
Abstract
Charged particle reconstruction in the presence of many simultaneous proton–proton (\(p {} p \)) collisions in the LHC is a challenging task for the ATLAS experiment’s reconstruction software due to the combinatorial complexity. This paper describes the major changes made to adapt the software to reconstruct high-activity collisions with an average of 50 or more simultaneous \(p {} p \) interactions per bunch crossing (pile-up) promptly using the available computing resources. The performance of the key components of the track reconstruction chain and its dependence on pile-up are evaluated, and the improvement achieved compared to the previous software version is quantified. For events with an average of \(60~p {} p \) collisions per bunch crossing, the updated track reconstruction is twice as fast as the previous version, without significant reduction in reconstruction efficiency and while reducing the rate of combinatorial fake tracks by more than a factor two.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The reconstruction of charged particle trajectories (tracking) in the inner detector (ID) and muon spectrometer (MS) is a central part of the ATLAS [1, 2] experiment’s event reconstruction. During Run 2 of the LHC (2015–2018), ID tracking was the most computing resource intensive component of the offline reconstruction workflow. Given the proximity to the interaction point (IP) and high granularity of the ID, a single inelastic \(p {} p \) interaction leads to up to 200 individual measurements being recorded in the silicon detectors.
During LHC physics data-taking, each proton bunch crossing results in a number of such \(p {} p \) interactions taking place simultaneously (pile-up). The expected number of these interactions, \(\mu \), is a function of the beam parameters and frequently reported as an average over an interval of data-taking time during which instantaneous luminosity, detector and trigger configuration and data quality conditions are considered constant. These intervals, also referred to as luminosity blocks (LB), in general correspond to 60 s of data-taking. In addition to this average value \(\langle \mu \rangle \), it is also possible to define a value specific to a particular \(p {} p \) interaction event, by accounting for the populations of the individual colliding proton bunches based on their location within the LHC bunch pattern. This more granular estimate of the pile-up is referred to as \(\mu _{\text {actual}}\) in the following.
In an average ATLAS bunch crossing event with \(\langle \mu \rangle \) between 10 and 70, up to 15,000 silicon hits need to be processed, decoded, and combined into clusters. The clusters then need to be combined into short track seeds that the reconstruction subsequently attempts to extend through the entire ID to identify the charged particles (tracks) and precisely reconstruct their trajectories. The same has to be done for measurements in the MS to identify muon tracks, and the ID and MS tracks have to be combined to obtain final muon candidates.
In addition to the growing computational effort, the quality of the track candidates becomes challenging to maintain under high pile-up. Firstly, the high density of clusters leads to incorrect cluster-to-track association, potentially degrading the reconstructed track properties relative to their true values. Secondly, collections of unrelated clusters can be combined into false-positive (“fake”) tracks, which happens more frequently as the number of available clusters increases with pile-up.

Distribution of the average number of \(p {} p \) collisions at the ATLAS interaction point during the Run 2 and the 2022 Run 3 LHC data-taking. The dashed line depicts the Run 2 distribution normalised to the same integral as the Run 3 distribution
The peak instantaneous luminosity delivered to ATLAS during LHC Run 2 was \(1.9\times 10^{34} \text {cm}^{-2}\text {s}^{-1}\) [3], twice the original LHC design value for which the detector and reconstruction software were initially optimized. The ongoing LHC Run 3 aims to surpass this value and record up to \(300~\text {fb}^{-1}\) of collision data at \(\sqrt{s} = 13.6~\text {TeV} \) in the period 2022–2025. Figure 1 shows the distribution of \(\langle \mu \rangle \) at the ATLAS interaction point for the Run 2 data-taking compared to 2022, the first year of Run 3. While this value predominantly ranged from 20 to 40 during Run 2, a large fraction of the Run 3 dataset is recorded at 50 or more \(p {} p \) interactions per bunch-crossing, with peak values beyond 60 during the 2022 data-taking, exceeding the average value during LHC Run 2 by a large margin. This is expected to increase further during the following years of Run 3, as the full potential of the LHC is exploited.
An extensive set of updates to the ATLAS reconstruction software for Run 3 enables the ID track and muon reconstruction algorithms to cope with such conditions. One key improvement to the entire ATLAS reconstruction for the new run is the adoption of multi-threading to make more efficient use of the available computing resources [4]. In addition to this infrastructural change, a major effort was carried out to improve the per-thread performance of track reconstruction in the ID and MS while maintaining comparable or even superior quality of the reconstructed tracks. This paper describes the changes made in this effort and demonstrates their impact on the computational and physics performance of track reconstruction in collision data.
This paper is structured as follows: the ATLAS detector is described in “The ATLAS Detector”, and an overview of the legacy ATLAS track reconstruction chain used in Run 2 is detailed in “Legacy Track Reconstruction in ATLAS”. The datasets used and the methology for benchmarking are covered in “Benchmarking Methodology, Data and Simulation Samples”, “Software Optimisation” outlines the optimisation procedure, and finally the performance results are delineated in “Performance Results”.
The ATLAS Detector
The ATLAS detector [1, 2] at the LHC covers nearly the entire solid angle around the collision point.Footnote 1 It consists of an inner tracking detector surrounded by a thin superconducting solenoid, electromagnetic and hadron calorimeters, and a muon spectrometer incorporating three large superconducting air-core toroidal magnets.
The ID is immersed in a 2 T axial magnetic field and provides charged-particle tracking in the range \(|\eta | < 2.5\). The high-granularity silicon pixel detector is comprised of 4 concentric barrel layers and 3 endcap disks on each side. It covers the vertex region and typically provides four measurements per track, the first hit normally being in the insertable B-layer (IBL), which was installed before Run 2 [5, 6]. It is followed by the silicon microstrip tracker (SCT), which is comprised of four barrel layers and 9 planar endcap discs per side, with pairs of modules mounted at a small stereo angle allowing for two measurements per traversed module layer. It usually provides eight measurements per track. These silicon detectors are complemented by the transition radiation tracker (TRT), which enables radially extended track reconstruction up to \(|\eta | = 2.0\) and typically records 30 drift time measurements for each track. The TRT also provides electron identification information based on the fraction of hits above a higher energy-deposit threshold corresponding to transition radiation. Figure 2 illustrates the ID detector layout for a quadrant of the full r–z plane.
The calorimeter system covers the pseudorapidity range \(|\eta | < 4.9\). Within the region \(|\eta |< 3.2\), electromagnetic calorimetry is provided by barrel and endcap high-granularity lead/liquid-argon (LAr) calorimeters, with an additional thin LAr presampler covering \(|\eta | < 1.8\) to correct for energy loss in material upstream of the calorimeters. Hadron calorimetry is provided by the steel/scintillator-tile calorimeter, segmented into three barrel structures within \(|\eta | < 1.7\), and two copper/LAr hadron endcap calorimeters. The solid angle coverage is completed with forward copper/LAr and tungsten/LAr calorimeter modules optimised for electromagnetic and hadronic energy measurements respectively.

Illustration of the barrel region of the ATLAS ID [10] as operated during Run 2 and Run 3

r–z view of a quadrant of the ATLAS MS layout [11] as operated until Run 3. The green and light blue areas indicate MDT precision tracking chambers, empty and violet boxes indicate RPC and TGC trigger chambers, respectively, and yellow rectangles indicate CSC precision chambers. In Run 3, the innermost endcap layer has been replaced by the New Small Wheel
The MS comprises separate trigger and high-precision tracking chambers measuring the deflection of muons in a magnetic field generated by the superconducting air-core toroidal magnets. The field integral of the toroids ranges between 2.0 and 6.0 Tm across most of the detector. Three layers of precision tracking detectors, each consisting of monitored drift tube (MDT) chambers, cover the region \(|\eta | < 2.7\). In Runs 1 and 2, cathode-strip chambers (CSCs) took the place of the innermost MDT chambers in the \(|\eta | > 2.0\) region, where the background is highest. The muon trigger system covers the range \(|\eta | < 2.4\) with resistive-plate chambers (RPC) in the barrel and thin-gap chambers (TGC) in the endcap regions. In the barrel, two RPC chamber layers surround the middle radial MDT layer, forming a common tracking station, and a third RPC chamber layer is located close to the outer MDT layer, forming the outer tracking station. The inner barrel muon station consists exclusively of MDT chambers. In the endcaps, a layer of TGC chambers is located in front of the inner MDT layer, forming the innermost tracking station together with the CSCs up to Run 3. One further TGC layer is mounted in front of, and another two behind, the middle endcap MDT layer to form the middle endcap tracking station. The outer endcap station is comprised of MDT chambers. In Run 3, to cope with further increasing radiation background, the full innermost layer of the MS endcap detector was replaced by the New Small Wheel, introducing Micromegas (MM) detectors as precision tracking chambers in combination with small-strip Thin Gap Chambers (sTGC) [7] while maintaining the same pseudorapidity acceptance of \(|\eta | < 2.7\). The Run 2 MS layout is visualised in the r–z plane in Fig. 3.
Interesting events are selected by the first-level trigger system, which is implemented in custom hardware, followed by selections made by algorithms implemented in software in the high-level trigger [8]. The first-level trigger accepts events from the 40 MHz bunch crossings at a rate below 100 kHz, which the high-level trigger further reduces in order to record events to disk at about 1 kHz for Run 2 data-taking.

Simplified overview of the primary tracking chain and secondary back-tracking chain used in ATLAS ID track reconstruction. The primary reconstruction runs from inside-out, starting from silicon space-points in the innermost Pixel and SCT subdetectors. The secondary back-tracking chain runs from outside-in, seeded from leftover TRT hits within electromagnetic calorimeter regions of interest
An extensive software suite [9] is used in the reconstruction and analysis of real and simulated data, in detector operations, and in the trigger and data acquisition systems of the experiment.
Legacy Track Reconstruction in ATLAS
Particle trajectories are described by five parameters \(\left( d_{0}, z_{0}, \phi , \theta , \frac{q}{p}\right) \) defined with respect to a reference axis, where \(\textit{d}_{0}\) and \(\textit{z}_{0}\) are the transverse and longitudinal impact parameters, \(\phi \) and \(\theta \) the azimuthal and polar angle, and \(\frac{q}{p}\) the charge divided by the momentum. The default reference for ATLAS tracks is an axis in the global z direction centered on the beam spot. The goal of track reconstruction is to identify sets of electronic signals (“hits”) in the tracking detectors originating from a common charged particle and to estimate the track parameters of the corresponding trajectory. The collection of hits with its associated track parameter estimate is referred to as a track.
The original ATLAS track reconstruction performed during LHC Run 2 is extensively documented and characterised in other sources for both ID [10, 12,13,14,15] and muon [16] tracking. A brief overview of this workflow, also referred to as the legacy reconstruction, is provided in the following.
Inner Detector Tracks
The ID track reconstruction is shown schematically in Fig. 4. The procedure in the ID starts with a pre-processing stage: signals from adjacent channels in the Pixel and SCT subdetectors are combined into clusters that are interpreted as the deposits left by incident charged particles. Pairs of one-dimensional SCT clusters on either side of a sensor module or individual pixel clusters are then converted into 3-dimensional space-points, with position uncertainties determined by the detector geometry and sensor pitch. In the case of SCT space-points, the missing second coordinate is obtained through the stereo angle between the strips on both sides of the sensor module. ID tracks are reconstructed for \(p_{\text {T}} > 500~\text {MeV} \) and \(|\eta |<2.5\), where the minimum momentum is driven by the track curvature in the magnetic field and the pseudorapidity interval by the instrumented detector geometry.
Primary Inside-Out Pass
The primary ATLAS ID track reconstruction starts by forming so-called track seeds, triplets of compatible space-points in the Pixel and SCT subdetectors that could feasibly originate from a single charged particle track produced near the \(p {} p \) interaction point. Search roads (sets of detector modules expected to contain clusters compatible with the seed) in 3D space are built through the remaining detector based on the estimated seed trajectory, and the seeds are extended with additional clusters along the search road into silicon track candidates by means of a combinatorial Kalman Filter [17].
To resolve overlaps between track candidates and reject fake tracks, a dedicated ambiguity resolution step is performed. This scores track candidates based on a range of quality criteria. Lower-quality candidates sharing a large number of associated hits with higher-quality ones are rejected, and the shared hits are assigned to the tracks that are retained. A limited number of hits shared between different tracks is permitted, to maintain high performance in dense topologies such as cores of high-energy jets, where the separation between charged particles is expected to reach below the magnitude of the sensor pitch. Clusters determined to consist of more than one charged particle crossing are split among track candidates, with position and uncertainty estimates for each particle crossing provided by a neural network-based algorithm [13, 18] that also assigns a probability for one, two, or more particles to have contributed to the cluster.
The refined and purified track candidates determined in the ambiguity resolution step are re-fit using a global \(\chi ^2\) method to obtain the final, high-precision track parameter estimates. The precision fit runs several iterations until it aborts or achieves the precision required. Aborted fits lead to the track candidates being discarded. An extension of the track into the TRT subdetector is attempted by collecting drift-circles close to the extrapolated trajectory of the track and performing an iterative re-fit of the entire track including the TRT drift-circles. The additional measurements benefit extended tracks by improving the momentum resolution and allowing for particle identification. To prevent spurious or low-quality extensions which can degrade the momentum resolution, the fraction of so-called precision hits is considered. For a hit to be considered a precision hit, the trajectory of the incoming track has to coincide with the measured drift circle radius of the TRT hit within a given threshold expressed as a multiple of the drift radius uncertainty, set to 2.5 in the legacy reconstruction. The precision hit fraction is updated up to the third iteration of the TRT extension fit. For tracks with at least 15 overall TRT hits, at least \(30\%\) of the TRT hits along a track have to be classified as precision hits for the TRT extension to be retained. The rate of succesful TRT extensions depends on the subdetector occupancy, but is generally well above \(90\%\) for muon tracks that traverse the entire ID.
Back-Tracking and Specialised Passes
The primary ID track reconstruction pass is optimised for particles produced at the location of the \(p {} p \) interactions. To increase acceptance for particles produced at a greater distance from the beamline, such as electrons originating from photon conversions in the detector material, secondary track reconstruction (back-tracking) is performed using the detector hits not already assigned to tracks. Here, track reconstruction is only attempted in regions of interest determined by deposits in the electromagnetic calorimeter and starts with sets of mutually compatible hits in the TRT (“segments”) compatible with the region of interest. In the presence of such a segment, short silicon track seeds consisting of two space-points are constructed in the Pixel and SCT subdetectors. They are extended through the silicon detectors using the same combinatorial Kalman filter used in the primary inside-out pass. A dedicated ambiguity resolution is run upon these track candidates and the resulting tracks are re-fit including TRT extensions.
Further dedicated track reconstruction is performed to reconstruct short track segments from muons in \(|\eta |>2.5\), where only the pixel detector is traversed, as well as short tracks compatible with decaying, short-lived charged particles. In each case, only leftover hits not used in the prior reconstruction stages are used, to limit combinatorial complexity and avoid track duplication.
Vertexing
After the track candidate search has been finalised, the locations of the underlying \(p {} p \) interactions (vertices) are identified by a dedicated vertex reconstruction procedure [19]. A first step obtains an initial position estimate for a vertex from the distributions of the z coordinates of closest approach of the tracks to the beamline. Then, a fit of the vertex location is performed, taking into account all tracks loosely compatible with the initial position estimate. Before the changes reported later in this paper, this fit was performed using an iterative procedure, constructing one vertex at a time and removing the associated tracks from consideration before repeating the procedure. The search for secondary vertices from decays of short-lived particles that travel a measurable distance within the tracking volume is not a part of this procedure and instead performed in separate, dedicated downstream reconstruction steps [20, 21], and therefore not included in the optimisation described in this paper.
Large-\(d_{0}\) Tracking
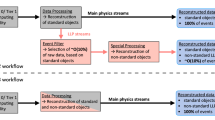
The track reconstruction procedure is optimised to reconstruct tracks that have a small distance of closest approach orthogonal to the beam line (transverse impact parameter, \(d_{0}\)). Physics analyses making use of highly displaced tracks, for example to reconstruct decays of long-lived massive particles within the ID volume, need to run an additional track reconstruction pass, referred to as Large Radius Tracking (LRT), on hits not used by the previous passes [22]. This pass is similar to the primary inside-out track reconstruction, but configured with a wider search space in the transverse and longitudinal impact parameters, enabling reconstruction of displaced tracks at the price of a drastically slowed execution speed. In the legacy software, this additional pass would only be run in a special workflow on a pre-selected sub-set comprising \({\mathcal {O}}(1\%)\) of the total dataset, to remain computationally feasible. The pre-selection relies on trigger and offline reconstruction without LRT tracks and is driven by the targeted physics analysis signatures.

Simplified overview of the primary outside–in combined tracking chain and secondary inside–out chain used in ATLAS muon track reconstruction. The primary chain starts from the MS, building track candidates before attempting to combine them with ID tracks. The secondary chain starts from ID tracks and attempts to recover muons missed by the primary chain by extending the tracks through the calorimeters and muon spectrometer. They can either be identified as muons using calorimeter- or segment-tagging or extended into inside–out combined muon candidates if sufficient compatible MS measurements are found
Muon Reconstruction
Muons are reconstructed using two complementary strategies [16], combining information of the MS with measurements in the inner detector and calorimeters. The procedure is organised into a pre-processing step followed by two tracking passes - a primary outside–in tracking pass that reconstructs the bulk of the muons, and a secondary inside–out pass that recovers muons in phase-space regions where the outside–in pass is not fully efficient. Figure 5 illustrates this schematically. Muons are reconstructed primarily for \(p_{\text {T}} > 3~\text {GeV} \) [23] and \(|\eta |<2.7\). The momentum reach is limited by the energy lost while traversing the calorimeters and the pseudorapidity interval by the instrumented muon spectrometer geometry. Muons candidates using ID information are further limited to \(|\eta |<2.5\).
Pre-Processing and Segment Creation
In a pre-processing step, signals from adjacent channels in the CSC subdetector are combined into clustersFootnote 2. The individual MDT drift circles, CSC, TGC and RPC clusters are collectively referred to as ’hits’ or ’measurements’ in the following. ID tracks to be considered for the creation of muon candidates are pre-selected by requiring a minimum quantity of silicon detector hits. Their trajectories are extrapolated outward through the detector to obtain the expected location at which they enter the MS tracking volume, as well as their momentum at this intersection point.
The formation of straight line muon segments in the MS is initiated in regions of size \(0.4 \times 0.4\) in the \(\eta \)–\(\phi \) plane around activity in the trigger chambers. A Hough transform [24] is used in each MDT chamber and close-by trigger chambers to search for hits aligned on a common trajectory in the bending plane of the detector. The MDT and trigger hits in each muon station are then combined into local muon segments by fitting a straight-line trajectory model to the measurements. The coordinate orthogonal to the bending plane is determined using the trigger chambers if available, while segments comprised of only MDT measurements are assumed to be at the centre of the respective MDT chamber with a large associated uncertainty on the \(\phi \) coordinate. A dedicated combinatorial search in the \(\eta \) and \(\phi \) detector planes is used to identify segments in the CSC chambers in Run 1 and Run 2 data. When building segments, the MDT drift time measurements are calibrated to account for the particle crossing location along the length of the drift tube using the search road position and direction.
Outside-in Reconstruction
The first reconstruction pass is responsible for reconstructing the bulk of the muons and is referred to as “outside-in” reconstruction. It starts by combining the segments across all layers of the MS to form MS-tracks. The track parameters of a starting seed segment are propagated between the MS layers to collect compatible segments, using a parabolic trajectory estimate to account for the bending in the magnetic field at first order. This procedure is initially seeded from the middle chamber layer with the largest number of available trigger chambers before also including the other layers. A requirement for the trajectory to point in the approximate direction of the beam line reduces combinatorics, and trigger chamber information is added to obtain three-dimensional trajectory estimates. After this pattern recognition step is complete, a global \(\chi ^2\) fit of the muon trajectory is performed, taking into account the full track propagation through the inhomogenous magnetic field, possible interactions of the muon with detector material, and the best available knowledge of the real chamber positions obtained using the alignment procedure, exploiting the full \(\eta \) and \(\phi \) track direction information available at this stage of the reconstruction. Following the initial fit iteration, incompatible measurements are removed from the track candidate, and compatible measurements along the trajectory that were not assigned to the original candidate are added. The trajectory parameters are refined by a repeated fit to the updated track candidate. Ambiguities between track candidates are resolved by assigning hits to tracks with higher hit multiplicity and fit quality and rejecting lower-quality tracks that share a large fraction of hits with preferred candidates. To retain efficiency for low-mass dimuon systems, tracks are allowed to share hits in two stations if they do not share hits in a third station. The MS track trajectories are then extrapolated back to the beam line and re-fit accounting for the muon energy loss inside the calorimeter. The energy loss is estimated using an analytic parameterization derived from a detailed description of the detector geometry combined with the energy measured in the calorimeter. The tracks resulting from this procedure have their track parameters expressed relative to the beam line.
MS tracks within \(|\eta | < 2.5\) are combined with ID tracks to improve the track parameter resolution. This procedure starts by collecting ID track candidates around the MS track within an angular compatibility window of size \(0.5 \times 1.0\) in the \(\eta \) and \(\phi \) coordinates expressed at the beam line. The initial set of candidates is ranked based on a \(\chi ^2\) comparison between the ID and MS track parameters, and for each candidate a fit of the trajectory to the full set of ID and MS track measurements is attempted, with a global minimization yielding a combined track candidate. The fit accounts for energy loss inside the calorimeter and alignment uncertainties including relative mis-alignment between the ID and MS. MS measurements may be added to or removed from the candidate based on the global fit quality. Finally, the combination with the ID track candidate yielding the best combined fit quality for the given MS track is retained. The combined muons obtained in the outside-in chain represent over \(95\%\) of the muons reconstructed in ATLAS [16]. In the region \(|\eta | > 2.5\), where no full ID tracks are available, MS tracks may be combined with the short pixel track segments discussed in “Inner Detector Tracks”, to improve the impact parameter estimate. The resulting subset of the combined muons is called silicon-associated forward muons. If no compatible ID track is found for a given MS track, it is extrapolated to the beam line, taking into account the calorimetric energy loss, and retained as a standalone muon. Such muons primarily add acceptance in \(|\eta | > 2.5\) for cases where no pixel track segment is available.
Inside-out Recovery
An inside-out recovery chain complements the outside-in pass to reconstruct muons that have low transverse momenta or enter detector regions where the MS is not fully instrumented. It comprises three different algorithms: segment-tagged, calorimeter-tagged and inside-out combined muon reconstruction. All start from ID track candidates and attempt either to identify them as muons or use them as the starting points for combined muon candidates. To prepare this step, the ID track trajectories are extrapolated through the full MS, recording their predicted crossing location and momentum for any muon chambers they traverse, for use in the inside-out combined reconstruction that will be explained below.
Segment-tagged muon reconstruction allows ATLAS to recover muons with very low transverse momenta that do not pass beyond the first MS layer. ID tracks are identified as muons through the presence of compatible muon segments. To find compatible segments, the trajectories of ID tracks are initially extrapolated to a simplified representation of the MS modelled as a series of concentric hollow cylinders representing the barrel layers, and disks representing the endcap layers. For MS segments that cross these layers in locations and with momenta compatible with the ID track, the trajectory of the track is further projected onto the muon chamber of the respective segment, and a more precise compatibility test is performed based on the track and segment directions and their crossing point in the chamber. If at least one compatible segment is found in this way, the track is identified as a muon. In this reconstruction strategy, the MS information is only used for particle identification, and no combined fit is attempted.
Calorimeter-tagged muons exploit the fact that muons are minimum ionizing particles (MIPs) to recover acceptance in the region \(|\eta |<0.1\), where gaps in the MS exist to leave space for calorimeter and ID cabling. Calorimeter clusters along the projected ID track trajectory through the calorimeter are collected and evaluated for compatibility with a MIP signature. If they satisfy this signature, the ID track is identified as a muon, without using information from the MS.
The inside-out combined reconstruction chain allows to recover combined muons with low transverse momenta that are not found by the outside–in reconstruction. It starts from ID track candidates. The predicted muon chamber crossing locations and directions of their trajectories, as evaluated in the pre-processing phase, are used to build search roads in the MS. Using these roads, a dedicated muon segment-finding pass is performed. The direction and momentum information from the ID-based search roads is used to calibrate the MDT measurements for this phase, allowing to account for the predicted location of the charge deposit along the wire direction when interpreting the drift time measurement. The found segments are collected and added to the track. Using the ID track and the segments recovered in this way, a global re-fit is performed in the same way as for the outside-in chain, to obtain combined muon candidates.
Benchmarking Methodology, Data and Simulation Samples
The impact of the software improvements that will be discussed in the following sections on the reconstruction performance is evaluated using collision data and Monte-Carlo (MC) simulated top quark pair production (\(t\bar{t}\)) samples.
To evaluate the data reconstruction performance for a given value of pile-up in “Performance Results”, the raw data of a set of 500–1000 consecutive collision events from a common LB are reconstructed, and the processing time taken for the reconstruction as well as the size of the output written to disk are recorded. This procedure is repeated for sets of events at different pile-up values. The samples are taken from a single LHC fill (fill number 6291) recorded towards the end of the 2017 data-taking campaign and covering a range of pile-up values between \(\langle \mu \rangle =15.5\) and 60. In addition, a set of samples from an LHC fill recorded during 2022 as part of Run 3 (fill number 8112) with pile-up values between 22.4 and 54.8 allows ATLAS to compare this information with the Run 2 data ID track reconstruction using the same software. This ensures consistent data-taking conditions across all pile-up values. Finally, a set of 300 events from LHC fill 5824, recorded in 2017 at \(\langle \mu \rangle =50\), is used in automated monitoring of ATLAS reconstruction run time on a daily basis. Run times measured in the course of this monitoring are used to evaluate the incremental speed-up of track reconstructions as changes are made in “Software Optimisation”. All events taken from these two fills fall under the so-called good-run list (GRL), meaning that the respective LB satisfy all data quality requirements of the ATLAS physics dataset [25]. An LHC fill with up to \(\langle \mu \rangle =90\) recorded in late 2018 (fill 7358) as part of a machine-development campaign is used in addition, to extend the study towards even larger values of pile-up. Unlike the 2017 and 2022 data, this run is not considered part of the ATLAS physics dataset due to the nonstandard data-taking conditions. Since the ID and MS were fully operational, it is possible to use these events to obtain an estimate of the scaling behaviour of track reconstruction performance under extreme pile-up conditions.
When evaluating the fraction of successfully reconstructed charged particles, MC simulated \(t\bar{t}\) events are used. The production of these \(t\bar{t}\) events is modelled using the Powheg Box v2 [26,27,28,29] generator at next-to-leading order QCD precision with the NNPDF3.0nlo [30] parton distribution function (PDF) set and the \(h_\textrm{damp}\) parameterFootnote 3 set to 1.5 \(m_{\textrm{top}}\) [31]. The events are interfaced to PYTHIA 8.230 [32] to model the parton shower, hadronisation, and underlying event, with parameters set according to the A14 tune [33] and using the NNPDF2.3lo set of PDFs [34]. The decays of bottom and charm hadrons are performed by EVTGEN 1.6.0 [35]. The effect of pile-up was modelled by overlaying the simulated hard-scattering event with inelastic pp events generated with PYTHIA 8.186 [36] using the NNPDF2.3lo set of parton distribution functions [34] and the A3 set of tuned parameters [37]. For the purpose of studying the reconstruction performance at different levels of pile-up, the number of events to overlay for each simulated \(t\bar{t}\) event was sampled from a flat distribution in the interval \(\left[ 0,80\right] \).
All benchmark studies described in this paper were run as the only active user on a dedicated machine equipped with an AMD EPYC™ 7302 16-core processor, running the CERN CENTOS 7 operating system. The processor was operated in “performance” mode, with simultaneous multi-threading (SMT) and frequency boosting disabled. A HS06 score of 22.6 per core was obtained for the processor in this configuration, and a score of 1038 is reported for a dual-processor setup [38] operating with all cores and SMT enabled. The machine was kept at a stable 50% in capacity by running an appropriate number of reconstruction tasks simultaneously. In order to exclude the impact of multi-threading from the comparison, all tests were run in single-thread mode.

Incremental improvement in execution speed for ID track (a) or muon (b) reconstruction in a set of \(\langle \mu \rangle =50\) collision data events as improvements are added to the reconstruction software for Run 3. The blue shaded area indicates the time, relative to the initial Run 3 software implementation, taken for the track reconstruction. The purple area indicates the time added by the additional LRT. A set of improvements to implementation details of the muon algorithms not discussed in more detail are summarised as “Misc. optimisations” in b. Due to changes required to ensure thread-safety, the unoptimised initial performance of the Run 3 software, referred to as “Baseline”, was approximately \(20\%\) slower than the previous software used during Run 2
The executable binary files tested in this work are identical to those most commonly used for the experiment’s regular data reconstruction. As a result, different versions of the software differ not only in terms of their own programming, but also in terms of the method of compilation as well as external libraries and the compilation thereof. All versions of the software were compiled with the default compilation settings as they were defined in the ATLAS software project at the time of their release. Since the optimisation flags are partially set according to compiler presets, the exact details may differ between compiler versions. In all cases, however, the code is compiled for a generic x86-64 architecture, implying support for vector instruction set extensions up to SSE2. The binaries produced are therefore unable to exploit more modern architectural features like AVX. The binaries for the legacy reconstruction were compiled using version 6.2.0 of the GNU Compiler Collection, whereas the updated software release utilises version 11.2.0.
The reconstruction run times cited in the following represent the particular set of test events they were evaluated on. Due to statistical fluctuations in the number of charged particles produced per collision event and the particle flux through the various regions of the detector, the run time is expected to vary for evaluations of different sets of events from the same LB. Based on trials performed by sampling different, equal sized sets of events, this variation is found to be on the order of \(15\%\) for ID track reconstruction and up to \(40\%\) for muon reconstruction, since muons are produced more rarely. However, when evaluating the run time differences between the different software releases, the variation is less than \(10\%\) in both cases, as the changes in absolute run time due to different particle multiplicities largely cancel out in this metric. For a given set of events, the stability of the measured run time across repeated reconstruction runs on the same machine was evaluated to be better than \(5\%\).
Software Optimisation
A number of changes to the tracking software were introduced in order to optimise the computational performance and the size of the generated output for the conditions expected during LHC Run 3 data-taking. In addition to general algorithmic improvements, the guiding principle is to abort the track reconstruction as early as possible for candidates that are not expected to result in high-quality tracks. This minimises the number of executions of the downstream algorithms, thus saving time and resources. The experience obtained by operating the reconstruction during Run 1 and Run 2 also allows ATLAS to operate the algorithms with less conservative tolerances than were originally implemented, gaining execution speed without sacrificing reconstruction acceptance.
The reduction in the single-thread CPU timing of ID track and muon reconstruction as optimisations were incrementally added over time is shown in Fig. 6 for a set of events recorded at \(\langle \mu \rangle =50\). The starting point for the optimisations, referred to as “Baseline” in the Figure, is a version of the legacy reconstruction with an initial set of modifications required to ensure thread-safety, and as a consequence slower than the original legacy software implementation described in “Legacy Track Reconstruction in ATLAS”. The individual improvements will be detailed in the following.
Inner Detector Tracks
The seeding formation time of the inside-out track reconstruction was optimised to prevent seeds unlikely to result in tracks from being passed into downstream processing. The optimisations include narrowing the acceptance threshold for the estimated impact parameters of SCT seeds from 2 cm to 5 mm, reducing the tolerance in the search road used to extend the seeds from 20 to 12 mm, and preventing Pixel seeds sharing space-points with another seed of lower estimated transverse impact parameter from passing into further processing. The reduced redundancy resulting from the last of these changes was mitigated by exploiting the availability of four pixel layers since the installation of the IBL [6, 39] in 2015 by using confirmation space-points to detect promising seeds. A confirmation space-point is a fourth space-point from a different detector layer which, if used to replace the outermost space-point on a given seed, results in a new seed with a curvature compatible with the original, indicating it is likely part of the same charged-particle trajectory. In the updated seed formation procedure, all confirmed seeds are accepted for further processing, even if they share space-points with other seeds. Finally, the window in the transverse impact parameter for accepting seeds dynamically adjusts depending on the deviation of the seed from a straight line in the r–z plane, where no deflection due to the magnetic field is expected at the length scale of a seed. The criterion becomes stricter for seeds with a strong deviation from a straight line as these are more likely to be combinatorial artifacts. The introduction of these improvements corresponds to the entry “Seed and pattern” in Fig. 6a.
The seeding strategy was further optimised to speed up the seed formation itself, as it contributes a significant fraction of the overall track reconstruction run time due to the combinatorial complexity of the process. This was achieved by adapting the size of the angular regions within which seeds are formed. The regions were reduced to correspond to the track curvature in the magnetic field expected to occur at the lowest track transverse momentum to be reconstructed (\({500\,\textrm{MeV}}\) in the primary ATLAS tracking pass), instead of the wider angular regions used previously. In addition, the knowledge of the detector geometry is applied more rigorously, removing space points from consideration as central point of a seed if they are placed on the outermost or innermost layers of a subdetector or in \(\eta \) regions where the subsequent layers provide no acceptance. This improves execution speed without significantly changing the number of tracks being reconstructed. This set of changes is denoted as “Seed region size” in Fig. 6a. Together, the improvements upon the seeding and early track-finding phases reduce the overall ID track reconstruction time by half. They have only a minor impact on the number of correctly reconstructed tracks, while strongly suppressing the occurrence of falsely reconstructed tracks, as will be shown in the following Section.
The number of incorrect tracks propagating beyond the initial track-finding stage was further reduced by a re-tuning of the selection criteria applied to the candidates. Instead of seven silicon clusters per track, at least eight are required in the updated tracking, and the permitted transverse impact parameter range of silicon-seeded tracks is restricted to \(|d_0|<5\text { mm}\) instead of \(|d_0|<10\text { mm}\). This reduces the acceptance of track reconstruction in terms of both displacement and production radius by a small fraction, but significantly lowers the rate of low-quality tracks being reconstructed and written to storage. The reduction in inital track candidates achieved by this optimisation also reduces the number of executions of the subsequent ambiguity resolution procedure and TRT extension phases per event, reducing the track reconstruction time per event by approximately 25% (as shown in Fig. 6). The tuning of the track selection criteria is referred to as “New tracking cuts” in Fig. 6a.
The TRT extension was sped up significantly by aborting the iterative track fit procedure early for candidates with insufficient precision hits in the TRT. While the required precision hit fraction of \(30\%\) has remained unchanged compared to the legacy reconstruction, the compatibility threshold for precision hits was reduced from 2.5 to 1.75, lowering the fraction of spurious TRT extensions and benefiting momentum resolutions through the reduction of poor-quality TRT extensions. In addition, the iterative fit is now aborted after the third iteration if the final precision hit fraction obtained at this stage does not satisfy the requirement, rather than continuing the fit iterations up to convergence before deciding whether to retain the extension as in the legacy reconstruction. These changes do not impact reconstruction efficiency or the rate of incorrectly reconstructed tracks, but speed up the TRT extension step by nearly \(30\%\). In Fig. 6a, the improvements to the TRT extension are included under the entry “Additional optimization”.
A large number of falsely reconstructed tracks was previously generated by the TRT-seeded back-tracking step. This was reduced by limiting the back-tracking to regions of interest seeded by energy deposits in the electromagnetic calorimeter (\(E_{\textrm{T}} > 6~\text {GeV} \)). The recovery of late-appearing tracks from electron conversions, which is the main purpose of this reconstruction step, is degraded at only a negligible level since these topologies coincide with significant calorimetric deposits. However, the number of erroneously reconstructed track candidates is reduced and the execution speed of the back-tracking phase is improved by a factor of 20. This benefits the overall track reconstruction speed on the order of \(5\%\) at \(\langle \mu \rangle =50\), as is visible in Fig. 6. These improvements are denoted “Backtracking” in Fig. 6a. Larger gains are achieved at higher pile-up, as the detector occupancy grows.
The iterative vertex finding algorithm (described in “Legacy Track Reconstruction in ATLAS”) was replaced by an adaptive multi-vertex fitter algorithm [40] in which vertex candidates are allowed to compete for tracks in order to reduce the chance of nearby \(p {} p \) interactions being reconstructed as a single merged vertex. The initial vertex locations are estimated with high accuracy using a Gaussian resolution model for the track impact parameter. This updated algorithm is implemented within the A Common Tracking Software (ACTS) framework [41] which will be the backend of ATLAS track reconstruction during LHC Run 4. This represents the first production use of this framework in an LHC experiment. The improved vertex finding is included under the entry “Additional optimization” in Fig. 6a.
Further execution speed was gained by carefully optimising the software implementation of each reconstruction step individually. Notable examples include a re-organisation of the search for holes on tracks performed as part of the precision fit; exploitation of the navigation between detector surfaces already being performed by the track fit procedure; optimisation of the space-point formation by minimising the number of required matrix multiplications; and the re-writing of parts of the Runge-Kutta propagator implementation used to extrapolate trajectories through the inhomogenous magnetic field of the detector to exploit vectorised instructions where possible. These changes are also part of the entry “Additional optimization” in Fig. 6a.
The improvements to the track seeding and finding steps also directly benefitted the LRT reconstruction. Together with further dedicated improvements to the LRT strategy [22], this made it feasible to integrate fully the LRT pass in the updated ATLAS track reconstruction that is performed for all events. Removing the need for a custom workflow involving a pre-selection step represents a major extension of the ATLAS physics potential. In the following study of reconstruction performance, the impact of the LRT step will be pointed out separately, as it was not run by default in the legacy reconstruction. The impact of adding LRT is shown by a dedicated entry denoted “Add LRT” in Fig. 6a.
Muon Reconstruction
The muon reconstruction run time was found to scale strongly with the number of ID track candidates considered during the process. The computational effort of both the outside-in and the inside-out passes scales linearly with the number of ID tracks, as the time-consuming combined fits and extrapolations are repeated for each candidate track. The superlinear rate of fake ID tracks with growing pile-up in the legacy software was thus directly reflected in a decreasing speed of muon reconstruction. For this reason, the stricter selection criteria in the improved ID track reconstruction discussed above also benefit the muon reconstruction speed at the order of \(30\%\) at high pile-up. The impact is visible under the label “New tracking cuts” in Fig. 6b.
Before making changes to the muon reconstruction strategy, a series of optimisations to implementation details of the existing algorithms were performed, focusing on memory management and removal of redundant repetition of calculations. These sped up muon reconstruction by around \(20\%\) and are referred to as “Misc. optimizations” in Fig. 6b.
Dedicated tuning was performed to reduce the number of ID track candidates entering the primary outside-in combined muon reconstruction chain. Following the strategy of aborting reconstruction of non-promising candidates as early as possible, the angular window in the \(\eta \)–\(\phi \) plane applied to select ID tracks for a combined fit was reduced in size from \(0.5 \times 1.0\) to \(0.2\times 0.2\). The use of these stricter tolerances was enabled by comparing the track directions expressed at the MS entrance, rather than the \(p {} p \) interaction region, which increases precision of the MS track parameters. These parameters are already available for ID tracks as a result of the calorimeter extrapolation performed by default on all ATLAS tracks, allowing them to be used without additional overhead. This yields a factor of two speedup of the combined muon reconstruction at \(\langle \mu \rangle =50\). The introduction of these improvements is labeled as “Outside-in tuning” Fig. 6b.
Several further key improvements were made to the inside-out muon chain. A fundamental change in strategy motivated by the proven reliability and maturity of the combined reconstruction achieved by the end of Run 2 is to no longer execute the inside-out chain independently of the combined reconstruction. The improved inside-out recovery chain only considers ID tracks not already used to form an outside-in combined muon track. This removes the need to extrapolate every ID track candidate through the full MS in preparation for the inside-out combined muon recovery, as \(95\%\) of all muons are already found through the outside-in reconstruction. The ID track extrapolation was also sped up by incrementally propagating the track parameters between adjacent muon chambers, rather than performing a full extrapolation from the MS entrance for each chamber. Together, these changes yielded a \(20\%\) speed-up of muon reconstruction. To further suppress scaling with increasing pile-up, ID tracks are considered in the inside-out combined or segment–tagged reconstruction only if hits or segments not belonging to outside–in combined muons exist in the MS chambers towards which their trajectories are oriented. These changes are together shown under the label “ID selection for IO” in Fig. 6b.
The segment-tagged muon reconstruction procedure, which in the legacy reconstruction performed extrapolations of all ID tracks to its internal simplified detector geometry in order to match segments to tracks, now instead re-uses the results of the ID track extrapolation to muon chambers performed for the inside-out combined reconstruction. This removes the majority of track extrapolations required during the segment-tagged reconstruction and speeds up the remaining extrapolations for the precise track-segment matching at the level of chambers, because the remaining extrapolation of the ID track to the reference surface of the segments now occurs over a very short distance. This results in a factor of 15 reduction in processing time for the segment-tagging algorithm, and with the other improvements contributes to an overall speed-up of the inside-out recovery by a factor of five to six in the improved reconstruction. Fig. 6b includes this change under the label “Extrapolation for IO”.

Relative computational performance improvement of key reconstruction steps obtained in the updated reconstruction software compared to that of the legacy implementation when reconstructing a set of LHC Run 2 data events, as a function of \(\langle \mu \rangle \), for ID track (a) and muon (b) reconstruction. The “Miscellaneous” category includes event data model handling, vertex reconstruction, reading of detector condition information and, for the ID track reconstruction, also cluster formation in the Pixel and SCT subdetectors
Finally, second iterations of both the outside-in combined muon reconstruction and the inside-out recovery steps were added using the set of ID tracks recovered by the LRT step. The algorithmic workflow is identical to the regular muon reconstruction chain, with the exception that no standalone or silicon-associated forward muons are created. This allows the reconstruction of combined and segment-tagged muon candidates with \(|d_{0}|\) up to 300 mm. As this iteration is run independently of the primary muon reconstruction, MS tracks and muon segments may be re-used between the primary and LRT passes. For example, an MS track forming a combined muon with an LRT track may have been reconstructed as a standalone muon in the primary pass. This overlap is resolved in a follow-up step after reconstruction, by preferring combined muons over standalone muons sharing the same MS track and, in the case of two combined muons sharing the same MS track, retaining the one with the better compatibility between ID and MS track directions in the \(\eta \) coordinate. This approach was adopted to ensure that the output of the primary muon reconstruction pass remains unchanged if the LRT step is enabled or disabled, a concern during the commissioning of this new feature in reconstruction. The label “Add LRT” indicates the activation of LRT muon reconstruction in Fig. 6b.
An additional major effort resulted in the successful inclusion of the sTGC and MM measurements from the New Small Wheel in the reconstruction of Run 3 data. This work is however not part of the algorithmic optimisations discussed in this paper and will be reported separately. In the following, muon reconstruction will only be studied on Run 2 data where a meaningful comparison to the legacy reconstruction is possible.
Performance Results
In the following, the performance of the updated reconstruction is compared to the original, single-threaded software version that was used at the time of data-taking to reconstruct the Run 2 ATLAS dataset. An emphasis is placed on the evolution of the results as a function of pile-up.
Figure 7 shows the relative speedup obtained for the main components of track reconstruction when compared to the original legacy software, as a function of the amount of pile-up. The run time of the ID tracking pattern recognition step has been reduced by up to a factor of four, and the other steps of ID tracking are faster by factors of up to two. This includes drift circle creation, TRT segment making, TRT-seeded back-tracking and TRT extension finding and fitting. For muon reconstruction, the inside-out recovery step has been significantly sped up. The reduced number of ID track extrapolations performed plays a major part in the factor of five to six run-time reduction for this component. The outside-in combined track muon reconstruction step is also faster by a factor of up to two, profiting from the reduced number of input tracks and the optimised MS–ID track matching, while the pre-processing step has been sped up by a factor of up to two due to a more efficient implementation of the segment formation.
A comparison of the average total track reconstruction time per event between the updated and legacy reconstruction software is shown as a function of pile-up in Fig. 8 for ID tracks and in Fig. 9 for muon tracks. The time is decomposed into the key reconstruction steps, and the bottom panels indicate the fraction of the total time contributed by each step. For the legacy reconstruction, the track-finding step was by far the largest CPU consumer for track and total ATLAS reconstruction, and it scaled superlinearly with \(\langle \mu \rangle \). This behaviour has been rectified in the updated reconstruction. After the optimisations, the pile–up dependency of reconstruction time is closer to linear in the range relevant for Run 3, showing that the updated tracking software is well prepared for high-\(\langle \mu \rangle \) data-taking. A reduction of the total ID tracking and vertexing CPU time per event by a factor of three is visible for \(\langle \mu \rangle = 60\), and the CPU time taken is distributed more evenly between the individual components. For muon reconstruction shown in Fig. 9, the strong impact of the improvements to the inside-out muon recovery is immediately visible, driving an overall factor of approximately three speedup of muon reconstruction. In the updated reconstruction, the inside-out recovery, which represented up to \(40\%\) of the muon reconstruction time in the legacy reconstruction, contributes only a minor fraction of the total processing time. The majority of the run time is now spent in the outside-in combined reconstruction, which is also responsible for reconstructing \(95\%\) of the muon candidates.

Breakdown of the average CPU time required per event for ID track and vertex reconstruction when reconstructing a set of LHC Run 2 data events, as a function of \(\langle \mu \rangle \), comparing the legacy (a) and updated (b) configurations. The bottom panel shows the fraction of the total track reconstruction time taken by each component. The “Miscellaneous” category includes event data model handling, vertex reconstruction, reading of detector condition information and, for the ID track reconstruction, also cluster formation in the Pixel and SCT subdetectors

Breakdown of the average CPU time required per event for muon reconstruction when reconstructing a set of LHC Run 2 data events, as a function of \(\langle \mu \rangle \), for the legacy (a) and updated (b) configurations. The bottom panel shows the fraction of the total track reconstruction time taken by each component. The “Miscellaneous” category includes event data model handling, vertex reconstruction, reading of detector condition information and, for the ID track reconstruction, also cluster formation in the Pixel and SCT subdetectors
Figure 10 shows the total track reconstruction time as a function of \(\langle \mu \rangle \), including the reconstruction of data taken during an LHC machine-development fill at very high-\(\langle \mu \rangle \) in 2018. This allows ATLAS to evaluate the reconstruction speed under such challenging conditions beyond the expected values for Run 3. For both muon and ID track reconstruction, the updated reconstruction is more than twice as fast as the previous version at \(\langle \mu \rangle =60\), even after including the new LRT step. Nearly linear scaling of the CPU consumption with \(\langle \mu \rangle \) is now observed compared to the behaviour seen for the legacy reconstruction, and even when reconstructing data taken at \(\langle \mu \rangle =90\), the updated reconstruction achieves a processing speed comparable to the legacy reconstruction at \(\langle \mu \rangle =60\) when applied to a similar workload. The benefits from the improvements become more obvious with increasing pile-up.
For the ID track reconstruction, the CPU time taken to reconstruct a set of Run 3 collision data events is also studied, with the LRT step included. The timing of Run 3 reconstruction is found to be consistent with the expectation obtained by evaluating the updated reconstruction on Run 2 data. A slightly faster reconstruction compared to the Run 2 reference is due to temporary failures of Pixel detector modules during the 2022 data-taking, which result in a reduced number of space points to process. For muon reconstruction, a direct comparison of reconstruction times between Run 2 and Run 3 data is not meaningful as discussed previously.

Processing time taken per event versus average pile-up to reconstruct ID tracks and vertices (a) or muons (b) in the same events, for the the updated (purple) and legacy (green) reconstruction software. The updated reconstruction is also evaluated when including the impact of the additional LRT step (blue). The bottom panel depicts the time taken relative to the legacy reconstruction run time. The shaded area indicates data events taken from a 2018 machine development run not passing the full ATLAS data quality requirements

Number of seed tracks processed divided by the final number of tracks created in the silicon-seeded tracking as a function of \(\langle \mu \rangle \) (a) and average number of tracks reconstructed per event as a function of the value \(\mu _{\text {actual}}\), with a linear fit to the range \(10 \le \mu _{\text {actual}}\le 30\) superimposed as a dashed line (b)
The improved efficiency of the ID track reconstruction is further illustrated in Fig. 11. Figure 11a shows the number of processed track seeds divided by the final number of tracks created in the silicon-seeded track finding process as a function of \(\langle \mu \rangle \). The ratio of seeds to output tracks is reduced by a factor of almost two in the updated reconstruction. To reconstruct the same number of tracks, the costly algorithms responsible for extending a seed through the tracker into a candidate are thus called only half the number of times on average. This allows ATLAS to achieve the large speedup of the track finding stage shown in Figure 7. Figure 11b depicts the average number of tracks reconstructed per event as a function of \(\mu _{\text {actual}}\). A linear fit to \(10< \mu _{\text {actual}}< 30\) is superimposed as a dashed line on the full range of \(\mu _{\text {actual}}\). The number of genuine track candidates per event is proportional to the number of charged particles produced in the \(p {} p \) collisions and thus scales linearly with \(\mu _{\text {actual}}\). The number of fake tracks scales superlinearly with \(\mu _{\text {actual}}\), reflecting the growth of combinatorics. A clear non-linear component amounting to up to \(30\%\) of the total number of tracks is visible for the legacy reconstruction, whereas the updated reconstruction shows nearly ideal linear behaviour. The formation of fake tracks has become very rare in the updated tracking, further improving computational efficiency but also benefiting the reconstruction of track-based physical observables and reducing the disk storage requirements per event.

Event size of the inner detector reconstruction output in the ATLAS event data format for the same set of reconstructed data events as a function of average pile-up, comparing the legacy and updated releases. The shaded panel on the right indicates data events taken from a 2018 machine development run not passing the full ATLAS data quality requirements
The improvement in data storage requirements resulting from the updated ID track reconstruction is also visible in Fig. 12, which shows the average disk space required to store ID tracks in kilobytes per event for the standard ATLAS event data format. The observed 20-\(50\%\) reduction compared to the legacy reconstruction is a direct consequence of reducing the rate of misreconstructed ID tracks by a combination of the algorithmic improvements and stricter silicon hit count and impact parameter requirements discussed above. Even after including the additional tracks from the LRT, a reduction of up to \(40\%\) is achieved at \(\langle \mu \rangle =60\), a value that can be expected for future Run 3 data. Additionally, the growth of the disk usage with increasing pile-up is observed to be smaller in the updated software release, leading to larger improvements at even higher values of \(\langle \mu \rangle \).
The new deployment of the ACTS software framework in ATLAS for primary vertex reconstruction results in a significant reduction of primary vertexing CPU time. Figure 13 shows a comparison of the primary vertex reconstruction time required per event between the ACTS-provided Adaptive Multi-Vertex Finder algorithm and the previously deployed ATLAS implementation. An average reduction of CPU time of more than a factor of 1.5 is seen while the ACTS implementation yields physics results that are identical to those from the previous non-ACTS version. The now fully integrated ACTS vertexing software makes additional functionality with further potential for CPU improvements available for future developments.

A comparison of primary vertex reconstruction processing time taken per event, versus average pile-up, for the ATLAS (non-ACTS) version of the Adaptive Multi-Vertex Finder Algorithm and the ACTS-provided implementation. The shaded area indicates data events taken from a 2018 machine development run not passing the full ATLAS data quality requirements

Fraction of the total CPU consumption of full ATLAS reconstruction represented by ID tracking and Muon reconstruction for the legacy (a) and updated (b) reconstruction, for one data run at \(\langle \mu \rangle = 50\). In the updated reconstruction, several algorithms, such as jet reconstruction and hadronic tau decay candidate identification, are no longer included in the main ATLAS reconstruction and hence no longer enter the sum
Figure 14 shows that ID track and Muon reconstruction accounted for around \(68\%\) and \(13\%\) of the total ATLAS event reconstruction CPU time in the legacy software release, respectively. As a result, the speed improvements described in this paper scale almost directly to an improvement of the total ATLAS event reconstruction. In the updated reconstruction, this fraction is approximately retained when including the LRT. This is because several other algorithms, such as jet reconstruction and hadronic tau decay candidate identification, which contributed around \(3\%\) of the total reconstruction time, have been moved from the main reconstruction pass into the downstream processing in the updated ATLAS event reconstruction. This reduction in runtime of non-tracking algorithms in the main reconstruction step is almost proportional to the speedup achieved in tracking. In addition, a large number of the most time-consuming non-tracking algorithms, such as streaming the reconstructed event data to disk, scale in run time with the number of reconstructed track candidates and thus benefit from the reduced rate of misreconstructed tracks. Accordingly, the total reconstruction time per event has decreased from 9.1 s to 4.8 s on the machine specified in “Benchmarking Methodology, Data and Simulation Samples”. This indicates that track reconstruction remains the most promising part of event reconstruction to achieve further improvements in overall throughput.

ID Tracking efficiency as a function of \(p_{\text {T}} \) in simulated \(t{\bar{t}}\) events with a flat \(\langle \mu \rangle \) distribution between 0 and 80, in a comparison of the updated and legacy reconstructions. The error bars indicate statistical uncertainties
Finally, the software improvements have not negatively impacted the track reconstruction physics performance compared to the legacy reconstruction. The tracking efficiency, defined as the fraction of charged particles originating from the primary \(p {} p \) interaction successfully reconstructed, is shown for the ID comparing the updated and legacy reconstruction in Fig. 15 as a function of the charged particle transverse momentum. Simulated \(t{\bar{t}}\) events are studied, leading to a track sample dominated by pions. The efficiency loss is smaller than \(4\%\) at low \(p_{\text {T}} \) and smaller than \(1\%\) at larger transverse momenta. The slight reduction compared to the legacy implementation is a result of the stricter requirements on the number of silicon clusters and impact parameter for a track to be retained, and does not affect the reconstruction of muons as minimum ionising particles. Figure 16 depicts the reconstruction efficiency obtained for simulated single muons of \(p_{\text {T}} = 10~\text {GeV} \) for ID tracks and muons satisfying the Medium [16] identification criteria, which preferentially select combined muons and represent the requirements most frequently applied in ATLAS physics analyses. The muon reconstruction efficiency is shown relative to the successful identification of an ID track, making the total muon reconstruction efficiency the product of the two values depicted individually. The updated ID track reconstruction achieves an efficiency within five per-mille of the legacy reconstruction across the full instrumented pseudorapidity range. The muon reconstruction efficiency, once an ID track is found, is slightly improved compared to the legacy implementation. In \(|\eta |<0.1\), the muon reconstruction efficiency is reduced for both software releases due to limited detector acceptance, as the MS has gaps for service cabling in this region. In both figures, the simulations include the best available knowledge of inoperative detector modules. In the improved reconstruction, this includes a slightly larger number of defects as compared to the legacy software implementation, reflecting the updated detector status after the conclusion of LHC Run 2. This more conservative estimate of detector availability is part of the reason for the small difference between the software releases.

Tracking efficiency for simulated single muons using the Run 2 detector geometry with \(p_{\text {T}} = 10~\text {GeV} {}\) for ID track (a) or muon reconstruction using the Medium working point in case an ID track was successfully reconstructed (b), as a function of \(\eta \), in a comparison of the updated and legacy reconstructions. The error bars indicate statistical uncertainties
Conclusions
LHC Run 3 challenges experiments’ event reconstruction with a significant increase in the amount of pile-up activity. In ATLAS, the inner detector and muon track reconstruction software has been re-optimized in order to meet this challenge, ensuring that prompt event reconstruction remains feasible within the available computing resources. The improvements exploit the increased experience in operating the experiment by employing stricter tolerances where possible and relying more on the sharing of information between previously independent algorithms. Non-promising track and muon candidates are rejected as early as possible, minimizing the number of calls to downstream algorithms within the reconstruction chain. An execution speed improvement between a factor of 2 and 4, depending on the pile-up, is achieved for both ID track and muon reconstruction. The number of fake tracks has been reduced to less than half of the previous amount and up to \(40\%\) less storage space is required for the tracks. At the same time, the reconstruction efficiency is nearly completely retained. The performance and reconstruction speed remain stable at pile-up values well beyond the design values for LHC Run 3, giving confidence in the robustness of ATLAS event reconstruction to evolving operating conditions. The improvements allow the execution of an additional reconstruction pass to recover tracks not pointing towards the beamline in the standard reconstruction, benefiting long-lived particle searches while retaining a significant overall performance improvement compared to the past software version.
Notes
ATLAS uses a right-handed coordinate system with its origin at the nominal interaction point (IP) in the centre of the detector and the \(z\)-axis along the beam pipe. The \(x\)-axis points from the IP to the centre of the LHC ring, and the \(y\)-axis points upwards. Cylindrical coordinates \((r,\phi )\) are used in the transverse plane, \(\phi \) being the azimuthal angle around the \(z\)-axis. The pseudorapidity is defined in terms of the polar angle \(\theta \) as \(\eta = -\ln \tan (\theta /2)\). Angular distance is measured in units of \(\Delta R \equiv \sqrt{(\Delta \eta )^{2} + (\Delta \phi )^{2}}\).
This is not needed for the MDT chambers, since muons are not expected to create signals across multiple tubes within the same MDT layer.
The \(h_\textrm{damp}\) parameter is a resummation damping factor and one of the parameters that controls the matching of POWHEG matrix elements to the parton shower, it thus effectively regulates the high-\(p_{\text {T}}\) radiation against which the \(t\bar{t}\) system recoils.
References
ATLAS Collaboration (2008) The ATLAS experiment at the CERN Large Hadron Collider. JINST 3:S08003. https://doi.org/10.1088/1748-0221/3/08/S08003
ATLAS Collaboration (2023) The ATLAS experiment at the CERN Large Hadron Collider: a description of the detector configuration for Run 3, arXiv: 2305.16623 [physics.ins-det]
ATLAS Collaboration (2022) Luminosity determination in p p collisions at \(\sqrt{s}= \)13 TeV using the ATLAS detector at the LHC, arXiv: 2212.09379 [hep-ex]
ATLAS Collaboration (2021) Performance of multi-threaded reconstruction in ATLAS, ATL-SOFT-PUB-2021-002, https://cds.cern.ch/record/2771777
ATLAS Collaboration (2010) ATLAS insertable B-layer: technical design report, ATLAS-TDR-19; CERN-LHCC-2010-013, https://cds.cern.ch/record/1291633, Addendum: ATLAS-TDR-19-ADD-1; CERN-LHCC-2012-009, 2012, https://cds.cern.ch/record/1451888
Abbott B et al (2018) Production and integration of the ATLAS insertable B-Iayer. JINST 13:T05008. https://doi.org/10.1088/1748-0221/13/05/T05008. arXiv: 1803.00844 [physics.ins-det]
ATLAS Collaboration (2013) ATLAS new small wheel: technical design report, ATLAS-TDR-020; CERN-LHCC-2013-006, https://cds.cern.ch/record/1552862
ATLAS Collaboration (2017) Performance of the ATLAS trigger system in 2015, Eur. Phys. J. C 77, 317,https://doi.org/10.1140/epjc/s10052-017-4852-3, arXiv: 1611.09661 [hep-ex]
ATLAS Collaboration (2021) The ATLAS collaboration software and firmware, ATL-SOFT-PUB-2021-001, https://cds.cern.ch/record/2767187
ATLAS Collaboration (2017) Performance of the ATLAS track reconstruction algorithms in dense environments in LHC Run 2, Eur. Phys. J. C 77, 673,https://doi.org/10.1140/epjc/s10052-017-5225-7, arXiv: 1704.07983 [hep-ex]
ATLAS Collaboration (2012) A measurement of the muon reconstruction efficiency in 2010 ATLAS data using \(J/\psi \) decays, ATLAS-CONF-2012-125, https://cds.cern.ch/record/1474642
ATLAS Collaboration (2015) Early inner detector tracking performance in the 2015 data at \(\sqrt{s}=\) 13 TeV, ATL-PHYS-PUB-2015-051, https://cds.cern.ch/record/2110140
ATLAS Collaboration (2018) Training and validation of the ATLAS pixel clustering neural networks, ATL-PHYS-PUB-2018-002, https://cds.cern.ch/record/2309474
ATLAS Collaboration (2015) Alignment of the ATLAS inner detector with the initial LHC data at \(\sqrt{s}= 13\) TeV, ATL-PHYS-PUB-2015-031, https://cds.cern.ch/record/2038139
ATLAS Collaboration (2020) Alignment of the ATLAS inner detector in Run-2, Eur. Phys. J. C 80, 1194, https://doi.org/10.1140/epjc/s10052-020-08700-6, arXiv: 2007.07624 [hep-ex]
ATLAS Collaboration (2021) Muon reconstruction and identification efficiency in ATLAS using the full Run 2 \(pp\) collision data set at \(\sqrt{s}=\) 13 TeV, Eur Phys J C 81, 578, https://doi.org/10.1140/epjc/s10052-021-09233-2, arXiv: 2012.00578 [hep-ex]
Frühwirth R (1987) Application of Kalman filtering to track and vertex fitting, Nucl Instrum Meth A Accelerators, Spectrometers, Detectors and Associated Equipment 262, 444, https://doi.org/10.1016/0168-9002(87)90887-4. issn: 0168-9002
Khoda EE (2019) ATLAS pixel cluster splitting using mixture density networks, PoS LHCP2019, 009. https://doi.org/10.22323/1.350.0009
ATLAS Collaboration (2017) Reconstruction of primary vertices at the ATLAS experiment in Run 1 proton–proton collisions at the LHC. Eur Phys J C 77, 332, https://doi.org/10.1140/epjc/s10052-017-4887-5 . arXiv: 1611.10235 [hep-ex]
ATLAS Collaboration (2019) Performance of vertex reconstruction algorithms for detection of new long-lived particle decays within the ATLAS inner detector, ATL-PHYS-PUB-2019-013, https://cds.cern.ch/record/2669425
ATLAS Collaboration (2017) Secondary vertex finding for jet flavour identification with the ATLAS detector, ATL-PHYS-PUB-2017-011, https://cds.cern.ch/record/2270366
ATLAS Collaboration (2023) Performance of the reconstruction of large impact parameter tracks in the ATLAS inner detector. Eur Phys J C 83, 1081
ATLAS Collaboration (2020) Identification of very-low transverse momentum muons in the ATLAS experiment, ATL-PHYS-PUB-2020-002, https://cds.cern.ch/record/2710574
Duda RO, Hart PE (1972) Use of the Hough transformation to detect lines and curves in pictures. Commun ACM 15:11. https://doi.org/10.1145/361237.361242
ATLAS Collaboration (2020) ATLAS data quality operations and performance for 2015–2018 data-taking, JINST 15, P04003, https://doi.org/10.1088/1748-0221/15/04/P04003 , arXiv: 1911.04632 [physics.ins-det]
Frixione S, Ridolfi G, Nason P (2007) A positive-weight next-to-leading-order Monte Carlo for heavy flavour hadroproduction. JHEP 09:126. https://doi.org/10.1088/1126-6708/2007/09/126. arXiv: 0707.3088 [hep-ph]
Nason P (2004) A new method for combining NLO QCD with shower Monte Carlo algorithms. JHEP 11:040. https://doi.org/10.1088/1126-6708/2004/11/040. arXiv: hep-ph/0409146
Frixione S, Nason P, Oleari C (2007) Matching NLO QCD computations with parton shower simulations: the POWHEG method. JHEP 11:070. https://doi.org/10.1088/1126-6708/2007/11/070. arXiv: 0709.2092 [hep-ph]
Alioli S, Nason P, Oleari C, Re E (2010) A general framework for implementing NLO calculations in shower Monte Carlo programs: the POWHEG BOX. JHEP 06:043. https://doi.org/10.1007/JHEP06(2010)043. arXiv: 1002.2581 [hep-ph]
The NNPDF Collaboration (2015) Ball RD et al Parton distributions for the LHC run II, JHEP 04, 040, https://doi.org/10.1007/JHEP04(2015)040 , arXiv: 1410.8849 [hep-ph]
ATLAS Collaboration (2016) Studies on top-quark Monte Carlo modelling for Top2016, ATL-PHYS-PUB-2016-020, https://cds.cern.ch/record/2216168
Sjöstrand T et al (2015) An introduction to PYTHIA 8.2, Comput. Phys. Commun. 191, 159, https://doi.org/10.1016/j.cpc.2015.01.024, arXiv: 1410.3012 [hep-ph]
ATLAS Collaboration (2014) ATLAS Pythia 8 tunes to 7 TeV data, ATL-PHYS-PUB-2014-021, https://cds.cern.ch/record/1966419
NNPDF Collaboration (2013) R. D. Ball et al., Parton distributions with LHC data, Nucl Phys B 867: 244. https://doi.org/10.1016/j.nuclphysb.2012.10.003, arXiv: 1207.1303 [hep-ph]
Lange DJ (2001) The EvtGen particle decay simulation package. Nucl Instrum Meth A 462:152. https://doi.org/10.1016/S0168-9002(01)00089-4
Sjöstrand T, Mrenna S, Skands P (2008) A brief introduction to PYTHIA 8.1, Comput Phys Commun 178, 852, https://doi.org/10.1016/j.cpc.2008.01.036 , arXiv: 0710.3820 [hep-ph]
ATLAS Collaboration (2016) The Pythia 8 A3 tune description of ATLAS minimum bias and inelastic measurements incorporating the Donnachie–Landshoff diffractive model, ATL-PHYS-PUB-2016-017, https://cds.cern.ch/record/2206965
HEPiX Benchmarking Working Group, Results for SL7 x86_64 (gcc 4.8) Benchmark environment, https://w3.hepix.org/benchmarking/sl7-x86_64-gcc48.html
ATLAS Collaboration (2010) ATLAS insertable B-layer technical design report, ATLAS-TDR-19; CERN-LHCC-2010-013, https://cds.cern.ch/record/1291633, Addendum: ATLAS-TDR-19-ADD-1; CERN-LHCC-2012-009, 2012, https://cds.cern.ch/record/1451888
ATLAS Collaboration (2019) Development of ATLAS primary vertex reconstruction for LHC Run 3, ATL-PHYS-PUB-2019-015, https://cds.cern.ch/record/2670380
Ai X et al (2022) A common tracking software project, computing and software for big science 6:8. issn: 2510-2044. https://doi.org/10.1007/s41781-021-00078-8
ATLAS Collaboration (2021) ATLAS computing acknowledgements, ATL-SOFT-PUB-2021-003, https://cds.cern.ch/record/2776662
Acknowledgements
We thank CERN for the very successful operation of the LHC, as well as the support staff from our institutions without whom ATLAS could not be operated efficiently.
We acknowledge the support of ANPCyT, Argentina; YerPhI, Armenia; ARC, Australia; BMWFW and FWF, Austria; ANAS, Azerbaijan; CNPq and FAPESP, Brazil; NSERC, NRC and CFI, Canada; CERN; ANID, Chile; CAS, MOST and NSFC, China; Minciencias, Colombia; MEYS CR, Czech Republic; DNRF and DNSRC, Denmark; IN2P3-CNRS and CEA-DRF/IRFU, France; SRNSFG, Georgia; BMBF, HGF and MPG, Germany; GSRI, Greece; RGC and Hong Kong SAR, China; ISF and Benoziyo Center, Israel; INFN, Italy; MEXT and JSPS, Japan; CNRST, Morocco; NWO, Netherlands; RCN, Norway; MEiN, Poland; FCT, Portugal; MNE/IFA, Romania; MESTD, Serbia; MSSR, Slovakia; ARRS and MIZŠ, Slovenia; DSI/NRF, South Africa; MICINN, Spain; SRC and Wallenberg Foundation, Sweden; SERI, SNSF and Cantons of Bern and Geneva, Switzerland; MOST, Taiwan; TENMAK, Türkiye; STFC, United Kingdom; DOE and NSF, United States of America. In addition, individual groups and members have received support from BCKDF, CANARIE, Compute Canada and CRC, Canada; PRIMUS 21/SCI/017 and UNCE SCI/013, Czech Republic; COST, ERC, ERDF, Horizon 2020 and Marie Skłodowska-Curie Actions, European Union; Investissements d’Avenir Labex, Investissements d’Avenir Idex and ANR, France; DFG and AvH Foundation, Germany; Herakleitos, Thales and Aristeia programmes co-financed by EU-ESF and the Greek NSRF, Greece; BSF-NSF and MINERVA, Israel; Norwegian Financial Mechanism 2014-2021, Norway; NCN and NAWA, Poland; La Caixa Banking Foundation, CERCA Programme Generalitat de Catalunya and PROMETEO and GenT Programmes Generalitat Valenciana, Spain; Göran Gustafssons Stiftelse, Sweden; The Royal Society and Leverhulme Trust, United Kingdom.
The crucial computing support from all WLCG partners is acknowledged gratefully, in particular from CERN, the ATLAS Tier-1 facilities at TRIUMF (Canada), NDGF (Denmark, Norway, Sweden), CC-IN2P3 (France), KIT/GridKA (Germany), INFN-CNAF (Italy), NL-T1 (Netherlands), PIC (Spain), ASGC (Taiwan), RAL (UK) and BNL (USA), the Tier-2 facilities worldwide and large non-WLCG resource providers. Major contributors of computing resources are listed in Ref. [42].
Author information
Authors and Affiliations
Consortia
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
The ATLAS Collaboration., Aad, G., Abbott, B. et al. Software Performance of the ATLAS Track Reconstruction for LHC Run 3. Comput Softw Big Sci 8, 9 (2024). https://doi.org/10.1007/s41781-023-00111-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s41781-023-00111-y