
Abstract
Purpose
As the concept of Industry 4.0 is introduced, the significance of Smart Fault Diagnosis in the industry is increased. Therefore, it is essential to develop accurate, robust, and lightweight intelligent fault diagnosis approach that can be executed in real-time even with embedded systems. Additionally, it is preferable to use a single method for multi-purposes such as the fault detection, identification, and severity assessment. This study proposed a new approach called GaBoT for fault diagnosis of rotating machinery to satisfy those requirements.
Method
The proposed approach adopted the concept of the ensemble of ensembles by boosting random forest. The statistical features of discrete wavelet transform were considered since they are easy and fast to obtain. Model optimization was conducted by employing genetic algorithm to alleviate the computational load without decreasing the model performance. The proposed approach has been validated by unseen data from an experimental dataset including shaft, rotor, and bearing faults.
Results
The experimental results indicate that the proposed approach can effectively find the fault type with 99.85% accuracy. Besides, it successfully determines the fault severity by accuracy values between 96.45 and 99.72%. GABoT can also determine the imbalance severity in the presence of three bearing faults.
Conclusion
Employing GA eliminated most of the redundant features and reduced the model execution time consumption. The results yielded that GABoT is a highly accurate model, and can be utilized in real-time fault diagnosis of rotating machinery.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
Introduction
Fault diagnosis is a critical task in all industrial machines since a fault occurrence may adversely impact the manufacturing procedure or completely halt the entire production. In general, the time consumption and cost of such an interruption and repair procedure of the machinery is extremely high. Incorrect fault diagnostics may also result similarly. In that case, the time and cost spent to repair the machine become futile, and the machinery will be still faulty, which increases the expenditures to an even higher level. Considering such potentially negative consequences, researchers conducted various studies to identify the machinery faults effectively. Vibration signals, thermal images, and acoustic data are acquired to detect such faults by employing signal processing methods. Following the growing idea of the fourth generation of the industrial revolution, or Industry 4.0, the significance of the necessity for smart fault diagnosis (SFD) techniques has increased [1,2,3,4,5]. Thanks to the advancements in computer technology, numerous studies were conducted to develop, optimize, or improve SFD methods [6,7,8,9] SFD techniques employ machine learning algorithms on the data acquired from the faulty machinery or a component of a machine to identify the machinery faults. The considered dataset may or not be pre-processed depending on the selected intelligent method to conduct the fault diagnosis. Based on the type of the obtained data, SFD techniques can be divided into two categories namely, image-based SFD (ISFD) [10,11,12] and sensor-based SFD (SSFD) [13,14,15] methods. ISFD techniques employ image data to perform an SFD operation. The dataset of ISFD methods may include image [16], thermal [17], magnetic [18], X-ray [19], or signal images [20]. Such images contain useful information to identify the fault accurately by employing deep learning techniques. However, the hardware to obtain those images is generally expensive and resolution sensitivity issues may negatively impact the positive aspects of ISFD techniques as the more resolution results in better performance yet cause increment in hardware cost and usually higher file sizes to deal with [21,22,23]. In addition, even if a regular device or a sensor (for signal imaging) is considered, time-consuming further processing techniques will be required to obtain the information from a low-quality image or convert a signal to a signal image effectively. Such processing methods may require expertise, a long period, and powerful devices. Besides, the size of the images poses another issue especially in real-time fault monitoring cases due to the concept of big data. The transfer of the image data from the machinery to the data center may take additional time and also require powerful hardware (i.e., server, storage, communication technology). In the case of long-distance transmissions, the time required to transmit the data may reach even higher amounts. SSFD methods utilize sensor datasets to conduct SFD procedures. Such data may comprise vibration [24], microphone [25], pressure, voltage data [26], and/or tachometer [27], which contain essential information that indicates the health of the machinery. The placement, selection, and calibration of the sensors may become a challenging process if a sensitive measurement is needed. The acquisition of the sensor data is generally easy and inexpensive. On the other hand, reading, understanding, and processing the raw sensor data may require expertise and powerful devices. Hence, using SSFD techniques with machine learning is practical. Besides, most of the machine learning techniques used in the SSFD method can be employed with small embedded systems. For real-time monitoring purposes, the sensor data may be less challenging compared to image data depending on the requirements of an intelligent model. The main reason is the quality of the data, which has a significant impact on the model performance for a specific task. Setting the trade-off between the data quality and the model performance is essential since leveraging the resolution of the data results in generally higher model performance [22] but adversely impacts the data transmission in a real-time condition due to the higher file size. In such conditions, it is required to either use more advanced hardware for data transfer that increases the cost or reduce the quality, which may reduce the model performance. Although there are situations where an image file has a lower size compared to a 1-D signal file, the sensor data may be more advantageous compared to the image file in case of the requirement for high-quality data. When high-quality image data is needed for prediction, it is challenging to perform a continuous data transfer as the full image will be transmitted within a period. On the other hand, depending on the requirements of an intelligent model, a small window of high-quality time series data may provide useful and sufficient information for prediction without waiting to transfer a massive amount of data. That also may reduce the time consumption during data transfer and result in predictions within shorter time intervals. For instance, the dataset MaFaulDA was collected considering a high-quality sampling rate of 50 kHz considering a 5-s measurement interval. The total number of data points per measurement is 250,000. The file size of each measurement is around 17 MB meaning that 1 s of data has only 3.4 MB and has 50,000 data points [27]. In a study [28], the performance of an approach for fault diagnosis of rotating machines was measured by using the MaFaulDa dataset. The number of data points required for one prediction was 6500, which took 0.13 s to be transferred. In terms of file size, this corresponds to 442 kB, which is nearly half the size of a raw thermal image having 640 × 480 pixels and is considered a good quality image [29]. Although 1-D time series data have such an advantage in terms of file size, one should always keep in mind that this varies depending on the problem and its requirements. As mentioned above, researchers conducted numerous studies in the field of fault diagnosis of the elements of machinery. Those that considered SSFD-based data are briefly given as follows.
Han et al. [30] considered multiple-scale features, and statistical features of time and frequency-domain data for fault detection of rolling bearing and gear faults. They used a probabilistic neural network (PNN), support vector machine (SVM), random forest (RF), and extreme learning machine (ELM) individually for comparison. They obtained an accuracy value of 99.24% in the identification of the fault type. Yang et al. [31] used bearing accelerometer data to detect faults in bearings using a transfer neural network (FTNN). The transferable features were obtained via a convolutional neural network (CNN). They obtained an 84.32% accuracy value with their proposed approach in the identification of the types of bearing faults. Li et al. [32] proposed a multiscale local feature learning combination (MLFC) based on a backpropagated neural network (BPNN) approach using accelerometer data for fault diagnosis of rolling bearings. They employed the discrete wavelet transform (DWT) for signal processing to use the decomposed signal for training BPNN. Their proposed approach identified the bearing faults with an average accuracy of 99.31%. Wu et al. [33] used accelerometer data for fault diagnosis of bearing faults regarding two severity levels based on few-shot transfer learning. They not only measured the performance of the proposed approach, but also discussed the concepts of task plasticity, data dependency, and transferability of various cases in their proposed approach. Cheng et al. [34] presented a continuous wavelet transform (CWT) based local binary convolutional neural network (LBCNN) for fault diagnosis of bearings using 1-D time series vibration data. To validate the proposed approach, they considered healthy, inner, and outer race faulty bearings under different loads. They concluded that their proposed approach identifies the fault between 94.51 and 96.07% accuracy values. Yu et al. [35] considered vibration data for fault diagnosis of rotating machines by graph-weighted reinforcement networks. They investigated the model performance regarding high noise and small samples. They achieved 92.14% accuracy with 30 training samples for a gearbox test rig. de Sá Só Martins et al. [36] examined imbalance and misalignment combined faults by employing SVM, RF, and k-nearest neighbors (kNN) using accelerometer data. They also considered the severities of those faults in combination. They achieve the best accuracy value for RF with an overall value of 81.41%.
Model selection is critical to constitute an effective SFD approach along with the data collection procedure. Ensemble learning approaches were considered several times in fault analysis to benefit from the aggregation of the outcomes of base learners that improves the ultimate model. Some studies that focused on the ensemble learning approaches are briefly expressed below.
Hu et al. [37] proposed a machinery fault detection technique based on multi-scale dimensionless indicators (MSDI) and RF. They employed the variational mode decomposition method as the signal processing technique. They considered six types of MSDI based on the decomposed signals. They concluded that the average accuracy of the proposed method reached 95.58%. Besides, they claimed that their proposed method increased the accuracy of the fault detection procedure by 7.25%. Roy et al. [38] used the autocorrelation-based random forest for bearing fault detection. They considered 33 different features for the feature extraction procedure, including statistical and signal parameters. They compared their technique with different classifiers and examined the importance of features. Zhang et al. [39] proposed multi-feature and AdaBoost with a back-propagated neural network for fault diagnosis in a gearbox. They considered six states of the gearbox and decomposed the signal of these states by employing empirical mode decomposition for noise reduction. Afterward, they conducted the feature extraction procedure by considering time domain and frequency band energy features. Their proposed approach gave an accuracy value of 96.94% in identifying the fault types in a gearbox. Toma and Kim [40] investigated three different wavelet types and ensemble machine learning algorithms for fault detection in induction motors. They considered random forest (RF) and extreme gradient boosting (XGBoost) to classify the bearing faults of the induction motors. They concluded that the accuracy value of their proposed approach reached 99.00%. Wang et al. [41] employed wavelet packet decomposition (WPD) and random forest (RF) for fault diagnosis of rolling bearings. They considered a mutual dimensionless index as the input of the RF-based fault diagnosis model. They concluded that the proposed method reached 88.23% classification accuracy. Tang et al. [42] employed an edited version of Light Gradient Boosting Machines (LightGBM) for fault detection in wind turbine gearboxes. They considered the maximum information coefficient for feature selection after normalizing the data. They assessed their proposed approach based on false alarm rates and missing detection rates and found that LightGBM can detect the faults with an accuracy up to 98.67%. Wu et al. [43] utilized ReliefF and eXtreme Gradient Boosting techniques for fault diagnosis of wind turbines using SCADA data. They compared their approach with several algorithms such as SVM and Ada Boost. They achieved perfect performance metrics in identifying different fault types related to wind turbines. Hosseinpour-Zamaq et al. [44] employed RF to identify faulty pinions in a gearbox regarding three different rotational speeds. They used a correlation-based future selection technique to find the best features, which resulted in an overall accuracy of 92.5%.
Following the model selection, it is generally suggested to perform optimization in various ways such as feature selection, model hyperparameter tuning, and parameter optimization related to data processing. Genetic algorithm (GA) was considered for fault diagnosis problems to optimize all the concepts given above. Some studies that considered GA are summarized as follows.
Unal et al. [45] proposed a genetic algorithm (GA) optimized neural network (NN) technique to identify the faults in rolling bearings considering accelerometer data. They concluded that their proposed approach could identify the fault type with approximately 98.00% accuracy value. Tyagi and Panigrahi [46] presented a hybrid technique, namely GA-back-propagated NN by using accelerometer data. They considered surface wear fault, chipped tooth fault, and missing tooth fault to evaluate the performance of the proposed method. They concluded that the accuracy can reach 100.00% as the number of generations reaches 2000 or more. Cerrada et al. [47] proposed a fault detection approach for spur gears based on GA and RF. The feature selection procedure was conducted by GA and the fault classification in spur gears was performed by RF. According to their outcomes, the feature set was reduced to 122 from 359 and the accuracy of the proposed method was evaluated as approximately 97.00%. Jalali et al. [48] combined a GA with SVM to conduct fault detection procedures for ball-bearing faults. They considered 24 statistical features for the feature extraction procedure. They obtained accuracy values of 97.14% and 93.33% for training and testing data, respectively. Lee et al. [49] used a memory space computation genetic algorithm (MSCGA) for feature selection for intelligent fault diagnosis of bearings. They employed SVM, kNN, RF, decision trees (DT), and discriminate analysis (DA) as classifiers to assess the performance of MSCGA, which was found as an effective optimization technique. Wei et al. [50] proposed a GA-based variational mode decomposition (VMD)—Pseudo Wigner-Vile Distribution (PWVD) based few-shot transfer and mete learning approach for bearing fault diagnosis. They employed GA to set the penalty factor and modal numbers in VMD. They obtained an overall identification accuracy of 98.00% for the 10-way 5-shot scenario.
Based on the literature review, Table 1 gives the comparison of the present study with the state of the art.
As seen in Table 1, most of the studies focused on identifying individual bearing faults, and a few of those also considered conducting fault severity analysis. Besides, concurrent or multiple fault cases have not been extensively investigated yet. Most of the fault diagnosis approaches that existed in the literature only focused on the accuracy of the SFD method, which may give fallacious or insufficient information about the performance of the corresponding approach and may overlook the fault-specific performance of an SFD technique [56]. Therefore, it can be interpreted that both fault severity analysis and concurrent fault diagnosis still need to be investigated in more detail.
As for an ensemble learning-based SFD technique, most of the studies employed Random Forest (RF). However, RF may show some issues (underfitting, overfitting, biased classification) regarding the classification problem, data distribution, data size, and repetitive data [57, 58]. To alleviate such drawbacks, RF can be employed as the base learner of an ensemble learner, AdaBoost, which improves itself by tuning the weight of the data and evaluating the error [59, 60]. This study proposes a new approach, Genetic Algorithm based Boosted Trees (GABoT), for fault diagnosis of rotating machinery, considering the issues indicated above. The sensor data have been processed by employing Discrete Wavelet Transform (DWT) to extract the statistical features of each decomposition level. For this purpose, bior3.1 mother wavelet has been considered. Following the feature extraction procedure, a genetic algorithm (GA) has been used to automatically choose the most informative features to alleviate the computational load. Afterward, by using the reduced feature vectors, AdaBoost with Random Forest (Boosted Trees) has been utilized to identify both the fault and its severity. The performance of the proposed approach is assessed by considering the machinery fault dataset [27, 61] in terms of evaluation metrics such as accuracy, precision, and recall, to build the smart model. The flowchart of the study has been briefly presented in Fig. 1. The contributions of this work are summarized as follows.
-
1.
Introducing an approach, Genetic Algorithm Optimized Boosted Trees (GABoT) for both fault type and severity identification regarding single and compound faults in rotating machinery for the first time.
-
2.
Investigating the fault-specific performance of GABoT for the first time through covering a variety of shaft, rotor, and bearing faults to ensure its generalizability in terms of fault types.
-
3.
Examining the suitability of the GABoT for the real-time fault analysis conditions by measuring its success, robustness, sensitivity, and time consumption.
-
4.
Assessing the proposed approach through comparisons with other studies regarding fault-specific accuracy, overall accuracy, and model training and testing time.

The flowchart of the study
The remained part of the manuscript has been organized as follows. The second section presents the details of the proposed approach. The third section includes the description of the considered dataset and the evaluated experimental results. Finally, the last section remarks on the conclusions of the study.
Proposed Approach
The proposed approach comprises three main procedures, namely, Signal Processing, Feature Extraction, Optimization, and Fault Diagnosis. In the Signal Processing phase, the raw data have been decomposed via Discrete Wavelet Transform (DWT). In the Feature Extraction phase, a number of 12 statistical features of the signal have been obtained from the decomposed signal considering each sensor type and axis. These features are mean, median, root mean square, standard deviation, variance, 5th percentile value, 25th percentile value, 75th percentile value, 95th percentile value, mean-crossings, zero-crossings, and Shannon entropy. In the Optimization and Fault Diagnosis procedure, the Genetic Algorithm (GA) has been employed to reduce the number of features for an accurate and fast smart fault diagnosis method. Afterwards, the Boosted Trees (BoT) or AdaBoost with Random Forest machine learning algorithm has been employed to identify the machinery fault and its severity. The proposed approach has been briefly presented in Fig. 2. The concepts that have been considered to build the proposed model have been briefly explained in the following sections.

Illustration of the optimization procedure
Discrete Wavelet Transform
Discrete Wavelet Transform (DWT) is a technique that decomposes the signal considering a two-parameter system. Therefore, the DWT can be briefly explained mathematically as follows [62].
where φi,k(t) denotes the wavelet function, i and k are the integer indices, and ai,k is the set of two-dimensional coefficients of expansion. The wavelet or mother wavelet function can be defined as [62]
Substituting Eq. (2) into Eq. (1) gives
To examine the wavelets in different scales, the concept of multiresolution could be considered since it gives finer details when it is formulated [62]. To understand the concept deeper, the scaling function λ(t) can be considered instead of the wavelet function. Note that the wavelet function can be derived from the scaling function. The scaling function can be defined as [62]
By using the basic scaling function given in Eq. (4), a two-dimensional function is obtained by translation and scaling as [62]
Hence, the signal f(t) can be expressed as
Considering multiresolution, the fundamental mathematical requirement can be expressed as [41, 62].
and
where Ai is the ith subspace of L2 norm. Since the natural scaling condition has to be satisfied, the signal f(t) also has to scale as [62]
Considering Eq. (7) and Eq. (9), it can be concluded that if the scaling function is the element of Ai, it is also the member of Ai+1. Hence, the scaling function can be defined considering a weighted sum of shifted scaling function as [62]
where w(p) is the sequence of the scaling coefficients. As mentioned before, the wavelet function can be derived from the scaling function. The significant information of a signal can be efficiently expressed or developed by using the wavelet function instead of the scaling function [62]. It is required that the wavelet functions and scaling functions have to be orthogonal since orthogonality provides the expansion coefficients to be simply calculated. In addition, it enables to division of the signal energy within the wavelet domain. Such a requirement can be expressed as [62]
Since the subspaces are also orthogonal, Eq. (10) can be redefined in terms of the wavelet function as [62]
where w1(p) is one set of the coefficients. The mother wavelet expression, given in Eq. (2) can be derived by Eq. (12) for an expansion [62]. Employing the scaling function and the mother wavelet, any function, y(t), could be written in L2 (R) as
where the left-side summation represents the low resolution, while the right-side is the higher resolution. c(k) and d(i,k) represent the approximation and detail coefficients, respectively.
Genetic Algorithm
The optimization procedure has been conducted by employing a Genetic Algorithm to evaluate the most essential or informative features automatically. Inspired by the natural selection process, the Genetic Algorithm is a metaheuristic algorithm that is used for optimization and searching problems [63]. As shown in Fig. 2, the Genetic Algorithm first determines the fitness score of the initial population. If the termination criterion (e.g., a threshold for the fitness value) is satisfied, then the algorithm stops working and gives the outcomes. If not, then the algorithm enters into the tournament process where the best candidate(s) from the existing generation is selected. Afterward, the crossover phase takes place, where an exchange between parents occurs from a random point. By doing so, new optimized offspring is created. The mutation process takes place after crossover where one or more randomly selected individuals (genes) are replaced to obtain solutions where local optima are avoided [64]. The fitness score of the new generations is calculated and again, the termination criterion is checked. This procedure is executed until the termination criteria are satisfied. In this study, the fitness score has been related to the training accuracy of the Boosted Trees or AdaBoost with Random Forest model.
Ensemble Model: Boosted Trees
As for the ensemble model, AdaBoost with Random Forest has been considered. AdaBoost (AB) or Adaptive Boosting aims to obtain an optimal model by using boosting rules. It enhances the performance of the weak classifier by combining the weak hypothesis that is evaluated per iteration p. Following the final boosting procedure after the final iteration Ps, the model is at its highest performance. The mathematical expressions for such a procedure can be given as follows.
where BPs is the boosted model, ξs denotes the weak learner, and x represents the inputs. A hypothesis h(x) is produced by the weak learner considering each sample in the dataset. As seen from Eq. (14) The error value of the final iteration, errPs is obtained by the sum of the error of the earlier round with the result of the multiplication of the produced hypothesis and the coefficient γp. This procedure is conducted until the final error is minimized [65]. As for the weak learner, another ensemble method Random Forest (RF) has been considered. The reasons for such selection are implied in the first section of the study. RF combines decision trees and aims to lower the variance value by averaging the results. Consequently, it creates a community, which consists of low-correlated trees. The trees, which are grown by observations on randomly selected data are constituted to obtain the forest. The algorithm chooses the classes by performing a majority voting procedure or averaging the predictions, which are evaluated from individual trees. The mathematical expression of such a procedure can be summarized as follows.
where o(x) represents the prediction evaluated for individual decision trees considering x observation. Rn is the number of iterations, O(x) is optimized the average prediction of the sums of prediction o(x), and err is the error value, which is obtained from the difference between the actual and the predicted observations [66].
Experimental Analysis
The performance of the proposed approach, GABoT has been validated by considering a public rotating machinery dataset, MaFaulDa [27, 61], which comprises numerous fault cases. The details of the dataset have been presented in the following subsection.
The Dataset and Signal Pre-processing
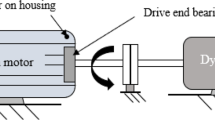
MaFaulDa dataset [27, 61] comprises one healthy and nine different fault cases including the severity values of three faults. The data is acquired sequentially considering a 50 kHz sampling rate for 5 s. The experimental setup built for data acquisition is shown in Fig. 3 [27, 61].

The details of the considered machinery faults for this dataset have been presented in Table 2 [27, 61]. All data was collected through microphone, tachometer, one tri-axial, and three one-axial accelerometers. The tri-axial accelerometer was placed on the bearing located at the end of the shaft (overhang), and one-axial accelerometers were located on the bearing placed between the rotor and the motor (underhang) as seen in Fig. 3.
The illustrations of the collected underhang accelerometer data, considering healthy and imbalance faults have been presented in Figs. 4 and 5.

Underhang accelerometer data of the healthy and imbalanced machinery

Underhang accelerometer data of the imbalanced machinery considering three different severity values
The discrete wavelet transform has been employed considering level 4 decomposition [67]. As the wavelet type, bior3.1 has been considered. [68, 69]. Figure 6 shows the illustrations of the decomposition procedure for the z-axis of the underhang accelerometer, tachometer, and microphone, respectively.

The illustrations of the detail coefficients of underhang accelerometer (z-axis), tachometer, and microphone
The dataset was collected under different rotational speeds which may result in the model mispredicting the case since there is a chance that the model may consider such a variation in speed as abnormal data and therefore, may come up with a prediction of some specific fault while the machine is perfectly healthy. Using a tachometer provides such a change to the model under healthy conditions and makes the model robust against speed changes during operation. In addition to the variation in the rotational speed, the dataset also comprises different ranges of fault severities, which may both help or hinder the intelligent model depending on the severity value. The acoustic data collected by the microphone contains the characteristics of the faulty component as the accelerometer data does. Especially under small fault severity values, it is challenging to observe the impacts of such faults on a signal. Although using additional sensors is not always desirable, microphone data may boost the information obtained from the accelerometer for identifying faults at their beginning. Using different types of sensors also brings a multi-modal solution when developing an intelligent approach for a fault diagnosis problem, increasing the model generalizability and therefore, make the model applicable for different rotating machines that use similar components. Based on that motivation, microphone and tachometer have been considered in addition to the accelerometers.
Optimization and Fault Diagnosis
It is aimed to reduce the number of feature vectors as much as possible to obtain a fast and accurate ensemble learning (EL) based SFD model for fault diagnosis. Since 12 features have been extracted for 8 sensor axes (one from the microphone, one from tachometer, 3 × 2 from two tri-axial accelerometers), a total of 96 feature vectors have been obtained. To determine the optimal number of feature vectors, the Genetic Algorithm (GA) has been executed by considering a 0.9 crossover ratio, 0.03 mutation ratio, and 30 for the initial population [64]. GA has been executed considering a maximum of 10, 20, and 30 numbers of feature vectors to find the most suitable threshold in terms of the maximum number of feature vectors required to perform the fault diagnosis efficiently. As a result, the maximum number of the feature vector is obtained as 20 since the number of 10 feature vectors may decrease the performance metrics of the EL model while 30 feature vectors have not significantly impacted either the speed or the metrics of the GABoT model. The fitness value is considered as the average training accuracy of the model trained by optimized features. The termination criterion of GA is defined as five consecutive high fitness scores having a difference of no more than 0.001. The optimized model evaluation has been conducted by considering fivefold cross-validation. This method divides the dataset randomly into 80–20% train and test data to train and test the proposed approach. This procedure is repeated 5 times. The train and test data differ for each fold due to the randomized split. An illustration that represents fitness scores over generations for the severity detection of imbalance fault is shown in Fig. 7. The number of generations required for optimization varied for each case. The details of the genetic algorithm results are presented in Table 3.

Genetic algorithm implementation on the severity detection of imbalance fault
Experimental Results
All analyses have been conducted via Python 3.9. Following the fivefold cross-validation procedure, the performance metrics of the GABoT model have been evaluated. Table 4 presents the testing accuracy, precision, and recall metrics of the proposed approach in identifying the healthy or faulty condition of the machine including the fault type. Figure 8 shows the confusion matrix of the proposed method for the corresponding case.

Confusion matrix of GABoT in identifying the condition of machinery (H: Healthy, HM: Horizontal Misalignment, VM: Vertical Misalignment, IMB: Imbalance, OB: Ball Fault—Overhang, OC: Cage Fault—Overhang, OO: Outer Race Fault—Overhang, UB: Ball Fault—Underhang, UC: Cage Fault—Underhang, UO: Outer Race Fault—Underhang)
As seen from both Table 4 and Fig. 8, the proposed approach successfully identifies either the healthy state of the machine or the fault type of the machinery with an average accuracy of 99.85%. Considering the precision and recall values, the proposed approach is both robust and responsive as it deals with different faults of the machinery. To evaluate the performance of the proposed method for fault severity, it has been tested by considering the various fault severity values of Horizontal Misalignment, Vertical Misalignment, and Imbalance faults. Table 5 presents the testing performance metrics of the proposed approach in the case of determining the fault severity. Figures 9, 10 and 11 show the confusion matrices of the corresponding fault cases.

Confusion matrix of GABoT in determining the fault severity of horizontal misalignment fault

Confusion matrix of GABoT in determining the fault severity of vertical misalignment fault

Confusion matrix of GABoT in determining the fault severity of imbalance fault
As seen in Table 5, Figs. 9, 10 and 11, the severity of vertical misalignment, horizontal misalignment, and imbalance faults has been accurately determined by the proposed approach by average accuracy values of 99.72%, 96.45%, and 98.50%, respectively. The precision and recall values are also in line with the accuracy values, which indicate that the proposed model is robust and responsive in the determination of fault severity. As seen in Figs. 9, 10 and 11, the fault severity of horizontal misalignment is predicted almost perfectly (99.21–100.00%) For vertical misalignment faults with severity values lower than 1.40 mm, the proposed approach determines the severity by 98.12–98.56% accuracy. On the other hand, the performance of the proposed approach identifies the severity of such a fault by 90.37–98.24% as the severity value reaches higher than 1.40 mm. For the imbalance fault, the proposed method has also determined the severity accurately. The seven severity values of imbalance fault have been identified by accuracy values changing between 95.26 and 100.00%. As seen from the confusion matrix shown in Fig. 11, a small error value of 3.62% for 20 g (predicted as 10 g) and 1.76% for 10 g (predicted as 20 g) have been observed. A similar condition has been observed for the vertical misalignment with a severity of 1.78 mm. Nevertheless, either the average performance metrics or the severity-based accuracy values given in Table 4, Figs. 9, 10 and 11 have indicated that the proposed approach is effective in determining the severity of faults. Table 6, Figs. 12 and 13 give the testing performance metrics and corresponding confusion matrices of bearing faults considering overhang and underhang bearing locations and balanced and imbalanced conditions. 0 g means that there is no imbalance, while other values indicate an imbalanced setup with different severity values.

Confusion matrix of GABoT in identifying the imbalance severity in the presence of a ball fault, b cage fault, and c outer race fault of the overhang bearing

Confusion matrix of GABoT in identifying the imbalance severity in the presence of a ball fault, b cage fault, and c outer race fault of the underhang bearing
As seen from Table 6, Figs. 12 and 13, the proposed approach effectively identified the severity of imbalance fault under the ball, cage, and outer race faults of overhang and underhang bearings by average accuracy values of 98.86%, 98.56%, and 99.37%, respectively. The precision and recall values for these cases differ between 0.979 and 0.997, which indicates that the proposed approach is also robust and sensitive just as it is for fault identification and fault severity. Besides, it can be interpreted that the proposed method can identify both the severity and the fault types in the presence of two faults since it successfully predicts the severity of imbalance faults when a bearing fault is present at the same time. Interpreting the performance metrics, it can be concluded that the proposed approach is effective in diagnosing healthy and faulty machinery in terms of fault type, fault severity, and bearing-imbalance faults. Table 7 presents the comparison of the performance metrics of the proposed approach with other studies that used the same dataset. The highest scores have been indicated with bold font. As seen in Table 7, the proposed approach outperforms other methods that were validated with the same dataset for all cases.
The considered data was collected under varying rotational speeds, which means the data was not the same for each measurement and therefore, significantly affected the probability distribution making the fault diagnosis task challenging. The high precision value (0.998) of the proposed approach under this situation proves that the model is robust since it makes accurate predictions under such variation. Another proof of its robustness is its performance in distinguishing 10 machine conditions individually. According to the confusion matrix of the testing set given in Fig. 8, the lowest case-specific accuracy is obtained for the horizontal misalignment by 99.36%. This situation and the high recall value (0.998) approach indicate that the proposed approach is responsive against characteristic changes in the data meaning that it can accurately recognize one class and differentiate from the other ones successfully.
A similar situation is also observed for the fault severity analysis. The overall precision (0.982) and recall value (0.982) obtained for the fault severity identification indicate that GaBoT is also robust and responsive due to the same reasons indicated above. Even with its worst performance (i.e., finding the fault severity of 1.78 mm for the vertical misalignment case), it has a performance above 90.00%, which is still high and sufficient for real-time applications.
Based on all the findings, it can be interpreted that the proposed approach GaBoT is an effective, robust, and responsive approach for fault analysis in rotating machines owing to its high accuracy, precision, and recall values even in the presence of different operating status and a considerable variety of machinery conditions.
Conclusions
Smart fault diagnosis (SFD) techniques are essential and their significance has kept increasing for the industry since the beginning of the fourth industrial revolution. This study has aimed to contribute to the field of SFD methods by proposing a new and practical approach, GABoT. According to the numerical results, the following conclusions have been drawn.
-
The proposed approach, GABoT, successfully identified the healthy and faulty rotating machinery considering the type of fault with an average accuracy of 99.85%. Besides, due to the high precision (0.998) and recall (0.998) values, it can be concluded that the proposed model is robust and responsive when it deals with data from different cases of machinery.
-
In the case of faulty machinery, the proposed approach can effectively determine the fault severity. Considering horizontal misalignment, vertical misalignment, and imbalance faults, the accuracy values of the proposed model are 99.72%, 96.45%, and 98.50%, respectively. GABoT is also robust and responsive in determining the fault severity due to its high precision and recall values (0.965–0.997).
-
The proposed method can determine the fault severity of imbalance fault in the presence of overhang and underhang bearing ball, cage, and outer race faults by 98.86%, 98.56%, and 99.37%, respectively. The robustness and sensitiveness of the proposed approach are satisfactory due to high precision and recall values (0.979–0.997).
-
The proposed approach has been optimized by employing a genetic algorithm. Hence, the number of feature vectors is reduced by at least 79%. Such a reduction would also decrease the time and memory consumption required to conduct fault detection in rotating machinery.
-
The proposed approach outperforms the existing methods that were validated by considering the same dataset. Hence, it can be concluded that GABoT can be employed effectively in fault diagnosis of rotating machinery.
-
GABoT is a highly accurate sensor-based optimized model, which also does not require long pre-processing procedures. Besides, it employs platform-free algorithms which means that it can be used in any operating system and embedded system. Due to such positive aspects, it can be used in real-time SFD procedures effectively.
References
Chen X, Wang S, Qiao B, Chen Q (2018) Basic research on machinery fault diagnostics: past, present, and future trends. Mech Syst Signal Process 45:5–32. https://doi.org/10.1007/s11465-018-0472-3
Franciosi C, Iung B, Miranda S, Riemma S (2018) Maintenance for sustainability in the industry 4.0 context: a scoping literature review. IFAC-PapersOnLine 51:903–908. https://doi.org/10.1016/j.ifacol.2018.08.459
Zonta T, da Costa CA, da Rosa RR, de Lima MJ, da Trindade ES, Li GP (2020) Predictive maintenance in the industry 4.0: a systematic literature review. Comput Ind Eng 150:106889. https://doi.org/10.1016/j.cie.2020.106889
Ceruti A, Marzocca P, Liveranni A, Bil C (2019) Maintenance in aeronautics in an industry 4.0 context: the role of augmented reality and additive manufacturing. J Comput Des Eng 6:516–526. https://doi.org/10.1016/j.jcde.2019.02.001
Zhang Y, Jia Y, Wu W, Cheng Z, Su X, Lin A (2020) A diagnosis method for the compound fault of gearboxes based on multi-feature and Bp-AdaBoost. Symmetry 12:461. https://doi.org/10.3390/sym12030461
Samanta B, Al-Balushi K, Al-Araimi S (2003) Artificial neural networks and support vector machines with genetic algorithm for bearing fault detection. Eng Appl Artif Intell 16:657–665. https://doi.org/10.1016/j.engappai.2003.09.006
Jia F, Lei Y, Guo L, Lin J, Xing S (2018) A neural network constructed by deep learning technique and its application to intelligent fault diagnosis of machines. Neurocomput 39:25. https://doi.org/10.1016/j.neucom.2017.07.032
Chen X, Wang S, Qiao B, Chen Q (2018) Basic research on machinery fault diagnostics: past, present, and future trends. Front Mech Eng 13:264–291. https://doi.org/10.1007/s11465-018-0472-3
Kouadri A, Hajji M, Harkat MF, Abodayeh K, Mansouri M, Nounou H, Nounou M (2020) Hidden Markov model based principal component analysis for intelligent fault diagnosis of wind energy converter systems. Renew Energy 150:598–606. https://doi.org/10.1016/j.renene.2020.01.010
Mian T, Choudhary A, Fatima S (2023) Vibration and infrared thermography based multiple fault diagnosis of bearing using deep learning. Nondestruct Test Eval 38(2):275–296. https://doi.org/10.1080/10589759.2022.2118747
Shao H, Li W, Cai B, Wan J, Xiao Y, Yan S (2023) Dual-threshold attention-guided GAN and limited infrared thermal images for rotating machinery fault diagnosis under speed fluctuation. IEEE Trans Industr Inf 19:9933–9942. https://doi.org/10.1109/TII.2022.3232766
Li X, Shao H, Lu S, Xiang J, Cai B (2022) Highly efficient fault diagnosis of rotating machinery under time-varying speeds using LSISMM and small infrared thermal images. IEEE Trans Syst Man Cybern Syst 52:7328–7340. https://doi.org/10.1109/TSMC.2022.3151185
Yang D, Karimi HR, Pawelczyk M (2023) A new intelligent fault diagnosis framework for rotating machinery based on deep transfer reinforcement learning. Control Eng Pract 134:105475. https://doi.org/10.1016/j.conengprac.2023.105475
Zhang L, Zhang Y, Li G (2023) Fault-diagnosis method for rotating machinery based on SVMD entropy and machine learning. Algorithms 16:304. https://doi.org/10.3390/a16060304
Mehta M, Chen S, Tang H, Shao C (2023) A federated learning approach to mixed fault diagnosis in rotating machinery. J Manuf Syst 68:687–694. https://doi.org/10.1109/TSMC.2022.3151185
Piechocki M, Pajchrowski T, Kraft M, Wolkiewicz M, Ewert P (2023) Unraveling induction motor state through thermal imaging and edge processing: a step towards explainable fault diagnosis. Eksploatacja i Niezawodność 25(3):170114. https://doi.org/10.17531/ein/170114
Younus AM, Yang BS (2012) Intelligent fault diagnosis of rotating machinery using infrared thermal image. Expert Syst Appl 39:2082–2091. https://doi.org/10.1016/j.eswa.2011.08.004
Feng J, Li F, Lu S, Liu J, Ma D (2017) Injurious or noninjurious detect identification from MFL images in pipeline inspection using convolutional neural network. IEEE Trans Instrum Meas 66:1883–1892. https://doi.org/10.1109/TIM.2017.2673024
Jiang L, Wang Y, Tang Z, Miao Y, Chen S (2021) Casting defect detection in X-ray images using convolutional neural networks and attention-guided data augmentation. Measurement 170:108736. https://doi.org/10.1016/j.measurement.2020.108736
Ruiz M, Mujica LE, Alférez S, Acho L, Tutivén C, Vidal Y, Rodellar J, Pozo F (2018) Wind turbine fault detection and classification by means of image texture analysis. Mech Syst Signal Process 107:149–167. https://doi.org/10.1016/j.ymssp.2017.12.035
Ren Z, Fang F, Yan N, Wu Y (2021) State of the art in defect detection based on machine vision. Int J Precis Eng Manuf Green Technol 9:661–691. https://doi.org/10.1007/s40684-021-00343-6
Glowacz A (2021) Fault diagnosis of electric impact drills using thermal imaging. Measurement 171:108815. https://doi.org/10.1016/j.measurement.2020.108815
He Y, Deng B, Wang H, Cheng L, Zhou K, Cai S et al (2021) Infrared machine vision and infrared thermography with deep learning: a review. Infrared Phys Technol 116:103754. https://doi.org/10.1016/j.infrared.2021.103754
Song L, Wang H, Chen P (2018) Vibration-based intelligent fault diagnosis for roller bearing in low-speed rotating machinery. IEEE Trans Instrum Meas 67:1887–1899. https://doi.org/10.1109/TIM.2018.2806984
Park J, Kim S, Choi JH, Lee SH (2021) Frequency energy shift method for bearing fault prognosis using microphone sensor. Mech Syst Signal Process 147:107068. https://doi.org/10.1016/j.ymssp.2020.107068
Ji D, Yao X, Li S, Tang Y, Tian Y (2021) Model-free fault diagnosis for autonomous underwater vehicles using sequence convolutional neural network. Ocean Eng 232:108874. https://doi.org/10.1016/j.oceaneng.2021.108874
Marins MA, Ribeiro FML, Netto SL, da Silva EAB (2018) Improved similarity-based modeling for the classification of rotating machine failures. J Franklin Inst 355:1913–1930. https://doi.org/10.1016/j.jfranklin.2017.07.038
Das O (2023) Real-time intelligent fault diagnosis of rotating machines based on Archimedes algorithm optimised gradient boosting. Nondestruct Test Eval 39:474–512. https://doi.org/10.1080/10589759.2023.2274015
Choudhary A, Mian T, Fatima S (2021) Convolutional neural network based bearing fault diagnosis of rotating machine using thermal images. Measurement 176:109196. https://doi.org/10.1016/j.measurement.2021.109196
Han T, Jiang D, Zhao Q, Wang L, Yin K (2018) Comparison of random forest, artificial neural networks and support vector machine for intelligent diagnosis of rotating machinery. Trans Inst Meas Control 20:2681–2693. https://doi.org/10.1177/0142331217708242
Yang B, Lei Y, Jia F, Xing S (2019) An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech Syst Signal Process 122:692–706. https://doi.org/10.1016/j.ymssp.2018.12.051
Li J, Yao X, Wang X, Yu Q, Zhang Y (2020) Multiscale local features learning based on BP neural network for rolling bearing intelligent fault diagnosis. Measurement 153:107419. https://doi.org/10.1016/j.measurement.2019.107419
Wu J, Zhao Z, Sun C, Yan R, Chen X (2020) Few-shot transfer learning for intelligent fault diagnosis of machine. Measurement 166:108202. https://doi.org/10.1016/j.measurement.2020.108202
Cheng Y, Lin M, Wu J, Zhu H, Shao X (2021) Intelligent fault diagnosis of rotating machinery based on continuous transform-local binary convolutional neural network. Knowledge-Based Syst 216:106796. https://doi.org/10.1016/j.knosys.2021.106796
Yu X, Tang B, Deng L (2023) Fault diagnosis of rotating machinery based on graph weighted reinforcement networks under small samples and strong noise. Mech Syst Signal Process 186:109848
de Sá Só Martins DH, Viana DP, de Lima AA, Pinto MF, Tarrataca L, Lopes e Silva F et al (2021) Diagnostic and severity analysis of combined failures composed by imbalance and misalignment in rotating machines. Int J Adv Manuf Technol 114:3077–3092
Hu Q, Si XS, Zhang QH, Qin AS (2020) A rotating machinery fault diagnosis method based on multi-scale dimensionless indicators and random forests. Mech Syst Signal Process 139:106609. https://doi.org/10.1016/j.ymssp.2019.106609
Roy SS, Dey S, Chatterjee S (2020) Autocorrelation aided random forest classifier-based bearing fault detection framework. IEEE Sens J 20:10792–10800. https://doi.org/10.1109/JSEN.2020.2995109
Zhang Y, Chen J, Li F, Zhang K, Lv H, He S, Xu E (2022) Intelligent fault diagnosis of machines with small & imbalanced data: a state-of-the-art review and possible extensions. ISA Trans 119:152–171. https://doi.org/10.1016/j.isatra.2021.02.042
Toma RN, Kim JM (2020) Bearing fault classification of induction motors using discrete wavelet transform and ensemble machine learning algorithms. Appl Sci 10:5251. https://doi.org/10.3390/app10155251
Wang Z, Zhang Q, Xiong J, Xiao M, Sun G, He J (2017) Fault diagnosis of a rolling bearing using wavelet packet denoising and random forest. IEEE Sens J 17:5581–5588. https://doi.org/10.1109/JSEN.2017.2726011
Tang M, Zhao Q, Ding SX, Wu H, Li L, Long W et al (2020) An improved lightgbm algorithm for online fault detection of wind turbine gearboxes. Energies 13:807. https://doi.org/10.3390/en13040807
Wu Z, Wang X, Jiang B (2020) Fault diagnosis for wind turbines based on Relieff and extreme gradient boosting. Appl Sci 10:3258. https://doi.org/10.3390/app10093258
Hosseinpour-Zarnaq M, Omid M, Biabani-Aghdam E (2022) Fault diagnosis of tractor auxiliary gearbox using vibration analysis and random forest classifier. Inf Process Agric 9:60–67. https://doi.org/10.1016/j.inpa.2021.01.002
Unal M, Onat M, Demetgul M, Kucuk H (2014) Fault diagnosis of rolling bearings using a genetic algorithm optimized neural network. Measurement 58:187–196. https://doi.org/10.1016/j.measurement.2014.08.041
Tyagi S, Panigrahi SK (2017) A hybrid genetic algorithm and back-propagation classifier for gearbox fault diagnosis. Appl Artif Intell 31(7–8):593–612. https://doi.org/10.1080/08839514.2017.1413066
Cerrada M, Zurita G, Cabrera D, Sánchez RV, Artés M, Li C (2016) Fault diagnosis in spur gears based on genetic algorithm and random forest. Mech Syst Signal Process 70–71:87–103. https://doi.org/10.1016/j.ymssp.2015.08.030
Jalali SK, Ghandi H, Motamedi M (2020) Intelligent condition monitoring of ball bearings faults by combination of genetic algorithm and support vector machines. J Nondestruct Eval 39:25. https://doi.org/10.1007/s10921-020-0665-7
Lee C-Y, Le T-A, Hung C-L (2023) A feature selection approach based on memory space computation genetic algorithm applied in bearing fault diagnosis model. IEEE Access 11:51282–51295. https://doi.org/10.1109/ACCESS.2023.3274696
Wei P, Liu M, Wang X (2023) Few-shot bearing fault diagnosis using GAVMD–PWVD time–frequency image based on meta-transfer learning. J Braz Soc Mech Sci Eng 45:277. https://doi.org/10.1007/s40430-023-04202-0
Saari J, Lundberg J, Odelius J, Rantatalo M (2018) Selection of features for fault diagnosis on rotating machines using random forest and wavelet analysis. Insight Non-Destr Test Cond Monit 60:434–442. https://doi.org/10.1784/insi.2018.60.8.434
Lu J, Qian W, Li S, Cui R (2021) Enhanced K-nearest neighbor for intelligent fault diagnosis of rotating machinery. Appl Sci 11:919. https://doi.org/10.3390/app11030919
Mishra RK, Choudhary A, Fatima S et al (2023) Multi-fault diagnosis of rotating machine under uncertain speed conditions. J Vib Eng Technol. https://doi.org/10.1007/s42417-023-01141-x
Fu S, Wu Y, Wang R, Mao M (2023) A bearing fault diagnosis method based on wavelet denoising and machine learning. Appl Sci 13:5936. https://doi.org/10.3390/app13105936
Jin Z, He D, Lao Z, Wei Z, Yin X, Yang W (2022) Early intelligent fault diagnosis of rotating machinery based on IWOA-VMD and DMKELM. Nonlinear Dyn 111:5287–5306. https://doi.org/10.1007/s11071-022-08109-8
Nath AG, Udmale SS, Singh SK (2021) Role of artificial intelligence in rotor fault diagnosis: a comprehensive review. Artif Intell Rev 54:2609–2668. https://doi.org/10.1007/s10462-020-09910-w
Strobl C, Boulesteix AL, Zeileis A, Hothorn T (2007) Bias in random forest variable importance measures: illustrations, sources, and a solution. BMC Bioinformatics 8:25. https://doi.org/10.1186/1471-2105-8-25
Song J (2015) Bias corrections for random forest in regression using residual rotation. J Korean Stat Soc 44:321. https://doi.org/10.1016/j.jkss.2015.01.003
Mishra S, Mishra D, Santra G (2017) Adaptive boosting of weak regressors for forecasting of crop production considering climatic variability: an empirical assessment. J King Saud Univ Comput Inf Sci 32:949. https://doi.org/10.1016/j.jksuci.2017.12.004
Muharam FM, Nurulhuda K, Zulkafli Z, Tarmizi MA, Abdullah ANH, Che Hashim MF, Mohd Zad SN, Radhwane D, Ismail MR (2021) UAV and random forest-adaboost (RFA)-based estimation of rice plant traits. Agronomy 11(5):915. https://doi.org/10.3390/agronomy11050915
MaFaulDa (2016) Machinery fault database. Available from http://www02.smt.ufrj.br/offshore/mfs. Last accessed 26 Mar 2024
Burrus CS, Gopinath RA, Guo H (1998) Introduction to wavelets and wavelet transforms a primer. Prentice-Hall, Englewood Cliffs
Perreira GC, Oliveira MMF, Ebecken NFF (2013) Genetic optimization of artificial neural networks to forecast virioplankton abundance from cytometric data. J Intell Learn Syst Appl 5:57–66. https://doi.org/10.4236/jilsa.2013.51007
Hassanat A, Almohammadi K, Alkafaween E, Abunawas E, Hammouri A, Prasath VBS (2019) Choosing mutation and crossover ratios for genetic algorithms—a review with a new dynamic approach. Information 10:390. https://doi.org/10.3390/info10120390
Schapire RE (2013) Explaining adaboost. Empirical Inference. Springer, Berlin, pp 37–52
Breiman L (2001) Random forests. Mach Learn 45:5–12. https://doi.org/10.1023/A:1010933404324
Tang X, Xue B, Jia L, Zhang H (2017) Quantitative analysis of pit defects in automobile engine cylinder cavity using the radial basis function neural network-genetic algorithm model. Struct Health Monit 16:696–710. https://doi.org/10.1177/1475921716680591
Hu Q, He Z, Zhang Z, Zi Y (2007) Fault diagnosis of rotating machinery based on improved wavelet package transform and SVMs ensemble. Mech Syst Signal Process 21:688–705. https://doi.org/10.1016/j.ymssp.2006.01.007
Liu D, Xiao Z, Hu X, Zhang C, Malik O (2019) Feature extraction of rotor fault based on EEMD and curve code. Measurement 135:712–724. https://doi.org/10.1016/j.measurement.2018.12.009
Viana DP, López RZ, Lima AA, Prego TM, Netto SL, da Silva EAB (2016) The influence of the feature vector on the classification of mechanical faults using neural networks. In: VII Latin American symposium on circuits and systems, pp 115–118. https://doi.org/10.1109/LASCAS.2016.7451023
Ribeiro F, Marins M, Netto S, da Silva E (2017) Rotating machinery fault diagnosis using similarity-based models. In: XXXV Simpósio Brasileiro de Telecomminicações e Processamento de Sinais
Rocha D (2018) Aprendizado de máquina aplicado ao reconhecimento automático de falhas em máquinas rotativas. Master’s Thesis, Universidade Federal de Minas Gerais
Martins D, Hemerly D, Lima A, Silva F, Prego T, Ribeiro F, Netto S, da Silva E (2019) Application of machine learning to evaluate funbalance severity in rotating machines. In: Proceedings of the 10th international conference on rotor dynamics, pp 144–160. https://doi.org/10.1007/978-3-319-99268-6_11
Souza RM, Nascimento EGS, Miranda UA, Silva WJD, Lepikson HA (2021) Deep learning for diagnosis and classification of faults in industrial rotating machinery. Comput Ind Eng 153:107060. https://doi.org/10.1016/j.cie.2020.107060
Saufi SR, Isham MF, Ahmad ZA et al (2023) Machinery fault diagnosis based on a modified hybrid deep sparse autoencoder using a raw vibration time-series signal. J Ambient Intell Human Comput 14:3827–3838. https://doi.org/10.1007/s12652-022-04436-1
Magadán L, Roldán-Gómez J, Granda JC, Suárez FJ (2023) Early fault classification in rotating machinery with limited data using TabPFN. IEEE Sensors 23(24):30960–30970. https://doi.org/10.1109/jsen.2023.3331100
Zhao Z, Jiao Y, Zhang X (2023) A fault diagnosis method of rotor system based on parallel convolutional neural network architecture with attention mechanism. J Signal Process Syst 95:965–977. https://doi.org/10.1007/s11265-023-01846-y
Wang Z, Shen H, Xiong W, Zhang X, Hou J (2023) Method for diagnosing bearing faults in electromechanical equipment based on improved prototypical networks. Sensors 23:4485. https://doi.org/10.3390/s23094485
Alkhanafseh Y, Akinci TC, Ayaz E, Martinez-Morales AA (2024) Advanced dual RNN architecture for electrical motor fault classification. IEEE Access 12:2965–2976. https://doi.org/10.1109/ACCESS.2023.3344676
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bagci Das, D., Das, O. GABoT: A Lightweight Real-Time Adaptable Approach for Intelligent Fault Diagnosis of Rotating Machinery. J. Vib. Eng. Technol. (2024). https://doi.org/10.1007/s42417-024-01440-x
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42417-024-01440-x