
Abstract
Statistical treatment rules map data into treatment choices. Optimal treatment rules maximize social welfare. Although some finite sample results exist, it is generally difficult to prove that a particular treatment rule is optimal. This paper develops asymptotic and numerical results on minimax-regret treatment rules when there are many treatments. I first extend a result of Hirano and Porter (Econometrica 77:1683–1701, 2009) to show that an empirical success rule is asymptotically optimal under the minimax-regret criterion. The key difference is that I use a permutation invariance argument from Lehmann (Ann Math Stat 37:1–6, 1966) to solve the limit experiment instead of applying results from hypothesis testing. I then compare the finite sample performance of several treatment rules. I find that the empirical success rule performs poorly in unbalanced designs, and that when prior information about treatments is symmetric, balanced designs are preferred to unbalanced designs. Finally, I discuss how to compute optimal finite sample rules by applying methods from computational game theory.
Similar content being viewed by others

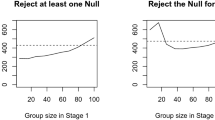
Notes
The finite sample results in section 3 of Tetenov (2012), which allow for unbounded support, are an exception.
Although I require the design to be ‘asymptotically balanced’; see section 2.5.
This can be achieved by simply adding the same constant to all welfare values, which will not affect the decision problem.
One possibility is to consider the \(\lambda _k\)’s as unknown parameters of the sampling process, rather than known constants. They can then be included in the local parameterization. I leave this extension to future research.
Note that a balanced allocation requires a total sample size that is a multiple of the number of treatments, K.
Without commitment, we are back in the situation of looking at decision rules for an ex ante known allocation.
For example, see List et al. (2011).
Another rule, suggested by Schlag (2006), is to randomly drop data until sample sizes are equal. I do not consider this rule here.
This case, the ex ante known allocation with a balanced design, is what Stoye (2009a) called “matched pairs.” In this case, his proposition 1(i) shows that the empirical success rule is finite sample minimax-regret optimal, when outcomes are binary. His proposition 2 then extends this result to outcomes with bounded support by using the the binary randomization technique. Here my focus is on unbalanced designs, in which case the finite sample optimal rule is unknown.
I also considered the uniform prior, \(\alpha =\beta =1\), and the Jeffreys prior, \(\alpha =\beta =1/2\). These rules tend to perform slightly worse than \(\delta ^{\textsc {M}}\), but better than empirical success or Stoye’s rule.
Abughalous and Miescke (1989) also discuss Bayes rules in this two treatment, unbalanced allocation setting, under 0-1 loss and monotone permutation invariance loss.
This does not mean that they are not admissible, however. Note for example when \(N_1=3\), \(N_2=2\), the empirical success rule is the best of the five. For normal data, Miescke and Park (1999) prove that the empirical success rule is admissible for regret loss. I am not aware of a proof for binary outcomes, however.
This is Schlag’s (2006) “Eleven tests needed for a recommendation” result. (By ‘tests’ he means ‘observations’.)
Required so that a perfect balanced design is possible.
See proposition 6 of Stoye (2007a).
Although all optimal rules yield the same value of maximal regret, and hence the decision-maker is technically indifferent between them.
In general, homotopy methods whose only goal is to find one solution apply to arbitrary systems. Only the all-solutions homotopy imposes the polynomial restriction.
Compare the assumption of invariance to the assumption that \(P_\theta\) is exchangeable. Exchangeability is stronger: it says that \(g_j(X) \sim P_\theta\) for all j—we do not have to permute the parameters. Also note that this invariant distribution assumption is violated as soon as we allow unequal sample sizes. For example, if \(T_0 \sim {\mathcal {N}}(\mu _0,\sigma ^2/N_0)\) and \(T_1 \sim {\mathcal {N}}(\mu _1,\sigma ^2/N_1)\), then permuting the indices yields \(T_0 \sim {\mathcal {N}}(\mu _0,\sigma ^2/N_1)\) and \(T_1 \sim {\mathcal {N}}(\mu _1,\sigma ^2/N_0)\), which is not true when \(N_0 \ne N_1\).
See Berger (1985) page 396 for proof.
References
Abughalous, M., & Miescke, K. J. (1989). On selecting the largest success probability under unequal sample sizes. Journal of Statistical Planning and Inference, 21, 53–68.
Bahadur, R. (1950). On a problem in the theory of k populations. The Annals of Mathematical Statistics, 21, 362–375.
Bahadur, R., & Goodman, L. (1952). Impartial decision rules and sufficient statistics. The Annals of Mathematical Statistics, 23, 553–562.
Berger, J. O. (1985). Statistical Decision Theory and Bayesian Analysis, 2nd ed., Springer Verlag.
Bofinger, E. (1985). Monotonicity of the probability of correct selection or are bigger samples better? Journal of the Royal Statistical Society. Series B (Methodological), 47, 84–89.
Borkovsky, R. N., Doraszelski, U., & Kryukov, Y. (2010). A user’s guide to solving dynamic stochastic games using the homotopy method. Operations Research, 58, 1116–1132.
Chamberlain, G. (2000). Econometrics and decision theory. Journal of Econometrics, 95, 255–283.
Dehejia, R. (2005). Program evaluation as a decision problem. Journal of Econometrics, 125, 141–173.
Hirano, K., & Porter, J. R. (2009). Asymptotics for statistical treatment rules. Econometrica, 77, 1683–1701.
Judd, K. L. (1998). Numerical Methods in Economics, The MIT press.
Judd, K. L., Renner, P., & Schmedders, K. (2012). Finding all pure-strategy equilibria in dynamic and static games with continuous strategies, Working paper.
Kallus, N. (2018). Balanced policy evaluation and learning, Advances in Neural Information Processing Systems, 31.
Kitagawa, T., & Tetenov, A. (2017). Who should be treated? empirical welfare maximization methods for treatment choice, cemmap Working Paper (CWP24/17).
Kitagawa, T., & Tetenov, A. (2018). Who should be treated? empirical welfare maximization methods for treatment choice. Econometrica, 86, 591–616.
Kubler, F., & Schmedders, K. (2010). Tackling multiplicity of equilibria with Gröbner bases. Operations research, 58, 1037–1050.
Le Cam, L. M. (1986). Asymptotic Methods in Statistical Decision Theory. New York: Springer-Verlag.
Lehmann, E. (1966). On a theorem of Bahadur and Goodman. The Annals of Mathematical Statistics, 37, 1–6.
List, J. A., Sadoff, S., & Wagner, M. (2011). So you want to run an experiment, now what? Some Simple Rules of Thumb for Optimal Experimental Design, Experimental Economics, 14, 439–457.
Manski, C. F. (2000). Identification problems and decisions under ambiguity: Empirical analysis of treatment response and normative analysis of treatment choice. Journal of Econometrics, 95, 415–442.
Manski, C. F. (2004). Statistical treatment rules for heterogeneous populations. Econometrica, 72, 1221–1246.
Schlag, K. H. (2006). Eleven-Tests needed for a recommendation, Working Paper.
Manski, C. F. (2007). Identification for prediction and decision. Harvard University Press.
Manski, C. F. (2007). Minimax-regret treatment choice with missing outcome data. Journal of Econometrics, 139, 105–115.
Manski, C. F. (2009). Diversified treatment under ambiguity. International Economic Review, 50, 1013–1041.
Manski, C. F., & Tetenov, A. (2007). Admissible treatment rules for a risk-averse planner with experimental data on an innovation. Journal of Statistical Planning and Inference, 137, 1998–2010.
Manski, C. F. (2016). Sufficient trial size to inform clinical practice. Proceedings of the National Academy of Sciences, 113, 10518–10523.
Masten, M. A. (2013). Equilibrium Models in Econometrics, Ph.D. thesis, Northwestern University.
Miescke, K. J., & Park, H. (1999). On the natural selection rule under normality. Statistics & Decisions, Supplemental Issue No., 4, 165–178.
Otsu, T. (2008). Large deviation asymptotics for statistical treatment rules. Economics Letters, 101, 53–56.
Schlag, K. H. (2003). How to minimize maximum regret in repeated decision-making, Working Paper.
Song, K. (2014). Point decisions for interval-identified parameters. Econometric Theory, 30, 334–356.
Stoye, J. (2007a). Minimax-regret treatment choice with finite samples and missing outcome data, in Proceedings of the Fifth International Symposium on Imprecise Probability: Theories and Applications, ed. by M. Z. G. de Cooman, J. Veinarová.
Stoye, J. (2007). Minimax regret treatment choice with incomplete data and many treatments. Econometric Theory, 23, 190–199.
Stoye, J. (2009). Minimax regret treatment choice with finite samples. Journal of Econometrics, 151, 70–81.
Stoye, J. (2009b). Web Appendix to “Minimax regret treatment choice with finite samples”, Mimeo.
Stoye, J. (2012). Minimax regret treatment choice with covariates or with limited validity of experiments. Journal of Econometrics, 166, 138–156.
Tetenov, A. (2012). Statistical treatment choice based on asymmetric minimax regret criteria. Journal of Econometrics, 166, 157–165.
Tong, Y., & Wetzell, D. (1979). On the behaviour of the probability function for selecting the best normal population. Biometrika, 66, 174–176.
Van der Vaart, A. W. (1998). Asymptotic Statistics. Cambridge University Press.
Wald, A. (1945). Statistical decision functions which minimize the maximum risk. The Annals of Mathematics, 46, 265–280.
Wald, A. (1950). Statistical Decision Functions. Wiley.
Zhou, Z., Athey, S., & Wager, S. (2023). Offline multi-action policy learning: Generalization and optimization. Operations Research, 71, 148–183.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This is a revised version of chapter 2 of my Northwestern University Ph.D. dissertation, Masten (2013). I thank Charles Manski for his guidance, advice, and many helpful discussions, Ivan Canay and Aleksey Tetenov for many helpful comments, as well as the editor and a referee who also provided helpful feedback.
Appendices
A Proofs
Proof of proposition 1
Assumption 3.2 implies that the sequence of experiments
is locally asymptotically normal with norming rate \(\sqrt{N}\). Let
where \(h = (h_1',\ldots ,h_K')'\). Then
where
Here \(\Delta _{N,\theta _0} {\mathop {\rightsquigarrow }\limits ^{\theta _0}} {\mathcal {N}}(0,{\textbf{I}}_0)\). The corresponding limit experiment consists of observing K independent normally distributed variables with means \(h_k\) and variances \(\lambda _k^{-1} I_0^{-1}\).
Since \({\hat{\theta }}_{k,N}\) is a best regular estimator of \(\theta _k\), the converse part of lemma 8.14 of Van der Vaart (1998) implies that the estimator sequence \({\hat{\theta }}_{k,N}\) satisfies the expansion
By the delta method,
where recall that
Recall that \({\hat{\varvec{\theta }}}_N = ({\hat{\theta }}_{1,N}',\ldots ,{\hat{\theta }}_{K,N}')'\), \({\textbf{w}}({\hat{\varvec{\theta }}}_N) = (w({\hat{\theta }}_{1,N}),\ldots ,w({\hat{\theta }}_{K,N}))'\), and
Then the previous results show that
where note that
Hence, by Slutsky’s theorem (this allows us to drop the \(o_{P_{\theta _0}}(1)\) terms) and a multivariate CLT, we have
where \(\psi _{\theta _\theta } = {\dot{{\textbf{w}}}}' {\textbf{I}}_0^{-1} \dot{\varvec{\ell }}_{\theta _0}\), and we have defined
Then \({\mathbb {E}}_{\theta _0} \dot{\varvec{\ell }}_{\theta _0} \dot{\varvec{\ell }}_{\theta _0}' = {\textbf{I}}_0\), where note that the off-diagonal entries are zero since the K samples are independent and the expected score is zero. Hence the third line follows since
and
Thus, by Le Cam’s third lemma (see example 6.7, page 90 of (Van der Vaart, 1998)):
\(\square\)
Proof of theorem 2
This result follows from the results in appendix B, as summarized in corollary S1. Note that assumption 5 ensures that the variances are equal in the limit experiment, as needed to apply those results. \(\square\)
The following lemma restates the parts of lemma 4 of Hirano and Porter (2009) which are relevant here, for reference.
Lemma S1
(Hirano and Porter (2009) lemma 4) Suppose assumptions 1–4 hold. Let \(\delta _N\) be a sequence of treatment assignment rules which is matched by a rule \(\delta\) in the limit experiment, as given by the asymptotic representation theorem. Let J be a finite subset of \({\mathbb {R}}^{\dim (h)}\). If
holds for all \(h \in {\mathbb {R}}^{\dim (h)}\), then
where the outer supremum over J is taken over all finite subsets J of \({\mathbb {R}}^{\dim (h)}\).
Proof of lemma 2
By the asymptotic representation theorem, \(\delta _N \in {\mathcal {D}}\) is matched by a rule \({\tilde{\delta }}\), meaning that \({\mathbb {E}}_{\theta _0 + h/\sqrt{N}} \delta _{k,N} \rightarrow {\mathbb {E}}_h {\tilde{\delta }}_k\) for all h. Consequently, by our risk function calculations in section 2.3, we have
for all h. Thus
where the first line follows by lemma 4 of Hirano and Porter (2009). \(\square\)
Proof of theorem 3
By proposition 1,
for all h. Thus, by our risk calculations in section 2.3, \(\delta _N^*\) is matched in the limit experiment by \(\delta ^*\); that is,
for all h. Then
where the outer supremum over J is taken over all finite subsets of \({\mathbb {R}}^{\dim (h)}\). The first line follows by lemma 4 of Hirano and Porter (2009). The second line follows since \(\delta ^*\) is optimal in the limit experiment, by theorem 2. \(\square\)
B The finite-sample results of Bahadur, Goodman, and Lehmann
In this appendix I reproduce several results from Lehmann (1966), who built on Bahadur (1950) and Bahadur and Goodman (1952). Theorem 2 in the present paper is an immediate corollary of these results. None of the results in this section are new (except for corollary S2, which is a minor extension); I include them here for reference and accessibility. I have also made a few notational changes. The basic approach is to first show that the empirical success rule is uniformly best within the class of permutation invariant rules, and then show that this implies that it is a minimax rule among all possible rules. Although theorem 2 only requires this result to hold for normally distributed data, the result holds more generally, and so I present the general result here.
Suppose there are K treatments. From each treatment group \(k=1,\ldots ,K\) we observe a vector of outcomes \(X_k\). Let \(P_\theta\) denote the joint distribution of the data \(X = (X_1,\ldots ,X_K)\), where \(\theta = (\theta _1,\ldots ,\theta _K)\) and \(\theta _k \in {\mathbb {R}}\). Let \(L(k,\theta ) = L_k(\theta )\) denote the loss from assigning everyone to treatment k. Let
be a finite group of transformations.
Example 2
(Permutation group) Let \(\pi : \{1,\ldots ,K \} \rightarrow \{ 1,\ldots , K \}\) be a function which permutes the indices of \(\theta\). So \(\pi (k)\) denotes the new index which k is mapped into. \(\pi ^{-1}(k)\) denotes the old index which maps into the new kth spot. Let \(\{ \pi _j \}\) be the set of all J permutations of indices. The set of transformations
which permute the indices of \(\theta\) is called the permutation group. For example, let \(\theta = (\theta _1,\theta _2,\theta _3)\). Consider the particular permutation \(\pi _j\) with \(\pi _j(1) = 2\), \(\pi _j(2) = 1\), and \(\pi _j(3) = 3\). Then
Assume from now on that G is the permutation group. Let \(\delta\) denote an arbitrary treatment rule. We say \(\delta\) is invariant under G if
Assumption S1
The following hold.
-
1.
(Invariant distribution). \(P_\theta\) is invariant under G. That is, the distribution of \(g_j(X)\) is \(P_{g_j(\theta )}\) for all j.Footnote 20
-
2.
(Invariant loss). \(L(k,\theta )\) is invariant under G. That is, if \(L((1,\ldots ,K),\theta )\) is the vector of losses then
$$\begin{aligned} L(g_j((1,\ldots ,K)),g_j(\theta )) = L((1,\ldots ,K),\theta ) \end{aligned}$$for all j.
-
3.
(Independence). \(X = (X_1,\ldots ,X_K)\) has a probability density of the form
$$\begin{aligned} h_\theta (T) = C(\theta ) f_{\theta _1}(T_1) \cdots f_{\theta _K}(T_K), \end{aligned}$$with respect to a \(\sigma\)-finite measure \(\nu\), where \(T_k = T_k(X_k)\), are real valued statistics, and \(T = (T_1,\ldots ,T_K)\).
-
4.
(MLR). \(f_{\theta _k}\) has monotone (non-decreasing) likelihood ratio in \(T_k\) for each k.
-
5.
(Monotone loss). Larger parameter values are weakly preferred. That is, the loss function L satisfies
$$\begin{aligned} \theta _i < \theta _j \qquad \Rightarrow \qquad L_i(\theta ) \ge L_j(\theta ). \end{aligned}$$
Example 3
(Independent normal observations with equal variances) Let \(X_k \sim {\mathcal {N}}(\theta _k,\sigma ^2)\), and \(X_k\) is independent of all other observations. Then this data satisfies assumptions (1), (3), and (4), with \(T_k = X_k\).
Example 4
(Regret loss) The regret loss function
satisfies (2) and (5).
Let
denote the set of treatments which yield the largest observed statistics \(T_k\). Define the empirical success rule by
When the \(T_k\) are continuously distributed, it is not necessary to define what \(\delta ^*\) does in the event of ties, since they occur with probability zero. When \(T_k\) are discretely distributed, however, ties may occur with positive probability.
Theorem S1
(Bahadur–Goodman–Lehmann) Suppose assumption S1 holds. Then the empirical success rule (8) uniformly over \(\theta\) minimizes the risk \(R(\delta ,\theta )\) among all rules \(\delta\) based on T which are invariant under G.
Proof
First note that \(\delta ^*\) is invariant under G. By lemma 1 of Lehmann (1966) (see below), it suffices to prove that, for all \(\theta\), \(\delta ^*\) minimizes risk averaged over all permutations,
among all procedures (not just invariant ones). The risk of a rule \(\delta\) is
Average risk is
where we defined
Suppose without loss of generality that \(\theta _1< \cdots < \theta _K\). We will show that, for a fixed t, \(A_k(t)\) is minimized over k by any i such that
Consequently, the average risk \(r(\delta ,\theta )\) is minimized for any rule \(\delta\) which puts \(\delta _k(t) = 0\) whenever \(t_k < \max t_i\). Finally, since the lemma requires the procedure \(\delta ^*\) to be invariant under G, we break ties between maxima at random with equal probability.
Thus all we have to do is show that for a fixed t,
\(A_i\) minimized means \(A_i \le A_k\) for all k, or \(A_i - A_k \le 0\) for all k. Thus consider the difference
We will look at each term in the sum separately. Consider a permutation g defined by \(\pi\) such that \(\pi ^{-1} i < \pi ^{-1} k\). By our ordering of the parameters, this implies that \(\theta _{\pi ^{-1} i} < \theta _{\pi ^{-1} k}\). Let \(g'\) be the permutation obtained from g by swapping \(\pi ^{-1} i\) and \(\pi ^{-1} k\).
The contribution to \(A_i - A_k\) from the terms corresponding to g and \(g'\) is
Since the loss function is invariant,
So the previous equation reduces to
The first piece is positive (nonnegative at least) since \(\theta _{\pi ^{-1} k} > \theta _{\pi ^{-1} i}\). Consider the sign of the second term. By the form of the density,
Since \(g'\) is the same permutation as g, except that \(j_i\) and \(j_k\) are switched, \(h_{g'\theta }(t)\) is the same as above, except that \(f_{\theta _{\pi ^{-1} i}}\) is evaluated at \(t_k\) and \(f_{\theta _{\pi ^{-1} k}}\) is evaluated at \(t_i\). Thus, when we compare the difference \(h_{g \theta }(t) - h_{g'\theta }(t)\) to zero, we can divide by all the shared terms (including the constant C, which is invariant), which all cancel, leaving just the \(\pi ^{-1} i\) and \(\pi ^{-1} k\) terms remaining.
Thus
The last line follows since \(\theta _{\pi ^{-1} k} \ge \theta _{\pi ^{-1} i}\) and \(f_\theta\) has MLR. Thus, when \(t_k \le t_i\), the second term is negative, and hence the entire term is negative.
Now, every permutation \(g_{\pi }\) must have either \(\pi ^{-1} i < \pi ^{-1} k\) or \(\pi ^{-1} i > \pi ^{-1} k\). So if we consider the set of all permutations with \(\pi ^{-1} i < \pi ^{-1} k\) then we can uniquely pair each one of these with a permutation with \(\pi ^{-1} k < \pi ^{-1} i\). This is what we did above. By doing so, we have considered every term in the summation which defines \(A_i - A_k\). Thus, when \(t_k \le t_i\), every term in the sum has the desired sign, and hence
as desired. \(\square\)
Lemma S2
(Lehmann (1966) lemma 1) Fix \(\theta\). A necessary and sufficient condition for an invariant procedure \(\delta ^*\) to minimize the risk \(R(\delta ,\theta )\) among all invariant procedures is that it minimizes the average risk
among all procedures (not just the invariant ones).
Proof
-
1.
(Sufficient). Let \(\delta ^*\) be an invariant procedure which minimizes average risk \(r(\delta ,\theta )\) among all procedures. Let \(\delta '\) be any other invariant procedure. Now, the risk function of any invariant procedure is constant over each orbitFootnote 21
$$\begin{aligned} \{ g_j \theta : j =1,\ldots ,J \}. \end{aligned}$$Thus
$$\begin{aligned} R(\delta ',\theta ,) = r(\delta ', \theta ) \qquad \text{and} \qquad R(\delta ^*,\theta ) = r(\delta ^*, \theta ), \end{aligned}$$since both \(\delta '\) and \(\delta ^*\) are invariant. By the assumption that \(\delta ^*\) minimizes average risk among all procedures,
$$\begin{aligned} r(\delta ^*, \theta ) \le r(\delta ', \theta ). \end{aligned}$$Hence
$$\begin{aligned} R(\delta ^*, \theta ) \le R(\delta ', \theta ). \end{aligned}$$ -
2.
(Necessary). Suppose that \(\delta ^*\) minimizes risk \(R(\delta , \theta )\) among all invariant procedures. Let \(\delta '\) be any procedure. There exists an invariant procedure \(\delta ''\) such that
$$\begin{aligned} r(\delta ', \theta ) = r(\delta '', \theta ). \end{aligned}$$For example, we can take
$$\begin{aligned} \delta '' = \frac{1}{J} \sum _{j=1}^J g_j [\delta ' (g_j^{-1} X)]. \end{aligned}$$Thus we have
$$\begin{aligned} r(\delta ', \theta )&= r(\delta '', \theta ) \\&= R(\delta '', \theta ) \\&\ge R(\delta ^*, \theta ) \\&= r(\delta ^*, \theta ). \end{aligned}$$
\(\square\)
Finally, this result implies certain optimality properties among all rules, not just permutation invariant ones. To this end, suppose all rules are ranked by a complete and transitive ordering \(\succeq\).
Example 5
The minimax criterion orders rules as follows: \(\delta ' \succeq \delta\) if
This ordering satisfies all the assumptions of Lehmann’s lemma 2 below.
Lemma S3
(Lehmann (1966) lemma 2)
-
1.
If the ordering \(\succeq\) is such that
-
(a)
\(\delta ' \succeq \delta\) implies \(g \delta g^{-1} \succeq g \delta ' g^{-1}\), and
-
(b)
for any finite set of rules \(\delta ^{(i)}\), \(i=1,\ldots ,r\), \(\delta ^{(i)} \succeq \delta\) for all i implies \(\frac{1}{r} \sum _{i=1}^r \delta ^{(i)} \succeq \delta\).
then given any procedure \(\delta\) there exists an invariant procedure \(\delta '\) such that \(\delta ' \succeq \delta\).
-
(a)
-
2.
Suppose that in addition to (a) and (b) above, the ordering satisfies
-
(c)
\(R(\delta ',\theta ) \le R(\delta , \theta )\) for all \(\theta\) implies \(\delta ' \succeq \delta\).
Then, if there exists a procedure \(\delta ^*\) that uniformly minimizes the risk among all invariant procedures, \(\delta ^*\) is optimal with respect to the ordering \(\succeq\). That is, \(\delta ^* \succeq \delta\) for all \(\delta\).
-
(c)
Proof
-
1.
Note that
$$\begin{aligned} \delta ' = \frac{1}{r} \sum _{j=1}^r g_j \delta g_j^{-1} \end{aligned}$$is invariant and, by (a) and (b), at least as good as \(\delta\).
-
2.
Let \(\delta\) be any rule. By part 1, there exists an invariant \(\delta '\) that is preferred to \(\delta\). \(\delta ^*\) uniformly minimizes risk among all invariant procedures. In particular, it has uniformly smaller risk than \(\delta '\). Thus, by (c), \(\delta ^* \succeq \delta ' \succeq \delta\).
\(\square\)
Thus, combining the BHL theorem with Lehmann’s lemma 2 yields the following result.
Corollary S1
The empirical success rule (8) is minimax optimal under regret loss in the experiment where, for all k, \(X_k \sim {\mathcal {N}}(\theta _k,\sigma ^2)\) and \(X_k\) is independent of all other observations.
As a final remark, Schlag (2003) showed that when outcomes have an arbitrary distribution on a common bounded support, it suffices to only consider binary outcomes by performing a ‘binary randomization’. This technique can be used to extend the Bahadur-Goodman-Lehman result as follows.
Corollary S2
Let \(X_k\) be a vector \((X_{k,1},\ldots ,X_{k,n_k})\) of \(n_k\) scalar observations. Suppose \(n_1 = \cdots = n_K\). Suppose the parameter space for the distribution of \(X_{k,i}\) is the set of all distributions with common bounded support, for all \(i=1,\ldots ,n_k\), for all k. Then the empirical success rule (8) is minimax optimal under any loss function satisfying assumptions (2) and (5).
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Masten, M.A. Minimax-regret treatment rules with many treatments. JER 74, 501–537 (2023). https://doi.org/10.1007/s42973-023-00147-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42973-023-00147-0