
Abstract
The aim of this paper is to achieve the optimal hyperparameters setup of a convolutional neural network (CNN) to address the localization of a mobile robot. The localization problem is solved with a hierarchical approach by using omnidirectional images as provided by a catadioptric visual sensor, with no panoramic conversion. In this way, we propose adapting and re-training AlexNet with a double purpose. First, to perform the rough localization step by means of a room retrieval task. Second, to carry out the fine localization step within the retrieved room, in which the CNN is used to obtain a holistic descriptor that is compared with the visual model of the retrieved room by means of a nearest neighbour search. To achieve this, a CNN has been adapted and re-trained to address both the room retrieval problem and the obtention of holistic descriptors from raw omnidirectional images. The novelty of this work is the use of a data augmentation technique and Bayesian optimization to address the training process robustly. As shown in the present paper, these tools have proven to be an efficient and robust solution to the localization problem even with substantial changes of the lighting conditions of the target environment.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Recently, the localization problem in mobile autonomous robots has been addressed in a robust way by means of omnidirectional cameras along with computer vision techniques. The cost of this kind of cameras is relatively low compared to other types of sensors and they provide a wide range of information with a 360° field of view. To extract the most relevant information from the images, the holistic (or global-appearance) description is nowadays an extended approach since it permits carrying out the localization more directly, based on a pairwise comparison between descriptors.
In addition, an efficient method to tackle the localization task is using hierarchical models with holistic descriptors in such a way that the localization can be resolved in two main steps. This approach involves sorting the visual information hierarchically into different layers of information. Subsequently, the localization is addressed in several steps. First, a rough localization step is performed to segment the room or area of the environment where the robot is, and second, a fine localization step, which is carried out in that pre-selected area.
Artificial intelligence (AI) techniques have been increasingly used over the past few years to tackle computer vision and robotics problems due to the hardware development. Among the different AI techniques, convolutional neural networks (CNN) have been proposed to address a wide range of problems in mobile robotics. They require a training process which must be robust and varied since it plays an important role in the success of the desired task. Therefore, the following issues must be considered: (1) a varied and large training dataset and (2) training parameters must be cautiously selected.
Related with the above information, the main objective of this work is to evaluate and optimize the training process of a CNN used in order to tackle the mapping and localization tasks of a mobile robot, which moves in an indoor environment in real operation conditions. This purpose is addressed by using the images obtained by an omnidirectional vision sensor installed on the mobile robot. In this way, the success of the proposed approach will depend on the correct performance of the two steps of the hierarchical localization using the visual information stored in the map.
This paper presents a novel localization approach based on a CNN that uses omnidirectional images with no panoramic conversion. Additionally, this work presents an efficient CNN training optimization process based on Bayesian optimization. The CNN will be re-adapted and used with a dual purpose: (1) the rough localization step which is carried out as a room retrieval problem and (2) the fine localization step which consists of refining the previous localization within the retrieved room by means of global-appearance descriptors obtained from intermediate layers of the same CNN. The main contributions of this paper can be summarized as follows.
-
We adapt and re-train a CNN with a robust training method in order to retrieve the room from which the robot captured an omnidirectional image. The training process relies on a data augmentation approach, which considers a variety of visual effects that can occur in a real application, and a Bayesian optimization of the main hyperparameters.
-
We use the re-trained CNN to obtain a holistic descriptor that is compared with the visual model of the retrieved room by a nearest neighbour search.
-
We propose and test the performance of this deep learning technique to address a hierarchical localization and study the influence of the different values of the optimal hyperparameters found with Bayesian optimization.
This work is an extension of the initial developments presented in [1]. In the present work, our proposal is more exhaustively put in context among the current developments on mapping and localization of mobile robots. Also, the training process is more exhaustively studied and a wider variety of experiments is carried out with the aim of studying and optimizing the performance of the proposed tools under real operation conditions.
The following sections are structured as follows. First, in the “State of the Art” section we present a review of the state of the art on mapping, localization and the role of artificial intelligence (AI) in mobile robotics. Second, we describe the methods proposed to adapt and train the CNN in “Training Process” section. After that, we explain in “Experiments” section our localization approach based on the adapted CNN and present the experiments carried out to test and validate the proposed method. Finally, conclusions and future works are outlined in “Conclusions” section.
State of the Art
Mapping and Localization
In recent years, the deployment of autonomous mobile robots has increased substantially due to their ability to automate processes and/or perform a number of tasks. To autonomously move in an a priori unknown environment, a mobile robot should be able to create a model of this environment (map) that allows it to estimate its pose (position and orientation) in a sufficiently precise way. In addition, to navigate, the robot must be able to detect obstacles or objects that may cause collisions.
Consequently, mapping and localization are two areas of study in the field of mobile robotics, and a robust solution to these tasks would enable the development of other high-level missions, such as exploration, trajectory planning and integrated navigation. Both mapping and localization are two very active areas of work, for which a multitude of solutions have been proposed, allowing the construction of maps with various types of sensors [2], multiple degrees of freedom [3], hierarchical organisation of the information in the model [4] and inclusion of semantic information [5]. However, the performance of most of these solutions decreases substantially when the robot navigates around complex and realistic environments [6]. For this reason, it is particularly interesting to study the localization of mobile robots in indoor environments, where GPS information is not always available and where the presence of people and other dynamic elements can cause unexpected situations that the robot must be able to deal with.
To build a model of the environment and estimate the robot’s position, the robot must be equipped with sensors that allow it to know the state of the environment and obtain relevant information from it. In this sense, the use of visual sensors is particularly appropriate to solve these tasks due to the large volume of information they capture. In particular, the use of omnidirectional cameras together with computer vision techniques has proven to be a solid alternative to address the localization task in mobile robotics [7]. This kind of cameras have a field of view up to 360\(^{\circ }\) and a relatively low cost compared to other types of sensors. In previous research works they have also been incorporated in vehicles whose trajectory is predicted with high accuracy [8]. Kuutti et al., [9] evaluated a variety of vehicle localization techniques and investigated their application to autonomous vehicles, all of them based on vision systems.
When working with images to solve the mapping and localization problem, it is necessary to extract relevant information from these scenes that is useful for the robot to robustly estimate its pose. This description of scenes can be done by extracting local features or global appearance descriptors. On the one hand, local features are based on the extraction of characteristic points, objects or regions of the scene. Each feature is described by a descriptor vector whereby a scene is represented by a set of features with their associated descriptors [10]. On the other hand, global appearance descriptors represent each scene using a single descriptor that collects the global information of the image, that is, departing from an image and through some mathematical transformations, a single vector is obtained (\(\vec {d}\in {\mathbb {R}}^{l\times 1}\)). Payá et al. [11] demonstrated that these holistic descriptors can be used for localization and map creation. Also, hierarchical localization can be addressed using omnidirectional images together with holistic descriptors [12, 13]. In the related literature, numerous works can be found that propose analytical methods for obtaining both types of descriptors.
Artificial Intelligence in Robotics
Relevant information from a scene can also be extracted using AI algorithms. This field has taken advantage of the improvement of hardware, which has led to the development of new algorithms and models that have been applied to different areas of knowledge, including robotics [14]. For instance, some authors have tackled the localization problem by using a classifier that classifies landmark observations [15]. Shvets et al. [16] use segmentation to discriminate between different surgical instruments. Other authors have proposed Convolutional Neural Networks to address robotic grasping from monocular images [17]. Many works have demonstrated the success of CNNs in the field of mobile robotics. In this way, Tai et al. [18] trained a CNN to address the problem of obstacle avoidance and navigation; Ameri et al. [19] carried out UAV localization in urban areas; Sandino et al. [20] also made use of UAVs and AI to carry out aerial mapping of forests affected by different pathogens; and Xu et al. [21] propose an indoor global localization system based on the training of a CNN. Also, Sinha et al. [22] use a CNN in combination with a monocular camera to tackle the re-localization in GPS-denied environments. To conclude, Chaves et al. [23] propose to build a semantic map by training a CNN for object detection.
Turning to feature extraction, some works have proposed the use of CNNs for the extraction of holistic descriptors. In this sense, the intermediate layers of CNNs can be used to obtain descriptors that characterize the input images. To cite some examples, Arroyo et al. [24] train a CNN to generate descriptors which are expected to be invariant against seasonal changes, so they can be used for localization tasks all year round. Support Vector Machines (SVM) are also proposed for feature extraction [25]. Cebollada et al. [26] address the localization task as an image retrieval problem by using descriptors obtained from intermediate layers of a retrained CNN. This work transforms omnidirectional images into panoramic ones with the computational cost that it implies. Among the techniques for feature extraction presented above and in line with previous works, the present work addresses the fine localization step by using the holistic descriptors from the intermediate layers of a CNN retrained with omnidirectional images with no panoramic conversion.
Regarding the training phase, deep learning models need a wide range of data to obtain a robust performance. Nevertheless, sometimes the available dataset is not large enough and therefore the CNN is not able to completely model the tendency of the data. This phenomenon is commonly known as underfitting. Hence, in this paper we use the data augmentation technique to avoid this problem, which consists in applying a set of modifications to the original data to increase the size of the training dataset. In this case, data augmentation is used to create new images by applying different effects to the original ones. Many authors have used the data augmentation technique to improve the performance of their models. For instance, Ding et al. [27] investigate the capability of a CNN combined with three different types of data augmentation operations to improve the performance of Synthetic Aperture Radar target recognition with the aim of achieving invariance against target translation, speckle variation in different observations, and pose missing. Salamon et al. [28] propose a CNN for environmental sound classification and an audio data augmentation for overcoming the lack of this kind of data. However, none of the methods proposed above address the visual effects that can occur when a robot navigates under real-operation conditions.
Another undesirable effect that can occur in the training phase is the overfitting, which consists in creating a model that is so tight to the training data that it does not generalize well to the test data. In this sense, both data augmentation and optimization of the training hyperparameters are beneficial to avoid this effect. As for the optimization of training hyperparameters, in the machine learning field, they are mainly related to loss function optimization algorithms, such as Stochastic Gradient Descent (SGD). It is important not to confuse hyperparameters with model parameters (bias and weights), whose values are adjusted during the training process. For example, whereas the weights of the CNNs are parameters, the learning rate is a hyperparameter. As the hyperparameters modify in some way the algorithm that optimizes the loss function, they are involved in the estimation of the model parameters so their values must be chosen carefully. Such parameters are usually determined by the practitioner and adjusted for a given predictive modelling problem. But, the network designer cannot know in advance the best values of the hyperparameters for a given problem. Consequently, it is common to set values that worked well in other similar problems, or search for the best value by trial and error.
The methods used to set the hyperparameters are of great relevance as the correct training of the model depends on them. Optimization methods like random search or grid search have proven to improve the results achieved by previous standard methods [29]. In consequence, hyperparameter optimization has become an active research area [29,30,31] due to the fact that the optimization methods are able to obtain a hyperparameter configuration similar or better than the established by human domain experts [32, 33]. Recently, Bayesian optimization has shown to achieve good performances without compromising efficiency [34, 35].
To sum up, some authors have developed CNNs to carry out classification tasks. Additionally, previous works have also proposed solving the localization task by using intermediate layers of CNN as holistic description method. The present work tries to go one step beyond and proposes an approach based on a unique CNN which is re-adapted to address both tasks at the same time (room retrieval and holistic description) therefore solving the complete hierarchical localization problem. Furthermore, we focus in achieving a robust training process relying on a data augmentation approach and a Bayesian optimization of the main hyperparameters.
Training Process
The objective of the present work is building a deep learning model that is not only capable of retrieving the room where the robot captured the image, but also of providing a global-appearance descriptor with a better performance than hand-crafted methods. Retrieving the room is approached as a classification task, where the CNN is trained with visual data and the corresponding label of each image. Once the CNN is properly trained, it will be used with a double purpose: (1) solving the rough localization step as a room retrieval problem and (2) addressing the fine localization step by using the intermediate layers of the network to obtain holistic descriptors and using them to estimate the position within the room selected in the previous step.
CNN Adaption
Training a CNN from scratch involves a wide experience with network architectures, a large and wide training dataset and a significant computing time. Hence, the proposal of this work is in line with previous ones [26]: adapting and re-training CNNs. The purpose is to provide an efficient solution, avoiding complex and computing-time-demanding deep learning models. In that way, we propose to take AlexNet as a starting point [13, 36], owing to its simplicity and the success achieved in previous works, especially, when it is re-trained for new classification tasks by means of transfer learning [37]. Also, Cebollada et al. [26] achieve successful results re-adapting and retraining AlexNet. These previous works are based on non-panoramic and panoramic images. However, the present work proposes using omnidirectional images in order to study the feasibility of AlexNet when departing from this kind of images. This approach presents a double benefit: (a) saving computing time, since we use raw omnidirectional images with no panoramic conversion and (2) obtaining global-appearance descriptors from omnidirectional images by means of a CNN, which has been barely studied in the current state of the art. Furthermore, we propose a Bayesian optimization to find the optimal hyperparameter setup for training the model.
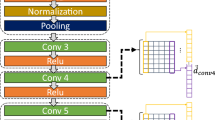
As for the CNN adaption, some layers of AlexNet need to be modified to address the proposed room retrieval task. In particular, the input layer is resized from \(227 \times 227 \times 3\) pixels to \(470 \times 470 \times 3\) pixels, the fully connected layer \(fc_6\) together with the softmax and the classification layer are replaced. Also, the \(fc_8\) layer needs to be modified to return an array of nine components, corresponding to the nine rooms of the target environment described in “The Freiburg Dataset” section. The original purpose of AlexNet is to classify among 1000 classes. However, in this work, we only have nine classes so the softmax and classification layers are modified to calculate the probability among those categories. Figure 1 shows the architecture of AlexNet adapted to the proposed room retrieval. Thus, after these adaptations, the entire architecture is retrained, taking advantage of AlexNet’s initial weights.

Architecture of AlexNet adapted and re-trained to retrieve the room where the image was captured within the environment. Extracted from [1]
Data Augmentation
Data augmentation has been proposed in this paper to prevent the CNN from over-fitting and consequently, improving the performance of the model. This technique basically consists in increasing the number of training images, i.e. creating new ones through the application of different effects. Furthermore, if visual effects are considered in the data augmentation, the deep learning model is expected to be robust against them. The data augmentation proposed in this work is based on applying a variety of visual effects over the training images which can actually occur when a robot is capturing images in real operation conditions:
-
Rotation: This effect consists in applying a random rotation between 10\(^{\circ }\) and 350\(^{\circ }\) to the omnidirectional image.
-
Reflection: The omnidirectional image is reflected.
-
Brightness: We create a new image brighter than the original one by assigning values between 0 (minimum brightness) and 1 (maximum brightness) to those which are between 0 and 0.5 in the original image, through a linear transformation. Moreover, pixels which are between 0.5 and 1 in the original image are set to 1.
-
Darkness: This effect creates a new image which is darker than the original one, and consists in assigning values between 0 and 1 to those which are between 0.3 and 1 in the original image, through a linear transformation. Furthermore, pixels which are between 0 and 0.3 in the original image are set to 0. These last two effects try to simulate some changes in the lighting conditions that can occur in the environment. Furthermore, these effects are not applied at the same time on the same image.
-
Gaussian noise: This effect consists in applying a white Gaussian noise to the image.
-
Occlusion: It consists in introducing geometrical gray objects in random parts of the image to simulate occlusions caused by people or some components of the sensor setup.
-
Blur effect: This effect tries to simulate images under dynamic conditions that can occur when the camera is moving (the image is blurred).
Figure 2 shows an example of the effects applied to a sample of omnidirectional image from the training dataset. The first image corresponds to the original one and the rest of images include the different effects presented above (they have been separately applied). The augmented dataset departs from the original training dataset, which contains 519 images, and all possible combinations of the presented effects are applied to it (except for the brightness and darkness effects). Therefore, the augmented dataset contains 213.504 images.

Example of data augmentation where only one effect is applied over each image. a Original image captured within the Freiburg environment, b blur effect, c random rotation, d reflection, e darkness, f brightness, g Gaussian noise and h occlusions. The images contained in this dataset can be downloaded from the web site https://www.cas.kth.se/COLD/
Bayesian Optimization
The present work proposes to carry out an optimization of the hyperparameters to achieve an optimal training of the model. The values taken by the hyperparameters can be crucial and vary depending on the task to be performed by the network and the input data. In addition, there are different hyperparameters depending on the optimization algorithm selected to minimize the loss function. In this work different optimization functions have been explored such as Stochastic Gradient Descent with Momentum (SGDM), Adaptive Moments (Adam) and Root Mean Squared Propagation (RMSProp). The optimization function is selected before starting the hyperparameters optimization and it will remain constant during the whole process.
As for the hyperparameter optimization algorithm, Bayesian optimization is used in this work due to its great potential, since it is able to identify parts of the space that are unlikely to provide a good outcome, and avoid running tests of those hyperparameter values. The hyperparameters evaluated are the following:
-
Max Epochs. This parameter is a positive integer that refers to the maximum number of epochs during which training is carried out.
-
Initial Learn Rate. Positive scalar that determines the initial step size for moving toward a minimum of a loss function.
-
Learn Rate Drop Period. Positive scalar value that indicates the number of epochs for dropping the learning rate.
-
Learn Rate Drop Factor. Scalar value from 0 to 1 that indicates the factor for dropping the learning rate.
-
Momentum. This parameter is a scalar value from 0 to 1 related to the SGDM optimization function. It refers to the contribution of the previous iteration to the current one to maintain a coherent direction towards the minimum of the loss function. If its value is 0, the previous step has no contribution, but if its value is 1, the previous step has the maximal contribution.
-
L2 Regularization. This parameter is a positive scalar value that adds a regularization term (or weight decay) to the loss function. Its purpose is to reduce the generalization error and prevent over-fitting.
-
Squared Gradient Decay Factor. This parameter is a positive scalar (lower than 1) related to Adam and RMSProp optimization algorithms. It indicates the decay rate of squared gradient moving average.
-
Gradient Decay Factor. This parameter is a positive scalar (lower than 1) related to Adam. It indicates the decay rate of gradient moving average.
-
Epsilon. This parameter is a positive scalar that is only used with Adam and RMSProp. It indicates the denominator offset to avoid dividing by zero in the network parameter update.
Experiments
Localization
The present work proposes to carry out a hierarchical localization using a CNN which is adapted and retrained with a twofold purpose: (a) approaching the rough localization step as a room retrieval problem, in which a test image is classified by their similarity to a set of possible rooms; and (b) obtaining a holistic descriptor for each input image from the intermediate layers of the CNN. The low-level layer is formed by the descriptors of the training images, which permit solving the fine localization step as an image retrieval between the descriptor of the test image and the descriptors of the training images.
As for the hierarchical localization, the rough localization step provides a faster localization by identifying the room where the robot captured the image, and the fine localization step makes it possible to know the position of the robot within the pre-selected room by using more accurate information. Figure 3 shows a diagram of the proposed hierarchical localization. First, the rough localization step is carried out by retrieving the room \(c_i\) where a test image \(im_\mathrm{test}\) was captured as a classification problem. At the same time, the CNN is not only capable of classifying the image in its room, but can also provide holistic descriptors from intermediate layers. Then, once the room is retrieved, the fine localization step is carried out by comparing the descriptor of the test image \(\vec {d}_\mathrm{test}\) with the descriptors \(D_{c_i}=\{ \vec {d}_{c_i,1},\vec {d}_{c_i,2},\ldots ,\vec {d}_{c_i,N_{i}}\}\) corresponding to the training dataset images belonging to the retrieved room \(c_i\) and the most similar descriptor \(\vec {d}_{c_i,k}\) is retrieved. To conclude, the position where the robot captured the test image is estimated as the coordinates where \(im_{c_i,k}\) was captured.
The Freiburg Dataset
The present work uses the images available in the Freiburg dataset, which is part of the COLD (COsy Localization Database) database [38]. The Freiburg dataset contains omnidirectional images captured by a robot that follows different paths in a building of the Freiburg University. The robot visits different rooms such as kitchens, corridors, printer areas, bathrooms, personal offices, etc. The image capturing task is tackled under real operation conditions. For example, changes in the furniture, people that appear in the scenes, changes in the illumination conditions (cloudy days, sunny days and nights), etc. Hence, to evaluate the effect of those changes in the localization task, we propose using some of the images captured on cloudy days as training data. Moreover, we use another dataset of cloudy images (different to the previous one) to evaluate the localization task with no illumination changes. Furthermore, in order to evaluate the localization with illumination changes, we use the datasets captured in sunny days and at night. Apart from the images, the dataset also provides a ground truth (obtained with a laser sensor), which is used in the present work with the only purpose to measure the localization error.

Diagram of the proposed hierarchical localization. The test image \(im_\mathrm{test}\) is the input of the CNN, which is capable of estimating the most likely room \(c_i\) and generating a holistic descriptor \(\vec {d}_\mathrm{test}\) from one of the intermediate layers. This descriptor is compared with the descriptors from the training dataset included in the retrieved room by means of a nearest neighbour search. Consequently, the image that corresponds to the most similar descriptor (\(im_{c_i,k}\)) gives the position where \(im_\mathrm{test}\) was captured. Extracted from [1]
Regarding the capturing process, as the robot is capturing images while it moves, the images may contain blur effects or other dynamic changes. In addition, the selected environment contains the longest trajectory among those available in the database. Finally, wide windows and glass walls are present in numerous points of the environment, what makes the visual localization an especially challenging problem. Therefore, the environment has the perfect conditions to evaluate the proposed localization methods under real operation conditions.
The selected dataset contains images captured in 9 different rooms: a kitchen, a bathroom, a printer area, a stair area, a long corridor and four offices. The cloudy dataset is downsampled to obtain a resulting dataset with an average distance of 20 cm between the capture points of consecutive images, which will lead to training dataset 1, with 519 images. This dataset is used to train the CNNs and as a ground truth. The training dataset 2 is obtained by normalizing the number of images from each room of training dataset 1, resulting in a total of 230 images. The objective of this dataset is to prevent the CNN from learning the probability that an image of a room appears as a function of the number of samples it contains. Additionally, the training dataset 1 is augmented as described in “Data Augmentation” section, resulting in the training dataset 3, which contains 213.504 images. These datasets will be used, individually, to train the CNNs. In this way, it will be possible to know the effect of the data selection and augmentation on the performance of the network.
Regarding the test data, different datasets are considered: test dataset 1, containing images captured in cloudy conditions (along a route which is different from training set 1), with a total of 2595 images; test dataset 2, containing all images captured in sunny conditions (2807 images) and test dataset 3, with all images captured at night (2876 images). Therefore, the training of the network is carried out, in all cases, with images captured in cloudy conditions, and the test will be carried out with three different conditions: cloudy, sunny or night, so it will be possible to test the robustness of the network against this type of lighting changes.
As a summary, Table 1 shows the number of images in each room for each of the data sets mentioned above. Furthermore, it should be remembered that the training datasets are subdivided into training (80%) and training validation (20%).
CNN Training and Room Retrieval
The rough localization step is addressed as a room retrieval problem, approached as a classification problem. A CNN is trained or re-trained to retrieve the room where the robot captured the input image. Regarding the training process, ten experiments have been carried out. The first five experiments do not consider hyperparameters optimization and the rest include Bayesian Optimization to tackle the hyperparameters optimization.
-
Experiment 1: Training the adapted CNN with the training dataset 1 without using the weights and bias of AlexNet (no transfer learning).
-
Experiment 2: Re-training the adapted CNN with the training dataset 1 departing from the weights and bias of AlexNet (transfer learning).
-
Experiment 3: Re-training the adapted CNN with the training dataset 1 departing from the weights and bias of AlexNet (transfer learning). In this case, the adapted CNN is slightly different, since the input layer has not been resized. Consequently, the dimensions of the input images need to be reduced from \(470 \times 470 \times 3\) pixels to \(227 \times 227 \times 3\) pixels.
-
Experiment 4: Re-training the adapted CNN with the training dataset 2 departing from the weights and bias of AlexNet (transfer learning).
-
Experiment 5: Re-training the adapted CNN with the training dataset 3 departing from the weights and bias of AlexNet (transfer learning).
-
Experiment 6: Re-training the adapted CNN with the training dataset 1 departing from the weights and bias of AlexNet (transfer learning). In this experiment, the next hyperparameters are optimized: Initial Learn Rate, Momentum and L2 Regularization. Also, 30 different combinations of values are tested to perform the optimization.
-
Experiment 7: Re-training the adapted CNN with the training dataset 3 departing from the weights and bias of AlexNet (transfer learning) and the hyperparameters that were found as optimal for experiment 6.
-
Experiment 8: Re-training the adapted CNN with the training dataset 3 departing from the weights and bias of AlexNet (transfer learning). In this experiment, the next hyperparameters are optimized: Momentum. Also, 8 different combinations of values are tested to perform the optimization.
-
Experiment 9: Re-training the adapted CNN with the training dataset 3 departing from the weights and bias of AlexNet (transfer learning). In this experiment, the next hyperparameters are optimized: Initial Learn Rate and Momentum. Also, 8 different combinations of values are tested to perform the optimization.
-
Experiment 10: Re-training the adapted CNN with the training dataset 3 departing from the weights and bias of AlexNet (transfer learning). In this experiment, the next hyperparameters are optimized: Initial Learn Rate and L2 Regularization. Also, 30 different combinations of values are tested to perform the optimization.
Figure 5 shows the value of the objective function after performing the hyperparameter optimization of the experiments 8 and 10. As for the experiments in which a Bayesian optimization has been carried out (from experiment 6 to 10), the Table 2 shows the selected hyperparameters, the range of values they can adopt and the optimal values found after the optimization process for each experiment. Additionally, the Fig. 4 shows the classification accuracy for the test images.
As this figure shows, in the case of experiment 1, training without using the weights and bias of AlexNet is not beneficial for the CNN performance. The best result for sunny conditions is obtained in experiment 2. In the third experiment, which used the original input layer of Alexnet, the accuracy slightly decreases for cloudy and sunny conditions. As for the experiment 4, it can be seen that normalising the number of images does not improve the results in this case, since it implies reducing the number of training images and therefore losing valuable information. This figure also shows that the data augmentation (training dataset 3, which is used in experiments 5, 7, 8, 9 and 10) does not improve the classification results with sunny condition. Therefore, we have carried out a deeper analysis of this case and we show, in Fig. 6, the confusion matrices of the best case of the experiment 2 (with no data augmentation) and 8 (with data augmentation). From these figures, we can conclude that the data augmentation improves the success ratio of the room retrieval in almost every room. The CNN only makes mistakes in the “Printer Area”, a room where the sunbeams pass through the windows at an oblique angle. This fact causes confusion in the model if it is trained with a data augmentation dataset. Finally, the experiments with Bayesian Optimization improved their results for both cloudy and night conditions.

Success ratio of the CNN for the room retrieval task. Results obtained under cloudy (blue), night (red) and sunny (yellow) illumination conditions

Value of the objective function after performing the Bayesian optimization in experiment a 8 and b 10

Confusion matrices for sunny conditions in the best case of experiment a 2 and b 8
Hierarchical Localization by Using Holistic Descriptors
This section shows the experimental part corresponding to the hierarchical localization. As mentioned above, the hierarchical localization proposed in this work is composed of two steps. The rough localization step, which consists in re-training a CNN to carry out the room retrieval task, whose results are shown in “CNN Training and Room Retrieval” section and the fine localization step, which consists is using the previous CNN to obtain holistic descriptors to estimate the position where an image was captured by using a nearest neighbour search method. This section analyses the second step. Among the different intermediate layers of the CNN to extract the descriptor, we have studied the fully connected layers 6 and 7, as they have shown more robustness against changes of lighting conditions in preliminary experiments. In fact, \(fc_6\) is studied more exhaustively as these preliminary experiments showed an improved performance.
Therefore, nine experiments have been carried out to study the second step of the hierarchical localization, departing from the “CNN Training and Room Retrieval” section. The subindex of CNN indicates to which experiment (“CNN Training and Room Retrieval” section) the CNN corresponds:
-
CNN \(_2\)+\(fc_6\): The rough step is carried out by using the CNN trained in the experiment 2 and the fine step uses the same CNN to obtain holistic descriptors from the layer \(fc_6\).
-
CNN \(_2\)+\(fc_7\): The rough step is carried out by using the CNN trained in the experiment 2 and the fine step uses the same CNN to obtain holistic descriptors from the layer \(fc_7\).
-
CNN \(_2\)+AlexNet: The rough step is carried out by using the CNN trained in the experiment 2 and the fine step uses AlexNet to obtain holistic descriptors from the layer \(fc_6\).
-
CNN \(_5\)+\(fc_6\): The rough step is carried out by using the CNN trained in the experiment 5 and the fine step uses the same CNN to obtain holistic descriptors from the layer \(fc_6\).
-
CNN \(_6\)+\(fc_6\): The rough step is carried out by using the CNN trained in the experiment 6 and the fine step uses the same CNN to obtain holistic descriptors from the layer \(fc_6\).
-
CNN \(_7\)+\(fc_6\): The rough step is carried out by using the CNN trained in the experiment 7 and the fine step uses the same CNN to obtain holistic descriptors from the layer \(fc_6\).
-
CNN \(_8\)+\(fc_6\): The rough step is carried out by using the CNN trained in the experiment 8 and the fine step uses the same CNN to obtain holistic descriptors from the layer \(fc_6\).
-
CNN \(_9\)+\(fc_6\): The rough step is carried out by using the CNN trained in the experiment 9 and the fine step uses the same CNN to obtain holistic descriptors from the layer \(fc_6\).
-
CNN \(_{10}\)+\(fc_6\): The rough step is carried out by using the CNN trained in the experiment 10 and the fine step uses the same CNN to obtain holistic descriptors from the layer \(fc_6\).
The error of localization is computed as the Euclidean distance between the estimated position and the current position, which is given by the ground truth. Furthermore, we have evaluated the localization error considering separately the three illumination conditions, since the aim of this work is to study the robustness of the proposed method in real operating conditions. The results obtained are shown in Fig. 7.

Hierarchical localization results (localization error in meters). Results obtained with cloudy (blue), night (red) and sunny (yellow) illumination conditions
In the hierarchical localization, the localization error is strongly related to the success rate of room retrieval, as expected. That is, if the CNN fails in the room retrieval, the error of localization substantially increases. In consequence, the best localization error under sunny condition is found with the CNN\(_2\), which has the best accuracy for this lighting condition. As for cloudy and night, the best values are given with CNN\(_5\), CNN\(_7\), CNN\(_8\) and CNN\(_9\), whose training included Bayesian optimization.
To compare the proposed method with other existing works, Table 3 evaluates the localization results obtained in the present work against those obtained by Cebollada et al. [39], who presented a hierarchical localization using hand-crafted features (HOG and gist) and tested them with the COLD database.
Regarding the results obtained in Table 3, the localization error for sunny and night conditions is better in the present work. It should be noted that the proposed method, thanks to the training that we develop, proves to be robust against substantial changes in the environment, achieving relatively good and balanced results for the three illumination conditions. The table shows that gist works better when the test images present the same conditions (cloudy) than the images in the model, but the errors of such hand-crafted descriptors are substantially higher under night and sunny conditions. The performance of the present work is more competitive under such challenging conditions.
Conclusions
In this work, a deep learning technique has been evaluated to build hierarchical topological models for localization. This technique consists in training a convolutional neural network for addressing a room retrieval task. Furthermore, the CNN is also used to obtain a holistic descriptor from the intermediate layers in order to extract relevant information that characterizes the input images. Additionally, the use of two techniques to improve the training process of a CNN has been evaluated: data augmentation and hyperparameter optimization.
As for the hyperparameter optimization, the Bayesian optimization has shown to improve the training process of the CNN, since the accuracy of the CNN for the room retrieval task increases, in general terms, when this approach is considered. Moreover, the CNN performs better when trained with an augmented dataset. Regarding the results obtained with images captured at night, they are similar to those obtained with no illumination changes (i.e., under cloudy conditions), which is a great improvement. However, the performance slightly decreases with sunny illumination conditions. As mentioned in “CNN Training and Room Retrieval” section, we cannot say in general that data augmentation performs poorly in sunny conditions. As detailed, the success rate increases for most rooms, except for the first one (printer area), which is severely affected by the sunbeams. This fact increases the number of confusions and leads to a drop in the global accuracy for sunny conditions.
As shown in the experiments, it is beneficial for the CNN to adapt its input layer to the size of the images, instead of resizing the images to the size of the input layer. Moreover, re-training the CNN departing from the AlexNet weights and bias (transfer learning) has proved to be a more robust option than training from scratch. Additionally, training a CNN with omnidirectional images has presented good results to carry out a room retrieval task. This is a novelty in the field, since scarce works have approached the localization task by means of a deep learning model based on omnidirectional images.
Therefore, in the present work a CNN has been proposed to carry out a hierarchical localization by retrieving the room where an image was captured and also, obtaining holistic descriptors. This method has successfully demonstrated to be able to address the localization task, obtaining results of localization error considerably low with cloudy and night conditions. The minimum error achieved is 25 cm, which is a relatively competitive result if we consider that the average distance between consecutive images in the training dataset is around 20 cm. In the hierarchical localization, the localization error is strongly related to the success rate of room retrieval. Consequently, the localization error for sunny conditions is higher due to the lower accuracy in the room retrieval. On the contrary, the localization error for night and cloudy conditions are almost equal.
Finally, the major drawback of using CNNs to obtain visual descriptors, compared to other purely analytic methods such as HOG or gist is that a training process is required. Notwithstanding that, this training is done offline, before solving the localization process. Once the network is trained and ready, the robot only has to capture new images and input them to the network to estimate its position.
In future works, studying more advanced techniques for the reduction of the localization error under sunny illumination conditions is a priority. Furthermore, we will evaluate other deep learning techniques such us Siamese Neural Networks, LSTM networks or autoencoders. Finally, we will approach the localization problem in outdoor environments using CNNs, considering the specificities of such scenarios.
References
Cabrera J, Cebollada S, Payá L, Flores M, Reinoso O. A robust CNN training approach to address hierarchical localization with omnidirectional images. In: Proceedings of the 18th International Conference on Informatics in Control, Automation and Robotics - ICINCO. SciTePress, Portugal; 2021, pp. 301–310. DOIurlhttps://doi.org/10.5220/0010574603010310. Ed. INSTICC.
Kim P, Chen J, Cho YK. SLAM-driven robotic mapping and registration of 3D point clouds. Autom Constr. 2018;89:38–48. https://doi.org/10.1016/j.autcon.2018.01.009.
Rebecq H, Horstschaefer T, Gallego G, Scaramuzza D. EVO: a geometric approach to event-based 6-DOF parallel tracking and mapping in real time. IEEE Robot Autom Lett. 2017;2:593–600.
Ruiz-Sarmiento J-R, Galindo C, Gonzalez-Jimenez J. Building multiversal semantic maps for mobile robot operation. Knowl Based Syst. 2017;119:257–72. https://doi.org/10.1016/j.knosys.2016.12.016.
Sualeh M, Kim G-W. Simultaneous localization and mapping in the epoch of semantics: a survey. Int J Control Autom Syst. 2018;17:729–42.
Garcia-Fidalgo E, Ortiz A. Vision-based topological mapping and localization methods: A survey. Robot Auton Syst. 2015;64:1–20. https://doi.org/10.1016/j.robot.2014.11.009.
Payá L, Gil A, Reinoso O. A state-of-the-art review on mapping and localization of mobile robots using omnidirectional vision sensors. J Sens. 2017;2017:1–20. https://doi.org/10.1155/2017/3497650.
Tardif J-P, Pavlidis Y, Daniilidis K. Monocular visual odometry in urban environments using an omnidirectional camera. In: 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems; 2008, p. 2538. https://doi.org/10.1109/IROS.2008.4651205.
Kuutti S, Fallah S, Katsaros K, Dianati M, Mccullough F, Mouzakitis A. A survey of the state-of-the-art localisation techniques and their potentials for autonomous vehicle applications. IEEE Internet Things J. 2018;5:829–46. https://doi.org/10.1109/JIOT.2018.2812300.
Andreasson H, Treptow A, Duckett T. Localization for mobile robots using panoramic vision, local features and particle filter. In: Proceedings of the 2005 IEEE International Conference on Robotics and Automation; 2005, pp. 3348–3353. https://doi.org/10.1109/ROBOT.2005.1570627.
Payá L, Amorós F, Fernández L, Reinoso O. Performance of global-appearance descriptors in map building and localization using omnidirectional vision. Sensors. 2014;14(2):3033–64.
Cebollada S, Payá L, Román V, Reinoso O. Hierarchical localization in topological models under varying illumination using holistic visual descriptors. IEEE Access. 2019;7:49580–95. https://doi.org/10.1109/ACCESS.2019.2910581.
Payá L, Peidró A, Amorós F, Valiente D, Reinoso O. Modeling environments hierarchically with omnidirectional imaging and global-appearance descriptors. Rem Sens. 2018;10(4):522.
Cebollada S, Payá L, Flores M, Peidró A, Reinoso O. A state-of-the-art review on mobile robotics tasks using artificial intelligence and visual data. Expert Syst Appl. 2021;167:114195. https://doi.org/10.1016/j.eswa.2020.114195.
Dymczyk M, Gilitschenski I, Nieto J, Lynen S, Zeisl B, Siegwart R. LandmarkBoost: Efficient visualContext classifiers for robust localization. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS); 2018, pp. 677–684. https://doi.org/10.1109/IROS.2018.8594100.
Shvets AA, Rakhlin A, Kalinin AA, Iglovikov VI. Automatic instrument segmentation in robot-assisted surgery using deep learning. In: 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA); 2018, pp. 624–628. https://doi.org/10.1109/ICMLA.2018.00100.
Levine S, Pastor P, Krizhevsky A, Ibarz J, Quillen D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int J Robot Res. 2018;37(4–5):421–36.
Tai L, Liu M. Mobile robots exploration through CNN-based reinforcement learning. Robot Biomim. 2016;3:24. https://doi.org/10.1186/s40638-016-0055-x.
Amer K, Samy M, ElHakim R, Shaker M, ElHelw M. Convolutional neural network-based deep urban signatures with application to drone localization. In: 2017 IEEE International Conference on Computer Vision Workshop (ICCVW). IEEE Computer Society, Los Alamitos, CA; 2017, pp. 2138–2145. https://doi.org/10.1109/ICCVW.2017.250.
Sandino J, Pegg G, Gonzalez L, Smith G. Aerial mapping of forests affected by pathogens using UAVs, hyperspectral sensors, and artificial intelligence. Sensors. 2018;18:944. https://doi.org/10.3390/s18040944.
Xu S, Chou W, Dong H. A robust indoor localization system integrating visual localization aided by CNN-based image retrieval with Monte Carlo localization. Sensors. 2019;19(2):249. https://doi.org/10.3390/s19020249.
Sinha H, Patrikar J, Dhekane EG, Pandey G, Kothari M. Convolutional neural network based sensors for mobile robot relocalization. In: 2018 23rd International Conference on Methods Models in Automation Robotics (MMAR); 2018, pp. 774–779. https://doi.org/10.1109/MMAR.2018.8485921.
Chaves D, Ruiz-Sarmiento JR, Petkov N, Gonzalez-Jimenez J. Integration of CNN into a robotic architecture to build semantic maps of indoor environments. In: International Work-Conference on Artificial Neural Networks. Springer; 2019, pp. 313–324.
Arroyo R, Alcantarilla PF, Bergasa LM, Romera E. Fusion and binarization of CNN features for robust topological localization across seasons. In: 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS); 2016, pp. 4656–4663. https://doi.org/10.1109/IROS.2016.7759685.
Wozniak P, Afrisal H, Esparza RG, Kwolek B. Scene recognition for indoor localization of mobile robots using deep CNN. In: International Conference on Computer Vision and Graphics. Springer; 2018, pp. 137–147.
Cebollada S, Payá L, Flores M, Román V, Peidró A, Reinoso O. A deep learning tool to solve localization in mobile autonomous robotics. In: ICINCO 2020, 17th International Conference on Informatics in Control, Automation and Robotics (Lieusaint-Paris, France, 7–9 July, 2020). Ed. INSTICC, Portugal; 2020.
Ding J, Chen B, Liu H, Huang M. Convolutional neural network with data augmentation for SAR target recognition. IEEE Geosci Remote Sens Lett. 2016;13(3):364–8.
Salamon J, Bello JP. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process Lett. 2017;24(3):279–83. https://doi.org/10.1109/LSP.2017.2657381.
Bergstra J, Bengio Y. Random search for hyper-parameter optimization. J Mach Learn Res. 2012;13:281–305.
Falkner S, Klein A, Hutter F. BOHB: Robust and efficient hyperparameter optimization at scale. arXiv preprint arXiv:1807.01774 (2018).
Feurer M, Hutter F. Hyperparameter optimization. In: Hutter F, Kotthoff L, Vanschoren J, editors. Automated machine learning. The Springer Series on Challenges in Machine Learning. Cham: Springer; 2019. p. 3–33.
Bergstra J, Yamins D, Cox DD. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In: ICML’13: Proceedings of the 30th International Conference on International Conference on Machine Learning; 2013.
Kotthoff L, Thornton C, Hoos HH, Hutter F, Leyton-Brown K. Auto-WEKA: Automatic model selection and hyperparameter optimization in WEKA. In: Hutter F, Kotthoff L, Vanschoren J, editors. Automated machine learning. The Springer Series on Challenges in Machine Learning. Cham: Springer; 2019.
Snoek J, Rippel O, Swersky K, Kiros R, Satish N, Sundaram N, Patwary M, Prabhat M, Adams R. Calable Bayesian optimization using deep neural networks. In: International Conference on Machine Learning; 2015, pp. 2171–2180.
Domhan T, Springenberg JT, Hutter F. Speeding up automatic hyperparameter optimization of deep neural networks by extrapolation of learning curves. In: Twenty-Fourth International Joint Conference on Artificial Intelligence; 2015.
Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst. 2012;25:1097–105.
Han D, Liu Q, Fan W. A new image classification method using CNN transfer learning and web data augmentation. Expert Syst Appl. 2018;95:43–56.
Pronobis A, Caputo B. COLD: COsy Localization Database. Int J Robot Res (IJRR). 2009;28(5):588–94. https://doi.org/10.1177/0278364909103912.
Cebollada S, Payá L, Mayol W, Reinoso O. Evaluation of clustering methods in compression of topological models and visual place recognition using global appearance descriptors. Appl Sci. 2019;9(3):377.
Acknowledgements
This work is part of the project PID2020-116418RB-I00 funded by MCIN/AEI/10.13039/501100011033 and of the project PROMETEO/2021/075 funded by Generalitat Valenciana.
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Informatics in Control, Automation and Robotics” guest edited by Kurosh Madani, Oleg Gusikhin and Henk Nijmeijer.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cabrera, J.J., Cebollada, S., Flores, M. et al. Training, Optimization and Validation of a CNN for Room Retrieval and Description of Omnidirectional Images. SN COMPUT. SCI. 3, 271 (2022). https://doi.org/10.1007/s42979-022-01127-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-022-01127-8