
Abstract
Advances in technology are having a large effect on the priorities for innovation in statistical ecology. Collaborations between statisticians and ecologists have always been important in driving methodological development, but increasingly, expertise from computer scientists and engineers is also needed. We discuss changes that are occurring and that may occur in the future in surveys for estimating animal abundance. As technology advances, we expect classical distance sampling and capture-recapture to decrease in importance, as camera (still and video) survey, acoustic survey, spatial capture-recapture and genetic methods continue to develop and find new applications. We explore how these changes are impacting the work of the statistical ecologist.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
New technologies can present opportunities to wildlife managers, for example by delivering abundance estimates of populations with greater precision or lower bias than is possible by existing methods, or by offering the promise of successful monitoring of populations for which no suitable method currently exists. It is unsurprising therefore that practitioners are often quick to respond to the availability of new technologies. However, these technologies often generate data that require innovation from statistical ecologists. In this paper, we summarize some recent developments in wildlife population assessment methods in response to technological change, and we consider likely impacts on methodology of future technological changes. We focus mainly on two classical approaches for estimating animal abundance: distance sampling and capture-recapture. In addition, we look at how advances in genetics can contribute for example to estimating the size of harvested populations, or populations for which samples of DNA, for example through dung or hair, can be collected. We also consider briefly the impacts of new technology on occupancy methods, N-mixture models and random encounter models.
We can conceptualise the problem of estimating abundance through the following general formula.
where N is population size, estimated by \(\hat{N}\),
\(i = 1, \ldots ,n\) corresponds to n detected animal groups,
\(\alpha_{i}\) is the probability that the ith detection is a false positive estimated by \(\hat{\alpha }_{i},\)
\(s_{i}\) is the number of animals in the ith detected group (\(s_{i} = 1\) if animals are solitary),
\(p_{i}\) is the probability of detection for the ith group, estimated by \(\hat{p}_{i},\)
and \(a_{i}\) is the probability that the ith group was available for detection, estimated by \(\hat{a}_{i}\).
Equation (1) demonstrates a central principle of estimating abundance, that along with the numbers of animals seen we must also collect information on the probability of seeing each one. This is exemplified in Eq. (1) by the probabilities of detection and availability, one or both of which must typically be estimated in any given wildlife survey scenario. In effect, these probabilities are corrections for false negatives: animals that were present but undetected. Although not all estimators of abundance that we consider have the same form as Eq. (1), the general formulation provides a useful way of thinking about the statistical framework. The various methods we consider can often be thought of as different ways to estimate one or more of the above quantities.
2 Distance Sampling
Distance sampling refers to a suite of methods for which detection probability is estimated as a function of distances to detected objects from a line or point, allowing estimation of abundance as in Eq. (1) (Buckland et al. [13]). The two methods most frequently used are line transect sampling and point transect sampling. Lines or points are superimposed over the study area according to a suitable survey design, and observers travel along the lines or visit the points, to record any animals from the population of interest, together with their distance from the line or point from which they are detected. These distances are used to fit a model for the detection function, which is the probability of detecting an animal expressed as a function of distance from the line or point, and possibly of additional covariates. A simple distance sampling estimator is obtained from (1) by using these estimated detection probabilities for the quantities \({\widehat{p}}_{i}\), and assuming that there are no problems with availability or false positives.
2.1 Shipboard and Aerial Line Transect Surveys
Currently, the dominant form of distance sampling is line transect sampling. Most large-scale surveys are conducted from aircraft or ships, although some must necessarily be conducted at ground level, for example where forest canopy precludes aerial survey, or underwater, where the species of interest may not be sufficiently detectable from the surface. We expect to see large changes in how large-scale surveys are conducted, as a result of technological advances.
Most large-scale line transect surveys conducted by human observers on-board aircraft or ships are likely to be replaced in the near future by aerial surveys using high-resolution imagery (Fig. 1). This change has already started, especially in the context of seabird and sea mammal surveys in areas where offshore windfarms have been proposed or constructed (Buckland et al. [11]). Acoustic surveys will also play a key role for surveys at sea aimed at animals that produce sounds, such as cetaceans (Marques et al. [56]). These may be conducted using towed hydrophone arrays (e.g. Lewis et al. [52]) or drifting instruments (Barlow et al. [3]). Analytical approaches that allow the integration of multiple data sources, for example visual data and passive acoustic monitoring (PAM) data, to generate a single density estimate will be needed (e.g. Frasier et al. [29]). Furthermore, piloted aircraft are likely to be replaced by pilotless long-range drones, assuming that legislation on the operation of drones allows. The advantages of these changes are clear:
-
Safety of observers and pilot is not put at risk.
-
The survey generates verifiable data, so that independent analyses can be conducted on the recorded images. The raw data have not been biased by an observer’s interpretation of what was detected.
-
The surveys can be conducted at higher altitude than is possible with human observers, thus avoiding animal disturbance.
-
Thermal imaging cameras can allow surveys to be conducted over habitats where animals are difficult to see from the air, such as forest canopy and scrublands.
-
Detectability of animals is unlikely to fall off with distance from the line, as distance from the high-altitude camera changes little with distance from the line.
-
The camera is slung below the aircraft, and so visibility directly below is clear. This is not true for observers on-board aircraft, which complicates the analysis of line transect data from aerial surveys using observers.

Representation of an aerial survey using cameras. The cameras capture images extending a distance w either side of the central transect line. In this survey, there was a forward-facing camera and a backward-facing camera, providing double-platform data for estimating availability of diving marine mammals with short dive duration
Technological advances are needed for these changes to become widespread. A camera surveys a narrower strip below the aircraft than does a human observer. This can be circumvented by increasing the altitude of the drone, and by having multiple cameras, each covering its own survey strip. The equipment on-board the drone must be able to either store or transmit many large, high-resolution images. Reliability and range of drones needs to be high, while the cost needs to come down. Military-style drones can have ranges of several thousand kilometres, a capability that would be of value for surveying large and remote areas.
Equivalently, at sea, vessels might be replaced by underwater autonomous vehicles (e.g. Suberg et al. [77]), gliders or drifting buoys, especially so for cetaceans that produce sounds that might make them far more detectable acoustically than visually. We expect developments to be required for obtaining reliable distances from PAM detections, both at the hardware level (e.g. sets of sensors capable of estimating distances to individual sounds) and at the analytical level (obtaining distances from a vertical detection angle, e.g. Barlow et al. [3]). Analytical three-dimensional distance sampling methods, such as those developed by Cox et al. [20], can be used to handle non-uniform distribution in the water column.
Going a step further, satellite images are starting to be used to assess wildlife abundance. Fretwell et al. [30] estimated the total population size of emperor penguins from satellite imagery. Since the satellite survey of southern right whales carried out by Fretwell et al. [32], several surveys of whale populations have been carried out, as reviewed by Höschle et al. [42]. Other species surveyed using satellite imagery include albatrosses (Fretwell et al. [31]) and elephants (Duporge et al. [23]).
There are statistical challenges from using high-resolution images. Superficially, it may appear that the problem of estimating abundance is made easier, as there is no need to model the detection function. However, not all animals within the area covered by an image may be available for detection when the image is recorded. Whales may be below the surface, and terrestrial animals may be under tree canopy or underground. Especially with satellite images, some animals may be obscured by cloud cover. Thus availability of animals may need to be modelled. In some circumstances, this might be achievable internal to the survey. For example, a drone might have one camera aimed forwards, while a second camera is aimed backwards. The two cameras then search the same area but at slightly different times. Stevenson et al. [74] and Borchers et al. [6] developed methods to analyse such data while taking account of the uncertainty in identifying duplicate detections across the two sets of images. This strategy can be effective for animals that are intermittently available, with just short gaps of unavailability, for example porpoise that surface frequently. Other solutions include having two aircraft in tandem (Hiby and Lovell [38]), or having a single aircraft conduct two passes over the same strip (Hiby [39]). A terrestrial or shipboard survey may be necessary to estimate availability in some circumstances. In some studies, radio or satellite tags are attached to a sample of animals, and these may provide data for estimating availability. Given that availability may vary by location and season, such data should be collected synchronously with the survey if at all possible. If the probability of detection needs to be estimated separately from availability, this can be done for example using double-platform data, with possibly different technologies on each platform, such as visual and infrared cameras.
Perhaps the biggest challenge for the analyst is to process the large number of high-resolution images. Both statisticians and computer scientists can contribute here. There are usually two stages involved in analysing the images. The first is to use a relatively rapid algorithm to identify whether an image has any objects of potential interest. A good algorithm will eliminate a large majority of images for most surveys, so that the volume of data for analysis at the second stage is much reduced. The second stage uses a more time-intensive algorithm to identify what the objects in the image are. For example, the first stage might identify that there are marine mammals in an image, while the second stage might identify the species of marine mammal. A related challenge is to estimate the false positive and false negative rates, allowing the abundance estimate to be corrected. This might be achieved by having experts interpret a subset of images, allowing calibration factors to be estimated.
Examples of using deep learning methods to identify animals from images include Chabot et al. [18] for polar bears and Norouzzadeh et al. [60] for animals in the Serengeti.
2.2 Camera-Trap Distance Sampling
Given that ground-level surveys can often be conducted at low cost, we anticipate that such surveys will remain popular. However, we also expect many such surveys to be replaced by point transect surveys for which either camera traps or acoustic detectors will be placed at the points. In both methods, a point transect survey design is used, but cameras or acoustic detectors replace human observers. This creates a problem for standard distance sampling methods, which essentially assume that animals are frozen in place while locations relative to the point are recorded. If the animals are moving around, the longer the recording period at a point, the more animals will be detected, generating upward bias in abundance estimates. This is usually a minor issue for surveys carried out by observers, who only remain at a point for a few minutes, but cameras or acoustic detectors typically remain in place for long periods. Thus snapshot methods (Buckland [10]) are used. The term ‘snapshot method’ indicates that locations of detected animals are recorded at snapshot moments—instants in time, as distinct from detections within a prolonged time period.
For camera-trap distance sampling, the simplest approach is to use time-lapse photography, in which images are taken at pre-defined snapshot moments. Then provided distances of animals in images can be estimated, analysis follows exactly as for conventional point transect sampling, treating the snapshot moments as multiple visits to each point.
For many surveys, especially those for which animals can only be detected in images if they are close to the camera (such as in rain forest), the time-lapse method generates many images, but with very few detections of target animals. Thus, usually cameras with sensors to detect animal movement are used. Then, images are only taken when there is at least one animal moving in the sensor detection sector. This necessitates a few changes to the conventional distance sampling method (Howe et al. [43]). First, to avoid bias, the snapshot moments need to be close together, so that an animal is unlikely to pass right through the sensor detection sector between two successive snapshots. Second, the nominal snapshot moments need to be defined, given the images available. If video is taken, and snapshots are defined to be say every four seconds, then the video can be used to determine where the animal is relative to the point, for as long as it remains in the sensor detection sector, at each snapshot moment. Otherwise, position at snapshot moments may need to be estimated from the images available. The nominal snapshot moments continue once every four seconds (say), even when no animals are present, so time that the camera is operating must be recorded, from which the number of nominal snapshot moments can be calculated. The same animal may be recorded several times as it passes through the sensor detection sector, so data tend to be over-dispersed, and this needs to be allowed for in the analysis (Howe et al. [44]). One further complication is that an animal may be in the sector but without triggering the sensor, for example because it is resting (not moving), or is underground or hidden in a tree. Thus, again, availability must be estimated. This can often be done without collecting additional data, provided it can be assumed that all animals are active and detectable at the time of day when activity is greatest (Rowcliffe et al. [68]).
Estimation of distance of animals from the camera can be a time-consuming process. Laser rangefinders are now routinely used in many terrestrial surveys using observers, and autofocus cameras readily adjust focus to the distance of the object from the lens. An apparently modest advance would be to develop a camera to automatically record the distance to any animal that triggers the movement sensor, at the moment the sensor is triggered. Linked to this, a statistical innovation would be a model for animal movement, so that the positions at which an image of the animal is taken are used to fit a model of its track through the sensor detection sector. (Many animals occur in groups, so such a system should be capable of tracing each animal within a group.) This will allow distances from the camera at the nominal snapshot moments (which do not necessarily correspond to the moments at which images are taken) to be estimated more easily and reliably. Another useful technical innovation would be to develop camera traps that are less likely to cause a response in the target animals, for example with quieter camera action, more camouflaged cameras, and use of odour-free materials. With current cameras, animals of many species often respond by approaching the camera (and perhaps damaging it), or avoiding the camera, or simply watching it for a period. This generates a biased set of detection distances, and hence biased abundance estimates.
Automated identification of any animal that triggers the camera will avoid the need for expert observers to examine each image. As with aerial images, calibration may be needed, with a subset of images examined by expert observers, to correct for false positives. (Detection function modelling, as for conventional distance sampling, together with availability modelling, will correct for false negatives.)
One difference from aerial surveys is that the first stage of analysis of images from aerial surveys is not needed here, as there is no image corresponding to the large number of nominal snapshot moments for which the sensor was not triggered.
2.3 Acoustic Distance Sampling
In acoustic distance sampling surveys, an acoustic detector, or preferably an array of acoustic detectors, is placed at each point of the design. Although distances can in principle be estimated by modelling the volume of a sound as a function of distance, such estimates may be subject to large errors, for example because calls may not be omnidirectional, or habitat and topology affect the volume and direction of sounds arriving at the sensor. Use of a small array of synchronized detectors allows distances to be estimated by triangulation (Blumstein et al. [4]).
In principle, standard point transect sampling methods could be used to analyse the data. However, this approach makes quite restrictive assumptions: we must assume that repeat detections of a single animal can be identified, and that we can measure the distance from the point to the average location of the animal during the period that the acoustic sensors are in place. Although a snapshot approach could be adopted to avoid bias from animal movement (Buckland [10]), it is more difficult to determine where an animal is at each snapshot moment from intermittent sound than it is from continuous visual images.
In practice, it is usually better to treat the individual cue (call or song) as the observation, rather than the animal. This cue-counting approach is not biased when animal movement is non-responsive (independent of the sensors). The distance to be estimated is the distance to each detected cue, rather than to the centre of a cluster of detections of a given animal. A disadvantage of the approach is that the cue rate (average number of cues per animal per unit of time) must be estimated concurrently with the acoustic survey. Thus a representative sample of animals must be monitored, to determine how many cues they produce in a given period of time. As we just need the average cue rate across animals, a relatively small sample of representative animals typically gives adequate precision. However, since we need to estimate the cue rate for the time and space in which the survey takes place (Marques et al. [57]), we anticipate studies investigating factors that affect cue rates to become increasingly common.
A technological development that would be welcome is tags of long duration, giving the potential to link cue production rates to external factors such as time of year and behaviour. Another technological advance required is tags that allow unambiguous identification of individual animals, which is particularly difficult for animals with low-frequency calls, such as baleen whales (Stimpert et al. [75]). Both of these are key to reliable estimation of cue rates from tag data, and hence to further development of cue-counting approaches.
The design for a cue-count survey should be randomised just as for a conventional distance sampling survey. Animals do not need to be detectable from multiple points of the design, so the points can be widely spaced, allowing surveys of large study areas to be carried out.
Cue counting was originally developed for surveying whales by detecting their blows while travelling along transect lines (Hiby [37]), but it can equally be carried out from fixed points (Buckland [10]), which is a more practical option for acoustic surveys.
To avoid the need for an expert to listen to all recordings, automated methods are needed. As with the analysis of images, there are typically two stages in the analysis of sound recordings. First, calls need to be isolated from background noise and other calls, and second, the isolated calls must be identified. An algorithm can be trained using a sample of calls of known identity, and within a survey, the results might be calibrated against a subset of recordings analysed by experts.
A wide variety of automatic detectors has been used, considering sound characteristics in both the time and the frequency domain. Various methods have been adopted, such as cross-correlation and peaks-above-threshold approaches. As this is a classification task, the development of machine learning approaches has recently taken off and seems promising (see, e.g. Greener et al. [34] for a review of machine learning in biology). In particular, representing the sound as a spectrogram has recently opened the door to the use of convolution neural networks to identify sounds automatically (Stowell [76]).
Harris et al. [36] explore the ability to use Ocean Bottom Seismometers for density estimation using large-scale passive acoustic monitoring, and active development of methods for estimating distances to detected sounds from such seismometers is ongoing.
2.4 Other Distance Sampling Methods
Technological innovations open up opportunities to develop new survey methods. These often allow assessment of populations that previously could not be reliably monitored. We include a few examples here of variations of distance sampling that have been made more practical by technological advances.
Indirect distance sampling surveys (Laing et al. [50]), in which objects produced by animals are recorded, include line transect surveys of dung (e.g. deer or elephants) or nests (e.g. apes). Standard line transect methods are used to estimate density of these objects. To convert these estimates of object density to estimates of animal density and abundance, we need to estimate two further quantities: the mean deposition rate (on average, how many objects per unit of time are generated per animal in the lead-up to the line transect survey); and the mean decay rate of objects, which is the reciprocal of the mean time for an object to decay. Technology can help to estimate both these quantities. Electronic monitoring of a sample of animals can estimate deposition rate (for example by attaching a tiny camera to the animal), and GPS can be used to help observers efficiently relocate objects being monitored to estimate decay rate.
Trapping and lure point transects (Buckland et al. [14]) provide another variation in point transect sampling. A trap or lure is placed at each point of a point transect design, and the number of animals arriving in a fixed time is recorded. The difficulty is that animals are deliberately drawn towards the survey devices, so we do not know the size of the area that these animals are drawn from. To resolve this problem, the survey is supplemented by trials involving a sample of animals whose locations are known when the traps or lures are set, identifying which of those animals are subsequently recorded at the trap or lure. We can then model the probability of detection of an animal at the point, as a function of its initial distance from the point (and possibly of additional covariates). A bonus of this approach is that for the monitored animals, we know how many were not subsequently detected, which allows straightforward estimation of the detection function without having to assume that animals at zero distance are detected with certainty. Technology can provide the lure, for example by playing calls to attract animals (Summers and Buckland [78]; Okot Omoya et al. [62]), or allow tracking of the sample of animals involved in trials (Potts et al. [65]). Again GPS makes this type of survey much easier to implement.
Three-dimensional distance sampling surveys have been used for marine sonar surveys (Cox et al. [20]). We expect such methods to become more widespread, for example to estimate abundance from bird radar surveys (Buckland et al. [13]: 195–198). In such surveys, density varies with vertical height or depth, and this variation must be modelled.
Where non-responsive animal movement is sufficient to generate bias in distance sampling estimates, a movement model can be built into a distance sampling analysis (Glennie et al. [33]). We anticipate further advances in this area, for example to exploit data from GPS tags placed on a sample of animals.
3 Spatial Capture-Recapture
Capture-recapture methods were originally developed for scenarios in which a sample of animals is caught in traps, marked, and released, and recaptures are attempted on one or more further occasions. In the classical formulation, the spatial location of the traps is ignored in the survey design and analysis. For spatially organised species, including those that are territorial or restricted in movement, spatial capture-recapture (SCR) methods are of greater value (Efford [25]; Borchers and Efford [5]; Royle and Young [71]). In particular, the effective area covered by the survey can be estimated, so the SCR method enables estimation of animal density. This contrasts with classical capture-recapture, for which the size of the area from which the captured animals are drawn is not estimable from the survey. Further, modelling the impact of spatial location on detectability is useful for mitigating the heterogeneity that plagues classical capture-recapture abundance estimates (Link [53]).
3.1 Camera-Trap Surveys
Camera-trap spatial capture-recapture surveys (Fig. 2) have become an important tool in the management of many charismatic megafauna. There are important differences between camera-trap spatial capture-recapture surveys and camera-trap distance sampling surveys. Spatial capture-recapture has two advantages. First, the traps do not need to be randomly located; provided they cover the study area adequately and sample an adequate range of distances from animal activity centres, they can be positioned where they are most likely to detect target animals. Second, the analyses can yield maps of estimated territories of detected animals, with associated uncertainty, in addition to an abundance estimate.

SLT-NCF (Snow Leopard Trust - Nature Conservation Foundation)
Snow leopard inspecting a camera trap. Spatial capture-recapture is widely used to analyse images captured of animals for which individuals have unique natural markings, such as snow leopards, tigers and jaguars.
SCR also has two disadvantages. First, we need to be able to identify individuals in the target population, to determine at which traps each animal is detected. Second, traps must be sufficiently close together that we can expect many animals to be detected at multiple traps, while being separated enough that an animal detected by one camera is not certain to be detected by all cameras. When surveying large regions, the need to put cameras sufficiently close together leads to designs similar to those for point transect or camera-trap distance sampling surveys, but with individual cameras at points replaced by arrays of cameras. The number of cameras per array is a design variable; methods have been developed to optimise the number and placement of cameras (see Durbach et al. [24], and references therein).
The technological advances that would be useful are the same as for camera-trap distance sampling, except that the spatial capture-recapture approach does not need estimates of the distance of the animal from the camera. There is, however, an additional requirement for automated image analysis, as we now need to be able to identify individual animals from the images, rather than simply to identify the species. This is a much more challenging task, and methods currently available have variable performance—see Matthé et al. [58] for a recent review of methods.
For many species, it seems unlikely that automated image analysis will produce error-free individual identification in the foreseeable future. Similar to the situation with respect to species identification in distance sampling camera surveys, SCR methods are designed to deal with false negatives in identification, whereas methods for dealing with false positives largely remain to be developed. The problem of incorrect individual identity assignment is more challenging than erroneous species identification, because every incorrect identity assignment changes the capture history not only of the individual to which it is assigned, but also of the (unknown) individual to which it really belongs. When a photograph fails to be matched to other photographs of the same individual, a new capture history called a “ghost” history is created, thereby overcounting the number of distinct animals in the sample and resulting in an overestimate of population size.
One way of dealing with this is to discard detections whose identities are not certain, but this sacrifices sample size. A more efficient way is to keep these detections but assign them no identity (Jimenéz et al. [45]). There are also SCR models called “spatial mark-resight” models, developed first by Sollmann et al. [72], that require only some individuals in the population to be identifiable, and “spatial partial identity” models for dealing with partially identified animals (for example when photographs of left and right flanks cannot be identified as being from the same animal), first developed by Augustine et al. [1]
The development of statistical methods to deal with identification uncertainty in SCR is already a growing area, and we anticipate that this and integration with automated species identification methods will be one of the main growth areas for SCR methods. There are current ongoing efforts to fully automate the process going from raw images to density estimates via SCR methods, and when the associated hurdles are overcome, these surveys might become even more widespread.
3.2 Acoustic Surveys
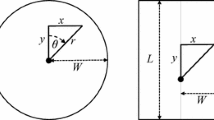
In camera-trap surveys, the observational unit is an individual animal, whereas in acoustic surveys it is more commonly a call of an individual animal. In distance sampling surveys this has little impact on the survey design, so sensor placements for acoustic distance sampling surveys follow largely the same design as those for camera-trap surveys. However, for spatial capture-recapture, acoustic designs will typically differ from camera-trap designs because spacing needs to be determined by sound propagation rather than by animal mobility. Acoustic sensors need to be placed to ensure that a single call is typically detected by multiple sensors, but not by all sensors, so detector spacing is species-dependent. For example, recent surveys of gibbons have detectors placed hundreds of metres apart (Kidney et al. [48]), while in surveys of frogs, they are only a few metres apart (Fig. 3; Measey et al. [59]). As for camera-trap SCR surveys, acoustic SCR surveys require multiple sensors at each sample location.

Representation of an acoustic survey of moss frogs (Arthroleptella lightfooti) in South Africa. Spatial capture-recapture allows 95% contours for a calling frog’s location to be estimated. In this example, a call was detected from three of the six acoustic sensors, indicated by a circle around the cross. Contours obtained from four models are shown: (a) model with covariates signal strength (SS) and time of arrival (TOA); (b) model with covariate SS only; (c) model with TOA only; and (d) model without covariates
Unlike acoustic distance sampling surveys, it is not necessary to estimate distances to calls, but if estimates of distance, received sound level and/or bearing are available then inference can be greatly improved (Borchers et al. [7]). This auxiliary data also helps determine whether calls recorded by different sensors are the same call. If calls are to be linked to individual animals, it similarly helps identify which detections arose from which animals.
For acoustic surveys in remote locations, whether distance sampling or SCR methods are used, it would be useful to develop solar panel or bio-battery power sources for acoustic sensors. Methods for precisely synchronising the clocks on recorders within an array are also needed, as even a small amount of clock drift can make it difficult to identify whether or not calls received at multiple detectors are the same call. A particular challenge is to develop data transfer technology capable of transmitting recordings and associated data from field sensors, perhaps to a drone passing overhead, which is difficult because acoustic survey files tend to be large. One solution might be to develop on-board call identification software on the acoustic sensors themselves, to reduce the volume of data that needs to be transferred. Acoustic recorders typically produce data files that are orders of magnitude larger than those produced by camera traps, so data transfer and storage are significant considerations.
3.3 Transects, Area Searches and Genetic SCR
SCR methods can also be used when observations are continuous in space, rather than restricted to discrete sensor points, for example arising from sampling along transect lines or searching an area (Royle and Young [71], Efford [26]). In these cases, observations are often of animal signs such as scat, from which identities may be obtained using genetic identification methods, rather than of animals themselves. If, when surveying along transects, animals themselves are observed, and distances to them can be obtained, then SCR survey methods reduce to mark-recapture line transect survey methods (Borchers et al. [7]). An interesting example by Pirrota et al. [64] conceptualizes photo-ID data as an SCR search, where grid cells over which the boat is travelling are considered active traps while the boat is there on-effort, and are switched off while the boat is away. Further similar analytical developments to conceptualize specialized surveys into SCR approaches might arise in the future.
4 Other Survey Methods
4.1 Genetic Surveys
There are two main approaches to abundance estimation using genetic surveys. In the first approach, DNA samples are used as the method of identifying individual animals in capture-recapture studies (Fewster [28]). As long as animals can be identified accurately, capture-recapture or SCR analyses can proceed as usual. The second approach is called close-kin mark-recapture (Fig. 4), and produces estimates of population size by modelling levels of relatedness among the animals in the sample, based on the rationale that a sample from a small population will contain a higher proportion of close relatives than one from a larger population (Bravington et al. [8]; Hillary et al. [40]).

Concept plan for close-kin mark-recapture in a simple scenario where adults and juveniles are distinguishable and there is no mortality. A The sample consists of four adults (blue) and seven juveniles (orange). Genetic profiling reveals five parent–offspring relationships within the sample, shown by dark blue arrow links. B Each juvenile has two parents, so the seven juveniles in the sample imply there are 14 arrow links to be found in the wider population. The sample detected five of these 14 links (dark blue arrows). Unsampled links are shown with pale blue arrows. C The four sampled adults supplied 5/14 of the links known to be present, so the estimate of adult population size is 4/(5/14) = 11.2 adults. Estimated adults are shown in grey. The estimate acknowledges that some of the unsampled adults will be parents to more than one juvenile
For the first approach of capture-recapture, multiple samples from individual animals are needed, so DNA samples must be obtained without changing the animal’s behaviour or causing distress. On the other hand, for close-kin mark-recapture it is possible to estimate population size from just one sampling event, allowing the method to be applied to harvested populations such as fish where the sample consists of animals caught for food. In either approach, DNA samples are processed in the laboratory to reveal a set of genetic reads known as the genotype for each one. In principle, each individual’s genotype should be sufficient to identify it uniquely, with the exception of identical twins. However, in practice the creation of genotypes can be error-prone, so identification of individuals or close relatives is not always straightforward (Taberlet and Luikart [80]).
Genetic samples can be high-quality tissue or blood samples, which usually give reliable information but create challenges in sample collection; or poor-quality dropped samples such as scat or feathers, which can be collected non-invasively but contain low quantities of DNA and generate genotypes with a high level of error. For high-quality DNA sampling, appropriate field protocols depend on the species and create some technological challenges. Sampling cetaceans is often done using biopsy darts that are fired at the animal using a device such as a veterinary rifle (Carroll et al. [16]). The darts glance off the animal’s thick blubber without causing distress, scooping up a small amount of tissue in the process, and must then be retrieved from the water. Another approach is to acquire DNA by sampling cetacean blows using drones (Robinson and Nuuttila [66]). Some terrestrial animals shed hairs with follicles attached, in which case high-quality DNA can be obtained using simple devices such as hair snags or sticky tapes (Horsup et al. [41]). An opportunity for future innovation would be to conduct genetic capture-recapture indirectly using blood parasites such as mosquitoes, leeches, or ticks that feed on the host species of interest. Sampling parasites, rather than the hosts themselves, could offer a non-invasive method of obtaining high-quality DNA if suitable sampling protocols can be devised.
Low-quality DNA samples include droppings and scat, hair without follicles, and feathers. In some cases these can be collected according to a formal survey design, for example a spatial capture-recapture design can deploy hair traps instead of camera traps (Efford et al. [27]). However, droppings are more likely to be available opportunistically, which creates the challenge of finding them. Trained dogs can be helpful in finding scat, but dog presence may cause distress to the target animals and dogs must be trained not to follow scent trails leading to the animal itself. Robots with the capability to locate and collect scat would be an exciting innovation for some species. In marine environments, whale scat can be collected from floating faeces shortly after defaecation (Carroll et al. [17]) and contains sufficient DNA to identify individuals.
A key area of innovation for genetic surveys is laboratory methods for creating genotypes. A genotype is a sample of genetic reads from the individual’s DNA, taken at positions on the genome called markers that can be accurately located for all individuals. Until recently, most studies used a type of genetic marker called microsatellites; these are regions of DNA where a short sequence is repeated multiple times and the number of repeats varies among different individuals. Microsatellite genotypes are typically constructed using 10 to 20 markers. For high-quality DNA samples, each marker typically has an error or dropout rate of a few per cent, allowing most samples to be matched unambiguously to individuals (Vale et al. [81]; Fewster [28]). However, the error rate is much worse for low-quality DNA samples, so matching of samples to individuals can be problematic (Wright et al. [82]).
More recently, laboratory advances have focused on a different type of genetic marker called SNPs (single nucleotide polymorphisms) which are individual genetic bases that vary among individuals. Each SNP marker typically has only two variant alleles, but thousands of markers can be extracted at low cost using modern laboratory methods. For high-quality DNA samples, SNP genotyping largely resolves the problems of identifying individuals and close-kin, because even an error rate of a few per cent per marker still leaves sufficiently many matches to establish identity and relatedness of samples (Hillary et al. [40]). However, innovations are still needed for low-quality DNA samples. At a laboratory level, one enhancement is to design marker panels that are robust to degradation of DNA, for example by finding markers that only rely on short strands of DNA. At a statistical level, methods that can tolerate a level of error without biasing the analysis would save considerable time and cost in laboratory processing. Multiple genotyping of each sample is often practised for low-quality DNA, and this can be used to provide information on genotyping error rates (Wright et al. [82]).
In addition to genetic capture-recapture and close-kin mark-recapture, there have also been recent attempts to estimate abundance using environmental DNA (eDNA), based on the idea that the amount of eDNA collected from a species should be informative about its abundance (Lacoursière-Roussel et al. [49]; Spear et al. [73]). Although eDNA analysis is clearly suitable for occupancy models, as described below, its suitability for abundance estimation is still under investigation, and results have so far been more promising in aquatic environments than terrestrial environments (e.g. Di Muri et al. [22], Breton et al. [9]). Nonetheless, if the approach proves suitable for some taxa, we anticipate new analytical procedures will be needed, both for DNA processing and for statistical analysis of the resulting data.
4.2 Occupancy Methods
Occupancy methods involve repeat visits to sites, recording which species are detected on each visit (MacKenzie et al. [55]). Species presence might be recorded by observers seeing or hearing animals, or by animal sign, camera traps, or acoustic detectors. Recent interest in using environmental DNA (eDNA) for occupancy analysis has sparked development of statistical methods to deal with false positives in species detections (Griffin et al. [35]; Buxton et al. [15]).
Occupancy methods give estimates of the probability that a given species is detected, and temporal trends in this probability may allow inference on whether the species is declining or increasing. A negative slope to the trend is likely to indicate a decrease in abundance but cannot be assumed to indicate the rate of change in abundance. For example, a species might halve in abundance, and yet remain easily detectable at all sites within a survey, in which case the probability of detection may show no downward trend. Royle and Nichols [70] developed a simple binomial model to relate detection probability to abundance, based on the assumption that more abundant species are more likely to be detected. Their approach has been found to give biased estimates of abundance which nevertheless correlate strongly with estimates that are known to be unbiased, so they can often be used to infer trends in abundance (O’Brien et al. [61]).
In many surveys, it is not practical or cost-effective to estimate abundance, but the presence/absence data are readily recorded. Strictly, ‘absence’ means that a species was not recorded on a given visit, which does not necessarily mean that the species was absent from that site at the time. Thus, it is important to have methods that reliably model such data. We expect to see increased interest in such approaches, as they potentially allow biodiversity trends to be quantified both for taxa that are not amenable to more sophisticated data recording, and in countries that do not have the resources to conduct more sophisticated surveys. A priority therefore is to develop methods that make less restrictive assumptions. There may also be merit in developing hybrid methods. For example, a small number of sites might be surveyed using methods that allow direct estimation of abundance, together with less rigorous data from many more sites gathered by citizen scientists (Lepczyk et al. [51]).
4.3 N-Mixture Models
N-mixture models (Royle [69]) are popular because they allow estimation of abundance when only repeat counts are available from a sample of sites. As with occupancy methods, technology such as camera traps and acoustic detectors increases the diversity of surveys that can potentially be analysed using N-mixture models.
Although the original approach has been extended (Dénes et al. [21]; Chandler and Royle [19]), there is very limited information in a series of counts to allow reliable separation of abundance and detectability (Barker et al. [2]), and the method is sensitive to failures of the strong assumptions necessary to allow estimation of the model’s parameters (Link et al. [54]). Barker et al. [2] recommend that users gather auxiliary data for estimating detectability, to improve reliability of the abundance estimates, and we expect methodological developments that exploit this approach.
4.4 Random Encounter Models
Random encounter models (Rowcliffe et al. [67]) were developed for estimating animal abundance from camera-trap data, when animals are not individually identifiable. They assume that animals move randomly and independently of each other, and use functional relationships between encounter rates, the dimensions of the camera’s detection zone, and the speed of animal movement to estimate the density. The approach is generalized and given a stronger methodological basis by Jourdain et al. [47].
Although Jourdain et al. [47] allow animal speeds to vary, and develop an integrated modelling approach, they do not explicitly incorporate an animal movement model. Repeat detections of the same animal from a camera trap provides some information on movement, provided each detection can be accurately located, and so this gives the potential for modelling animal movement within the survey region. Such modelling will be enhanced if movement data are available for a few tagged animals. Palencia et al. [63] compare REM, CTDS and SCR approaches and conclude that camera traps with fast response and recovery times are important for all approaches, hinting at the need for further hardware development, but also for the need to develop analytical frameworks to deal with potential reactions to the camera traps.
4.5 Citizen-Science Surveys
Citizen-science surveys (Lepczyk et al. [51]) have gained rapidly in popularity in recent years, partly as a result of technological advances. Smart phones allow citizen scientists to submit records through apps, and photographs may be attached for verification. Apps that identify species from photographs (such as iNaturalist, https://www.inaturalist.org/) and sound (such as BirdNet, https://birdnet.cornell.edu/) are also improving rapidly. Records collected in this way mostly involve purposive sampling, with no formal survey design. Increasingly however, such surveys are becoming more structured, and we expect this trend to continue, with designed surveys over wide regions becoming more commonplace.
Another contribution made by citizen scientists to wildlife monitoring is crowd-sourcing the review of images or sound-files for species of interest. An example is the Snapshot Serengeti project (Swanson et al. [79]) which generates large numbers of images recorded by camera traps. Citizen scientists access the project website, receive some training, and are then qualified to review images and record the animals shown. These citizen scientists can be located anywhere, creating considerable processing capacity. Multiple citizen scientists review any particular image, so images only need to be sent for expert review if there is significant disagreement amongst them. It should be noted however that deep learning techniques have been developed that achieve similar levels of performance in this project (Norouzzadeh et al. [60]).
We anticipate that the number and variety of surveys that utilise new technology to involve citizen scientists will continue to expand rapidly, with many of these surveys gaining designed structures that will allow more solid inference. We also expect such surveys to become increasingly international, with some reaching global extent.
The contributions of citizen scientists to biodiversity monitoring over large regions are discussed by Buckland and Johnston [12], and the challenges facing those who use citizen-science datasets to monitor biodiversity are discussed by Johnston et al. [46].
5 Discussion
Technology is increasingly the driver for innovation in statistical ecology. Statisticians need to be aware of technological advances, both existing and potential, to reduce the risk of expending effort in developing methodologies that quickly become obsolete.
Currently, there is little if any collaboration between the engineers who create new technologies, and the statisticians who develop the associated methodology. Statisticians typically develop methods for pre-existing technologies, expending effort on dealing with technological limitations that could potentially have been avoided had there been statistical input at the design stage. Meanwhile engineers often have limited understanding of the analytic value of different technological advances, in terms of their potential to deliver precise estimates of abundance or other parameters. Often, sensor equipment is designed with no analytic method in mind at all, leading to masses of unused data and unfulfilled potential.
Ideally, the design of new equipment or algorithms for creating data should be a collaborative venture between the technologists building the equipment, and statistical experts who can ensure the resulting datasets are sufficiently informative and robust to address the questions of interest. Many of the technologies we have described here require statistical input at the design stage. For example, the two-camera surveys in Sect. 2.1 described by Stevenson et al. [74] and Borchers et al. [6] require a sequence of images of the same geographic location that are separated in time. Creating such images is an engineering challenge, but statistical input is needed to decide specifications such as a suitable time lag between images, which can impact heavily upon the engineering design. Other examples include the design of acoustic equipment, in which some design features such as clock synchronisation or measures of direction may bring significant analytic value, whereas others such as measures of sound intensity may be of little consequence; or algorithms for identifying detections in acoustic recordings or images, for which it appears not to be widely known among algorithm designers that false positives are considerably more problematic from an analytic perspective than false negatives. Statistical collaboration in the design, specifications, and piloting of new technologies will help to ensure that new developments reach their analytic potential, and will expedite faster and more efficient advances in the future.
References
Augustine BC, Royle JA, Kelly MJ, Satter CB, Alonso RS, Boydston EE, Crooks KR (2018) Spatial capture-recapture with partial identity: an application to camera traps. Ann Appl Stat 11:67–95
Barker RJ, Schofield MR, Link WA, Sauer JR (2018) On the robustness of N-mixture models for count data. Biometrics 74:369–377
Barlow J, Fregosi S, Thomas L, Harris D, Griffiths ET (2021) Acoustic detection range and population density of Cuvier’s beaked whales estimated from near-surface hydrophones. J Acoust Soc Am 149:111–125
Blumstein DT, Mennill DJ, Clemins P, Girod L, Yao K, Patricelli G, Deppe JL, Krakauer AH, Clark C, Cortopassi KA, Hanser SF, McCowan B, Ali AM, Kirschel ANG (2011) Acoustic monitoring in terrestrial environments using microphone arrays: applications, technological considerations and prospectus. J Appl Ecol 48:758–767
Borchers DL, Efford MG (2008) Spatially explicit maximum likelihood methods for capture-recapture studies. Biometrics 64:377–385
Borchers DL, Nightingale P, Stevenson BC, Fewster RM (2022) A latent capture history model for digital aerial surveys. Biometrics 78:274–285
Borchers DL, Stevenson BC, Kidney D, Thomas L, Marques TA (2015) A unifying model for capture-recapture and distance sampling surveys of wildlife populations. J Amer Statist Assoc 110:195–204
Bravington MV, Skaug HJ, Anderson EC (2016) Close-kin mark-recapture. Stat Sci 31:259–274
Breton B-AA, Beaty L, Bennett AM, Kyle CJ, Lesbarrères D, Vilaça ST, Wikston MJH, Wilson CC, Murray DL (2022) Testing the effectiveness of environmental DNA (eDNA) to quantify larval amphibian abundance. Environ DNA 4:1229–1240
Buckland ST (2006) Point transect surveys for songbirds: robust methodologies. Auk 123:345–357
Buckland ST, Burt ML, Rexstad EA, Mellor M, Williams AE, Woodward R (2012) Aerial surveys of seabirds: the advent of digital methods. J App Ecol 49:960–967
Buckland ST, Johnston A (2017) Monitoring the biodiversity of regions: key principles and possible pitfalls. Biol Conserv 214:23–34
Buckland ST, Rexstad EA, Marques TA, Oedekoven CS (2015) Distance sampling: methods and applications. Springer, New York
Buckland ST, Summers RW, Borchers DL, Thomas L (2006) Point transect sampling with traps or lures. J App Ecol 43:377–384
Buxton A, Matechou E, Griffin J, Diana A, Griffiths RA (2021) Optimising sampling and analysis protocols in environmental DNA studies. Sci Rep 11:11637
Carroll EL, Childerhouse SJ, Fewster RM, Patenaude NJ, Steel D, Dunshea G, Boren L, Baker CS (2013) Accounting for female reproductive cycles in a superpopulation capture-recapture framework: application to southern right whales (Eubalaena australis). Ecol Appl 23:1677–1690
Carroll EL, Gallego R, Sewell MA, Ross HA, O’Rorke R, Newcomb RD, Constantine R (2019) Multi-locus DNA metabarcoding of zooplankton communities and scat reveal trophic interactions of a generalist predator. Sci Rep 9:281
Chabot D, Stapleton S, Francis CM (2022) Using web images to train a deep neural network to detect sparsely distributed wildlife in large volumes of remotely sensed imagery: a case study of polar bears on sea ice. Eco Inform 68:101547
Chandler RB, Royle JA (2013) Spatially explicit models for inference about density in unmarked or partially marked populations. Ann Appl Stat 7:936–954
Cox MJ, Borchers DL, Demer DA, Cutter GR, Brierley AS (2011) Estimating the density of Antarctic krill (Euphasia superba) from multi-beam echo-sounder observations using distance sampling methods. Appl Stat 60:301–316
Dénes FV, Silveira LF, Beissinger SR (2015) Estimating abundance of unmarked animal populations: accounting for imperfect detection and other sources of zero inflation. Methods Ecol Evol 6:543–556
Di Muri C, Lawson Handley L, Bean CW, Li J, Peirson G, Sellers GS, Walsh K, Watson HV, Winfield IJ, Hänfling B (2020) Read counts from environmental DNA (eDNA) metabarcoding reflect fish abundance and biomass in drained ponds. Metabarcoding Metagenom 4:e56959
Duporge I, Isupova O, Reece S, Macdonald DW, Wang T (2021) Using very-high-resolution satellite imagery and deep learning to detect and count African elephants in heterogeneous landscapes. Remote Sens Ecol Conserv 7:369–381
Durbach I, Borchers DL, Sutherland C, Sharma K (2021) Fast, flexible alternatives to regular grid designs for spatial capture-recapture. Methods Ecol Evol 12:298–310
Efford MG (2004) Density estimation in live-trapping studies. Oikos 106:598–610
Efford MG (2011) Estimation of population density by spatially explicit capture-recapture analysis of data from area searches. Ecology 92:2202–2207
Efford MG, Borchers DL, Byrom AE (2009) Density estimation by spatially explicit capture-recapture: likelihood-based methods. In: Thompson DL, Cooch EG, Conroy MJ (eds) Modeling demographic processes in marked populations. Springer, New York, pp 255–269
Fewster RM (2017) Some applications of genetics in statistical ecology. Adv Stat Anal 101:349–379
Frasier KE, Garrison LP, Soldevilla MS, Wiggins SM, Hildebrand JA (2021) Cetacean distribution models based on visual and passive acoustic data. Sci Rep 11:8240
Fretwell PT, LaRue MA, Morin P, Kooyman GL, Wienecke B, Ratcliffe N, Fox AJ, Fleming AH, Porter C, Trathan PN (2012) An emperor penguin population estimate: the first global, synoptic survey of a species from space. PLoS ONE 7:e33751
Fretwell PT, Scofield P, Phillips RA (2017) Using super-high resolution satellite imagery to census threatened albatrosses. Ibis 159:481–490
Fretwell PT, Staniland IJ, Forcada J (2014) Whales from space: counting southern right whales by satellite. PLoS ONE 9:e88655
Glennie R, Buckland ST, Langrock R, Gerrodette T, Ballance LT, Chivers SJ, Scott MD, Perrin WF (2021) Incorporating animal movement into distance sampling. J Am Stat Assoc 116:107–115
Greener JG, Kandathil SM, Moffat L, Jones DT (2021) A guide to machine learning for biologists. Nat Rev Mol Cell Biol 23:40–55
Griffin JE, Matechou E, Buxton AS, Bormpoudakis D, Griffiths RA (2020) Modelling environmental DNA data; Bayesian variable selection accounting for false positive and false negative errors. J. R. Stat Soc Ser C Appl Stat 69:377–392
Harris DV, Matias L, Thomas L, Harwood J, Geissler W (2013) Applying distance sampling to fin whale calls recorded by single seismic instruments in the northeast Atlantic. J Acoust Soc Am 134:3522
Hiby AR (1985) An approach to estimating population densities of great whales from sighting surveys. IMA J Math Appl Med Biol 2:201–220
Hiby L, Lovell P (1998) Using aircraft in tandem formation to estimate abundance of harbour porpoise. Biometrics 54:1280–1289
Hiby L (1999) The objective identification of duplicate sightings in aerial survey for porpoise. In: Garner GW, Amstrup SC, Laake JL, Manly BFJ, McDonald LL, Robertson DG (eds) Marine mammal survey and assessment methods. Balkema, Rotterdam, pp 179–189
Hillary RM, Bravington MV, Patterson TA, Grewe P, Bradford R, Feutry P, Gunasekera R, Peddemors V, Werry J, Francis MP, Duffy CAJ, Bruce BD (2018) Genetic relatedness reveals total population size of white sharks in eastern Australia and New Zealand. Sci Rep 8:2661
Horsup AB, Austin JJ, Fewster RM, Hansen BD, Harper DE, Molyneux JA, White LC, Taylor AC (2021) Demographic trends and reproductive patterns in the northern hairy-nosed wombat Lasiorhinus krefftii at Epping Forest National Park (Scientific), Central Queensland. Aust Mammal 43:72–84
Höschle C, Cubaynes HC, Clarke PJ, Humphries G, Borowicz A (2021) The potential of satellite imagery for surveying whales. Sensors 21:963
Howe EJ, Buckland ST, Després-Einspenner M-L, Kühl HS (2017) Distance sampling with camera traps. Methods Ecol Evol 8:1558–1565
Howe EJ, Buckland ST, Després-Einspenner M-L, Kühl HS (2019) Model selection with overdispersed distance sampling data. Methods Ecol Evol 10:38–47
Jimenéz J, Augustine BC, Linden DW, Chandler RB, Royle JA (2021) Spatial capture-recapture with random thinning for unidentified encounters. Ecol Evol 11:1187–1198
Johnston A, Matechou E, Dennis EB (2022) Outstanding challenges and future directions for biodiversity monitoring using citizen science data. Methods Ecol Evol. https://doi.org/10.1111/2041-210X.13834
Jourdain NOAS, Cole DJ, Ridout MS, Rowcliffe JM (2020) New methods for estimating animal density from camera trap data. J Agric Biol Environ Stat 25:148–167
Kidney D, Rawson BM, Borchers DL, Thomas L, Marques TA, Stevenson B (2016) An efficient acoustic density estimation method with human detectors, applied to gibbons in Cambodia. PLoS ONE 11:e0155066
Lacoursière-Roussel A, Rosabal M, Bernatchez L (2016) Estimating fish abundance and biomass from eDNA concentrations: variability among capture methods and environmental conditions. Mol Ecol Resour 16:1401–1414
Laing SE, Buckland ST, Burn RW, Lambie D, Amphlett A (2003) Dung and nest surveys: estimating decay rates. J App Ecol 40:1102–1111
Lepczyk CA, Boyle OD, Vargo TLV (eds) (2020) Handbook of citizen science in ecology and conservation. University of California Press, Oakland
Lewis T, Gillespie D, Lacey C, Matthews J, Danbolt M, Leaper R, McLanaghan R, Moscrop A (2007) Sperm whale abundance estimates from acoustic surveys of the Ionian Sea and Straits of Sicily in 2003. J Mar Biol Assoc UK 87:353–357
Link WA (2004) Individual heterogeneity and identifiability in capture-recapture models. Anim Biodivers Conserv 27:87–91
Link WA, Schofield MR, Barker RJ, Sauer JR (2018) On the robustness of N-mixture models. Ecology 99:1547–1551
MacKenzie DI, Nichols JD, Royle JA, Pollock KH, Bailey L, Hines JE (2006) Occupancy estimation and modeling: inferring patterns and dynamics of species occurrence. Academic Press, New York
Marques TA, Thomas L, Martin SW, Mellinger DK, Ward JA, Moretti DJ, Harris D, Tyack PL (2013) Estimating animal population density using passive acoustics. Biol Rev 88:287–309
Marques TA, Thomas L, Ward J, DiMarzio N, Tyack PL (2009) Estimating cetacean population density using fixed passive acoustic sensors: an example with Blainville’s beaked whales. J Acoust Soc Am 125:1982–1994
Matthé M, Sannolo M, Winiarski K, Spitzen van der Sluijs A, Goedbloed D, Steinfartz S, Stachow U (2017) Comparison of photo-matching algorithms commonly used for photographic capture-recapture studies. Ecol Evol 7:5861–5872
Measey GJ, Stevenson BC, Scott T, Altwegg R, Borchers DL (2017) Counting chirps: acoustic monitoring of cryptic frogs. J Appl Ecol 54:894–902
Norouzzadeh MS, Nguyen A, Kosmala M, Swanson A, Palmer MS, Packer C, Clune J (2018) Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proc Natl Acad Sci 115:E5716–E5725
O’Brien TG, Akampurila JE, Beaudrot L, Boekee K, Brncic T, Hickey J, Jansen PA, Kayijamahe C, Moore J, Mugerwa B, Mulindahabi F, Ndoundou-Hockemba M, Niyigaba P, Nyiratuza M, Opepa CK, Rovero F, Uzabaho E, Strindberg S (2019) Camera trapping reveals trends in forest duiker populations in African National Parks. Remote Sens Ecol Conserv 6:168–180
Okot Omoya E, Mudumba T, Buckland ST, Mulondo P, Plumptre AJ (2014) Estimating population sizes of lions Panthera leo and spotted hyaenas Crocuta crocuta in Uganda’s savannah national parks using lure count methods. Oryx 48:394–401
Palencia P, Rowcliffe JM, Vicente J, Acevedo P (2021) Assessing the camera trap methodologies used to estimate density of unmarked populations. J Appl Ecol 58:1583–1592
Pirotta E, Thompson PM, Cheney B, Donovan CR, Lusseau D (2014) Estimating spatial, temporal and individual variability in dolphin cumulative exposure to boat traffic using spatially explicit capture-recapture methods. Anim Conserv 18:20–31
Potts JM, Buckland ST, Thomas L, Savage A (2012) Estimating abundance of cryptic but trappable animals using trapping point transects: a case study for Key Largo woodrats. Methods Ecol Evol 3:695–703
Robinson CV, Nuuttila HK (2020) Don’t hold your breath: limited DNA capture using non-invasive blow sampling for small cetaceans. Aquat Mamm J 46:32–41
Rowcliffe JM, Field J, Turvey ST, Carbone C (2008) Estimating animal density using camera traps without the need for individual recognition. J Appl Ecol 45:1228–1236
Rowcliffe JM, Kays R, Kranstauber B, Carbone C, Jansen PA (2014) Quantifying levels of animal activity using camera trap data. Methods Ecol Evol 5:1170–1179
Royle JA (2004) N-mixture models for estimating population size from spatially replicated counts. Biometrics 60:108–115
Royle JA, Nichols JD (2003) Estimating abundance from repeated presence-absence data or point counts. Ecology 84:777–790
Royle JA, Young KV (2008) A hierarchical model for spatial capture-recapture data. Ecology 89:2281–2289
Sollmann R, Gardner B, Parsons AW, Stocking JJ, McClintock BT, Simons TR, Pollock KH, O’Connell AF (2013) A spatial mark-resight model augmented with telemetry data. Ecology 94:553–559
Spear MJ, Embke HS, Krysan PJ, Zanden MJV (2020) Application of eDNA as a tool for assessing fish population abundance. Environ DNA 3:83–91
Stevenson BC, Borchers DL, Fewster RM (2019) Cluster capture-recapture to account for identification uncertainty on aerial surveys of animal populations. Biometrics 75:326–336
Stimpert AK, Lammers MO, Pack AA, Au WWL (2020) Variations in received levels on a sound and movement tag on a singing humpback whale: implications for caller identification. J Acoust Soc Am 147:3684–3690
Stowell D (2022) Computational bioacoustics with deep learning: a review and roadmap. PeerJ 1:e131520
Suberg L, Wynn RB, van der Kooij J, Fernand L, Fielding S, Guihen D, Gillespie D, Johnson M, Gkikopoulou KC, Allan IJ, Vrana B, Miller PI, Smeed D, Jones AR (2014) Assessing the potential of autonomous submarine gliders for ecosystem monitoring across multiple trophic levels (plankton to cetaceans) and pollutants in shallow shelf seas. Methods Oceanogr 10:70–89
Summers RW, Buckland ST (2011) A first survey of the global population size and distribution of the Scottish crossbill Loxia scotica. Bird Conserv Int 21:186–198
Swanson A, Kosmala M, Lintott C, Simpson R, Smith A, Packer C (2015) Snapshot Serengeti, high-frequency annotated camera trap images of 40 mammalian species in an African savanna. Sci Data 2:150026
Taberlet P, Luikart G (1999) Non-invasive genetic sampling and individual identification. Biol J Linn Soc 68:41–55
Vale RTR, Fewster RM, Carroll EL, Patenaude NJ (2013) Maximum likelihood estimation for model Mt,α for capture–recapture data with misidentification. Biometrics 70:962–971
Wright JA, Barker RJ, Schofield MR, Frantz AC, Byrom AE, Gleeson DM (2009) Incorporating genotype uncertainty into mark-recapture-type models for estimating abundance using DNA samples. Biometrics 65:833–840
Acknowledgements
TAM’s time for this review was covered under the ACCURATE project, funded by the US Navy Living Marine Resources program (contract no. N3943019C2176), and he also thanks partial support by CEAUL (funded by FCT—Fundação para a Ciência e a Tecnologia, Portugal, through the project UIDB/00006/2020). We would like to thank the editors and reviewers for their supportive and valuable comments.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Ecological Statistics” Guest edited by Tiago A. Marques, Ben Stevenson, Charlotte Jones-Todd, Théo Michelot and Ben Swallow.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Buckland, S.T., Borchers, D.L., Marques, T.A. et al. Wildlife Population Assessment: Changing Priorities Driven by Technological Advances. J Stat Theory Pract 17, 20 (2023). https://doi.org/10.1007/s42519-023-00319-6
Accepted:
Published:
DOI: https://doi.org/10.1007/s42519-023-00319-6