
Abstract
In recent years, the widespread adoption of navigation apps by motorists has raised questions about their impact on local traffic patterns. Users increasingly rely on these apps to find better, real-time routes to minimize travel time. This study uses microscopic traffic simulations to examine the connection between navigation app use and traffic congestion. The research incorporates both static and dynamic routing to model user behavior. Dynamic routing represents motorists who actively adjust their routes based on app guidance during trips, while static routing models users who stick to known fastest paths. Key traffic metrics, including flow, density, speed, travel time, delay time, and queue lengths, are assessed to evaluate the outcomes. Additionally, we explore congestion propagation at various levels of navigation app adoption. To understand congestion dynamics, we apply a susceptible–infected–recovered (SIR) model, commonly used in disease spread studies. Our findings reveal that traffic system performance improves when 30–60% of users follow dynamic routing. The SIR model supports these findings, highlighting the most efficient congestion propagation-to-dissipation ratio when 40% of users adopt dynamic routing, as indicated by the lowest basic reproductive number. This research provides valuable insights into the intricate relationship between navigation apps and traffic congestion, with implications for transportation planning and management.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The rising popularity of traffic navigation applications (apps) such as Google Maps, Apple Maps, and Waze, has resulted in the redirection of an increasing number of vehicles around congested freeways and boulevards, leading them through residential areas with lighter traffic and fewer stoplights that are not intended for large volumes of traffic. In some instances, these apps even divert drivers to streets ill-suited to function as thoroughfares. These effects of navigation app use have been noticed as early as 2015. Notable examples include Sherman Oaks in Los Angeles, California, USA McCarty (2016) and, more recently, San Jose Mission District in Fremont, California, according to the city’s Public Works Department.
Navigation app use has not resolved Braess’s paradox Cabannes et al. (2019); rather, it has given rise to a new form of Braess’s paradox Bittihn and Schadschneider (2021). In the toy example experiment performed in ref. Cabannes et al. (2019), they found that navigation apps can lead to increased overall travel time for all users. Given that, this study aims to examine the impact of information-aware routing, facilitated by navigation apps, on traffic flow and congestion. In addition, this article investigates the extent of the impact by evaluating how selfish routing algorithms contribute to the redistribution of traffic in previously uncongested areas and the consequent implications on traffic congestion. If these effects are not adequately acknowledged and addressed, urban areas may experience increased traffic on roads that are ill-equipped to support heavy traffic flow, leading to exacerbated congestion and the deterioration of infrastructure (e.g., pavement potholes). Consequently, it is crucial to communicate the impact of information-aware routing among residents and other stakeholders. Previous studies illustrating the negative externalities of navigation apps at different adoption levels also include refs. Thai et al. (2016) and Festa and Goatin (2019). Ref. Shaqfeh et al. (2020) emphasizes that the sharing of real-time traffic information with all users of a transportation network is sub-optimal.
This sub-optimality can be associated with the individual decisions made by road users (i.e., drivers). These decisions, known as selfish routing, involve drivers individually optimizing their travel times without considering the impact on others Pigou (1932). This local optimization does not achieve global optimality, resulting in decreased network performance Roughgarden (2002) and an increased price of anarchy. The price of anarchy is defined as the ratio between user equilibrium (UE) and system optimum (SO) Youn et al. (2008). UE, described by Wardrop’s first principle of traffic flow, is achieved when no road users can switch to a road with lower cost (i.e., travel time or distance). In transportation, UE is one form of Nash equilibrium Nash (1950). SO, as defined by Wardrop’s second principle, involves users minimizing the total network travel cost Wardrop (1952). UE is generally considered sub-optimal and greater than SO Youn et al. (2008) and Roughgarden (2005). “The use of apps leads to a system-wide convergence toward Nash equilibrium" Cabannes et al. (2018).
Moreover, the state of the network can be affected by varying compliance rates in the use of navigation apps. Previous studies have shown that compliance rates for navigation app suggestions can vary van Essen et al. (2020) Ringhand and Vollrath (2018). For instance, van Essen et al. van Essen et al. (2020) found compliance rates of 46% in their stated preference experiment, and varied percentages of 88% and 31% in their revealed preference experiment when the usual route and a social (or less selfish) detour were advised, respectively. Additionally, the work by Samson and Sumi (2019) and Yang et al. Yang et al. (2021) provide insights into the factors that influence driver trust and acceptance of these apps and their route suggestions, highlighting the roles of perceived reliability and ease of use in compliance. Vosough and Roncoli (2024) also provide additional insights into how to affect acceptance and compliance rates by offering more information when a less selfish behavior is suggested by such apps.
To understand what is happening in the network, several models and approaches are commonly used to analyze and predict traffic congestion patterns and how they spread. These include traffic flow models such as the Greenshields Model which is a simple model that assumes a linear relationship between traffic density and traffic speed Greenshields (1935); Lighthill–Whitham–Richards (LWR) Model which is a macroscopic traffic flow model that describes the evolution of traffic density and speed based on conservation principles Lighthill and Whitham (1955) and Richards (1956); and, Cell Transmission Model (CTM) which divides the road into discrete cells and models traffic flow as a flow of vehicles between cells Daganzo (1994). There are also models built on percolation theory Ambühl (2023), machine learning-based approaches, and queueing theory as discussed in the work of Saberi, et al. Saberi (2020) wherein they highlighted in their work that, although widely employed, existing models are predominantly constructed on input (arrival) and output (departure) rates. Consequently, they introduced a simplified model to examine the spread of traffic congestion within a network, employing a basic contagion model that relies solely on the average speed of road segments—a concept further investigated in this paper by comparing the results to conventional key performance indicators (KPIs), such as flow, density, speed, travel time, delay time, and queue length.
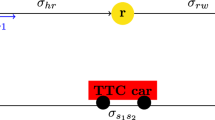
Contribution: We focus on examining the changes and impacts of information-aware routing through the use of traffic assignment models. Our key contribution lies in the adoption of the Susceptible–Infected–Recovered (SIR) model to study congestion propagation and dissipation, drawing an analogy to the spread of diseases as depicted in Fig. 1. Traditionally employed for disease spread analysis, the SIR model is repurposed to investigate congestion propagation within the network and understand how routing choices influence congestion spread, aiming to identify an optimal user range for dynamic routing to minimize average costs and achieve system optimality. We demonstrate that parameter fitting to this model using negative log-likelihood can effectively explain the spread of congestion in the network, without relying on conventional examination of KPIs.

Analogy between the spread of diseases and the dynamics of traffic congestion using SIR model
We used this method to describe how traffic spreads and recovers over time. This helped us investigate how fast congestion spread over the network in the case of the city of Fremont using the results of simulations and comparing them across the scenarios described in Sect. Scenarios. To summarize, we take into account the different percentages of users that follow routing from navigation apps which can be represented by dynamic en-route routing behavior, while the rest of the users follow fixed routing behavior. We also discuss how the negative log-likelihood, which falls under the broad category of statistical estimation and optimization methods, particularly within the fields of statistics and machine learning, can be employed to estimate the parameters of the SIR model. This method captures the effects to the overall traffic system, the evaluation we have shown is as a collective or aggregated result rather than the performance of individual cars.
Significance: With the growing interest in autonomous vehicle research, it is essential to recognize that these vehicles will rely on route recommendations and guidance from algorithms employed by navigation apps. Gaining insights into the potential impacts of varying penetration rates on fixed and dynamic en-route routing behaviors could motivate future researchers and scientists to reassess the design of routing algorithms, especially for navigation apps. Analyzing people’s movements through information and communication technologies could provide valuable insights into changes in routing patterns at various scales leading to a better understanding of human mobility.
Data and Simulation Development
To conduct our experiments, we developed a microscopic traffic simulation for the San Jose Mission District, focusing on Interstate Highway 680 (I-680) and Mission Boulevard (State Route 238/262) in Fremont, CA, USA, using Aimsun Next 22.0.1. Aimsun (2022). The required inputs for a microsimulation are a road network and a dataset of timed origin–destination demand (TODD). Actual traffic data are also used to calibrate and validate the simulation. The discussion in this section was lifted and modified from the work of Cabannes, et al. Cabannes et al. (2023).
Road network: The road network is composed of road sections connected through signalized or unsignalized intersections. To create this network, the authors downloaded the OpenStreetMap (OSM)Haklay and Weber (2008) network model using the bounding box defined by the following coordinates: North: 37.5524, East: \(-\)121.9089, South: 37.4907, and West: \(-\)121.9544 as shown in Fig. 2, which was cleaned in ArcGIS, a geographic information systems (GIS) software. After importing the network into Aimsun. Google satellite, Maps, and StreetView images were used to perform manual adjustments to ensure the correctness of connectivity, yield and stop sign locations, and lane counts.

OpenStreetMap network with the bounding box on the left and the corresponding Aimsun network after cleaning on the right
Then, we used the data provided by the City of Fremont to set the road speed limits. Meanwhile, road capacities are adjusted using the data from the Behavior, Energy, Autonomy, and Mobility (BEAM) model which is an open-source agent-based regional transportation model Bae (2019). Then, the traffic signal plans including the road detectors, ramp meters and the master control plan from the city and CalTrans were added using the Aimsun graphical user interface (GUI).
In summary, the modeled network has 4397 links with a total of 393.27 km section length. This includes 111 freeway sections, 1370 primary road and secondary road sections, 2916 residential road sections, and 2013 nodes (intersections), 313 of which have stop signs and 37 of which have traffic lights (26 operated by the city and 11 operated by CalTrans).
Origin–destination demand: The origins, destinations, and departure times for every vehicle are aggregated into TODD matrices. Origins (or destinations) are clustered into transportation analysis zones (TAZ), which are bijective to the set of centroids connected to internal or external entry or exit points in the network.
The 20.8 square kilometers network area is divided into 76 internal centroids and 10 external centroids. Departure times are aggregated into 15-minute time intervals between 2–8 PM. Each simulation runs for this six-hour period. Based on real-world observations, congestion forms from 2 to 4 PM, peaks between 4 and 6:30 PM, and dissipates from 6:30 to 8 PM. About 130,000 vehicles are modeled (including 62,000 commuters or ‘through’ traffic and 68,000 residents or local demand). In this work, the demand data was derived from the SF-CHAMP demand model Khani et al. (2013) from the San Francisco County Transportation Authority and from a StreetLight study performed for the City of Fremont.
After this, we also performed calibration and validation of the model. To do this, we used actual ground flow data from 56 city flow detectors and 27 CalTrans Performance Measurement Systems (PeMS) detectors Chen et al. (2001). We also used actual speed data from MapBox API. Also, while the model is only showing a six-hour window, it was calibrated against data for three (3) weekdays (Tuesday–Thursday) that, according to the city of Fremont, are known to capture the more typical behavior of traffic and are more of a concern for them, given congestion forms during this time.
Scenarios
Using the calibrated and validated simulation model, scenarios are developed to understand the impacts of navigation app usage. To do this, the total traffic demand, \(\mathcal {T}_{ij}\), within any given origin, i, and destination, j, is split by \(\alpha\) which is the percentage of users following fixed routing behavior and the remainder of the demand, \(1-\alpha\), follows dynamic en-route routing behavior as described in Eq. (1). The parameter \(\alpha\) is varied at 10% interval from 100% to 0%. This setup is similar to the work of Shaqfeh, et al. Shaqfeh et al. (2020).
To determine the paths that will be taken by users following fixed routing behavior, the static user equilibrium (SUE) is first solved, and the resulting paths are then saved, serving as input to the simulation. We assume that the path assignment from SUE represents the paths that drivers will take when they remain on their known routes from their origin to their destination, ideally resulting in the shortest path. Given that it was solved using SUE, there can be more than one path between any given origin–destination (OD) pair, ij. A lower percentage of SUE path assignment users corresponds to a higher percentage of app users in the scenario. For the dynamic en-route routing behavior, we used stochastic route choice (SRC) for route assignment to allow the possibility of users changing paths while on their way to their destinations, which typically occurs when people actively use navigation apps while driving. The probabilities of being assigned to a path are calculated using the C-Logit model. The routing behavior compliance setup is illustrated in Fig. 3.

Routing behavior compliance setup. The routing behaviors of the users are divided into ‘Fixed’, where the paths used are determined by static user equilibrium (SUE), and ‘Dynamic en-route’, which uses route assignment based on stochastic route choice (SRC) varied at 10% intervals
In total, there are 11 scenarios considering \(\alpha = 100,90,80,...,0\%\) in Eq. (1) with three (3) replications per scenario which are varied by the input seed. The results are then averaged.
Routing
As previously mentioned, the drivers can either follow fixed or dynamic en-route routing behavior. The paths to be used by static routing vehicles were determined using static traffic assignment (STA) which was solved using an optimization problem with the classical Rosenthal potential Rosenthal (1973) as the objective function and variational inequalities to balance demand and path flows, and ensure non-negativity of flows. This is solved as an optimization problem defined in ref. Patriksson (2015). The Frank and Wolfe algorithm Frank and Wolfe (1956) is used to assign traffic using shortest paths and adjust them based on the cost functions of the links. This gives the traffic assignment results at the end of the set time horizon. This is resolved at 15-minute intervals, where the results from the previous time step serve as input for calculating the updated costs for the current time step. This approach allows us to capture the possibility of a driver following a fixed route, who might be aware of an alternate route upon departure that could offer an equal or less cost to the well-known shortest path.
Meanwhile, the paths used by dynamic en-route users are determined using stochastic route choice (SRC) using the C-logit model, in which the probability of choosing a path p, \(P_p\), is defined in Eq. (2). C-logit considers an additional parameter called the commonality factor, \(CF_p\), which is defined in equation (3) to eliminate the drawback of independence of irrelevant alternative (IIA) assumption of the conventional multinomial logit (MNL) model where it considers that the relative odds of choosing one alternative over another are unaffected by the presence or absence of other alternatives Cascetta (2013). Consistent with the MNL model, it uses the perceived utility for a chosen path p denoted as \(V_{p}\) (changing it to \(p'\) for an alternative path), and a scaling parameter, \(\theta\). The perceived utility for both the chosen and alternative paths is the negative of the cost of the path which is equal to \(-CP_{p} / 3600\) where \(CP_{p}\) is the cost of path p, measured in hours. \(CP_{p}\) is taken as the sum of the travel time of all the links composing a given path and 3600 is the conversion factor from hours to seconds. The link costs are updated every one (1) minute, so the probabilities calculated from C-Logit are also updated, and users have the opportunity to switch paths according to these values.
where \(L_{p p'}\) is the cost of links common to paths p and \(p'\), and \(L_p\) and \(L_p'\) are the individual costs of paths p and \(p'\) respectively from the set of paths K. Meanwhile, \(\zeta\) and \(\Psi\) are the parameters of \(CF_p\). Larger values of \(\zeta\) place greater weighting on the commonality factor, and \(\Psi \in [0,2]\) has less influence than \(\zeta\) and has the opposite effect. The simulations use \(\theta = 1, \zeta = 0.3, \Psi = 1\). These parameters were determined in the model calibration and validation as discussed in the work of Cabannes, et al. Cabannes et al. (2023).
The use of both SUE and C-logit allowed the exploration of other feasible routes between any origin–destination pair considering different values of \(\alpha\), an illustration of this is shown for the the top origin–destination pair as shown in Fig. 4.

Routes for the top origin–destination pair at varied percentages of dynamic en-route users. This illustrates the case when (a) dynamic en-route = 0%, (b) dynamic en-route = 30%, and (c) dynamic en-route = 60%. It can be noticed here how alternate routes would pass through the city and on less-utilized local roads
Spread of Congestion
The simplest model of the spread of a disease over a network is the Susceptible-Infected-Recovered (SIR) model of epidemic disease. Despite being originally a model for epidemic diseases, it has been used in many applications including the spread of traffic congestion as originally studied in Wu et al. (2004) and applied in an empirical study later in Saberi (2020). The SIR model is appropriate given that traffic congestion propagates over time and space, similar to an epidemic disease. Variations of this model include the SI model, which eliminates the recovered phase, often applicable to diseases in plants where they would eventually die and not recover, and the SIS model, which considers that anyone who recovers could belong again to the susceptible group. The SIR model is also more appropriate when the analysis is focused on a shorter time span, such as rush hour, which applies to the presented case study of Fremont, CA. Furthermore, in the understanding of routing, we do not anticipate a full gridlock or complete jam. The simulation accounts for the selection of alternate routes and the eventual dissipation of demand.
SIR Model
The spread of congestion can be described using parameters \(\beta\) and \(\gamma\), which describe congestion propagation and congestion dissipation rate, respectively. The simple SIR model uses the ordinary differential equations shown in Eqs. (4)–(6) which can be adopted in understanding congestion propagation and dissipation in a network Wu et al. (2004) as supported by empirical studies Saberi (2020). The inputs to these equations are the following:
-
S(t) = fraction of free-flow links
-
I(t) = fraction of congested links
-
R(t) = fraction of recovered links
These equations describe transmission, propagation, and dissipation rate respectively.
The links are classified whether they are congested or not based on Eq. (7). The congestion classification uses a threshold \(\rho\) which defines the tolerance for congestion with \(\rho \in [0, 1]\). Higher values of \(\rho\) correspond to lower tolerance for congestion, (e.g., at a set speed limit of 60 miles per hour (mph), when \(\rho\) is 0.3, a speed of 53 mph is not classified as congested but would be classified as congested if we changed \(\rho\) to 0.9). This means that with a higher value of \(\rho\), more links are classified as congested as illustrated in Fig. 5. To show more links being congested, we chose \(\rho = 0.9\).

Spatial distribution of congestion in the Fremont network at 6:00 p.m., showing the congested links (coded red) on the network when 90% of the drivers follow dynamic en-route assignment when (a) \(\rho = 0.3\), (b) \(\rho = 0.6\), and (c) \(\rho = 0.9\)
This allows us to do a binary classification to determine whether a link or section \(c_i\) is congested (\(c_i(t) = 1\) when \(\lambda _i(t) < \rho\)) or not (\(c_i(t) = 0\) when \(\lambda _i(t) \ge \rho\)). Then I(t) is calculated using equation (8). To consider all the links of the network, it can be taken that \(S(t) + I(t) + R(t) = 1\).
Using this, the parameters \(\beta\) and \(\gamma\) are estimated. Note that given the equations for SIR, these two parameters are interdependent. So, the final results are the calculated values of the basic reproductive number \(R_{0}\) which is the ratio of propagation over recovery rates vs. scenarios to explain the extent to which congestion builds up in a network and how fast it recovers. \(R_{0}\) is calculated using Eq. (9). Higher values of \(R_{0}\) indicates that congestion is spreading faster and dissipating slower.
Parameter Estimation
To estimate the parameters for a SIR model, we employed a three-step approach that involves initializing the parameters, simulating the model, and refining the estimations based on the original data. The estimation of the congestion propagation rate (\(\beta\)) and congestion dissipation rate (\(\gamma\)) is essential for accurately predicting the dynamics of congestion spread.
-
1.
Initialization: We provided initial guesses for the model parameters (\(\beta _0\) = 0.4, \(\gamma _0\) = 0.25) and \(R(0) = 0\) assuming there are no links at the recovery stage at the start of the simulation. I(0) which is the fraction of congested links at \(t=0\), is calculated from the sum of \(c_i\) divided by the total number of links \(N=4,397\) and the links in free-flow is \(S(0) = 1 - I(0) - R(0)\).
-
2.
Simulation: With the initial conditions and parameter guesses, we simulated the SIR model to predict the number of congested links at each time step.
-
3.
Parameter Refinement: We compared the modeled congested links with the actual data and adjusted the model parameters to minimize the difference the negative log-likelihood function as shown in Eq. (10). This optimization step is achieved using the Nelder–Mead method, Nelder and Mead (1965) and Gao and Han (2012), to find the best parameter values that fit the data.
where \(y_i\) is the actual data, \(\hat{y}_i\) is the model output, and PoissonPMF is the probability mass function (PMF) for Poisson distribution calculated using the SciPy package Virtanen et al. (2020).
Results
In our study, we explore the behavior of navigation apps in the context of traffic congestion management. Navigation apps can be interpreted as a greedy algorithm in a broader sense, where they recommend the best available routes to individual users at any given time. For instance, during periods of high congestion on highways, the apps often suggest alternative routes through less-utilized local roads. Importantly, this individual behavior has a cumulative effect on the overall traffic system, leading to increased use of alternative routes and alleviation of congestion in previously uncongested areas. To assess the impact on the overall traffic system, our evaluation presented in this section is collective or aggregated results rather than focusing on individual car performance.
Assuming a certain percentage of drivers will receive information while en-route to their destination, while others will not and will stick to a route more familiar to them or one they would have preferred from their point of origin. In reality, navigation will be used, but compliance is something that’s hard to determine. The route choice model we selected allowed us to simulate this behavior. The actual level of compliance can be determined if a less disaggregated result is analyzed. Additionally, we understand that actual compliance rates may vary depending on factors, such as driver preferences, familiarity with the area, and traffic conditions.
Figure 6 illustrates how the different scenarios perform using conventional metrics including mean flow (veh/h), mean density (veh/km per lane), mean speed (km/h), mean travel time (sec/km), mean delay time (sec), and mean queue (veh). It can be seen in the heatmap with the corresponding values that it performs better if there are 30–60% dynamic en-route users. This is mostly consistent across all metrics. Meanwhile, it performs poorly when there are 0%, 90%, and 100% dynamic en-route users. As a sample illustration, Fig. 7 shows the comparison of links that get congested with 90% and 40% dynamic en-route users at 5:30 pm.

Heatmap of metrics for system-wide averages: mean flow (veh/h), mean density (veh/km per lane), mean speed (km/h), mean travel time (sec/km), mean delay time (sec), and mean queue (veh)
The average delay time had significantly improved when there are 30-60% dynamic en-route users, which indicates a reduction in the difference between the expected travel time (the time a vehicle would take to traverse the route under ideal conditions) and the actual travel time, and thus a more time-efficient network. A similar trend is also observed in the size of the queue, where more vehicles were able to enter the network to finish the travel without being held out due to the congestion. Meanwhile, the mean speed does not vary significantly given that there are still many uncongested sections (mostly residential roads) of the entire network. However, the slight change should be sufficient to indicate that there is indeed an effect with a varied percentage of users following ‘Dynamic En-route’ when we consider the entirety of the network.

Comparison of the spatial distribution of congestion in the Fremont network at 5:30 p.m. showing the congested links (coded red) on the network with \(\rho = 0.9\). (a): when 40% of the drivers follow dynamic en-route assignment with different thresholds \(\rho\); (b): when 90% of the drivers follow dynamic en-route assignment
Then, using the SIR model, we fit the parameters to determine the congestion. Figures 8 and 9 illustrate how the infection curve generated by these parameters performs when compared to actual data. In both figures, it can be observed that while the trend is not perfectly explained by the experimental data from the simulation, when we generated the curves from the SIR model, they show an interesting trend almost similar to how congested links increase toward peak hours and decrease toward the end of the simulation, consistent to how traffic congestion forms and dissipates over time.

Fitted SIR model to dynamics of the system with estimated parameters \(\beta = 0.229558\) and \(\gamma = 0.171211\) when \(\rho = 0.9\) with 50% Dynamic En-Route Users

Fitted SIR model to dynamics of the system with estimated parameters \(\beta = 0.213965\) and \(\gamma = 0.147720\) when \(\rho = 0.9\) with 100% Dynamic En-Route Users
Finally, we illustrate the impact of the spread of congestion across different scenarios using the basic reproduction number, \(R_0\), from the SIR model. In Fig. 10, we can observe that \(R_0\) is generally lower for scenarios with a lower percentage of dynamic en-route users. The least value can be observed when 40% of the users are following dynamic routing. This indicates that the overall performance of the network is improved, and congestion is less likely to persist in the network. We may associate the increase in the \(R_0\) value with the increased percentage of users following dynamic en-route routing, as there are more routes explored by the users that could lead to congestion in previously uncongested areas, particularly within residential areas. Figure 11 shows the dynamics of congestion propagation considering all the three traffic congestion states — free flow S(t), congested I(t), and recovered R(t). The trend shown by each curve shows a similar pattern when compared to the SIR model applied in epidemiology.

SIR model estimated basic reproductive number, \(R_0\), for all simulation scenarios using \(\rho\) = 0.9, with a plot for polynomial fit

Three-state model showing how congestion spread for the scenario with the least \(R_0\) value in log scale (90% dynamic en-route, \(\beta = 0.252400\), \(\gamma = 0.169535\))
Conclusion
Overall, our research contributes to the understanding of navigation app usage and its potential consequences on traffic flow and how congestion forms by employing advanced large-scale microscopic traffic simulation techniques. Our results augment existing studies that highlight the possible negative effects of navigation apps due to their growing usage. We demonstrated these effects by varying the proportion of users adopting static and dynamic routing in our simulations.
Our findings indicate that the simulations produce better results when approximately 30–60% of users employ dynamic en-route navigation. This observation provides valuable insights into the impact of routing strategies on overall traffic performance and congestion. We have successfully supported these results by applying the SIR model, specifically by calculating the basic reproductive number, \(R_0\). This approach allowed us to quantify the effects of navigation apps on traffic patterns, emphasizing the potential for increased congestion and its subsequent implications.
These could be addressed by policies that encourage dynamic routing adoption and limit it once a certain percentage of users have switched to alternative routes suggested by navigation apps. We believe that understanding the collective benefits of each routing scheme is the first step toward developing new algorithms or design mechanisms for routing apps. However, this would be challenging because navigation apps would need to be designed to directly evaluate compliance and potentially stop suggesting new routes when a desired threshold is met. Instead, it might be more effective to implement policies that promote ecological transportation options, such as cycling and Mobility as a Service (MaaS), or other more sustainable methods. Focusing on these alternatives could also reduce the environmental impact of transportation, rather than solely enhancing the efficiency of car travel.
While our findings may be comparable to those of other similar studies using numerical experiments, our study focuses on a specific area and involves specific assumptions about drivers’ behavior, such as the choice between fixed and dynamic routing. Therefore, one should exercise caution when extrapolating these findings to understand the broader implications of navigation apps on traffic congestion.
Given this, future work in this field may include examining the reproducibility of such results in other areas. There could also be more work done to determine the optimal percentage of road users that should be routed dynamically instead of setting a range; but, because there are a lot of elements affecting traffic conditions leading to uncertainties, setting a target range might be more beneficial over time instead of trying to determine a fixed value. If a fixed optimal value is determined, it will be ideal to perform a sensitivity analysis to see how the behavior might change under different conditions (e.g., weather conditions, the effect of road accidents, etc.). Further studies on driver compliance with navigation apps could also be considered as a part of future work.
Finally, since our study primarily focuses on the impact of navigation apps on traffic flow and congestion, we acknowledge that there could be additional consequences, such as increased inequity in air and noise pollution. We recognize the importance of these broader effects on urban life, which can also be considered in future research.
Supplementary information
The simulation experiment pipeline is built upon the open-source tools for traffic microsimulation creation, calibration, and validation with Aimsun, available at https://github.com/Fremont-project/traffic-microsimulation.
The parameter estimation process for the SIR model is partially adapted from the model published by Epimath Lab. The original code is available at https://github.com/epimath/param-estimation-SIR.
Data availability
The code and other relevant materials used in this paper are shared at this GitHub repository: https://github.com/CarlQGan/Spread_of_Congestion.git; the databases needed to run the code are shared at this Google Drive folder: https://drive.google.com/drive/folders/1gZ5YEo79munkY4b-V4b44c8qG3LJJuqv?usp=drive_link.
References
Aimsun (2022). Aimsun Next 22 User’s Manual. Barcelona, Spain, aimsun next 22.0.1 edn
Ambühl L, Menendez M, González MC (2023) Understanding congestion propagation by combining percolation theory with the macroscopic fundamental diagram. Commun Phys 6(1):26
Bae S et al. (2019). Behavior, Energy, Autonomy. Mobility Modeling Framework. Tech, Rep
Bittihn S, Schadschneider A (2021) Braess’ paradox in the age of traffic information. J Stat Mech 2021:33401
Cabannes, T. et al. (2018). Measuring Regret in Routing: Assessing the Impact of Increased App Usage. 21st International Conference on Intelligent Transportation Systems (ITSC)
Cabannes T, Sangiovanni M, Keimer A, Bayen AM (2019) Regrets in routing networks: measuring the impact of routing apps in traffic. ACM Trans Spatial Algorithms Syst 5:1–9
Cabannes, T. et al. (2023). Creating, Calibrating, and Validating Large-Scale Microscopic Traffic Simulation. Transportation Research Board 102nd Annual Meeting
Cascetta E (2013) Transportation systems engineering: theory and methods applied optimization. Springer, Cham
Chen C, Petty K, Skabardonis A, Varaiya P, Jia Z (2001) Freeway performance measurement system: mining loop detector data. Transp Res Rec 1748:96–102
Daganzo CF (1994) The cell transmission model: a dynamic representation of highway traffic consistent with the hydrodynamic theory. Transp Res B Methodol 28:269–287
Festa, A. & Goatin, P. (2019). Modeling the impact of on-line navigation devices in traffic flows. 2019 IEEE 58th Conference on Decision and Control (CDC) 323–328
Frank M, Wolfe P (1956) An algorithm for quadratic programming. Naval Res Logis Q 3:95–110
Fundamental Algorithms for Scientific Computing in Python (2020) Virtanen, P. et al. SciPy 1.0. Nature Methods 17:261–272
Gao F, Han L (2012) Implementing the Nelder-Mead simplex algorithm with adaptive parameters. Comput Optim Appl 51:259–277
Greenshields BD (1935) A study of traffic capacity. Highw Res Board 14:448–477
Haklay M, Weber P (2008) Openstreetmap: user-generated street maps. IEEE Pervasive Comput 7:12–18
Khani A, Sall E, Zorn L, Hickman M (2013) Integration of the FAST-TrIPs person-based dynamic transit assignment model, the SF-CHAMP regional, activity-based travel demand model, and san francisco’s citywide dynamic traffic assignment model. Tech, Rep
Lighthill MJ, Whitham GB (1955) On kinematic waves. II. A theory of traffic flow on long crowded roads. Proc R Soc Lond Ser A Math Phys Sci 229:317–345
McCarty M (2016) The Road Less Traveled? National Public Radio, Not Since Waze Came to Los Angeles
Nash JF (1950) Equilibrium Points in n-Person Games. Proc Natl Acad Sci PNAS 36:48–49
Nelder JA, Mead R (1965) A simplex method for function minimization. Comput J 7:308–313
Patriksson M (2015) The traffic assignment problem: models and methods. Dover Publications Inc, Mineola
Pigou AC (1932) The Economics of Welfare, 4th edn. Macmillan and Co., Limited, St. Martin’s St., London
Richards PI (1956) Shock waves on the highway. Oper Res 4:42–51
Ringhand M, Vollrath M (2018) Make this detour and be unselfish! Influencing urban route choice by explaining traffic management. Transport Res F Traffic Psychol Behav 53:99–116
Rosenthal RW (1973) The network equilibrium problem in integers. Networks 3:53–59
Roughgarden TA (2002) Selfish routing. Cornell University, Ithaca
Roughgarden T (2005) Selfish routing and the price of anarchy. MIT Press, Cambridge
Saberi M et al (2020) A simple contagion process describes spreading of traffic jams in urban networks. Nat Commun 11:1616–1616
Samson, B. P. V. & Sumi, Y. (2019). Exploring Factors that Influence Connected Drivers to (Not) Use or Follow Recommended Optimal Routes. Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems 1–14
Shaqfeh, M., Hessien, S. & Serpedin, E. (2020). Utility of Traffic Information in Dynamic Routing: Is Sharing Information Always Useful? 2020 IEEE 3rd Connected and Automated Vehicles Symposium (CAVS) 1–6
Thai, J., Laurent-Brouty, N. & Bayen, A. M. (2016). Negative externalities of GPS-enabled routing applications: A game theoretical approach. 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC) 595–601
van Essen M, Thomas T, van Berkum E, Chorus C (2020) Travelers’ compliance with social routing advice: evidence from SP and RP experiments. Transportation 47:1047–1070
Vosough S, Roncoli C (2024) Achieving social routing via navigation apps: user acceptance of travel time sacrifice. Transp Policy 148:246–256
Wardrop JG (1952) Some theoretical aspects of road traffic research. Institution of Civil Engineers, London
Wu J, Gao Z, Sun H (2004) Simulation of traffic congestion with SIR model. Modern Phys Lett B Condensed Matter Phys Stat Phys Appl Phys 18:1537–1542
Yang L, Bian Y, Zhao X, Liu X, Yao X (2021) Drivers’ acceptance of mobile navigation applications: An extended technology acceptance model considering drivers’ sense of direction, navigation application affinity and distraction perception. Int J Hum Comput Stud 145:102507
Youn H, Gastner MT, Jeong H (2008) Price of anarchy in transportation networks: efficiency and optimality control. Phys Rev Lett 101:128701
Acknowledgements
The authors are thankful to the City of Fremont and Aimsum, along with their support team. We would also like to express our gratitude to our lab-mates who assisted us in developing the simulation, with special thanks to T. Cabannes, who led the Fremont project, and J. Lee, who aided in the design of these experiments. A. R. Bagabaldo extends his gratitude to the Philippines CHED, DOST-SEI, and Mapua University for providing his Ph.D. scholarship.
Funding
The authors did not receive direct funding to conduct this study that would in any way have affected the conduct of the study and the results.
Author information
Authors and Affiliations
Contributions
All authors significantly contributed to this work. A. R. Bagabaldo conceived, designed, and performed the study. A. R. Bagabaldo and Q. Gan collected and analyzed the data. Q. Gan worked on parameter estimation of the model used in the study and is responsible for updating the code repository. A. Bayen and M. C. Gonzalez contributed to the interpretation of results and provided critical revisions. A. R. Bagabaldo and Q. Gan drafted the manuscript, and all authors provided important intellectual content during revisions. All authors approved the final version for publication and agreed to be accountable for all aspects of the work, ensuring its integrity and accuracy.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest as defined by Springer or other interests that might be perceived to influence the results and/or discussion reported in this paper.
Ethical approval and consent to participate
Not applicable.
Consent for publication
All authors of the manuscript hereby confirm their unanimous agreement to the terms and conditions outlined in the consent for publication statement.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bagabaldo, A.R., Gan, Q., Bayen, A.M. et al. Impact of navigation apps on congestion and spread dynamics on a transportation network. Data Sci. Transp. 6, 12 (2024). https://doi.org/10.1007/s42421-024-00099-w
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42421-024-00099-w