
Abstract
The macroscopic fundamental diagram (MFD) captures an orderly relationship among traffic flow, density, and speed at the network level. It is a simple yet powerful tool for modeling traffic dynamics in large urban networks with broad application in traffic control and management. However, empirically derived MFDs in urban regions require high-resolution traffic data from the network. Having the network flow and vehicular density estimated at the (granular) census tract level using vehicle probe data, we apply machine learning methods to predict the MFDs across U.S. urban areas and capture the impacts of location-specific input features on the network flow–density relationships at a large scale. The results show that, among the four tested machine learning approaches (Random Forest, XGBoost, Support Vector Machine, and Neural Network), XGBoost delivers the best performance in predicting network traffic flow based on vehicular density and location attributes. Using interaction Shapley Additive explanation (SHAP) values and partial correlation analysis, we examine the factors influencing MFD shapes across different locations. Our empirical findings reveal that across U.S. urban areas, network topology, transportation infrastructure, and land use are primary factors shaping MFD curves, while demand and trip-related factors play a lesser role. Specifically, higher ranking roads, centrality, and development levels correlate positively with network capacity and critical density, whereas negative associations are observed for network connectivity, mixed-use development, and road roughness levels.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Traffic in an urban network becomes congested once a critical number of vehicles is reached. A macroscopic fundamental diagrams (MFD) describe an orderly and consistent relationship between average vehicle flow and average traffic density when both are measured across a specific urban network. Such relationships have been proven to exist and can be estimated from simulation and empirical data in field studies (Geroliminis and Daganzo 2008; Daganzo and Geroliminis 2008; Daganzo 2007) or approximated analytically (Tilg et al. 2020).
The MFD (see Fig. 1) usually exhibits an uncongested branch, when increasing the number of vehicles in the network (indicated by traffic density) increases the travel production (indicated by space mean flow), and a congested branch when the opposite is true. The urban network system’s capacity and critical density are reached at the boundary between the two phases (Fig. 1). The shape of MFDs depends on network topology, traffic signal settings, block lengths, free-flow speeds, level of inhomogeneity, and routing behaviors that are specific to a given network location (Tilg et al. 2020; Daganzo et al. 2011; Girault et al. 2016).

a San Francisco tract-level traffic density at 5 PM; b observed flow–density scatter at an example sub-region of downtown San Francisco with illustration of network capacity and critical density and traffic regimes using data from this study
The MFD model is one of the most famous examples of parsimonious traffic models for the aggregate behavior of large systems with many agents (Daganzo et al. 2012). Understanding network-wide traffic through MFDs can optimally allocate demand to existing networks, improving performance by maximizing network production and avoiding congestion. With reduced computational complexity and improved system-level representation and interpretability, MFDs are well suited to analyzing a large space of policy options and uncovering general insights into large-scale strategies. Example applications include perimeter flow control (Geroliminis et al. 2013; Haddad and Geroliminis 2012), area-wide congestion pricing (Loder et al. 2022; Zheng et al. 2012), space allocation (Zheng and Geroliminis 2013), street network configuration (Ortigosa et al. 2015, 2019), vehicle routing (Yildirimoglu and Geroliminis 2014), physics-informed traffic data imputation (Xue et al. 2024), and regional evacuation (Zhang et al. 2015).
Despite the wide application of MFDs, the functional relationships between average flow and density or the shapes of the MFD curves have only been empirically derived for a limited number of networks such as Daganzo et al. (2011); Daganzo and Geroliminis (2008); Geroliminis et al. (2007); Loder et al. (2019). Literature has been particularly sparse in empirically derived MFDs in U.S. urban locations. For example, only one U.S. city (Los Angeles) was included in a recent study that estimated MFD functional forms in 41 cities (mainly in Europe) around the world using existing traffic monitoring systems located on main urban roads (Loder et al. 2019).
Furthermore, the empirical functional form, fs(.) that describes MFD curves (i.e., flow as a function of density) at a given location s have been typically predetermined, based on traffic engineers’ prior experience, as multi-regime linear, polynomial, or exponential functions (see review in Ambühl et al. (2020); Ma et al. (2024)). There has been no consensus on the “best” functional form to use across networks. Ma et al. (2024) proposed an automatic functional form selection approach based on the measurement data. However, while suitable functional forms can be determined for given networks, the resulting parameter estimates may vary by contextual factors (Koch et al. 2022) and therefore, are not readily transferrable from one location to another for applications in urban areas lack of empirical data.
Machine learning models, on the other hand, do not rely on predefined functional forms and hold the potential to flexibly predict the shapes of MFD curves across locations after the locational contextual variables are introduced into the training of large-scale flow–density data across network types (see Eq. (1)).
where q is the network average flow, k is the network average density, \(\overrightarrow{X}\) are contextual factors associated with the network location, such as network topology, road infrastructure, and land use patterns, and \(f(.)\) represents the relationship learned by machine learning models.
Given the learned f(.), MFD curves (i.e., flow as a function of density) can be flexibly derived for any location as shown in Eq. (2). Essentially, the flow–density MFD curve fs(.) at location s can be derived by plugging in the values of location features \(\overrightarrow{X}={\overrightarrow{X}}_{s}\) into f(.) as follows.
Although machine-learning-based methods were proposed in the literature (Sekuła et al. 2018; Saffari et al. 2023; Ka et al.2024; Rahman and Hasan 2023), they were mostly focused on estimation of actual flow and density rather than learning the shapes of MFDs (or flow–density relationships) across different types of networks. Koch et al. (2022) introduced contextual information into a physics-based machine learning framework to generate parameterized segment-level (rather than macroscopic or network level) fundamental diagrams based on simulation data. Such pioneering work is yet to be extended to macroscopic network level.
The lack of empirically derived, machine-learning-based flow–density relationships and subsequent limited understanding of MFD shape differences across network locations in the U.S. are mainly due to the limited availability of traffic volume data (traffic flow) (Azfar et al. 2024). Unlike speed data, which is readily available network-wide through probe vendors (e.g., INRIX, HERE, TomTom), reliable volume data generally exist only at sparsely located continuous count stations such as loop detector data. However, in addition to their spatial sparsity, loop detector data are prone to placement biases, such as detectors not being uniformly distributed to represent the entire link, being located in more congested locations (over-estimation of network-wide congestion), or not representative of the overall O-D distribution of the network (Tilg et al. 2020; Saffari et al. 2020, 2022). Lee et al. (2023) demonstrated that the shape of MFD curves was biased by positions of the loop detectors.
Probe vehicle data, on the other hand, represent a better spatial coverage for estimation of MFDs than loop detector data (Leclercq et al. 2014; Verendel and Yeh 2019), with improved accuracy especially when fused with loop detector data as demonstrated in Saffari et al. (2022). In recent work, Sekuła et al. (2018) developed and applied a novel approach for estimating traffic volumes that combines a widely used profiling method (Schrank et al. 2015) and an artificial neural network (ANN) model trained with vehicle probe data for the state of Maryland. Saffari et al. (2023) used simulation data to demonstrate a methodology to estimate average flow and density of the network from probe vehicle data without known penetration rate. Ka et al. ( 2024) employed a physics-informed machine learning approach to accurately estimate traffic states using mobile location data. When expanded to all 50 states in the U.S., the probe vehicle-based volume estimation can provide wide coverage of the different road networks to facilitate the empirical flow–density relationships (i.e., MFD curves) across locations.
To address the aforementioned research gaps related to empirically derived and location-flexible MFD models across U.S. urban areas, this paper develops the first application of machine learning methods to derive the empirical flow–density relationships for MFD models by leveraging the volume and speed estimates (following Sekuła et al. (2018)) nation-wide using HERE probe data. Note that most of the prior MFD studies using probe data were focused on estimation of actual flow and density (such as Saffari et al. (2023), whereas this paper is distinctively focused on interrogating the shape or relationship between average flow and density at the network level.
We demonstrate the ability of machine learning methods to predict location-dependent flow–density relationships and generate insights on important location factors that underly the differences in the resulting shape of MFD curves. We particularly focus on the differences in critical density and network capacity (as illustrated in Fig. 1) that delineate the boundary of the network traffic between being in the uncongested and congested branches of the MFD curves.
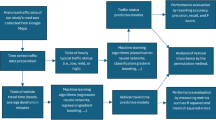
First, we process both the traffic data and location attributes, and then these data are used to train and compare the performance of four machine learning methods. Finally, TreeExplainer (Lundberg et al. 2020) is used to identify and interpret important factors influencing the flow–density relationships across different locations, including a wide range of transportation supply and demand characteristics such as road network topology, land use, transportation infrastructure, and demand characteristics. The overview of the data and analysis process is illustrated in Fig. 2.

Overview of data process and analysis of the paper
The rest of the paper is organized into the following sections. Section 2 describes the data sources and preprocesses that generate network-level flow and density and location factors. Section 3 introduces the machine learning methods, how they are applied to our data, and the interpretation methods used. Section 4 presents the results, including the data processing results, performance of the machine learning models, and an interpretation of important factors. Section 5 concludes the paper.
Input Data Preprocesses and Description
Two main input data streams are needed to feed into the machine learning models used in this study, the probe data-derived volume (traffic flow) and density at network level, and location attributes such as land use, transportation infrastructure, network topology, and travel demand, that may affect the flow–density relationships. These data are processed to the same geographic resolution.
Network-Level Flow and Density Data Process
Road Segment-Level Volume Estimation
Three months of HERE probe data (Sept–Nov) in 2019 were licensed for the full U.S. network geometry, traffic counts, speeds, number of probes, and weather data were pre-processed and ultimately conflated to prepare the data for model calibration. Following the method developed in Sekuła et al. (2018), a fully connected feedforward multi-layer Artificial Neural Network (ANN) model was applied to calibrate, test, and validate consistent models to estimate traffic counts (volume) for road segments belonging to different functional road classes (FRCs) at 15 min granularity. Performance is evaluated in comparison with existing traffic count observations. The calibrate model is then applied statewide for each state to estimate traffic volume at 15 min intervals at 1,216,779 TMC (Traffic Message Channel) road segments. The segment-level estimated volume and reported HERE probe vehicle average link speeds are used in the next step for deriving network-level flow and density.
A detailed description of the HERE probe data, traffic volume estimation, model calibration, and validation strategy can be found in Sekuła et al. (2018) as well as in the Supporting Information of this paper.
Network-Level Flow and Density Aggregation at Urban Census Tracts
The vehicle flow (\({q}_{i}\)) at a given road segment (\(i\)) is computed by averaging the volume data over monitored lanes and over the observation period to get the number of vehicles per lane per second. Then the harmonic mean speed (\({v}_{i}\)) is derived from the observed speed data collocated with the volume monitor. Traffic density (\({k}_{i}\)) is derived using the macroscopic flow equation \(q=kv\). Then network-level average flow (\(\widehat{q})\) and density (\(\widehat{k})\) are calculated as essentially the spatially weighted average of all the individual links for the given spatial unit (Ambühl et al. 2020) shown below in Eqs. (3) and (4), where \({l}_{i}\) is the segment length and \({n}_{i}\) is the number of lanes for segment \(i\).
The aggregation is performed for each census tract, with a typical size of 0.6–1 km2 in densely populated urban areas. The choice of spatial unit is to ensure the spatial alignment with the available location features to avoid interpolation errors as well as to limit network inhomogeneity that may arise from aggregation.
Freeway segments (FRCs 1 and 2), which generally account for less than 3% of the total lane miles in urban tracts as defined in the transportation typology (Popovich et al. 2021), are excluded in the aggregation to avoid the influence of higher speed and volume from these non-typical road types in urban areas.
The upper bound of the flow–density scatter that represents the MFD relationships are used for training the ML models. The upper-bound flow and density values corresponding to the top 20% of the flow values per density bin are used as the outcome flow, with each density bin corresponding to 1/50 of the density range observed.
Finally, to ensure the derived MFD models capture homogeneous traffic patterns at the census-tract level, the study only selects urban census tracts (microtypes 1 and 2 defined in the transportation typology (Popovich et al. 2021)) with land areas less than 10 km2 (Loder et al. 2019).
Location Attributes Process
In addition to the network flow and density derived from HERE data, various location-specific transportation supply and demand characteristics are also collected from various data sources and aggregated at the census tract level to predict tract level flow at a given density, i.e., the MFD. These features help explain how land use, transportation infrastructure, network topology, and travel demand characteristics may affect flow–density relationships across different locations. A total of 38 location attributes are included: land use attributes such as fraction of land use types; network attributes such as network circuity, dead-end fraction, intersection density, street length, composition of road functional classes; and road supply and demand characteristics that may affect the network utilization and, thus, influence the MFD shape: e.g., lane-meter per capita, trip length distributions.
The input features, including variable names and descriptions, and their data sources are provided in Table 1 with data sources from Boeing (2020); “National Transportation Atlas Database” n.d.; Dewitz (2016); Census Bureau (2017); Census Bureau (n.d.).
Due to the large number of input features and high correlation among them (Fig. S5 in Supporting Information), factor analysis is used to reduce the dimensionality and derive interpretable location factors. An Exploratory Factor Analysis (EFA) is performed using the Python package ‘FactorAnalyzer’ with data from 19,361 census tracts after removing tracts larger than 10 km2 in land area or with missing values.
Machine Learning and Interpretation Methods
Machine Learning Methods
We apply four machine learning methods (briefly described below) to predict network flow from given density and location factors. A total of 16,808,176 network-level data points from 9,528 census tracts are used. The data are split into 80% for training and 20% for testing, with network density and location factors as input features and network flow as the outcome. In this study, due to the computational burden of parameter tuning on such large samples (16.8 million of the full sample), hyperparameter tuning across the methods described below is performed using 10,000 samples randomly selected from the full dataset.
Random Forest
This algorithm (Breiman 2001) builds an ensemble of decision trees, or tree predictors, which depend on randomly and independently sampled vectors over the same distribution. The strength, correlation, and monitor error are closely followed to track the growing features in response to branch splitting.
This study uses the random forest regressor from the ‘scikit-learn’ package (Pedregosa, et al. 2011) to train the random forest model. The hyperparameters of tree size are tuned to achieve the best model accuracy (or lowest squared error).
XGBoost
This algorithm is based on the standard gradient boosting methods but employs a new regularization technique, instead of optimizing the loss function, to minimize overfitting (Chen and Guestrin 2016). This tactic allows XGBoost to be faster and more robust during tuning.
In this study, the ‘XGBoost’ package (Chen and Guestrin 2016) is used to estimate the gradient boosting tree. ‘XGBoost’ allows parameter tuning for a variety of hyperparameters, and the notable hyperparameters, including learning rate, tree size, and regularization terms, are tuned to minimize the squared error of the model.
Support Vector Machine (SVM)
This algorithm is another ML method that addresses nonlinearity in the data (Hastie et al. 2009). SVM regression works by projecting input factors into linear-separatable spaces and finding the best fit linear function in that space. The projection is performed using various linear or nonlinear kernel functions. SVMs are one of the most robust prediction methods, insensitive to outliers and less prone to overfitting when using the ‘loss + penalty’ function as the objective.
In this study, due to the low scalability of SVM regression on large a dataset, an ensemble approach is adopted to combine the predictions from a large number of SVM regressors, with each SVM trained on a smaller subsample (10,000 samples) from the training data. The Radial Basis Function (RBF) kernel is adopted for the nonlinear projection of input factors, as RBF can combine multiple polynomial kernels multiple times of different degrees efficiently, and outperforms other kernels.
Neural Network—Multilayer Perceptron (MLP)
This algorithm is one of the simplest multi-layered neural network architectures, consisting of a hierarchical structure of layers containing individual artificial neurons (Ruppert 2004). For the current application, we implement an MLP architecture with 3 hidden layers, with 100, 50, and 5 neurons, respectively. The Adaptive Movement Estimation algorithm (ADAM) (Kingma and Ba 2017) is an extension of the stochastic gradient descent that automatically updates the learning rate by taking into account the average of the second moments of the gradients. We employed ADAM with a starting learning rate of 0.01. The loss function for this regression task is the mean squared error (MSE). We train the model for 10 k epochs.
Interpretation Methods of Location Factors
Interaction SHAP Values
The shapes of the MFD curves vary by network locations. In this study, the importance of the location factors lies in their interaction effects with density, that is, their ability to influence the prediction of outcome flow as an interacting factor with input density. However, traditionally, local explanations based on feature attribution assign a single number to each input feature. Such simplified representation comes at the cost of combining main and interaction effects. For some ML methods, especially tree-based methods, SHAP also provides measurements of local interaction effects under TreeExplainer based on a generalization of Shapley values (Lundberg et al. 2020; Fujimoto et al. 2006), which was previously applied to transportation research (Jin, et al. 2022).
The interaction SHAP values allocate credit not just among each factor, but among all pairs of factors, to separate out main and interaction effects for individual model predictions and uncover important patterns in joint effect of factor combinations. For TreeExplainers, the SHAP interaction value is defined as:
And,
And
where \({\phi }_{i,j}\left(f,x\right)\) is the interaction SHAP value between factor \(i\) and \(j\), for the estimated model \(f(.)\) and specific input \(x\); \(S\) is the subset of factors; \(\text{\rm M}\) is the set of all m input features; \({f}_{x}\) is the conditional expectation function of the output under input \(x\) and estimated model \(f(.)\).
In this study, the interaction SHAP values of the location factor and density pairs are used to.
-
Rank the importance of location factors
-
Interpret the directionality of their influence on flow–density relationships (i.e., the MFD shapes)
Interpret Location Dependence of Network Capacity and Critical Density
The critical density and network capacity are two important traffic control parameters related to MFD shapes. These two parameters (as illustrated in Fig. 1) delineate the boundary between uncongested and congested branches of the MFD curves, representing the optimal performance of the network.
In this study, the network capacity is derived from the flow–density scatters at a given census tract, as the 99th percentile of the flow values. The critical density is the network density associated with the network capacity flow value. The location dependence of these turning points will be examined through their partial correlation with individual location factors. The partial correlation coefficient is used here because it takes out the confounding effects introduced by other correlated location factors.
Results and Discussion
Input Data Preprocessing Results
Aggregated Network Flow and Density
The road segment-level HERE data are aggregated to derive flow and density in 9,528 census tracts and used for final MFD estimation, with sufficient coverage for major U.S. cities and urban areas as indicated in Fig. 3.

Network traffic density at 5:00PM in urban tracts across the U.S. with inserts showing the zoomed-in view of the tract-level density in six cities and the flow–density scatters (i.e., observed MFDs) for three randomly selected urban tracts in each city
The tract-level median density at 5:00 PM is shown for urban tracts across the U.S. in Fig. 3 with higher densities appearing in major urban areas known for experiencing chronic congestion according to the Texas Transportation Institute’s Urban Mobility Report (Institute and “Urban Mobility Report”. 2023). Zoomed-in views of six selected cities are provided in Fig. 3 together with the observed MFDs derived from HERE probe data at three randomly selected tracts in each city.
The observed MFDs shown in Fig. 3 give a good example of MFD shapes varying by the location of the networks. The network capacities are generally below 600 #veh/lane/hour, with the lowest in Chicago (around 360 #veh/lane/hour). The critical density varies but generally occurs after traffic density reaches 10 veh/km/lane. In addition to the variation between cities, from the MFD plots we can see, the MFD curves exhibit within-city variation. Urban road networks in Los Angeles are observed to have greater variation in capacity, while networks in Chicago have more homogeneous MFDs.
Location Factors Derived
Through parallel analysis (Horn 1965), the top 13 factors (ranked by their eigen values) are selected to achieve the balance between the variance explained and the interpretability of the factors (Fig. S6). Figure 4 depicts the 13 factors indicated by the columns, and how the raw features that are defined in Table 1 (shown as y-axis) are loaded on the factors. Feature loading values smaller than 0.25 in magnitude are not shown in the figure. The complete factor loadings that formally define the factors mathematically are included in the Supporting Information Table S2. The location factors are named based on the most prominent component features with relative high factor loadings. Summary explanation and description of each location factor are presented in Table 2 according to the most prominent features.

Raw features (y-axis) and their factor loadings on the 13 derived location factors (x-axis)
Among the resulting factors, “freeway”, “non-freeway arterial”, and “development level” indicate distribution of the road classes, density of major roads, and level of urbanization, combining various network and traffic attributes. Factors such as “network connectivity”, “network complexity”, “core–edge network”, and “network circuity” represent the network topology mostly relying on network features from OpenStreetMap (Boeing 2020).
Factors including “mixed-use districts”, “job hub”, “bike potential”, “walk potential”, and “median travel”, capture the land use and/or demand characteristics (i.e., trip lengths) of each tract. Finally, “roadway roughness” suggests the vertical alignment of the roads and the easiness of driving on those roads. Those factors help capture the major location-specific infrastructure and traffic characteristics, and can affect the MFD trends due to their potential impacts on traffic flow and network utilization.
Performance of Machine Learning Models
The model performance, when predicting network flow from given density and location factors in the 20% testing data, is evaluated using four metrics: R2, mean absolute error (MAE), root mean squared error (RMSE), and mean absolute percentage error (MAPE) in Table 3. Across all four metrics, XGBoost consistently shows the best performance among the machine learning models evaluated here. This conclusion can also be visually confirmed by comparing the observed vs predicted network flows from the XGBoost model in Fig. 5 (a). In addition, we have trained the models without introducing the location factors as a baseline performance (metrics shown in parenthesis in Table 3) for comparison. We can see that the performances of all models without location factors are similar to each other, and are much worse than the performances when locational factors are included.

Comparison between observed and XGBoost model predicted values for a network flow, and derived MFD shape-related parameters b network capacity, and c critical density. Color indicates the density of the points
Taking the best-performing XGBoost model, we further evaluate its ability to capture two of the MFD shape parameters: network capacity and critical density, derived from the observed vs. predicted MFD curves in Fig. 5 (b) and (c). The comparison indicates reasonable agreement between modeled and observed turning points of the MFD curves, with correlation of 0.97 and 0.76 for network capacity and critical density, respectively, across U.S. urban tracts.
Influence of Location Factors on MFD Shapes
Importance Ranking of Location Factors
Coupled with the best-performing XGBoost model, TreeExplainer uncovers the influence of location factors on MFD shapes learned by the model using the interaction SHAP values. Figure 6 presents the importance ranking of the location factors according to their mean absolute interaction SHAP values with density.

Importance ranking of location factors based on their effects on MFD shapes
The top-ranking factors are mostly related to network topology (such as network connectivity, network complexity, core edge network, and network circuity), transportation infrastructure characteristics—such as composition of the road functional classes (freeway and non-freeway arterial) and roadway condition (roadway roughness) and factors reflecting a combination of network and land use attributes (such as development level).
In contrast, the demand- and trip-related factors, such as trip distance-related factors (median travel, bike potential and walk potential) and trip origin–destination-related factor (job hub) are ranked at the bottom.
One exception in demand-related factor is the “mixed use districts” factor. This factor captures both land use (with high development intensity) and trip origin and destination (high in both home and job locations) and ranked higher than other demand-related factors (6th among the 13 factors).
This ranking of location factors largely aligns well with existing literature. The shape of MFDs has been considered in the literature to be mainly determined by the urban road structure and network topology, traffic control, and the level of inhomogeneity in the distribution of traffic. Although it is still under debate whether the MFD shape depends on demand characteristics such as trip origins and destinations, trip lengths, and routing choice, most of the MFD literature assumes it is more or less independent of demand when the trip length remains roughly constant (Laval and Castrillón 2015). In addition, this study used the upper bound of the flow–density scatter, representing more stable MFD relationships, for training the ML models. This approach may have reduced the sensitivity of MFD shapes to real-time demand characteristics.
Interpretation of Location Dependence of MFD Shapes
Interaction SHAP values of density with a location factor describes how the effects on flow of given density are modified by the respective location factor. The resulting change in MFD shapes from the interactions needs to be interpreted within the context of a reference level of flow to density relationship. Implications on how the consequent network critical density and capacity from MFD shapes change from these factors can be subsequently derived in some cases.
Two examples are shown in Fig. 7 for “network connectivity” and “freeway” factors. In each case, the dependence of flow on density is decomposed into effects of density without interaction (i.e., a reference level MFD shape) and interaction effects alone.

Example interpretation of location factor effects on MFD shapes. a SHAP dependence plot showing effects of density on flow without interaction effects of network connectivity; b interaction effects of density with network connectivity on flow; c simplified graphical interpretation of change in MFD curve in the context of a and b; d SHAP dependence plot showing effects of density on flow without interaction effects of freeway factor; e interaction effects of density with freeway factor on flow; f simplified graphical interpretation of changes in MFD curve in the context of d and e. The arrows in c and f indicate the directional change in capacity and critical density as we move from blue to red curves
Note that SHAP values are computed after the average effects are removed over all density ranges, so we should interpret the directionality of influence based on the slope of the dependence plots rather than the sign of individual points.
We can see in Fig. 7a that flow increases with density before 10 veh/lane/km, representing an uncongested/free-flow regime. The turning points (critical density) are located between 10 and 30 veh/lane/km. Figure 7b shows how the effect of density on flow (i.e., Figure 7a) is mediated by network connectivity. Before density reaches 10 veh/lane/km, the points in Fig. 7b fall on a relatively flat line (i.e., slope is around 0), indicating little change in the flow–density relationship introduced by network connectivity. After 10 veh/lane/km, interaction effects from high and low connectivity begin to diverge. Networks with higher connectivity tend to have lower flow as density goes up relative to the reference curve (i.e., bending the MFD curve down sooner), resulting the red curve illustrated in Fig. 7c, while the opposite is true for networks with lower connectivity, resulting the blue curve in Fig. 7c. In this case, higher connectivity lowers the network capacity and critical density.
Figure 7d is the SHAP dependence plot of flow on density after removing the interaction effects from the freeway factor, while Fig. 7e is the interaction effect alone. We can see high freeway fraction networks always increase flow as density goes up, and vice versa. The interaction effects on MFD curves are illustrated in Fig. 7f, indicating MFD curves “bends” down sooner in networks with lower freeway fractions than in those with higher freeway fractions. As a result, both the capacity and critical density of the network increase with the fraction of freeways.
Location dependence of MFD shapes in above two examples aligns well with empirical knowledge. Higher ranking roads correlate with better highway performance characterized by higher capacity or traffic throughput and higher speed. Downtown locations where roads are more connected (e.g., marked by grid-like network and higher road density) may increase the opportunities for vehicle to interact (e.g., at the intersections) and, thus, slow down traffic.
Interaction SHAP values of the rest of the top eight ranking factors are plotted against density in Fig. 8, color coded by the factor scores. We can see “non-freeway arterial”, “core–edge network”, “roadway roughness”, and “development level” all largely exhibit diverging effects between high and low factor scores after density value reaches 10 veh/lane/km. Networks with higher non-freeway arterials (i.e., high ranking roads that are not freeways), higher core–edge patterns, or higher development level tend to further increase flow with given density when the network begins to enter the congested regime, so the network can accommodate more vehicles before getting congested. On the other hand, increasing “roadway roughness” tends to decrease flow with density, resulting in a reduced capacity and critical density.

Interaction SHAP values of density with the rest of the top eight location factors
In the case of “network circuity” and “mixed use district”, these factors have a clear bi-directional influence on the flow–density relationship with the change of directions around density value of 10 veh/lane/km. For example, network with lower circuity tends to be associated with lower flows before the network gets congested, but once the congestion emerges, lower circuity helps increase flow with density. This could be due to lower circuity helping propagate the congestion more efficiently which increases the network utilization to accommodate more vehicles. However, these large directional changes around the turning point tend to cancel each other, making it difficult to directly infer the changes in network capacity and critical density from the interaction SHAP plots.
Partial Correlation of MFD Parameters with Location Factors
To examine the associations between the top eight location factors and the key MFD shape parameters (critical density and network capacity) directly, we compute their partial correlation coefficients based on parameters derived from the observed and predicted MFD curves (Table 4). Partial correlation reflects the directional association between a location factor and MFD shape parameters after confounding effects from other location factors are linearly removed. In contrast, the correlation coefficients without removing confounding effects are different in the signs and magnitude (Table S3) and can be misleading for interpretation.
The directionality of the associations between these MFD shape parameters and the location factors is closely aligned between predicted and observed MFD curves (Table 3), which again confirms the model’s ability to capture MFD shape variations across locations.
An important observation is that associations of a given location factor with critical density and network capacity are largely in the same direction when the association is relatively strong (i.e., the colored values in Table 4). This helps explain why network capacity varies with critical density in the same directions across locations as observed in the literature (Loder et al. 2019) as well as in our predicted and observed data (Fig. 9).

Relationship between network capacity and critical density from observed and predicted data. For observed data, the fitted line from predicted values is overlaid as dashed line as a comparison. Similarly, in predicted data, fitted line from observed data is overlaid as a dashed line
Discussion of the Influence of Location Factors
Physical explanation of the association of location factors and the shape of MFDs as revealed in the partial correlation and SHAP dependency plots are explored in the context of the factor characteristics.
According to the partial correlation coefficients in Table 4, networks with more higher-ranking roads (such as freeways and major arterials) tend to accommodate more vehicles before congestion sets in and has higher capacity (equivalently higher free-flow speed), which is as expected.
The networks with core–edge patterns and higher development level are also associated with increased network capacity and critical density. Core–edge patterns are likely to create fewer vehicle conflicts introduced by otherwise gridiron networks. Higher development levels are located in highly developed and populated areas with tracts smaller in size (Table S2 in Supporting Information), which helps to improve lane utilization and network homogeneity.
On the other hand, higher network connectivity (e.g., in downtown areas), mixed-use district, and road roughness are associated with decreased network capacity and critical density so that the networks accommodate fewer vehicles before getting congested. Higher connectivity tends to create more opportunities for vehicles to interact in the network (e.g., at the intersections), which slows down traffic. Similarly, road roughness introduces more irregularities into the vehicle’s driving cycles (e.g., stop and go, acceleration, deceleration etc.) which may contribute to the slowdown of traffic. Mixed-use districts balancing residential and job activities and tends to be larger in size, and thus the network utilization and traffic are likely to be less homogeneous, leading to a decrease in the performance of the network.
Another important observation is that network circuity ranks the second among all location factors according to the interaction SHAP values and yet it showed weak association with critical density and network capacity. This is likely due to that, despite the large changes introduced by this interacting factor across all density values according to Fig. 8a, the overall effects around the turning point tend to cancel each other because of the opposite directions of influences as discussed earlier.
Note that the locational dependence of MFDs explored in this paper is entirely data driven, which are intended to provide initial empirical insights. Due to the un-even penetration rates of probe vehicles across road functional types and different states (as shown in the Supporting Information), the observed association between the location factors and MFD shapes could potentially be biased toward roads and states that have better coverage of probe vehicles. As a result, the underlying mechanism from the data-driven associations reported here warrants further physics-informed research (such as analytical models, or physics-informed machine learning (Ka et al. 2024)) to confirm a causal relationship, before such insights can be applied in practice.
Conclusion
Macroscopic fundamental diagram is a parsimonious modeling tool used in urban traffic management for capturing the interrelationship between vehicular flow, density, and speed at a network-wide level. However, in practice, due to historical data limitations, empirically derived MFD models are sparse in the literature, especially for U.S. cities. Leveraging large-scale and granular census-tract-level flow and density data derived from vehicle probes, this paper has presented the first application of machine learning methods to both predict MFDs and interpret the important location factors underlying different MFD shapes of urban networks across the entire United States.
Among the four machine learning methods tested, XGBoost is found to deliver the best performance to predict the network traffic flow for given vehicular density and location attributes. In particular, predictions from XGBoost effectively capture both local flow values of a given network density and the key traffic control parameters related to MFD shape, i.e., critical density and network capacity.
While previous literature investigated influencing factors of MFD in urban areas with isolated focus on topological attributes of the network (Loder et al. 2019; Wong et al. 2021), this paper simultaneously investigates a wide range of location factors including network topology, transportation infrastructure, and land use that together help control for potential confounding effects.
The interaction Shapley Additive explanation (SHAP) values are used to determine the importance and influence of location factors, such as land use, transportation infrastructure, and network topology, on the shape of MFD curves. We find top-ranking factors are mostly related to network topology, transportation infrastructure, and land use, whereas demand- and trip-related factors are ranked lower. The ranking of these location factors is largely aligned with the literature.
The directionality of the associations between MFD shape parameters (network capacity and critical density) and location factors has good agreement between model predictions and observations, both confirming the model’s ability to capture changes of MFD shapes across locations and revealing potential synergistic and trade-off effects of land use and network design to be considered in transportation and land use planning.
The analysis framework developed in this work can generate data-driven MFDs and a deeper empirical understanding of their shape dependence on network, infrastructure, and land use characteristics. These empirical insights once confirmed with physics-based models can be used by transportation authorities to derive and optimize location-specific MFDs, facilitating more informed management and planning decisions at the network level.
References
Bureau of Transportation Statistics, “National Transportation Atlas Database.” [Online]. Available: https://www.bts.gov/ntad
Ambühl L, Loder A, Bliemer MCJ, Menendez M, Axhausen KW (2020) A functional form with a physical meaning for the macroscopic fundamental diagram. Transport Res Part b: Methodol 137:119–132. https://doi.org/10.1016/j.trb.2018.10.013
Azfar T, Li J, Yu H, Cheu RL, Lv Y, Ke R (2024) Deep Learning-Based Computer Vision Methods for Complex Traffic Environments Perception: A Review. Data Sci Transp 6(1):1. https://doi.org/10.1007/s42421-023-00086-7
Boeing G (2020) A multi-scale analysis of 27,000 urban street networks: Every US city, town, urbanized area, and Zillow neighborhood. Environent Plann b: Urban Analyt and City Sci 47(4):590–608. https://doi.org/10.1177/2399808318784595
Breiman L (2001) Random Forests. Mach Learn 45(1):5–32. https://doi.org/10.1023/A:1010933404324
U.S. Census Bureau, “2014–2018 American Community Survey 5-year Public Use Microdata Samples.” [Online]. Available: https://www.census.gov/programs-surveys/acs/technical-documentation/table-and-geography-changes/2018/5-year.html
U.S. Census Bureau, “TIGER/Line Shapefile, 2017, 2010 Census Urban Area National.” Accessed: Jul. 01, 2022. [Online]. Available: https://catalog.data.gov/dataset/tiger-line-shapefile-2017-2010-nation-u-s-2010-census-urban-area-national
U.S. Census Bureau. Longitudinal-Employer Household Dynamics Program., “LEHD Origin-Destination Employment Statistics (LODES), Version 7.” Accessed: May 07, 2023. [Online]. Available: https://lehd.ces.census.gov/data/lodes/LODES7/
T. Chen and C. Guestrin, “XGBoost: A Scalable Tree Boosting System,” In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016, https://doi.org/10.1145/2939672.2939785.
Daganzo CF (2007) Urban gridlock: Macroscopic modeling and mitigation approaches. Transport Res Part b: Methodol 41(1):49–62. https://doi.org/10.1016/j.trb.2006.03.001
Daganzo CF, Geroliminis N (2008) An analytical approximation for the macroscopic fundamental diagram of urban traffic. Transport Res Part b: Methodol 42(9):771–781. https://doi.org/10.1016/j.trb.2008.06.008
Daganzo CF, Geroliminis N (2008) An analytical approximation for the macroscopic fundamental diagram of urban traffic. Transport Res Part B: Methodol. https://doi.org/10.1016/j.trb.2008.06.008
Daganzo CF, Gayah VV, Gonzales EJ (2011) Macroscopic relations of urban traffic variables: Bifurcations, multivaluedness and instability. Transport Res Part b: Methodo 45(1):278–288. https://doi.org/10.1016/j.trb.2010.06.006
Daganzo CF, Gayah VV, Gonzales EJ (2012) The potential of parsimonious models for understanding large scale transportation systems and answering big picture questions. EURO J Transp Logist 1(1):47–65. https://doi.org/10.1007/s13676-012-0003-z
Dewitz, J., National Land Cover Database (NLCD) 2016 Products (ver. 3.0, November 2023): U.S. Geological Survey data. https://doi.org/10.5066/P96HHBIE
Fujimoto K, Kojadinovic I, Marichal J-L (2006) Axiomatic characterizations of probabilistic and cardinal-probabilistic interaction indices. Games Econom Behav 55(1):72–99. https://doi.org/10.1016/j.geb.2005.03.002
Geroliminis N (2007) Macroscopic modeling of traffic in cities. In: Daganzo CF (ed) Transportation Research Board 86th Annual Meeting. Springer, p 413
Geroliminis N, Daganzo CF (2008) Existence of urban-scale macroscopic fundamental diagrams: Some experimental findings. Transport Res Part b: Methodol 42(9):759–770. https://doi.org/10.1016/j.trb.2008.02.002
Geroliminis N, Haddad J, Ramezani M (2013) Optimal Perimeter Control for Two Urban Regions With Macroscopic Fundamental Diagrams: A Model Predictive Approach. IEEE Trans Intell Transp Syst 14(1):348–359. https://doi.org/10.1109/TITS.2012.2216877
Girault J-T, Gayah VV, Guler I, Menendez M (2016) Exploratory Analysis of Signal Coordination Impacts on Macroscopic Fundamental Diagram. Transp Res Rec 2560(1):36–46. https://doi.org/10.3141/2560-05
Haddad J, Geroliminis N (2012) On the stability of traffic perimeter control in two-region urban cities. Transport Res Part b: Methodol 46(9):1159–1176. https://doi.org/10.1016/j.trb.2012.04.004
Hastie T, Tibshirani R, Friedman J (2009) The Elements of Statistical Learning. Springer Series in Statistics. Springer, New York
Horn JL (1965) A rationale and test for the number of factors in factor analysis. Psychometrika 30(2):179–185. https://doi.org/10.1007/BF02289447
Texas Transportation Institute, “Urban Mobility Report.” https://mobility.tamu.edu/umr/.
L. Jin et al., “What Makes You Hold on to That Old Car? Joint Insights From Machine Learning and Multinomial Logit on Vehicle-Level Transaction Decisions,” Frontiers in Future Transportation, vol. 3, 2022, Accessed: Jul. 27, 2022. [Online]. Available: https://www.frontiersin.org/articles/https://doi.org/10.3389/ffutr.2022.894654
Ka E, Xue J, Leclercq L, Ukkusuri SV (2024) A physics-informed machine learning for generalized bathtub model in large-scale urban networks. Transport Res Part c: Emerg Technol 164:104661. https://doi.org/10.1016/j.trc.2024.104661
Kingma DP, Ba J (2017) Adam: A Method for Stochastic Optimization. arXiv. https://doi.org/10.48550/arXiv.1412.6980
Koch J, Maxner T, Amatya V, Ranjbari A, Dowling C (2022) Physics-informed machine learning of parameterized fundamental diagrams. arXiv. https://doi.org/10.48550/arXiv.2208.00880
Laval JA, Castrillón F (2015) Stochastic approximations for the macroscopic fundamental diagram of urban networks. Transport Res Part b: Methodol 81:904–916. https://doi.org/10.1016/j.trb.2015.09.002
Leclercq L, Chiabaut N, Trinquier B (2014) Macroscopic Fundamental Diagrams: A cross-comparison of estimation methods. Transport Res Part b: Methodol 62:1–12. https://doi.org/10.1016/j.trb.2014.01.007
Lee G, Ding Z, Laval J (2023) Effects of loop detector position on the macroscopic fundamental diagram. Transport Res Part c: Emerg Technol 154:104239. https://doi.org/10.1016/j.trc.2023.104239
Loder A, Ambühl L, Menendez M, Axhausen KW (2019) Understanding traffic capacity of urban networks. Sci Rep. https://doi.org/10.1038/s41598-019-51539-5
Loder A, Bliemer MCJ, Axhausen KW (2022) Optimal pricing and investment in a multi-modal city — Introducing a macroscopic network design problem based on the MFD. Transport Res Part a: Policy Pract 156:113–132. https://doi.org/10.1016/j.tra.2021.11.026
Lundberg SM et al (2020) From local explanations to global understanding with explainable AI for trees. Nat Mach Intellig 2(1):56–67. https://doi.org/10.1038/s42256-019-0138-9
Ma W, Huang Y, Jin X, Zhong R (2024) Functional form selection and calibration of macroscopic fundamental diagrams. Physica A 640:129691. https://doi.org/10.1016/j.physa.2024.129691
Ortigosa J, Menendez M, Gayah VV (2015) Analysis of Network Exit Functions for Various Urban Grid Network Configurations. Transp Res Rec 2491(1):12–21. https://doi.org/10.3141/2491-02
Ortigosa J, Gayah VV, Menendez M (2019) Analysis of one-way and two-way street configurations on urban grid networks. Transportmetrica b: Transport Dynamics 7(1):61–81. https://doi.org/10.1080/21680566.2017.1337528
Pedregosa F et al (2011) Scikit-Learn: Machine Learning in Python. J Mach Learn Res 12:2825–2830
Popovich N et al (2021) A methodology to develop a geospatial transportation typology. J Transp Geogr 93:103061. https://doi.org/10.1016/j.jtrangeo.2021.103061
Rahman R, Hasan S (2023) Data-Driven Traffic Assignment: A Novel Approach for Learning Traffic Flow Patterns Using Graph Convolutional Neural Network. Data Sci Transp 5(2):11. https://doi.org/10.1007/s42421-023-00073-y
Ruppert D (2004) The elements of statistical learning: data mining, inference, and prediction. Taylor Francis. https://doi.org/10.1198/jasa.2004.s339
Saffari E, Yildirimoglu M, Hickman M (2020) A methodology for identifying critical links and estimating macroscopic fundamental diagram in large-scale urban networks. Transport Res Part c: Emerg Technol 119:102743. https://doi.org/10.1016/j.trc.2020.102743
Saffari E, Yildirimoglu M, Hickman M (2022) Data fusion for estimating Macroscopic Fundamental Diagram in large-scale urban networks. Transport Res Part c: Emerg Technol 137:103555. https://doi.org/10.1016/j.trc.2022.103555
Saffari E, Yildirimoglu M, Hickman M (2023) Estimation of Macroscopic Fundamental Diagram Solely From Probe Vehicle Trajectories With an Unknown Penetration Rate. IEEE Trans Intell Transp Syst 24(12):14970–14981. https://doi.org/10.1109/TITS.2023.3303439
Schrank D, Eisele B, Lomax T, Bak J (2015) Appendix A: Methodology for the 2015 urban mobility scorecard, Texas Transportation Institute, Technical report
Sekuła P, Marković N, Vander Laan Z, Sadabadi KF (2018) Estimating historical hourly traffic volumes via machine learning and vehicle probe data: A Maryland case study. Transport Res Part C: Emerg Technol. https://doi.org/10.1016/j.trc.2018.10.012
Tilg G, Amini S, Busch F (2020) Evaluation of analytical approximation methods for the macroscopic fundamental diagram. Transport Res Part c: Emerg Technol 114:1–19. https://doi.org/10.1016/j.trc.2020.02.003
Verendel V, Yeh S (2019) Measuring Traffic in Cities Through a Large-Scale Online Platform. J Big Data Anal Transp 1(2):161–173. https://doi.org/10.1007/s42421-019-00007-7
Wong W, Wong SC, Liu HX (2021) Network topological effects on the macroscopic fundamental Diagram. Transportmetrica b: Transport Dynamics 9(1):376–398. https://doi.org/10.1080/21680566.2020.1865850
Xue J, Ka E, Feng Y, Ukkusuri SV (2024) Network macroscopic fundamental diagram-informed graph learning for traffic state imputation. Transport Res Part B: Methodol. https://doi.org/10.1016/j.trb.2024.102996
Yildirimoglu M, Geroliminis N (2014) Approximating dynamic equilibrium conditions with macroscopic fundamental diagrams. Transport Res Part b: Methodol 70:186–200. https://doi.org/10.1016/j.trb.2014.09.002
Zhang Z, Parr SA, Jiang H, Wolshon B (2015) Optimization model for regional evacuation transportation system using macroscopic productivity function. Transport Res Part b: Methodol 81:616–630. https://doi.org/10.1016/j.trb.2015.07.012
Zheng N, Geroliminis N (2013) On the Distribution of Urban Road Space for Multimodal Congested Networks. Procedia Soc Behav Sci 80:119–138. https://doi.org/10.1016/j.sbspro.2013.05.009
Zheng N, Waraich RA, Axhausen KW, Geroliminis N (2012) A dynamic cordon pricing scheme combining the Macroscopic Fundamental Diagram and an agent-based traffic model. Transport Res Part a: Policy Pract 46(8):1291–1303. https://doi.org/10.1016/j.tra.2012.05.006
Funding
This research was funded by the Federal Highway Administration (FHWA) Office of Transportation Policy Studies, under Interagency Agreement 693JJ318N300068 with the U.S. Department of Energy under Contract No. DE-AC02-05CH11231 to Lawrence Berkeley National Laboratory.
Author information
Authors and Affiliations
Contributions
All authors: Conceptualization; LJ, XX, YW, AL, KFA: Methodology, data curation, formal analysis, software, visualization, writing—original draft preparation; ZN, DRD: Data curation, reviewing and editing. CAS, MA, MA: Writing—reviewing and editing. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of Interest
There is no financial or non-financial conflict of interest for the current work.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jin, L., Xu, X., Wang, Y. et al. Macroscopic Traffic Modeling Using Probe Vehicle Data: A Machine Learning Approach. Data Sci. Transp. 6, 17 (2024). https://doi.org/10.1007/s42421-024-00102-4
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42421-024-00102-4