosting—were proposed for the tree-based models (Sutton, 2005). The bagging technique divides the initial training dataset into several subsets and choses them randomly with replacements to train their corresponding decision trees. As a result, the bagging technique produces an ensemble of different tree models. The random forest introduces the random selection of features within the training dataset (Prasad et al., 2006). We implemented the random forest model to predict the road flooding risk. In contrast to the subset replacement method of the random forest model, boosting uses the same dataset to build decision trees for all iterations and revises the weights of inputs in each iteration. The boosting technique analyzes the data of a simple decision tree for errors. Consecutive trees increase the weight of an input misclassified by the previous tree and are more likely to classify it correctly. As a result, the boosting technique output is an ensemble of different tree models. As the first successful implementation of boosting technique for binary classification, AdaBoost (Schapire, 2013), the most popular forest-based boosting method, has demonstrated strong predictive power for flood risk (Coltin et al., 2016; Liu et al., 2017). We compared the performances of AdaBoost with that of the random forest model for predicting road flood risks with our defined features.
In particular, to properly use the random forest, we tuned two critical parameters to reduce error rates, the number of trees and tree depth. The number of trees defines forest size. Increasing forest size can reduce errors and involve more features for decisions (Liaw & Wiener, 2002); however, such an increase requires a greater computational demand. Tree depth refers to the longest path between the root node and the leaf node. The greater the tree depth, the more splits are expected, which captures more information from the feature data; however, a very deep tree could result in overfitting. Referring to Mobley et al. (2021), we initially set the number of trees to 200 and the tree depth to 90 in our model.
To enable variable selection for enhancing the generalizability of models for predicting road inundation, we used the aggregated decrease in Gini impurity to evaluate feature importance. A greater aggregated decrease in the Gini impurity signifies a more important role of the feature (prediction variables).
This research implemented the 10-iteration fivefold cross-validation process to evaluate the performances of random forest and AdaBoost models for predicting road flooding risk in both Hurricane Harvey and Tropical Storm Imelda. We used 80% of our initial datasets for model training and validation and 20% for model testing in both cases. To maintain the high-level randomness for each fold split of training and test datasets, we employed the train_test_split function from the scikit-learn library. To evaluate the performances of random forest and AdaBoost models, we used average accuracy, and average area under the curve (AUC) of the receiver operating characteristic (ROC) in the 10-iteration fivefold cross-validation process. We used the flooded roads as a positive class for the probability predictions. Accuracy reflects the percentage of correctly predicted roads with flood risks and those with non-flood risks (Eq. (1)). Precision indicates the percentage of correctly predicted roads with flood risks over roads predicted with flood risks (Eq. (2)). Sensitivity, as known as Recall, denotes the percentage of correctly predicted roads with flood risks over roads indeed with flood risks (Eq. (3)). The AUC of the ROC reveals the estimates of the probability that the models will correctly predict flooded roads as roads with flood risks. With the prediction results, the ROC curve could be defined by the relationship between true positive and false positive rates (Eq. (3) through (5)).
where true positive denotes the situation where models correctly predicted the road flooding risk, while true negative is for the result of correct prediction of non-flood risks of roads; false positive refers to the outcome where models incorrectly predicted the road flooding risk, while false negative is for the result that models incorrectly predicted the non-flooded status of roads.
3 Results
3.1 Model performances of random forest and AdaBoost
With the 10-iteration fivefold cross-validations, we computed the average of accuracy and AUC for the model performance (Table 2). We also recorded the variations of each evaluation matrix (accuracy and AUC ranges in Table 2). The random forest model showed better performance for predicting road flooding risks for both storm events than the AdaBoost model in terms of accuracy. The random forest model demonstrated higher accuracy (0.900 versus 0.764) for predicting road inundation in Hurricane Harvey than that for Tropical Storm Imelda, which is the same as observed in the AdaBoost model. In terms of AUCs, both random forest and AdaBoost models also performed better for predicting road inundation for Hurricane Harvey than for Tropical Storm Imelda. This can be explained by the differences between Waze reports and INRIX traffic data. Waze reports were collected from Waze users, while INRIX traffic data was collected mainly by sensors. Humans are more sensitive to floods than are sensors, and as such, they may report flood risks on Waze when shallow water was found on the roads. Using roads with null values for average traffic speed to denote roads with flood risks in Hurricane Harvey is a more stringent standard (as most traffic data was collected by sensors) than the voluntary and subjective Waze reports, because roads identified with flood risks derived from Waze reports during Tropical Storm Imelda might still be available for traffic use.
Using the average of the calculated results of true positive and false positive rates from the 10-iteration fivefold cross-validation process, we created ROC curves from random forest and AdaBoost models for both events (Fig. 4). The random forest and AdaBoost average AUC were 0. 790 ± 0.040 and 0.720 ± 0.060 respectively for Tropical Storm Imelda, and 0.860 ± 0.100 and 0.810 ± 0.140 respectively for Hurricane Harvey (Table 2). In other words, the chance of the random forest model correctly predicting a road with a high probability of being inundated in Hurricane Harvey is 86.0%, while that of the AdaBoost model is 81.0%. Meanwhile, the random forest model had a probability of 79.0% to accurately predict road flooding risk in Tropical Storm Imelda; the AdaBoost model had only 72.0%.

Part 1: Receiver operating characteristic (ROC) curves for 10- iteration fivefold cross-validation with random forest model for Tropical Storm Imelda (a) and Hurricane Harvey (b); Part 2: Receiver operating characteristic (ROC) curves for tenfold cross-validation with AdaBoost model for Tropical Storm Imelda (c) and Hurricane Harvey (d)
Furthermore, our results demonstrate better performance than existing studies, which shows the capability of our models to predict road flooding risk. Lee et al., (2017) used both random forest and boosted tree models to predict the spatial distribution of flood risks in the Seoul metropolitan area. They used the input features such as distance from the river (m), slope length factor (SLF), topographic wetness index (TWI), stream power index, and digital elevation model (DEM). Their regression computations of random forest and boosted tree models showed AUCs of 0.7878 and 0.7755, respectively. Compared with Lee et al., (2017), our random forest models had higher AUCs for both Hurricane Harvey (0.860) and Tropical Storm Imelda (0.790). For comparison of boosted tree and AdaBoost models, the AUC for Hurricane Harvey (0.810) is greater, while that of Tropical Storm Imelda (0.720) is less than that in Lee et al. (2017). The better performances of the same (random forest) and similar (AdaBoost versus boosting tree) models in this study may be owing to the improved selection of input features such as the temporal precipitation features.
3.2 Model stability of random forest
Given that the random forest model demonstrated better performance than the AdaBoost model, we further tested its stability with varying probability thresholds for detecting road inundation. The default probability threshold is 0.50: if the predicted flood probability of a road is less than 0.50, the random forest model denotes this road as the non-flooded class (i.e., negative class); otherwise, that road is categorized as flooded (i.e., positive class). False negative prediction refers to the result that roads with flood risks are incorrectly predicted as non-flooded roads, which could falsely inform residents to shelter in place or travel through high-flood-risk roads. Therefore, we tested the stability of the random forest model by adjusting the probability thresholds from 0.40 to 0.60 with a step of 0.01 and observing the variations of false negative percentages for both storm events. The false negative percentage was computed using the Eq. (6). For each probability threshold, the fivefold cross-validation process was implemented and the average false negative rate was calculated. With computed false negative rates, we plot their curves for Tropical Storm Imelda (green curve) and Hurricane Harvey (blue curve) in Fig. 5.

False negative percentages from fivefold cross-validation with random forest model by varying probability thresholds for Tropical Storm Imelda (green curve) and Hurricane Harvey (blue curve). FN means false negative
Figure 5 reveals that the random forest model had a stable performance for predicting road inundations during Hurricane Harvey. With a probability threshold ranging from 0.40 to 0.60, we observed the false negative percentage changes from 0.16 to 0.19. For Tropical Storm Imelda, we discerned a significant variation of false negative percentage (from 0.08 to 0.28) when adjusting the probability threshold. When the probability threshold is 0.50, the false negative percentage is 0.16 which is the lower boundary of the false negative percentage range of Hurricane Harvey. Therefore, setting the probability threshold as 0.50 is reasonable for the random forest model for Hurricane Harvey, while selecting the probability threshold from 0.40 to 0.50 would yield a lower false negative percentage for Tropical Storm Imelda. In addition to the consideration of false negative percentage, precision (Eq. (2)) and recall (Eq. (4)) could also be considerations when selecting the probability threshold for Tropical Storm Imelda. For example, a threshold leading to higher recall identifies more roads with flood risks correctly without considering false-positive predictions; thus, it’s a relatively conservative threshold.
3.3 Feature importance for random forest
This section illustrates the rank of feature importance by random forest model for Tropical Storm Imelda (Fig. 6a) and Hurricane Harvey (Fig. 6b). A significant difference between these ranks is the rank of precipitation features. The precipitation features are a stronger indicator of road flooding risk during Hurricane Harvey than that in Tropical Storm Imelda. National Hurricane Center reports (Blake & Zelinsky, 2018; Latto & Berg, 2020) indicate that the rainfall volume brought by Hurricane Harvey is much larger than that of Tropical Storm Imelda (60.58 inches vs. 44.49 inches). Accordingly, rainfall could have resulted in more severe flood risks in Hurricane Harvey. Consequently, precipitation features have higher ranks of importance during Hurricane Harvey than Tropical Storm Imelda.

Feature importance results for Tropical Storm Imelda (a) and Hurricane Harvey (b) with random forest. A larger value of feature importance indicates a more important role of that feature
In addition to precipitation features, ranks of topographic and hydrologic features remain almost constant for both storm cases, excluding the ranks of stream proximity (i.e., Distance2Stream) and height above nearest drainage (HAND). The general trend is that topographic features are stronger predictors of road inundation than hydrologic features for both events using the random forest model. Specifically, factors influencing the infiltration of stormwater into the ground, such as saturated hydraulic conductivity of soil (AverageKSAT), impervious surface (impervious), and roughness (AverageRoughness), were poor predictors of road inundation in both storms, whereas factors influencing where water tends to accumulate such as Elevation, HAND, Distance2Coast, Distance2Stream, were all strong predictors of road inundation. This finding is consistent with existing studies, as elevation is one of the frequently used factors for flood hazard simulations (Mobley et al., 2019), and proximity to coast was found to be a strong indicator of flood damage (Brody et al., 2015).
3.4 Prediction results
With 20% of the test dataset used for both cases, we predicted the flooding probabilities of these roads using the random forest model (Fig. 7). Points with varying colors from blue to red represent roads with low to high probabilities of getting flooded. Figure 7a (Tropical Storm Imelda) illustrates that roads at high risk of being flooded are mainly in the center of Houston, while Fig. 7b (Hurricane Harvey) shows those with high flood-risk levels mainly surround the boundary of Harris County. As we can see in Fig. 7, red-shaded roads present a very high risk of flooding, suggesting communities should avoid these roads for traveling or evacuation, while the blue ones are relatively safe as they are less likely to be flooded. Meyerland neighborhood (the green-shaded region in Fig. 7b) is almost entirely located within the 100-year floodplain and was inundated in Hurricane Harvey. From the predicted probability in Fig. 7b, we can see one road within this region has a probability of 57.30% being inundated.

Examples of predictions of probabilities for roads becoming flooded in Tropical Storm Imelda (a) and Hurricane Harvey (b)
According to the predicted probabilities (Fig. 7), we can denote the predictive flooding status of roads with proper probability thresholds. Referring to Fig. 5, we used probability thresholds of 0.45 and 0.50 to detect inundated roads (i.e., positive class) during Tropical Storm Imelda and Hurricane Harvey, respectively. Then, we showed examples of the prediction results for both cases in Fig. 8, where the green links represent roads with true positive predictions, red for false negative predictions, brown for false positive predictions, and blue for true negative predictions.

Examples of prediction results for roads with and without flood risks for Tropical Storm Imelda (a) and Hurricane Harvey (b) according to the predicted probabilities in Figs. 7a and 7b, respectively. Each link represents the road with road point used for model test. For better presentations, we show only the roads used in our test dataset
4 Discussions
This study demonstrates that roads with high flood-risk potential can be accurately predicted using topographic, hydrologic, and temporal precipitation features in the context of two storm cases in Harris County. For predicting road flooding probability, precipitation features for extreme storm events (Hurricane Harvey) are more important predictors than topographic and hydrologic features. In addition, topographic features (elevation, coastal and stream proximity and height above nearest drainage) generally have greater influence than hydrologic features (roughness, imperviousness, and saturated hydraulic conductivity) for predicting road inundations, which is generally consistent with the results reported by Mobley et al., (2021) and Lee et al., (2017). Compared with existing studies using random forest and boosted tree models for flood risk predictions (Lee et al., 2017), our corresponding models demonstrate higher AUC values. This difference is likely to be explained by the addition of temporal precipitation features as inputs for predicting flooded roads in our study, particularly for storm events with extreme precipitation such as Hurricane Harvey. In addition, this study contributes to demonstrating that the two commonly used tree-based models have solid predictive capabilities for detecting roads at risk for flooding based on two novel and emerging datasets, road user-reported inundation information and traffic speed data. The random forest model demonstrates better performance than the AdaBoost model.
As we are concerned with reducing false negative predictions, we use the false negative percentage with varying probability thresholds to test model stability. The results show that the random forest model has stable performances for Hurricane Harvey with minor variations of false negative percentage when adjusting probability thresholds but present significant variations across false negative percentage for Tropical Storm Imelda. This discrepancy could be attributed to the difference between crowdsourced data (Waze report) and sensor data (INRIX traffic). Since users of crowdsourced data were more sensitive to road flooding than were traffic sensors, roads that may not be severely inundated (still passable) during Tropical Storm Imelda were more likely to be labeled as flooded roads, which can further impact the model’s stability.
There exist limitations in the proposed models. A proper selection method for identifying non-flooded roads plays a critical role in improving model performances (Darabi et al., 2019). In this study, we randomly selected equivalent-size of roads without flood warnings for Imelda based on the Waze report and roads with traffic speed values for Hurricane Harvey based on INRIX traffic data as non-flooded roads. In addition, we used two different datasets for two different storm cases due to limited data availability. We cannot collect Waze data for Hurricane Harvey in 2017 as Waze reports data became available after 2018. INRIX traffic data for Tropical Storm Imelda was not available to the research team due to its high costs. Using different datasets could impact the model performance due to their different natures as mentioned earlier in this section; however, our results demonstrate that different datasets could be used for training machine learning models for predicting road flooding risk, and future users can choose their datasets and features based on availability and characteristics of flooding events and impact areas. Future work will focus on investigating the impacts of methods for identifying non-flooded roads and random selections on model performance. Also, although the Waze report and fine-grained traffic data can provide information to validate road inundation models, the length of each road segments is much longer than the resolution of input features, which may bring in aggregation biases. The models may require further validation when finer road inundation information is available. Another limitation comes from our use of points to represent locations of road segments as their lengths vary and so do their topographic, hydrologic and precipitation features, which may bring in uncertainties in the predictions of their inundation probabilities. Our future work will consider using integrated values of the three categories of features as predictor variables for these road segments.
In addition, the assignment of topographic and hydrologic features to roads can also affect the model performance. We used roughness and imperviousness from the 2016 National Land Cover Database for both flooding cases. However, these variables can be impacted by large-scale changes in urbanization over time. The consequence is that the roughness and imperviousness are less representative of actual hydrologic conditions in 2017 and 2019, which may explain the low-level rank of their importance for predicting roads with flood risks (Fig. 4). Upon the availability of data for topographic and hydrologic features, future work could consider the impact of urban development by including proper features which are not available in the study periods.
5 Concluding Remarks
The study and findings contribute to the emerging field of smart flood resilience focusing on harnessing community-scale big data and machine learning approach to enhance disaster resilience capabilities, such as predictive flood risk mapping at the road level (Dong et al., 2020c). This study addressed two limitations in the existing studies, lack of inundation data for validation and data integration by implementing the crowdsourced and traffic data as indications of road flooding status and by incorporating topographic, hydrologic, and temporal precipitation features for risk predictions. The main contribution of this study is to demonstrate the capability of the two commonly used machine learning methods to predict road flooding risk based on emerging datasets and various features. In addition, this study provides a potential tool to detect roads with varying flood risk levels using topographic, hydrologic, and precipitation features (Fig. 7). This potential tool can be integrated with a percolation analysis of the road network (Dong et al., 2020c, 2021) so that the removal of roads can refer to the roads with a higher predicted probability of getting flooded (Li et al., 2015), which is a more precise method than relying on floodplain maps. We also show that the random forest model (trained on Tropical Storm Imelda) performs better prediction for flood events without abrupt severe rainfalls and the model trained on Hurricane Harvey is better for floods with slow-moving extreme rainfalls. The AUCs of random forest models for Imelda and Harvey are 0.790 and 0.860 respectively, and rainfall volumes and periods caused by Harvey are more severe than those due to Imelda (Blake & Zelinsky, 2018; Latto & Berg, 2020).
Our findings can help potentially impacted communities identify roads that are more likely to be inundated by floods. This foresight could be incorporated into navigation applications to help drivers avoid roads with high flooding probability when accessing essential facilities (e.g., hospitals). Incidents from past events indicate that driving through flooded roads is among the leading cause of deaths during urban floods (Jonkman & Kelman, 2005); our model could help affected residents avoid driving into flooded roads. Through collaborations with local officials and disaster managers, we can share our model and predicted results with them. The officials can deliver our model prediction results to the affected residents through their public social media account and weather report TV channels. This study also provides a tool for emergency management agencies (EMAs) to design response strategies. For instance, EMAs could evacuate communities that are likely to lose access to critical facilities due to inundated roads. Also, EMAs can inform road infrastructure operators and maintainers to take protective actions, such as putting sandbags, to ensure the functionality of the critical roads that connect communities and resources. Furthermore, our model could help EMAs update floodplain maps with more specific infrastructure risk information, which could guide the urban plan strategies for future flood hazard mitigation. Current 100- and 500-year floodplain maps of Harris County (Harris County Flood Control District) indicate the regions with potential flood risk. Through a comparison of floodplain maps with flood maps of Hurricane Harvey, we have found many regions in the northwest of Harris County were flooded in Harvey which are not in the 100- and 500-year floodplain maps. Floodplain maps do not indicate the flood risks (e.g., risk levels and probabilities to be flooded) of infrastructures such as road segments, electricity, and utility. Our models can be easily produced and maintained with updated topographic, hydraulic and precipitation features. As a result, infrastructure risk insights from our models could better reflect the updated topographic and hydraulic features and the changes to infrastructure risks could be incorporated into floodplain maps.
In summary, this study provides models to predict road flooding risk with topographic, hydrologic, and precipitation features. This modeling cannot only be generalized to other flood events and regions with proper topographic, hydrologic, and precipitation features for predicting flooded roads, but also be used as a tool to design road failure scenarios (roads with a predictive probability of getting flooded) for percolation analysis of road network. Our model can also benefit potentially impacted communities and emergency management agencies’ preparedness and response actions to hurricanes and floods. The model and results contribute to the emerging field of smart flood resilience (Fan et al., 2021) aiming to harness heterogeneous datasets to improve situational awareness and predictive monitoring during disasters.
Availability of data and materials
The data that support the findings of this study are available from Waze and INRIX, but restrictions apply to the availability of these data, which were used under license for the current study. The data can be accessed upon request submitted on each data provider. Other data (flood inundations and flood claims) we use in this study are all publicly available.
References
Arcement, G. J., & Schneider, V. R. (1989). Guide for selecting Manning's roughness coefficients for natural channels and flood plains. https://ton.sdsu.edu/usgs_report_2339.pdf.
Anderson, B. G., Rutherfurd, I. D., & Western, A. W. (2006). An analysis of the influence of riparian vegetation on the propagation of flood waves. Environmental Modelling & Software, 21(9), 1290–1296.
Bates, P. D., & De Roo, A. P. J. (2000). A simple raster-based model for flood inundation simulation. Journal of Hydrology, 236(1–2), 54–77.
Blake, E., & Zelinsky, D. (2018). National Hurricane Center Tropical Cyclone Report: Hurricane Harvey. Available at https://www.nhc.noaa.gov/data/tcr/AL092017_Harvey.pdf. Accessed 25 Jan 2023.
Brody, S. D., Highfield, W. E., & Blessing, R. (2015). An analysis of the effects of land use and land cover on flood losses along the Gulf of Mexico coast from 1999 to 2009. JAWRA Journal of the American Water Resources Association, 51(6), 1556–1567.
Bui, D. T., Ngo, P. T. T., Pham, T. D., Jaafari, A., Minh, N. Q., Hoa, P. V., & Samui, P. (2019). A novel hybrid approach based on a swarm intelligence optimized extreme learning machine for flash flood susceptibility mapping. CATENA, 179, 184–196.
Chaudhry, M. A., Naeem, U. A., & Hashmi, H. N. (2018). Performance evaluation of 1-D numerical model HEC-RAS towards modeling sediment depositions and sediment flushing operations for the reservoirs. Environmental Monitoring and Assessment, 190(7), 1–18.
Chen, A. S., Djordjevic, S., Leandro, J., & Savic, D. (2007). The urban inundation model with bidirectional flow interaction between 2D overland surface and 1D sewer networks. In Novatech 2007-6ème Conférence sur les techniques et stratégies durables pour la gestion des eaux urbaines par temps de pluie/Sixth International Conference on Sustainable Techniques and Strategies in Urban Water Management. GRAIE, Lyon, France.
Chen, W., Huang, G., Zhang, H., & Wang, W. (2018). Urban inundation response to rainstorm patterns with a coupled hydrodynamic model: A case study in Haidian Island, China. Journal of Hydrology, 564, 1022–1035.
Coles, D., Yu, D., Wilby, R. L., Green, D., & Herring, Z. (2017). Beyond ‘flood hotspots’: Modelling emergency service accessibility during flooding in York, UK. Journal of Hydrology, 546, 419–436.
Coltin, B., McMichael, S., Smith, T., & Fong, T. (2016). Automatic boosted flood mapping from satellite data. International Journal of Remote Sensing, 37(5), 993–1015.
Darabi, H., Choubin, B., Rahmati, O., Haghighi, A. T., Pradhan, B., & Kløve, B. (2019). Urban flood risk mapping using the GARP and QUEST models: A comparative study of machine learning techniques. Journal of Hydrology, 569, 142–154.
Dodangeh, E., Choubin, B., Eigdir, A. N., Nabipour, N., Panahi, M., Shamshirband, S., & Mosavi, A. (2020). Integrated machine learning methods with resampling algorithms for flood susceptibility prediction. Science of the Total Environment, 705, 135983.
Dong, S., Esmalian, A., Farahmand, H., & Mostafavi, A. (2020a). An integrated physical-social analysis of disrupted access to critical facilities and community service-loss tolerance in urban flooding. Computers, Environment and Urban Systems, 80, 101443.
Dong, S., Li, Q., Farahmand, H., Mostafavi, A., Berke, P. R., & Vedlitz, A. (2020b). Institutional connectedness in resilience planning and management of interdependent infrastructure systems. Journal of Management in Engineering, 36(6), 04020075.
Dong, S., Yu, T., Farahmand, H., & Mostafavi, A. (2020c). Probabilistic modeling of cascading failure risk in interdependent channel and road networks in urban flooding. Sustainable Cities and Society, 62, 102398.
Dong, S., Malecha, M., Farahmand, H., Mostafavi, A., Berke, P. R., & Woodruff, S. C. (2021). Integrated infrastructure-plan analysis for resilience enhancement of post-hazards access to critical facilities. Cities, 117, 103318.
Drobot, S. D., Benight, C., & Gruntfest, E. C. (2007). Risk factors for driving into flooded roads. Environmental Hazards, 7(3), 227–234.
Fan, C., Jiang, X., & Mostafavi, A. (2020). A network percolation-based contagion model of flood propagation and recession in urban road networks. Scientific Reports, 10(1), 1–12.
Fan, C., Zhang, C., Yahja, A., & Mostafavi, A. (2021). Disaster City Digital Twin: A vision for integrating artificial and human intelligence for disaster management. International Journal of Information Management, 56, 102049.
Garousi-Nejad, I., Tarboton, D. G., Aboutalebi, M., & Torres-Rua, A. F. (2019). Terrain analysis enhancements to the height above nearest drainage flood inundation mapping method. Water Resources Research, 55(10), 7983–8009.
Gori, A., Blessing, R., Juan, A., Brody, S., & Bedient, P. (2019). Characterizing urbanization impacts on floodplain through integrated land use, hydrologic, and hydraulic modeling. Journal of Hydrology, 568, 82–95.
Hosseini, F. S., Choubin, B., Mosavi, A., Nabipour, N., Shamshirband, S., Darabi, H., & Haghighi, A. T. (2020). Flash-flood hazard assessment using ensembles and Bayesian-based machine learning models: Application of the simulated annealing feature selection method. Science of the Total Environment, 711, 135161.
Hou, J., Zhou, N., Chen, G., Huang, M., & Bai, G. (2021). Rapid forecasting of urban flood inundation using multiple machine learning models. Natural Hazards, 108(2), 2335–2356.
Huang, Q., Wang, J., Li, M., Fei, M., & Dong, J. (2017). Modeling the influence of urbanization on urban pluvial flooding: A scenario-based case study in Shanghai. China. Natural Hazards, 87(2), 1035–1055.
Jamali, B., Löwe, R., Bach, P. M., Urich, C., Arnbjerg-Nielsen, K., & Deletic, A. (2018). A rapid urban flood inundation and damage assessment model. Journal of Hydrology, 564, 1085–1098.
Jamali, B., Bach, P. M., Cunningham, L., & Deletic, A. (2019). A Cellular Automata fast flood evaluation (CA-ffé) model. Water Resources Research, 55(6), 4936–4953.
Janizadeh, S., Avand, M., Jaafari, A., Phong, T. V., Bayat, M., Ahmadisharaf, E., ... & Lee, S. (2019). Prediction success of machine learning methods for flash flood susceptibility mapping in the tafresh watershed, Iran. Sustainability, 11(19), 5426.
Jonkman, S. N., & Kelman, I. (2005). An analysis of the causes and circumstances of flood disaster deaths. Disasters, 29(1), 75–97.
Kalyanapu, A. J., Burian, S. J., & McPherson, T. N. (2009). Effect of land use-based surface roughness on hydrologic model output. Journal of Spatial Hydrology, 9(2).
Latto, A., & Berg, R. (2020). National Hurricane Center Tropical Cyclone Report: Tropical Storm Imelda. Available at https://www.nhc.noaa.gov/data/tcr/AL112019_Imelda.pdf. Accessed 25 Jan 2023.
Lee, C. C. B., & Gharaibeh, N. G. (2020). Automating the evaluation of urban roadside drainage systems using mobile lidar data. Computers, Environment and Urban Systems, 82, 101502.
Lee, S., Kim, J. C., Jung, H. S., Lee, M. J., & Lee, S. (2017). Spatial prediction of flood susceptibility using random-forest and boosted-tree models in Seoul metropolitan city, Korea. Geomatics, Natural Hazards and Risk, 8(2), 1185–1203.
Li, D., Zhang, Q., Zio, E., Havlin, S., & Kang, R. (2015). Network reliability analysis based on percolation theory. Reliability Engineering & System Safety, 142, 556–562.
Liaw, A., & Wiener, M. (2002). Classification and regression by randomForest. R News, 2(3), 18–22.
Liu, L., Liu, Y., Wang, X., Yu, D., Liu, K., Huang, H., & Hu, G. (2015). Developing an effective 2-D urban flood inundation model for city emergency management based on cellular automata. Natural Hazards and Earth System Sciences, 15(3), 381–391.
Liu, X., Sahli, H., Meng, Y., Huang, Q., & Lin, L. (2017). Flood inundation mapping from optical satellite images using spatiotemporal context learning and modest AdaBoost. Remote Sensing, 9(6), 617.
Liu, Y. Y., Maidment, D. R., Tarboton, D. G., Zheng, X., Yildirim, A., Sazib, N. S., & Wang, S. (2016). A CyberGIS approach to generating high-resolution height above nearest drainage (HAND) raster for national flood mapping. The Third International Conference on CyberGIS and Geospatial Data Science (CyberGIS’16), Urbana, IL.
Lyu, H. M., Shen, S. L., Yang, J., & Yin, Z. Y. (2019). Inundation analysis of metro systems with the storm water management model incorporated into a geographical information system: A case study in Shanghai. Hydrology and Earth System Sciences, 23(10), 4293–4307.
Mobley, W., Sebastian, A., Highfield, W., & Brody, S. D. (2019). Estimating flood extent during Hurricane Harvey using maximum entropy to build a hazard distribution model. Journal of Flood Risk Management, 12, e12549.
Mobley, W., Sebastian, A., Blessing, R., Highfield, W. E., Stearns, L., & Brody, S. D. (2021). Quantification of continuous flood hazard using random forest classification and flood insurance claims at large spatial scales: A pilot study in southeast Texas. Natural Hazards and Earth System Sciences, 21(2), 807–822.
Nguyen, D. H., & Bae, D. H. (2020). Correcting mean areal precipitation forecasts to improve urban flooding predictions by using long short-term memory network. Journal of Hydrology, 584, 124710.
NOAA (National Oceanic and Atmospheric Administration). (2017). Fast facts: Hurricane costs. NOAA.
Nobre, A. D., Cuartas, L. A., Hodnett, M., Rennó, C. D., Rodrigues, G., Silveira, A., & Saleska, S. (2011). Height Above the Nearest Drainage–a hydrologically relevant new terrain model. Journal of Hydrology, 404(1–2), 13–29.
Podesta, C., Coleman, N., Esmalian, A., Yuan, F., & Mostafavi, A. (2021). Quantifying community resilience based on fluctuations in visits to points-of-interest derived from digital trace data. Journal of the Royal Society Interface, 18(177), 20210158.
Prasad, A. M., Iverson, L. R., & Liaw, A. (2006). Newer classification and regression tree techniques: Bagging and random forests for ecological prediction. Ecosystems, 9(2), 181–199.
Pregnolato, M., Ford, A., Wilkinson, S. M., & Dawson, R. J. (2017). The impact of flooding on road transport: A depthdisruption function. Transportation research part D: transport and environment, 55, 67-81.
Qian, Z. (2010). Without zoning: Urban development and land use controls in Houston. Cities, 27(1), 31–41.
Rawls, W. J., Brakensiek, D. L., & Miller, N. (1983). Green-Ampt infiltration parameters from soils data. Journal of Hydraulic Engineering, 109(1), 62–70.
Schapire, R. E. (2013). Explaining adaboost. In Empirical inference (pp. 37–52). Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-41136-6_5.
Sebastian, A., Gori, A., Blessing, R. B., van der Wiel, K., & Bass, B. (2019). Disentangling the impacts of human and environmental change on catchment response during Hurricane Harvey. Environmental Research Letters, 14(12), 124023.
Smith, R. A., Bates, P. D., & Hayes, C. (2012). Evaluation of a coastal flood inundation model using hard and soft data. Environmental Modelling & Software, 30, 35–46.
Sutton, C. D. (2005). Classification and regression trees, bagging, and boosting. Handbook of Statistics, 24, 303–329.
Tehrany, M. S., Kumar, L., & Shabani, F. (2019). A novel GIS-based ensemble technique for flood susceptibility mapping using evidential belief function and support vector machine: Brisbane. Australia. Peerj, 7, e7653.
Thomas, H., & Nisbet, T. R. (2007). An assessment of the impact of floodplain woodland on flood flows. Water and Environment Journal, 21(2), 114–126.
Versini, P. A. (2012). Use of radar rainfall estimates and forecasts to prevent flash flood in real time by using a road inundation warning system. Journal of Hydrology, 416, 157–170.
Yin, J., Yu, D., Yin, Z., Liu, M., & He, Q. (2016a). Evaluating the impact and risk of pluvial flash flood on intra-urban road network: A case study in the city center of Shanghai, China. Journal of Hydrology, 537, 138–145.
Yin, J., Yu, D., & Wilby, R. (2016b). Modelling the impact of land subsidence on urban pluvial flooding: A case study of downtown Shanghai, China. Science of the Total Environment, 544, 744–753.
Yu, D., Yin, J., & Liu, M. (2016). Validating city-scale surface water flood modelling using crowd-sourced data. Environmental Research Letters, 11(12), 124011.
Yuan, F., Liu, R., Mao, L., & Li, M. (2021a). Internet of people enabled framework for evaluating performance loss and resilience of urban critical infrastructures. Safety Science, 134, 105079.
Yuan, F., Xu, Y., Li, Q., & Mostafavi, A. (2022). Spatio-temporal graph convolutional networks for road network inundation status prediction during urban flooding. Computers, Environment and Urban Systems, 97, 101870.
Yuan, F., Yang, Y., Li, Q., & Mostafavi, A. (2021c). Unraveling the temporal importance of community-scale human activity features for rapid assessment of flood impacts. IEEE Access, 10, 1138–1150.
Acknowledgements
The authors would like to acknowledge the funding support from the X-Grant program (Presidential Excellence Fund) from the Texas A&M University. The authors would also like to acknowledge INRIX, and WAZE for providing the traffic data and WAZE report data respectively. Any opinions, findings, and conclusions or recommendations expressed in this research are those of the authors and do not necessarily reflect the views of the funding agencies.
Funding
The authors would like to acknowledge the funding support from the X-Grant program (Presidential Excellence Fund) from the Texas A&M University.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and model training were performed by Faxi Yuan. The first draft of the manuscript was written by Faxi Yuan and all authors commented on the previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yuan, F., Lee, CC., Mobley, W. et al. Predicting road flooding risk with crowdsourced reports and fine-grained traffic data. Comput.Urban Sci. 3, 15 (2023). https://doi.org/10.1007/s43762-023-00082-1
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s43762-023-00082-1